

CAMixerSR:只有细节需要更多关注
CAMixerSR:只有细节需要更多关注
为了满足对大图像(2K-8K)超分辨率(SR)快速增长的需求,主流方法遵循两条独立的轨道:①通过内容感知路由加速现有网络;②通过令牌混合器重构设计更好的超分辨率网络。尽管直接,但它们遇到了不可避免的缺陷(例如,不灵活的路由或非歧视性处理),限制了质量-复杂性权衡的进一步改进。为了消除这些缺点,通过提出一种内容感知混合器(CAMixer)来整合这些方案,该混合器为简单上下文分配卷积,为稀疏纹理分配额外的可变形窗口注意力。具体来说,CAMixer使用一个可学习的预测器来生成多个引导带,包括窗口扭曲的偏移、窗口分类的掩码和赋予卷积动态特性的卷积注意,这调节了注意以自适应地包含更多有用的纹理,并提高了卷积的表示能力。进一步引入了全局分类损失来提高预测器的准确性。通过简单地堆叠CAMixers,获得了CAMixerSR,它在大图像SR、轻量级SR和全向图像SR上实现了卓越的性能。
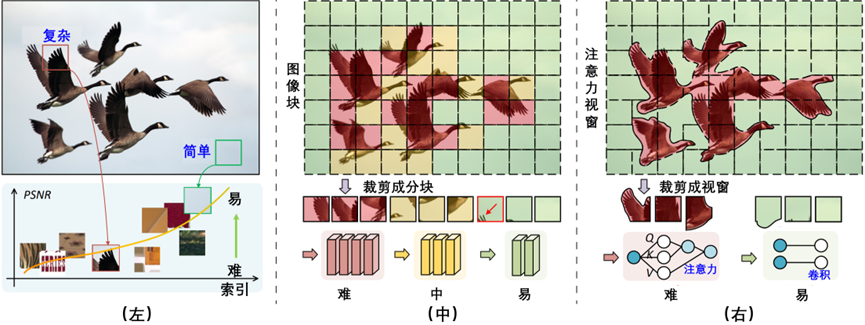
ClassSR框架和CAMixer的比较,如图3-17所示。
添加图片注释,不超过 140 字(可选)
图3-17 ClassSR框架和CAMixer的比较
在图3-17中,(左)平原/复杂斑块的恢复难度不同。(中)ClassSR将输入图像裁剪为子图像,通过不同复杂度的模型进行判别处理。(右)引入了一个内容感知混合器(CAMixer)来计算复杂区域的自关注,进而简化上下文的卷积。
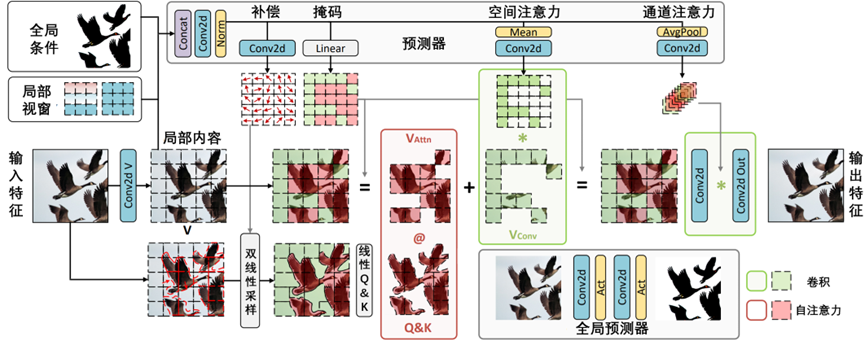
改进的CAMixer概述,如图3-18所示。
添加图片注释,不超过 140 字(可选)
图3-18 改进的CAMixer概述
在图3-18中,CAMixer由3部分组成:预测器、自注意分支和卷积分支。
人工智能芯片与自动驾驶
