


百度飞桨应用技术分析
百度飞桨应用技术分析
百度飞桨:以开源视觉算法升级智慧交通
交通是兴国之要、强国之基。随着城市的快速发展、车辆和行人数量的日益增多,强依赖人力管控的传统交通治理模式在交通拥堵治理、信号调控、秩序改善等典型场景上,都遇到种种挑战。利用人工智能技术能够有效提高对交通问题的治理效率,实现全方位、24小时地异常情况预警与智能分析,从而提高执法效率,缓解交通堵塞,大幅减少碳排,支撑传统交通行业的转化升级,从真正意义上实现“数字化”、“智能化”与“减碳化”。百度飞桨针对城市轨道交通、道路交通及高速公路,提供围绕人、车、路、环境的智能感知与分析能力,助力开发者高效建设智能化的路网运行感知体系、实时的预报预警体系和高效的应急保障体系,快速实现车流监测、车辆跟踪定位、异常停留检测、人车关系判断等十余种任务,从而缓解交通拥堵、改善交通状况,发挥城市交通最大效能。

飞桨智能交通全景这一系列开源算法被包括武汉铁路局、上海天覆科技、北京德厚泉等知名企业广泛应用在出入口车辆管控、智能查车、车牌识别等典型交通治理场景,精度最高可提升至95%以上。从“人眼看”全面升级至“天眼算”,实现人力成本降低60%以上的卓越效果。人工智能技术的日益成熟带动行业中越来越多的企业尝试应用AI能力,飞桨与行业重点合作伙伴梳理、抽象出以下典型交通治理场景,为开发者提供交通智能化更多的思路。
场景一:交通拥堵治理
交通监管中最高频的场景即是出入口车流量监控,及时预警道路拥堵情况,不仅可以大幅优化城市交通状况,更可大幅减少不必要碳排放。实际应用中面临拍摄角度与光线多变、涉及车辆类型繁多、统计与预警实时性要求高三大难题,飞桨实时多目标跟踪PP-Tracking中提供的车流量统计算法则能完美“消化”这三大难题,应用服务器端轻量级版FairMOT模型预测得到目标轨迹与ID信息,支持自定义流量统计时间间隔,实现动态人流/车流的实时去重计数。
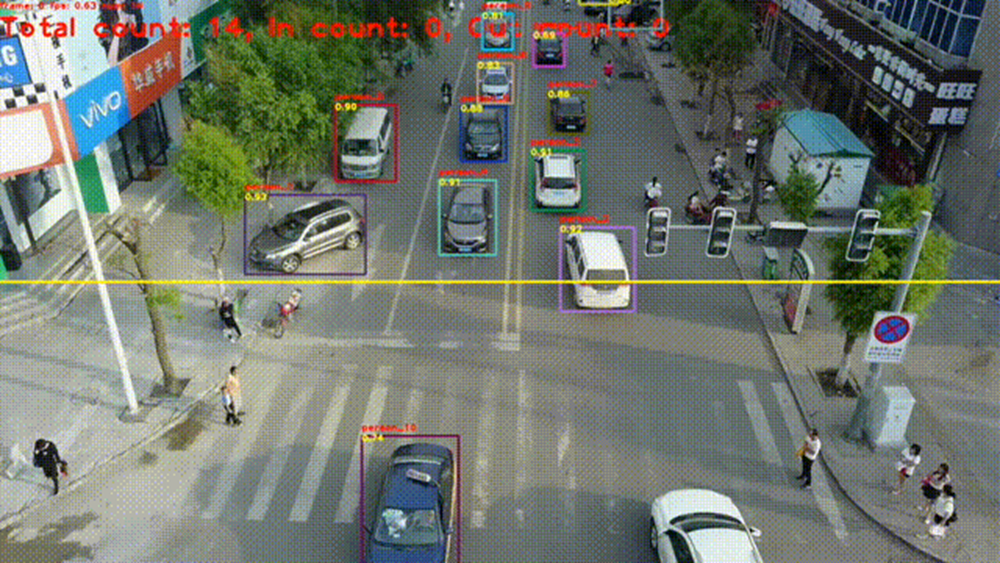
飞桨多目标跟踪能力:https://github.com/PaddlePaddle/PaddleDetection/blob/develop/deploy/pptracking/README_cn.md
场景二:交通违章事件精准识别
通过飞桨目标检测、多目标跟踪的技术,可对车辆异常停留、车辆违停、车辆逆行等交通违规事件进行毫秒级精准识别,提前阻止交通事故发生,保障道路运行安全。

视频数据引用自:http://www.sutpc.com/news/jishufenxiang/800.html飞桨相关技术介绍:https://github.com/PaddlePaddle/PaddleDetection/blob/develop/README_cn.md
场景三:智能车辆人员监管
传统车辆人员监察依靠人力抽查,对人力消耗极大,而机器视觉方式也无法完全代替人工,需要人工反复审核,无法从根本上解决人力成本与准确度的平衡。飞桨所提供的目标检测、多目标跟踪、OCR技术,助力北京德厚泉科技公司零人工成本实现车辆进出数量统计、车牌识别、人车关系分析,如检测保安是否按规定查车等,不仅完全释放人力,其识别准确性达到97%,真正意义上实现智能化升级。



飞桨行人分析技术介绍:
https://github.com/PaddlePaddle/PaddleDetection/tree/develop/deploy/pphuman在未来,飞桨会持续丰富场景化能力,围绕人、车、路、环境不断拓展垂类能力,新增车辆分析相关能力,囊括车辆属性(车牌、颜色、车型等)、车辆异常(逆行、超速、撞击)等功能。以最低门槛、最高性能为初心,助力智慧交通实现运行模式的智能化、信息化升级, 加快发展“绿色AI”,引导算力算法低碳发展,助力“双碳”目标更好实现。飞桨目标检测套件项目地址:
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/README_cn.md
百度王海峰披露飞桨生态最新成果 开发者数量已达800万
8月16日,由深度学习技术及应用国家工程研究中心主办的WAVE SUMMIT深度学习开发者大会2023在北京举行。百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰做了主题演讲。王海峰首次对外表示,大语言模型具备了理解、生成、逻辑、记忆等人工智能的核心基础能力,为通用人工智能带来曙光。
飞桨开发者数已达800万
模型数超80万
WAVE SUMMIT深度学习开发者大会始于2019年4月。王海峰在首届大会上提出,深度学习具有很强的通用性,并具备标准化、自动化和模块化的工业大生产特征,推动人工智能进入工业大生产阶段。四年来,深度学习技术和应用的发展充分验证了这一观点。深度学习技术的通用性越来越强,深度学习平台的标准化、自动化和模块化特征越来越显著,而预训练大模型的兴起,使得人工智能应用的深度和广度进一步拓展。人工智能已进入工业大生产阶段。
标准化方面,框架和模型联合优化,多硬件统一适配,应用模式简洁高效,大幅降低人工智能应用门槛;自动化方面,从训练、适配,到推理部署,提升人工智能研发全流程效率;模块化方面,丰富的产业级模型库,支撑人工智能在广泛场景的便捷应用。

据了解,得益于飞桨产业级深度学习开源开放平台和文心大模型的互相促进,飞桨生态愈加繁荣,已凝聚800万开发者,服务22万家企事业单位,基于飞桨创建了80万个模型。王海峰阐释了飞桨开发者社区AI Studio中文名“星河社区”的隽永含义,“文心加飞桨,翩然赴星河”。和所有的开发者一起,在飞桨和文心的加持下,共建星河社区,共赴通用人工智能的星辰大海。

大语言模型为通用人工智能带来曙光
王海峰表示,人工智能具有多种典型能力,理解、生成、逻辑、记忆是其中的核心基础能力,这四项能力越强,越接近通用人工智能,而大语言模型具备了这四项能力,为通用人工智能带来曙光。
具体而言,人工智能的典型能力如创作、编程、解题、规划等都依赖于理解、生成、逻辑、记忆等核心基础能力,依赖程度有所不同。以解题为例,从读懂题目、解答题目到最后写出答案,需要理解、记忆、逻辑及生成能力的综合运用。
如何获得这些能力呢?以文心一言为例,首先从数万亿数据和数千亿知识中融合学习得到预训练大模型,在此基础上采用有监督精调、人类反馈的强化学习和提示等技术,并具备知识增强、检索增强和对话增强等技术优势。
进一步地,通过多种策略优化数据源及数据分布、基础模型长文建模、多类型多阶段有监督精调、多任务自适应有监督精调、多层次多粒度奖励模型等技术创新,全面提升基础通用能力。在检索增强和知识增强的基础上,通过知识点增强,提升对世界知识的掌握和运用;通过大规模逻辑数据构建、逻辑知识建模、多粒度语义知识组合以及符号神经网络,提升逻辑能力;通过构建数据、内容、模型和系统安全的全面安全体系,保障大模型的安全性。
效率方面,通过飞桨端到端自适应混合并行训练技术以及压缩、推理、服务部署的协同优化,文心大模型训练速度达到原来的3倍,推理速度达到原来的30多倍。
应用方面,通过数据驱动、提示构建,以及插件增强进行场景适配,协同优化。文心一言已上线百度搜索、览卷文档、E 言易图、说图解画、一镜流影五大插件,使模型具备生成实时准确信息、长文本摘要和问答、数据洞察和图表制作、基于图片的创作和问答、文生视频等能力。插件机制扩展了大模型能力边界,更适应场景需要。王海峰表示,未来百度将与开发者共建插件生态,共享技术创新成果。
以大语言模型为代表的人工智能正在深入千行百业,加速产业升级和经济增长。在这个进程中,技术创新和应用落地形成良性循环,理解、生成、逻辑、记忆等能力持续提升,产业应用的广度和深度持续拓展,大语言模型为通用人工智能带来曙光。
参考文献链接
https://mp.weixin.qq.com/s/1lSuw6QK5jbrHhIV0e-2Vg
https://mp.weixin.qq.com/s/_V72Br1yLKG53DPxAq3wNg

