

TubeFormer DeepLab:视频掩码转换器
TubeFormer DeepLab:视频掩码转换器
TubeFormer-DeepLab: Video Mask Transformer
https://arxiv.org/pdf/2205.15361.pdf
摘要
展示了TubeFormer DeepLab,这是第一次尝试以统一的方式解决多个核心视频分割任务。不同的视频分割任务(例如,视频语义/实例/全景分割)通常被认为是不同的问题。在不同的社区中采用的最先进的模式出现了分歧,在每项任务中都采用了截然不同的方法。相比之下,得出了一个关键的观察结果,即视频分割任务通常可以公式化为将不同的预测标签分配给视频管的问题(其中,通过沿时间轴链接分割掩码来获得管),并且标签可以根据目标任务编码不同的值。这一观察结果促使开发TubeFormer DeepLab,这是一种简单有效的视频掩码转换器模型,广泛适用于多个视频分割任务。
TubeFormer DeepLab直接预测具有特定任务标签(纯语义类别,或同时具有语义类别和实例身份)的视频管道,这不仅显著简化了视频分割模型,而且在多个视频分割基准上提高了最先进的结果。
1.简介
视频分割任务可以公式化为将视频帧划分为具有不同预测标签的管道,其中管道包含沿时间轴链接的分割掩码。基于目标任务,预测的标签可以仅编码语义类别(例如,视频语义分割(VSS)),或者同时编码语义类别和实例身份(例如,仅针对前景“事物”的视频实例分割(VIS),或者针对前景“物物”和背景“事物”进行视频全景分割(VPS))(图1)。
然而,几个视频分割任务(即为管道分配预测标签)的潜在相似性长期以来一直被忽视,因此为视频语义和全景分割开发的模型从根本上产生了分歧。例如,一些VSS方法扭曲视频帧之间的特征,而现代VIS模型预测数百个帧级实例掩码,然后将它们传播到其他相邻帧。为了使事情变得更加复杂,现有技术的VPS方法采用单独的预测分支,分别针对语义分割、实例分割和对象跟踪。

图1. 视频分割任务可以被公式化为将视频帧(例如,剪辑)分割成具有不同标签的管(即,沿着时间链接的分割掩模)。TubeFormer DeepLab直接预测类标记的管道,为视频语义分割(VSS)、视频实例分割(VIS)和视频全景分割(VPS)提供了一个简单通用的解决方案。

图2. 提出的分层双路径转换器对VSS、VIS和VPS任务的三个连续输入帧(a)进行关注。当全局记忆学习单个管状区域的时空聚集注意力时(b),潜在记忆学习任务特定注意力(c)。
在这项工作中,没有加剧视频分割模型之间的分歧,而是后退一步,重新思考以下问题:能否利用视频分割任务之间的相似性,开发一个既有效又普遍适用的单一模型?为了回答这个问题,提出了TubeFormer DeepLab,它通过直接预测类标记的管道来构建用于视频分割的掩码转换器,其中标签根据目标任务编码不同的值。
具体来说,与其他Transformer架构类似,TubeFormer DeepLab扩展了掩码Transformer以生成一组对,每个对包含一个类预测和一个管道嵌入向量。管道嵌入矢量乘以卷积网络获得的视频像素嵌入特征,得到管道预测。
因此,TubeFormer DeepLab首次尝试在通用框架中解决多个核心视频分割任务,而无需将系统适应任何特定任务的设计。将图像级掩模变换器简单地应用于视频域并不能产生令人满意的结果,这主要是由于难以学习对具有大空间分辨率的视频片段(即多帧)特征的关注。为了缓解这个问题,引入了负责在视频帧(即单帧)特征和潜在存储器之间传递消息的潜在双路径变换器块,然后引入了学习视频片段特征和全局存储器之间的注意事项的全局双路径变换器块。这种分层的双路径转换器框架有助于注意力学习,并显著提高视频分割结果。
有趣的是,如图6所示,2,潜在记忆学习特定任务的注意力,而全局记忆学习单个管状区域的时空聚集注意力。此外,将全局记忆分为两组,特定于事物的全局记忆和特定于物质的全局记忆,目的是利用“事物”(可计数实例)和“物质”(无定形区域)的不同性质。
在推理过程中,实际上只能拟合视频片段(即短视频序列)进行视频分割。
因此,通过应用视频拼接[69]来合并剪辑分割结果,可以获得整个视频序列分割结果。为了增强视频片段之间的一致性,还提出了时间一致性损失,该损失鼓励模型在片段之间的重叠帧中学习一致的预测。
最后,通过扩展图像级特定于事物的复制粘贴,提出了一种简单有效的数据增强策略。
方法名为剪辑粘贴(剪辑级复制粘贴),将视频剪辑中的“东西”或“东西”(或两者)区域随机粘贴到目标视频剪辑。
为了证明提出的TubeFormer DeepLab的有效性,在多个核心视频分割数据集上进行了实验,包括KITTI-STEP(VPS)、VSPW(VSS)、YouTube VIS(VIS)、SemKITTI DVPS(深度感知VPS)和最近的VIPSeg(VPS。单一模型不仅显著简化了视频分割系统(例如,所提出的模型是端到端训练的,不需要任何特定任务的设计),而且在几个基准上提高了最先进的性能。特别是,TubeFormer DeepLab在KITTI-STEP测试集上以+13.1 STQ、TCB在VSPW测试集上的+21 mIoU、IFC在YouTube-VIS-2019 valset上的+2.9 track mAP、ViPDeepLab在SemKITTI DVPS测试集上为+3.6 DSTQ、Clip PanoFCN[63]在VIPSeg测试集上分别以+13.6 STQ和+3.9 VPQ的成绩优于已发表的作品Motion DeepLab。
实验结果验证了TubeFormer DeepLab在视频分割任务中的总体功效。
2.相关工作
视频语义分割(VSS)。将图像语义分割扩展到视频域需要预测具有不同语义类别的视频中的所有像素[8,64]。现有方法通过翘曲模块来利用时间信息。最近,Mao等人引入了一种大规模的VSS基准,称为VSPW(野外视频场景解析),以及一个坚实的基线,该基线通过扩展和到时间维度来有效地聚合视频上下文信息。
视频实例分割(VIS)。结合多对象跟踪和实例分割,视频实例分割旨在跟踪视频帧中的实例掩码。大多数最先进的VIS方法是基于检测的方法,允许重叠掩模预测(例如,基于掩模R-CNN、FCOS或DETR)。
工作类似于并行工作IFC,后者使用内存特征进行视频实例分割。然而,工作没有利用内存特性进行帧间通信,因此不需要额外的模块来执行这样的任务。相反,潜在存储器特征被部署在所提出的潜在双路径变换器块中,以便于全帧分割。最后,LatentGNN还探索了图形神经网络中的潜在特征。
视频全景分割(VPS)。最近,全景分割也被扩展到视频领域。视频全景分割试图统一视频语义和实例分割,需要时间一致的全景分割结果。与VIS不同,VPS不允许重叠的实例掩码,并要求标记每个像素,包括“thing”和“stuff”像素。由于VPS的复杂性,目前最先进的方法采用了复杂的管道。
具体而言,VPSNet包含多个任务专用头,包括Mask R-CNN、可变形卷积和MaskTrack,分别用于分割、语义分割和跟踪,而ViP DeepLab通过添加另一个下一帧实例分割分支来扩展Panoptic DeepLab(其分别采用专用于语义和实例分割的双ASPP和双解码器结构)。另一方面,方法通过使用掩模变换器来直接预测剪辑级掩模分割结果,显著简化了电流管道。最后,提出的模型也可以很容易地扩展到最近的深度感知视频全景分割(DVPS)任务,这进一步需要在VPS结果的基础上进行每像素深度估计。注意到,目前工作,视频K-Net,扩展K-Net,还开发了一个统一的视频全景分割框架。
3.方法
在本节中,将介绍几个视频分割任务的公式,然后介绍启发TubeFormer DeepLab的通用公式。然后,介绍了它的模型设计、训练和推理策略。
3.1视频分割公式
用

表示一个包含空间大小为

的T个视频帧的输入视频剪辑(如果存储器允许,T可以等于视频序列长度)。
视频剪辑用一组类标记的管进行注释(管被定义为沿时间轴链接的分段掩码):

,其中K个地面真值管

彼此不重叠,并且

表示管的

地面真值类标签。下面,简要介绍几个任务。
视频语义分割(VSS)通常根据视频像素分类来制定,其中过扭曲或聚合来自相邻帧的特征来丰富用于分类的像素特征。形式上,该模型预测了每个视频像素在预定义类别集C={1,…,D}上的概率分布:

,其中

是D维概率单纯形。然后通过取其argmax来获得最终分割输出

(即,

)。
视频实例分割(VIS)要求对视频中的对象实例进行分割和时间链接。对于视频中每个检测到的前景“事物”i,模型预测一个视频管(即,视频级实例掩码轨迹)

,其中仅为事物类定义了C上的概率分布

。根据目标数据集或评估度量,模型可能会生成重叠的视频管(例如,Youtbue VIS采用trackmAP,允许重叠的预测管,而KITTIMOTS采用HOTA,不允许)。
视频全景分割(VPS)要求“事物”和“事物”类的语义和实例分割结果在时间上一致。具体地说,该模型预测了一组不重叠的视频管

,其中

表示预测的管,并且

表示将类c分配给属于预定义类别集c的管

的概率,该预定义类别集同时包含“thing”和“stuff”类。
深度感知视频全景分割(DVPS)建立在VPS之上,额外需要一个模型来估计每个像素的深度值。与VPS输出类似,预测具有以下格式:

,其中,

表示估计的深度值,

是目标数据集中指定的最大深度值。因此,数据集包含地面实况深度。
一般任务制定。尽管任务之间存在表面上的差异,但发现了潜在的相似性,即视频分割任务通常可以被公式化为将不同的预测标签分配给视频管的问题,并且标签可能根据目标任务编码不同的值。例如,如果只预测语义类别,则成为视频语义分割。
类似地,如果同时需要语义类别和实例标识(即,每个类别标识对一个预测管道),则它变成视频实例分割(如果只考虑前景“事物”类)或视频全景分割。
这促使开发一种通用的视频分割模型,该模型直接预测类标记的管道

(以及可选的深度,如果需要的话)。
3.2.TubeFormer DeepLab架构
首先介绍了TubeFormer DeepLab Simple,这是视频级别基线,它将通过提出的潜在双路径转换器进行改进,从而产生最终的TubeFormer DeepLab。
TubeFormer DeepLab Simple。采用每剪辑流水线,它获取视频剪辑并输出剪辑级别的结果。TubeFormer DeepLab Simple在双路径架构中集成了CNN主干和全局内存功能,即全局双路径转换器。

图3. TubeFormer DeepLab架构概述。TubeFormer DeepLab扩展掩码转换器以生成一组对,每个对包含一个类预测

和一个管道嵌入向量w。管道嵌入向量乘以视频像素嵌入特征

通过卷积网络获得的,产生管预测

。引入了一种分层结构,该分层结构具有负责在帧级特征

和潜在存储器 之间传递消息的潜在双路径变换器块,然后是学习视频剪辑特征
之间传递消息的潜在双路径变换器块,然后是学习视频剪辑特征

和全局存储器

之间的注意力的全局双路径变换块。
给定输入视频剪辑v,CNN主干独立处理输入帧,并生成像素特征

,其中C是通道。像素自关注经由轴向关注块在帧级别(帧到帧,F2F)执行。然后,全局双路径变换器以每剪辑的方式进行操作,获得平坦的视频像素特征

和一维全局存储器

长度N(即预测集的大小)。通过全球双路径转换器,期待三个注意事项:
(1) 存储器到视频(M2V)注意力(其中视频特征将每个剪辑的信息编码到存储器特征),
(2) 记忆对记忆(M2M)自关注,以及
(3) 视频到存储器(V2M)注意力(其中视频像素特征通过接收在全局存储器中收集的管级信息来完善自身)。全局双路径变换器块可以在网络的任何层处堆叠多次。
在全局存储器的顶部,有两个输出头:一个分段头和一个类头,每个头由两个完全连接(FC)层组成。大小为N的全局存储器独立地传递到两个头,导致N个唯一的管嵌入

和N个相应的类预测

。注意,可能的类别

包括“无”类别∅,以防嵌入不对应于夹子中的任何区域。
视频管预测

在一次拍摄中被计算为解码的视频像素特征x之间的点积

并且管嵌入件w:

最终的视频片段分割

可以通过将N个二进制视频管与其对应的类预测相组合来获得。
具有潜在双路径转换器的TubeFormer DeepLab。当处理高分辨率输入或大量输入帧时,在视频片段(即多帧)特征中建模长程交互尤其困难。为了缓解这一问题并促进注意力学习,提出了一种分层结构,它允许两个级别的注意力机制:帧级别,然后是视频级别。注意,视频级别的注意力是由上述全局双路径转换器执行的。
具有潜在双路径转换器的TubeFormer DeepLab。当处理高分辨率输入或大量输入帧时,在视频片段(即多帧)特征中建模长程交互尤其困难。为了缓解这一问题并促进注意力学习,提出了一种分层结构,它允许两个级别的注意力机制:帧级别,然后是视频级别。注意,视频级别的注意力是由上述全局双路径转换器执行的。
在全局双路径转换器之前,引入了一种新的潜在双路径转换器块,负责在帧级特征和潜在存储器之间传递消息。它并行(分批)处理单个视频帧。潜在记忆受到具有潜在表示的图形模型的启发,允许对高复杂度的图亲和力进行低秩表示。
与IFC同时,发现潜在特征有助于注意力学习。然而,将它们部署在不同的框架中(例如,双路径转换器和无跨帧通信)。
具体地说,初始潜在记忆

为按帧复制并与每帧的特征配对

(平坦化)来构造输入。通过潜在双路径转换器,潜在存储器首先通过潜伏帧(L2F)注意力从帧特征中收集消息,并在它们之间进行潜伏到潜伏(L2L)的自注意力。然后,来自潜在存储器的每帧知识通过帧到潜在(F2L)注意力传播回帧特征。注意,潜在记忆特征是像全局记忆特征一样的可训练参数。然而,它们只部署在潜在空间(即中间层)中,不会在最终输出层中使用。
如图3所示,分层双路径转换器块由一系列一个轴向注意力块、潜在双路径转换器和全局双路径转换器组成。多个块的堆叠将交替潜在通信和全局通信,允许像素特征通过关注帧级和视频级存储器来完善自身,反之亦然。这反过来丰富了所有三种路径的特征:像素路径、延迟记忆路径和全局记忆路径,并能够学习给定视频片段的更全面的表示。
全局记忆与分裂的东西。为了进一步提高分割质量,建议将全局记忆分为两组:特定于事物的全局记忆和特定于学生的全局记忆。最初,中的全局记忆以统一的方式处理事物掩码和填充掩码。
然而,该设计忽略了它们之间的自然差异——一个图像中可能有同一事物类的多个实例,但每个事物类最多允许有一个掩码。因此,将全局内存中N个元素中的最后一个|C stuff|专门用于预测stuff类。排序是通过将特定于事物的全局内存分配给基本事实事物类来强制执行的,而不是将它们包括在二部分匹配中。
3.3训练策略
VPQ式损耗。为了统一训练TubeFormer DeepLab执行各种视频分割任务,采用了VPQ风格的损失,直接优化了一组类标记的管道。与图像级PQ风格损失类似,从视频全景质量(VPQ)中获得灵感,并在视频剪辑中近似优化VPQ。
首先,类标记的地面实况管道

和预测管道

之间的VPQ风格相似性度量可以定义为:

,其中,

表示预测正确管道类

的概率,

测量预测管道

和地面实况管道

之间的Dice系数。将预测管道与地面实况管道匹配,并通过最大化总VPQ样式相似性来优化预测。实施细节遵循PQstyle损失。此外,将辅助损失推广到视频片段,导致管道ID交叉熵损失、视频语义分割损失和视频实例判别损失。
共享语义和全景预测。最初,使用单独的语义解码器将辅助语义分割损失应用于主干特征。
相反,建议将损失直接应用于解码的视频像素特征

(cf.Eq.(1)),其学习用于分割的更好的特征。
时间一致性损失。VPQ风格的损失有利于学习输入片段内的时空一致性。为了在更长的视频上进一步实现剪辑到剪辑的一致性,建议在剪辑之间应用时间一致性损失。具体来说,最小化从两个片段的重叠帧预测的N个管状logits之间的距离。使用L1损失作为一致性度量。损失通过像素特征和N个全局内存特征的点积反向传播,影响像素和全局内存路径。
TubeFormer DeepLab由此实现了隐含的多剪辑一致性,这使得训练目标与整个视频推理管道对称。剪辑级复制粘贴。此外,还通过扩展图像级特定于事物的复制粘贴,提出了一种简单有效的数据增强策略。增强方法名为剪辑粘贴(剪辑级复制粘贴),将视频剪辑中的“东西”或“东西”(或两者)区域管随机粘贴到目标视频剪辑。使用概率为0.5的剪辑粘贴。
深度预测分支。为了使TubeFormerDeepLab能够执行单目深度估计,在CNN主干特征

的基础上添加了一个小型深度预测模块(即ASPP和DeepLabv3+轻量级解码器)。
注意,如果将深度预测添加到解码的视频像素特征x中,发现性能会略有下降

,表明在情况下,将深度估计与分割预测共享是不有益的。应用Sigmoid将深度预测约束在范围(0,1)内,然后将其乘以最大深度。使用比例不变对数误差和相对平方误差的组合作为训练损失。当与其他损失联合训练时,深度损失权重设置为100。
3.4.推理策略
剪辑级别推断。剪辑级别的分割是通过简单地执行两次argmax来推断的。具体而言,为每个管预测一个类标签:

。然后,每个像素分配一个管ID的

:

。在实践中,推理将类置信度低于0.7的管道ID设置为void。
对于视频实例分割,还探索了置换任务分配方案,该方案将每个对象查询的预测视为一个对象掩码方案。
视频级推理。在剪辑级别,TubeFormerDeepLab为T个视频帧输出时间一致的结果。为了获得视频级别的预测,对具有T−1个重叠帧的每T个连续帧执行剪辑级别的推断(即,在每个推断步骤仅沿时间轴移动一帧)。然后,通过基于它们的IOU在重叠帧中匹配管,将剪辑级别的结果缝合在一起。
4.实验结果
提出的TubeFormer DeepLab是一个通用的视频分割模型。为了证明其有效性,分别在KITTI-STEP、VIPSeg、VSPW、YouTube VIS、SemKITTI DVPS上进行了用于视频泛光分割(VPS)、视频语义分割(VSS)、视频实例分割(VIS)和深度感知视频泛光切分(DVPS)的实验。
4.1.数据集
KITTI-STEP是一个新的视频全景分割数据集,它额外注释了KITTI-MOTS的语义分割。它包含19个语义类(类似于Cityscapes),其中两个类(“行人”和“汽车”)带有跟踪ID。
对于评估,KITTI-STEP采用STQ(分割和跟踪质量),这是SQ(分割质量)和AQ(关联质量)的几何平均值。
VIPSeg也是一个新的视频全景分割数据集,适用于各种野外场景。它包含124个语义类(58个“事物”类和66个“东西”类)和3536个视频,每个视频的时间跨度为3到10秒。
VSPW是最近一个大规模的视频语义分割数据集,包含124个语义类。VSPW采用mIoU作为评估度量。
YouTube VIS包含两个版本用于视频实例分割;YouTube-VIS-2019包含40个语义类,YouTube-VIS-2021是一个改进版本,具有更高数量的实例和视频。
Youtube VIS采用track mAP进行评估。
SemKITTI DVPS是一个新的深度感知视频全景分割数据集,它是通过将SemanticKITTI的3D点云全景注释投影到2D图像平面来获得的。它包含19个类,
其中8个被注释有跟踪ID。为了进行评估,SemKITTI DVPS使用DSTQ(深度感知STQ),它除了STQ之外,还考虑了更深入的度量。
4.2.实施细节
TubeFormer DeepLab以MaX DeepLab为基础,提供官方代码库。超参数大多遵循设置。除非特别说明,否则使用他们的小模型MaX-DeepLab-S,它在最后两个阶段(即第4阶段和第5阶段)用轴向注意力块增强ResNet-50。还通过将第4阶段中的轴对称块堆叠n次来放大主干[16],并在实验中将其称为TubeFormer DeepLab Bn。对于VPS,在城市景观和COCO上预训练模型,而对于其他实验,只在COCO上进行预训练。
预训练程序与之前的工作类似。使用预训练的权重,TubeFormer DeepLab在目标数据集上使用16的批量大小进行训练,除YouTube VIS数据集的T=5外,所有数据集的T均为2。
使用全局存储器大小N=128(即输出大小)、潜在存储器大小L=16和C=128通道。在结果中使用“TF-DL”表示TubeFormer DeepLab。
4.3.主要结果
[VPS]在具有挑战性的视频全景分割数据集KITTISTEP上对TubeFormer DeepLab进行了评估。模型以65.25 STQ(70.27 SQ和60.59 AQ)实现了最先进的性能。在单一统一方法中,模型排名第一,显著优于已发表的基线MotionDeepLab[79]+13.1 STQ。模型在没有利用额外的3D对象公式、深度信息或伪标签,甚至没有使用单独和集成方法进行跟踪和分割的情况下,与赢得挑战的方法表现相当。尽管如此,模型提供了最佳的分割质量(70.27平方米),展示了TubeFormerDeepLab的分割能力。

表2. [VPS]VIPSeg val和测试集结果,使用最新的测试服务器
https://codalab.lisn.upsaclay.fr/competitions/9743

表3. [VSS]VSPW值集结果。比较包括已发表和未发表的方法。

表4. [VSS]VSPW测试集结果。排名包括已发表和未发表的方法。一些方法使用模型集成、多尺度推理或师生伪标记策略来提高测试集的性能。在最下面的一行中,还使用位于的最新测试服务器包括新的测试集结果
https://codalab.lisn.upsaclay.fr/ competitions/7869

表5. [VIS]YouTube-VIS-2019 val集结果。

表6. [VIS]YouTube-VIS-2021 val集结果。T是从Youtube-VIS-2019环境中感染的。

表7. [DVPS]SemKITTI DVPS测试集结果。排名包括已发表和未发表的方法。
在最近的视频全景分割数据集VIPSeg上进一步评估了TubeFormer DeepLab。
在测试集上,方法比Clip PanoFCN(建立在Panopitc FCN之上)的STQ和VPQ分别高13.6和3.9。
[VSS]在视频语义分割数据集VSPW上评估了TubeFormer DeepLab。在表3中显示了val集上的单模型单尺度结果。在表中,TubeFormer DeepLab的性能优于所有基于最先进主干和解码器的竞争方法。表4显示了测试集的结果。单模型TubeFormer DeepLab在不使用模型集成、多尺度推理和伪标签的情况下,与ICCV 2021挑战赛的获胜者取得了有竞争力的结果(在17个中排名第4)。最后,在测试集上获得了比已发表的工作TCB更好的+21mIoU。
如表4底部所示,还包括使用最新测试服务器的新测试集结果。
[VIS]证明了TubeFormer DeepLab足够通用,可以统一解决实例级视频分割问题。通过将背景区域视为单个“物质”类,可以无缝地应用相同的模型、损失和训练过程。在测试中,探索了管ID分配的每像素和每掩码argmax。

图4. KITTI-STEP序列可视化。从左到右:输入帧(T=3)、全局记忆注意力、潜在记忆注意力和视频全景分割结果。全局记忆注意力被选择用于预测的感兴趣的管状区域:人行道上的一名行人和两辆汽车(左、右),而潜在记忆注意力则被选择用于4(L=16)个潜在记忆。
表5和表6显示了与YouTube VIS 2019和2021数据集上最新方法的比较。
请注意,TubeFormer DeepLab为每个对象预测一个唯一的掩码,而其他方法通常会生成多个重叠的掩码,这受到AP度量的青睐。
在端到端方法中,TubeFormer-DeepLab-B4比VisTR高出+7.4,比IFC高出+2.9 AP。
T=5的模型在使用小T值的方法中得分最高。此外,在AR1中的收益是显著的,这表明TubeFormerDeepLab在非重叠分割场景中的优势。
模型与Seq-Mask RCNN的性能相当。指出,TubeFormer DeepLab是一种端到端的近在线方法,而Seq-Mask R-CNN依赖于类似STM[66]的结构在整个序列中传播掩码建议,因此是离线的(T=36)。
[DVPS]在SemKITTI DVPS数据集上评估了TubeFormer DeepLab的深度感知视频全景分割。表7显示了测试集的结果。
在用于KITTI-STEP的TubeFormer DeepLab中添加深度预测分支,其性能比ViP DeepLab高出+3.4 DSTQ,并达到了最先进的67.0 DSTQ。
训练策略。此外,表8b显示,所提出的时间一致性损失有助于TubeFormerDeepLab学习剪辑到剪辑的一致性,并改善了对比训练剪辑长度(T)更长的视频的推断,
如+0.5STQ增益所示。所提出的剪辑级复制粘贴(剪辑粘贴)为管级分割增加了更多的训练样本,并进一步提高了+0.9STQ。缩放比例。在表8c中研究了TubeFormer DeepLab的缩放。在ImageNet-22k数据集上进行预训练可获得+1.6 STQ,在训练中添加COCO可进一步获得+1.9 STQ。还探索通过将第4阶段的轴向注意力块堆叠n次来扩展主干(TubeFormer DeepLab Bn)。每n的增加将引入+13M个参数。注意到,将堆栈从n=1增加到n=3将STQ从73.19提高到74.25。进一步扩展到n=4开始饱和,可能受到KITTI-STEP数据集规模的限制。
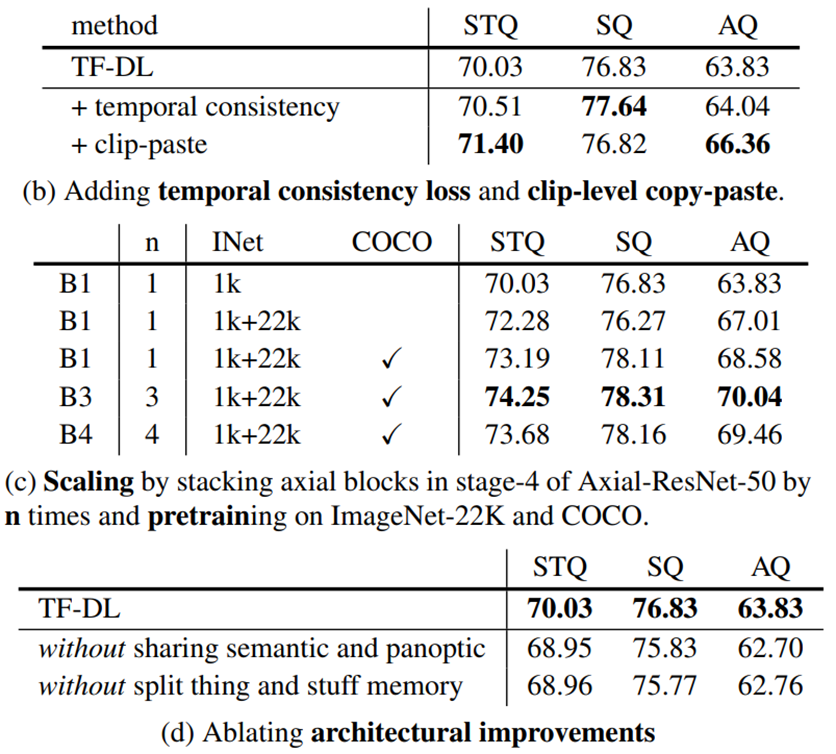
表8. KITTI-STEP瓣膜组的消融研究。
观察到,TubeFormer DeepLab可以在更大规模的数据集上进一步扩展到n=4,其中TubeFormer-DeepLab-B4在VSPW和YouTube VIS数据集上表现更好。架构改进。点燃新架构设计:
(1) 共享语义和全景预测,以及
(2) 将全局内存拆分为单独的thing和stuff类。
如表8d所示,通过恢复TubeFormer DeepLab的(1)或(2)的变化,观察到性能下降了-1.1STQ。
4.5.可视化
在图4中,可视化了所提出的分层双路径转换器如何将注意力集中在三个连续帧的输入剪辑上。首先通过从TubeFormer DeepLab视频全景预测中选择四个感兴趣的输出区域来可视化全局记忆注意力。探讨了四个特定于管的全局记忆嵌入和所有像素之间的注意力权重。看到,对于单个事物或物质管道,全局记忆注意力在空间和时间上是很好地分离的。
此外,选择了四个潜在记忆指数,并在图4c中可视化它们的注意力图。发现,一些潜在的记忆学会了在空间上专注于某些区域(场景的左侧与右侧)或关注语义相似的区域(汽车或背景),以便于每帧注意力。由于全局和潜在的双路径转换器的分层关注,TubeFormer DeepLab可以成为一个成功的管道转换器。
最后,为每个视频分割任务提供了更多的可视化效果,并在https://youtu.be/twoJyHpkTbQ.
5.更多实验结果
在本节中,提供了更多的实验结果,并将方法与已发表的作品进行了详细比较。
不包括未发表和并发的ICCV 2021挑战条目,这些条目通常采用复杂的管道,例如模型集合、不同子任务的单独模型(例如跟踪和分割)、多尺度推理或伪标签。在表格中,明确列出了采用的主干和解码器,以便进行详细比较。注意到,用于不同视频分割任务的大多数最先进的方法都有根本的分歧,而提出的TubeFormer DeepLab是一个用于一般视频分割任务简单统一的系统。
[VPS]表9总结了对KITTI-STEP值集的结果。如表所示,TubeFormer-DeepLab-B1采用ResNet-50和轴向注意力,分别显著优于Motion DeepLab(w/ResNet-50、双ASPP和双解码器)和VPSNet(w/ResNet-50、FPN和Mask R-CNN多头预测)+12和+14 STQ。还报告了VPQ度量(另一种流行的视频全景分割度量)的结果。同样,模型比Motion DeepLab和VPSNet的VPQ性能好+11.1和+8.1。
[VSS]在表10中,报告了VSPW值集的结果。如表所示,TubeFormer-DeepLab-B1采用ResNet-50和轴向注意力,显著优于TCB(带时空OCRNet和一种新的记忆方案)+20.2mIoU。
TubeFormerDeepLab-B1在VC8和VC16(提出的另一种视频语义分割指标)方面也显示出更好的结果。
[VIS]表11总结了在Youtube-VIS2019值集上的结果,以及几种最先进的方法。
在预测非重叠分割的方法中,TubeFormer-DeepLab-B1(每像素)采用ResNet-50和轴向注意力,比STEmSeg(使用ResNet-50、FPN及其新颖的基于3D卷积的TSE解码器和多头预测)高出+5.8 AP。TubeFormer-DeepLab-B1(每像素)也比具有ResNet-101主干的STEm-Seg好+1.8 AP。如果也增加主干容量,TubeFormer-DeepLab-B4(每像素)的性能比STEm-Seg w/ResNet-101好10.8 AP。
TubeFormer-DeepLab-B1(每像素)的性能比其他最先进的方法差,包括MaskProp、Seq-Mask R-CNN和并行工作IFC,因为每像素推理方案生成不重叠的预测(即,最终输出中每个像素只有一个预测),这不受跟踪AP度量的影响。为了弥补这一差距,采用了掩码合并方案(表示为每个掩码),其中每个对象查询都生成一个掩码建议。在TubeFormer DeepLab框架中,每掩模方案比每像素方案显著提高了2个AP以上。
大模型TubeFormer-DeepLab-B4具有每个掩码方案,其性能优于MaskProp、VisTR和IFC,并且与最佳模型Seq-mask R-CNN的性能相当,后者依赖于类STM结构在整个序列中传播掩码建议。
值得注意的是,模型产生了最好的AR1和AR10(分别比第二好的Seq-Mask RCNN方法好+3.9和+3.0 AR),证明了预测的高分割质量。此外,TubeFormer DeepLab使用较小的剪辑值(T=5),而其他现有技术的基于提案的方法使用较大的剪辑(T=13或36)。
6.可视化
在图5、6和7中,可视化了所提出的分层双路径转换器如何对视频全景/语义/实例分割任务(分别为VPS、VSS和VIS)进行关注。使用三个连续帧的输入片段进行可视化。对于每个样本,从TubeFormerDeepLab预测中选择几个感兴趣的输出管。在b列中,探测所选特定于管的全局内存嵌入和所有像素之间的注意力权重。
在所有三个任务中,观察到全局记忆注意力在空间和时间上对单个管状区域进行聚类,同时尊重任务之间的不同要求。也就是说,一个全局内存对VSS中的每个语义类别负责,但对VIS中的每个实例标识负责,而这两种情况都出现在VPS任务中。

表9. [VPS]KITTI-STEP值集结果。†:轴向注意力块[76]用于最后两个阶段。

表10. [VSS]VSPW值集结果。†:轴向注意力块用于最后两个阶段。

表11. [VIS]YouTube-VIS-2019 val集结果。†:轴向注意力块用于最后两个阶段。ResNet-50-n4将第4阶段中的层数缩放4倍(即,总共24个块),得到具有104层的主干。
在c列中,选择了四个潜在记忆指数,并可视化它们的注意力图。通常,对于所有任务,一些潜在记忆都会学习在空间上专门处理某些区域(场景的左侧和右侧)或关注管道边界。有趣的是,发现一些潜在记忆集中在相对较远的区域(图5c右下角),这通常需要更多的关注。有时,它对移动物体的零件或小物体更感兴趣(例如,图6中的移动臂和路障锥体,分别为左下角和右下角)。
潜在记忆的任务特定行为也可以在图6c和图7c之间进行比较。VSS中的潜在内存不会区分同一语义类的实例。相比之下,VIS中的注意力是特定于实例的。如图7c左上角所示,突出显示了两头大象被遮挡的鼻子,这有望有助于实例识别。此外,不同的潜在记忆关注单个或不同倍数的实例。
此外,图8在SemKITTI DVPS数据集上可视化了深度感知视频全景分割结果,其中TubeFormer DeepLab能够生成时间一致的全景分割和单目深度估计结果。
7.讨论
最近文献中有一些关于开发通用或统一的语义分割模型(例如,全景分割)的炒作。想强调的是,全景分割的目标是统一语义和实例分割,因此,一个设计良好的全景分割模型自然也应该在语义分割和实例分割上表现出公平的性能。例如,Panoptic DeepLab及其Naive Student版本已经证明,现代全景分割模型可以同时在语义、实例和全景分割方面实现最先进的性能。工作遵循相同的方向,致力于视频分割任务。

图5. [VPS]KITTI-STEP序列可视化。从左到右:输入帧(T=3)、全局记忆注意力、潜在记忆注意力和视频全景分割结果。全局记忆注意力被选择用于感兴趣的预测管区域,并且潜在记忆注意力被选用于4个(L=16中的)潜在记忆。
8.限制
目前,所提出的TubeFormer DeepLab执行剪辑级视频分割,剪辑值T=2(对于VPS和VSS)或T=5(对于VIS)。因此,模型执行短期跟踪,并且可能会错过跟踪长度大于所用剪辑值的对象。这一限制也反映在主论文表1中报告的AQ(关联质量)中(即KITTI-STEP测试集结果)。留下了如何有效地将长期跟踪纳入TubeFormer DeepLab进行功能工作的问题。
无论如何,提出的TubeFormer DeepLab首次尝试从统一的方法解决多个视频分割任务。希望简单有效的模型能成为未来研究的坚实基础。
9.结论
介绍了TubeFormer DeepLab,这是一种基于掩码转换器的视频分割新架构。视频分割任务,特别是视频语义/实例/全景分割,已经由根本不同的模型来处理。提出了一种新的范式,将视频分割任务表述为用不同的预测标签分割视频管道的问题。TubeFormer DeepLab直接预测类标记管道,为多个视频分割任务提供通用解决方案。希望方法将启发未来在视频分割任务统一方面的研究。
参考文献链接
TubeFormer-DeepLab: Video Mask Transformer
https://arxiv.org/pdf/2205.15361.pdf


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2023-01-24 自动驾驶OS战略分析
2022-01-24 电子产品解决方案
2021-01-24 使用Runtime执行推理(C++)
2021-01-24 HiLink & LiteOS & IoT芯片 让IoT开发简单高效
2021-01-24 HiCar基本功能介绍
2021-01-24 HiCar技术概述
2021-01-24 MindSpore部署图像分割示例程序