word2vec详解与实战
有那么一句话
不懂word2vec,就别说自己是研究人工智能->机器学习->自然语言处理(NLP)->文本挖掘的
所以接下来我就从头至尾的详细讲解一下word2vec这个东西。
简要介绍
先直接给出维基百科上最权威的解释(大家英语水平够格的话一定要充分理解这个最权威的解释,比国内的某些长篇啰嗦解释简直不知道简洁清楚多少倍!):
Word2vec is a group of related models that are used to produce word embeddings. These models are shallow, two-layer neural networks that are trained to reconstruct linguistic contexts of words. Word2vec takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space. Word vectors are positioned in the vector space such that words that share common contexts in the corpus are located in close proximity to one another in the space.
下面说一说我对word2vec的简要概括:
-
它是Google在2013年开源的一款用于词向量计算的工具
-
word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练
-
该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性
另外简要列出人们容易对word2vec产生的两大误区:
-
很多人误以为word2vec是一种深度学习算法,其实word2vec算法的背后是一个浅层神经网络(正如维基百科所述:These models are shallow, two-layer neural networks)
-
word2vec是一个计算word vector的开源工具,当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。吹毛求疵一点的话,很多人以为word2vec指的是一个算法或模型,其实也是一种谬误。
那么最重要的一点来了,word2vec实际中到底有啥用(外行人士往往最关注的问题!):
- 可以这么说,NLP能够涉及到的应用都可以有word2vec的影子!因为word2vec训练后的词向量是NLP领域的最基础的东西,我们随后可以利用它训练出的词向量来进行相似度比较、分类、推荐等等。换句话说,word2vec在NLP领域里的作用就好比在数学领域里1+1=2的作用,其他方法都是在此基础上进一步实现的,所以你说它重不重要呢!当然NLP领域里还有其他训练词向量的方法,这里先不作介绍了,不能跑题哈!感兴趣的可以自行搜索
词的向量化表示
用词向量来表示词的思想并不是从word2vec出现才开始的,很早之前就有大牛提出来了!主要有两大方式,一种是传统的one-hot representation,另一种的改进高级的distributed represetation。
-
独热表示(one-hot representation)
它是最早最传统的方式,它的基本思想是:词向量维度大小为整个词汇表的大小(整个词汇表中有多少个词,词向量就为多少维),对于每个具体的词汇表中的词,将对应的位置置为1。这里举个例子方便理解,若整个词汇表有5个词(my name is zhang san), 那么 my这个词的向量化就表示为(1,0,0,0,0),is这个词的向量化表示为(0,0,1,0,0),其他以此类推,是不是很好理解!但是one-hot representation有两大缺点:
-
存在维度灾难,即向量维度会随着句子的词数量(整个词汇表大小)的增加而增加,我们的词汇表一般都非常大(百万量级),那么one-hot representation会将没词向量化为百万个0中的一个1,向量稀疏的有些令人发指!
-
存在词汇鸿沟,即任意两个词之间没有联系,one-hot representatio无法表示出语义层面上词汇之间的相关信息,这一点也是非常致命的!
-
-
分布式表示(distributed represetation)
Distributed represetation 可以解决one-hot represetation的缺点,它的基本思想是:通过训练,将词映射为连续稠密的向量。这样我们不仅可以直接刻画词汇之间的相似性,还可以建立一个从向量到概率的平滑函数模型,使得相似的词向量可以映射到相近的概率空间上。
那么如何将稀疏离散的one-hot词向量映射为稠密连续的distributional representation呢?
这里稍微举一个小例子:我们可以构造一个term-document矩阵$ A_: $,矩阵的行$ A_{i,:}$对应着词典里的一个word;矩阵的列$ A_{:,j} $对应着训练语料里的一篇文档;矩阵里的元素$ A_{ij} $代表着word $ w_i $在文档$ D_j $中出现的次数(或频率)。那么,我们就可以根据上述特性利用下面两个方法来提取向量:
-
提取行向量(该词在各个文档中的出现情况)做为该词的语义向量
-
提取列向量(该文档中各个词的出现情况)作为文档的主题向量
类似地,我们还可以构造一个word-context矩阵。这两类矩阵的行向量所计算的相似度有着细微的差异:term-document矩阵会给经常出现在同一篇document里的两个word赋予更高的相似度;而word-context矩阵会给那些有着相同context(上下文)的两个word赋予更高的相似度。后者相对于前者是一种更高阶的相似度,所以应用更加广泛。
不过此方法仍然存在数据稀疏、维度灾难的问题,接下来就需要对矩阵进行降维了(常利用SVD奇异值分解),即将原始的稀疏矩阵分解为两个低秩矩阵乘积的形式,这个我会在之后和大家分享~
有一个有趣的研究表明,训练后的词向量有如下性质:$$ \vec {King} - \vec {Man} + \vec {Woman} = \vec {Queen} $$类似这种的还有许多,多么好的训练结果啊!所以我们一旦得到词向量,我们可以利用它进行很多有趣的研究。那么这么理想的训练结果是怎么训练的呢,接下来就和大家分享两种训练模型~
-
两种原始训练模型
在word2vec出现之前,就已经有用神经网络来训练词向量的了。采用的方法一般是三层神经网络,即输入层、隐藏层、输出层(softmax层),那么他们的输入和输出是怎么定义的呢?这就需要介绍CBOW和Skip-gram这两种模型了。
这两个模型都是直接以得到词向量为目标的模型,它们获取word embedding(Distributed representation)的方式是无监督的,只需要语料本身,而不需要任何标注信息,训练时所使用的监督信息并不来自外部标注。但word2vec之所以引爆了DL(深度学习)在NLP(自然语言处理)中的应用更可能是因为它在语义方面的一些优良性质,比如相似度方面和词类比(word analogy)现象,便于神经网络从它开始继续去提取一些high level的东西,进而去完成复杂的任务。
CBOW(Continuous Bag-of-Words)
对于CBOW模型需要注意以下几点:
-
在CBOW模型中,目标词是一个词串中间的词,其拥有的上下文(context)为前后各n个词(n为设定的窗口大小)。
-
在原始的CBOW模型中,任意一个词将得到两个词向量(word embedding):
-
作为中心词的词向量(输出词向量)
-
作为周围词的词向量(输入词向量)
-
-
词表中每个词的词向量都存在一个矩阵中,即每个词的词向量存储于两个矩阵中(每个词有两套词向量)。输入词矩阵中,其每一列都是一个词作为周围词时的词向量;输出词矩阵中,其每一行都是一个词作为中心词时的词向量。若想取出词作为周围词时的词向量,只要知道词在词表中的编号即可,取出的操作相当于用输入词矩阵乘以词的one-hot representation。
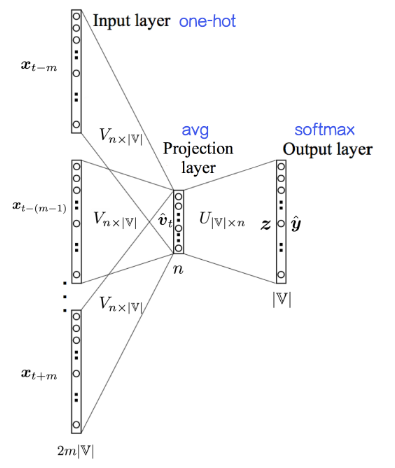
CBOW模型的各层解释(以窗口大小为2为例):
-
输入层:4个节点,上下文共4个词的one-hot represetation
-
输入层到投影层的连接边:输入词矩阵 (将中心词的上下文由one-hot represetation 转化为词向量word embbedding)
-
投影层:1个节点,上下文共4个词的词向量的平均值
CBOW像词袋模型(BoW)一样抛弃了词序信息,然后窗口在语料上滑动,就成了连续词袋(Continuous Bag-of-Words)。丢掉词序看起来不太好,不过这里开个玩笑:“研表究明,汉字的序顺并不定一能影阅响读,事证实明了当你看这完句话之后才发字现都乱是的”。
-
投影层到输出层的连接边:输出词矩阵
-
输出层(softmax层):n个节点(n为整个词汇表大小),每个节点代表中心词是该节点对应词的概率(我们训练的目标是期望训练样本特定词对应的softmax概率最大)
CBOW模型没有隐藏层,投影之后就用softmax()输出目标词是某个词的概率,进而减少了计算时间
这样表述相对清楚,将one-hot到word embedding那一步描述了出来。这里的投影层并没有做任何的非线性激活操作,直接就是Softmax层。换句话说,如果只看投影层到输出层的话,其实就是个Softmax回归模型,但标记信息是词串中心词,而不是外部标注。
Skip-gram
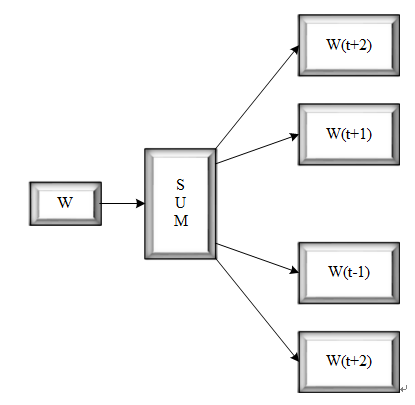
Skip-gram模型就是将CBOW模型反过来,其它完全一样,这里就不再赘述嘞~
下面比较一下两种模型的优缺点:
-
skip-gram比Cbow准确率高,能更好的处理生僻字(即出现频率低的字)。因为在计算时,Cbow会将context word加起来,所以在遇到生僻词时预测效果将会大大降低,而skip-gram则会预测生僻字的使用环境
-
Cbow比skip-gram训练快
词相似度(word analogy)
-
word analogy是一种有趣的现象,可以作为评估词向量的质量的一项任务。
-
word analogy是指训练出的word embedding可以通过加减法操作,来对应某种关系。举个例子$$ \vec {King} - \vec {Man} + \vec {Woman} = \vec {Queen} $$
-
word analogy现象不只存在于语义相似,也存在于语法相似。
两种加速(改进)方法
上面和大家分享了原始的CBOW和Skip-gram模型,但是word2vec并不是直接采用上述原始模型的,因为我们一般的词汇表都是百万量级的,如果采用原始模型就意味着softmax层需要输出这百万量级词汇的各个概率,不太现实啊!所以word2vec进行了如下两种方法的改进。
-
负采样(Negative Sample)
-
哈夫曼树 (Hierarchical Softmax)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号