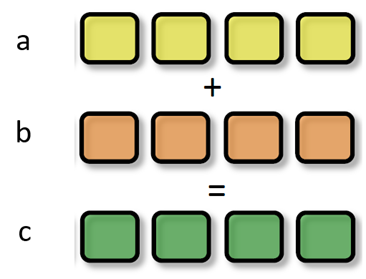SIMD和SIMT技术分析
SIMD(Single Instruction Multiple Data)是单指令多数据,在GPU的ALU单元内,一条指令可以处理多维向量(一般是4D)的数据。比如,有以下shader指令:
float4 c = a + b; // a, b都是float4类型
对于没有SIMD的处理单元,需要4条指令将4个float数值相加,汇编伪代码如下:
ADD c.x, a.x, b.x
ADD c.y, a.y, b.y
ADD c.z, a.z, b.z
ADD c.w, a.w, b.w
但有了SIMD技术,只需一条指令即可处理完:
SIMD_ADD c, a, b
SIMT(Single Instruction Multiple Threads,单指令多线程)是SIMD的升级版,可对GPU中单个SM中的多个Core同时处理同一指令,并且每个Core存取的数据可以是不同的。
SIMT_ADD c, a, b
上述指令会被同时送入在单个SM中被编组的所有Core中,同时执行运算,但a、b 、c的值可以不一样:
在获取数据之后,在SM中以32个线程为一组的线程束(Warp)来调度,来开始处理顶点数据。Warp是典型的单指令多线程(SIMT,SIMD单指令多数据的升级)的实现,也就是32个线程同时执行的指令是一模一样的,只是线程数据不一样,这样的好处就是一个warp只需要一个套逻辑对指令进行解码和执行就可以了,芯片可以做的更小更快,之所以可以这么做是由于GPU需要处理的任务是天然并行的。
Tesla微观架构总览图如上。下面将阐述特性和概念:
- · 拥有7组TPC(Texture/Processor Cluster,纹理处理簇)
- · 每个TPC有两组SM(Stream Multiprocessor,流多处理器)
- · 每个SM包含:
- 6个SP(Streaming Processor,流处理器)
- 2个SFU(Special Function Unit,特殊函数单元)
- L1缓存、MT Issue(多线程指令获取)、C-Cache(常量缓存)、共享内存
- 1、将主存的处理数据复制到显存中。
- 2、CPU指令驱动GPU。
- 3、GPU中的每个运算单元并行处理。此步会从显存存取数据。
- 4、GPU将显存结果,传回主存。
- 每个Warp:
- 16个Core
- Warp编排器(Warp Scheduler)
- 分发单元(Dispatch Unit)
- 每个Core:
- 1个FPU(浮点数单元)
- 1个ALU(逻辑运算单元)
下段是计算漫反射的经典代码:
sampler mySamp;
Texture2D<float3> myTex;
float3 lightDir;
float4 diffuseShader(float3 norm, float2 uv)
{
float3 kd;
kd = myTex.Sample(mySamp, uv);
kd *= clamp( dot(lightDir, norm), 0.0, 1.0);
return float4(kd, 1.0);
}
经过编译后,成为汇编代码:
<diffuseShader>:
sample r0, v4, t0, s0
mul r3, v0, cb0[0]
madd r3, v1, cb0[1], r3
madd r3, v2, cb0[2], r3
clmp r3, r3, l(0.0), l(1.0)
mul o0, r0, r3
mul o1, r1, r3
mul o2, r2, r3
mov o3, l(1.0)
在执行阶段,以上汇编代码会被GPU推送到执行上下文(Execution Context),然后ALU会逐条获取(Detch)、解码(Decode)汇编指令,并执行。
对于SIMT架构的GPU,汇编指令有所不同,变成了SIMT特定指令代码:
<VEC8_diffuseShader>:
VEC8_sample vec_r0, vec_v4, t0, vec_s0
VEC8_mul vec_r3, vec_v0, cb0[0]
VEC8_madd vec_r3, vec_v1, cb0[1], vec_r3
VEC8_madd vec_r3, vec_v2, cb0[2], vec_r3
VEC8_clmp vec_r3, vec_r3, l(0.0), l(1.0)
VEC8_mul vec_o0, vec_r0, vec_r3
VEC8_mul vec_o1, vec_r1, vec_r3
VEC8_mul vec_o2, vec_r2, vec_r3
VEC8_mov o3, l(1.0)
并且,Context以Core为单位组成共享的结构,同一个Core的多个ALU,共享一组Context:
如果有多个Core,就会有更多的ALU,同时参与shader计算,每个Core执行的数据是不一样的,可能是顶点、图元、像素等任何数据:
通用流水线处理器技术参数
申威111
• 采用新一代“申威64”核心技术,核心流水线升级为4译码7发射结构,单核性能大幅有提升(整数性能提高62%,浮点性能提高53%);
• 采用低功耗流片工艺,实现更低功耗,典型课题下芯片的整体运行功耗为3W以内;
• 集成丰富的I/O外设接口,可适应多种不同的应用场景;
• 坚持宽温度范围设计,增强芯片适应面;
• 产品已达到国军标B级标准,可以面向军工、工控等领域应用。
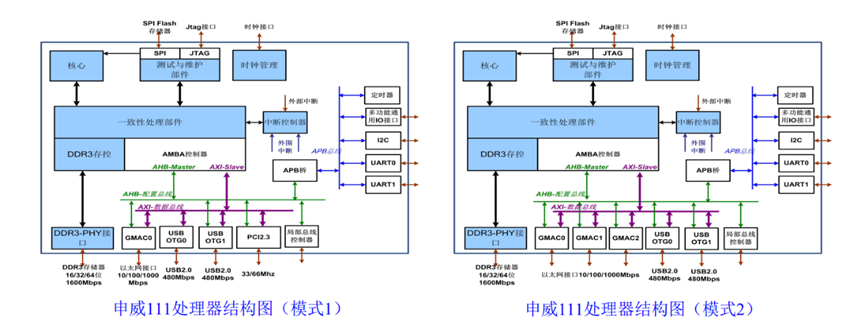
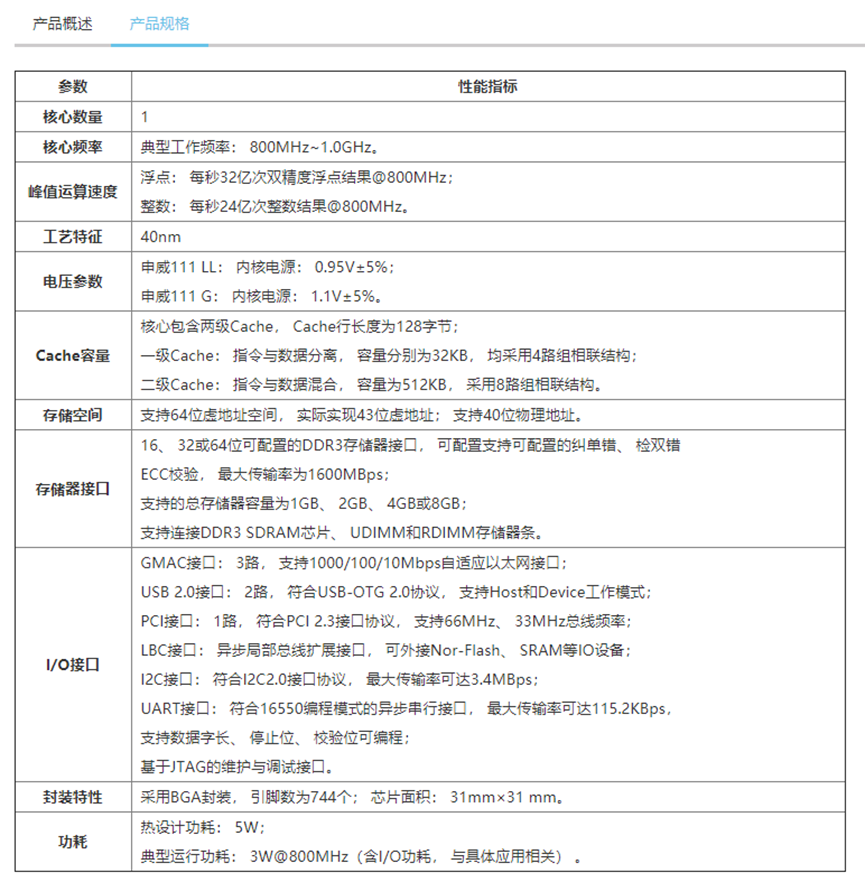
申威111是基于第三代“申威64”核心的国产嵌入式处理器,主要面向高密度计算型嵌入式应用需求。申威111处理器有两款产品:采用40nmLL工艺的产品(申威111LL)已量产。
申威111LL采用SoC技术,集成1个64位RISC结构的申威处理器核心,工作频率800MHz-1.0GHz。集成单路DDR3存储控制器,还集成了PCI、Ethernet、USB、UART、I2C、LBC等标准I/O接口,这些I/O接口可以根据系统应用需求配置成两种不同模式。
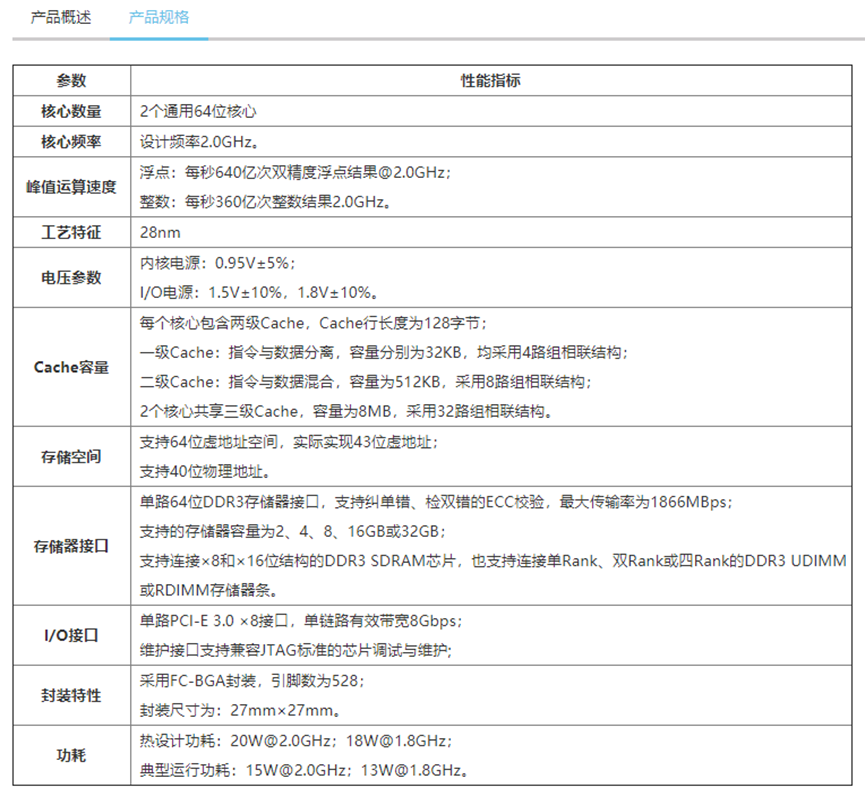
申威221
• 基于第三代“申威64”核心(增强版)研制的2核心通用处理器,采用28nm代工工艺,工作频率设计目标为2GHz;
• 2个核心共享片上三级共享Cache,并且三级Cache容量达到8MB;
• 计算性能:主频2GHz时的双精度浮点性能可高达64GFlops;
• 访存性能:集成单路64位DDR3存储控制器,传输率最高达2133MBps,支持ECC校验;最大可支持内存容量高达32GB;
• I/O性能:单路PCI-E3.0×8接口,双向聚合有效带宽提高到16Gbps。
申威221处理器是基于第三代“申威64”核心(增强版)的国产高性能多核处理器,主要面向高密度计算型嵌入式应用需求。
申威221采用对称多核结构和SoC技术,单芯片集成了2个64位RISC结构的申威处理器核心,目标设计主频为2GHz。芯片还集成单路DDR3存储控制器和单路PCI-E3.0标准I/O接口。
参考链接:
Arm Cortex-M23 MCU,Arm Cortex-M33 MCU与RISC-V MCU技术
本文介绍以下技术
Arm Cortex-M23 MCU
Arm Cortex-M33 MCU
RISC-V
MCU
基于ARM Cortex-M和RISC-V内核,提供了丰富的产品组合和全面的软硬件支持
Arm® Cortex®-M23 MCU
基于Arm® Cortex®-M23内核的32位通用微控制器(MCU)
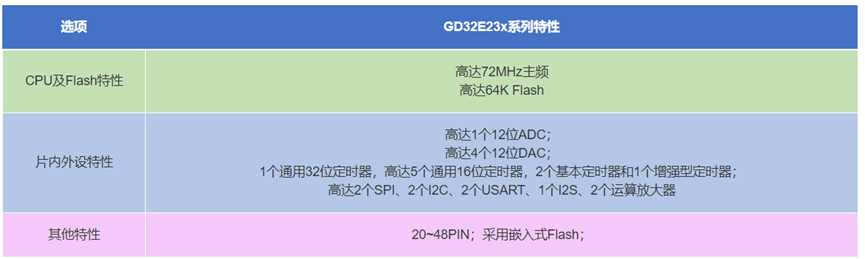
Arm® Cortex®-M23是Cortex®-M0和Cortex®-M0+的继任者,基于最新的Armv8-M架构的嵌入式微处理器内核。采用冯诺依曼结构二级流水线,支持完整的Armv8-M基准指令集,最大限度地提高了代码的紧凑性。并兼容所有的Armv6-M指令,可以帮助工程师轻而易举地将代码从Cortex®-M0/M0+处理器转移至Cortex®-M23。全新的Cortex®-M23内核配备了单周期硬件乘法器、硬件除法器、硬件分频器、嵌套向量中断控制器(NVIC)等独立资源,并强化了调试纠错与追溯能力更易于开发。后续产品亦可以通过加载TrustZone®技术,以硬件形式支持可信和非可信软件强制隔离与防护,出色实现多项安全需求。 GD32E23x系列Cortex®-M23内核MCU是具备了小尺寸、低成本、高能效和灵活性优势,并支持安全性扩展的最新嵌入式应用解决方案。
GD32E230/231/232系列
- 全系列采用嵌入式Flash
- 16K~64K Flash
- 4K~8K SRAM
- 1.8~3.6V供电,5V容忍I/O
- -40℃~105 ℃工业级温度范围
- 全系列硬件管脚及软件兼容
基于ARM Cortex-M和RISC-V内核,提供了丰富的产品组合和全面的软硬件支持
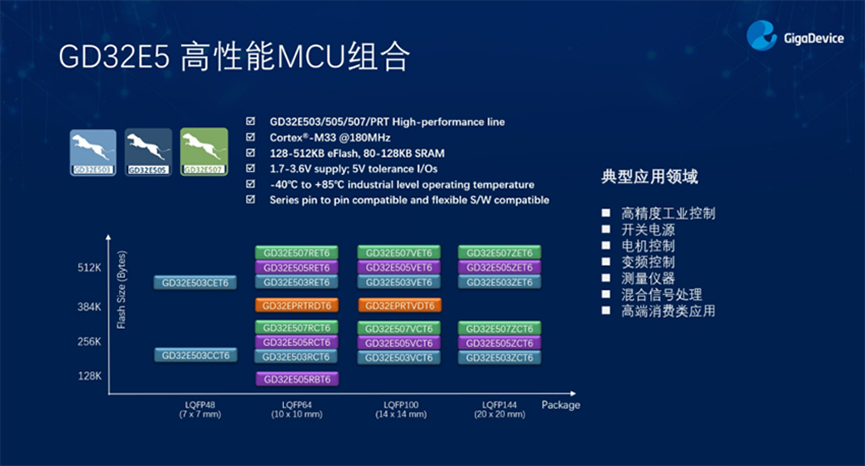
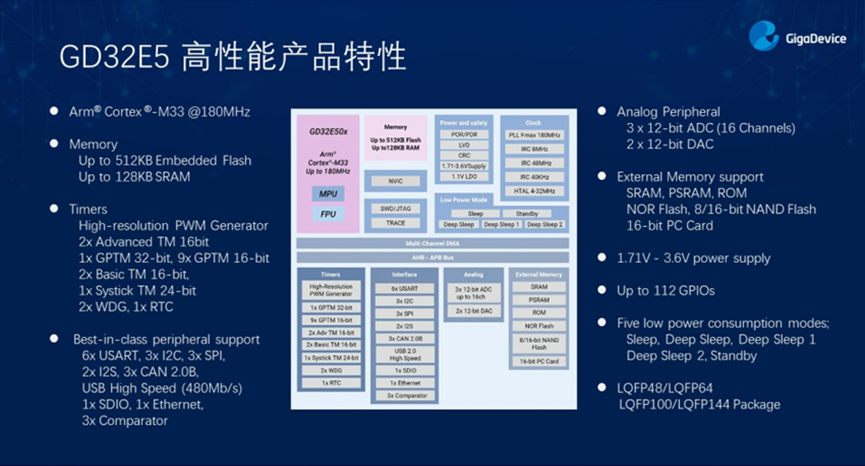
Arm® Cortex®-M33
MCU
基于Arm® Cortex®-M33内核的32位通用微控制器(MCU)
RISC-V
MCU
基于ARM Cortex-M和RISC-V内核,提供了丰富的产品组合和全面的软硬件支持
RISC-V MCU
基于RISC-V内核的32位通用微控制器(MCU)
GD32VF103系列MCU采用了全新的基于开源指令集架构RISC-V的Bumblebee处理器内核,兆易创新(Gigadevice)的RISC-V处理器内核IP和解决方案厂商芯来科技(Nuclei System Technology),面向物联网及其它超低功耗场景应用,自主联合开发的一款商用RISC-V处理器内核。 GD32VF103系列RISC-V MCU提供了108MHz的运算主频,以及16KB到128KB的片上闪存和6KB到32KB的SRAM缓存,gFlash®专利技术支持内核访问闪存高速零等待。Bumblebee内核还内置了单周期硬件乘法器、硬件除法器和加速单元,应对高级运算和数据处理的挑战。
参考链接:
CPU0 处理器的架构及应用
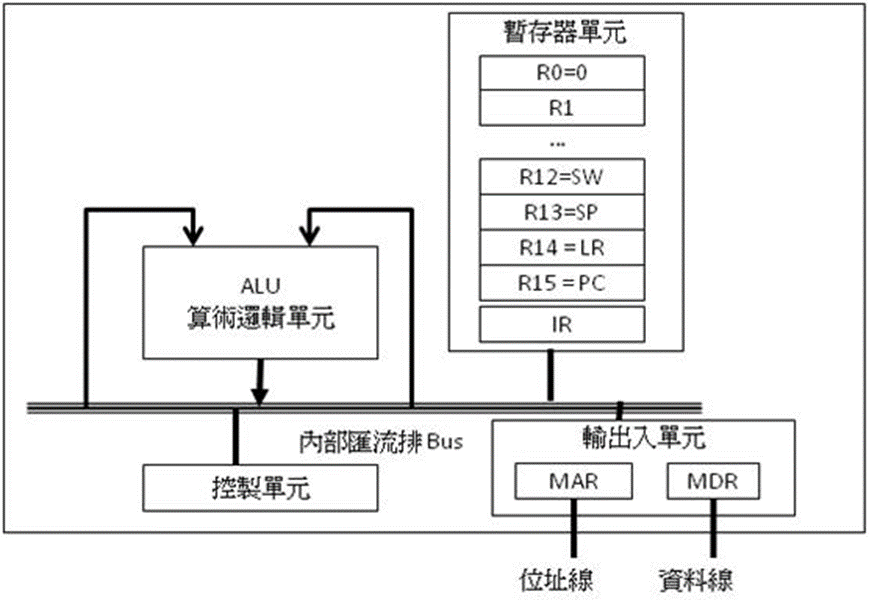
简介
CPU0 是一个 32 位的处理器,包含 R0..R15, IR, MAR, MDR 等缓存器,结构如下图所示。
图 1 :CPU0 处理器的结构
其中各个缓存器的用途如下所示:
|
IR
|
指令缓存器
|
|
R0
|
常数缓存器, 值永远为 0。
|
|
R1~R11
|
通用型缓存器。
|
|
R12
|
状态缓存器 (Status Word : SW)
|
|
R13
|
堆栈指针缓存器 (Stack Pointer : SP)
|
|
R14
|
链接缓存器 (Link Register : LR)
|
|
R15
|
程序计数器 (Program Counter : PC)
|
|
MAR
|
地址缓存器 (Memory Address Register)
|
|
MDR
|
数据缓存器 (Memory Data Register)
|
CPU0 的指令集
CPU0 的指令分为三种类型,L 型通常为加载储存指令、A 型以算术指令为主、J 型则通常为跳跃指令,下图显示了这三种类型指令的编码格式。
图 2:CPU0 的三种指令格式
以下是 CPU0 处理器的指令表格式
表 1 :CPU0 的指令表
在第二版的 CPU0_v2 中,补上了以下指令:
|
类型
|
格式
|
指令
|
OP
|
说明
|
语法
|
语意
|
|
浮点运算
|
A
|
FADD
|
41
|
浮点加法
|
FADD Ra, Rb, Rc
|
Ra = Rb + Rc
|
|
浮点运算
|
A
|
FSUB
|
42
|
浮点减法
|
FSUB Ra, Rb, Rc
|
Ra = Rb + Rc
|
|
浮点运算
|
A
|
FMUL
|
43
|
浮点乘法
|
FMUL Ra, Rb, Rc
|
Ra = Rb * Rc
|
|
浮点运算
|
A
|
FADD
|
44
|
浮点除法
|
FDIV Ra, Rb, Rc
|
Ra = Rb / Rc
|
|
中断处理
|
J
|
IRET
|
2D
|
中断返回
|
IRET
|
PC = LR; INT 0
|
状态缓存器
CPU0 的状态缓存器,包含 N, Z, C, V
等状态,以及 I, T 等中断模式位。结构如下图所示。
图 3:CPU0 的状态缓存器
当 CMP Ra, Rb 指令执行时,状态标志会因而改变。
假如 Ra > Rb, 则会设定状态 N=0, Z=0
假如 Ra < Rb, 则会设定状态 N=1, Z=0
假如 Ra = Rb, 则会设定状态 N=0, Z=1
于是条件式跳跃的 JGT, JLT, JGE, JLE, JEQ, JNE 等指令,就可以根据状态缓存器中的 N, Z 标志进行跳跃操作。
指令的执行步骤
CPU0在执行一个指令时,必须经过取指、译码与执行等三大阶段。
- 提取阶段
- 操作1、提取指令 :IR = [PC]
- 操作2、更新计数器 :PC = PC + 4
- 解碼阶段
- 操作3、解碼 :控制单元对IR进行译码后,设定数据流向开关与 ALU 的运算模式
- 运行时间
- 操作4、执行 :数据流入 ALU,经过运算后,流回指定的缓存器
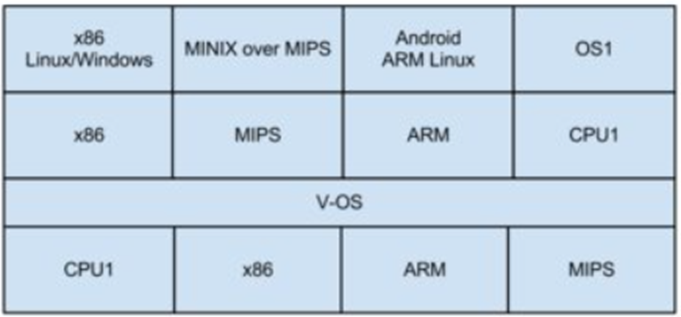
V-OS: 横跨操作系统与硬件的虚拟机系统
- 设计一个虚拟机系统,可以将 CPU A, B, C, D, E … 模拟成另外任何一种 CPU,这样是否能解决所有的跨平台问题呢?
- QEMU 其实可以做到类似的操作,想法与 QEMU 不同点在于 QEMU 是在操作系统层次之上的,做法是在操作系统层次之下的。
- 这样子就可以将在任何一个 CPU 上,跑另一个操作系统的程序,但是,不知速度会比 QEMU 快还是慢呢?
- 这种做法姑且可以想象为「云端虚拟机」!
- 不知大家觉得可能吗?有用吗?
图一:V-OS 系统的架构图
CC1 编译程序
为了说明编译程序是如何设计出来的,在开放计算机计划中,设计了一个功能完备,简化过的 C 语言,这个语言称为 C1 语言,是
C0 语言的扩充版。
CC1 编译程序是一个 C1 语言的编译程序,具有完成的编译程序功能。在程序设计上,CC1 又被进一步拆解为 1. 词汇分析
2. 语法分析 3. 语意分析 4. 中间码产生 5. 汇编语言产生 等阶段,这所有的阶段,都会存取一个共同的数据结构,就是符号表。
因此,整个 CC1 编译程序,进一步分解为下列程序模块。
|
模块
|
核心对象
|
程序
|
|
词汇分析 (Lexical Analysis)
|
Scanner
|
Scanner.c, Scanner.h
|
|
语法分析 (Syntax Analysis)
|
Parser
|
Parser.c, Parser.h
|
|
语意分析 (Semantic Analysis)
|
Semantic
|
Semantic.c, Semantic.h
|
|
中间码产生 (Intermediate Code)
|
PCode
|
PCode.c, PCode.h
|
|
汇编语言产生 (Code Generation)
|
Generator
|
Generator.c, Generator.h
|
|
符号表 (Symbol Table)
|
SymTable
|
SymTable.c, SymTable.h
|
Lua
Lua 的 BNF
chunk ::= {stat [`;´]} [laststat [`;´]]
block ::= chunk
stat ::= varlist `=´ explist |
functioncall |
do block end |
while exp do block end |
repeat block until exp |
if exp then block {elseif exp then block} [else block] end |
for Name `=´ exp `,´ exp [`,´ exp] do block end |
for namelist in explist do block end |
function funcname funcbody |
local function Name funcbody |
local namelist [`=´ explist]
laststat ::= return [explist] | break
funcname ::= Name {`.´ Name} [`:´ Name]
varlist ::= var {`,´ var}
var ::= Name | prefixexp `[´ exp `]´ | prefixexp `.´ Name
namelist ::= Name {`,´ Name}
explist ::= {exp `,´} exp
exp ::= nil | false | true | Number | String | `...´ | function |
prefixexp | tableconstructor | exp binop exp | unop exp
prefixexp ::= var | functioncall | `(´ exp `)´
functioncall ::= prefixexp args | prefixexp `:´ Name args
args ::= `(´ [explist] `)´ | tableconstructor | String
function ::= function funcbody
funcbody ::= `(´ [parlist] `)´ block end
parlist ::= namelist [`,´ `...´] | `...´
tableconstructor ::= `{´ [fieldlist] `}´
fieldlist ::= field {fieldsep field} [fieldsep]
field ::= `[´ exp `]´ `=´ exp | Name `=´ exp | exp
fieldsep ::= `,´ | `;´
binop ::= `+´ | `-´ | `*´ | `/´ | `^´ | `%´ | `..´ |
`<´ | `<=´ | `>´ | `>=´ | `==´ | `~=´ |
and | or
unop ::= `-´ | not | `#´
CC1 编译程序的符号表
#ifndef SYMTABLE_H
#define SYMTABLE_H
#include "lib.h"
#include "HashTable.h"
#include "Tree.h"
// 型态 Type 有:函数、结构与指针与基本型态
// 基本 : int x;
// 指标 : int *px;
// 函数 : int total(int a[]) {...};
// 结构 : struct Person { ... };
typedef struct _Method {
char *name;
char *returnType;
Array *params;
} Method;
typedef struct _Struct {
char *name;
Array *fields;
} Struct;
typedef union _Type {
Method *pmethod;
Struct *pstruct;
char *pbtype;
} Type;
// 符号的值可能是 byte, int, float 或 pointer (包含 struct, method, type*)
typedef union _Value {
BYTE bvalue;
int ivalue;
float fvalue;
void *pvalue;
} Value;
// 变量符号: int x; Symbol(name=x, tag=VAR, type=int)
// 函数符号: int total(int a[]) {...}; Symbol(name=total, tag=METHOD, type=int)
// 结构符号: struct Person { ... }; Symbol(name=x, tag=ETYPE, type=int)
typedef struct _Symbol { // 符号记录
void *scope; // 所属领域
char *name; // 符号名称 (x, px, Person, total)
char *tag; // 符号标记 (变量定义 VAR 函数定义 METHOD、结构定义 STRUCT)
Type type; // 符号的形态
Value value; // 符号的值
} Symbol;
typedef HashTable SymTable;
Symbol *SymNew(void *scope, char *name, char *tag);
void SymFree(Symbol *s);
void TypeFree(Type *type);
SymTable *SymTableNew();
Symbol *SymTablePut(SymTable *table, Symbol *sym);
Symbol* SymTableGet(SymTable *table, void *scope, char *name);
void SymTableFree(SymTable *table);
void SymTableDebug(SymTable *table);
#endif
CC1 的词汇分析 (Scanner) 程序
档案:Scanner.h
#ifndef SCANNER_H
#define SCANNER_H
#include "lib.h"
typedef struct { // 扫描仪的对象结构
char *text; // 输入的程序 (text)
int len; // 程序的总长度
// 注意:以下的 xSave 都是在 ScannerStore() 与 ScannerRestore() 时使用的备份。
int i, iSave; // 目前词汇的位置
int line, lineSave; // 目前词汇的行号
int pos, posSave; // 目前词汇的起始点
char *tag, *tagSave; // 词汇的标记
char token[100], tokenSave[100]; // 目前的词汇
} Scanner;
void ScannerTest(char *fileName); // Scanner 词汇分析阶段的测试程序。
Scanner* ScannerNew(char *pText); // 建立新的词汇分析 Scanner 对象
void ScannerFree(Scanner *s); // 释放 Scanner 对象
void ScannerStore(Scanner *s); // 储存 Scanner 的目前状态
void ScannerRestore(Scanner *s); // 恢复 Scanner 的储存状态
BOOL ScannerIsNext(Scanner *s, char *pTags); // 检查下一个词汇是否符合 tag 标记。
void ScannerNext(Scanner *s); // 取得下一个词汇 (token)
char ch(Scanner *s); // 取得目前字符
void cnext(Scanner *s); // 前进到下一个字符
char *tokenToTag(char *token); // 对词汇 (token) 进行标记 (tag)
// 宣告 Token 变量,包含关键词 if, for, 运算符 ++, / 与 非终端项目 IF, FOR...
#define DEF(var, str) extern char var[];
#include "Token.h"
#undef DEF
#endif
档案:Scanner.c
#include <string.h>
#include "Scanner.h"
// 宣告关键词的字符串变量,像是 char kIF[]="if"; ...char EXP[]="EXP";...
#define DEF(var, str) char var[]=str;
#include "Token.h"
#undef DEF
// 宣告关键词数组, gTagList={...,"if", ...,"EXP", ... };
char *gTokenList[] = {
#define DEF(var, str) var,
#include "Token.h"
#undef DEF
};
// 功能:Scanner 词汇分析阶段的测试程序。
// 范例:ScannerTest("test.c1");
void ScannerTest(char *fileName) {
debug("======================ScannerTest()=========================\n");
char *text = fileToStr(fileName); // 读取整个程序文件,成为一个字符串 text
Scanner *s = ScannerNew(text); // 建立 Scanner 对象
while (TRUE) { // 不断扫描词汇,直到档案结束
ScannerNext(s); // 取得下一个词汇
debug("token=%-10s tag=%-10s line=%-4d pos=%-3d\n",
s->token, s->tag, s->line, s->pos);
if (s->tag == kEND) // 已经到程序结尾
break; // 结束扫描
}
ScannerFree(s); // 释放 Scanner 对象
strFree(text); // 释放字符串 text
memCheck(); // 检查内存
}
// 功能:建立新的词汇分析 Scanner 对象
// 范例:Scanner *s = ScannerNew(text);
Scanner* ScannerNew(char *pText) {
Scanner *s = ObjNew(Scanner, 1);
s->text = pText;
s->len = strlen(pText);
s->i = 0;
s->line = 1;
s->pos = 1;
// ScannerNext(s);
return s;
}
// 功能:释放 Scanner 对象
// 范例:ScannerFree(s);
void ScannerFree(Scanner *s) {
ObjFree(s);
}
// 功能:储存 Scanner 的目前状态
// 说明:剖析时若「偷看」后面几个 token,就必须使用 ScannerStore() 储存,然后呼叫
// ScannerNext() 偷看,之后再用 ScannerRestore() 恢复,以完成整个偷看过程。
// 范例:ScannerStore(s);
void ScannerStore(Scanner *s) {
s->iSave = s->i;
s->posSave = s->pos;
s->lineSave = s->line;
s->tagSave = s->tag;
strcpy(s->tokenSave, s->token);
}
// 功能:恢复 Scanner 的储存状态
// 范例:ScannerRestore(s);
void ScannerRestore(Scanner *s) {
s->i = s->iSave;
s->pos = s->posSave;
s->line = s->lineSave;
s->tag = s->tagSave;
strcpy(s->token, s->tokenSave);
}
// 功能:检查下一个词汇是否符合 tag 标记。
// 范例:if (ScannerIsNext(s, "+|-|*|/")) ScannerNext(s);
BOOL ScannerIsNext(Scanner *s, char *pTags) { // 检查下一个词汇的型态
char tTags[MAX_LEN+1];
sprintf(tTags, "|%s|", pTags);
if (strPartOf(s->tag, tTags))
return TRUE;
else
return FALSE;
}
// 功能:取得目前字符
// 范例:while (strMember(ch(s), DIGIT)) cnext(s);
char ch(Scanner *s) {
return s->text[s->i];
}
// 功能:前进到下一个字符
// 范例:while (strMember(ch(s), DIGIT)) cnext(s);
void cnext(Scanner *s) {
s->i++;s->pos++;
}
#define OP "+-*/%<=>!&|" // 运算符号字符集 (用来取得 +,-,*,/, ++, ...)
// 功能:Scanner 词汇分析阶段的测试程序。
// 范例:ScannerTest("test.c1");
void ScannerNext(Scanner *s) { // 扫描下一个词汇
while (strMember(ch(s), SPACE)) { // 忽略空白
if (ch(s)=='\n') {
s->line++;
s->pos = 1;
}
cnext(s);
}
if (s->i >= s->len) { // 如果超过程序结尾
s->tag = kEND; // 传回 tag = kEND
s->token[0] = '\0'; // 传回 token = 空字符串
return;
}
char c = ch(s); // 取得下一个字符
int begin = s->i; // 记住词汇开始点
if (c == '\"') { // 如果是 " 代表字符串开头
// 字符串常数 : string = ".."
cnext(s); // 跳过 "
while (ch(s) != '\"') cnext(s); // 一直读到下一个 " 符号为止。
cnext(s); // 跳过 "
} else if (strMember(c, OP)) { // 如果是OP(+-*/<=>!等符号)
// 运算符号 : OP = ++, --, <=, >=, ...
while (strMember(ch(s), OP)) cnext(s); // 一直读到不是OP为止
} else if (strMember(c, DIGIT)) { // 如果是数字
// 数字常数 : number = 312, 77568, ...
while (strMember(ch(s), DIGIT)) cnext(s); // 一直读到不是数字为止
// 浮点常数 : float = 3.14, ...
if (ch(s) == '.') cnext(s); // 取得小数点
while (strMember(ch(s), DIGIT)) cnext(s); // 取得小数部分
} else if (strMember(c, ALPHA)) { // 如果是英文字母
// 基本词汇 : token = int, sum, i, for, if, x1y2z, ....
while (strMember(ch(s), ALPHA) || strMember(ch(s), DIGIT))
cnext(s); // 一直读到不是英文字母 (或数字)为止
} else // 其他符号,都解读为单一字符
cnext(s); // 传回单一字符
// 字符串扫描完了,设定 token 为(begin…textIdx) 之间的子字符串
strSubstr(s->token, s->text, begin, (s->i) - begin);
// 设定 token 的标记 tag
s->tag = tokenToTag(s->token);
}
// 功能:Scanner 词汇分析阶段的测试程序。
// 范例:ScannerTest("test.c1");
char *tokenToTag(char *token) { // 判断并取得 token的型态
if (token[0] == '\"') // 如果以符号 " 开头,则
return CSTR; // 型态为 STRING
else if (strMember(token[0], DIGIT)) {// 如果是数字开头,则
if (strMember('.', token))
return CFLOAT;
else
return CINT;
} else { // 否则 (像是 +,-,*,/,>,<,….)
char *tag = NULL;
// 若是 keyword (包含 关键词 if, for 与 +, ->, {, ++ 等合法符号
// 则传回查表结果 (字符串指针)。
int i;
for (i=0; gTokenList[i] != kEND; i++) {
if (strEqual(token, gTokenList[i])) // 找到该 token,传回字符串指针。
return gTokenList[i];
}
if (strMember(token[0], ALPHA)) // 如果是英文字母开头
return ID; // 则型态为 ID
else
ERROR();
}
}
输入范例
int x=1, y=2;
struct Date {
int year, month, day;
}
struct Person {
char *name;
Date birthday;
}
int total(int* a) {
int s = 0;
for (int i=0; i<10; i++)
s = s+a[i];
return s;
}
char* getName(Person *p) {
return p->name;
}
int main() {
int b[10], a=3;
int t = total(b);
Person p;
p.birthday.year = 1990;
t = 3 + (5 * a);
return t;
}
测试程序 ScannerTest() 的执行结果
======================ScannerTest()===================
token=int tag=int line=1 pos=4
token=x tag=ID line=1 pos=6
token== tag== line=1 pos=7
token=1 tag=CINT line=1 pos=8
token=, tag=, line=1 pos=9
token=y tag=ID line=1 pos=11
token== tag== line=1 pos=12
token=2 tag=CINT line=1 pos=13
token=; tag=; line=1 pos=14
token=struct tag=struct line=3 pos=8
token=Date tag=ID line=3 pos=13
token={ tag={ line=3 pos=15
token=int tag=int line=4 pos=9
token=year tag=ID line=4 pos=14
token=, tag=, line=4 pos=15
token=month tag=ID line=4 pos=21
token=, tag=, line=4 pos=22
token=day tag=ID line=4 pos=26
token=; tag=; line=4 pos=27
token=} tag=} line=5 pos=3
token=struct tag=struct line=7 pos=8
token=Person tag=ID line=7 pos=15
token={ tag={ line=7 pos=17
token=char tag=char line=8 pos=7
token=* tag=* line=8 pos=9
token=name tag=ID line=8 pos=13
token=; tag=; line=8 pos=14
token=Date tag=ID line=9 pos=7
token=birthday tag=ID line=9 pos=16
token=; tag=; line=9 pos=17
token=} tag=} line=10 pos=3
token=int tag=int line=12 pos=5
token=total tag=ID line=12 pos=11
token=( tag=( line=12 pos=12
token=int tag=int line=12 pos=15
token=* tag=* line=12 pos=16
token=a tag=ID line=12 pos=18
token=) tag=) line=12 pos=19
token={ tag={ line=12 pos=21
token=int tag=int line=13 pos=6
token=s tag=ID line=13 pos=8
token== tag== line=13 pos=10
token=0 tag=CINT line=13 pos=12
token=; tag=; line=13 pos=13
token=for tag=for line=14 pos=6
token=( tag=( line=14 pos=8
token=int tag=int line=14 pos=11
token=i tag=ID line=14 pos=13
token== tag== line=14 pos=14
token=0 tag=CINT line=14 pos=15
token=; tag=; line=14 pos=16
token=i tag=ID line=14 pos=18
token=< tag=< line=14 pos=19
token=10 tag=CINT line=14 pos=21
token=; tag=; line=14 pos=22
token=i tag=ID line=14 pos=24
token=++ tag=++ line=14 pos=26
token=) tag=) line=14 pos=27
token=s tag=ID line=15 pos=5
token== tag== line=15 pos=7
token=s tag=ID line=15 pos=9
token=+ tag=+ line=15 pos=10
token=a tag=ID line=15 pos=11
token=[ tag=[ line=15 pos=12
token=i tag=ID line=15 pos=13
token=] tag=] line=15 pos=14
token=; tag=; line=15 pos=15
token=return tag=return line=16 pos=9
token=s tag=ID line=16 pos=11
token=; tag=; line=16 pos=12
token=} tag=} line=17 pos=3
token=char tag=char line=19 pos=6
token=* tag=* line=19 pos=7
token=getName tag=ID line=19 pos=15
token=( tag=( line=19 pos=16
token=Person tag=ID line=19 pos=22
token=* tag=* line=19 pos=24
token=p tag=ID line=19 pos=25
token=) tag=) line=19 pos=26
token={ tag={ line=19 pos=28
token=return tag=return line=20 pos=9
token=p tag=ID line=20 pos=11
token=-> tag=-> line=20 pos=13
token=name tag=ID line=20 pos=17
token=; tag=; line=20 pos=18
token=} tag=} line=21 pos=3
token=int tag=int line=23 pos=5
token=main tag=ID line=23 pos=10
token=( tag=( line=23 pos=11
token=) tag=) line=23 pos=12
token={ tag={ line=23 pos=14
token=int tag=int line=24 pos=6
token=b tag=ID line=24 pos=8
token=[ tag=[ line=24 pos=9
token=10 tag=CINT line=24 pos=11
token=] tag=] line=24 pos=12
token=, tag=, line=24 pos=13
token=a tag=ID line=24 pos=15
token== tag== line=24 pos=16
token=3 tag=CINT line=24 pos=17
token=; tag=; line=24 pos=18
token=int tag=int line=25 pos=6
token=t tag=ID line=25 pos=8
token== tag== line=25 pos=10
token=total tag=ID line=25 pos=16
token=( tag=( line=25 pos=17
token=b tag=ID line=25 pos=18
token=) tag=) line=25 pos=19
token=; tag=; line=25 pos=20
token=Person tag=ID line=26 pos=9
token=p tag=ID line=26 pos=11
token=; tag=; line=26 pos=12
token=p tag=ID line=27 pos=4
token=. tag=. line=27 pos=5
token=birthday tag=ID line=27 pos=13
token=. tag=. line=27 pos=14
token=year tag=ID line=27 pos=18
token== tag== line=27 pos=20
token=1990 tag=CINT line=27 pos=25
token=; tag=; line=27 pos=26
token=t tag=ID line=28 pos=4
token== tag== line=28 pos=6
token=3 tag=CINT line=28 pos=8
token=+ tag=+ line=28 pos=10
token=( tag=( line=28 pos=12
token=5 tag=CINT line=28 pos=13
token=* tag=* line=28 pos=15
token=a tag=ID line=28 pos=17
token=) tag=) line=28 pos=18
token=; tag=; line=28 pos=19
token=return tag=return line=29 pos=9
token=t tag=ID line=29 pos=11
token=; tag=; line=29 pos=12
token=} tag=} line=30 pos=3
token= tag=_?END?_ line=32 pos=3
Memory:newCount=438 freeCount=438
程序语言 C1 的语法规则
EBNF 语法
// =============== C1 语言的 EBNF 语法规则 ==================================
// PROG = (STRUCT | METHOD | DECL ; )*
// METHOD = TYPE ** ID(PARAM_LIST?) BLOCK
// STRUCT = struct ID { DECL_LIST ; }
// BLOCK = { BASE* }
// BASE = IF | FOR | WHILE | BLOCK | STMT ;
// IF = if (EXP) BASE (else BASE)?
// FOR = for (STMT ; EXP ; STMT) BASE
// WHILE = while (EXP) BASE
// STMT = return EXP | DECL | PATH (EXP_LIST) | PATH = EXP | PATH OP1
// VAR = ** ID ([ integer ])* (= EXP)?
// EXP = TERM (OP2 TERM)?
// TERM = ( EXP (OP2 EXP)? ) | CINT | CFLOAT | CSTR | PATH
// PATH = ATOM ((.|->) ATOM)*
// ATOM = ID (([ EXP ])* |( EXP_LIST? ))
// DECL = TYPE VAR_LIST
// PARAM = TYPE VAR
// VAR_LIST = VAR (, VAR)*
// EXP_LIST = EXP (, EXP)*
// DECL_LIST = DECL (; DECL)*
// PARAM_LIST = PARAM (, PARAM)*
// TYPE = (byte | char | int | float | ID) // 最后一个 ID 必须是 TYPE [STRUCT]
// ID = [A-Za-z_][0-9A-Za-z_]*
// CINT = [0-9]+
// CFLOAT = [0-9]+.[0-9]+
// CSTR = ".*"
// OP2 = +|-|/|*|%|&|&&|^|<<|>>|<|>|<=|>=|==|!=| 与 | , ||
// OP1 = ++ | --
C1 语言的剖析器 -- CC1
开放计算机计划 — 最新版本下载
- ss1v0.50.zip — 包含虚拟机 VM1, 组译器 AS1, 编译程序 CC1 (剖析器完成,符号表完成,程序代码产生修改中)
档案:Parser.h
// =============== C1 语言的 EBNF 语法规则 ==================================
// PROG = (STRUCT | METHOD | DECL ; )*
// METHOD = TYPE ** ID(PARAM_LIST?) BLOCK
// STRUCT = struct ID { DECL_LIST ; }
// BLOCK = { BASE* }
// BASE = IF | FOR | WHILE | BLOCK | STMT ;
// IF = if (EXP) BASE (else BASE)?
// FOR = for (STMT ; EXP ; STMT) BASE
// WHILE = while (EXP) BASE
// STMT = return EXP | DECL | PATH (EXP_LIST) | PATH = EXP | PATH OP1
// VAR = ** ID ([ integer ])* (= EXP)?
// EXP = TERM (OP2 TERM)?
// TERM = ( EXP (OP2 EXP)? ) | CINT | CFLOAT | CSTR | PATH
// PATH = ATOM ((.|->) ATOM)*
// ATOM = ID (([ EXP ])* |( EXP_LIST? ))
// DECL = TYPE VAR_LIST
// PARAM = TYPE VAR
// VAR_LIST = VAR (, VAR)*
// EXP_LIST = EXP (, EXP)*
// DECL_LIST = DECL (; DECL)*
// PARAM_LIST = PARAM (, PARAM)*
// TYPE = (byte | char | int | float | ID) // 最后一个 ID 必须是 TYPE [STRUCT]
// ID = [A-Za-z_][0-9A-Za-z_]*
// CINT = [0-9]+
// CFLOAT = [0-9]+.[0-9]+
// CSTR = ".*"
// OP2 = +|-|/|*|%|&|&&|^|<<|>>|<|>|<=|>=|==|!=| 与 | , ||
// OP1 = ++ | --
#ifndef PARSER_H
#define PARSER_H
#include "Scanner.h"
#include "Tree.h"
#include "Lib.h"
#include "Semantic.h"
typedef struct { // 剖析器的对象结构
Array *nodeStack; // 剖析过程用的节点 node 堆栈 (从树根到目前节点间的所有节点形成的堆栈)。
Array *blockStack; // 符号区块堆栈,变量 id 的区块范围,像是 PROG, STRUCT, METHOD, BLOCK 等。
Var decl; // 在 parseType 时用来记住型态的变量。
Scanner *scanner; // 词汇扫描仪 (Lexical Analysis)
SymTable *symTable; // 符号表
char spaces[MAX_LEN]; // 用来暂存空白字符串的变量。
} Parser;
Tree *parse(char *text, SymTable *symTable);// 剖析器的主程序
Parser *ParserNew(Scanner *scanner, SymTable *symTable); // 剖析器的建构函数
Tree *ParserParse(Parser *p, char *text); // 剖析器的剖析函数
void ParserFree(Parser *parser); // 释放内存
Tree* parseProg(Parser *p); // PROG = (STRUCT | METHOD | DECL ; )*
Tree* parseBase(Parser *p); // BASE = IF | FOR | WHILE | BLOCK | STMT ;
Tree* parseStruct(Parser *p); // STRUCT = struct ID { DECL_LIST ; }
Tree* parseMethod(Parser *p); // METHOD = TYPE ** ID(PARAM_LIST?) BLOCK
Tree* parseDecl(Parser *p); // DECL = TYPE VAR_LIST
Tree* parseIf(Parser *p); // IF = if (EXP) BASE (else BASE)?
Tree* parseFor(Parser *p); // FOR = for (STMT ; EXP ; STMT) BASE
Tree* parseWhile(Parser *p); // WHILE = while (EXP) BASE
Tree* parseStmt(Parser *p); // STMT = return EXP | DECL | PATH (EXP_LIST) | PATH = EXP | PATH OP1
Tree* parseBlock(Parser *p); // BLOCK = { BASE* }
Tree* parseVar(Parser *p); // VAR = ** ID ([ integer ])* (= EXP)?
Tree* parseExp(Parser *p); // EXP = TERM (OP2 TERM)?
Tree* parseTerm(Parser *p); // TERM = ( EXP (OP2 EXP)? ) | CINT | CFLOAT | CSTR | PATH
Tree* parsePath(Parser *p); // PATH = ATOM ((.|->) ATOM)*
Tree* parseAtom(Parser *p); // ATOM = ID (([ EXP ])* |( EXP_LIST? ))
Tree* parseDecl(Parser *p); // DECL = TYPE VAR_LIST
Tree* parseParam(Parser *p); // PARAM = TYPE VAR
Tree* parseVarList(Parser *p); // VAR_LIST = VAR (, VAR)*
Tree* parseExpList(Parser *p); // EXP_LIST = EXP (, EXP)*
Tree* parseDeclList(Parser *p); // DECL_LIST = DECL (; DECL)*
Tree* parseParamList(Parser *p);// PARAM_LIST = PARAM (, PARAM)*
Tree* parseType(Parser *p); // TYPE = (byte | char | int | float | ID)
Tree* parseId(Parser *p); // ID = [A-Za-z_][0-9A-Za-z_]*
BOOL isMethod(Parser *p); // 判断接下来是否为 METHOD 程序区块。
BOOL isDecl(Parser *p); // 判断接下来是否为 DECL 宣告语句
// push() : 功能:建立 tag 标记的非终端节点,并建立语意结构,然后推入堆栈中
// 范例:Tree *node = push(p, IF, SemIF);
#define push(p, tag, SemType) sem=ObjNew(SemType, 1);Tree *node=push1(p, tag);node->sem=sem;
Tree *push1(Parser *p, char* tag); // 建立标记为 tag 的新子树。
Tree *pop(Parser *p, char* tag); // 从堆栈中取出剖析完成的子树,并检查标记是否为 tag。
BOOL isNext(Parser *p, char *tags); // 检查下一个 token 的 tag 是否属于 tags 标记之一。
Tree *next(Parser *p, char *tags); // 取得下一个 token,并确认其 tag 为 tags 标记之一。
char *token(Tree *node); // 取得树叶节点 node 的 token。
void pushBlock(Parser *p, Symbol *sym); // 将区块符号推入堆栈
#define popBlock(p) ArrayPop(p->blockStack) // 从堆栈取出区块符号
#define peekBlock(p) ArrayPeek(p->blockStack) // 取得最上面的区块符号
// Token 的集合,用来检查是关键词,操作数,基本型态,或者只是变量 ID。
#define SET_KEYWORDS "|if|else|for|while|return|def|int|byte|char|float|struct|"
#define SET_OP1 "|++|--|"
#define SET_OP2 "|+|-|*|/|%|^|&|<<|>>|==|!=|<=|>=|<|>|&&||||"
#define SET_BTYPE "|int|byte|char|float|"
#endif
档案:Parser.c
#include "Parser.h"
// 功能:Parser 剖析阶段的测试程序。
// 范例:ParserTest("test.c1");
void ParserTest(char *fileName) {
debug("=======ParserTest()==========\n");
SymTable *symTable = SymTableNew(); // 建立符号表
char *text = fileToStr(fileName); // 读入 C1 语言程序代码,成为一字符串
Tree *tree = parse(text, symTable); // 剖析该程序代码,建立剖析树与符号表。
SymTableDebug(symTable); // 印出符号表。
TreeFree(tree); // 释放剖析树。
strFree(text); // 释放程序代码字符串
SymTableFree(symTable); // 释放符号表
memCheck(); // 检查内存
}
// 功能:剖析阶段的主程序
// 范例:Tree *tree = parse(text, symTable);
Tree *parse(char *text, SymTable *symTable) { // 剖析器的主要函数
Scanner *scanner = ScannerNew(text); // 建立扫描仪 (词汇分析用)
Parser *p=ParserNew(scanner, symTable); // 建立剖析器 (语法剖析用)
Tree *tree = ParserParse(p, text); // 剖析程序为语法树
ParserFree(p); // 释放颇析树
ScannerFree(scanner); // 释放扫描仪
return tree; // 传回剖析器
}
// 功能:建立新的剖析器 Parser 对象
// 范例:Parser *p = ParserNew(scanner, symTable);
Parser *ParserNew(Scanner *scanner, SymTable *symTable) {
Parser *p = ObjNew(Parser, 1); // 分配剖析器空间
p->nodeStack = ArrayNew(10); // 分配 nodeStack 堆栈空间
p->blockStack = ArrayNew(10); // 分配 blockStack 堆栈空间
p->scanner = scanner; // 设定扫瞄器
p->symTable = symTable; // 设定符号表
ScannerNext(scanner); // 本剖析器总是先取得下一个 token,以便 isNext() 进行判断。
return p;
}
// 功能:释放剖析器对象的内存
// 范例:ParserFree(p);
void ParserFree(Parser *p) {
ArrayFree(p->blockStack, (FuncPtr1) BlockFree); // 释放 blockStack 堆栈空间
ArrayFree(p->nodeStack, NULL); // 释放 nodeStack 堆栈空间
ObjFree(p); // 释放剖析器空间
}
// 功能:剖析整个程序代码 (text)。
// 范例:ParserParse(p, text);
Tree *ParserParse(Parser *p, char *text) { // 剖析对象的主函数
debug("======= parsing ========\n");
Tree *tree = parseProg(p); // 开始剖析整个程序 (PROG),并建立语法树 p->tree
if (p->nodeStack->count != 0) { // 如果剖析完成后堆栈是空的,那就是剖析成功
ERROR();// 否则就是剖析失败,有语法错误
}
return tree;
}
// 语法:PROG = (STRUCT | METHOD | DECL ; )*
// 功能:剖析 PROG 并建立语法树
// 范例:Tree *prog = parseProg(p);
Tree *parseProg(Parser *p) { // 剖析 PROG 规则
SemProg *sem=push(p, PROG, SemProg); // 建立 PROG 的语法树及语意结构
pushBlock(p, Global); // 推入全局区块
while (!isNext(p, kEND)) { // 剖析 BASE,直到程序结束或碰到 } 为止
if (isNext(p, "struct"))
parseStruct(p);
else { // 由于 METHOD 与 DECL 的开头都是 TYPE **ID ...,因此必须判断是哪一种情况。
if (isMethod(p)) { // 向前偷看后发现是 TYPE **ID(,所以是 Method
parseMethod(p);
} else { // 否则就必须是 DECL ;
parseDecl(p);
next(p, ";");
}
}
}
popBlock(p); // 取出全局区块
return pop(p, PROG); // 取出 PROG 的整棵语法树
}
// 语法:METHOD = TYPE **ID (PARAM_LIST?) BLOCK
// 功能:判断到底接下来是否为 METHOD,是的话传回 TRUE,否则传回 FALSE
// 由于 METHOD 与 DECL 的开头都是 TYPE **ID ...,因此必须判断是哪一种情况。
// 本函数会向前偷看,如果发现是 TYPE **ID(,那就应该是 Method。
// 范例:if (isMethod(p)) parseMethod(p);
BOOL isMethod(Parser *p) {
BOOL rzFlag = TRUE;
Scanner *s = p->scanner; // s=扫描仪
ScannerStore(s); // 储存扫描仪状态
if (isNext(p, "int|byte|char|float|ID")) // 偷看 TYPE
ScannerNext(s); // 略过 TYPE
else
rzFlag=FALSE;
while (isNext(p, "*")) ScannerNext(s); // 偷看并略过星号
if (isNext(p, ID)) // 偷看 ID
ScannerNext(s); // 略过 ID
else
rzFlag=FALSE;
if (!isNext(p, "(")) rzFlag=FALSE; // 如果接下来是 (,那么就应该是 Method。
ScannerRestore(s); // 恢复扫描仪状态。
return rzFlag;
}
// 语法:METHOD = TYPE **ID (PARAM_LIST?) BLOCK
// 功能:剖析 METHOD 并建立语法树
// 范例:Tree *method = parseMethod(p);
Tree* parseMethod(Parser *p) {
SemMethod *sem=push(p, METHOD, SemMethod); // 建立 METHOD 的语法树及语意结构
sem->type=parseType(p); // 剖析 TYPE
// 剖析 ** (n 个星号, n>=0)
int starCount = 0; // 星号数量的初始值
while (isNext(p, "*")) { // 如果下一个是星号
next(p, "*"); // 取得该星号
starCount ++; // 将星号数加一
}
sem->id = next(p, ID); // 剖析 ID
// 建立 ID 的符号记录 Symbol(id, METHOD)
char *id = token(sem->id); // 取得符号名称。
Symbol *sym = SymNew(Global, id, SymMethod); // 建立符号记录
Method *method = sym->typePtr; // 设定 method 结构。
method->ret.typeSym = p->decl.typeSym; // 设定传回符号
method->ret.starCount = p->decl.starCount; // 设定传回符号的星号个数。
SymTablePut(p->symTable, sym); // 将符号记录放入符号表中
pushBlock(p, sym); // 将 Method 符号推入区块堆栈
sem->symMethod = sym; // 设定语意结构 sem 的 symMethod 字段
// 剖析参数部分 (PARAM_LIST?)
next(p, "(");
if (!isNext(p, ")")) // 如果接下来不是 ),那就是有 PARAM_LIST
sem->paramList = parseParamList(p); // 剖析 PARAM_LIST
next(p, ")");
sem->block = parseBlock(p); // 剖析 BLOCK
popBlock(p);
return pop(p, METHOD); // 取出 METHOD 的语法树。
}
// 语法:STRUCT = struct ID { (DECL ;)* }
// 功能:剖析 STRUCT 并建立语法树
// 范例:Tree *s = parseStruct(p);
Tree* parseStruct(Parser *p) {
SemStruct *sem=push(p, STRUCT, SemStruct); // 建立 STRUCT 语法树
next(p, "struct"); // 剖析 struct
sem->id = next(p, ID); // 剖析 ID
// 建立 ID 的符号记录 Symbol(id, METHOD)
char *id = token(sem->id); // 取得符号名称。
Symbol *sym = SymNew(Global, id, SymStruct); // 建立符号 -- 结构。
SymTablePut(p->symTable, sym); // 放入符号表。
sem->symStruct = sym; // 设定语意结构 sem 的 symMethod 字段
pushBlock(p, sym); // 将 Struct 区块推入堆栈
// 剖析 { (DECL ;)* }
next(p, "{");
while (!isNext(p, "}")) {
parseDecl(p);
next(p, ";");
}
next(p, "}");
popBlock(p); // 从区块堆栈中取出 Struct 区块
return pop(p, STRUCT); // 取出 STRUCT 的语法树。
}
// 语法:BASE = IF | FOR | WHILE | BLOCK | STMT ;
// 功能:剖析 BASE 并建立 BASE 的语法树
// 范例:Tree *base = parseBase(p);
Tree* parseBase(Parser *p) { // 剖析 BASE 规则
SemBase *sem=push(p, BASE, SemBase); // 建立 BASE 的语法树及语意结构
if (isNext(p, "if")) // 如果下一个词汇是 if
parseIf(p); // 剖析 IF 程序段
else if (isNext(p, "for")) // 如果下一个词汇是 for
parseFor(p); // 剖析 FOR 程序段
else if (isNext(p, "while")) // 如果下一个词汇是 for
parseWhile(p); // 剖析 WHILE 程序段
else if (isNext(p, "{")) // 如果下一个词汇是 {
parseBlock(p); // 剖析 BLOCK 程序段
else { // 否则应该是 STMT ;
parseStmt(p); // 剖析 STMT 程序段
next(p, ";"); // 取得分号 ;
}
return pop(p, BASE); // 取出 BASE 的剖析树
}
// 语法:BLOCK = { BASE* }
// 功能:剖析 BLOCK 并建立语法树
// 范例:Tree *block = parseBlock(p);
Tree* parseBlock(Parser *p) {
SemBlock *sem=push(p, BLOCK, SemBlock); // 建立 BLOCK 的语法树及语意结构
Symbol *pblock = peekBlock(p); // 取得父区块
Symbol *sym = SymNew(pblock, "", SymBlock); // 建立区块符号
Block *block = sym->typePtr; // 设定 block 结构。
SymTablePut(p->symTable, sym); // 将本区块加入到符号表中
sem->symBlock = sym; // 设定本节点的语意结构 symBlock 为本区块
pushBlock(p, sym); // 将符号推入区块堆栈
next(p, "{"); // 剖析 { BASE* }
while (!isNext(p, "}"))
parseBase(p);
next(p, "}");
popBlock(p); // 从区块堆栈中取出 Block 区块
return pop(p, BLOCK); // 取出 BLOCK 的语法树。
}
// 语法:FOR = for (STMT ; EXP ; STMT) BASE
// 功能:剖析 FOR 并建立语法树
// 范例:Tree *f = parseFor(p);
Tree* parseFor(Parser *p) {
SemFor *sem=push(p, FOR, SemFor); // 建立 FOR 的语法树及语意结构
next(p, "for"); // 取得 for
next(p, "("); // 取得 (
sem->stmt1 = parseStmt(p); // 剖析 STMT
next(p, ";"); // 取得 ;
sem->exp = parseExp(p); // 剖析 EXP
next(p, ";"); // 取得 ;
sem->stmt2 = parseStmt(p); // 剖析 STMT
next(p, ")"); // 取得 )
parseBase(p); // 剖析 BASE
return pop(p, FOR); // 取出 FOR 的语法树。
}
// 语法:IF = if (EXP) BASE (else BASE)?
// 功能:剖析 IF 并建立语法树
// 范例:Tree *f = parseIf(p);
Tree* parseIf(Parser *p) {
SemIf *sem=push(p, IF, SemIf); // 建立 IF 的语法树及语意结构
next(p, "if"); // 取得 if
next(p, "("); // 取得 (
sem->exp = parseExp(p); // 剖析 EXP
next(p, ")"); // 取得 )
sem->base1 = parseBase(p); // 剖析 BASE
if (isNext(p, "else")) { // 如果下一个是 else
next(p, "else"); // 取得 else
sem->base2 = parseBase(p); // 剖析下一个 BASE
}
return pop(p, IF); // 取出 IF 的语法树。
}
// 语法:WHILE = while (EXP) BASE
// 功能:剖析 WHILE 并建立语法树
// 范例:Tree *w = parseWhile(p);
Tree* parseWhile(Parser *p) {
SemWhile *sem=push(p, WHILE, SemWhile);// 建立 WHILE 的语法树及语意结构
next(p, "while"); // 取得 while
next(p, "("); // 取得 (
sem->exp = parseExp(p); // 剖析 EXP
next(p, ")"); // 取得 )
sem->base = parseBase(p); // 剖析 BASE
return pop(p, WHILE); // 取出 WHILE 的语法树。
}
// 语法:STMT = return EXP | DECL | PATH (EXP_LIST) | PATH = EXP | PATH OP1
// 功能:剖析 STMT 并建立语法树
// 范例:Tree *stmt = parseStmt(p);
Tree* parseStmt(Parser *p) {
SemStmt *sem=push(p, STMT, SemStmt);// 建立 STMT 的语法树及语意结构
if (isNext(p, "return")) { // 如果下一个是 return,就剖析 return EXP
next(p, "return");
sem->exp = parseExp(p);
} else if (isDecl(p)) { // 如果是 DECL
sem->decl = parseDecl(p); // 剖析 DECL
} else { // 否则下一个必须是 PATH
sem->path = parsePath(p); // 剖析 PATH
if (isNext(p, "(")) { // 下一个是 (,代表是 PATH (EXP_LIST) 的情况
next(p, "(");
sem->expList = parseExpList(p);
next(p, ")");
} else if (isNext(p, "=")) { // 下一个是 =,代表是 PATH = EXP 的情况
next(p, "=");
sem->exp = parseExp(p);
} else if (isNext(p, SET_OP1)) { // 下一个是OP1,代表是 PATH OP1 的情况
next(p, SET_OP1);
} else
ERROR();
}
return pop(p, STMT); // 取出 STMT 的语法树。
}
// 语法:PATH = ATOM ((.|->) ATOM)*
// 功能:剖析 PATH 并建立语法树
// 范例:Tree *path = parsePath(p);
Tree* parsePath(Parser *p) {
SemPath *sem=push(p, PATH, SemPath);// 建立 PATH 的语法树及语意结构
parseAtom(p); // 剖析 DECL
while (isNext(p, ".|->")) { // 不断取得 (.|->) ATOM
next(p, ".|->");
parseAtom(p);
}
return pop(p, PATH); // 取出 PATH 的语法树。
}
// 语法:ATOM = ID (([ EXP ])* |( EXP_LIST? ))
// 功能:剖析 ATOM 并建立语法树
// 范例:Tree *atom = parseAtom(p);
Tree* parseAtom(Parser *p) {
SemAtom *sem=push(p, ATOM, SemAtom); // 建立 ATOM 的语法树及语意结构
sem->id = next(p, ID); // 取得 ID
sem->subTag = ID; // 设定子标签 (ID, CALL 或 ARRAY_MEMBER),让语义分析与程序产生时使用
if (isNext(p, "(")) { // 如果接下来是 (,则应该是函数呼叫 ID ( EXP_LIST? )
next(p, "(");
if (!isNext(p, ")"))
sem->expList = parseExpList(p);
next(p, ")");
sem->subTag = CALL;
} else if (isNext(p, "[")) { // 如果接下来是 [,则应该是数组宣告 ID ([ EXP ])*
sem->subTag = ARRAY_MEMBER;
while (isNext(p, "[")) {
next(p, "[");
Tree *exp = parseExp(p);
next(p, "]");
}
}
return pop(p, ATOM); // 取出 ATOM 的语法树。
}
// 语法:PARAM = TYPE VAR
// 功能:剖析 PARAM 并建立语法树
// 范例:Tree *param = parseParam(p);
Tree* parseParam(Parser *p) {
SemParam *sem = push(p, PARAM, SemParam);// 建立 PARAM 的语法树及语意结构
sem->type = parseType(p); // 剖析 TYPE
sem->var = parseVar(p); // 剖析 VAR
return pop(p, PARAM); // 取出 PARAM 的语法树。
}
// 语法:DECL = TYPE VAR_LIST
// 功能:判断到底接下来是否为 DECL,是的话传回 TRUE,否则传回 FALSE
// 本函数会向前偷看,如果发现是 (int|byte|char|float|ID)** ID,那就是 DECL
// 范例:if (isDecl(p)) parseDecl(p);
BOOL isDecl(Parser *p) {
BOOL rzFlag = TRUE;
Scanner *s = p->scanner; // s=扫描仪
ScannerStore(s); // 储存扫描仪状态
if (isNext(p, "int|byte|char|float|ID"))// 偷看 TYPE
ScannerNext(s); // 略过 TYPE
else
rzFlag=FALSE;
while (isNext(p, "*")) ScannerNext(s); // 偷看并略过星号
if (!isNext(p, ID)) rzFlag=FALSE; // 偷看 ID
ScannerRestore(s); // 恢复扫描仪状态。
return rzFlag;
}
// 语法:DECL = TYPE VAR_LIST
// 功能:剖析 PROG 并建立语法树
// 范例:Tree *decl = parseDecl(p);
Tree* parseDecl(Parser *p) {
SemDecl *sem = push(p, DECL, SemDecl);// 建立 DECL 的语法树及语意结构
sem->type = parseType(p); // 剖析 TYPE
sem->varList = parseVarList(p); // 剖析 VAR_LIST
return pop(p, DECL); // 取出 DECL 的语法树。
}
// 语法:TYPE = (int | byte | char | float | ID) // ID is STRUCT_TYPE
// 功能:剖析 TYPE 并建立语法树
// 范例:Tree *type = parseType(p);
Tree* parseType(Parser *p) {
SemType *sem=push(p, TYPE, SemType);// 建立 TYPE 的语法树及语意结构
Tree *type = next(p, "int|byte|char|float|ID"); // 取得 (int | byte | char | float | ID)
char *typeName = token(type); // 取得型态名称
p->decl.typeSym = SymTableGet(p->symTable, Global, typeName); // 从符号表中查出该型态的符号
ASSERT(p->decl.typeSym != NULL);
return pop(p, TYPE); // 取出 TYPE 的语法树。
}
// 语法:VAR = ** ID ([ CINT ])* (= EXP)?
// 功能:剖析 VAR 并建立语法树
// 范例:Tree *var = parseVar(p);
Tree* parseVar(Parser *p) {
SemVar *sem = push(p, VAR, SemVar); // 建立 VAR 的语法树及语意结构
int starCount = 0; // 星号数量初始值为 0
while (isNext(p, "*")) { // 剖析 **
next(p, "*"); // 取得星号
starCount ++; // 计算星号数量
}
sem->id = next(p, ID); // 剖析 ID
// 建立 ID 的符号记录 Symbol(id, SymVar)
Symbol *pblock = peekBlock(p); // 取得父区块符号
char *id = token(sem->id); // 取得变量名称
Symbol *sym = SymNew(pblock, id, SymVar); // 建立变量符号
Var *var = sym->typePtr; // 取出变量结构
var->starCount = starCount; // 设定变量结构中的星号数量
var->typeSym = p->decl.typeSym; // 设定变量结构中的符号
var->dimCount = 0; // 设定变量结构中的数组维度
SymTablePut(p->symTable, sym); // 将变量加入符号表中
while (isNext(p, "[")) { // 剖析 ([ CINT ])*
next(p, "[");
Tree *cint = next(p, "CINT");
ASSERT(var->dimCount<DIM_MAX);
var->dim[var->dimCount++] = atoi(token(cint));
next(p, "]");
}
if (pblock->symType == SymStruct) { // 如果父区块是 Struct,那此 VAR 就是字段宣告。
Struct *stru = pblock->typePtr;
ArrayAdd(stru->fields, sym); // 将变量加入 Struct 的字段 fields 中。
} else if (pblock->symType == SymMethod) { // 如果父区块是 Method,那此 VAR 就是参数宣告。
Method *method = pblock->typePtr;
ArrayAdd(method->params, sym); // 将变数加入 Method 的参数 params 中。
} else if (pblock->symType == SymBlock) { // 如果父区块是 Block,那此 VAR 就是局部变量。
Block *block = pblock->typePtr;
ArrayAdd(block->vars, sym);// 将变数加入 Block 的局部变量 vars 中。
}
if (isNext(p, "=")) { // 剖析 (= EXP)?
next(p, "=");
sem->exp = parseExp(p);
}
return pop(p, VAR); // 取出 VAR 的语法树。
}
// 语法:EXP = TERM (OP2 TERM)?
// 功能:剖析 EXP 并建立语法树
// 范例:Tree *exp = parseExp(p);
Tree* parseExp(Parser *p) {
SemExp *sem = push(p, EXP, SemExp);// 建立 EXP 的语法树及语意结构
sem->term1 = parseTerm(p); // 剖析 TERM
if (isNext(p, SET_OP2)) { // 如果接下来是 OP2 ,则剖析 (OP2 TERM)?
sem->op = next(p, SET_OP2);
sem->term2 = parseTerm(p);
}
return pop(p, EXP); // 取出 EXP 的语法树。
}
// 语法:TERM = ( EXP (OP2 EXP)? ) | CINT | CFLOAT | CSTR | PATH
// 功能:剖析 TERM 并建立语法树
// 范例:Tree *term = parseTerm(p);
Tree* parseTerm(Parser *p) {
SemTerm *sem = push(p, TERM, SemTerm);// 建立 TERM 的语法树及语意结构
if (isNext(p, "(")) { // 如果下一个是 (,那就是 ( EXP (OP2 EXP)? ) 的情况
next(p, "(");
sem->exp1 = parseExp(p);
if (!isNext(p, ")")) { // 看看是否有 (OP2 EXP)
next(p, SET_OP2);
sem->exp2 = parseExp(p);
}
next(p, ")");
} else if (isNext(p, "CINT|CFLOAT|CSTR")) { // 如果是 CINT, CFLOAT 或 CSTR
next(p, "CINT|CFLOAT|CSTR"); // 取得 CINT, CFLOAT 或 CSTR
} else
parsePath(p); // 否则应该是 PATH,剖析之
return pop(p, TERM); // 取出 TERM 的语法树。
}
// 语法:VAR_LIST = VAR (, VAR)*
// 功能:剖析 VarList 并建立语法树
// 范例:Tree *varList = parseVarList(p);
Tree* parseVarList(Parser *p) {
SemVarList *sem = push(p, VAR_LIST, SemVarList);// 建立 VAR_LIST 的语法树及语意结构
parseVar(p); // 剖析 VAR
while (isNext(p, ",")) { // 剖析 (,VAR)*
next(p, ",");
parseVar(p);
}
return pop(p, VAR_LIST); // 取出 VAR_LIST 的语法树。
}
// 语法:EXP_LIST = EXP (, EXP)*
// 功能:剖析 EXP_LIST 并建立语法树
// 范例:Tree *expList = parseExpList(p);
Tree* parseExpList(Parser *p) {
SemExpList *sem = push(p, EXP_LIST, SemExpList);// 建立 EXP_LIST 的语法树及语意结构
parseExp(p); // 剖析 EXP
while (isNext(p, ",")) { // 剖析 (, EXP)*
next(p, ",");
parseExp(p);
}
return pop(p, EXP_LIST); // 取出 EXP_LIST 的语法树。
}
// 语法:DECL_LIST = DECL (; DECL)*
// 功能:剖析 DECL_LIST 并建立语法树
// 范例:Tree *declList = parseDeclList(p);
Tree* parseDeclList(Parser *p) {
SemDeclList *sem=push(p, DECL_LIST, SemDeclList);// 建立 DECL_LIST 的语法树及语意结构
parseDecl(p); // 剖析 DECL
while (isNext(p, ";")) { // 剖析 (; DECL)*
next(p, ";");
parseDecl(p);
}
return pop(p, DECL_LIST); // 取出 DECL_LIST 的语法树。
}
// 语法:PARAM_LIST = PARAM (, PARAM)*
// 功能:剖析 PARAM_LIST 并建立语法树
// 范例:Tree *paramList = parseParamList(p);
Tree* parseParamList(Parser *p) {
SemParamList *sem=push(p, PARAM_LIST, SemParamList);// 建立 PARAM_LIST 的语法树及语意结构
parseParam(p); // 剖析 PARAM
while (isNext(p, ";")) { // 剖析 (, PARAM)*
next(p, ";");
parseParam(p);
}
return pop(p, PARAM_LIST); // 取出 PARAM_LIST 的语法树。
}
// ========================== 基本函数 ====================================
// 功能:取得 p->nodeStack->count 个空白, 以便印出剖析树时能有阶层式的排版。
// 范例:debug("%s KEY:%s\n", level(p), s->tag);
char* level(Parser *p) {
return strFill(p->spaces, ' ', p->nodeStack->count);
}
// 功能:判断下一个 token 的标记是否为 tags 其中之一
// 范例:if (isNext(p, "struct")) parseStruct(p);
BOOL isNext(Parser *p, char *tags) { // 检查下一个词汇的型态
Scanner *s = p->scanner;
char tTags[MAX_LEN+1];
sprintf(tTags, "|%s|", tags);
if (strPartOf(s->tag, tTags))
return TRUE;
else
return FALSE;
}
// 功能:取得下一个 token (标记必须为 tag 其中之一),然后挂到剖析树上
// 范例:Tree *node = next(p, "CINT|CFLOAT|CSTR");
Tree *next(Parser *p, char *tags) { // 检查下一个词汇的型态
Scanner *s = p->scanner;
if (isNext(p, tags)) { // 如果是pTypes型态之一
Tree *child = TreeNew(s->tag);
child->sem = strNew(s->token); // 建立词汇节点(token,type)
Tree *parentTree = ArrayPeek(p->nodeStack); // 取得父节点,
TreeAddChild(parentTree, child); // 加入父节点成为子树
if (strEqual(s->tag, s->token))
debug("%s KEY:%s\n", level(p), s->tag);
else
debug("%s %s:%s\n", level(p), s->tag, s->token);
ScannerNext(s);
return child; // 传回该词汇
} else { // 否则(下一个节点型态错误)
debug("next():token=%s, tag=%s is not in tag(%s)\n", s->token, s->tag, tags); // 印出错误讯息
ERROR();
return NULL;
}
}
// 功能:建立 tag 标记的非终端节点,并且推入堆栈中
// 范例:Tree *node = push1(p, IF);
Tree* push1(Parser *p, char* tag) { // 建立 pType 型态的子树,推入堆栈中
debug("%s+%s\n", level(p), tag);
Tree *node = TreeNew(tag);
ArrayPush(p->nodeStack, node);
return node;
}
// 功能:取出 tag 标记的非终端节点,然后挂到剖析树上
// 范例:Tree *node = pop(p, IF);
Tree* pop(Parser *p, char* tag) { // 取出 pTag 标记的子树
Tree *tree = ArrayPop(p->nodeStack); // 取得堆栈最上层的子树
debug("%s-%s\n", level(p), tree->tag); // 印出以便观察
if (strcmp(tree->tag, tag)!=0) { // 如果型态不符合
debug("pop(%s):should be %s\n",tree->tag, tag); // 印出错误讯息
ERROR();
}
if (p->nodeStack->count > 0) { // 如果堆栈不是空的
Tree *parentTree = ArrayPeek(p->nodeStack); // 取出上一层剖析树
TreeAddChild(parentTree, tree); // 将建构完成的剖析树挂到树上,成为子树
}
return tree;
}
// 功能:取得树叶节点中的词汇 (token)
// 范例:char *token = token(node);
char *token(Tree *node) {
return (char*) node->sem;
}
// 功能:将区块符号 sym 推入区块堆栈中
// 范例:pushBlock(p, sym);
void pushBlock(Parser *p, Symbol *sym) {
ArrayPush(p->blockStack, sym);
}
测试输入程序:被剖析者 — test.c1
int x=1, y=2;
struct Date {
int year, month, day;
}
struct Person {
char *name;
Date birthday;
}
int total(int* a) {
int s = 0;
for (int i=0; i<10; i++)
s = s+a[i];
return s;
}
char* getName(Person *p) {
return p->name;
}
int main() {
int b[10], a=3;
int t = total(b);
Person p;
p.birthday.year = 1990;
t = 3 + (5 * a);
return t;
}
剖析器的输出结果
======= parsing ========
+PROG
+DECL
+TYPE
KEY:int
-TYPE
+VAR_LIST
+VAR
ID:x
V x 0 003E2558 0040A340 int:*0:[0]
KEY:=
+EXP
+TERM
CINT:1
-TERM
-EXP
-VAR
KEY:,
+VAR
ID:y
V y 0 003E6590 0040A340 int:*0:[0]
KEY:=
+EXP
+TERM
CINT:2
-TERM
-EXP
-VAR
-VAR_LIST
-DECL
KEY:;
+STRUCT
KEY:struct
ID:Date
S Date 0 003E6830 0040A340
KEY:{
+DECL
+TYPE
KEY:int
-TYPE
+VAR_LIST
+VAR
ID:year
V year 0 003E6A80 003E6830 int:*0:[0]
-VAR
KEY:,
+VAR
ID:month
V month 0 003E6BD8 003E6830 int:*0:[0]
-VAR
KEY:,
+VAR
ID:day
V day 0 003E6D18 003E6830 int:*0:[0]
-VAR
-VAR_LIST
-DECL
KEY:;
KEY:}
-STRUCT
+STRUCT
KEY:struct
ID:Person
S Person 0 003E6EB8 0040A340
KEY:{
+DECL
+TYPE
KEY:char
-TYPE
+VAR_LIST
+VAR
KEY:*
ID:name
V name 0 003E7148 003E6EB8 char:*1:[0]
-VAR
-VAR_LIST
-DECL
KEY:;
+DECL
+TYPE
ID:Date
-TYPE
+VAR_LIST
+VAR
ID:birthday
V birthday 0 003E7398 003E6EB8 Date:*0:[0]
-VAR
-VAR_LIST
-DECL
KEY:;
KEY:}
-STRUCT
+METHOD
+TYPE
KEY:int
-TYPE
ID:total
M total 0 003E75F8 0040A340
KEY:(
+PARAM_LIST
+PARAM
+TYPE
KEY:int
-TYPE
+VAR
KEY:*
ID:a
V a 0 003E78A8 003E75F8 int:*1:[0]
-VAR
-PARAM
-PARAM_LIST
KEY:)
+BLOCK
B 0 003E79B0 003E75F8
KEY:{
+BASE
+STMT
+DECL
+TYPE
KEY:int
-TYPE
+VAR_LIST
+VAR
ID:s
V s 0 003E7C60 003E79B0 int:*0:[0]
KEY:=
+EXP
+TERM
CINT:0
-TERM
-EXP
-VAR
-VAR_LIST
-DECL
-STMT
KEY:;
-BASE
+BASE
+FOR
KEY:for
KEY:(
+STMT
+DECL
+TYPE
KEY:int
-TYPE
+VAR_LIST
+VAR
ID:i
V i 0 003E8128 003E79B0 int:*0:[0]
KEY:=
+EXP
+TERM
CINT:0
-TERM
-EXP
-VAR
-VAR_LIST
-DECL
-STMT
KEY:;
+EXP
+TERM
+PATH
+ATOM
ID:i
-ATOM
-PATH
-TERM
KEY:<
+TERM
CINT:10
-TERM
-EXP
KEY:;
+STMT
+PATH
+ATOM
ID:i
-ATOM
-PATH
KEY:++
-STMT
KEY:)
+BASE
+STMT
+PATH
+ATOM
ID:s
-ATOM
-PATH
KEY:=
+EXP
+TERM
+PATH
+ATOM
ID:s
-ATOM
-PATH
-TERM
KEY:+
+TERM
+PATH
+ATOM
ID:a
KEY:[
+EXP
+TERM
+PATH
+ATOM
ID:i
-ATOM
-PATH
-TERM
-EXP
KEY:]
-ATOM
-PATH
-TERM
-EXP
-STMT
KEY:;
-BASE
-FOR
-BASE
+BASE
+STMT
KEY:return
+EXP
+TERM
+PATH
+ATOM
ID:s
-ATOM
-PATH
-TERM
-EXP
-STMT
KEY:;
-BASE
KEY:}
-BLOCK
-METHOD
+METHOD
+TYPE
KEY:char
-TYPE
KEY:*
ID:getName
M getName 0 003E9270 0040A340
KEY:(
+PARAM_LIST
+PARAM
+TYPE
ID:Person
-TYPE
+VAR
KEY:*
ID:p
V p 0 003E9518 003E9270 Person:*1:[0]
-VAR
-PARAM
-PARAM_LIST
KEY:)
+BLOCK
B 0 003E9608 003E9270
KEY:{
+BASE
+STMT
KEY:return
+EXP
+TERM
+PATH
+ATOM
ID:p
-ATOM
KEY:->
+ATOM
ID:name
-ATOM
-PATH
-TERM
-EXP
-STMT
KEY:;
-BASE
KEY:}
-BLOCK
-METHOD
+METHOD
+TYPE
KEY:int
-TYPE
ID:main
M main 0 003E9B70 0040A340
KEY:(
KEY:)
+BLOCK
B 0 003E9CD8 003E9B70
KEY:{
+BASE
+STMT
+DECL
+TYPE
KEY:int
-TYPE
+VAR_LIST
+VAR
ID:b
V b 0 003E9F88 003E9CD8 int:*0:[0]
KEY:[
CINT:10
KEY:]
-VAR
KEY:,
+VAR
ID:a
V a 0 003EA170 003E9CD8 int:*0:[0]
KEY:=
+EXP
+TERM
CINT:3
-TERM
-EXP
-VAR
-VAR_LIST
-DECL
-STMT
KEY:;
-BASE
+BASE
+STMT
+DECL
+TYPE
KEY:int
-TYPE
+VAR_LIST
+VAR
ID:t
V t 0 003EA560 003E9CD8 int:*0:[0]
KEY:=
+EXP
+TERM
+PATH
+ATOM
ID:total
KEY:(
+EXP_LIST
+EXP
+TERM
+PATH
+ATOM
ID:b
-ATOM
-PATH
-TERM
-EXP
-EXP_LIST
KEY:)
-ATOM
-PATH
-TERM
-EXP
-VAR
-VAR_LIST
-DECL
-STMT
KEY:;
-BASE
+BASE
+STMT
+DECL
+TYPE
ID:Person
-TYPE
+VAR_LIST
+VAR
ID:p
V p 0 003EAC48 003E9CD8 Person:*0:[0]
-VAR
-VAR_LIST
-DECL
-STMT
KEY:;
-BASE
+BASE
+STMT
+PATH
+ATOM
ID:p
-ATOM
KEY:.
+ATOM
ID:birthday
-ATOM
KEY:.
+ATOM
ID:year
-ATOM
-PATH
KEY:=
+EXP
+TERM
CINT:1990
-TERM
-EXP
-STMT
KEY:;
-BASE
+BASE
+STMT
+PATH
+ATOM
ID:t
-ATOM
-PATH
KEY:=
+EXP
+TERM
CINT:3
-TERM
KEY:+
+TERM
KEY:(
+EXP
+TERM
CINT:5
-TERM
KEY:*
+TERM
+PATH
+ATOM
ID:a
-ATOM
-PATH
-TERM
-EXP
KEY:)
-TERM
-EXP
-STMT
KEY:;
-BASE
+BASE
+STMT
KEY:return
+EXP
+TERM
+PATH
+ATOM
ID:t
-ATOM
-PATH
-TERM
-EXP
-STMT
KEY:;
-BASE
KEY:}
-BLOCK
-METHOD
-PROG
type name size this scope varType
V i 0 003E8128 003E79B0 int:*0:[0]
M main 0 003E9B70 0040A340
V month 0 003E6BD8 003E6830 int:*0:[0]
V name 0 003E7148 003E6EB8 char:*1:[0]
M total 0 003E75F8 0040A340
V x 0 003E2558 0040A340 int:*0:[0]
V s 0 003E7C60 003E79B0 int:*0:[0]
V y 0 003E6590 0040A340 int:*0:[0]
B 0 003E9CD8 003E9B70
V a 0 003EA170 003E9CD8 int:*0:[0]
V b 0 003E9F88 003E9CD8 int:*0:[1]
S Person 0 003E6EB8 0040A340
T int 4 003E5EB0 0040A340
V a 0 003E78A8 003E75F8 int:*1:[0]
V p 0 003EAC48 003E9CD8 Person:*0:[0]
T char 1 003E57E0 0040A340
V t 0 003EA560 003E9CD8 int:*0:[0]
T float 4 003E5778 0040A340
B 0 003E79B0 003E75F8
V day 0 003E6D18 003E6830 int:*0:[0]
M getName 0 003E9270 0040A340
V birthday 0 003E7398 003E6EB8 Date:*0:[0]
V p 0 003E9518 003E9270 Person:*1:[0]
V year 0 003E6A80 003E6830 int:*0:[0]
S Date 0 003E6830 0040A340
B 0 003E9608 003E9270
Memory:newCount=2090 freeCount=2090
C1 程序语言
范例一
int x=1, y=2;
struct Date {
int year, month, day;
}
struct Person {
char *name;
Date birthday;
}
int total(int* a) {
int s = 0;
for (int i=0; i<10; i++)
s = s+a[i];
return s;
}
char* getName(Person *p) {
return p->name;
}
int main() {
int b[10], a=3;
int t = total(b);
Person p;
p.birthday.year = 1990;
t = 3 + (5 * a);
return t;
}
参考链接:
中国存储芯片破局之路
半导体存储芯片分类浅述
提到存储器,不会陌生,最早听的CD,看的DVD就属于光学存储器。以前老式电脑用的方形磁盘,软盘就属于磁性存储器。但也有可能现在很多年轻人对这些老古董没有概念,特别是CD和软盘,现在已经很难在市场上看到。因为无论是光学存储器还是磁性存储器,都干不过半导体存储器。半导体存储器以其稳定的质量,高速的存储速度,相同存储容量下更小的体积,可选择性更广的存储容量和存储应用种类等优点,逐步发展成为目前应用领域最广,市场规模最大的存储器件。
NAND Flash
半导体存储芯片属于通用型集成电路,是集成电路中规模占比最大的细分产品之一。根据WSTS 的统计数据,2021年全球集成电路规模约为4608亿美元,其中存储芯片就占到了超过3成,达到了1538亿美元。其中DRAM和NAND
FLASH两大类存储芯片合计占到了其中的97%,余下的NOR
FLASH占了2%,其它存储芯片合计占比仅1%。
存储芯片按断电后是否能保留住存储的数据,分为易失性存储芯片和非易失性存储芯片。
易失性存储芯片,顾名思义就是容易丢失数据的存储芯片。但不要误解,这并不是说这类存储芯片的质量有任何的问题,而是因为其存储技术特点造成的。主要的易失性存储芯片有DRAM和SRAM两种。DRAM因为是通过电容冲放电来读取数据,所以需要不断充放电刷新,一旦断电,保存的数据就会消失。SRAM虽然不需要反复刷新,主要通过更为复杂的设计来读取和保持数据,但一旦断电,也会导致信号不断衰减到不可读取。虽然SRAM速度更快,能耗更低,但因为其设计复杂导致容量小,价格贵,所以只用在高带宽,低功耗的场景。比如CPU内部的一级缓存和内置的二级缓存。应用最广泛就是DRAM,其高速,低成本,高容量的特点给予了产品高性价比,广泛用于计算机,手机,服务器的运行数据保存应用领域。就是电脑和手机里的内存条和内存模组,就是DRAM存储器。

海力士韩国新FAB厂
和易失性存储芯片对应的就是非易失性存储芯片,很容易理解就是在断电后一样可以持续保存数据信息的存储芯片。比如日常生活中普遍使用的U盘和移动硬盘,就是典型的非易失性存储芯片产品。非易失性存储芯片可以分为闪存,就是FLASH
和只读存储器两大类。Flash是市场主流,其又可以按存储单元结构和原理的不同分为NAND FLASH和 NOR FLASH。NAND是NOTAND的缩写,代表是与非, NOR是NOTNOR的缩写,代表是或非。两相比较,NAND FLASH 的存储单元尺寸更小,密度更高,单位容量成本更低,读写速度快,具有更长的寿命,被大量应用在电脑,手机,固态硬盘,服务器等领域。这种属于非易失性存储芯片的NAND FLASH和前面提到的属于易失性存储芯片的DRAM,这两种存储芯片就占了全球半导体存储芯片市场规模的97%。
而这1538亿美元的全球半导体存储芯片市场,基本被几家外资半导体大厂瓜分,全球存储芯片市场进一步集中。作为半导体集成电路消费大国,2021年全年进口半导体集成电路4326亿美元,位居单一商品进口额第一。其中存储芯片进口总额1196亿美元,占全年半导体芯片进口总额的27.6%。可以说中国每年买了全世界生产的存储芯片一半的量。中国政府和企业为了扭转这一局面,近二十年投入了大量的资金和人力,也受到了以美国为首的西方国家和头部存储厂商的打压,从早年的福建晋华案,到最近的对长江存储和长鑫存储被制裁,想要从存储芯片打开突破口还有长期的硬仗要打。

中国是全球最大的半导体单一市场
福建晋华案(上)
前面提到,全球每年的存储芯片的市场规模在1600亿美元左右,而且随着高性能计算机,服务器,边缘计算,智能穿戴市场,物联网和车联网全球市场规模的不断做大,存储器市场将迎来爆发式的增长。存储芯片作为通用型集成电路,产品自主性强,需求量大适合规模化生产,产品价格和市场行情具有周期性特点,因此全球存储芯片市场长期以来就是各国政府和企业的必争之地。
在之前提到日本半导体产业紧急强化法案的时候就谈到之前日本半导体产业的崛起,在八十年代日本半导体出口一度占据全球半导体市场一半的量,培养出日立,NEC,富士通,三菱和东芝一系列半导体大厂。最风光的时期,日本企业占领全球DRAM市场90%以上的份额,规模效益帮助日本企业直接把DRAM的价格打到地板价,也直接打的英特尔和AMD宣布退出DRAM市场竞争。在日本企业高歌猛进之时,美国政府直接出手,逼迫日本政府先后签订广场协议和美日半导体协议,又通过扶持韩国三星和半导体反倾销调查直接干废了日本半导体产业。替代的是韩国半导体企业的崛起。这些在前面谈韩国半导体政策和日本半导体产业法案的时候都详细提到过,有兴趣的小伙伴可以在喜马拉雅搜索大国阳谋-半导体芯片说去收听下。
全球存储芯片市场规模
目前的存储芯片主要是被美韩两国的企业瓜分。前面提到的NAND FLASH和DRAM两大类存储芯片市场呈现出高度集中化的特点。根据OMDIA的数据,2020年NAND
FLASH 98%的全球市场由韩国三星,日本铠侠,美国美光,韩国SK海力士,美国英特尔六家公司瓜分。其中海力士收购了英特尔的NAND FLASH业务,占比达到20%,仅次于三星的34%。而DRAM市场因为极高的资金,技术和专利壁垒,更呈现出高度垄断形势,全球近95%的市场份额被三星,海力士和美光三家企业占据。

韩国半导体巨头擅长反周期投资,进一步打击对竞争对手
中国作为存储芯片消费大国,每年花费在在进口存储芯片的资金超千亿美元。面对被外资垄断的存储芯片市场,尝尽大厂动不动就以停电,设备检修,火灾等借口进行断供和要求涨价行为的国内各行业,可以说天下苦三星尔等久矣!加上存储芯片特别是DRAM的制程技术相对成熟,理所当然的被中国政府和企业定为重点国产替代目标。
2016年2月,泉州,晋江两级政府拉上福建省电子信息集团,晋江能源投资集团有限公司共同出资近60亿美元,通过成立福建晋华在福建省晋江市计划建设12英寸DRAM产线,规划目标产能每月六万片。并与台湾联电签订合作协议,晋华提供3亿美元委托联电采购专用设备,再提供4亿美元主要依靠联电研发32纳米DRAM制程技术,不但设备都放置在联电的南科12A厂,而且研发成功的技术也将由联电和晋华共同所有。简单来说就是晋华出钱,联电提供技术,如果成功,将彻底改变存储芯片市场格局,因此合作双方都极为重视这次合作。联电为了协助晋华12英寸DRAM工厂的建设,更是派出了资深副总裁担任晋华总经理。
福建晋华案(下)
正当双方撸起袖子准备大干一场的时候,始终在背后关注的美光开始率先发难。2017年9月,美光指控其前雇员跳槽到联电时,窃取带走了美光的DRAM机密资料,并用于晋华32纳米DRAM的芯片开发。紧接着在当年12月,美光马上向美国加州联邦法院提交控告,指控晋华和联电窃取商业机密。作为反击,晋华马上在2018年1月向福州市人民法院对美光提出控诉,指控美光在华销售产品涉嫌侵犯其专利权。
美光用于生产尖端3D存储芯片的衬底
2018年7月3号,福州中级法院针对美光半导体西安和上海工厂发布初步禁令,禁止美光在中国销售包含固态硬盘和记忆卡产品在内的26款DRAM和闪存产品。联电也发布相关声明自证清白,强调联电过去投入了大量资金研发半导体逻辑和存储器芯片技术,并取得了大量的专利,联电将持续启动专利侵权诉讼,维护专利权。如果说这种相互起诉还只是商务竞争层面的斗争。之后美国政府的强势介入,彻底让这场竞争丧失了悬念。
2018年10月29日,美国以莫须有的罪名将福建晋华列入实体清单,声称晋华一直使用怀疑是从美国进口的DRAM技术,可能威胁美国芯片供应商向美国政府提供用于高科技系统产品的能力,因此将晋华列入出口限制名单,并在第二天立即生效。发布消息的当天,各大半导体设备厂商的驻场技术人员就撤出了晋华,所有产线设备进入停机状态。直到今天这些设备依旧静静的躺在晋华的厂房内,而当时产线距离研发成功投产大概也就差三个月的时间。
紧接着,美国商务部对联电,晋华,以及包括晋华总经理陈正坤在内的数人提起司法诉讼,其中的经济间谍罪一旦成立,陈正坤等人将面临最高15年的有期徒刑和500万美元的罚款,而对联电和晋华的罚款更将高达200亿美元。
随着美国商务部下场干预,原本还只是商务竞争的互相诉讼迅速变成了刑事犯罪的指控,更上升到大国博弈的层面。联电马上开始和晋华进行切割,开始向美光妥协,并向美国司法部提交量刑建议函,希望通过承认侵害一项营业机密,加上支付6000万美元以换取和美国司法部达成和解,并承诺在3年主管管理缓刑期间与美国司法部合作。紧接着联电又与美光达成全球谅解协议,联电一次性支付和解金给美光,双方各自撤回所有在各国针对对方的诉讼。联电通过认罪赔钱,迅速从这场纷争中脱身,这使晋华处境更加艰难。即使在联电提交法院的600多万份文件中找不到一项证据,但依旧被美国定义为恶劣企业,固定在限制出口的实体清单内。基本没有翻盘的希望,近60亿美元投资的12英寸DRAM产线也再无重启的可能。
经此一役,台湾半导体企业对大陆半导体企业的合作评估更加小心谨慎。近年来更是对大陆半导体企业和资本拒而远之。也让认识到技术不是无根之水,必须掌握在自己手里才能确保将来不会再被釜底抽薪。时不待,长江存储和长鑫存储分头发力,再次举起存储芯片国产化的大旗。
长鑫存储专攻DRAM
2016年,当福建晋华如火如荼的筹备12英寸产线的时候,已经在NORFLASH细分领域杀出一条血路的兆易创新,也决定向被国际巨头高度垄断的DRAM存储领域进军,在合肥政府的大力加持下,长鑫存储在安徽合肥成立。当年急于加强自身存在感的合肥政府,为了能让自己的经济发展配得上省会城市的身份,决定把合肥打造成一个IC之都。在听到兆易创新打算建设DRAM代工厂时,马上和兆易创新签下合约共同创立合肥长鑫,并提供率先提供75%的项目资金,兆易创新只需出剩下的25%。并且合肥政府不干预长鑫营运,完全由兆易创新负责营运。2016年5月,合肥长鑫正式诞生,和同年成立的福建晋华,长江存储组成存储器三驾马车,一同踏上了存储芯片国产化的征程。因为长鑫诞生在5月6号,所以也被称为506项目,多年之后506项目也成为存储器国产三驾马车中第一个宣布投片的项目。
和福建晋华一样,合肥长鑫把目标定在了市场需求最大的DRAM市场。但与福建晋华完全依赖台湾联华电子开发DRAM技术不同,合肥长鑫在芯片大佬朱一明的领导下,一开始就决定把技术捏在自己手里。合肥长鑫在用两年时间陆续完成厂房建设,设备安装和验机的同时,也马不停蹄的在一边满世界收罗DRAM先进技术,一边大力投入资金自己吸收研发相关技术。
作为技术落后的追赶者,最简单有效的方法要么收购拥有先进技术的企业,或者退一步收购其先进的技术,但在技术是核心竞争力的今天,没有一家公司会愿意把核心技术对外出售,更不会把拥有先进技术的公司这样下金蛋的母鸡拱手让人。当今存储器市场霸主三星,海力士和美光,每一家都在巨资推进存储颗粒制造技术和提升制程能力的同时,对自己的技术进行着人盯人式的严密的监控,每年大量的资金投入到技术封锁和专利诉讼,不予余力的加固和推高技术壁垒。
但中国的半导体人并没有绝望,巨大的技术差距,反而给带来机会。上世纪八九十年代半导体市场的日美争霸,到后面的韩国半导体企业的崛起,欧洲半导体企业加入后的四国大战,基本都是在存储器市场的绞杀,那一段时间城头大王旗此起彼伏,不但美国政府下场干预,韩国更是倾举国之力几乎赌上国运,期间出现了许多优秀的公司,最终湮灭在这修罗场,硝烟散去后,让看到了机会。
2019年5月在上海举办的GSA存储器峰会上,合肥长鑫首次公布了DRAM技术来源,是已经破产十余年,曾经的世界存储器巨人奇梦达。合肥长鑫共获得约2.8TB的技术数据,约一千多万份与DRAM相关的技术文件。更同时宣布,长鑫烧掉超25亿美元的研发资金,一举将奇梦达46纳米的工艺突破推进到10纳米,和世界第一梯队的差距只剩一个身位。之后更是在2019年上市LPDDR4存储产品,并在2020年2月开始大规模销售。这是第一个真正意义上的国产化内存芯片。自此世界DRAM市场被撕开了一道口子。
按以往的剧情发展,这个时候就应该准备应对马上到来的专利诉讼了,长鑫通过收购奇梦达的专利真能避开专利讹诈吗?让来看看奇梦达的专利纯洁度有多高?
悲剧英雄奇梦达
1999年英飞凌从西门子独立并逐步成长为一家著名的半导体公司,近些年来在碳化硅领域英飞凌长线布局,成为市场的领导者和技术的领先者。但在存储芯片领域,当年的英飞凌却患得患失,最终在与有举国之力支持的韩国半导体企业的竞争中全线溃败。
2005年,英飞凌将存储业务独立出来成立了奇梦达公司,当时的奇梦达可谓风光无限,第一家拥有12英寸/300毫米晶圆产线的内存厂家,并在全球拥有5个300毫米的晶圆生产基地,是当年300毫米晶圆使用率最高的企业。
与台湾南亚科合资成立华亚科,将90纳米的工艺率先推进到75纳米,推出DRAm两大分支技术之一的DRAM沟槽式技术,同时在全球拥有5个全球研发中心。更是在2008年宣布突破30纳米工艺,计划跳过GDDR4,直接上GDDR5内存。
可以说奇梦达通过在技术和设备工艺上激进的投入,在当年处于绝对领先的地位。但这也导致其在2008年上半年EBIT从2007上半年盈利3.35亿欧元,直接到亏损10.58亿欧元。这简直可以用触目惊心来形容,放在平时也许能勉强支撑,但这却是发生在2008年。2008年下半年开始全球性的金融危机率先从美国爆发,并蔓延至全球。这给本来就已经疲软的DRAm颗粒市场带来了沉重一击,价格一路下跌,在跌破现金成本价后,更是在三星为代表的韩国企业的反周期投资的推波助澜下,价格直接雪崩跌破材料价,暴跌至0.31美元。而同一时期DRAM生产厂商的材料成本就要0.7美元,现金成本更是高达1.4美元,作为欧洲企业的奇梦达本身人力成本就高,导致产品定价本就略高于亚洲企业,韩国企业的落井下石直接把奇梦达推到了破产的边缘。
关于韩国企业的反周期投资策略,感兴趣的可以去听一下前几期的关于韩国半导体企业的相关节目-K计划-韩国超级半导体战略解读。与韩国政府举全国之力支持韩国半导体企业恰恰相反,德国政府在最后时刻出乎意料的放弃了救助奇梦达,因此奇梦达彻底跌入破产深渊,开启了各种资产甩卖。
2009年,德国政府明确放弃救助奇梦达,母公司英飞凌也拒绝伸出援手。奇梦达正式宣布破产。期间,奇梦达并非没有做出过自救的努力,2008年10月将其在华亚科的全部股份作价4亿美元出售给美光。10月更是宣布数千人的裁员计划。但这一切在天量的财务亏损前面几乎就是杯水车薪。谁也不会想到母公司英飞凌和德国政府会放弃当时技术领先,单月12寸晶圆产量位居世界第五的奇梦达。
破产后的奇梦达在破产管理人的主持下,从土地到厂房,从股权到技术专利,开始全球甩卖。正所谓一鲸落万物生。奇梦达在全球的工厂成为了各家争抢的目标。德州仪器通过收购其在美国的12寸晶圆厂成为全球第一家12寸晶圆模拟芯片厂家。
中国企业也没有闲着,奇梦达在西安的研发中心和在欧洲的高端封测生产线被中方合作伙伴收购,并在一系列的分立合并后成为组建紫光半导体产业集团的重要部分。奇梦达在苏州的模组厂和封测厂被国资苏州创投收购,之后又被晶方科技收入囊中。这可谓是当时中国最为成功的抄底。
除了工厂和产线,最吸引人们目光的是其大量的专利技术的去向。2012年,其破产管理人宣布开始抛售近7500份的专利技术。
曾经的合作伙伴华邦选择和日企尔必达合作,买断了奇梦达的GDDR产品的技术授权,从此拿到GDDR市场入场券,并获得当时最先进的46纳米制程工艺技术。同一时期,华亚科也获得了一部分的GDDR技术授权,用以抵偿奇梦达欠下的货款。这时已经是华亚科股东的美光更是在不久的将来收购了尔必达,奇梦达的技术授权转到了美光手中,这也使美光在将来对长鑫进行专利讹诈埋下了种子。这在后面会再展开。
奇梦达梦回长鑫
也许是想重返存储器市场,从金融危机中缓过来的奇梦达母公司英飞凌出人意料的在2014年通过支付近2.6亿欧元,将奇梦达的所有专利打包收购。其中1.35亿用于破产争议的庭外和解,1.25亿用于打包收购专利。正当市场都等着看英飞凌将以何种方式重返存储器市场时,英飞凌却又在一年后再一次让所有人大跌眼镜,其出乎意料的将所有奇梦达专利以不到当年收购价两成的价格贱卖给了北极星公司。一家专门以倒卖专利的国际专利贩子。
这让长鑫存储看到了机会,通过不断在市场上的搜寻,长鑫从北极星和其母公司Wi-Lan公司手中买下了奇梦达的内存专利。具体金额没有在公开市场披露,但考虑到目前中国半导体企业对技术的渴望和在世界半导体供应链中到处被封锁和制裁的现状,这必定是一笔让Wi-Lan无法拒绝的报价。但对于财大气粗的长鑫来说获得奇梦达的技术遗产,这只是DRAM突围战中的第一步。长鑫通过进一步25亿美元的研发投入,将制程工艺从46纳米推进到了10纳米,一举进入DRAM第一梯队,死死咬住了三星,海力士和美光。
这一度让看到了芯片自给率大幅提高的可能,作为存储芯片消费大国,如果能在DRAM存储芯片领域实现国产化,那将颠覆整个存储器行业格局。但福建晋华的教训依然在眼前,考虑到奇梦达的专利当年一样授权给了华邦,华亚科,尔必达,而美光又收购了华亚科和尔必达,这就给美光进行专利诉讼纠缠留下了机会。并且美光也曾对长鑫露出獠牙,在2020年,美光就在公开场合声称长鑫的DRAm芯片技术侵犯其专利,并表示将对长鑫提起专利诉讼。
但之后又没有了下文,有分析指出美光是在等待一个合适的时机,在利益可以最大化的时候对长鑫提起专利诉讼和索赔。熟悉西方公司专利讼棍惯常伎俩的人都对这种手法不会陌生。西方公司都会等到目标公司业务扩大到一定规模的时候才提起专利诉讼,俗称“养案”。越高的涉案标的意味着更高额的专利赔偿,不但自己可以轻松的赚的盆满钵满,更能使目标公司赔的万劫不复,永世不得翻身。
因此美光极有可能在长鑫的DDR4大批量出货,并发布DDR5产品时对长鑫提起专利诉讼,提出天量索赔的同时,进一步阻止长鑫DDR5 产品的上市。也有可能是因为美国已经通过对源于美国半导体技术出口限制进一步针对长鑫存储进行了制裁,不但将长鑫和长存一起列入实体清单,同时撤走了全部美国专家和美籍工作人员,这直接使长鑫原本计划在今年启动的第二工厂扩建计划推迟到了2024到2025年,并不得不进行裁员,鉴于目前的国际形势和半导体市场现状,明年能否顺利开工不容乐观。因此美光并不急于对长鑫动手。可见即使有了专利技术和海量资金,长鑫存储的DRAm国产化之路依旧困难重重。
峰回路转的长江存储
2022年底,长江存储宣布推出232层3D NAND Flash产品,同时也宣告经过近八年的不断追赶,排除外界阻碍和干扰,长江存储终于挤入NAND Flash世界第一技术阵营。
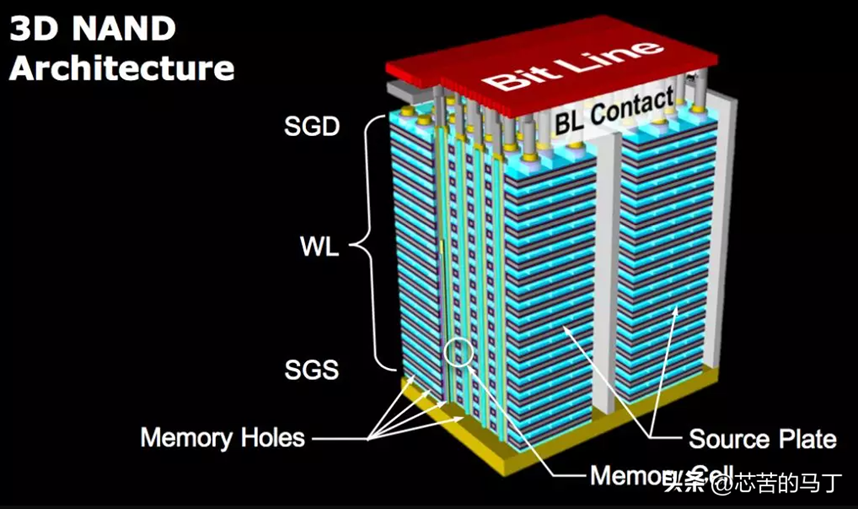
3D NAND架构
谁又能想到,今天的存储芯片龙头企业,当年差点被外资收购,如果不是一根筋的湖北省政府,换了其他地方政府,也许就是不一样的结果。长江存储的历史可以追溯到十几年前的武汉新芯。也就是长江存储的前身,成立于2006年。不得不说现在看来2006年绝对是中国半导体的耻辱之年,当年爆出了震惊世界的交大汉芯造假事件,2006年农历新年到来之际,清华大学水木清华BBS上,爆出猛料,公开指责上海交大微电子学院院长陈进教授通过汉芯造假,申报数十个科研项目,骗取国家数亿元的科研经费。
这成为戳破皇帝的新装的有力一击,不到一个月事件调查组就得出结论,汉芯一号造假基本属实,现在都知道了,当年所谓的国产突破的汉芯一号,就是请农民工打磨掉了摩托罗拉的芯片logo后,再印上了汉芯一号,科技含量不高于农民工半天工时。一个给国人带来无比自豪的科技突破,变成了一起让人瞠目结舌的重大科研造假事件,时至今日相关方面都没有公布相关责任人员的处理结果,这在当年成了中国半导体人的奇耻大辱,因为这起事件,让本就不受待见的半导体产业处境更是艰难,在当年地方政府本来就对投资吞金兽,回报周期长,风险高的半导体产业避之不及。除了这个科技丑闻后,更是不愿意谈这个浑水,可以说交大汉芯事件给了中国半导体国产化沉重一击,其负面影响一直到现在都没有完全消除。
而长江存储的前身武汉新芯就成立在这个半导体产业的多事之秋,就注定了武汉新芯的命运多舛。可以说当年上马这个投资规模百亿的项目的时候,既无人才又无技术,有的只有一股狠劲。新芯的运气也差点,最初瞄准的是DRAm市场,之后又决定转身去做NANDFlash闪存,但2006年开始建厂,到2008年正式量产65纳米闪存,正好碰上金融危机和半导体下行周期,这是奇梦达都爬不出来的大坑。
随着最后的大客户飞索半导体濒临破产,武汉新芯的最后一根救命稻草也没了。有着12寸现成晶圆线的武汉新芯很快成为国际大厂的收购目标。关键时期,又是中芯国际出手,与新芯成立合资公司。虽然,合资后的日子大家都不好过,武汉新芯又在2013年从中芯国际独立,也曾经一度依靠给飞索和豪威做代工维持工厂运转,但至少保住了国产存储的血脉。在艰难挣扎前行了近十年后,终于等到了中国半导体产业国家层面战略支持的到来。
2015年,中国发布中国制造2025白皮书,宣布力争到2025年,国家半导体产品自给率从不到30%提高到70%。同时国家宣布成立芯片大基金,开启了万亿级别的烧钱竞争,武汉新芯依靠多年来在代工时期积累的经验和技术,在国家级存储基地的竞争中脱颖而出,2016年随着大基金的注入和紫光集团入主,武汉新芯一夜逆袭,重组后成了注册资金数百亿,背靠国家级大基金的存储一哥长江存储。此时手里的NANDFlash的制程技术已经推进到了32纳米,但和国际一流玩家的差距巨大。
半导体技术代差对于企业来说是难于逾越的鸿沟,一旦落后,追赶者与领先者的差距只会越拉越大,因为技术的追赶需要海量的资金,这些资金一般是通过产品在市场上的高额毛利来回血,但市场只会追逐最先进的制程和技术产品,领先者依靠技术优势和成本优势不但在先进产品市场赚钱,更可以在成熟技术产品市场上进行低价倾销,让追赶者即使研发出产品也无利润可图,追赶者往往连研发成本都收不回来。这也是为什么最后只有两三家头部企业可以有资本和动力继续研发先进技术,因为追赶者无力承担巨额的研发费用,而头部玩家谁也不敢在先进技术的竞赛中落后。
这个时候,单单依靠市场经济和企业行为是永远赶不上国际领先水平的,更不用说超越了。经过曲折漫长的发展,有了国家大基金支持的长江存储开启了其逆袭之路。长江存储成立后的第二年,2017年长江存储推出32层闪存,当时市场主流产品是64层闪存。两年后的2019年,长江存储推出64层闪存并量产,当年主流产品达到了128层,三星继续领先并主导国际闪存市场。如果一直这样按部就班的追赶,将长时间慢人一步,虽然现在钱不是问题,但数年来的卧薪尝胆,等待是能扬眉吐气的一天。
长江存储继续努力研发自产自研的晶栈Xtacking架构,终于在2020年直接跳过96层,实现128层的技术突破。同年三星,海力士和美光的技术水平一样是128层,另一家国际大厂铠侠也只有112层的闪存产品。历经五年,终于赶上了世界第一梯队的技术水平。在2021年实现128层闪存产品量产的同时,232层闪存的研发也在紧张的推进中,终于在2022年几乎与美光同时宣布实现232层闪存产品的量产,处于行业领先地位。公平竞争,中国半导体人没有怕过谁。
长江存储的光速进步很难低调,自然吸引了美国商务部的阴冷的目光。没有意外,2022年长江存储被列入美国贸易黑名单,同时美国对中国实施设备和技术出口管制,美国设备商科磊,泛林集团和应用材料公司相继撤走了设备调试和维护工程师,也停止对长江存储提供生产设备。荷兰ASML公司也拒绝提供EUV光刻机,而EUV光刻机是将闪存技术推向300层以上的必须设备。考虑到近期德国和日本对中国企业半导体原材料管制的跟进,在长江存储面前的是一条更为艰难的国产存储芯片突围之路。
参考文献链接
https://mp.weixin.qq.com/s/RGarEZhF5jJgUjd0mdp3zQ