

如何使用 LLVM 编写编译器
如何使用 LLVM 编写编译器
在本文中,将探讨一个简单的编译器的实现,该编译器能够将 IBM RPG 编程语言转换为现代硬件的可执行机器代码。它不是一个功能齐全的RPG编译器:它实现了语言的一些基本结构,但它足以理解如何使用LLVM基础设施来处理高级语言。
本文涵盖的主题包括:
- 使用 ANTLR 创建编译器前端
- 使用 LLVM 基础架构和核心库生成机器代码
- 生成用于源代码级调试的调试信息
生成机器可执行代码的主要好处是最佳性能和对运行时环境的最低要求。像往常一样,该项目的源代码可在GitHub上找到,网址为:https://github.com/Strumenta/article-llvm-rpg。LLVM基础设施主要在C++,因此这是一个C++项目。
什么是LLVM?
正在编写一个编译器能够将高级人类可读代码转换为可执行机器代码的软件涉及大量工作。但是,通过使用LLVM,将获得两个主要好处:
- 将获得的可执行文件将非常快,因为LLVM是一个成熟的工业级项目,具有出色的优化
- LLVM能够为不同的平台生成机器代码。通过为语言(RPG)编写前端,将能够获得LLVM支持的所有平台的可执行文件,而无需额外的工作
更详细地说,LLVM提供了一个简化此过程的基础架构,提供了工具和API来为现有语言编写编译器或实现全新的编程语言。它被设计为非常模块化,并支持所有编译阶段,包括前端处理、代码生成、优化等。LLVM的主要构建块可以细分为三个逻辑类别:前端,中间表示(IR)和后端。
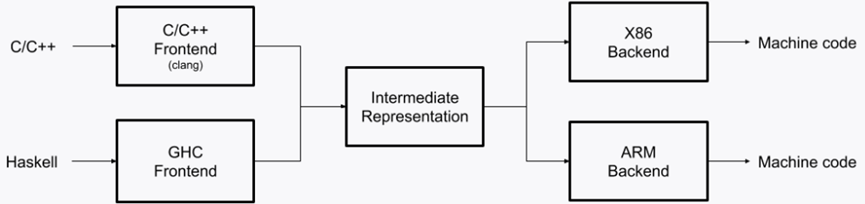
前端组件负责将源代码转换为中间表示(IR),这是LLVM基础架构的核心。IR 用于所有 LLVM 编译阶段,并且可以根据其存储位置具有不同的格式:在编译器内存中、作为位码在磁盘上或作为人类可读的汇编语言。中间表示 (IR) 是一个静态单一分配(SSA)提供类型安全性、灵活性和实现高级语言功能的表示形式。
后端模块负责将 IR 转换为特定硬件,例如英特尔 X86 或 ARM 架构。
为特定 CPU 模型生成机器代码是一项非常复杂的任务,需要深入了解指令集的许多低级细节。此外,机器代码优化是另一项涉及复杂算法的任务,难以开发,调试和维护。LLVM选择SSA表示,这是因为它可以应用一堆众所周知的代码优化算法。LLVM 后端接收输入有效的 IR 代码,并生成优化的机器代码,从而简化编译器实现.
LLVM项目在Apache许可证v2.0下发布(有一些例外),它允许将软件作为商业产品的一部分。
LLVM 基础架构
LLVM 基础结构的安装取决于目标操作系统。
简单的方法是从 llvm.org 下载二进制发行版。如网站上所述,平台之间存在差异。
第二个选项包括克隆 Github 存储库,并按照说明从头开始构建 LLVM 基础架构。
LLVM 是一个 C/C++ 项目,需要 CMake 来生成项目文件,需要一个 C/C++ 编译器来构建项目二进制文件工具和库。
选择了第二个选项,在 Ubuntu Linux 机器上构建了 LLVM 项目,这个过程花费了很多小时,必须修复一些小问题,例如缺少依赖项。尽可能从头开始编译项目,以熟悉项目的结构和创建的二进制文件。一旦LLVM基础设施准备就绪,就可以使用clang查看人类可读的中间表示(IR),clang是C语言家族语言的前端。
hello.c
#include <stdio.h>
int main() {
int a = 1;
int b = 1;
int c = a + b;
printf("%d\n",c);
}
从shell调用提供命令行开关的 clang, 以生成 LLVM IR。
strumenta@system-76:~hello$ clang -emit-llvm -S hello.c -o hello.ll
将生成hello.ll作为输出。
hello.ll
; ModuleID = 'hello.c'
source_filename = "hello.c"
target triple = "x86_64-pc-linux-gnu"
@.str = private unnamed_addr constant [4 x i8] c"%d\0A\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i32 1, i32* %1, align 4
store i32 1, i32* %2, align 4
%4 = load i32, i32* %1, align 4
%5 = load i32, i32* %2, align 4
%6 = add nsw i32 %4, %5
store i32 %6, i32* %3, align 4
%7 = load i32, i32* %3, align 4
%8 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %7)
ret i32 0
}
declare dso_local i32 @printf(i8*, ...) #1
该文件hello.ll是将hello.c C程序翻译成LLVM IR。可以直接执行IR的lli的IR。
strumenta@system-76:~hello$ lli hello.ll
2
要创建可执行二进制文件,可以将 IR 文件传递给 clang。
strumenta@system-76:~hello$ clang -x ir hello.ll -o hello.out
strumenta@system-76:~hello$./hello.out
2
上面的可执行目标是主机 CPU,但 LLVM 可以为许多 CPU 模型生成程序集,也可以为 WebAssembly 运行时生成位码。
RPG语言
RPG语言(Report Program Generator)由IBM于1959年开发,目的是从数据文件生成报告。对于Strumenta,非常了解RPG程序,因为为它创建了一个开源的JVM解释器,可以在GitHub上找到。稍后会详细介绍。
该语言随着时间的推移而发展,如今RPG中的软件仍在许多行业中使用和维护,并得到IBM的全力支持。
尽管该语言的最新版本提供了自由格式的源代码条目,但提供的示例是在原始固定格式定义规范中,该规范要求在行中对代码进行特定定位。
丁腈橡胶 S 8 0
上面的示例声明了 NBR 变量,该变量是一个具有 8 位数字和 0 位十进制的标量变量。语句由 C 标识,下面是赋值示例。
C Eval NBR = 55
使用 ANTLR 实现 LLVM 前端
该项目中的前端解析器是使用 ANTLR 生成的,从 Ryan Eberly 创建的 RPG 语言的开源语法开始,并作为 Github 的一部分在Jariko项目。Jariko是Strumenta设计的开源JVM解释器,并与客户Sme.UP合作开发。
ANTLR 生成词法分析和解析器,用于馈送符号表并创建抽象语法树,然后代码生成器遍历 AST 以生成 LLVM IR。
这编译器是用 C/C++ 编写的,可以在 C++ 中找到有关为 ANTLR 生成解析器的详细信息 Getting Started with ANTLR in C++。
编译器体系结构很简单。词法分析器和解析器由 ANTLR 从语法文件开始生成。解析器实现转换抽象语法树 (AST) 中的解析树并填充符号表。
代码生成器处理生成 IR 作为输出的 AST 和符号表。

要实现从解析树到符号表和 AST 的转换,需要扩展 ANTLR 生成的 Visitor 类。根据语言的复杂性,访问者子类可能会变得很大。为简单起见,该过程分为两个阶段,第一个过程是填充符号表的数据声明,第二个过程负责语句和 AST 生成。
此设计决策允许维护两个具有明确定义行为的分离的访客子类。

RpgVisitor 扩展了 ANTLR 生成的解析器,并实现了子类中使用的通用功能,例如表达式求值。
RpgDeclarationVisitor 负责处理数据声明并填充符号表,而 CodeVisitor 则创建 AST。
compiler.cpp
// First Pass parse declarations
RpgDeclarationVisitor declarationVisitor(file,this);
declarationVisitor.visit(tree);
symbolTable->dump();
// Second Pass parse statements
RpgCodeVisitor codeVisitor(file,this);
codeVisitor.visit(tree);
codeVisitor.dump();
// Code Generation
GeneratorLLVM *generator = new GeneratorLLVM(file,emitDebugInfo);
generator->process(symbolTable,ast);
generator->dump();
最后一部分执行代码生成,它采用符号表和 AST 并生成 LLVM IR。emitDebugInfo 用于指示代码生成器,包含可用于使用调试器运行代码的调试信息。
符号表
符号表是一个数据库,其中包含有关变量、子例程、数据结构等的信息。该项目中使用的设计允许存储RPG数据声明。

符号由其名称和一个或多个符号类型表示,该符号类型存储符号的特征,例如大小、小数位数或函数中的参数列表。
类的子类用于存储此类信息。
访问符号表的键是符号的名称。符号按范围进行组织。在RPG语言的这种特定实现中,所有符号都是全局的,因此所有符号都存储在同一个范围内。
例如,考虑 RPG 中的简单标量定义:
D NBR S 8 0
该声明将 NBR 定义为一个独立的字段,它是一个普通的标量变量。它有一个名称 (NBR),定义类型为“S”,8 位数字和 0 位小数。
符号表中声明的表示形式将是具有 SymbolSpecifier 的 Symbol 类的实例,该 SymbolSpecifier 包含有关其类型的相关信息。符号使用名称作为键存储在Map中。
现在让考虑一个数组声明
D NBR S 8 0 DIM(10)
与前面的情况一样,符号表中的表示形式,将是具有 SymbolSpecifier 和 ArrayDeclarator 的 Symbol 类的实例。

符号表 API 提供将符号添加到特定范围的方法。
在声明处理期间,类检测数据声明,检查语法树并创建具有相应属性的符号实例。
例如,看看下面的代码片段:
declaration.cpp
Any RpgDeclarationVisitor::visitDspec(DspecContext *ctx) {
/* Attempts to create the symbol */
try {
std::shared_ptr<Symbol> symbol = this->parseSymbol(ctx);
compiler->symbolTable->add(symbol);
} catch(RpgException& e) {
std::cerr << "ERROR " << this->filename << "(" << ctx->getStart()->getLine() << ") : " << e.getMessage() << std::endl;
exit(-1);
}
return RpgParserBaseVisitor::visitDspec(ctx);
}
解析树的处理在 parseSymbol 方法中实现。
std::shared_ptr<Symbol> RpgDeclarationVisitor::parseSymbol(DspecContext *ctx) {
if (ctx->ds_name()) {
int size = 0;
int decimals = 0;
/* Symbol Name */
std::string tmp(ctx->ds_name()->getText());
std::string name = trim(tmp);
if(!name.empty()) {
/* Size and decimals */
size = stoi(ctx->TO_POSITION()->getText());
if (ctx->DECIMAL_POSITIONS()) {
if (is_number(ctx->DECIMAL_POSITIONS()->getText())) {
decimals = stoi(ctx->DECIMAL_POSITIONS()->getText());
if(decimals > 0) {
throw RpgException( ctx->getText() + " DECIMAL not supported");
}
}
}
/* Creates the symbol and the specifier */
std::shared_ptr<Symbol> symbol = std::make_shared<Symbol>(name, ctx->ds_name()->getStart()->getLine());
std::shared_ptr<SymbolSpecifier> specifier = std::make_shared<SymbolSpecifier>("S", size, decimals);
for (auto keyword : ctx->keyword()) {
if (keyword->keyword_dim()) {
int arraySize = stoi(keyword->keyword_dim()->simpleExpression()->getText());
std::shared_ptr<ArrayDeclarator> declarator = std::make_shared<ArrayDeclarator>(arraySize);
symbol->addDeclarator(declarator);
}
if (keyword->keyword_inz()) {
if(keyword->keyword_inz()->simpleExpression()->expression()) {
std::shared_ptr<Expression> expression = RpgVisitor::parseExpression(keyword->keyword_inz()->simpleExpression()->expression());
specifier.get()->setValue(expression);
} else {
std::shared_ptr<Expression> expression = RpgVisitor::parseExpression(keyword->keyword_inz()->simpleExpression());
specifier.get()->setValue(expression);
}
}
}
symbol->addSpecifier(specifier);
return symbol;
}
throw RpgException( ctx->getText() + " INVALID identifier ");
}
throw RpgException( ctx->getText() + " UNABLE to parse declaration ");
}
尽管符号表结构能够表示典型的 RPG 数据声明,并且 LLVM 为本项目范围提供了对定点算术和数据类型的支持,但仅支持 64 位整数类型。
抽象语法树 (AST)
编译器的第二遍包括处理代码语句和表达式以及生成 AST。
AST 中的所有节点都是 Node 类的子类,它们存储有关语句的信息,例如源代码中的行、类型和访问者在遍历树时调用的 accept 方法。

类图是实际 AST 的简化版本,但提供了数据结构背后的基本思想。Node 类包含实现树结构的 Node 实例的向量。
RpgCodeVisitor 扩展了 ANTLR 生成的访问者,并实现了创建树结构的逻辑,从而将节点插入到相应的分支中。例如,当解析器检测到赋值语句时,它会从解析树中提取相关信息,创建适当的 Node 子类并将其插入到 AST 中。
parser.cpp
antlrcpp::Any RpgCodeVisitor::visitCsEVAL(CsEVALContext *ctx) {
if(ctx->target()) {
std::string target = ctx->target()->getText();
/* Parse the right side of the assignment */
std::shared_ptr<Expression> expression =
parseExpression(ctx->fixedexpression->expression());
/* Creates the assignment statement node */
std::shared_ptr<AssignmentStatement> assignment =
AssignmentStatement::create(
target,
expression,
ctx->getStart()->getLine());
/* Add the node to the AST */
addNode(assignment);
}
return RpgParserBaseVisitor::visitCsEVAL(ctx);
}
addNode 方法实现将新节点插入树中的正确位置的逻辑。
每个节点都实现接受方法,该方法将生成器类作为参数,并调用实现访问者模式功能的相应访问方法。
ast.h
class AssignmentStatement : public Statement {
public:
/* Creates the assignment statement node */
llvm::Value *accept(Generator *v, void *param = nullptr) override {
return v->visit(this,param);
}
};
代码生成器是基类,声明一个访问方法,该方法将 Node 作为参数,用于 Node 的每个子类。具体的 GeneratorLLVM 派生自 Generator 类并实现访问方法,每个方法都为特定 AST 节点实现部分代码生成。在代码生成过程中生成的指令,由 GeneratorLLVM 类通过后面描述的 LLVM API 进行维护。
generator.h
class Generator {
public:
virtual void declare(Symbol *) = 0;
virtual llvm::Value* visit(AssignmentStatement *assignment,void *param)=0;
virtual llvm::Value* visit(MathExpression *expression,void *param)=0;
virtual llvm::Value* visit(ComparisonExpression *expression,void *param)=0;
virtual llvm::Value* visit(IntegerLiteral *integer,void *param)=0;
virtual llvm::Value* visit(Identifier *string,void *param)=0;
virtual llvm::Value* visit(SelectStatement *select,void *param)=0;
virtual llvm::Value* visit(ForStatement *loop,void *param)=0;
virtual llvm::Value* visit(SubroutineDeclaration *subroutine,void *param)=0;
virtual llvm::Value* visit(SubroutineInvocation *subroutine,void *param)=0;
};
LLVM IR API
到目前为止,介绍一下解析器实现以及捕获有关RPG源代码的相关信息所需的数据结构,下一步介绍生成IR表示。
在继续之前,有必要提供有关 LLVM 中,可用于生成 IR 的 API 的详细信息。
使用 IR 需要三个主要构造:IR: llvm::Module, llvm::IRBuilder and llvm::Context。
llvm::Module 类是用于存储代码的顶级容器,它提供了定义函数和全局变量的方法。
llvm::IRBuilder是一个帮助器对象,它提供生成 LLVM 指令的方法,如存储、加载、添加等,跟踪插入指令的位置并提供设置插入位置的方法。
最后,llvm::Context 是一个包含内部 LLVM 数据结构的对象,在许多 IRbuilder 方法中都需要它作为参数。
在这个项目中,llvm::Module, llvm::IRBuilder和llvm::Context被声明为 GeneratorLLVM 类的属性,并在构造函数中初始化。
generator.h
class GeneratorLLVM : public Generator {
public:
GeneratorLLVM(std::string name, bool emitDebugInfo = false) {
/* Module instantiation */
this->module = std::make_unique<llvm::Module>(llvm::StringRef(name),llvmContext);
/* IRBuilder instantiation */
this->builder = std::make_unique<llvm::IRBuilder<>>(llvmContext);
}
private:
std::unique_ptr<llvm::Module> module;
std::unique_ptr<llvm::IRBuilder<>> builder;
llvm::LLVMContext llvmContext;
}
LLVM IR API 的另一个关键类是 llvm::Value 类,它是所有计算值和其他键类(如 llvm::Instruction和llvm::Function)的基类。 LLVM IR API 提供了许多其他返回 llvm::Value子类的帮助程序类,例如,为了表示整数常量,API 提供了llvm::ConstantInt::get 返回llvm::ConstantInt 子类的方法。 此实现中的代码生成器使用此方法,例如,在处理 IntegerLiteral 节点时。
llvm::Value* GeneratorLLVM::visit(IntegerLiteral *integer,void *param) {
int64_t ivalue = stoi(integer->getValue());
/* Creates the LLVM constant representation */
return llvm::ConstantInt::get(llvmContext,llvm::APInt(64,ivalue,true));
}
llvm::Value 也是 llvm:BasicBlock 的基类,这是 LLVM IR 的另一个重要概念,表示非终止指令列表,后跟单个终止指令。
为了解释llvm:BasicBlock的基本思想,让考虑一个函数。
函数的主体是一个 llvm:BasicBlock,其中非终止指令表示代码的逻辑,终止符指令是返回指令。在处理 SubroutineDeclaration 节点时,可以找到函数定义的一个实际示例。
llvm::Value* GeneratorLLVM::visit(SubroutineDeclaration *subroutine) {
/* Lookup if the Module to find the function definition */
llvm::Function *function = module->getFunction(subroutine->getName());
if(function) {
/* Creates a new BasicBlock as the body of the function. */
llvm::BasicBlock *body =
llvm::BasicBlock::Create(llvmContext, "entry", function);
// Instruct the builder to generate the instruction in the body
builder->SetInsertPoint(body);
/* Emit the subroutine body, non-terminating instructions */
for (auto stmt = s>getNodes().begin(); stmt != s->getNodes().end();) {
stmt->get()->accept( this );
}
/* Insert the block terminator */
llvm::Value *ret =
llvm:: ConstantInt::get(llvmContext, llvm::APInt(32, 0, true));
builder->CreateRet(ret);
} else {
std::cout << subroutine->getName() << " not found!" << std::endl;
}
}
生成 LLVM IR:数据声明
LLVM IR 的生成发生在 GeneratorLLVM 类中,该类实现将符号表转换为数据声明的逻辑,并遍历 AST 以生成 IR 代码指令。
GeneratorLLVM 类的作用类似于提供 accept 方法的 AST Node 类的访问者。
generator.cpp
void GeneratorLLVM::process(std::shared_ptr<SymbolTable> symbolTable,std::shared_ptr<AST> ast) {
// Generates data declaration
std::map<...> global = symbolTable->getSymbols(0);
for(auto symbol = global.begin(); symbol != global.end();symbol++) {
declare(symbol->second.get());
}
// Generates the runtime initialization function
initializeRunTime(symbolTable);
// Generates code
for(node = ast->getNodes().begin();node!= ast->getNodes().end();++node) {
node->get()->accept(this);
}
}
代码非常简单。对于符号表中的每个符号,将生成一个数据声明。最后一个循环用于遍历 AST,并生成执行代码所需的 IR 指令。
要有一个想法生成LLVM IR,下面是一个基本RPG数据声明的示例。
D COUNT S 8 0
D NBR S 8 0
D RESULT S 8 0 INZ(1)
如前所述,GeneratorLLMV 类定义了两个属性,它们表示与 LLVM 库 llvm::Module 和 llvm::IRBuilder 的接口。GeneratorLLVM 的 declare 方法使用 llvm::Module 来创建全局变量。
void GeneratorLLVM::declare(class Symbol *symbol) {
// Declares a global variable
SymbolSpecifier *variable = symbol->getSpecifier();
if(variable) {
if( !module->getNamedGlobal(symbol->getName())) {
if(variable->getDecimals() == 0) {
module->getOrInsertGlobal(
symbol->getName(),
builder->getInt64Ty()
);
}
// Creates the variable
llvm::GlobalVariable *var =
module->getNamedGlobal(symbol->getName());
if(var) {
llvm::Constant *initValue =
llvm::ConstantInt::get(
llvmContext, llvm::APInt(64, 0, true)
);
var->setInitializer(initValue);
var->setLinkage(llvm::GlobalValue::CommonLinkage);
}
}
}
该方法将 Symbol 作为参数,使用 module->getNamedGlobal(symbol->getName()) 检查该符号是否已在模块中定义,然后创建执行 module->getOrInsertGlobal(...) 的全局变量。
如上所述,此实现仅支持整数类型,因此变量创建为 int64。
最后一步包括初始化,默认情况下设置为 0。
// Data declarations
@COUNT = common global i64 0
@NBR = common global i64 0
@RESULT = common global i64 0
初始化运行时用于生成数据初始化所需的代码。
在此示例中,RESULT 变量指定初始化值 1。在此实现中,初始化有意生成为执行开始时调用的单独函数,以在初始化值为表达式时生成指令。
D A S 8 0 INZ(1)
D B S 8 0 INZ(A+1)
初始化运行时负责生成 INZ 函数,生成计算表达式并将初始化值存储到目标变量中所需的代码。
void GeneratorLLVM::initializeRunTime(std::shared_ptr<SymbolTable> symbolTable) {
/* Emit the INZ function */
std::vector<llvm::Type*> params;
llvm::FunctionType *ft =
llvm::FunctionType::get(llvm::Type::getVoidTy(llvmContext),params,false);
llvm::Function *inz = llvm::Function::Create(ft,
llvm::Function::ExternalLinkage, "INZ", this->module.get());
llvm::BasicBlock *BB = llvm::BasicBlock::Create(llvmContext, "",inz);
builder->SetInsertPoint(BB);
/* Process the symbol table and create the initialization values */
std::map<..> global = symbolTable->getSymbols(0);
for(auto symbol = global.begin(); symbol != global.end();symbol++) {
SymbolSpecifier *specifier = symbol->second->getSpecifier();
if(specifier) {
llvm::Constant *initValue;
llvm::GlobalVariable *var = module->getNamedGlobal(symbol->first);
try {
std::shared_ptr<Expression> expression =
specifier->getValue();
if(expression) {
/* Evaluates the initialization expression */
llvm::Value* value = expression->accept(this);
/* Creates the store instruction */
builder->CreateStore(value,var);
}
} catch(RpgException& e) {
std::cerr << "ERROR " << this->filename << "(" <<
symbol->getLine() << ") : " << e.getMessage() << std::endl;
exit(-1);
}
}
}
/* Function terminator */
builder->CreateRetVoid();
if(llvm::verifyFunction(*inz)) {
std::cout << "verify function INZ failed!" << std::endl;
}
}
该实现提供了发现有关LLVM API的更多信息的机会。
llvm::FunctionType::get 创建函数的签名,在本例中它是一个没有参数的 void 函数。llvm::Function::create 调用在当前模块中创建函数 “INZ”。
上面 RPG 示例生成的 IR 输出如下所示:
// Data declarations
@COUNT = common global i64 0
@NBR = common global i64 0
@RESULT = common global i64 0
// main
define i32 @main(i32 %0) {
entry:
call void @INZ() // Runtime initialization
ret i32 0
}
// Runtime initialization function
define void @INZ() {
store i64 1, i64* @RESULT, align 4 // INZ(1)
ret void
}
代码生成器已将 INZ 函数的调用作为主函数中的第一个语句包含在内,这可确保正确初始化变量。
生成 LLVM IR:代码生成
代码生成器的最后阶段遍历 AST ,并发出实现 RPG 程序逻辑所需的 IR 指令。
如AST部分所述,GeneratorLLVM实现了访问者模式,该模式为Node的每个子类实现了访问方法。“赋值语句”节点包含目标变量的名称和要生成的表达式。
llvm::Value* GeneratorLLVM::visit(AssignmentStatement *assignment,void *param) {
/* Retrieve the global variable */
llvm::GlobalVariable* target =
module->getGlobalVariable(assignment->getTarget());
if(!target) {
std::cout << assignment->getTarget() << " not found!" << std::endl;
return nullptr;
}
if(assignment->getExpression()) {
/* Visit and resolve the expression */
llvm::Value* v = assignment->getExpression()->accept(this);
if(v) {
/* Emit the store instruction */
builder->CreateStore(v, target);
}
}
return target;
}
该实现使用 llvm::Module->getGlobalVariable 方法,从全局存储中检索变量,访问表达式子树以生成实现计算所需的 IR 指令,最后使用 llvm::builder->CreateStore 方法生成赋值指令。
RPG source code
C EVAL COUNT = 0
LLVM IR
store i64 0, i64* @COUNT, align 4
生成一个访问 MathExpression AST 节点的表达式,该节点包含左侧和右侧以及存储为令牌类型的运算符。
llvm::Value* GeneratorLLVM::visit(MathExpression *expression) {
std::cout << expression->toString() << std::endl;
llvm::Value* L = expression->getLeft()->accept(this,param);
llvm::Value* R = expression->getRight()->accept(this,param);
switch (expression->getType()) {
case Token::PLUS:
return builder->CreateAdd(L, R, "addtmp");;
case Token::MINUS:
return builder->CreateSub(L, R, "subtmp");
case Token::MULTIPLY:
return builder->CreateMul(L, R, "multmp");
case Token::DIVIDE:
return builder->CreateSDiv(L, R, "divtmp");
}
return nullptr;
}
基于运算符 llvm::builder 发出相应的 IR 指令,“tmp”参数由 LLVM 在内部用于表示临时值。
RPG source code
C EVAL COUNT = A + 1
LLVM IR
%1 = load i64, i64* @A, align 4
%addtmp = add i64 %1, 1
store i64 %addtmp, i64* @COUNT, align 4
在这种情况下,LLVM 实现发现 2 乘以 1 的结果是 2,因此无需发出乘法指令。
比较表达式的处理以非常相似的方式工作,生成 IR 比较指令。
llvm::Value *GeneratorLLVM::visit(ComparisonExpression *expression) {
llvm::Value* L = expression->getLeft()->accept(this,param);
llvm::Value* R = expression->getRight()->accept(this,param);
switch (expression->getType()) {
case Token::EQUAL:
return builder->CreateICmp(llvm::ICmpInst::ICMP_EQ,L,R,"");
case Token::NE:
return builder->CreateICmp(llvm::ICmpInst::ICMP_NE,L,R,"");
case Token::LE:
return builder->CreateICmp(llvm::ICmpInst::ICMP_SLE,L,R,"");
case Token::GE:
return builder->CreateICmp(llvm::ICmpInst::ICMP_SGE,L,R,"");
case Token::GT:
return builder->CreateICmp(llvm::ICmpInst::ICMP_SGT,L,R,"");
case Token::LT:
return builder->CreateICmp(llvm::ICmpInst::ICMP_SLT,L,R,"");
default:
break;
}
return nullptr;
}
ComparisonExpression 在 RPG SELECT 语句中用于计算 WHEN 条件。
C SELECT
C WHEN NBR = 0
C EVAL RESULT = 0
C WHEN NBR = 1
C EVAL RESULT = 1
C OTHER
C EVAL RESULT = A + B
C ENDSLSELECT 语句稍微复杂一些,它提供了探索涉及条件分支的 LLVM API 的其他功能的机会。
llvm::Value* GeneratorLLVM::visit(SelectStatement *select) {
/* Create the SELECT block linked to the parent */
llvm::Function *selectBlock = builder->GetInsertBlock()->getParent();
/* Creates a block for the ENDSL, does not requires a terminator */
llvm::BasicBlock *selectEnd = llvm::BasicBlock::Create(llvmContext, "endselect");
/* Creates a block for the OTHER clause (if any) */
llvm::BasicBlock *otherBlock = nullptr;
if (select->getOther()) {
otherBlock = llvm::BasicBlock::Create(llvmContext, "other");
}
// Creates a block for each WHEN clause
for (int i = 0; i < select->getWhen().size(); i++) {
llvm::BasicBlock *trueBlock = llvm::BasicBlock::Create(llvmContext, "when_true", selectBlock);
llvm::BasicBlock *falseBlock;
// Last WHEN clause, if the OTHER is present became the false block
if (i == select->getWhen().size() - 1) {
if (otherBlock) {
falseBlock = otherBlock;
} else {
falseBlock = selectEnd;
}
} else {
falseBlock = llvm::BasicBlock::Create(llvmContext, "else");
}
llvm::Value *condition =
select->getWhen().at(i)->getExpression()->accept(this);
builder->CreateCondBr(condition, trueBlock, falseBlock);
// Emits the true block
builder->SetInsertPoint(trueBlock);
for (auto stmt = select->getWhen().at(i)->getNodes().begin();
stmt != select->getWhen().at(i)->getNodes().end(); ++stmt) {
stmt->get()->accept(this );
}
builder->CreateBr(selectEnd);
// Emits the true false block
selectBlock->getBasicBlockList().push_back(falseBlock);
builder->SetInsertPoint(falseBlock);
}
// Emits the other block
if (otherBlock) {
selectBlock->getBasicBlockList().push_back(otherBlock);
builder->SetInsertPoint(otherBlock);
for (auto stmt = select->getOther()->getNodes().begin(); stmt != select->getOther()->getNodes().end(); ++stmt) {
stmt->get()->accept(this,param);
}
builder->CreateBr(selectEnd);
}
/* Emits the ENDSL block */
selectBlock->getBasicBlockList().push_back(selectEnd);
builder->SetInsertPoint(selectEnd);
}
其关键概念是LLV llvm::builder->CreateCondBr(condition,trueBlock,falseBlock)方法,该方法接受条件指令和两个llvm::BasicBlock,第一个表示条件为真时要执行的指令,如果条件为假,则第二个表示要执行的指令。
这种方法的复杂性包括创建适当的区块链,以便在条件为真时执行相应的指令,否则继续评估下一个条件。其他 clausole是可选的,只有在存在的情况下才会考虑。
LLVM IR
%1 = load i64, i64* @NBR, align 4
/* evaluates WHEN NBR = 0 */
%2 = icmp eq i64 %1, 0
br i1 %2, label %when_true, label %else
/* WHEN NBR = 0 is true */
when_true:
store i64 0, i64* @RESULT, align 4
br label %endselect
/* WHEN NBR = 0 is false */
else:
%3 = load i64, i64* @NBR, align 4
/* evaluates WHEN NBR = 1 */
%4 = icmp eq i64 %3, 1
br i1 %4, label %when_true1, label %other2
/* WHEN NBR = 1 is true */
when_true1:
store i64 1, i64* @RESULT, align 4
br label %endselect
/* WHEN NBR = 1 is false */
other2:
/* OTHER */
%5 = load i64, i64* @A, align 4
%6 = load i64, i64* @B, align 4
%addtmp = add i64 %5, %6
store i64 %addtmp, i64* @RESULT, align 4
endselect:
最后一个 RPG 语句是 RPG FOR 循环,它由 ForStatement AST 节点表示。与 SELECT 语句类似,键是 llvm::builder->CreateCondBr,它评估循环是否已完成。
除了条件分支之外,还需要生成递增循环变量所需的指令。
llvm::Value *GeneratorLLVM::visit(ForStatement *loop,void *param) {
/* Initialize the loop variable */
llvm::Value *startVal = loop->getStart()->accept(this);
/* Loop variable */
llvm::GlobalVariable* variable =
module->getGlobalVariable(loop->getStart().get()->getTarget());
llvm::Function *forLoop = builder->GetInsertBlock()->getParent();
llvm::BasicBlock *loopBody = llvm::BasicBlock::Create(llvmContext, "loop", forLoop);
/* Start insertion in loop body */
builder->SetInsertPoint(loopBody);
/* Adds the statements to the loop body */
for (auto stmt = loop->getNodes().begin(); stmt != loop->getNodes().end(); ++stmt) {
stmt->get()->accept(this);
}
/* Computes the step value */
llvm::Value *step = nullptr;
if(loop->getStep()) {
step = loop->getStep()->accept(this);
} else {
/* If not specified step is 1 */
step = llvm:: ConstantInt::get(llvmContext, llvm::APInt(64, 1, true));
}
/* Emits instructions to update the loop variable */
llvm::Value* next = builder->CreateLoad(variable);
llvm::Value* tmp = builder->CreateAdd(next, step, "next");
builder->CreateStore(tmp, variable);
/* Create the "exit loop" block */.
llvm::BasicBlock *loopEnd = builder->GetInsertBlock();
llvm::BasicBlock *afterBB = llvm::BasicBlock::Create(llvmContext, "exitLoop", forLoop);
llvm::Value *endCond = loop->getEnd()->accept(this);
/* Insert the conditional branch */
builder->CreateCondBr(endCond, loopBody, loopEnd);
/* Restore the insert point the end of the loop */
builder->SetInsertPoint(loopEnd);
}
RPG
C FOR COUNT = 2 TO NBR
C EVAL A = B
C EVAL B = RESULT
C ENDFOR
LLVM IR
/* FOR COUNT = 2 initialize COUNT */
store i64 2, i64* @COUNT, align 4
loop:
%7 = load i64, i64* @B, align 4
store i64 %7, i64* @A, align 4
%8 = load i64, i64* @RESULT, align 4
store i64 %8, i64* @B, align 4
/* UPDATE COUNT */
%9 = load i64, i64* @COUNT, align 4
%next = add i64 %9, 1
store i64 %next, i64* @COUNT, align 4
/* TO NBR compare if COUNT == NBR */
%10 = load i64, i64* @COUNT, align 4
%11 = load i64, i64* @NBR, align 4
%12 = icmp sle i64 %10, %11
/* REPEAT from label loop or exit */
br i1 %12, label %loop, label %exitLoop
exitLoop:
在输出中,IR 相对容易识别 IR 指令是如何由 llvm::builder 生成的。
可以使用LLVM选择工具生成为FIB子例程生成的构建块的图形表示,以生成算法逻辑的图形表示。
strumenta@system-76:~hello$ llvm-as < hello.ll | opt -analyze -view-cfg

运行时函数
LLVM API 提供了创建和调用模块中定义的函数的方法。可以调用库中实现的外部函数,例如标准 C 库函数 printf。
要从 IR 调用 printf 函数,需要提供函数定义并提供所需的参数。
下面的 RPG 代码实现了计算斐波那契数的算法,该算法取自佛朗哥·隆巴多提供的示例,可在贾里科GitHub 存储库。
CALCFIB.rpgle
* Calculates number of Fibonacci in an iterative way
D ppdat S 8
D NBR S 8 0
D RESULT S 8 0 INZ(0)
D COUNT S 8 0
D A S 8 0 INZ(0)
D B S 8 0 INZ(1)
C *entry plist
C parm ppdat I
*
C Eval NBR = 55
C EXSR FIB
C DSPLY RESULT
*--------------------------------------------------------------*
C FIB BEGSR
C EVAL COUNT = 0
C SELECT
C WHEN NBR = 0
C EVAL RESULT = 0
C WHEN NBR = 1
C EVAL RESULT = 1
C WHEN NBR = 2
C EVAL RESULT = 2
C OTHER
C FOR COUNT = 2 TO NBR
C EVAL RESULT = A + B
C EVAL A = B
C EVAL B = RESULT
C DSPLY RESULT
C ENDFOR
C ENDSL
C ENDSR
C SETON LR
DSPLY的实现执行标准printf C函数的调用,它与原始RPG功能略有不同,因为它只能接受变量作为参数。
要调用 printf 函数,需要提供函数定义、格式字符串和返回值。初始化运行时负责创建格式字符串和外部函数的声明。
/* Emit the format string for the printf */
std::string str = "%lld\n";
auto charType = llvm::IntegerType::get(llvmContext, 8);
/* Initialize the vector */
std::vector<llvm::Constant *> chars(str.length());
for(unsigned int i = 0; i < str.size(); i++) {
chars[i] = llvm::ConstantInt::get(charType, str[i]);
}
/* Add '\0' at the end of the string */
chars.push_back(llvm::ConstantInt::get(charType, 0));
/* Initialize the string from the characters */
auto stringType = llvm::ArrayType::get(charType, chars.size());
/* declaration statement */
auto globalDeclaration = (llvm::GlobalVariable*) module->getOrInsertGlobal("pstr", stringType);
globalDeclaration->setInitializer(llvm::ConstantArray::get(stringType, chars));
globalDeclaration->setConstant(true);
globalDeclaration->setLinkage(llvm::GlobalValue::LinkageTypes::PrivateLinkage);
globalDeclaration->setUnnamedAddr (llvm::GlobalValue::UnnamedAddr::Global);
std::vector<llvm::Type*> pparams;
pparams.push_back(llvm::Type::getInt8PtrTy(llvmContext));
llvm::FunctionType *pft = llvm::FunctionType::get(llvm::Type::getInt32Ty(llvmContext),pparams, true);
llvm::Function *printf = llvm::Function::Create(pft, llvm::Function::ExternalLinkage, "printf", this->module.get());
这比平时稍微复杂一些,因为 C printf 函数需要一个指向格式参数字符串的指针,并且必须使用 llvm::ConstantExpr::getBitCast 进行转换。参数被推送到一个向量中,printf 函数声明从模块中检索,最后可以使用 builder->CreateCall 创建调用语句。
llvm::Value *GeneratorLLVM::visit(DisplayStatement *dsply,void *param) {
auto charType = llvm::IntegerType::get(llvmContext, 8);
llvm::Value* format =
llvm::ConstantExpr::getBitCast(module->getNamedGlobal("pstr"),
charType->getPointerTo());
llvm::Value* variable =
builder->CreateLoad(module->getGlobalVariable(
dsply->getIdentifier()->getValue()));
std::vector<llvm::Value *> args;
args.push_back(format);
args.push_back(variable);
llvm::Function *target = module->getFunction("printf");
llvm::CallInst *printf = builder->CreateCall(target, args);
return printf;
}
RPG CODE
C DSPLY RESULT
LLVM IR
%2 = load i64, i64* @RESULT, align 4
%3 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([5 x i8], [5 x i8]* @pstr, i32 0, i32 0), i64 %2)
可以运行FIBCALC.rpgle,使用rpg编译器生成LLVM IR代码。
strumenta@system-76:~fib$./rpg CALCFIB.rpgle > calcfib.ll
Compiling file:CALCFIB.rpgle

调试
现代软件开发通常发生在环境(IDE)中,该环境提供源代码级别的调试,可以一次单步执行一行,检查变量并设置断点。为了支持源代码级调试,编译器必须包含其他信息以标识源代码中的相应位置。
LLVM 提供了用于生成调试信息的 llvm::D IBuilder。
此项目中描述的编译器可以使用命令行上的 –debug 选项生成调试信息。
LLVM使用一种称为DWARF的格式,这是一种紧凑的编码来表示源代码中的类型,代码和变量位置。
像 gdb 这样的调试器支持 DWARF 格式,从而有机会在源代码级别调试代码。
使用调试信息生成斐波那契 IR 后,可以使用 clang 制作可执行文件。
strumenta@system-76:~fib$./rpg --debug CALCFIB.rpgle > calcfib.ll
strumenta@system-76:~fib$ clang -x ir calcfib.ll -o calcfib.out
Microsoft(TM)Visual Studio Code是一个IDE,可以使用gdb作为集成的调试器,但具有更直观的用户界面。

结论
在本文中,已经了解了如何构建一个简单但高效的编译器。通过利用LLVM,可以用有限的投资构建工业级编译器。使用像 LLVM 这样成熟的产品会带来一些额外的好处,例如对调试的高级支持。
LLVM 基础结构提供了用于生成 IR 和生成二进制可执行代码的工具和库。
当用ANTLR补充LLVM时,解析器生成得到了一个非常有效的组合。
虽然这些出色的工具大大降低了开发编译器,要实现高级语言(如 RPG)中提供的全部功能,例如不同的数据类型、数据结构、字符串表示和操作、内置函数、文件管理等,仍然需要付出巨大的努力。
为了简化该过程,可以利用现有的C / C++库为两种语言通用的函数(即数学函数)创建一个接口,并为不可用的函数提供实现。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2022-10-25 软硬件融合-芯片-自动驾驶-汽车混战
2021-10-25 Tesla Model汽车架构与FSD供应链