
AI芯片与GPU技术市场分析
AI芯片与GPU技术市场分析
中国AI芯片提速了
美国芯片技术的领先地位
1、介绍摩尔定理和美国芯片巨头
在介绍美国芯片技术的领先地位之前,我们首先要了解摩尔定理的重要性。摩尔定理由美国芯片行业先驱戈登·摩尔于1965年提出,预测了集成电路中晶体管数量每隔18至24个月翻倍,而成本则约每隔24个月减半。这一定律推动着芯片技术的快速发展,使得美国成为全球芯片技术的领先者。

美国芯片巨头如英特尔、高通、美光科技等公司在全球半导体市场占据着重要地位,并持续推动着芯片技术的创新。这些公司拥有先进的制造工艺和研发能力,使得美国芯片技术在世界上具有较高竞争力。

美国对中国半导体产业的限制
1、美国的限制政策
美方对华芯片限制的措施主要包括对中国企业的制裁和对芯片出口的限制。美国政府以国家安全为由,对中国一些企业实施禁运措施,禁止美国企业向其供应芯片和相关技术。同时,美国还限制了一些先进工艺的芯片出口给中国企业,限制了中国半导体产业的发展。

这些限制措施对中国半导体产业造成了一定的困扰,但也激发了中国加强自主研发和创新的决心。

中国半导体行业的突破
1、中国芯片行业的自主研发
面对美国的限制,中国芯片行业加大了自主研发的力度。中国科学院和龙芯公司正式宣布取得重大突破,推出了具有自主知识产权的龙芯系列芯片。这些芯片采用了先进的制造工艺,并在性能和功耗方面取得了显著突破。

此外,中国半导体产业还加强了与国际合作伙伴的交流与合作,吸引了一批优秀的芯片设计和制造人才。通过自主研发和创新,中国半导体行业正在逐步缩小与国际先进水平的差距。

中国芯片在市场上的竞争
1、国产芯片的迎头赶超
随着中国芯片技术的进步,国产芯片在市场上的竞争力不断增强。中国公司如华为、海思、中芯国际等在手机、通信、物联网等领域推出了一系列优秀的芯片产品,取得了良好的市场反响。

国产芯片的迎头赶超不仅提高了中国半导体产业的地位和影响力,也为中国科技企业提供了更多的自主可控的核心技术支持。
中国芯片在AI领域的突破
1、中国芯片在GPU和光计算领域的突破
中国芯片在人工智能领域取得了重要的突破。中科院和龙芯公司推出的龙芯系列芯片在GPU和光计算方面取得了重大进展,为人工智能应用提供了更强大的计算能力。
这些突破不仅提升了中国芯片在人工智能领域的竞争力,也推动了中国在AI领域的发展。中国芯片的突破为人工智能应用的普及和推广提供了重要支撑。
总结:
中国芯片的突破和发展正在改变全球半导体产业的格局。面对美国对华芯片限制的挑战,中国通过自主研发和创新不断提升芯片技术,取得了显著的进展。国产芯片在市场上的竞争力不断增强,中国芯片在AI领域也取得了重要突破。中国芯片的崛起必将对全球半导体产业产生深远的影响。
十大国产GPU产品及规格概述
国产GPU 持续发力,对标行业龙头缩小差距。GPU 有两条主要的发展路线:分别为传统的 2D/3D 图形渲染 GPU 和专注高性能计算的 GP GPU。
近年来,国产GPU 厂商在图形渲染 GPU 和高性能计算 GPGPU 领域上均推出了较为成熟的产品,在性能上不断追赶行业主流产品,在特定领域达到业界一流水平。生态方面国产厂商大多兼容英伟达 CUDA,融入大生态进而实现客户端导入。



1、寒武纪
寒武纪自 2016 年成立以来一直专注于人工智能芯片产品研发与技术创新,致力于打造人工智能领域的核心处理器芯片。公司主要提供云端智能芯片及加速卡、训练整机、边缘智能芯片及加速卡、终端智能处理器 IP 及配套基础软件开发平台,产品广泛应用于消费电子、数据中心、云计算等诸多场景。

2022 年 3 月 21 日,公司正式发布新款训练加速卡 MLU370-X8,搭载双芯片四芯粒思元 370,集成寒武纪 MLU-Link™多芯互联技术,在业界广泛应用于YOLOv3、Transformer 等训练任务中。

MLU 370-S4、MLU370-X4 和 MLU370-X 均基于思元 370 智能芯片的技术,通过 Chiplet 技术灵活组合产品的特性,可满足更多市场需求。
2、海光信息
海光信息主要从事高端处理器、加速器等计算芯片产品和系统的研发、设计和销售。公司的产品包括海光通用处理器(CPU)和海光协处理器(DCU),具有成熟而丰富的应用生态环境,内置专用安全硬件,可满足互联网、金融、能源等行业的广泛应用需求。

公司 DCU 系列产品海光 8100 采用先进的 FinFET 工艺,以 GPGPU 架构为基础,兼容通用的“类 CUDA”环境以及国际主流商业计算软件和人工智能软件,可充分挖掘应用的并行性,发挥其大规模并行计算的能力。

3、景嘉微
景嘉微致力于信息探测、处理与传递领域的技术和综合应用。公司产品涵盖集成电路设计、小型雷达系统、无线通信系统、电磁频谱应用系统等方向,广泛应用于有高可靠性要求的航空、航天、航海、车载等专业领域。
公司先后自研制成功 JM5 系列、JM7 系列、JM9 系列高性能 GPU 芯片,其中最新的 JM9 系列两款图形处理芯片皆已完成阶段性测试工作,并进入放量阶段。JM9 系列芯片应用领域广泛,可满足个性化桌面办公、网络安全保护、轨交服务终端、多屏高清显示输出和人机交互等多样化需求。

4、芯原股份
芯原依托自主半导体 IP,为客户提供平台化、全方位、一站式芯片定制服务和半导体 IP 授权服务,拥有独特的“芯片设计平台即服务”经营模式。公司可提供高清视频、物联网连接、数据中心等多种一站式芯片定制解决方案,拥有自主可控的图形处理器 IP、神经网络处理器 IP 等五类处理器 IP 及 1400 多个数模混合 IP 和射频 IP,可快速打造出从定义到测试封装完成的半导体产品,业务范围覆盖消费电子、汽车电子、物联网等多种应用领域。据 IPnest 在 2021 年的统计,芯原的半导体 IP 销售收入排中国大陆第二,全球第七,其中公司的图形处理器 IP 排名全球前三。

公司的 GPU IP 已被众多主流和高端的汽车品牌所采用,同时,公司基于约 20年 Vivante GPU 的研发经验,所推出的 Vivante 3D GPGPU IP 还可提供从低功嵌入式设备到高性能服务器的计算能力,满足广泛的人工智能计算需求。
5、壁仞科技
壁仞科技创立于 2019 年,在 GPU、DSA(专用加速器)和计算机体系结构等领域具有深厚的技术积累。公司致力于开发原创性的通用计算体系,建立高效的软硬件平台,同时在智能计算领域提供一体化的解决方案。

2022 年 8 月公司发布的通用 GPU 芯片 BR100 创下全球通用 GPU 算力记录,峰值算力达到国际厂商在售旗舰产品 3 倍以上。BR100 率先采用 Chiplet 技术、新一代主机接口PCIe 5.0、支持 CXL 互连协议,确立了公司在国内厂商间的技术领先地位。公司坚持自主研发,同步推出原创架构“壁立仞”和自研BIRENSUPA 软件平台,实现了 BR100 性能的大幅提升。
以壁仞科技于 2022 年8 月发布的首款 GP GPU BR100 为例,该芯片采用 Chiplet 技术,16 位浮点算力达到 1000T 以上、8 位定点算力达到 2000T 以上,单芯片峰值算力达到 PFLOPS级别,是国际厂商在售旗舰产品的 3 倍以上,创造了全球通用 GPU 的算力记录。
6、摩尔线程
摩尔线程专注于设计高性能通用 GPU 芯片,提供图形计算和 AI 计算的元计算平台的集成电路高科技公司。公司高管团队来自英伟达、AMD、ARM 等知名芯片公司,拥有丰富的 GPU 研究经验,致力于创新面向元计算应用的新一代GPU,构建融合视觉计算、3D 图形计算、科学计算及人工智能计算的综合计算平台,建立基于云原生 GPU 计算的生态系统。

2022 年 11 月,公司推出基于第二代 MUSA 架构的处理器“春晓”,并基于“春晓”GPU 发布面向消费领域的国产芯片显卡 MTT S80 和面向服务器应用的MTTS3000 显卡。同时,公司围绕 MUSA 发布了系列 GPU 软件栈与应用工具,包括 MUSA 开发者套件、云原生 sGPU 技术及元宇宙平台 MTVERSE 等。
7、芯动科技
芯动科技是国内一站式 IP 和芯片定制及 GPU 领军企业,聚焦计算、存储、连接等三大赛道,提供从 55 纳米到 5 纳米全套高速 IP 核以及高性能定制芯片解决方案。公司拥有经验丰富的技术团队,成立 16 年来已赋能全球数百家知名客户,授权逾 80 亿颗高端 SoC 芯片进入规模量产,拥有过十亿颗 FinFET 定制芯片成功量产经验。

公司瞄准商用市场推出芯动风华系列 GPU。该系列 GPU 性能强劲、跑分领先、功耗低、自带智能计算能力,且全面支持国内外 CPU/OS 和生态,包括 Linux、Windows 和 Android。
8、兆芯
兆芯成立于 2013 年,提供高效、兼容、安全的自主通用处理器和芯片组等产品,公司掌握自主通用处理器及其系统平台芯片研发设计的核心技术,全面覆盖其微架构与实现技术等关键领域,拥有较为完整的知识产权体系,截至目前已获权约 1300 件专利。
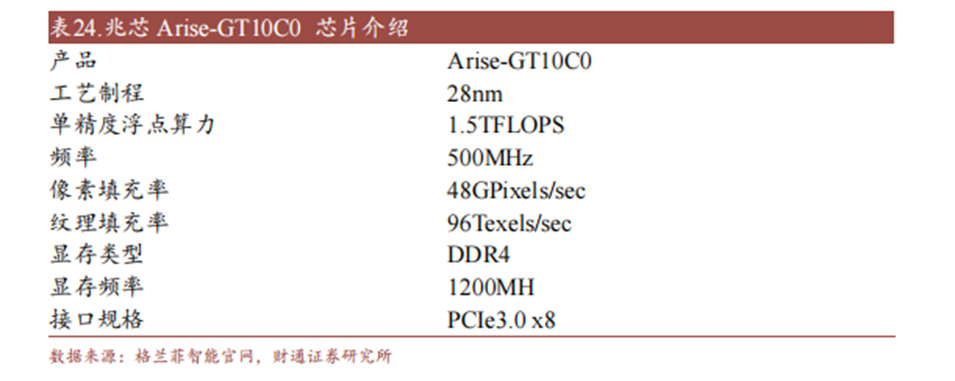
2020 年,兆芯将自身 GPU 业务进行切分独立,建立了格兰菲智能科技有限公司。公司目前已推出 Arise-GT10C0 芯片及 Glenfly Arise-GT-10C0 显卡。芯片内置完全独立自主研发的新一代图形图像处理引擎,兼容银河麒麟 KOS、统信软件 UOS、Windows 等主流操作系统,同时可在 X86、ARM、MIPS 等主流硬件台操作运行,支持多种图形和图像的 API 接口标准。
9、天数智芯
天数智芯致力于开发自主可控、国际领先的高性能通用 GPU 产品并提供解决方案,是国内头部通用 GPU 高端芯片及超级算力系统提供商。公司以“成为智能社会的赋能者”为使命,立足客户、市场的需求,加速 AI 计算与图形渲染融合,探索通用 GPU 赶超发展道路,产品广泛应用于智算重心、智慧医疗、互联网、智能制造等领域。

12 月 20 日,天数智芯推出通用 GPU 推理产品“智铠 100”及其丰富的 AI 应用案例。智铠 100 计算性能高、应用覆盖广、使用成本低,支持 FP32、FP16、INT8多精度混合计算,可提供最高 384TFlops@int8、96TFlops@FP16、24TFlops@FP32 的峰值算力,800GB/s 的理论峰值带宽以及 128 路并发的多种视频规格解码能力。
10、沐曦
沐曦于 2020 年 9 月成立于上海,致力于为异构计算提供全栈 GPU 芯片及解决方案,可广泛应用于人工智能、智慧城市、自动驾驶、数字孪生、元宇宙等前沿领域。公司拥有技术完备、设计和产业化经验丰富的团队,核心成员平均拥有近20 年高性能 GPU 产品端到端研发经验。

公司拥有完全自主研发的 GPU IP、指令集和架构,以及兼容主流 GPU 生态的完整软件栈(MXMACA),产品具备高能效、高通用性。目前已推出 MXN 系列GPU(曦思)用于 AI 推理,MXC 系列 GPU(曦云)用于 AI 训练及通用计算,以及 MXG 系列 GPU(曦彩)用于图形渲染,可满足数据中心对高能效和高通用性的算力需求。
参考文献链接
https://mp.weixin.qq.com/s/ZJ0DplL5UyFzgvVy7VZsFQ
https://mp.weixin.qq.com/s/iWQLkBrPGsgaRt9nGt7DLQ

