


插入排序-----希尔排序
希尔排序的实质就是分组插入排序,该方法又称缩小增量排序,因DL.Shell于1959年提出而得名。
希尔排序是不稳定的排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
希尔排序通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了(此时插入排序较快)。
假设有一个很小的数据在一个已按升序排好序的数组的末端。如果用复杂度为O(n^2)的排序(冒泡排序或直接插入排序),可能会进行n次的比较和交换才能将该数据移至正确位置。而希尔排序会用较大的步长移动数据,所以小数据只需进行少数比较和交换即可到正确位置。
思想:希尔排序也是一种插入排序方法,实际上是一种分组插入方法。先取定一个小于n的整数d1作为第一个增量,把表的全部记录分成d1个组,所有距离为d1的倍数的记录放在同一个组中,在各组内进行直接插入排序;然后,取第二个增量d2(<d1),重复上述的分组和排序,直至所取的增量dt=1(dt<dt-1<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
例如:将 n 个记录分成 d 个子序列:
{ R[0], R[d], R[2d],…, R[kd] }
{ R[1], R[1+d], R[1+2d],…,R[1+kd] }
…
{ R[d-1],R[2d-1],R[3d-1],…,R[(k+1)d-1] }
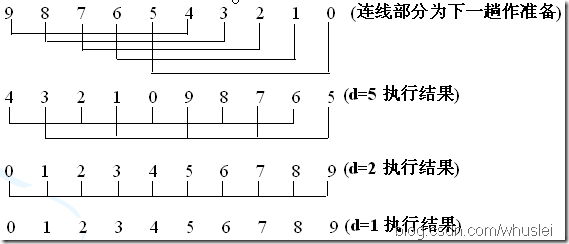
说明:d=5 时,先从A[d]开始向前插入,判断A[d-d],然后A[d+1]与A[(d+1)-d]比较,如此类推,这一回合后将原序列分为d个组。<由后向前>
时间复杂度。
最好情况:由于希尔排序的好坏和步长d的选择有很多关系,因此,目前还没有得出最好的步长如何选择(现在有些比较好的选择了,但不确定是否是最好的)。所以,不知道最好的情况下的算法时间复杂度。
最坏情况下:O(N*logN),最坏的情况下和平均情况下差不多。
平均情况下:O(N*logN)
稳定性。
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。(有个猜测,方便记忆:一般来说,若存在不相邻元素间交换,则很可能是不稳定的排序。)
代码如下:
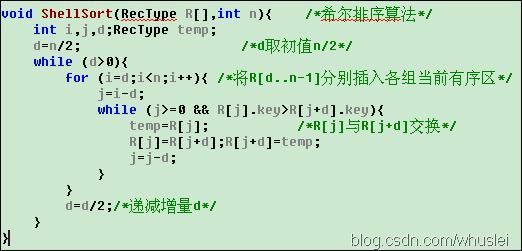
希尔排序的时间复杂度步长的选取有很大关系。上述方法采用的是步长减半的方法,这样其步长增量不互斥,那么小的增量可能根本不起作用。
有两种改进的增量方法:
Hibbard增量序列
D=2^k-1;这样相邻的步长互质
最坏时间复杂度: O(N^3/2)
平均时间复杂度:O(N^5/4) (猜想)
Sedgewick序列增量
{1,5,19,41,109.........}
——9x4^i-9x2^i+1或4^i-3x2^i+1
时间复杂度:
平均时间复杂度:O(N^7/6) (猜想)
最坏时间复杂度:O(N^4/3) (猜想)

