

PromptKD:视觉语言模型的无监督提示提取
PromptKD:视觉语言模型的无监督提示提取
快速学习已成为增强视觉语言模型(VLM)的一种有价值的技术,例如用于特定领域下游任务的CLIP。现有的工作主要集中在设计各种学习形式的提示,忽视了提示作为从大型教师模型中学习的有效蒸馏器的潜力。介绍了一种无监督的领域提示蒸馏框架,旨在通过使用未标记的领域图像进行提示驱动的模仿,将较大教师模型的知识转移到轻量级目标模型。具体来说,改进方法的框架由两个不同的阶段组成。在初始阶段,使用域(少镜头)标签对大型CLIP教师模型进行预训练。经过预训练后,利用CLIP的独特解耦模态特性,通过教师文本编码器一次性预计算文本特征并将其存储为类向量。在后续阶段,存储的类向量在教师和学生图像编码器之间共享,用于计算预测的logits。此外,通过KL散度对齐教师和学生模型的逻辑,鼓励学生图像编码器通过可学习的提示生成与教师相似的概率分布。所提出的快速蒸馏过程消除了对标记数据的依赖,使算法能够利用域内大量未标记的图像。最后,利用训练有素的学生图像编码器和预存的文本特征(类向量)进行推理。这是第一个(1)对CLIP进行无监督的领域特定提示驱动知识提取的人,以及(2)建立一种实用的文本特征预存储机制作为教师和学生之间的共享类向量。在11个数据集上进行的广泛实验证明了改进方法的有效性。代码可在以下网址公开获取https://github.com/zhengli97/PromptKD。
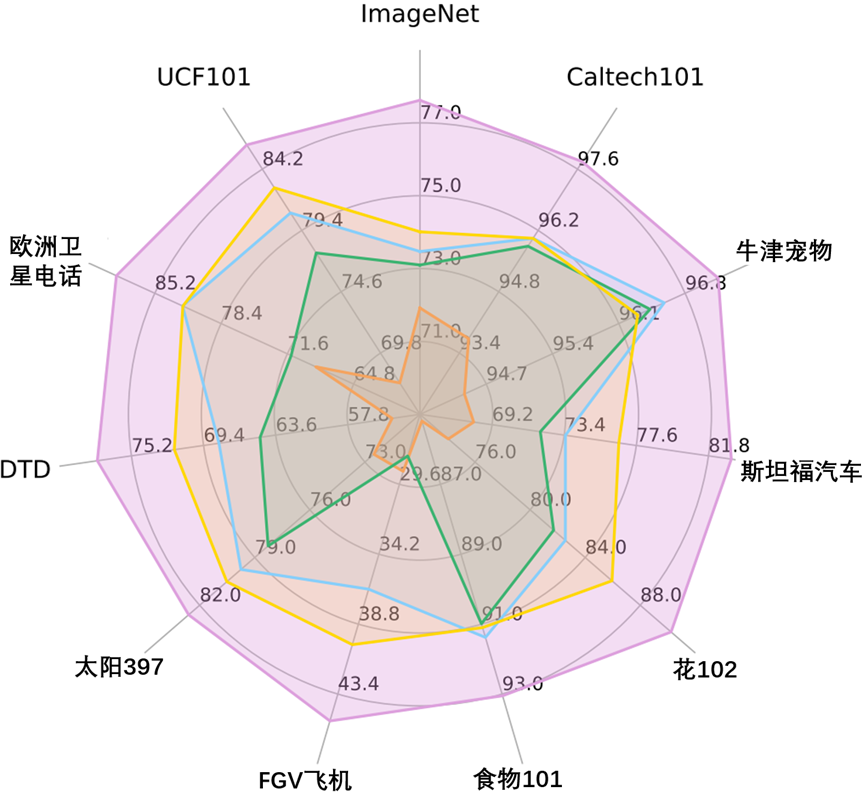
基于新泛化的谐波均值(HM)比较,如图3-25所示。
添加图片注释,不超过 140 字(可选)
图3-25 基于新泛化的谐波均值(HM)比较
在图3-25中,所有方法均采用预训练CLIP模型中的ViT-B/16图像编码器。PromptKD在11个不同的识别数据集上实现了最先进的性能。
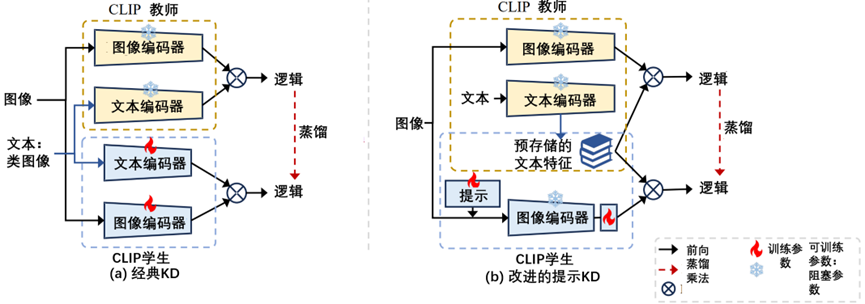
CLIP的经典KD范式(同样是CLIP-KD)和快速蒸馏框架之间的架构比较,如图3-26所示。
添加图片注释,不超过 140 字(可选)
图3-26 CLIP的经典KD范式(同样是CLIP-KD)和快速蒸馏框架之间的架构比较
在图3-26中,(a)经典的KD方法在独立的教师和学生模型之间进行蒸馏。学生通常完全被老师的软标签所迷惑。(b)PromptKD打破了师生独立的规则。建议重用教师预训练阶段之前训练有素的文本特征,并将其合并到学生图像编码器中,以进行提取和推理。
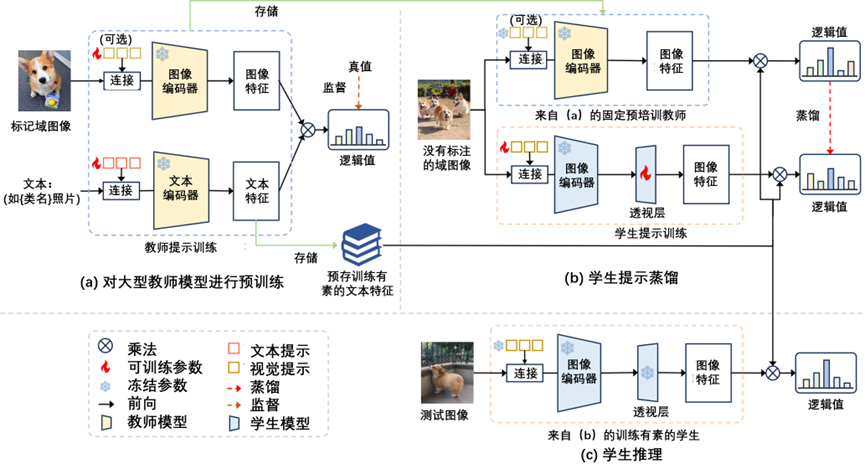
提出的快速蒸馏(PromptKD)框架概述,如图3-27所示。
添加图片注释,不超过 140 字(可选)
图3-27 提出的快速蒸馏(PromptKD)框架概述
在图3-27中,(a)首先使用现有的最先进的快速学习方法和标记的训练图像,对大型CLIP教师模型进行预训练。然后,将所有可能类的训练有素的文本特征保存到下一阶段。(b)在蒸馏阶段,训练侧重于学生图像提示和项目层,当使用预先保存的文本特征作为类向量时,没有与文本编码过程相关的额外计算开销。(c)最后,利用训练有素的学生和预先存储的类向量进行推理。
人工智能芯片与自动驾驶


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2023-10-28 Mel频谱与MFCC技术分析
2022-10-28 自动驾驶- SSD/ZNS技术分析
2021-10-28 全文翻译(三) TVM An Automated End-to-End Optimizing Compiler