
VHM与CoWoS技术杂谈
VHM与CoWoS技术杂谈
CoWoS是什么?CoWoS有几种变体?
真正的瓶颈-CoWoS
尽管Nvidia试图大幅增加产量,最高端的Nvidia GPU H100将一直售罄到明年第一季度。
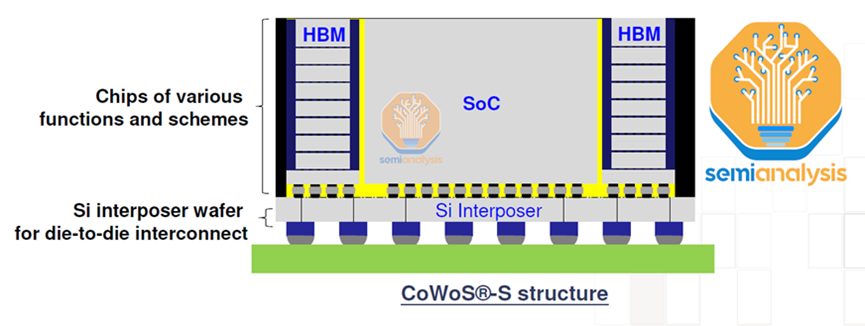
真正的瓶颈是CoWoS容量。CoWoS是台积电的一种2.5D封装技术,其中多个有源硅芯片(通常的配置是逻辑和HBM堆栈)集成在无源硅中介层上。中介层充当顶部有源芯片的通信层。然后将内插器和有源硅连接到包含要放置在系统PCB上的I/O的封装基板。
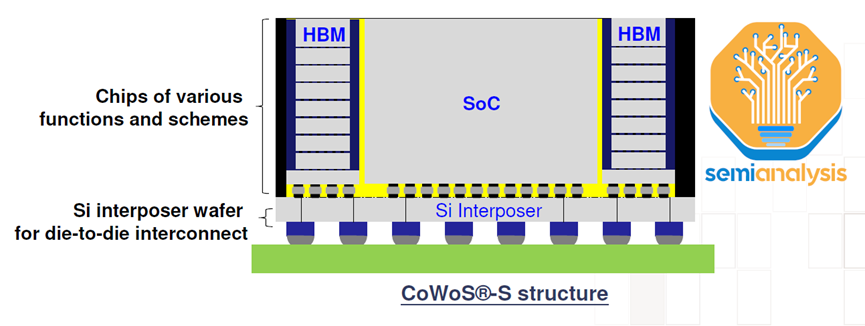
HBM和CoWoS是相辅相成的。HBM的高焊盘数和短迹线长度要求需要2.5D先进封装技术,如CoWoS,以实现这种密集的短连接,这在PCB甚至封装基板上是无法实现的。CoWoS是主流封装技术,以合理的成本提供最高的互连密度和最大的封装尺寸。由于目前几乎所有的HBM系统都封装在CoWos上,所有先进的人工智能加速器都使用HBM,因此几乎所有领先的数据中心GPU都是台积电封装在Co Wos上的。
虽然3D封装技术,如台积电的SoIC可以直接在逻辑上堆叠芯片,但由于热量和成本,它对HBM没有意义。SoIC在互连密度方面处于不同的数量级,更适合用芯片堆叠来扩展片内缓存,这一点可以从AMD的3D V-Cache解决方案中看出。AMD的Xilinx也是多年前将多个FPGA芯片组合在一起的第一批CoWoS用户。
虽然还有一些其他应用程序使用CoWoS,例如网络(其中一些用于网络GPU集群,如Broadcom的Jericho3-AI)、超级计算和FPGA,但绝大多数CoWoS需求来自人工智能。与半导体供应链的其他部分不同,其他主要终端市场的疲软意味着有足够的闲置空间来吸收GPU需求的巨大增长,CoWoS和HBM已经是大多数面向人工智能的技术,因此所有闲置空间已在第一季度被吸收。随着GPU需求的爆炸式增长,供应链中的这些部分无法跟上并成为GPU供应的瓶颈。
要求大幅增加后端容量,特别是在CoWoS中。
台积电一直在为更多的封装需求做好准备,但可能没想到这一波生成式人工智能需求来得如此之快。6月,台积电宣布在竹南开设先进后端晶圆厂6。该晶圆厂占地14.3公顷足以容纳每年100万片晶圆的3DFabric产能。这不仅包括CoWoS,还包括SoIC和InFO技术。
有趣的是,该工厂比台积电其他封装工厂的总和还要大。虽然这只是洁净室空间,远未配备齐全的工具来实际提供如此大的容量,但很明显,台积电正在做好准备,预计对其先进封装解决方案的需求会增加。
确实有点帮助的是,在Wafer级别的扇出封装能力(主要用于智能手机SoC)方面存在不足,其中一些可以在CoWoS过程中重新使用。特别是有一些重叠的过程,如沉积,电镀,反磨,成型,放置,和RDL形成。将通过CoWoS流程和所有的公司谁看到了积极的需求,因为它在一个后续部分。设备供应链中存在着有意义的转变。
还有来自英特尔、三星和OSAT的其他2.5D封装技术(如ASE的FOEB),CoWoS是唯一在大容量中使用的技术,因为TSMC是人工智能加速器的最主要的晶圆厂。甚至英特尔哈巴纳的加速器都是由台积电制造和封装的。
CoWoS变体
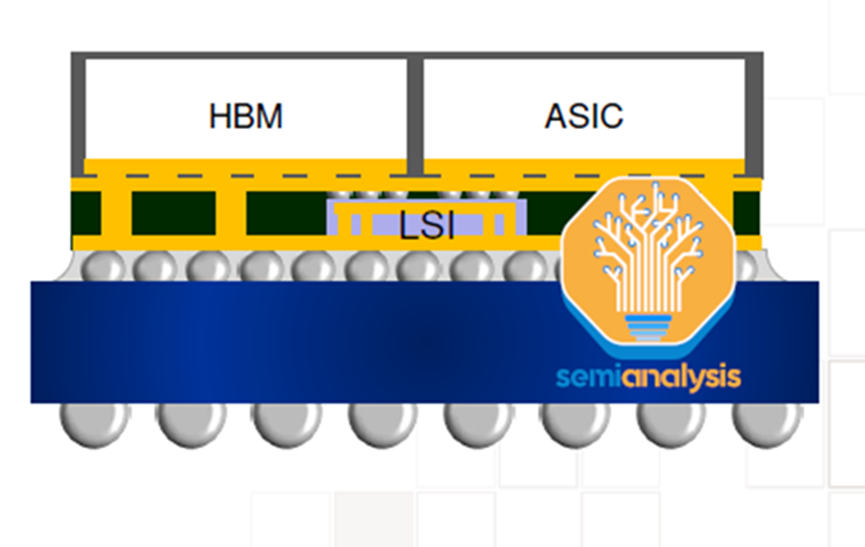
CoWoS有几种变体,但原始CoWoS-S仍然是大批量生产中的唯一配置。这是如上所述的经典配置:逻辑芯片+HBM芯片通过带有TSV的硅基中介层连接。然后将中介层放置在有机封装基板上。

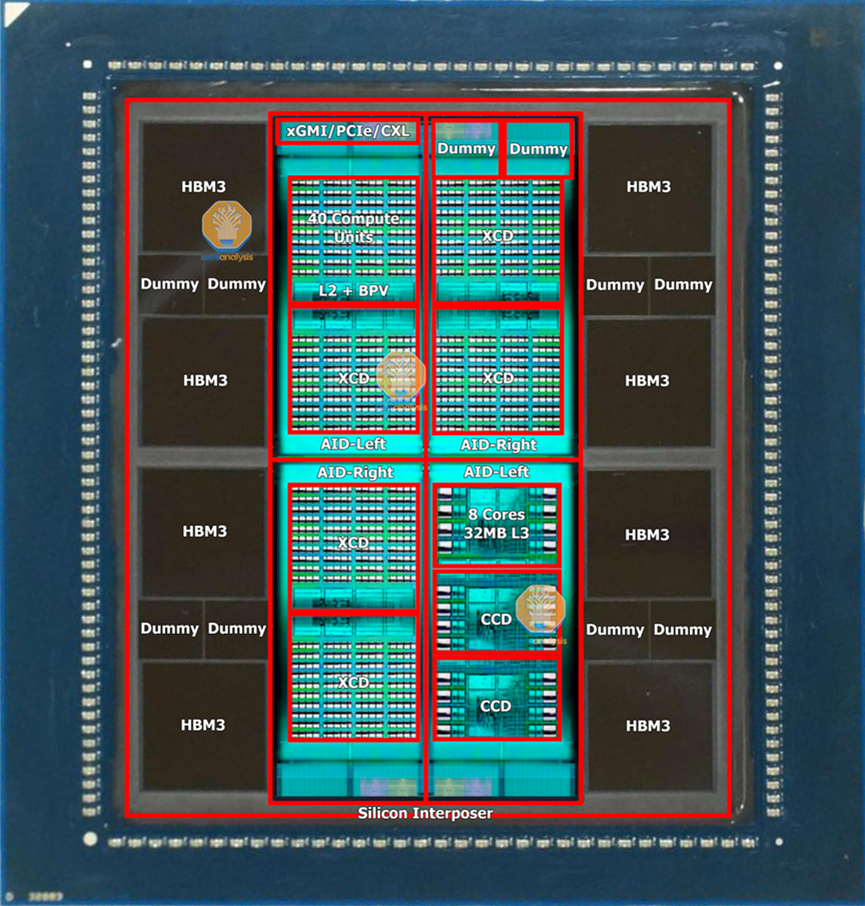
硅中介层的一项支持技术是一种称为掩模版缝合的技术。由于光刻工具狭缝/扫描最大尺寸,芯片的最大尺寸通常为26mmx33mm。随着GPU芯片本身接近这一极限,并且还需要在其周围安装HBM,中介层需要很大,并且将远远超出这一标线极限。台积电解决了这与网线拼接,这使他们的模式插入式多次的刻线限制(目前最高3.5倍与AMD MI 300)。
CoWOS-R使用在具有再分布层(RDL)的有机衬底上,而不是硅中间层。这是一个成本较低的变体,牺牲的I/O密度,由于使用有机RDL,而不是基于硅的插入物。正如已经详细介绍的,AMD的MI300最初是在CoWoS-R上设计的,但认为,由于翘曲和热稳定性问题,AMD不得不使用CoWoS-S。
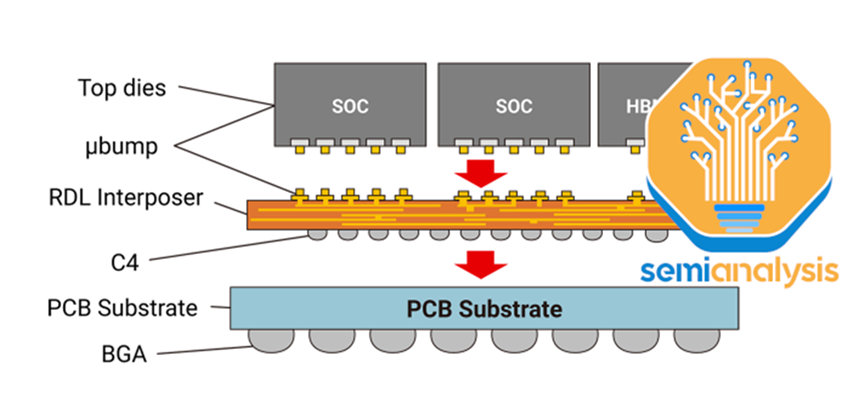
CoWoS-L采用RDL内插器,但包含有源和/或无源硅桥,用于嵌入内插器中的管芯到管芯互连。这是台积电的相当于英特尔的EMIB封装技术。这将允许更大的封装尺寸,因为硅插入物越来越难以扩展。MI300 Co WO S-S可能是一个单一的硅插入器的限制附近。
这将是更经济的更大的设计去与CoWoS-L台积电正在研究一个CoWoS-L的超级载波内插器在6倍分划板的大小。对于CoWOS-S,他们没有提到 4x reticle 之外的任何内容。这是因为硅插入物的脆弱性。这种硅中间层只有100微米厚,在工艺流程中,随着中间层尺寸的增大,存在分层或开裂的风险。
据 DigiTimes 报道,台积电正在加快与后端设备供应商的合作,因为它开始了晶圆基板上芯片(CoWoS)封装产能的扩张计划。英伟达在人工智能和高性能计算领域占据主导地位的计算GPU短缺,主要归因于台积电有限的CoWoS封装生产能力。
有报道称,台积电计划到 2023 年底将CoWoS 产能从每月 8,000 片晶圆增加到每月 11,000 片晶圆,然后到 2024 年底增加到每月 14,500 至 16,600 片晶圆左右。此前有传言称英伟达将提高 CoWoS 产能到 2024 年底,每月生产 20,000 片晶圆。
Nvidia、亚马逊、博通、思科和赛灵思等主要科技巨头都增加了对台积电先进 CoWoS 封装的需求,并消耗了他们能获得的每一片晶圆。据 DigiTimes 报道,台积电因此被迫重新订购必要的设备和材料。人工智能服务器的产量显着增加,刺激了对这些先进封装服务本已强烈的需求。
Nvidia 已经预订了台积电明年可用 CoWoS 产能的 40%。然而,报告称,由于严重短缺,Nvidia 已开始探索与其二级供应商的选择,向 Amkor Technology 和联华电子 (UMC) 下订单,尽管这些订单相对较小。
台积电还开始实施战略变革,例如将其部分 InFO 产能从台湾北部龙潭工厂重新分配到台湾南部科学园区 (STSP)。它还在快速推进龙潭基地的扩建。此外,台积电正在增加其内部 CoWoS 产量,同时将部分 OS 制造外包给其他封装和测试 (OSAT) 公司。例如,Siliconware Precision Industries (SPIL) 就是这一外包计划的受益者之一。
台积电前段时间开设了先进后端 Fab 6 工厂。它将扩大其前端 3D 堆叠 SoIC(CoW、WoW)技术和后端 3D 封装方法(InFO、CoWoS)的先进封装产能。目前,该晶圆厂已为 SoIC 做好准备。先进后端 Fab 6 每年可处理约 100 万片 300 毫米晶圆,每年进行超过 1000 万小时的测试,其洁净室空间大于台积电所有其他先进封装设施的洁净室空间总和。
Advanced Backend Fab 6 最令人印象深刻的功能之一是广泛的五合一智能自动化物料搬运系统。该系统控制生产流程并立即检测缺陷,从而提高良率。这对于 AMD MI300 等复杂的多小芯片组件至关重要,因为封装缺陷会立即导致所有小芯片无法使用,从而导致重大损失。该工厂的数据处理能力比平均速度快 500 倍,可以维护全面的生产记录并跟踪其处理的每个芯片。
Nvidia 将 CoWoS 用于其非常成功的 A100、A30、A800、H100 和 H800 计算 GPU。AMD 的 Instinct MI100、Instinct MI200/MI200/MI250X 以及即将推出的 Instinct MI300 也使用 CoWoS。
VHM,包含DRAM设计及DRAM与逻辑芯片集成接口,提供DRAM晶圆代工制造服务,并由台积电提供逻辑制程晶圆代工及3D堆叠制造服务。
CoWoS 是台积电的一种2.5D封装技术,其中多个有源硅芯片(通常的配置是逻辑和 HBM 堆栈)集成在无源硅中介层上。中介层充当顶部有源芯片的通信层。然后将内插器和有源硅连接到包含要放置在系统PCB上。CoWos是最流行的 GPU 和 AI 加速器封装技术,因为它是共同封装 HBM 和逻辑以获得训练和推理。
爱普宣告成功实现VHM™,DRAM与逻辑芯片的真3D异构集成

爱普科技股份有限公司(TWSE: 6531,下称 “爱普科技”)宣布已成功实现异构集成高带宽存储器(VHM™),即DRAM与逻辑芯片的真3D堆叠异构集成。此3D整合芯片提供了相对于高带宽存储器(HBM)十倍以上的高速带宽;其搭载超过4GB的存储器容量,更是7纳米制程逻辑芯片内存SRAM最大容量的五到十倍。
AI趋势起飞态势明确,存储器设计IC厂爱普表示,近期客户询问度明显提高,许多新项目正陆续洽谈中,预期存储器技术将逐步进入HPC等主流市场,包括AI或超级电脑相关应用,至于IoT客户库存调整已于第1季进入尾声,第2季起可望重回成长轨道。
生成式AI将带动高带宽存储器(HBM)成为首波受惠者,未来将迈向市场主流。不过爱普指出,AI运算将需要使用大容量,高速存储器可以快速执行运算,以应用于机器学习及推论(Inference)。
爱普开发的定制化高速存储器(VHM)产品及设计,藉由3D堆叠技术(3DIC)整合异质晶圆,相较于HBM更具有带宽及功耗优势,主要应用于高速运算的AI、网通等领域。
因应近期ChatGPT热潮兴起,带动超大型AI模型演算法备受重视。爱普表示,此类演算法的架构有赖于在带宽、容量及能效上持续优化的硬件设计来支持,爱普有能力成为这场技术革命的主要参与者。
据WSTS预估,2023年存储器整体销售额将年减17.0%,至1,116.24亿美元。但在5G、AI、和 IoT持续演进发展的趋势下,各终端应用所需存储器容量及带宽大幅提升,预期景气回温后才能重回成长。
爱普AI事业部2022年主要收入来自加密货币市场,但市场经历低潮变动,压缩爱普的AI事业部WoW产品需求,但2022年AI事业营收仍有年成长约5%,爱普表示,加密货币的应用市场预计在2023年仍面临调整。
VHM技术已获得重量级客户的关注及青睐,并启动在主流应用程序的概念验证(POC) 项目,对于市场传出,VHM顺利抢得AI相关商机应用,爱普表示,POC项目与量产还有距离,正向看待VHM渗透率持续成长,但具体时间点仍有变量。
爱普2023年5月营收达到新台币4.09亿元,月成长近3成,累计1~5月营收14.48亿元,年衰退42%,由于IoT存储器的库存去化进入尾声,开发新案最快可望于下半年逐渐贡献营收,随着库存去化至合理水准,下半年表现将优于上半年。
随着AIoT带动,DRAM的需求更加多元化,预期省电、高效能、微型化为主要特性,对于低功耗及低引脚数的定制化存储器将成为出货主流,预期新案陆续步入量产后,未来2年IoT RAM亦会有较快速的成长。
爱普科技提供VHM™,包含客制化DRAM设计及DRAM与逻辑芯片集成接口的VHM™ LInK IP,力晶积成电子制造股份有限公司(ESB: 6770,下称“力积电”)则是提供客制化DRAM晶圆代工制造服务,并由台湾集成电路股份有限公司(TWSE: 2330,下称 “台积电”)提供逻辑制程晶圆代工及3D堆叠制造服务。而此3D堆叠芯片客户为鲸链科技股份有限公司,是一家专注科技创新的无晶圆厂半导体及系统方案供应商。
半导体产业的封装技术已从传统的2D封装演进到2.5D,再到真正的3D封装技术。2.5D封装(过去常被泛称为”3D”)是将多片芯片封装于同一块硅中介板(Silicon Interposer)上,而真正的3D封装技术则是以垂直的连接方式,将多片芯片直接立体地互相堆叠。
2.5D封装时的存储器带宽受限于硅中介板上可载的横向连接数量;而3D封装因为采用垂直连接的方式,其连接数量几乎不会受限。得益于此,相较于2.5D封装,逻辑芯片与DRAM的3D集成,可在显著降低传输功耗的同时,大幅提升存储器的带宽。
逻辑芯片与DRAM的3D集成是力积电在AI存储器战略上的最新成果,这项3D技术将为DRAM的带宽创造前所未有的可能性,对于AI、网通及图像处理等特别需要大量带宽的应用,将有极大的帮助。
爱普科技能与台积电及力积电等业界领导大厂,一同在逻辑芯片与DRAM的3D集成上展开密切合作,帮助客户实现前所未有的产品效能。爱普科技的使命即是提供优良的存储器解决方案,让客户的产品更有竞争力,创造更多商机。
爱普以VHM技术向HBM下战帖
随着人工智慧(AI)、高速运算(HPC)等前瞻技术的演进,业界对存储体频宽的要求与日俱进,目前以高频宽存储体(High Bandwidth Memory,HBM)为主流。不过2021年8月,客製化存储体厂爱普宣布成功实现异质整合高频宽存储体(Very High-Bandwidth Memory,VHM),并携手台积电、力积电打造用于以太币挖矿机的ASIC,意欲发起革命挑战HBM的地位。
这颗ASIC是少见的3D堆叠IC,以38nm的DRAM和55nm的逻辑晶片堆叠而成。由力积电负责客製化的动态随机存取存储体(DRAM)晶圆代工服务,台积电提供逻辑製程晶圆代工及3D堆叠服务,爱普则拿出两大武器,客製化DRAM设计及系统单晶片(SoC) 整合介面VHMLink IP,客户是台湾的鲸链科技。这个多方合作的心血结晶ASIC,已于去年量产。
爱普自2019年转型后,专注在DRAM的客製化;本就在极度碎片化市场拚搏的他们,对客製化DRAM的技术并不陌生,不过VHM技术却是崭新且难度相当高的尝试。为了研发这堪称革命性的创新技术,爱普团队几乎从零开始摸索,总算用三年多的时间,打磨出VHM的技术。
AI或其他应用存储体和SoC每秒数据的数据流量,是现行方案的10~100倍,这是无法解决的问题,HBM一般摆在逻辑晶片周边,每颗晶片分别以1,024支接脚连接SoC,若要符合现行频宽需求,增加HBM颗数是一种作法,但2.5D封装需将晶片和SoC摆在硅中介层(Interposer)上再封装,空间有所侷限,要摆100颗几乎是不可能,这也是为何要客製化发明一个技术。
所谓存储体频宽,指处理器从存储体读取或储存资料的速率。以HBM来说,已量产且频宽最快为HBM2E,每堆叠存储体频宽最高461GB/s (Gigabyte per second),每个接脚的传输速率为3.6Gbps (bit per second),传输每位元约消耗6pJ的能量;据爱普提供的资料,VHM虽每个接脚的传输速率较慢,为0.5Gbps,不过提供比HBM多出近十倍的存储体频宽,来到4,600GB/s,传输每位元消耗的能量则不到1pJ。
VHM与市面上其他DRAM解决方案,高频宽及功耗等特性有较佳的表现。
3D堆叠IC设计难关多 爱普手握两大武器
存储体频宽之所以能大幅提升,关键之一就在3D堆叠;藉由这样的方式,比起用2.5D封装的HBM,爱普所设计面积832mm2的DRAM晶片跟SoC透过数万支接脚连接,实现频宽大幅提升、功耗显着下降,并节省空间的效益。单以规格来看,VHM确实展现优于HBM的特性,但之所以到现在才问世,原因在3D堆叠衍生出的良率、散热等难题,让业界对投入研发的态度相对保守。
3D堆叠IC概念约莫十年前出现,然而直到近年摩尔定律的延续遇上瓶颈,发展才开始缓步增速,像台积电这样的领导大厂,也是到2020年才发表3D Fabric先进封装技术。业界之所以保守,归纳出几个难解的问题,包括堆叠造成良率下降;单片晶圆就有的散热问题,堆叠后的问题更难解;还有晶圆的裸晶(Die)也要一样大;另外还有同步性等难关,设计上的挑战相当多。
再者,这类产品从前端架构就要跟客户紧密合作,物联网(IoT)存储体的客製化,可能大多是接脚的修改,VHM产品针对晶粒的形状大小、频宽、功率、温度等面向都要考量,尤其这类的存储体非常重视功耗跟传输速度,功耗大一点点就会非常热,需要极致的客製化,一个案子可能就要耗费数年,但从产品需求来看,所有会面临的问题都克服了!
爱普耗时三年,掌握VHM和传输介面IP VHMLink技术。
除了DRAM的客製化,就是VHM Link IP。VHM Link IP是传输介面的IP,整合了DRAM的控制器,以及DRAM储存及读取资料时的时脉产生器;内建BIST (Built in Self test)修复功能,以提升良率与降低晶片的测试成本;定义逻辑晶片和VHM DRAM间的传输协定,确保DRAM能藉由逻辑晶片I/O顺畅的进行数据传输。
让客户的SoC,跟很多个存储体的数个位址能频繁且快速的沟通,以前2.5D只是单纯到隔壁邻居家敲门拿东西,3D堆叠则是1楼跟2楼间有很多电梯,如何控制电梯赶快把东西拿下来,就是厉害的地方。也就是藉由VHM Link IP,让VHM能用更少的功耗实现跟SoC间的高速资料传输。据爱普内部资料,同样支应4TB/s频宽,VHM单颗即可符合需求,功耗不到20W;HBM则需使用10颗,总功耗超过200W。
提到这颗以太币挖矿机ASIC,之后会慢慢看到那颗ASIC打死大厂的GPU,以太币挖矿机的演算法是纯粹靠数据流量,量越大跑得越快。客户导入VHM做出以太币挖矿机的ASIC,数据流量是主流大厂GPU的十倍。现在的产品还只是原型(Prototype) ,未来效能还有机会再往上走。
VHM挑战主流地位,瞄準网通市场进攻
着眼AI等前瞻科技持续演进,未来高频宽的需求可预见将只增不减。挖矿机是现阶段试验技术最好的场域,接下来CPU、GPU都有机会採用这样的架构。即便VHM仍处在有应用、非主流的阶段,坚信爱普独门的VHM技术跃升主流,将是整个产业发展下必然的趋势,不可能有别的方法解决频宽问题,一定要用3D解决,只是时间问题。
网通产业,已看到现有技术无法满足需求的现象。网路交换器(Switch)的资料需要先经过缓冲(Buffer)辨识资料,才能正常运作,交换器现在每个接口(Port)速度接近1TB/s,5个接口就需求5TB/s的频宽,静态随机存取存储体(SRAM)容量不够,HBM会需求太多颗放不下,到TB量体已经没有存储体解决方案,唯有VHM可以跟得上网通的速度。
任何技术要变成主流,需要时间,也需要关键应用,才有机会开枝散叶,网通会是VHM第一个主流突破点。不过除此之外,他也坦言3D IC供应链现阶段不够成熟,影响客户导入的意愿,也是客户最不满意的环节,尤其3D堆叠技术,主流代工厂有在开发技术,但由于量还未起来,动作相对保守,建产能都是两、三间非主流的厂商,还需要一点时间。
不像有些技术要成熟,需动辄数十年,认为凭藉过去三年多研发的经验,VHM几年内就有机会渐趋成熟。据悉,爱普在今年初,以发行普通股参与海外存託凭证形式,办理发行总金额达1.89亿美元(约新台币57亿元)的现金增资,其中一个目的,也就是为了更深度投入该技术的发展,和伙伴共同推动供应链加速迈向成熟。
爱普并仍积极向外寻找合作伙伴,盼进一步扩大VHM的应用市场,日前加入OpenCAPI联盟,与业界一同加速近存储体运算(near-memory computing)的发展;另,也成为由台积电、日月光、高通、AMD等国际大厂组成的小晶片互连产业联盟(Universal Chiplet Interconnect Express,UCIe)的一员,目标与产业界共同完善小晶片(Chiplet)生态系。
遭遇逆风Q2毛利降要靠技术力突围
爱普历经转骨,近年营运趋稳,去年全年营收66.2亿元,税后纯益20.3亿元,每股纯益13.67元,皆为历年新高;今年上半年遭遇中国大陆封控、乌俄战争等逆风袭击,加上产业进入库存调整期,第二季单季毛利率降至41%,为近六季低点。但以提高产品IP含量拉升毛利率的策略不变,未来一两季会调整产品组合,并释出预期第三季单季毛利率将较第二季41%回升、第四季稳中求升的展望。
在AI事业部分,VHM在以太币挖矿领域新设计案不少,也有非挖矿的NRE,长期将专注在VHM跟各领域的推进,为建立完整生态圈及VHM导入主流努力。IoT部分,在IoT需求持续放大的趋势下,公司已发展十余年、拥有相对成熟技术的虚拟静态随机存取存储体(Pseudo SRAM,PSRAM)产品,可望发挥竞争优势,带来稳定且持续成长的现金流。
IoT事业目前佔爱普八成营收,是其得以持续投入资源在AI事业的重要泉源。谈及爱普的竞争优势,IoT设备要求体积小、续航力强,所需的存储体容量落在16~512Mb间,SRAM容量多在8Mb以下、DRAM最低4Gb又太大,这就是PSRAM适合发挥的空间,而爱普的强项是会成为第一个为客户应用量身订做、定出规格的厂商,这是标準DRAM做不到的。
因应IoT市场的趋势,爱普今年也推出512Mb UHS (Ultra High Speed)系列产品AP351216C及AP351208,以及32Mb ULS (Ultra Low Swing)系列产品AP43208B;UHS系列频宽比传统PSRAM高五倍,ULS功耗仅传统DRAM的三分之一。IoT着重小型化跟低功耗,比如,现在爱普产品的待机功耗落在10μA左右,以电池供电的电錶至少要能用十年是基本,至今仍在不断最佳化内部电路,朝越来越细的环节做精进。
未来DRAM主流应用将走向客製化
AI跟IoT两大事业体发展逐渐迈向稳健成长,爱普下一阶段的重点,将锁定近年当红的元宇宙(Metaverse)。元宇宙现在趋势是终端装置的极致微型化,一定会看到手机变得更轻、更小来搭配AR/VR智慧眼镜,甚至慢慢发展到最后也不用手机,就像智慧手錶以前要搭配手机,现在也能单独使用,那也就是智慧眼镜的进程。智慧眼镜取代手机,是一定会发生的。
当AR/VR追求微型化到极致,存储体一定要用非常小型的,那也就是客製化的战场。综观未来DRAM发展趋势,他甚至大胆预期,现在AI、IoT等前瞻应用,鲜少厂商使用双倍资料率(DDR) DRAM,甚至HBM都有人不想用,这意味着主流应用,将可能走向极致的客製化,未来应用也会离标準品越来越远,最后价值可能不在製造端,设计公司将掌握最多价值。
高度客製化是肯定的,因为标準化到此为止!任何客户只要发现市场上买不到某些产品,就会寻找像爱普这样的厂商来做客製化,谁是客製化的主要供应商还都不知道,爱普虽是规模相对小的公司,不过已站在DRAM客製化的最前端。
对于市场瀰漫着一股悲观气氛,市场循环就像一天睡醒后很快到晚上又天黑,一阵子造成大家营收下来、过阵子又回来,循环相较于技术改进很短暂,但技术循环是不会改变的,做的技术发展可以赢过市场循环。展望未来,IoT现在市场规模是5亿美元,AI规模是10亿美元,两个市场才刚开始,之后很可能是现在的数倍规模,潜在成长机会还很大。
台积电CoWoS产能已满负荷:AMD将在其他有CoWoS封装
台积电CoWoS产能已满负荷:AMD将在其他有CoWoS封装能力的公司寻找合作

近年来,随着人工智能(AI)的快速发展,对 CoWoS包装产业的需求也越来越大。台积电的高功率半导体制程能力已经超负荷运转,其能力和需求量的缺口越来越大。
据报道, AMD在人工智能方面的进展大大超过了人们的预料,而最新推出的MI300系统,更是把全世界人工智能领域的机遇推上了一个新的高峰。但是,随着市场的日益加剧, AMD面临着一个严峻的挑战,那就是高端包装技术,它是供给端的核心。
台积电的 CoWoS (CoWoS)的产能已达到饱和,因此 AMD必须和其它具有 CoWoS (CoWoS)技术的厂商进行协作,才能跟上市场的需要。
AMD为什么如此急切地寻求其它的合伙人?
只有掌握了高端包装技术的人才,才有可能在未来的 AI领域取得领先。

前段时间几年,大家都看到了 AI市场的火热。随着大数据、云计算和物联网等技术的飞速发展,人工智能在人类社会的各个领域得到了广泛的应用。
这不但给 AI芯片企业带来了巨大的商机,同时也促进了其商业化的进程。
其中,包装是制造 AI芯片的一个重要步骤,是不可忽视的。芯片的性能,可靠性,成本都受到芯片的封装工艺的影响。随着 AI芯片的高集成度、高速度的通讯需求,其封装成为了 AI芯片研究的重点。
其中,Chip-on-Wafer-on-Substrate (Chip-on-Wafer-Substrate)因其特有的优点而备受关注。CoWoS将一块晶片包在另外一块晶片上,再把晶片贴在基板上,这样就能大幅提升晶片之间的通讯速率,并且减少功率消耗。
同时, CoWoS还可以进一步提高芯片的集成度和体积,从而更好地适应 AI芯片对高性能、低功耗、小型化的要求。
不过,台积电的多点水系统能力早就达到了极限,这对于像 AMD这样的依靠多点水系统的晶片厂商来说是很大的负担。
同时, AMD也应该积极寻找能够与其它具备相同功能的 CoWoS产品供应商进行协作,以适应市场的需要。日月光,安科,力成,京和电子等包装企业将会与 AMD及其它厂商展开业务往来。
AMD重新制定策略:携手并进才是关键
AMD公司在面临包装工艺的严峻考验后,迅速调整策略,开始与其它具备相似封装性能的厂商进行合作。此举不但帮助解决了台积电在多点云服务方面的不足,同时也加速了 AMD公司的 AI晶片的研发与市场推广。
通过与封装厂商的深度协作,使 AMD能够更好的适应新的市场需要,增强企业的竞争能力。、
另外, AMD公司的策略调整,对包装行业的发展起到了一定的促进作用。由于 AI的发展前景广阔,各芯片企业对其进行了大量的封装。通过与美国 AMD公司等国际著名厂商的联手,使其在工艺上有了长足的进步,使其能够更好的适应市场的需要。
这样一种双赢的方式,将会是未来人工智能产业发展的一个新方向。伴随着 AI行业的蓬勃发展,产业链中的企业间协同发展是大势所趋。
从设计、生产、封装到测试等各个环节,各企业必须齐心协力,才能战胜这一市场的考验。而在此基础上,还需要国家与行业机构加大对人工智能产业的指导与支持,以推动人工智能产业的良性发展。
其中,作为其中一个重要的组成部分,包装企业的科技含量与实力,将决定着整个智能工业的整体运行效率与竞争实力。对此,包装企业应该加强对产品的研究开发与人员培训,以提升其自主创新的实力与层次。
此外,通过和 AMD等国际著名的半导体厂商进行深度的战略伙伴关系,也是一种有效的策略。
总而言之,在当前人工智能发展迅速、竞争日趋激烈的背景下,如何实现产业链中各企业之间的有效合作已成为必然。由于台积电的 CoWoS产品已经完全达到了饱和状态,因此 AMD很明智地决定与其它拥有 CoWoS包装技术的厂商进行合作。
这对企业而言,既是一次难得的商机,也是一次难得的机会。
什么是CoWoS?用最简单的方式带你了解半导体封装!
过去数十年来,为了扩增芯片的晶体管数量以推升运算效能,半导体制造技术已从1971年10,000nm制程进步至2022年3nm制程,逐渐逼近目前已知的物理极限,但随着人工智能、AIGC等相关应用高速发展,设备端对于核心芯片的效能需求将越来越高; 在制程技术提升可能遭遇瓶颈,但是运算资源需求持续走高的情况下,透过先进封装技术提升芯片之晶体管数量就显得格外重要。
半导体先进封装技术
这两年「先进封装」被聊得很多,「封装」大概可以类比为对电子芯片的保护壳,保护电路芯片免受外界环境的不良影响。 当然芯片封装还涉及到固定、散热增强,以及与外界的电气、讯号互连等问题,而「先进封装」的核心还在「先进」二字上,主要是针对 7nm 以下晶圆的封装技术; 然而,人工智能浪潮下,带动AI伺服需求成长,也带动英伟达GPU绘图芯片需求,而GPU的CoWoS先进封装产能供不应求,那究竟什么是CoWoS?
什么是CoWoS?
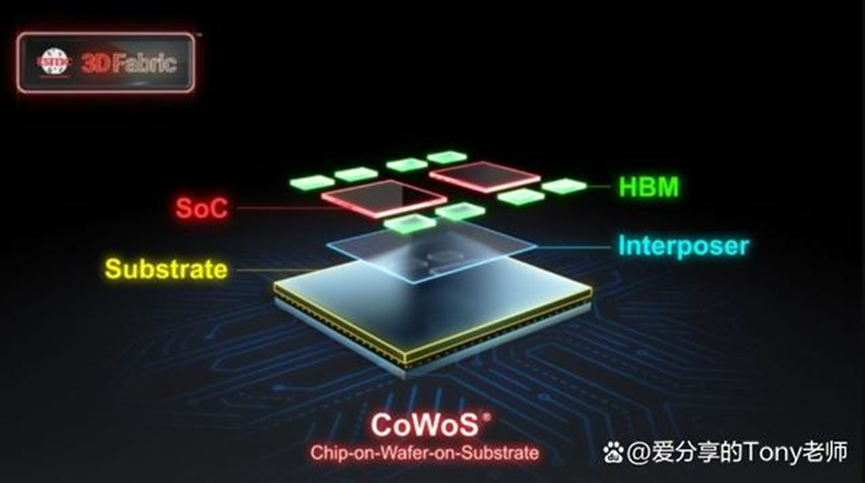
CoWoS 是一种 2.5D、3D 的封装技术,可以分成「CoW」和「WoS」来看。 「CoW(Chip-on-Wafer)」是晶片堆叠; 「WoS(Wafer-on-Substrate)」则是将芯片堆叠在基板上。 CoWoS 就是把芯片堆叠起来,再封装于基板上,最终形成 2.5D、3D 的形态,可以减少芯片的空间,同时还减少功耗和成本。 下图为CoWoS封装示意图,将逻辑芯片及HBM(高带宽记忆体)先连接于中介板上,透过中介板内微小金属线来整合左右不同芯片的电子讯号,同时经由「砂穿孔(TSV)」技术来连结下方基板,最终透过金属球衔接至外部电路。
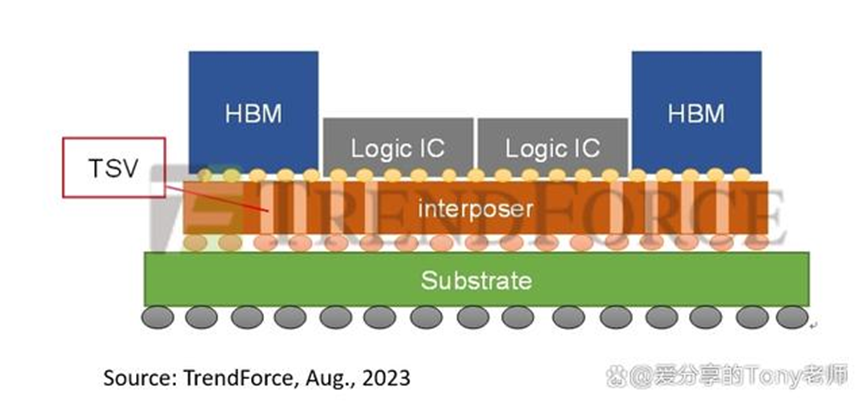
而2.5D与3D封装技术则是差别在堆叠方式。 2.5D 封装是指将芯片堆叠于中间层之上或透过硅桥连接芯片,以水平堆叠的方式,主要应用于拼接逻辑运算芯片和高带宽存储器; 3D 封装则是垂直堆叠芯片的技术,主要面向高效能逻辑芯片、SoC 制造。
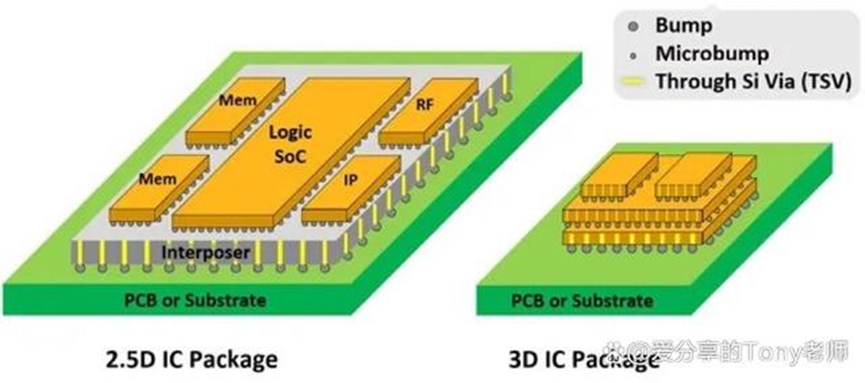
▲2.5D和3D封装的差异
先进封装,但不在封装厂完成!
说到先进封装,首先想到的会是台积电而非传统封测大厂,因为先进封装已经面临到 7nm 以下,而传统封装厂研发速度已无法跟进晶圆制程的脚步,其中 CoWoS 中的 CoW 部分过于精密,只能由台积电制造,所以才会造就这番景象。 同时,台积电拥有许多全世界的高阶客户,为此「一条龙」的服务更能同时维持制程与封装部分的良率,未来面对高阶客户的交付工作也将更为极致。
CoWoS的应用发展
高端芯片走向多个小芯片、内存,堆叠成为必然发展趋势,CoWoS 封装技术应用的领域广泛,包含高效能运算 HPC、AI 人工智能、数据中心、5G、物联网、车用电子等等,可以说在未来的各大趋势,CoWoS 封装技术会扮演着相当重要的地位。
过去的芯片效能都仰赖半导体制程的改进而提升,但随着元件尺寸越来越接近物理极限,芯片微缩难度越来越高,要保持小体积、高效能的晶片设计,半导体产业不仅持续发展先进制程,同时也朝晶片架构着手改进,让芯片从原先的单层,转向多层堆叠。 也因如此,先进封装也成为延续摩尔定律的关键推手之一,在半导体产业中引领浪潮。
全球HBM3需求爆发;慧荣加入NXP合作伙伴;韩国5月存储芯片出口同比减53%
今日热点
1. 全球竞逐AI,HBM3需求爆发
2. 慧荣加入NXP合作伙伴计划,进军车用市场
3. 群联成全球第一家通过ASPICE CL3等级独立控制芯片商
4. Pure Storage领先业界,供所有存储需求全快闪解决方案
5. 韩国ICT出口连降11个月,5月存储芯片出口同比减53%
6. 印度政府给中国手机厂商提出三要求
01
全球竞逐AI,HBM3需求爆发
超威、英伟达在AI领域大PK,为全球的AI带入另一个高潮,由于AI对运算能力与频宽要求更高,刺激高频宽半导体(HBM3)需求爆发,爱普、宜鼎在AI服务器半导体应用着墨最深,近期客户询问度大增,尤其爱普早与超威在新世代半导体技术有合作,营运可期。
业界分析,就英伟达AI平台来看,搭载的高频宽半导体容量是传统服务器的数百倍,并非传统半导体可取代。这次超威更端出搭载八个MI300X芯片的Instinct运算平台,内存高达1.5TB的第三代高频宽半导体,并宣称MI300X的半导体是英伟达最强AI芯片H1000的2.4倍,频宽是H100的1.6倍,预料引爆更多高频宽半导体需求。
爱普与超威已有新世代半导体合作。爱普2022年第2季宣布,加入由台积电、英特尔、超威等共同推动的UCIe联盟,期望通过其DRAM介面异质整合高频宽半导体(VHM)技术,推动小芯片(chiplet)生态圈发展,与国际大厂在AI及高效能运算(HPC)3D先进封装领域扩大合作。
爱普认为,现阶段高频宽半导体HBM以及2.5D不能满足市场高端需求,以近期很红的ChatGPT来说,用的是Open AI技术,有1,300个模型参数,要强大半导体支援,但会遇到频宽问题,爱普的3DIC堆叠的VHM是选择之一,未来商机很大。
爱普强调,现阶段AI事业应用逐步扩及高效能运算相关客户,已经启动的POC(概念验证)项目进展顺利,新的项目亦正洽谈中。
宜鼎也被市场视为AI服务器半导体厂商,耕耘AI及AIoT多年,子公司安缇主攻边缘运算服务器GPU。据悉,当前AI相关产品占营收比重约9%,将持续增加。
02
慧荣加入NXP合作伙伴计划
NAND快闪半导体体控制芯片领导厂商慧荣科技今日宣布加入恩智浦(NXP)合作伙伴计划,成为注册合作伙伴,并参加6月13至14日于美国加州圣塔克拉拉所举办的NXP Connects。
通过合作伙伴关系,慧荣科技的NAND存储解决方案及图形显示SoC能与NXP众多的车用电子产品相结合,提供卓越的效能及稳定的品质,以满足汽车行业的独特需求,达到相辅相成的合作效果。

慧荣展示专为自动驾驶和电动车应用所设计的Ferri嵌入式储存解决方案,包括FerriSSD、Ferri-eMMC和Ferri-UFS。
Ferri 嵌入式储存解决方案采用台积电车用晶圆生产流程制造,符合AEC-Q100及ASPICE认证标准,满足资讯娱乐系统、先进辅助驾驶系统(ADAS)和车载资通系统等各种汽车应用对高可靠性、数据整合性及效能的严苛要求。
慧荣也在NXP Connects展示SM768图形显示SoC。SM768 可与i.MX family等NXP SoC一起执行。如此结合可让NXP平台透过USB介面支援4K超高画质解析度。
通过成为NXP注册合作伙伴,慧荣将与NXP携手致力于提供领先的配套平台解决方案,推动创新并促进自动驾驶和电动车市场的持续成长。
03
群联成为全球第一家通过ASPICE CL3等级独立控制芯片商
快闪半导体控制芯片暨存储解决方案整合服务厂商群联14)日宣布通过符合Automotive SPICE(简称 A-SPICE or ASPICE)Capability Level 3 (CL3) 能力等级,成为全球第一家独立控制芯片商的嵌入式 eMMC控制芯片,通过此项车用固件开发与验证流程的供应商。
群联是全球最大车用eMMC控制芯片供应商,目前已有完整车用存储方案,包含eMMC、BGA SSD、UFS及SD/microSD等,为全球最完整的车用存储方案供应商。
近年来随着车用电子的蓬勃发展,驱动车用芯片新技术的加速兴起与需求量大增, 也因此车厂对于供应商的要求日渐严谨,而Automotive SPICE能力等级便逐渐成为全球汽车制造商对供应商的标准要求之一。该标准是整合全球汽车行业在软件与固件开发管理的经验,透过制定研发阶段监控与管理相关流程,希望提高车用软件与固件产品的交付品质,进而提升行车安全。
目前 ASPICE 是国际公认含金量最高的软固件开发标准,根据 ASPICE 标准的定义,能力等级3 (CL3)是指“已确立”(Established),也是目前已知全球各车厂 对 ASPICE 的最高要求。此等级特征为除了工作产出有达到要求外,企业也须有 一套标准化的方法来评估各流程的执行绩效与管理工作产出,且有制定并执行根 据专案属性与特征的流程裁剪规则。
群联电子表示,群联投入车用储存控制芯片研发已超过十年以上,近几年更是投入近百人团队致力导入 ASPICE 流程,这次能通过 ASPICE 能力 等级3 (CL3) 的评级,不仅是对群联研发团队的肯定,更是宣示群联的车用存储方案技术与固件研发流程已达国际级最高水平,符合所有一线车厂的要求。
04
Pure Storage提供所有存储需求全快闪解决方案
拥有全球最先进数据存储技术与服务的IT先驱Pure Storage(PSTG)在美国拉斯维加斯举办Pure Accelerate 2023,宣布推出次世代FlashArray//XTM和//CTM R4机种,瞄准数据成长、应用程式型态改变,企业必须以更少的能源、更短的时间等,完成更多任务,而全新FlashArray在效能和规模上都大幅跃进,能提升高达40%的效能,使客户节省74%的总体拥有成本。

董事长Charles Giancarlo表示,公司提供业界最一致、最可靠的产品阵容,能满足所有企业的存储需求,不仅可靠性比竞争对手高10倍,电源与空间效率的全快闪更高出2至5倍、比硬盘高10倍。
Pure Storage在Pure Accelerate 2023,宣布已达成最初设立目标,成为第一家以全快闪解决方案满足客户全方位存储需求的技术供应商,凭借着公司在原生快闪管理上独一无二的优势、以及Purity架构、Evergreen订阅服务与云端营运模式,使得Pure Storage 成为市场上唯一能够做到这点的存储品牌。
Charles Giancarlo指出,在人们迈入AI新时代,相较于竞争对手的传统硬盘(HDD)与固态硬盘(SSD)全快闪产品,公司的产品阵容具有绝佳经济性以及营运和环保的双重效率,这对客户来说,将比以往更加重要。
Charles Giancarlo进一步说,Pure Storage每年的增长速度都快于市场。已向全球多达11,500家,不同类型的产业与工作负载之客户,证明拥有绝对优势,包括可靠性比竞争对手高10倍、电源与空间效率比竞争对手的全快闪高2至5倍、比硬盘高10倍、人力作业比传统存储减少5至10倍、总体拥有成本(TCO)比竞争对手的快闪与硬盘至少降低50%。

另外,Charles Giancarlo强调,Pure Storage DirectFlash技术,独家运用件体直接写入快闪半导体,不同于同行采取较昂贵、缺乏效率且生命周期较短的固态硬盘(SSD),公司高度整合的产品线,涵盖一套通用的作业系统(Purity 操作环境)以及一套管理系统(Pure1),不论是在向上扩充或向外扩充的平台都能运作。
论及近期最热的AI议题,Charles Giancarlo直言,不论是从消费者的角度,或者是企业主的角度,都很关注ChatGPT的动态和未来的趋势。公司在过去的五年,一直致力于AI项目,目前有超过一百多的客户使用Pure Storage的产品,进行从机器学习到分析的应用,甚至还参与了十项有关自动驾驶汽车计划,以及金融交易等,AI将成为企业营运的推动力之一。
Pure Storage在今年稍早已推出了FlashBlade//E向外扩充非结构化的数据存储库,专为支援整合式档案与物件工作负载而打造,如今又再度将FlashArray//E延伸到Pure//E家族,支援整合式区块与档案,提供可无缝扩充至4PB的容量。
据悉,全快闪阵列(AFA)是一种存储基础架构,它使用的是快闪半导体硬盘,而不是传统硬盘/ 旋转磁盘机;全快闪存储也被称为固态磁碟阵列(SSA),而AFA以及SSA提供高速及高效能,能为企业应用程式带来极大优势。
05
韩国5月存储芯片出口同比减少53%
韩国科学技术信息通信部14日表示,韩国5月信息通信技术(ICT)出口额同比减少28.5%,为144.5亿美元,自去年7月起连降11个月。

按品目来看,半导体出口同比减少35.7%,显示器减少12%,电脑及周边设备减少53.1%,手机减少17.2%,通信设备减少11.1%。半导体出口中,存储芯片出口同比锐减53.1%,为34.1亿美元;系统芯片同比下降4.9%,为36.4亿美元,降幅时隔5个月来缩至一位数。
按地区来看,面向中国(含香港,-31.6%)、越南(-14.6%)、美国(-36%)、欧盟(-30.7%)、日本(-10.9%)的出口额均减少。
同期,进口额同比下滑11.2%,为112亿美元。ICT贸易收支实现32.5亿美元顺差,规模较去年同期(75.9亿美元)腰斩。
06
印度政府对中国手机厂商提出三要求
据印度媒体消息,印度政府对来自中国的手机厂商提出要求,首席执行官、首席财务官等高管要职,应由印度籍人士担任。

印度政府官员在电子和信息技术部最近举行的会议上,与小米、OPPO、realme和vivo等中国智能手机制造商讨论了这些问题。
要求中国小米、OPPO、realme和vivo等智能手机制造商任命印度籍人士担任首席执行官、首席运营官、首席财务官和首席技术官等职位。
将合同制造工作委托给印度公司,开发有当地企业参与的制造流程,并通过当地经销商出口。
中国公司要遵守法律,不得在印度逃税。
一位熟悉中企在印度情况的人士表示,印度政府的这种行为是“霸凌”,等于“变相收购中国企业”。另一位人士提到,印度政府之前对中企也有类似要求。
此前印度执法局向小米印度公司及3家银行发出通知,指控小米违反《外汇管理法》,小米账户内被冻结的48亿元可能被没收,引发国际媒体持续关注,小米13日回应:“小米在全球范围内坚持合法合规经营,并遵守经营地的相关法律法规。”
数据显示,小米集团2022年经调整净利润为人民币85亿元。这笔资金相当于小米去年净利润的57%。
香港行业分析机构Counterpoint数据显示,2023年第一季度,小米在印度智能手机市场的市场份额是16%,OPPO占12%,Realme占9%,vivo占17%。
参考文献链接
https://www.elecfans.com/d/2187145.html
https://blog.csdn.net/m0_47486219/article/details/119934172
https://baijiahao.baidu.com/s?id=1773720578944567247&wfr=spider&for=pc
https://www.sohu.com/a/685700118_120111001

