

LEAD:用于无源通用域自适应的学习分解
通用领域适应(UniDA)的目标是在存在协变量和标签转移的情况下进行知识转移。最近,出现了无源通用域适配(SF UniDA),可以在不访问源数据的情况下实现UniDA,由于数据保护政策,这往往更实用。主要的挑战在于确定协变量移位样本是否属于目标私有未知类别。现有的方法通过手工制作阈值或开发耗时的迭代聚类策略来解决这个问题。提出了一种新的学习分解(LEAD)思想,该思想将特征解耦为源已知和未知成分,以识别目标私有数据。从技术上讲,LEAD最初利用正交分解分析进行特征分解。然后,LEAD构建实例级决策边界,以自适应地识别目标私有数据。在各种UniDA场景中进行的广泛实验证明了LEAD的有效性和优越性。值得注意的是,在VisDA数据集的OPDA场景中,LEAD的总体H得分比GLC高出3.5%,并减少了75%的时间来推导伪标签决策边界。此外,LEAD也很有吸引力,因为它是对大多数现有方法的补充。
传统通用域适配(UniDA)和无源通用域适配图(SF-UniDA)学习分解(LEAD),如图3-30所示。

图3-30 传统通用域适配(UniDA)和无源通用域适配图(SF-UniDA)学习分解(LEAD)
在图3-30中,(a)传统通用域适配(UniDA)和无源通用域适配图(SF-UniDA)。传统的UniDA方法需要同时来自源域和目标域的数据。在SF-UniDA中,源数据仅用于预训练。通过利用目标数据和源模型
进行自适应。(b)学习分解(LEAD)框架概述。伪标记是UniDA和SF UniDA的一项重要技术。主要目标是识别与公共标签集关联的目标数据,并排除目标私有标签空间内的数据。与现有的通过手工制作预测阈值或迭代全局聚类来执行私有数据识别的方法不同,从特征分解的角度来解决这个问题。其基本原理是,尽管特征空间可能发生变化,但目标私有数据预计将包含源模型正交补码(源未知)空间中的更多成分。从技术上讲,LEAD首先执行正交分解,将目标特征分解为源已知和未知部分,即

和

,

被认为是私人数据的指标。接下来,LEAD采用双分量高斯混合模型来估计

的分布。此后,LEAD设计了一个名为共同得分

的指标,该指标考虑了到目标原型和源锚点(从

导出)的距离,以促进导出实例级决策边界
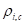
。LEAD提供了一个优雅的解决方案来区分目标私有数据,减少了繁琐的手工阈值调整或对耗时的迭代聚类的依赖。LEAD还可以作为大多数现有SF-UniDA方法的补充方法。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2023-11-23 RISC-V微控制器与嵌入式系统
2022-11-23 RISC-V-HPC市场-汽车电动化分析
2021-11-23 华为八爪鱼自动驾驶云
2020-11-23 在OpenShift平台上验证NVIDIA DGX系统的分布式多节点自动驾驶AI训练
2020-11-23 NVIDIA DRIVE AGX开发工具包
2020-11-23 大数据目标检测推理管道部署