

无监督域自适应的域不可知相互激励
无监督域自适应的域不可知相互激励
传统的无监督域自适应(UDA)致力于最大限度地减少域之间的分布差异,这忽视了从数据中利用丰富的语义,并难以处理复杂的域转换。一种有前景的技术是利用大规模预训练视觉语言模型的知识进行更有指导的适应。尽管做出了一些努力,但当前的方法通常会学习文本提示,分别嵌入源域和目标域的域语义,并在每个域内进行分类,从而限制了跨域知识转移。此外,仅提示语言分支缺乏动态适应两种模式的灵活性。为了弥合这一差距,提出了领域不可知相互提示(DAMP),通过相互对齐视觉和文本嵌入来利用领域不变语义。具体来说,图像上下文信息被用来以领域无关和实例条件化的方式提示语言分支。同时,基于领域无关的文本提示施加视觉提示,以引出领域不变的视觉嵌入。这两个提示分支通过交叉注意力模块相互学习,并通过语义一致性损失和实例区分对比损失进行正则化。在三个UDA基准上的实验证明了DAMP优于最先进的方法。
现有方法和改进方法比较,如图3-28所示。

图3-28 现有方法和改进方法比较
在图3-28中,顶部:现有的基于提示的方法(例如DAPrompt)只学习文本提示来嵌入每个域的语义,并单独执行分类,这限制了跨域知识传递和特征对齐。底部:改进方法相互学习文本和视觉提示,使嵌入的两种方式都保持域不变,从而更好地利用源知识和灵活性对齐。
所提出的DAMP框架概述,如图3-29所示。

图3-29 所提出的DAMP框架概述
在图3-29中,

和
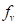
的参数被冻结,在训练过程中只有

和

是可调的。蓝色箭头表示文本数据工作流,而绿色和紫色箭头分别表示源图像和目标图像的数据工作流。只描述了源弱增强样本的提示过程。所有其他样本都遵循相同的过程。

、

和

是正则化,分别使提示域不可知、实例条件化和语义兼容。
人工智能芯片与自动驾驶


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2023-11-23 RISC-V微控制器与嵌入式系统
2022-11-23 RISC-V-HPC市场-汽车电动化分析
2021-11-23 华为八爪鱼自动驾驶云
2020-11-23 在OpenShift平台上验证NVIDIA DGX系统的分布式多节点自动驾驶AI训练
2020-11-23 NVIDIA DRIVE AGX开发工具包
2020-11-23 大数据目标检测推理管道部署