
大模型算力AI芯片与RISC –V分析
大模型算力AI芯片与RISC –V分析
RISC -V跑大模型
2022年,ChatGPT的出现震惊了全世界,在短短几个月的时间内,ChatGPT的月活跃用户达到了1亿。ChatGPT的成功让许多人第一次知道了大语言模型(Large Language Model)的概念,而2023年Meta发布的LLaMA则在ChatGPT的基础上又往前跨了一大步,它大大降低了LLM的使用难度,让LLM真正“走进基层”。那LLaMA是什么呢?1. LLaMA介绍在介绍LLaMA之前,首先要介绍一下LLM(Large Language Model)。
可以将LLM看成一位知识渊博的老师,在经过大量的知识学习(大量文本数据的训练)后,LLM会基于它的知识库,给出问题的最佳答案,可以使用LLM来完成文本总结、翻译、情感分析等工作。最近几年,是LLM的高速发展期,很多科技巨头都在LLM投入大量的资金。下面是这几年LLM的成果图:
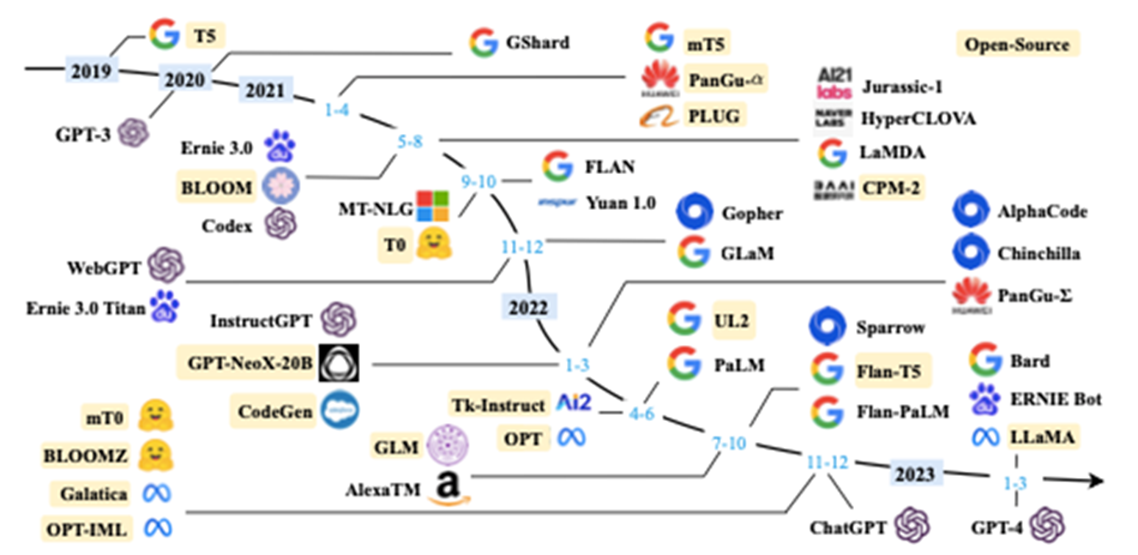
近年来现有大型语言模型(大小大于10B)的时间表但对于个人研究者而言,LLM的使用是有一定的门槛,一般的LLM模型对硬件的要求比较高,而一些开发公司出于商业的目的,并不打算将项目的源码进行开源,这都限制了个人研究者从更深的层次去了解LLM,在一定程度上这影响了LLM的发展(Android能有今天地位,离不开开源和方便使用,这为它后来的迅速发展打下了良好的基础)。好在2023年Meta发布的LLaMA(Language Learning through Multimodal Autoregressive Models)给了对LLM感兴趣的开发者另一个选项,相较于其他的LLM模型而言,LLaMA优势在于它足够亲民且开源。从亲民的角度来说,LLaMA的规模仅为ChatGPT的“十分之一”,但性能却优于OpenAI的GPT-3模型,而且LLaMA只是一个基础模型,它完全可以使用公开的数据模型进行训练,这都使得LLaMA的使用门槛被大大降低;从开源的角度来说,LLaMA可以说是被迫开源,因为技术方面的问题,Meta暂缓了开源过程,但在发布后的不久,LLaMA的模型文件就被泄露了,那么,问题来了,这究竟是故意的还是不小心的呢?2. llama.cppllama.cpp是由保加利亚索非亚的Georgi Gerganov基于LLaMA模型开发的纯C版本。Georgi Gerganov是一位资深的开源社区开发者,曾经还为OpenAI的自动语音识别模型开发了whisper.cpp。llama.cpp可以让使用者在没有GPU的情况下也能运行LLaMA模型。所以它一经发布,就吸引了大量对LLaMA感兴趣的人下载使用,很快就有人找到了在Windows上运行LLaMA的方法,之后又实现了在手机上的运行。llama.cpp大大降低了LLaMA的使用门槛,通过llama.cpp,LLaMA展现了它无与伦比的语言学习能力,为打开了一座探索语言世界的新大门。值得一提的是,Georgi Gerganov在公布llama.cpp后的几个月就自主创业,成立了ggml.ai公司,这个公司的合伙人有GitHub前CEO Nat Friedman和Y-Combinator的Daniel Gross。ggml.ai的成立也引起了许多业内大佬的注意,或许它之后会为AI的发展带来一些不一样的东西。3. 硬件平台简介3.1 RISC-V简介澎峰科技联合创始人王军辉说“2023年是RISC-V高性能计算元年”。因为2023年算能推出了全球第一颗已量产的RISC-V服务器级64核CPU,这意味RISC-V进入高性能计算领域的未来已经不远了。那么,RISC-V到底是什么?简单来说,RISC-V和熟悉的X86、ARM一样,都是指令集架构,但X86属于复杂指令集(CSIC),RISC-V和ARM属于精简指令集(RISC)。虽然CISC指令丰富功能强大,但随着CISC的逐步发展,过于复杂的指令不仅会导致指令使用率不均衡(效率低),也加大了超大规模集成电路实现的难度。相对的,RISC的优势在于指令简单,使用率均衡,执行效率高。同时,通常基于RISC的芯片易于实现电路设计和大规模集成。正如文章开篇所展示的,在基于SG2042的RISC-V平台上完成了LLaMA的移植。LLM和RISC-V都是近两年比较热门的东西,同时又有很大的空白供开发者们探索和建设,所以觉得把两者结合这是一件很有意思也很有意义的事情。下面简单介绍一下使用的开发平台。3.2 平台RISC-V服务器主板(搭载全球第一颗量产的服务器级64核RISC-V芯片SG2042)

3.3 基本配置
|
硬件平台配置 |
|
|
CPU |
SG2042(64 Core@2.0GHz) |
|
DDR |
32GB 3200MHz |
|
Local Storage |
1T M.2 NVMe SSD |
|
操作系统配置 |
|
|
OS |
Ubuntu |
|
Kernel |
Linux 5.19.17 |
算力突围之战:AI芯片封堵再加剧,国内算力需求寻路
关于英伟达A800芯片可能被禁售的消息,正在引发连锁反应。
一位英伟达芯片代理商表示,大约一周前,关于英伟达A800芯片被禁售的这个信号“让市场上的A800价格一下子涨了起来。”
据这位代理商介绍,英伟达A800 80GB PCie标准版GPU的市场价,15天前在9万元人民币/颗,“现在(一颗)11万元左右。”即便价格飞涨,他表示,英伟达的高端算力GPU芯片依然是“抢手货”,在他看来,英伟达的H800系列GPU芯片目前还可以正常供应,只不过价格更高了。
一面是越来越贵、越来越稀缺的高端芯片,一面是下游需求高涨的“百模大战”,寻找另一条道路,成为迫在眉睫的选择。
在被认为是“史上最火爆”的上海2023年世界人工智能大会(WAIC)上,算力需求和缺口成为了高频词汇。
7月7日上午,清华大学电子工程系教授汪玉表示,若以大语言模型作为底座,同时处理国14亿人的推理请求,所需的计算量超过目前国数据中心总算力的3个数量级。他由此强调国现有算力资源的紧张程度。
“没有大算力,做大模型就是天方夜谭。”中国工程院院士、鹏城实验室主任高文也在WAIC上透露,团队正在紧锣密鼓地对一个2000亿参数的大模型进行训练,至少“需要4000块卡训练100天”。
云计算技术专家刘世民早早注意到,国内正式渠道如今愈发买不到高端AI芯片,面对算力发展遭遇限制,他也看到,一些云厂商基于相关AI产品可以提供GPU算力这一最基础的AI服务,当然,其中不乏AWS、Azure这样的海外云服务商。
“目前算力比较紧张,所以会选择租赁云算力。”云从科技研究院的孙进透露,买不到高端算力卡,加之自建算力集群周期长,即便租赁云算力成本相较自建要高,“高出50%~100%”,但这依然成为一些对算力有需求的科技公司的选择。
如今,这条道路也在面临更多挑战:7月4日,有消息称美国计划对使用亚马逊云、微软云等海外云计算服务的中国企业施加限制。这是继2022年美国限制对华半导体出口,2023年拉拢日本、荷兰对华限制出口先进芯片制造设备后又一举措,“现在估计又要封堵云GPU了。” Vibranium Consulting副总裁陈沛说。
围堵加码
陈沛介绍,云GPU要比自建GPU算力集群贵,“大型云厂商的价格差不多一小时2-3美元。”据他所知,AWS、Azure这样的大型云服务商在新加坡有提供部分种类的云算力服务,在中国亦然。
2022年8月,当英伟达的GPU计算芯片A100和H100被美国政府要求限制向中国出口后,对高端算力有需求的厂商,还可以在拥有先进制程AI芯片的AWS、Azure等云厂商提供的云端算力服务中得到满足。
而今限制如果继续升级,中国厂商未来若想使用AWS、Azure等海外云服务商的云端算力服务,也要获得美国政府许可才行。
2022年,由IDC、浪潮信息、清华大学全球产业研究院联合编制了一份《2021-2022全球计算力指数评估报告》,量化揭示了算力的重要性:全球各国算力规模与经济发展水平显著正相关,计算力指数平均每提高1点,数字经济和GDP将分别增长3.5‰和1.8‰;美国和中国的计算力指数分别为77分和70分,同属国别计算力的领跑者。
上述半导体行业观察人士建议,正在算力侧展开自研创新的中国厂商们,当下“需要丢掉幻想”,她认为,只有不断攻克芯片的成熟制程,叠加软件创新才能共同提升算力。
在中国算力突围路径中,国产GPU芯片自研替代被认为是第一大选择,但这一选择需要时间。目前最现实的选择是,如何最大化地利用现有的高端芯片资源。
算力共享
按照外媒此前披露,作为微软全力扶持的AI创业公司,OpenAI拥有微软Azure云最高优先级的支持——约有2.5万个英伟达GPU正在支持GPT大模型的训练,这是目前世界上规模最庞大的AI服务器之一。而OpenAI光用在训练ChatGPT上,就使用了1万个英伟达的GPU。
但即便是微软,GPU也面临缺口。2023年6月,在公开的OpenAI CEO Sam Altman 谈话纪要中提到,GPU的短缺拖延了Open AI客户的许多短期计划。但这份谈话纪要很快被删除。
按照此前媒体报道,目前中国企业GPU芯片持有量超过1万枚的不超过5家,拥有1万枚A100的至多1家。且由于美国2022年8月开始算力封锁,这些存货的剩余使用寿命约为4-6年。
但现实正在急剧变化:伴随着2023年以来的生成式AI浪潮和大模型井喷,此前存在的缺口无疑还在进一步放大。
由此,在国内推动“算力共享”被提上日程。
北京市经信局4月下旬公布的“北京市通用人工智能产业创新伙伴计划”,进展迅速。7月3日,计划公布了第二批伙伴名单中共有63家企业,其中包括百度、京东、神州数码和金山等10家算力供应伙伴。
北京市经信局公布的第一批算力供应方伙伴名单只有两家,一个是北京超级云计算中心,另一个便是阿里云计算有限公司。
2022年8月30日,阿里云推出飞天智算平台的同时,还启动了张北和乌兰察布两座超大规模智算中心,以公有云和专有云两种模式,为各类机构提供服务。
彼时阿里云表示,其智算平台以及智算中心可将计算资源利用率提高3倍以上,AI训练效率提升11倍。毫无疑问,当国内算力供应因芯片卡短缺陷入紧张时,云端算力可以补位。
当阿里云提出“算力普惠”的目标愿景时,华为也通过推出昇腾AI集群解决方案,以填补着算力需求和硬件算力供给间的沟壑。在7月6日下午的WAIC上,华为昇腾计算业务总裁张迪煊宣布,昇腾AI集群规模从最初的4000卡扩展升级至16000卡,成为业内首个万卡AI集群,其算力已经在支撑像科大讯飞等企业进行大模型训练以及智能化转型。
AI缺口
如今受益于昇腾AI集群的算力支持,讯飞星火大模型的优化训练在有序进行中。科大讯飞高级副总裁胡国平在WAIC上强调,所有的大模型训练都强烈依赖高端AI芯片集群和生态。
不过,孙进告诉记者,云端算力共享或租赁,往往适用于低频训练需求的厂商。“基于同样或同类型的算力芯片,云厂商提供的云GPU确实可以形成替代。”但他表示,“各地建设的训练算力集群,大部分是消费级推理卡集群,或者是CPU集群。”
一般来说,算力被分为三类:通用算力、智能算力、超算算力。在传统产业数字化转型的场景中,基于普通CPU芯片集成的服务器所能提供的通用算力就可满足;而人工智能发展、大模型的训练和推理,这些对应的则是智能算力,是要基于AI芯片所提供的算力。此外,天体物理、航空航天等复杂运算则需要超算算力。
据工信部消息,近年来中国算力产业规模快速增长,年增长率近30%,算力规模排名全球第二,仅次于美国。
但当下的问题在于,这其中一部分并不是本轮生成式AI所需求的智能算力,而只是通用算力。
此前发布的《中国算力指数发展白皮书(2022)》显示,中、美在全球算力规模中的份额分别为33%、34%,其中通用算力份额分别为26%、37%,智能算力分别为28%、45%,超级算力分别为18%、48%。
在刘世民看来,算力共享确实可以让更多企业能用上算力,但先进芯片所代表的高端算力,一旦被限制,势必限制国内算力的增长。而今,中国的人工智能产业又已经步入AIGC时代,参与其中的厂商需要进行的是高频训练,持续的优化迭代。
值得关注的是,算力需求暴增下,供给背后的国产GPU自研以及软件创新,都将是中国厂商亦步亦趋要解决的问题。
陈沛说,种种限制框架下,英伟达提供的高端算力,在市场上不只受欢迎,还是刚需。陈沛记得2020年OpenAI训练GPT-3时,用的是英伟达GPU芯片V100,“一万颗,耗时14.8天”,但在一周前,他看到英伟达发出的最新测试结果中显示,仅用3000多颗H100 GPU芯片,11分钟就完成了GPT-3的模型训练。
“英伟达依然是AI训练领域的老大。”陈沛说。
一位国产AI大模型厂商的创始人也告诉记者,目前其自研的大模型正在储备的英伟达算力芯片上“跑着”,尽管芯片禁售是未来式,但面对大模型浪潮所带来的高频算力需求,目前没有太多的备选方案。
参考文献链接
https://mp.weixin.qq.com/s/KpZWQlnjtmscVUrlJ5QjQA
https://m.wind.com.cn/mobwftweb/M/news.html?share=wechat&show=wft&shareCode=92bf28cfa7aa52887d24c0c8a3b9ee22&code=FE327CD41D28&newsopenstyle=wind&lan=cn&device=ios&fontsize=normal&related=true&version=23.5.1&skin=#/7A602E2DC66277414E6CCE4C4268F651

