

Kubernetes之Pod工作负载
Pod 工作负载,亦称 Pod 控制器。在 Kubernetes 平台上,我们很少会直接创建一个 Pod,因为直接管理单个 Pod 的工作量将会非常繁琐。我们可以使用 Kubernetes API 创建工作负载对象, 这些对象所表达的是比 Pod 更高级别的抽象概念,Kubernetes 控制平面根据我们定义的工作负载对象规约自动管理 Pod 对象。
一、ReplicationController、ReplicaSet 与 Deployment
在 Kubernetes 中,ReplicationController、ReplicaSet 与 Deployment 都是用于管理无状态应用的工作负载 API 对象,都是通过指定 Pod 标签选择器管理对应的 Pod 集合,确保在任何时候都有指定数量的完全相同的 Pod 副本处于运行状态。
在最早的 Kubernetes 版本中,最先出现的是 ReplicationController。随着 Kubernetes 的发展,后来才出现了 ReplicaSet。ReplicaSet 与 ReplicationController 目的相同且行为类似,但 ReplicaSet 进一步增强了 Pod 标签选择器的灵活性,ReplicationController 的 Pod 标签选择器只能选择一个 Pod 标签,而 ReplicaSet 拥有集合式的标签选择器,可以选择多个 Pod 标签。也就是说,如果使用 ReplicationController 来管理 pod 副本集,同一副本集内的 Pod 都需要设置相同的标签,而使用 ReplicaSet 来管理 pod 副本集的话,同一副本集内的 Pod 可设置不同的标签。所以,ReplicaSet 相当于 ReplicationController 的继承者,相比于 ReplicationController,应优先考虑使用 ReplicaSet。
Deployment 则是一个更高级的概念,它拥有并管理其 ReplicaSet,创建 Deployment 的时候即会自动创建对应的 ReplicaSet。使用 Deployment 时,ReplicaSet 为 Deployment 提供编排 Pod 创建、删除和更新的机制,而 Deployment 则额外支持了滚动更新等更多有用的功能。所以,建议使用 Deployment 而不是直接使用 ReplicaSet, 除非你需要自定义更新业务流程或根本不需要更新。
1. ReplicationController 和 ReplicaSet
ReplicationController 和 ReplicaSet 都是通过 Pod 标签选择器 .spec.selector 确保在任何时候都有特定数量的 Pod 副本处于运行状态,不同的是,前者只支持选择一个标签,而后者则可支持多个标签。
二者皆不局限于拥有并管理在其模板中设置的 Pod,只要与其 Pod 标签选择器匹配,就算不是当前 ReplicationController 或 ReplicaSet 创建的 Pod,也会将它们纳入管理集合。同时,可以通过改变 Pod 的标签,从 ReplicationController 或 ReplicaSet 中移除 Pod,这种技术可以用来从服务中去除 Pod,以便进行排错、数据恢复等。
使用 kubectl delete 删除 ReplicationController 或 ReplicaSet 时,会自动删除所有依赖的 Pod。若只想删除 ReplicationController 或 ReplicaSet 而不影响各个 Pod,只需为 kubectl delete 指定 --cascade=orphan 选项即可,此后还能创建一个 .spec.selector 相同的新的 ReplicationController 或 ReplicaSet 来接管这些 Pod。
2. Deployment
(1)创建 Deployment
<1>Deployment yaml 配置

<2>创建 Deployment

<3>查看 Deployment 上线状态

<4>查看 ReplicaSet

<5>查看 Pod

可看到 Pod 的标签多了一个 pod-template-hash:
Deployment 控制器将 pod-template-hash 标签添加到 Deployment 所创建或收留的每个 ReplicaSet 。
此标签可确保 Deployment 的子 ReplicaSets 不重叠。 标签是通过对 ReplicaSet 的 PodTemplate 进行哈希处理。 所生成的哈希值被添加到 ReplicaSet 选择算符、Pod 模板标签,并存在于在 ReplicaSet 可能拥有的任何现有 Pod 中。
(2)更新 Deployment
仅当 Deployment Pod 模板(即 .spec.template)发生改变时,例如模板的标签或容器镜像被更新, 才会触发 Deployment 上线。其他更新(如对 Deployment 执行扩缩容的操作)不会触发上线动作。
下面实践通过更新容器镜像来触发 Deployment 的更新:
<1>更新容器镜像
更新容器镜像可使用命令 kubectl set image deployment/wjt-deployment wjt-pod-container=... 或 kubectl edit deployment/wjt-deployment,这里使用前者进行演示:

<2>查看 Deployment 与 ReplicaSet

可以看到 Deployment 创建了新的 ReplicaSet 并将其扩容至 3 节点,而将旧的 ReplicaSet 缩容至 0 节点。
<3>查看 Pod

从 pod-template-hash 可以看得到,3 个 Pod 副本都已更新。
<4>查看 deployment 详情

从 NewReplicaSet 字段可以看到 Deployment 管理的 ReplicaSet 已切换至新建的 ReplicaSet。
从 Events 字段记录的信息可以看到,新的 ReplicaSet 逐步扩容,旧的 ReplicaSet 逐步缩容,此即所谓的滚动更新。如 RollingUpdateStrategy 字段所示,Deployment 更新时,会确保 Pod 副本最大不可用比例为 25%,而且启动的 Pod 个数最多比期望值多 25%。
当 Deployment 正在上线时被更新,Deployment 会针对更新创建一个新的 ReplicaSet 并开始对其扩容,之前正在被扩容的 ReplicaSet (控制标签匹配 .spec.selector 但模板不匹配 .spec.template)会被翻转,添加到旧 ReplicaSets 列表并开始缩容。
(3)回滚 Deployment
回滚 Deployment 时只有 Pod 模板部分会被回滚。
下面先模拟更新容器镜像名称错误,再进行回滚操作:
<1>更新容器镜像名称错误导致更新过程停止

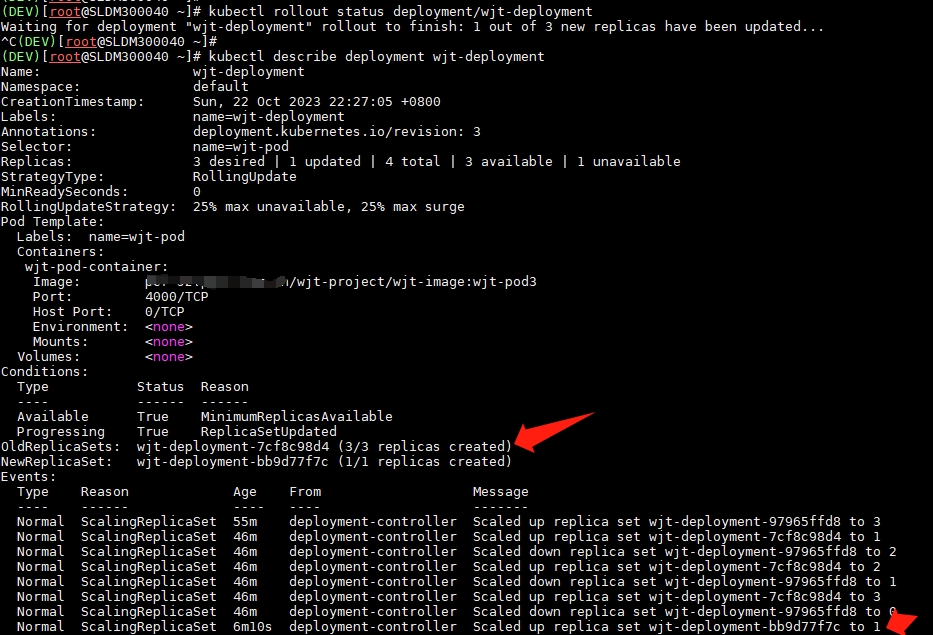
可以看到,新的 ReplicaSet 创建了 1 个 Pod 以后,在拉取容器镜像报错了,在 RollingUpdateStrategy 配置的滚动更新策略下,Deployment 自动停止了有问题的上线过程。
接下来需要先查看当前 Deployment 上线的历史版本,并决定将其回滚到其中一个没有问题的版本。
<2>检查 Deployment 上线历史

<3>回滚 Deployment 到之前的版本


可以看到,Deployment 已将其管理的 ReplicaSet 切回原来的 ReplicaSet,并将新的 ReplicaSet 缩容至节点为 0。
(4)缩放 Deployment
在 Kubernetes 中,可以通过执行命令对 Deployment 进行缩放操作,例如,将 Deployment 从 3 个节点扩展为 10 个节点:

如果集群启动了 Pod 的水平自动缩放,还可以为 Deployment 设置自动缩放器,并基于现有 Pod 的 CPU 利用率选择要运行的 Pod 的下限和上限:
1 | kubectl autoscale deployment/wjt-deployment --min=10 --max=15 --cpu-percent=80 |
Deployiment 在滚动更新的过程中,其管理的 Pod 集群存在同时运行多个版本应用程序的情况,若此时自动缩放器刚好需要执行缩放操作,则其缩放的副本会分配到存在 Pod 运行的多个 ReplicaSet 中,分配比例则是各个 RaplicaSet 中运行的 Pod 的数量之比。
(5)暂停、恢复 Deployment 的上线过程
在 Kubernetes 中,对 Deployment 的 Pod 模板的每次更新都会触发 Deployment 的上线。如果想对 Pod 做多次更新后再上线,则可以先暂停 Deployment 的上线过程:
1 | kubectl rollout pause deployment/wjt-deployment |
执行完多次更新操作以后,再恢复 Deployment 的上线过程:
1 | kubectl rollout resume deployment/wjt-deployment |
这样就可以将针对 Pod 模板的多次更新一次性上线,避免触发不必要的上线操作。
注意:不能回滚处于暂停状态的 Deployment,除非先恢复其执行状态。
(6)关键配置项
<1>清理策略(.spec.revisionHistoryLimit):指定保留当前 Deployment 的历史版本 ReplicaSet 的数量,多余的 ReplicaSet 将在后台被垃圾回收,默认为 10。
<2>副本数量(.spec.replicas):指定当前 Deployment 的 Pod 副本数量。
<3>更新策略(.spec.strategy)

Deployment 的更新策略类型(.spec.strategy.type)可配置以下两种:
Recreate:重新创建。先成功终止所有旧版本的 Pod 以后,再创建新版本的 Pod。
RollingUpdate:滚动更新。先终止一部分旧版本的 Pod,再创建一部分新版本的 Pod,以此类推,滚动更新。
采用滚动更新策略时,还需配置更新过程中不可用 Pod 的个数上限(.spec.strategy.rollingUpdate.maxUnavailable)和可以创建的超出期望 Pod 个数的 Pod 数量(.spec.strategy.rollingUpdate.maxSurge),二者都可以配置为绝对数字或百分比。
二、StatefulSet
1. 基本作用
StatefulSet 是用来管理有状态应用的工作负载 API 对象。
StatefulSet 用来管理某 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符。StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID,这些 Pod 不能相互替换,无论怎么调度,每个 Pod 都有一个永久不变的 ID。
2. 简单使用
StatefulSet 当前需要无头服务来负责 Pod 的网络标识,所以创建 StatefulSet 之前需要先创建一个无头服务。
(1)一个简单的 StatefulSet yaml 配置

(2)创建 statefulSet

(3)查看 StatefulSet 详情

3. 部署、扩缩与更新
(1)部署和扩缩保证
<1>对于包含 N 个 副本的 StatefulSet,当部署 Pod 时,它们是依次创建的,顺序为 0..N-1。
<2>当删除 Pod 时,它们是逆序终止的,顺序为 N-1..0。
<3>在将扩缩操作应用到 Pod 之前,它前面的所有 Pod 必须是 Running 和 Ready 状态。
<4>在一个 Pod 终止之前,它后面的所有 Pod 必须完全关闭。
(2)更新策略
StatefulSet 的 .spec.updateStrategy.type 支持两种更新策略的配置:
<1>OnDelete:StatefulSet 的控制器将不会自动更新 StatefulSet 中的 Pod, 用户必须手动删除 Pod 以便让控制器创建新的 Pod,以此来对 StatefulSet 的 .spec.template 的变动作出反应。
<2>RollingUpdate:对 StatefulSet 中的 Pod 执行自动的滚动更新。这是默认的更新策略。
三、DaemonSet
1. 基本作用
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet 的一些典型用法:
<1>在每个节点上运行集群守护进程
<2>在每个节点上运行日志收集守护进程
<3>在每个节点上运行监控守护进程
2. 简单使用
(1)DaemonSet yaml
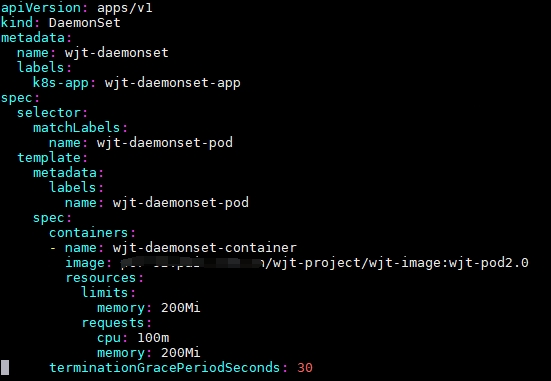
(2)创建 DaemonSet

(3)查看 DaemonSet 详情

3. DeamonSet Pods 调度原理
DaemonSet 可用于确保所有符合条件的节点都运行该 Pod 的一个副本。 DaemonSet 控制器为每个符合条件的节点创建一个 Pod,并添加 Pod 的 spec.affinity.nodeAffinity 字段以匹配目标主机。Pod 被创建之后,默认的调度程序通常通过设置 .spec.nodeName 字段来接管 Pod 并将 Pod 绑定到目标主机。如果新的 Pod 无法放在节点上,则默认的调度程序可能会根据新 Pod 的优先级抢占 (驱逐)某些现存的 Pod。
查看 DaemonSet Pod 字段:

四、Job 与 CronJob
在 Kubernetes 中,支持批处理、离线任务的工作负载 API 对象有 Job 和 CronJob,其中 Job 是一次性任务,只要指定数量的 Pod 成功终止,任务即结束,而 CronJob 是定时任务,它会在指定时间点创建 Job,从而间接创建 Pod,执行任务。
1. Job
(1)基本作用
Job 会创建一个或者多个 Pod,并将继续重试 Pod 的执行,直到指定数量的 Pod 成功终止。 随着 Pod 成功结束,Job 跟踪记录成功完成的 Pod 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。
(2)简单使用
<1> Job yaml

spec.completions 指定需成功终止的 Pod 的个数,.spec.parallelism 指定并发执行的 Pod 的个数。
<2>创建 Job

<3>查看 Job 详情

该 Job 已经运行结束,一共有 10 个 Pod 执行完成,并发数为 4(从 Events 记录的每个 Pod 的创建时间可大致看出)。
(3)Job 类型
<1>非并行 Job
通常只启动一个 Pod,除非该 Pod 失败。当 Pod 成功终止,立即视 Job 为完成状态。
可以不设置 spec.completions 和 spec.parallelism。 这两个属性都不设置时,均取默认值 1。
<2>具有确定完成计数的并行 Job
通过设置 .spec.completions 为非 0 的正整数来指定需成功终止的 Pod 的个数,通过设置 .spec.parallelism 来指定并发执行的 Pod 的个数,也可以不设置,默认为 1。
Job 用来代表整个任务,当成功的 Pod 个数达到 .spec.completions 时,Job 被视为完成。
<3>带工作队列的并行 Job
多个 Pod 之间必须相互协调,或者借助外部服务确定每个 Pod 要处理哪个工作条目。 例如,任一 Pod 都可以从工作队列中取走最多 N 个工作条目。
每个 Pod 都可以独立确定是否其它 Pod 都已完成,进而确定 Job 是否完成。
当 Job 中任何 Pod 成功终止,不再创建新 Pod。
一旦至少 1 个 Pod 成功完成,并且所有 Pod 都已终止,即可宣告 Job 成功完成。
一旦任何 Pod 成功退出,任何其它 Pod 都不应再对此任务执行任何操作或生成任何输出。 所有 Pod 都应启动退出过程。
需要将.spec.parallelism 设置为一个非负整数,不能设置 .spec.completions,默认值为 .spec.parallelism。
2. CronJob
(1)基本作用
CronJob 用于执行排期操作,例如备份、生成报告等。 一个 CronJob 对象就像 Unix 系统上的 crontab(cron table)文件中的一行。 它用 Cron 格式进行编写, 并周期性地在给定的调度时间执行 Job。
(2)简单使用
<1>CronJob yaml

<2>创建 CronJob


该 CronJob 每两分钟就会创建一个 Job,再由该 Job 创建一个 Pod 去执行任务。
<3>查看 CronJob 详情

(3)相关配置
<1>任务延迟开始的最后期限
.spec.startingDeadlineSeconds:表示任务如果由于某种原因错过了调度时间,开始该任务的截止时间的秒数。CronJob 控制器将会计算从预期创建 Job 到当前时间的时间差。 如果时间差大于该限制,则跳过此次执行。
<2>并发性规则
.spec.concurrencyPolicy:声明了 CronJob 创建的任务执行时发生重叠如何处理。 spec 仅能声明下列规则中的一种:
Allow(默认):CronJob 允许并发任务执行。
Forbid: CronJob 不允许并发任务执行;如果新任务的执行时间到了而老任务没有执行完,CronJob 会忽略新任务的执行。
Replace:如果新任务的执行时间到了而老任务没有执行完,CronJob 会用新任务替换当前正在运行的任务。
<3>任务历史限制
.spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit:应保留多少已完成和失败的任务。 默认设置分别为 3 和 1。将限制设置为 0 代表相应类型的任务完成后不会保留。
参考:
《Kubernetes 权威指南第 5 版》


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!