RISCV技术分析
初识RISC-V
https://www.cnblogs.com/wahahahehehe/p/15574316.html
了解RISC-V之前,先熟悉一个概念,指令集架构(Instruction Set Architecture,ISA)。
先来回顾一下,用C语言的编写的hello world程序,如下所示。
| |
void main()
|
| |
{
|
| |
printf("Hello, World!");
|
| |
}
|
该程序在PC、8位MCU、32位MCU这些不同的平台上都能正常运行,这是为什么呢?
答案就是有一套标准规范,正因为编译器和芯片设计时都遵循这套规范,使得高级语言编写的程序,经指定编译器编译后,能直接运行在对应的芯片上。
这套标准规范就是指令集架构(Instruction Set Architecture,ISA)。ISA主要分为复杂指令集(Complex Instruction Set Computer,CISC)和精简指令集(Reduced Instruction Set Computer,RISC),典型代表如下表1.1所示:
表1.1 复杂指令集和精简指令集
|
类型
|
名称
|
特点
|
应用领域
|
|
复杂指令集CISC
|
x86
|
性能高
速度快
兼容性好
|
PC
服务器
|
|
精简指令集RISC
|
ARM
|
生态成熟
非离散
需授权
|
移动设备
嵌入式设备
|
|
RISC-V
|
开源
模块化
简洁
可拓展
|
物联网
人工智能
边缘计算
|
ISA是底层硬件电路面向上层软件程序提供的一层接口规范,即机器语言程序所运行的计算机硬件和软件之间的桥梁。ISA主要定义了如下内容:
1) 基本数据类型及格式(byte、int、word……)
2) 指令格式,寻址方式和可访问地址空间大小
3) 程序可访问的通用寄存器的个数、位数和编号
4) 控制寄存器的定义
5) I/O空间的编址方式
6) 异常或中断的处理方式
7) 机器工作状态的定义和切换
8)……
ISA规定了机器级程序的格式和行为,即ISA具有软件看得见(能感觉到)的特性,因此用机器指令或汇编指令编写机器级程序时,必须熟悉对应平台的ISA。不过程序员大多使用高级语言(C/C++、Java)编写程序,由工具链编译转换为对应的机器语言,不需要了解ISA和底层硬件的执行机理。
RISC由美国加州大学伯克利分校教授David
Patterson发明。
RISC-V(读作”risk-five“),表示第五代精简指令集,起源于2010年伯克利大学并行计算实验室(Par Lab) 的1位教授和2个研究生的一个项目(该项目也由David Patterson指导),希望选择一款指令集用于科研和教学,该项目在x86、ARM等指令集架构中徘徊,最终决定自己设计一个全新的指令集,RISC-V由此诞生。RISC-V的最初目标是实用、开源、可在学术上使用,并且在任何硬件或软件设计中部署时无需版税。
2015年,为了更好的推动RISC-V在技术和商业上的发展,3位创始人做了如下安排:
1)成立RISC-V基金会,维护指令集架构的完整性和非碎片化。
2)成立SiFive公司,推动RISC-V商业化。
2019年,RISC-V基金会宣布将总部迁往瑞士,改名
RISC-V国际基金会。作为全球性非营利组织,已在全球
70多个国家拥有
2000+成员。包括华为、中兴、阿里巴巴、乐鑫等众多国内企业。
通过十多年的发展,RISC-V这一星星之火已有燎原之势。未来RISC-V很可能发展成为世界主流CPU之一,从而在CPU领域形成Intel
(x86)、ARM、RISC-V三分天下的格局。
1.模块化的指令子集
RISC-V指令集采用模块化的方式进行组织设计,由基本指令集和扩展指令集组成,每个模块用一个英文字母表示。
其中,整数(Integer)指令集用字母“I”表示,这是RISC-V处理器最基本也是唯一强制要求实现的指令集。其他指令集均为可选模块,可自行选择是否支持。
RISC-V指令模块描述如下表1.2所示:
表1.2 RISC-V指令模块描述
|
类型
|
指令集
|
指令数
|
状态
|
描述
|
|
基本指令集
|
RV32I
|
47
|
批准
|
32位地址与整数指令
支持32个通用寄存器
|
|
RV32E
|
47
|
草稿
|
RV32I的子集
支持16个通用寄存器
|
|
RV64I
|
59
|
批准
|
64位地址与整数指令集及
部分32位整数指令
支持32个通用寄存器
|
|
RV128I
|
71
|
草稿
|
128位地址与整数指令集及
部分64位和32位整数指令
支持32个通用寄存器
|
|
扩展指令集
|
M
|
8
|
批准
|
乘法(Multiplication)与除法指令
|
|
A
|
11
|
批准
|
存储器原子(Automic)操作指令
|
|
F
|
26
|
批准
|
单精度(32bit)浮点(Float)运算指令
|
|
D
|
26
|
批准
|
双精度(64bit)浮点(Double)运算指令
|
|
C
|
46
|
批准
|
压缩(Compressed)指令,指令长度位16bit
|
|
Zicsr
|
6
|
批准
|
控制和状态寄存器访问指令
|
通常把模块“I”、“M”、“A”、“F”和“D”的特定组合“IMAFD”称为通用组合(General),用字母“G”表示。如用RV32G表示RV32IMAFD。
2.可配置的寄存器
RV32I支持32个通用寄存器x0~x31,每个寄存器长度均为32位,其中寄存器x0恒为0,剩余31个为任意读/写的通用寄存器。
为了增加汇编程序的阅读性,汇编编程时通常采用应用程序二进制接口协议(Application Binary Interface,ABI)定义的寄存器名称。
RV32I通用寄存器如下表1.3所示:
表1.3 RV32I通用寄存器
|
寄存器名称
|
ABI名称
|
说明
|
存储者
|
|
x0
|
zero
|
读取时总为0,写入时不起任何效果
|
N/A
|
|
x1
|
ra
|
程序返回地址
|
Caller
|
|
x2
|
sp
|
栈空间指针
|
callee
|
|
x3
|
gp
|
全局变量指针(基地址)
|
/
|
|
x4
|
tp
|
线程变量指针(基地址)
|
/
|
|
x5 ~ x7
|
t0 ~ t2
|
临时寄存器
|
Caller
|
|
x8
|
s0/fp
|
保存寄存器/帧指针(配合栈指针界定函数栈)
|
Callee
|
|
x9
|
s1
|
保存寄存器(被调用函数使用时需备份并在退出时恢复)
|
Callee
|
|
x10, x11
|
a0, a1
|
函数参数寄存器(用于函数参数/返回值)
|
Caller
|
|
x12 ~ x17
|
a2 ~ a7
|
函数参数寄存器(用于函数参数)
|
Caller
|
|
x18 ~ x27
|
s2 ~ s11
|
保存寄存器(被调用函数使用时需备份并在退出时恢复)
|
Callee
|
|
x28 ~ x31
|
t3 ~ t6
|
临时寄存器
|
Caller
|
其中,Caller与Callee分别表示为:
Caller:来访者,简单来说就是打电话的,即调用函数的函数。
Callee:被访者,简单来说就是接电话的,即被调用函数。
如图1.1表示调用与被调用函数图示。
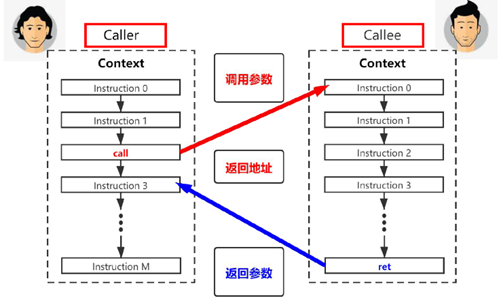
图1.1 调用与被调用函数图示
从图1.1中,可以得到以下结论:
1)寄存器的宽度由ISA指定,如RV32的通用寄存器宽度为32位,RV64的通用寄存器宽度为64位。
2) 如果支持浮点指令,则需额外支持32个浮点(Float Point)寄存器。
3)不同于ARM,RISC-V中PC指针不占用通过寄存器,而是独立的,程序执行中自动变化,无法通过通用寄存器访问和修改PC值。
3.特权级别
RISC-V规定如下四个特权级别(privilege
level),如表1.4所示:
表1.4 RV32I通用寄存器
|
等级(Level)
|
编码(Encoding)
|
名称(Name)
|
缩写(Abbreviation)
|
|
0
|
00
|
用户/应用模式(User/Application)
|
U
|
|
1
|
01
|
管理员模式(Supervisor )
|
S
|
|
2
|
10
|
Reserved
|
-
|
|
3
|
11
|
机器模式(Machine)
|
M
|
RISC-V特权级别可分为以下三种模式:
1)机器模式(M),RISC-V处理器在复位后自动进入机器模式(M),因此,机器模式是所有RISC-V处理器唯一必须要实现的特权模式。此模式下运行的程序权限最高,支持处理器的所有指令,可以访问处理器的全部资源。
2)用户模式(U),该模式是可选的,权限最低。此模型下仅可访问限定的资源。
3)管理员模式(S),该模式也是可选的,旨在支持Linux、Windows等操作系统。管理员模式可访问的资源比用户模式多,但比机器模式少。
通过不同特权模式的组合,可设计面向不同应用场景的处理器,如表1.5所示:
表1.5不同特权模式的组合设计处理器
|
模式数量
|
支持模式
|
目标应用
|
|
1
|
M
|
简单嵌入式系统
|
|
2
|
M,U
|
安全嵌入式系统
|
|
3
|
M,S,U
|
支持Unix、Linux、Windows等操作系统
|
1.2 RISC-V处理器及Roadmap
1.2.1 自研RISC-V处理器
从2017年开始关注并研究RISC-V开源指令集的32位MCU架构,针对快速中断响应、高带宽数据DMA进行优化,自定义压缩指令,研发设计硬件压栈(HPE,Hardware Prologue/Epilogue),并创新性提出免表中断(VTF,Vector Table Free)技术,即免查表方式中断寻址技术,同时引入两线仿真调试接口。
目前已形成了侧重于低功耗或高性能等,多个版本的RISC-V处理器。特点如下表1.6所示:
表1.6 多个版本的RISC-V处理器
|
Core
|
特点
|
|
支持指令
|
流水线
|
特权模式
|
中断嵌套
|
硬件压栈
|
免表中断
|
整数除法周期
|
内存保护
|
|
|
V2A
|
RV32EC
|
2级
|
M
|
2级
|
0
|
2路
|
-
|
无
|
|
|
V3A
|
RV32IMAC
|
3级
|
M+U
|
2级
|
2级
|
4路
|
17
|
无
|
|
|
V4A
|
RV32IMAC
|
3级
|
M+U
|
2级
|
2级
|
4路
|
17
|
RV标准PMU
|
|
|
V4B
|
RV32IMAC
|
3级
|
M+U
|
2级
|
2级
|
4路
|
9
|
无
|
|
|
V4C
|
RV32IMAC
|
3级
|
M+U
|
2级
|
2级
|
4路
|
5
|
RV标准PMU
|
|
|
V4F
|
RV32IMAFC
|
3级
|
M+U
|
8级
|
3级
|
4路
|
5
|
RV标准PMU
|
|
结合多年USB、低功耗蓝牙、以太网等接口的设计经验,基于多款自研RISC-V处理器,并基于32位通用MCU架构外加USB高速PHY、蓝牙收发器、以太网PHY等专业接口模块,推出增强版MCU+系列产品,如图1.2所示。
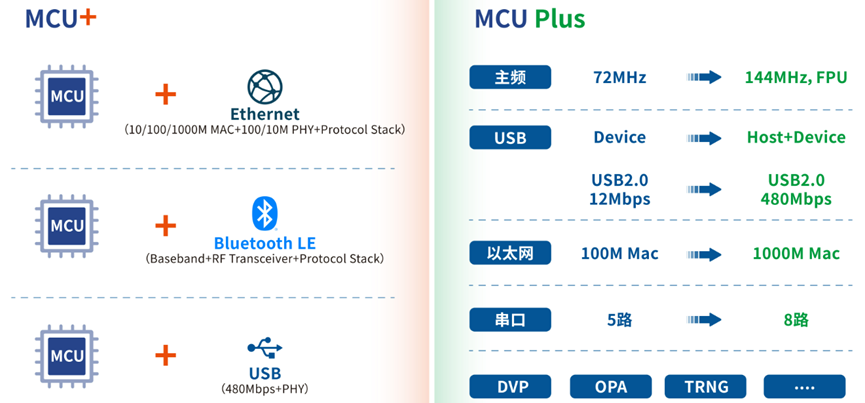
图1.2 增强版MCU+系列产品图示
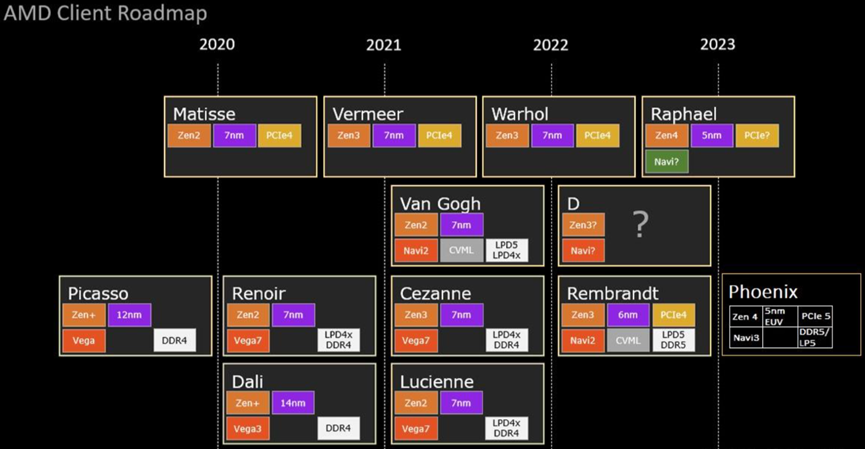
RISC-V系列MCU Roadmap如下图1.3所示:
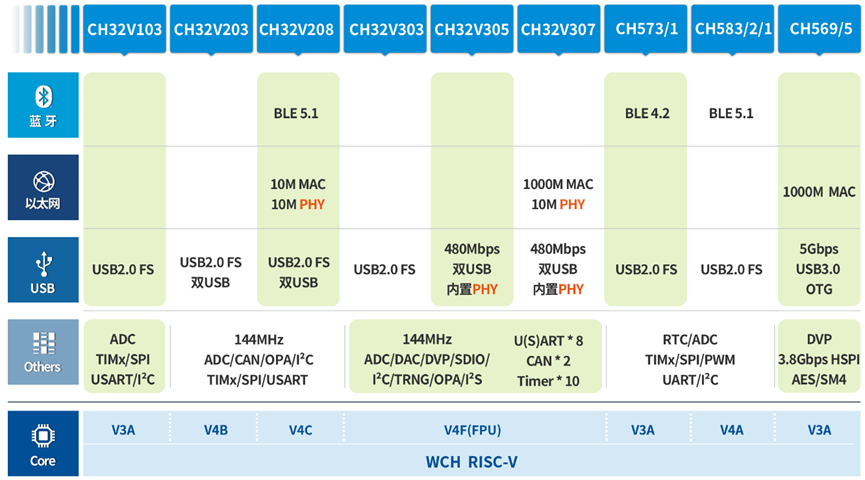
图1.3 RISC-V系列MCU
Roadmap
基于工业级互联型RISC-V MCU CH32V307,通过讲解RISC-V常用汇编指令,分析CH32V307的每个外设功能及使用方法,配合详细的示例代码,帮助大家熟悉RISC-V平台的嵌入式开发。
CH32V307配备了硬件堆栈区、快速中断入口,在标准RISC-V基础上大大提高了中断响应速度。加入单精度浮点指令集,扩充堆栈区,具有更高的运算性能。扩展串口U(S)ART数量到8组,电机定时器到4组。提供USB2.0高速接口(480Mbps)并内置了PHY收发器,以太网MAC升级到千兆并集成了10M-PHY模块。
详细参数如下图1.4所示:
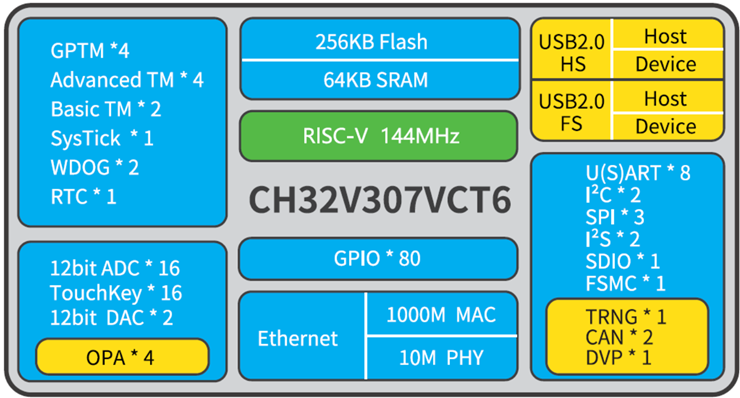
图1.4 RISC-V MCU CH32V307详细参数
1.3.1. risv 相关背景
1. ARM授权费
从技术的角度来看,以RISC为架构体系的ARM指令集的指令格式统一、种类少、寻址方式少,简单的指令意味着相应硬件线路可以尽量做到最佳化,从而提高执行速率。而RISC-V指令集,也是基于RISC原理建立的开放指令集架构(ISA)。两者区别可能在于,ARM标准授权方式只能根据自身需求,调整产品频率和功耗,不可以更改原有设计,以至于ARM架构文档冗长,指令数目复杂;RISC-V规避了这个缺点,架构文档页数仅有200多页,指令数目少,自由定制,操作方便。
一旦成为行业标准,垄断态势便会出现。ARM的技术授权模式会要求客户选择一种特定的芯片设计方案,并且支付许可费,这笔费用可能会达到上百万美金,芯片投产以后,再按照芯片量缴纳授权费。对于大型公司来说,在实力允许范围内,一次性支付大笔许可费;对于小型公司而言,许可费便会牵制住其前进的脚步。ARM新的收费模式,允许芯片厂商能够支付一笔适量的预付款,便可以获得需要的所有芯片技术组合,这个组合会包括SOC设计所需的基本知识产权和工具,芯片生产是再支付授权费和专利费即可。有人说,ARM推出新的授权方式是迫于RISC-V开源架构带来的市场压力,其实有一定道理。
2. riscv 发展历史
2010年,加州大学伯克利分校的一个研究团队准备设计CPU是,在选择指令集是遇到了困难,英特尔严防死守、ARM授权费太贵。无奈之下,花费了四年时间完成了RISC-V的指令集开发,并且该指令集彻底开放。正是因为RISC-V选择了对商业公司非常友好的BSD开源协议,以及RISC-V兼具精简和灵活等优点,众多商业公司纷纷关注RISC-V。
2010年,加州大学伯克利分校的一个研究团队正在准备启动一个新项目。在为新项目选择指令集的时候,他们发现,x86指令集被Intel控制得死死的,ARM指令集的授权费又非常贵,MIPS、SPARC、PowerPC也存在知识产权问题。在这种情况下,研究团队毅然决定,从零开始,设计一套全新的指令集。在外人看来,这是一件令人望而却步的工作。但事实上,伯克利的研究团队只召集了一个4人小组,用了3个月的时间,就完成了RISC-V的指令集开发。虽然看似非常轻松,但其实是有前提的。RISC-V之所以是个V(Five),就是因为它之前已经有过I、II、III、IV。负责带队研制这些RISC指令集的,不是别人,正是伯克利分校的David Patterson教授,就是RISC指令集的真正创始人。当年那篇正式提出精简指令集设计思想的开创性论文——《精简指令集计算机概述》,就是他和另一位名叫Ditzel的学者共同发表的。正是因为有相关的技术沉淀,伯克利分校的团队才能在短期内做出了RISC-V。
RISC-V指令集非常精简和灵活。它的第一个版本只包含了不到50条指令,可以用于实现一个具备定点运算和特权模式等基本功能的处理器。如果用户需要的话,也可以根据自己的需求自定义新指令。
高校毕竟是高校,功利心没有那么重。再加上研究团队本身确实也没钱没人去维护它。所以,在做出RISC-V指令集之后,研究团队决定,将它彻底开放,使用BSD License开源协议。BSD(Berkeley Software Distribution)开源协议是一个自由度非常大的协议,几乎可以说是“为所欲为”。它允许使用者修改和重新发布开源代码,也允许基于开源代码开发商业软件发布和销售。这就意味着,任何人都可以基于RISC-V指令集进行芯片设计和开发,然后拿去卖钱,而不需要支付授权费用。这就很好了,大批公司开始加入对RISC-V的研究和二次开发之中。
短短几年的时间里,包括谷歌、华为、IBM、镁光、英伟达、高通、三星、西部数据等商业公司,以及加州大学伯克利分校、麻省理工学院、普林斯顿大学、ETH Zurich、印度理工学院、洛伦兹国家实验室、新加坡南洋理工大学以及中科院计算所等学术机构,都纷纷加入RISC-V基金会。目前,RISC-V基金会共有包括18家白金会员在内的235家会员单位(数据截止2019年7月10日)。这些会员单位中包含了半导体设计制造公司、系统集成商、设备制造商、军工企业、科研机构、高校等各式各样的组织,足以说明RISC-V的影响力在不断扩大。因此,包括中科院计算所、华为公司、阿里巴巴集团等在内的20多个国内企事业单位,选择加入了RISC-V基金会。阿里还是其中的白金会员。2018年7月,上海经信委出台了国内首个支持RISC-V的政策。10月,中国RISC-V产业联盟成立。产品方面,中天微和华米科技先后发布了基于RISC-V指令集的处理器。
随着高通入股 sifive,清华伯克利联合成立国际 Risc-V 实验室,以及华米发布采用自研 Risc-V 的小米手环4,Risc-V
势头越发凶猛,大有追赶 ARM 之势。在技术上,Linux
5.1 官方内核默认支持了 Risc-V,Qemu 4.0.0
对 Risc-V 也提供了全面支持,而 Qemu Risc-V
Hypervisor / Xvisor 模拟也在紧锣密鼓开展,系统层面,Buildroot,
Openembedded,Debian,Fedora 的开发也如火如荼。
3. riscv 风险
ARM公司就专门建了一个域名为riscv-basics.com的网站,里面的内容主题为“设计系统芯片之前需要考虑的五件事”,从成本、生态系统、碎片化风险、安全性和设计保证上对RISC-V进行攻击。
尽管RISC-V在这场短暂的竞争中获胜,但ARM提出的那五个方面的质疑,也不是完全没有道理。尤其是碎片化问题,作为开源技术,RISC-V的确很难规避。
所谓碎片化:由于RISC-V允许用户自己任意添加新的指令,但照此趋势发展下去,可能以后很多芯片厂商开发出的RISC-V架构处理器,尽管都归属于同一RISC-V体系,但在实际应用搭配时,却不能够适配同样版本的软件。
4. 指令集
RISC-V是一个典型三操作数、加载-存储形式的RISC架构,包括三个基本指令集和6个扩展指令集,如表1.7所示,其中RV32E是RV32I的子集,不单独计算。
表1.7
RISC-V的指令集组成。
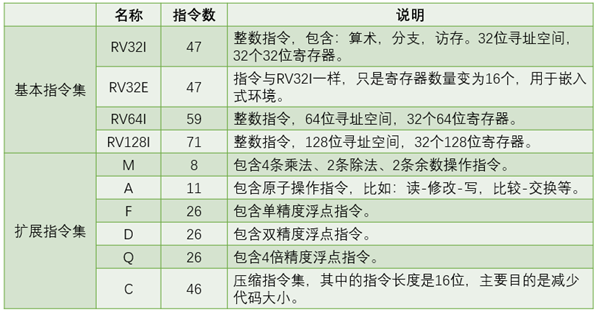
基本指令集的名称后缀都是I,表示Integer,任何一款采用RISC-V架构的处理器都要实现一个基本指令集,根据需要,可以实现多种扩展指令集,例如:如果实现了RV32IM,表示实现了32位基本指令集和乘法除法扩展指令集。如果实现了RV32IMAFD,那么可以使用RV32G来表示,表示实现了通用标量处理器指令集。这里只介绍RV32I的基本情况。
RV32I 指令集有47条指令,能够满足现代操作系统运行的基本要求,47条指令按照
功能可以分为如下几类。
1)整数运算指令:实现算术、逻辑、比较等运算。
2)分支转移指令:实现条件转移、无条件转移等运算,并且没有延迟槽。
3)加载存储指令:实现字节、半字、字的加载、存储操作,采用的都是寄存器相对寻址方式。
4)控制与状态寄存器访问指令:实现对系统控制与状态寄存器的原子读-写、原子读-修改、原子读-清零等操作。
5)系统调用指令:实现系统调用、调试等功能。
模块化的RISC-V架构,能够使得用户能够灵活选择不同的模块组合,以满足不同的应用场景。譬如针对于小面积低功耗嵌入式场景,用户可以选择RV32IC组合的指令集,仅使用Machine Mode(机器模式);而高性能应用操作系统场景,则可以选择譬如RV32IMFDC的指令集,使用Machine Mode(机器模式)与User Mode(用户模式)两种模式。而他们共同的部分则可以相互兼容。
ARM的架构分为A、R和M三个系列,分别针对于Application(应用操作系统)、Real-Time(实时)和Embedded(嵌入式)三个领域,彼此之间并不兼容。
1.3.2 可配置的通用寄存器组
RISC-V架构支持32位或者64位的架构,32位架构由RV32表示,其每个通用寄存器的宽度为32比特;64位架构由RV64表示,其每个通用寄存器的宽度为64比特。
RISC-V架构的整数通用寄存器组,包含32个(I架构)或者16个(E架构)通用整数寄存器,其中整数寄存器0被预留为常数0,其他的31个(I架构)或者15个(E架构)为普通的通用整数寄存器。
如果使用了浮点模块(F或者D),则需要另外一个独立的浮点寄存器组,包含32个通用浮点寄存器。如果仅使用F模块的浮点指令子集,则每个通用浮点寄存器的宽度为32比特;如果使用了D模块的浮点指令子集,则每个通用浮点寄存器的宽度为64比特。
1.规整的指令编码
在流水线中能够尽早尽快的读取通用寄存器组,往往是处理器流水线设计的期望之一,这样可以提高处理器性能和优化时序。这个看似简单的道理,在很多现存的商用RISC架构中都难以实现,因为经过多年反复修改,不断添加新指令后,其指令编码中的寄存器索引位置变得非常的凌乱,给译码器造成了负担。
得益于后发优势,同时总结了多年来处理器发展的教训,RISC-V的指令集编码非常的规整,指令所需的通用寄存器的索引(Index)都被放在固定的位置,如图1.5所示。因此指令译码器(Instruction Decoder)可以非常便捷的译码出寄存器索引,然后读取通用寄存器组(Register File,Regfile)。

图1.5 RISC-V的指令集编码格式
2.简洁的存储器访问指令
与所有的RISC处理器架构一样,RISC-V架构使用专用的存储器读(Load)指令和存储器写(Store)指令访问存储器(Memory),其他的普通指令无法访问存储器,这种架构是RISC架构的常用的一个基本策略,这种策略使得处理器核的硬件设计变得简单。
存储器访问的基本单位是字节(Byte)。RISC-V的存储器读和存储器写指令支持一个字节(8位),半字(16位),单字(32位)为单位的存储器读写操作,如果是64位架构还可以支持一个双字(64位)为单位的存储器读写操作。
RISC-V架构的存储器访问指令还有如下显著特点:
1)为了提高存储器读写的性能,RISC-V架构推荐使用地址对齐的存储器读写操作,但是地址非对齐的存储器操作RISC-V架构也支持,处理器可以选择用硬件来支持,也可以选择用软件来支持。
2)由于现在的主流应用是小端格式(Little-Endian),RISC-V架构仅支持小端格式。有关小端格式和大端格式的定义和区别,本文在此不做过多介绍,若对此不甚了解的初学者可以自行查阅学习。
3)很多的RISC处理器都支持地址自增或者自减模式,这种自增或者自减的模式虽然能够提高处理器访问连续存储器地址区间的性能,但是也增加了设计处理器的难度。RISC-V架构的存储器读和存储器写指令不支持地址自增自减的模式。
4)RISC-V架构采用松散存储器模型(Relaxed Memory Model),松散存储器模型对于访问不同地址的存储器读写指令的执行顺序不作要求,除非使用明确的存储器屏障(Fence)指令加以屏蔽。
这些选择都清楚地反映了RISC-V架构,力图简化基本指令集,从而简化硬件设计的哲学。RISC-V架构如此定义非常合理,能够达到能屈能伸的效果。譬如:对于低功耗的简单CPU,可以使用非常简单的硬件电路,即可完成设计;而对于追求高性能的超标量处理器,则可以通过复杂设计的动态硬件调度能力来提高性能。
3.高效的分支跳转指令
1)RISC-V架构有两条无条件跳转指令(Unconditional Jump),jal与jalr指令。跳转链接(Jump and Link)指令jal可用于进行子程序调用,同时将子程序返回地址存在链接寄存器(Link Register:由某一个通用整数寄存器担任)中。跳转链接寄存器(Jump
and Link-Register)指令jalr指令能够用于子程序返回指令,通过将jal指令(跳转进入子程序)保存的链接寄存器用于jalr指令的基地址寄存器,则可以从子程序返回。
2)RISC-V架构有6条带条件跳转指令(Conditional Branch),这种带条件的跳转指令跟普通的运算指令一样直接使用2个整数操作数,然后对其进行比较,如果比较的条件满足时,则进行跳转。因此,此类指令将比较与跳转两个操作放到了一条指令里完成。
作为比较,很多的其他RISC架构的处理器需要使用两条独立的指令。第一条指令先使用比较指令,比较的结果被保存到状态寄存器之中;第二条指令使用跳转指令,判断前一条指令保存在状态寄存器当中的比较结果为真时则进行跳转。相比而言RISC-V的这种带条件跳转指令不仅减少了指令的条数,同时硬件设计上更加简单。
3)对于没有配备硬件分支预测器的低端CPU,为了保证其性能,RISC-V的架构明确要求其采用默认的静态分支预测机制,即:如果是向后跳转的条件跳转指令,则预测为“跳”;如果是向前跳转的条件跳转指令,则预测为“不跳”,并且RISC-V架构要求编译器也按照这种默认的静态分支预测机制来编译生成汇编代码,从而让低端的CPU也能得到不错的性能。
为了使硬件设计尽量简单,RISC-V架构特地定义了所有的带条件跳转指令跳转目标的偏移量(相对于当前指令的地址)都是有符号数,并且其符号位被编码在固定的位置。因此,这种静态预测机制在硬件上非常容易实现,硬件译码器可以轻松的找到这个固定的位置,并判断其是0还是1来判断其是正数还是负数,如果是负数则表示跳转的目标地址为当前地址减去偏移量,也就是向后跳转,则预测为“跳”。当然对于配备有硬件分支预测器的高端CPU,则可以采用高级的动态分支预测机制来保证性能。
4.简洁的子程序调用
为了理解此节,需先对一般RISC架构中程序调用子函数的过程予以介绍,其过程如下:
1)进入子函数之后需要用存储器写(Store)指令来将当前的上下文(通用寄存器等的值)保存到系统存储器的堆栈区内,这个过程通常称为“保存现场”。
2)在退出子程序之时,需要用存储器读(Load)指令来将之前保存的上下文(通用寄存器等的值)从系统存储器的堆栈区读出来,这个过程通常称为“恢复现场”。
“保存现场”和“恢复现场”的过程,通常由编译器编译生成的指令来完成,使用高层语言(譬如C或者C++)开发的开发者,对此可以不用太关心。高层语言的程序中,直接写上一个子函数调用即可,但是这个底层发生的“保存现场”和“恢复现场”的过程,却是实实在在地发生着(可以从编译出的汇编语言里面,看到那些“保存现场”和“恢复现场”的汇编指令),并且还需要消耗若干的CPU执行时间。
为了加速这个“保存现场”和“恢复现场”的过程,有的RISC架构发明了一次写多个寄存器到存储器中(Store Multiple),或者一次从存储器中读多个寄存器出来(Load Multiple)的指令,此类指令的好处是,一条指令就可以完成很多事情,从而减少汇编指令的代码量,节省代码的空间大小。但是此种“Load Multiple”和“Store Multiple”的弊端是,会让CPU的硬件设计变得复杂,增加硬件的开销,也可能损伤时序使得CPU的主频无法提高,在设计此类处理器时,一般需要克服不少困难。
RISC-V架构则放弃使用这种“Load Multiple”和“Store Multiple”指令。并解释,如果有的场合比较介意这种“保存现场”和“恢复现场”的指令条数,那么可以使用公用的程序库(专门用于保存和恢复现场)来进行,这样就可以省掉,在每个子函数调用的过程中,都放置数目不等的“保存现场”和“恢复现场”的指令。
此选择再次印证了RISC-V追求硬件简单的哲学,因为放弃“Load Multiple”和“Store Multiple”指令,可以大幅简化CPU的硬件设计,对于低功耗小面积的CPU,可以选择非常简单的电路进行实现,而高性能超标量处理器,由于硬件动态调度能力很强,可以有强大的分支预测电路,保证CPU能够快速的跳转执行,从而可以选择使用公用的程序库(专门用于保存和恢复现场)的方式,减少代码量,但是同时达到高性能。
5.无条件码执行
很多早期的RISC架构发明了带条件码的指令,譬如在指令编码的头几位表示的是条件码(Conditional
Code),只有该条件码对应的条件为真时,该指令才被真正执行。
这种将条件码编码到指令中的形式,可以使得编译器将短小的循环,编译成带条件码的指令,而不用编译成分支跳转指令。这样便减少了分支跳转的出现,一方面减少了指令的数目;另一方面也避免了分支跳转带来的性能损失。然而,这种“条件码”指令的弊端,同样会使得CPU的硬件设计变得复杂,增加硬件的开销,也可能损伤时序使得CPU的主频无法提高,笔者在曾经设计此类处理器时便深受其苦。
RISC-V架构则放弃使用这种带“条件码”指令的方式,对于任何的条件判断,都使用普通的带条件分支跳转指令。此选择再次印证了RISC-V追求硬件简单的哲学,因为放弃带“条件码”指令的方式,可以大幅简化CPU的硬件设计,对于低功耗小面积的CPU,可以选择非常简单的电路进行实现,而高性能超标量处理器,由于硬件动态调度能力很强,可以有强大的分支预测电路,保证CPU能够快速的跳转执行达到高性能。
6.无分支延迟槽
很多早期的RISC架构均使用了“分支延迟槽(Delay Slot)”,最具有代表性的便是MIPS架构,在很多经典的计算机体系结构教材中,均使用MIPS对分支延迟槽进行过介绍。分支延迟槽就是指,在每一条分支指令后面,紧跟的一条或者若干条指令,不受分支跳转的影响,不管分支是否跳转,这后面的几条指令都一定会被执行。
早期的RISC架构,很多采用了分支延迟槽诞生的原因,主要是因为当时的处理器流水线比较简单,没有使用高级的硬件动态分支预测器,所以使用分支延迟槽,能够取得可观的性能效果。然而,这种分支延迟槽,使得CPU的硬件设计变得极为的别扭,CPU设计人员对此往往苦不堪言。
RISC-V架构则放弃了分支延迟槽,再次印证了RISC-V力图简化硬件的哲学,因为现代的高性能处理器的分支预测算法精度已经非常高,可以有强大的分支预测电路,保证CPU能够准确的预测跳转执行达到高性能。而对于低功耗小面积的CPU,由于无需支持分支延迟槽,硬件得到极大简化,也能进一步减少功耗和提高时序。
7.无零开销硬件循环
很多RISC架构还支持零开销硬件循环(Zero Overhead Hardware Loop)指令,其思想是通过硬件的直接参与,通过设置某些循环次数寄存器(Loop Count),然后可以让程序自动地进行循环,每一次循环则Loop Count自动减1,这样持续循环直到Loop Count的值变成0,则退出循环。
之所以提出发明这种硬件协助的零开销循环,是因为在软件代码中的for 循环(for i=0; i<N; i++)极为常见,而这种软件代码通过编译器编译之后,往往会编译成若干条加法指令和条件分支跳转指令,从而达到循环的效果。一方面这些加法和条件跳转指令占据了指令的条数;另外一方面条件分支跳转,如存在着分支预测的性能问题。而硬件协助的零开销循环,则将这些工作由硬件直接完成,省掉了这些加法和条件跳转指令,减少了指令条数且提高了性能。
然而有得必有失,此类零开销硬件循环指令,大幅地增加了硬件设计的复杂度。因此,零开销循环指令与RISC-V架构简化硬件的哲学是完全相反的,在RISC-V架构中,自然没有使用此类零开销硬件循环指令。
1.3.3 简洁的运算指令
在RISC-V架构使用模块化的方式组织不同的指令子集,最基本的整数指令子集(I字母表示)支持的运算,包括加法、减法、移位、按位逻辑操作和比较操作。这些基本的运算操作,能够通过组合或者函数库的方式,完成更多的复杂操作(譬如乘除法和浮点操作),从而能够完成大多数的软件操作。
整数乘除法指令子集(M字母表示)支持的运算包括,有符号或者无符号的乘法和除法操作。乘法操作能够支持两个32位的整数相乘,得到一个64位的结果;除法操作能够支持两个32位的整数相除,得到一个32位的商与32位的余数。
单精度浮点指令子集(F字母表示)与双精度浮点指令子集(D字母表示)支持的运算,包括浮点加减法,乘除法,乘累加,开平方根和比较等操作,同时提供整数与浮点,单精度与双精度浮点彼此之间的格式转换操作。
很多RISC架构的处理器在运算指令产生错误之时,譬如上溢(Overflow)、下溢(Underflow)、非规格化浮点数(Subnormal)和除零(Divide by Zero),都会产生软件异常。RISC-V架构的一个特殊之处是,对任何的运算指令错误(包括整数与浮点指令)均不产生异常,而是产生某个特殊的默认值,同时,设置某些状态寄存器的状态位。RISC-V架构推荐软件通过其他方法来找到这些错误。再次清楚地反映了RISC-V架构力图简化基本的指令集,从而简化硬件设计的哲学。
1.优雅的压缩指令子集
基本的RISC-V基本整数指令子集(字母I表示 )规定的指令长度,均为等长的32位,这种等长指令定义,使得仅支持整数指令子集的基本RISC-V CPU,非常容易设计。但是等长的32位编码指令,也会造成代码体积(Code Size)相对较大的问题。
为了满足某些对于代码体积要求较高的场景(譬如嵌入式领域),RISC-V定义了一种可选的压缩(Compressed)指令子集,由字母C表示,也可以由RVC表示。RISC-V具有后发优势,从一开始便规划了压缩指令,预留了足够的编码空间,16位长指令与普通的32位长指令,可以无缝自由地交织在一起,处理器也没有定义额外的状态。
RISC-V压缩指令的另外一个特别之处是,16位指令的压缩策略是,将一部分普通最常用的的32位指令中的信息,进行压缩重排得到(譬如假设一条指令使用了两个同样的操作数索引,则可以省去其中一个索引的编码空间),因此每一条16位长的指令,都能一一找到其对应的原始32位指令。因此,程序编译成为压缩指令,仅在汇编器阶段就可以完成,极大的简化了编译器工具链的负担。
RISC-V架构的研究者进行了详细的代码体积分析,如图3所示,通过分析结果可以看出,RV32C的代码体积相比RV32的代码,体积减少了百分之四十,并且与ARM,MIPS和x86等架构相比,都有不错的表现。
2.特权模式
RISC-V架构定义了三种工作模式,又称特权模式(Privileged
Mode):
1)Machine Mode:机器模式,简称M Mode。
2)Supervisor Mode:监督模式,简称S Mode。
3)User Mode:用户模式,简称U Mode。
RISC-V架构定义M Mode为必选模式,另外两种为可选模式。通过不同的模式组合,可以实现不同的系统。
RISC-V架构也支持几种不同的存储器地址管理机制,包括对于物理地址和虚拟地址的管理机制,使得RISC-V架构能够支持,从简单的嵌入式系统(直接操作物理地址),到复杂的操作系统(直接操作虚拟地址)的各种系统。
3.CSR寄存器
RISC-V架构定义了一些控制和状态寄存器(Control
and Status Register,CSR),用于配置或记录一些运行的状态。CSR寄存器是处理器核内部的寄存器,使用其自己的地址编码空间和存储器寻址的地址区间完全无关系。
CSR寄存器的访问采用专用的CSR指令,包括CSRRW、CSRRS、CSRRC、CSRRWI、CSRRSI以及CSRRCI指令。
4.中断和异常
中断和异常机制往往是处理器指令集架构中,最为复杂而关键的部分。RISC-V架构定义了一套相对简单基本的中断和异常机制,但是也允许用户对其进行定制和扩展。
5.矢量指令子集
RISC-V架构目前虽然还没有定型矢量(Vector)指令子集,但是从目前的草案中已经可以看出,RISC-V矢量指令子集的设计理念非常的先进,由于后发优势及借助矢量架构多年发展成熟的结论,RISC-V架构将使用可变长度的矢量,而不是矢量定长的SIMD指令集(譬如ARM的NEON和Intel的MMX),从而能够灵活的支持不同的实现。追求低功耗小面积的CPU,可以选择使用长度较短的硬件矢量进行实现,而高性能的CPU,则可以选择较长的硬件矢量进行实现,并且同样的软件代码能够彼此兼容。
6.自定制指令扩展
除了上述阐述的模块化指令子集的可扩展、可选择,RISC-V架构还有一个非常重要的特性,那就是支持第三方的扩展。用户可以扩展自己的指令子集,RISC-V预留了大量的指令编码空间,用于用户的自定义扩展,同时,还定义了四条Custom指令,可供用户直接使用,每条Custom指令,都有几个比特位的子编码空间预留,因此,用户可以直接使用四条Custom指令,扩展出几十条自定义的指令。
1.3.4 总结与比较
处理器设计技术经过几十年的衍进,随着大规模集成电路设计技术的发展直至今天,呈现出如下特点:
1)由于高性能处理器的硬件调度能力已经非常强劲且主频很高,因此,硬件设计希望指令集尽可能的规整、简单,从而,使得处理器可以设计出更高的主频与更低的面积。
2)以IoT应用为主的极低功耗处理器更加苛求低功耗与低面积。
3)存储器的资源也比早期的RISC处理器更加丰富。
如上种种这些因素,使得很多早期的RISC架构设计理念(依据当时技术背景而诞生),时至今日不仅不能帮助现代处理器设计,反而成了负担桎梏。某些早期RISC架构定义的特性,一方面使得高性能处理器的硬件设计束手束脚;另一方面又使得极低功耗的处理器硬件设计,背负不必要的复杂度。
得益于后发优势,全新的RISC-V架构,能够规避所有这些已知的负担,同时,利用其先进的设计哲学,设计出一套“现代”的指令集。这里再次将其特点总结如表1.8所示。
表1.8 RISC-V指令集架构特点总结
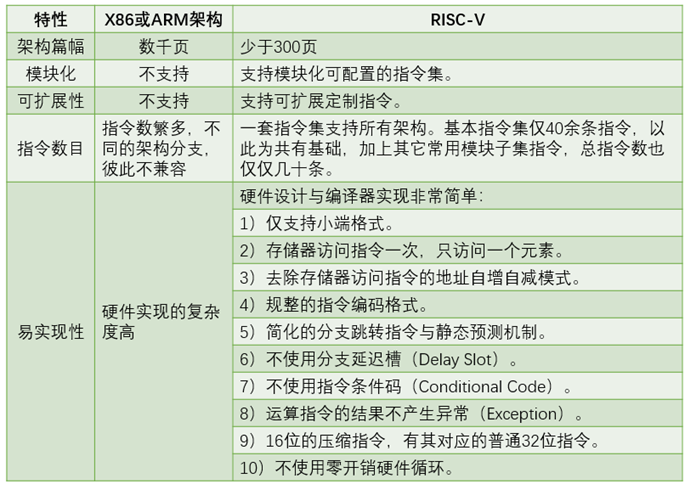
图1.6表示RISC-V指令实现流程与性能参数特性。
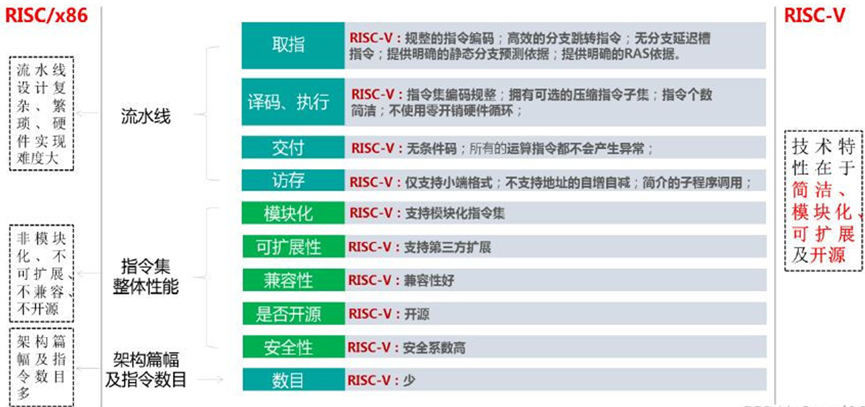
图1.6 RISC-V指令实现流程与性能参数特性
一言以蔽之,RISC-V的特点在于极简、模块化以及可定制扩展,通过这些指令集的组合或者扩展,几乎可以构建适用于任何一个领域的微处理器,比如云计算、存储、并行计算、虚拟化/容器、MCU、应用处理器和DSP处理器等。
1.3.5. 基于RISC-V的开源处理器
目前基于RISC-V架构的开源处理器有很多,既有标量处理器Rocket,也有超标量处理器BOOM,还有面向嵌入式领域的Z-scale、PicoRV32等。
1. 标量处理器——Rocket
Rocket是UCB设计的一款64位、5级流水线、单发射顺序执行处理器,主要特点有:
1)支持MMU,支持分页虚拟内存,所以可以移植Linux操作系统。
2)具有兼容IEEE 754-2008标准的FPU。
3)具有分支预测功能,具有BTB(Branch Prediction Buff)、BHT(Branch History Table)、RAS(Return Address Stack)。
表1.9表示ARM Cortex-A5与采用RISC-V指令集架构的Rocket比较
表1.9 ARM Cortex-A5与采用RISC-V指令集架构的Rocket比较
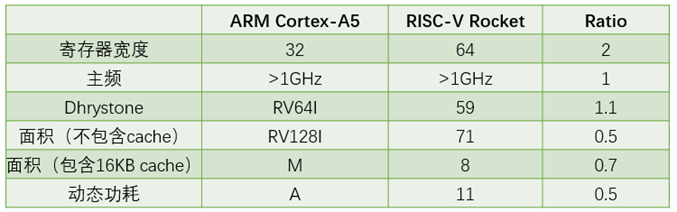
UCB的研究人员设计的一款采用RISC-V指令集架构的开源处理器Rocket,并且已经成功流片了11次,其中采用台积电40nm工艺时的性能与采用同样工艺的,都是标量处理器的ARM Cortex-A5的性能对比如表3所示。可见Rocket占用更小的面积,使用更小的功耗,但是性能却更优。
Rocket是采用Chisel(Constructing Hardware in an Scala Embedded Language)编写的,这也是UCB设计的一种开源的硬件编程语言,是Scala语言的领域特定应用,可以充分利用Scala的优势,将面向对象(object orientation)、函数式编程(functional programming)、类型参数化(parameterized
types)、类型推断(type inference)等概念引入硬件编程语言,从而提供更加强大的硬件开发能力。Chisel除了开源之外,还有一个优势就是使用Chisel编写的硬件电路,可以通过编译得到对应的Verilog设计,还可以得到对应的C++模拟器。Rocket使用Chisel编写,就可以很容易得到对应的软件模拟器。同时,因为Chisel是面向对象的,所以Rocket的很多类可以被其他开源处理器、开源SoC直接使用。
2.超标量乱序执行处理器——BOOM
BOOM(Berkeley Out-of-Order
Machine)是UCB设计的一款64位超标量、乱序执行处理器,支持RV64G,也是采用Chisel编写,利用Chisel的优势,只使用了9000行代码,流水线可以划分为六个阶段:取指、译码/重命名/指令分配、发射/读寄存器、执行、访存、回写。
借助于Chisel,BOOM是可参数化配置的超标量处理器,可配置的参数包括:
1)取指、译码、提交、指令发射的宽度。
2)重排序缓存ROB(Re-Order Buffer)、物理寄存器的大小。
3)取指令缓存、RAS、BTB、加载、存储队列的深度。
4)有序发射还是无序发射。
5)L1 cache的路数。
6)MSHRs(Miss Status Handling Registers)的大小。
7)是否使能L2 C。
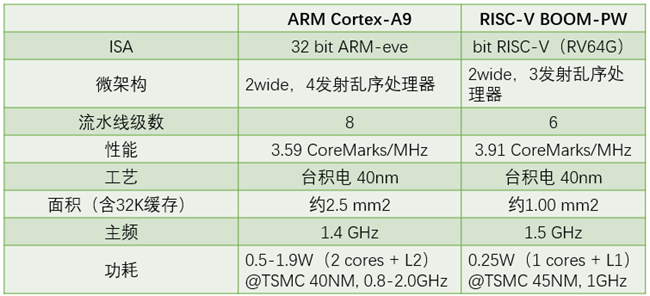
UCB已经在40nm工艺上对BOOM进行了流片,测试结果如表1.10所示。可见BOOM与商业产品ARM Cortex-A9的性能要略优,体现在面积小、功耗低。
表1.10 UCB已经在40nm工艺上对BOOM流片的测试结果
1.4.
RISC-V详细介绍
1.4.1不断增长的指令数量
如图1.7表示x86指令集自诞生依赖,指令数量的增长。x86在1978年诞生时有80条指令,到2015年增长了16倍,到了1338条指令,并且一直在增长。令人惊讶的是,这张图的数据仍显保守。2015年在英特尔的资料上有着3600条指令的统计结果[Rodgers and Uhlig 2017],这意味着x86指令的增长速率提高到了(在1978年到2015年之内)每4天增长一条。用汇编语言指令计算,向必算入了机器语言指令。这个增长的很大一部分是因为x86 ISA依赖于SIMD指令来实现数据级并行。
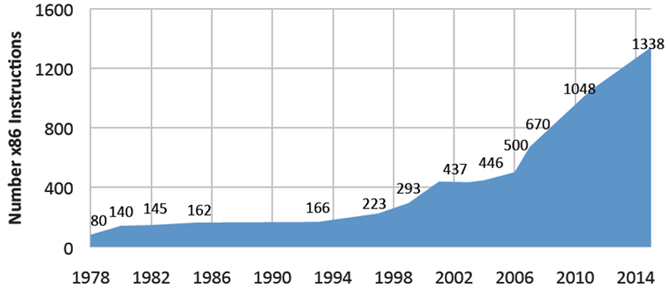
图1.7 x86指令集自诞生依赖,指令数量的增长
1.4.2 RISC-V架构设计思想
1.如何设计一个好的ISA?
在介绍 RISC-V 这个 ISA 之前,了解计算机架构师在设计 ISA 时的基本原则和必须做出的权衡是有用的。如下的列表列出了七种衡量标准。页边放置了对应的七个图标,以突出显示 RISC-V 在随后章节中应对它们的实例。(印刷版的封底有所有图标的图例。)
1)成本(美元硬币)。
2)简洁性(轮子)。
3)性能(速度计)。
4)架构和具体实现的分离(分开的两个半圆)。
5)提升空间(手风琴)。
6)程序大小(相对的压迫着一条线的两个箭头)。
7)易于编程/编译/链接(儿童积木“像 ABC 一样简单”)。
RISC-V的不同寻常之处,除了在于它是最近诞生的和开源的以外,还在于它是模块化的,这点几乎与所有以往的ISA不同。它的核心是一个名为RV32I的基础ISA,运行一个完整的软件栈。RV32I是固定的,永远不会改变。这为编译器编工程师,操作系统开发人员以及汇编语言程序员提供了稳定的目标。模块化来源于可选的标准扩展,根据应用程序的需要,硬件可以包含或不包含这些扩展。这种模块化特性使得RISC-V具有了袖珍化、低能耗的特点,而这对于嵌入式应用可能至关重要。RISC-V编译器得知当前硬件包含哪些扩展后,便可以生成当前硬件条件下的最佳代码。惯例是把代表扩展的字母附加到指令集名称之后作为指示。例如,RV32IMFD将乘法(RV32M),单精度浮点(RV32F)和双精度浮点(RV32D)的扩展添加到了基础指令集(RV32I)中。
2.RISC-V之RV32I
这里介绍RV32I 基础指令集的一页图形表示。对于每幅图,将有下划线的字母从左到右连接起来,即可组成完整的 RV32I 指令集。对于每一个图,集合标志{}内列举了指令的 所有变体,变体用加下划线的字母或下划线字符_表示。特别的,下划线字符_表示对于此 指令变体不需用字符表示。例如,下图1.8表示了这四个 RV32I 指令:slt,slti,sltu,sltiu:

图1.8 四个 RV32I 指令
3.四个典型特点
首先,指令只有六种格式,并且所有的指令都是 32 位长,这简化了指令解码。ARM-32, 还有更典型的 x86-32,都有许多不同的指令格式,使得解码部件在低端实现中偏昂贵,在中高端处理器设计中,容易带来性能挑战。
第二,RISC-V指令提供三个寄存器操作数,而不是像x86-32一样,让源操作数和目的操作数共享一个字段。当一个操作天然就需要有三个不同的操作数,但是 ISA 只提供了两个操作数时,编译器或者汇编程序程序员,就需要多使用一条move(搬运)指令,来保存目的寄存器的值。
第三,在RISC-V中对于所有指令,要读写的寄存器的标识符总是在同一位置,意味着在解码指令之前,就可以先开始访问寄存器。在许多其他的ISA中,某些指令字段在部分指令中被重用作为源目的地,在其他指令中又被作为目的操作数(例如,ARM-32 和 MIPS-32)。因此,为了取出正确的指令字段,需要本就可能紧张的时序解码路径上,添加额外的解码逻辑,使得解码路径的时序更为紧张。
第四,这些格式的立即数字段总是符号扩展,符号位总是在指令中最高位。这意味着可能成为关键路径的立即数符号扩展,可以在指令解码之前进行。
下表1.11显示了六种基本指令格式,分别是:用于寄存器-寄存器操作的 R 类型指令,用于短立即数和访存 load 操作的 I 型指令,用于访存 store 操作的 S 型指令,用于条件跳转操作的B类型指令,用于长立即数的U型指令和用于无条件跳转的J型指令。
用生成的立即数值中的位置(而不是通常的指令立即数域中的位置)(imm[x])标记每个立即数域。控制状态寄存器指令使用I型格式的稍微不同的做法。
表1.11 RISC-V指令格式

解释说明:四种基础指令格式 R/I/S/U
imm:立即数。
rs1:源寄存器1。
rs2:源寄存器2。
rd:目标寄存器。
opcode:操作码。
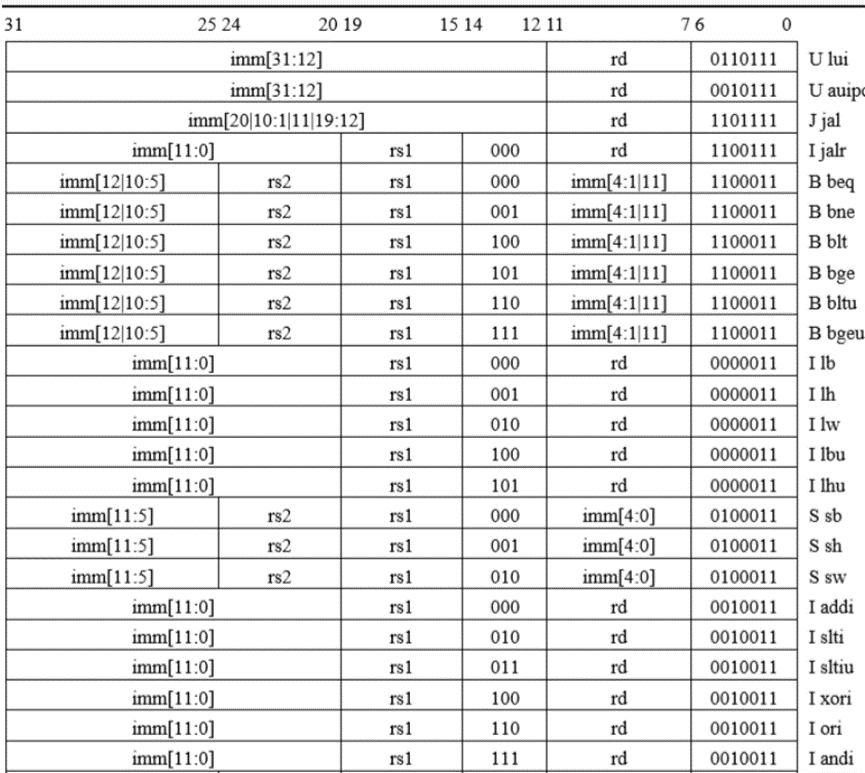
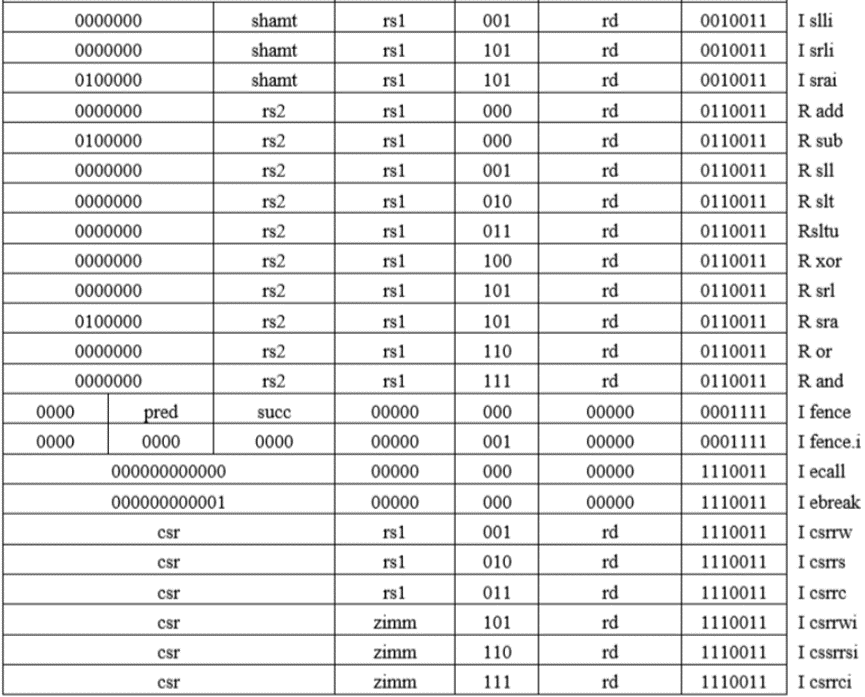
如表1.12表示RV32I带有指令布局,操作码,格式类型和名称的操作码映射。
表1.12 RV32I带有指令布局,操作码,格式类型和名称的操作码映射
1.4.3 RISC-V之乘除法指令
1.指令格式
RV32M 具有有符号和无符号整数的除法指令:divide(div)和 divide unsigned(divu),它们将被放入目标寄存器。在少数情况下,程序员需要余数而不是商,因此 RV32M 提供 remainder(rem)和 remainder unsigned(remu),它们在目标寄存器写入余数,而不是商,如表1.13所示。
表1.13 RV32M除法指令格式
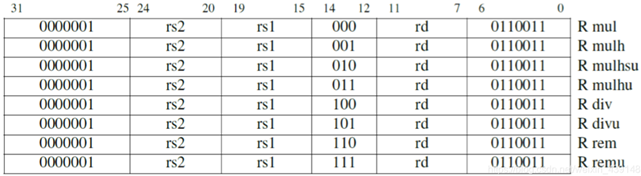
为了正确地得到一个有符号或无符号的 64 位积,RISC-V 中带有四个乘法指令。要得到整数 32 位乘积(64 位中的低 32 位),就用 mul 指令。要得到高 32 位,如果 操作数都是有符号数,就用 mulh 指令;如果操作数都是无符号数,就用 mulhu 指令;如果一个有符号一个无符号,可以用 mulhsu 指令。在一条指令中,完成把 64 位积写入两个 32 位寄存器的操作,会使硬件设计变得复杂,所以 RV32M 需要两条乘法指令,才能得到一个完整 的 64 位积。
2. 用乘法代替常数除法
对许多微处理器来说,整数除法是相对较慢的操作。如前述,除数为 2 的幂次的无符号除法,可以用右移来代替。事实证明,通过乘以近似倒数,再修正积的高32位的方法,可以优化除数为其它数的除法。例如,图1.9显示了3为除数的无符号除法的代码。

图1.9:RV32M中用乘法来实现除以常数操作的代码。要证明该算法适用于任何除数,通过详细的数值分析,而对于奇特除数,其中的修正步骤更为复杂。
先把数装到t0里面。
addi是立即数与寄存器的数相加,t0-1365放回t0。
a0和t0相乘(无符号)。
立即数→移,也就是a1右移1位。
也就是说,从数值上来讲,可以通过乘法代替常数除法。
1.4.3 RISC-V之RV64
尽管 RV64I 有 64 位地址,且默认数据大小为 64 位,32 位字仍然是程序中的有效数据类型。因此,RV64I需要支持字,就像 RV32I 需要支持字节和半字一样。
更具体地说,由于寄存器现在是 64 位宽,RV64I 添加字版本的加法和减法指令:addw,addiw,subw。这些指令将计算结果截断为 32 位,结果符号扩展后再写入目标寄存器。RV64I也包括字版本的移位指令(sllw,slliw,srlw,srliw,sraw,sraiw),以获得 32 位移位结果,而不是 64 位移位结果。要进行 64 位数据传输,RV64 提供了加载和存储双字指令:ld,sd。
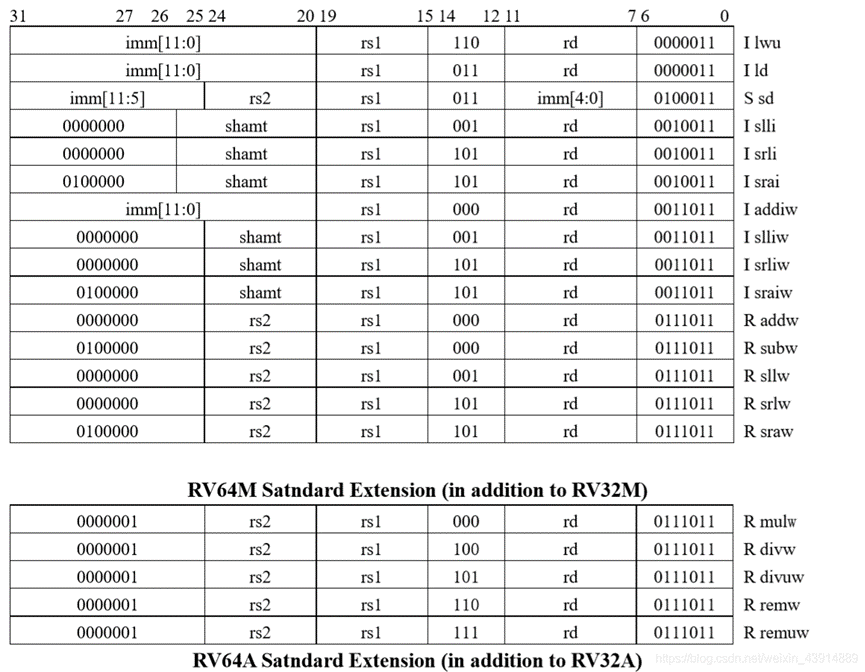
最后,就像 RV32I 中有无符号版本的加载单字节和加载半字的指令,RV64I 也有一个无符号版本的加载字:lwu。出于类似的原因,RV64需要添加字版本的乘法,除法和取余指令:mulw,divw,divuw, remw,remuw。为了支持对单字及双字的同步操作,RV64A 为其所有的 11 条指令,都添加了双字版本。
由于版本众多,这里只选择有代表性的来了解。如表1.14表示RV64A与RV64M标准扩张版示例。
表1.14 RV64A与RV64M标准扩张版示例
RV64F 和 RV64D 添加了整数双字转换指令,并称它们为长整数,以避免与双精度浮点数据混淆:fcvt.l.s,fcvt.l.d,fcvt.lu.s,fcvt.lu.d,fcvt.s.l,fcvt.s.lu,fcvt.d.l,fcvt.d.lu。由于整数 x 寄存器现在是 64 位宽,它们现在可以保存双精度浮点数据,因此 RV64D 增加了两个浮点指令:fmv.x.w 和 fmv.w.x。这里暂时不讲解压缩指令。
1.4.4 RISC-V的特权架构
到目前为止,主要关注 RISC-V 对通用计算的支持:引入的所有指令都在用户模式(应用程序的代码在此模式下运行)下可用。这里介绍两种新的权限模式:运行最可信的代码的机器模式(machine mode),以及为 Linux,FreeBSD 和 Windows 等操作系统 提供支持的监管者模式(supervisor mode)。这两种新模式都比用和模式有着更高的权限。有更多权限的模式,通常可以使用权限较低的模式的所用功能,并且它们还有一些低权限模式下不可用的额外功能,例如处理中断和执行 I/O 的功能。处理器通常大部分时间都运行在权限最低的模式下,处理中断和异常时,会将控制权移交到更高权限的模式。嵌入式系统运行时(runtime)和操作系统,用这些新模式的功能来响应外部事件,如网络数据包的到达;支持多任务处理和任务间保护;抽象和虚拟化硬件功能等。
1.机器模式
机器模式(缩写为 M 模式,M-mode)是
RISC-V 中,hart(hardware thread,硬件线
程)可以执行的最高权限模式。在 M 模式下运行的 hart 对内存,I/O 和一些对于启动和配置系统来说,必要的底层功能有着完全的使用权。因此它是唯一所有标准 RISC-V 处理器都必须实现的权限模式。实际上简单的 RISC-V 微控制器仅支持 M 模式。
机器模式最重要的特性是拦截和处理异常(不寻常的运行时事件)的能力。RISC-V 将异常分为两类。
一类是同步异常,这类异常在指令执行期间产生,如访问了无效的存储器地址,或执行了具有无效操作码的指令时。
另一类是中断,它是与指令流异步的外部事件,比如鼠标的单击。RISC-V 中实现精确例外:保证异常之前的所有指令都完整地执行了,而后续的指令都没有开始执行(或等同于没有执行)。
在 M 模式运行期间可能发生的同步例外,还有以下五种:
1)访问错误异常。当物理内存的地址不支持访问类型时发生(例如尝试写入 ROM)。
2)断点异常。在执行 ebreak 指令,或者地址或数据与调试触发器匹配时发生。
3)环境调用异常。在执行 ecall 指令时发生。
4)非法指令异常。在译码阶段发现无效操作码时发生。
5)非对齐地址异常。在有效地址不能被访问大小整除时发生,例如地址为 0x12 的 amoadd.w。
有三种标准的中断源:软件、时钟和外部来源。软件中断通过向内存映射寄存器中存
数来触发,并通常用于由一个 hart 中断另一个 hart(在其他架构中称为处理器间中断机
制)。当实时计数器 mtime 大于 hart 的时间比较器(一个名为 mtimecmp 的内存映射寄存 器)时,会触发时钟中断。外部中断由平台级中断控制器(大多数外部设备连接到这个中断控制器)引发。
2.监管者模式
更复杂的 RISC-V 处理器,用和几乎所有通用架构相同的方式,处理这些问题:使用基于页面的虚拟内存。这个功能构成了监管者模式(S 模式)的核心,这是一种可选的权限模式,旨在支持现代类 Unix 操作系统,如 Linux,FreeBSD 和
Windows。S 模式比 U 模式权限更高,但比 M 模式低。与 U 模式一样,S 模式下运行的软件,不能使用 M 模式的 CSR 和 指令,并且受到
PMP 的限制。
这里介绍 S 模式的中断和异常,后面将详细介绍 S 模式下的虚拟内存系统。默认情况下,发生所有异常(不论在什么权限模式下)的时候,控制权都会被移交到 M 模式的异常处理程序。但是 Unix 系统中的大多数例外,都应该进行 S 模式下的系统调用。M 模式的异常处理程序,可以将异常重新导向 S 模式,但这些额外的操作,会减慢大多数 异常的处理速度。因此,RISC-V 提供了一种异常委托机制。通过该机制,可以选择性地将中断和同步异常交给 S 模式处理,而完全绕过M模式。
S 模式提供了一种传统的虚拟内存系统,它将内存划分为固定大小的页,以便进行地址转换和对内存内容的保护。启用分页的时候,大多数地址(包括 load 和 store 的有效地址和
PC 中的地址)都是虚拟地址。要访问物理内存,它们必须被转换为真正的物理地址,这通过遍历一种称为页表的高基数树实现。页表中的叶节点指示虚地址是否已经被映射到了真正的物理页面。如果是,则指示了哪些权限模式和通过哪种类型的访问,可以操作这个页。
3.扩展指令集
目前官方提供的risc-v扩展指令集有如下几个(确定将会实现的)。
11.1 “B”标准扩展:位操作 …
11.2 “E”标准扩展:嵌入式 …
11.3 “H”特权态架构扩展:支持管理程序(Hypervisor) …
11.4 “J”标准扩展:动态翻译语言 …
11.5 “L”标准扩展:十进制浮点 …
11.6 “N”标准扩展:用户态中断 …
11.7 “P”标准扩展:封装的单指令多数据(Packed-SIMD)指令 …
11.8 “Q”标准扩展:四精度浮点 …
目前根据已经开源的设计方案,大多专注于B/J/Q/L指令的相关扩展。
1.4.5 AI中涉及的运算操作
1.机器学习
1)矩阵的转置、求逆运算。
2)矩阵的切片与扩张。
3)矩阵的乘法,点积,内积,外积,元素积。
4)矩阵的加法,求和(包括求元素的平方和),L1,L2正则化。
5)取指数与对数(逻辑回归,信息熵等)。
6)标准化、归一化操作。
2.深度学习
1)线性层:矩阵的外积。
2)卷积层:矩阵的内积。
3)池化层:求矩阵平均值(求和),或求最大值。
4)残差网络,GoogleNet等,矩阵拼接。
5)随机梯度下降,keep prob:随机值生成。
6)压缩解压缩。
7)加密解密(MAC运算等)# 5,6两个点涉及大整数操作以及优化,质数生成。
8)张量、矢量、标量的运算。
1.4.6 现有的AI指令集或其他底层解决方案
1.TPU解决方案
在TPU中,它使用若干条指令来完成矩阵的乘法运算,其中使用Read_Host_Memory来从主存中读取数据至通用缓存(Unified Buffer)中;使用Read_Weights来将权重读取至矩阵单元中。在进行矩阵运算时,使用MatrixMultiply或Convolve来进行矩阵乘法。最后使用Write_Host_Memory来将数据写回主存中。但是在TPU中,它的矩阵乘法对操作数的尺寸存在限制,在MatrixMultiply或Convolve中,其限制操作数为B256 与256256,若矩阵尺寸大与此值,则不太方便直接使用TPU进行运算;若矩阵尺寸小于此值,则需要先对多余部分填充0后,再进行计算。
2.X86
在X86_64中,其在AVX、AVX2等指令集中,提供了VMULPS、VMULPD、VADDPS、VADDPD等一系列SIMD指令,这些指令可以使用一条指令来完成多组数据的运算。在矩阵乘法等应用中,数据之间没有相互依赖性,因此可以使用SIMD指令来提高运算效率。如图1.10表示VMULPS指令示意图。
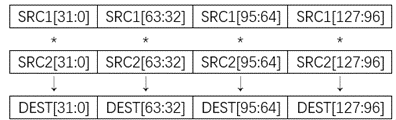
图1.10 VMULPS指令示意图
与TPU相比,AVX至运算数据的尺寸上没有太多的限制,即使数据的规模较大,也可以拆分为多交指令执行。但这也造成AVX指令集的并行化程度一般不高,通常一条指令只能处理4-8条数据,效率远不如TPU等专门双击的架构,在人工智能的应用上,仍然难以满足需要。
3.现有AI芯片
现有的AI芯片,比如寒武纪的产品,为了AI的运算,也做了大量适配,比如构建大量的乘法器,用来在一个周期内并行处理多个乘法操作,相应地指令集也会向着这个方向进行优化,如华为Ascend 系列AI芯片,内置的都是运算密集型CISC指令集来为AI运算做优化。但是这种设计模式的功耗,以及设计的繁琐程度都很高,所以集成AI优化的RISC-V,应该在保持灵活小巧的基础上,对矩阵运算等AI领域常见的基本数学运算做优化,对机器学习和深度学习有一个泛化支持,虽然速度可能没CISC那么高,但是可以保持其精简以及自由拓展的特点。
4.现有AI软件与芯片设计关系详解
本例以 Hanguang AI为例子,主要内容来自官方文档,如图1.11所示。
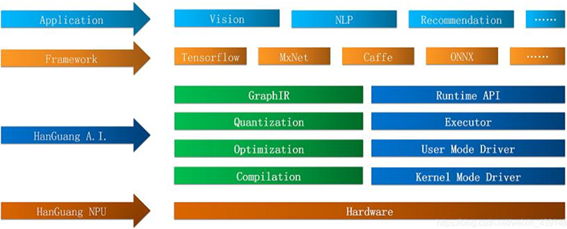
图1.11 阿里HanGuang芯片
HanGuang Al是阿里巴巴-迖摩院旗下平头哥半导体有限公司开发的,人工智能芯片软件开发包J 巨前,主要服务于业界领先的含光800人工智能推理芯片。 使用HanGuang Al在含光800芯片上,开发深度学习应用,可以获得言吞吐量和低延迟的高性能体验。
HanGuang Al软件架构如下图1.12所示。
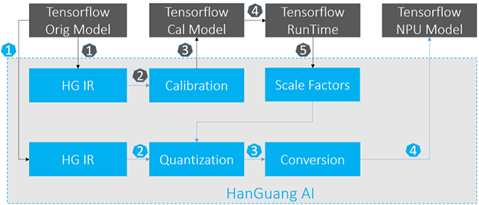
图1.12 阿里HanGuang软件架构
可以看到,当前AI软件的主要工作,还是分为了3个大部分,其中和AI芯片设计打交道的主要是量化、编译过程,如图1.13所示。
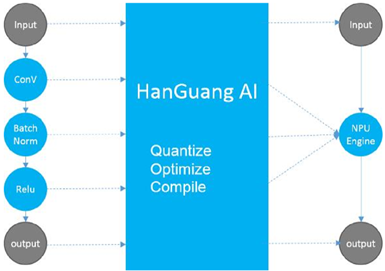
图1.13 阿里HanGuang软件架构优化编译
所以在设计是重点关注算子的底层编译实现,也就是说,通过算子的提取,计算代替传统的分析方法,这是一种高效运用在工业界的方法。
参考资料
In-Datacenter Performance Analysis of a
Tensor Processing Unit
https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
含光800软件介绍.pdf
参考文献链接
2、编译过程
将.C文件转变为最终的.hex或.bin目标文件,需要经过预处理、编译、汇编、链接这四个步骤。

2.1 预处理(Pre-Processing)
主要包括宏定义(#define),文件包含(#include),条件编译(#ifdef)三部分。
预处理期间将检查包含预处理指令的语句和宏定义,并对其进行响应和替换,并删除程序中的注释和多余空白字符,最后会生成 .i 文件。
2.2 编译(Compiling)
编译器会将预处理完的 .i 文件进行一些列的语法分析,并优化后生成对应的汇编代码,生成 .s 文件。
RISC-V MCU的工程采用GCC编译,官方工具链地址:https://github.com/riscv/riscv-gnu-toolchain。
当然,各厂家会根据自家的内核设计,修改对应的工具链以支持其特色功能,如RISC-V MCU所特有的HPE硬件压栈和VTF免表中断技术,需要在中断服务函数增加指令
__attribute__((interrupt("WCH-Interrupt-fast"))),然后在编译时会识别并省略软件压栈的过程。
2.3 汇编(Assembling)
通过汇编器将编译器生成的 .s 汇编程序汇编为机器语言或指令,也就是可以机器可以执行的二进制程序,生成 .o 文件。
2.4 链接(Linking)
根据“*.ld”链接文件将多个目标文件(.o)和库文件(.a)输入文件链接成一个可执行输出文件(.elf)。涉及到对空间和地址的分配以及符号解析与重定位。
3、elf、hex、bin文件说明
使用MRS编译时,最终生成的可执行文件为elf、hex或bin文件,这些文件之间的联系如下:
3.1 elf文件
ELF(Executable
and Linkable Format),可执行与可链接格式。
elf是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储格式文件。这是UNIX系统实验室(USL)作为应用程序二进制接口(Application Binary Interface,ABI),而开发和发布的,也是Linux的主要可执行文件格式。
ELF文件记录的信息更多、更复杂。主要包含以下内容:
ELF头(ELF header) - 描述文件的主要特性:类型,CPU架构,入口地址,现有部分的大小和偏移等等;
程序头表(Program header
table) - 列举了所有有效的段(segments)和他们的属性。程序头表需要加载器将文件中的节加载到虚拟内存段中;
节头表(Section header
table) - 包含对节(sections)的描述。
3.2 hex文件
HEX格式文件由Intel制定的一种十六进制标准文件格式,一种ASCII文本文件。文件的每一行都包含了 一个HEX记录。这些记录是由一些代表机器语言代码和常量的16进制数据组成的。Intel HEX文件常用来传输要存储在ROM 或者 EPROM中的程序和数据。大部分的EPROM编程器和FLASH能使用Intel
HEX文件。
格式如下:
|
行开始
|
数据长度
|
地址
|
数据类型
|
数据
|
校验
|
|
:
|
BB
|
AAAA
|
TT
|
D……D
|
CC
|
| |
1字节
|
2字节
|
1字节
|
n字节
|
1字节
|
1):冒号,代表行开始。
2)BB代表Bytes,数据长度。
3)AAAA代码Address,表示数据这行数据的存储地址。
4)TT代表Type,数据类型(标识)。
A)00:数据标识。
B)01:文件结束标识。
C)02:扩展段地址。
D)03:开始段地址。
E)04:线性地址。
F)05:线性开始地址。
5)D……D代表Data,有效数据。
6)CC代表CheckSum,校验和。
3.3 bin文件
bin是binary的缩写,即二进制文件,全是0或1的文件,最底层的可执行的机器码。只包含程序数据。bin文件的大小直接反应所占flash内存的大小。
3.4 转换关系
因为bin、hex都是只是记录数据的,但elf类型不仅记录数据还有程序描述,所以elf文件通过gcc中的objcopy可转换成hex或bin文件,hex文件也可转换成bin文件,但反之不可。
3.5 总结
bin文件最小最简单,但是安全性差,功能性差,hex包含头尾和检验,就有很好的安全性,但是文件比bin大,功能没有elf强大;elf功能多,但是文件最大。
在使用工程编译结果是,最好有bin或者hex同时具有elf文件,elf用于仿真和调试,但输出的到工厂的文件可以使用hex和bin。
RISC-V MCU启动文件分析
启动文件由汇编语言编写,是MCU上电复位后第一个执行的程序。主要执行以下内容:
初始化gp(global pointer)全局指针寄存器、sp(stack pointer)栈指针寄存器
将data数据从flash中加载至RAM中
清空bss段数据
初始化中断向量表
配置系统时钟
从Machine模式切换到User模式,进入main函数运行
CH32V103启动文件如下:
/**********************************
(C) COPYRIGHT *******************************
* File Name : startup_ch32v10x.s
* Author : WCH
* Version : V1.0.0
* Date : 2020/04/30
*
Description : CH32V10x vector
table for eclipse toolchain.
*******************************************************************************/
.section .init,"ax",@progbits /* 声明section 为 .init */
.global _start /* 指明标签_start的属性为全局性的 */
.align 1
_start: /* 标签_start处 */
j handle_reset /* 跳转至 handle_reset处 */
.word 0x00000013 /* 内核设计需要,不用关注 */
.word 0x00000013
.word 0x00000013
.word 0x00000013
.word 0x00000013
.word 0x00000013
.word 0x00000013
.word 0x00000013
.word 0x00000013
.word 0x00000013
.word 0x00000013
.word 0x00000013
.word 0x00100073
.section
.vector,"ax",@progbits
.align
1
_vector_base: /* 中断向量表 */
.option norvc;
j
_start
.word
0
j
NMI_Handler /* NMI
Handler */
j
HardFault_Handler /*
Hard Fault Handler */
.word
0
.word
0
.word
0
.word
0
.word
0
.word
0
.word
0
.word
0
j
SysTick_Handler /*
SysTick Handler */
.word
0
j
SW_handler /* SW
Handler */
.word
0
/* External Interrupts */
j
WWDG_IRQHandler /*
Window Watchdog */
j
PVD_IRQHandler /* PVD
through EXTI Line detect */
j
TAMPER_IRQHandler /*
TAMPER */
j
RTC_IRQHandler /* RTC
*/
j
FLASH_IRQHandler /*
Flash */
j
RCC_IRQHandler /* RCC
*/
j
EXTI0_IRQHandler /* EXTI
Line 0 */
j
EXTI1_IRQHandler /* EXTI
Line 1 */
j
EXTI2_IRQHandler /* EXTI
Line 2 */
j
EXTI3_IRQHandler /* EXTI
Line 3 */
j
EXTI4_IRQHandler /* EXTI
Line 4 */
j
DMA1_Channel1_IRQHandler /* DMA1
Channel 1 */
j
DMA1_Channel2_IRQHandler /* DMA1
Channel 2 */
j
DMA1_Channel3_IRQHandler /* DMA1
Channel 3 */
j
DMA1_Channel4_IRQHandler /* DMA1
Channel 4 */
j
DMA1_Channel5_IRQHandler /* DMA1
Channel 5 */
j
DMA1_Channel6_IRQHandler /* DMA1
Channel 6 */
j
DMA1_Channel7_IRQHandler /* DMA1
Channel 7 */
j
ADC1_2_IRQHandler /*
ADC1_2 */
.word
0
.word
0
.word
0
.word
0
j
EXTI9_5_IRQHandler /* EXTI
Line 9..5 */
j
TIM1_BRK_IRQHandler /* TIM1 Break */
j
TIM1_UP_IRQHandler /* TIM1
Update */
j
TIM1_TRG_COM_IRQHandler /* TIM1
Trigger and Commutation */
j
TIM1_CC_IRQHandler /* TIM1
Capture Compare */
j
TIM2_IRQHandler /* TIM2 */
j
TIM3_IRQHandler /* TIM3
*/
j
TIM4_IRQHandler /* TIM4
*/
j
I2C1_EV_IRQHandler /* I2C1
Event */
j
I2C1_ER_IRQHandler /* I2C1
Error */
j
I2C2_EV_IRQHandler /* I2C2
Event */
j
I2C2_ER_IRQHandler /* I2C2
Error */
j
SPI1_IRQHandler /* SPI1
*/
j
SPI2_IRQHandler /* SPI2
*/
j
USART1_IRQHandler /* USART1
*/
j
USART2_IRQHandler /*
USART2 */
j
USART3_IRQHandler /*
USART3 */
j
EXTI15_10_IRQHandler /* EXTI
Line 15..10 */
j
RTCAlarm_IRQHandler /* RTC
Alarm through EXTI Line */
j
USBWakeUp_IRQHandler /* USB
Wakeup from suspend */
j
USBHD_IRQHandler /*
USBHD */
.option rvc;
.section
.text. , "ax",
@progbits /* 中断服务程序弱定义
*/
.weak
NMI_Handler
.weak
HardFault_Handler
.weak
SysTick_Handler
.weak
SW_handler
.weak
WWDG_IRQHandler
.weak
PVD_IRQHandler
.weak
TAMPER_IRQHandler
.weak
RTC_IRQHandler
.weak
FLASH_IRQHandler
.weak
RCC_IRQHandler
.weak
EXTI0_IRQHandler
.weak
EXTI1_IRQHandler
.weak
EXTI2_IRQHandler
.weak
EXTI3_IRQHandler
.weak
EXTI4_IRQHandler
.weak
DMA1_Channel1_IRQHandler
.weak
DMA1_Channel2_IRQHandler
.weak
DMA1_Channel3_IRQHandler
.weak
DMA1_Channel4_IRQHandler
.weak
DMA1_Channel5_IRQHandler
.weak
DMA1_Channel6_IRQHandler
.weak
DMA1_Channel7_IRQHandler
.weak
ADC1_2_IRQHandler
.weak
EXTI9_5_IRQHandler
.weak
TIM1_BRK_IRQHandler
.weak
TIM1_UP_IRQHandler
.weak
TIM1_TRG_COM_IRQHandler
.weak
TIM1_CC_IRQHandler
.weak
TIM2_IRQHandler
.weak
TIM3_IRQHandler
.weak
TIM4_IRQHandler
.weak
I2C1_EV_IRQHandler
.weak
I2C1_ER_IRQHandler
.weak
I2C2_EV_IRQHandler
.weak
I2C2_ER_IRQHandler
.weak
SPI1_IRQHandler
.weak
SPI2_IRQHandler
.weak
USART1_IRQHandler
.weak
USART2_IRQHandler
.weak
USART3_IRQHandler
.weak
EXTI15_10_IRQHandler
.weak
RTCAlarm_IRQHandler
.weak
USBWakeUp_IRQHandler
.weak
USBHD_IRQHandler
.section .text.handle_reset,"ax",@progbits
.weak handle_reset
.align 1
handle_reset: /* handle_reset起始位置 */
.option push
.option norelax
la gp, __global_pointer$ /* 将ld文件中的标签__global_pointer所处的地址值赋给gp寄存器 */
.option pop
1:
la sp, _eusrstack /* 将ld文件中的标签_eusrstack所处的地址值赋给sp寄存器 */
2:
/* Load data section from flash to RAM */
la a0, _data_lma
la a1, _data_vma
la a2, _edata
bgeu a1, a2, 2f
1:
lw t0, (a0)
sw t0, (a1)
addi a0, a0, 4
addi a1, a1, 4
bltu a1, a2, 1b
2:
/* clear bss section */
la a0, _sbss
la a1, _ebss
bgeu a0, a1, 2f
1:
sw zero, (a0)
addi a0, a0, 4
bltu a0, a1, 1b
2:
/* enable all interrupt */ /* csrs ,根据寄存器中每个为1的位,把CSR寄存器对应位置位 */
li t0, 0x88
csrs mstatus, t0 /* 状态寄存器mstatus赋值为0x88,打开所有中断,设置MPP值为00 */
la t0, _vector_base
ori t0, t0, 1
csrw mtvec, t0 /* 将中断向量表的首地址赋值给mtvec寄存器(中断发生时PC的地址)
*/
jal
SystemInit /* 设置MCU系统时钟 */
la t0, main
csrw mepc, t0
mret
/*
mret返回指令(M模式特有的指令),调用该指令会进行如下操作:
- 将PC指针设置为mepc的值
- 将mstatus的MPIE域复制到MIE来恢复之前的中断使能
- 将权限模式设置为mstatus的MPP域中的值。
芯片上电默认进入的是机器模式,通过将mstatus中的MPP值设置为00(00: User,
01: Supervisor, 11: Machine),
并将main函数的地址赋值给mepc,调用mret,使得用户在进入main函数运行时,芯片由机器模式切换为用户模式。
*/
RISC-V MCU
CH32V307/CH32V203/CH32V003等 ld链接脚本说明
1、什么是ld链接脚本?
通常,程序编译的最后一步就是链接,此过程根据“*.ld”链接文件将多个目标文件(.o)和库文件(.a)输入文件链接成一个可执行输出文件(.elf)。涉及到对空间和地址的分配以及符号解析与重定位。
而ld链接脚本控制这整个链接过程,主要用于规定各输入文件中的程序、数据等内容段在输出文件中的空间和地址如何分配。通俗的讲,链接脚本用于描述输入文件中的段,将其映射到输出文件中,并指定输出文件中的内存分配。
2、ld链接脚本的主要内容
2.1 链接配置(可选)
常见的配置有入口地址、输出格式、符号变量的定义等。如:
ENTRY( _start )
/* 入口地址 */
__stack_size =
2048; /* 定义栈大小 */
PROVIDE(
_stack_size = __stack_size );/* 定义_stack_size符号,类似于全局变量 */
2.2 内存布局定义
对MCU的Flash及RAM空间进行分配,其中以ORIGIN定义地址空间的起始地址,LENGTH定义地址空间的长度。
语法如下:
MEMORY
{
name[(attr)] : ORIGIN = origin, LENGTH =
length
...
}
这里的attr只能由以下特性组成
'R' - Read-only
section
'W' - Read/write
section
'X' - Executable
section
'A' -
Allocatable section
'I' -
Initialized section
'L' - Same as I
'!' - Invert the
sense of any of the attributes that follow
2.3 段链接定义
用于定义目标文件(.o)的text、data、bss等段的链接分布。语法如下:
SECTIONS
{
section [address] [(type)] :
[AT(lma)]
[ALIGN(section_align) | ALIGN_WITH_INPUT]
[SUBALIGN(subsection_align)]
[constraint]
{
output-section-command
output-section-command
...
} [>region] [AT>lma_region] [:phdr
:phdr ...] [=fillexp] [,]
...
}
/* 大多数的段仅使用了上述部分属性,可以简写成如下形式 */
SECTIONS
{
...
secname :
{
output-section-command
}
...
}
链接脚本本质就是描述输入和输出。secname表示输出文件的段,而output-section-command用来描述输出文件的这个段从哪些文件里抽取而来,即输入目标文件(.o)和库文件(.a)。
Section 分为loadable(可加载)和allocatable(可分配)两种类型。不可加载也不可分配的内存段,通常包含一些调试等信息。
loadable:程序运行时,该段应该被加载到内存中。
allocatable:该段内容被预留出,同时不应该加载任何其他内容(某些情况下,这些内存必须归零)。
loadable和allocatable的section都有两个地址:"VMA"和"LMA"。
VMA (the virtual
memory address):运行输出文件时,该section的地址。可选项,可不配置。
LMA (load memory
address):加载section时的地址。
在大多数情况下,这两个地址时相同的。但有些情况下,需将代码从Flash中加载至RAM运行,此时Flash地址为LAM,RAM地址为VMA。如:
.data :
{
*(.data .data.*)
. = ALIGN(8);
PROVIDE( __global_pointer$ = . + 0x800
);
*(.sdata .sdata.*)
*(.sdata2.*)
. = ALIGN(4);
PROVIDE( _edata = .);
} >RAM AT>FLASH
上述示例中,.data段的内容会放在Flash中,但是运行时,会加载至RAM中(通常为初始化全局变量),即.data段的VMA为RAM,LMA为Flash。
3、常用关键字及命令
3.1 ENTRY
语法:ENTRY(symbol),程序中要执行的第一个指令,也称入口点。示例:
/* Entry Point
*/
ENTRY( _start )
/* CH32V103为启动文件 j handle_reset 指令*/
3.2 PROVIDE
语法:PROVIDE (symbol =
expression),用于定义一个可被引用的符号,类似于全局变量。示例:
PROVIDE( end = .
);
3.3 HIDDEN
语法:HIDDEN (symbol =
expression),对于ELF目标端口,符号将被隐藏且不被导出。示例:
HIDDEN (mySymbol
= .);
3.4
PROVIDE_HIDDEN
语法:PROVIDE_HIDDEN
(symbol = expression),是PROVIDE 和HIDDEN的结合体,类似于局部变量。示例:
PROVIDE_HIDDEN
(__preinit_array_start = .);
3.5 点位符号 '.'
‘.’表示当前地址,它是一个变量,总是代表输出文件中的一个地址(根据输入文件section的大小不断增加,不能倒退,且只用于SECTIONS指令中)。它可以被赋值也可以赋值给某个变量;也可进行算术运算用于产生指定长度的内存空间。示例:
PROVIDE( end = .
); /* 当前地址赋值给 end符号 */
.stack
ORIGIN(RAM) + LENGTH(RAM) - __stack_size :
{
. = ALIGN(4);
PROVIDE(_susrstack = . );
. = . + __stack_size; /* 当前地址加上__stack_size长度,产生__stack_size长度的空间*/
PROVIDE( _eusrstack = .);
} >RAM
3.6 KEEP
当链接器使用('--gc-sections')进行垃圾回收时,KEEP()可以使得被标记段的内容不被清楚。示例
.init :
{
_sinit = .;
. = ALIGN(4);
KEEP(*(SORT_NONE(.init)))
. = ALIGN(4);
_einit = .;
} >FLASH
AT>FLASH
3.7 ASSERT
语法:ASSERT(exp, message),确保exp是非零值,如果为零,将以错误码的形式退出链接文件,并输出message。主要用于添加断言,定位问题。
4. 完整ld链接脚本示例
以RISC-V MCU CH32V307 的链接脚本为例为例。
/* 程序主入口, _start ,具体内容在启动文件中定义 */
ENTRY( _start
)
/* 定义栈大小为 2048 Bytes */
__stack_size =
2048;
/* 定义一个名为_stack_size的变量,在后面的
.stack段中用到 */
PROVIDE(
_stack_size = __stack_size );
/*
内存分布声明
定义Flash、RAM的大小,起始位置
Flash 起始地址为 0x00000000,长度为 192KB
RAM
起始地址为 0x20000000,长度为 128KB
-------
其中Flash的起始位置设定为虚拟的0x0000000,MCU内部做了 0x00000000 到
0x08000000 的映射。
内核启动始终从0地址开始取值,即 PC = 0;所以ld中设定Flash的虚拟地址为0x00000000是可以的。
如果需要将flash的起始地址设定为实际地址 0x08000000,考虑到启动文件中第一条指令为 j handle_reset,
j handle_reset为跳转指令,把PC设为当前PC值 + 偏移地址,偏移地址的范围为 2^21 = 2MB = ±1MB,
启动时PC = 0,而 handle_reset 的地址在0x0800xxxx处,远远超过 ±1MB的范围,
此时需要手动偏移PC,把PC值偏移到handle_reset
±1MB 的跳转范围内,方法如下:
在 j handle_reset前面加上两条指令:
lui t0, 0x08000 # t0赋值为 0x08000000
jr
8(t0) # 跳转至 t0+8 = 0x08000008位置,即PC
= 0x08000008
以上两条指令占了8字节,所以 0x08000008的位置刚好是 j handle_reset指令的位置,此时PC值为0x08000008,可以完成跳转
特别的,当把Flash的起始地址设置为实际地址即0x08000000,需要用到wch-link仿真调试时,
需要修改MRS安装目录下的 wch-riscv.cfg文件
文件位置为:.\MounRiver_Studio\toolchain\OpenOCD\bin\wch-riscv.cfg
将文件中 wlink_set_address 0x00000000 修改为
wlink_set_address 0x08000000
*/
MEMORY
{
FLASH (rx) : ORIGIN = 0x00000000, LENGTH =
192K
RAM (xrw)
: ORIGIN = 0x20000000, LENGTH = 128K
}
/* 段声明 */
SECTIONS
{
/* 初始化段,程序的入口 _start 存放在该段 */
.init :
{
_sinit = .;
. = ALIGN(4);
KEEP(*(SORT_NONE(.init)))
. = ALIGN(4);
_einit = .;
} >FLASH AT>FLASH
/* 存放中断向量表 */
.vector :
{
*(.vector);
. = ALIGN(64);
} >FLASH AT>FLASH
/* 代码段 */
.text :
{
. = ALIGN(4);
*(.text)
*(.text.*)
*(.rodata)
*(.rodata*)
*(.gnu.linkonce.t.*)
. = ALIGN(4);
} >FLASH AT>FLASH
.fini :
{
KEEP(*(SORT_NONE(.fini)))
. = ALIGN(4);
} >FLASH AT>FLASH
PROVIDE( _etext = . );
PROVIDE( _eitcm = . );
.preinit_array :
{
PROVIDE_HIDDEN (__preinit_array_start =
.);
KEEP (*(.preinit_array))
PROVIDE_HIDDEN (__preinit_array_end =
.);
} >FLASH AT>FLASH
.init_array :
{
PROVIDE_HIDDEN (__init_array_start =
.);
KEEP
(*(SORT_BY_INIT_PRIORITY(.init_array.*) SORT_BY_INIT_PRIORITY(.ctors.*)))
KEEP (*(.init_array EXCLUDE_FILE
(*crtbegin.o *crtbegin?.o *crtend.o *crtend?.o ) .ctors))
PROVIDE_HIDDEN (__init_array_end = .);
} >FLASH AT>FLASH
.fini_array :
{
PROVIDE_HIDDEN (__fini_array_start =
.);
KEEP
(*(SORT_BY_INIT_PRIORITY(.fini_array.*) SORT_BY_INIT_PRIORITY(.dtors.*)))
KEEP (*(.fini_array EXCLUDE_FILE (*crtbegin.o
*crtbegin?.o *crtend.o *crtend?.o ) .dtors))
PROVIDE_HIDDEN (__fini_array_end = .);
} >FLASH AT>FLASH
.ctors :
{
/* gcc uses crtbegin.o to find the
start of
the constructors, so we make sure it is
first.
Because this is a wildcard, it
doesn't matter if the user does not
actually link against crtbegin.o; the
linker won't look for a file to match a
wildcard. The wildcard also means that it
doesn't matter which directory
crtbegin.o
is in.
*/
KEEP (*crtbegin.o(.ctors))
KEEP (*crtbegin?.o(.ctors))
/* We don't want to include the .ctor
section from
the crtend.o file until after the
sorted ctors.
The .ctor section from the crtend file
contains the
end of ctors marker and it must be last
*/
KEEP (*(EXCLUDE_FILE (*crtend.o
*crtend?.o ) .ctors))
KEEP (*(SORT(.ctors.*)))
KEEP (*(.ctors))
} >FLASH AT>FLASH
.dtors :
{
KEEP (*crtbegin.o(.dtors))
KEEP (*crtbegin?.o(.dtors))
KEEP (*(EXCLUDE_FILE (*crtend.o
*crtend?.o ) .dtors))
KEEP (*(SORT(.dtors.*)))
KEEP (*(.dtors))
} >FLASH AT>FLASH
/*
该段定义了全局变量 _data_vma,
因为从该段开始第一次声明
保存在RAM中的段,
所以_data_vma变量的地址为RAM的起始地址 0x20000000
*/
.dalign :
{
. = ALIGN(4);
PROVIDE(_data_vma = .);
} >RAM AT>FLASH
/*
该段定义了全局变量_data_lma,
此段位于前面各段末尾,用于存放data段中的保存在flash数据
程序运行时会从该地址加载data段数据到RAM中
*/
.dlalign :
{
. = ALIGN(4);
PROVIDE(_data_lma = .);
} >FLASH AT>FLASH
.data :
{
*(.gnu.linkonce.r.*)
*(.data .data.*)
*(.gnu.linkonce.d.*)
. = ALIGN(8);
PROVIDE( __global_pointer$ = . + 0x800
);
*(.sdata .sdata.*)
*(.sdata2.*)
*(.gnu.linkonce.s.*)
. = ALIGN(8);
*(.srodata.cst16)
*(.srodata.cst8)
*(.srodata.cst4)
*(.srodata.cst2)
*(.srodata .srodata.*)
. = ALIGN(4);
PROVIDE( _edata = .); /* _edata代表data段结尾地址 */
} >RAM AT>FLASH
.bss :
{
. = ALIGN(4);
PROVIDE( _sbss = .); /* _sbss代表bss段起始地址 */
*(.sbss*)
*(.gnu.linkonce.sb.*)
*(.bss*)
*(.gnu.linkonce.b.*)
*(COMMON*)
. = ALIGN(4);
PROVIDE( _ebss = .); /* _ebss代表bss段结尾地址 */
} >RAM AT>FLASH
PROVIDE( _end = _ebss); /* 堆起始地址 */
PROVIDE( end = . );
/*
stack 栈段
起始地址为 ORIGIN(RAM) + LENGTH(RAM) -
__stack_size
*/
.stack ORIGIN(RAM) + LENGTH(RAM) -
__stack_size :
{
PROVIDE( _heap_end = . ); /* 堆结束 ORIGIN(RAM) + LENGTH(RAM) - __stack_size
*/
. = ALIGN(4);
PROVIDE(_susrstack = . ); /* 栈底 ORIGIN(RAM) + LENGTH(RAM) - __stack_size */
. = . + __stack_size;
PROVIDE( _eusrstack = .); /* 栈顶 即 ORIGIN(RAM) + LENGTH(RAM) */
} >RAM
}
5. C文件中读取ld中全局变量示例
以读取 栈顶 _eusrstack 和
栈底 _susrstack 变量为例:
int main(void)
{
Delay_Init();
USART_Printf_Init(115200);
printf("ch32v307 hello
world\r\n");
extern uint32_t _eusrstack; /* 声明外部变量 _eusrstack */
printf("_eusrstack address =
0x%08x\r\n",&_eusrstack);
extern uint32_t _susrstack; /* 声明外部变量 _susrstack */
printf("_susrstack address =
0x%08x\r\n",&_susrstack);
while(1)
{
;
}
}
输出结果如下:
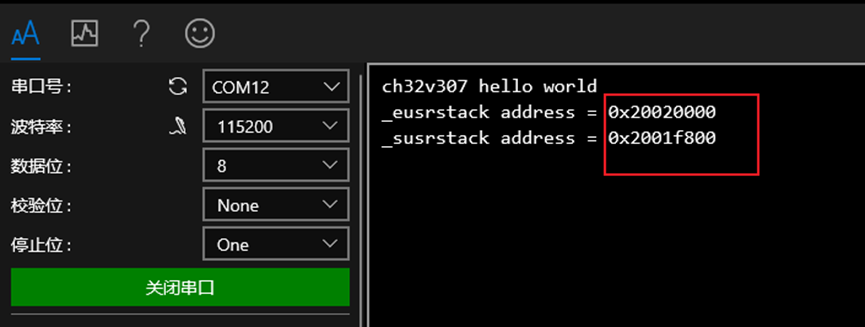
通过上一节ld文件分析:
- 栈底 _susrstack 的地址为 ORIGIN(RAM) +
LENGTH(RAM) - __stack_size = 0x2000000 + 128K - 2048 = 0x2001f800
- 栈顶 _eusrstack 的地址为 ORIGIN(RAM) +
LENGTH(RAM) = 0x2000000 + 128K = 0x20020000
读取的结果符合预期。
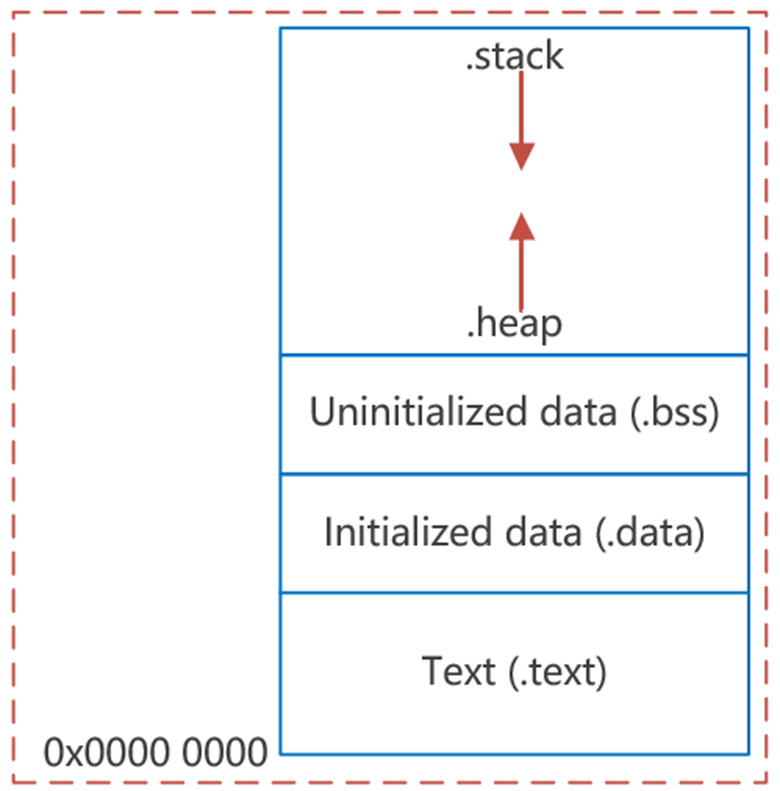
RISC-V MCU堆栈机制
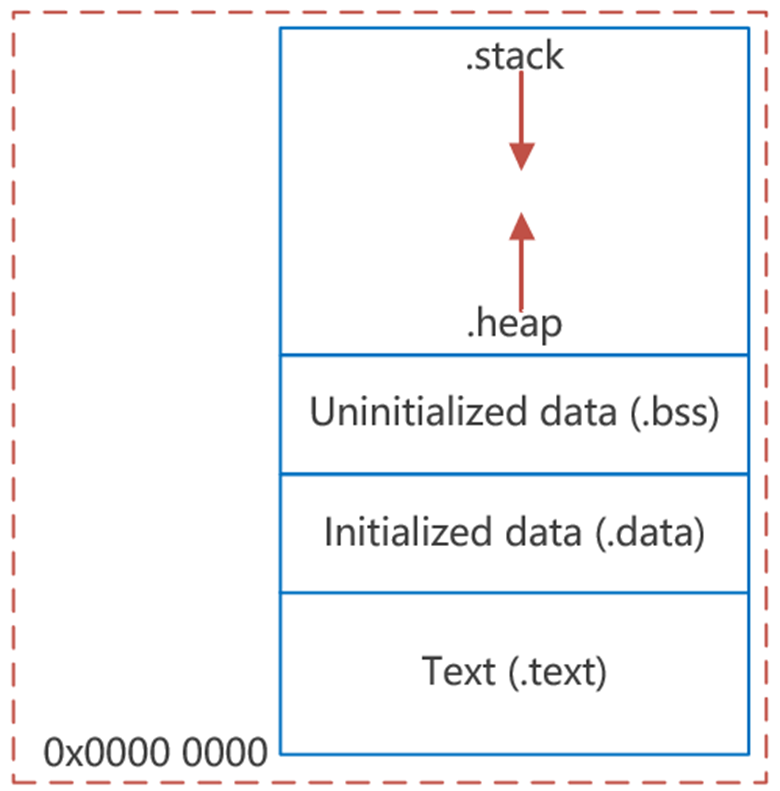
1、什么是堆栈?
在嵌入式的世界里,堆栈通常指的是栈,严格来说,堆栈分为堆(Heap)和栈(Stack)。
栈(Stack): 一种顺序数据结构,满足后进先出(Last-In / First-Out)的原则,由编译器自动分配和释放。使用一级缓存,调用完立即释放。
堆(Heap):类似于链表结构,可对任意位置进行操作,通常由程序员手动分配,使用完需及时释放(free),不然容易造成内存泄漏。使用二级缓存。
2、堆栈的作用
函数调用时,如果函数参数和局部变量很多,寄存器放不下,需要开辟栈空间存储。
中断发生时,栈空间用于存放当前执行程序的现场数据(下一条指令地址、各种缓存数据),以便中断结束后恢复现场。
3、堆栈大小定义
RISC-V MCU的堆栈大小通常在ld链接脚本中定义,关于ld链接脚本可查看该文:RISC-V MCU ld链接脚本说明。
ENTRY( _start )
/* 入口地址 */
__stack_size =
2048; /* 定义栈大小 */
PROVIDE(
_stack_size = __stack_size );/* 定义_stack_size符号,类似于全局变量 */
MEMORY
{
FLASH (rx) : ORIGIN = 0x00000000 , LENGTH =
0x10000
RAM (xrw) : ORIGIN = 0x20000000 , LENGTH =
0x5000
}
/*
...
中间省略
...
*/
.stack
ORIGIN(RAM) + LENGTH(RAM) - __stack_size :
/* 分配栈空间0x20004800 ~
0x20005000,共2KB */
{
. = ALIGN(4);
PROVIDE(_susrstack = . );
. = . + __stack_size;
PROVIDE( _eusrstack = .);
} >RAM
以RISC-V MCU CH32V103为例,在其ld链接脚本中,定义了_stack_size符号,值为 2048 Byte,后面使用该值在.stack段中分配栈空间,可更改此值调整栈空间大小。
CH32V103 的RAM共20KB,除去程序用到的data、bss段,剩下空间即为动态数据段,供堆栈的动态使用。
ld链接脚本中,没有明确定义heap堆的大小,按照其定义,动态数据段,除了stack占用的,剩下的都可用于heap,通过malloc进行动态管理。
4、压栈出栈过程
以CH32V103 printf函数调用为例,其反汇编代码如下:
000007a4
<iprintf>:
7a4: 7139 addi sp,sp,-64 # 调整堆栈指针sp,分配64字节的栈空间
7a6: da3e sw a5,52(sp) # 压栈,保存a5寄存器的值
7a8: d22e sw a1,36(sp) # 压栈,按需保存相应的寄存器
7aa: d432 sw a2,40(sp)
7ac: d636 sw a3,44(sp)
7ae: d83a sw a4,48(sp)
7b0: dc42 sw a6,56(sp)
7b2: de46 sw a7,60(sp)
7b4: 80818793 addi a5,gp,-2040 # 20000078 <_impure_ptr>
7b8: cc22 sw s0,24(sp) # 压栈,保存帧指针fp(s0)
7ba: 4380 lw s0,0(a5)
7bc: ca26 sw s1,20(sp)
7be: ce06 sw ra,28(sp) # 压栈,保存返回地址(ra寄存器)
7c0: 84aa mv s1,a0
7c2: c409 beqz s0,7cc
<iprintf+0x28>
7c4: 4c1c lw a5,24(s0)
7c6: e399 bnez a5,7cc
<iprintf+0x28>
7c8: 8522 mv a0,s0
7ca: 2315 jal cee
<__sinit>
7cc: 440c lw a1,8(s0)
7ce: 1054 addi a3,sp,36
7d0: 8626 mv a2,s1
7d2: 8522 mv a0,s0
7d4: c636 sw a3,12(sp)
7d6: 167000ef jal ra,113c <_vfiprintf_r>
7da: 40f2 lw ra,28(sp) # 出栈,恢复返回地址(ra寄存器)
7dc: 4462 lw s0,24(sp) # 出栈,恢复帧指针fp(s0)
7de: 44d2 lw s1,20(sp) # 出栈,按需恢复相应的寄存器
7e0: 6121 addi sp,sp,64 # 释放栈空间
7e2: 8082 ret #
函数返回,根据ra寄存器地址返回
5、malloc使用注意事项
CH32V103默认工程中,heap只有起始地址,没有结束地址约束,这样最终会导致malloc永远都不会返回NULL。
如果使用malloc时,需进行如下操作:
重写_sbrk函数,代码如下,放在工程任意位置,推荐放在debug.c 文件中。
_sbrk代码原型:https://github.com/riscv/riscv-newlib/blob/riscv-newlib-3.1.0/libgloss/libnosys/sbrk.c
void
*_sbrk(ptrdiff_t incr)
{
extern char _end[];
extern char _heap_end[];
static char *curbrk = _end;
if ((curbrk + incr < _end) || (curbrk
+ incr > _heap_end))
return NULL - 1;
curbrk += incr;
return curbrk - incr;
}
修改ld链接脚本,定义heap大小
默认RAM中除去data、bss、stack等剩余的都为heap空间
增加PROVIDE( _heap_end =
. ); 定义,位置如下:
PROVIDE( _end = _ebss);
PROVIDE( end = . ); /* 定义heap起始位置 */
.stack ORIGIN(RAM) + LENGTH(RAM) -
__stack_size :
{
PROVIDE( _heap_end = . ); /* 定义heap结束位置,默认到栈底结束 */
. = ALIGN(4);
PROVIDE(_susrstack = . );
/*ASSERT ((. >
0x20005000),"ERROR:No room left for the stack");*/
. = . + __stack_size;
PROVIDE( _eusrstack = .);
} >RAM
指定heap大小的修改方式如下:
增加 PROVIDE( _heap_end =
. + 0x400); 定义,位置如下:
PROVIDE( _end = _ebss);
PROVIDE( end = . ); /* 定义heap起始位置 */
PROVIDE( _heap_end = . + 0x400); /* 定义heap结束位置,长度为1KB */
.stack ORIGIN(RAM) + LENGTH(RAM) -
__stack_size :
{
. = ALIGN(4);
PROVIDE(_susrstack = . );
/*ASSERT ((. >
0x20005000),"ERROR:No room left for the stack");*/
. = . + __stack_size;
PROVIDE( _eusrstack = .);
} >RAM
RISC-V gp全局指针寄存器说明
gp,global pointer,全局指针寄存器,RISC-V
32个寄存器之一,为了优化±2KB内全局变量的访问。
gp寄存器在启动代码中加载为__global_pointer$的地址,并且之后不能被改变。
linker时使用__global_pointer$来比较全局变量的地址,如果在范围内,就替换掉lui或puipc指令的
absolute/pc-relative寻址,变为gp-relative寻址,使得代码效率更高。该过程被称为linker relaxation(链接器松弛),也可以使用-Wl,--no-relax来关闭此功能。
如:需要读取全局变量 tao_global的值,地址位0x20000100,gp指针地址为0x20000800;
普通调用方式为:
lui
a5,0x20000 /* 将0x20000100高20位0x20000 左移12位赋给a5寄存器 */
lw a5,256(a5)
/* 加载a5+256(0x100,0x20000100低12位)的值至a5寄存器 */
gp指针优化调用方式:
lw a5,-1792(gp)
/* 加载gp-1792地址处的值至a5,即0x20000100处的值*/
通过gp指针,访问其值±2KB,即4KB范围内的全局变量,可以节约一条指令。
4KB区域可以位于寻址内存中任意位置,但是为了使优化更有效率,最好覆盖最频繁使用的RAM区域。对于标准的newlib应用程序,这是分配.sdata部分的区域,因为它包含了诸如_impure_ptr、malloc_sbrk_base等变量。因此,定义应该被放在.sdata部分之前。以RISC-V MCU CH32V103 ld文件为例:
.data :
{
*(.gnu.linkonce.r.*)
*(.data
.data.*)
*(.gnu.linkonce.d.*)
. = ALIGN(8);
PROVIDE(
__global_pointer$ = . + 0x800 ); /* __global_pointer地址*/
*(.sdata
.sdata.*)
*(.sdata2.*)
*(.gnu.linkonce.s.*)
.
= ALIGN(8);
*(.srodata.cst16)
*(.srodata.cst8)
*(.srodata.cst4)
*(.srodata.cst2)
*(.srodata
.srodata.*)
.
= ALIGN(4);
PROVIDE( _edata = .);
} >RAM AT>FLASH
gp指针优化代码空间
通常情况下,gp指针定义在data区,有时候为了优化代码密度,可以根据实际情况修改gp指针的位置,如工程中定义了大量的初始化为0或未初始化的全局数组作为缓冲区,可以将gp指针的位置定义到bss段。
最易变的关键词 - volatile
1、volatile关键字
volatile 是易变的、不稳定的意思。和const一样是一种类型修饰符,volatile关键字修饰的变量,编译器对访问该变量的代码不再进行优化,从而可以提供对特殊地址的稳定访问。
以前只是听过这个关键词,知道它的存在,但从来没用过。用此文记录下在开发RISC-V MCU过程中,未用volatile修饰标志位变量,编译器进行优化,导致程序运行异常。
2、Demo
开发中,常见的需求,主循环中根据中断中修改的标志位,运行不同的功能,
#include
"debug.h"
uint8_t
flag_interrupt = 0;
int main(void)
{
USART_Printf_Init(115200);
printf("SystemClk:%d\r\n",SystemCoreClock);
EXTI0_INT_INIT();
while(1)
{
if(flag_interrupt == 1)
{
flag_interrupt = 0;
printf("do
something\r\n");
}
}
}
/* 外部中断服务函数*/
__attribute__((interrupt("WCH-Interrupt-fast")))
void
EXTI0_IRQHandler(void)
{
if(EXTI_GetITStatus(EXTI_Line0)==SET) //EXTI_GetITStatus用来获取中断标志位状态
{
flag_interrupt = 1;
printf("Run at
EXTI\r\n");
EXTI_ClearITPendingBit(EXTI_Line0); //清除中断标志位
}
}
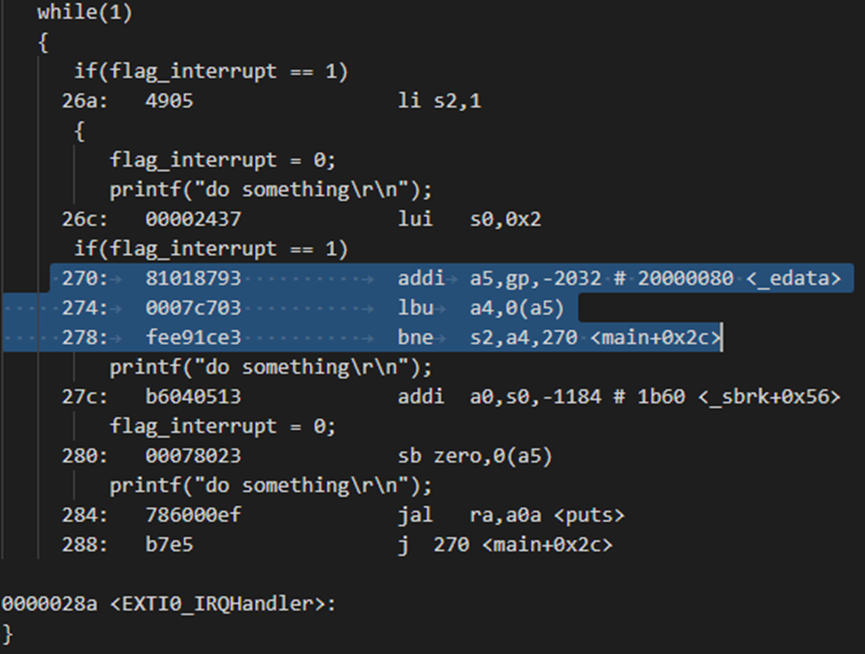
进入中断服务函数,改变了flag_interrupt的值,但是主函数仍然没有运行相应的程序,很是奇怪,检查反汇编代码,才发现是编译器对flag_interrupt变量的访问进行了优化,如图,
|
278: 01271063 bne a4,s2,278
<main+0x34> #
不相等就跳转至0x278的位置,即还是本条语句的位置,
|
可以看到,编译器对flag_interrupt变量的访问进行了优化,没有重新去0x20000080的位置进行取值,而是每次都用a4寄存器的值与s2寄存器(值为1)比较,不相等还是跳回本条语句的位置,重复运行,导致即使在中断中改变了其值,主循环中也不能运行对应的功能。这时候就需要使用volatile关键字对flag_interrupt进行修饰。
| |
volatile uint8_t
flag_interrupt = 0;
|
查看反汇编代码,编译器未对flag_interrupt变量进行优化,老老实实的每次去源地址0x20000080处取值访问。
RISC-V MCU将常量定义到指定的Flash地址 -- 以CH32V103为例
Keil MDK开发ARM 内核的MCU时,将常量定义到指定的Flash地址中,使用 _attribute_( at(绝对地址) )即可,如:
const u32
myConstVariable_1[128] __attribute__((at(0x08001000))) =
{0x12345678,0x22221111};//定位在flash中,其他flash补充为0
RISC-V MCU ,通过Mounriver Studio(MRS)开发时,暂时不支持_attribute_( at(绝对地址) )命令。可通过如下步骤实现:
1、编辑ld链接文件,添加SECTIONS段
.flash_test_address :
{
. = ALIGN(4); /*4字节对齐*/
. = ORIGIN(FLASH)+0x1000; /*ORIGIN(FLASH)为 MEMORY定义的FLASH的起始地址(CH32V103为0x08000000),指定到从FLASH起始的0x1000长度的位置*/
KEEP(*(SORT_NONE(.test_address_1))) /*链接时*KEEP()可以使得被标记段的内容不被清除*/
. = ALIGN(4);
} >FLASH AT>FLASH
如需将变量定义到Flash的最后,将此段添加到 .text段后面,注意指定的Flash地址要大于程序编译大小。
2、函数中使用__attribute__((section(".xxx")))定义常量
2.1 定义单字节常量
const uint8_t
myConstVariable_1 __attribute__((section(".test_address_1"))) =
0x11;/*地址为0x00001000*/
查看map文件,常量地址如下:
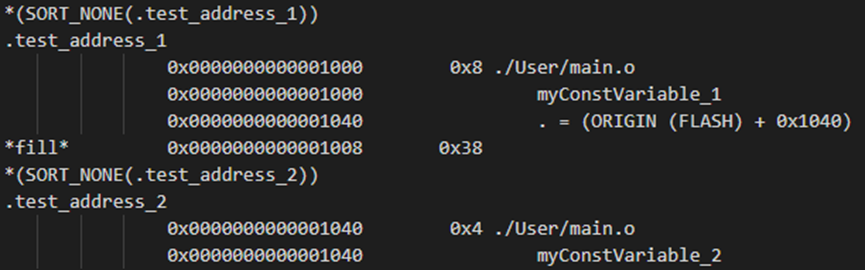
sections
.flash_test_address段中以4字节对齐,其余3字节补0。
二进制bin文件0x1000地址信息如下;

2.2 定义连续的多个单字节常量
const uint8_t
myConstVariable_1 __attribute__((section(".test_address_1"))) = 0x11;
/*地址为0x00001002*/
const uint8_t
myConstVariable_2 __attribute__((section(".test_address_1"))) = 0x22;
/*地址为0x00001001*/
const uint8_t
myConstVariable_3 __attribute__((section(".test_address_1"))) = 0x33;
/*地址为0x00001000*/
ld文件中flash_test_address 段默认从指定地址开始为其分配连续的地址,查看map文件,常量地址如下:
二进制bin文件0x1000地址信息如下;
2.3 定义多个不连续的常量
此时需要修改ld文件
.flash_test_address
:
{
. = ALIGN(4); /*4字节对齐*/
. = ORIGIN(FLASH)+0x1000; /*ORIGIN(FLASH)为 MEMORY定义的FLASH的起始地址(CH32V103为0x08000000),指定到从FLASH起始的0x1000长度的位置*/
KEEP(*(SORT_NONE(.test_address_1))) /*链接时*KEEP()可以使得被标记段的内容不被清除*/
. = ORIGIN(FLASH)+0x1040; /*ORIGIN(FLASH)为 MEMORY定义的FLASH的起始地址(CH32V103为0x08000000),指定到从FLASH起始的0x1040长度的位置*/
KEEP(*(SORT_NONE(.test_address_2))) /*链接时*KEEP()可以使得被标记段的内容不被清除*/
. = ALIGN(4);
} >FLASH AT>FLASH
在函数中定义两个指定地址的常量
const uint8_t
myConstVariable_1[8] __attribute__((section(".test_address_1"))) =
{0x11,0x22,0x33,0x44}; /*首地址为0x00001000*/
const uint8_t
myConstVariable_2[4] __attribute__((section(".test_address_2"))) =
{0x55,0x66}; /*首地址为0x00001040*/
查看map文件,常量地址如下:
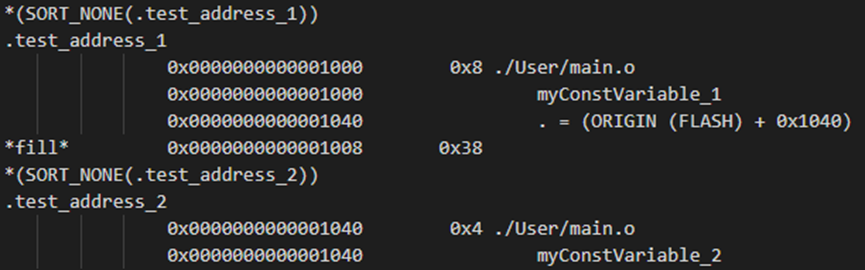
二进制bin文件0x1000地址信息如下;

这样指定的方式会造成中间段有56个字节的flash无法分配内容,浪费了,不建议这样指定,如果实在要这样做,需要严格把控,可根据间隔的大小,指定编译后小于该间隔的函数存储到该flash块。
如指定函数Delay_Init编译后存放test_address_1块内,紧跟定义的常量后。
/*******************************************************************************
* Function
Name : Delay_Init
*
Description : Initializes Delay
Funcation.
* Input : None
* Return : None
*******************************************************************************/
__attribute__((section(".test_address_1")))
void Delay_Init(void)
{
p_us=SystemCoreClock/8000000;
p_ms=(uint16_t)p_us*1000;
}
Delay_Init函数编译后的大小为0x2a,编译后的map文件如下:
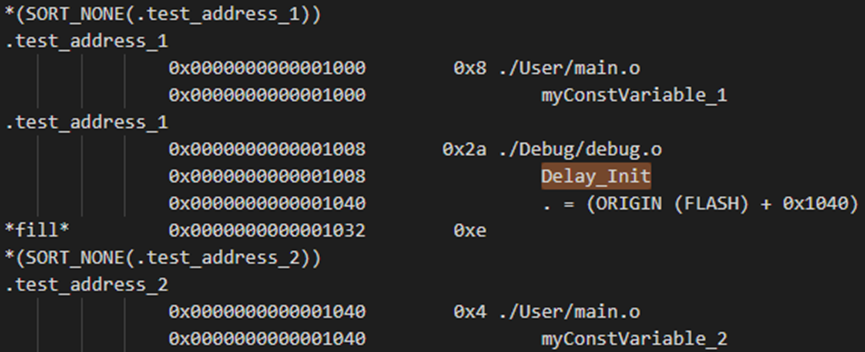
二进制bin文件0x1000地址信息如下:

(新增的A2 4A 04 指令暂时不详)





