---恢复内容开始---
今天在训练时遇到的问题
把损失函数由 MSE 改成 L1 Loss 的时候 Loss 有了明显的下降
以前一直觉得 MSE 相对来说会更好 ,因为求导的话有标签与结果的差值作为系数,相差越大梯度越大。 L1 Loss 梯度都是一样的。
查了一下,看到了另一种说法:
当预测值与目标值相差很大时, 梯度容易爆炸, 因为梯度里包含了x−t. 所以rgb在Fast RCNN里提出了SmoothL1Loss.
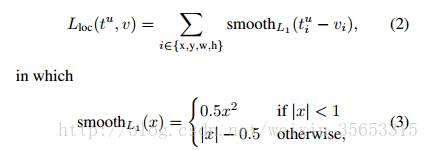
当差值太大时, 原先L2梯度里的x−t被替换成了±1, 这样就避免了梯度爆炸, 也就是它更加健壮.
这。。。。应该就是原因吧
---恢复内容结束---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号