


3DS-SLAM一种面向3D对象检测的语义SLAM动态室内环境
3DS-SLAM一种面向3D对象检测的语义SLAM动态室内环境
环境中可变因素的存在可能会导致相机定位精度的下降,因为这违反了同步定位和映射(SLAM)算法中静态环境的基本假设。
最近针对动态环境的语义SLAM系统要么仅依赖于2D语义信息,要么仅依赖几何信息,或者以松散集成的方式组合它们的结果。介绍了3DSSLAM,即3D语义SLAM,它是为具有视觉3D对象检测的动态场景量身定制的。3DS-SLAM是一种严格耦合的算法,可以顺序地解决语义和几何约束。设计了一种3D局部感知混合变换器,用于基于点云的对象检测,以识别动态对象。随后,提出了一种基于HDBSCAN聚类的动态特征滤波器来提取具有显著绝对深度差异的对象。
与ORB-SLAM2相比,3DS-SLAM在TUM RGB-D数据集的动态序列中表现出98.01%的平均改进。此外,它的性能超过了为动态环境设计的其他四个领先的SLAM系统。代码和预训练模型可在https://github.com/saikrishna-ghanta/3ds-slam
I.简介
同时定位和测绘(SLAM)创建其未知环境的地图,同时使用安装在系统上的传感器的数据确定其自身的位置。尽管不同的传感器可以在SLAM系统中形成地图,但视觉SLAM由于能够产生对许多应用有用的细粒度地图信息而变得越来越受欢迎,例如机器人、运输、搜救、建筑和许多其他应用。视觉SLAM主要依赖于各种类型的相机,包括单眼、立体和RGBD相机,因为与其他传感器(如激光)相比,它们能够理解场景。
视觉SLAM经过三十多年的不断发展,逐渐成熟,并在静态场景中证明了其功效。尽管传统的视觉SLAM系统在受控环境中具有优势,但如ORB-SLAM2、LSD-SLAM和RGBD-SLAM-V2,在面临充满挑战的环境(如动态或恶劣条件)时可能会表现出脆弱性。
在视觉SLAM中,对象识别是理解周围场景的固有组件。
近年来,3D对象检测已经引起了人们的极大兴趣,因为它的目标是在3D点空间内同时定位和对象识别。三维物体检测作为理解室内三维空间语义知识的重要基础,在视觉/语义SLAM中具有重要的研究意义。因此,将三维目标检测算法与Visual SLAM无缝集成是一个具有深远意义的关键研究方向。

图1. 3DS-SLAM-概述:用于室内动态环境的3D视觉SLAM系统。现有的ORB-SLAM2由于移动人员的动态特征而失败,使得估计的轨迹无法使用。3DS-SLAM采用HTx架构进行3D对象检测,并利用HDBSCAN提取动态特征(红点),提高整体稳定性。
然而,在存在动态对象的情况下,传统的视觉SLAM系统在准确性和鲁棒性方面面临挑战,这主要是由于图像中的动态点引起的数据关联问题。研究人员已经寻求缓解这些挑战的解决方案,利用深度学习技术在动态环境中解决视觉SLAM问题。这些方法利用技术,例如2D对象检测、语义分割、解决几何约束(例如RANSAC、DBSCAN)和核/投影约束。传统的方法结合了几何和语义信息,采用了两种投票策略——(i)如果语义和几何模块都将特征识别为动态的,则将其归类为动态的;以及(ii)如果至少一个模块将其识别为动态的,则将其视为动态的。具有这些投票策略的视觉SLAM系统通常被认为是松散耦合的SLAM系统。
在基于深度学习的方法中,语义分割在保持实时性能的同时,在像素级提供了精确的对象掩码。然而,它受到高计算成本和捕捉运动物体的精度潜力的限制。相比之下,2D对象检测虽然使用边界框更快,但可能会遇到背景噪声和复杂情况。
对于前景-背景分离,RANSAC算法在静态或轻度动态环境中工作良好,但当高度动态的物体在相机的视场中占主导地位时,它会遇到困难。
为了应对这些挑战,推出了3DS-SLAM,这是第一个针对动态室内设置进行优化的高性能3D视觉SLAM系统。
在ORB-SLAM2的基础上,3DS-SLAM提出了用于语义信息(3D对象提取)的混合变换器架构(HTx),并使用HDBSCAN(基于层次密度的空间聚类)来解决几何约束,HTx结果如图1所示。在SLAM的2D对象检测之上使用3D对象检测提供了改进的空间理解、更好的遮挡处理、准确的尺度估计和增强的运动跟踪能力。通过在公开的数据集上进行全面的实验,证明了方法优于当前最先进的方法(SOTA)动态视觉SLAM方法,证明了在高动态场景中具有卓越的定位精度。
贡献摘要如下:
•一种轻量级的3D HTx对象检测架构,集成了视觉SLAM系统,为动态环境提供3D语义空间信息。
•集成HTx和HDBSCAN的新型端到端管道,可有效解决语义和几何约束,优化整体性能。
•实验验证表明,3DS-SLAM在动态场景中提高了姿态的准确性和稳定性,优于现有方法。
二、背景/相关工作
A.具有语义和几何约束的可视化SLAM
在工作的背景下,将讨论基于ORB-SLAM2的现有技术框架,以解决语义和几何约束。CFP-SLAM结合了2D对象检测,并结合了基于语义和粗略到精细静态概率的核线几何信息来估计相机姿态。然而,CFP-SLAM在RGB序列中失败,相机旋转发生巨大变化,这是由于核极约束方法中的缺陷。
另一种方法,即SaD-SLAM,在动态环境中通过基于Mask-RCNN的特征点融合,扩展了基于语义深度的可移动对象跟踪和增强的相机姿态估计的ORBSLAM2。
SOF-SLAM,一个为动态环境量身定制的语义SLAM系统。
SOF-SLAM使用语义光流和SegNet的逐像素分割来确保利用静态特征在动态环境中精确估计相机姿态。在DS-SLAM中,通过SegNet获取语义信息,结合稀疏光流和运动一致性分析来区分个体的动态和静态特征。
另一方面,DynaSLAM集成了遮罩R-CNN和多视图几何技术来处理动态元素。
在YOLO-SLAM中,Darknet19-YOLOv3和一种新颖的基于深度的几何约束方法相结合,有效地减少了动态特征的影响。
B.三维物体检测和变压器
在3D对象检测中,在架构利用方面区分了三个特征类别:
(i) 点特征,(ii)体素特征,和(iii)点体素特征。变换器架构的最新进展促使人们致力于点和体素对象检测。3-DETR,一种结合了非参数查询和傅立叶位置嵌入的典型转换器架构,在ScanNetV2和SUNRGB-D数据集上,与VoteNet等高度优化的方法相比,性能提高了9.5%。PVT-SSD[26]提出了一种同时具有点和体素特征表示的混合方法。
该架构利用基于体素的稀疏卷积来执行特征提取,并结合用于3D对象检测的点体素变换器(PVT)。在HVNet中,作者提出使用多尺度体素特征编码器来提取特征,然后使用动态特征投影和卷积骨干网络进行预测。早期的研究工作主要是在将数据输入到架构中时结合点和体素特征。
然而,在现有的研究工作中,为了增强3D对象检测的弹性,点云和算法复杂性以及实时约束等某些因素在很大程度上没有得到解决。HTx引入了一种混合框架,该框架利用了利用来自原始点的特征的类感知3D对象检测和利用体素特征的部分感知3D对象探测。因此,这项工作通过开发能够理解3D场景的基于HTx的视觉SLAM来增强机器人的感知能力。
III、 3DS-SLAM:方法
A.系统架构
所提出的3DS-SLAM扩展了最初为静态环境设计的ORB-SLAM2的功能,通过合并两个额外的线程——3D对象检测和动态特征过滤器,如图2所示。这些线程有效地过滤动态点,确保精确的相机轨迹估计。对于语义信息,3D对象检测线程采用轻量级HTx架构,而动态特征过滤线程则利用基于几何深度的HDBSCAN聚类来区分动态点。该系统利用HTx架构从RGB和深度图像中提取的点云中提取语义信息。
B.混合变压器:轻型3D物体探测器
在视觉SLAM中,传感器捕获的帧往往表现出不完整的前景对象,这可能导致对象检测受损。这就需要开发部分对象定位方法,以了解这些不完整的对象局部表示。所提出的HTx架构将输入作为3D点云来预测对象位置,包括对象的深度、方向和位置。提出的HTx架构是基于用于部件感知对象定位和类感知对象定位的构建块设计的。HTx架构在数据级别上与现有的transformer架构的不同之处在于结合了点云预处理,并利用点和体素特征进行局部感知对象定位。
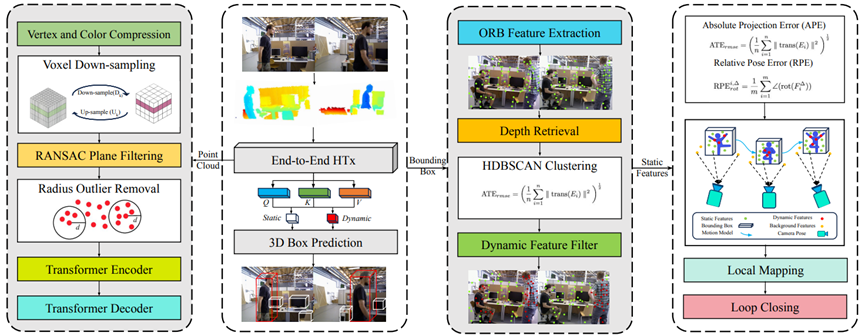
图2:3DS-SLAM-框架:主要分为三个部分:
1)三维物体检测线程。
2)动态特征去除线程。
3)从ORB-SLAM2适配的跟踪、局部映射、局部关闭线程。
点云由一组无序的N个点组成,每个点都无缝地连接到其三维XYZ坐标上。
由于与图像相比,点云的计算复杂度增加,本研究努力进行广泛的预处理,以有效压缩点云。此外,点云固有的排列不变性,加上颜色信息和点法线的包含,也导致了3D对象检测的大量计算开销。从之前的工作中获得灵感,HTx架构通过放弃使用颜色和点法线信息进行对象检测,优先考虑实时效率。此外,还进行了重要的数据预处理技术,如体素下采样、平面滤波、基于半径的外轮廓去除。
1) 体素下采样:设 是在3D空间中具有N个点的点云。体素下采样过程包括定义体素大小,以及使用
是在3D空间中具有N个点的点云。体素下采样过程包括定义体素大小,以及使用

基底函数,将每个点与其对应的体素(i,j,k)相关联:
 。
。
然后,下采样的点云由每个体素的质心
 表示,这是通过计算该体素内所有点的坐标平均值来确定的,得到的点云
表示,这是通过计算该体素内所有点的坐标平均值来确定的,得到的点云
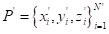
。
2) RANSAC地面滤波:目标是找到一个由方程ax+by+cz+d=0表示的平面,该平面最适合点的子集。RANSAC迭代地随机选择最小的点集来估计平面参数,在距离阈值内形成内点的一致集,并选择具有最大一致集的平面作为最终的最佳拟合地平面。
3) 基于半径的异常值去除:从预处理的点云P′′和用户定义的半径R中,该迭代算法将该半径内邻居较少的点识别为异常值。对于每个点
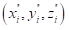 ,它计算以
,它计算以
 为中心的半径R内的点ni的数量,如果ni低于阈值,则该点被视为异常值,并从点云中排除。
为中心的半径R内的点ni的数量,如果ni低于阈值,则该点被视为异常值,并从点云中排除。
4) Transformer架构:3DS-SLAM采用了一个3D对象检测框架,该框架建立在Facebook AI研究开创性的3DETR架构之上。
对该架构进行了重大修改,以增强其与视觉SLAM系统的兼容性,特别是通过增强引入的部分感知对象检测层。这解决了现有视觉SLAM系统中的一个关键缺口,由于部分可见的物体、相机旋转和其他环境因素,该系统无法解决关键机器人应用中的物体检测问题。由于为部分感知和类感知对象定位设计损失函数的复杂性,开发了两个独立的损失函数。
预测MLP(多层感知器)生成3D边界框

,该3D边界框用实际框b进行进一步评估。每个预测框
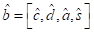
包括(1)几何元素
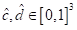 ,其定义了盒子的中心和维度,表示类和方向残差的一个
,其定义了盒子的中心和维度,表示类和方向残差的一个
 ,以及(2)包含在K个语义对象类和“背景”类上的概率分布的语义项
,以及(2)包含在K个语义对象类和“背景”类上的概率分布的语义项
 。雇佣了ℓ1中心维度和长方体维度的回归损失,以及角残差的Huber回归损失,以及角和语义分类的交叉熵损失,如下所示:
。雇佣了ℓ1中心维度和长方体维度的回归损失,以及角残差的Huber回归损失,以及角和语义分类的交叉熵损失,如下所示:

5) 部件感知对象定位:通过将每个点表示为其在地面实况对象的3D边界框内的相对位置来定义每个点的对象内部件位置。使用三个连续值来表示该目标对象内局部位置,表示为 ,
, ,
,
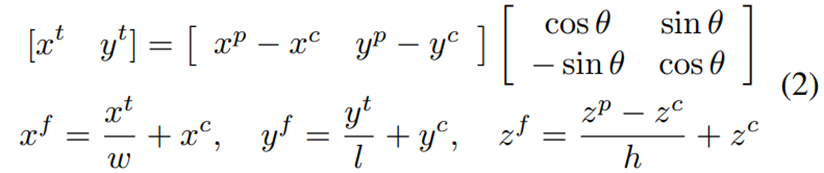
其中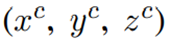 表示地面实况边界框的中心,表示其在三维空间中的位置。盒子的大小和方向由(h,w,l,θ)表示,对应于它的高度、宽度和顶视图角度。
表示地面实况边界框的中心,表示其在三维空间中的位置。盒子的大小和方向由(h,w,l,θ)表示,对应于它的高度、宽度和顶视图角度。 被视为每个点迭代的临时变量。估计每个点的对象内局部位置,表示为
被视为每个点迭代的临时变量。估计每个点的对象内局部位置,表示为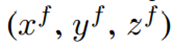
对每个点使用二进制交叉熵损失,定义如下:

3)其中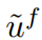 表示预测的对象内部分位置,
表示预测的对象内部分位置,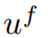 表示对应的实际对象内部分的位置,
表示对应的实际对象内部分的位置, 。
。
C.HDBSCAN聚类和动态特征滤波器
对象检测方法可能无法准确地提供对象遮罩,尤其是在处理填充相机视场的大部分的非刚体时。
这通常会导致许多背景点云包含在对象的边界框中。为了解决这个问题,将重点放在人类主体上,作为非刚性前景体的例子。人类通常表现出与背景的深度连续性和显著的深度差异。
因此,当一个人的边界框主导相机的视图时,优化了本地HDBSCAN密度聚类算法,以区分边界框内前景中的点和背景中的点。通过组合具有浅深度的点组,可以识别前景(动态关键点)。这种自适应方法增强了HDBSCAN算法的鲁棒性,并有效地处理了人们被其他物体部分遮挡的情况。此外,与DBSCAN相比,HDBSCAN对参数选择更具鲁棒性,并有效地处理不同密度的多维数据。
HDBSCAN算法用于处理3D空间关键点K和深度图数据D,创建表示为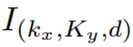 的点空间。在HDBSCAN中,点密度由核心距离k(i)定义,该距离表示到点的第k个最近邻居的欧几里得距离。为了区分低密度点(高核心距离),使用如等式4所示的称为相互可达性距离
的点空间。在HDBSCAN中,点密度由核心距离k(i)定义,该距离表示到点的第k个最近邻居的欧几里得距离。为了区分低密度点(高核心距离),使用如等式4所示的称为相互可达性距离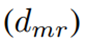 的距离度量。
的距离度量。
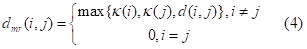
4) 基于使用λ值定义的聚类稳定性和持久性来提取聚类。所提出的HDBSCAN修改能够有效地提取前景和背景的两个聚类,分别用关键点和深度图表示动态和静态特征。
IV、 实验分析与结果
进行了实验,以评估从TUM RGB-D数据集中提取的8个动态序列中的3DS-SLAM,包括4个 坐姿和4个
坐姿和4个 步行序列,相机运动包括静态、xyz、半球和滚转-俯仰-偏航(rpy)。
步行序列,相机运动包括静态、xyz、半球和滚转-俯仰-偏航(rpy)。
将3DS-SLAM与简单的语义ORB-SLAM2系统进行了比较,证明了方法的优越性。随后,针对动态环境中的SOTA SLAM系统评估了方法,提供了有价值的见解。还展示了系统在受控实验室环境中的能力。
这些实验使用了一台带有Ubuntu 20.04、i9 CPU、16GB RAM和RTX 3070 Ti GPU的计算机。此外,3DS-SLAM将绝对轨迹误差(ATE)和相对姿态误差(RPE)作为评估性能的指标。
ATE量化全局轨迹精度,而RPE测量固定时间间隔内的局部一致性。首先,分析了三维物体检测和几何深度滤波器的性能,然后将3DS-SLAM的稳定性和鲁棒性与现有工作进行了比较。使用绝对轨迹误差(ATE)和相对姿态误差(RPE)的均方根误差(RMSE)和标准差(S.D.)进行了相对比较,以评估3DS-SLAM的性能。
A.3D对象检测和HDBSCAN的性能
3DS-SLAM是针对关键机器人应用而开发的,采用基于点云的混合3D对象检测方法。HTx架构是在SUNRGB-D数据集上训练的,该数据集包含室内环境中的700个标记对象,并考虑到未来在标准工业机器人应用中的影响,如伸手、抓握和拾取和放置。SUNRGB-D中的对象类别数量几乎是YOLO使用的coco数据集[33]中的类别数量的九倍。
HTx架构实现了57.85的mAP25值,与性能最好的3D对象检测模型相当。此外,它与动态特征过滤器的紧密集成增强了SLAM的整体视觉性能。图3(a)-(e)直观地描述了类感知HTx在各种场景中的结果,并将其性能与部分感知对象定位进行了比较(第二行)。
部分感知对象定位显著增强了3DS-SLAM的性能,在TUM RGB-D序列中尤为明显。

图3:在以下情况下,使用和不使用部分感知对象定位的3D对象检测结果:(a)对象在相机视场内的有限可见性(b)动态对象的快速运动。(c) 摄影机旋转产生的奇异视点。(d) 模糊的图像。(e) 连续帧局部对象检测。
3D对象检测结果在所有帧中保持一致的准确性,与现有的缺乏多个帧的漏检测补偿的2D对象检测架构相比,产生了显著更平滑的3DS-SLAM体验。图4表示3DS-SLAM的综合结果,显示了时间连续检测。三维边界框和动态点用红色表示,而静态点用绿色表示。
B.SLAM与SOTA框架的性能比较
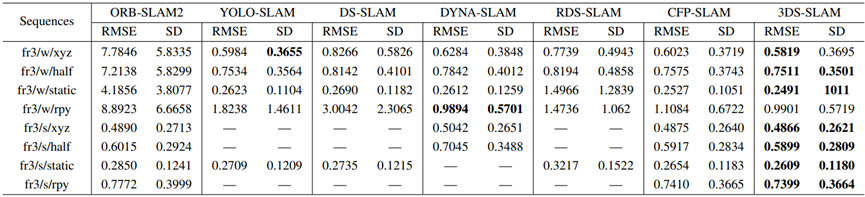
对方法与几种最先进的动态SLAM方法进行了比较分析,包括ORB-SLAM2、YOLO-SLAM、DS-SLAM[12]、DYNA-SLAM、RDS-SLAM和CFP-SLAM,与ORB-SLAM相比,这些方法也表现出了优越的性能。定量评估结果可在表I、表II和表III中找到,其显示了所有八个TUM RGB-D序列的ATE、翻译RPE和旋转RPE。

图4:3DS-SLAM在两组连续图像中的总体结果,中间留下4帧。

图5:3DS-SLAM和ORB-SLAM2高低动态序列的轨迹比较
表I:绝对轨迹误差(ATE)与现有体系结构的比较
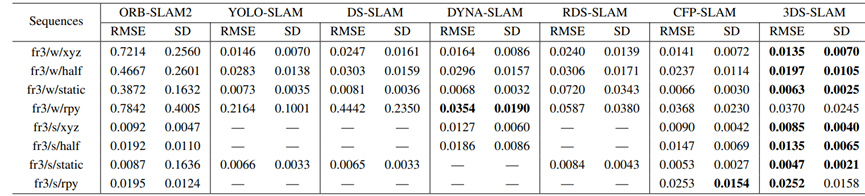
--表示相应的数据,在相应的文献中没有提及。粗体文本表示优于所有其他方案的方案。
在rpy序列中,大量的相机角度变化和与动态对象的大距离可能会导致点云中对象的遗漏,这主要是由于深度相机的范围有限。
因此,特征匹配中的这种不足略微影响了方法的性能。图5表示3DS-SLAM和ORB-SLAM2的3D轨迹的2D投影。在高动态序列和低动态序列中,提出的3DS-SLAM轨迹都与地面实况密切匹配,而ORB-SLAM2估计的轨迹与地面实况存在显著偏差。总体而言,在来自TUM RGB-D数据集的动态序列中,3DS-SLAM比ORB-SLAM2表现出98.01%的显著平均改进。
表二:平移相对位姿误差与现有结构的比较
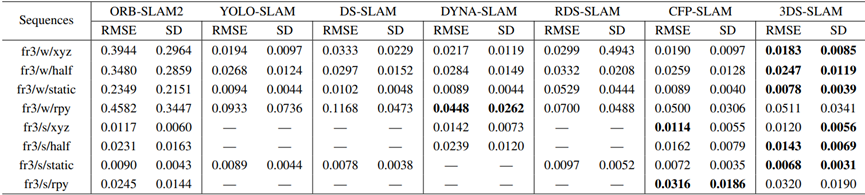
表III:旋转相对姿态误差(RPE)与现有结构的比较
解决语义和几何约束所需的时间
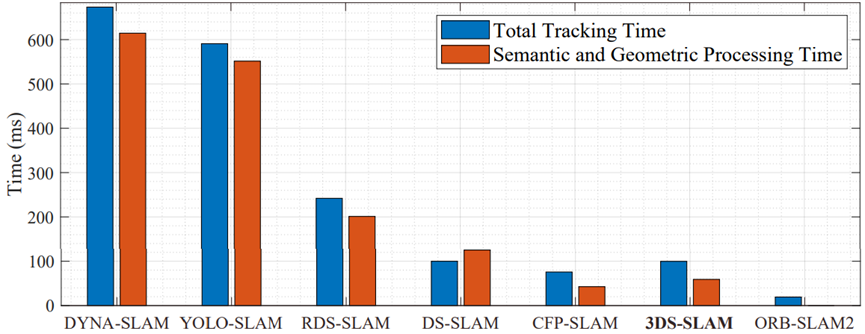
图6:执行时间与现有SLAM的比较。
实时性能和计算效率对于快速准确的可视化SLAM框架至关重要。图6展示了现有架构之间处理时间的比较,其中语义和几何约束的处理包括3D对象检测和动态特征过滤。姿态估计和ORB特征提取有助于整个跟踪持续时间。虽然DYNA-SLAM和YOLO-SLAM表现出强大的跟踪能力,但由于分别使用Mask R-CNN和Darknet19-YOLOv3,它们的处理时间延长。
DS-SLAM和CFP-SLAM快速处理帧,但难以处理具有快速相机旋转功能的序列。与现有的SLAM系统相比,3DS-SLAM不仅满足实时性要求,而且保持了高精度水平。为了提高其计算效率,实现了关键措施:1)通过连续帧的ORB特征提取并行执行语义和几何线程。2) 点云预处理消除了不必要的数据,从而提高了速度和准确性。
C.讨论
在实时场景中,现有的2D视觉SLAM框架面临挑战,尤其是在检测丢失对象[37]和定位动态对象方面。在动态环境中,物体运动、相机视野内的部分物体可见性、图像模糊、变化的照明条件以及由于旋转而导致的独特相机角度等因素对关键机器人应用中的物体检测构成了重大障碍。因此,需要开发明确应用于对象检测器的用于丢失对象检测和动态对象定位的方法。然而,这些方法显著增加了现有视觉SLAM系统所需的计算时间。
例如,CFP-SLAM通过将扩展卡尔曼滤波器和匈牙利算法与YOLOv5明确结合来解决丢失物体的挑战,但缺乏计算效率。相比之下,3DS-SLAM主要旨在通过隐式地将部分感知对象定位与对象检测相结合来解决视觉SLAM中的动态对象缺失问题。
与现有视觉SLAM实践中看到的深度图与RGB图像的手动参数融合相比,将点云合并到框架中改进了动态对象定位。它还克服了由于环境因素和关键机器人环境而导致的与2D对象检测相关的限制。3DSSLAM系统提供了几个优势和未来的潜力,包括增强对物体识别的3D场景理解,在具有挑战性的照明和纹理条件下增强鲁棒性,以及有效处理桌子和床等悬挂结构。
V.结论
在这项研究工作中,提出了一种新的视觉SLAM方法,该方法采用了为高度动态环境量身定制的3D混合变压器架构。这项研究通过结合3D场景理解,为增强视觉SLAM系统的功效做出了广泛贡献。严格的评估表明,算法在广泛的场景中实现了卓越的定位精度,涵盖了低动态和高动态环境,同时也表现出了值得称赞的实时性能。未来,将主要致力于为重建的点云地图设计一种轻量级的存储格式,该格式可广泛用于机器人的精确操作和导航。

