NPU开发指南-加速器架构的设计空间探索
以下以最近的一篇论文为例,来分析加速器架构的设计空间探索,DeFiNES: Enabling Fast Exploration of the Depth-first Scheduling Space for DNN Accelerators through Analytical Modeling,链接地址:https://arxiv.org/pdf/2212.05344.pdf。
3.1.1. NPU加速器建模概述
对NPU进行建模的主要目的是快速评估不同算法、硬件、数据流下的延时、功耗开销,因此在架构的设计初期,可以评估性能瓶颈,方便优化架构。在架构和数据流确定后,建模可以快速评估网络在加速器上的执行效率。对其建模可以从从算法维度和硬件维度进行。
算法维度:以一定的方式表示需要加速的网络,如一些中间件描述,主要包括算子的类型、网络的层数以及操作数精度等信息,这一部分可以由自定义的网络描述文件表示,也可以由编译器解析网络文件生成,目的在于定量的描述工作负载。
硬件维度:包括计算资源和存储资源两部分,不同的NPU具有不同数量的计算资源,加速不同算子的并行度,也会有所区别。不同NPU的存储层次结构,也有很大区别,权重、特征是否共用同一片缓存,或者有各自独立的缓存,每一级存储的容量、带宽以及相互之间的连接关系,都是设计空间的一部分。
对功耗而言,通常具有统一的分析方法,通过每个操作的功耗,比如一次乘法,加载一个数据等需要的功耗,以及总的操作次数相乘后累加,就可以估算出整体的功耗。延时可以通过RTL/FPGA等精确的仿真得到,适用于架构与数据流确定的情况。另外有一些基于数学方法分析的建模方法,并不会实际执行网络,而是根据网络参数、硬件参数进行数学推导,估算延时。对访存的估计与需求有关,有些建模方法只关注于对DRAM的访问,有些则会同时考虑到片上不同存储单元间的数据移动。
建模越精确,其越贴近特定的架构,更有利于评估算法在特定硬件上的计算效率。建模越模糊,越具有普适性,有利于在加速器设计初期,进行设计空间探索。
以下以最近的一篇论文为例,来分析加速器架构的设计空间探索,DeFiNES: Enabling Fast Exploration of the Depth-first Scheduling Space for DNN Accelerators through Analytical Modeling,链接地址:https://arxiv.org/pdf/2212.05344.pdf。考虑了PE利用和内存层级结构,对于PE的利用,其主要是PE间的数据交互,排列和连接方式,并没有太大的探索空间。即计算和数据搬移的共同代价,在一些架构分析的时候,对内存层级关注较低,多集中on-off芯片,这里深度优先的搜索加速器架构空间,配合cost model(成本模型)找到最优架构模型。从几个层面,逐次计算分块大小(会影响到层间输入/输出,位于那个内存层级上,以及权重复用的问题,即权重访问的频次),数据复用模式(即cache已计算的的数据,还是完全重新数据)以及层间融合(将层间存储在已知存储区内,完成上一层的输出,送入到下一层的输入),减少高层存储访问三个方面来探讨搜索空间,需要一定的权衡折中。
对于成本模型,文章并没有作详细的介绍,成本模型一般考虑延迟和功耗两部分,尚未解决的问题:文章主要针对卷积进行的分析,以transform为代表的大模型,计算模式则完成不同,卷积计算中,权重复用,特征映射的滑动,以及感受野计算区域变化等和transform差距较大。
优点是:详细的内存层级分布的探讨和不同容量层级的内存分布,值得借鉴。
缺点是: 成本模型并未真正提及,对于卷积并没有关注到深度和point两种常见版本,对于transform新的计算模式并未涉及。
图1. 从(a)单层一次调度到(b)逐层调度,再到(c)深度优先调度,以保持较低的激活率内存级别。“L”:神经网络层;“T”:分块;“LB”:本地缓冲区(小型片上存储器);“GB”:全局缓冲区(较大的片上存储器)。
图2. DF设计空间的第一个轴:分块尺寸。用于图层尺寸标注在(a)中:K表示输出通道;C表示输入通道;OX和OY是特性映射空间维度;FX和FY是权重空间维度。
从图2这里可以看到,卷积的计算特点,权重在输入空间滑动带来的三个结果:1.支持逐个模块的计算,即这里延申的跨层的分块计算块 2,数据的生产者消费者模式,即stride和内核大小差异引起的数据复用,和层间连接的数据交付 3。计算模式导致的存储结构,权重在层内的复用,而分块大小影响了计算时,权重的访问频次.基于此我们看到收感受野的影响(即卷积的计算结构)看到在融合层的时候,较大的分块大小带来了较好的计算效率,对比图中可以看到tile_size=4*4,最上层的输入为10*10,tile_size为1*1,输入为7*7。

图3. DF设计空间的第二个轴:重叠存储模式。工作量为图2(a)中的第2层和第3层;图例见图2(a)。
紫色的表示计算已经生成的数据,对于图a为完全每次都从第一层开始重新计算的模式,表示最后一层生成一个1*1*c绿色的数据,倒数第二层需要提供3*3*c绿色数据,第一层需要提供绿色5*5*c绿色数据,因为其属于fully recompute,即没有数据复用,可以看到底层的c个数据需求,前两层分别需要用到9c个和25c个。对于图b,属于H-cached,V-recompute,即水平方向缓存,垂直方向计算,最后一行中,生成一个1*1*c绿色数据,对应上面一层需要3*3*c的数据块产于运算,这其中需要复用cached的红色2*3*c的数据,和新加入了绿的1*3*c的数据,这其中新加入的1*3的绿色数据会设置成new to-cache 1*3*c的数据为下一次的领域计算作为cache,如图种蓝色框对应,中图种新读入的1*3*c的数据,则对应最上层需要new to-cache 1*5*c的数据,图c同理。
图4. 分块尺寸(第一轴)和融合深度(第三轴)的影响。ST:融合层堆栈。
对于a,当一层一个stack的时候,每一层的权重比较小,则将其放置在LB中,因为其stack很浅,每层的between stack的I/O都会写到最慢的DRAM中,而其per stack的I/O(上一层的输出传递到下一层的输入)也只能在低级别存储中传递。
B vs C 相同之处,都进行了融合,对比a来说,因为层融合了,stack变深,多层间累计的权重变大,权重从原来图a中位于LB,被迫放在了GB中,对于b与c,看到分块粒度变细后,其相应的执行次数变多,则权重访问频次变高,c的 权重 reuse变少。对于和a比较,因为融合了,per stack的I/O(上一层的输出传递到下一层的输入)从a中的DRAM(因为a为单层执行,即每次结果需要放回到DRAM,则between-stack的I/O放在DRAM,因为只有一层,其输出perI/O和between stack是一样的)移动到了GB中(b)或者LB中(c),因为分块粒度变小,所以c的per-stack位于LB中,而b 的per-stack位于GB中,对于between stack是位于stack之间的,无论b还是c都还是写入到最外层DRAM中,对于b和c而言融合 层比较浅,对比可以看出分块越细,即细分,则每一层的特征映射变小,per-stack的I/O越容易放到高速缓存中,看到在图C中 每个堆栈的输入特征映射&输出特征映射集中在最底层的LB上,而图B中,则在放在GB中,即所谓细分-->每堆栈激活次数较少. 但是同时也带来的缺点,多个分块则意味着更多次的访问权重,即所谓的细分->较少的本地内存权重重用,再C中可以看到关于W为less reuse
B vs D,对比可以看到,融合层数越多,即 融合更深,即每个stack包含的层数多,一个stack包含了多层的权重也就多,因此每堆叠权重更多,对应图b中,权重可以在GB中,在图d,图e中,权重数据量较多,则都集中在了DRAM上, 融合更深好处是这些stack中逐层之间的activation在高速存储中完成了交换(即上一层的输出是下一层的输入),图d中DRAM中没有 between-stack I/O,I/O集中在下面的高速层,即less between -stack activation
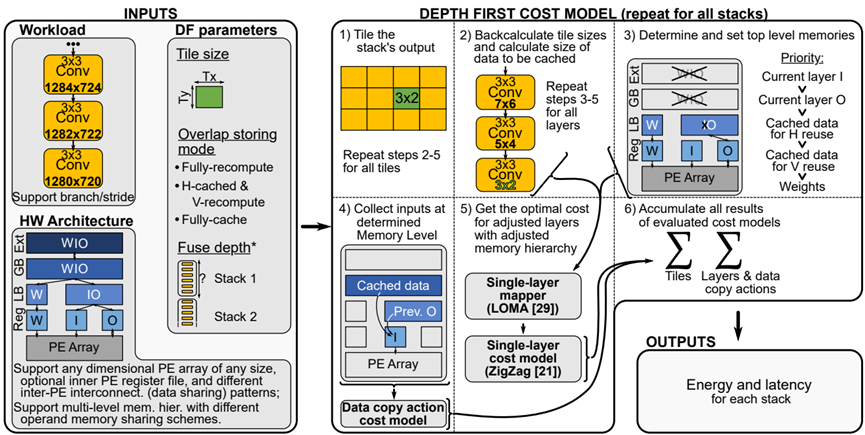
图5. DeFiNES概述。(*:可选输入,可自动设置。)
因为第一行/列中的块还没有可用的缓存数据——同样,最后一列/行中的块也不必为它们的邻居存储重叠,因此不是所有的分块都是相同的。
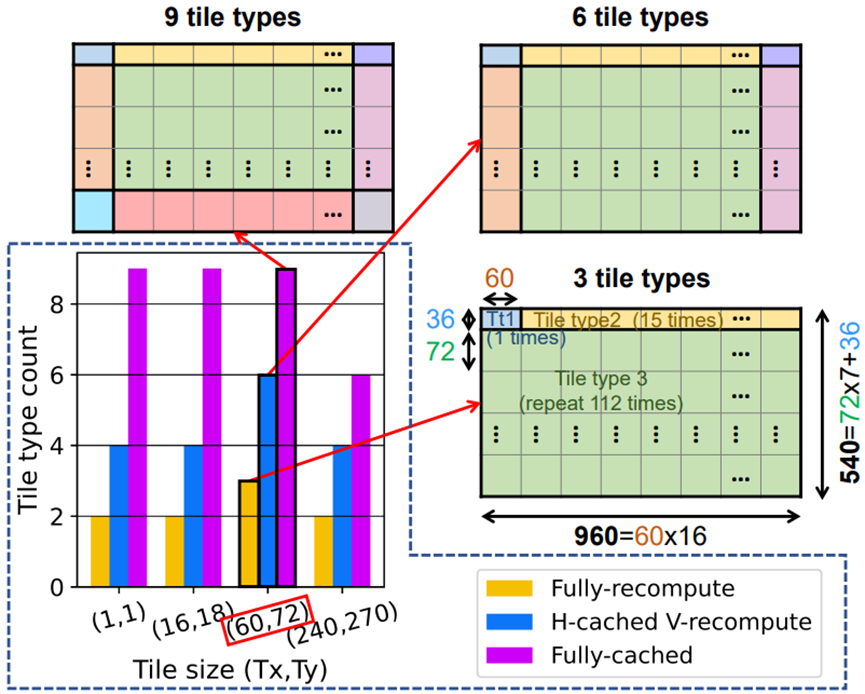
图6.不同分块大小和重叠存储模式的分块类型计数。这个本例中使用的工作负载是FSRCNN,其最终输出特性映射的空间维度为960×540。进一步使用3分块类型示例,如图9和图10所示。
以下图来看那些数据可以利用cached data,那些用来cache for neighbors
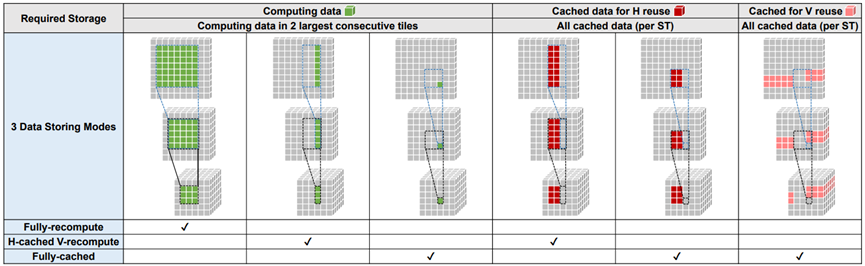
图7. 不同重叠存储模式所需的数据存储。ST:融合层堆栈。
5_step3 内存排列分布来看

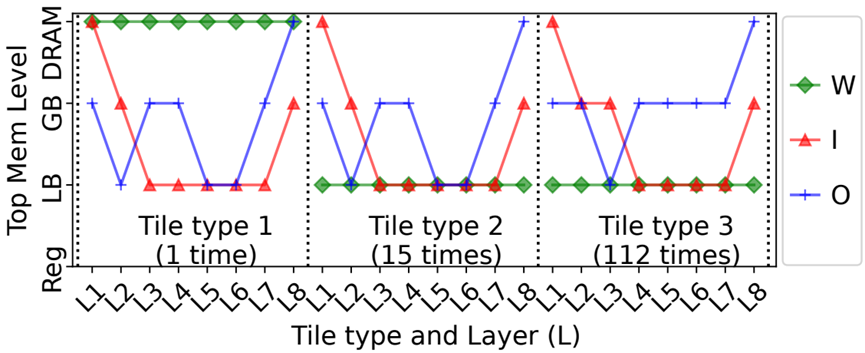
图9. 操作数W、I和O的,每个唯一层分块组合的,确定顶部内存级别的可视化。DF计划取自图6中的3分块类型示例。HW架构是表I中的Idx2。值得注意的是:1)对于权重,第一分块的所有层从DRAM获取权重,而其他层分块组合从LB获取权重;2)对于输入和输出,所有分块的第一层,从DRAM获得输入,所有分块最后一层写入。
图9中为例看到,图像被分割成了3种分块,对于分块1,数目为1个,其权重首次需要从DRAM逐层搬移到进来,看到在分块类型1中,其权重位于DRAM中,再其后的type2(15个)和type3(112个),权重是完全复用的,所以一直在LB结构中,对应于5_step3图中W位于LB中,而I因为有存储计算时的cache存在,前一层生成的输出可能部分被缓存起来,或者使用更低的内存级别用来作为下一层的输入,只会在每种type切换的时候,会从DRAM中读取一次数据,因此,从DRAM中读入后,以后的每次使用中,需要的一部分是新数据,一部分是来源于cache的数据,在type2和type3中,则基本都为LB中,而对于O只有在type类型切换,和最终结果则写出到DRAM中。从图5中step4可以看到,prev的output feautre map在内存层级中更优先于Cached data。
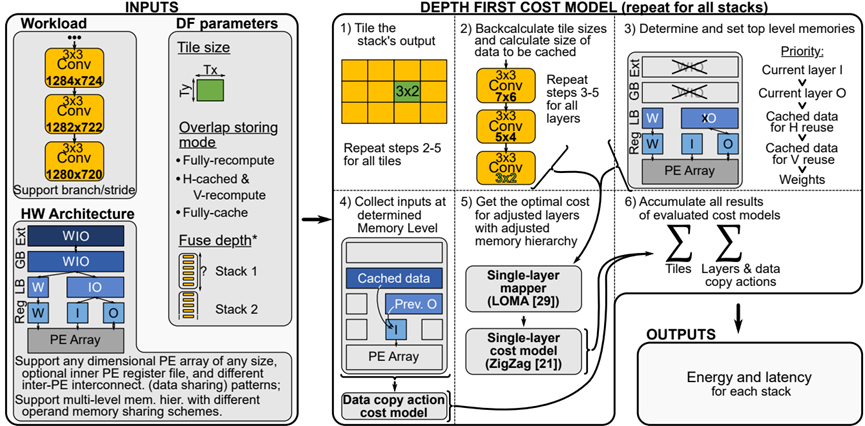
图5.DeFiNes的概述。(*:可选输入,可自动设置。)

图10. 图9中示例的分块类型2和3中激活数据大小的可视化。LB和GB的容量在y轴上标出。图9和图10一起表明:1)当总激活大小(I+O)可以放入LB(例如,分块类型2-L6)时,LB是I/O的顶部存储器;2) 当总激活大小(I+O)不能容纳LB,而I或O可以容纳(例如,分块类型3-L6)时,I优先使用LB作为其最高内存级别,而O被推到GB。
端到端的功耗匹配更具挑战性,因为它对几个细粒度设计和布局方面非常敏感,例如:
1)稀疏性,DepFiN使用稀疏性来关闭逻辑活动以节省功率;
2)位置和路由效应,导致数据传输比内存读/写成本更昂贵,还包括稀疏依赖效应;
表1. (A)五种硬件架构及其DF-FRIENDLY变体和(B)案例研究中使用的五种DNN工作负载。

看table1看到对于架构进行like DF 手动改造的时候,对于Meta原型DF处理器,本地缓存 减少了权重的分配,增大了I&O的数量,并对 I&O 进行复用,增加I&O有助于融合的层次更深,支持更大一点的分块大小,对于tpu-like DF, 减少了reg for Mac group的数目,增加了本地缓存种I&O. 对于edge tpu-like DFT中,处理方式和Meta原型DF类似,都是减少了权重的LB的分配,增大了I&O,即更加关注可以用来在层间I/O传递。给定一个工作负载和架构,深度优先策略的影响,以上图中Meta原型DF架构和FSRCNN作为工作负载
case1:使用FSRCNN and Meta原型DF 分别作为targeted 工作负载 和 HW architecture. 对于三个DF影响因子,分块大小,重叠存储模式和融合深度,对应该case,其第三个轴融合深度固定在整个DNN上,因为FSRCNN的总权重很小(15.6KB),因此所有权值都适合Meta原型DF架构的权重可以全部放进片上本地缓存(看到该架构的权重使用的本地缓存是32K),因此不把整个DNN融合成一个堆栈是没有好处。

图12. 元原型DF架构,处理具有不同DF策略的,FSRCNN的总能量和延迟。
从图中,看右下角,不同计算模式下,它们的能量和延迟数(分别为19.1和29)是相同的,因为此时的分块大小为960*540即为全图,因此不存在分块,即转换为了LBL,因为不同的重叠存储模式对LBL没有影响。
1.考虑相同重叠存储模式下,即同一个图内比较,发现不同的分块尺寸,分块尺寸太小和太大都是次优的。分块尺寸过大,会导致访问一些非常慢的存储层级,分块尺寸很小,则导致会大量访问权重,太大太小都不是最好的选择,最好的点总是在中间的某个地方。
2.考虑不同重叠存储模式下相同的分块大小的情况下,即同一相对坐标下的跨图进行比较,大多数情况下能耗顺序为:full -cached < H-cached V-recompute < full -recompute,这个也易于解释,适当的存储结构减少了大量的重复计算
4.fully recompute比完全缓存d更喜欢更大的分块大小。完全缓存d倾向于小一些的分块.
对上图中,分析器对角线对应的分块组合,其对应的计算量如下
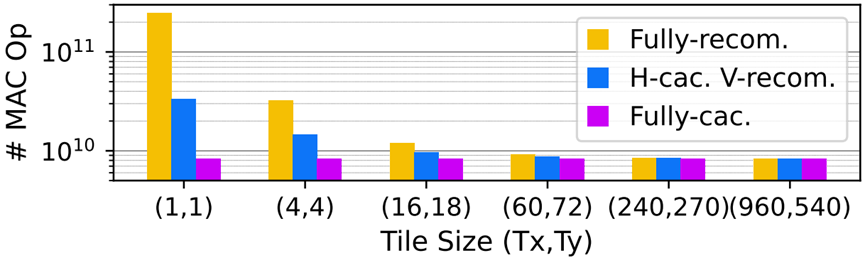
图13. 不同测向策略的MAC操作计数。

图2. DF设计空间的第一个轴:分块尺寸。对于(a)中的层尺寸表示法:K表示输出通道;C表示输入通道;OX和OY是特征图的空间维度;FX和FY是权重空间维度。
图13可以看到分块越小,则计算量反而越大,因为数据复用比例较低,在图13种可以看到在fully recom对应的1*1下,计算量最多,
以图2为例子,可以看到,对于分块1*1,则顶层需要的计算为7*7,而对于分块2*2 则需要的仅仅为8*8,因此可以看到分块大小的大小并不是和计算量成线性关系,分块长宽增大一倍,计算量并没有相应的增大,而是小于其增速,则说明,分块越小,计算量较大,对于三种存储模式都是满足这个规律,只是full-cache 影响很小,统观全图,总的情况下满足fully-recom>H-cac,V-recom>Fully-cac. 再看到随着分块大小的增大,因为cache的数据(用于减少重复计算量)的数据通常为kernel width-1列(H-cac,V-recom),或者(kernel width*kernel width-1)个(对应于Fully-cac),但是相对于大的内核大小而言,cache起来的数据占的比例在减小,因此cached data的作用在降低,这也是在前面,对于上一层输出的输出特征映射比cached data更优先占用较快存储,随着分块大小增大,比如增加到960*540这个时候cache的意义也就没意义了(即转换成了LBL),因此计算量也就一样了。
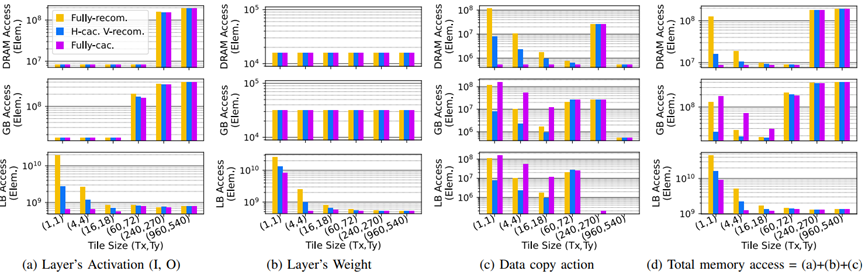
图14:不同内存级别的不同数据类型的内存访问,用于元原型DF架构处理具有不同DF策略的FSRCNN。
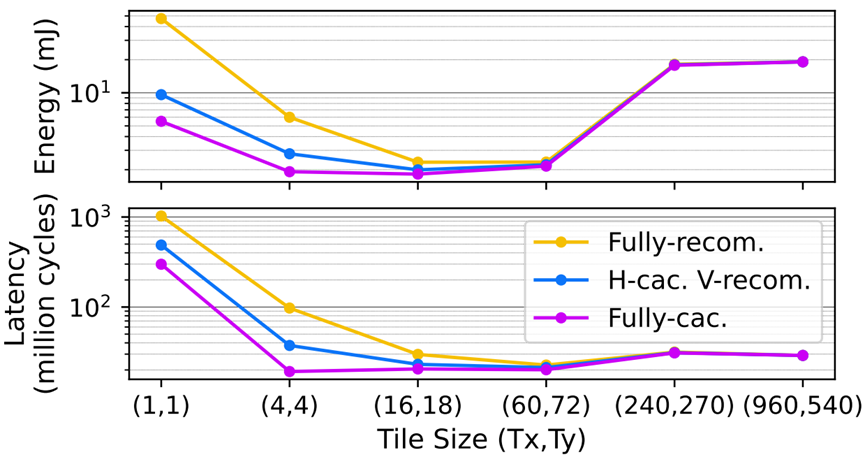
图15.图14中设计点的总能量和延迟。
将深度优先应用于多个工作负载来分析其各自的性能,这里使用了如下的5种策略,和五个网络,其中FSRCNN/DMCNN-VD/MCCNN属于激活占主要的类的工作负载,而MobileNetV1/Resnet18则属于权重占主导的工作负载。
· Single layer: layers are completely evaluated one at a time, feature maps are always stored to and fetched fromDRAM in between layers;
· 逐层: layers are completely evaluated one at a time,that means no tile, intermediate feature maps are passed on to the next layer in the lowest memory level they fit in;
· 完全缓存d DF with 4*72 tiles, which is the bestfound in case study 1;
· The best strategy found when a single strategy is used for all fused layer stacks;
· The 最佳组合, where different stacks can use different DF strategies.
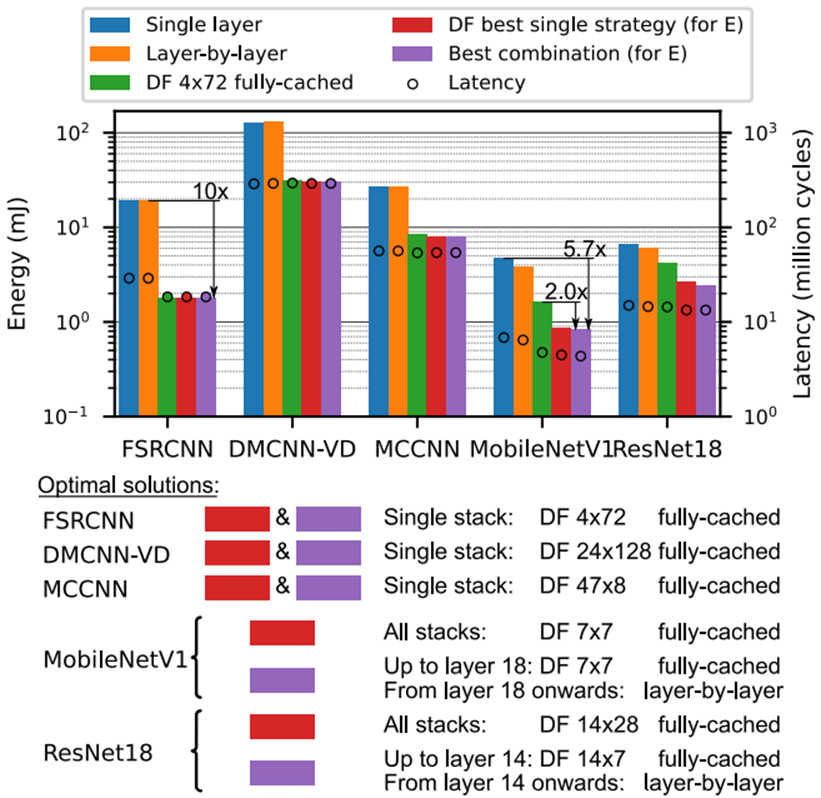
图16. 案例研究2:不同的工作负载导致不同的最佳解决方案(在类似元原型的DF硬件上的所有结果)。
FSRCNN/DMCNN-VD/MCCNN属于激活占主要的类的工作负载,这一类的特点权重比较少,适合多层进行融合, 且权重通常多位于本地sram中,且适合再进行 layer 融合的时候,stack的层次比较深,看到这三个网络的权重都在几十到几百K字节,适合融合深度与单个通道,因此对于单层是一种比较差的选择,这一类的另一个特点是激活占主要,则适合对激活 作 分块处理,因此,对于逐层也是一种比较差的选择,对应于图16 .FSRCNN/DMCNN-VD,MCCNN,使用单层/逐层的时候效果都比较差。相应的这几种网络更适合选择完全缓存的分块,其多层融合的单一堆栈,对应于这三种网络,绿色DF 4x72 完全缓存,红色DF最佳单一策略和紫色的最佳组合的效果都比较好。
再来看单一策略对不同网络的影响,对于单层,即每层作为一个stack,对应于图中蓝色条,对于逐层的黄色条,无论那种网络,这两张选择,其能量和延迟都比较高. 因为其前者需要访问最慢的DRAM,后者无法分块,也需要访问较慢的存储结构,再来看DF最佳单一策略和最佳组合的两种情况下,即红色和紫色,对前三个网络都选择用了比较合适的单一堆栈,即所有的layer总体融合一个单一堆栈,其分块选取了较为合适的4*72/24*128/47*8,对于数据存储,都选择了据存储性能为完全缓存>H-cac,V-recom>Fully-cac,可以看到这三个网络都取得了不错的延迟和能量,绿色框DF 分块采取相互适配的大小4*72,4*72模式也是在case1中对激活类型占优的网络找到的最优解,数据存储 选取为完全缓存d。在图中对于FSRCNN/DMCNN-VD/MCCNN,其DF 4x72 完全缓存,DF最佳单一策略,最佳组合占优,而单层/逐层不占优
而对于MobileNetV1/Resnet18则属于权重占主导的工作负载,这一类的特点激活相对比较少,因此 红色的DF最佳单一策略和紫色的最佳组合中stack采取了不同的方式,以MobileNetV1为例子, DF最佳单个策略(一个单一的策略用于所有的融合层堆栈)中每一个stack,选取了7*7的分块大小,数据存储为完全缓存d,而对于组合模式(不同的堆栈可以使用不同的DF策略),则不同层使用不同的模式,前面18层使用一个固定的分块大小,使用完全缓存, 而对于后面的层,以mobilenetV1为例子,而MobileNetV1和ResNet18的权重占主导地位(特征图较小,并在各层之间逐渐减少),在18层后,特征映射已经变得比较小,即不再对特征映射作分块处理。所以使用了逐层,总的来说更细粒度调度策略的紫色的最佳组合的效果最好。
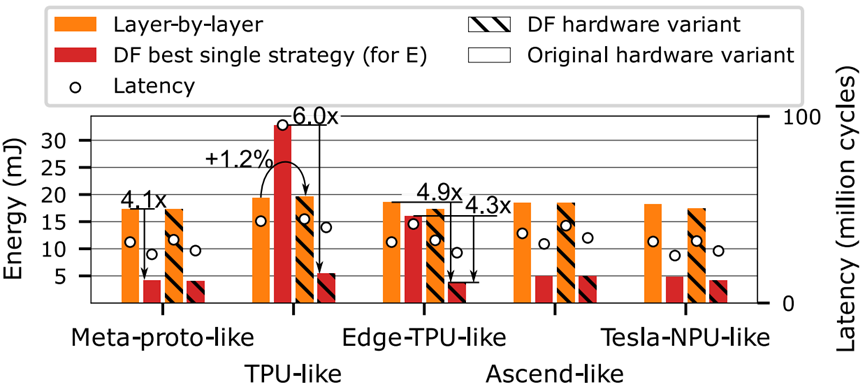
图17. 案例研究3:不同硬件架构的能量和延迟(5个工作负载的几何平均值),当逐层应用或最佳DF调度策略。
表2. 相关DF建模框架比较
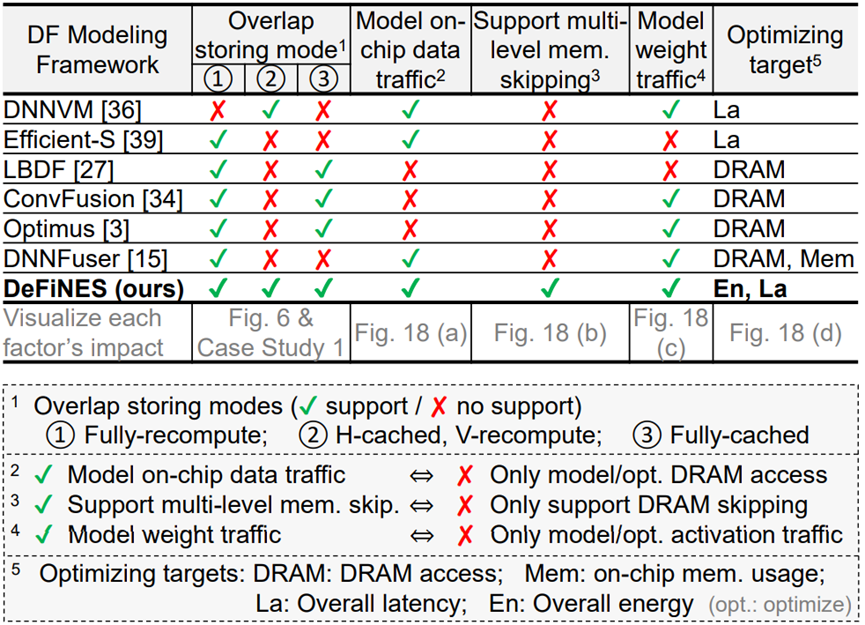

图18. 评估表2中不同因素的实验
NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。
在GX8010中,CPU和MCU各有一个NPU,MCU中的NPU相对较小,习惯上称为SNPU。
NPU处理器包括了乘加、激活函数、二维数据运算、解压缩等模块。
乘加模块用于计算矩阵乘加、卷积、点乘等功能,NPU内部有64个MAC,SNPU有32个。
激活函数模块采用最高12阶参数拟合的方式实现神经网络中的激活函数,NPU内部有6个MAC,SNPU有3个。
二维数据运算模块用于实现对一个平面的运算,如降采样、平面数据拷贝等,NPU内部有1个MAC,SNPU有1个。
解压缩模块用于对权重数据的解压。为了解决物联网设备中内存带宽小的特点,在NPU编译器中会对神经网络中的权重进行压缩,在几乎不影响精度的情况下,可以实现6-10倍的压缩效果。
为了能将基于TensorFlow的模型用NPU运行,需要使用gxDNN工具。
gxDNN用于将用户生成的Tensorflow模型编译成可以被NPU硬件模块执行的指令,并提供了一套API让用户方便地运行TensorFlow模型。

图:gxDNN神经网络处理器的作用
NPU编译工具用于生成能够被NPU执行器执行的文件,该文件里包含了NPU执行指令和模型的描述信息。一般在PC机上使用。
NPU执行器提供了一套API,用于解析执行文件,加载模型,输入数据,运行模型得到输出结果。它需要在有NPU硬件模块的机器上使用。
1. 在PC上生成TensorFlow的Graph(pb文件)和Variable(ckpt文件)后,将两者合并为一个pb文件。
2. 在PC上使用GXDNN的NPU编译器,将pb文件转化成能被NPU加载执行的指令文件,在CPU上该文件称为NPU文件,在MCU上为C文件。
3. 芯片端调用NPU API,导入模型,传入输入数据,运行模型,得到输出数据。

NPU编译器简介
TensorFlow的运算流程基于图(graph),图的结点称为op,op将0个或多个输入数据进行计算,生成0个或多个输出数据。NPU编译器的主要工作就是把一个个op转变成可以被NPU硬件模块执行的命令。
针对CPU和MCU的不同特性,生成的指令文件格式也不相同。
用户使用NPU编译工具生成NPU指令文件后,需要调用NPU执行器的API接口,让模型“跑”起来。
由于CPU和MCU的系统不同,提供的API接口也不同。详见 模型部署
· NPU 200M,SNPU 120M, npu_compiler 1.0.14 版本下测试
· ASR模型 (FC320 LSTM400 LSTM400 LSTM400 LSTM400 FC211)
· Lenet5 (1x28x28 -> Conv2D 5x5x1x32卷积核 -> Relu -> MaxPool -> Conv2D 5x5x32x64卷积核 -> Relu -> MaxPool -> FC 3136x1024权重 -> FC 1024x10权重)
· AlexNet (3x112x112 -> Conv2D 11x11x1x64卷积核 -> Relu -> MaxPool -> Conv2D 5x5x64x192卷积核 -> Relu -> MaxPool -> Conv2D 3x3x192x384卷积核 -> Relu -> Conv2D 3x3x384x384卷积核 -> Relu -> Conv2D 3x3x384x256卷积核 -> Relu -> MaxPool)
· MobileNet V2 (模型结构如下)

编译器安装
NPU编译器目前只支持Python2环境下安装和使用。
安装gxDNN工具链
更新gxDNN工具链
pip install --upgrade npu_compiler
查看工具链版本
安装或更新完成后,可以使用如下命令查看当前工具链的版本号。
编译器使用
工具链介绍
gxnpuc
用于把模型文件编译成能在 NPU 上运行的 npu 文件。
usage: gxnpuc [-h] [-V] [-L] [-v] [-m] [-c CMD [CMD ...]] [config_filename]
NPU Compiler
positional arguments:
config_filename config file
optional arguments:
-h, --help show this help message and exit
-V, --version show program's version number and exit
-L, --list list supported ops
-v, --verbose verbosely list the processed ops
-m, --meminfo verbosely list memory info of ops
-c CMD [CMD ...], --cmd CMD [CMD ...]
use command line configuration
配置文件说明
gxnpudebug
如果编译时配置文件中的 DEBUG_INFO_ENABLE 选项设置为 true,编译出的 npu 文件带上了调试信息,此时可以使用调试工具 gxnpudebug 工具来处理该文件。
usage: gxnpudebug [-h] [-S] [-P] file [file ...]
optional arguments:
-h, --help show this help message and exit
-P, --print_info print debug info
-S, --strip strip debug info
gxnpu_rebuild_ckpt
对权重数据做量化或做float16,并重新生成 ckpt 文件,用于评估模型压缩后对结果的影响。
usage: gxnpu_rebuild_ckpt [-h] config_filename
配置文件说明
编译模型
模型文件准备
· 准备TensorFlow生成的PB和CKPT文件,或saved_model方式生成的模型文件。
· 通过TensorFlow提供的freeze_graph.py脚本生成frozen pb文件。
编写配置文件
· 编写yaml配置文件,包括pb文件名,输出文件名,输出文件类型,是否压缩,压缩类型,输入节点名和维度信息,输出节点名等。
编译
gxnpuc config.yaml
需要注意,NPU工具链必须在安装有TensorFlow的环境下使用。
优化模型
为了让模型更高效地运行在 NPU 处理器上,需要对模型做一些优化。
· 做卷积和降采样的数据格式需要用 NCHW 格式,优化过程可以参考这里 。
· 各 OP 的 shape 需要确定,即和 shape 有关的 OP value 需要确定。
· Softmax 不建议放在 NPU 中,因为 NPU 使用 FP16 数据格式,容易导致数据溢出。
CPU中使用NPU或SNPU
生成能在CPU上运行的模型文件,需要在编译模型的配置文件中指定: OUTPUT_TYPE: raw 在CPU上内存资源相对丰富,模型指令以文件方式加载,能提高灵活性。 NPU处理器的输入输出数据类型都是float16,float16和float32的转换由API内部完成,上层应用不需关心。
调用API流程
MCU中使用SNPU
生成能在MCU上运行的模型文件,需要在编译模型的配置文件中指定: OUTPUT_TYPE: c_code 在MCU上内存资源紧缺,生成的模型文件为C文件,能直接参与编译。这样的优点是不需要解析模型文件,缺点是换模型就得重新编译。 另外,由于MCU效率较低,float16和float32的转换不能在MCU上做,必须由DSP或ARM来转。
调用API流程
* Copyright (C) 1991-2017 NationalChip Co., Ltd
* gxdnn.h NPU Task loader and executor
/*===============================================================================================*/
typedef void* GxDnnDevice;
GXDNN_RESULT_SUCCESS = 0,
GXDNN_RESULT_WRONG_PARAMETER,
GXDNN_RESULT_MEMORY_NOT_ENOUGH,
GXDNN_RESULT_DEVICE_ERROR,
GXDNN_RESULT_FILE_NOT_FOUND,
GXDNN_RESULT_UNKNOWN_ERROR,
/*===============================================================================================*/
* @param [in] devicePath the path to device
* [out] device a handle to the openned device
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_RESULT_WRONG_PARAMETER wrong parameter
* GXDNN_RESULT_DEVICE_ERROR device error
* @remark if devicePath is "/dev/gxnpu", open npu device
* devicePath is "/dev/gxsnpu", open snpu device
GxDnnResult GxDnnOpenDevice(const char *devicePath,
/*===============================================================================================*/
* @brief Close NPU device
* @param [in] device the handle to openned device
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_RESULT_WRONG_PARAMETER wrong parameter
* GXDNN_RESULT_DEVICE_ERROR device error
GxDnnResult GxDnnCloseDevice(GxDnnDevice device);
/*===============================================================================================*/
* @brief Load NPU Task from file (in Linux/MacOSX)
* @param [in] device the device handle
* [in] taskPath the path to NPU task file
* [out] task a handle to the loaded task
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_RESULT_WRONG_PARAMETER wrong parameter
* GXDNN_RESULT_MEMORY_NOT_ENOUGH no enough memory
* GXDNN_RESULT_DEVICE_ERROR device error
* GXDNN_RESULT_FILE_NOT_FOUND file not found
* GXDNN_RESULT_UNSUPPORT unsupport NPU type or npu task version
GxDnnResult GxDnnCreateTaskFromFile(GxDnnDevice device,
/*===============================================================================================*/
* @brief Load NPU task from memory
* @param [in] device the device handle
* [in] taskBuffer the pointer to NPU task buffer
* [in] bufferSize the buffer size of the NPU task buffer
* [out] task a handle to the loaded task
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_RESULT_WRONG_PARAMETER wrong parameter
* GXDNN_RESULT_MEMORY_NOT_ENOUGH no enough memory
* GXDNN_RESULT_DEVICE_ERROR device error
* GXDNN_RESULT_UNSUPPORT unsupport NPU type or npu task version
GxDnnResult GxDnnCreateTaskFromBuffer(GxDnnDevice device,
const unsigned char *taskBuffer,
/*===============================================================================================*/
* @brief Release NPU task
* @param [in] task the loaded task handle
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_RESULT_WRONG_PARAMETER wrong parameter
GxDnnResult GxDnnReleaseTask(GxDnnTask task);
/*===============================================================================================*/
#define MAX_SHAPE_SIZE 10
typedef struct NpuIOInfo {
int direction; /* 0: Input; 1: Output */
char name[MAX_NAME_SIZE]; /* name of the IO */
int shape[MAX_SHAPE_SIZE]; /* the shape of the IO */
unsigned int dimension; /* the dimension of the IO */
void *dataBuffer; /* the data buffer */
int bufferSize; /* the data buffer size */
* @brief Get the IO Num of the loaded task
* @param [in] task the loaded task
* [out] inputNum Input number
* [out] outputNum Output Number
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_RESULT_WRONG_PARAMETER wrong parameter
GxDnnResult GxDnnGetTaskIONum(GxDnnTask task,
/*===============================================================================================*/
* @brief Get the IO Info of the loaded task
* @param [in] task the loaded task
* [out] inputInfo the input information List
* [in] inputInfoSize the size of the output info list buffer
* [out] outputInfo the output information list
* [in] outputInfoSize the size of the output info list buffer
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_ERR_BAD_PARAMETER wrong parameter
GxDnnResult GxDnnGetTaskIOInfo(GxDnnTask task,
/*===============================================================================================*/
* @brief The event handler
* @param [in] task the running task
* [in] event the event type
* [in] userData the userData passed by GxDnnRunTask
* @return int 0 break the task
* not 0 continue the task
typedef int (*GxDnnEventHandler)(GxDnnTask task, GxDnnEvent event, void *userData);
/*===============================================================================================*/
* @param [in] task the loaded task
* [in] priority the task priority
* [in] eventHandler the event callback (see remark)
* [in] userData a void data will be passed to event handler
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_RESULT_WRONG_PARAMETER wrong parameter
* @remark if eventHandler == NULL, the function will not return until finish or error happens;
* if the task is running, the task will stop first;
GxDnnResult GxDnnRunTask(GxDnnTask task,
GxDnnEventHandler eventHandler,
/*===============================================================================================*/
* @param [in] task the loaded task
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_RESULT_WRONG_PARAMETER wrong parameter
* @remark if the task is running, the event handler will be invoked
GxDnnResult GxDnnStopTask(GxDnnTask task);
/*===============================================================================================*/
typedef struct NpuDevUtilInfo {
* @brief Get device utilization information
* @param [in] GxDnnDevice device
* [out] GxDnnDevUtilInfo info
* @return GxDnnResult GXDNN_RESULT_SUCCESS succeed without error
* GXDNN_RESULT_WRONG_PARAMETER wrong parameter
* GXDNN_RESULT_DEVICE_ERROR device error
GxDnnResult GxDnnGetDeviceUtil(GxDnnDevice device, GxDnnDevUtilInfo *info);
/*===============================================================================================*/
/* Voice Signal Preprocess
* Copyright (C) 1991-2017 Nationalchip Co., Ltd
* snpu.h: Device Driver for SNPU
int SnpuLoadFirmware(void);
int SnpuFloat32To16(unsigned int *in_data, unsigned short *out_data, int num, int exponent_width);
int SnpuFloat16To32(unsigned short *in_data, unsigned int *out_data, int num, int exponent_width);
typedef int (*SNPU_CALLBACK)(SNPU_STATE state, void *private_data);
const char *version; // version in model.c
void *ops; // ops_content in model.c
void *data; // cpu_content in model.c
void *input; // input in model.c
void *output; // output in model.c
void *cmd; // npu_content in model.c
void *tmp_mem; // tmp_content in model.c
int SnpuRunTask(SNPU_TASK *task, SNPU_CALLBACK callback, void *private_data);
SNPU_STATE SnpuGetState(void);
NPU使用示例
MNIST 示例
MNIST是一个入门级的计算机视觉数据集,它的输入是像素为28x28的手写数字图片,输出是图片对应的0-9数字的概率。下面以TensorFlow自带的mnist 模型(TensorFlow v1.0)为例,说明gxDNN的使用。
生成NPU文件
这个示例的MNIST计算模型非常简单,可以用一个公式来表示: y = x * W + b (训练的过程中还会去计算softmax,但由于我们正式使用时只需要获取结果中最大值的索引,而softmax是个单调递增函数,因此省去这个函数不会对结果有影响)。其中x为输入数据,y为输出数据,W和b为训练的参数。训练的过程就是不断通过计算出来的y和期望的y_去调整W和b的过程。 在NPU上,我们只需要用到训练好的W和b,而不需要训练的过程。
生成ckpt和pb文件
为了方便的获取到输入结点和输出结点,我们给输入结点和输出结点取个名字,把x取名为input_x,把y取名为result: 把mnist_softmax.py第40行
x = tf.placeholder(tf.float32, [None, 784])
x = tf.placeholder(tf.float32, [None, 784], name="input_x")
y = tf.matmul(x, W) + b
y = tf.add(tf.matmul(x, W), b, name="result")
为了生成ckpt和pb文件,在main函数末尾添加:
saver = tf.train.Saver()
saver.save(sess, "mnist.ckpt")
tf.train.write_graph(sess.graph_def, "./", "mnist.pb")
运行程序后,当前路径下会生成mnist.ckpt.*和mnist.pb文件。
把ckpt和pb文件合并成一个pb文件
使用freeze_graph.py脚本将mnist.ckpt.*和mnist.pb合并为一个pb文件。 注意:不同TensorFlow版本的freeze_graph.py脚本可能不同。
python freeze_graph.py --input_graph=mnist.pb --input_checkpoint=./mnist.ckpt --output_graph=mnist_with_ckpt.pb --output_node_names=result
生成mnist_with_ckpt.pb文件。 其中,--input_graph后跟输入pb名,--input_checkpoint后跟输入ckpt名,--output_graph后跟合成的pb文件名,--output_node_names后跟输出结点名称,如有多个,用逗号分隔。 执行完成后,在当前路径下生成mnist_with_ckpt.pb文件。
如果是saved_model方式保存的模型,使用如下命令合成pb文件
python freeze_graph.py --input_saved_model_dir=./saved_model_dir --output_graph=mnist_with_ckpt.pb --output_node_names=result
编辑NPU配置文件
CORENAME: LEO #
PB_FILE: mnist_with_ckpt.pb #
OUTPUT_FILE: mnist.npu #
SECURE: false #
NPU_UNIT: NPU64 # NPU
COMPRESS: true #
COMPRESS_QUANT_BITS: 8 #
OUTPUT_TYPE: raw # NPU
INPUT_OPS:
input_x: [1, 784] #
OUTPUT_OPS: [result] #
编译
gxnpuc mnist_config.yaml
gxnpuc --config=./mnist_config.yaml
执行NPU文件
NPU文件生成后,需要调用API,把模型部署到GX8010开发板上运行。
调用SDK流程
mnist示例
代码请参考这里。程序要求用户输入一个保存有28x28个像素值的二进制文件,输出识别的数字。
images中存放的是若干个二进制测试文件。其内容为28x28的已做归一化的像素值。
执行make生成可执行文件test_mnist.elf。
把mnist.npu、test_mnist.elf和images目录放到GX8010开发板上,并运行,打印如下:
./test_mnist.elf images/image0
Digit: 7
./test_mnist.elf images/image1
Digit: 2
./test_mnist.elf images/image2
Digit: 1
./test_mnist.elf images/image3
Digit: 0
./test_mnist.elf images/image4
Digit: 4
./test_mnist.elf images/image5
Digit: 1
NPU模拟器
概述
NPU模拟器能够在PC机上模拟NPU硬件行为,使用NPU模拟器,用户可以在缺少硬件环境的情况下,方便地部署和调试模型,验证模型搭建是否正确,测试模型准确率等。
代码获取
NPU模拟器的库和示例代码在我们的阿里云代码服务器上,如果您需要下载权限,请告知我们的FAE,我们会给您释放下载代码的权限。
编译运行
我们同时发布了带有版本信息的动态库libgxdnn.so和静态库libgxdnn.a,您可以按需使用。
编译工具可以使用gcc,链接时需要加上C++的标准库-lstdc++,需要注意的是,gxdnn库的版本号需要和NPU编译器的版本号一致。
一文看懂芯片的NPU算力到底有什么用?算力是怎么评估的?
算力简单说就是计算能力,按《中国算力发展指数白皮书》中的定义算力是设备通过处理数据,实现特定结果输出的计算能力。2018年诺贝尔经济学奖获得者William D. Nordhau滤《计算过程》一文中提出:“算力是设备根据内部每秒可处理的信息数据量"。算力实现的核心是CPU、GPU等各类计算芯片,并由计算机、服务器、高性能计多集群和各类智能终端等承载,海量数据处理和各种数字化应用都离不开算力的加工和计算。
以AI为例,CPU、GPU、DSP等都可以运行,但是还是有专用的AI芯片,为什么呢?也跟算力有关。
· CPU(central processing unit)是通用处理器,可以处理一切事物,就像一把瑞士军刀,哪方面都能做但都不是专业高效的。
· GPU(Graphics Processing Unit)是专门用来处理图形图像相关的处理器,与CPU相比GPU处理的数据类型单一,因为运算与AI相似以及容易组成大的集群,所以进行AI运算时在性能、功耗等很多方面远远优于CPU,经常被拿来处理AI运算。
· DSP(digital signal processor),是专门用来处理数字信号的,DSP与GPU情况相似,也会被拿来做AI运算,比如高通的手机SoC。
AI芯片是专门用来处理AI相关运算的芯片,这与CPU、GPU、DSP的“兼职”做AI运算不同,即便是最高效的GPU与AI芯片相比也是有差距的,AI芯片在时延、性能、功耗、能效比等方面全面的超过上面提到的各种处理器。以知名的谷歌的TPU为例,如下图所示,TPU的主要计算资源为:
· Matrix Multiply Unit:矩阵乘单元
· Accumulators:存储矩阵乘加输出的中间结果






