


图的增删、遍历与应用实现
本文主要以一个带权有向图为例,讲解图相关的一些算法实现(Go语言),包括图的顶点和边的插入与删除操作,还有图的深度优先遍历和广度优先遍历,以及图的一些引申应用:最小生成树、从源点到其余各点的最短路径、拓扑排序。
一、图的概念
图是由顶点集合及顶点间的关系(边)集合组成的一种数据结构。
关于图的更多基本术语的概念可以参考:https://www.jianshu.com/p/d9ca383e2bd8
二、图的存储表示
图的存储表示形式有两种:邻接矩阵、邻接表,下面分别是这两种存储表示形式的示例。
一个无向图的邻接矩阵表示示例如下:
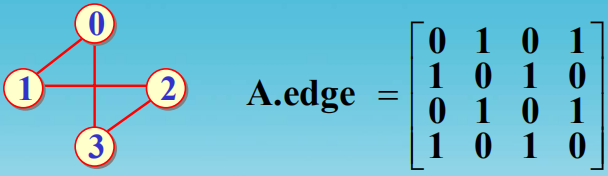
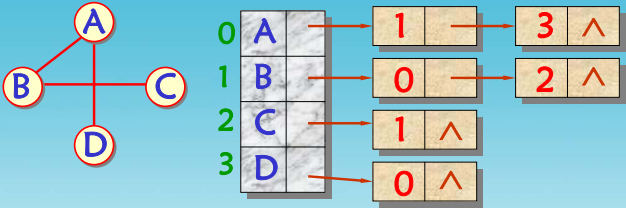
一个无向图的邻接表表示示例如下:
本文主要以一个带权有向图为例,使用邻接表进行存储表示,代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | /*** 带权有向图顶点数组节点结构**/type VertexArrayNode struct { data byte //顶点数据 link *EdgeListNode //出边链表}/*** 带权有向图出边链表节点结构**/type EdgeListNode struct { vertexArrayIndex int //顶点数组索引 weight int //权重值 next *EdgeListNode //下一个指向节点}/*** 带权有向图结构**/type ListGraph struct { slice []*VertexArrayNode //顶点数组 size int //顶点数量}/*** 创建空带权有向图**/func NewListGraph() *ListGraph { return &ListGraph{ slice: make([]*VertexArrayNode, 10), size: 0, }}/*** 打印**/func (lg *ListGraph) Print() { for i := 0; i < lg.size; i++ { fmt.Print(string(lg.slice[i].data), ": (") ptr := lg.slice[i].link for ptr != nil { fmt.Print("index:", ptr.vertexArrayIndex, ",weight:", ptr.weight, " ") ptr = ptr.next } fmt.Println(")") }} |
三、图的顶点和边的插入与删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 | /*** 插入顶点**/func (lg *ListGraph) InsertVertex(data byte) error { if lg.VertexIndex(data) != -1 { return errors.New("节点已存在") } vertex := &VertexArrayNode{data: data} lg.size++ if lg.size <= len(lg.slice) { lg.slice[lg.size-1] = vertex } else { lg.slice = append(lg.slice, vertex) } return nil}/*** 删除顶点**/func (lg *ListGraph) RemoveVertex(data byte) error { index := lg.VertexIndex(data) if index == -1 { return errors.New("节点不存在") } for i := index + 1; i < lg.size; i++ { lg.slice[i-1] = lg.slice[i] } lg.size-- return nil}/*** 插入边**/func (lg *ListGraph) InsertEdge(from byte, to byte, weight int) error { fromIndex := lg.VertexIndex(from) toIndex := lg.VertexIndex(to) if fromIndex == -1 || toIndex == -1 { return errors.New("边节点不存在") } ptr := lg.slice[fromIndex].link for ptr != nil { if ptr.vertexArrayIndex == toIndex { return errors.New("边已存在") } ptr = ptr.next } elNode := &EdgeListNode{ vertexArrayIndex: toIndex, weight: weight, next: lg.slice[fromIndex].link, } lg.slice[fromIndex].link = elNode return nil}/*** 删除边**/func (lg *ListGraph) RemoveEdge(from byte, to byte) error { fromIndex := lg.VertexIndex(from) toIndex := lg.VertexIndex(to) if fromIndex == -1 || toIndex == -1 { return errors.New("边节点不存在") } ptr := lg.slice[fromIndex].link parent := lg.slice[fromIndex].link for ptr != nil { if ptr.vertexArrayIndex == toIndex { if parent == ptr { lg.slice[fromIndex].link = ptr.next } else { parent.next = ptr.next } } parent = ptr ptr = ptr.next } return errors.New("边不存在")}/*** 返回某个节点的索引**/func (lg *ListGraph) VertexIndex(data byte) int { for i := 0; i < lg.size; i++ { if lg.slice[i].data == data { return i } } return -1} |
四、图的遍历
1. 深度优先遍历
算法描述:
(1)在访问图中某一起始顶点V后,由V出发,访问它的任一邻接顶点W1;再从W1出发,访问与W1邻接但还没有访问过的顶点W2;然后再从W2出发,进行类似的访问操作,一直执行下去,直到到达所有邻接顶点都已被访问过的顶点U为止。
(2)接着,往回退一步,退到前一次刚访问过的顶点,看看是否还有其它没有被访问过的邻接顶点。如果有,则访问此顶点,然后以此顶点为起始顶点进行(1)操作;如果没有,就再往回退一步进行搜索。
(3)重复(1)和(2),直到连通图中所有顶点都被访问过为止。
此过程为递归过程。
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | /*** 深度优先遍历**/func (lg *ListGraph) Dfs(start byte) { index := lg.VertexIndex(start) if index == -1 { fmt.Println("节点不存在:", string(start)) } visited := make([]int, lg.size) //访问标记 lg._dfs(index, visited) fmt.Println()}/*** 深度优先遍历(递归,Dfs方法调用)**/func (lg *ListGraph) _dfs(startIndex int, visited []int) { if visited[startIndex] == 1 { //避免重复访问 return } fmt.Print(string(lg.slice[startIndex].data), " ") visited[startIndex] = 1 ptr := lg.slice[startIndex].link for ptr != nil { lg._dfs(ptr.vertexArrayIndex, visited) ptr = ptr.next }} |
2. 广度优先遍历
算法描述:
在访问了起始顶点V之后,由V出发,依次访问V的各个未被访问过的邻接顶点W1,W2,...,然后再顺序访问W1,W2,...的所有还未被访问过的邻接顶点。再从这些访问过的顶点出发,访问它们的所有还未被访问过的邻接顶点,...一直执行,直到图中所有顶点都被访问过为止。
此过程是一种分层的搜索过程,不是递归过程,每向前走一步可能访问多个顶点,所以需要使用一个队列来存放依次访问的顶点。
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | /*** 广度优先遍历**/func (lg *ListGraph) Bfs(start byte) { index := lg.VertexIndex(start) if index == -1 { fmt.Println("节点不存在:", string(start)) } visited := make([]int, lg.size) //访问标记 lq := listQueue.NewListQueue() //链表队列 lq.Push(index) for !lq.IsEmpty() { index, _ := lq.Pop() if visited[index] == 1 { //已经访问过 continue } fmt.Print(string(lg.slice[index].data), " ") visited[index] = 1 ptr := lg.slice[index].link for ptr != nil { lq.Push(ptr.vertexArrayIndex) ptr = ptr.next } } fmt.Println()} |
上面代码中使用的链表队列在我的另一篇博文有讲解:https://www.cnblogs.com/wujuntian/p/12263763.html,这里直接使用这个包。
五、最小生成树
在有n个顶点的带权值的网结构图中,选取n-1条边,使得将图中所有顶点连接起来的权值和最低。把构造连通网的最小代价生成树称为最小生成树。最小生成树的实现有两种经典算法。
1. 普里姆算法
基本思想:
从顶点入手找边
算法描述:
(1)将所有顶点分组,出发点为第一组,其余所有节点为第二组。
(2)在一端属于第一组,另一端属于第二组的边中选择一条权值最小的。
(3)把这条边中原属于第二组的节点放入第一组中。
(4)重复(2)和(3),直到第二组节点为空为止。
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | /*** 最小生成树(普里姆算法)**/func (lg *ListGraph) MinSpanTree_Prim(start byte) { index := lg.VertexIndex(start) if index == -1 { fmt.Println("节点不存在:", string(start)) } visited := make([]int, lg.size) //访问标记 visited[index] = 1 count := 0 //已找到的边数 var minIndex int var minFrom, minTo byte type fromTo struct { from byte to byte weight int } edges := make([]fromTo, lg.size-1) //最小生成树的所有边 for count < lg.size-1 { //需要找到lg.size-1条边 minWeight := 32767 for i := 0; i < lg.size; i++ { //从已访问过的节点找到通向未访问过的节点的最小权值路径 if visited[i] == 0 { continue } ptr := lg.slice[i].link for ptr != nil { if visited[ptr.vertexArrayIndex] == 0 && ptr.weight < minWeight { minWeight = ptr.weight minIndex = ptr.vertexArrayIndex minFrom = lg.slice[i].data minTo = lg.slice[ptr.vertexArrayIndex].data } ptr = ptr.next } } visited[minIndex] = 1 edges[count] = fromTo{ from: minFrom, to: minTo, weight: minWeight, } count++ } sumWeight := 0 fmt.Println("最小生成树所有边:") for i := 0; i < count; i++ { fmt.Println("from:", string(edges[i].from), ", to:", string(edges[i].to), ", weight:", edges[i].weight) sumWeight += edges[i].weight } fmt.Println("最小生成树路径权值和:", sumWeight)} |
2. 克鲁斯卡尔算法
基本思想:
从边入手找顶点
算法描述:
(1)先构造一个只有n个顶点的子图SG。
(2)然后从权值最小的边开始,若它的加入不使SG中产生回路,则在SG上加上这条边。
(3)反复执行第二步,直至加上n-1条边为止。
六、从源点到其余各点的最短路径
1. 问题描述
给定一个带权有向图D与源点V,求从V到D中其它顶点的最短路径。
2. 算法描述
(1)将从V到其所有邻接顶点的边的权值作为从V到其所有邻接节点的路径值,不邻接的顶点的路径值暂时初始化为正无穷大。
(2)从(1)中得到的所有路径值中选取一个最小值min,设其对应的顶点为W,则V到W的最短路径已确定。
(3)从W出发,遍历其邻接的顶点W1,W2,...,若min+W到W1的边的权值<V到W1路径值,则更新V到W1的路径值为min+W到W1的边的权值。
(4)重复(2)和(3),直至V到其它所有顶点的最短路径都已确定。
3. 代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | /*** 从源点到其余各点的最短路径**/func (lg *ListGraph) ShortestPath(start byte) { index := lg.VertexIndex(start) if index == -1 { fmt.Println("节点不存在:", string(start)) } weights := make([]int, lg.size) //源点到其余各点的路径长度 //初始化 for i := 0; i < lg.size; i++ { weights[i] = 32767 } weights[index] = 0 ptr := lg.slice[index].link for ptr != nil { weights[ptr.vertexArrayIndex] = ptr.weight ptr = ptr.next } visited := make([]int, lg.size) //已确定最短路径的节点 visited[index] = 1 count := 1 var minIndex int for count < lg.size { //需要确定lg.size个节点的最短路径 minWeight := 32767 for i := 0; i < lg.size; i++ { //找出源点通向节点的最短路径 if weights[i] < minWeight && visited[i] == 0 { minWeight = weights[i] minIndex = i } } visited[minIndex] = 1 //确定节点最短路径 count++ ptr = lg.slice[minIndex].link for ptr != nil { //以此最短路径节点为起点,更新其可以到达的各个节点的最短路径 if minWeight+ptr.weight < weights[ptr.vertexArrayIndex] && visited[ptr.vertexArrayIndex] == 0 { weights[ptr.vertexArrayIndex] = minWeight + ptr.weight } ptr = ptr.next } } for i := 0; i < lg.size; i++ { fmt.Println(string(lg.slice[i].data), ": ", weights[i]) }} |
七、拓扑排序
1. 问题描述
需要完成多个任务,而任务与任务之间存在一定依赖关系,被依赖的任务需要先完成才能执行其它任务,求输出这些任务的一种符合要求的完成顺序。
2. 算法描述
(1)将这些任务作为顶点,任务之间的依赖关系作为有向边,被依赖者指向依赖者,构建一个有向图。
(2)遍历有向图的所有顶点,计算所有顶点的入度,并将入度为0的顶点入栈(这里也可以使用队列)。
(3)出栈一个入度为0的顶点,输出之。
(4)遍历这个顶点的所有邻接顶点,将其邻接顶点的入度都减1,若入度已减为0,则将顶点入栈。
(5)重复(3)和(4),直到出现以下情况之一:
全部顶点都已输出,则拓扑排序完成。
图中还有未输出的顶点,但已没有入度为0的节点,说明有向图中存在环,拓扑排序无法完成。
3. 代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | /*** 拓扑排序**/func (lg *ListGraph) Topological() { pene := make([]int, lg.size) //各个节点的入度 for i := 0; i < lg.size; i++ { //各个节点的入度初始化 ptr := lg.slice[i].link for ptr != nil { pene[ptr.vertexArrayIndex]++ ptr = ptr.next } } as := arrayStack.NewArrayStack() //数组栈 for i := 0; i < lg.size; i++ { //入度为0的节点索引入栈 if pene[i] == 0 { as.Push(i) } } var topoData []byte //拓扑排序序列 for !as.IsEmpty() { index, _ := as.Pop() topoData = append(topoData, lg.slice[index].data) ptr := lg.slice[index].link for ptr != nil { //更新所有到达节点的入度 index = ptr.vertexArrayIndex pene[index]-- if pene[index] == 0 { as.Push(index) } ptr = ptr.next } } if len(topoData) < lg.size { fmt.Println("有向图中存在回路,拓扑排序失败") } else { for i := 0; i < lg.size; i++ { fmt.Print(string(topoData[i]), " ") } }} |
上面代码中使用的数组栈在我的另一篇博文有讲解:https://www.cnblogs.com/wujuntian/p/12263652.html,这里直接使用这个包。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2017-02-11 MySQL索引(2)