

Codegen方言介绍
Codegen方言介绍
主要介绍CodeGen过程中使用的Dialect(方言),以及对设计演变的一些观察。
介绍
对MLIR基础架构中CodeGen进行概述,特别是LLVM项目代码库中可用的部分(upstream或intree)。虽然偶尔会提到LLVM项目代码库之外的MLIR用户,但没有被深入分析,只是为了说明而引用,主要讨论MLIR CodeGen基础架构。
现状
分类
MLIR中与多个CodeGen相关的方言大致可以沿着两个维度进行: 张量/缓存与有效载荷/结构。
一种方言在张量/缓存维度上,表明了数据的抽象是深度学习框架中的张量,还是传统的底层编译器所期望的内存数据缓存区。张量被视为不可变的值,不一定与内存有关,对张量的操作通常也不会有副作用。这些操作之间的数据流,可以用传统静态单一赋值(SSA)形式来表示。这是使MLIR成为机器学习程序强大的转换工具的一个方面,它允许对张量操作进行简单的重写。另一方面,缓存是可变的,可能会被多个目标使用,例如,多个目标可能指向同一个底层内存。数据流只能通过特定的依赖关系与混叠分析(aliasing analyses)来提取。张量的抽象与缓存的抽象之间的转换是通过缓存过程来完成的,缓存过程逐步将张量与缓存关联起来,并最终替换它们。一些方言,如线性代数(Linalg)标准,包含对张量与缓存的操作。一些Linalg操作甚至可以同时对两者进行操作。
一种方言在有效载荷/结构维度上的位置,表明了它是描述应该执行什么计算负载,还是应该如何执行结构。例如,大多数标准方言中的数学运算指定了要执行的计算方法,例如,反正切计算,而没有进一步的细节。另一方面,SCF 方言定义了所包含的计算是如何执行的,例如,重复执行直到满足某个运行时条件,而不限制条件是什么,以及执行什么计算。类似地,异步方言表示适用于不同负载级别的通用执行模型。
维度上的区分没有明确的界限,特别是在高级抽象层次上。许多操作至少部分地指定了结构。例如,向量方言操作意味着SIMD执行模型。在编译过程中,如何执行的说明部分,会变得更加详细与低级。同时,抽象堆栈的低层级倾向于将结构操作与负载操作分离开来,以便只转换前者,同时只对负载保持抽象理解,例如,访问的数据或估计的成本。

兴趣方言
MLIR CodeGen 生成的流程要经过一系列中间步骤,这些步骤的特点是使用最新的方言。方言可以根据抽象级别,粗略地组织成一个堆栈。将表示从高级抽象转换为低级抽象,即下译,通常是直接下译,而相反的过程一般不成立。

大多数管道通过线性代数(Linalg)方言进入内树型方言的基础架构,Linalg方言表示对数据进行结构化计算。这种方言是专门支持各种转换,方言的操作既支持张量操作数,也支持缓存操作数,缓存过程可以在不改变操作本身的情况下进行。此外,Linalg提供了具有特定负载的命名操作,如矩阵乘法与卷积,以及只定义结构的通用操作。这两种形式之间可以进行转换。Linalg方言操作的固有迭代结构,可转换为向量操作,以及围绕向量或标量操作的(仿射方言)循环。
异步方言捕获了一个通用的异步编程模型,可能出现在不同的级别上:在较高的级别上,它用于跨设备与设备内部组织大型计算块;在较低的级别上,它可以包装原语指令序列。
向量方言(注意,向量方言类型属于内置方言,可以在向量方言之外使用)是SIMD(或SIMT)执行模型的中级抽象。它利用MLIR的多维向量类型,使用不同平台特定的低级方言。可通过线程显式表示,将向量抽象用于目标GPU设备(SIMT)。
仿射方言是MLIR对多面体编译的一种尝试。它封装了相关编程模型的限制,并定义了相应的操作,即仿射循环、条件假设等控制流结构与仿射对应的内存操作。它的主要目标是实现多面体变换,如自动并行化、用于局部改进的循环融合与平铺,以及MLIR中的循环向量化。
SCF方言(结构化控制流方言)包含了在比控制流图(CFG)分支更高级别的控制流,例如,(并行)for与while循环。这种方言用于表示(或转换)计算的结构,而不影响有效负载。这是仿射与线性代数的下译目标,也可以用作低级表示(如C语言)到MLIR代码生成基础架构的接口。
从SCF方言中,可以获得各种编程模型,即GPU/SIMT、异步、OpenMP与OpenACC。每个模型都由相应的方言表示,其中的操作很少受优化转换的影响。然而,这些表示是实现特定编程模型的转换,例如,异步方言的转换。
SCF也可以转换为标准CFG表示,用块之间的分支替换结构化控制流。分支操作包含在标准方言中,以及各种抽象级别上的许多其他操作。例如,标准方言还包含对张量与向量的点操作,缓存区与张量之间的转换,标量的三角运算等。因此,标准方言被分裂成多个定义的方言。
标准方言的部分(标量与向量的操作,以及分支操作)被转换为特定目标的方言,这些方言主要用作MLIR代码生成基础架构。这些方言包括LLVM、NVVM、ROCDL、AVX、Neon、SVE与SPIR-V方言,所有这些方言都包括外部格式、IR或指令集。除了规范化外,这些方言不需要进行转换。
Shape方言用于描述独立负载结构的数据形状。它出现在代码生成管道的入口层,通常会下译到算术或规范化地址。
PDL(模式描述语言)与PDLInterp 方言,用作下一代MLIR的基础架构。因此,它们从不出现在CodeGen管道中,但在描述其操作时,可能是必要的。
现有管道Tensorflow内核生成器
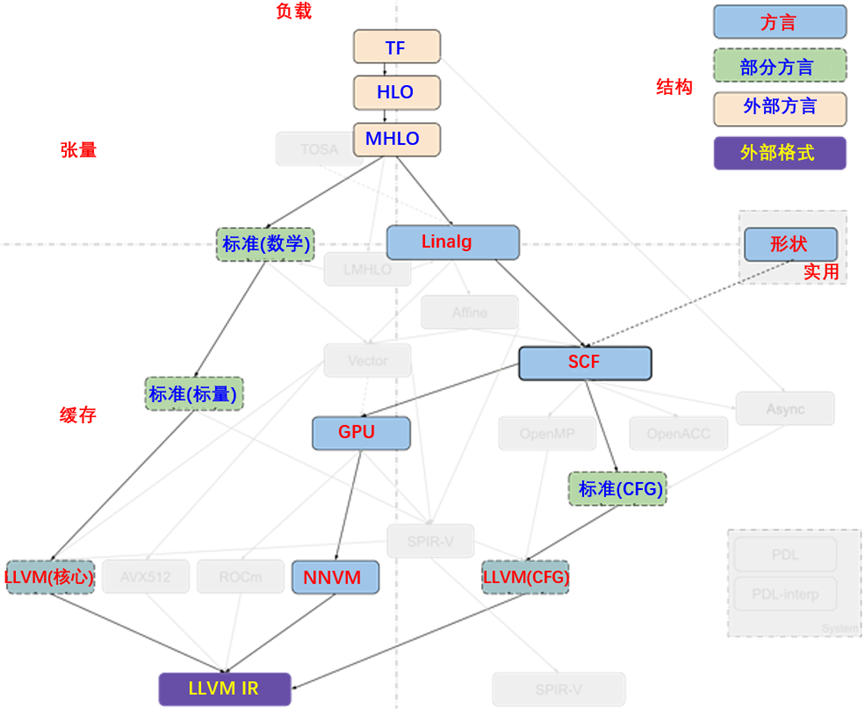
Tensorflow内核生成器项目,从Tensorflow (TF) 方言开始,最近已经转向MHLO (Meta HLO,由于隐式广播移除等特性,更适合编译,并支持动态形状,其中HLO是高级优化器表示,源自XLA),而不是LMHLO(后期MHLO,与MHLO相同,但在缓存区而不是张量上)。在线性代数(Linalg)上调用缓存前,先执行融合操作。循环转换(如平铺)发生在SCF级别,然后转换为特定的GPU方言,而有效负载操作则转换为LLVM方言。现在已经退役的原型,已经尝试针对缓存上的Linalg,使用LMHLO方言,并在SCF上执行所有转换,其中SCF可能比Tensorflow抽象更复杂。在生成多个Tensorflow内核时,将会使用异步方言来分组计算。
IREE编译器(LLVM目标)
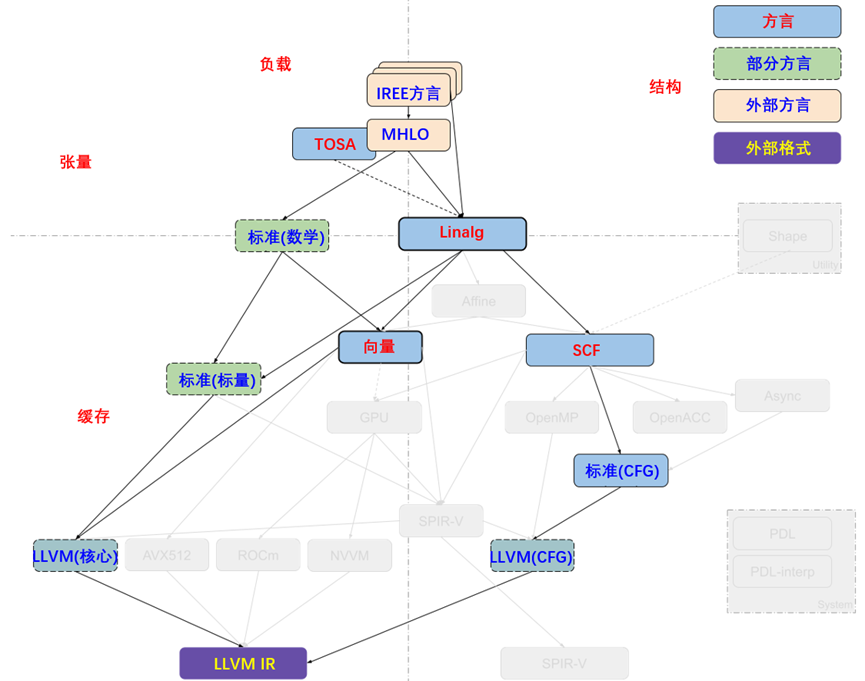
IREE(中级表示执行环境)有它自身的高级表示,它有一组方言,从代码生成来说,这些方言在张量上不断进化。这种中级表示执行环境的方言,主要用于组织计算的有效载荷,可表示为MHLO、TOSA、缓存上的Linalg等。大多数转换都发生在Linalg中,要么是张量级,要么是缓冲级。可通过向量方言,执行文件的首选路径,可以进行特定的转换。当从Linalg下译时,SCF可用向量操作的控制流,但对这些操作不执行任何转换。SCF本质上不再进行结构优化。向量方言可以逐步下译为简单的抽象,直到最终的LLVM方言。
IREE 编译器 (SPIR-V目标)

SPIR-V (标准可移植中间表示,Khronos组标准)是IREE编译器的主要目标。顶层流程类似于LLVM IR的流程,大多数转换发生在张量与向量层的Linalg上。较低的转换直接转到具有丰富操作集的SPIR-V,该操作集跨越多个抽象级别:高级操作、结构化控制流与类指令的原语。该流程通过GPU方言进行设备操作,如标识符提取,并使用IREE的运行时来管理GPU内核。
允许IREE从向量方言转换为GPU方言,将GPU线程用作向量通道(在warp或block级别)。有些转换可以直接从Linalg与向量方言转换到SPIR-V,绕过中间阶段,但可能会逐渐用下译方法替代。
多面体编译器

从HLO开始,绕过Linalg的多面体编译流,可以通过转换LMHLO的仿射方言或任何其他缓存操作来实现。大多数转换发生在仿射方言上,这是多面体转换的主要抽象。然后代码被下译到SCF控制流,并进行标准内存操作,然后被转换为特定平台的抽象,如OpenMP或GPU。
多面体模型还支持早期的向量化,从仿射控制流构造到向量方言,而不是循环向量化。
对于多面体编译器来说,可使用低级抽象(如C编程语言)表示的代码。
分析
Crossing方言
事后看来,似乎在这个分类中跨维度边界的方言(GPU、线性代数与向量方言)在被接受为核心生态系统的一部分之前需要进行最多的讨论与迭代。即使是现在,MLIR基础架构的用户报告说,理解一些方言的定位仍然具有挑战性。例如,IREE使用与设备上执行相关的部分GPU方言,而不是与管理数据与来自主机的内核相关的部分,它们与结构的关系更密切,而不是与负载的关系。类似地,关于将张量与memref抽象与相应操作连接起来的讨论需要很大的努力才能收敛。
这表明,如果将新的方言或较小的IR概念与其他方言与设计空间明确定位,那么它们可以更容易地进行讨论并达成共识。当有必要跨越抽象之间的鸿沟时,最好单独讨论它,并以在不同方言之间泛化为目标(例如,缓存过程)。
中心线性代数
线性代数方言是MLIR代码生成管道的主要接口之一。它最近的发展使它同时作用于张量与缓存区,使缓冲成为方言内部的转换。它有足够的关于操作的高级信息来执行转换,而不需要昂贵的分析,特别是在将张量作为值进行操作时。一些转换,如融合元素操作与tiling,并结合它们来生成不完全嵌套的计算,可以捕获针对广泛架构所需的足够数量的转换。此外,命名操作的概念支持构建在线性代数计算模式上的有效负载操作。
当生产用户开始依赖线性代数时,在几乎所有的编译管道中使用它会增加线性代数的维护压力与稳定性要求。事实上,它跨缓存区与张量工作,并且可能同时捕获有效载荷与计算结构,这使得理解线性代数在某种程度上成为理解任何MLIR代码生成管道的必要条件。虽然有一个良好定义与维护的接口是有好处的,但必须特别注意确保线性代数仍然可以与其他方言组合,并且转换算法不会为它过度设计。
管道互补转换的差异
生态系统中出现了几个并行编译管道。以GPU为目标的案例尤其具有说明意义:优化转换、并行检测与设备映射决策可以在各种不同的方言中发生(线性代数、仿射、SCF),这可能最终会部分地重新实现彼此的功能;设备映射可以使用SCF或向量方言从显式循环或向量派生SIMT线程。最后,GPU库支持更高级的操作,如收缩与卷积,这些操作可以从代码生成管道的接口直接针对它们。
现在比以往任何时候都更重要的是确保表示与转换组合并相互补充,以实现MLIR统一编译基础架构的承诺,而不是构建独立的并行流。这并不一定意味着立即重用所有组件,但要尽可能避免可组合性差的模式。特定于领域与目标的编译器的效用是不可否认的,但是项目可能需要投资于横切表示,使用属性与接口的通用机制。以GPU为例,设备映射策略表示为可以附加到不同操作(例如线性代数泛型或并行SCF循环)的属性,可以通过接口进行转换,而不需要知道特定操作的细节。
构建小型可重用摘要
可以观察到在代码生成管道的更高级别上执行大多数转换的一个不足为奇的趋势:在这些级别上很容易获得或容易提取必要的有效性信息,而不需要进行复杂的分析。然而,更高层次的抽象通常对可表示的内容有更严格的限制。在追求这类抽象的好处时,重要的是要记住表现力与至少在较低级别执行一些转换的能力,以快速增加表现力,而无需重新实现顶级抽象(HLO中的动态形状就是一个很好的例子)。
需要更多结构
另一个正在出现的趋势是更大量的方言与逐步下译执行不离开方言的边界。一些例子包括对张量进行线性代数运算(转换为使用缓存区),GPU方言块缩减(分解为shuffle),以及标准中的数学运算(可以扩展为更小的运算或使用其他标准运算近似)。正在到达这样一个点:一种方言包含几个松散连接的操作子集。这导致了将标准方言拆分为多个组成部分的提议。然而,分裂可能并不总是可取的,甚至是可行的:相同的线性代数操作接受张量与缓存区,所以在没有大量重复的情况下分离T线性代数与B线性代数是具有挑战性的。这就需要以编程上可以理解的方式在方言中构造操作。
主机/设备或程序/内核作为附加轴
最后,在更大的、主要与ml相关的流程中,MLIR的使用促使与计算的整体组织相关的方面(例如,在分布式系统上反映模型映射的操作,以及与嵌入MLIR的框架的交互,通常在主机上)与单个计算的组织(例如,与内核或另一个大型计算单元的内部对应的操作,可能卸载到一个设备)。对于宿主部分,代码生成可能也是必要的,并且通常需要不同于内核部分的转换。
这种分离的具体例子包括GPU方言,它包含从主机控制执行的操作与在GPU上执行的操作,这可能会受益于分离成独立的方言,以及异步方言,它在两个层次上使用:组织独立的内核的执行与通过针对LLVM协程在内核内并行执行。
参考文献链接
https://discourse.llvm.org/t/codegen-dialect-overview/2723


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2023-04-07 NPU大算力技术分析
2022-04-07 服务器方案与DPU市场
2021-04-07 Xilinx低比特率高品质 ABR 视频实时转码(HPE 参考架构)
2021-04-07 Xilinx FPGA全局介绍
2020-04-07 车辆变道方案
2020-04-07 多款激光雷达性能测估
2020-04-07 SOLO: 按位置分割对象