NLP文本分类
 因为目前有在做涉及到文本分析(情感分析)的项目,也想为以后的相关项目做下知识储备,最近开始入坑Tensorflow的一些深度学习的NLP相关实践,同时学习了文本分类领域中基于深度学习的模型的一些应用知识(然而还是个菜鸟,半懂不懂的哈哈哈)。这里对相关知识进行了总结,巩固个人知识体系,同时分享给大家~
因为目前有在做涉及到文本分析(情感分析)的项目,也想为以后的相关项目做下知识储备,最近开始入坑Tensorflow的一些深度学习的NLP相关实践,同时学习了文本分类领域中基于深度学习的模型的一些应用知识(然而还是个菜鸟,半懂不懂的哈哈哈)。这里对相关知识进行了总结,巩固个人知识体系,同时分享给大家~
引言
其实最近挺纠结的,有一点点焦虑,因为自己一直都期望往自然语言处理的方向发展,梦想成为一名NLP算法工程师,也正是我喜欢的事,而不是为了生存而工作。我觉得这也是我这辈子为数不多的剩下的可以自己去追求自己喜欢的东西的机会了。然而现实很残酷,大部分的公司算法工程师一般都是名牌大学,硕士起招,如同一个跨不过的门槛,让人望而却步,即使我觉得可能这个方向以后的路并不如其他的唾手可得的路轻松,但我的心中却一直有一股信念让我义无反顾,不管怎样,梦还是要有的,万一实现了呢~ 
扯得有点远了hhh,回到文章,因为目前有在做涉及到文本分析(情感分析)的项目,也想为以后的相关项目做下知识储备,最近开始入坑Tensorflow的一些深度学习的NLP相关实践,同时学习了文本分类领域中基于深度学习的模型的一些应用知识(然而还是个菜鸟,半懂不懂的哈哈哈)。这里对相关知识进行了总结,巩固个人知识体系,同时分享给大家~
(提前声明:菜鸡观点,非大佬观点,欢迎纠正,也会不断修正的)
持续更新........
基于深度学习的文本分类
文本分类领域,目前主要可分为:
- 情感分析
- 新闻分析
- 主题分类
- 问答系统
- 自然语言推理(NLI)
五大领域(当然也有一些其他细分领域,这里不进行讨论)。近几年随着深度学习在自然语言处理领域的应用,文本分类也进入了由深度学习模型所导引的第三个阶段,逐渐超越了基于传统机器学习的方法。
目前,学术界针对文本分类所提出的深度学习模型大致有150多种,根据结构可分为11大类:
- 前馈网络:将文本视为词袋
- 基于RNN的模型:将文本视为一系列单词,旨在捕获文本单词依存关系和文本结构
- 基于CNN的模型:经过训练,可以识别文本分类的文本模式(例如关键短语)。
- 胶囊网络(Capsule networks):解决了CNN在池化操作时所带来的信息丢失问题。
- 注意力机制:可有效识别文本中的相关单词,并已成为开发DL模型的有用工具。
- 内存增强网络:将神经网络与某种外部存储器结合在一起,该模型可以读取和写入。
- 图神经网络:旨在捕获自然语言的内部图结构,例如句法和语义解析树。
- 暹罗神经网络(Siamese):专门用于文本匹配,这是文本分类的特殊情况。
- 混合模型(Hybrid models):结合了注意力,RNN,CNN等以捕获句子和文档的局部和全局特征。
- Transformers:比RNN拥有更多并行处理,从而可以使用GPU高效的(预)训练非常大的语言模型。
- 监督学习之外的建模技术:包括使用自动编码器和对抗训练的无监督学习,以及强化学习。
阿巴阿巴,如果看不太懂也没关系,我也只认识比较经典的几个hhh,但是可以了解下做储备嘛,也许哪一天就接触到了呢~下面这张图是2013年至2020年发布的一些很经典的深度学习文本嵌入和分类模型。我们可以看到入门的word2vec在2013年就已经提出来了,还有当下比较热门的Tree-LSTM、BERT也是前几年提出来的,的确是更新很快啊emmmm...
如何选择合适的神经网络模型
我们在针对文本分类任务选择最佳的神经网络结构时,常常会很迷茫,像我这种菜鸟就是百度下哪个模型社区比较火就用大佬们的代码来复现hhh(当然使用比较多也说明这个模型的性能和适用性不会太差)。老师常说,其实要多试,采用精度最高的。呜呜呜,然而现实是前期用来做精度验证的数据集的标注就是一个很大的工程量了,然后每一个模型的实现也.....很!复!杂!啊!超级烧脑,毕竟神经网络的构建可不是传统机器学习算法那样调一两个参数就好了~
当然,多试肯定是要多试的,但是我们应该有选择性的试,那么,初步的筛选、确定模型的类别就很重要了,这一点其实很靠经验,我这个菜鸡就不教坏大家了,我们来看下大佬的官方思路:
神经网络结构的选择取决于目标任务和领域,领域内标签的可用性,应用程序的延迟和容量限制等,这些导致选择差异会很大。尽管毫无疑问,开发一个文本分类器是反复试错的过程,但通过在公共基准(例如GLUE )上分析最近的结果,我们提出了以下方法来简化该过程,该过程包括五个步骤:
- 选择PLM(PLM,pretraining language model预训练语言模型):使用PLM可以显着改善所有流行的文本分类任务,并且自动编码的PLM(例如BERT或RoBERTa)通常比自回归PLM(例如OpenAI GPT)更好。Hugging face拥有为各种任务开发的丰富的PLM仓库。
- 领域适应性:大多数PLM在通用领域的文本语料库(例如Web)上训练。如果目标领域与通用的领域有很大的不同,我们可以考虑使用领域内的数据,不断地预训练该PLM来调整PLM。对于具有大量未标记文本的领域数据,例如生物医学,从头开始进行语言模型的预先训练也可能是一个不错的选择。
- 特定于任务的模型设计:给定输入文本,PLM在上下文表示中产生向量序列。然后,在顶部添加一个或多个特定任务的层,以生成目标任务的最终输出。特定任务层的体系结构的选择取决于任务的性质,例如,需要捕获文本的语言结构。比如,前馈神经网络将文本视为词袋,RNN可以捕获单词顺序,CNN擅长识别诸如关键短语之类的模式,注意力机制可以有效地识别文本中的相关单词,而暹罗神经网络则可以用于文本匹配任务,如果自然语言的图形结构(例如,分析树)对目标任务有用,那么GNN可能是一个不错的选择。
- 特定于任务的微调整:根据领域内标签的可用性,可以使用固定的PLM单独训练特定任务的层,也可以与PLM一起训练特定任务的层。如果需要构建多个相似的文本分类器(例如,针对不同领域的新闻分类器),则多任务微调是利用相似领域的标记数据的好选择。
- 模型压缩:PLM成本很高。它们通常需要通过例如知识蒸馏进行压缩,以满足实际应用中的延迟和容量限制。
是不是看不懂了,我摊牌了,第一遍读完我整个人都是懵的,然后又仔细读了两遍,好像懂了一点点,又百度了一些专业名词,又懂了一丢丢了,但还是懂一半啊哈哈哈哈。估计要真正走一遍流程之后采用完全解读吧!等之后有时间实践一遍我再重新更新解读一下!
模型性能分析
当下常用的用于评估文本分类模型性能的指标,以下介绍4种:
-
准确率和错误率(Accuracy and Error Rate):评估分类模型质量的主要指标,是从整体角度出发的。假设TP,FP,TN,FN分别表示真积极,假积极,真消极和假消极,𝑁为样本总数。分类精度和错误率在等式中定义如下:
- Accuracy=(TP+TN)/N
- Error Rate=(FP+FN)/N
- Error Rate= 1-Accuracy
-
精度/召回率/ F1分数(Precision / Recall / F1 score):也是主要指标,针对于预测结果而言的。F1分数是精度和查全率的调和平均值。一般情况下用于单个分类类别样本的验证,对于多类别分类问题,也可以为每个类别标签计算精度和召回率,并分析类别标签上的各个性能,或者对这些值取平均值以获取整体精度和召回率。F1较高说明模型比较理想。
- Precision = TP/(TP+FP)
- Recall = TP/(TP+TN)
- F1 score = 2Precision*Recall/(Precision+Recall)
-
Exact Match(EM):精确匹配度量标准是问答系统的一种流行度量标准,它可以测量与任何一个基本事实答案均精确匹配的预测百分比。EM是用于SQuAD的主要指标之一。
-
Mean Reciprocal Rank(MRR):MRR通常用于评估NLP任务中的排名算法的性能,例如查询文档排名和QA。𝑄是所有可能答案的集合,ranki是真相答案的排名位置。
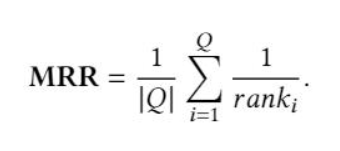
- 其他广泛使用的指标包括平均精度Mean Average Precision(MAP),曲线下面积 Area Under Curve(AUC),错误发现率False DiscoveryRate,错误遗漏率False Omission Rate,仅举几例。
相关的定义百度很多hhh,这里有几个点是我在学习过程中注意到的:
- 很多人会把Accuracy和Precision搞混,虽然中文转换过来经常回混用,但切记这是两个不同的东西,一个时相对整体的指标,一个是相对于预测结果的。
- 一般情况下,查准率(精度)和查全率(召回率)不能同时提高。这是很多人都不太会注意的点,所以解释一下,一般当查准率比较低时,我们会提高阈值,即减少输入的测试样本,从而保证模型预测出的正例都是真实的正例,很明显这个时候虽然查准率提高了,但我输入的总测试样本减少了,导致有些样本你本来可以正确预测的,但你并没有输入。这个就是提高 Precision 而导致 Recall 降低的过程,你也可以反过来,得到的就是提高 Recall 而导致 Precision 降低的过程。所以,一般Precision高,Recall低;Recall低高,Precision低
- P-R曲线问题,这里贴一张在网上淘到的某位大佬的笔记hhh,所以就截图放进来了,讲的很透彻:

当然深度学习模型性能分析除了使用常用的评估文本分类模型性能的指标进行评估外,还可以与传统的机器学习算法或其他非深度学习模型指标进行一个对比,进一步来凸显性能的提升。
看法:机遇与挑战
深度学习其实是一个很早前提出来的东西,却在近几年火得一塌糊涂,不仅源于相关理论、硬件条件的发展,当然也源于其强大的应用成效。借助深度学习模型,CV和NLP的相关领域也取得了很大的进步。前沿、先进的新颖思路也层出不穷,如神经嵌入,注意力机制,自我注意力,Transformer,BERT和XLNet,这些思想导致了过去十年的快速发展。在这方面,国内其实做的还不够完善,相比于国外大量成熟的落地项目和开源工具。然而,由于中文语言的特殊性,我们也看到中文自然语言处理,中文文本分析还具有很大的发展改善空间。很多公司也开拓了中文文本分析的一站式业务,并致力于 提升其适用性和精确度。
缺少大规模的中文领域数据集,这是我在中文自然语言探索时所发现的一个国内学术的重大缺失,这在一定程度上也抑制了一些相关领域的发展,同时也难以形成一个微细分通用领域的模型评测度量,这也导致了很多小型团队的研究成果也难以推广。在这个基础上,针对更具挑战性的文本分类任务构建新的数据集,例如具有多步推理的QA,针对多语言文档的文本分类,用于极长的文档的文本分类也将成为下一个中文文本分析领域飞速发展的突破口。(仅代表个人观点hhh)
除此之外,因为目前大多数的深度学习模型是受监督类型,所以需要大量的领域标注文本,需要大量人力和时间成本的投入,虽然目前已经有了少量学习和零学习Few-Shot and Zero-Shot Learning概念的提出,但仍不够成熟,如何更好地、较为平衡地降低模型的输入成本是一个下一个待解决的问题。
增加对常识知识进行建模的探索。在这一点上,领域知识图谱的构建是一个重要的分支。结合知识图谱进行深度学习,进而提高模型性能的能力,在提高解释性的同时,无疑也增加了机器对语义的理解,这和人的思维是很接近的,而不只是一个不可预测的黑箱模型。在此基础上,实现以人们类似的思维方式基于对未知数的“默认”假设进行推理,而不只是依赖于数字模型。目前,知识图谱构建的研究在国内已经有了大量的探索,趋向一个较为成熟的阶段,而结合知识图谱进行深度学习的研究却鲜有团队进行探索,或者说在萌芽阶段(如果没记错大部分是基于图数据库的深度学习),至少还没有较为著名的开源项目(可能是我没发现哈哈哈)。
黑箱模型的深层探索。虽然深度学习模型在具有挑战性的基准上取得了可喜的性能,但是其中大多数模型都是无法解释的。例如,为什么一个模型在一个数据集上胜过另一个模型,而在其他数据集上却表现不佳?深度学习模型究竟学到了什么?能在给定的数据集上达到一定精度的最小神经网络架构是什么?尽管注意力和自我注意力机制为回答这些问题提供了一些见识,但仍缺乏对这些模型的基本行为和动力学的详细研究。更好地了解这些模型的理论方面可以帮助开发针对各种文本分析场景的更好的模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号