
GPU与DSA架构分析
GPU与DSA架构分析
GPU、GPGPU、DSA、FPGA、ASIC等AI芯片特性及对比
GPU
GPU(Graphics Processing Unit,图形处理器)是一种专门用于处理图形和图像的处理器。它是计算机的重要组成部分,主要用于加速图形和图像的处理和渲染。与传统的中央处理器(CPU)相比,GPU具有更多的并行处理单元和更高的内存带宽,使其能够同时处理大量的图形和图像数据。
GPU最初是为了游戏和图形应用而设计的,但随着科学计算和机器学习等领域的发展,GPU也被广泛应用于科学计算、数据分析和人工智能等领域。由于其强大的并行处理能力,GPU能够在短时间内完成大量的计算任务,大大提高了计算效率。
现代的GPU通常由许多处理核心组成,每个核心都可以同时执行多个指令,从而实现高度并行的计算。此外,GPU还具有专门的内存和缓存系统,用于存储和访问图形和图像数据。GPU还支持各种图形编程接口和编程语言,如OpenGL、DirectX和CUDA等,使开发者能够利用其强大的计算能力进行图形和图像处理。
GPGPU
GPGPU(General-Purpose Graphics Processing Unit,通用图形处理器)是指将GPU用于通用计算的技术和方法。传统上,GPU主要用于图形和图像处理,但随着GPU的计算能力不断提升,人们开始探索将GPU应用于其他领域的通用计算任务。
GPGPU的核心思想是利用GPU的并行处理能力来加速各种计算任务。GPU具有数百甚至上千个处理核心,每个核心都可以同时执行多个指令,从而实现高度并行的计算。这种并行处理能力使得GPU在处理大规模数据和复杂计算任务时能够显著提高计算效率。
为了实现GPGPU,开发者需要使用特定的编程模型和工具。目前最常用的GPGPU编程模型是CUDA(Compute Unified Device Architecture)和OpenCL(Open Computing Language)。CUDA是由NVIDIA开发的一种基于C/C++的编程模型,它允许开发者直接使用GPU的计算能力进行并行计算。OpenCL是一种开放的跨平台编程语言,可以在不同的GPU和CPU上实现并行计算。
GPGPU的应用领域非常广泛。它被用于科学计算、数据分析、机器学习、深度学习、密码学、图像处理等各种领域。通过利用GPU的并行处理能力,GPGPU可以加速这些领域中的计算任务,提高计算效率,缩短计算时间。
英伟达通过了近20年的努力将GPU变为大众认知里的通用芯片,从建立CUDA软件生态到成熟,让GPGPU能做图形加速,AI计算,科学计算,在当下最为火热的AI市场里供不应求。
DSA
DSA(Domain Specific Architecture,领域特定架构)是指为特定领域或应用定制的计算机架构。与通用计算架构相比,DSA专注于解决某一特定领域或应用的需求,通过定制化硬件和软件设计来提供更高的性能和效率。
DSA的设计目标是针对特定领域的特定需求进行优化,以提供更高的计算性能、能效和资源利用率。DSA通常会针对特定领域的算法、数据结构和操作模式进行优化,以实现更高效的数据处理和计算。这可能涉及到定制化的硬件设计、特定指令集、专用加速器等。
DSA在各个领域都有应用,例如人工智能领域的神经网络加速器、密码学领域的加密芯片、图像处理领域的图像处理器等。通过定制化的硬件和软件设计,DSA能够满足特定领域的需求,提供更高的性能和效率。
国内AI大芯片初创公司非常特别,有跟随英伟达路线做GPGPU的初创公司,可以叫他们“追随派”。也有另辟蹊径,设计AI专用芯片(也就是DSA)的“创新派”。谷歌定义的TPU专用性很强,是一个典型的领域专用芯片DSA。国内也有多家走DSA路径创业的AI大芯片公司,比如寒武纪、昆仑芯、燧原科技、瀚博半导体、墨芯人工智能。
用搭乐高来理解设计GPGPU和DSA的难度,设计GPGPU就是面向18岁以上玩家的乐高,有许多精细的小模块,拼起来难度大但作品很精巧。设计DSA就像是面向5岁的乐高,模块更大拼起来更容易。相比之下,DSA路径的公司想兼容CUDA生态的难度比GPGPU路径的公司难度更大。
FPGA
FPGA(Field-Programmable Gate Array,现场可编程门阵列)是一种可编程逻辑器件,它可以根据用户的需求和设计进行自定义的硬件功能实现。FPGA具有灵活性和可重构性,可以在设计完成后进行现场编程,改变其内部的逻辑功能和连接关系,从而适应不同的应用需求。图片
FPGA由一系列可编程的逻辑块(Logic Block)和可编程的互连资源(Interconnect Resources)组成。逻辑块通常包含可编程的逻辑门、寄存器和其他功能元件,而互连资源则用于连接逻辑块之间的信号路径。通过编写硬件描述语言(HDL)的代码,用户可以将其设计转化为FPGA内部的逻辑电路,并通过现场编程将其加载到FPGA中。
FPGA在各个领域都有广泛的应用。由于其可编程性和并行处理能力,FPGA常用于数字信号处理、通信系统、图像处理、嵌入式系统、网络加速、机器学习加速等领域。FPGA可以根据应用需求进行定制化设计,提供高性能、低功耗和低延迟的硬件加速解决方案。
FPGA具有足够的计算能力和足够的灵活性。FPGA的计算速度快是源于它本质上是无指令、无需共享内存的体系结构。对于保存状态的需求,FPGA中的寄存器和片上内存(BRAM)是属于各自的控制逻辑的,无需不必要的仲裁和缓存,因此FPGA在运算速度足够快,优于GPU。同时FPGA也是一种半定制的硬件,通过编程可定义其中的单元配置和链接架构进行计算,因此具有较强的灵活性。相对于GPU,FPGA能管理能运算,但是相对开发周期长,复杂算法开发难度大。FPGA适合定制化场景较浓,但需求量又不大的场景。
ASIC
ASIC(Application-Specific Integrated Circuit,特定应用集成电路)是一种专门为特定应用或特定功能而设计和定制的集成电路。与通用集成电路(如微处理器)相比,ASIC在硬件层面上进行了定制化设计,以满足特定应用的需求。
ASIC可以根据特定应用的需求进行高度优化,以提供更高的性能、更低的功耗和更小的尺寸。它通常包含了特定应用所需的功能模块、逻辑电路、存储器以及其他特定的电路组件。ASIC的设计通常涉及硬件描述语言(HDL)的编写、逻辑综合、布局布线、验证和制造等步骤。
由于ASIC是针对特定应用进行设计和制造的,因此它可以提供更高的性能和更低的功耗。与通用集成电路相比,ASIC通常具有更高的集成度、更低的延迟和更小的功耗。然而,ASIC的制造成本较高,并且设计周期较长,因此通常适用于大规模生产和长期使用的应用。
ASIC在各个领域都有广泛的应用,例如通信系统、嵌入式系统、图像处理、网络设备、汽车电子、物联网等。通过定制化的硬件设计,ASIC能够提供高性能、低功耗和紧凑的解决方案,满足特定应用的需求。
ASIC根据产品的需求进行特定设计和制造的集成电路,能够在特定功能上进行强化,具有更高的处理速度和更低的能耗,适合需求量大,对芯片定制要求较高的场景。缺点是研发成本高,前期研发投入周期长,且由于是定制化,可复制性一般,因此只有用量足够大时才能够分摊前期投入,降低成本。
DSA AI芯片,相对GPGPU,能效上有多大优势?是从哪些方面提升了能效?
前言
对于近年来出现的各种AI芯片架构,大家经常看到的论述是:AI芯片由于是DSA(Domain Specific Architecture),因此在AI计算领域,拥有比GPGPU架构的芯片更好的能效。这个论述是真的吗?那各种DSA的AI芯片,实际上究竟有多大的能效优势呢?主要是从哪些方面提高了能效?“But at what cost?“(玩下BBC的梗)。这应该是一个大家非常感兴趣的话题。我把平时看到的一些论文,会议PPT资料,官方文档,网站报道等公开的信息总结起来,结合自己的经验,加入一些对相关架构的看法,总结一下给感兴趣的朋友。
能效,主要在用的是三个指标:
1. TOPS/W,这是一种静态的能效参数,通常用Tensor(有的也包括Vector一起)的算力,和TDP的一个比值。TOPS和数据类型相关,推理常用INT8和FP16,不同架构的配比还不一样,1:1,2:1,4:1比较常见。
2. Perf/W,是实际的端到端的模型推理或训练的结果和TDP功率的比值。和TOPS/W相比,它包含了整个软件栈和AI芯片硬件的整体性能,具有更实际的意义。文中主要用IPS/W表示。
3. Perf/TCO,从系统层面,考虑性能和总的成本的比,其中成本包含除Power以外的其他相关的整体系统成本,实际主要是数据中心使用得考虑得比较多。比如加上CPU,Video,机柜组成的全系统成本。
但实际上,我经常在想,作为一个架构师,应该考虑的是更加广义上的Perf/TCO。这个C(cost)还要包括这个架构的实现(软硬件开发实现,具体就是硬件开发难度,软件栈,编译器,业务逻辑模型支持难度等)。扯远了。。。
这里主要分析推理的能效,使用TOPS/W作为基础,这是比较容易首先获得的数据,各个芯片一般都有公布,所以可以对比。另外,由于Perf/W能更好的反应实际性能和功率的关系,如果能得到这个数据,我会更加偏向于使用这个数据。
架构选择上,以GPGPU,Nvidia A100作为对比基础,分别选择了Google TPU(Tensor大核代表),Groq TSP(流水线型代表),Tenstorrent Grayskull(manycore小核代表),Qualcomm Cloud AI 100 (DSP+DSA混合),OPPO MariSilicon X(影像专用架构代表)。尽量避免国内同行架构,话题太敏感。另外数据是公开的数据,有些源头不大一致,不过差距不大,不影响分析。
GPGPU
选NV Ampere A100作为代表,7nm,PCIe,40G HBM2e的版本250W。TOPS/W方面,INT8 : FP16 = 2 : 1。INT8 624TOPS/250W = 2.5TOPS/W。FP16, (312+78)TOPS/250W = 1.5TFOPS/W。
Perf/W方面,根据MLPerf结果,Resnet50 32778IPS/250W = 130 IPS/W。Bert base,2836 IPS/250W = 11 IPS/W。
根据我的判断,MLPerf上的结果,应该是没有加入A100 高级特性的成绩,比如:Sparsity,residency control,Compression等。都用起来的话,应该还是小几十个点的提升。
其他家的GPGPU就不拿出来看了,大致差不多。AMD的MI更注重高精度的AI,因此在INT8方面投入不多,而且也没有上面的提到的为AI所加的高级特性。
Google TPU
Google是AI芯片里走在最前面的公司,从第一代开始业务落地,当前已经是第4代了。而且不想一般公司,Google非常开放,把每一代的架构,理念甚至一些详细设计,参数,结果数据等都公开出来,非常大气。这些详细的资料,让我们从第一代的脉动矩阵设计理念和细节开始,看着它怎么一步一步扩展到训练,然后在第4代推理/训练双产品线。它的架构变化过程,包括脉动矩阵的变化,vector/scalar的变化,memory系统的变化,都是非常有益架构师学习和思考的。所以非常感谢Google的大气!
TPUv4i比较适合拿来对比,因为同是7nm而训练的v4还没看足够信息。不过TPU主打BF16,它的INT8和BF16是相同的算力。所以INT8的TOPS/W很低,138/175=0.8 TOPS/W,当然BF16也能保持在0.8TOPS/W,不过还是低于NV A100的。
从Perf/W上看,没有看到直接数据,只有和T4的对比,性能差不多是T4的两倍,Perf/W和T4差不多。从T4推算,Resnet50在70 IPS/W上下,Bert在5 IPS/W上下。都不及升级后的A100。
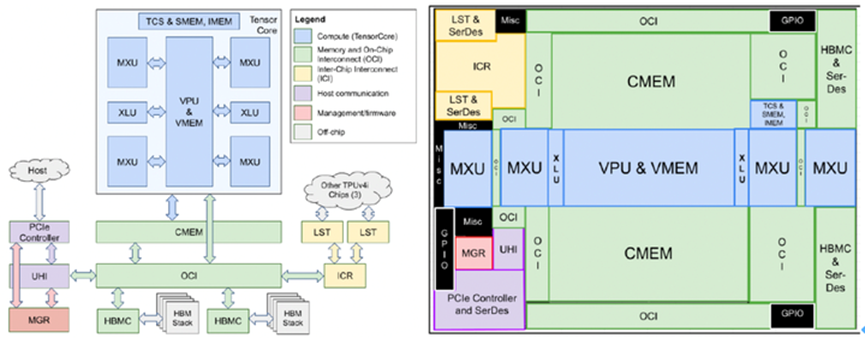
为什么TPUv4i的性能和能效不如A100 GPGPU?几点想法:
• 首先,4个大核(128*128)统一调度,利用率很难做高。注意它才33%的FLOPS/s利用率,还是在128M超大CMEM(SRAM)下得到的。不少人包括Google自己都对大核和小核做过对比,比如Google的NeuroMeter建模框架(见HPCA21论文)。
• 利用率不高一个原因,是指令集通过Bundle做静态调度。这种以前GPU上用过的方式,不如现代GPU上的精巧调度效率高。不过这没有可比性,TPU的计算粒度大,需要不同于GPU Warp scheduler的另一种动态调度以增加并行。
• 大尺寸CMEM和高带宽HBM两者同时拥有太奢侈。大尺寸CMEM能保证大部分数据内部访问就可以配LPDDR之类的低功耗DRAM了。
• 从CMEM到VMEM到VPU/MXM看起来路程短,但由于CMEM大,整个路径的控制,MUX之类的都是很费power的。大的脉动矩阵,非整除的tensor size和启动/结束时等方面效率都会有损失。
• 对整个解决出发点有点争议(给我有点理论派的感觉),Google从单芯片(也就是单核,不是单卡,或者更卡)的角度出发去分析CMEM,HBM的带宽和size大小,想去保证各种模型能很好地跑在一个核的最佳配比,最后就出来一个超大的芯片,里面只有4个MXM计算单元,面积只有11%,能效就更难提高。
虽然TPU的超大核的设计,大部分模型可以单核搞定,但也应该做到一定的平衡,支持一定程度的model splitting,也就是小核心的tiling。其实它的TPUv4就是单芯片双核心。如果TPUv4i也差不多类似的组合,128CMEM给两个核心共享或者每个64M,BF16的TOPS/W差不多能到276/250=1 TOPS/W。和A100就更接近了。
Groq TSP
Groq TSP和Google TPU有些近亲,因为Groq是由TPU团队的八位核心开发者离职后于2016年创办的。所以虽然两者的核心思路完全不一样,但给人的感觉差不多。
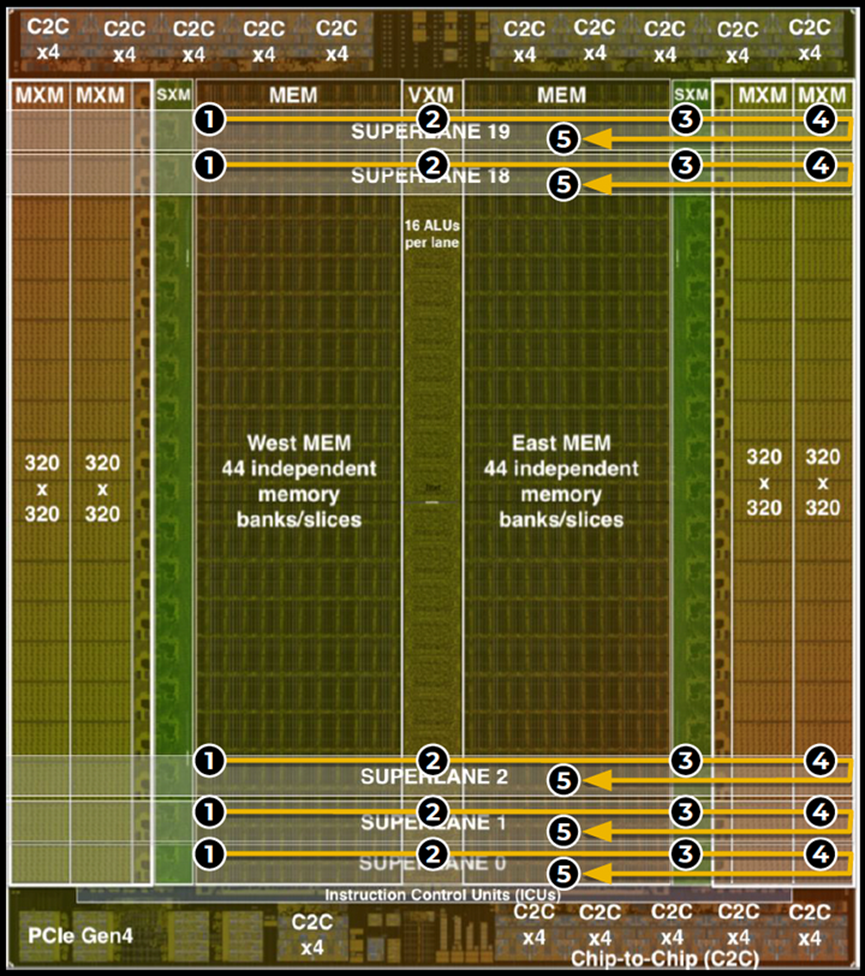
TOPS/W数据,INT8 : FP16是4:1,INT8 820TOPS/300W=2.7 TOPS/W,而FP16只有205TOPS/300W=0.7 TOPS/W,和TPUv4i还真是差不多了呢。不过它的工艺上要落后吃点亏。
只不过整体的TOPS很高,特别是INT8的,曾经宣传1000TOPS。220MB SRAM可以容纳下Bert base。不过也是利用率很低,实际性能Resnet50 20400 IPS/300W=68 IPS/W,没看到Bert的成绩,说明之前软件还不成熟。总体上说,能效上看起来和TPU差不多。
其实两年前就在关注TSP,特别是ISC2020上它的详细介绍,一个原因就是它的算力/功耗和含光800NPU差不多,而且有一些理念也类似。有些方面它还支持更多的特性,比如C2C互联。但对比Resnet50性能,会发现比含光差得比较多,不到含光的1/3。对比含光的公开的PPT,就会发现主要的区别:TSP的pipeline太过于简单,和Google TPU的bundle类似,只有大概一个matrix+2个vector的操作,这样就需要更频繁的去MEM里读/写数据,导致了3倍的差距。从某个角度看,他们有点限制在了TPUv1的思维里,换了汤(计算/存储组织方式,ISA)没换药(实质控制和数据流),只不过TPU往训练方面功能性发展,而TSP往Producer-consumer的流水线固定pipeline模式最大化TOPS方向发展。
想想这是人之常情,很难完全丢掉原来的思维模式。但从另一个角度说,TSP架构还能有比较大的提升空间(比TPU脉动矩阵还是要灵活些),感兴趣的话可以去看看它的论文和ISC2020的PPT,拓展一些思路。
下面看看不同的架构模式:manycore
Tenstorrent Grayskull
知乎上挺多人谈起过这个芯片和架构,Tenstorrent 2016初就成立了,Jim Keller加入,名声大作。在它的宣传中,已经不是强调”Spatial computing”,这个理念不新鲜,已有挺多的芯片了。它强调的是”The first conditional execution architecture for AI“。猜测Jim加入应该也是被这个架构的原始理念所吸引,然后可以在后续的架构和高级特性上充分发挥了一把,这个架构的灵活度和发挥空间非常大。
先把能效数据列一下:
TOPS/W方面,8bit,368TOPS/75W=4.9 TOPS/W,FP16,92TOPS/75W=1.2 TOPS/W。可以看得出,16bit数据和A100差不多,但8bit基本上是A100的两倍。看了一下第三代的训练Wormhole在FP16的算力和功耗都x2了,所以还是相同的184TOPS/150W=1.2 TOPS/W。
Perf/W方面表现更出色。Resnet50 22431 IPS/75W=300 IPS/W,Bert 2830 IPS/75W=38 IPS/W。下图是它的宣传文用到的Resnet50的能效对比图。
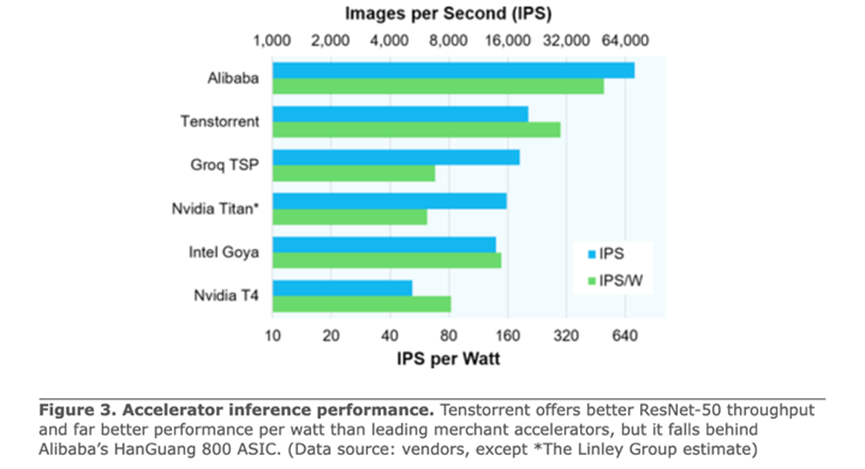
Perf/W的数据对比,基本上是A100 GPGPU的3倍上下。这个结果是不包含conditional execution的优化提升的,可以假定需要做的计算量和GPGPU差距不大,那它的能效提高,应该是由软硬件结合的,以可配置Spatial Dataflow的方式获得的。具体的说,
• 将Graph的多层算子编译优化布局在tiled Tensix core,权重可驻留SRAM。
• 布局可以用多算子fused的方式,将Matrix/Conv的Tensor计算和Vector计算融合,从而可以从分提升V/T并发。
• 将计算以mini-tensor的粒度打包压缩,最优化传输路径,包括broadcast等,尽量最小化传输开销。
这里各家的做法可能有些区别,和各自的tiled core的微架构相关。Graphcore IPU的应该是最成熟,在中国业务落地做得最好的。有熟悉的同学方便的话可以分享一下。从GPGPU的角度,硬件调度block/warp,以硬件资源和时间利用率为主要因素,很难考虑cache locality方面。想要好的memory(shared+cache)使用,大部分依靠kernel写法,以及task graph,residency control等结合起来,效果编译器能帮的比较少。而且由于GPGPU的shared memory + residency memory都不大,操作空间很有限。而manycore架构多了编译器根据graph,考虑计算/存储/依赖等因素来优化布局,分配调度资源,提高能效。
Tenstorrent更大胆的创新是,聚焦在Dynamic Execution,看起来比其他家做的更激进,能大幅地减少一些模型的计算量。Dynamic Execution包括几个软硬件结合的优化:control flow, compression, sparsity, dynamic precision and conditional execution。
Tenstorrent通过core内的5个RISC-V CPU做复杂的控制流,实现了细粒度的条件执行,动态稀疏等特性,让一些比较稀疏模型的能效可以在软件优化配合下提高一个数量级。特别是应用在Bert中效果非常好,因为模型是固定sequence length,但实际输入长度短很多,有很多0。但conditional execution的应用场景也应该比较有限(看起来比如Resnet50这类网络可能就收益很小)。而且软硬件的复杂度感觉很大,我是基本想不清楚它的一整套工作流程,比如这5个CPU和主compute单元之间的编程和运行交互机制。后面继续学习,说不定能产生一些对项目有用的灵感。
关于这些创新,要说还是有些工程上的疑问,一个是精度,推理结果的精度还是很重要的,我们接触下来的客户大都很在乎这个。一个是适用性,就是有多少应用收益。还有一个是复杂度,感觉用于训练复杂度还会剧增,复杂度对应的是人才,资金和时间。在了解RISC-V CPU和计算模块的协作方式后,我会去尝试写写这种模式下的伪代码,琢磨一下软件栈的实现,看能不能预估一下工程上的难度。
看了几个国外比较有特色的AI芯片架构。基本上startup比较倾向于创新架构,他们也有比较充分的时间去慢慢打磨架构。像Groq/Tenstorrent,5年多时间还没有业务落地。而相对传统的企业,因为有市场的压力,有每年的迭代的要求,所以会选择一些比较稳妥的架构逐步演进方式,比如下面的高通。
Qualcomm Cloud AI 100
Qualcomm AI加速引擎发展到现在已经是第7代了。从最原始的Hexagon DSP,一代一代的,从VLIW,HW multi-threading,然后加Vector SIMD,然后加上Tensor Unit,配上比较大的VTCM (Vector Tightly Couple Memory,也就是shared memory)。和NV/AMD发展路线图差不多,但聚焦在移动和推理,所以也有区别。一路下来,高通AI引擎发展迅速,手机8Gen1 NPU性能已经遥遥领先,更是快速杀入数据中心和车载芯片市场。特别是在车载方面,好多汽车大厂合作,后起之秀啊!
以Cloud AI 100为例看看Qualcomm的AI引擎,能效表现和Tenstorrent Grayskull差不多,还稍微好一点。
TOPS/W方面,INT8 400 TOPS/75W=5.3T OPS/W,FP16 200 TOPS/75W=2.7 TOPS/W, 是2:1的比例,因此FP16方面比Grayskull高。
Perf/W方面,直接上图,它可能用的是实际功耗,我换成TDP,Resnet50 22252 IPS/75W=297 IPS/W,Bert 3688 IPS/75W=49 IPS/W。注意Bert使用的是混合精度。这个能效很高了,低功耗版本的还要更高。
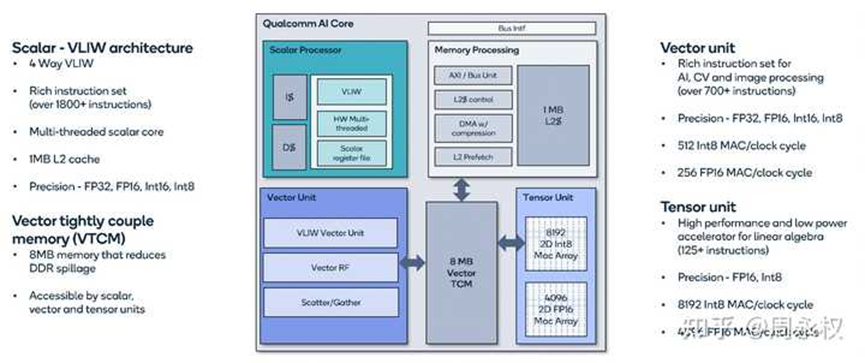
粗看它的架构设计,大概会觉得没什么特别的,scalar+vector+tensor+shared memory。就是软硬件的长时间打磨,很多细节一点一点累加起来才能得到好的能效。详细的材料可以看它的介绍,很多东西和GPGPU其实是差不多的。那为什么它的能耗表现比NV A100要好很多(2-3倍)?至少几个可见的因素:
• 更大的MAC(A100 tensor core的16倍),因此有更多数据的共享(broadcast),再加上conv的优化,大大地节省了VTCM到MAC array的功耗。
• 8M的VTCM,远大于A100的最大192K的Shared memory。可以提供非常灵活的优化,包括其中最关键的Depth first scheduling。而A100要做到这点,需要用residency control到L2里,而且最大也只有20M,long latency small size,不好用。
• 总共144M的SRAM,基本可以让一般模型on-chip常驻,从而使用带宽稍低的低功耗LPDDR。
• 它提到的功耗控制技巧:通过scheduling和编译器辅助。(编译器辅助相比硬件反馈式控制power有多少优势?学习中。。。)
当然还有就是NV GPGPU有更多的特性和使用场景,会增加面积,消耗和牺牲能效。另外Qualcomm这个对软件要求也会比较多。需要针对不同结构的模型细调。但看AI benchmark的分数,Snapdragon 8 Gen 1的得分已经是麒麟9000达芬奇的2.5倍,因此Qualcomm的软件栈应该还是比较成熟了。
OPPO MariSilicon X
最后关注一下DSA架构的另一个方向,就是极致的Domain Specific。以OPPO刚发布的MariSilicon X为例,它是一个影像专用NPU。
直接看报道的数据,
TOPS/W数据:18 TOPS,11.6TOPS/W。这个静态数据已经是A100的4倍多,Qualcomm AI 100的2倍多。
Perf/W方面,还没有具体的数据,专用的影像NPU,肯定不是跑Resnet50/Bert了。报道里提到一个有意思的对比,用的是OPPO自研的AI降噪模型, Find X3 Pro(骁龙888)2fps@1.7W,马里亚纳40fps@0.8W,马里亚纳的性能达到20倍,能效达到40倍。

TOPS/W的两倍提升比较好理解,来源于它特定的业务流水线:
• 高带宽大容量的on-chip SRAM,直接承接ISP输出和计算单元中转,不用去DDR。
• pipelined MariNeuro计算单元,利用率高,并可能只需要一种特定精度。
• 独立的专用LPDDR,不用通过长距离bus/crossbar而产生过多能耗。
至于20倍的性能,我想就来自于专用算法了。他提到的是自研降噪模型,要不就是用了比较特别不适合矩阵计算的算子,要不就是用了很多大尺寸卷积,比如AI benchmark里有一个Image Deblurring的PyNET模型(PyNET:Replacing Mobile Camera ISP with a Single Deep Learning Model )。然后MariNeuro计算单元里直接实现了特殊的卷积算法,比如变换域的卷积算法等等,国内做相关算法硬件的人还是挺多的。所以它实际的计算量就减少了很多很多。有20倍的性能提升就不足为奇了。
对于20倍性能,40倍能效的提升,让一个几乎不能应用的算法能用起来(>30FPS),所以额外增加了一个芯片,这个代价似乎是值得的?但这个实质的对比是,有没有一个能在通用NPU,比如最新的Qualcomm AI core上跑出差不多效果(可以差一点)的其他算法模型做替代?如果有,就是独立芯片就没太大的意义。不过是在刚开始还没足够能力做一个完整手机SoC的情况下,先跨一小步,做一个技术积累。
总结
本想简单地比较比较各种架构的能效,发现写起来就刹不住。稍微总结一下我的观点,纯粹个人见解,欢迎讨论:

1. TOPS/W稍微有些欺骗性,比如同一架构通过核心数和电压等调节,可以获得两倍以上的TOPS/W指标。它和能效不能线性挂钩,受到计算单元利用率和算法的影响比较大。
2. Perf/W相对来说更有意义。它体现了完整的端到端架构,软件和硬件实现的能效高低。
3. NPU和TSP的架构没能显示出比GPGPU更好的能效,体现了这种架构做高能效是比较难的。当然不是说这种架构都不能超过GPGPU,至少类似架构的含光800NPU在Resnet50能效上是3倍于A100的。
4. Qualcomm Cloud AI 100和Tenstorrent grayskull能效比较接近,是A100的2-3倍。它们都非常依赖于编译器和软件栈的优化以配合才能保证高能效。但它们主要的实现思路不一样。
5. Qualcomm Cloud AI 100主要是通过推理专用的DSP+DSA架构优化,结合软件栈的Depth first scheduling,将一个tiled的多层算子fused运行,即减少了memory访问,又增加了pipe的并行度。
6. Tenstorrent grayskull主要通过Spatial Dataflow的方式,将Graph的多层算子优化布局在tiled Tensix core,将计算以mini-tensor的粒度打包传输(broadcast),同样的能实现了类似Depth first scheduling的算子fused效果。更有创新的是,通过core内RISC-V CPU实现复杂的控制流,实现了细粒度的条件执行,动态稀疏等特性,让一些比较稀疏模型的能效可以在软件优化配合下提高一个数量级。
7. OPPO Marisilicon X通过影像专用,算法专用,对特定的算法是能达到几十倍的能效提升。
最后再展开一点,基于密集矩阵计算的数字电路芯片的AI加速架构,在能效上的上限比较低,相同工艺上看,看起来在GPGPU的5倍以下。这还是有很多的其他代价的前提下才能得到的,包括更少的功能和特性,更低精度,更复杂的编译器,软件栈等。
想要突破上限的两种思路:
1. 减少运算量,
• 广义的sparsity,利用神经网络的数据以及结构稀疏特性,去除不必要的计算,包括A100 sparsity这类不少公司在尝试的方法,也包括Tenstorrent尝试的conditional execution。
• 针对特定的一类算法。既包括卷积类的密集矩阵计算算子,也包括特殊的并行度差的算子。
2. 改变计算电路模式,还在探索阶段。
• 近存计算(Near-Memory-Computation )/存内计算(Computing-in-Memory)/ Computing-on-memory-boundary,模拟和数字结合,或纯数字。当前的各种实验数据,大概是几十到几百TOPS/W。
• 硅光(silicon photonics)等新型非数字电路模式。当然会衍生出其他能效问题,比如模数和数模转换能效等。
其实不论选择哪一种架构方向,都是要静下心来慢慢地打磨架构,硬件和软件。能效是一点一点积累的,很难有捷径。
参考文献链接
https://www.bilibili.com/read/cv25428782/?jump_opus=1
https://www.zhihu.com/question/510527941

