


RabbitMQ 可靠性保障
一、持久化
持久化可以提高 RabbitMQ 的可靠性,以防在异常情况(重启、关闭、宕机等)下的数据丢失。
RabbitMQ 的持久化分为三个部分:交换器的持久化、队列的持久化和消息的持久化。
1. 交换器持久化
交换器的持久化是通过在声明交换器时将 durable 参数置为 true 实现的:
1 2 3 4 5 6 7 8 9 | ch.ExchangeDeclare( "HelloEx2", //name "direct", //kind true, //durable:是否持久化。持久化可以将交换器存盘,在服务器重启的时候不会丢失相关信息。 false, //autoDelete false, //internal false, //noWait nil, //args) |
如果交换器不设置持久化,那么在 RabbitMQ 服务重启之后,相关的交换器元数据会丢失,不过消息不会丢失,只是不能将消息发送到这个交换器中了。对一个长期使用的交换器来说,建议将其置为持久化的。
2. 队列持久化
队列的持久化是通过在声明队列时将 durable 参数置为 true 实现的:
1 2 3 4 5 6 7 8 | ch.QueueDeclare( "helloQ2", //name true, //durable:是否持久化。持久化的队列会存盘,在服务器重启的时候可以保证不丢失相关信息。 false, //autoDelete false, //exclusive false, //noWait nil, //args) |
如果队列不设置持久化,那么在 RabbitMQ 服务重启之后,相关队列的元数据会丢失,此时数据也会丢失。
队列的持久化能保证其本身的元数据不会因异常情况而丢失,但是并不能保证内部所存储的消息不会丢失。要确保消息不会丢失,需要将消息本身也设置为持久化。
3. 消息持久化
通过将消息的投递模式 DeliveryMode 设置为 2(Persistent) 即可实现消息的持久化:
1 2 3 4 5 6 | amqp.Publishing{ ContentType: "text/plain", DeliveryMode: amqp.Persistent, //消息传输类型:1 amqp.Transient 不管队列是否持久化,消息都不会被持久 // 2 amqp.Persistent 只有队列是持久化的,消息才会持久化,否则消息同样不会持久化 Body: []byte("Hello World"), //消息内容} |
设置了队列和消息的持久化,当 RabbitMQ 服务重启之后,消息依旧存在。只有队列和消息都设置为持久化的,消息才会持久化。单单只设置队列持久化,重启之后消息会丢失;单单只设置消息的持久化,重启之后队列消失,继而消息也丢失。
4. 持久化抉择
可以将所有的消息都设置为持久化,但是这样会严重影响 RabbitMQ 的性能(随机)。写入磁盘的速度比写入内存的速度慢得不只一点点。对于可靠性不是那么高的消息可以不采用持久化处理以提高整体的吞吐量。在选择是否要将消息持久化时,需要在可靠性和吐吞量之间做一个权衡。
5. 持久化也无法保证数据不丢失
即使将交换器、队列、消息都设置为持久化,也不能百分之百保证数据不丢失。例如:
(1)当消费者接收到相关消息之后,还没来得及处理就宕机了。
解决方法:消费者订阅消息队列的时候设置 autoAck 为 false,收到消息,处理完业务逻辑之后再发送 ACK 确认收到消息。
(2)消息数据在操作系统缓存之中,尚未写入物理磁盘,RabbitMQ 发生了宕机、重启等。
解决方法:为消息队列配置镜像队列。相当于配置了副本,如果主节点(master)在此特殊时间内挂掉,可以自动切换到从节点(slave)。
二、生产者确认
如果不进行特殊配置,默认情况下发送消息的操作是不会返回任何信息给生产者的,也就是默认情况下生产者是不知道消息有没有正确地到达服务器的,无法保证消息发送的可靠性。
RabbitMQ 针对这个问题,提供了两种解决方式:
(1)通过事务机制实现;
(2)通过发送方确认(publisher confirm)机制实现。
1. 事务机制
RabbitMQ Go 语言客户端中与事务机制相关的方法有三个:
(1)Channel.Tx():将当前信道设置为事务模式。
(2)Channel.TxCommit():自动提交单个队列的所有发布和确认,并立即启动新事务。
(3)Channel.TxRollback():自动回滚单个队列的所有发布和确认,并立即启动新事务。
一旦信道进入事务模式,就不能退出事务模式,如果需要非事务模式,需要另外创建一个新的信道。
AMQP协议流转过程:
(1)Commit
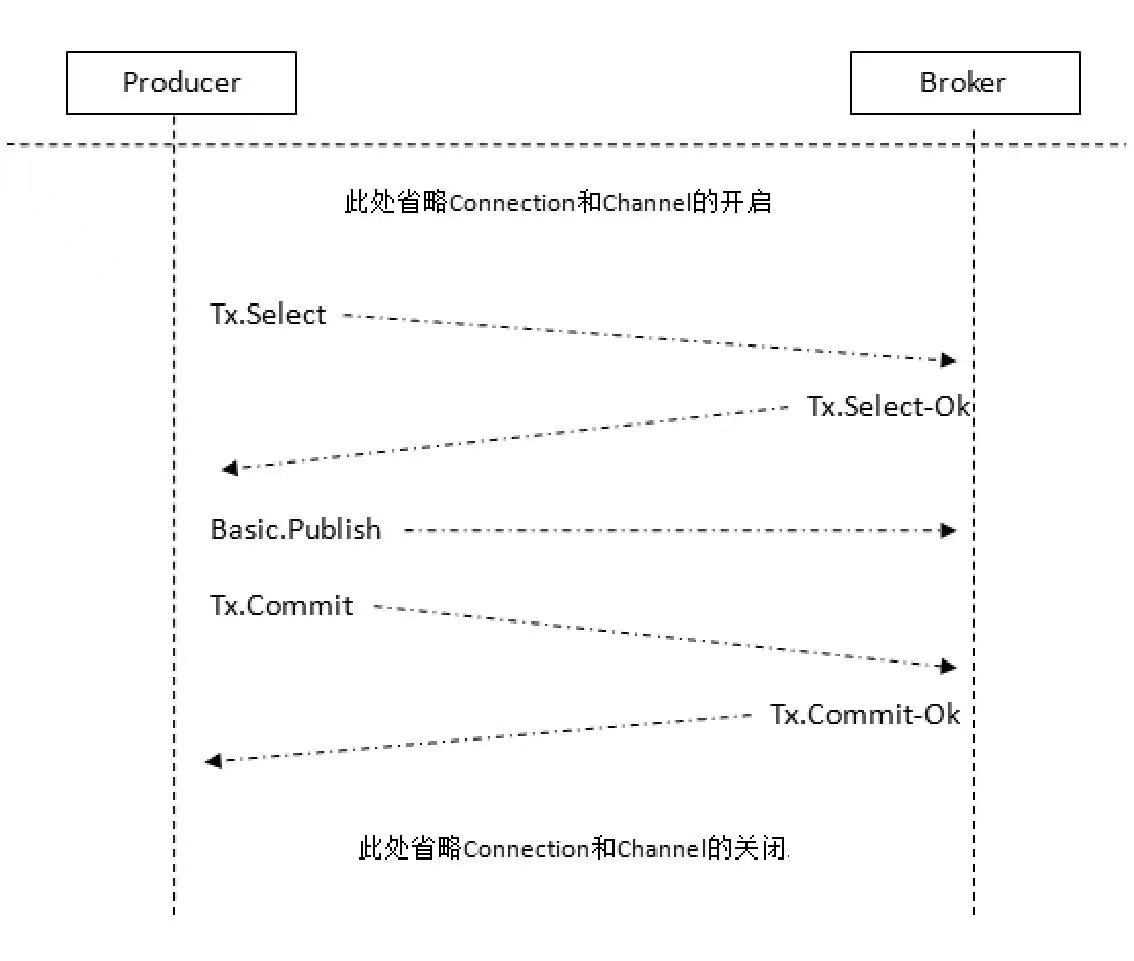
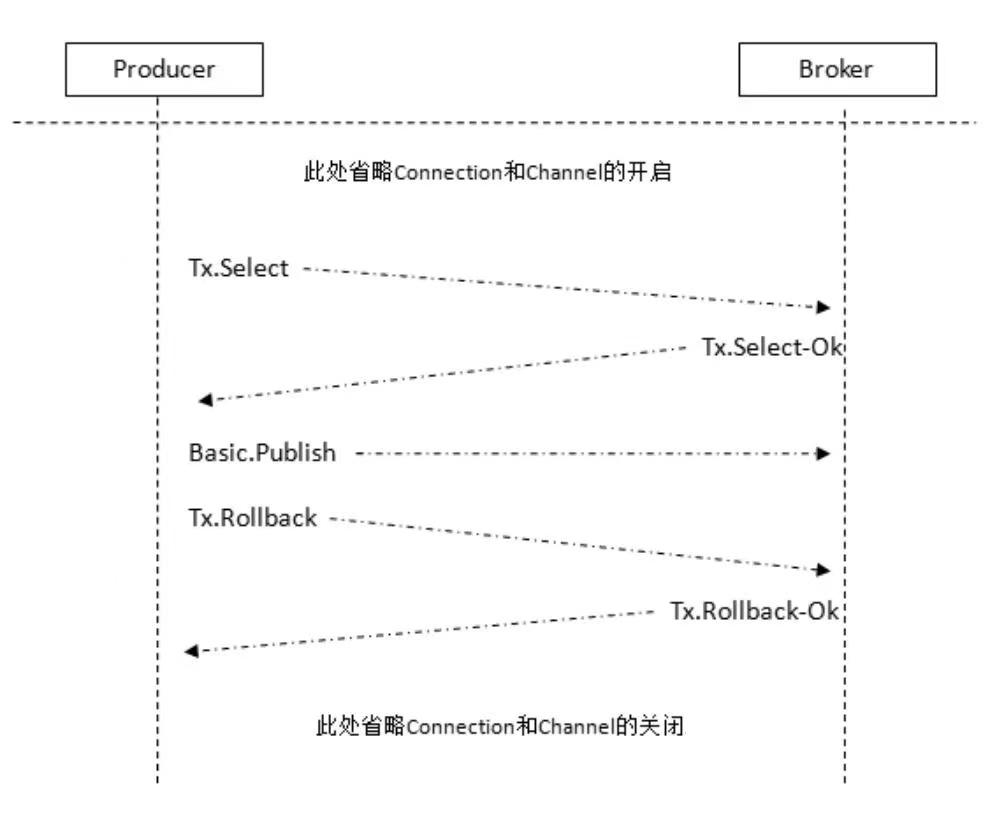
(2)Rollback
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | package mainimport ( "fmt" "github.com/streadway/amqp")func main() { // connect to rabbitmq conn, err := amqp.Dial("amqp://root:shiajun666@192.168.10.4:5672") if err != nil { fmt.Println("Connect to RabbitMQ failed: ", err) return } defer conn.Close() // open a channel ch, err := conn.Channel() if err != nil { fmt.Println("Open channel failed: ", err) return } defer ch.Close() // declare message queue _, err = ch.QueueDeclare( "tx_queue", //name true, //durable false, //autoDelete false, //exclusive false, //noWait nil, //args ) if err != nil { fmt.Println("Declare message queue failed: ", err) return } // start transaction err = ch.Tx() if err != nil { fmt.Println("Start transaction failed: ", err) return } var rbErr error for i := 0; i < 10; i++ { err = ch.Publish( "", //exchange "tx_queue", //key false, //mandatory false, //immediate amqp.Publishing{ ContentType: "text/plain", Body: []byte(fmt.Sprintf("tx message %d", i)), }, ) if err != nil { fmt.Printf("Publish message %d failed: %v\n", i, err) rbErr = ch.TxRollback() if rbErr != nil { fmt.Printf("Rollback message %d failed: %v\n", i, err) } continue } err = ch.TxCommit() if err != nil { fmt.Printf("Commit message %d failed: %v\n", i, err) } } fmt.Println("finish")} |
事务确实能够解决消息发送方和 RabbitMQ 之间消息确认的问题,只有消息成功被 RabbitMQ 接收,事务才能提交成功,否则便可在捕获异常之后进行事务回滚,与此同时可以进行消息重发。但是采用事务机制实现会“吸干” RabbitMQ 的性能,严重降低 RabbitMQ 的消息吞吐量。
那么有没有更好的方法既能保证消息发送方确认消息已经正确送达,又能基本上不带来性能上的损失呢?从 AMQP 协议层面来看并没有更好的办法,但是 RabbitMQ 提供了一个改进方案,即发送方确认机制。
2. 发送方确认机制
生产者将信道设置成 confirm(确认)模式,一旦信道进入 confirm 模式,所有在该信道上面发布的消息都会被指派一个唯一的 ID(从1开始),一旦消息被投递到所有匹配的队列之后,RabbitMQ 就会发送一个确认给生产者(包含消息的唯一 ID),这就使得生产者知晓消息已经正确到达了目的地了。如果消息和队列是可持久化的,那么确认消息会在消息写入磁盘之后发出。
AMQP协议流转过程:
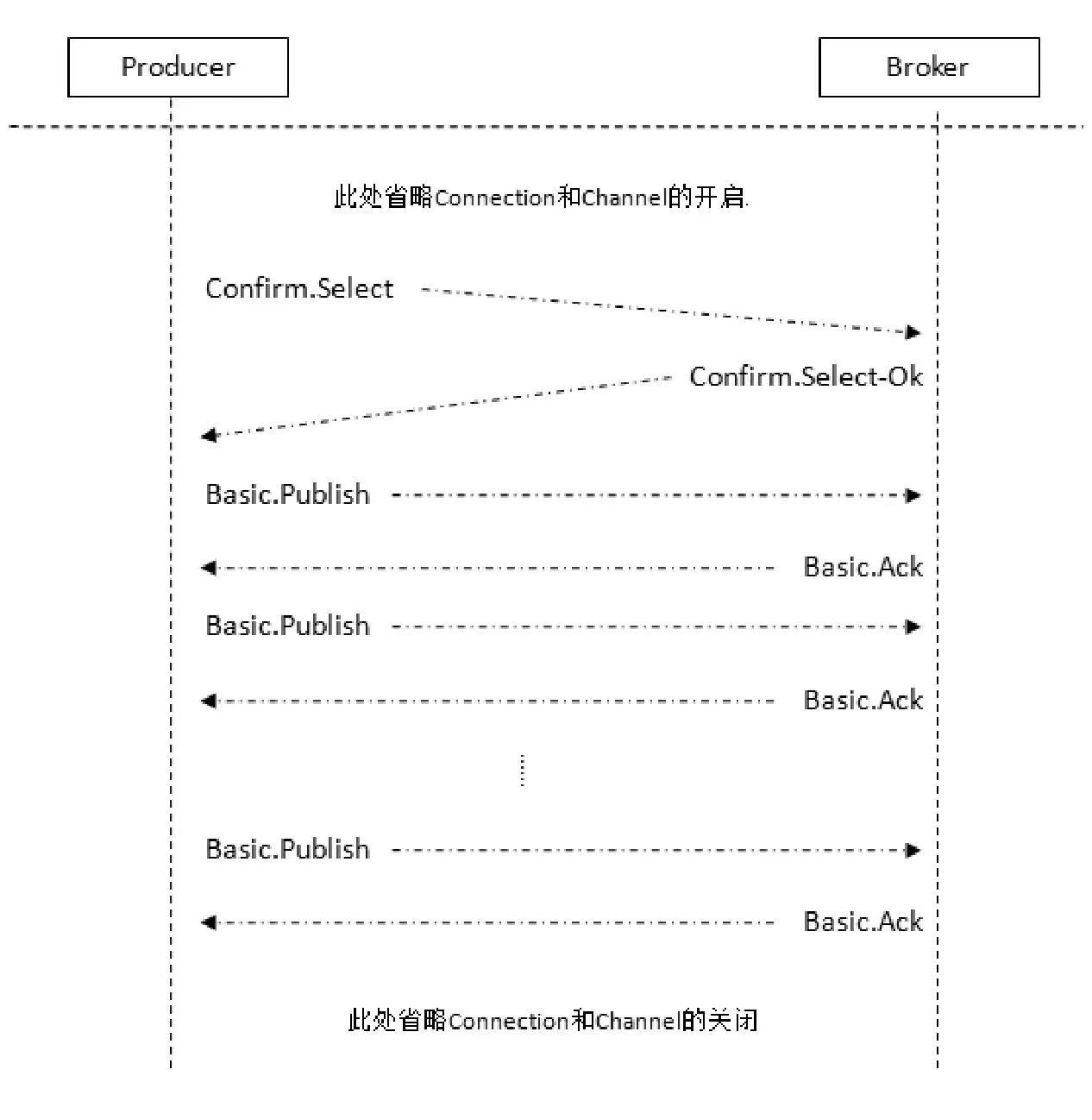
所有被发送的后续消息都被 ack 或者 nack 一次,不会出现一条消息既被 ack 又被 nack 的情况,并且 RabbitMQ 也并没有对消息被 confirm 的快慢做任何保证。
事务机制在一条消息发送之后会使发送端阻塞,以等待 RabbitMQ 的回应,之后才能继续发送下一条消息。相比之下,发送方确认机制最大的好处在于它是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用程序便可以通过回调方法来处理该确认消息。
异步确认的方法:
(1)批量 confirm 方法:每发送一批消息后,调用 channel.waitForConfirms 方法,等待服务器的确认返回。
(2)异步 confirm 方法:提供一个回调方法,服务端确认了一条或者多条消息后客户端会回调这个方法进行处理。
批量 confirm 方法在出现返回 Basic.Nack 或者超时情况时,客户端需要将这一批次的消息全部重发(客户端需要为每一个信道维护一个“unconfirm”的消息序号集合),这会带来明显的重复消息数量,并且当消息经常丢失时,批量 confirm 的性能应该是不升反降的。所以强烈建议使用异步 confirm 方法。
异步 confirm 方法代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 | package mainimport ( "fmt" "github.com/streadway/amqp")func main() { // connect to rabbitmq conn, err := amqp.Dial("amqp://root:shiajun666@192.168.10.4:5672") if err != nil { fmt.Println("Connect to RabbitMQ failed: ", err) return } defer conn.Close() // open a channel ch, err := conn.Channel() if err != nil { fmt.Println("Open channel failed: ", err) return } defer ch.Close() // declare an exchange err = ch.ExchangeDeclare( "con-exchange", //name "direct", //kind true, //durable false, //autoDelete false, //internal false, //noWait nil, //args ) if err != nil { fmt.Println("Declare exchange failed: ", err) return } // declare an queue _, err = ch.QueueDeclare( "con-queue", //name true, //durable false, //autoDelete false, //exclusive false, //noWait nil, //args ) if err != nil { fmt.Println("Declare queue failed: ", err) return } // bind the exchange with the queue err = ch.QueueBind( "con-queue", //name "confirm", //key "con-exchange", //exchange false, //noWait nil, //args ) if err != nil { fmt.Println("Bind the exchange with the queue failed: ", err) return } // put the channel into confirm mode err = ch.Confirm(false) if err != nil { fmt.Println("Put the channel into confirm mode failed: ", err) return } msgNum := 10 // registers a confirmation listener confirmCh := ch.NotifyPublish(make(chan amqp.Confirmation, msgNum)) // receive confirmations go func() { for { select { case confirmation := <-confirmCh: if confirmation.Ack { fmt.Printf("Message[DeliveryTag:%d] publish success\n", confirmation.DeliveryTag) } else { fmt.Printf("Message[DeliveryTag:%d] publish failed\n", confirmation.DeliveryTag) } } } }() // send messages msgCount := 0 for msgCount < msgNum { err = ch.Publish( "con-exchange", //exchange "confirm", //key false, //mandatory false, //immediate amqp.Publishing{ //msg ContentType: "text/plain", DeliveryMode: amqp.Persistent, Body: []byte(fmt.Sprintf("Hello World - %d", msgCount)), }, ) if err != nil { fmt.Printf("Send message - %d failed: %v", msgCount, err) continue } fmt.Printf("Send message - %d success\n", msgCount) msgCount++ } for { select {} }} |
首先调用 Channel.Confirm() 将当前信道设置为 confirm(确认)模式,然后调用 Channel.NotifyPublish() 注册确认信息监听,最后在单独的一个 goroutine 中接收 RabbitMQ 返回的发布确认信息。监听的 Channel 会随着信道的关闭而关闭。
注:
事务机制和 publisher confirm 机制两者是互斥的,不能共存。
发布确认信息返回的顺序与消息发布顺序不一定是一致的。
监听的 Channel 容量不能小于发布消息的数量,否则若在确认过程中对连接或信道做其他操作,将会导致死锁。
事务机制和 publisher confirm 机制确保的是消息能够正确地发送至 RabbitMQ,这里的“发送至RabbitMQ” 的含义是指消息被正确地发往至 RabbitMQ 的交换器,如果此交换器没有匹配的队列,那么消息也会丢失。所以在使用这两种机制的时候要确保所涉及的交换器能够有匹配的队列。更进一步地讲,发送方要配合 mandatory 参数或者备份交换器一起使用来提高消息传输的可靠性。
三、消费端要点
1. 消息分发控制
当 RabbitMQ 队列拥有多个消费者时,队列收到的消息将以轮询(round-robin)的分发方式发送给消费者。每条消息只会发送给订阅列表里的一个消费者。
但轮询的分发方式有个弊端,那就是 RabbitMQ 不关心各个消费者处理消息的进度情况,总是将消息平均分发到每一个消费者,这样会造成整体应用吞吐量下降。想要解决这个问题,可以调用 Channel.Qos() 设置信道上的消费者所能保持的最大未确认消息的数量,函数原型为:
func (ch *Channel) Qos(prefetchCount, prefetchSize int, global bool) error
参数解析:
prefetchCount:消费者所能保持的最大未确认消息的数量。0 表示没有上限。
prefetchSize:消费者所能保持的未确认消息的总体大小。0 表示没有上限。
global:用于一个信道同时消费多个队列的情况,具体规则如下:

调用 Channel.Qos() 以后,RabbitMQ 会保存一个消费者的列表,每发送一条消息都会为对应的消费者计数,如果达到了所设定的上限,那么 RabbitMQ 就不会向这个消费者再发送任何消息。直到消费者确认了某条消息之后,RabbitMQ 将相应的计数减1,之后消费者可以继续接收消息,直到再次到达计数上限。
当个某个信道同时消费多个队列,且设置了 prefetchCount 大于0时,这个信道需要和各个队列协调以确保发送的消息都没有超过所限定的 prefetchCount 的值,这样会使 RabbitMQ 的性能降低,尤其是这些队列分散在集群中的多个 Broker 节点之中。同时,如果在订阅消息之前,既设置了 global 为 true 的限制,又设置了 global 为 false 的限制,也会增加 RabbitMQ 的负载,因为 RabbitMQ 需要更多的资源来协调完成这些限制。如无特殊需要,最好只使用 global 为 false 的设置,这也是默认的设置。
Channel.Qos() 只对推模式的消费方式有效,对拉模式的消费方式无效。
2. 消息顺序性
RabbitMQ 无法保证消费者消费到的消息和发送者发布的消息的顺序是一致的。
如果要保证消息的顺序性,需要业务方使用 RabbitMQ 之后做进一步的处理,比如在消息体内添加全局有序标识(类似Sequence ID)来实现。
四、总结:RabbitMQ 消息传输全链路可靠性保障方案
RabbitMQ 消息传输的完整链路为:生产者 -> RabbitMQ 交换器 -> RabbitMQ 队列 -> 消费者,为了保证整个传输过程的可靠性,需要在传输链路的各个环节都做好可靠性保障。
1. 生产者 -> RabbitMQ 交换器
为了确保消息从生产者到达 RabbitMQ 交换器,可引入事务机制或发送方确认机制,根据 RabbitMQ 的确认返回来确认每个消息是否发送成功,然后对发送失败的消息进行重试。
为保证消息发布的吞吐量,推荐使用较为轻量级的发送方确认机制,先调用 Channel.Confirm() 将当前信道设置为 confirm(确认)模式,然后调用 Channel.NotifyPublish() 异步监听 RabbitMQ 返回的确认信息。
2. RabbitMQ 交换器 -> RabbitMQ 队列
首先,确保交换器绑定了队列,且 Binding Key 与 Routing Key 匹配,这样消息才能成功路由到队列。
其次,当发生消息无法被路由到合适队列的情况,需要采取措施将消息返回或保存起来,方案有二:
(1)生产者调用 Channel.Publish() 发布消息时,设置 mandatory 为 true,这样消息无法路由时能返回给生产者。同时生产者需要调用 Channel.NotifyReturn() 添加监听器,获取到没有被正确路由到合适队列的消息。
(2)为交换器设置备份交换器(alternate-exchange),备份交换器绑定队列,这样消息无法路由时会被路由并保存到备份交换器绑定的队列中,不至丢失消息数据。
3. RabbitMQ 队列
首先,设置交换器、队列、消息持久化,降低 RabbitMQ 关闭或重启导致消息数据丢失的概率。
其次,为关键业务的消息队列设置镜像队列,防止队列挂掉,消息数据未刷盘而丢失。相当于配置了副本,如果主节点(master)在此特殊时间内挂掉,可以自动切换到从节点(slave)。
最后,为消息队列设置死信交换器(x-dead-letter-exchange),绑定死信队列,在消息过期,或被拒收,或消息队列达到最大长度时,消息能存入死信队列中,不至丢失。
4. RabbitMQ 队列 -> 消费者
消费者调用 Channel.Consume() 消费消息时,设置 autoAck 为 false,不自动确认消息,处理完业务逻辑后再手动调用 Delivery.Ack() 向 RabbitMQ 确认已收到消息,RabbitMQ 再删除消息。
为了提高应用可靠性与吞吐量,可以让多个消费者消费同一个队列,利用 RabbitMQ 的轮询分发机制在多个消费者之间实现负载均衡,并通过 Channel.Qos() 设置每个消费者能保持未确认的最大消息数量,根据各个消费者的消费进度情况进行分发,弥补轮询分发机制的不足。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2019-09-30 go读写excel文件
2019-09-30 go读写文本文件
2019-09-30 排序算法