


RabbitMQ 集群搭建与运维
一、集群搭建
RabbitMQ 集群对延迟非常敏感,应当只在本地局域网内使用。在广域网中不应该使用集群,而应该使用 Federation 或者 Shovel 来代替。
1. 安装 RabbitMQ
在各个节点正确安装 RabbitMQ。安装过程参考:https://www.cnblogs.com/wujuntian/p/16644894.html
2. 配置 hosts 文件
配置各个节点的 hosts 文件,添加 IP 地址与节点名称的映射信息,让各个节点都能互相识别对方的存在。

3. 编辑 cookie 文件
编辑 RabbitMQ 的 cookie 文件,以确保各个节点的 cookie 文件使用的是同一个值。可以直接使用其中一个节点的 cookie 文件内容。
cookie 文件默认路径为 /var/lib/rabbitmq/.erlang.cookie 或者 $HOME/.erlang.cookie。cookie 相当于密钥令牌,集群中的 RabbitMQ 节点需要通过交换密钥令牌以获得相互认证。

注意,该文件是只读的,需要先赋予可写权限再修改,改完再将可写权限去掉,否则启动 RabbitMQ 服务会报错。或者直接将其中一个节点的文件 scp 到其他节点上。(注意是否包含了回车符)
4. 配置集群
配置集群有三种方式:通过 rabbitmqctl 工具配置;通过 rabbitmq.config 配置文件配置;通过 rabbitmq-autocluster 插件配置。这里主要讲的是通过 rabbitmqctl 工具的方式配置集群,这种方式也是最常用的方式。
(1)启动各个节点的 RabbitMQ 服务
1 | rabbitmq-server |
此时,各个节点都是以独立节点存在的单个集群。分别查看各个集群的状态:
1 | rabbitmqctl cluster_status |
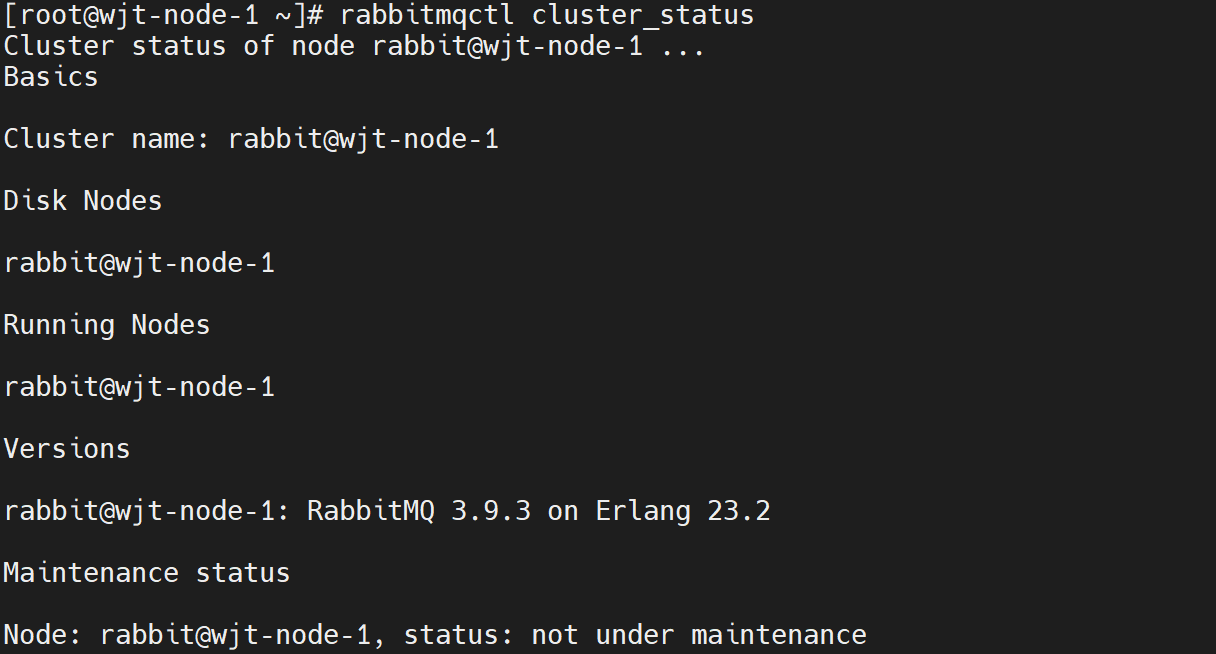
(部分截图)
(2)开放端口
25672:集群之间使用的端口。
4369:erlang 进程用来做 node 连接的端口。
1 2 3 | firewall-cmd --zone=public --add-port=25672/tcp --permanentfirewall-cmd --zone=public --add-port=4369/tcp --permanentfirewall-cmd --reload |
(3)以其中一个节点为基准,将其他节点加入这个基准节点的集群
1 2 3 4 | rabbitmqctl stop_apprabbitmqctl resetrabbitmqctl join_cluster {cluster_name}rabbitmqctl start_app |
在各个节点查询集群状态:
1 | rabbitmqctl cluster |
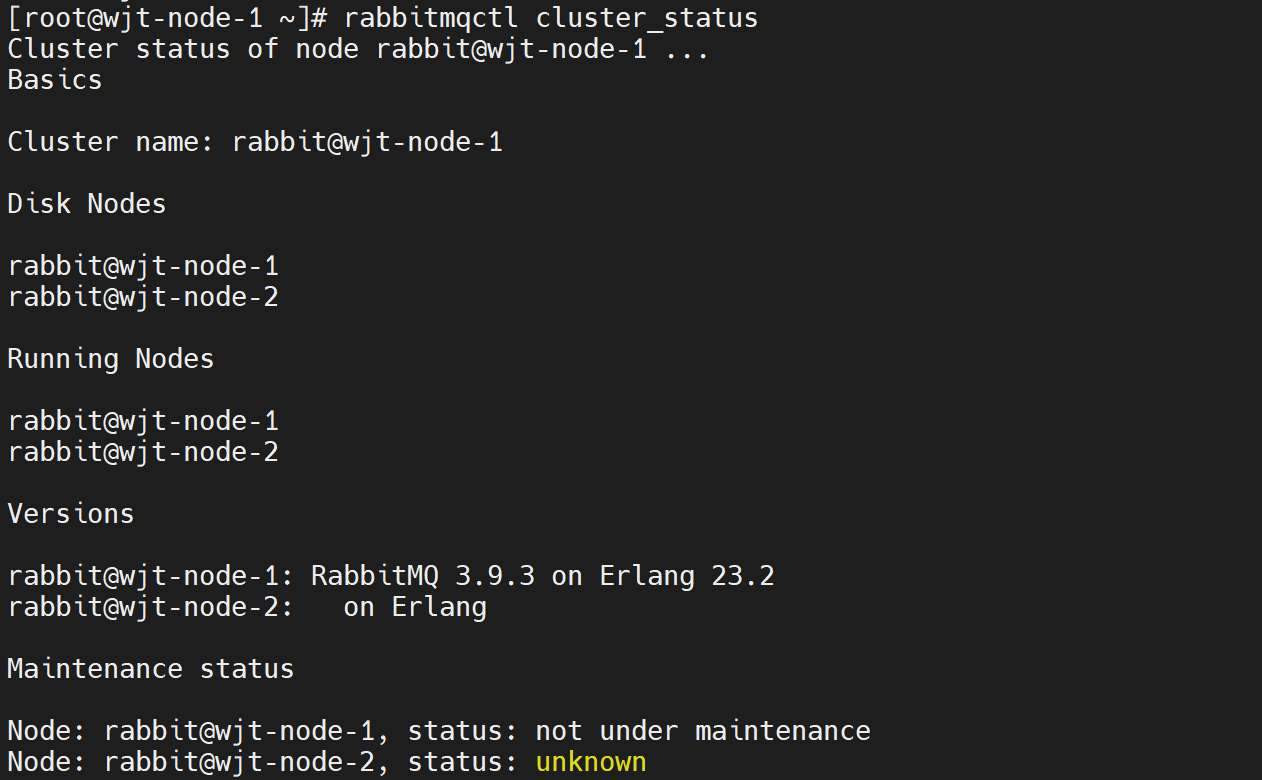
5. 集群重启
如果关闭了集群中的所有节点,则需要确保在启动的时候最后关闭的那个节点是第一个启动的。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的节点启动。这个等待时间是 30 秒,如果没有等到,那么这个先启动的节点也会失败。在最新的版本中会有重试机制,默认重试 10 次 30 秒以等待最后关闭的节点启动。在重试失败之后,当前节点也会因失败而关闭自身的应用。
如果最后一个关闭的节点最终由于某些异常而无法启动,则可以通过 rabbitmqctl forget_cluster_node 命令来将此节点剔出当前集群。如果集群中的所有节点由于某些非正常因素,比如断电而关闭,那么集群中的节点都会认为还有其他节点在它后面关闭,此时需要调用 rabbitmqctl force_boot 命令来启动一个节点,之后集群才能正常启动。
6. 单机多节点配置
在一台机器上部署多个 RabbitMQ 服务节点,需要确保每个节点都有独立的名称、数据存储位置、端口号(包括插件的端口号)等。
首先需要确保机器上已经安装了 Erlang 和 RabbitMQ 的程序。其次,为每个 RabbitMQ 服务节点设置不同的端口号和节点名称来启动相应的服务。
二、服务日志
RabbitMQ 日志中包含各种类型的事件,比如连接尝试、服务启动、插件安装及解析请求时的错误等。
1. 日志文件
RabbitMQ 的日志默认存放在 $RABBITMQ_HOME/var/log/rabbitmq 文件夹内。在这个文件夹内RabbitMQ 会创建两个日志文件:
(1)RABBITMQ_NODENAME-sasl.log
当 RabbitMQ 记录 Erlang 相关信息时,它会将日志写入文件 RABBITMQ_NODENAME-sasl.log中。举例来说,可以在这个文件中找到 Erlang 的崩溃报告,有助于调试无法启动的 RabbitMQ 节点。RabbitMQ 应用服务启动的前提是 Erlang 虚拟机是运转正常的。
(2)RABBITMQ_NODENAME.log
如果想查看 RabbitMQ 应用服务的日志,则需要查阅 RABBITMQ_NODENAME.log 这个文件,所谓的 RabbitMQ 服务日志指的就是这个文件。
2. 日志设置
在 RabbitMQ 中,日志级别有 none、error、warning、info、debug 这 5 种,下一层级别的日志输出均包含上一层级别的日志输出。
(1)日志级别
日志级别可以通过 rabbitmq.config 配置文件中的 log_levels 参数来进行设置,默认为 [{connection,info}]。
(2)日志轮换
RabbitMQ 中可以通过 rabbitmqctl rotate_logsffix 命令来轮换日志。
也可以执行一个定时任务,比如使用 Linux crontab,以当前日期为后缀,每天执行一次切换日志的任务,这样在后面需要查阅日志的时候可以根据日期快速定位到相应的日志文件。
3. 日志收集与分析
RabbitMQ 默认会创建一些交换器,其中 amq.rabbitmq.log 就是用来收集 RabbitMQ 日志的,集群中所有的服务日志都会发往这个交换器中。这个交换器的类型为 topic,可以收集如前面所说的debug、info、warning 和 error 这 4 个级别的日志。
如果需要收集日志,可以创建 4 个日志队列 queue.debug、queue.info、queue.warning 和 queue.error,分别采用 debug、info、warning 和 error 这 4 个路由键来绑定交换器 amq.rabbitmq.log。如果要使用一个队列来收集所有级别的日志,可以使用“#”这个路由键。
对于每个级别的日志队列来说,比如 queue.info,它会收到每个节点的 info 级别的日志,不过这些日志是交错的,不能区分是哪个具体节点的日志。
如果需要分析日志,可以通过程序化的方式查看服务日志,设置相应的逻辑规则,将有用的日志信息过滤并保存起来以便后续的服务应用。也可以对服务日志添加监控,比如对其日志内容进行关键字检索,例如,通过检索日志的 running_partitioned_network 关键字来及时地探测到网络分区的发生,之后可以迅速采取措施以保证集群服务的鲁棒性。
当然对于日志的监控处理也可以采用第 3 方工具实现,如 Logstash 等。
三、集群数据分布
RabbitMQ 集群允许消费者和生产者在 RabbitMQ 单个节点崩溃的情况下继续运行,它可以通过添加更多的节点来线性地扩展消息通信的吞吐量。当失去一个 RabbitMQ 节点时,客户端能够重新连接到集群中的任何其他节点并继续生产或者消费。
不过 RabbitMQ 集群不能保证消息的万无一失,即使将消息、队列、交换器等都设置为可持久化,生产端和消费端都正确地使用了确认方式。当集群中一个 RabbitMQ 节点崩溃时,该节点上的所有队列中的消息也会丢失。
RabbitMQ 集群中的所有节点都会备份所有的元数据信息,包括以下内容:
(1)队列元数据:队列的名称及属性;
(2)交换器:交换器的名称及属性;
(3)绑定关系元数据:交换器与队列或者交换器与交换器之间的绑定关系;
(4)vhost 元数据:为 vhost 内的队列、交换器和绑定提供命名空间及安全属性。
但是不会备份消息(当然通过特殊的配置比如镜像队列可以解决这个问题)。基于存储空间和性能的考虑,在 RabbitMQ 集群中创建队列,集群只会在单个节点而不是在所有节点上创建队列的进程并包含完整的队列信息(元数据、状态、内容)。这样只有队列的宿主节点,即所有者节点知道队列的所有信息,所有其他非所有者节点只知道队列的元数据和指向该队列存在的那个节点的指针。因此当集群节点崩溃时,该节点的队列进程和关联的绑定都会消失。附加在那些队列上的消费者也会丢失其所订阅的信息,并且任何匹配该队列绑定信息的新消息也都会消失。
不同于队列那样拥有自己的进程,交换器其实只是一个名称和绑定列表。当消息发布到交换器时,实际上是由所连接的信道将消息上的路由键同交换器的绑定列表进行比较,然后再路由消息。当创建一个新的交换器时,RabbitMQ 所要做的就是将绑定列表添加到集群中的所有节点上。这样,每个节点上的每条信道都可以访问到新的交换器了。(在集群中创建队列、交换器或者绑定关系的时候,这些操作直到所有集群节点都成功提交元数据变更后才会返回)
访问 Web 管理页面可以看到队列对应的宿主节点是哪个(在哪个节点创建的):
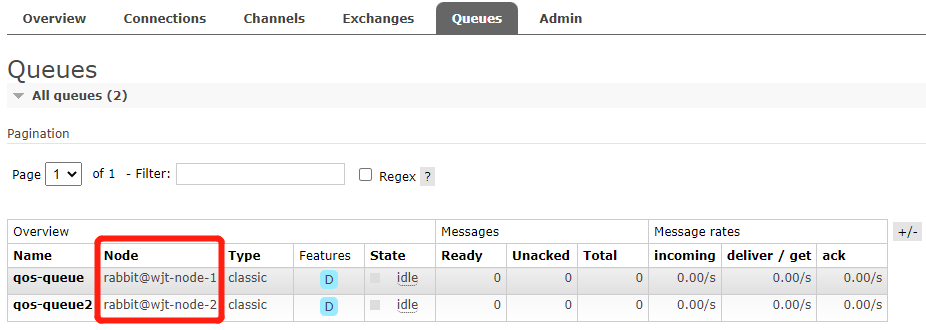
四、集群节点类型
RabbitMQ 中的每一个节点,不管是单一节点系统或者是集群中的一部分,要么是内存节点,要么是磁盘节点。内存节点将所有的队列、交换器、绑定关系、用户、权限和 vhost 的元数据定义都存储在内存中,而磁盘节点则将这些信息存储到磁盘中。单节点的集群中必然只有磁盘类型的节点,否则当重启 RabbitMQ 之后,所有关于系统的配置信息都会丢失。不过在集群中,可以选择配置部分节点为内存节点,这样可以获得更高的性能。
1. 如何设置
以下命令参数中,disc 表示磁盘节点,ram 表示内存节点。
(1)可在节点加入集群时指定节点类型:
1 2 3 | rabbitmqctl stop_apprabbitmqctl join_cluster {cluster_name} --{disc, ram}rabbitmqctl start_app |
不添加参数 --{disc, ram} 则默认此节点为磁盘节点。
(2)可在集群搭建完成后切换节点类型:
1 2 3 | rabbitmqctl stop_apprabbitmqctl change_cluster_node_type {disc, ram}rabbitmqctl start_app |
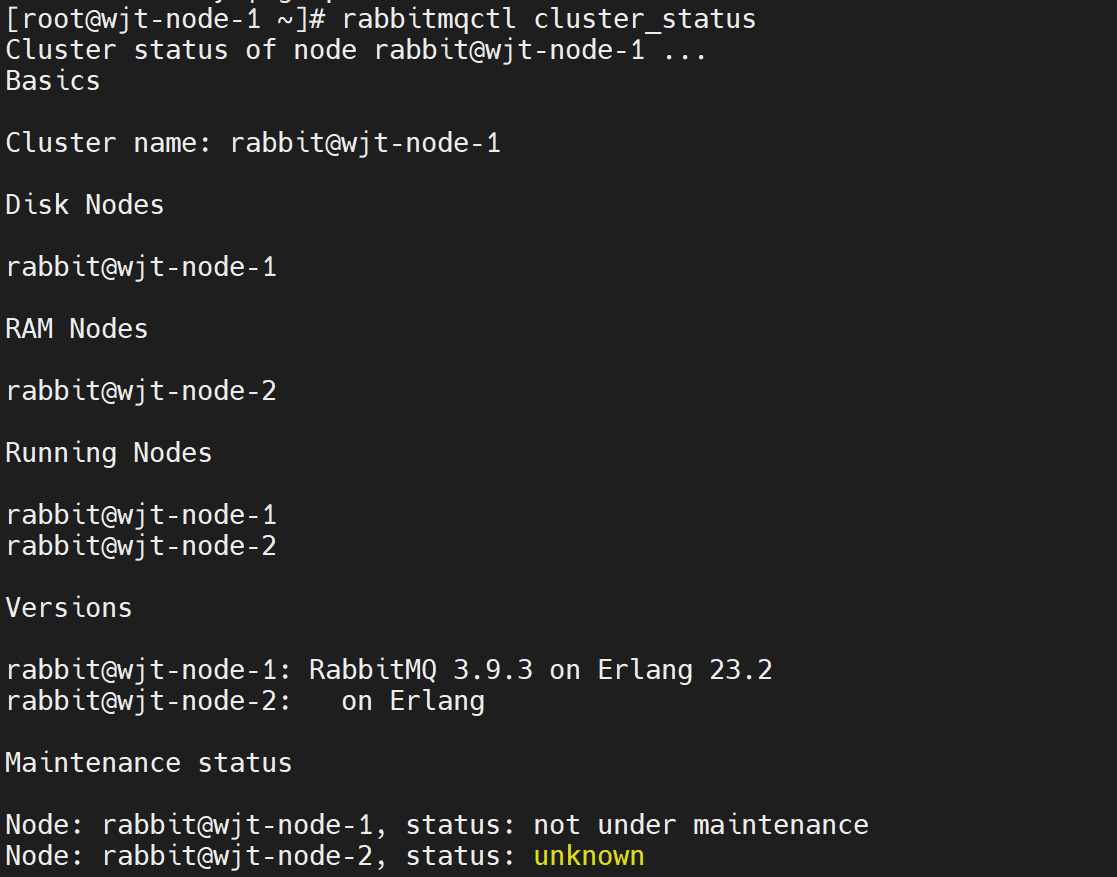
2. 如何抉择
在集群中创建队列、交换器或者绑定关系的时候,这些操作直到所有集群节点都成功提交元数据变更后才会返回。对内存节点来说,这意味着将变更写入内存;而对于磁盘节点来说,这意味着昂贵的磁盘写入操作。内存节点可以提供出色的性能,磁盘节点能够保证集群配置信息的高可靠性,如何在这两者之间进行抉择呢?
RabbitMQ 只要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点。当节点加入或者离开集群时,它们必须将变更通知到至少一个磁盘节点。如果只有一个磁盘节点,而且不凑巧的是它刚好崩溃了,那么集群可以继续发送或者接收消息,但是不能执行创建队列、交换器、绑定关系、用户,以及更改权限、添加或删除集群节点的操作了。也就是说,如果集群中唯一的磁盘节点崩溃,集群仍然可以保持运行,但是直到将该节点恢复到集群前,你无法更改任何东西。所以在建立集群的时候应该保证有两个或者多个磁盘节点的存在。
在内存节点重启后,它们会连接到预先配置的磁盘节点,下载当前集群元数据的副本。当在集群中添加内存节点时,确保告知其所有的磁盘节点(内存节点唯一存储到磁盘的元数据信息是集群中磁盘节点的地址)。只要内存节点可以找到至少一个磁盘节点,那么它就能在重启后重新加入集群中。
除非使用的是 RabbitMQ 的 RPC 功能,否则创建队列、交换器及绑定关系的操作确是甚少,大多数的操作就是生产或者消费消息。为了确保集群信息的可靠性,或者在不确定使用磁盘节点或者内存节点的时候,建议全部使用磁盘节点。
五、剔除单个节点
剔除集群单个节点有两种方式:
1. 方式一
首先在需要剔除的节点上执行 rabbitmqctl stop_app 或者 rabbitmqctl stop 命令来关闭 RabbitMQ 服务。之后再在集群其他节点上执行 rabbitmqctl forget_cluster_node {node_name} 命令将该节点剔除出去。这种方式适合被剔除节点不再运行 RabbitMQ 的情况。
另外,在关闭集群中的每个节点之后,如果最后一个关闭的节点最终由于某些异常而无法启动,则可以通过 rabbitmqctl forget_cluster_node 命令来将此节点剔除出当前集群。此时其他节点无法先启动 RabbitMQ 服务,所以需要加 --offline 参数,即:
1 | rabbitmqctl forget_cluster_node {node_name} --offline |
2. 方式二
在需要剔除的节点上执行 rabbitmqctl reset 命令。
rabbitmqctl reset 命令将清空节点的状态,并将其恢复到空白状态。当重设的节点是集群中的一部分时,该命令也会和集群中的磁盘节点进行通信,告诉它们该节点正在离开集群。不然集群会认为该节点出了故障,并期望其最终能够恢复过来。
如果不是由于启动顺序的缘故而不得不删除一个集群节点,建议采用这种方式。
六、集群节点升级
集群节点升级分三种情况:
1. 如果原集群上的配置和数据都可以舍弃,则可以删除原版本的 RabbitMQ,然后再重新安装配置即可。
2. 如果配置和数据不可丢弃,则需要先保存元数据,之后再关闭所有生产者并等待消费者消费完队列中的所有数据,紧接着关闭所有消费者,然后重新安装 RabbitMQ 并重建元数据。步骤如下:
(1)关闭所有节点的服务,注意采用 rabbitmqctl stop 命令关闭。
(2)保存各个节点的 Mnesia 数据。
(3)解压新版本的 RabbitMQ 到指定的目录。
(4)指定新版本的 Mnesia 路径为步骤 2 中保存的 Mnesia 数据路径。
(5)启动新版本的服务,注意先重启原版本中最后关闭的那个节点。
其中步骤 4 和步骤 5 可以一起操作,比如执行 RABBITMQ_MNESIA_BASE=/opt/mnesia rabbitmq-server-detached 命令,其中 /opt/mnesia 为原版本保存 Mnesia 数据的路径。
3. 如果有个新版本的集群,那么从旧版本迁移到新版本的集群中也不失为一个升级的好办法。
RabbitMQ 的版本有很多,难免会有数据格式不兼容的现象,最好先测试两个版本互通的可能性,然后再在线上环境中实地操作。
七、集群单节点故障恢复
所谓的单点故障是指集群中单个节点发生了故障,有可能会引起集群服务不可用、数据丢失等异常。配置数据节点冗余(镜像队列)可以有效地防止由于单点故障而降低整个集群的可用性、可靠性。
单节点故障包括:机器硬件故障、机器掉电、网络异常、服务进程异常。
1. 机器硬件故障
单节点机器硬件故障包括机器硬盘、内存、主板等故障造成的死机,无法从软件角度来恢复。此时需要在集群中的其他节点中执行 rabbitmqctl forget_cluster_node {node_name} 命令来将故障节点剔除。如果之前有客户端连接到此故障节点上,在故障发生时会有异常报出,此时需要将故障节点的 IP 地址从连接列表里删除,并让客户端重新与集群中的其他节点建立连接,以恢复整个应用。如果此故障机器修复或者原本有备用机器,那么也可以选择性的添加到集群中。
2. 机器掉电
当遇到机器掉电故障,需要等待电源接通之后重启机器。此时这个机器节点上的 RabbitMQ 处于stop 状态,但是此时不要盲目重启服务,否则可能会引起网络分区。此时同样需要在其他节点上执行 rabbitmqctl forget_cluster_node {node_name} 命令将此节点从集群中剔除,然后删除当前故障机器的 RabbitMQ 中的 Mnesia 数据(相当于重置),然后再重启 RabbitMQ 服务,最后再将此节点作为一个新的节点加入到当前集群中。
3. 网络异常
网线松动或者网卡损坏都会引起网络故障的发生。对于网线松动,无论是彻底断开,还是“藕断丝连”,只要它不降速,RabbitMQ 集群就没有任何影响。但是为了保险起见,建议先关闭故障机器的 RabbitMQ 进程,然后对网线进行更换或者修复操作,之后再考虑是否重新开启 RabbitMQ 进程。而网卡故障极易引起网络分区的发生,如果监控到网卡故障而网络分区尚未发生时,理应第一时间关闭此机器节点上的 RabbitMQ 进程,在网卡修复之前不建议再次开启。
4. 服务进程异常
对于服务进程异常,如 RabbitMQ 进程非预期终止,需要预先思考相关风险是否在可控范围之内。如果风险不可控,可以选择抛弃这个节点。一般情况下,重新启动 RabbitMQ 服务进程即可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2019-10-08 go递归遍历文件目录