DDR,总线,PCIE技术分析
PCIE开发笔记(一)简介篇

这是一个系列笔记,将会陆续进行更新。
最近接触到一个项目,需要使用PCIE协议,项目要求完成一个pcie板卡,最终可以通过电脑进行通信,完成电脑发送的指令。这当中需要完成硬件部分,使用FPGA板实现,同时需要编写Windows下的驱动编写。初次接触到PCIE协议,网络上的相关教程不够清晰,让人看了之后不知所以然,不适合完全没有基础的人学习(就是我这样的人)。经过较长时间阅读相关文档,其中也走了不少弯路,最后对PCIE的IP核使用有了一定的了解,所以想写下这篇笔记,一来方便以后自己温习,而来帮助其他新入门的同学,避免一些不必要的弯路。
因为各种的PCIE设备的设计与使用都是依据PCIE协议的,所以首先我们需要对PCIE协议有一个大致的了解,了解的深度即不要太大(因为相关协议的文档长达数千也,而且有些你可能就不会用),也不能太浅,不然当你阅读Xilinx的PCIE的集成核时会一头雾水,因为你会不了解其中的一些寄存机,结构。
首先你需要下载这两个文档《PCI_Express_Base_Specification_Revision》,《PCI Express System Architecture》。第一个文档是将PCIE设备进行通信时包的格式,以及设备中的寄存器的含义和使用,可以看做是一本工具书,当你开发时关于接口,包格式,寄存器问题是随时可以查阅的文档,没有必要去细读它。第二个是非常有必要去读的一个文档,有一个减缩版可以让你快速对整个体系有一个了解。
我们的开发学习笔记就从第二本的内容开始,对pcie有一个大体的了解。首先我们都知道在电脑中有很多设备使用pcie总线,例如显卡,网卡,硬盘。
首先我们简单介绍一下PCIE,PCIE是一种串行通信协议。在低速情况下,并行结构绝对是一种非常高效的传输方式,但是当传输速度非常高,并行传输的致命性缺点就出现了。因为时钟在高速的情况下,因为每一位在传输线路上不可能严格的一致,并行传输的一个字节中的每个位不会同时到达接受端就被放大了。而串行传输一位一位传输就不会出现这个问题。串行的优势就出现了,串行因为不存在并行的这些问题,就可以工作在非常高的频率下,用频率的提升掩盖它的劣势。
PCIE使用一对差分信号来传输一位信号,当D+比D-信号高时,传输的是逻辑1,反之为0,当相同时不工作。同时PCIE系统没有时钟线。

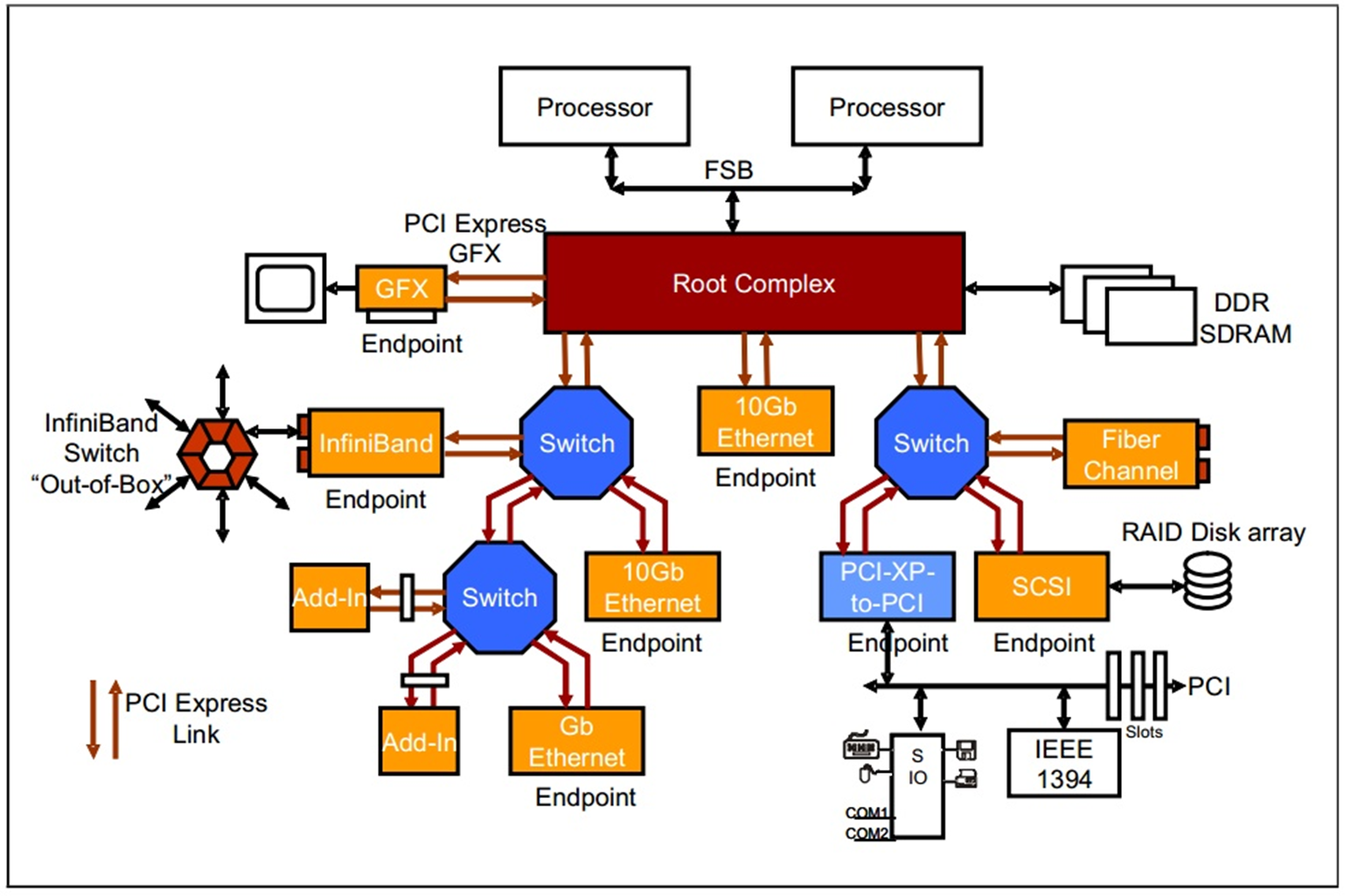
下面了解一下pcie总线的拓扑结构。
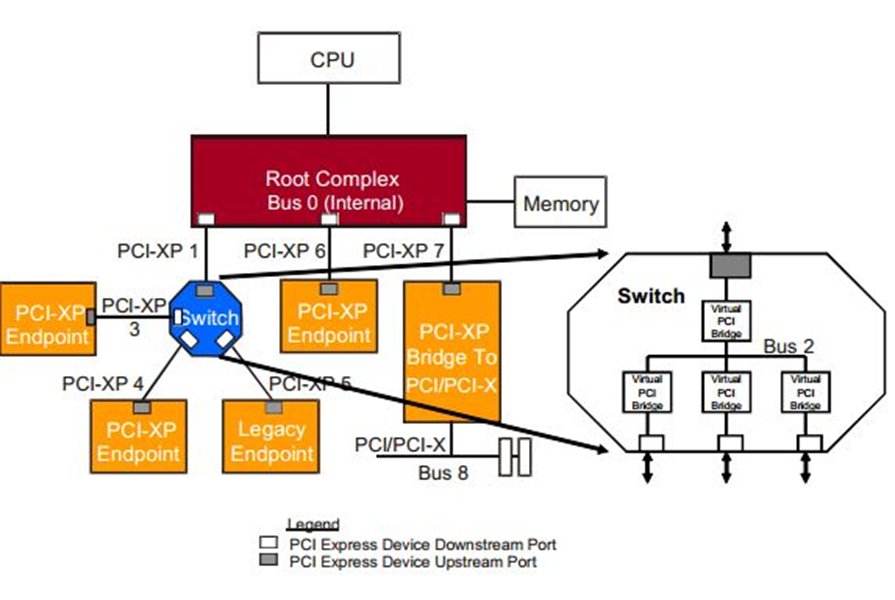
Fig.1 PCIE拓扑结构
从Fig1可以看出这个拓扑结构,CPU连接到根聚合体(Root Complex),RC负责完成从CPU总线域到外设域的转换,并且实现各种总线的聚合。将一部分CPU地址映射到内存,一部分地址映射到相应的相应的设备终端(比如板卡)。
pcie设备有两大类,一种是root port,另一种Endpoint。从字面意思可以了解这两类的作用,root port相当于一个根节点,将多个endpoint设备连接在一个节点,同时它完成数据的路由。上图中的Switch就是一个root port设备。而endpoint就是最终数据的接受者,命令的执行者。
这里我们就对pcie总线在计算机结构中的位置有一个大致的了解,下面我们对pcie数据的传输方式进行一个简单的介绍。pcie数据的传输方式类似于TCP/IP的方式,将数据按数据包的格式进行传输,同时对结构进行分层。

Fig.2 PCIE Device layers
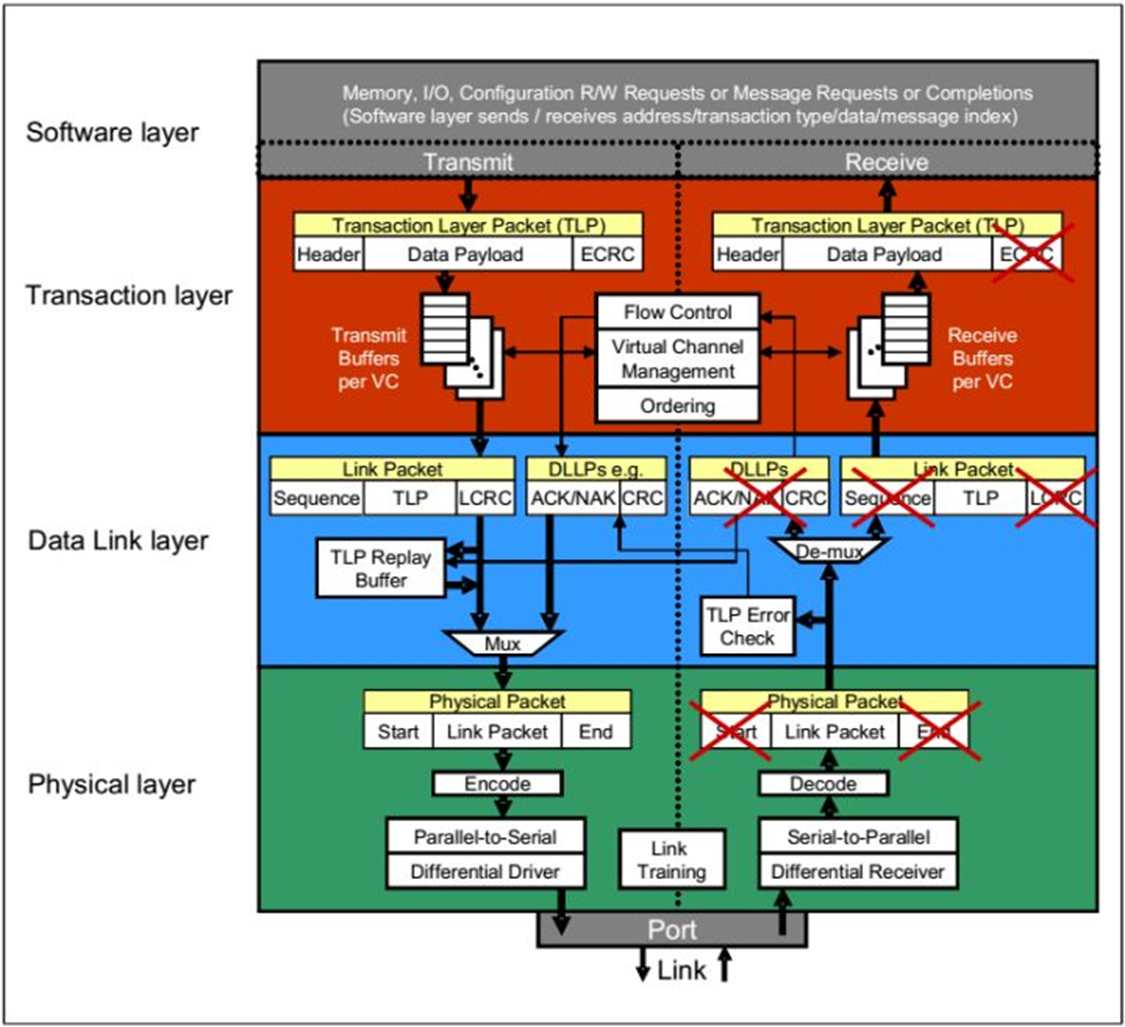
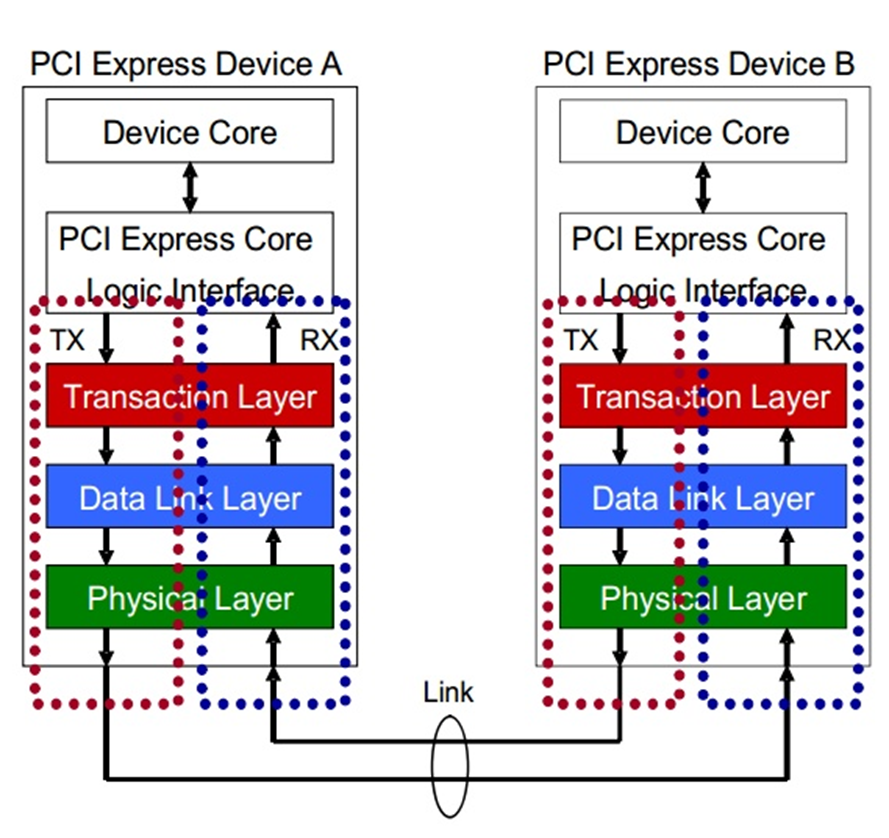
Fig.3 Detailed Block Diagram of PCI Express Device's Layer
PCIE的设备都具有这几个结构,每个结构的作用不同。我们首先说明数据传输时候的流程,PCIE协议传输数据是以数据包的形式传输。
首先说明在发送端,设备核或者应用软件产生数据信息,交由PCI Express Core Logic Interface将数据格式转换TL层可以接受的格式,TL层产生相应的数据包。然后数据包被存储在缓冲buffer中,准备传输给下一层数据链层(Data Link Layer)。数据链层将上一层传来的数据包添加一些额外的数据用来给接收端进行一些必要的数据正确性检查。然后物理层将数据包编码,通过多条链路使用模拟信号进行传输。
在接收端,接收端设备在物理层解码传输的数据,并将数据传输至上一层数据链层,数据链层将入站数据包进行正确性检查,如果没有错误就将数据传输至TL层,TL层将数据包缓冲buffer,之后PCI Express Core Logic Interface将数据包转换成设备核或者软件能够处理的数据。
我们使用IP核进行开发时,这三个层都已经写好了。所以我们的主要的任务就是
写出fig.2中PCI Express Core Logic Interface,从他的字面我们就可以明白他的作用,就是一个接口,将数据从Device Core输出的数据格式转换IP核TL层接受的数据格式。
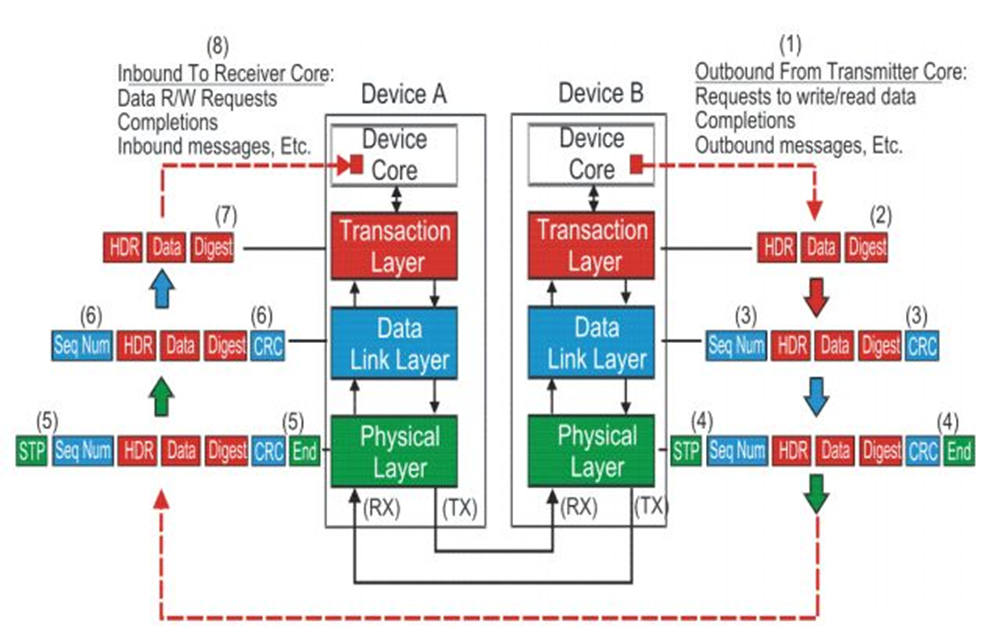
Fig.4 pcie数据包的处理
在TLP包传输的过程中会发生数据包的组装和拆解。
TLP包的组装
当数据从软件层或者设备核传来之后,TL层添加ECRC,
在DLL层在前段添加序列数字,在后面添加DLL层的CRC,
在物理层添加帧头和帧未。
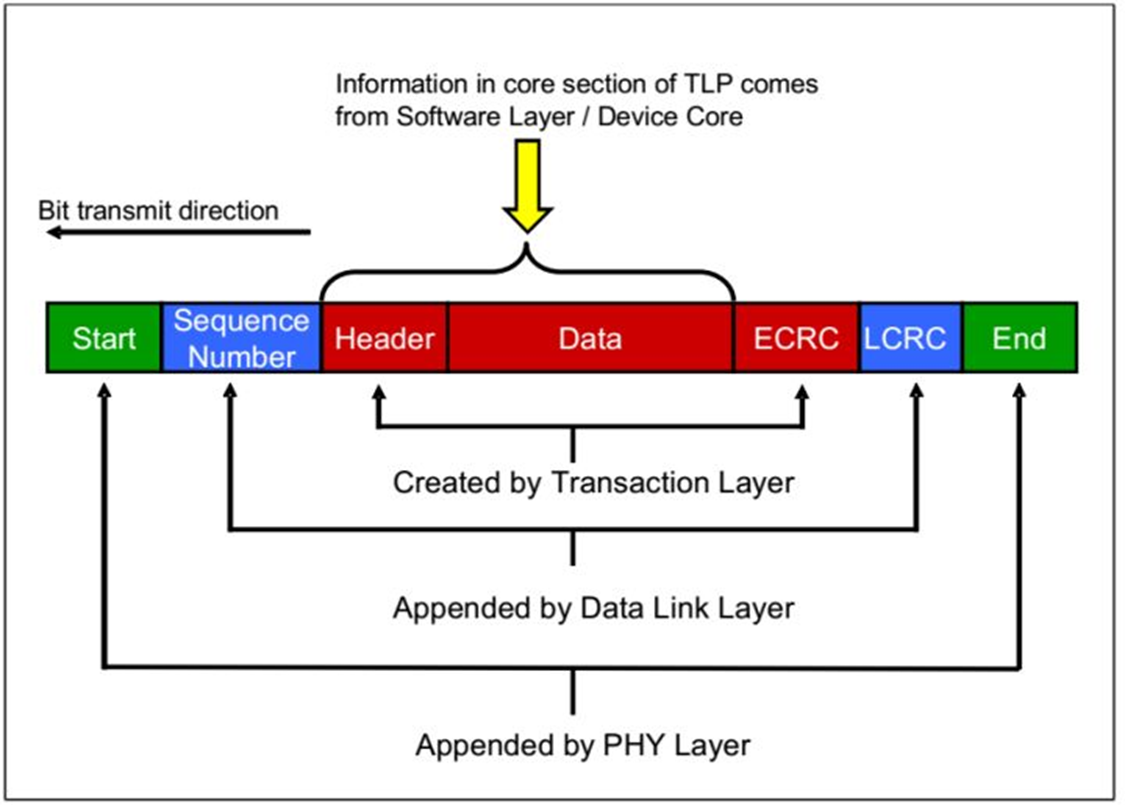
Fig.5 TLP Assembly
TLP的拆解是一个反过程。如Fig.6

Fig.6 TLP Disassembly
到这里笔记(一)就结束了。
PCIE开发笔记(二)TLP类型介绍篇
在学习笔记(一)中对PCIE协议有一个大致的了解,我们从他的拓扑结构可以看出PCIE设备是以peer to peer结构连接在一起的。并且点到点之间是以数据包的形式传输的。这篇笔记我们就对数据包进行一个大致的讲解。
我们上一篇说到,PCIE在逻辑上分为三层,分别是
1.
TL层,对应数据包为
TLP
2.
数据链层(Data Link Layer),对应数据包为
DLLP
3.
物理层(PHY Layer),对应数据包为
PLP
DLLP和PLP只会在相邻的两个设备之间传递,不会传递给第三个设备。
这里我们把重点着重放在
TL层产生的
TLP数据包。
我们首先给TLP数据包进行一个分类,主要可以分为以下四类:
1.与memory有关
2.与IO有关
3.与配置(configuration)
有关
4.与消息(message)
有关
configuration TLP是用来对PCIE设备进行配置专用的数据包,例如可以修改设备寄存器的值。
详细如table 1所示。

table.1
同时我们还可以从数据包从发送方到达接受方之后接受方是否返回一个数据包,将TLP分为两类:
1.Posted 接受方不返回数据包
2.Non_posted 接收方返回数据包
数据包相应的对应关系如table 2所示。

table.2
我们可以从它们的字面意思很轻易的理解它们。(configuration数据包是用来配置PCIE设备的专门的数据包,message是用来传递中断,错误信息,电源管理信息的专用数据包)
如何去辨别TLP的类型那?他们的差别主要在
TLP Header中,
TLP Header有两种格式,一种长度为
3DW,一种为
4DW。在TLP Header的Byte 0中有
Fmt和
Type两个部分,他们一起来表示TLP的类型。不同的类型长度不一样,详细参照table.3。
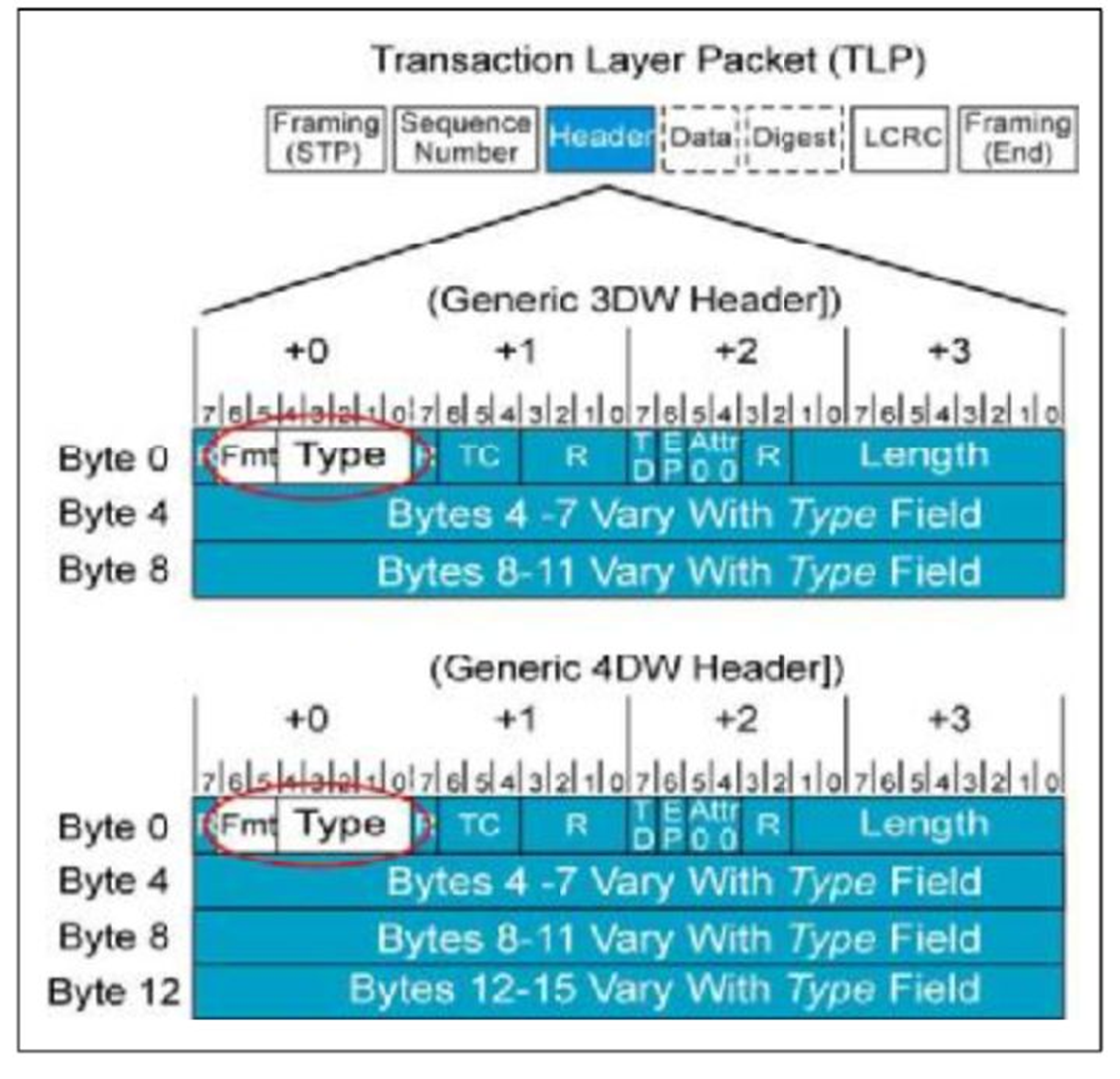
fig.1

table.3
下面我们详细的介绍它们。
1.Non-Posted Read
Transactions操作
请求者(Requester)请求一个操作,数据包可以是
MRd,
IORd,
CfgRd0,
CfgRd1。当
接受者(Completer)接受之后,完成响应操作,之后返回一个数据包,可能是
CplD或者
Cpl。
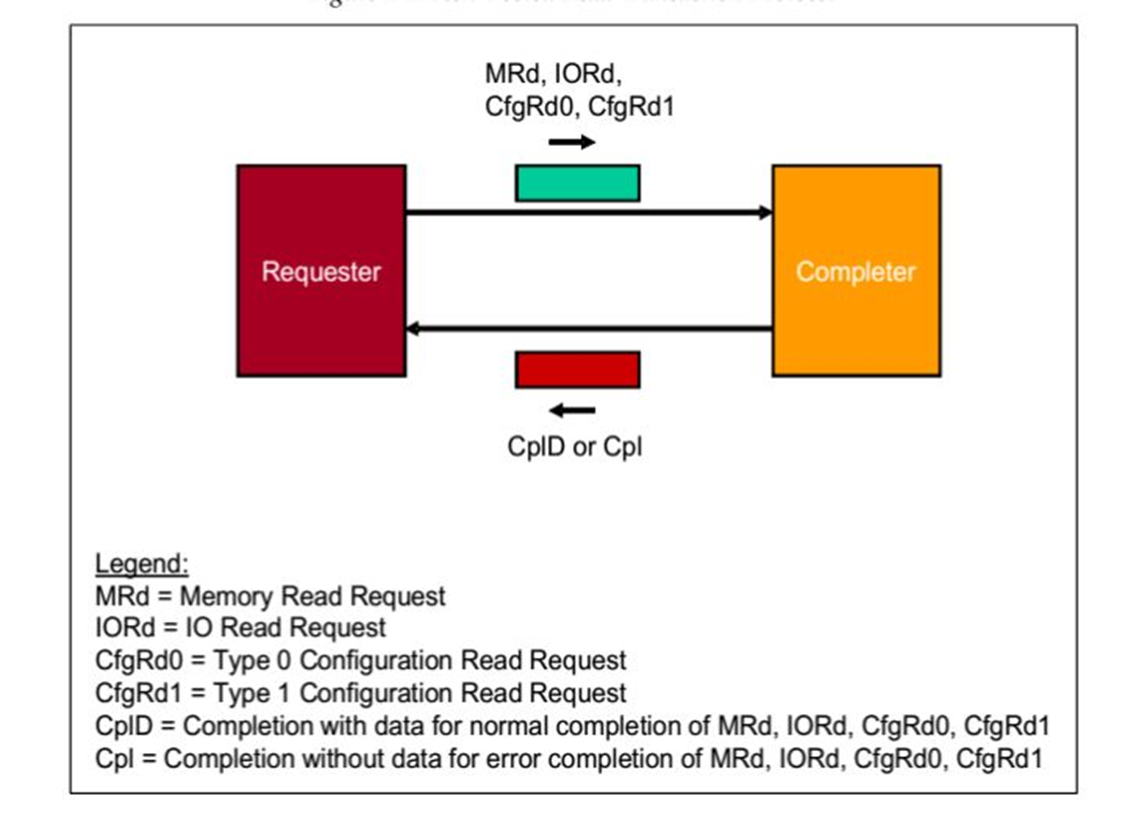
fig.2
2. Non-Posted Locked Read Transaction操作
请求者(Requester)请求一个操作,数据包是
MRdLk.当
接受者(Completer)接受之后,完成响应操作,之后返回一个数据包,可能是
CplDLk或者
CplLk。在
Requester接受到
Completion之前,数据包传递路径锁定。
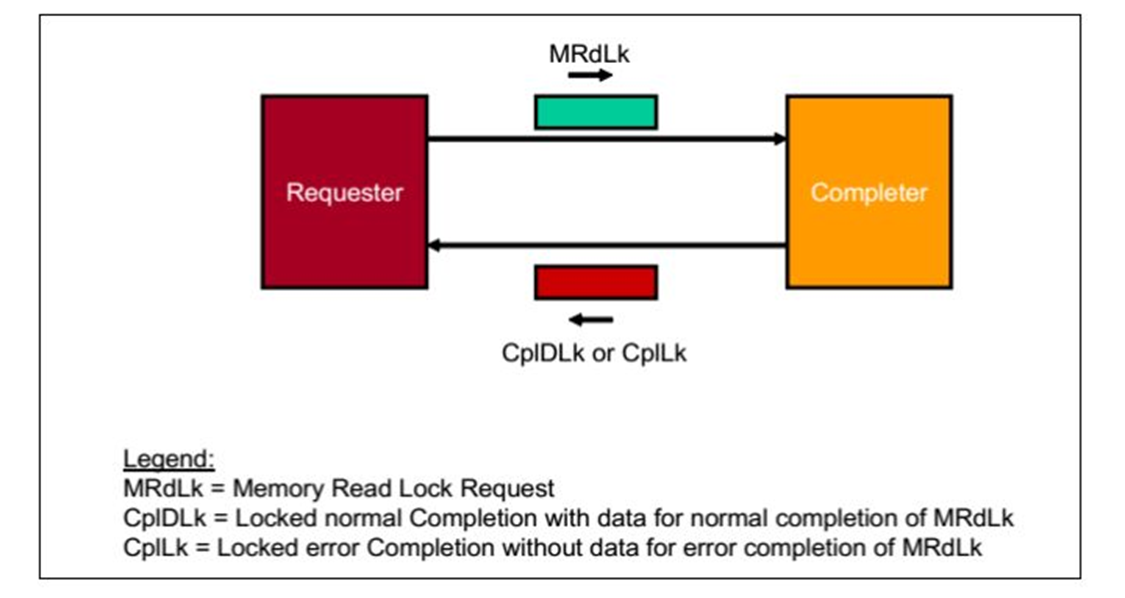
fig.3
3.Non-Posted Write Transactions 操作
请求者(Requester)请求一个操作,数据包是
IOWr,
CfgWr0,
CfgWr1。当
接受者(Completer)接受之后,完成响应操作,之后返回一个数据包,是
Cpl。
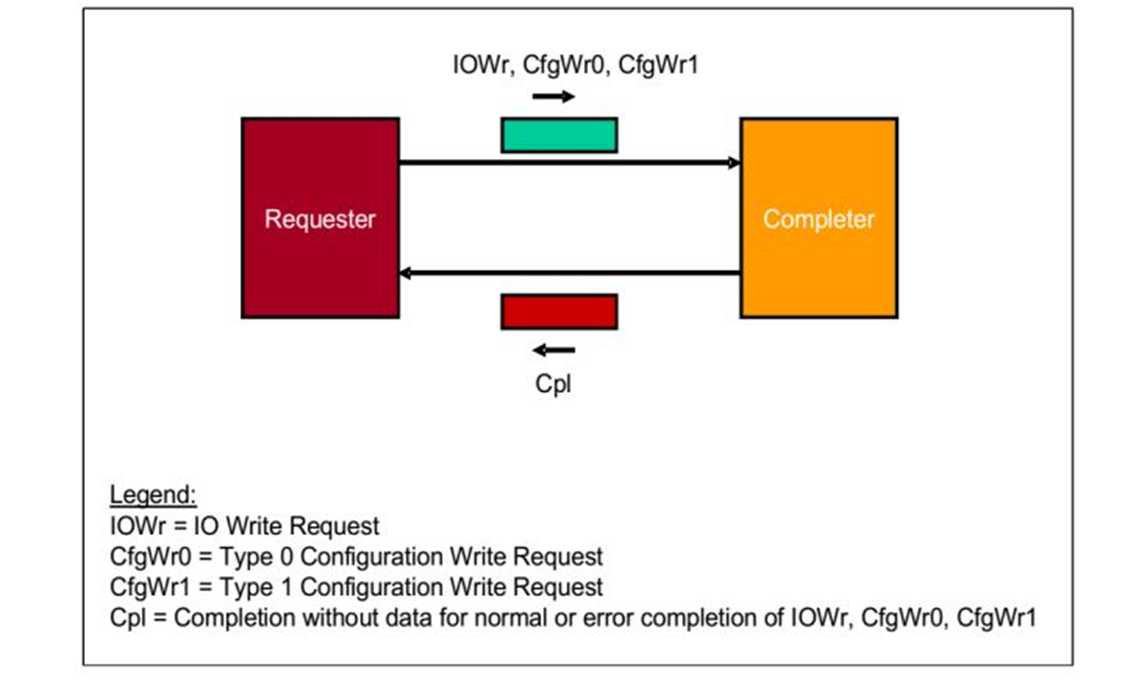
fig.4
4.Posted Memory Write Transactions 操作
请求者(Requester)请求一个操作,数据包是MWr.当
接受者(Completer)接受之后,不做任何反应。
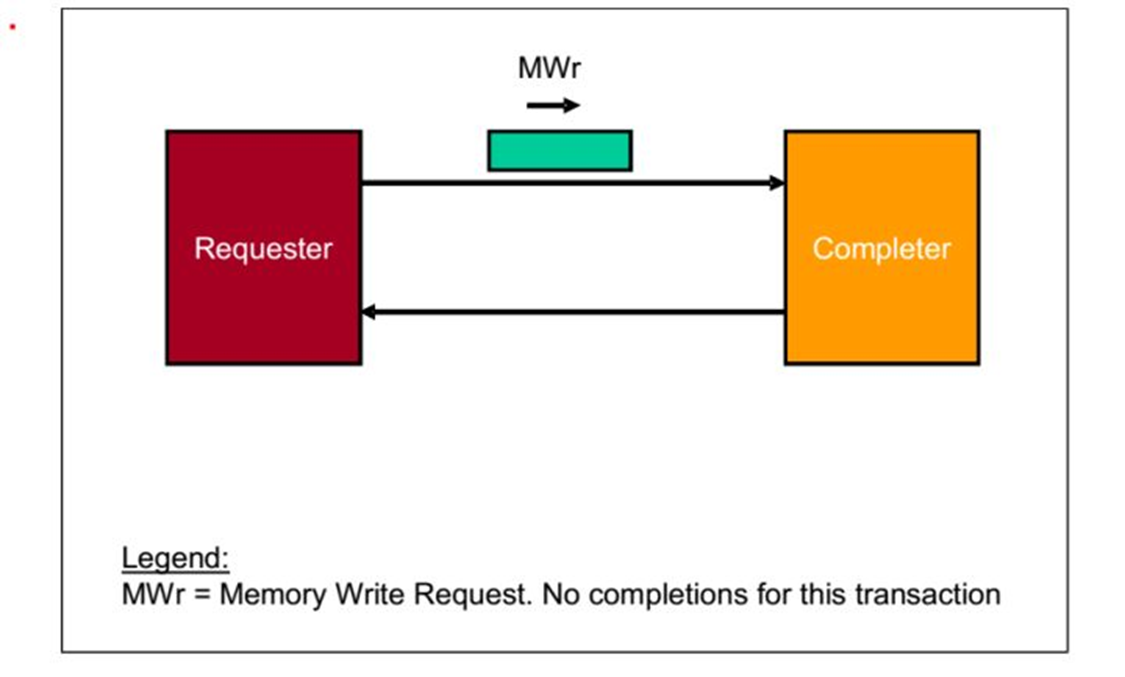
fig.5
5.Posted Message Transactions 操作
请求者(Requester)请求一个操作,数据包是Msg,MsgD.当
接受者(Completer)接受之后,不做任何反应。
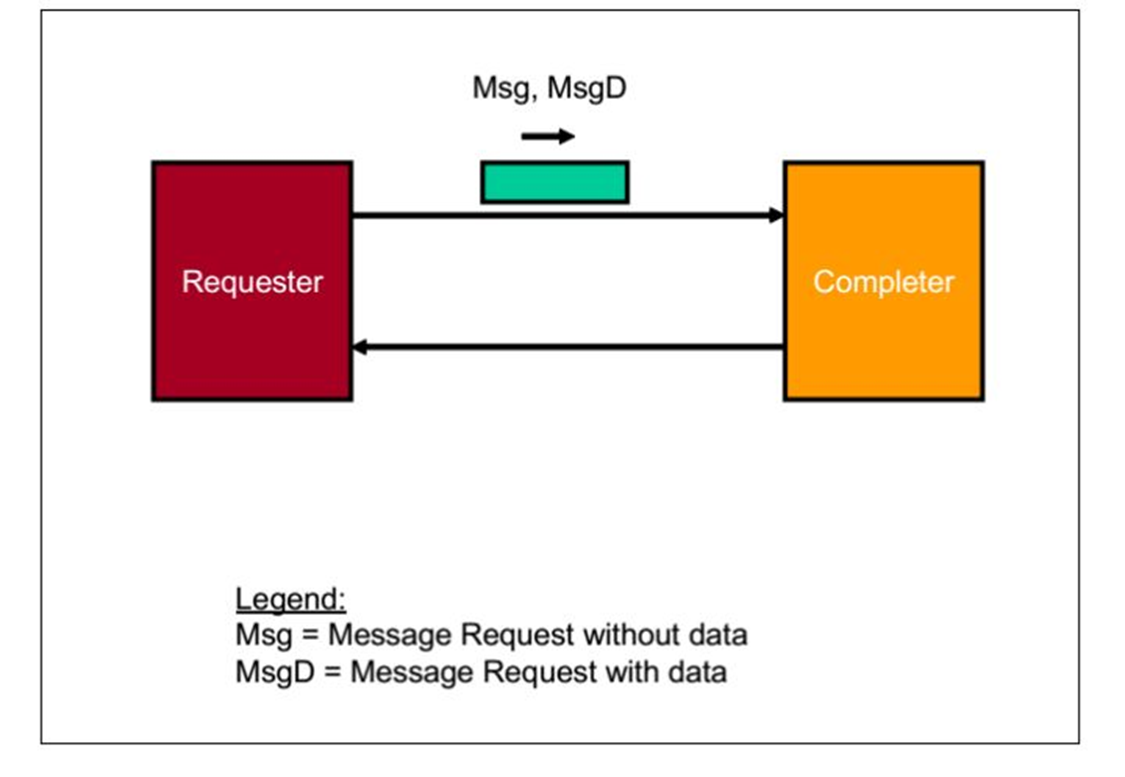
fig.6
下面我们举一些实际的例子:
1.CPU读取一个PCIE设备的memory
在PCIE的拓扑结构中,有一个非常重要的结构,它就是
Root
Complex(RC)结构。顾名思义,
它负责将几个不同的总线协议聚合在一起,如内存的
DDR总线,
处理器的前端总线Front Side Bus(FSB)。
在PCIE中,CPU的操作实际是由RC代替完成的,所以一定程度上也可以讲RC代表CPU。
所以当CPU想要访问Endpoint时
Step1:CPU让RC产生一个MRd,经过Switch A,Switch B(第一篇讲到过Switch),到达Endpoint。
Step2: Endpoint 接受数据包,进行数据读取。
Step3:Endpoint返回一个带有数据的Completion.
Step4: RC接受数据包,给CPU。

fig.7
其他类型就不再一一赘述了。这里TLP的分类就告一段落。
PCIE开发笔记(三)TLP路由篇
前两篇我们对TLP有一个大致的了解,现在有一个问题摆在我们面前,当一个设备想和另一个设备进行通信时,TLP是怎么找到这条路径,从而进行传播的,这就是路由问题。
上一篇我们讲过PLLP,PLP只在临近的两个设备之间传播,所以不存在路由问题。而TLP会在整个拓扑结构中传播,所以存在这个问题。
要路由首先要能明确的表示一个地址,寄存器,或者一个设备。
所以要介绍几个概念。
首先介绍一下地址空间(Address Space)这个概念。
系统将一部分地址分配给
内存(System Memory),一部分(
MMIO,Prefetchable Memory Devices)分配给
外设(如PCIE外设)。
IO接口也是这个样子。这样就可以
用一个统一的方式命名系统的存储空间。这称之为
地址空间。
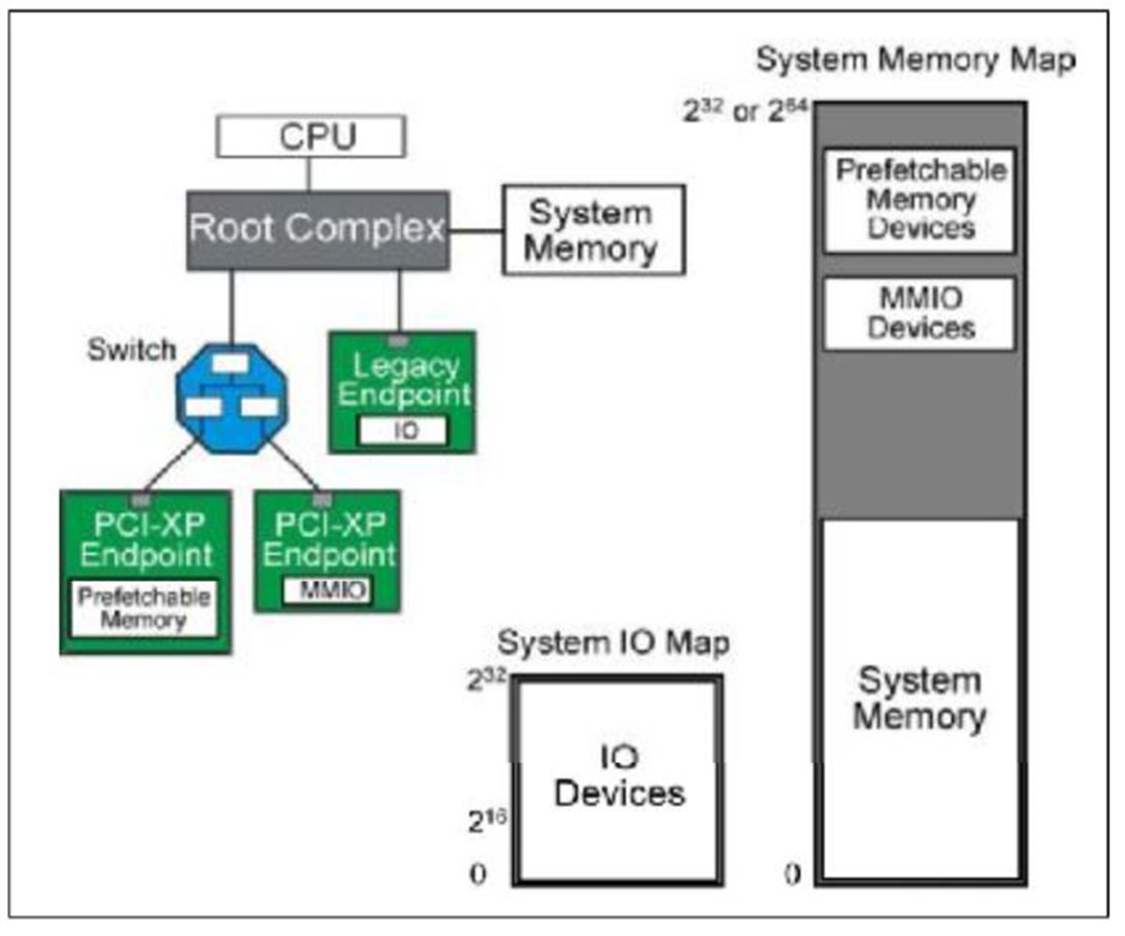
fig.1
同时,在整个系统初始化之后,每个设备会有一个设备号,总线号,功能号(Device number,ID Bus Number,Function Number),这样也可以唯一的确定一个设备。这些信息存储在设备的configurection头里面。
TLP路由总共有三种方式:
1.Address Routing 根据地址路由
2.ID Routing 根据ID路由
3.Implicit Routing 隐式路由
不同类型的TLP的路由方式不一样,具体如table.1.
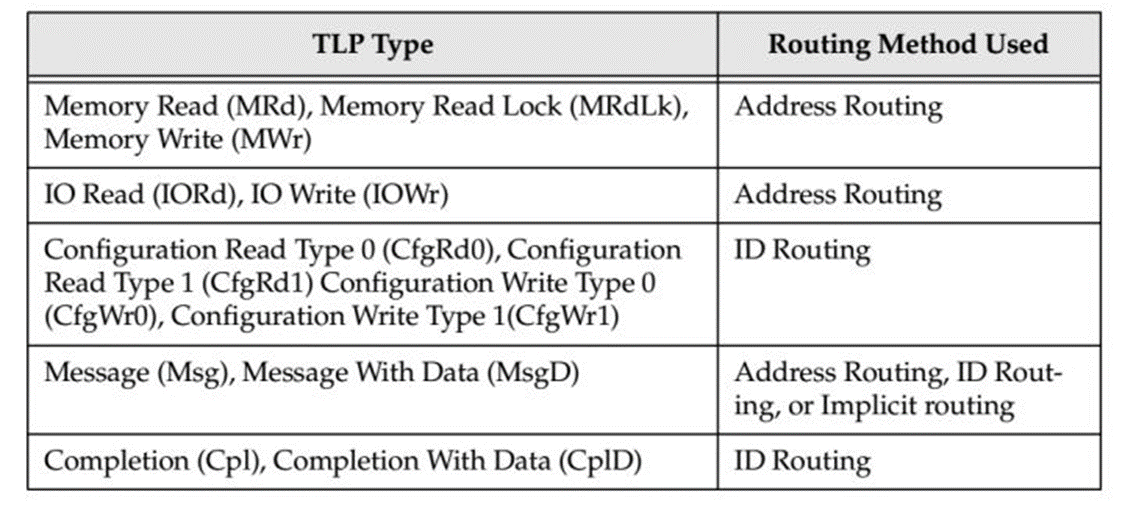
table.1
如果我们仔细思考会发现这样的路由方式是非常合理的
在PCIE拓扑结构中能够进行路由的结构只有
Switch和
RC。所以我们有必要介绍一下它们。 Switch就是一个多端口设备,用来连接多个设备。Switch可以理解为一个双层桥结构,其中还
包含一个虚拟总线连接这个双层桥。其中每个桥设备(Bridge)一端连接到一个外部PCIE设备,一段连接到虚拟总线。
对Switch结构进行Configuration配置是使用Type 1。
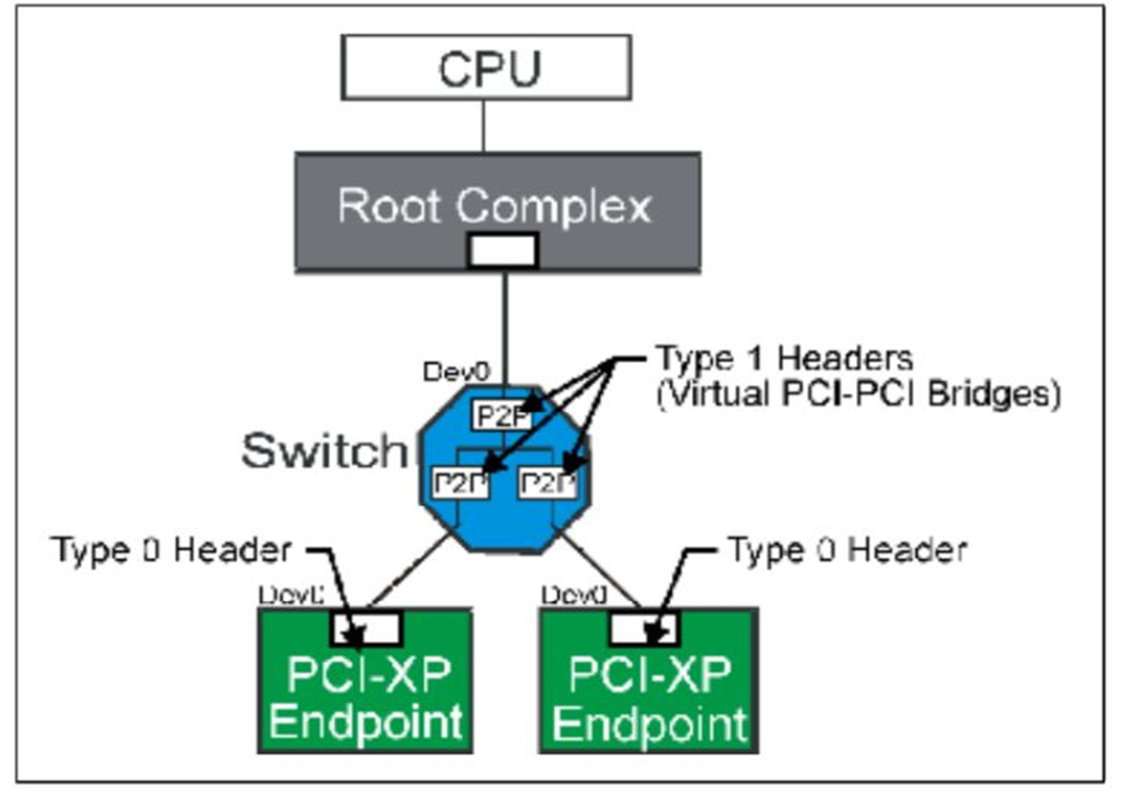
Fig.1
对于需要进行路由的设备,当它接受到一个TLP时,首先会判断这个TLP是不是发送给它自己的,如果是,接受它,如果不是,那就继续路由转发。
现在我们一一介绍:
1.Address Routing
当
PCIE设备想访问内存(system memory)时,或者CPU想访问PCIE设备的memory时,使用一个
含有地址请求包,这个时候就是
Address Routing方式。
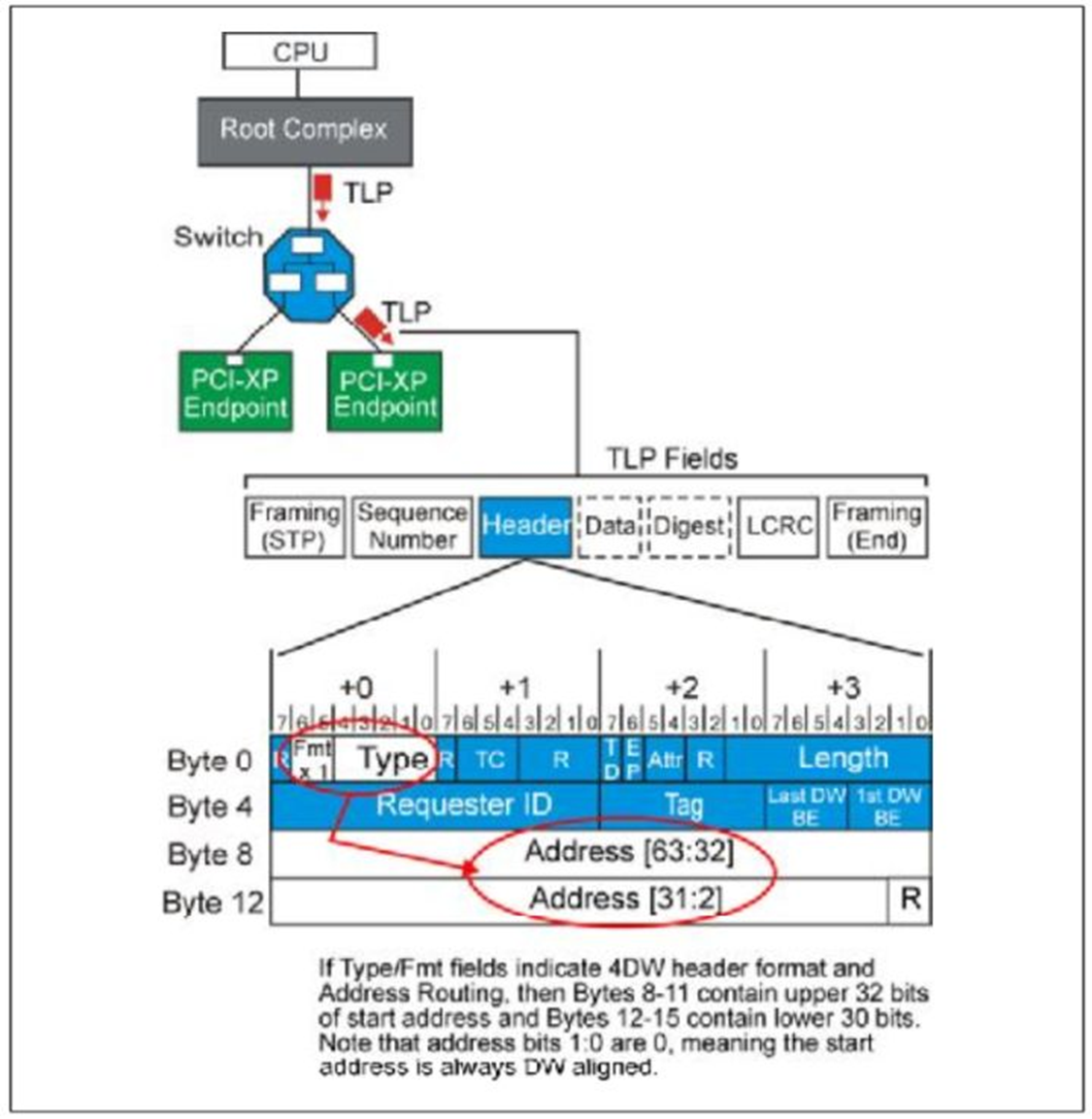
Fig.2
当一个Endpoint设备接受一个TLP之后,设备会首先检查它的
Header中的
Fmt和
Type,如果属于
Address Routing,检查是
3DW还是
4DW地址。然后设备将会对比设备的
Configuration中的
Base Address Register和
TLP头中的地址,如果相同,就接受这个
TLP,不相同就拒绝。
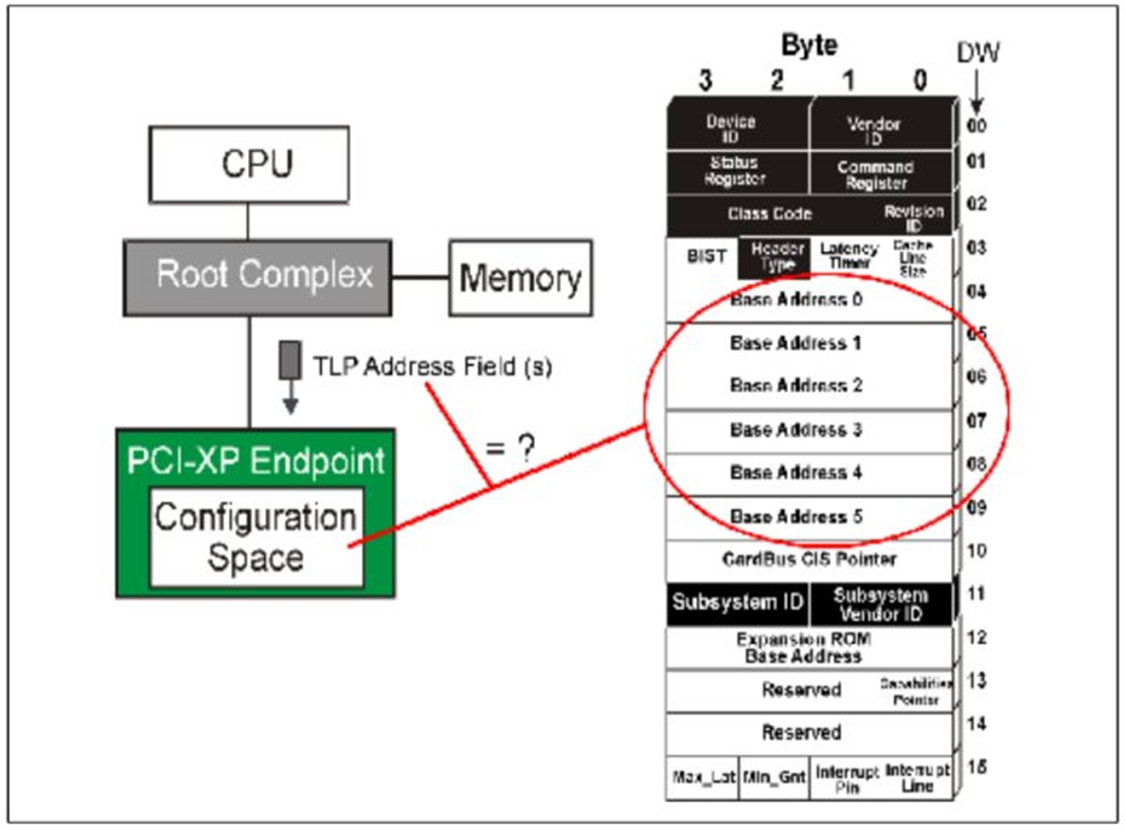
Fig.3
当一个Switch设备接受一个TLP之后,首先检查是否为Address Routing,如果是,那它就
对比TLP中目的地址和自己的Configuration中的Base Address Register,
如果相同,
就自己接受这个数据包,
如果不同,它会去检查是否符合它下游设备的Base/Limit Register地址范围。

Fig.4
关于Switch补充下列几点:
- 如果TLP中的地址符合它下游的任意一个Base/Limit Register地址范围,它就会将数据包向下游传递。
- 如果传递到下游的TLP不在下游设备的BAR(Base Address Register)或者Base/Limit
Register。那么下游就向上游传递一个unspported请求。
- 向上游传播的TLP永远向上游传播,除非TLP中的地址符合Switch的BAR或者某个下游分支。
当进行
Configuration Write/Read,或者发送
Message时使用
ID,都将使用
ID Routing方式。
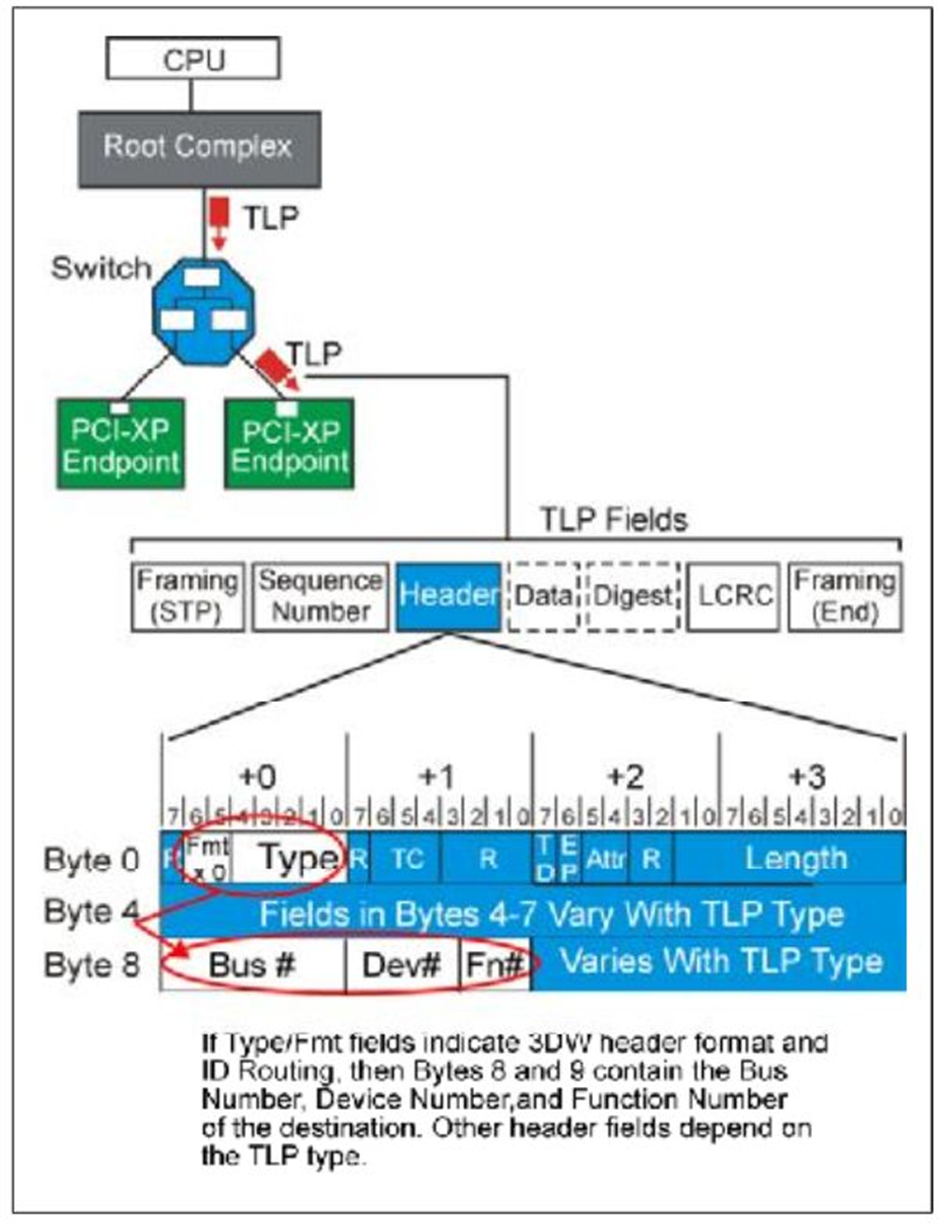
Fig.5
当一个Endpoint设备接受到一个ID Routing TLP之后,它会对比它在初始化时得到的Bus#,Dev#,Fn#,如果相同,就接受,不接受就拒绝这个消息。如Fig.5所示。当系统Reset之后,所有设备的ID都变为0,并且不接受任何TLP,直到Configuration Write TLP到达,设备获取ID,再接受TLP。
当一个Switch设备接受一个TLP时,它会首先判断这个TLP的ID的自己的ID是否相同,如果相同,它就内部接受这个TLP。如果不相同,它就检查它是否和它的下有设备的ID是否相同。
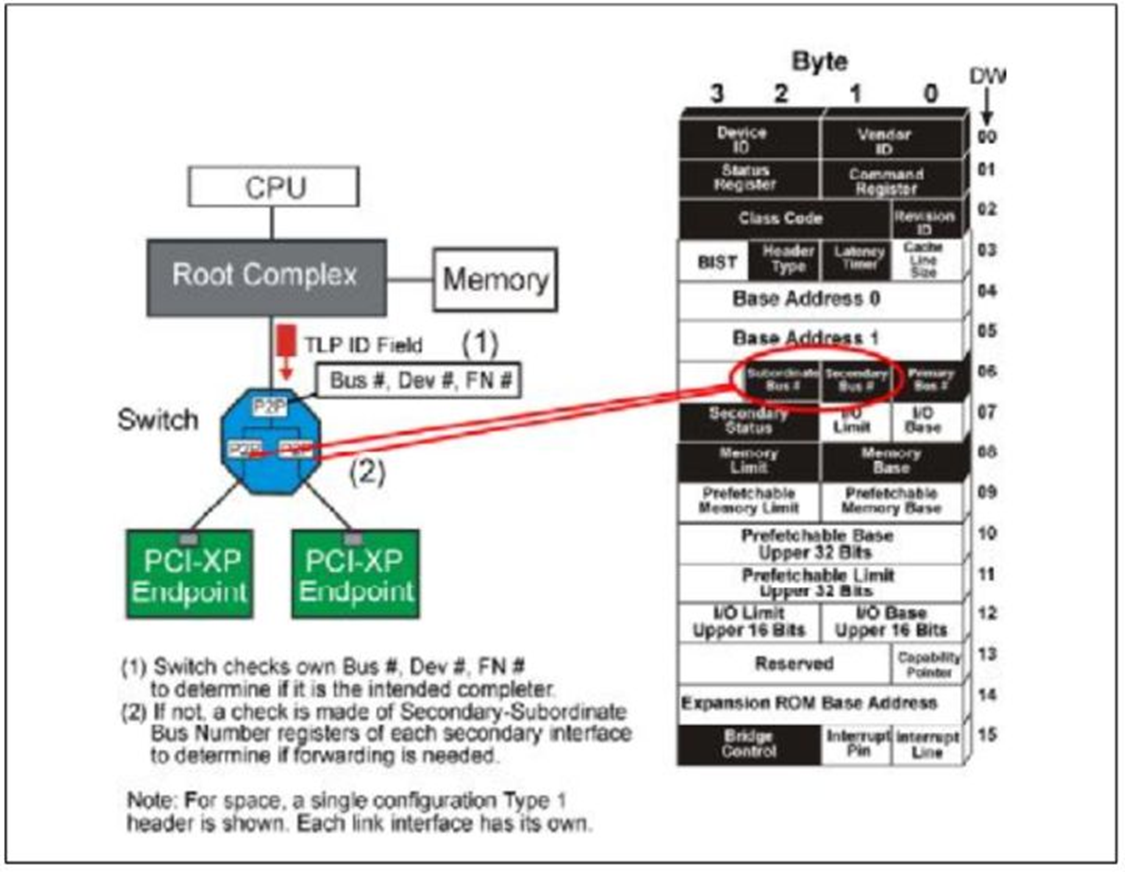
Fig.6
关于Switch补充下列几点:
- 如果TLP的ID和它的下游任意接口的configuration中的Secondary-Subordinate
Register符合,它就向下游传播这个包。
- 如果传递到下游的TLP不和下游设备自身的ID符合。那么下游就向上游传递一个unspported请求。
- 向上游传播的TLP会一直向上游传播,除非TLP是传递给Switch或者某个分支的。
3.Implicit Routing
只有
Message使用
Implicit Routing。详细信息见Table.2。

Table.2
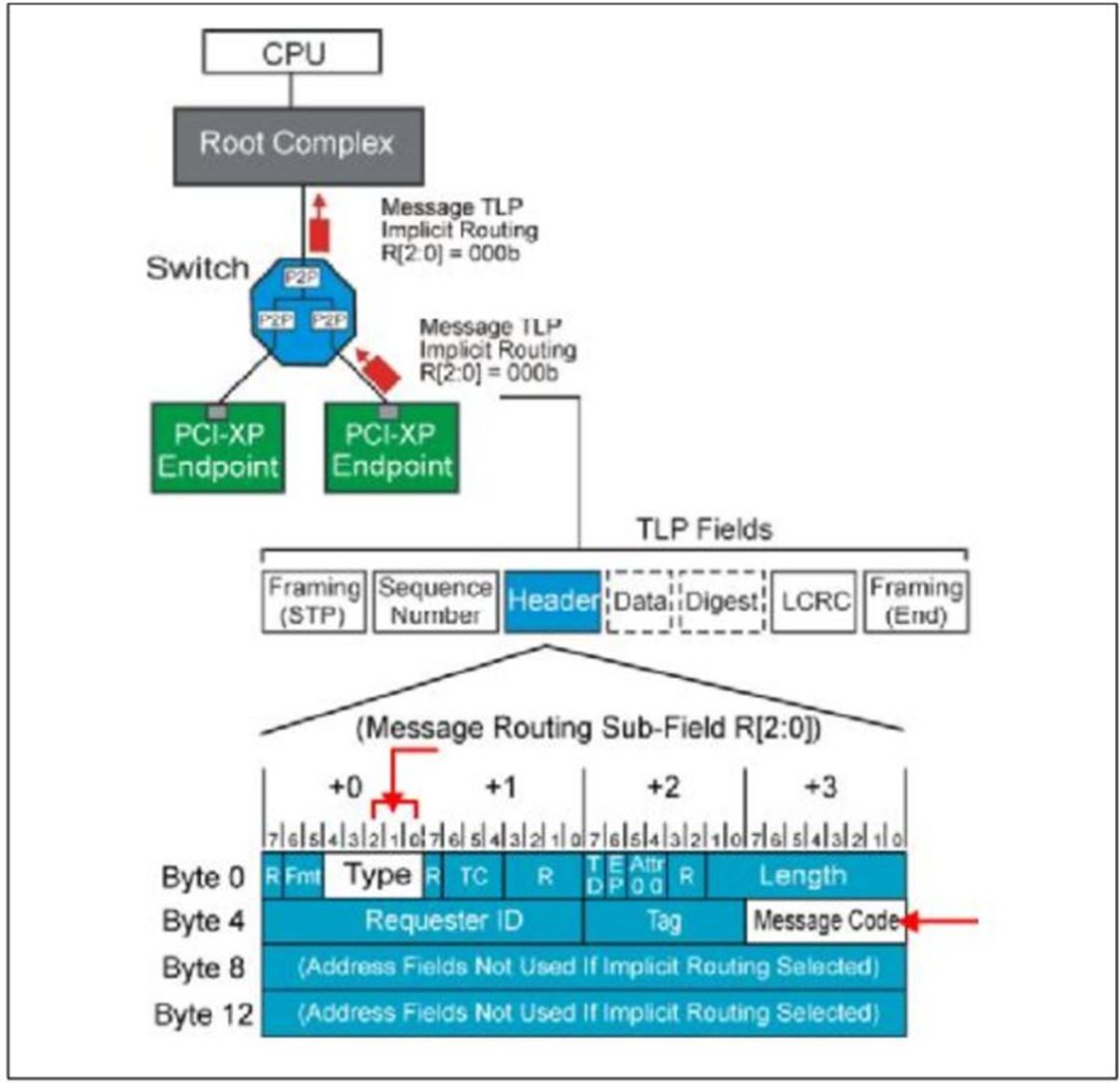
Fig.7
当一个Endpoint设备接受到一个Implicit Routing TLP之后,它只会简单的检查这个TLP是不是适合自己,然后去接受。
当一个Switch设备接受一个TLP时,它会考虑这个TLP接受的端口,并根据它的TLP头判断这个TLP是不是合理的。例如
- Switch设备接受一个从上游来的Broadcast Message之后,它会转发给自己所有的下游连接,当Switch从下游设备接受一个Broadcast Message之后,它会把它当做一个畸形TLP。
- Switch设备在下游端口接受到一个向RC传播的TLP,它会把这个TLP传播到所有的上游接口,因为它知道RC一定在它的上游。反之,如果从它的上游接受一个这样的TLP,那显然是一个错误的TLP。
- 如果Switch接受一个TLP之后,TLP表示应该在他的接受者处停止,那么Switch就接受这个消息,不再转发。
到这里三种路由方式就介绍完成了。
PCIE开发笔记(四)PCIE系统configuration和设备枚举篇
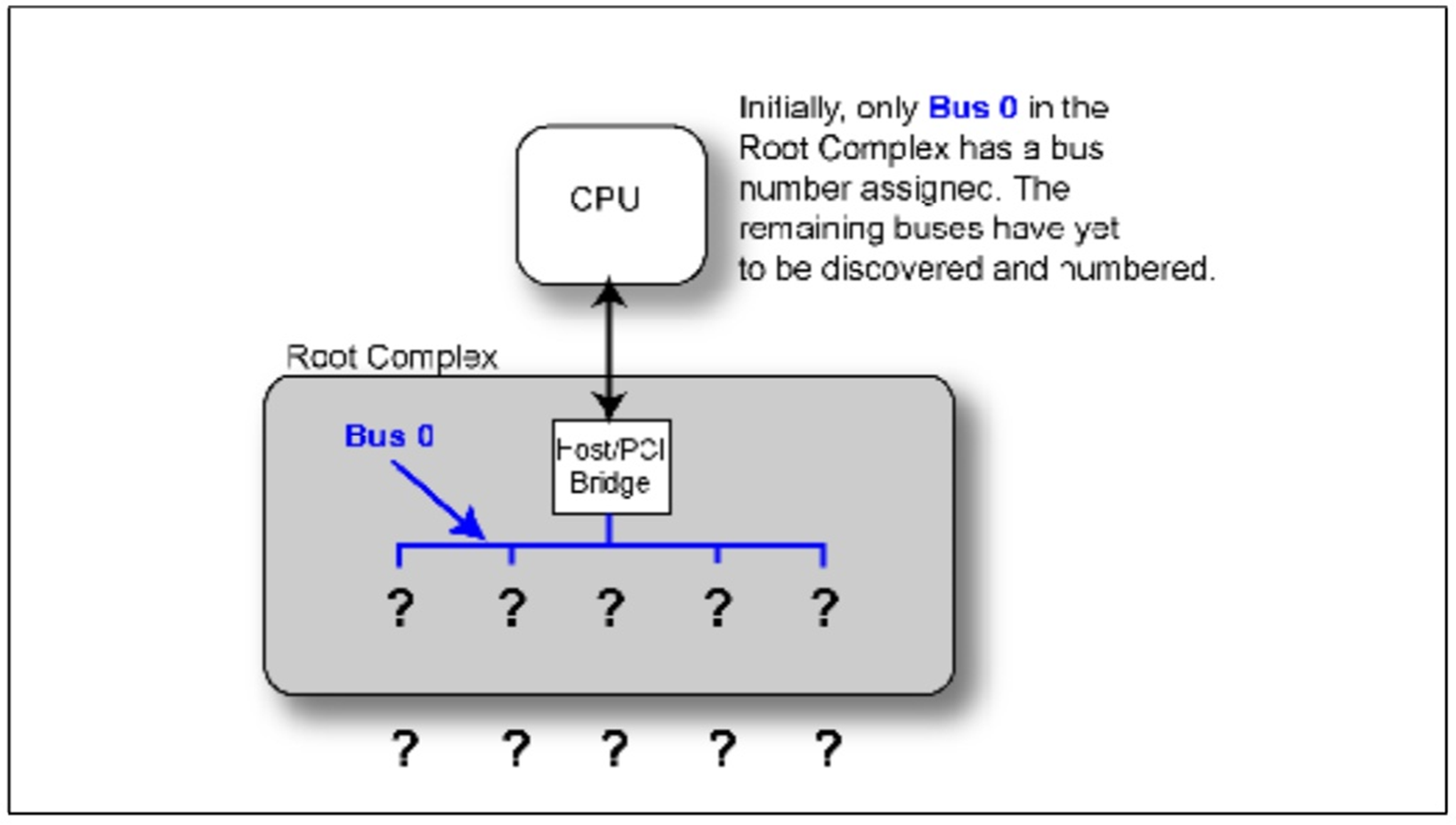
在上一篇我们介绍了路由方式。其中有ID Routing这种方式。但是我们应该有一个疑惑,就是设备它的Bus
Number,Device Number,Function Number是怎样得到的。
首先我们可以排除一种情况,就是这些ID不可能是硬编码在设备中的,应为PCIE拓扑结构千变万化,如果使用硬编码那就与这种情况矛盾。实际上在一个PCIE系统在Power On或者Reset之后,会经历一个初始化和设备枚举的过程,这个枚举过程结束之后就会得到他的所有ID。
现在我们就开始介绍PCIE设备是怎么被发现的,整个拓扑结构是怎么建立的。
首先,在一个PCIE Device中支持最高8个Function,那什么是Function?一个设备它可以同时具有几个功能,每个功能对用一个Function,且每个Function必须拥有一个Configuration来配置他的必要属性。且如果一个设备只有一个Function,那么他的Function Number必须为0,如果这个设备是一个多Function的设备,那么它的第一个Function Number必须为0,其余的Function Number可以不必按照顺序递增。
我们再介绍几个概念,Rrimary Bus代表的一个桥设备直接相连的上游Bus Number。Secondary Bus代表的一个桥设备直接相连的下游Bus Number。Sub Bus Number代表这个桥下游最远的Bus
Number。
在设备启动之后整个系统的拓扑结构是未知的,只有RC内部总线是已知的,命名为Bus 0,这是硬件编码在芯片当中的。
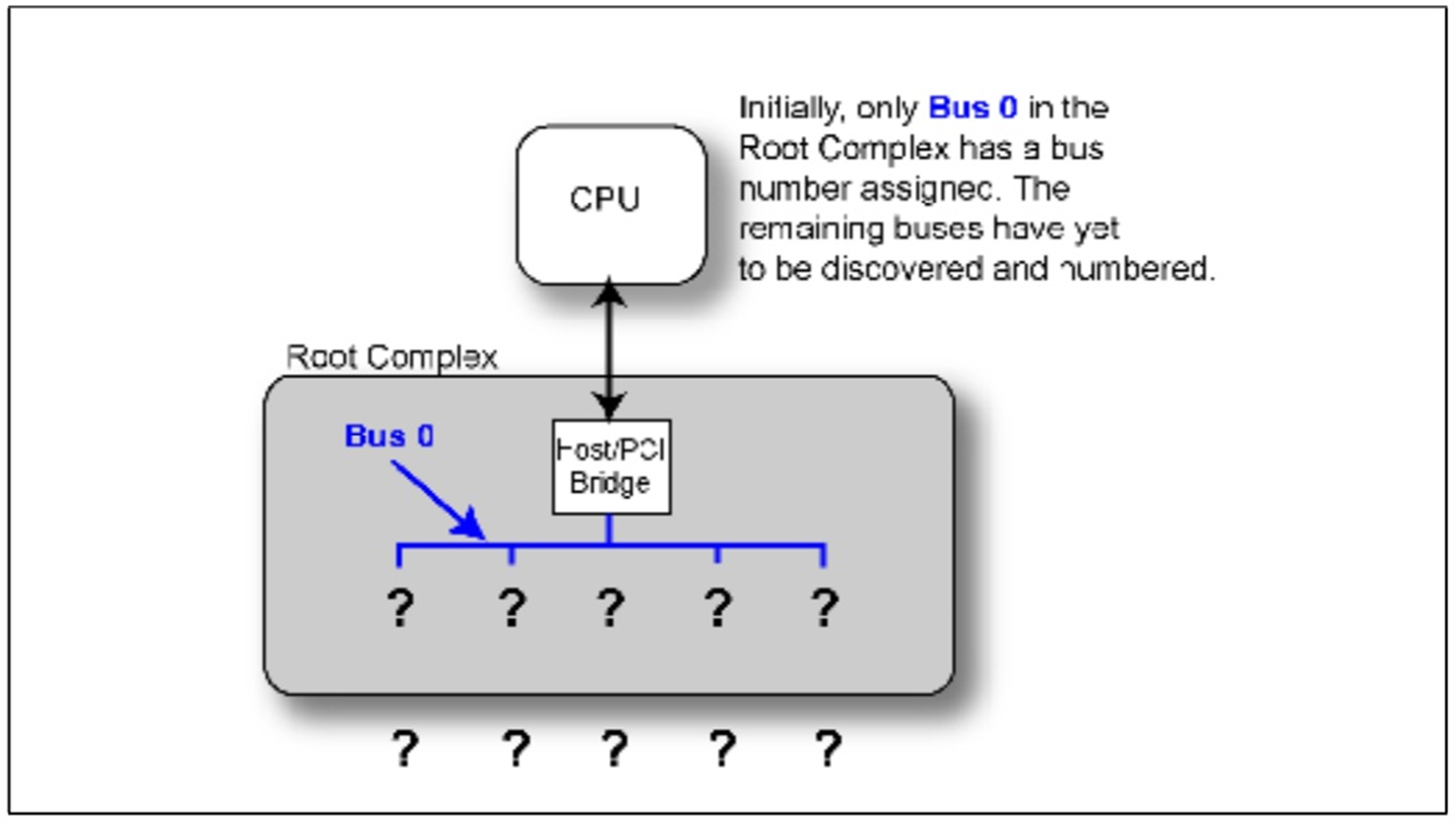

Fig.1
那么系统是怎么识别一个Function是否存在哪?我们以Type 0结构的Configuration为例,有
Device ID和
Vendor ID,它们都是
硬编码在芯片当中,不同的设备有着不同的
ID,其中值
FFFFh保留 ,任何设备不能使用。当RC发出一个
Configuration读请求时,如果返回的不是FFFFh,那么
系统就认为存在这样的设备,如果返回的为
FFFFh那么系统就认为
不存在这个设备。

Fig.2
在上一篇中我们说到过,这个系统中,只有RC能进行Configuration Write操作,否则整个体系会发生混乱。
那么RC是怎么产生一个Configuration Write或者Configuration Read操作的?我们都知道RC只是代替CPU进行操作的,那么CPU怎么样才能让RC产生一个这样的操作那?有几种想法可以实现,例如,我们把所有Configuration空间映射到系统的Memory Space中,但是如果系统存在大量的设备,那么将占据大量的Memory Space,这样是不高效的。所以一个非常聪明的方法被提出(另外一种方法这里就不提了)。
系统将IO Space中从0CF8h-0CFBh这32bit划分为Configuration Address Port,将0CFCh-0CFFh这32bit划分为Configuration Data Port。
Configuration Address Port有一下定义:
Fig.3
- Bit0-1是硬编码进芯片的。
- Bit2-7定义Target dword,表明要写的comfiguration space的位置。Configuration Space总计有64个Dword。
- Bit8-23为目标的ID。
- Bit31为使能位,为一时使能工作。
当CPU想要进行一个Configuration Write时,它只需在Configuration Address Port写进它的地址,和Target dwor。在Configuration Data Port写入数据,使能就完成一个配置写操作了。当CPU从Configuration Data Port进行读操作就完成配置读操作了。
以前说到Configuration 分为Type 0和Type 1两类。这里我们说明一下它们的区别。
首先它们的TLP Header不一样,但是它们最大的不同如下:
当CPU产生一个Configuration Write时,如果
写的目的Bus等于RC的Bus,那RC会直接
产生一个Type 0,然后Bus中的某个设备接受它。如果
不相同,那么
它将产生一个Type 1,并且
继续向下传播。下游的桥接受后,它会是首先对比
目的Bus和自己的
Secondary Bus,如果相同的话,它会将这个TLP
从Type 1转化为Type 0,然后
Bus上的某个设备接受它,如果
Secondary Bus<目的Bus,这个桥设备不对这个TLP进行类型转换
,继续向下传播,直到目的Bus=Secondary Bus再完成类型转换。**
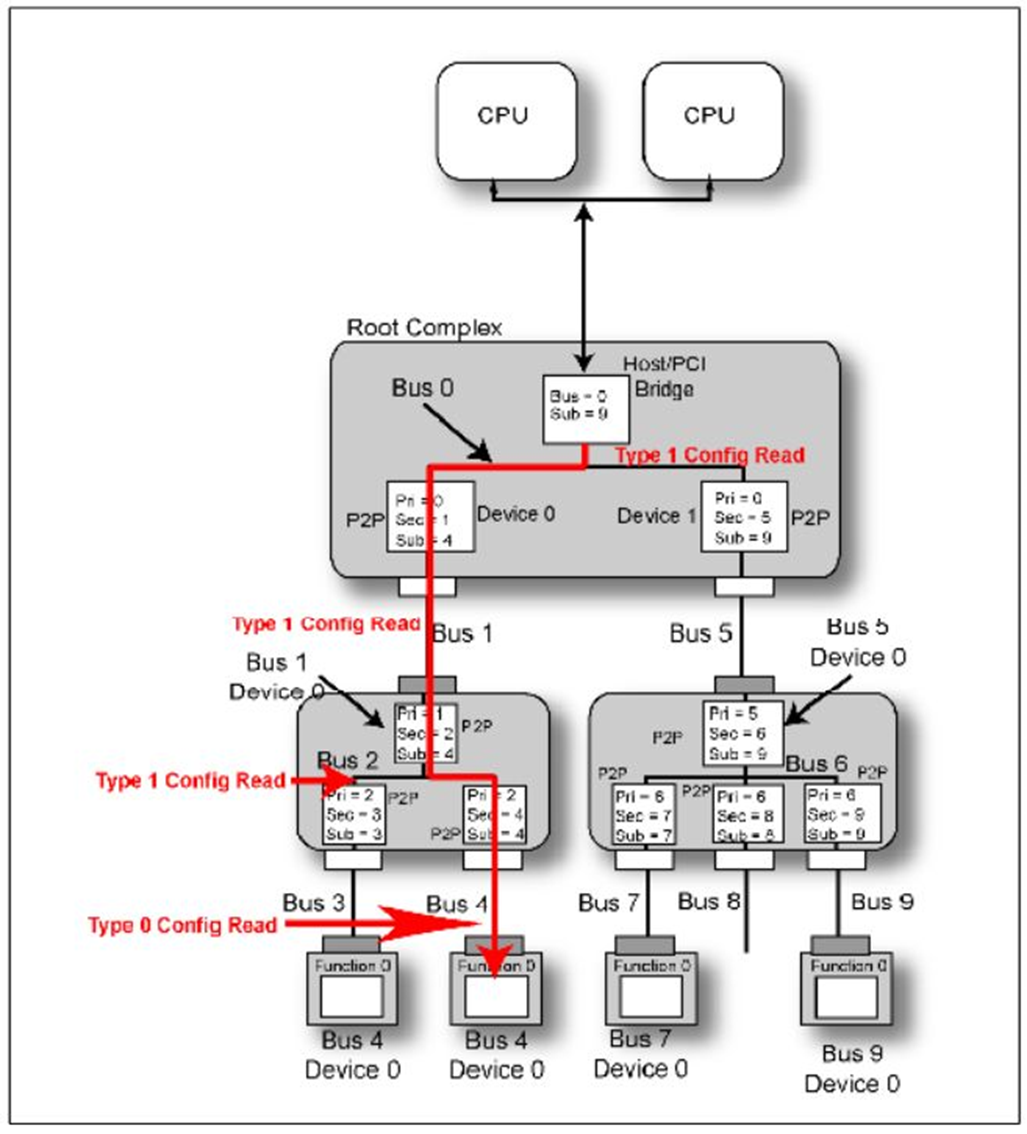
Fig.4
现在我们开始介绍如何进行设备枚举。
在系统上电或者Reset之后,设备会有一个初始化的过程,这个过程中设备的寄存器都是无意义的,当初始化之后,所有寄存器数据稳定并且有意义。这是才可以进行Configuration和设备的枚举。

Fig.5
在系统完成初始化之后,整个系统如Fig.3所示,只有RC中的Bus被硬编码为Bus 0。这时枚举程序开始工作,首先他将要做的是:
1.枚举程序将要
探测Bus 0下面有几个设备,
PCIE允许每个总线上最多存在32个Device。上面我们已经介绍了怎么探测一个设备是否存在,这时RC将要
产生一个Configuration Read TLP,目的ID为
Bus 0,Device 0,Function 0,读取
Vendor ID,如果返回的
不是FFFFh,那表明存在
Device 0,Function 0。
跳到下一步。如果
返回为FFFFh,那就
表明一定不存在Device 0。那么程序就开始
探测是否存在Bus 0,Device 1,Function 0。
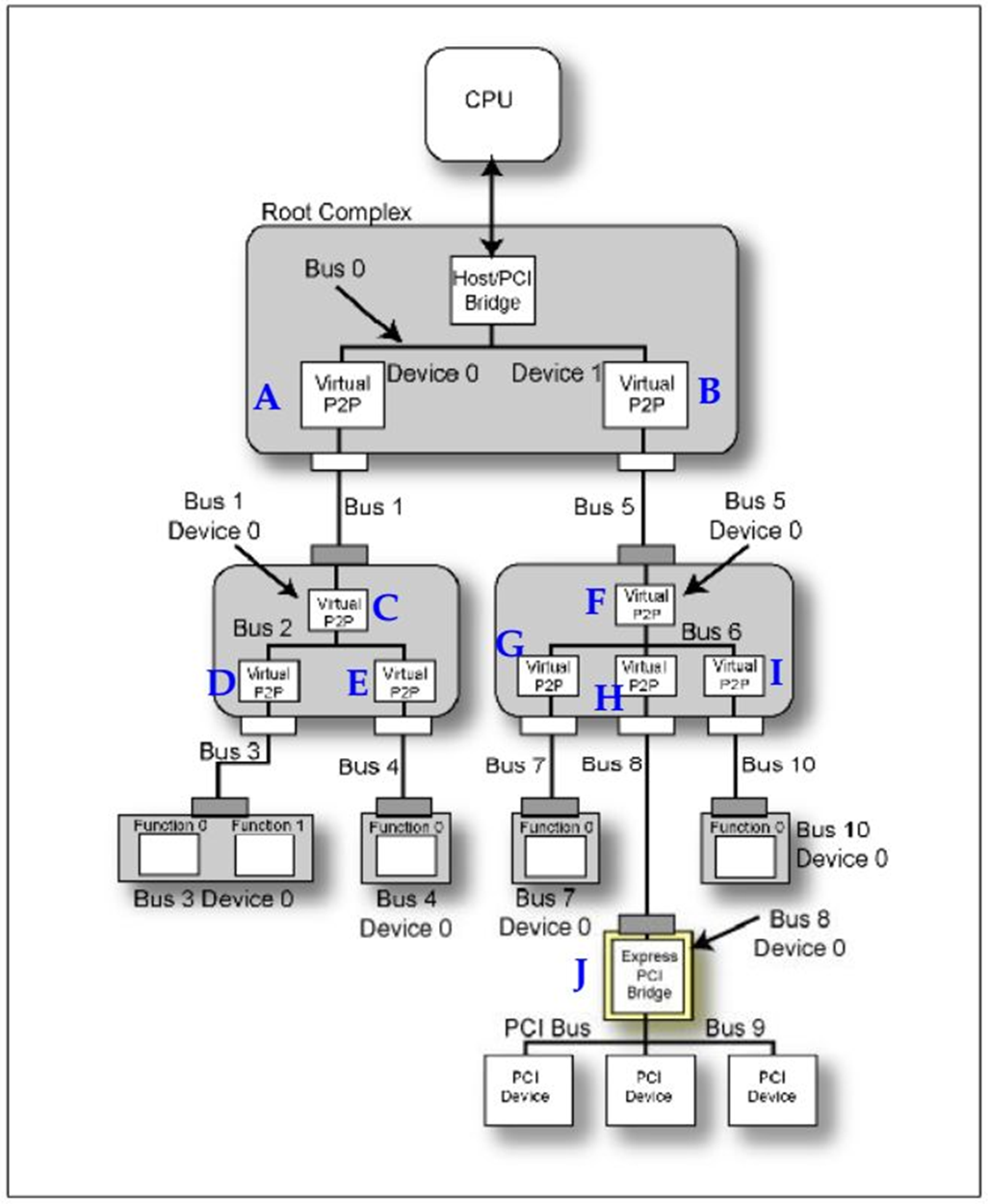
Fig.6
2.上一步探测到
Device 0(Fig.2中的A)存在。在设备的
Header Type field中存在
Header Type Register,
Capability Register。这两个
Register表明
Device的一些特性。
Header Type Register的
Bit 7表明他是否是一个
多功能设备(Multi-function Device)。
Capability Register的Bit4-7表明
这个设备的类型,详细如Table.1。假设现在枚举程序开始读取Bus 0,Device 0,Function 0的这两个寄存器,返回Header Type数据为00000001b,表明这是一个单Function,桥设备说明它还有下游设备即存在Bus 1。
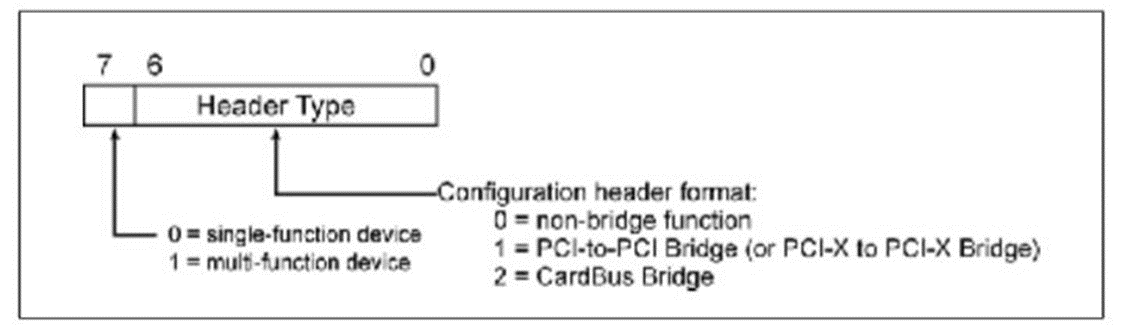
Fig.7 Header Type Register
Fig.8 Capability Register
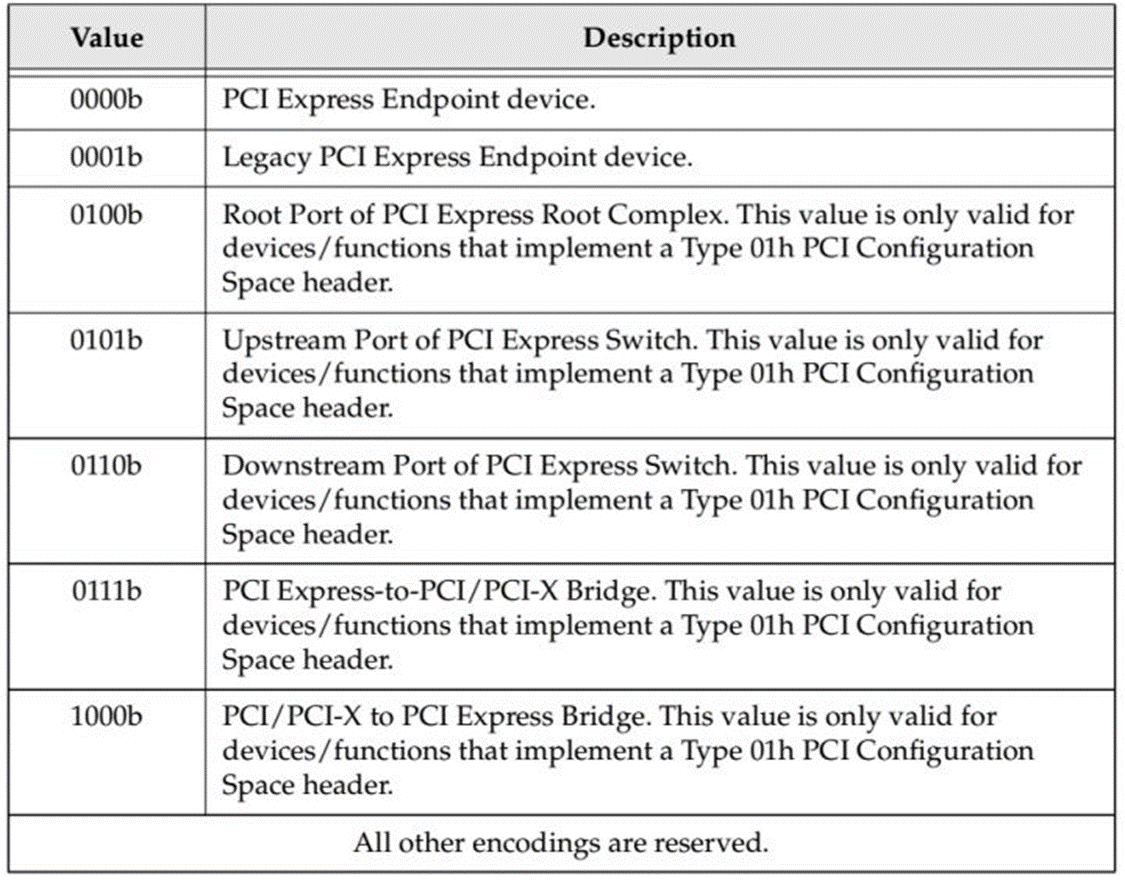
Table.1
3.现在程序进行一系列Configuration Write操作,将A设备(Fig.2)的Primary Bus Number Register=0,Secondary Bus Number Register=1,Subordinate Bus Number Register=1.现在桥A就可以感知他的下游总线为Bus 1,下游最远的总线为Bus 1.
4.程序更新RC的相关寄存器。
5.程序读取A的Capability Register,得到Device/Port Type Field=0100b,表明这是RC的一个Root Port。
6.程序必须执行Depth-first Search。也就是说在探测Bus 0上的其他设备,程序应该首先探测Device A下面的所有设备。
7.程序读取Bus 1,Device 0,Function 0的Vendor ID,一个有效的值返回,表示存在这个设备C。
8.读取Header Type field,返回00000001,表明C是一个桥,且C是一个单功能设备。
9.C的Capability
Register Device/Port Type Field=0101b,表明这是一个Switch的上行端口。
10.程序对C重复像步骤3一样的操作。
11.同时更新Host/bridge和桥A的Subordinate Bus Number=2。
12.继续Depth-first Search,发现设备D。读取相关寄存器,得知D为Switch的下游接口桥设备。得知Bus 3的存在。对D的寄存器修改,更新上游设备。
13.对Bus 3 上的设备进行探测,发现Bus 3,Device 0。读寄存器,发现为Endpoint多功能设备。
14.结束Depth-first Search,回滚到Bus 2,继续探测设备,然后执行Depth-first Search。
15.重复上述过程完成所有设备遍历。
同时还有一个问题摆在面前,一个Function是怎么知道它自己的Bus Number和Device Number的。一个Function一定知道自己的Function Number的,Device的设计者在设计的时候会以某种方式例如硬编码寄存器方式告诉它自己的Function Number。而Bus Number和Device
Number不可能以这种方式实现,因为设备它不同的位置它的ID不一样。当一个Configuration TLP到达一个Completer后,Completer会以某种方式记录TLP Header中的目的ID,也就是自己的ID,从而获得自己的ID。
当以上说有的操作完成之后,这个体系的ID都已经建立,那么所有的Configuration都可以正确的进行传播,然后其他程序才会正常的进行工作,例如,我们知道Address
Routing这种方式,当采用这种方式进行工作时,需要首先对Base Address Register进行Configuration,才能正常的路由。而如果没有建立一个正确的ID体系是无法进行Configuration的。关于BAR寄存器的相关设置稍后在讲解。
随后我将介绍大致介绍基于WinDriver的驱动程序和PIO这一简单的PCIE设备。最近比较忙,当我有足够时间的话,我会一并写出发布。
PCIE开发笔记(五)PCIE设备热插拔篇
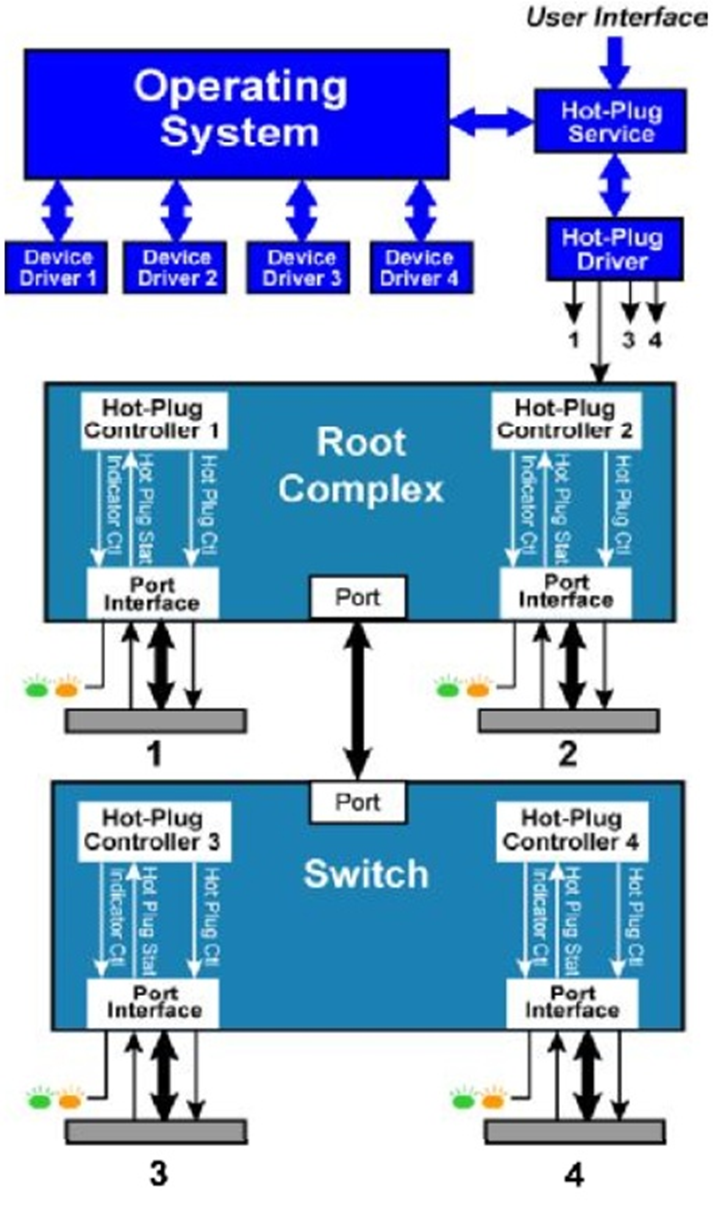
我们主要介绍PCI_E设备的热插拔(Hot Plug)功能。
热插拔是一个非常重要的功能,很多系统需要热插拔功能从而尽最大可能减少系统停机的时间。
PCI设备需要额外的控制逻辑去控制PCI板卡,来完成例如上电,复位,时钟,以及指示器显示。PCI_E相较于PCI设备具有原生的热插拔功能(native feature),而不需要去设置额外的设备去实现热插拔功能。
PCI_E的热插拔功能需要在热插拔控制器(Hot Plug Controller)的协助下完成,该控制器用来控制一些必要的控制信号。这些控制器存在在相互独立的根节点(Root)或者开关(Switch)中,与相应的端口(port)相连。同时PCI_E协议为该控制器定义了一些必要的寄存器。这些控制器在热插拔软件控制下,使着相连的端口的控制信号有序地变化。
一个控制器必须实现以下功能。
- 置位或者不置位与PCI_E设备相连的PERST#复位信号。
- 给PCI_E设备上电或者断电。
- 选择性地打开或者关闭用来表示当前设备状态的指示器(例如LED指示灯)。
- 检测PCI_E设备插入的插槽(slot)发生的事件(例如移去一个设备),并将这些事件通过中断方式报告给软件。
PCI_E设备和PCI设备通过一种称作无意外(no surprises)方式实现热插拔。用户不允许在未告知系统软件的情况下插入或者移除一个PCI_E设备。用户告知软件将要插入或者移除一个设备之后,软件将进行相关操作,之后告知用户是否可以进行安全的进行这个操作(通过相应的指示器)。然后用户才可以进行接下来的操作。
同时PCI_E设备也可以通过
突然意外(surprise removal)的方式移除设备。它通过两根探测引脚(
PRSNT1#,PRSNT2#)来实现,两个引脚如Fig1,Fig2所示。这两个引脚比其余的引脚更短,那么在用户移除设备的时候这两根信号会首先断开,系统会迅速的检测到,并迅速做出反应,从而安全移除设备。

Fig1

Fig.2
在上面简单的接受之后我们开始介绍实现热插拔必备部分:
首先介绍软件部分。
下表将详细介绍实现热插拔必须的软件,以及它们的层次结构。
操作系统提供给用户调用,来请求关闭一个设备或者打开一个刚刚插入设备。
一个用来处理操作系统发起的请求的服务程序,主要包括例如提供插槽的标识符、打开或者关闭设备、打开或者关闭指示器、返回当前某个插槽的状态(ON or OFF)。
- Standardized Hot-Plug
System Driver
由主板提供,接受来自Hot-Plug Service的请求,控制热插拔控制器(Hot Plug Controller)完成响应请求 。
对于一些比较特殊的设备,完成热插拔需要设备的驱动设备来协作。比如,当一个设备移除之后,要将设备的驱动程序设备为静默状态,不再工作。
硬件部分
下表详细的介绍了实现热插拔必须的硬件部分。
- Hot-Plug Controller 热插拔控制器
用来接收处理Hot-Plug System Driver发出的指令,一个控制器连接一个支持热插拔的端口(port),PCI_E协议为控制器定义了标准软件接口。
- Card Slot Power
Switching Logic
在热插拔控制器的控制下完成PCI_E设备的上电与断电。
在热插拔控制器的控制下对与PCI_E设备连接的PERST#复位信号置1或者置0。
每一个插槽分配一个指示器,由热插拔控制器控制,指示当前插槽是否上电。
每一个插槽分配一个按钮,当用户请求一个热插拔操作时,按压这个按钮。
每一个插槽分配一个指示器。指示器用来引起操作者的注意,表明存在一个热插拔问题,或者热插拔失败,由热插拔控制器控制。如图Fig.3就是一个服务器硬盘的示意图。

Fig.3
总共有两种卡存在信号,PRSENT1#,PRSNT2#。作用上面我们已经介绍过了。
完成上述必要部分的介绍之后,我们开始介绍PCI_E设备热插拔实现框架,了解上述各个部分是如何连接,相互协作的。同时与PCI设备的热插拔进行对比。
首先我们介绍PCI设备的热插拔框架,PCI是共享总线结构,即一条总线上连接多个设备,在实现热插拔过程就需要额外的逻辑电路,如图Fig.4,系统存在一个总的Hot-Plug Controller,在控制器里面存在各个插槽对应的控制器,控制器在
Hot-Plug System Driver的控制下完成热插拔过程。
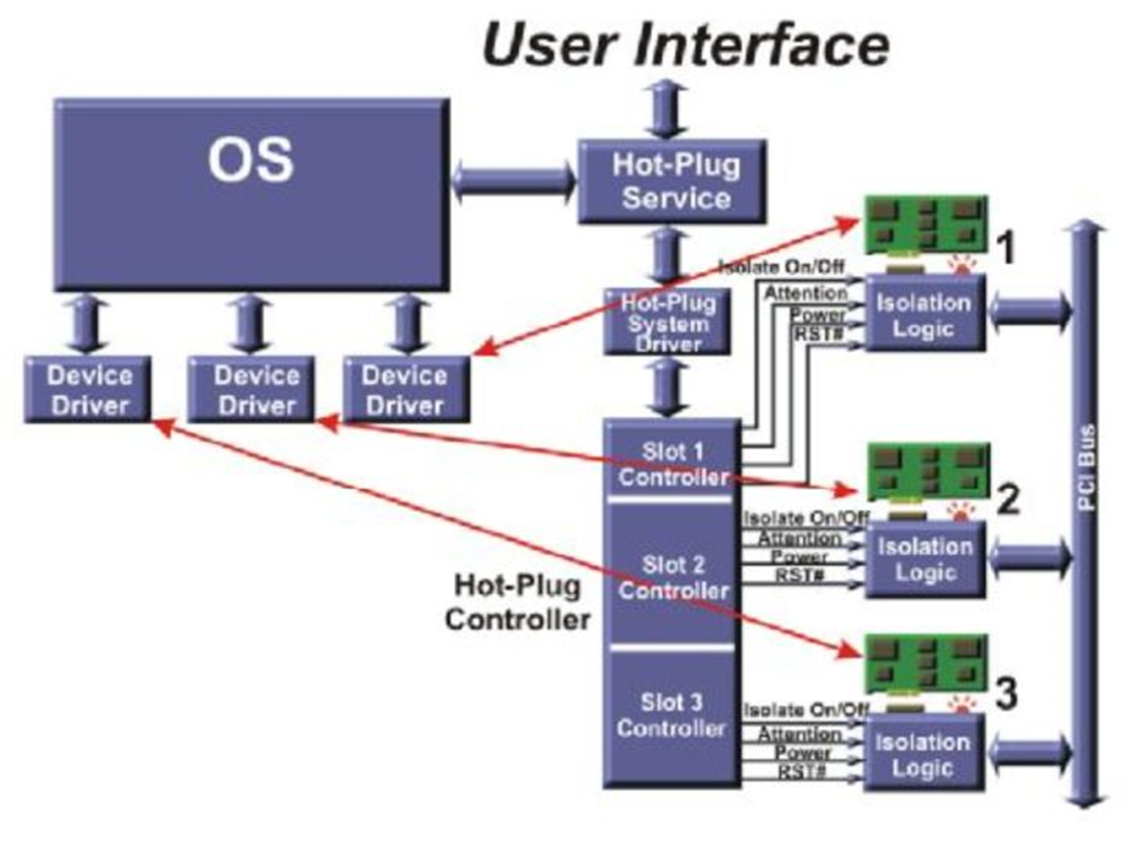
Fig.4
而PCI_E是点对点(Peer To Peer)拓扑结构,同时原生支持热插拔功能,这就决定它的系统框架不同于PCI。如图Fig.5,热插拔控制器分散存在于每个
根聚合点(Root complex)或者
开关(Switch)中,每个
端口(Port)对应一个控制器,不再需要一个单独额外的控制器。用户通过调用用户接口来一层一层实现最后的热插拔功能。
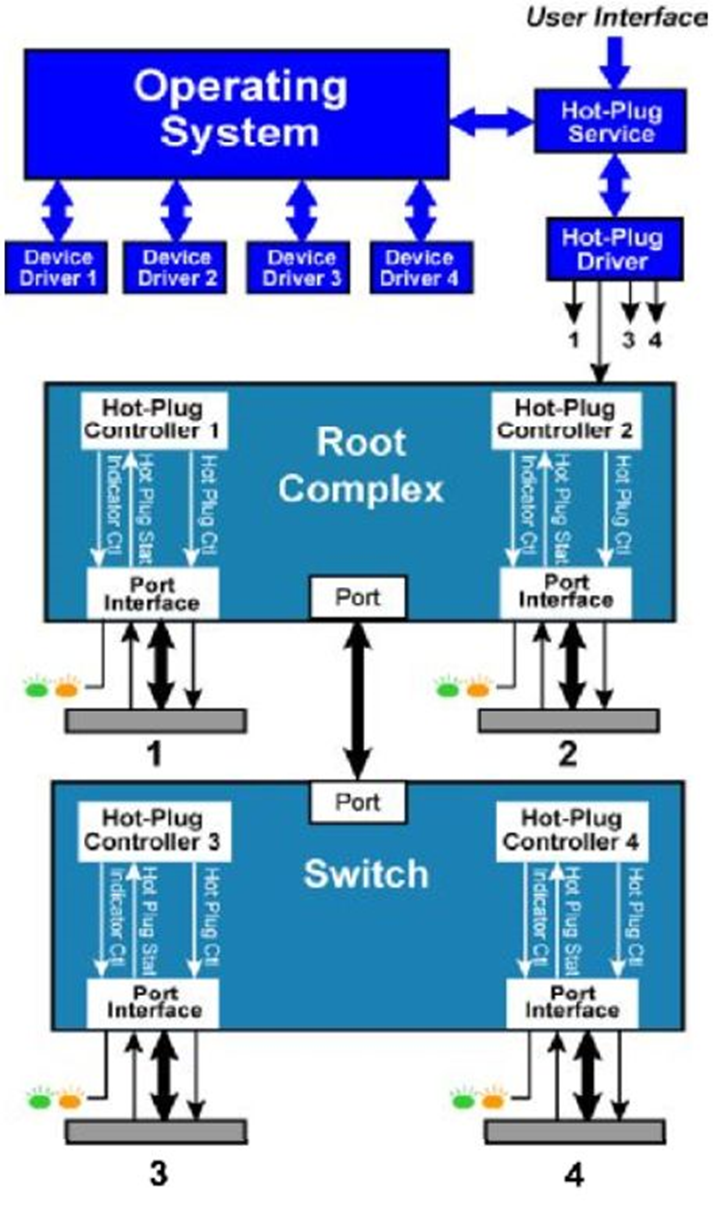
Fig.5
下面我们开始介绍PCI_E设备的实现热插拔的具体过程。(这里假设操作系统完成对一个新插入的设备的配置,我们以前的教程有提到过)。
热插拔过程可以分为这几个过程(以移除为例):
- 用户要移除某个设备,通过物理方式(例如按下按钮)或者软件方式告知操作系统。
- 操作系统接收到请求之后进行一些必要的操作(例如完成现在正在进行的写操作,并禁止接收新的操作),然后通过物理(例如指示灯)或者软件的方式告知用户你的请求是否可以满足。
- 如果第二步操作系统告知用户可以进行请求的操作的话,Hot-Plug System Driver将插槽(slot)关闭。通过控制根聚合点(Root complex)或者开关(Switch)中相应的寄存器完成插槽状态的转换。具体的寄存器介绍稍后介绍。
- 用户移除相应的设备。
首先介绍打开或者关闭插槽的过程。
首先了解两个状态:
该状态有如下特点:
\1. 插槽已经上电。
\2. 参考时钟REFCLK已经打开。
\3. 插槽连接状态处在活跃状态(active),或者由于电源管理(Active
State Power Management)处于待命状态(L0s or L1)。
\4. 复位信号PERST#置0。
该状态有如下特点:
\1. 插槽断电
\2. 参考时钟REFCLK已经关闭。
\3. 连接状态处于静默状态(inactive)。相应信号线处于高组态。
\4. 复位信号PERST#置1。
下面我们介绍关闭和打开插槽的具体流程。
关闭插槽过程:
\1. 将链路链接关闭。端口在物理层(Physical Later)将相关信号设置为高阻态。
\2. 将插槽的复位信号PERST#置1。
\3. 关闭插槽的参考时钟REFCLK 。
\4. 将插槽断电。
打开插槽过程:
\1. 将插槽上电。
\2. 打开插槽的参考时钟REFCLK。
\3. 将复位信号PERST#置0。
一旦插槽上电,参考时钟打开,复位信号置0之后,链接两端将会进行链路训练和初始化,之后就可以收发TLP了。
下面我们将详细介绍设备移除和设备插入过程:
移除方式可以以物理方式和软件方式两种方式进行。
当以物理方式时:
\1. 当通过物理方式告知系统将要移除设备。操作者需要按下插槽中Attention Button。热插拔控制器侦测到这个事件之后,给根聚合点传递一个中断。
\2. Hot Plug Service调用Hot-Plug System Driver,读取现在插槽的状态。之后Hot
Plug Service向Hot-Plug System Driver发送一个请求,要求Hot-Plug Controller控制Power Indicator从常亮转向闪烁。操作者可以在五秒内再次按下Attention Button中止移除。
\3. 当第二步读取卡槽状态,卡移除请求验证成功,并且热插拔软件允许该操作之后,Power
Indicator将持续闪烁。当设备正在进行一些非常重要的操作时,热插拔软件可能不允许该操作。如果软件不允许该操作时,软件将会拒绝该操作,并让Hot-PlugController将Power Indicator停止闪烁,保持常亮。
\4. 如果该操作被允许,Hot Plug Service命令Device Driver静默,完成已经接收的操作,并不在进行接受或发出任何请求。
\5. 软件操作链接两侧端口的Link Control Register关闭两侧设备的数据通道。
\6. 软件通过Hot-Plug Controller将插槽关闭。
\7. 在断电成功之后,软件通过Hot-Plug Controller将Power Indicator电源指示器关闭,此时操作者知道设备此时可以安全的移除设备了。
8.操作者将
卡扣(
Mechanical Retention Latch,将设备固定在主板上的设备,可选设备,上面有一个传感器,检测卡扣是否发开,如图Fig.5)打开,将所有连接线(如备用电源线)断开此时卡移除掉。此步骤与硬件有关,
可选。

Fig.5
\9. 操作系统将分配给设备的内存空间(Memory Space),IO空间(IO Space),中断线回收再利用。
当以软件方式移除时与物理方式基本相同,但是前两步替换为以下步骤:
操作者发出一个与设备相连的物理插槽号(Physical Slot Number)的移除请求。然后软件显示一个信息要求操作者确认,此时Power Indicator开始由常亮转向闪烁。
插入也分为物理方式和软件方式,设备插入过程是移除的一个反过程,我们这里假设插入的插槽已经断电。
物理方式具体过程如下:
- 操作者将设备插入,关上卡扣。如果卡扣存在传感器的话,Hot-Plug Controller将会感知到卡扣已经关闭,这是控制器将会将备用信号和备用电源连接到插槽。
- 操作者通过按压Attention Button来通知Hot-Plug Seriver。同时引起状态寄存器相应位置位,并引发中断事件,发往根聚合点。然后,软件读取插槽状态,辨识请求。
- Hot-Plug Service向Hot-Plug System Driver发出请求要求Hot Plug Controller闪烁插槽的Power Indicator,提示现在不能再移除设备了。操作者乐意在闪烁开始5秒内再次按压Attention Button来取消插入请求。
- 当设备允许请求时,Power
Indicator将保持闪烁。可能因为设备安全因素禁止插入某些插槽,热插拔软件将不允许该操作。如果软件不允许该操作时,软件将会拒绝该操作,并让Hot-Plug Controller将Power Indicator熄灭。同时建议系统用消息或者日志的方式记录禁止的原因。
- Hot-Plug Service向Hot-Plug System Driver发送命令,将相应卡槽打开。
- 一旦插槽打开,软件命令将Power
Indicator打开。
- 一旦链路训练完成,操作系统开始进行设备枚举,分配Bus Number,Device Number,Function Number,并配置相应配置空间(configuration space)。
- 操作系统根据设备信息加载相应的驱动程序。
- 操作系统调用驱动程序执行设备的初始化代码,设置配置空间相应的命令寄存器,使能设备,完成初始化。
软件过程可以类比,到此这个热插拔过程介绍就完成了。
下面介绍PCI_E建议的用户接口和相应寄存器介绍。
首先介绍软件之间的接口。协议没有详细的定义这些接口,但是它定义了一些基础的类型和它的内容。Hot-Plug Service和Hot-Plug System Driver之间的接口如下:
- Query Hot-Plug system
Driver
输入:none 输出: Hot-Plug System Driver控制的逻辑插槽ID
功能:询问Hot-Plug System Driver控制的的插槽,并返回其逻辑插槽ID。
输入:逻辑插槽ID、新的状态、新的Attention Indicator状态、新的Power Indicator
状态
输出:请求完成状态
功能:用来控制slot和与之相关的Indicator。
输入:逻辑插槽ID 输出:插槽状态 设备电源需求
功能:返回插槽状态,Hot-Plug System Driver返回相比相应信息。
下面介绍热插拔控制器的可编程接口。PCI_E协议已经在配置空间中定义了相关寄存器。
Hot-Plug System Driver通过控制Fig.6红圈内有相关寄存器来控制热插拔控制器,进而实现热插拔。

Fig.6
- Slot Capabilities
Register 这个寄存器主要表明设备存在哪些指示器,传感器。存在在插槽和设备的配置空间中。硬件必须要初始化这个寄存器以表明设备实现哪些硬件了。软件通过读该寄存器来获取硬件信息。Fig.7是该寄存器示意图,Table.2是详细描述。
一张图对PCIe进行扫盲(史无前例的好文章)
博观而约取,厚积而薄发
写在开始的话,不知道看了多少资料才总结出一点知识,能输入已经很不容易,何况想要输出,有十能输出一二就算不错了。所以这个过程中真的很难坚持下来,何况没有实际项目作为载体,真的不知道实际运用中这些知识够不够用,这只是基于我之前的经验,认为一个全新的硬件模块中需要掌握的部分。
1 首先要了解这个硬件的用途,物理接口,pin定义。
2 要知道需要做什么样的配置才能使得设备达到我们的预期。
3 设备工作中最重要的就是三个模块,正确识别,注册中断以及终端处理函数,数据传输。
完成以上三步一个硬件模块的bringup就完成了。本文忽略了大部分细节,只为了用最短的篇幅描述好PCIe。
MSI、MSI-X中断和TLP这里不详细展开去说,必要的时候会带出来。
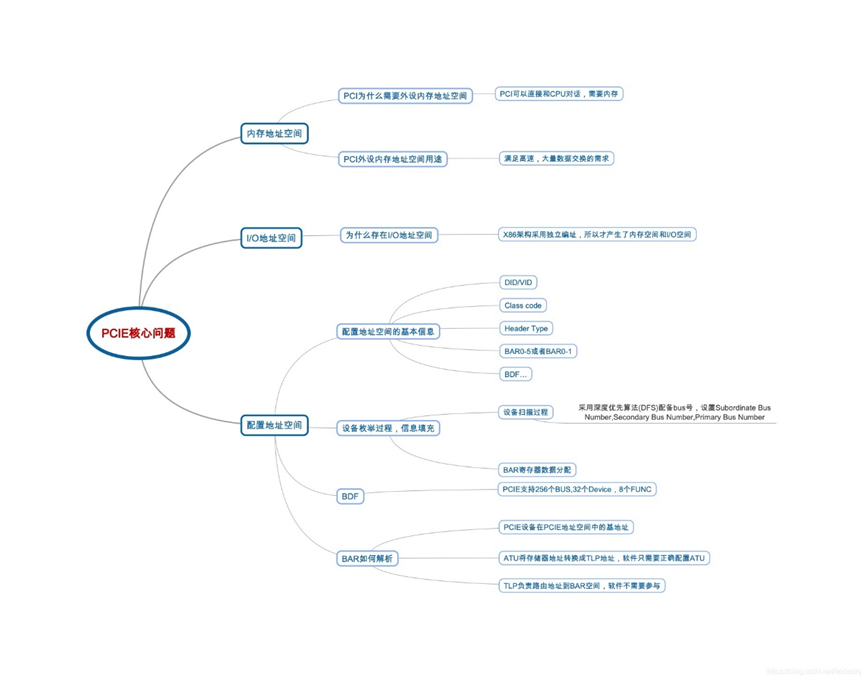
首先用一张图来直观的呈现出要了解PCIe,我们需要知道的一些基本概念。

DDR 基础介绍
存储器memory,是电子设备的基础核心部件之一,全球memory市场规模约700亿美元,在全球3352亿美元的集成电路产业中,占据23%的份额。
随着今年存储器价格的飙涨,各大memory厂商赚得盆满钵满,甚至把memory称为印钞机也丝毫不为过。与此同时,存储器在真金白银的交换中,也充分证明了自己在电子信息产业江湖中的地位。
存储器的分类
存储介质的形式有很多种,从穿孔纸卡、磁鼓、磁芯、磁带、磁盘,到半导体DRAM内存,以及SD卡,固态硬盘、SSD、闪存等各种存储介质。
存储器大致可以分为掉电易失性(Volatile
Memory)和非掉电易失性(Non-volatile
memory)。
目前全球存储器市场最大的集中在
DRAM、NAND Flash、NORFlash三大类
这三类存储器,主要用在哪里呢?
DRAM
4GB就是内存部分,DRAM,用来存放当前正在执行的数据和程序, 例如屏幕前的你正在刷的微信;
NAND
FLASH
64GB就是闪存部分,NAND FLASH,用来存放长期信息,例如各位宝宝的美颜美照,你的聊天记录,还有其他……当然了,也正是因为我们存的东西越来越多,二维空间已经无法存放这么多的信息,生生逼着NAND走向了三维空间,也就是3D NAND。

3D NAND的构造就像一个摩天大楼
此外,一些新型的存储器也在研究的过程中,例如磁阻式RAM (MRAM--ST-MRAM、STT-MRAM)、电阻式RAM(ReRAM),PRAM、FeRAM等。

1
Write / Erase pulse width dependency
流程如下
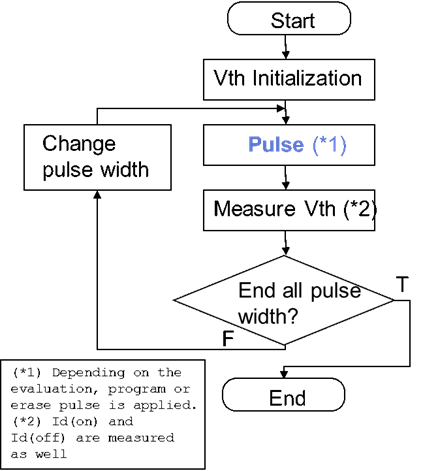
问题 1-a) 脉冲波形失真
根据以上测试流程,首先我们的工程师编写程序写进一个理想脉冲。

然而由于传输线的多重反射及电感效应,实际测试脉冲已经引入了失真:

问题 1-b) 复杂的时序图生成

2
Endurance Test的流程如下

3
Disturb test
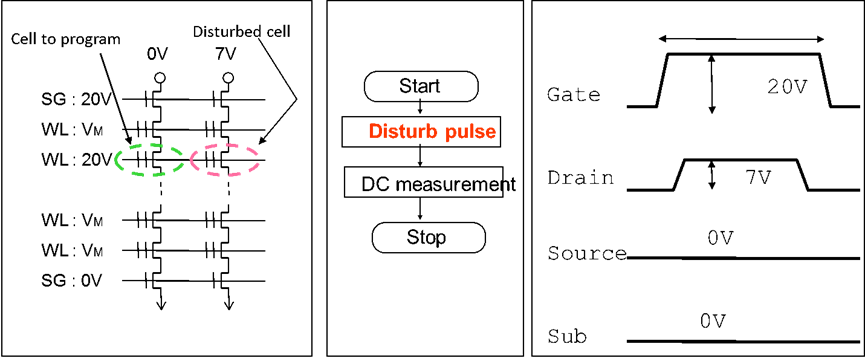
Issue 3-a) 测试设备的灵活性,例如:在两个cell上同时加压,一个为工作单元, 一个为干扰单元
Issue 3-b) 要求比较高的电压加速degradation (e.g. > 40Vfor NAND)
总结以上部分,可得在存储器单元主要三种功能测试中,主要的测试挑战如下

面对如此错综复杂的考量,正确的方法,是使用Keysight HV-SPGU module in B1500A(HighVoltage Semiconductor Pulse Generator Unit),这是基于Keysight半导体参数分析仪(也就是Tracer)B1500A的高压脉冲产生单元,它可以产生± 40V的电压脉冲,用于memory cell 的disturb test。
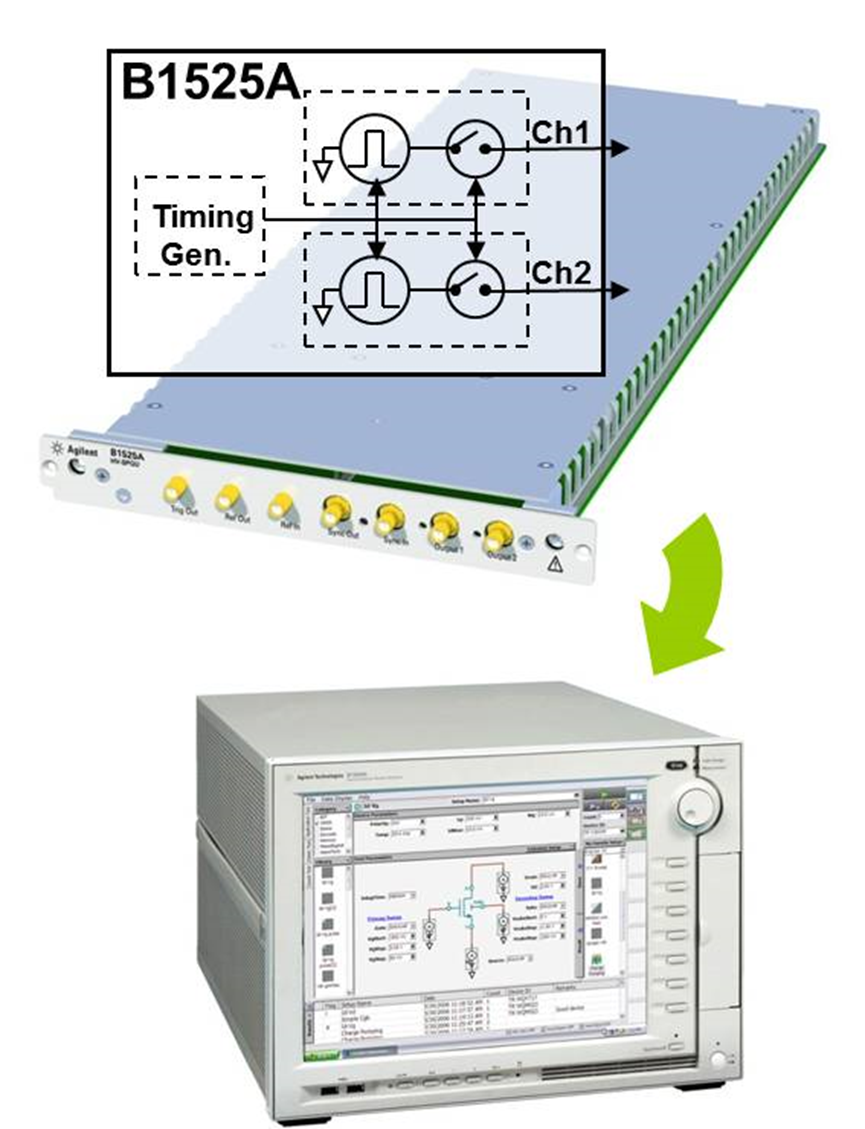
从正面面板,可以看到这一个可配置于B1500A的模块,每个模块有两个channel,也就是说对于5插槽的B1500A,最高可以配置10个channel。
除了高压、通道数之外,我们接下来来了解一下它在复杂波形生成、超高脉冲精度、以及测试软件等方面的能力,看它是如何在方方面面满足memory
cell测试的全部要求。
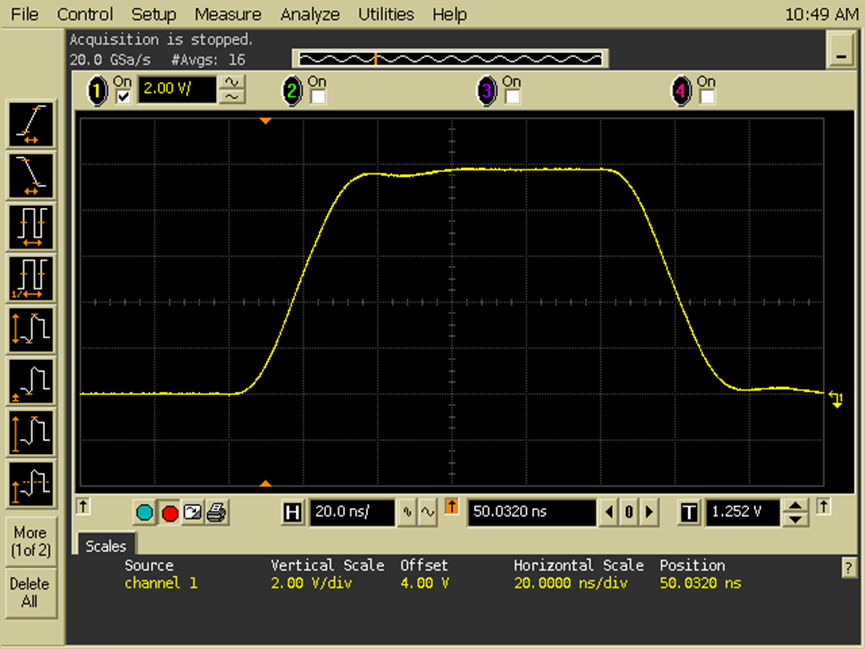
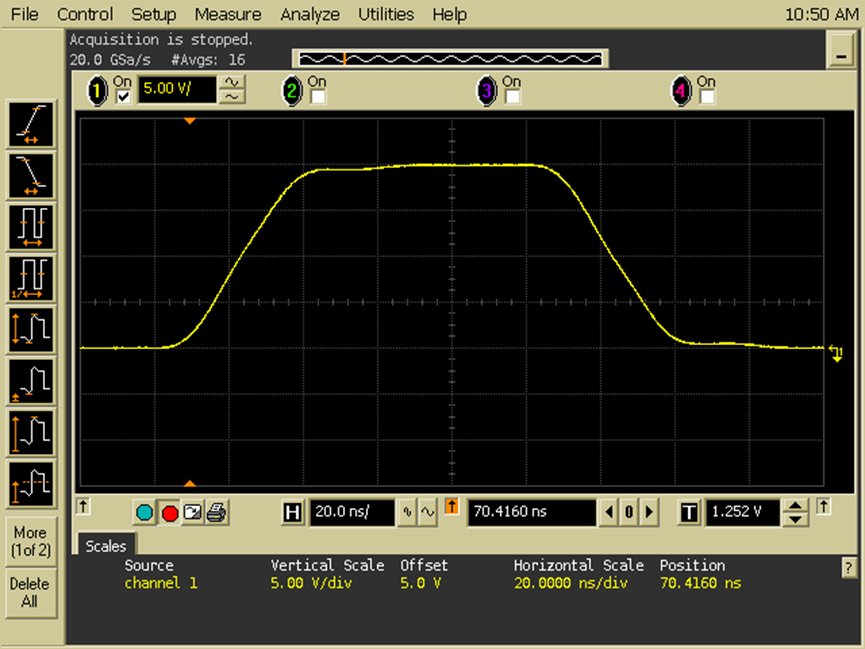
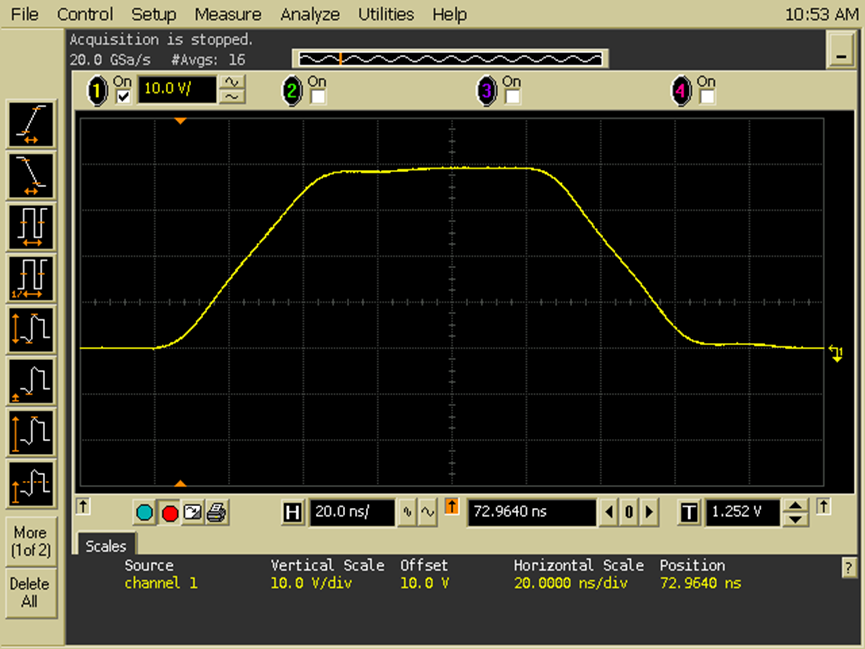
看精度

Ttransient=20ns;Vamp=10V
Ttransient=20ns;Vamp=20V
Ttransient=30ns;Vamp=40V
DDR总线的设计、调试和验证
在计算机架构中,DDR作为程序运算的动态存储器,面对如高性能计算、图形计算、移动计算、工业应用等领域的要求,发展出DDR4,以及用于图形计算的GDDR5, HBM2,面向移动计算的低功耗LPDDR4等标准。
处理器的运算速度越来越快,DDR的性能也要求越来越高,明显的趋势是DDR总线工作频率持续提升, DDR4 达到3.2GT/s, 用于智能手机等低功耗场合的LPDDR4速率甚至超越了DDR4,最高达到4.2GT/s,JEDEC在年中的论坛中提出未来的DDR5工作速率将达到6.4GT/s,由于速率的提升,DDR5中将可能考虑在接收端采用多阶DFE均衡器,而在强调性能的图形计算领域,规划中的GDDR6的工作速率可能会达到16GT/s。另一方面由于能耗比的要求,DDR标准在演进中工作电压持续走低,如LPDDR4X的工作电压降低至0.6V。
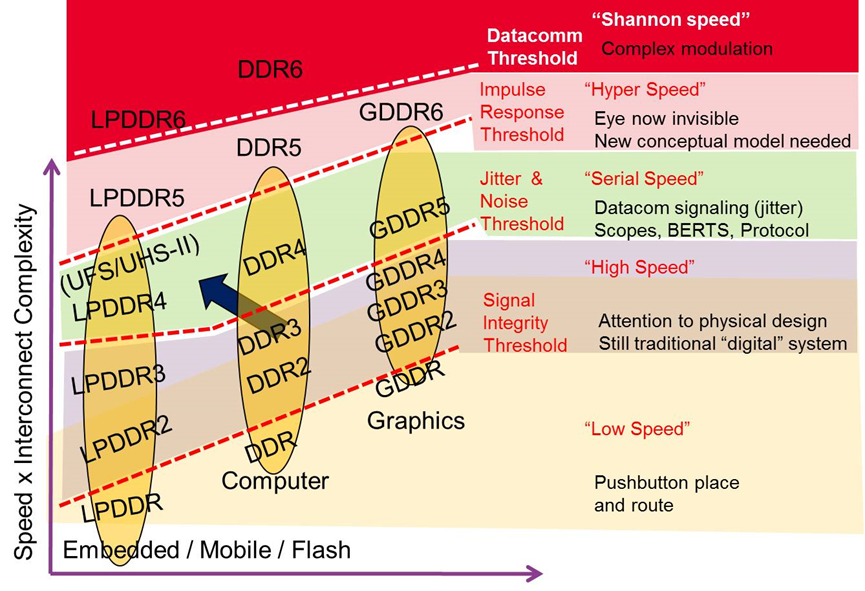
DDR总线采用源同步的技术,多比特并行通信的机制,总线中会存在同步开关噪声和串扰等问题;由于信号速率持续提升单个比特位宽收窄,导致时序裕度变的很紧张,抖动问题也越发明显;而工作电压的降低,噪声和电源完整性的问题也变得非常显著。DDR4总线既有并行总线存在的问题,也要面临如同高速SERDES设计中存在的挑战,可以说是在数字系统中最为复杂的一环,如果不能保证DDR总线的可靠运行,有可能会导致整个硬件系统的崩溃。
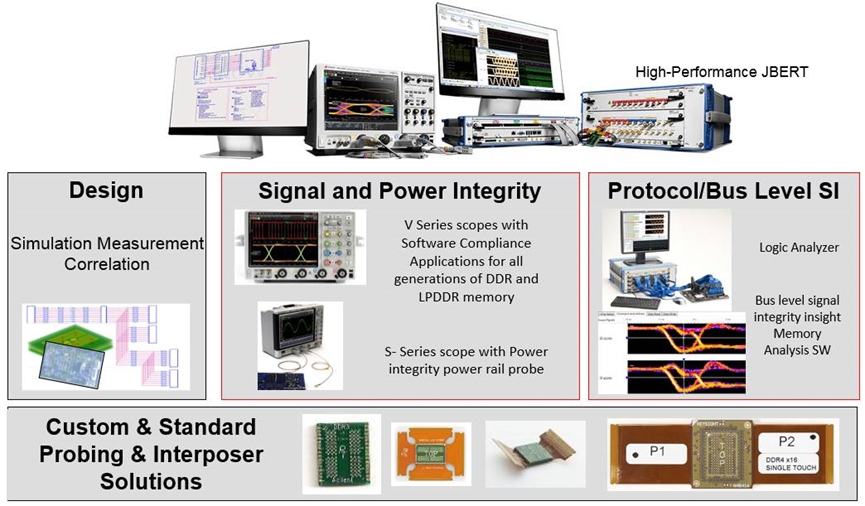
针对这些问题,提供了从DDR4总线的设计仿真和分析,到系统上电后DDR4信号完整性验证、时序验证、眼图轮廓测试、电源完整性验证,以及总线时序一致性分析,故障定位,性能统计等等完整的解决方案。(如下图所示)
JEDEC协会定义的DDR4信号特性主要包括以下主要内容↘↘↘
Electrical
- VIH/VIL,VOH/VOL
- Overshoot/undershoot
- Crossingpoint
Timing
- Pre/Postamble timing
- DQS/DQ/CLKDelta time
Eyediagram
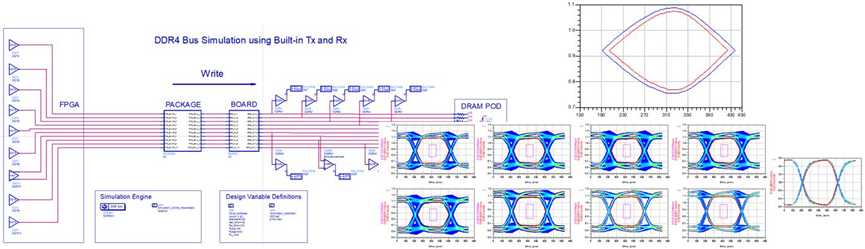
ADS仿真软件的DDR4总线仿真器,提供了统计眼图分析的功能,能够在短时间内统计计算在极低误码率(1e-16)下的DQ眼图,根据规范判断模板是否违规。另外基于总线的仿真,也很易于仿真基于串扰因素下的眼图质量。
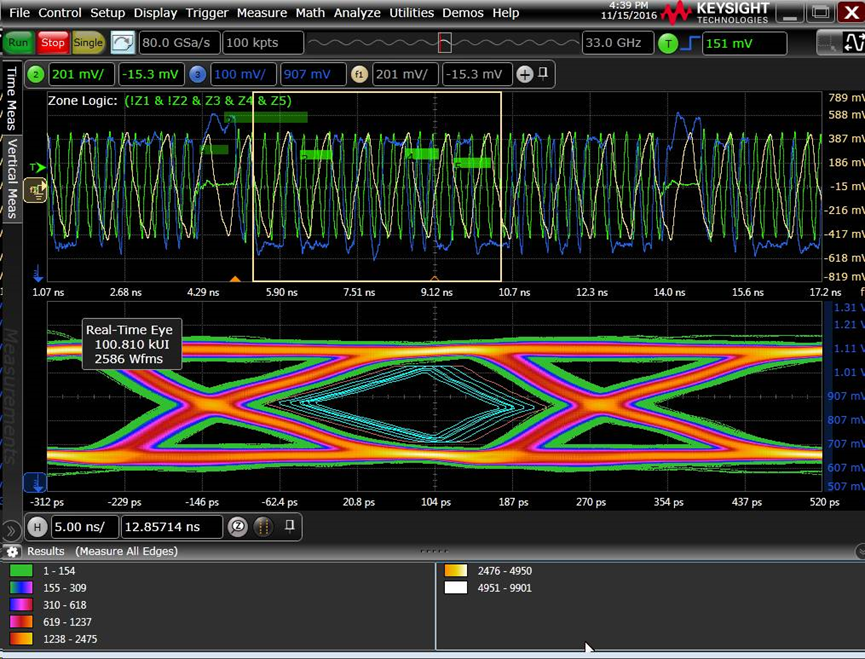
基于示波器的DDR4信号实测,可以利用大家熟悉的InfiniiScan区域触发功能,很容易分离出“写”信号,再通过Gating功能对Burst写信号做时钟恢复和眼图重建,再进行Eye Contour测量,并验证1e-16误码率下的眼图模板是否违规。如果是使用一致性测试软件,就不用手动操作,软件会自动跟踪和分离波形并实现眼图测试(如下图所示)

最后,对于物理层无论是仿真还是一致性测试软件得到的数据,都可以通过数据分析工具N8844A导入到云端,通过可视化工具,生成统计分析表格,对比性分析高低温、高低电压等极端情况下不同的测试结果,比较不同被测件异同。为开发测试部门提供灵活和有效的大数据分析平台。
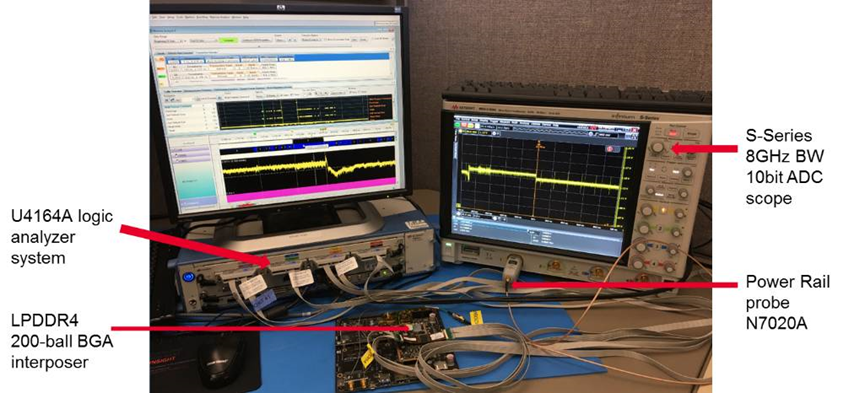
再通过逻辑分析仪的内存软件解析DDR总线的操作和分析性能,可以分析出由于系统中集中的读操作,以及LPDDR4的速率切换导致了电源电压的波动,以及特定命令操作导致的电压跌落现象。
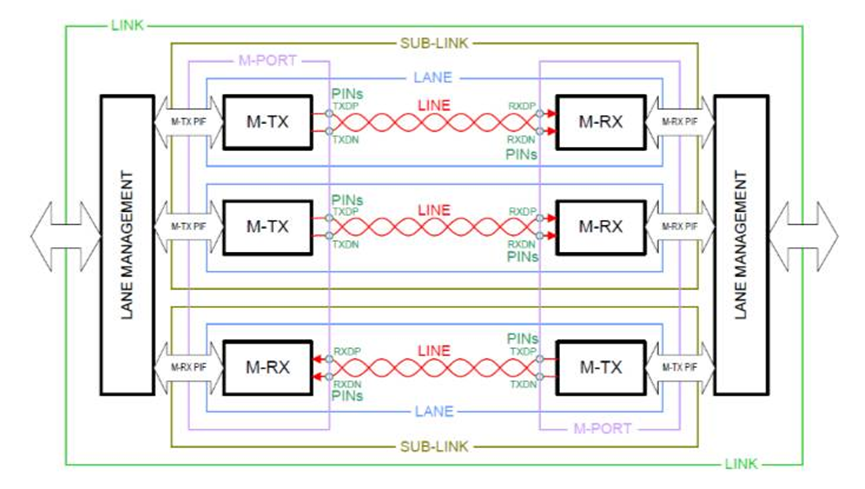
M-PHY物理层主要有如下主要的特点
每个信号通路是单向传输,信号采用差分传输机制,信号有高速HS和低速LS两种模式,高速信号采用8b/10b编码,使用PLL类型端时钟恢复,在突发的开始需要同步信号;低速信号则使用PWM调制方式。M-PHY有两种电压摆幅大幅度LA和小幅度SA,可以工作在端接模式和非端接模式,后一种可以在低功耗要求时使用。
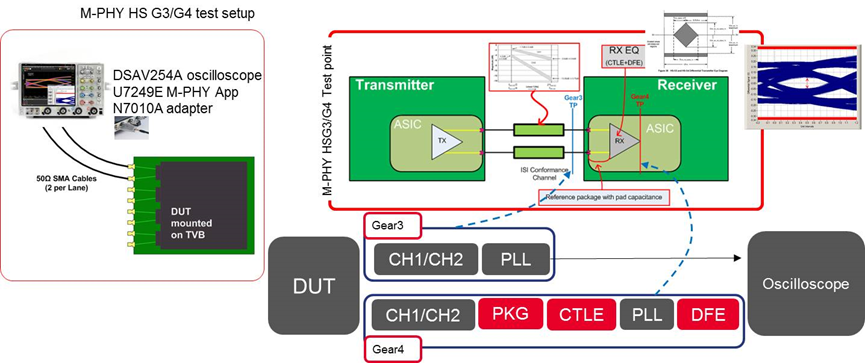
M-PHY一致性测试规范包括了发射端,接收端,接口及互连S参数和阻抗三部分内容。
发射端测试方案如下:
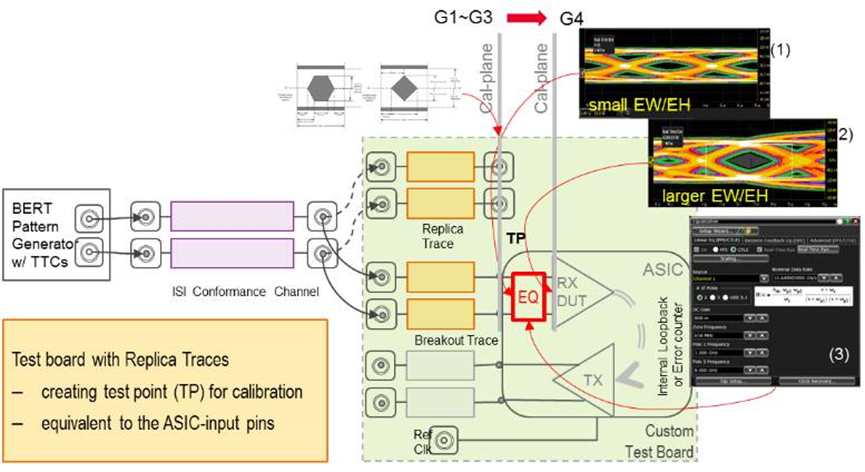
接收端测试方案如下:
System Bus 系统总线
总线基本概念、总线设计要素 、总线设计要素、总线标准、总线互连结构
总线的分类 °总线在各层次上提供部件之间的连接和交换信息通路 总线在各层次上提供部件之间的连接和交换信息通路 °分为以下几类:
• 芯片内总线:在芯片内部各元件之间提供连接 在芯片内部各元件之间提供连接 - 例如,CPU芯片内部,各寄存器、ALU、指令部件等之间有总线相连
、指令部件等之间有总线相连
• 系统总线:在系统主要功能部件 在系统主要功能部件 在系统主要功能部件(CPU 、MM和各种I/O控制器)间提供连接
- 单总线结构 – 将CPU、MM和各种I/O适配卡通过底板总线(Backplane Bus)互连,底板总 线为标准总线(Industry
standard)
- 多总线结构 – 将CPU、Cache、MM和各种I/O适配卡用局部总线、 适配卡用局部总线、处理器-主存总线、高 速I/O总线、扩充I/O总线等互连。主要有两大类: Processor- Memory Bus (Design specific or proprietary)
» 短而快,仅需与内存匹配 仅需与内存匹配 仅需与内存匹配,使CPU-MM之间达最大带宽 I/O Bus (Industry standard)
» 长而慢,需适应多种设备 需适应多种设备 需适应多种设备,一侧连接到Processor- Memory Bus 或 Backplane Bus,另一侧连到I/O控制器
(注:Intel公司在推出845、850等芯片组时,对“System Bus”有专门的定义, 有专门的定义,将
处理器总线称为前端总线(Front Bus)或系统总线)
• 通信总线:在主机和I/O设备之间或计算机系统之间提供连接
- 通常是电缆式总线, 通常是电缆式总线,如SCSI、RS-232、USB等
Intel 体系结构中特指的“系统总线”
北桥芯片组把处理器–存储器总线分成了两个总线: 存储器总线分成了两个总线: 处理器总线(系统总线,前端总线) 存储器总线
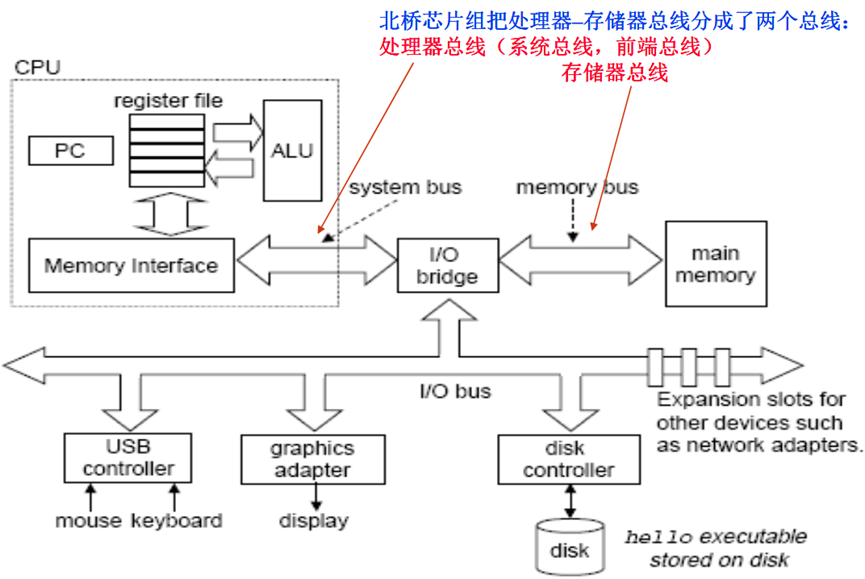
系统总线的组成
系统总线通常由一组 系统总线通常由一组控制线、一组数据线和一组地址线构成。也有些总线没有单独的地址 也有些总线没有单独的地址
线,地址信息通过数据线来传送 地址信息通过数据线来传送 地址信息通过数据线来传送,这种情况称为数据/地址复用。
• 数据线(Data Bus):承载在源和目部件之间传输的信息。
承载在源和目部件之间传输的信息。数据线的宽度反映一次能 数据线的宽度反映一次能 传送的数据的位数。 传送的数据的位数。
• 地址线(Address Bus)
:给出源数据或目的数据所在的主存单元或I/O端口的地址。 地址线的宽度反映最大的寻址空间。 地址线的宽度反映最大的寻址空间。
• 控制线(Control Bus)
:控制对数据线和地址线的访问和使用。 控制对数据线和地址线的访问和使用。用来传输定时信号 用来传输定时信号 和命令信息。典型的控制信号包括 典型的控制信号包括
典型的控制信号包括:
- 时钟(Clock):用于总线同步。
用于总线同步。
- 复位(Reset):初始化所有设备。
初始化所有设备。
- 总线请求(Bus Request):表明发出该请求信号的设备要使用总线。
表明发出该请求信号的设备要使用总线。
- 总线允许(Bus Grant):表明接收到该允许信号的设备可以使用总线。
表明接收到该允许信号的设备可以使用总线。
- 中断请求(Interrupt
Request):表明某个中断正在请求。 表明某个中断正在请求。
- 中断回答(Interrupt
Acknowledge) :表明某个中断请求已被接受。 表明某个中断请求已被接受。
- 存储器读(memory read):从指定的主存单元中读数据到数据总线上。
从指定的主存单元中读数据到数据总线上。
- 存储器写(memory write):将数据总线上的数据写到指定的主存单元中。
将数据总线上的数据写到指定的主存单元中。
- I/O读(I/O read):从指定的I/O端口中读数据到数据总线上。 端口中读数据到数据总线上。
- I/O写(I/O Write)
:将数据总线上的数据写到指定的I/O端口中。
- 传输确认(transmission
Acknowledge) :表示数据已被接收或已被送到总线
总线设计要素
总线设计要考虑的基本要素
尽管有许多不同的总线实现方式,但总线设计的基本要素和考察的性能指标一样
①信号线类型(Signal line
type): 专用(Separate) / 复用(Multiplexed)
②仲裁方法(Arbitrating):
集中式(Center) / 分布式(distributed)
③定时方式(Timing):
同步通信 (Synchronous) / 异步通信
(Asynchronous)
④事务类型(Bus
Transaction): 总线所支持的各种数据传输类型和其他总线操作类型, 总线所支持的各种数据传输类型和其他总线操作类型,如: 存储器读、存储器写、I/O读、I/O写、读指令、中断响应等
⑤总线带宽(Bus
Bandwidth): 单位时间内在总线上传输的最大数据量(是一种传输能力) 相当于公路的最大载客量。例如,沪宁高速每车道最多每5分钟发一辆车,每辆车最多50人,共有6个车道,则最大流量为多少(?人/小时)? 最大载客量:6道x12车/小时x50人/车= 3600人/小时
信号线类型
总线的信号线类型有:专用、复用
• 专用信号线:
- 信号线专用来传送某一种信息。 例如,使用分立的数据线和地址线 ,使用分立的数据线和地址线,使得数据信息专门由数据线传
,使得数据信息专门由数据线传 输,地址信息专门由地址线传输 地址信息专门由地址线传输。
• 复用信号线:
- 信号线在不同的时间传输不同的信息。 例如,许多总线采用数据 ,许多总线采用数据/地址线分时复用方式,用一组数据线在总 ,用一组数据线在总 线事务的地址阶段传送地址信息,在数据阶段传送数据信息 ,在数据阶段传送数据信息。这样
就使得地址和数据通过同一组数据线进行传输。
• 信号分时复用的优缺点:
- 优:减少总线条数,缩小体积、降低成本。
- 缺:总线模块的电路变复杂 总线模块的电路变复杂,且不能并行。
总线裁决(总线控制/使用/访问权的获得 /访问权的获得)
总线被多个设备共享,但每一时刻只能有一对设备使用总线传输信息 ,但每一时刻只能有一对设备使用总线传输信息。
什么是总线裁决? 当多个设备需要使用总线进行通信时,采用某种策略选择一个设备使用总线 ,采用某种策略选择一个设备使用总线 ° 为什么要进行总线裁决
为什么要进行总线裁决 ? 总线被连接在其上的所有设备共享,如果没有任何控制 ,如果没有任何控制,那么当多个设备需 ,那么当多个设备需
要进行通信时,每个设备都试图为各自的传输将信号送到总线上 ,每个设备都试图为各自的传输将信号送到总线上,这样就会 产生混乱。所以必须进行总线裁决 。所以必须进行总线裁决 °
如何避免上述混乱 如何避免上述混乱?
• 在总线中引入一个或多个总线主控设备,只能主控设备控制总线 ,只能主控设备控制总线
- 主控设备:能发起总线请求并控制总线 :能发起总线请求并控制总线。(如:处理器)
- 从设备:只能响应从主控设备发来的总线命令 :只能响应从主控设备发来的总线命令。(如:主存)
• 利用总线裁决决定哪个总线主控设备将在下次得到总线使用权
总线裁决(总线控制/使用/访问权的获得 /访问权的获得)
①总线裁决信号:总线请求线和总线许可线
总线请求线可以和数据线复用,但这样会影响带宽
如:数据线和总线请求线复用时,总线裁决和数据传输不能同时进行
②总线裁决有两种方式:集中式和分布式
集中式:将控制逻辑做在一个专门的总线控制器或总线裁决器中,通过将所有的总线请求集中起来,利用一个特定的裁决算法进行裁决
菊花链(Daisy chain)
计数器定时查询(Query by a counter)
集中并行(Centralized, Parallel)
分布式:没有专门的总线控制器,其控制逻辑分散在各个部件或设备中
自举式(Self-selection)
冲突检测 (Collision detection)
③裁决方案应在以下两个因素间进行平衡
等级性(Priority)—具有高优先级的设备应该先被服务
公平性(Fairness)—即使具有最低优先权的设备也不能永远得不到总线使用权
菊花链总线裁决
Grant从最高优先权的设备,依次向最低优先权的设备串行相连。如果到达的设备有总线请求,则Grant信号就不再往下传,该设备建立总线忙Busy信号,表示它已获得了总线使用权。
相当于“击鼓传花”。
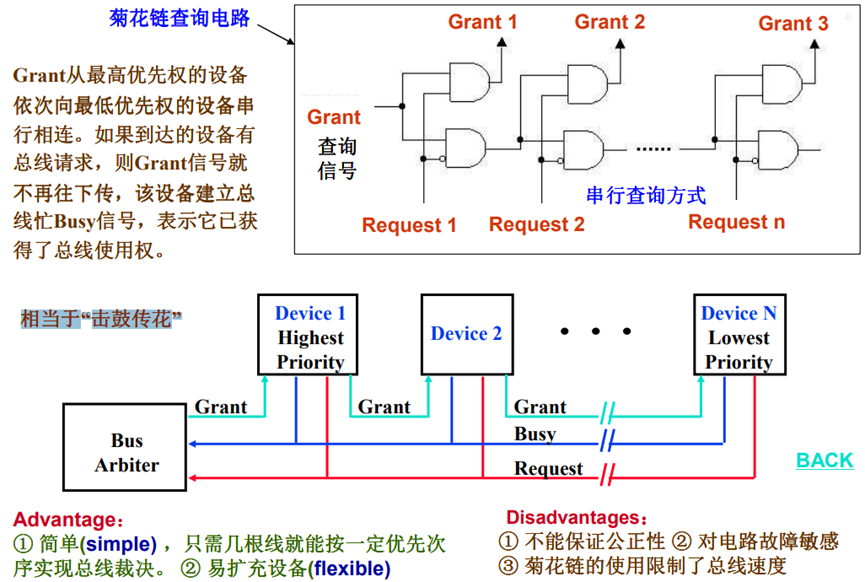
Advantage:
① 简单(simple) ,只需几根线就能按一定优先次序实现总线裁决。
② 易扩充设备(flexible)
Disadvantages:
① 不能保证公正性
② 对电路故障敏感
③ 菊花链的使用限制了总线速度
计数器定时查询裁决
°基本思想:比菊花链查询多一组设备线( 比菊花链查询多一组设备线(DevID),少一根总线允许线 ),少一根总线允许线BG。总线控制器接收 。总线控制器接收
到BR送来的总线请求信号后, 送来的总线请求信号后,在总线未被使用 在总线未被使用 在总线未被使用(Busy=0)的情况下,由计数器开始计数 由计数器开始计数 由计数器开始计数, 并将计数值通过设备线向各设备发出。 并将计数值通过设备线向各设备发出。当某个有总线请求的设备号与计数值一致时
当某个有总线请求的设备号与计数值一致时 当某个有总线请求的设备号与计数值一致时,该设备 便获得总线使用权, 便获得总线使用权,此时终止计数查询 此时终止计数查询
此时终止计数查询,同时该设备建立总线忙 同时该设备建立总线忙Busy信号。
°优点: ① 灵活,设备的优先级可通过设置不同的计数初始值来改变。
若每次初值皆为0,则固定;
若每次初值总是刚获得总线使用权的设备,则是平等的循环优先级方式。
② 对电路故障不如菊花链查询那样敏感。
° 缺点:
① 需要增加一组设备线
② 总线设备的控制逻辑变复杂(需对设备号进行译码比较等)
相当于“点名报到”

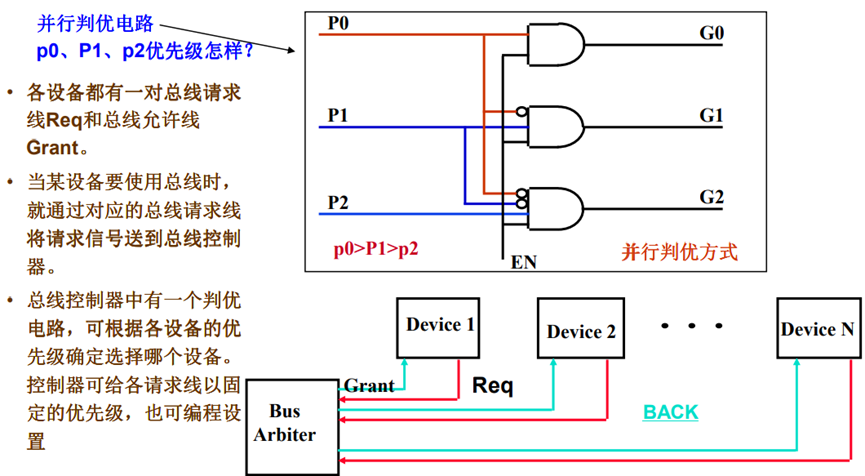
独立请求方式裁决
相当于“领导说了算”
• 各设备都有一对总线请求线Req和总线允许线 Grant。
• 当某设备要使用总线时,就通过对应的总线请求线,将请求信号送到总线控制器。
• 总线控制器中有一个判优电路,可根据各设备的优先级确定选择哪个设备。控制器可给各请求线以固定的优先级,也可编程设置。
问题:如果有N个设备,则菊花 链和独立请求各需多少裁决线?
优点:① 响应速度快。 ② 若可编程,则优先级灵活
缺点:① 控制逻辑复杂,控制线数量多。
裁决算法:总线控制器可采用固定的并行判优算法、平等的循环菊花链算法、动态优先级算法(如:最近最少用算法、先来先服务算法)等。
自举分布式裁决
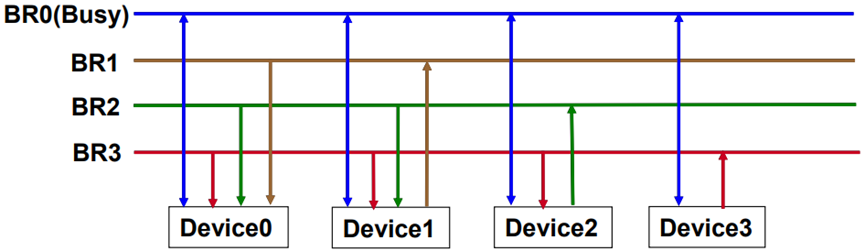
优先级固定,各设备独立决定自己是否是最高优先级请求者 各设备独立决定自己是否是最高优先级请求者
• 需请求总线的设备在各自对应的总线请求线上送出请求信号
• 在总线裁决期间每个设备将比自己优先级高的请求线上的信号取回分析: 在总线裁决期间每个设备将比自己优先级高的请求线上的信号取回分析:
- 若有总线请求信号, 若有总线请求信号,则本设备不能立即使用总线 则本设备不能立即使用总线
- 若没有,则可以立即使用总线,并通过总线忙信号阻止其他设备使用总线
- 最低优先级设备可以不需要总线请求线,为什么?
- 需要较多连线用于请求信号,所以,许多总线用数据线DB作为总线请求线
N个设备要多少请求信号? N条!
- NuBus(MacintoshII
中的底板式总线)、 中的底板式总线)、SCSI总线等采用该方案
上图中的优先级 (优先级)是什么?
设备3>设备2>设备1>设备0
冲突检测方式裁决
基本思想:
当某个设备要使用总线时,它首先检查一下是否有其他设备正在使用总线
如果没有,那它就置总线忙,然后使用总线;
若两个设备同时检测到总线空闲,则可能会同时使用总线 ,此时发生冲突;
一个设备在传输过程中,它会帧听总线以检测是否发生了冲突;
当冲突发生时,两个设备都会停止传输,延迟一个随机时间后再重新使用总线
- 该方案一般用在网络通信总线上,如:Ethernet总线等。
总线定时方式
° 什么是总线的定时
通过总线裁决确定了哪个设备可以使用总线,那么一个取得了总线控制权的设备,如何控制总线进行总线操作呢?也即如何来定义总线事务中的每一步,何时开始、何时结束呢?这就是总线通信的定时问题。
° 总线通信的定时方式
• Synchronous (同步):用时钟来同步定时
• Asynchronous(异步):用握手信号定时
• Semi-Synchronous (半同步):同步(时钟)和异步(握手信号)结合
• Split transaction(拆分事务):在从设备准备数据时,释放总线
处理器-存储器总线都采用同步方式
异步方式只有通信总线或I/O才会使用
I/O总线大多采用半同步方式
拆分事务方式可以提高总线的有效带宽
同步总线 (Synchronous Bus)
简单的同步协议如下图:一个总线事务:地址阶段 + 数据阶段 + … + 数据阶段
控制线上用一个时钟信号进行定时,有确定的通信协议
Advantage(优点): 控制逻辑少而速度快
Disadvantages(缺点):
(1)所有设备在同一个时钟速率下运行,故以最慢速设备为准
(2)由于时钟偏移问题 )由于时钟偏移问题,同步总线不能很长
实际上,存储器总线比这种协议的总线复杂得多
存储器(从设备)响应需要一段时间,并不能在随后的时钟周期就准备好数据
异步总线 (Asynchronous Bus)
° 非时钟定时,没有一个公共的时钟标准。因此,能够连接带宽范围很大的各种设备。总线能够加长而不用担心时钟偏移(clock skew)问题
° 采用握手协议(handshaking
protocol)即:应答方式。
• 只有当双方都同意时,发送者或接收者才会进入到下一步,协议通过一对附加的“握手”信号线(Ready、Ack)来实现
°异步通信有非互锁、半互锁和全互锁三种方式

• 优点:灵活,可挂接各种具有不同工作速度的设备
• 缺点:① 对噪声较敏感(任何时候都可能接收到对方的应答信号)
② 接口逻辑较复杂
Handshaking Protocol(握手协议 )
一个总线事务:地址阶段 + 数据阶段 + … + 数据阶段
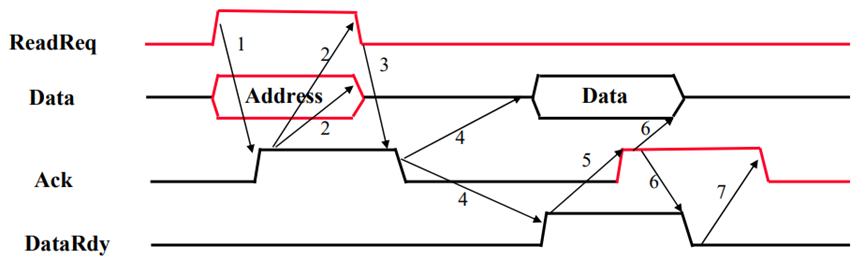
° Three control lines
• ReadReq: 请求读内存单元
(地址信息同时送到地址/数据线上)
• DataRdy: 表示已准备好数据
(数据同时送到地址/数据线上)
• Ack: ReadReq or DataRdy的回答信号
° 上述为read过程, 但write操作基本类似
ReadReq和Ack之间的握手过程
完成数据信息的传输
一共有多少次握手?
7次
是全互锁方式!
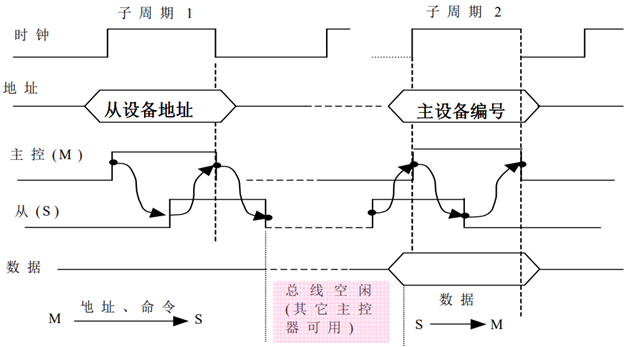
半同步总线
为解决异步方式对噪声敏感的问题,在异步总线中引入时钟信号
就绪和应答等握手信号 (如:Wait信号、TRDY和IRDY信号等) ,都在时钟的上升沿,有效
信号的有效时间,限制在时钟到达的时刻, 信号的有效时间限制在时钟到达的时刻,而不受其他时间的信号干扰

° 通过“Wait”信号从设备告知,主设备何时数据有效
° 结合了同步和异步的优点。既保持了“所有信号都由时钟定时”的特点, 又允许“不同速度设备共存于总线”
Split Bus Transaction(拆分总线事务 )
将一个事务分成两个子过程:
• 过程 1:主控设备 A获得总线使用权后,将请求的事务类型、地址及其他信息(如 A的标识等) 发到总线,从设备 B记下这些信息。A发完信息后便立即释放总线,其他设备便可使用总线。
• 过程 2:B收到 A发来的信息后,按照 A的要求准备数据,准备好后,B便请求使用总线,获使用权后,B将 A的编号及所需数据送到总线,A便可接收。
Split Bus Transaction( 拆分总线事务 )
° 请求 - 回答方式 (Request-Reply )
• CPU启动一次读或写事务
- 传送信息:address,
data, and command
• 然后等待存储器回答
° 分离总线事务方式(Split
Bus Transaction )
• CPU启动一次读/写事务后,释放总线
- 传送信息:address,
data (Write ), and command
• 存储器启动一次回答事务,请求使用总线
- 传送信息: data (read)
or acknowledge (write)
优点:系统总效率改善 (例如,在存储器存取数据时可以释放总线,以被其他设备使用)
缺点:单独的事务响应时间变长,增加复杂性。
例1:同步和异步总线的最大带宽比较
举例:假定同步总线的时钟周期为50ns,每次总线传输花1个时钟周期,异步总线每次握手需要40ns,两种总线的数据都是32位宽 ,存储器的取数时间为200ns
。要求求出从该存储器中读出一个字时两种总线的带宽 。
分析如下: 同步总线的步骤和时间为:
(1)发送地址和读命令到存储器:50ns
(2)存储器读数据:200ns
(3)传送数据到CPU:50ns
所以总时间为300ns,故最大总线带宽为4B/300ns,即:13.3MB/s。
异步总线的步骤和时间为:
第1步为:40ns;
第2、3、4步为:Max(3x40ns,200ns)=200ns;
(第2、3、4步都和存储器访问时间重叠)
第5、6、7步为:3x40ns=120ns。
总时间为360ns,故最大带宽为4B/360ns=11.1MB/s
由此可知:同步总线仅比异步快大约20%。要获得这样的速度,异步总线上的设备和存储器必须足够快,以使每次在40 ns内能完成一个子过程。
例2:数据块大小对带宽的影响
假定有一个系统具有下列特性:
(1)系统支持4~16个32位字的块访问。
(2)64位同步总线,时钟频率为200MHz,每个64位数据传输需一个时钟周期,地址发送到存储器需1个时钟周期。
(3)在每次总线操作(事务)间有两个空闲时钟周期。
(4)存储器访问时间,对于开始的4个字是200ns,随后每4个字是20ns。
假定先前读出的数据在总线上传送的同时,随后4个字的存储器读操作,也在重叠进行,
一个总线事务由一个地址传送,后跟一个数据块传送组成。
请求出分别用4-字块和16-字块方式,读取256个字时的持续带宽和等待时间。并且求出两种情况下,每秒钟内的有效总线事务数。
举例-数据块大小对带宽的影响
分析 4-字块传送情况:
对于4-字块传送方式,一次总线事务由一个地址传送,后跟一个一次总线事务,由一个地址传送,后跟一个4-字块的数据传送组成。也即每个总线事务传送一个4个字的数据块。每个数据块所花时间为:
(1) 发送一个地址到主存,花1个时钟周期
(2) 从主存读4个字花:200ns/(5ns/Cycle)=40个时钟周期 (一个周期是109ns/200MHz=1000/200=5ns)
(3) 4个字(128位)的传输需2个时钟周期 (一个64位数据传输需1个时钟周期)
(4) 在这次传送和下次之间有2个空闲时钟周期
所以一次总线事务总共需45个周期,256个字需256/4=64个事务,所以整个传送需 45x64=2880个时钟周期,因而总等待时间为:2880周期x 5ns/周期=14400ns。每秒钟的 总线事务数为: 64 x (1s/14400ns) = 4.44M个。总线带宽为:(256 x 4B)/14400ns =71.11MB/s。

举例-数据块大小对带宽的影响
分析 16-字块传送情况:
对于16-字块传送,一次总线事务由一个地址传送,后跟一个16-字块的数据传送组成。也即每个总线事务传送一个16个字的数据块。
第一个4-字所花时间为:
(1) 发送一个地址到主存花1个时钟周期
(2) 从主存读开始的4字花:200ns/(5ns/Cycle)=40个时钟周期
(3) 传4个字需2个时钟周期,在传输期间存储器开始读取下一个4字 。
(4) 在本次和下次之间有2个空闲时钟,此期间下一个4字已读完
所以,16字中其余三个4字只要重复上述最后两步。因此对于16-字块传送,一次总线事务共需花费的周期数为:1+40+4 x (2 +2) = 57个周期,256个字需256 / 16=16个事务。因此,整个传送需57 x 16 = 912个时钟周期。故总等待时间为:912周期x 5ns /周期=4560ns。 几乎仅是前者的1/3。每秒钟的总线事务个数为:16 x (1s / 4560ns) = 3.51M个。总线带宽 为:(256 x 4B)x (1s/4560ns) =224.56MB/s,比前者高3.6倍。 由此可见,大数据块传输的优势非常明显。

Latency = 912 clock cycles
Bandwidth = 224.56MB/sec
增加同步总线带宽的措施
提高时钟频率
° Data bus width(增加数据线宽度)
• 能同时传送更多位
• Example: SPARCstation 20’s memory bus 有 128 bit
• Cost: more bus lines
° Block transfers(允许大数据块传送)
• 背对背总线周期,也称为突发(Burst)传输方式
• 只要开始送一次地址,后面连续送数据
• Cost: (a)增加复杂性
(b)延长响应时间
° Split Bus Transaction(拆分总线事务)
• 一次总线事务时间延长,但整个系统带宽增加
• Cost: (a) 增加复杂性
(b) 延长响应时间
° 不采用分时复用方式
• 地址和数据可以同时送出
• Cost(代价): (a)
more bus lines, (b) 增加复杂性
关于I/O总线标准
°I/O总线是各类I/O控制器与CPU、内存之间传输数据的一组公用信号线,这些信号线在物理上与主板扩展槽中插入的扩展卡(I/O控制器)
直接连接。
°I/O总线是标准总线,I/O总线标准有:
• ISA / EISA总线:(已逐步被淘汰)
• Multibus总线:(已逐步被淘汰)
• PCI总线:前几年PC机所用的主流标准
• PCI-Express(高速PCI总线):目前PC机所用的主流标准
°I/O总线的带宽
• 总线的数据传输速率(MB/s) =
数据线位数/8×总线工作频率 ×总线工作频率(MHz)×每个总线周期的传输次数。
PCI总线扩展槽

PCI总线标准
(1) 信号线
PCI有50根必须的信号线。按功能可分为以下几组:
• 系统信号:包括时钟和复位线。
• 地址和数据信号:包含32根分时复用的地址/数据线、4根分时复用的总线命令/字节使能线,以及对这36根信号线进行奇偶校验的一根校验信号线。
• 接口控制信号:对总线事务进行定时控制,用于在事务的发起者和响应者之间进行协调。
• 裁决信号:它不同于其他信号,不是所有设备共享同一根信号线,而是每个总线主控设备都有一对仲裁线:总线请求和总线允许。PCI采用集中式裁决,所有设备的仲裁线都连接到一个总线裁决器中。
• 错误报告信号:用于报告奇偶校验错以及其他错误。
(2)
PCI命令
• 总线活动以发生在总线主控设备和从设备之间的总线事务形式进行。总线主 控设备就是事务的发起者,从设备是事务的响应者,即目标。当总线主控设备获得总线使用权后,在事务的地址周期
,通过分时复用的总线命令/字节,使能信号线C/BE发出总线命令,也即事务类型。
PCI总线标准
PCI的总线命令(事务类型)有:
• 中断响应:用于对PCI总线上的中断控制器提出的,中断请求进行响应。地址线不起作用,在数据周期从中断控制器读取一个中断向量,此时C/BE信号线表示读取的中断向量的长度
• 特殊周期:用于总线主设备向一个或多个目标广播一条消息。
• I/O读和I/O写:I/O读/写命令用于在发起者和一个I/O控制器之间进行数据传送
• 存储器读、存储器行读、存储器多行读:用于总线主控设备从存储器中读取数据。 PCI支持突发传送,所以它将占用一个或多个数据周期。这些命令的解释依赖于总线上的存储控制器是否支持PCI的高速缓存协议。如果支持的话,那么,与存储器之间的数据传送以Cache行的方式进行
• 存储器写、存储器写并无效:这两种存储器写命令用于总线主控设备向存储器写数据,它们将占用一个或多个数据周期。其中存储器写并无效命令用于回写Cache行到存储器,所以它必须保证至少有一个Cache行被写回
• 配置读、配置写:用于一个总线主控设备,对连接到PCI总线上的设备中的配置参数,进行读或更新。每个PCI设备都有一个寄存器组(最多可有256个寄存器),这个寄存器用于系统初始化时对本设备进行配置
• 双地址周期:由一个事务发起者,用来表明它将使用64位地址来寻址。
PCI总线标准
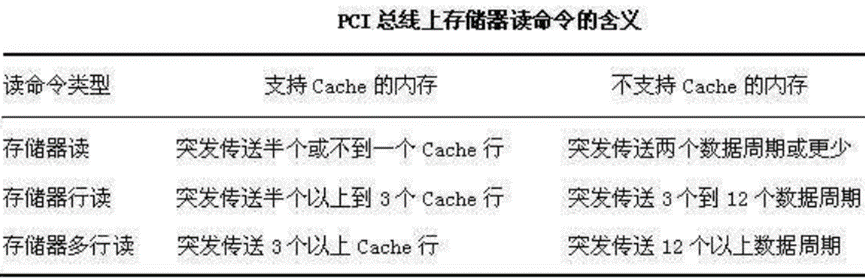
存储器读、存储器行读、存储器多行读:用于总线主控设备从存储器中读取数据。PCI支持突发传送,所以它将占用一个或多个数据周期。这些命令的解释,依赖于总线上的存储控制器是否支持PCI的高速缓存协议。如果支持的话,那么,与存储器之间的数据传送,以Cache行的方式进行。
PCI总线标准
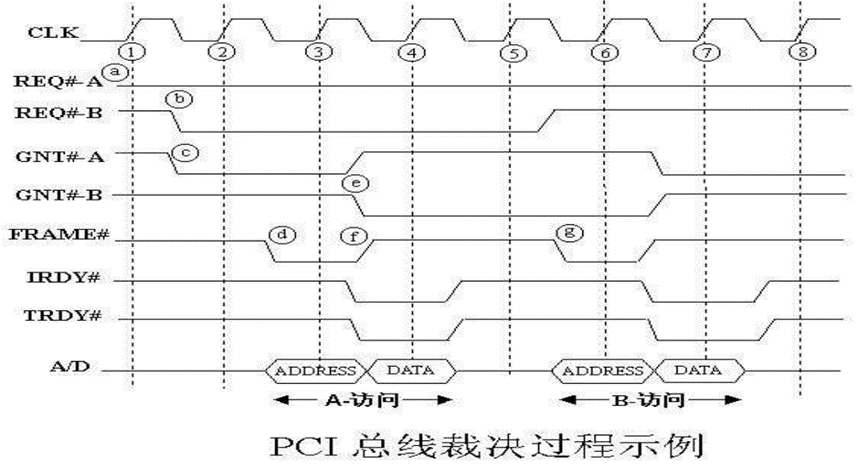
(3) PCI数据传送过程
PCI总线上的数据传送由一个地址周期和一个或多个数据周期组成。
所有事件在时钟下降沿(即在时钟周期中间)同步。总线设备在时钟上升沿采样总线信号。
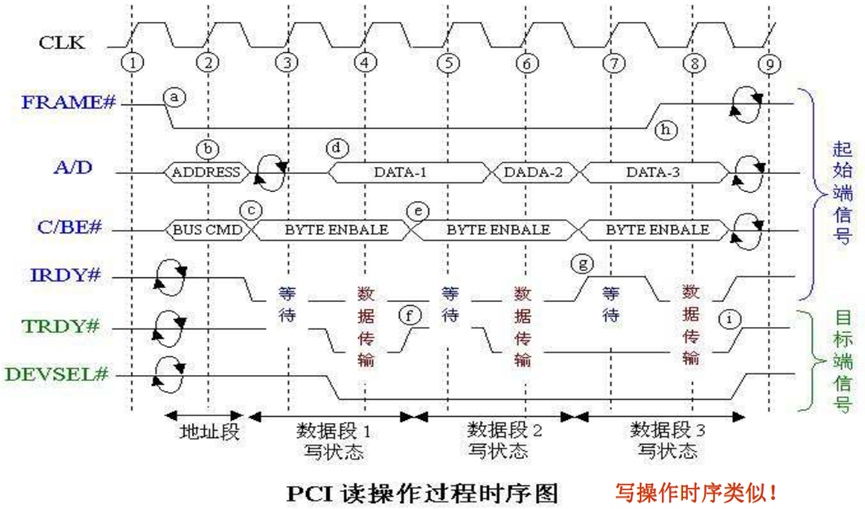
PCI总线标准
(4) PCI总线裁决
采用独立请求方式,有两个独立的裁决线:请求线REQ和允许线GNT。
总线仲裁器可使用静态的固定优先级法、循环优先级法或先来先服务法等仲裁算法。采用隐式仲裁方式,在总线进行数据传送时,进行总线仲裁,仲裁不会浪费总线周期。
I/O总线,I/O控制器与I/O设备的关系

° I/O设备通常都是物理上相互独立的设备,它们一般通过通信总线与I/O控制器连接
° I/O控制器通过扩展卡或者南桥芯片与I/O总线连接
° I/O总线经过北桥芯片与内存、CPU连接
I/O总线,I/O控制器与I/O设备的关系

小结
°总线是共享的传输介质和传输控制部件,用于在部件或设备间传输数据
°总线可能在芯片内、芯片之间、板卡之间和计算机系统之间连接
°I/O总线是I/O控制器与主机之间,传输数据的一组公用信号线,它们在物理上与主板扩展槽中,插入的扩展卡(I/O控制器)直接连接。
°总线可以采用“同步”或“异步”方式进行定时。
• 同步总线用“时钟”信号定时;异步总线用“握手信号”定时
• 可以结合同步和异步方式,进行半同步定时通信
• 可以把一个总线事务分离成两个事务,在从设备准备数据时释放总线释放总线(总线事务分离方式)
°总线的裁决:有集中和分布两类裁决方式
• 分布裁决:自举裁决、冲突检测
• 集中裁决:菊花链、独立请求并行判优
°总线标准(PCI总线)
°总线互连结构
• 单总线结构(早期计算机采用)
• 多总线结构(现代计算机采用)



