

MySQL使用规范
MySQL使用规范
explain:
这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。
expain出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra

|
列
|
列值
|
说明
|
|||||
|
SIMPLE
|
简单SELECT,不使用UNION或子查询等
|
||||||
|
PRIMARY
|
子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY
|
||||||
|
UNION
|
UNION中的第二个或后面的SELECT语句
|
||||||
|
select_type
|
DEPENDENT UNION
|
UNION中的第二个或后面的SELECT语句,取决于外面的查询
|
|||||
|
UNION RESULT
|
UNION的结果,union语句中第二个select开始后面所有select
|
||||||
|
SUBQUERY
|
子查询中的第一个SELECT,结果不依赖于外部查询
|
||||||
|
DEPENDENT SUBQUERY
|
子查询中的第一个SELECT,依赖于外部查询
|
||||||
|
DERIVED
|
派生表的SELECT, FROM子句的子查询
|
||||||
|
UNCACHEABLE SUBQUERY
|
一个子查询的结果不能被缓存,必须重新评估外链接的第一行
|
||||||
|
all
|
Full Table Scan, MySQL将遍历全表以找到匹配的行
|
||||||
|
index
|
Full Index Scan,index与ALL区别为index类型只遍历索引树
|
||||||
|
type
|
range
|
只检索给定范围的行,使用一个索引来选择行
|
依次从最优到最差分别为: system > const > eq_ref > ref > range > index > ALL
|
||||
|
ref
|
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
|
||||||
|
eq_ref
|
类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
|
||||||
|
const、system
|
当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
|
||||||
|
NULL
|
MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
|
||||||
|
rows
|
估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数 这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
|
||||||
|
Using where
|
查询的列未被索引覆盖,where筛选条件非索引的前导列
|
||||||
|
Extra
|
Using temporary
|
||||||
|
Using filesort
|
|||||||
|
Using index
|
查询的列被索引覆盖,并且where筛选条件是索引的前导列,是性能高的表现。一般是使用了覆盖索引(索引包含了所有查询的字段)。对于innodb来说,如果是辅助索引性能会有不少提高
|
能够触发覆盖索引
|
|||||
|
Using index condition
|
表示使用的索引方式为二级检索(非聚簇索引树)
|
降低磁盘IO和CPU计算
一张student表,表设计结构,索引,内容如下图
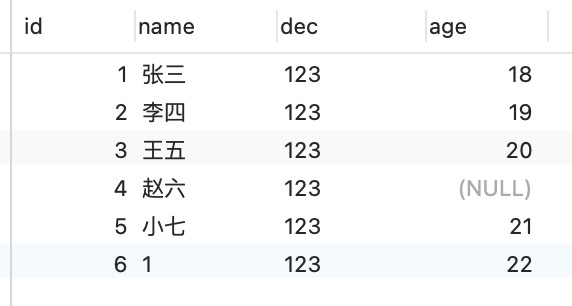
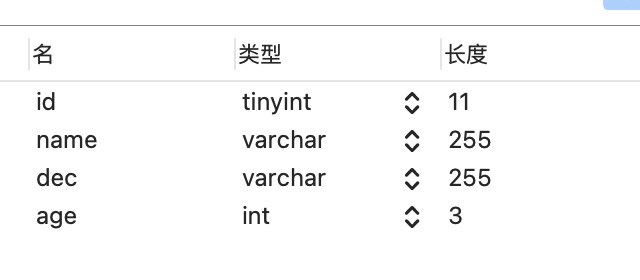

1.尽量不用join,必须要保证字符集属性类型和长度相同,并建立索引
字符集不同会触发全表扫描
2.禁止%开头查询,禁止 != , not in等负向查询,会全表扫描


第一条语句%开头,type类型为ALL,key没有命中索引, rows为6全表扫描,性能会很差。
第二条语句没有%开头, type类型为range, key命中索引, rows为1命中数据,性能会很好。
!=同理
3.字段类型, 与查询字段赋值类型必须相同


name类型为varchar,name=1类型不同,会有强制类型转换;name='1'类型相同。尽管命中了索引,但是第一条语句rows=6,全表扫描。
4.字段必须定义为not null,并提供默认值
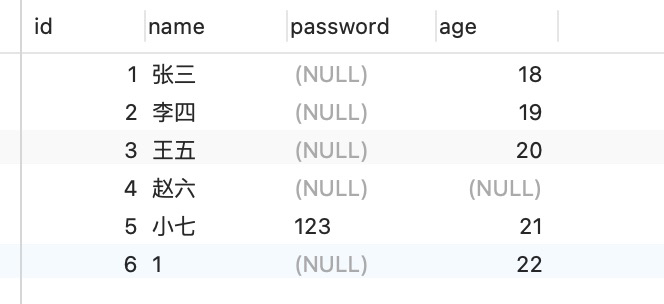
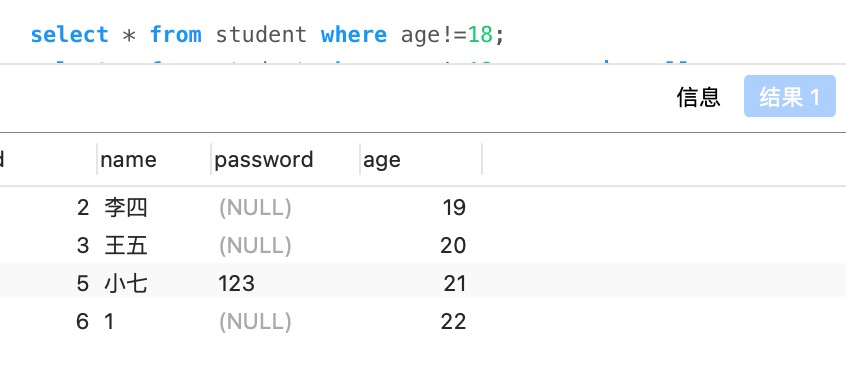
表中6条数据,通过sql查询age!=18的数据,可以预想会有5条数据,然而结果只有四条,漏掉的一条age允许为null
因此得对sql进行改造:
select * from student where age!=18 or age is null;
这样才能查询出默认值为null的数据,此为大坑。
5.禁止在列上进行函数或表达式计算
6.联合索引,区分度最高的放在最左边
过滤大量数据
7.联合索引,列个数不超过5个
降低数据库CPU计算
8.禁止使用外键约束,有服务端保证完整性
9.禁止使用存储过程,视图、触发器、Event
10. 禁止使用 SELECT * 必须使用 SELECT <字段列表> 查询
消耗更多的 CPU 和 IO 以网络带宽资源
无法使用覆盖索引
可减少表结构变更带来的影响
11.orderby, group by ,dictinct要加索引
12. 垂直拆分,将字段短、访问频率高的字段放在一张表内
1)数据库本身有自己的内存缓冲池,以row为单位缓存数据,短row能缓存更多数据
2)高频率访问row,能直接访问缓存池数据,减少访问磁盘
举例:
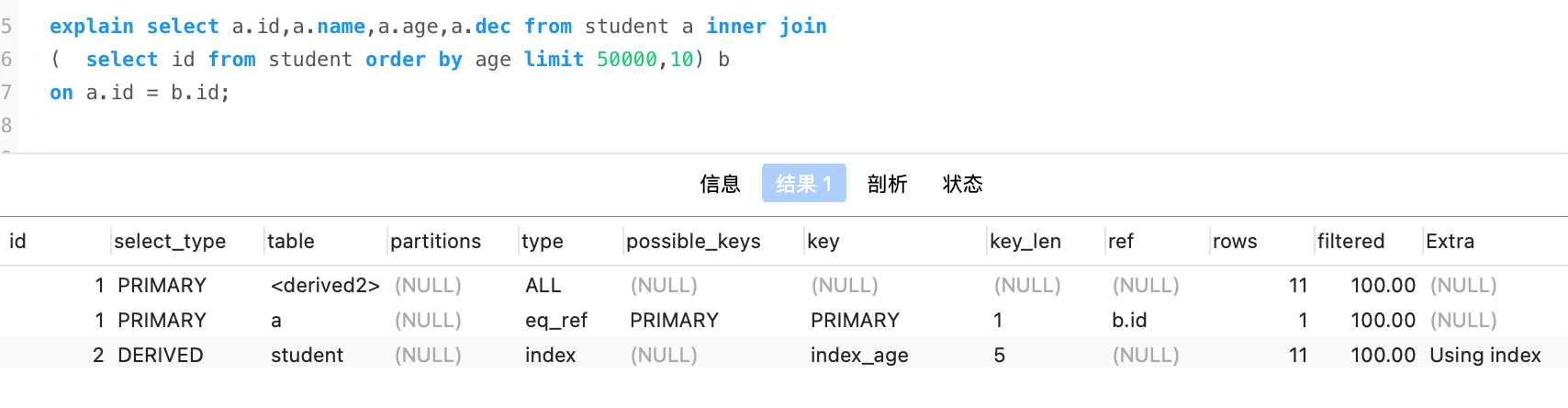
13.分页查询优化
1) select返回列较少或列宽较小的时候,我们可以通过建立复合索引的方式优化分页查
覆盖索引(covering index): 将查询的字段建立到联合索引里面。
此时只有name建立索引,explain结果如下, type为all全表扫描

优化: 通过name,age建立索引,explain结果如下, type为index, extra为Using index

2)select返回列较多或列宽较大的时候,可以先查询非聚簇索引树,在查询聚簇索引树,防止频繁回表操作
必须使用innodb(高并发数据量大)
必须要有注释
必须使用utf8或utf8mb4
数据库和表的字符集统一
禁止select *
不具备扩展性, 表结构会变更, 全部查出来传输字段也过长,需要多少列具体协商查询多少列
insert into 必须制定列
拒绝复杂sql,将大sql拆分多条简单sql
关于innodb和mysiam选型最关键两点:
事务:对一致性帮助很大
行锁: 对提高并发帮助很大
不命中索引,innodb不能用行锁,会走表锁,因为行锁是实现在索引上,而非锁在物理行记录上。
降低数据库磁盘IO
读多写少用缓存
前台后台分离架构
良好SQL
存储和索引
其余规范(线上环境):
禁止在服务器上私自安装mysql客户端来访问数据库
禁止在业务高峰期批量操作
禁止跳过工单跳过审批私自操作线上数据库

