图形API和GPU光线追踪分析
图形API和GPU光线追踪分析
阐述目前市面上的几种流行图形API对光线追踪支持的现状和技术。
1 DirectX RayTracing(DXR)
DirectX RayTracing(DXR)是DirectX 12引入的用以支持硬件光线追踪的图形API特性集。在最高级别,DXR为DirectX 12 API引入了四个新概念:
- 加速结构是一个对象,它以最适合GPU遍历的格式表示全3D环境。表示为两级层次结构,该结构提供了GPU的优化光线遍历,以及应用程序对动态对象的有效修改。
- DispatchRays是一种新的命令列表方法,是将光线追踪到场景中的起点,也是游戏将DXR工作负载提交给GPU的方式。
- 光线追踪管线状态是当今图形和计算管线状态对象的精神伴侣,它封装了光线追踪着色器和与光线追踪工作负载相关的其他状态。
- 一组新的HLSL着色器类型,包括光线生成、最近命中、任何命中和未命中着色器。它们指定了DXR工作负载在计算上实际执行的操作。调用DispatchRays时,将运行光线生成着色器。使用HLSL中新的TraceRay内部函数,光线生成着色器将光线追踪到场景中。根据光线在场景中的位置,可以在交叉点调用多个命中或未命中着色器中的一个,以允许游戏为每个对象指定其自己的着色器和纹理集,从而产生唯一的材质。

光线追踪在GPU内部的处理流程图。
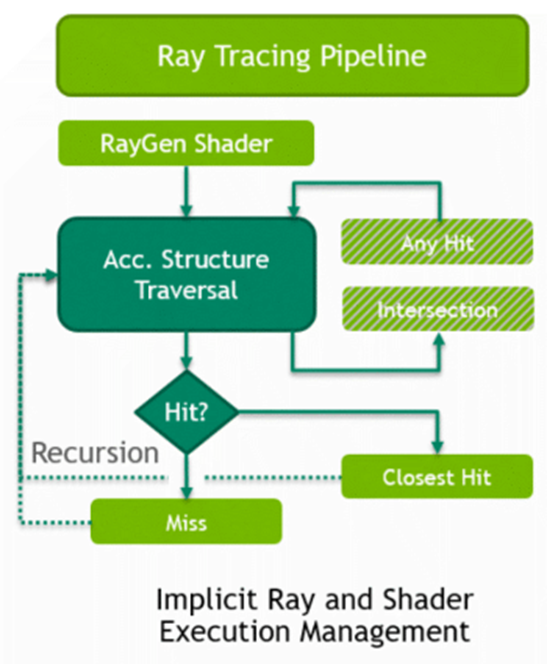
在DX12的全新图形API中,加入了可编程的光线追踪渲染管线(上图)。和传统光栅化管线一样,光线追踪的管线有固定的逻辑,也有可编程的部分。新管线中新增了5种着色器(Shader),分别是:
- Ray Generation:用于生成射线。在此shader中可以调用TraceRay()递归追踪光线。所有光线追踪工作的起点,从Host启动的线程的简单二维网格,追踪光线,写入最终输出。
- Intersection:当TraceRay()内检测到光线与物体相交时,会调用此shaderr,以便使用者检测此相交的物体是否特殊的图元(球体、细分表面或其它图元类型)。使用应用程序定义的图元计算光线交点,内置光线三角形交点。
- Any Hit:当TraceRay()内检测到光线与物体相交时,会调用此shader,以便使用者检测此相交的物体是否特殊的图元(球体、细分表面或其它图元类型)。在找到交点后调用,以任意顺序调用多个交点。
- Closest Hit和Miss:当TraceRay()遍历完整个场景后,会根据光线相交与否调用这两个Shader。Cloesit Hit可以执行像素着色处理,如材质、纹理查找、光照计算等。Cloesit Hit和Miss都可以继续递归调用TraceRay()。Closest Hit在光线的最近交点上调用,可以读取属性和追踪光线以修改有效载荷。Miss如果未找到并接受命中,则调用,可以追踪射线并修改射线有效载荷。
下面是以上部分shader的应用示例,以便更好说明它们的用途:
// 追踪光线时使用的数据负载,可自定义需要的数据。
struct Payload
{
float4 color;
float hitDistance;
};
// 追踪的加速结构,表示了场景的几何体。
RaytracingAccelerationStructure scene : register(t5);
[shader("raygeneration")]
void RayGenMain()
{
// 获取已调度二维工作项网格内的位置(通常映射到像素,因此可以表示像素坐标)。
uint2 launchIndex = DispatchRaysIndex();
// 定义一条射线,由原点、方向和间隔t组成。
RayDesc ray;
ray.Origin = SceneConstants.cameraPosition.
ray.Direction = computeRayDirection( launchIndex ); // 计算光线方向(非内建函数,实现忽略)
ray.TMin = 0;
ray.TMax = 100000;
Payload payload;
// 使用我们定义的有效载荷类型追踪射线,由此触发的着色器必须在相同的有效负载类型上运行。
TraceRay( scene, 0 /*flags*/, 0xFF /*mask*/, 0 /*hit group offset*/,
1 /*hit group index multiplier*/, 0 /*miss shader index*/, ray, payload );
outputTexture[launchIndex.xy] = payload.color;
}
// 属性包含命中信息,并由相交着色器填充。对于内置三角形相交着色器,属性始终由命中点的重心坐标组成。
struct Attributes
{
float2 barys;
};
[shader("closesthit")]
void ClosestHitMain( inout Payload payload, in Attributes attr )
{
// 读取相交属性并将结果写入有效负载。
payload.color = float4( attr.barys.x, attr.barys.y, 1 - attr.barys.x - attr.barys.y, 1 );
// 演示一个新的HLSL指令:沿当前光线的查询距离。
payload.hitDistance = RayTCurrent();
}
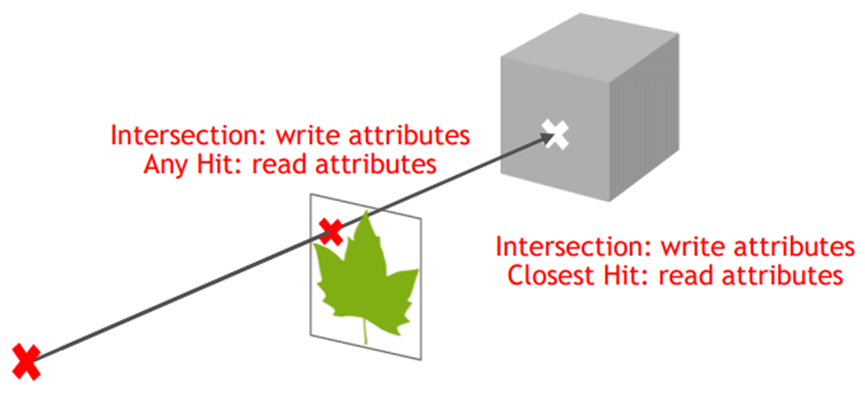
AnyHit和ClosetHit运行机制和区别示意图:
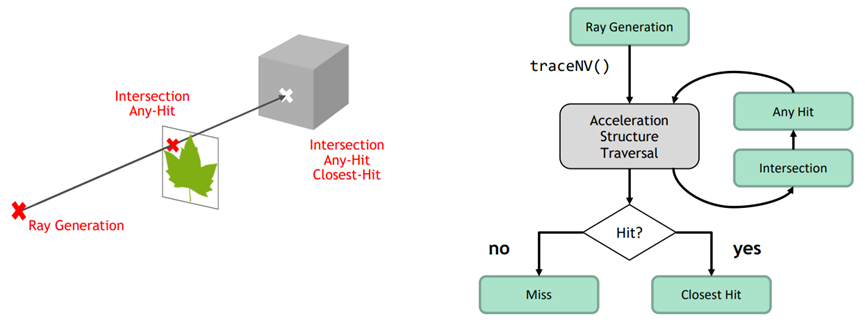
射线可以附带有效载荷——亦即应用程序定义的结构,用于在生成光线的命中阶段和着色器阶段之间传递数据,用于将最终交点信息返回到光线生成着色器:
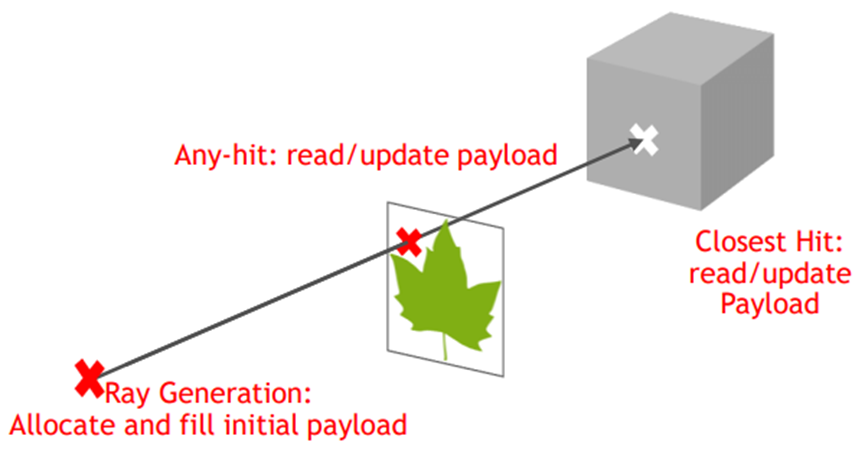
射线还可以有属性——应用程序定义的结构,用于将交点信息从交集着色器传递到命中着色器:
DXR被设计为允许实现独立地处理射线,包括各种类型的着色器,它们只能看到单条输入光线,不能看到或依赖运行中的其他光线的处理顺序。某些着色器类型可以在给定调用过程中生成多条光线(如果需要),可以查看光线处理的结果。无论如何,运行中生成的光线永远不会相互依赖。这种光线独立性打开了平行性的可能性。为了在执行期间利用这一点,典型的实现将在调度和其他任务之间进行平衡。
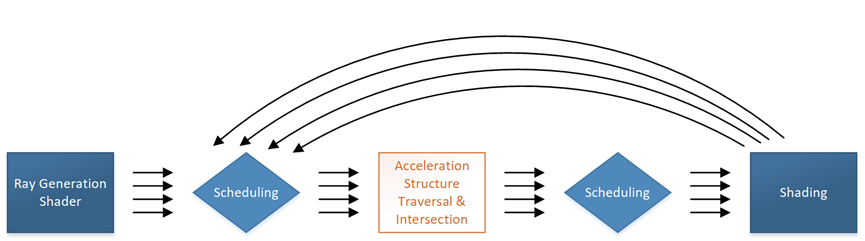
执行的调度部分是硬连接的(hard-wired),或者至少以可针对硬件定制的不透明方式实现。通常会使用排序工作等策略,以最大化线程之间的一致性,从API的角度来看,光线调度是内置功能。
光线追踪中的其他任务是固定功能和完全或部分可编程工作的组合,其中最大的固定功能任务是遍历由应用程序提供的几何结构构建的加速结构,目的是有效地找到潜在的射线交点,固定函数也支持三角形相交。着色器可编程性体现在生成射线、确定隐式几何图形的交点(与“固定函数三角形交点”选项相反)、处理光线交点(如曲面着色)或未命中。该应用程序还可以高度控制在任何给定情况下从着色器池中运行哪些着色器,以及每个着色器调用可以访问的纹理等资源的灵活性。
下图展示了硬件光线追踪体系涉及的概念、加速结构、内存布局以及运行机制:
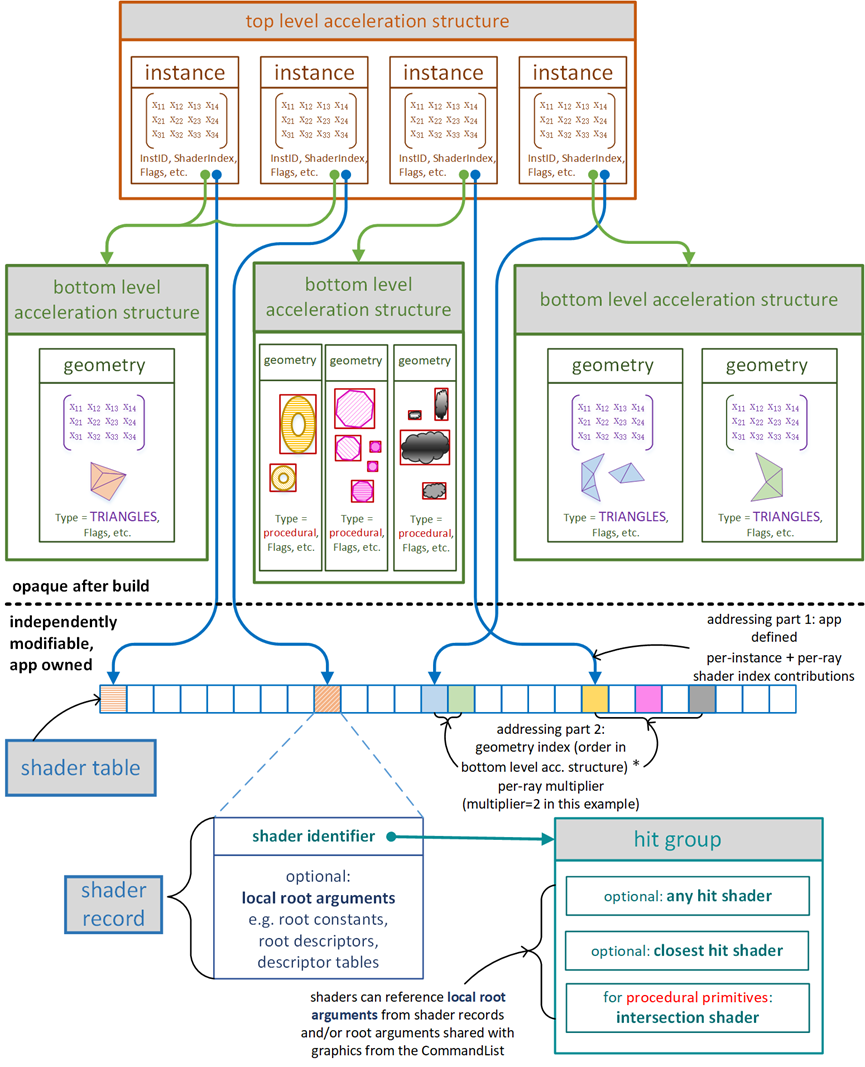
上图中涉及到加速结构(Acceleration Structure),其作用是保存场景的所有几何物体信息,在GPU内提供物体遍历、相交测试、光线构造等等的极限加速算法,使得光线追踪达到实时渲染级别,可以在应用程序通过BuildRaytracingAccelerationStructure()接口构建。
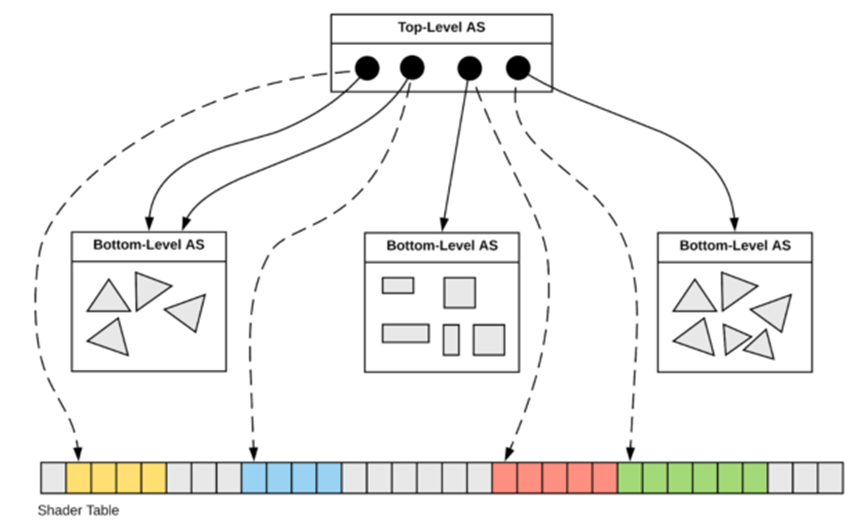
如上图,对于场景中的每个几何体,在GPU内部都存在两个级别的加速结构:
- 底层加速结构(Bottom-Level Acceleration Structure,BLAS)从输入的图元信息构建而成,如三角形、四边形。
- 顶层加速结构(Top-Level Acceleration Structure,TLAS)从底层加速结构创建而来,相当于是底层加速结构的实例,保存了底层结构的变换矩阵和shader偏移。
应用程序可以通过BuildRaytracingAccelerationStructure()中的D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAGS标记使得加速结构变成可更新的,或更新可更新的加速结构。在光线追踪性能方面,可更新加速结构(在更新之前和之后)不会像从头构建静态加速结构那样最佳,然而更新将比从头构建加速结构更快。
Shader绑定表(Shader Binding Table,SBT)描述了shader与场景的哪个物体关联,也包含了shader中涉及的所有资源(纹理、buffer、常量等)。
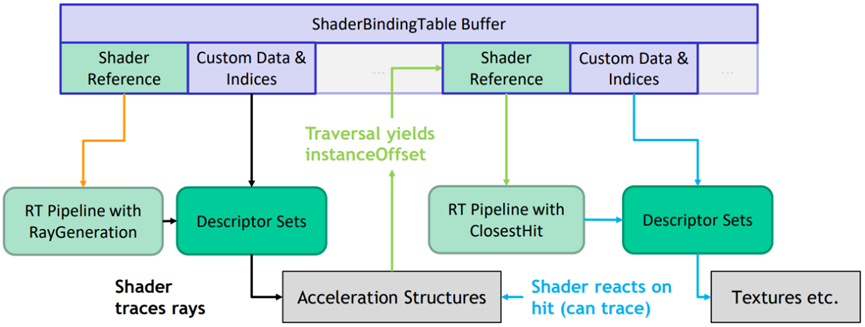
在GPU底层,Shader映射表是一个等尺寸的记录体(record),每个记录体关联着带着一组资源的shader(或相交组,Hit group)。通常每个几何体存在一个记录体。
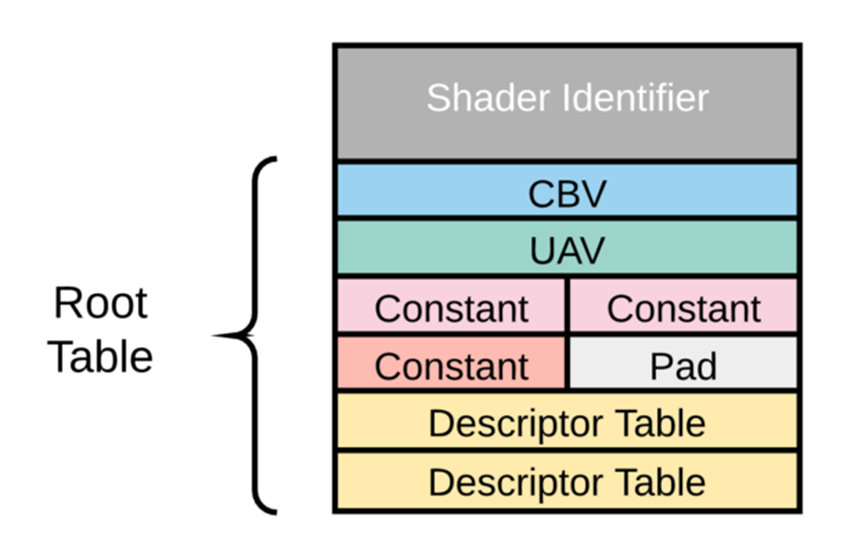
由上图可见,每个记录体由shader编号起始,随后存着CBV、UAV、常量、描述表等shader资源。这种双层架构的好处是将资源和实例化分离,加速实例创建和初始化,降低带宽和显存占用。
SBT针对典型光线追踪器的命中组记录布局,具有两种光线类型,渲染具有两个实例的场景,其中一个实例具有两种几何体。结合下图举个例子,每个命中组记录为32字节,步长为64字节。当追踪光线时,Rstride=2�������=2,并且Roffset�������对于主光线为0,对于遮挡光线为1。

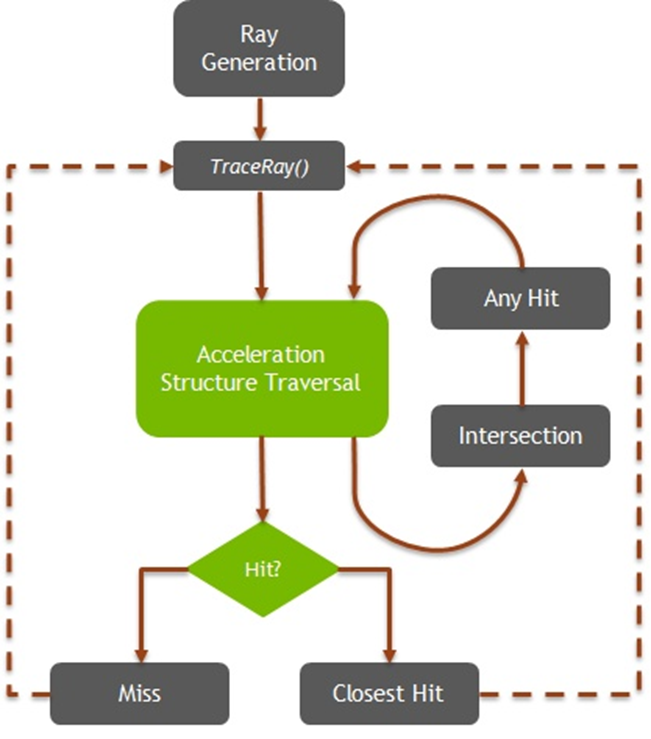
DXR的TraceRay运行流程如下:
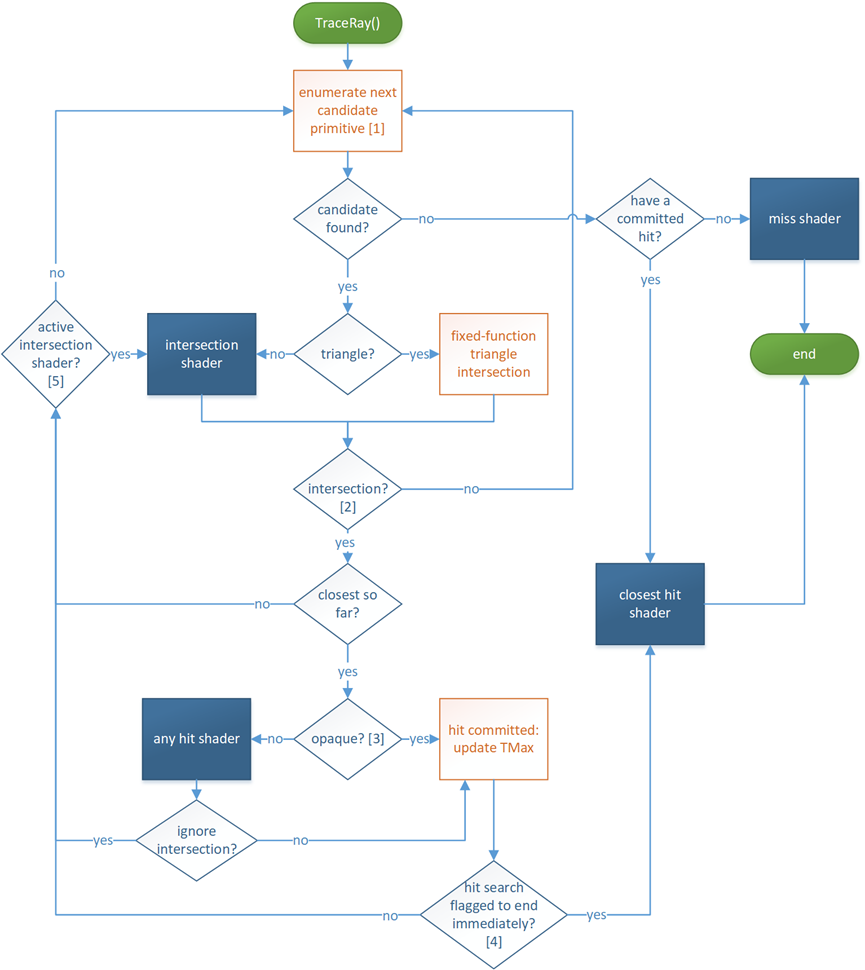
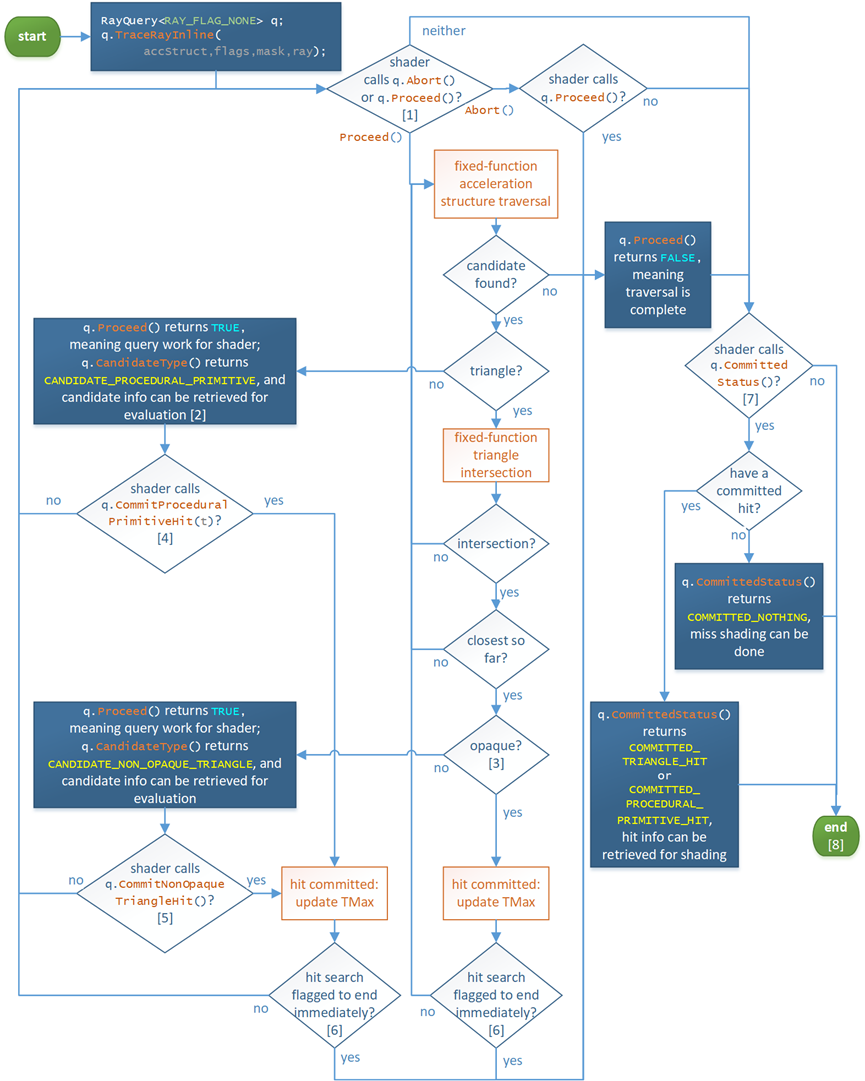
上图中:
[1] 此阶段搜索加速结构,以枚举可能与射线相交的图元,保守地:如果图元与射线相交且在当前射线范围内,则保证最终将枚举。如果基本体未与光线相交或在当前光线范围之外,则可以枚举或不枚举该基本体。请注意,提交命中时会更新TMax。
[2] 如果交集着色器正在运行并调用ReportHit(),则后续逻辑将处理交集,然后通过[5]返回交集着色器。
[3] 不透明度是通过检查交点的几何图形和实例标志以及光线标志来确定的。此外,如果没有任何命中着色器,几何体将被视为不透明。
[4] 如果设置了RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH光线标志,或者设置了名为AcceptHitAndEndSearch()的任何命中着色器,将中止在AcceptHitandSearch()调用点执行任何命中着色器。由于至少提交了此命中,因此迄今为止最接近的命中都会在其上运行最近的命中着色器(并且未通过RAY_FLAG_SKIP_CLOSEST_HIT_SHADER禁用)。
[5] 如果相交的图元不是三角形,则相交着色器仍处于活动状态并继续执行,因为它可能包含对ReportHit()的更多调用。
DXR还支持内联管线追踪模式,调用TraceRayInline()执行,是TraceRay()的变体,它的运行流程图如下:
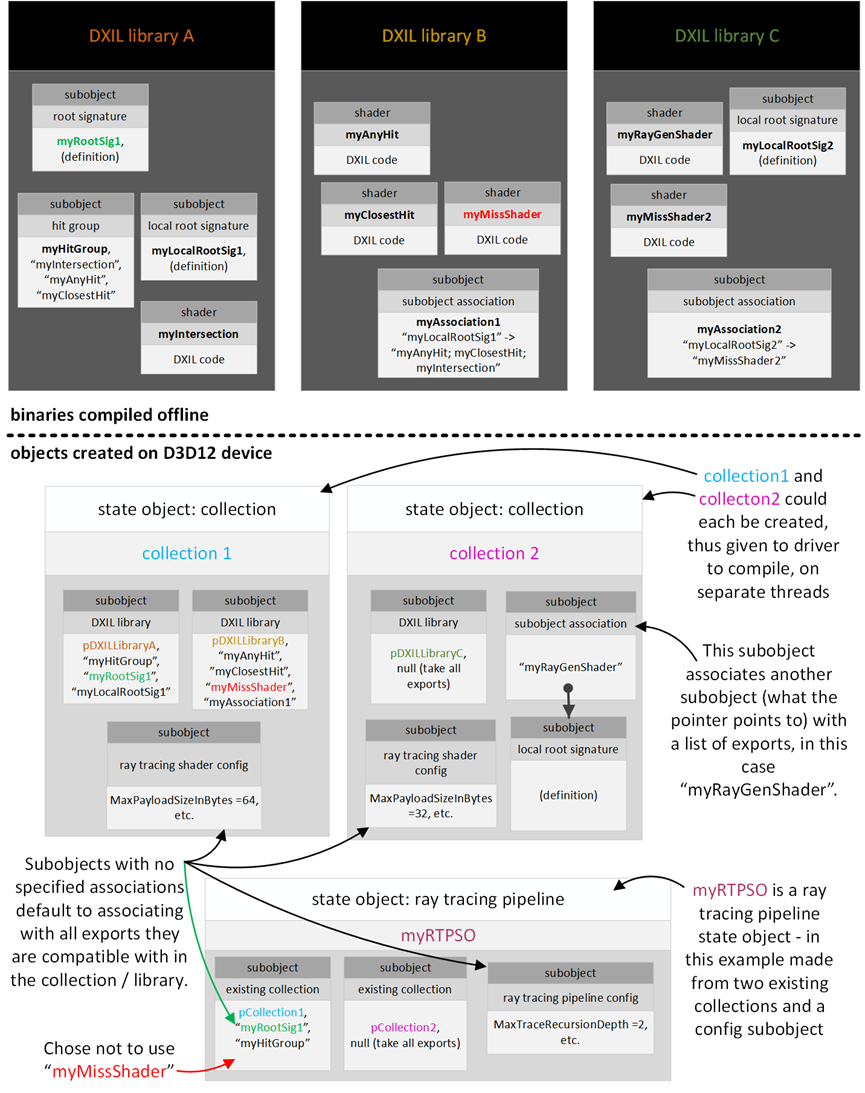
DXIL库和状态对象示例:
PIX作为Microsoft的老牌且强大的图形调试软件,在DXR发布之初就支持了对它的调试。利用PIX可方便调试各类调用栈、渲染状态及资源等信息。

使用DXR的步骤如下:
- 第一步是构建加速结构,它在两级层次结构中运行。在结构的底层,应用程序指定了一组几何图形,基本上是顶点和索引缓冲区,表示世界上不同的对象。在结构的顶层,应用程序指定了一个实例描述列表,其中包含对特定几何体的引用,以及一些附加的每个实例数据,如变换矩阵,这些数据可以以类似于当前游戏执行动态对象更新的方式逐帧更新。它们一起允许有效地遍历多个复杂几何图形。

两个几何体的实例,每个几何体都有自己的变换矩阵。
- 第二步是创建光线追踪管线状态。如今大多数游戏为了提高效率而将它们的绘制调用批处理在一起,例如首先渲染所有金属对象,然后渲染所有塑料对象。但由于无法准确预测特定光线将击中的材质,因此光线追踪不可能进行这样的批处理。相反,光线追踪管线状态允许指定多组光线追踪着色器和纹理资源。例如,与对象A的任何光线交点都应使用着色器P和纹理X,而与对象B的交点应使用着色器Q和纹理Y,使得应用程序可以让光线交点使用它们所击中的材质的正确纹理运行正确的着色器代码。
- 第三步是调用DispatchRays,它调用光线生成着色器。在该着色器中,应用程序调用TraceRay内在函数,触发加速结构的遍历,并最终执行适当的命中或未命中着色器。此外,还可以从命中和未命中着色器中调用TraceRay,允许光线递归或多重反弹效果。
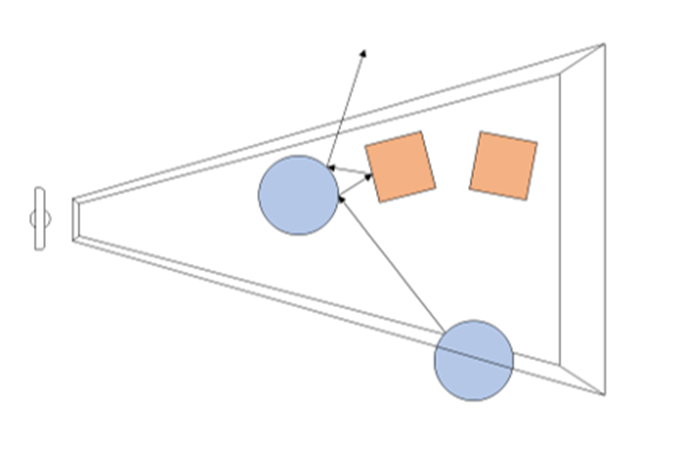
场景中光线递归的说明
注意,由于光线追踪管线省略了图形管线的许多固定功能单元,如输入汇编程序和输出合并器,因此由应用程序指定如何解释几何体。为着色器提供了执行此操作所需的最小属性集,即基本体中交点的重心坐标。最终,这种灵活性是DXR的一大优势,允许多种技术,而不需要强制要求特定格式或构造。
所有与光线追踪相关的GPU工作都通过应用程序调度的命令列表和队列进行调度。因此,光线追踪与其他工作(如光栅化或计算)紧密集成,并且可以通过多线程应用程序有效地排队。光线追踪着色器作为工作项网格进行调度,类似于计算着色器,允许实现利用GPU的大规模并行处理吞吐量,并根据给定硬件的情况执行工作项的低级别调度。
应用程序保留在必要时显式同步GPU工作和资源的责任,就像光栅化和计算一样,允许开发人员优化光线追踪、光栅化、计算工作和内存传输之间的最大重叠量。光线追踪和其他调度类型共享所有资源,如纹理、缓冲区和常量,从光线追踪着色器访问资源不需要转换、复制或映射。保存光线追踪特定数据的资源,如加速结构和着色器表,以及内存分配或传输不会隐式发生,着色器编译是显式的,完全受应用程序控制。着色器可以单独编译,也可以成批编译,如果需要,可以跨多个CPU线程并行编译。
2 Vulkan RayTracing
Vulkan光线追踪和DirectX相似,包含新增的Shader类型、加速结构等。

Vulkan的两层加速结构示意图。
Vulkan光线追踪的shader流程。
此外,Vulkan光线追踪是依靠Vulkan的诸多扩展实现的:
// Vulkan extension specifications
VK_KHR_acceleration_structure
VK_KHR_ray_tracing_pipeline
VK_KHR_ray_query
VK_KHR_pipeline_library
VK_KHR_deferred_host_operations
// SPIR-V extensions specifications
SPV_KHR_ray_tracing
SPV_KHR_ray_query
// GLSL extensions specifications
GLSL_EXT_ray_tracing
GLSL_EXT_ray_query
GLSL_EXT_ray_flags_primitive_culling
主要的类型:
- VkPhysicalDeviceAccelerationStructureFeaturesKHR:描述可由实现支持的加速结构特征的结构。
- VkPhysicalDeviceRayQueryFeaturesKHR:描述可由实现支持的光线查询功能的结构。
- VkPhysicalDeviceRayTracingPipelineFeaturesKHR:描述可由实现支持的光线追踪功能的结构。
- VkPhysicalDeviceAccelerationStructurePropertiesKHR:用于加速结构的物理设备的属性。
- VkPhysicalDeviceRayTracingPipelinePropertiesKHR:用于光线追踪的物理设备的属性。
其它特殊的类型:
- VK_KHR_deferred_host_operations:允许将高消耗的驱动程序操作卸载到应用程序管理的CPU线程池,以便在后台线程上完成或跨多个内核并行化任务,可用于光线追踪管线编译或基于CPU的加速结构构建。
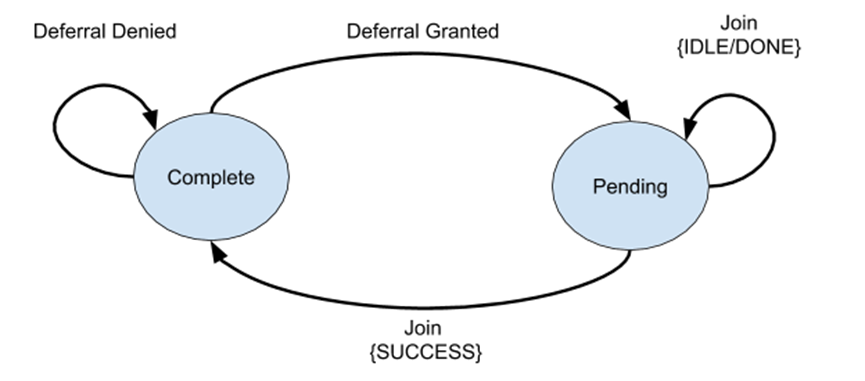
VkDeferredOperationKHR对象封装了延迟命令的执行状态,在其整个生命周期中将处于两种状态之一(完成或挂起)。
- VK_KHR_pipeline_library:提供了一组可链接到管线中的着色器的能力,在增量构建光线追踪管线时非常有用。
主机(Host)加速结构构建提供了利用闲置CPU提高性能的机会,考虑一个游戏中的假设情景(下图左),加速结构构造和更新在设备上实现,但应用程序有相当多的CPU空闲时间。将这些操作移动到主机允许CPU执行与前一帧渲染并行的下一帧加速结构,可以提高吞吐量,即使CPU需要更多的挂钟时间来执行相同的任务(下图右)。

在Vulkan中,根据加速结构追踪光线需要经过多个逻辑阶段,从而在如何追踪光线方面具有一定的灵活性。交点候选者最初纯粹基于其几何特性找到——是否存在沿光线与加速结构中描述的几何对象的交点?
相交测试在Vulkan中是无缝的(watertight),意味着对于加速度结构中描述的单个几何对象,光线不能通过三角形之间的间隙泄漏,并且不能报告同一位置不同三角形的多次命中。此举并不能保证邻接的相邻对象,但意味着单个模型中不会有洞或者过度着色。
一旦找到候选点,在确定交点之前会进行一系列剔除操作,这些剔除操作基于用于遍历的标志和加速结构的属性丢弃候选。剩余的不透明三角形候选被确认为有效交点,而AABB和非不透明三角形需要着色器代码以编程方式确定是否发生命中。
遍历继续,直到找到所有可能的候选,并确认或丢弃,并确定最近的命中,也可以使遍历提前结束,以避免不必要的处理。此举可用于检测遮挡,或在某些情况下用作优化。
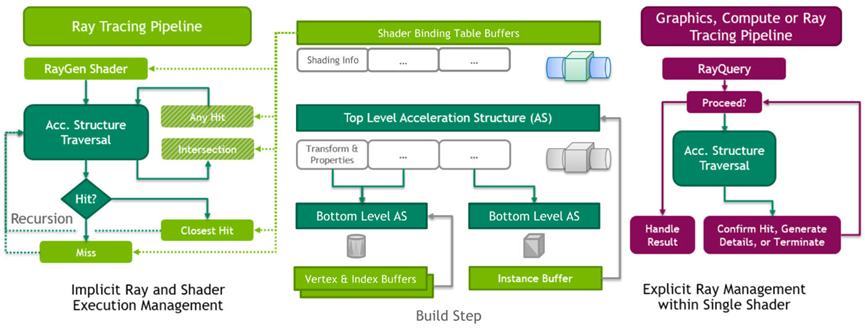
追踪光线和获得遍历结果可以通过Vulkan中的两种机制之一完成:光线追踪管线和光线查询(下图):
- 光线查询提供了对任何着色器阶段中光线遍历逻辑的直接访问,允许将它们插入现有着色器中,并增强这些着色器表达的效果。
- 光线追踪管线提供了一种带有动态着色器选择的专用光线追踪机制,使场景和可编程交集逻辑中使用的材质具有极大的灵活性。
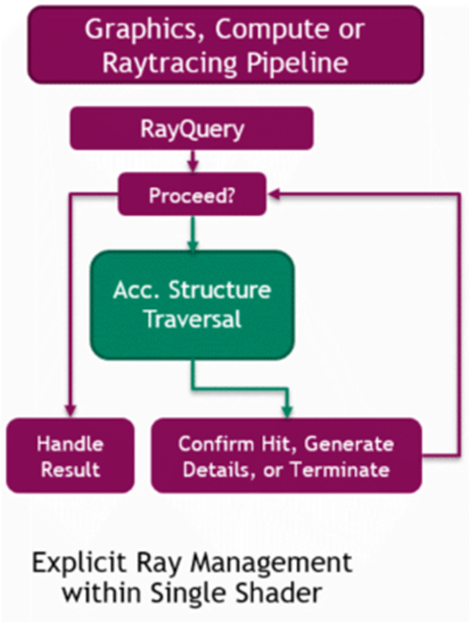
光线查询可用于执行光线遍历,并在任何着色器阶段返回结果。除了需要加速结构之外,光线查询仅使用一组新的着色器指令执行。光线查询使用要查询的加速结构、确定遍历属性的光线标志、剔除遮罩和被追踪光线的几何描述进行初始化。在遍历过程中,着色器可以访问潜在交点和提交交点的属性,以及光线查询本身的属性,从而能够根据几何体的相交、相交方式和位置进行复杂决策(下图)。

Vulkan光线追踪效果示例。
3 Metal RayTracing
Metal光线追踪的流程如下:

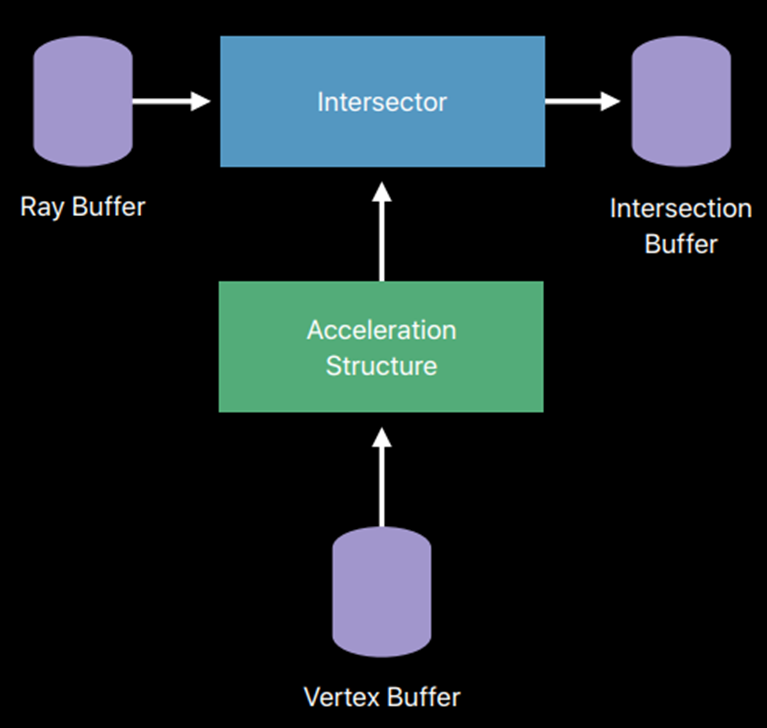
Metal性能着色器使用高性能相交器(MPSRayIntersector)解决了相交消耗高的问题,可加速GPU上的光线三角形相交测试,其接受通过Metal缓冲区的光线,并返回沿每个光线穿过金属缓冲区最近的交点(对于主光线)或任何交点(对于阴影光线)。Metal性能着色器构建了一种称为加速结构的数据结构,用于优化计算交点。Metal性能着色器从描述场景中三角形的顶点构建加速结构。若要搜索交点,可向交点提供加速度结构。
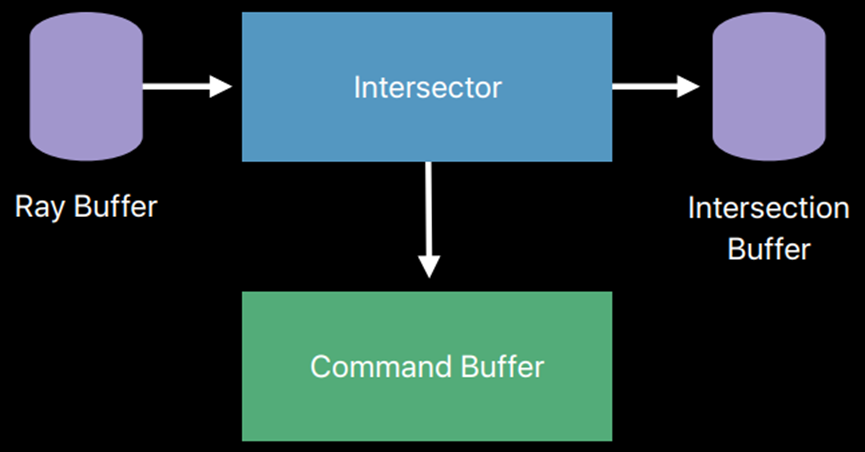
MPSRayIntersector在加速结构支持下的检测交点过程的示意图:

在顶点缓冲区中的三角形上构建加速结构(可在GPU上构建),将加速结构传递到MPSRayIntersector。
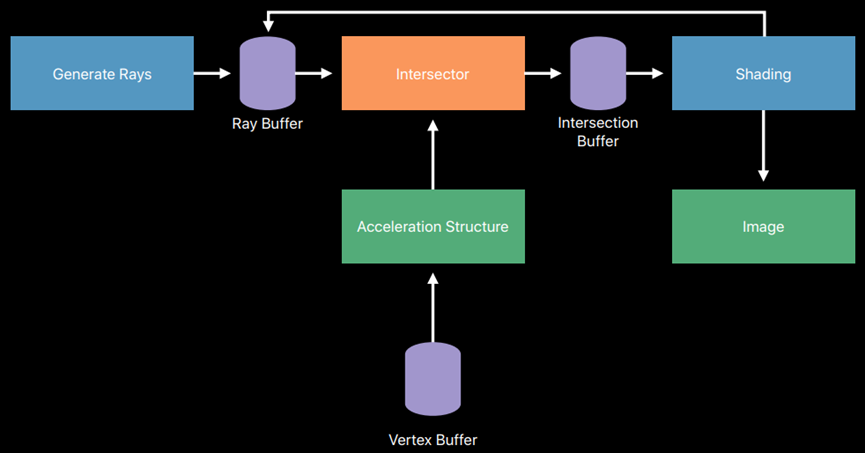
有了加速结构和交点检测器,流程变成了如下图所示:
对于动态物体,启用了Refit机制,比从头开始建造要快得多,在GPU上运行,无法添加或删除几何体,可能会降低加速结构质量。

对于两级加速结构,场景示例和数据结构如下:

在降噪方面,输入有本帧和上一帧的噪点图像、深度、法线和运动向量,结果降噪器处理后,输出降噪图像:

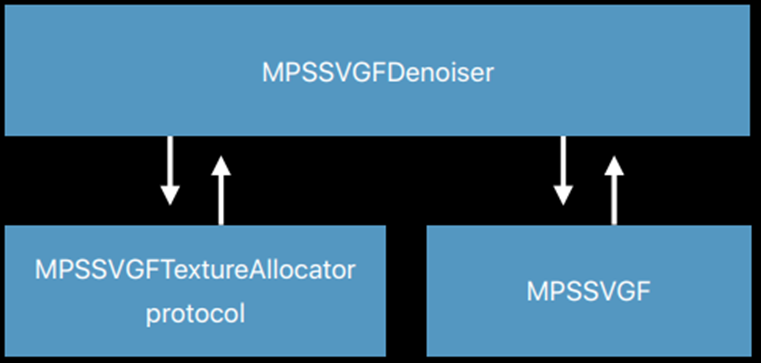
降噪算法采用了MPSSVGF,高质量的SVGF降噪算法,MPSSVGFDenoiser协调降噪过程,低级别控制:
在渲染过程中,和其他友商一样,采用了混合渲染管线:

在生成光线时,Metal按指定的顺序处理光线,块状线性布局可以提高光线一致性,提升缓存命中率,从而提高性能:

在计算阴影、AO等过程中,也使用了重要性采样来生成光线,相同视觉质量需要的光线更少。重要性采样过程中使用了半球、余弦采样、距离采样:

从左到右:半球、半球+余弦、半球+余弦+距离。
为了降低噪点,使用了Halton、Sobol等低差异序列,相邻像素采样方向不同,可以对所有像素使用相同的低差异采样。
对于GI,渲染流程如下:
Metal的优化技巧有:
- 减少带宽占用。合并负载和存储,尽可能使用较小的数据类型,分裂结构。反直觉——使用自己的原点和方向缓冲区,避免加载/存储不需要的结构成员。
- 减少寄存器压力。同时追踪存活的变量数量和大小,不要保留结构数据,小心循环计数器和函数调用。
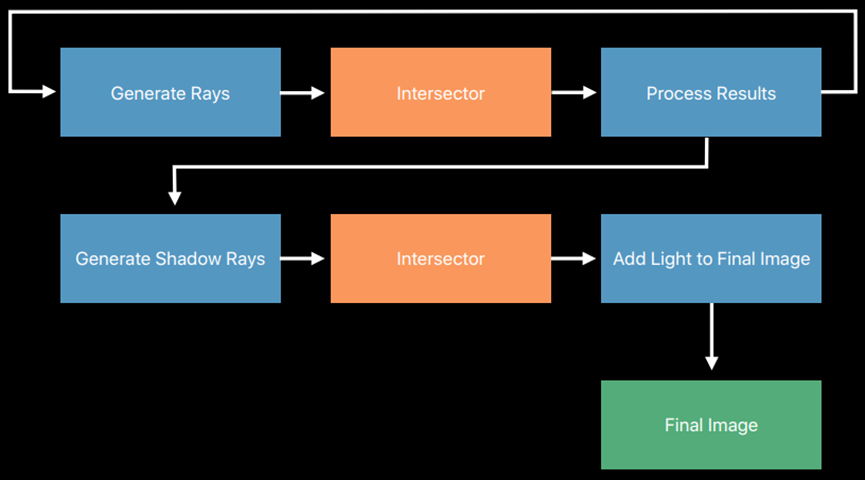
- 消除非活动光线。如离开场景,不再携带足够能量的光线,无法产生可测量的影响,透明表面的全内反射。经过多次迭代之后,最终存活的光线只有23%:
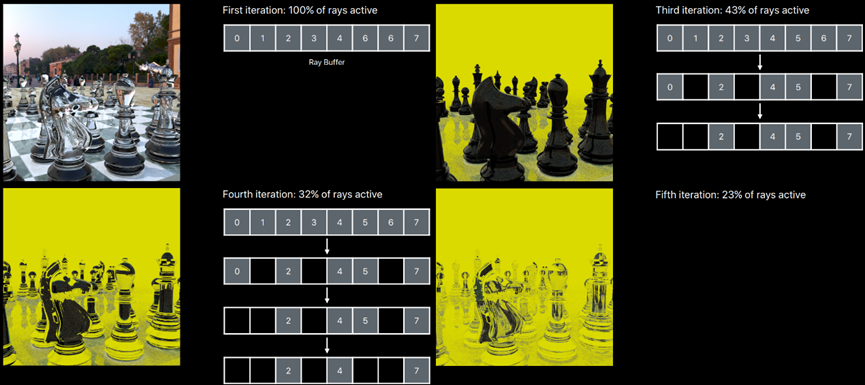
线程组变得很少使用,射线相交器仍必须处理非活动射线,控制流语句以剔除非活动光线。可以压实(Compaction)光线——仅将活动光线添加到下一个光线缓冲区,线程组得到充分利用,也适用于阴影光线。
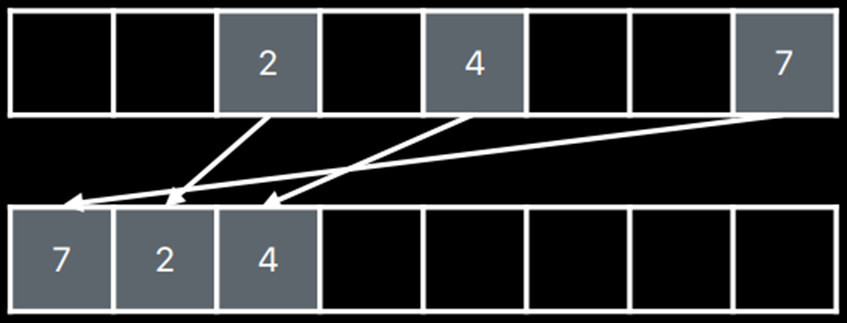
缓冲区索引不再映射到恒定像素位置,需要追踪每个光线的像素坐标。
此外,Metal还支持交叉分块(Interleaved Tiling),用于多个GPU:

较小的分块在GPU上更均匀地分布渲染,伪随机分配避免与场景相关,相同的GPU在每帧渲染相同的块。

ng)
分块分配时,为每个分块分配一个随机数,与阈值比较以选择GPU。

数据传输的流程如下:

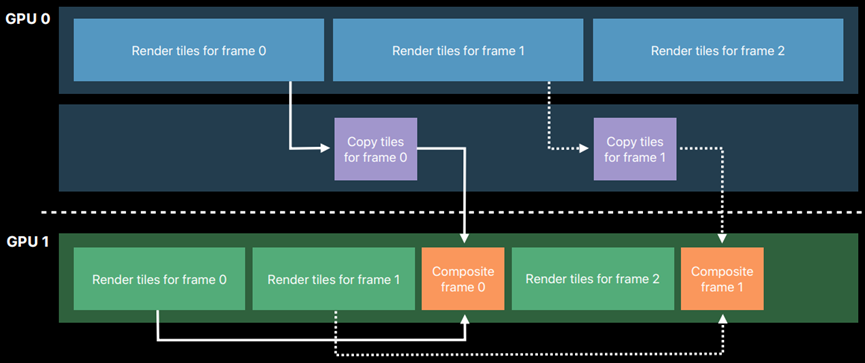
Metal的光线追踪场景通常遵循以下步骤:
1、将主光线从相机投射到场景,并在最近的交点处计算阴影。也就是说,距离摄影机最近的点,光线击中几何体。
2、将阴影光线从交点投射到光源。如果阴影光线由于相交几何体而未到达光源,则交点处于阴影中。
3、在随机方向上从交点投射次光线以模拟光反弹。在次级光线与几何体相交的位置添加照明贡献。
4 Ray tracing X(RTX)
NV作为世界级的图形学界的探索先锋队,在光线追踪方面有着深入的研发,最终抽象成技术标准RTX平台。
随着DirectX 12的DXR和Vulkan的支持,使得支持硬件级的光线追踪技术渐渐普及。NV最先在Turing架构的GPU支持了RTX技术:
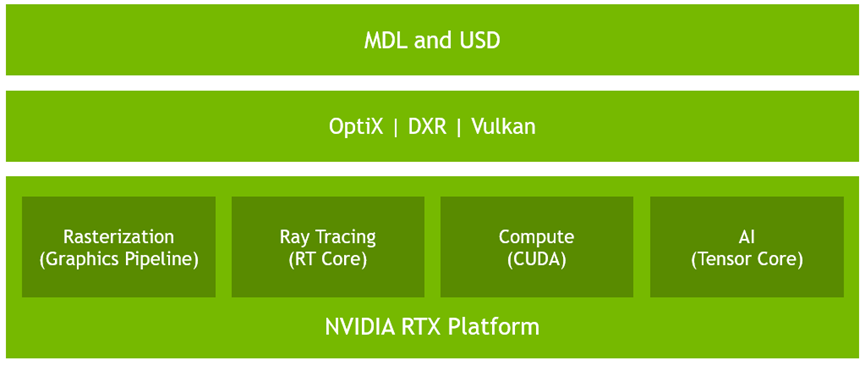
由上图可见,最上层是用户层(MDL和USD),包含了深度学习和普通应用开发;中间层是图形API层,支持RTX的有OptiX、DXR、Vulkan,OpenGL并不支持RTX;最底层就是RTX平台,它又包含了4个部分:传统的光栅化器、光线追踪(RT Core)、CUDA计算器、AI核心。

当然,除了Turing架构的GPU,还有PASCAL、VOLTA、TURING RTX等架构的众多款GPU支持RTX技术。(下图)

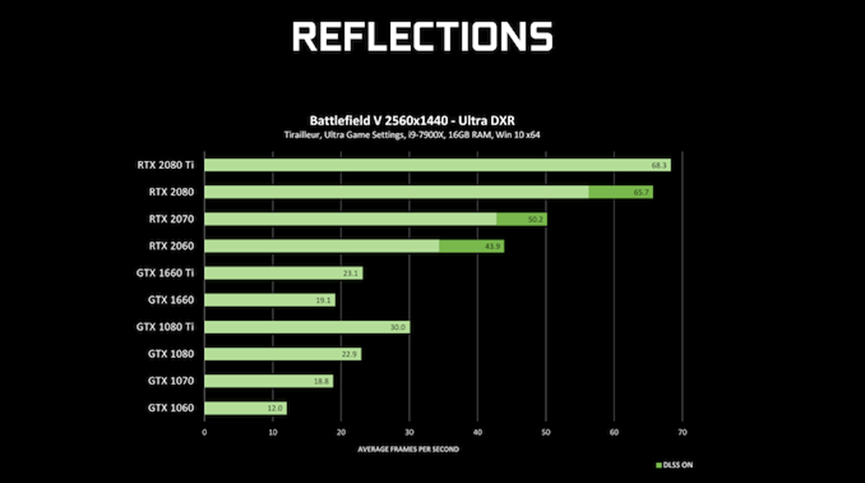
下图是若干款支持RTX技术的GPU运行同一个Demo(Battlefield)的性能对比:
此外,对于光线追踪,每种光线追踪的特性都会有不同的负载:

上图涉及的BVH(Bounding volume hierarchy)是层次包围盒,是一种加速场景物体查找的算法和结构体。
对于开发者,需要根据质量等级,做好各类指标预选项,以便程序能够良好地运行在各个画质级别的设备中。
TURING RTX的三大核心功能如下:

图灵还引入了新的工作流和效能测试标准:

利用RT Core和Tensor Core(DLSS),可以大幅提升渲染性能,缩减总时长:
NVIDIA Ampere体系架构GPU系列的最新成员GA102和GA104,GA102和GA104是新英伟达“GA10x”级Ampere架构GPU的一部分,GA10x GPU基于革命性的NVIDIA Turing GPU架构。
GeForce RTX 3090是GeForce RTX系列中性能最高的GPU,专为8K HDR游戏设计。凭借10496个CUDA内核、24GB GDDR6X内存和新的DLSS 8K模式,它可以在8K@60fps。GeForce RTX 3080的性能是GeForce RTX 2080的两倍,实现了GPU有史以来最大的一代飞跃,GeForce RTX 3070的性能可与NVIDIA上一代旗舰GPU GeForce RTX 2080 Ti相媲美,GA10x GPU中新增的HDMI 2.1和AV1解码功能允许用户使用HDR以8K的速度传输内容。
NVIDIA A40 GPU是数据中心在性能和多工作负载能力方面的一次革命性飞跃,它将一流的专业图形与强大的计算和AI加速相结合,以应对当今的设计、创意和科学挑战。A40具有与RTX A6000相同的内核数量和内存大小,将为下一代虚拟工作站和基于服务器的工作负载提供动力。NVIDIA A40的能效比上一代高出2倍,它为专业人士带来了光线追踪渲染、模拟、虚拟制作等最先进的功能。

Ampere GA10x体系结构具有巨大的飞跃。
GA102的关键特性有2倍FP32处理、第二代RT Core、第三代Tensor Core、GDDR6X和GDDR6内存、PCIe Gen 4等。
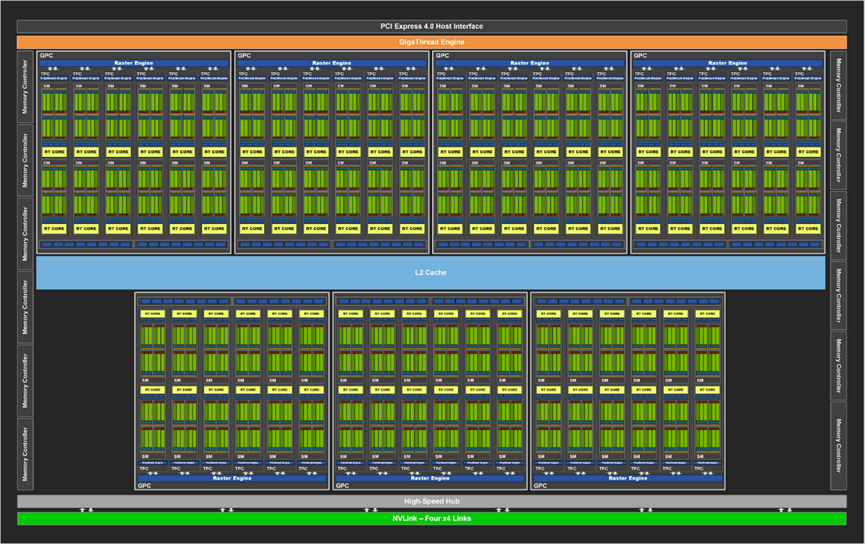
与之前的NVIDIA GPU一样,GA102由图形处理集群(Graphics Processing Cluster,GPC)、纹理处理集群(Texture Processing Cluster,TPC)、流式多处理器(Streaming Multiprocessor,SM)、光栅操作器(Raster Operator,ROP)和内存控制器组成。完整的GA102 GPU包含7个GPC、42个TPC和84个SM。
GPC是主要的高级硬件块,所有关键图形处理单元都位于GPC内部。每个GPC都包括一个专用的光栅引擎,现在还包括两个ROP分区(每个分区包含八个ROP单元),是NVIDIA Ampere Architecture GA10x GPU的一个新功能。GPC包括六个TPC,每个TPC包括两个SM和一个PolyMorph引擎。
GA102 GPU还具有168个FP64单元(每个SM两个),FP64 TFLOP速率是FP32操作TFLOP速率的1/64。包括少量的FP64硬件单元,以确保任何带有FP64代码的程序都能正确运行,包括FP64 Tensor Core代码。
GA10x GPU中的每个SM包含128个CUDA核、四个第三代Tensor核、一个256 KB的寄存器文件、四个纹理单元、一个第二代光线追踪核和128 KB的L1/共享内存,这些内存可以根据计算或图形工作负载的需要配置为不同的容量。GA102的内存子系统由12个32位内存控制器组成(共384位),512 KB的二级缓存与每个32位内存控制器配对,在完整的GA102 GPU上总容量为6144 KB。
Ampere架构还对ROP执行了优化。在以前的NVIDIA GPU中,ROP绑定到内存控制器和二级缓存。从GA10x GPU开始,ROP是GPC的一部分,通过增加ROP的总数和消除扫描转换前端和光栅操作后端之间的吞吐量不匹配来提高光栅操作的性能。每个GPC有7个GPC和16个ROP单元,完整的GA102 GPU由112个ROP组成,而不是先前在384位内存接口GPU(如前一代TU102)中可用的96个ROP。此方法可改进多采样抗锯齿、像素填充率和混合性能。
在SM架构方面,图灵SM是NVIDIA的第一个SM体系结构,包括用于光线追踪操作的专用内核。Volta GPU引入了张量核,Turing包括增强的第二代张量核。Turing和Volta SMs支持的另一项创新是并行执行FP32和INT32操作。GA10x SM改进了上述所有功能,同时还添加了许多强大的新功能。与以前的GPU一样,GA10x SM被划分为四个处理块(或分区),每个处理块都有一个64 KB的寄存器文件、一个L0指令缓存、一个warp调度程序、一个调度单元以及一组数学和其他单元。这四个分区共享一个128 KB的一级数据缓存/共享内存子系统。与每个分区包含两个第二代张量核、总共八个张量核的TU102 SM不同,新的GA10x SM每个分区包含一个第三代张量核,总共四个张量核,每个GA10x张量核的功能是图灵张量核的两倍。与Turing相比,GA10x SM的一级数据缓存和共享内存的组合容量要大33%。对于图形工作负载,缓存分区容量是图灵的两倍,从32KB增加到64KB。

GA10x Streaming Multiprocessor (SM) 。
GA10x SM继续支持图灵支持的双速FP16(HFMA)操作。与TU102、TU104和TU106图灵GPU类似,标准FP16操作由GA10x GPU中的张量核处理。FP32吞吐量的比较X因子如下表:
|
Turing |
GA10x |
|
|
FP32 |
1X |
2X |
|
FP16 |
2X |
2X |
如前所述,与前一代图灵体系结构一样,GA10x具有用于共享内存、一级数据缓存和纹理缓存的统一体系结构。这种统一设计可以根据工作负载进行重新配置,以便根据需要为L1或共享内存分配更多内存。一级数据缓存容量已增加到每个SM 128 KB。在计算模式下,GA10x SM将支持以下配置:
- 128 KB L1 + 0 KB Shared Memory
- 120 KB L1 + 8 KB Shared Memory
- 112 KB L1 + 16 KB Shared Memory
- 96 KB L1 + 32 KB Shared Memory
- 64 KB L1 + 64 KB Shared Memory
- 28 KB L1 + 100 KB Shared Memory
Ampere架构的RT Core比Turing的RT Core的射线/三角形相交测试速度提高了一倍:

GA10x GPU通过一种新功能增强了先前NVIDIA GPU的异步计算功能,该功能允许在每个GA10x GPU SM中同时处理RT Core和图形或RT Core和计算工作负载。GA10x SM可以同时处理两个计算工作负载,并且不像以前的GPU代那样仅限于同时计算和图形,允许基于计算的降噪算法等场景与基于RT Core的光线追踪工作同时运行。

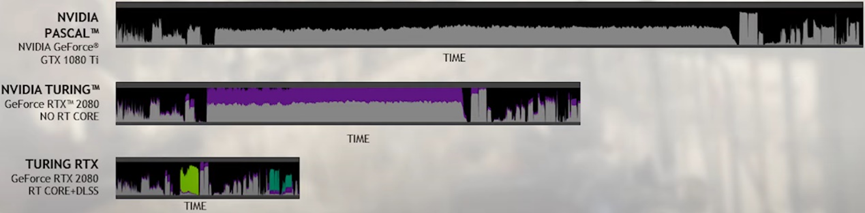
相比Turing架构,NVIDIA Ampere体系结构在渲染同一游戏中的同一帧时,可大大提高性能:
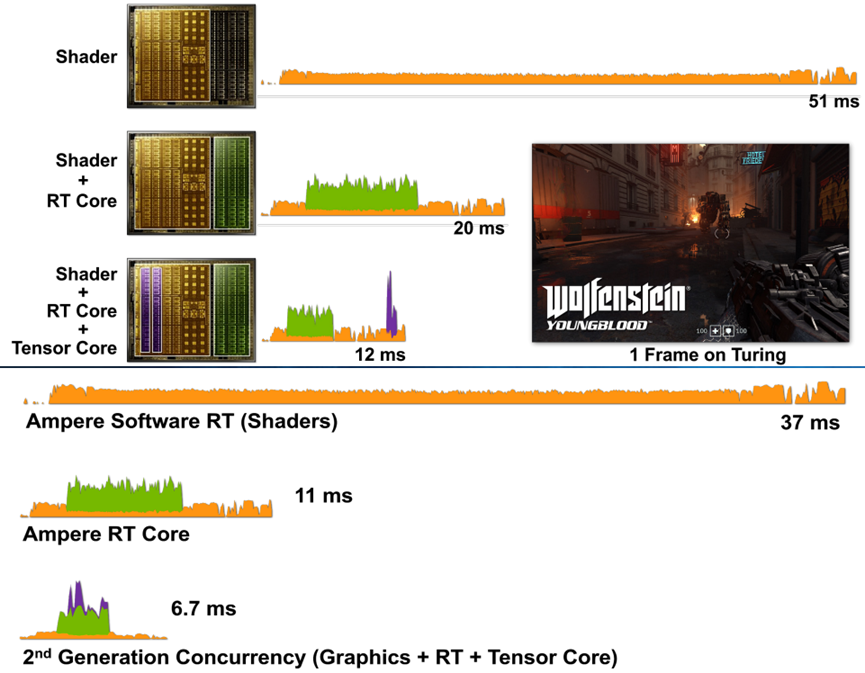
上:基于图灵的RTX 2080超级GPU渲染Wolfenstein的一帧:仅使用着色器核心(CUDA核心)、着色器核心+RT核心和着色器核心+RT核心+张量核心的Youngblood。请注意,在添加不同的RTX处理内核时,帧时间逐渐减少。
下:基于安培体系结构的RTX 3080 GPU渲染一帧Wolfenstein:Youngblood仅使用着色器核心(CUDA核心)、着色器核心+RT核心和着色器核心+RT核心+张量核心。
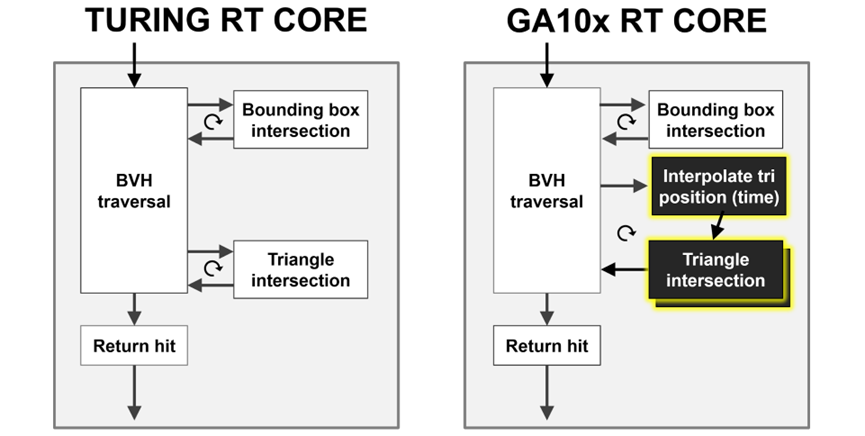
GA10x RT Core使光线/三角形相交测试速率比Turing RT Core提高了一倍,还添加了一个新的插值三角形位置加速单元,以协助光线追踪运动模糊操作。
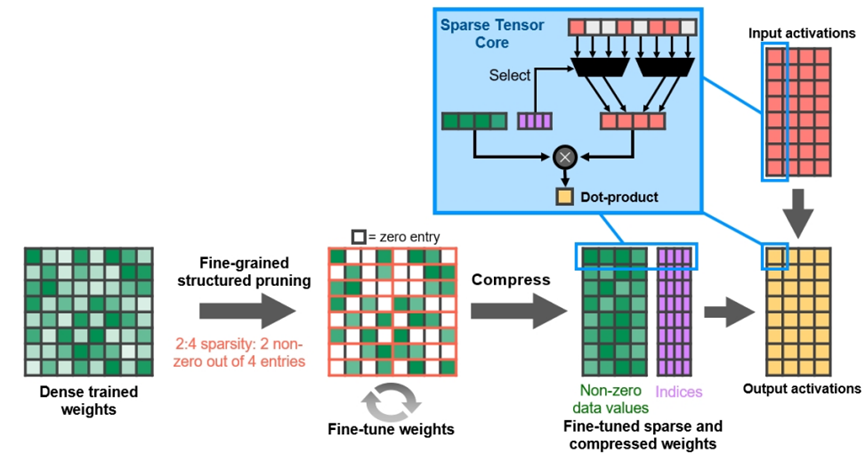
在启用稀疏性的情况下,GeForce RTX 3080提供的FP16 Tensor堆芯操作峰值吞吐量是GeForce RTX 2080 Super的2.7倍,后者具有密集的Tensor堆芯操作:

细粒度结构化稀疏性使用四取二非零模式修剪训练权重,然后是微调非零权重的简单通用方法。对权重进行压缩,使数据占用和带宽减少2倍,稀疏张量核心操作通过跳过零使数学吞吐量加倍。(下图)
下图显示了GDDR6(左)和GDDR6X(右)之间的数据眼(data eye)比较,通过GDDR6X接口可以以GDDR6的一半频率传输相同数量的数据,或者,在给定的工作频率下,GDDR6X可以使有效带宽比GDDR6增加一倍。
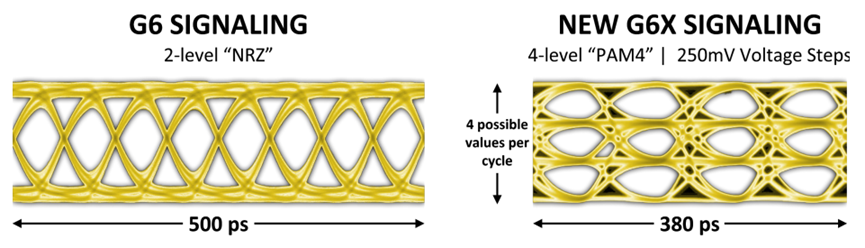
GDDR6X使用PAM4信令提高了性能和效率。
为了解决PAM4信令带来的信噪比挑战,开发了一种名为MTA(最大传输消除,见下图)的新编码方案,以限制高速信号的转移。MTA可防止信号从最高电平转换到最低电平,反之亦然,从而提高接口信噪比。它是通过在编码管脚上传输的字节中为每个管脚分配一部分数据突发(时间交错),然后使用明智选择的码字将数据突发的剩余部分映射到没有最大转换的序列来实现的。此外,还引入了新的接口培训、自适应和均衡方案。最后,封装和PCB设计需要仔细规划和全面的信号和电源完整性分析,以实现更高的数据速率。

在传统的存储模型中,游戏数据从硬盘读取,然后从系统内存和CPU传输,然后再传输到GPU,使得IO常常成为游戏的性能瓶颈:
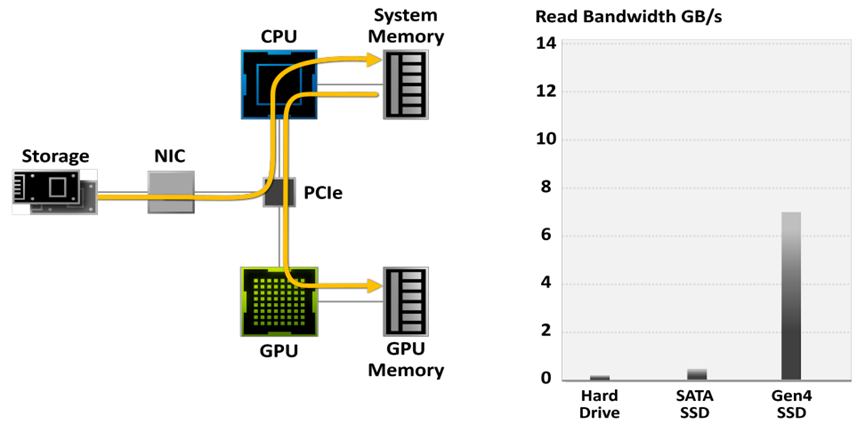
使用传统的存储模型,游戏解压缩可以消耗Threadripper CPU上的所有24个内核。现代游戏引擎已经超过了传统存储API的能力。需要新一代的输入/输出体系结构。数据传输速率为灰色条,所需CPU内核为黑色/蓝色块。需要压缩数据,但CPU无法跟上:
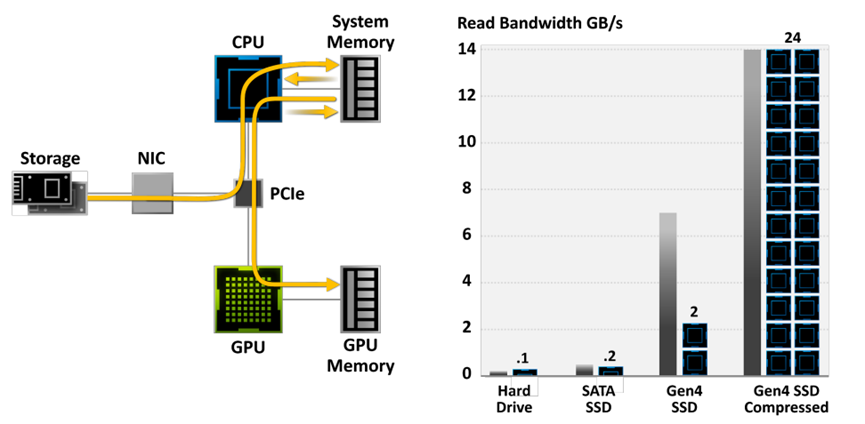
NVIDIA RTX IO插入Microsoft即将推出的DirectStorage API,这是一种新一代存储体系结构,专为配备最先进NVMe SSD的游戏PC和现代游戏所需的复杂工作负载而设计。总之,专门为游戏定制的流线型和并行化API可以显著减少IO开销,并最大限度地提高从NVMe SSD到支持RTX IO的GPU的性能/带宽。具体而言,NVIDIA RTX IO带来了基于GPU的无损解压缩,允许通过DirectStorage进行的读取保持压缩,并传送到GPU进行解压缩。此技术可消除CPU的负载,以更高效、更压缩的形式将数据从存储器移动到GPU,并将I/O性能提高了两倍。
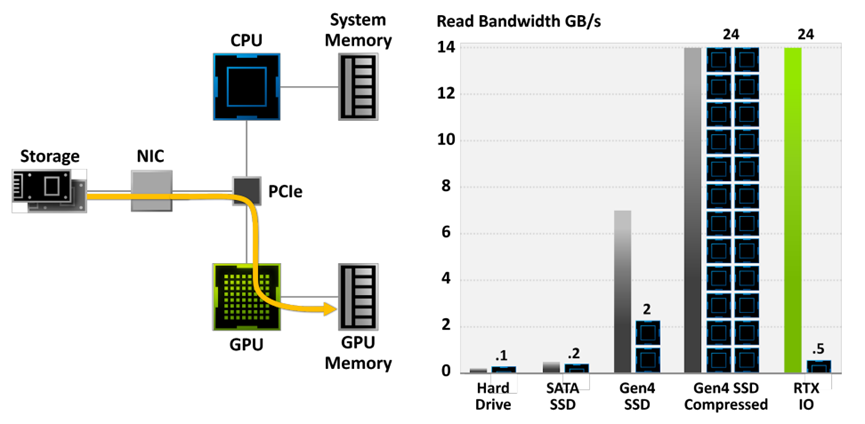
RTX IO提供100倍的吞吐量,20倍的CPU利用率。数据传输速率为灰色和绿色条,所需CPU内核为黑色/蓝色块。

关卡加载时间比较。负载测试在24核Threadripper 3960x平台上运行,原型Gen4 NVMe m.2 SSD,alpha软件。
5 Radeon Rays / ProRender
Radeon Rays是AMD的高效、高性能光线交点检测加速库,如Radeon ProRender所示。它支持一系列用例,包括用于游戏开发工作流的交互式灯光烘焙和实时间接声音模拟。特性具体有:
- 支持DirectX 12和Vulkan。
- 自定义AABB,GPU BVH加速,几何体更新而不完全重建。
- 全谱渲染。

- AI加速。
- 便于调试的日志记录机制、验证源代码更改的测试集。
- 基于MIT的开源。
Radeon Rays用于计算照明缓存,采用了混合全局照明解决方案,照明缓存使用层次结构,在屏幕空间追踪光线,作为最后手段的世界空间光线追踪,BVH流数据。Radeon ProRender是一种快速的GPU加速全局照明渲染器,游戏内容创建加速有潜力,提供开发人员SDK(C API)、创作者插件。


Radeon ProRender部分特性。

Radeon ProRender渲染样例。
Radeon ProRender利用新的OpenCL硬件加速渲染的函数,性能的提升取决于场景,具有更复杂着色器的场景通常从硬件加速光线追踪中获益较少。下图是一些简单的基准场景,使用AMD Radeon测试了硬件加速开关RX 6800 XT图形卡。
在GPU硬件方面,ZEN 2微体系结构的高级特性包含:
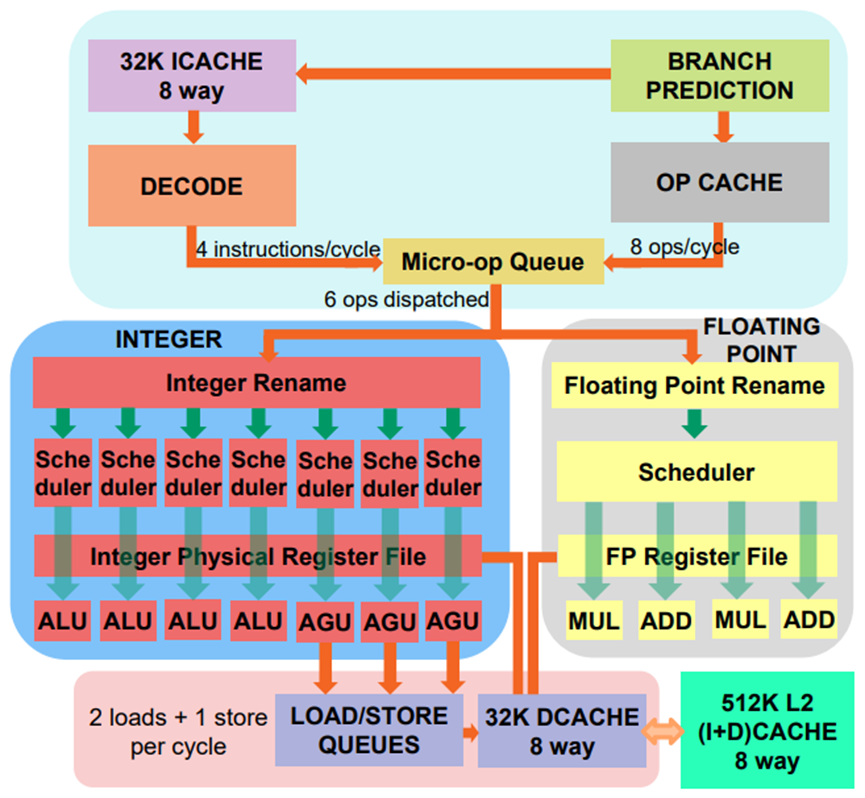
- 从ZEN到ZEN 2的IPC提高了15%。
- 2倍运算缓存容量。
- 重新优化的L1I 缓存(L1指令缓存)。
- 第三代地址生成单元。
- 2倍FP数据路径宽度。
- 2倍L3容量。
- 提高分支预测准确度。
- 硬件优化的安全缓解措施。
- 通过客户模式执行陷阱(GMET)实现安全虚拟化。
- 改善SMT公平性(对于ALU和AGU调度器)。
- 改进的写入组合缓冲区。
“RENOIR”8核处理器流程图如下:
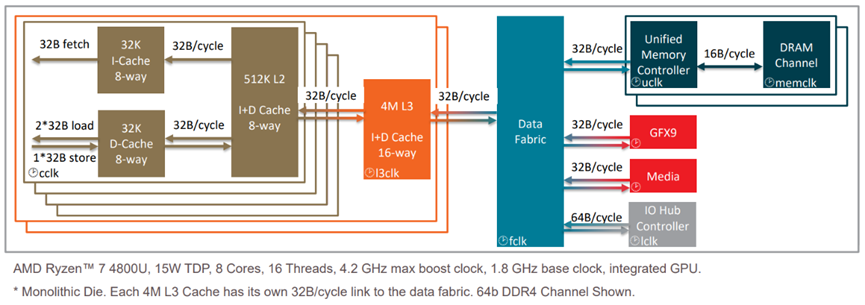
“MATISSE”16核处理器流程图如下:
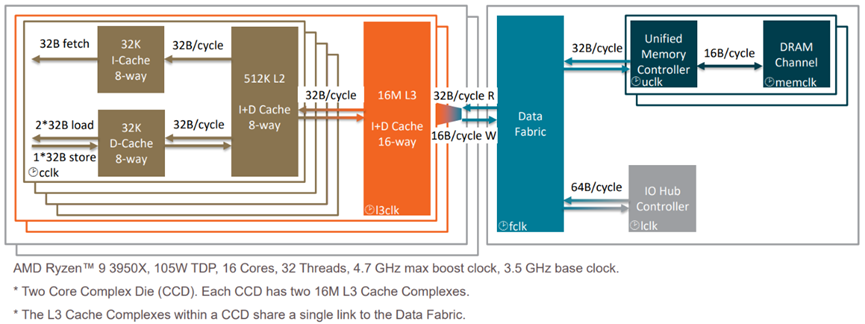
“CASTLE PEAK” 64核处理器流程图如下:
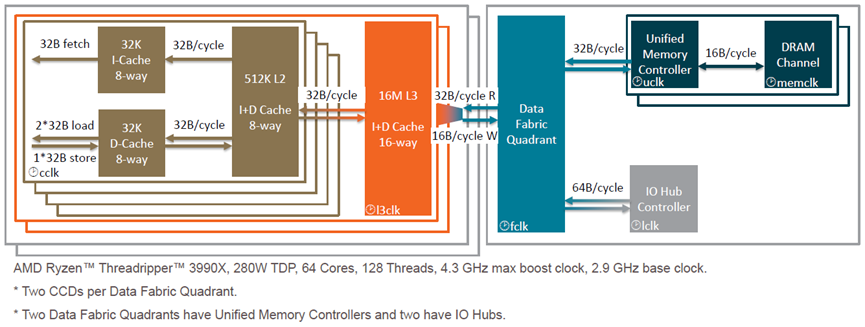
指令集演化历程如下:
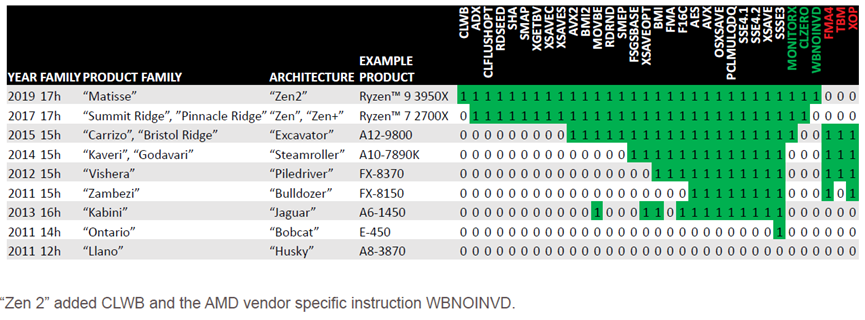
支持软件预取级别指令:
- 将缓存行从指定的内存地址加载到由位置引用T0、T1、T2或NTA指定的数据缓存级别。
- 如果检测到内存故障,则不会启动总线周期,指令被视为NOP。
- 预取电平T0/T1/T2在“Zen”和“Zen 2”微体系结构中的处理方式相同。
- 用预取NTA表示的非临时缓存填充提示减少了仅使用一次的数据的缓存污染。它不适用于小型数据集的缓存阻塞。用预取NTA填充到二级缓存中的行被标记为更快地从二级缓存移出,并且当从二级高速缓存移出时,不会插入三级缓存。
- 本指令的操作取决于实施。预取填充和逐出策略可能因其他处理器供应商或微体系结构代而异。
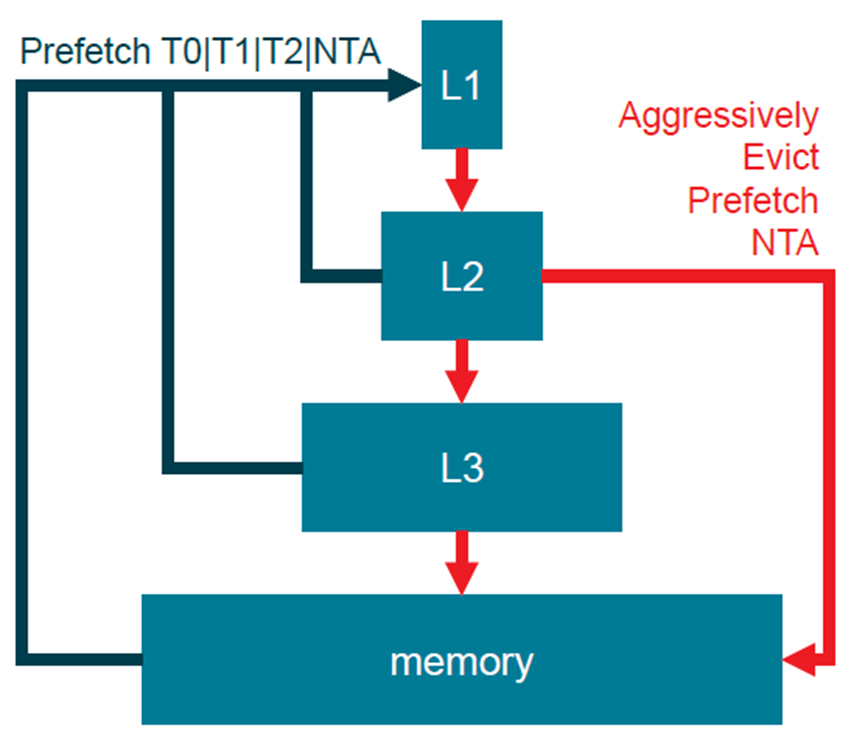
各种指令的缓存延迟如下表:

重装(refill)支持三种模式:在相同的CCX内、从局部DRAM、从其它CCX。(下图)
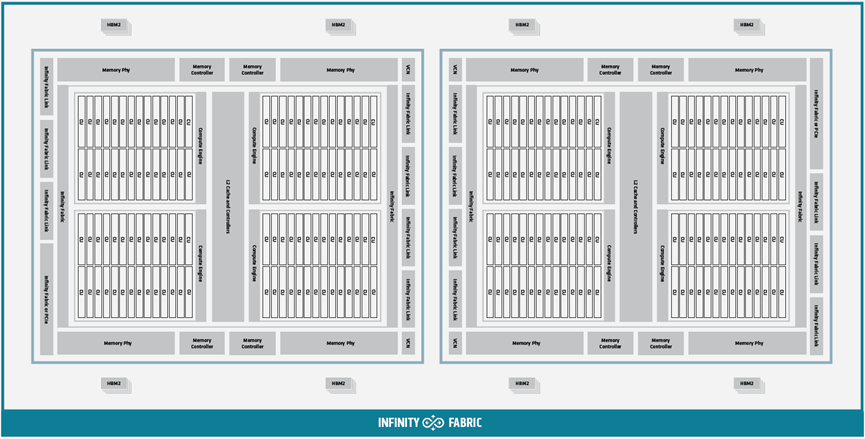
AMD Instinct MI200 Graphics Compute Die (GCD)如下所示:

MI200多芯片模块(AMD Instinct™ MI250/MI250X),其包括如图所示的两个图形计算裸片(GCD)。
flagship HPC节点结构图:
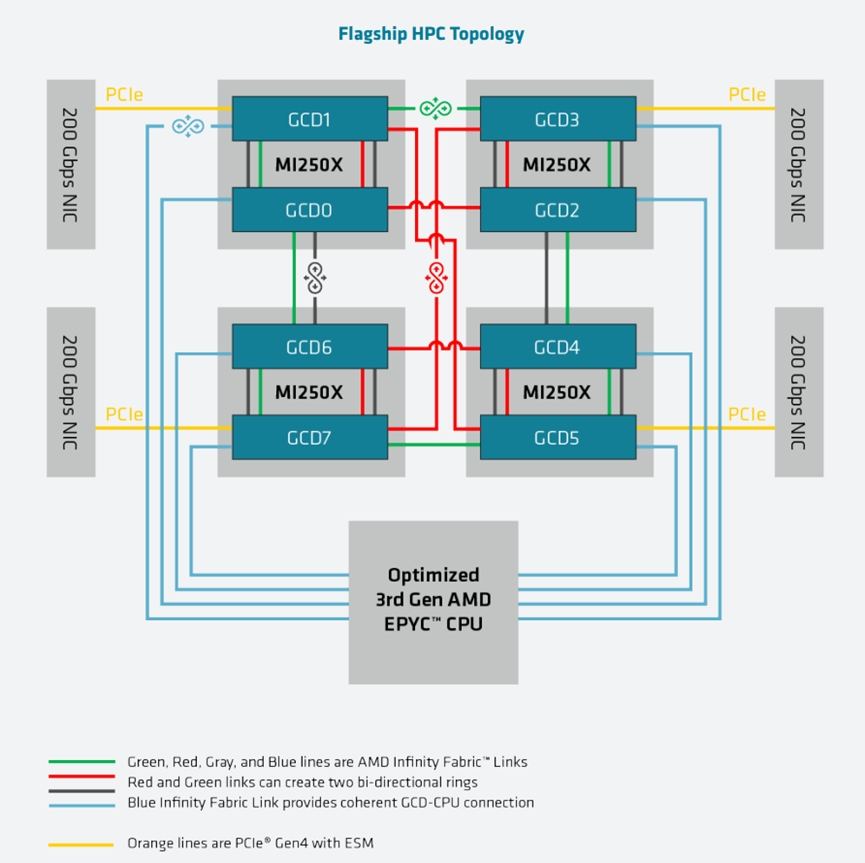
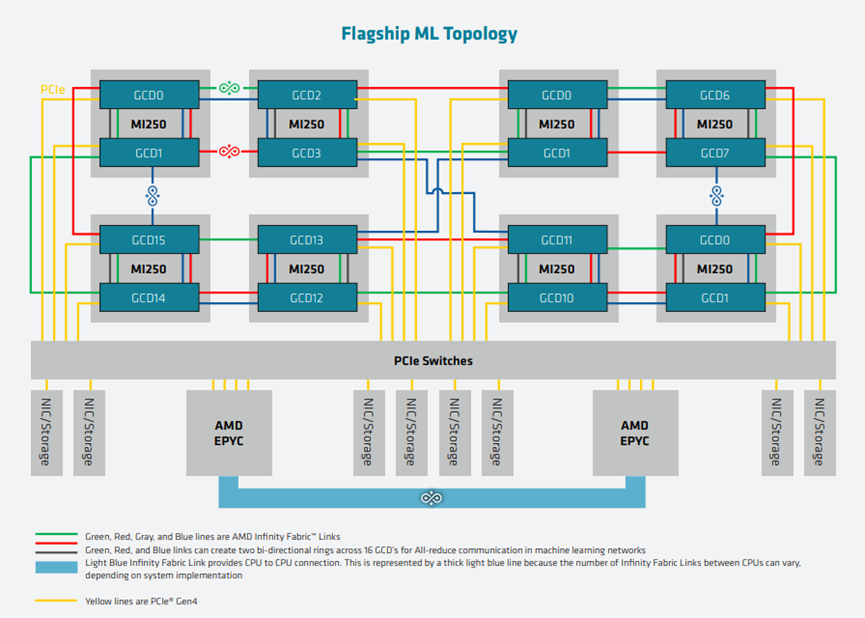
HPC/ML节点结构:

ML优化后的节点结构图:
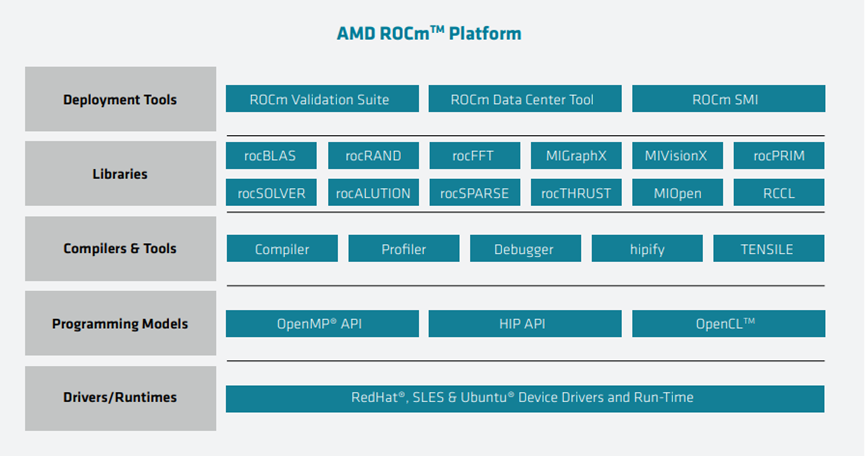
AMD的开源ROCm堆栈包括开发人员为科学计算和机器学习构建高性能应用程序所需的工具:
6 PowerVR
在2014年前后,ImageTech在PowerVR GR6500的系列GPU芯片中集成了光线追踪的相关单元:光线数据管理、场景加速结构生成、光线追踪单元及缓存加速等。
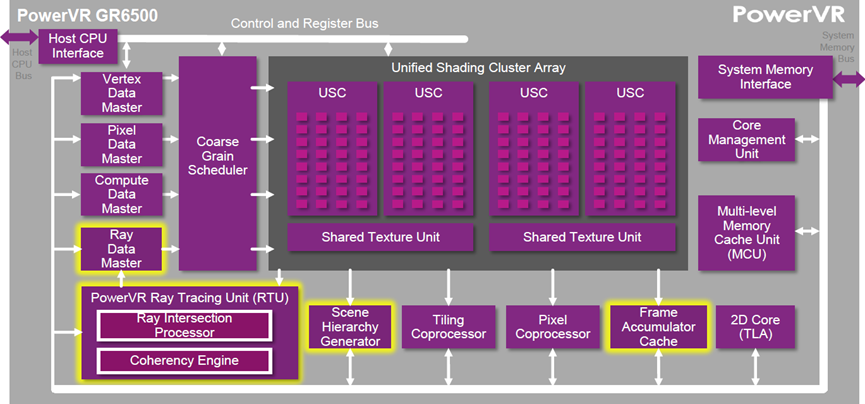
PowerVR Graphics Wizard硬件架构,新增了光线追踪相关的单元和处理。
Wizard的3个独特功能:固定功能射线盒和射线三角形测试器,一致性驱动的任务形成与调度,流式场景层次生成器。相干引擎(Coherency Engine)可以让我们同时处理下图所示的所有光线:

下图是其渲染效果:

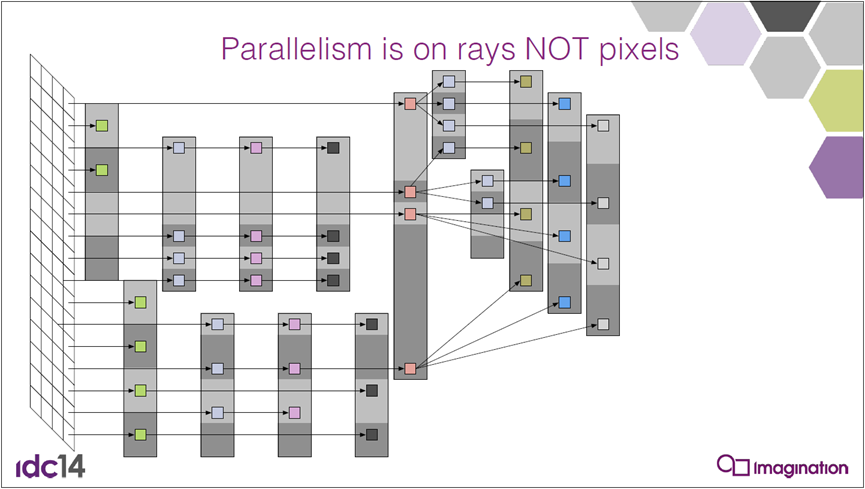
PowerVR并行的是光线而非像素:

光线采用了AABB测试,受“Fast Ray-Axis Aligned Bounding Box Overlap Tests with Plucker Coordinates” ( Jeffrey Mahovsky and Brian Wyvill)的启发。6条线构成了AABB的轮廓,光线原点和每个边向量的6个平面,平面法线和光线方向向量的点积,6个符号必须匹配且为负值。测试流程如下:

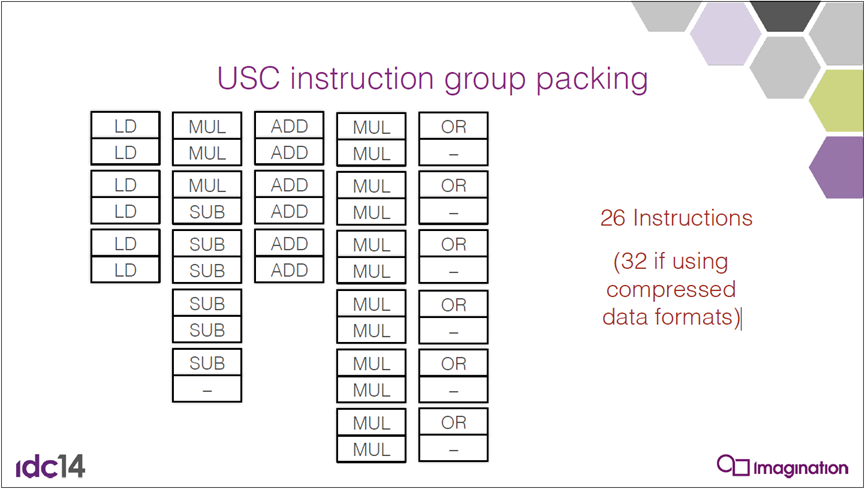
USC指令组打包,下图显示了26条指令(如果使用压缩数据格式,则为32条):
此功能的面积减少了44倍:

光线追踪单元和相干引擎的架构如下所示:

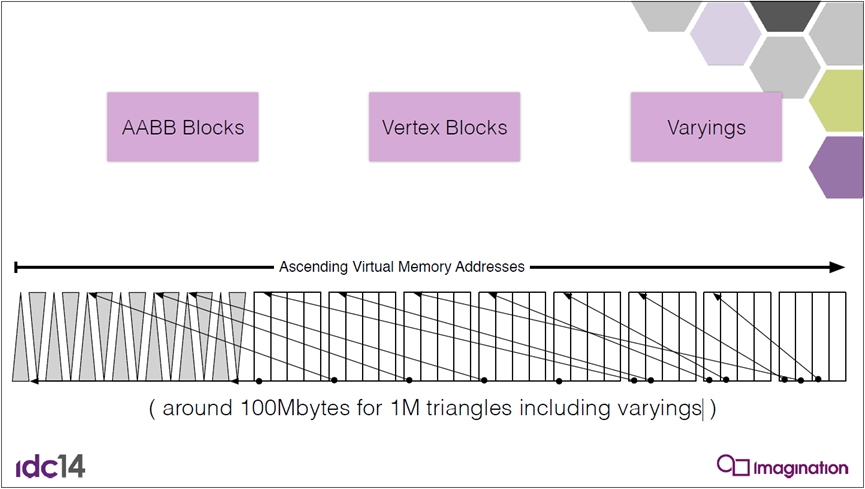
升序虚拟内存地址包含了AABB块、顶点块、变种等,大约100M,用于1百万个三角形,包括可变三角形:
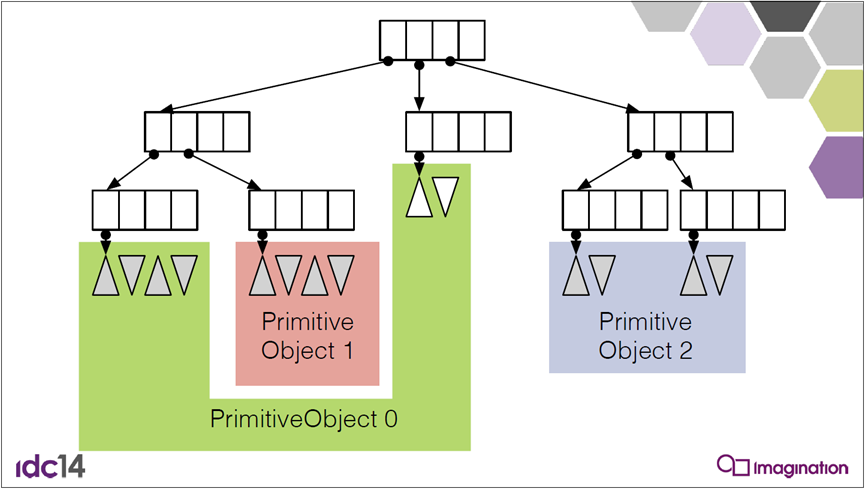
下图是流式场景层次生成器的效果和树形结构:

采用了一致性队列:
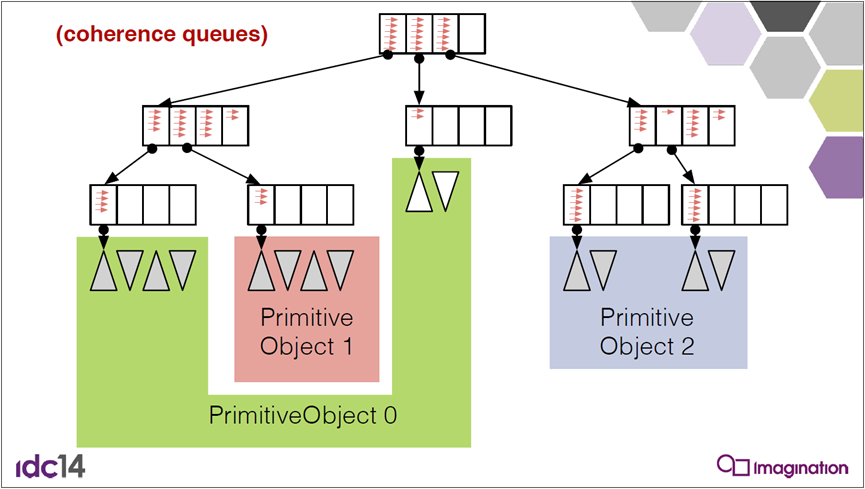
自动查找一致性路径:

场景层次生成器如下所示:

限制:场景由三角形表示——与今天相同,BVH采用经过优化的定义格式进行实现和遍历,三角形顺序通常必须遵循空间相干流,需要近似的场景比例估计,几何体着色器不与光线追踪管线内联。
加强的点在于:着色群集工作负荷不高于顶点着色器,只需处理在世界空间中实际移动的几何体,唯一算法仅将工作集约束到内部寄存器,单遍操作:与顶点着色器执行一致,很好地处理“长而瘦的三角形”问题,流式写入外部存储器,由于构建算法,无损压缩输出格式,紧凑逻辑。
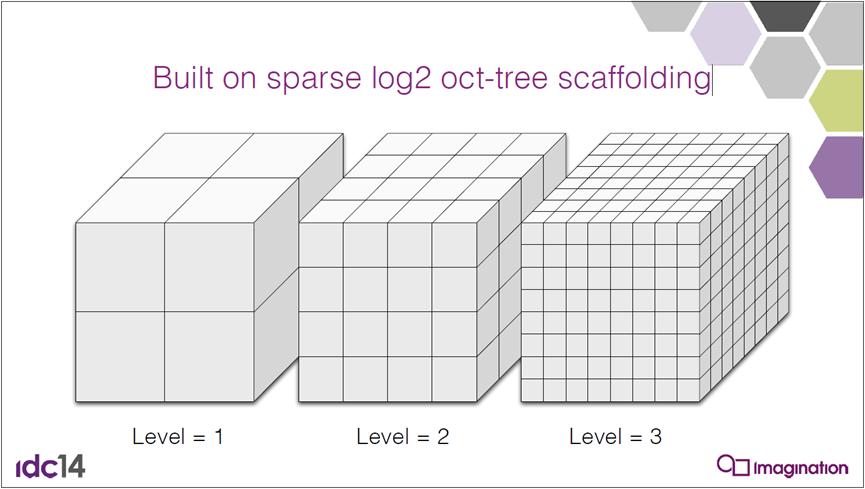
基于稀疏的log2八叉树层次结构:
整体执行流程如下:
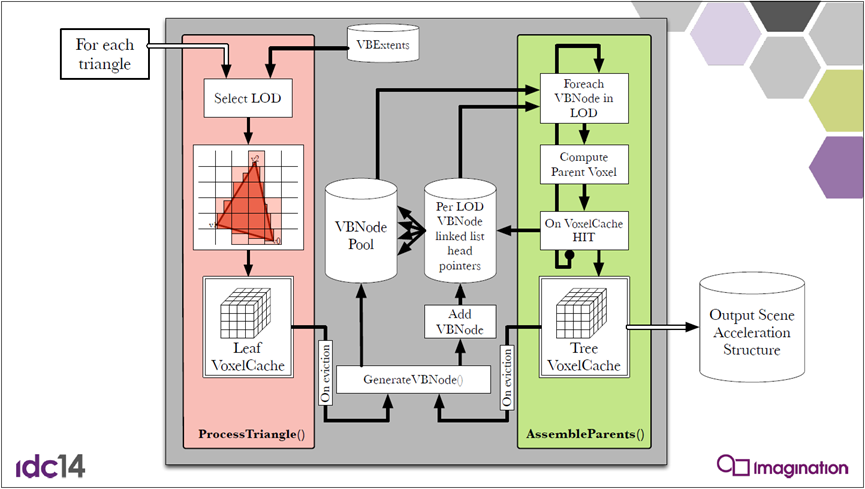
经过一些三角形处理之后的情形如下:

组装父节点之后:

一个级别的父节点组装后如下所示:

光追硬件架构各个部件的性能如下:

PowerVR光线追踪具有硬件中的场景层次生成器(SHG),SHG生成边界体层次结构数据结构,该数据结构被设计为大大提高检测哪些三角形与哪些光线相交的效率。使用蛮力方法将需要使用世界上的每个三角形测试每一条光线,过于昂贵而无法实时执行。下图是基于PowerVR GPU的实时光线追踪流程图:

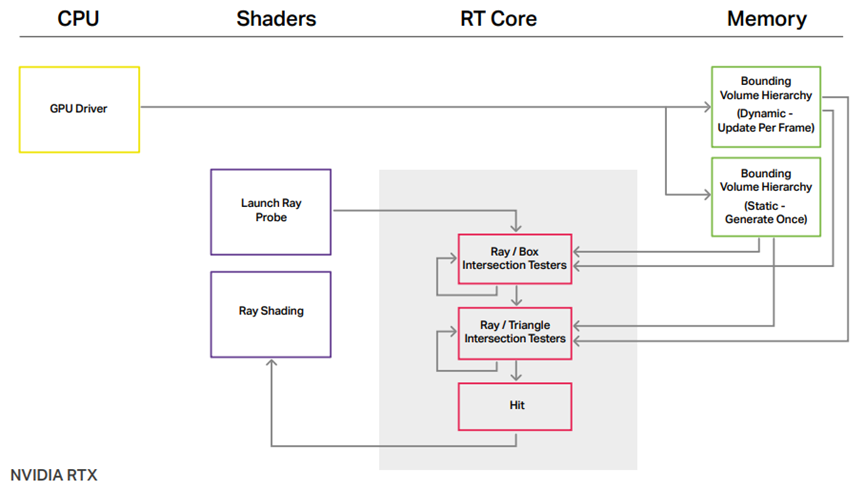
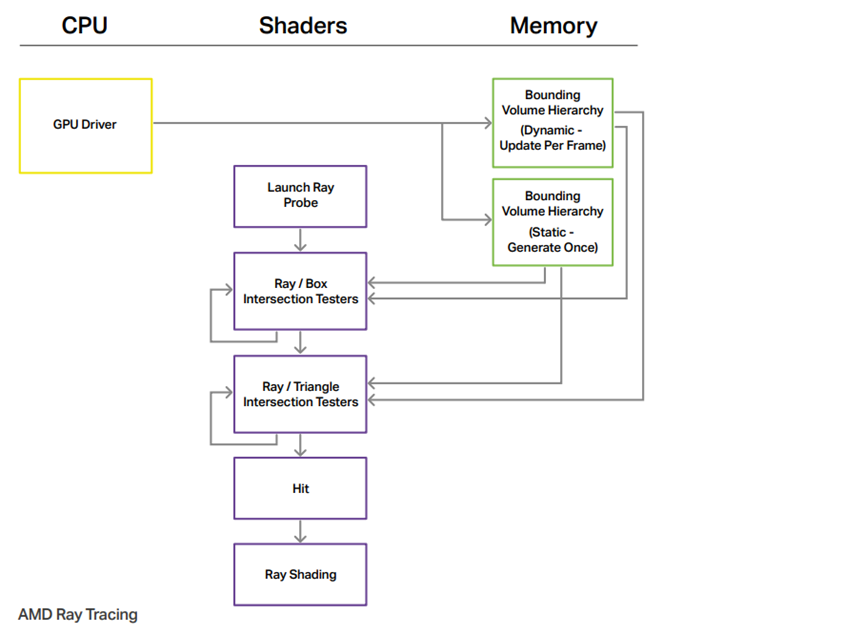
作为对比,以下分别是NV和AMD的实时光线追踪架构图: