

NPU基础与AI芯片杂谈
NPU基础与AI芯片杂谈
1.1 NPU 基础
近年来,随着人工智能技术的飞速发展,AI 专用处理器如 NPU(Neural Processing Unit)和 TPU(Tensor Processing Unit)也应运而生。这些处理器旨在加速深度学习和机器学习任务,相比传统的 CPU 和 GPU,它们在处理 AI 任务时表现出更高的效率和性能。
AI 专用处理器的发展可以追溯到 2016 年,谷歌推出了第一代 TPU,采用了独特的 TPU 核心脉动阵列设计,专门用于加速 TensorFlow 框架下的机器学习任务。此后,谷歌又陆续推出了多个 TPU 系列产品,不断优化其架构和性能。
华为也紧随其后,推出了自己的 AI 专用处理器——昇腾 NPU。昇腾 NPU 采用了创新的达芬奇架构,集成了大量的 AI 核心,可以高效地处理各种 AI 任务。华为还推出了多款搭载昇腾 NPU 的产品,如华为 Mate 系列手机和 Atlas 服务器等。
特斯拉作为一家以电动汽车和自动驾驶技术闻名的公司,也推出了自己的 AI 芯片——DOJO。DOJO 采用了独特的架构设计,旨在加速自动驾驶系统的训练和推理任务。
除了上述几家巨头外,国内外还有许多其他公司,也在积极布局 AI 芯片领域,如英伟达的 Xavier 和 Orin 系列、寒武纪的 MLU 系列、地平线的征程系列等。这些 AI 芯片在架构设计、性能表现、应用场景等方面各有特点,为 AI 技术的发展提供了强有力的硬件支持。
在接下来的内容中,将首先简单介绍引入什么是 AI 芯片,随后具体展开其的部署说明,技术发展路线和应用场景。
1.1.1 什么是 AI 芯片
AI 芯片是专门为加速人工智能应用中的大量针对矩阵计算任务而设计的处理器或计算模块。与传统的通用芯片如中央处理器(CPU)不同,AI 芯片采用针对特定领域优化的体系结构(Domain-Specific Architecture, DSA),侧重于提升执行 AI 算法所需的专用计算性能。
如下图所示的就是一个典型的 AI 芯片架构,假设所有场景围绕应用,那么其周围的例如解码芯片(如图中黄色部分 RSU)、FPGA 芯片(如图中粉色部分)等都是属于针对特定领域优化的芯片结构。

DSA 通常被称为针对特殊领域的加速器架构,因为与在通用 CPU 上执行整个应用程序相比,它们可以大幅提升特定应用的性能。DSA 可以通过更贴近应用的实际需求来实现更高的效率和性能。除了 AI 芯片,DSA 的其他例子还包括图形加速单元(GPU)、用于深度学习的神经网络处理器(NPU/TPU)以及软件定义网络(SDN)处理器等。
AI 芯片作为一种专用加速器,通过在硬件层面优化深度学习算法所需的矩阵乘法、卷积等关键运算,可以显著加速 AI 应用的执行速度,降低功耗。与在通用 CPU 上用软件模拟这些运算相比,AI 芯片能带来数量级的性能提升。因此,AI 芯片已成为人工智能技术实现落地的关键使能器。
架构区别如下图,CPU 最为均衡,可以处理多种类型的任务,各种组件比例适中;GPU 则减少了控制逻辑的存在但大量增加了 ALU 计算单元,提供给以高计算并行度;而 NPU 则是拥有大量 AI核,这可以高效完成针对性的 AI 计算任务。

AI 芯片的兴起源于深度学习的快速发展。随着神经网络模型的规模不断增大,其应用快速发展,训练和推理所需的计算量呈指数级增长,传统的通用芯片已无法满足性能和功耗的要求。与此同时,AI 应用对实时性和能效的需求也日益提高,尤其是在自动驾驶、智能安防、边缘计算等场景中。这些因素共同推动了 AI 芯片的发展。
目前,AI 芯片主要分为两大类:训练芯片和推理芯片。训练芯片用于神经网络的训练过程,通常需要更大的芯片面积和功耗预算,注重提供高吞吐量的计算能力。推理芯片则用于训练后模型的部署和执行,更加强调低功耗和实时性。典型的训练卡有 NVIDIA A100、NVIDIA DGX 系列、AMD Instinct MI 系列、Google TPU 系列、Intel Nervana NNP 系列、Huawei Ascend 910 等。
1.1.2 AI 芯片任务和部署
AI 芯片在人工智能的训练和推理任务中扮演着至关重要的角色。训练和推理是 AI 应用的两个主要阶段,对芯片的要求和特点也有所不同。
1. 训练阶段
在训练阶段,AI 芯片需要支持大规模的数据处理和复杂的模型训练。这需要芯片具有强大的并行计算能力、高带宽的存储器访问以及灵活的数据传输能力。
算力、存储、传输、功耗、散热、精度、灵活性、可扩展性、成本,九大要素构筑起训练阶段 AI 芯片的“金字塔”。
算力为基,强大的并行计算能力是训练模型的根基,支撑着复杂模型的构建与优化。高带宽存储器访问则如高速公路般畅通无阻,保证数据高效流动。灵活的数据传输能力则是穿针引线的关键,使模型训练过程更加顺畅。
功耗与散热如影随形,高性能计算往往伴随着高热量产生。因此,低功耗、良好的散热设计至关重要,避免过热导致性能下降甚至芯片损坏。
精度至上,训练阶段要求芯片具备高精度计算能力,确保模型参数的准确无误,为模型训练奠定坚实基础。
灵活为王,训练芯片需要兼容各类模型和算法,适应不断发展的 AI 技术,展现游刃有余的适应能力。
可扩展性则是未来之光,面对日益庞大的模型和数据集,芯片需具备强大的扩展能力,满足不断增长的计算需求。
成本考量亦不可忽视,高昂的价格可能会限制芯片的应用范围,因此合理的价格策略也是芯片赢得市场的重要因素。
昇腾 Ascend NPU、Google TPU、Graphcore IPU(分别如下图所示)等专门为 AI 训练设计的芯片,正朝着上述目标不断迈进,为大规模 AI 模型训练提供强劲动力。相信随着 AI 技术的飞速发展,训练芯片也将不断突破瓶颈,为 AI 应用带来更加广阔的空间。


2. 推理阶段
在推理阶段,AI 芯片需要在功耗、成本和实时性等方面进行优化,以满足不同应用场景的需求。云端推理通常对性能和吞吐量要求较高,因此需要使用高性能的 AI 芯片,如 GPU、FPGA 等。边缘和端侧推理对功耗和成本更加敏感,因此需要使用低功耗、低成本的 AI 芯片,如专门为移动和嵌入式设备设计的 NPU、TPU 等。
相较于训练芯片在幕后的默默付出,推理芯片则站在了 AI 应用的前沿,将训练好的模型转化为现实世界的智能服务。如果说训练芯片是 AI 技术的发动机,那么推理芯片就是将这股力量输送到应用场景的传动装置。那么为何国内热衷推理芯片?近年来,国内涌现出众多推理芯片厂商,这背后既有政策驱动的因素,也离不开市场需求的牵引。政策方面,国家层面高度重视 AI 产业发展,出台了一系列扶持政策,鼓励企业研发国产 AI 芯片。这为国内推理芯片厂商提供了良好的发展机遇。市场需求方面,随着 AI 应用的普及,对推理芯片的需求也日益旺盛。智能手机、智能家居、自动驾驶等领域,都对推理芯片有着巨大的需求。
推理芯片的关键因素与训练芯片相比,也在性能、功耗、成本等方面有着不同的要求。性能方面,推理芯片需要支持多种模型和算法,并能够以较低的延迟完成推理任务。功耗方面,推理芯片通常部署在边缘设备上,因此需要具有较低的功耗,以延长设备续航时间。成本方面,推理芯片需要价格亲民,才能被更广泛地应用。
除了上述因素之外,推理芯片还需要考虑:灵活性:推理芯片需要能够快速部署和更新模型,以适应不断变化的需求。安全性:推理芯片需要具备安全防护能力,防止数据泄露和安全攻击。随着 AI 应用的不断发展,AI 芯片的异构集成趋势也越来越明显。单一的芯片架构难以满足日益多样化的 AI 应用需求,因此,集成多种异构计算单元的 AI 芯片成为了主流方向。例如,集成 CPU、GPU、NPU 等多种计算单元的 AI 芯片,可以在训练和推理任务中发挥各自的优势,提供更加全面和高效的 AI 计算能力。
国内推理芯片市场呈现出百花齐放的局面,涌现出寒武纪、地平线、百度等一批优秀厂商。这些厂商推出的推理芯片(如下图分别所示),在性能、功耗、成本等方面取得了显著进步,并逐渐开始在智能手机、智能家居、自动驾驶等领域实现商用。



此外,AI 芯片的部署方式也在不断演进。传统的云端部署模式面临着数据传输和隐私安全等挑战,因此边缘和端侧部署成为了 AI 应用的重要趋势。通过将 AI 芯片和模型部署在边缘设备和终端设备上,可以大大减少数据传输的延迟和带宽压力,提高 AI 应用的实时性和安全性。同时,端侧部署也对 AI 芯片的功耗和成本提出了更高的要求。
1.1.3 AI 芯片技术路线
作为加速应用的 AI 芯片,主要的技术路线有三种:GPU、FPGA、ASIC。它们三者间的区别,如下图:

具体而言,将展开介绍三者的一些基础细节:
1. GPU
GPU 由于其强大的并行计算能力,已经成为目前最主流的 AI 芯片加速方案。GPU 厂商不断推出 专门针对 AI 加速的 GPU 产品,如 NVIDIA 的 Tesla 系列,AMD 的 Radeon Instinct 系列等。为了进一步提高 GPU 在 AI 领域的性能,厂商们也在不断对 GPU 的架构进行优化,如 NVIDIA 推出了专门为深度学习优化的张量核技术,可以大幅提高矩阵运算的速度。但是,GPU 作为一种通用计算芯片,在功耗和成本方面还有进一步优化的空间。此外,GPU 编程的难度也较高,对开发者的要求较高。
下图为 GPU 架构概略图:

2. FPGA
FPGA 作为一种可重构的硬件,在 AI 加速领域也有广泛的应用。与 GPU 相比,FPGA 的优势在于更低的功耗和更高的灵活性。FPGA 厂商也在不断推出针对 AI 应用的 FPGA 产品,如 Xilinx 的 Alveo 系列,Intel 的 Stratix 系列等。
这些产品通常集成了更多的数学运算单元,以及更大的片上存储和更高的内存带宽,以满足 AI 应用的需求。但是,FPGA 的编程难度较高,通常需要硬件描述语言(如 Verilog 或 VHDL)的知识。此外 FPGA 的成本也较高,在大规模部署时可能会受到限制。
下图为 FPGA 架构概略图:

3. ASIC
ASIC 作为专用芯片,可以针对特定的 AI 算法和应用场景进行优化,提供最高的性能和能效。许多科技巨头都在开发自己的 AI 专用 ASIC,如谷歌的 TPU、华为的昇腾 Ascend NPU 系列等。与 GPU 和 FPGA 相比,ASIC 可以在计算速度、功耗、成本等方面做到更加极致的优化。
但是,ASIC 的设计周期较长,前期投入大,灵活性也较差。此外,ASIC 芯片通常需要配合专门的软件栈和开发工具,生态系统的建设也是一大挑战。
下图为 ASIC 架构概略图:

1.1.4 AI 芯片应用场景
1. AI 计算中心
AI 计算中心是 AI 芯片的重要应用场景之一。随着 AI 技术的不断发展,对计算能力的需求也在不断增长。为了满足这一需求,NVIDIA、Huawei、Google 等头部厂商都相继发布了针对 AI 计算中心的 AI 训练加速器。这些加速器具有高性能、高能效的特点,可以大大提高 AI 模型的训练速度。
在 AI 计算中心中,互联带宽是一个重要的限制因素。目前主流的互联技术是 PCIe v4,但其功率限制在 300W 左右,已经无法满足日益增长的计算需求。因此,业界对 PCIe v5 的发布充满期待,希望通过更高的互联带宽来突破现有的限制。
除了互联带宽外,各大厂商还发布了高度可扩展的互联技术,可以将数千张加速卡连接在一起。这对于像 Cerebras、GraphCore、Groq、Tesla Dojo 这样的数据流加速器尤为重要,因为这些加速器需要显式/静态编程,或者需要将任务路由到计算硬件上。先进的互联技术使得这些加速器能够适应像 ChatGPT 这样参数量达到千亿级别的大型模型。
值得一提的是,虽然 Int8 精度在嵌入式、自主和数据中心推理应用中已经成为默认的数值精度,但在 AI 计算中心中,仍有部分加速器使用 FP16 或 BF16 进行训练或推理,以获得更高的计算精度。
2. 自动驾驶和安防应用
自动驾驶和安防是 AI 芯片的另一个重要应用场景。在自动驾驶领域,AI 芯片可以用于处理车载传感器采集的大量数据,实现对道路环境的实时感知和决策。目前,特斯拉、英伟达、Mobileye 等公司都在积极布局自动驾驶芯片,推动自动驾驶技术的发展和应用。
在安防领域,AI 芯片可以用于智能视频分析、人脸识别、行为分析等任务,提高安防系统的智能化水平。例如,海康威视、大华股份等安防巨头都在加大 AI 芯片的研发和应用力度,推出了一系列智能安防产品和解决方案。
3. IOT 应用
IoT 设备是 AI 芯片的另一个重要应用场景。随着 AI 技术的发展,越来越多的 IoT 设备开始搭载 AI 芯片,实现本地智能处理和决策。2017 年以来,苹果、华为海思、高通、联发科等主要芯片厂商相继发布了支持 AI 加速功能的新一代芯片,推动了 AI 在 IoT 领域的应用。
IoT 设备种类繁多,对 AI 芯片的需求也各不相同。例如,智能音箱对语音识别和自然语言处理的要求较高,而智能摄像头则对图像处理和目标检测的要求较高。因此,IoT 领域的 AI 芯片需要根据具体应用场景进行针对性设计和优化。
小结与讨论
AI 专用处理器如 NPU 和 TPU 的出现,极大地推动了人工智能技术的发展和应用。这些芯片在架构设计和性能优化方面不断创新,为各种 AI 任务提供了强大的计算支持。在具体应用场景方面,AI 芯片已经在智能手机、数据中心、自动驾驶、安防、IoT 等领域得到了广泛应用。不同的应用场景对 AI 芯片的要求各不相同,需要根据具体任务进行针对性设计和优化。
展望未来,随着 AI 技术的不断发展和应用需求的不断增长,AI 芯片必将迎来更加广阔的发展前景。各大科技巨头和芯片厂商也将继续加大在 AI 芯片领域的投入和创新,推动人工智能技术的进一步发展和普及。同时,AI 芯片的发展也将带动相关产业链的繁荣,为经济社会发展注入新的动力。
参考文献链接
https://chenzomi12.github.io/02Hardware02ChipBase/06NPUBase.html
超异构计算#
1.2 AI 芯片发展
人工智能的发展与芯片算力的提升密不可分,可以大致分为三个阶段:
1)第一阶段:芯片算力不足,神经网络没有被受到重视
在早期,受限于芯片算力,复杂的神经网络模型难以实现。这一时期的人工智能主要依赖于专家系统、决策树等传统方法。神经网络虽然在理论上已经被提出,但由于计算资源的匮乏,难以训练出有效的模型,因此没有受到广泛重视。
2)第二阶段:CPU 算力大幅提升,但仍然无法满足神经网络增长需求
随着摩尔定律的推进,CPU 性能不断提升。这为神经网络的发展提供了一定的计算基础。研究者们开始尝试更大规模的神经网络,并在一些领域取得了突破。但是,神经网络对算力的需求呈指数级增长,单纯依靠 CPU 的性能提升已经难以满足日益复杂的模型训练需求。
3) 第三阶段:GPU 和 AI 芯片新架构推动人工智能快速落地
为了解决算力瓶颈,研究者们开始将目光转向了其他计算架构。GPU 凭借其强大的并行计算能力,成为了深度学习的主要计算平台。与 CPU 相比,GPU 在矩阵运算等方面有着显著的优势,能够大幅加速神经网络训练。与此同时,一些专门针对 AI 加速的芯片架构也开始涌现,如 TPU、NPU 等。这些芯片在算力、功耗等方面进一步优化,为人工智能的落地应用扫清了障碍。
除了芯片算力外,算法的进步、数据的积累也是人工智能发展的重要推动力。在算力瓶颈得到缓解后,一些重要的神经网络结构如 CNN、RNN、Transformer 等被相继提出,并在图像、语音、自然语言处理等领域取得了突破性进展。海量的数据为模型训练提供了丰富的素材,使得神经网络能够学习到更加鲁棒和泛化的特征表示。
而更进一步,单一架构的使用也渐渐满足不了一些应用场景,针对于此,异构计算的概念也就应运而生。
1.2.1 异构与超异构场景
首先理解一下为什么需要异构?摩尔定律放缓,传统单一架构难以满足日益增长的计算需求。异构计算,犹如打破计算藩篱的利器,通过整合不同类型计算单元的优势,为计算难题提供全新的解决方案。
异构计算的主要优势有:
1)性能飞跃: 异构架构将 CPU、GPU、FPGA 等计算单元有机结合,充分发挥各自优势,实现 1+1>2 的效果,显著提升计算性能。
灵活定制: 针对不同计算任务,灵活选择合适的主张计算单元,实现资源的高效利用。
2)降低成本: 相比于昂贵的专用计算单元,异构架构用更低的成本实现更高的性能,带来更佳的性价比。
3)降低功耗: 异构架构能够根据任务需求动态调整资源分配,降低整体功耗,提升能源利用效率。
其应用场景也十分广泛,包括人工智能、高性能计算、大数据分析、图形处理等等
以一个具体的例子来引入:特斯拉 HW3 FSD 芯片(如下图),可以看到其单一芯片却有着 CPU,GPU,NPU 多种架构。

之所以有如此异构架构则是由需求(如下图所标示)决定的:身为汽车芯片,其要负责雷达、GPS、地图等等多种功能,这时单一传统的架构就会比较难以高效完成任务:
将各部分组件有机结合的异构芯片就可以更好的处理复杂情况,如下图,可以看到 GPU、NPU、Quad Cluster 等等硬件均被集合在一起,通过芯片外的 CPU 等等进行协同控制,这样就可以在多种任务的处理和切换时实现非常好的效果。

1.2.2 计算体系迎来异构
异构计算的出现和发展源于传统冯·诺依曼结构计算机受制于存储和计算单元之间的数据交换瓶颈,难以满足日益增长的计算需求,加之半导体工艺的发展使得 CPU 主频提升受到物理和功耗的限制,性能提升趋于缓慢。
为了突破单核 CPU 性能的瓶颈,业界开始探索并行计算技术,通过多核处理器或集群计算机实现高性能计算,然而并行计算中的微处理器仍受冯·诺依曼结构的制约,在处理数据密集型任务时,计算速度和性价比不尽如人意。
随着深度学习等人工智能技术的兴起,对计算能力提出了更高的要求,传统的 CPU 在处理神经网络训练和推理任务时,性能和效率远不及专门设计的 AI 芯片,如 GPU 和 NPU 等。异构计算通过集成不同类型的计算单元,发挥各自的计算优势,实现更高的性能和能效,AI 芯片在处理特定任务时,计算效率远超传统 CPU,有望成为未来计算机体系的标配。
尽管异构计算的发展仍面临系统功耗限制、上层基础软件的欠缺以及与芯片结构的匹配度不足等挑战,但通过优化异构计算平台的架构设计、开发高效的编程模型和运行时系统、提供易用的开发工具和库,可以更好地发挥异构计算的潜力,推动人工智能、大数据分析、科学计算等领域的进一步发展,异构计算有望成为未来计算机体系结构的主流趋势。
1. 异构的例子
下面将用一个最常见的 CPU-GPU 异构工作流来给出一个具体的例子,如下图:

具体流程为:
1)CPU 把数据准备好,并保存在 CPU 内存中。
2)将待处理的数据从 CPU 内存复制到 GPU 内存(图中 Step1)。
3)CPU 指示 GPU 工作,配置并启动 GPU 内核(图中 Step2)。
4)多个 GPU 内核并行执行,处理准备好的数据(图中 Step3)。
5)处理完成后,将处理结果复制回 CPU 内存(图中 Step4)。
6)CPU 把 GPU 的结果进行后续处理。
通过这样的异构设置,就可以更充分、高效地协同发挥不同组件的优势特性,以实现更高的性能。以游戏为例:现代游戏画面逼真复杂,对计算能力提出了极高要求。传统 CPU 难以满足如此严苛的性能需求,而 GPU 擅长图形处理,能够高效渲染游戏画面。异构计算将 CPU 和 GPU 优势互补,强强联合。CPU 负责游戏逻辑、场景构建等任务,GPU 则专注于画面渲染。两者分工协作,实现更高效的硬件利用率。
2. 异构的优势
接下来总结补充三点异构架构的优势:
1)适用于处理高性能计算:伴随着高性能计算类应用的发展,驱动算力需求不断攀升,但目前单一计算类型和架构的处理器已经无法处理更复杂、更多样的数据。数据中心如何在增强算力和性能的同时,具备应对多类型任务的处理能力,成为全球性的技术难题。异构并行计算架构作为高性能计算的一种主流解决方案,受到广泛关注。
2)适用于处理数据中心产生的海量数据:数据爆炸时代来临,使用单一架构来处理数据的时代已经过去。比如:个人互联网用户每天产生约 1GB 数据,智能汽车每天约 50GB,智能医院每天约 3TB 数据,智慧城市每天约 50PB 数据。数据的数量和多样性以及数据处理的地点、时间和方式也在迅速变化。无论工作任务是在边缘还是在云中,不管是人工智能工作任务还是存储工作任务,都需要有正确的架构和软件来充分利用这些特点。
3)可以共享内存空间,消除冗余内存副本:在此前的技术中,虽然 GPU 和 CPU 已整合到同一个芯片上,但是芯片在运算时要定位内存的位置仍然得经过繁杂的步骤,这是因为 CPU 和 GPU 的内存池仍然是独立运作。为了解决两者内存池独立的运算问题,当 CPU 程式需要在 GPU 上进行部分运算时,CPU 都必须从 CPU 的内存上复制所有的资料到 GPU 的内存上,而当 GPU 上的运算完成时,这些资料还得再复制回到 CPU 内存上。然而,将 CPU 与 GPU 放入同一架构,就能够消除冗余内存副本来改善问题,处理器不再需要将数据复制到自己的专用内存池来访问/更改该数据。统一内存池还意味着不需要第二个内存芯片池,即连接到 CPU 的 DRAM。
除了 CPU 和 GPU 异构以外,AISC 在异构体系中也扮演着重要的角色(如下图),尤其是对于 AI 加速。其通过驱动程序和 CSR 和可配置表项交互,以此来控制硬件运行。和 GPU 类似, ASIC 的运行依然需要 CPU 的参与:
1) 数据输入:数据在内存准备好,CPU 控制 ASIC 输入逻辑,把数据从内存搬到处理器
2) 数据输出:CPU 控制 ASIC 输出逻辑,把数据从处理器搬到内存,等待后续处理
3) 运行控制:控制 CSR、可配置表项、中断等
ASIC工作流示意图如下:

从 CPU 到 ASIC,会发现架构越来越碎片化,指令作为软件和硬件之间的媒介,其复杂度决定了系统的软硬件解耦程度。典型的处理器平台可以分为 CPU、协处理器、GPU、FPGA、DSA 和 ASIC。随着指令复杂度的提高,单个处理器能够覆盖的场景变得越来越小,处理器的形态也变得越来越多样化。这种碎片化趋势导致构建生态变得越来越困难。这形成了易用性和性能之间的权衡关系,如下图:

在 CPU+XPU 的异构计算中,XPU 的选择决定了整个系统的性能和灵活性特征。GPU 具有较好的灵活性,但性能效率不够极致;DSA 性能优异,但灵活性较差,难以适应复杂计算场景对灵活性的要求;FPGA 的功耗和成本较高,需要进行定制开发,落地案例相对较少;ASIC 的功能完全固定,难以适应灵活多变的复杂计算场景。
可以发现异构计算本身也还是存在着一些问题:
- 复杂计算:系统越复杂,需要选择越灵活的处理器;性能挑战越大,需要选择越偏向定制的加速处理器;
- 本质矛盾:单一处理器无法兼顾性能和灵活性;
为了解决异构计算存在的挑战,超异构概念应运而生。超异构架构将多种类型的 XPU 有机结合,融合了不同 XPU 的优势,能够同时兼顾性能和灵活性,满足复杂计算场景的需求。
1.2.4 从异构到超异构
首先从三个角度来理解一下为什么超异构的出现是应运而生的:
1)需求驱动:软件新应用层出不穷,两年一个新热点。 随着人工智能、大数据、元宇宙等新兴技术的快速发展,对计算能力提出了越来越高的要求。传统单一架构的计算模式难以满足日益增长的计算需求,亟需新的计算架构来突破性能瓶颈。已有的热点技术仍在快速演进。 例如,元宇宙需要将算力提升 1000 倍才能实现逼真的沉浸式体验。超异构计算能够通过融合不同类型计算单元的优势,显著提升计算性能,为元宇宙等新兴技术的落地提供强有力的支持。
2)工艺和封装支撑:Chiplet 封装使得在单芯片层次,可以构建规模数量级提升的超大系统。 Chiplet 封装技术将多个芯片封装在一个封装体内,可以显著提高芯片的集成度和性能。这使得在单一封装内集成多种类型的 XPU 成为可能,进一步推动了超异构计算的发展。
3)系统架构持续创新:通过架构创新,在单芯片层次,实现多个数量级的性能提升。 随着计算机体系结构的不断发展,新的架构设计不断涌现,例如异构架构、多核架构等。这些架构能够通过充分发挥不同类型处理器的优势,显著提升计算性能。异构编程很难,超异构编程更是难上加难。 如何更好地驾驭超异构,是成败的关键。近年来,随着异构编程模型和工具的不断完善,超异构编程的难度逐渐降低,这为超异构计算的推广应用奠定了基础。
通过以上三个角度可以推断,超异构计算的出现是顺应时代发展需求的必然选择。它能够突破传统单一架构的性能瓶颈,满足日益增长的计算需求,为各行各业的创新发展注入强劲动力。
了解背景后,来正式介绍超异构的概念,如下图:

超异构实际上就是集合了三种以上类型引擎/架构的超架构,但是这种集合非简单的集成,而是把更多的异构计算整合重构,各类型处理器间充分、灵活的 数据交互,形成统一的超异构计算体系。计算从单核的串行走向多核的并行;又进一步从同构并行走向异构并行。下图为异构计算的发展的概略流程图:

超异构有以下基本特征:
1) 超大规模的计算集群:超异构计算通常由大量计算节点组成,每个节点可以包含 CPU、GPU、FPGA、DSA 等多种类型的计算单元。这些计算节点通过高速互联网络连接在一起,形成一个超大规模的计算集群。超大规模的计算集群能够提供强大的计算能力,满足大数据分析、人工智能、科学计算等对计算能力要求高的应用场景。
2) 复杂计算系统,由分层分块组件组成,如下图所示。超异构计算系统的复杂性主要体现在以下几个方面:不同类型的计算单元具有不同的性能和特性,需要进行统一管理和调度;计算任务可能涉及多个计算节点,需要进行任务分解和数据通信;需要考虑功耗、可靠性等因素,进行系统优化。

1.2.5超异构的挑战与思考
可以分析超异构的概念和其必要性,但是显然超异构的实现也伴随着许多挑战,接下来将分点来介绍它们。
1. 超异构的软件层
1) 遇到挑战
软件需要跨平台复用:跨架构、跨不同处理器类型、跨厂家平台、跨不同位置、跨不同设备类型。因此软件架构的复杂性增长,会成为一个最大的挑战。如下图:

2)解决办法
①开放接口/架构及生态:形成标准的开放接口/架构;开发者遵循接口/架构开发产品和服务,从而形成开放生态;
②软件兼容:尽可能减少针对已有应用的定制化开发,兼容已有软件生态,通过基础软件(如编译层)对接加速应用软件;
③编程体系:提供门槛更低的编译体系,通过编程体系构建上层加速库从而对接领域应用,即提供门槛较低的标准领域编程语言(如英伟达的 CUDA、昇腾的 Ascend C);
④开放架构:进一步开放软硬件架构,防止架构过多导致的市场碎片化,如 90 年代编译器风起云涌到目前聚焦 2/3 个编译器;
2. 硬件定义软件 or 软件定义硬件
目前这个问题有三个可能的解,如下图,他们分别为:
硬件定义软件(HDW):硬件定义软件(HDW)是一种设计理念,它强调通过硬件来定义软件的功能和架构。在 HDW 模式下,软件的开发和部署更加依赖于底层硬件的特性,能够充分发挥硬件的性能优势。HDW 的核心思想是通过硬件加速器、专用指令集等技术,为软件提供硬件层面的支持,使软件能够更高效地运行。HDW 能够充分利用硬件的并行计算能力,显著提升软件的性能。
软件定义硬件(SDH):软件定义硬件(SDH)是一种设计理念,它强调通过软件来定义硬件的功能和性能。在 SDH 模式下,硬件的设计和实现更加灵活,能够快速响应软件的需求变化。SDH 的核心思想是通过软件抽象层(SAL)将软件和硬件解耦,使软件开发人员能够专注于软件的功能实现,而无需关注底层硬件的细节。SAL 为软件提供了统一的硬件接口,屏蔽了不同硬件平台之间的差异,使软件能够跨平台运行。
软硬件协同定义(Co-Design):软硬件协同定义(Co-Design)是一种设计理念,它强调软件和硬件的协同设计与优化,以实现最佳的系统性能。在 Co-Design 模式下,软件和硬件的设计团队紧密合作,共同探讨系统需求,并提出满足需求的软硬件解决方案。Co-Design 的核心思想是打破软件和硬件之间的传统界限,将软硬件设计视为一个整体,通过协同设计和优化来实现最佳的系统性能。Co-Design 能够充分发挥软件和硬件的各自优势,实现 1+1>2 的效果。

在计算机系统的发展历程中,硬件和软件的关系经历了从硬件定义软件到软件定义硬件的转变。早期的计算机系统,如早期的操作系统,其系统业务逻辑主要由硬件实现,软件只是起到辅助作用,并且软件的构建依赖于硬件提供的接口。然而,随着计算机技术的不断进步,软件定义硬件的概念逐渐兴起。
在软件定义硬件的模式下,系统的业务逻辑主要由软件来实现,硬件则扮演辅助角色。一个典型的例子是 AI4SIC 模拟仿真软件,它利用软件的灵活性和可编程性来模拟复杂的系统行为。此外,现代的硬件设备,如具有渲染管道的 GPU,其功能和行为可以通过软件进行编程和控制,使得硬件能够按照软件的逻辑执行操作。这种软件对硬件的可编程性大大提高了系统的灵活性和适应性。
除了软件主导系统逻辑和对硬件的可编程性之外,"软件定义硬件"还体现在硬件的构建过程中对软件接口的依赖。以 AI 算法为例,许多硬件加速器和专用芯片的设计都是基于特定的 AI 算法和框架,它们依赖于软件提供的接口和规范来实现硬件的功能。这种软件驱动的硬件构建方式使得硬件能够更好地适应不断变化的应用需求,并与软件生态系统紧密结合。
这个问题的答案实际上和系统复杂度密切相关。对于复杂度较小且迭代较慢的系统,如 CPU,可以快速设计优化的系统软硬件划分,先进行硬件开发,然后再开始系统层和应用层的软件开发,如 Windows 操作系统等。这种情况下,硬件在一定程度上定义了软件的开发和运行环境。
然而,随着系统复杂度的上升,如 GPU 所面临的情况,量变引起质变,系统迭代速度加快,直接实现一个完全优化的设计变得非常困难。在这种情况下,系统实现变成了一个演进式的过程。在前期,由于系统尚不稳定,算法和业务逻辑处于快速迭代阶段,需要快速实现新的想法。随着系统的发展,算法和业务逻辑逐渐稳定下来,后续可以通过逐步优化到 GPU、DSA 等硬件加速来持续提升性能。
从本质上讲,这是一个系统定义的过程。当系统复杂度过高时,实现难以一次到位,系统实现变成了一个持续优化和迭代的过程。软件和硬件之间的关系变得更加紧密和动态,软件的需求和发展推动着硬件的优化和演进,而硬件的进步又为软件的创新提供了新的可能性。
总之,在计算机系统的发展过程中,硬件定义软件和软件定义硬件这两种关系都存在,而系统复杂度的高低决定了这两种关系的主导地位。对于复杂度较低的系统,硬件定义软件的情况更为常见;而对于复杂度较高的系统,软件定义硬件的情况则更为普遍,系统实现变成了一个持续优化和迭代的过程。
3. 计算体系 vs 编译体系
超异构架构的处理器越来越多,需要构建高效、标准、开放接口和架构体系,才能构建一致性的宏架构(多种架构组合)平台,才能避免场景覆盖的碎片化。
现在正处于计算体系变革和编译体系变革 10 年,避免为了某个应用加速而去进行非必要大量上层应用迁移对接到硬件 API,应交由一致性的宏架构(多种架构组合)平台(编译/操作系统)。
小结与讨论
跨平台统一计算架构(如下图)是未来计算资源中心化的关键,通过将孤岛计算资源连接起来,实现计算资源池化,可以显著提升算力利用率。这种架构能够支持应用软件跨同类处理器架构、跨不同类处理器架构、跨芯片平台以及跨云边端运行,满足更复杂应用场景对算力无限的需求,形成开放生态。

为了实现软件应用算法对硬件加速的支持,需要调整软件架构,将控制面和计算/数据面分开,并实现接口标准化。同时,通过底层基础软件(编译器)自适应选择计算/数据,使数据输入/输出不仅可以来源于软件,还可以来源于硬件,甚至可以下沉到硬件独立传输计算。
在超异构系统中,采用极致性能优化的分层可编程体系架构,绝大部分计算交由 DSA 进行极致计算,使得系统整体性能效率接近 DSA。用户角度应用运行在 CPU 上,开发者感知的是 CPU 可编程,通过操作系统和编译器区分异构。Chiplet+超异构的组合,使得系统规模数量级提升,整体超异构系统性能实现数量级提升。
未来的计算架构将呈现出体系异构、平台化和开放生态的特点。超异构计算架构由 CPU、GPU、FPGA 和 DSA 多架构处理器组成,目标是接近 CPU 的灵活性和 ASIC 的性能效率,在不影响开发效率的情况下实现整体性能的数量级提升。平台化和可编程的目标是实现软件定义一切,硬件加速一切,通过完全可软件编程的硬件加速平台,满足多场景、多用户需求,适应业务演进。建立标准和开放生态,拥抱开源开放的生态,支持云原生、云网边端融合,实现用户无平台依赖。
参考文献链接
1.3 GPU 基础 (DONE)
GPU 是 Graphics Processing Unit(图形处理器)的简称,它是计算机系统中负责处理图形和图像相关任务的核心组件。GPU 的发展历史可以追溯到对计算机图形处理需求的不断增长,以及对图像渲染速度和质量的不断追求。从最初的简单图形处理功能到如今的高性能计算和深度学习加速器,GPU 经历了一系列重要的技术突破和发展转折。
在接下来的内容中,还将探讨 GPU 与 CPU 的区别,了解它们在设计、架构和用途上存在显著差异。此外,还将简短介绍一下 AI 发展和 GPU 的联系,并探讨 GPU 在各种领域的应用场景。
除了图形处理和人工智能,GPU 在科学计算、数据分析、加密货币挖矿等领域也有着广泛的应用。深入了解这些应用场景有助于更好地发挥 GPU 的潜力,解决各种复杂计算问题。现在让深入了解 GPU 的发展历史、与 CPU 的区别、AI 所需的重要性以及其广泛的应用领域。
1.3.1 GPU 发展历史
在 GPU 发展史上,第一代 GPU 可追溯至 1999 年之前。这一时期的 GPU 在图形处理领域进行了一定的创新,部分功能开始从 CPU 中分离出来,实现了针对图形处理的硬件加速。其中,最具代表性的是几何处理引擎,即 GEOMETRY ENGINE。该引擎主要用于加速 3D 图像处理,但相较于后来的 GPU,它并不具备软件编程特性。这意味着它的功能相对受限,只能执行预定义的图形处理任务,而无法像现代 GPU 那样灵活地适应不同的软件需求。
然而,尽管功能有限,第一代 GPU 的出现为图形处理领域的硬件加速打下了重要的基础,奠定了后续 GPU 技术发展的基石。

第二代 GPU 的发展跨越了 1999 年到 2005 年这段时期,其间取得了显著的进展。1999 年,英伟达发布了 GeForce256 图像处理芯片,这款芯片专为执行复杂的数学和几何计算而设计。与此前的 GPU 相比,GeForce256 将更多的晶体管用于执行单元,而不是像 CPU 那样用于复杂的控制单元和缓存。它成功地将诸如变换与光照(TRANSFORM AND LIGHTING)等功能从 CPU 中分离出来,实现了图形快速变换,标志着 GPU 的真正出现。
随着时间的推移,GPU 技术迅速发展。从 2000 年到 2005 年,GPU 的运算速度迅速超越了 CPU。在 2001 年,英伟达和 ATI 分别推出了 GeForce3 和 Radeon 8500,这些产品进一步推动了图形硬件的发展。图形硬件的流水线被定义为流处理器,顶点级可编程性开始出现,同时像素级也具有了有限的编程性。
尽管如此,第二代 GPU 的整体编程性仍然相对有限,与现代 GPU 相比仍有一定差距。然而,这一时期的 GPU 发展为后续的技术进步奠定了基础,为图形处理和计算领域的发展打下了坚实的基础。

从长远看,NVIDIA 的 GPU 在一开始就选择了正确的方向 MIMD,通过 G80 Series,Fermi,Kepler 和 Maxwell 四代大跨步进化,形成了完善和复杂的储存层次结构和指令派发/执行管线。ATI/AMD 在一开始选择了 VLIW5/4,即 SIMD,通过 GCN 向 MIMD 靠拢,但是进化不够完全(GCN 一开始就落后于 Kepler),所以图形性能和 GPGPU 效率低于对手。
NVIDIA 和 ATI 之争本质上是着色器管线与其他纹理,ROP 单元配置比例之争,A 认为计算用着色器越多越好,计算性能强大,N 认为纹理单元由于结构更简单电晶体更少,单位面积配置起来更划算,至于游戏则是越后期需要计算的比例越重。
第三代 GPU 的发展从 2006 年开始,带来了方便的编程环境创建,使得用户可以直接编写程序来利用 GPU 的并行计算能力。在 2006 年,英伟达和 ATI 分别推出了 CUDA(Compute Unified Device Architecture)和 CTM(CLOSE TO THE METAL)编程环境。
这一举措打破了 GPU 仅限于图形语言的局限,将 GPU 变成了真正的并行数据处理超级加速器。CUDA 和 CTM 的推出使得开发者可以更灵活地利用 GPU 的计算能力,为科学计算、数据分析等领域提供了更多可能性。
2008 年,苹果公司推出了一个通用的并行计算编程平台 OPENCL(Open Computing Language)。与 CUDA 不同,OPENCL 并不与特定的硬件绑定,而是与具体的计算设备无关,这使得它迅速成为移动端 GPU 的编程环境业界标准。OPENCL 的出现进一步推动了 GPU 在各种应用领域的普及和应用,为广大开发者提供了更广阔的创新空间。
第三代 GPU 的到来不仅提升了 GPU 的计算性能,更重要的是为其提供了更便捷、灵活的编程环境,使得 GPU 在科学计算、深度学习等领域的应用得以广泛推广,成为现代计算领域不可或缺的重要组成部分。
1.3.2 GPU vs CPU
现在探讨一下 CPU 和 GPU 在架构方面的主要区别,CPU 即中央处理单元(Central Processing Unit),负责处理操作系统和应用程序运行所需的各类计算任务,需要很强的通用性来处理各种不同的数据类型,同时逻辑判断又会引入大量的分支跳转和中断的处理,使得 CPU 的内部结构异常复杂。
GPU 即图形处理单元(Graphics Processing Unit),可以更高效地处理并行运行时复杂的数学运算,最初用于处理游戏和动画中的图形渲染任务,现在的用途已远超于此。两者具有相似的内部组件,包括核心、内存和控制单元。
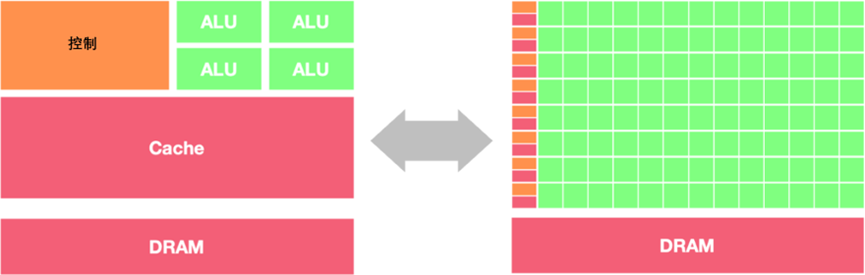
GPU 和 CPU 在架构方面的主要区别包括以下几点:
1)并行处理能力: CPU 拥有少量的强大计算单元(ALU),更适合处理顺序执行的任务,可以在很少的时钟周期内完成算术运算,时钟周期的频率很高,复杂的控制逻辑单元(Control)可以在程序有多个分支的情况下提供分支预测能力,因此 CPU 擅长逻辑控制和串行计算,流水线技术通过多个部件并行工作来缩短程序执行时间。GPU 控制单元可以把多个访问合并成,采用了数量众多的计算单元(ALU)和线程(Thread),大量的 ALU 可以实现非常大的计算吞吐量,超配的线程可以很好地平衡内存延时问题,因此可以同时处理多个任务,专注于大规模高度并行的计算任务。
2)内存架构: CPU 被缓存 Cache 占据了大量空间,大量缓存可以保存之后可能需要访问的数据,可以降低延时; GPU 缓存很少且为线程(Thread)服务,如果很多线程需要访问一个相同的数据,缓存会合并这些访问之后再去访问 DRMA,获取数据之后由 Cache 分发到数据对应的线程。 GPU 更多的寄存器可以支持大量 Thread。
3)指令集: CPU 的指令集更加通用,适合执行各种类型的任务; GPU 的指令集主要用于图形处理和通用计算,如 CUDA 和 OpenCL。
4)功耗和散热:CPU 的功耗相对较低,散热要求也相对较低;由于 GPU 的高度并行特性,其功耗通常较高,需要更好的散热系统来保持稳定运行。
因此,CPU 更适合处理顺序执行的任务,如操作系统、数据分析等;而 GPU 适合处理需要计算密集型 (Compute-intensive) 程序和大规模并行计算的任务,如图形处理、深度学习等。在异构系统中,GPU 和 CPU 经常会结合使用,以发挥各自的优势。
参考文献链接
1.4 AI 编译原理概述(DONE)
随着深度学习的应用场景不断泛化,深度学习计算任务也需要部署在不同的计算设备和硬件架构上;同时,实际部署或训练场景对性能往往也有着更为激进的要求,例如针对硬件的特点进行定制化。
这些需求在通用的 AI 框架中已经难已得到满足。由于深度学习计算任务在现有的 AI 框架中往往以 DSL(Domain Specific Language)的方式进行编程和表达,这本身使得深度学习计算任务的优化和执行天然符合传统计算机语言的编译和优化过程。因此,深度学习的编译与优化就是将当前的深度学习计算任务通过一层或多层中间表达进行翻译和优化,最终转化成目标硬件上的可执行代码的过程。本章将围绕现有 AI 编译器中的编译和优化工作的内容展开介绍。
1.4.1 GCC 主要特征(DONE)
GCC(GNU Compiler Collection,GNU 编译器集合)最初是作为 GNU 操作系统的编译器编写的,旨在为 GNU/Linux 系统开发一个高效的 C 编译器。其历史可以追溯到 1987 年,当时由理查德·斯托曼(Richard Stallman)创建,作为 GNU 项目的一部分。
最初,GCC 仅是一个用于编译 C 语言的编译器,但很快扩展以支持其他编程语言,其设计强调可移植性和模块化,使其能够适应多种硬件和操作系统环境。
在 1990 年代和 2000 年代,GCC 经历了几次重要的重构和扩展。改进包括引入新的优化技术、提升代码生成和分析能力,以及增强对新兴编程语言和硬件架构的支持。这些改进使得 GCC 成为编程社区中的重要工具,广泛应用于学术研究、商业开发和开源项目中。随着 GNU/Linux 系统的快速发展,GCC 逐渐扩展其支持范围,涵盖了包括 Microsoft Windows、BSD 系列、Solaris 和 Mac OS 在内的多种操作系统平台。
同时,GCC 的指导委员会根据其使命宣言做出重要决策,致力于持续发布高质量的版本。通过 Git 版本控制系统和每周的源代码快照,GCC 的最新源代码随时可供获取。任何人都被鼓励参与贡献或协助测试,以推动 GCC 的持续发展。
此外,GCC 还引入了与现代编程语言如 Swift 和 Java 相关的前端,使其成为一个全面而多功能的编译器。作为一个模块化设计的软件,GCC 提供了丰富的功能和灵活性,既能在本地平台上进行编译,也支持跨平台的交叉编译。作为自由软件的一部分,用户可以免费获取并自由使用 GCC,并且得到了自由软件基金会(Free Software Foundation,FSF)的强力支持。
GCC 具有以下主要特征:
1)可移植性:支持多种硬件平台,使得用户可以在不同的硬件架构上进行编译。
2)跨平台交叉编译:支持在一个平台上为另一个平台生成可执行文件,这对嵌入式开发尤为重要。
3)多语言前端:除了 C 语言,还支持 C++、Objective-C、Fortran、Ada、Go 和 D 等多种编程语言。
4)模块化设计:允许轻松添加新语言和 CPU 架构的支持,增强了扩展性。
5)开源自由软件:源代码公开,用户可以自由使用、修改和分发。
1. GCC 编译流程
GCC 的编译过程可以大致分为预处理、编译、汇编和链接四个阶段。

2. 源程序(文本)
当编写源程序时,通常会使用以 .c 或 .cpp 为扩展名的文件。下面以打印宏定义 HELLOWORD 为例,使用 C 语言编写 hello.c 源文件:
#include <stdio.h>
#define HELLOWORD ("hello world\n")
int main(void){
printf(HELLOWORD);
return 0;
}
3. 预处理(cpp)
生成文件 hello.i
gcc -E hello.c -o hello.i
在预处理过程中,源代码会被读入,并检查其中包含的预处理指令和宏定义,然后进行相应的替换操作。此外,预处理过程还会删除程序中的注释和多余空白字符。最终生成的.i 文件包含了经过预处理后的代码内容。
当高级语言代码经过预处理生成.i 文件时,预处理过程会涉及宏替换、条件编译等操作。以下是对这些预处理操作的解释:
1)头文件展开:
在预处理阶段,编译器会将源文件中包含的头文件内容插入到源文件中对应的位置,以便在编译时能够访问头文件中定义的函数、变量、宏等内容。
2)宏替换:
在预处理阶段,编译器会将源文件中定义的宏在使用时进行替换,即将宏名称替换为其定义的内容。这样可以简化代码编写,提高代码的可读性和可维护性。
3)条件编译:
通过预处理指令如 #if、#else、#ifdef 等,在编译前确定某些代码片段是否应被包含在最终的编译过程中。这样可以根据条件编译选择性地包含代码,实现不同平台、环境下的代码控制。
4)删除注释:
在预处理阶段,编译器会删除源文件中的注释,包括单行注释(//)和多行注释(/.../),这样可以提高编译速度并减少编译后代码的大小。
5)添加行号和文件名标识:
通过预处理指令如 #line,在预处理阶段添加行号和文件名标识到源文件中,便于在编译过程中定位错误信息和调试。
6)保留 #pragma 命令:
在预处理阶段,编译器会保留以#pragma 开头的预处理指令,如#pragma once、#pragma pack 等,这些指令可以用来指导编译器进行特定的处理,如控制编译器的行为或优化代码。
hello.i 文件部分内容如下,详细可见../code/gcc/hello.i 文件。
int main(void){
printf(("hello world\n"));
return 0;
}
在该文件中,已经将头文件包含进来,宏定义 HELLOWORD 替换为字符串"hello world\n",并删除了注释和多余空白字符。
4. 编译(ccl)
编译并不仅仅指将程序从源文件转换为二进制文件的整个过程,而是特指将经过预处理的文件(hello.i)转换为特定汇编代码文件(hello.s)的过程。
在这个过程中,经过预处理后的 .i 文件作为输入,通过编译器(ccl)生成相应的汇编代码.s 文件。编译器(ccl)是 GCC 的前端,其主要功能是将经过预处理的代码转换为汇编代码。编译阶段会对预处理后的.i 文件进行语法分析、词法分析以及各种优化,最终生成对应的汇编代码。
汇编代码是以文本形式存在的程序代码,接着经过编译生成.s 文件,是连接程序员编写的高级语言代码与计算机硬件之间的桥梁。
生成文件 hello.s:
gcc -S hello.i -o hello.s
打开 hello.s 后输出如下:
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 10, 15 sdk_version 10, 15, 6
.globl _main ## -- 启动main函数
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
subq $16, %rsp
movl $0, -4(%rbp)
leaq L_.str(%rip), %rdi
movb $0, %al
callq _printf
xorl %ecx, %ecx
movl %eax, -8(%rbp) ## 4字节溢出
movl %ecx, %eax
addq $16, %rsp
popq %rbp
retq
.cfi_endproc
## -- 结束main函数
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "hello world\n"
.subsections_via_symbols
现在 hello.s 文件中包含了完全是汇编指令的内容,表明 hello.c 文件已经被成功编译成了汇编语言。
5. 汇编(as)
在这一步中,将汇编代码转换成机器指令。这一步是通过汇编器(as)完成的。汇编器是 GCC 的后端,其主要功能是将汇编代码转换成机器指令。
汇编器的工作是将人类可读的汇编代码转换为机器指令或二进制码,生成一个可重定位的目标程序,通常以 .o 作为文件扩展名。这个目标文件包含了逐行转换后的机器码,以二进制形式存储。这种可重定位的目标程序为后续的链接和执行提供了基础,使得汇编代码能够被计算机直接执行。
生成文件 hello.o
gcc -c hello.s -o hello.o
6. 链接(ld)
链接过程中,链接器的作用是将目标文件与其他目标文件、库文件以及启动文件等进行链接,从而生成一个可执行文件。在链接的过程中,链接器会对符号进行解析、执行重定位、进行代码优化、确定空间布局,进行装载,并进行动态链接等操作。通过链接器的处理,将所有需要的依赖项打包成一个在特定平台可执行的目标程序,用户可以直接执行这个程序。
gcc -o hello.o -o hello
添加-v 参数,可以查看详细的编译过程:
gcc -v hello.c -o hello
1)静态链接
静态链接是指在链接程序时,需要使用的每个库函数的一份拷贝被加入到可执行文件中。通过静态链接使用静态库进行链接,生成的程序包含程序运行所需要的全部库,可以直接运行。然而,静态链接生成的程序体积较大。
2)动态链接
动态链接是指可执行文件只包含文件名,让载入器在运行时能够寻找程序所需的函数库。通过动态链接使用动态链接库进行链接,生成的程序在执行时需要加载所需的动态库才能运行。相比静态链接,动态链接生成的程序体积较小,但是必须依赖所需的动态库,否则无法执行。
1.4.2 GCC 编译方法
1. 本地编译
所谓本地编译,是指编译源代码的平台和执行源代码编译后程序的平台是同一个平台。这里的平台,可以理解为 CPU 架构+操作系统。比如,在 Intel x86 架构 或者 Windows 平台下、使用 Visual C++ 编译生成的可执行文件,在同样的 Intel x86 架构/Windows 10 下运行。
2. 交叉编译
所谓交叉编译(Cross_Compile),是指编译源代码的平台和执行源代码编译后程序的平台是两个不同的平台。比如,在 Intel x86 架构/Linux(Ubuntu)平台下、使用交叉编译工具链生成的可执行文件,在 ARM 架构/Linux 下运行。
与传统编译区别
传统的三段式划分是指将编译过程分为前端、优化、后端三个阶段,每个阶段都有专门的工具负责。

而在 GCC 中,编译过程被分成了预处理、编译、汇编、链接四个阶段 。其中 GCC 的预处理、编译阶段属于三段式划分的前端部分,汇编阶段属于三段式划分的后端部分。
GCC 的链接阶段是三段式划分后端部分的优化阶段合并,但其与端部分的目的一致,都是为了生成可执行文件。
GCC 编译过程的四个阶段与传统的三段式划分的前端、优化、后端三个阶段有一定的重合和对应关系,但 GCC 更为详细和全面地划分了编译过程,使得每个阶段的功能更加明确和独立。
参考文献链接
1.5 LLVM 架构设计和原理(DONE)
在上一节中,详细探讨了 GCC 的编译过程和原理。然而,由于 GCC 存在代码耦合度高、难以进行独立操作以及庞大的代码量等缺点。正是由于对这些问题的意识,人们开始期待新一代编译器的出现。将深入研究 LLVM 的架构设计和原理,以探索其与 GCC 不同之处。
1.5.1 LLVM 发展历程
在早期的 Apple MAC 电脑选择使用 GNU 编译器集合(GCC)作为官方编译器。尽管 GCC 在开源世界中表现良好,但苹果对编译工具提出了更高要求。苹果在增强 Objective-C 和 C 语言方面投入了大量努力,但 GCC 开发者对苹果在 Objective-C 支持方面的努力表示不满。因此,苹果基于 GCC 分为两个分支进行独立开发,导致苹果的编译器版本明显落后于官方 GCC 版本。
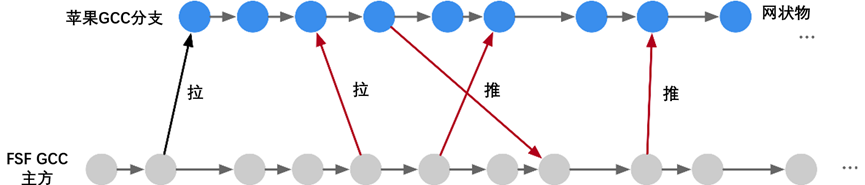
另一方面,GCC 的代码过于耦合,难以独立开发。随着版本更新,代码质量逐渐下降,而 GCC 无法以模块化方式调用实现 Apple 渴望的更好集成开发环境支持,这限制了 Apple 在编译器领域的发展。
面对这一系列问题,苹果一直寻找高效、模块化和更自由的开源替代方案。最终,苹果聘请了编译器领域的专家克里斯·拉特纳来领导 LLVM 项目的实现,标志着 LLVM 编译器的诞生。
1.5.2 LLVM 组件独立性
LLVM 具有一个显著的特点,即其组件的独立性和库化架构。在使用 LLVM 时,前端工程师只需实现相应的前端,而无需修改后端部分,从而使得添加新的编程语言变得更加简便。这是因为后端只需要将中间表示(IR)翻译成目标平台的机器码即可。
对于后端工程师而言,他们只需将目标硬件的特性如寄存器、硬件调度以及指令调度与 IR 进行对接,而无需干涉前端部分。这种灵活的架构使得编译器的前端和后端工程师能够相对独立地进行工作,从而极大地提高了开发效率和维护性。
在 LLVM 中,IR 扮演着至关重要的角色。它是一种类似汇编语言的底层语言,但具有强类型和精简指令集的特点(RISC),并对目标指令集进行了抽象。例如,在 IR 中,目标指令集的函数调用惯例会被抽象为 call 和 ret 指令,并使用明确的参数。
LLVM 支持三种不同的 IR 表达形式:人类可读的汇编形式、在 C++ 中的对象形式以及序列化后的 bitcode 形式。这种多样化的表达形式使得开发人员更好地理解和处理 IR,从而实现更加灵活和高效的编译工作。通过 IR 的抽象和统一,LLVM 极大地推动了编译体系的创新,为编程语言的快速开发和跨平台支持提供了强大的基础。
1.5.3 LLVM 中间表达
LLVM 提供了一套适用于编译器系统的中间语言(Intermediate Representation,IR),并围绕这个中间语言进行了大量的变换和优化。经过这些变换和优化,IR 可以被转换为目标平台相关的汇编语言代码。
与传统 GCC 的前端直接对应于后端不同,LLVM 的 IR 是统一的,可以适用于多种平台,进行优化和代码生成。
根据 2011 年的测试结果,LLVM 的性能在运行时平均比 GCC 低 10%。2013 年的测试显示,LLVM 能够编译出与 GCC 性能相近的执行代码。
GCC:

LLVM:

LLVM IR 的优点包括:
1)更独立:LLVM IR 设计为可在编译器之外的任意工具中重用,使得轻松集成其他类型的工具,如静态分析器和插桩器成为可能。
2)更正式:拥有明确定义和规范化的 C++ API,使得处理、转换和分析变得更加便捷。
3)更接近硬件:LLVM IR 提供了类似 RISCV 的模拟指令集和强类型系统,实现了其“通用表示”的目标。具有足够底层指令和细粒度类型的特性使得上层语言和 IR 的隔离变得简单,同时 IR 的行为更接近硬件,为进一步在 LLVM IR 上进行分析提供了可能性。
LLVM 整体架构
LLVM 是一个模块化和可重用的编译器和工具链技术库。它的整体架构包含从前端语言处理到最终生成目标机器码的完整优化流程。对于用户而言,通常会使用 Clang 作为前端,而 LLVM 的优化器和后端处理则是透明的。

1) 前端(Front-End):负责处理高级语言(如 C/C++/Obj-C)的编译,生成中间表示(IR)。
2) 优化器(Optimizer):对中间表示进行各种优化,提高代码执行效率。
3) 后端(Back-End):将优化后的中间表示转换为目标平台的机器码。
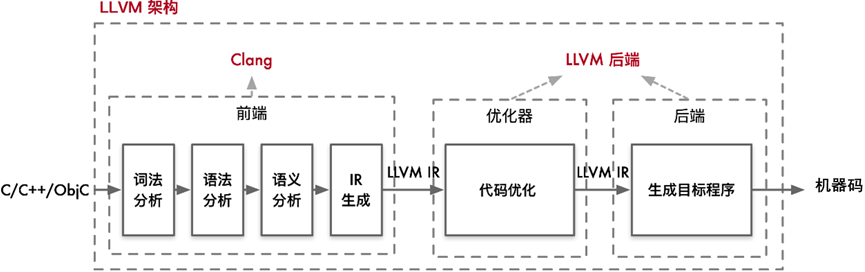
当用户编写的 C/C++/Obj-C 代码输入到 Clang 前端时,Clang 会执行以下步骤:
1) 词法分析(Lexical Analysis):将源代码转换为标记(tokens)。
2) 语法分析(Syntax Analysis):将标记转换为抽象语法树(AST)。
3)语义分析(Semantic Analysis):检查语义正确性,生成中间表示(IR)。
生成的抽象语法树(AST)通过进一步处理,转换为 LLVM 的中间表示(IR)。这个中间表示是一种平台无关的低级编程语言,用于连接前端和后端。
在详细的架构图中,可以看到 LLVM 的前端、优化器、后端等各个组件的交互。在前端,Clang 会将高级语言代码转换为为 LLVM 的中间表示(IR)。
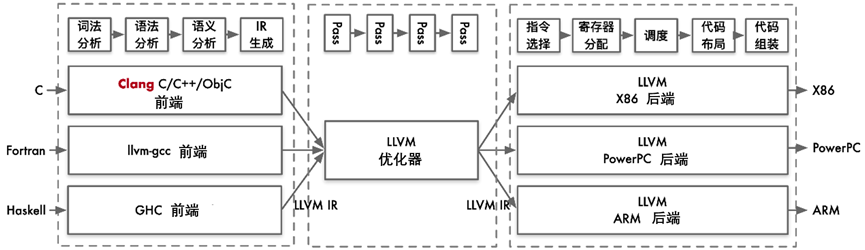
LLVM 的优化器通过多个优化 pass 来提升中间表示(IR)的性能。每个 pass 都对 IR 进行特定的优化操作,例如:
1) 常量折叠(Constant Folding):将编译时已知的常量表达式直接计算并替换。
2) 循环优化(Loop Optimizations):如循环展开、循环交换等,以提高循环执行效率。
3) 死代码消除(Dead Code Elimination):移除不必要的代码,提高执行效率。 经
过优化后的 IR 是一个更高效的中间表示,准备好进行后续的代码生成。
LLVM 的后端负责将优化后的中间表示转换为目标平台的机器码。这包含以下步骤:
1) 指令选择(Instruction Selection):将 IR 转换为目标架构的汇编指令。
2) 寄存器分配(Register Allocation):为指令分配合适的寄存器。
3) 指令调度(Instruction Scheduling):优化指令执行顺序,以提高指令流水线的效率。
4) 代码布局(Code Layout):调整代码的排列顺序,以适应目标硬件的执行特性。
5)代码生成(Code Generation):生成目标平台的汇编代码和最终的机器码。 最终,LLVM 后端输出目标平台的可执行文件。
LLVM 的整体架构清晰地分为前端、优化器和后端三个部分。用户与 Clang 前端直接交互,输入高级语言代码,而 Clang 将其转换为中间表示。之后,LLVM 的优化器和后端在后台处理,进行复杂的优化和代码生成步骤,最终输出高效的目标机器码。

在使用 LLVM 时,会从原始的 C 代码开始。这个 C 代码会经过一系列的预处理步骤,最终被转换为 LLVM 的中间表示文件(.ll 文件)或者 LLVM 字节码文件(.bc 文件)。
接下来使用 LLVM 的前端工具将中间表示文件编译成 IR。IR 的表示有两种方式,一种是 LLVM 汇编语言(.ll 文件),另一种是 LLVM 字节码(.bc 文件)。LLVM 汇编语言更为易读,方便人类阅读和理解。
IR 经过 LLVM 的后端编译器工具 llc 将 IR 转换为汇编代码(assembly code)。这个汇编代码是目标机器特定机器码指令的文本表示。
最后的两个步骤是将汇编代码汇编(assemble)成机器码文件,然后链接(link)生成可执行二进制文件,使其可以在特定平台上运行。
Clang + LLVM 案例实践
以下是对 Clang 编译过程中各个步骤的说明,其中 hello.c 是需要编译的 c 文件。
1)生成.i 文件
clang -E -c .\hello.c -o .\hello.i
这一步使用 Clang 的预处理器将 hello.c 文件中的所有预处理指令展开,生成预处理后的文件 hello.i。这包括展开宏定义、处理 #include 头文件等,生成一个纯 C 代码文件。
2)将预处理过后的.i 文件转化为.bc 文件
clang -emit-llvm .\hello.i -c -o .\hello.bc
这一步将预处理后的 hello.i 文件编译为 LLVM 位代码(bitcode)文件 hello.bc。LLVM 位代码是中间表示形式,可供进一步优化和转换。
clang -emit-llvm .\hello.c -S -o .\hello.ll
这一步将 hello.c 文件直接编译成 LLVM 中间表示的汇编代码文件 hello.ll,这是一种人类可读的中间表示形式,适用于进一步的分析和优化。
3)llc
在前面两个步骤中,生成了 .i 文件和 LLVM 位代码文件 .bc 或中间表示文件 .ll。接下来,可以使用 llc 工具将这些中间表示文件转换为目标平台的汇编代码。
llc .\hello.ll -o .\hello.s
llc .\hello.bc -o .\hello2.s
通过以上命令,分别将 hello.ll 文件和 hello.bc 文件编译为汇编代码文件 hello.s 和 hello2.s。由于 hello.ll 和 hello.bc 表示相同的代码逻辑,所以生成的汇编代码文件 hello.s 和 hello2.s 是相同的。
1) 转变为可执行的二进制文件
clang .\hello.s -o hello
2)查看编译过程
clang -ccc-print-phases .\hello.c
+- 0: input, ".\hello.c", c
+- 1: preprocessor, {0}, cpp-output
+- 2: compiler, {1}, ir
+- 3: backend, {2}, assembler
+- 4: assembler, {3}, object
+-5: linker, {4}, image
6: bind-arch,"x86_64", {5}, image
其中 0 是输入,1 是预处理,2 是编译,3 是后端优化,4 是产生汇编指令,5 是库链接,6 是生成可执行的 x86_64 二进制文件。
小结与思考
1) LLVM 把编译器移植到新语言只需要实现编译前端,复用已有的优化和后端;
2)LLVM 实现不同组件隔离为单独程序库,易于在整个编译流水线中集成转换和优化 Pass;
3)LLVM 作为实现各种静态和运行时编译语言的通用基础结构。
参考文献链接
1.6 LLVM IR 基本概念(DONE)
已经简要介绍了 LLVM 的基本概念和架构,现在将更深入地研究 LLVM 的 IR(中间表示)的概念。
了解 LLVM IR 的重要性是为了能够更好地理解编译器的运作原理,以及在编译过程中 IR 是如何被使用的。LLVM IR 提供了一种抽象程度适中的表示形式,同时能够涵盖绝大多数源代码所包含的信息,这使得编译器能够更为灵活地操作和优化代码。
将进一步探究 LLVM IR 的不同表示形式,将有助于更好地理解代码在编译器中是如何被处理和转换的。
1.6.1 LLVM IR 概述
编译器常见的作用是将源高级语言的代码编译到某种中间表示(Intermediate Representation,一般称为 IR),然后再将 IR 翻译为目标体系结构(具体硬件比如 MIPS 或 X86)的汇编语言或者硬件指令。
LLVM IR 提供了一种抽象层,使程序员可以更灵活地控制程序的编译和优化过程,同时保留了与硬件无关的特性。通过使用 LLVM IR,开发人员可以更好地理解程序的行为,提高代码的可移植性和性能优化的可能性。
1.6.2 LLVM 基本架构
目前常见的编译器都分为了三个部分,前端(Frontend),优化层(Optimizeation)以及后端(Backend),每一部分都承担了不同的功能:
1)前端:负责将高级源语言代码转换为 LLVM 的中间表示(IR),为后续的编译阶段打下基础。
2) 优化层:对生成的中间表示 IR 进行深入分析和优化,提升代码的性能和效率。
3)后端:将优化后的中间表示 IR 转换成目标机器的特定语言,确保代码能够在特定硬件上高效运行。
这种分层的方法不仅提高了编译过程的模块化,还使得编译器能够更灵活地适应不同的编程语言和目标平台。
在 LLVM 中不管是前端、优化层、还是后端都有大量的 IR,使得 LLVM 的模块化程度非常高,可以大量的复用一些相同的代码,非常方便的集成到不同的 IDE 和编译器当中。
经过中间表示 IR 这种做法相对于直接将源代码翻译为目标体系结构的好处主要有两个:
1)有一些优化技术是目标平台无关的,只需要在 IR 上做这些优化,再翻译到不同的汇编,这样就能够在所有支持的体系结构上实现这种优化,这大大的减少了开发的工作量。
2)其次,假设有 m 种源语言和 n 种目标平台,如果直接将源代码翻译为目标平台的代码,那么就需要编写 m * n 个不同的编译器。然而,如果采用一种 IR 作为中转,先将源语言编译到这种 IR,再将这种 IR 翻译到不同的目标平台上,那么就只需要实现 m + n 个编译器。
值得注意的是,LLVM 并非使用单一的 IR 进行表达,前端传给优化层时传递的是一种抽象语法树(Abstract Syntax Tree,AST)的 IR。因此 IR 是一种抽象表达,没有固定的形态。

抽象语法树的作用在于牢牢抓住程序的脉络,从而方便编译过程的后续环节(如代码生成)对程序进行解读。AST 就是开发者为语言量身定制的一套模型,基本上语言中的每种结构都与一种 AST 对象相对应。
在中端优化完成之后会传一个 DAG 图的 IR 给后端,DAG 图能够非常有效的去表示硬件的指定的顺序。
DAG(Directed Acyclic Graph,有向无环图)是图论中的一种数据结构,它是由顶点和有向边组成的图,其中顶点之间的边是有方向的,并且图中不存在任何环路(即不存在从某个顶点出发经过若干条边之后又回到该顶点的路径)。
在计算机科学中,DAG 图常常用于描述任务之间的依赖关系,例如在编译器和数据流分析中。DAG 图具有拓扑排序的特性,可以方便地对图中的节点进行排序,以确保按照依赖关系正确地执行任务。
编译的不同阶段会产生不同的数据结构和中间表达,如前端的抽象语法树(AST)、优化层的 DAG 图、后端的机器码等。后端优化时 DAG 图可能又转为普通的 IR 进行优化,最后再生产机器码。
1.6.3 LLVM IR 表示形式
LLVM IR 具有三种表示形式,这三种中间格式是完全等价的:
1) 在内存中的编译中间语言(无法通过文件的形式得到的指令类等)
2) 在硬盘上存储的二进制中间语言(格式为.bc)
3)人类可读的代码语言(格式为.ll)
接下来就看一下具体的 .ll 文件格式。
LLVM IR 示例与语法
1. 示例程序
编写一个简单的 C 语言程序,并将其编译为 LLVM IR。
test.c 文件内容如下:
#include <stdio.h>
void test(int a, int b)
{
int c = a + b;
}
int main(void)
{
int a = 10;
int b = 20;
test(a, b);
return 0;
}
接下来使用 Clang 编译器,将 C 语言源文件 test.c 编译成 LLVM 格式的中间代码。具体参数的含义如下:
1) clang:Clang 编译器
2) -S:生成汇编代码而非目标文件
3) -emit-llvm:生成 LLVM IR 中间代码
4).\test.c:要编译的 C 语言源文件
clang -S -emit-llvm .\test.c
在 LLVM IR 中,所生成的 .ll 文件的基本语法为:
1) 指令以分号 ; 开头表示注释
2) 全局表示以 @ 开头,局部变量以 % 开头
3) 使用 define 关键字定义函数,在本例中定义了两个函数:@test 和 @main
4) alloca 指令用于在堆栈上分配内存,类似于 C 语言中的变量声明
5) store 指令用于将值存储到指定地址
6) load 指令用于加载指定地址的值
7) add 指令用于对两个操作数进行加法运算
8) i32 32 位 4 个字节的意思
9) align 字节对齐
10)ret 指令用于从函数返回
编译完成后,生成的 test.ll 文件内容如下:
; ModuleID = '.\test.c'
source_filename = ".\\test.c"
target datalayout = "e-m:w-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-w64-windows-gnu"
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @test(i32 noundef %0, i32 noundef %1) #0 { ;定义全局函数@test(a,b)
%3 = alloca i32, align 4 ; 局部变量 c
%4 = alloca i32, align 4 ; 局部变量 d
%5 = alloca i32, align 4 ; 局部变量 e
store i32 %0, ptr %3, align 4 ; %0 赋值给%3 c=a
store i32 %1, ptr %4, align 4 ; %1 赋值给%4 d=b
%6 = load i32, ptr %3, align 4 ; 读取%3,值给%6 就是参数 a
%7 = load i32, ptr %4, align 4 ; 读取%4,值给%7 就是参数 b
%8 = add nsw i32 %6, %7
store i32 %8, ptr %5, align 4 ; 参数 %9 赋值给%5 e 就是转换前函数写的 int c 变量
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i32 0, ptr %1, align 4
store i32 10, ptr %2, align 4
store i32 20, ptr %3, align 4
%4 = load i32, ptr %2, align 4
%5 = load i32, ptr %3, align 4
call void @test(i32 noundef %4, i32 noundef %5)
ret i32 0
}
attributes #0 = { noinline nounwind optnone uwtable "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cmov,+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2, !3}
!llvm.ident = !{!4}
!0 = !{i32 1, !"wchar_size", i32 2}
!1 = !{i32 8, !"PIC Level", i32 2}
!2 = !{i32 7, !"uwtable", i32 2}
!3 = !{i32 1, !"MaxTLSAlign", i32 65536}
!4 = !{!"(built by Brecht Sanders, r4) clang version 17.0.6"}
以上程序中包含了两个函数:@test 和 @main。@test 函数接受两个整型参数并计算它们的和,将结果存储在一个局部变量中。@main 函数分配三个整型变量的内存空间,然后分别赋予初始值,并调用 @test 函数进行计算。最后 @main 函数返回整数值 0。
程序的完整执行流程如下:
- 在 @main 函数中,首先分配三个整型变量的内存空间 %1,%2,%3,分别存储 0,10,20
- 接下来加载 %2 和 %3 的值,将 10 和 20 作为参数调用 @test 函数
- 在 @test 函数中,分别将传入的参数 %0 和 %1 存储至本地变量 %3 和 %4 中
- 然后加载 %3 和 %4 的值,进行加法操作,并将结果存储至 %5 中
- 最后,程序返回整数值 0
LLVM IR 的代码和 C 语言编译生成的代码在功能实现上具有完全相同的特性。.ll 文件作为 LLVM IR 的一种中间语言,可以通过 LLVM 编译器将其转换为机器码,从而实现计算机程序的执行。
1.6.4 基本语法
除了上述示例代码中涉及到的基本语法外,LLVM IR 作为中间语言也同样有着条件语句、循环体和对指针操作的语法规则。
1. 条件语句
例如以下 C 语言代码:
#include <stdio.h>
int main()
{
int a = 10;
if(a%2 == 0)
return 0;
else
return 1;
}
在经过编译后的 .ll 文件的内容如下所示:
define i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%a = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 10, i32* %a, align 4
%0 = load i32, i32* %a, align 4
%rem = srem i32 %0, 2
%cmp = icmp eq i32 %rem, 0
br i1 %cmp, label %if.then, label %if.else
if.then: ; preds = %entry
store i32 0, i32* %retval, align 4
br label %return
if.else: ; preds = %entry
store i32 1, i32* %retval, align 4
br label %return
return: ; preds = %if.else, %if.then
%1 = load i32, i32* %retval, align 4
ret i32 %1
}
icmp 指令是根据比较规则,比较两个操作数,将比较的结果以布尔值或者布尔值向量返回,且对于操作数的限定是操作数为整数或整数值向量、指针或指针向量。其中,eq 是比较规则,%rem 和 0 是操作数,i32 是操作数类型,比较 %rem 与 0 的值是否相等,将比较的结果存放到 %cmp 中。
br 指令有两种形式,分别对应于条件分支和无条件分支。该指令的条件分支在形式上接受一个“i1”值和两个“label”值,用于将控制流传输到当前函数中的不同基本块,上面这条指令是条件分支,类似于 c 中的三目条件运算符 < expression ?Statement :statement>;无条件分支的话就是不用判断,直接跳转到指定的分支,类似于 c 中 goto,比如说这个就是无条件分支 br label %return。 br i1 %cmp, label %if.then, label %if.else 指令的意思是,i1 类型的变量 %cmp 的值如果为真,执行 if.then 否则执行 if.else。
2. 循环体
例如以下 C 程序代码:
#include <stdio.h>
int main()
{
int a = 0, b = 1;
while(a < 5)
{
a++;
b *= a;
}
return b;
}
在经过编译后的 .ll 文件的内容如下所示:
define i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%a = alloca i32, align 4
%b = alloca i32, align 4
store i32 0, i32* %retval, align 4
store i32 0, i32* %a, align 4
store i32 1, i32* %b, align 4
br label %while.cond
while.cond: ; preds = %while.body, %entry
%0 = load i32, i32* %a, align 4
%cmp = icmp slt i32 %0, 5
br i1 %cmp, label %while.body, label %while.end
while.body: ; preds = %while.cond
%1 = load i32, i32* %a, align 4
%inc = add nsw i32 %1, 1
store i32 %inc, i32* %a, align 4
%2 = load i32, i32* %a, align 4
%3 = load i32, i32* %b, align 4
%mul = mul nsw i32 %3, %2
store i32 %mul, i32* %b, align 4
br label %while.cond
while.end: ; preds = %while.cond
%4 = load i32, i32* %b, align 4
ret i32 %4
}
对比 if 语句可以发现,while 中几乎没有新的指令出现,所以说所谓的 while 循环,也就是“跳转+分支”这一结构。同理,for 循环 也可以由“跳转+分支”这一结构构成。
3. 指针
例如以下 C 程序代码:
int main(){
int i = 10;
int* pi = &i;
printf("i 的值为:%d",i);
printf("*pi 的值为:%d",*pi);
printf("&i 的地址值为:",%d);
printf("pi 的地址值为:",%d);
}
在经过编译后的 .ll 文件的内容如下所示:
@.str = private unnamed_addr constant [16 x i8] c"i\E7\9A\84\E5\80\BC\E4\B8\BA\EF\BC\9A%d\00", align 1
@.str.1 = private unnamed_addr constant [18 x i8] c"*pi\E7\9A\84\E5\80\BC\E4\B8\BA\EF\BC\9A%d\00", align 1
@.str.2 = private unnamed_addr constant [23 x i8] c"&i\E7\9A\84\E5\9C\B0\E5\9D\80\E5\80\BC\E4\B8\BA\EF\BC\9A%p\00", align 1
@.str.3 = private unnamed_addr constant [23 x i8] c"pi\E7\9A\84\E5\9C\B0\E5\9D\80\E5\80\BC\E4\B8\BA\EF\BC\9A%p\00", align 1
define i32 @main(){
entry:
%i = alloca i32, align 4
%pi = alloca i32*, align 8
store i32 10, i32* %i, align 4
store i32* %i, i32** %pi, align 8
%0 = load i32, i32* %i, align 4
%call = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([16 x i8], [16 x i8]* @.str, i32 0, i32 0), i32 %0)
%1 = load i32, i32* %i, align 4
%call1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([18 x i8], [18 x i8]* @.str.1, i32 0, i32 0), i32 %1)
%call2 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([23 x i8], [23 x i8]* @.str.2, i32 0, i32 0), i32* %i)
%2 = load i32*, i32** %pi, align 8
%call3 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([23 x i8], [23 x i8]* @.str.3, i32 0, i32 0), i32* %2)
ret i32 0
}
declare i32 @printf(i8*, ...)
对指针的操作就是指针的指针,开辟一块指针类型的内存,里面放个指针%pi = alloca i32*, align 8
此外,c 语言中常见的操作还有对数组和结构体的操作,内置函数和外部函数的引用等。
1.6.5 小结与思考
1)LLVM IR 表示形式: LLVM IR 是一种中间表示形式,类似汇编语言但更抽象,用于表示高级语言到机器码的转换过程。
2)LLVM IR 基本语法: LLVM IR 使用类似文本的语法表示,包括指令、注释、变量声明等内容。
3)LLVM IR 指令集: LLVM IR 包含一系列指令用于描述计算、内存访问、分支等操作,能够表示复杂的算法和数据流。
参考文献链接
1.6.6 LLVM IR 详解(DONE)
已经简要介绍了 LLVM 的基本概念和架构,现在将更深入地研究 LLVM 的 IR(中间表示)的概念。
了解 LLVM IR 的重要性是为了能够更好地理解编译器的运作原理,以及在编译过程中 IR 是如何被使用的。LLVM IR 提供了一种抽象程度适中的表示形式,同时能够涵盖绝大多数源代码所包含的信息,这使得编译器能够更为灵活地操作和优化代码。
将进一步探究 LLVM IR 的不同表示形式,将有助于更好地理解代码在编译器中是如何被处理和转换的。
1.6.7 LLVM IR 指令集
LLVM IR 是 LLVM 编译器框架中的一种中间语言,它提供了一个抽象层次,使得编译器能够在多个阶段进行优化和代码生成。LLVM IR 具有类精简指令集、使用三地址指令格式的特征,使其在编译器设计中非常强大和灵活。
LLVM IR 的设计理念类似于精简指令集(RISC),这意味着它倾向于使用简单且数量有限的指令来完成各种操作。其指令集支持简单指令的线性序列,比如加法、减法、比较和条件分支等。这使得编译器可以很容易地对代码进行线性扫描和优化。
RISC 架构的一个重要特征是指令执行的效率较高,因为每条指令都相对简单,执行速度快。
1. 三地址指令格式
三地址码是一种中间代码表示形式,广泛用于编译器设计中,LLVM IR 也采用三地址码的方式作为指令集的表示方式。它提供了一种简洁而灵活的方式来描述程序的中间步骤,有助于优化和代码生成。下面是对三地址码的详细总结。
1) 什么是三地址码
三地址码(Three-Address Code, TAC)是一种中间表示形式,每条指令最多包含三个操作数:两个源操作数和一个目标操作数。这些操作数可以是变量、常量或临时变量。三地址码可以看作是一系列的四元组(4-tuple),每个四元组表示一个简单的操作。
2) 四元组表示
每个三地址码指令都可以分解为一个四元组的形式:
(运算符, 操作数 1, 操作数 2, 结果)
1) 运算符(Operator):表示要执行的操作,例如加法(+)、减法(-)、乘法(*)、赋值(=)等。
2) 操作数 1(Operand1):第一个输入操作数。
3) 操作数 2(Operand2):第二个输入操作数(有些指令可能没有这个操作数)。
4) 结果(Result):操作的输出结果存储的位置。
不同类型的指令可以表示为不同的四元组格式:
|
指令类型 |
指令格式 |
四元组表示 |
|
赋值指令 |
z = x |
(=, x, ``, z) |
|
算术指令 |
z = x op y |
(op, x, y, z) |
|
一元运算 |
z = op y |
(op, y, ``, z) |
|
条件跳转 |
if x goto L |
(if, x, ``, L) |
|
无条件跳转 |
goto L |
(goto, , , L) |
|
函数调用 |
z = call f(a, b) |
(call, f, (a,b), z) |
|
返回指令 |
return x |
(return, x, , ) |
2. 三地址码的优点
1) 简单性:三地址码具有简单的指令格式,使得编译器可以方便地进行语义分析和中间代码生成。
2) 清晰性:每条指令执行一个简单操作,便于理解和调试。
3) 优化潜力:由于指令简单且结构固定,编译器可以容易地应用各种优化技术,如常量折叠、死代码消除和寄存器分配。
4) 独立性:三地址码独立于具体机器,可以在不同平台之间移植。
3. LLVM IR 中三地址码
LLVM IR 是 LLVM 编译器框架使用的一种中间表示,采用了类似三地址码的设计理念。以下是 LLVM IR 指令集的一些特点:
1) 虚拟寄存器:LLVM IR 使用虚拟寄存器,而不是物理寄存器。这些寄存器以 % 字符开头命名。
2) 类型系统:LLVM IR 使用强类型系统,每个值都有一个明确的类型。
3) 指令格式:LLVM IR 指令也可以看作三地址指令,例如:
%result = add i32 %a, %b
在这条指令中,%a 和 %b 是输入操作数,add 是运算符,%result 是结果。因此这条指令可以表示为四元组:
(add, %a, %b, %result)
4. LLVM IR 指令示例
以下是一个简单的 LLVM IR 示例,它展示了一个函数实现:
; 定义一个函数,接受两个 32 位整数参数并返回它们的和
define i32 @add(i32 %a, i32 %b) {
entry:
%result = add i32 %a, %b
ret i32 %result
}
这个例子中,加法指令和返回指令分别可以表示为四元组:
(add, %a, %b, %result)
(ret, %result, , )
三地址码是一种强大且灵活的中间表示形式,通过使用简单的四元组结构,可以有效地描述程序的中间步骤。LLVM IR 采用了类似三地址码的设计,使得编译器能够高效地进行优化和代码生成。理解三地址码的基本原理和其在 LLVM IR 中的应用,有助于深入掌握编译器技术和优化策略。
5. LLVM IR 设计原则
LLVM IR 是一种通用的、低级的虚拟指令集,用于编译器和工具链开发。以下是关于 LLVM IR 的指导原则和最佳实践的总结:
1)模块化设计
LLVM IR 设计为模块化的,代码和数据分为多个模块,每个模块包含多个函数、全局变量和其他定义。这种设计支持灵活的代码生成和优化。
2)中间表示层次
LLVM IR 是编译过程中的中间表示,位于源代码和机器码之间。这种层次化设计使得不同语言和目标架构可以共享通用的优化和代码生成技术。
3)静态单赋值形式(SSA)
LLVM IR 采用 SSA 形式,每个变量在代码中只被赋值一次。SSA 形式简化了数据流分析和优化,例如死代码消除和寄存器分配。
4)类型系统
LLVM IR 使用强类型系统,支持基本类型(如整数、浮点数)和复合类型(如数组、结构体)。类型系统确保了操作的合法性并支持类型检查和转换。
5)指令集
LLVM IR 提供丰富的指令集,包括算术运算、逻辑运算、内存操作和控制流指令。每条指令都指定了操作数类型,确保了代码的可移植性和一致性。
6)优化和扩展
LLVM IR 支持多种优化技术,包括常量折叠、循环优化和内联展开。它还支持通过插件和扩展添加自定义优化和分析。
7)目标无关性
LLVM IR 设计为目标无关的中间表示,可以跨不同的硬件和操作系统使用。这种目标无关性简化了跨平台编译和优化。
8)调试支持
LLVM IR 包含丰富的调试信息支持,可以生成调试符号和源代码映射,支持调试器如 GDB 和 LLDB。
这些原则和最佳实践使 LLVM IR 成为一个强大且灵活的工具,用于编译器开发和代码优化。它的模块化设计、强类型系统、丰富的指令集和目标无关性使其适用于广泛的应用场景,从语言前端到高级优化和代码生成。
6. 静态单赋值(SSA)
静态单赋值是指当程序中的每个变量都有且只有一个赋值语句时,称一个程序是 SSA 形式的。LLVM IR 中,每个变量都在使用前都必须先定义,且每个变量只能被赋值一次。以 1*2+3 为例:
%0 = mul i32 1, 2
%0 = add i32 %0, 3
ret i32 %0
静态单赋值形式是指每个变量只有一个赋值语句,所以上述代码的 %0 不能复用:
%0 = mul i32 1, 2
%1 = add i32 %0, 3
ret i32 %1
静态单赋值好处:
1) 每个值都由单一的赋值操作定义,这使得可以轻松地从值的使用点直接追溯到其定义的指令。这种特性极大地方便了编译器进行正向和反向的编译过程。
2) 此外,由于静态单赋值(SSA)形式构建了一个简单的使用-定义链,即一个值到达其使用点的定义列表,这极大地简化了代码优化过程。在 SSA 形式下,编译器可以更直观地识别和处理变量的依赖关系,从而提高优化的效率和效果。
7. LLVM IR 内存模型
在进行编译器优化时,需要了解 LLVM IR(中间表示)的内存模型。LLVM IR 的内存模型是基于基本块的,每个基本块都有自己的内存空间,指令只能在其内存空间内执行。
在 LLVM 架构中,几乎所有的实体都是一个 Value。Value 是一个非常基础的基类,其子类表示它们的结果可以被其他地方使用。继承自 User 的类表示它们会使用一个或多个 Value 对象。根据 Value 与 User 之间的关系,可以引申出 use-def 链和 def-use 链这两个概念。
1) use-def 链是指被某个 User 使用的 Value 列表;
2) def-use 链是指使用某个 Value 的 User 列表。实际上,LLVM 中还定义了一个 Use 类,Use 表示上述使用关系中的一个边。
8. LLVM IR 基本单位
1)Module
一个 LLVM IR 文件的基本单位是 Module。它包含了所有模块的元数据,例如文件名、目标平台、数据布局等。
; ModuleID = '.\test.c'
source_filename = ".\\test.c"
target datalayout = "e-m:w-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-w64-windows-gnu"
Module 类聚合了整个翻译单元中用到的所有数据,是 LLVM 术语中的“module”的同义词。可以通过 Module::iterator 遍历模块中的函数,使用 begin() 和 end() 方法获取这些迭代器。
2)Function
在 Module 中,可以定义多个函数(Function),每个函数都有自己的类型签名、参数列表、局部变量列表、基本块列表和属性列表等。
; Function Attrs: noinline nounwind optnone uwtable
define dso_local void @test(i32 noundef %0, i32 noundef %1) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, ptr %3, align 4
store i32 %1, ptr %4, align 4
%6 = load i32, ptr %3, align 4
%7 = load i32, ptr %4, align 4
%8 = add nsw i32 %6, %7
store i32 %8, ptr %5, align 4
ret void
}
Function 类包含有关函数定义和声明的所有对象。对于声明(可以用 isDeclaration() 检查),它仅包含函数原型。无论是定义还是声明,它都包含函数参数列表,可通过 getArgumentList() 或者 arg_begin() 和 arg_end() 方法访问。
3)BasicBlock
每个函数可以有多个基本块(BasicBlock),每个基本块由若干条指令(Instruction)组成,最后以一个终结指令(terminator instruction)结束。
BasicBlock 类封装了 LLVM 指令序列,可通过 begin()/end() 访问它们。可以利用 getTerminator() 方法直接访问它的最后一条指令,还可以通过 getSinglePredecessor() 方法访问前驱基本块。如果一个基本块有多个前驱,就需要遍历前驱列表。
4)指令
Instruction 类表示 LLVM IR 的运算原子,即单个指令。
可以通过一些方法获得高层级的断言,例如 isAssociative(),isCommutative(),isIdempotent() 和 isTerminator()。精确功能可以通过 getOpcode() 方法获知,它返回 llvm::Instruction 枚举的一个成员,代表 LLVM IR opcode。操作数可以通过 op_begin() 和 op_end() 方法访问,这些方法从 User 超类继承而来。
9. LLBM IR 整体示例
以下是一个完整的 LLVM IR 示例,包含 Module、Function、BasicBlock 和 Instruction:
; ModuleID = '.\test.c'
source_filename = ".\\test.c"
target datalayout = "e-m:w-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-w64-windows-gnu"
define dso_local void @test(i32 noundef %0, i32 noundef %1) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, ptr %3, align 4
store i32 %1, ptr %4, align 4
%6 = load i32, ptr %3, align 4
%7 = load i32, ptr %4, align 4
%8 = add nsw i32 %6, %7
store i32 %8, ptr %5, align 4
ret void
}
在这个示例中,Module 定义了文件的元数据,Function 定义了一个函数 @test,这个函数有两个 BasicBlock,其中包含了一系列的 Instruction。
10. 小结与思考
1) 三地址码: LLVM IR 使用三地址码形式表示指令,每条指令最多有三个操作数,包括目标操作数和两个源操作数。
2) LLVM IR 指令集: LLVM IR 包含一系列指令用于描述计算、内存访问、分支等操作,能够表示复杂的算法和数据流。
3) 静态单赋值: LLVM IR 使用静态单赋值形式表示变量,每个变量只能被赋值一次,在程序执行过程中可以方便进行分析和优化。
4) LLVM IR 内存模型: LLVM IR 提供了灵活的内存模型,包括指针操作、内存访问、内存管理等功能,支持复杂的数据结构和算法设计。
参考文献链接
1.6.8 CPU 计算时延
CPU(中央处理器)是计算机的核心组件,其性能对计算机系统的整体性能有着重要影响。CPU 计算时延是指从指令发出到完成整个指令操作所需的时间。理解 CPU 的计算时延对于优化计算性能和设计高效的计算系统至关重要。
1. CPU 计算时延的组成
CPU 计算时延主要由以下几个部分组成:
1) 指令提取时延(Instruction Fetch Time):指令提取时延是指从内存中读取指令到将其放入指令寄存器的时间。这个时延受内存速度和缓存命中率的影响。
2) 指令解码时延(Instruction Decode Time):指令解码时延是指将从内存中读取
的指令翻译成 CPU 能够理解的操作的时间。复杂指令集架构(CISC)通常比精简指令集架构(RISC)具有更长的解码时延。
3) 执行时延(Execution Time):执行时延是指 CPU 实际执行指令所需的时间。这个时延取决于指令的类型和 CPU 的架构,例如流水线深度、并行度等。
4) 存储器访问时延(Memory Access Time): 存储器访问时延是指 CPU 访问主存
储器或缓存所需的时间。这个时延受缓存层次结构(L1, L2, L3 缓存)和存储器带宽的影响。
5) 写回时延(Write-back Time):写回时延是指执行完指令后将结果写回寄存器或存储器的时间。这一过程也受缓存的影响。
2. 影响计算时延的因素
1) CPU 时钟频率(Clock Frequency):CPU 时钟频率越高,指令执行速度越快,计算时延越短。然而,过高的时钟频率会带来功耗和散热问题。
2) 流水线技术(Pipelining):流水线技术将指令执行分为多个阶段,每个阶段可以
并行处理不同的指令,从而提高指令吞吐量,降低时延。但流水线的深度和效率对时延有直接影响。
3) 并行处理(Parallel Processing):多核处理器和超线程技术允许多个指令同时执行,显著降低计算时延。并行处理的效率依赖于任务的可并行性。
4) 缓存命中率(Cache Hit Rate): 高缓存命中率可以显著减少存储器访问时延,
提高整体性能。缓存失效(Cache Miss)会导致较高的存储器访问时延。
5) 内存带宽(Memory Bandwidth):高内存带宽可以减少数据传输瓶颈,降低存储
器访问时延,提升计算性能。
3. 优化计算时延的方法
1)提高时钟频率:在不超出散热和功耗限制的情况下,提高 CPU 的时钟频率可以直
接减少计算时延。
2)优化流水线深度:适当增加流水线深度,提高指令并行处理能力,但需要平衡流
水线的复杂性和效率。
3) 增加缓存容量:增加 L1、L2、L3 缓存的容量和优化缓存管理策略,可以提高缓存命中率,减少存储器访问时延。
4) 使用高效的并行算法:开发和采用适合并行处理的算法,提高多核处理器的利用率,降低计算时延。
5) 提升内存子系统性能:采用高速内存技术和更高带宽的内存接口,减少数据传输时延,提高整体系统性能。
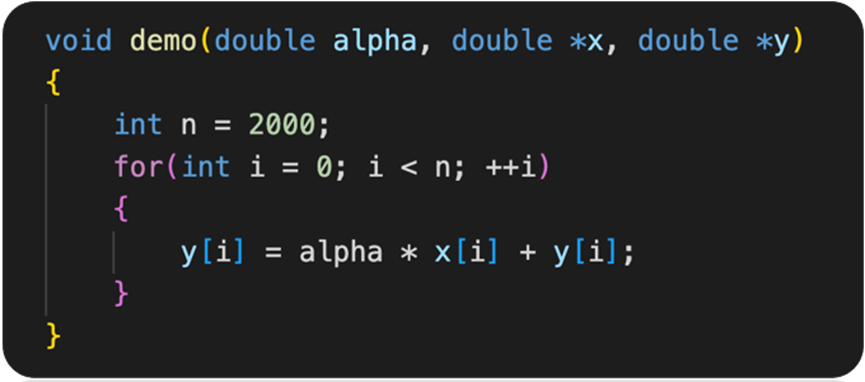
4. CPU 计算例子
图中展示了一个简单的 C 代码示例,用于计算 y[i] = alpha * x[i] + y[i]:
5. CPU 指令执行过程

1)横轴(Times):表示时间的推进。
2)纵轴:展示了不同操作(如加载、计算、写入)的时延。
6. 数据加载
Load from DRAM
load x[0] 和 load y[0]:从主存储器(DRAM)加载数据到缓存(cache)。这个过程涉及较高的内存时延(Memory latency)。
7. 缓存读取
读缓存:从缓存中读取已经加载的数据。相比从主存储器加载数据,缓存读取的时延较短。
8. 计算过程
1) Read x[0] 和 Read y[0]:从缓存中读取需要进行计算的变量 x[0] 和 y[0]。
2) α * x:进行乘法运算,计算 α * x。
3) + y:进行加法运算,将上一步的结果与 y 相加。
9. 写回结果
1) 写结果:将计算结果写回到缓存。这个步骤也包括较短的时延。
2) 写到缓存:最后一步,将计算结果从缓存写回到主存储器(如有需要)。
10. 时延分析
1) 内存延迟:图中用红色标注的长箭头表示内存时延,即从开始加载数据到数据被
缓存所需的总时间。这是影响计算速度的重要因素。
2) 计算时延:乘法和加法操作各自有独立的时延,分别用红色小箭头标注。
3) 缓存操作时延:读取和写入缓存的时延相对较短,用绿色箭头表示。
11. 计算速度决定性因素
图中展示的加载数据操作占用了很长的时间(Memory latency),CPU 在等待数据加载完成之前无法进行后续的计算操作。虽然计算本身(乘法和加法)以及缓存读取和写入的时间较短,但由于内存时延过长,整体计算过程被时延严重拖慢。
CPU 时延的产生

电信号在导体中的传播速度约为 60,000,000 米/秒。
假设计算机时钟频率为 3,000,000,000 赫兹(3 GHz),根据上图可知,从芯片到 DRAM 的信号传输距离大约为 50-100 毫米。
计算机时钟频率为 3 GHz,意味着每个时钟周期大约为 1 / 3,000,000,000 秒 ≈ 0.333 纳秒。
1) 电信号在 50 毫米的距离上传播的延迟:
电信号在 50 毫米的距离上传播的延迟约为 0.833 纳秒,这相当于 0.833 纳秒
/ 0.333 纳秒 ≈ 2.5 个时钟周期。
2) 电信号在 100 毫米的距离上传播的延迟:
电信号在 100 毫米的距离上传播的延迟约为 1.667 纳秒,这相当于 1.667 纳秒 / 0.333 纳秒 ≈ 5 个时钟周期。
这些传播延迟就是 CPU 的时钟周期,也是 CPU 计算的时延。
12. 什么是时钟周期
CPU 的时钟周期(Clock Cycle)是指 CPU 时钟信号的一个完整周期,它定义了 CPU 内部所有操作的基本时间单位。每个时钟周期内,CPU 完成一定量的工作,如取指令、解码指令、执行指令等。时钟周期是 CPU 性能的关键因素之一。
时钟周期的单位
时钟周期的单位通常是秒或其分量,如纳秒(ns)。时钟周期的长度由 CPU 的时钟频率决定:
1) 时钟频率(Clock Frequency):CPU 时钟频率指的是 CPU 每秒钟执行的时钟周
期数,单位是赫兹(Hz)。常见的时钟频率为几百 MHz 到几 GHz。
2) 时钟周期(Clock Cycle Time):时钟周期与时钟频率互为倒数。时钟频率为 3
GHz 的 CPU,其时钟周期为 1 / 3,000,000,000 秒 ≈ 0.333 纳秒。
13. CPU 的架构
CPU 的基本架构包含了控制单元(Control Unit)、算术逻辑单元(ALU)、缓存(Cache)和主存储器(DRAM)的各个部分,CPU 主要擅长的是逻辑控制,而非计算。
参考文献链接
1.6.9 LLVM 前端和优化层
LLVM 的 IR 贯穿了 LLVM 编译器的全生命周期,里面的每一个箭头都是一个 IR 的过程,这个就是整体 LLVM 最重要的核心概念。
有了 LVM IR 之后这并不意味着 LLVM 或者编译器的整个 Pipeline 都是使用一个单一的 IR,而是在编译的不同阶段会采用不同的数据结构,但总体来说还是会维护一个比较标准的 IR。接下来本节就具体的介绍一下 LLVM 的前端和优化层。
LLVM 前端 - Clang
LLVM 的前端其实是把源代码也就是 C、C++、Python 这些高级语言变为编译器的中间表示 LLVM IR 的过程。
这个阶段属于代码生成之前的过程,和硬件与目标无关,所以在前端的最后一个环节是 IR 的生成。
Clang 是一个强大的编译器工具,作为 LLVM 的前端承担着将 C、C++ 和 Objective-C 语言代码转换为 LLVM 中间表示(IR)的任务。
通过 Clang 的三个关键步骤:词法分析、语法分析和语义分析,源代码被逐步转化为高效的中间表示形式,为进一步的优化和目标代码生成做准备。
1)词法分析阶段负责将源代码分解为各种标记的流,例如关键字、标识符、运算符和常量等,这些标记构成了编程语言的基本单元。
2)语法分析器则负责根据编程语言的语法规则,将这些标记流组织成符合语言语法结构的语法树。
3)语义分析阶段则确保语法树的各部分之间的关系和含义是正确的,比如类型匹配、变量声明的范围等,以确保程序的正确性和可靠性。

每个编程语言前端都会有自己的词法分析器、语法分析器和语义分析器,它们的任务是将程序员编写的源代码转换为通用的抽象语法树(AST),这样可以为后续的处理步骤提供统一的数据结构表示。AST 是程序的一个中间表示形式,它便于进行代码分析、优化和转换。
1. 词法分析
前端的第一个步骤处理源代码的文本输入,词法分析 lexical analyze 用于标记源代码,将语言结构分解为一组单词和标记,去除注释、空白、制表符等。每个单词或者标记必须属于语言子集,语言的保留字被变换为编译器内部表示。
首先编写代码 hello.c,内容如下:
#include <stdio.h>
#define HELLOWORD ("Hello World\n")
int main() {
printf(HELLOWORD);
return 0;
}
对 hello.c 文件进行词法分析,执行以下代码:
clang -cc1 -dump-tokens hello.c
词法分析输出如下:
int 'int' [StartOfLine] Loc=<hello.c:5:1>
identifier 'main' [LeadingSpace] Loc=<hello.c:5:5>
l_paren '(' Loc=<hello.c:5:9>
void 'void' Loc=<hello.c:5:10>
r_paren ')' Loc=<hello.c:5:14>
l_brace '{' Loc=<hello.c:5:15>
identifier 'printf' [StartOfLine] [LeadingSpace] Loc=<hello.c:6:5>
l_paren '(' Loc=<hello.c:6:11>
l_paren '(' Loc=<hello.c:6:12 <Spelling=hello.c:3:19>>
string_literal '"hello world\n"' Loc=<hello.c:6:12 <Spelling=hello.c:3:20>>
r_paren ')' Loc=<hello.c:6:12 <Spelling=hello.c:3:35>>
r_paren ')' Loc=<hello.c:6:21>
semi ';' Loc=<hello.c:6:22>
return 'return' [StartOfLine] [LeadingSpace] Loc=<hello.c:7:5>
numeric_constant '0' [LeadingSpace] Loc=<hello.c:7:12>
semi ';' Loc=<hello.c:7:13>
r_brace '}' [StartOfLine] Loc=<hello.c:8:1>
eof '' Loc=<hello.c:8:2>
编译器通过词法分析过程将源代码解析为一系列符号,并准确记录它们在源文件中的位置。每个符号都被赋予一个 SourceLocation 类的实例,以便表示其在源文件中的确切位置,例如 Loc=<hello.c:6:11> 表示该符号出现在文件 hello.c 的第 6 行第 11 个位置。这种位置信息的精确记录为后续的语法分析和语义分析提供了重要的基础。
词法分析过程同时也在建立符号与位置之间的映射关系。这种精细的位置记录有助于编译器更好地理解代码的结构,并能够更有效地进行编译和优化。此外,它为程序员提供了更准确的编译器信息反馈,帮助他们更好地理解和调试代码。
在编译器的工作流程中,这种精准的位置记录和符号切分过程至关重要,为后续阶段的处理提供了可靠的基础,也为代码分析提供了更深层次的支持。
2. 语法分析
分组标记的目的是为了形成语法分析器(Syntactic Analyze)可以识别并验证其正确性的数据结构,最终构建出抽象语法树(AST)。通过将代码按照特定规则进行分组,使得语法分析器能够逐级检查每个标记是否符合语法规范。
在分组标记的过程中,可以通过不同的方式对表达式、语句和函数体等不同类型的标记进行分类。这种层层叠加的分组结构可以清晰地展现代码的层次结构,类似于树的概念。对于语法分析器而言,并不需要深入分析代码的含义,只需验证其结构是否符合语法规则。
对 hello.c 文件进行语法分析,执行以下代码:
clang -fsyntax-only -Xclang -ast-dump hello.c
语法分析输出如下:
TranslationUnitDecl 0x1c08a71cf28 <<invalid sloc>> <invalid sloc>
|-TypedefDecl 0x1c08a71d750 <<invalid sloc>> <invalid sloc> implicit __int128_t '__int128'
| `-BuiltinType 0x1c08a71d4f0 '__int128'
|-TypedefDecl 0x1c08a71d7c0 <<invalid sloc>> <invalid sloc> implicit __uint128_t 'unsigned __int128'
| `-BuiltinType 0x1c08a71d510 'unsigned __int128'
|-TypedefDecl 0x1c08a71dac8 <<invalid sloc>> <invalid sloc> implicit __NSConstantString 'struct __NSConstantString_tag'
| `-RecordType 0x1c08a71d8a0 'struct __NSConstantString_tag'
| `-Record 0x1c08a71d818 '__NSConstantString_tag'
|-TypedefDecl 0x1c08a71db60 <<invalid sloc>> <invalid sloc> implicit __builtin_ms_va_list 'char *'
| `-PointerType 0x1c08a71db20 'char *'
| `-BuiltinType 0x1c08a71cfd0 'char'
|-TypedefDecl 0x1c08a71dbd0 <<invalid sloc>> <invalid sloc> implicit referenced __builtin_va_list 'char *'
| `-PointerType 0x1c08a71db20 'char *'
| `-BuiltinType 0x1c08a71cfd0 'char'
|-TypedefDecl 0x1c08a71dcc0 <D:/package/mingw64/x86_64-w64-mingw32/include/vadefs.h:24:3, col:29> col:29 referenced __gnuc_va_list '__builtin_va_list':'char *'
| `-ElaboratedType 0x1c08a71dc80 '__builtin_va_list' sugar
| `-TypedefType 0x1c08a71dc50 '__builtin_va_list' sugar
| |-Typedef 0x1c08a71dbd0 '__builtin_va_list'
| `-PointerType 0x1c08a71db20 'char *'
| `-BuiltinType 0x1c08a71cfd0 'char'
|-TypedefDecl 0x1c08a71dd90 <line:31:3, col:26> col:26 referenced va_list '__gnuc_va_list':'char *'
| `-ElaboratedType 0x1c08a71dd50 '__gnuc_va_list' sugar
| `-TypedefType 0x1c08a71dd20 '__gnuc_va_list' sugar
| |-Typedef 0x1c08a71dcc0 '__gnuc_va_list'
| `-ElaboratedType 0x1c08a71dc80 '__builtin_va_list' sugar
| `-TypedefType 0x1c08a71dc50 '__builtin_va_list' sugar
| |-Typedef 0x1c08a71dbd0 '__builtin_va_list'
| `-PointerType 0x1c08a71db20 'char *'
| `-BuiltinType 0x1c08a71cfd0 'char'
|-FunctionDecl 0x1c08c19e690 <D:/package/mingw64/x86_64-w64-mingw32/include/_mingw.h:580:1, col:31> col:14 __debugbreak 'void (void) __attribute__((cdecl))':'void (void)'
|-FunctionDecl 0x1c08c19e848 prev 0x1c08c19e690 <line:90:31, line:592:1> line:581:36 __debugbreak 'void (void) __attribute__((cdecl))':'void (void)' extern inline
| |-CompoundStmt 0x1c08c19ea20 <line:582:1, line:592:1>
| | `-GCCAsmStmt 0x1c08c19e9c8 <line:584:3, col:35>
| |-AlwaysInlineAttr 0x1c08c19e8f0 <line:90:64> always_inline
| `-GNUInlineAttr 0x1c08c19e948 <col:82>
...
|-FunctionDecl 0x1c08c259c58 <col:24, D:/package/mingw64/x86_64-w64-mingw32/include/sec_api/stdio_s.h:870:117> col:26 _fread_nolock_s 'size_t (void *, size_t, size_t, size_t, FILE *) __attribute__((cdecl))':'size_t (void *, size_t, size_t, size_t, FILE *)'
| |-ParmVarDecl 0x1c08c259990 <col:42, col:48> col:48 _DstBuf 'void *'
| |-ParmVarDecl 0x1c08c259a08 <col:56, col:63> col:63 _DstSize 'size_t':'unsigned long long'
| |-ParmVarDecl 0x1c08c259a80 <col:72, col:79> col:79 _ElementSize 'size_t':'unsigned long long'
| |-ParmVarDecl 0x1c08c259af8 <col:92, col:99> col:99 _Count 'size_t':'unsigned long long'
| |-ParmVarDecl 0x1c08c259b78 <col:106, col:112> col:112 _File 'FILE *'
| `-DLLImportAttr 0x1c08c259d28 <D:/package/mingw64/x86_64-w64-mingw32/include/_mingw.h:52:40>
`-FunctionDecl 0x1c08c259e20 <hello.c:5:1, line:8:1> line:5:5 main 'int (void)'
`-CompoundStmt 0x1c08c25a058 <col:15, line:8:1>
|-CallExpr 0x1c08c259fd0 <line:6:5, col:21> 'int'
| |-ImplicitCastExpr 0x1c08c259fb8 <col:5> 'int (*)(const char *, ...)' <FunctionToPointerDecay>
| | `-DeclRefExpr 0x1c08c259ec8 <col:5> 'int (const char *, ...)' Function 0x1c08c1bb9d8 'printf' 'int (const char *, ...)'
| `-ImplicitCastExpr 0x1c08c25a010 <line:3:19, col:35> 'const char *' <NoOp>
| `-ImplicitCastExpr 0x1c08c259ff8 <col:19, col:35> 'char *' <ArrayToPointerDecay>
| `-ParenExpr 0x1c08c259f50 <col:19, col:35> 'char[13]' lvalue
| `-StringLiteral 0x1c08c259f28 <col:20> 'char[13]' lvalue "hello world\n"
`-ReturnStmt 0x1c08c25a048 <line:7:5, col:12>
`-IntegerLiteral 0x1c08c25a028 <col:12> 'int' 0
以上输出结果反映了对源代码进行语法分析后得到的抽象语法树(AST)。AST 是对源代码结构的一种抽象表示,其中各种节点代表了源代码中的不同语法结构,如声明、定义、表达式等。这些节点包括:
1) TypedefDecl:用于定义新类型的声明,如 __int128 和 char。
2) RecordType:描述了记录类型,例如 struct __NSConstantString_tag。
3) FunctionDecl:表示函数声明,包括函数名称、返回类型和参数信息。
4) ParmVarDecl:参数变量的声明,包括参数名称和类型。
5) CompoundStmt:表示由多个语句组成的语句块。
6) 函数调用表达式、声明引用表达式和隐式类型转换表达式等,用于描述不同的语法结构。
7)各种属性信息,如内联属性和 DLL 导入属性,用于描述代码的特性和行为。
这些节点之间通过边相连,反映了它们在源代码中的关系和层次。AST 为进一步的语义分析和编译过程提供了基础,是编译器理解和处理源代码的重要工具。
下图是 AST 的图形视图,可用下面的命令得到:
clang -fsyntax-only -Xclang -ast-view hello.c

AST 节点 CompoundStmt 包含 if 和 return 语句,IfStmt 和 ReturnStmt。每次对 a 和 b 的使用都生成一个到 int 类型的 ImplicitCastExpr,如 C 标准的要求。
ASTContext 类包含翻译单元的完整 AST。利用 ASTContext::getTranslationUnitDecl() 接口,从顶层 TranslationUnitDecl 实例开始,可以访问任何一个 AST 节点。
3. 语义分析
语法分析(Semantic Analyze)主要关注代码结构是否符合语法规则,而语义分析则负责确保代码的含义和逻辑正确。在语义分析阶段,编译器会检查变量的类型是否匹配、函数调用是否正确、表达式是否合理等,以确保代码在运行时不会出现逻辑错误。
语义分析借助符号表来检验代码是否符合语言类型系统。符号表存储标识符和其对应的类型之间的映射,以及其他必要信息。一种直观的类型检查方法是在解析阶段之后,遍历抽象语法树(AST),同时从符号表中获取关于类型的信息。
语义分析报错案例:
#include <stdio.h>
#define HELLOWORD ("hello world\n")
int a[4];
int a[5];
int main(void){
printf(HELLOWORD);
return 0;
}
执行
clang -c hello.c
这里的错误源于两个不同的变量用了相同的名字,它们的类型不同。这个错误必须在语义分析时被发现,相应地 Clang 报告了这个问题:
hello.c:6:5: error: redefinition of 'a' with a different type: 'int[5]' vs 'int[4]'
6 | int a[5];
| ^
hello.c:5:5: note: previous definition is here
5 | int a[4];
| ^
1 error generated.
语义分析的主要任务是检查代码的语义是否正确,并确保代码的类型正确。语义分析器检查代码的类型是否符合语言的类型系统,并确保代码的语义正确。
语义分析器的输出是类型无误的 AST,它是编译器后端的输入。
LLVM 优化层
LLVM 中间表示(IR)是连接前端和后端的中枢,让 LLVM 能够解析多种源语言,为多种目标生成代码。前端产生 IR,而后端接收 IR。IR 也是大部分 LLVM 目标无关的优化发生的地方。
LLVM 优化层在输入的时候是一个 AST 语法树,输出的时候已经是一个 DAG 图。优化层每一种优化的方式叫做 pass,pass 就是对程序做一次遍历。
4. Pass 基础概念
优化通常由分析 Pass 和转换 Pass 组成。
1) 分析 Pass(Analysis Pass):分析 Pass 用于分析程序的特定属性或行为而不对程序进行修改。它们通常用于收集程序的信息或执行静态分析,以便其他 Pass 可以使用这些信息进行进一步的优化。分析 Pass 通常是只读的,不会修改程序代码。
2) 转换 Pass(Transformation Pass):转换 Pass 用于修改程序代码以进行优化或
重构。它们会改变程序的结构或行为,以改善性能或满足特定的需求。转换 Pass 通常会应用各种优化技术来重写程序的部分或整体,以产生更高效的代码。
分析 Pass 用于收集信息和了解程序的行为,而转换 Pass 则用于修改程序以实现优化或修改功能。在 LLVM 中,这两种 Pass 通常结合使用,以实现对程序进行全面优化和改进。
优化过程需要执行以下代码:
首先需要生成 hello.bc 文件:
clang -emit-llvm -c hello.c -o hello.bc
然后执行优化过程:
opt -passes='instcount,adce,mdgc' -o hello-tmp.bc hello.bc -stats
就可以生成 hello-tmp.bc 文件,其中包含了优化后的 IR。
在上述过程中有很多不同阶段的 pass。
1) 以 adce(Aggressive Dead Code Elimination)为例:adce 是 Analysis Pass 类似死代码消除(Dead Code Elimination),它会分析代码中是否存在冗余的计算,如果存在,则将冗余的计算消除掉。
2) 以 mdgc(Merged Duplicates Global Constant)为例:mdgc 是 Transform Pass,它会合并多个全局常量,以减少内存占用。
5. Pass 依赖关系
在转换 Pass 和分析 Pass 之间,有两种主要的依赖类型:
1)显式依赖
转换 Pass 需要一种分析,则 Pass 管理器自动地安排它所依赖的分析 Pass 在它之前运行;
如果运行单个 Pass,它依赖其它 Pass,则 Pass 管理器会自动地安排必需的 Pass 在它之前运行。
DominatorTree &DT getAnalysis<DominatorTree>(Func);
在上面的例子 mdgc 中,分析 Pass 会分析有多少全局常量,然后转换 Pass 会将这些常量合并。
2)隐式依赖
转换或者分析 Pass 要求 IR 代码运用特定表达式。需要手动地以正确的顺序把这个 Pass 加到 Pass 队列中,通过命令行工具(clang 或者 opt)或者 Pass 管理器。
6. Pass API
Pass 类是实现优化的主要资源。然而,从不直接使用它,而是通过清楚的子类使用它。当实现一个 Pass 时,应该选择适合 Pss 的最佳粒度,适合此粒度的最佳子类,例如基于函数、模块、循环、强联通区域,等等。常见的这些子类如下:
1) ModulePass:这是最通用的 Pass;它一次分析整个模块,函数的次序不确定。它不限定使用者的行为,允许删除函数和其它修改。为了使用它,需要写一个类继承 ModulePass,并重载 runOnModule() 方法。
2) FunctionPass:这个子类允许一次处理一个函数,处理函数的次序不确定。这是应用最多的 Pass 类型。它禁止修改外部函数、删除函数、删除全局变量。为了使用它,需要写一个它的子类,重载 runOnFunction() 方法。
3) BasicBlockPass:这个类的粒度是基本块。FunctionPass 类禁止的修改在这里也是
禁止的。它还禁止修改或者删除外部基本块。使用者需要写一个类继承 BasicBlockPass,并重载它的 runOnBasicBlock() 方法。
7. 小结与思考
1) LLVM 的前端使用的是 Clang,其负责将源代码转换为 LLVM IR;
2) LLVM 的优化层则负责对 IR 进行优化,以提高代码的性能;
3) LLVM 的前端和优化层是 LLVM 编译器的核心,它们共同构成了 LLVM 编译器的整个生命周期。
参考文献链接
1.6.10 LLVM 后端代码生成(DONE)
已经介绍了 LLVM 的前端和优化层,前端主要对高级语言做一些词法的分析,把高级语言的特性转变为 token,再交给语法分析对代码的物理布局进行判别,之后交给语义分析对代码的的逻辑进行检查。优化层则是对代码进行优化,比如常量折叠、死代码消除、循环展开、内存分配优化等。
将介绍 LLVM 后端的生成代码过程,LLVM 后端的作用主要是将优化后的代码生成目标代码,目标代码可以是汇编语言、机器码。
1. 代码生成
LLVM 的后端是与特定硬件平台紧密相关的部分,它负责将经过优化的 LLVM IR 转换成目标代码,这个过程也被称为代码生成(Codegen)。不同硬件平台的后端实现了针对该平台的专门化指令集,例如 ARM 后端实现了针对 ARM 架构的汇编指令集,X86 后端实现了针对 X86 架构的汇编指令集,PowerPC 后端实现了针对 PowerPC 架构的汇编指令集。
在代码生成过程中,LLVM 后端会根据目标硬件平台的特性和要求,将 LLVM IR 转换为适合该平台的机器码或汇编语言。这个过程涉及到指令选择(Instruction Selection)、寄存器分配(Register Allocation)、指令调度(Instruction Scheduling)等关键步骤,以确保生成的目标代码在目标平台上能够高效运行。
LLVM 的代码生成能力使得开发者可以通过统一的编译器前端(如 Clang)生成针对不同硬件平台的优化代码,从而更容易实现跨平台开发和优化。同时,LLVM 后端的可扩展性也使得它能够应对新的硬件架构和指令集的发展,为编译器技术和工具链的进步提供了强大支持。
2. LLVM 后端 Pass
整个后端流水线涉及到四种不同层次的指令表示,包括:
1)内存中的 LLVM IR:LLVM 中间表现形式,提供了高级抽象的表示,用于描述程序的指令和数据流。
2)SelectionDAG 节点:在编译优化阶段生成的一种抽象的数据结构,用以表示程序的计算过程,帮助优化器进行高效的指令选择和调度。
3)Machinelnstr:机器相关的指令格式,用于描述特定目标架构下的指令集和操作码。
4) MCInst:机器指令,是具体的目标代码表示,包含了特定架构下的二进制编码指令。
在将 LLVM IR 转化为目标代码需要非常多的步骤,其 Pipeline 如下图所示:

LLVM IR 会变成和后端非常很接近的一些指令、函数、全局变量和寄存器的具体表示,流水线越向下就越接近实际硬件的目标指令。其中白色的 pass 是非必要 pass,灰色的 pass 是必要 pass,叫做 Super Path
3. 指令选择
在编译器的优化过程中,指令选择(Instruction Selection)是非常关键的一环。指令选择的主要任务是将中间表示(例如 LLVM IR)转换为目标特定的 SelectionDAG 节点,生成目标机器代码的指令序列,实现从高级语言表示到底层机器指令的转换。
具体来说,指令选择的过程包括以下几个关键步骤:
1) 将内存中的 LLVM IR 变换为目标特定的 SelectionDAG 节点。
2) 每个 SelectionDAG 节点能够表示单一基本块的计算过程。
3) 在 DAG 图中,节点表示具体执行的指令,而边则编码了指令之间的数据流依赖关系。
4) 目标是让 LLVM 代码生成程序库能够利用基于树的模式匹配指令选择算法,以实现高效的指令选择过程。

以上是一个 SelectionDAG 节点的例子。
1) 红色线:红色连接线主要用于强制相邻的节点在执行时紧挨着,表示这些节点之间必须没有其他指令。
2) 蓝色虚线:蓝色虚线连接代表非数据流链,用以强制两条指令的顺序,否则它们就是不相关的。
4. 指令调度
指令调度(Instruction Scheduling)是编译器优化的一部分,旨在通过重新排序程序中的指令来提高计算机程序的性能。这个过程通常包括前寄存器分配(Pre-Register Allocation, Pre-RA)调度和后寄存器分配(Post-Register Allocation, Post-RA)调度两个阶段。
5. 前寄存器分配调度
在前寄存器分配调度(Pre-RA Scheduling)阶段,编译器会对程序中的指令进行排序,同时尝试发现能够并行执行的指令。这种并行执行可以提高程序的吞吐量和执行效率。在现代计算机体系结构中,由于存在多级缓存和流水线等技术,指令调度可以帮助减少指令执行的停顿,并充分利用硬件资源。
一种常见的技术是基于数据依赖性进行指令调度。编译器会分析指令之间的数据依赖关系,然后将独立的指令重排序以并行执行,而不会改变程序的语义。这种优化可以通过重排指令来避免数据冒险(Data Hazard)和控制冒险(Control Hazard),从而提高程序的性能。
在指令调度的过程中,编译器可能会引入一些额外的指令(如填充指令)或调整指令的执行顺序,以最大程度地利用计算资源。例如,可以调整指令的执行顺序,以便在执行整数运算的同时进行浮点运算,或者在内存访问受限时插入其他计算指令。指令最终将被转换为三地址表示的 MachineInstr。
6. 寄存器分配
寄存器分配(Register Allocation)是编译器优化的重要步骤之一,其主要任务是将虚拟寄存器分配到有限数量的物理寄存器上,从而减少对内存的访问,提高程序的性能和效率。在 LLVM IR 中,寄存器分配的过程较为特殊,因为 LLVM IR 寄存器集是无限的,直到实施寄存器分配为止。
在寄存器分配中,编译器会尝试将虚拟寄存器映射到物理寄存器上,以便在执行指令时能够直接访问这些寄存器而不必通过内存。然而,由于物理寄存器数量有限,当虚拟寄存器的数量超过物理寄存器时,就需要使用一些策略来处理这种溢出(Spill)情况,将部分寄存器的内容存储到内存中,并在需要时重新加载。
寄存器分配算法可以分为多种类型,常见的包括:
1)贪心寄存器分配(Greedy Register Allocation):这是一种简单直接的算法,它会顺序地将虚拟寄存器分配给可用的物理寄存器,一旦物理寄存器被占用完时就进行溢出处理。虽然效率较高,但可能会导致局部最优解。
2)迭代寄存器合并(Iterated Register Coalescing):该算法尝试合并虚拟寄存器,使得原本需要分配到不同物理寄存器的虚拟寄存器可以合并到同一个物理寄存器上。这样可以减少溢出和重加载的次数,提高程序性能。
3)图着色(Graph Coloring):基于图的寄存器分配算法,将寄存器分配问题转化为图着色问题。通过建立虚拟寄存器之间的冲突图,尝试对图进行着色,从而确定哪些虚拟寄存器可以分配到同一个物理寄存器上,以最小化溢出次数。
寄存器分配在编译器优化中扮演着至关重要的角色,通过有效的寄存器分配算法可以显著提高程序的执行效率和性能。
7. 后寄存器分配调度
在后寄存器分配调度(Post-RA Scheduling)阶段,编译器对已经分配了寄存器的机器代码进行进一步优化。此阶段的目标是最大化硬件资源的利用,减少指令执行的停顿,并优化寄存器的使用。具体包括:
1) 处理资源冲突:调整指令顺序以避免资源冲突,例如寄存器使用冲突、流水线停顿等。
2) 插入填充指令:在必要时插入填充指令(如 NOP 指令)以消除潜在的流水线停
顿。
3)优化执行顺序:通过重新排列指令,使得整数运算、浮点运算、内存访问等能够并
行执行,从而提高性能。
以上是对指令调度和寄存器分配的基本介绍和常见算法。通过有效的指令调度和寄存器分配,可以显著提高程序的执行效率和性能。
8. 代码输出
代码生成是 LLVM 后端的重要阶段,其目标是将中间表示(Intermediate Representation, IR)转化为高效的目标机器代码。LLVM 的 代码生成 阶段由多个组件协同工作,并使用多种优化技术来生成高质量的代码。
9. 代码输出阶段优化
1)延迟槽填充(Delay Slot Filling) 在某些处理器架构(如 MIPS)中,分支指令后的指令会有一个延迟槽。LLVM 通过将不影响程序正确性的指令填充到这些延迟槽中,避免处理器空转,提高指令执行效率。延迟槽填充在 LLVM 的指令调度器中完成。
2)指令融合(Instruction Fusion) LLVM 利用指令融合技术将多条简单指令合并为一条复杂指令,减少指令数量和调度开销。例如,可以将两个相邻的加载和加法指令融合为一个加载并加法的指令。这种优化通常在指令选择器或指令调度器中完成。
3)启发式优化(Heuristic Optimization) 在 LLVM 的指令选择和调度过程中,使用启发式算法快速找到接近最优的解决方案。启发式算法通过评估指令组合的代价和收益,选择出最适合当前上下文的指令序列。LLVM 使用基于图形的调度算法,如 DAG(Directed Acyclic Graph)调度器,来实现启发式优化。
4)Profile-Guided Optimization(PGO) 性能分析优化是 LLVM 中的一种基于性能数据的优化技术。PGO 通过收集程序运行时的性能数据(如热点函数和分支预测信息),指导编译器在代码生成阶段进行优化,使生成的代码在实际运行时更高效。LLVM 在前端使用llvm-profdata工具收集性能数据,在后端的指令选择和调度过程中利用这些数据进行优化。
5) 循环优化 LLVM 在代码生成阶段对循环结构进行多种优化,包括:
① 循环展开(Loop Unrolling):通过展开循环体,减少循环控制开销,提高指令流水线效率。
② 循环交换(Loop Exchange):调整嵌套循环的顺序,提高数据局部性。
③ 循环合并(Loop Fusion):将多个循环合并为一个循环,减少循环开销。 这些优化在 LLVM 的循环优化器(Loop Optimizer)中实现,优化后的循环结构会在代码生成阶段进一步优化。
10. 代码输出的实现
在 LLVM 中,代码生成 由以下组件共同完成:
1)指令选择器(Instruction Selector) 指令选择器负责从 LLVM IR 中选择合适的目标机器指令。LLVM 使用多种指令选择算法,包括基于树模式匹配的SelectionDAG和基于表格驱动的GlobalISel。指令选择器将中间表示转化为机器指令的中间表示。
2)指令调度器(Instruction Scheduler) 指令调度器优化指令的执行顺序,以减少依赖关系和提高指令级并行性。LLVM 的调度器包括SelectionDAG调度器和机器码层的调度器,后者在目标机器码生成前优化指令序列。
3)寄存器分配器(Register Allocator) 寄存器分配器负责将虚拟寄存器映射到物理寄存器。LLVM 提供了多种寄存器分配算法,包括线性扫描分配器和基于图着色的分配器。寄存器分配器的目标是最小化寄存器溢出和寄存器间的冲突。
4)汇编生成器(Assembly Generator) 汇编生成器将优化后的机器指令转化为汇编代码。LLVM 的汇编生成器支持多种目标架构,生成的汇编代码可以通过汇编器转化为目标机器码。
5)机器代码生成器(Machine Code Generator) 机器代码生成器将汇编代码转化为最终的二进制机器代码。LLVM 的机器代码生成器直接生成目标文件或内存中的可执行代码,支持多种目标文件格式和平台。
通过这些组件的协同工作,LLVM 在 代码生成 阶段能够生成高效、正确的目标代码,满足不同应用场景的性能需求。LLVM 的模块化设计和丰富的优化技术使其成为现代编译器技术的领先者。
11. LLVM 编译器全流程
编译器工作流程为在高级语言 C/C++ 编译过程中,源代码经历了多个重要阶段,从词法分析到生成目标代码。整个过程涉及前端和后端的多个步骤,并通过中间表示(IR)在不同阶段对代码进行转换、优化和分析。

通过上述图像分别展示了 LLVM 的各个流程,和代码在不同流程下的状态,在本章的最后再回顾一下各个阶段所代表的功能和内容。
1) 前端阶段
①词法分析(Lexical Analysis):源代码被分解为词法单元,如标识符、关键字和常量。
②语法分析(Syntax Analysis):词法单元被组织成语法结构,构建抽象语法树(AST)。
③语义分析(Semantic Analysis):AST 被分析以确保语义的正确性和一致性。
2)中间表示(IR)阶段
①将 AST 转化为中间表示(IR),采用 SSA 形式的三地址指令表示代码结构。
②通过多段 pass 进行代码优化,包括常量传播、死代码消除、循环优化等,以提高代码性能和效率。
③IR 进一步转化为 DAG 图,其中每个节点代表一个指令,边表示数据流动。
3)后端阶段
①指令选择(Instruction Selection):根据目标平台特性选择合适的指令。
②寄存器分配(Register Allocation):分配寄存器以最大程度减少内存访问。
③指令调度(Instruction Scheduling):优化指令执行顺序以减少延迟。
最终生成目标代码,用于目标平台的执行。
Pass 管理:
在编译器的每个模块和 Pass 均可通过 Pass manager 进行管理,可以动态添加、删除或调整 Pass 来优化编译过程中的各个阶段。
4)基于 LLVM 项目
1)Modular
Youtube 上 LLVM 之父 Chris Lattner:编译器的黄金时代
随后,Chris Lattner 创立了 Modular,旨在重塑全球机器学习基础设施,涵盖编译器、运行时、异构计算,以及从边缘到数据中心的全方位支持,并特别注重可用性。Modular 旨在提升开发人员的效率,使他们能够更高效地开展工作。
2)Julia:面向科学计算的高性能动态编程语言
在其计算中,Julia 使用 LLVM JIT 编译。LLVM JIT 编译器通常不断地分析正在执行的代码,并且识别代码的一部分,使得从编译中获得的性能加速超过编译该代码的性能开销。
3)XLA:优化机器学习编译器
XLA(加速线性代数)是 Google 推出的一种针对特定领域的线性代数编译器,能够加快 TensorFlow 模型的运行速度,而且可能完全不需要更改源代码。
TensorFlow 中大部分代码和算子都是通过 XLA 编译的,XLA 的底层就是 LLVM,所以 XLA 可以利用到 LLVM 的很多特性,比如优化、代码生成、并行计算等。
4)JAX:高性能的数值计算库
JAX 是 Autograd 和 XLA 的结合,JAX 本身不是一个深度学习的框架,他是一个高性能的数值计算库,更是结合了可组合的函数转换库,用于高性能机器学习研究。
5)TensorFlow:机器学习平
TensorFlow 是一个端到端开源机器学习平台。它拥有一个全面而灵活的生态系统,其中包含各种工具、库和社区资源,可助力研究人员推动先进机器学习技术。
TensorFlow 可以更好的应用于工业生产环境,因为它可以利用到硬件加速器,并提供可靠的性能。
12. TVM 到端深度学习编译器
为了使得各种硬件后端的计算图层级和算子层级优化成为可能,TVM 从现有框架中取得 DL 程序的高层级表示,并产生多硬件平台后端上低层级的优化代码,其目标是展示与人工调优的竞争力。

TVM 主要功能模块介绍,如下所示:
1) LLVM 后端的作用是将优化后的代码生成目标代码,可以是汇编语言或机器码。
2) 生成过程包括指令选择、寄存器分配、指令调度、代码输出等步骤,可被不同后端实现。
3) LLVM 后端的可扩展性支持新硬件架构和指令集发展,推动编译器技术和工具链进步。
4) 前端和优化层提供统一的编译器前端,实现跨平台开发和优化。
5)基于 LLVM 的项目有 Modular、XLA、JAX、TensorFlow、TVM、Julia 等。
参考文献链接
参考文献链接
人工智能芯片与自动驾驶


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)
2023-08-10 新能源汽车比亚迪亮眼成绩杂谈
2022-08-10 NPU架构与算力分析
2021-08-10 CPU,GPU,Memory调度