

BEV自动驾驶3D检测算法分析
BEV自动驾驶3D检测算法分析
60多篇BEV算法你都知道吗?2023最新环视自动驾驶3D检测综述!
摘要
基于视觉的3D检测任务是感知自动驾驶系统的基本任务,这在许多研究人员和自动驾驶工程师中引起了极大的兴趣。然而,使用带有相机的2D传感器输入数据实现相当好的3D BEV(鸟瞰图)性能并不是一项容易的任务。本文对现有的基于视觉的3D检测方法进行了综述,聚焦于自动驾驶。论文利用Vision BEV检测方法对60多篇论文进行了详细分析,并强调了不同的分类,以详细了解常见趋势。此外还强调了文献和行业趋势如何转向基于环视图像的方法,并记下了该方法解决的特殊情况的想法。总之,基于当前技术的缺点,包括协作感知的方向,论文为未来的研究提出了3D视觉技术的想法。
代码链接:https://github.com/ApoorvRoboticist/VisionBEVDetectionSurvey
简介
目标检测对人类来说是一项微不足道的任务。几乎任何一个青少年都可以从汽车挡风玻璃外观看场景,并将所有的动态或静态代理放置在一张心理BEV(鸟瞰图)地图上。该虚拟地图包括每个代理的信息,但不限于中心坐标、尺寸、视角、航向角等。然而,在过去十年中,向计算机传授这一点一直是一项艰巨的任务。该任务需要识别和定位视野内的所有目标实例(如汽车、人类、街道标志等),如图1所示。类似地,分类、分割、密集深度估计、运动预测、场景理解等也是计算机视觉中的其他基本问题。

早期的目标检测模型建立在人工特征提取器上,如Viola Jones检测器(Viola&Jones,2001)、定向梯度直方图(HOG)(Dalal&Triggs,2005)等。然而,与当前方法相比,这些方法速度慢、不准确,在通用数据集上不可扩展。卷积神经网络(CNN)和图像分类的深度学习的引入改变了视觉感知的面貌。CNN在AlexNet 2012年ImageNet大规模视觉识别挑战赛(ILSVRC)中的使用(Krizhevsky等人,2012)激发了计算机视觉行业的进一步研究。3D目标检测的主流应用围绕自动驾驶、移动机器人视觉、安全摄像头等。摄像头的视野(FOV)有限,这导致了下一个突破性研究领域,即如何利用多个摄像头的视角来分析周围环境。
本次基于环视3D物体检测综述全面回顾了过去基于深度学习的方法和架构。本文的主要贡献如下:- 本文对主要的单目检测器基线进行了深入分析,启发了使用相机进行3D物体检测任务中的环视检测器研究;
- 进一步分析了当前计算机视觉行业发展中的主要环视检测器趋势,从而对它们进行分类;
对剩余问题进行了详细分析,并介绍了BEV 3D图像物体探测器的几个潜在研究方向,从而为未来的研究打开了大门。
背景
为了涵盖理解3D BEV物体检测任务所需的基本知识,论文讨论了四个方面:自动驾驶车辆(AV)上的传感器配置、常用数据集、自动驾驶中检测任务的常用评估指标,以及为什么鸟瞰图(BEV)对AV摄像机感知很重要?
传感器配置
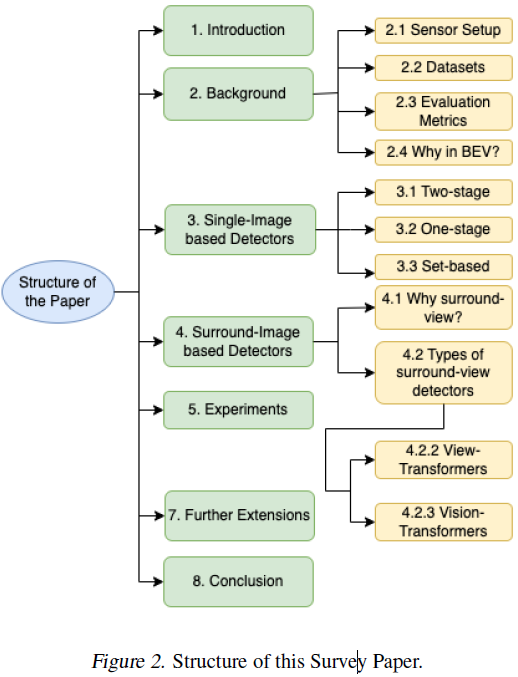
在了解自动驾驶汽车(AV)中的摄像头设置之前,先来了解一下为什么需要摄像头。与其他传感器相比,相机具有最密集的信息,这使得它们成为从AV中提取信息的最具挑战性的传感器之一,但同时也是最有用的。为了从数学上理解这一点,让我们看看图3中每个可视化中的数据点数量。将这些数据点(浮点数)作为传感器感知算法的输入,以覆盖360°视图,该传感器负责为AV做出决策。

与其他基于激光的传感器相比,相机也是最便宜的传感器之一。然而,它们在探测长距离物体方面非常好,以及与任何其他激光传感器相比,提取基于视觉的道路线索,如交通灯状态、停车标志等。AV上有一个环绕摄像头设置,这可能会因不同的自动驾驶汽车公司而异。通常每辆车有6~12个摄像头。需要这些多个相机来覆盖整个周围的3D场景。我们只能使用具有正常FOV(视野)的相机,否则可能会得到无法恢复的图像失真,如鱼眼相机(宽FOV),其仅适用于几十米。图4中可以看到AV空间中最受引用的基准数据集之一nuScenes(Caesar等人,2020)中的感知传感器设置。
数据集
常见数据集有nuScenes、KITTI、Waymo Open Dataset、Argoverse。 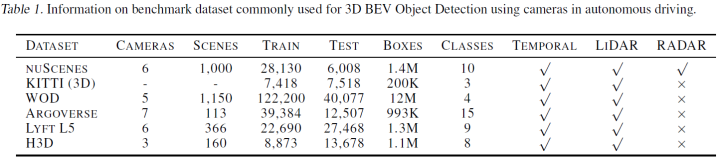
为什么选择BEV?
在鸟瞰图中使用3D代理的表示对于自动驾驶具有实际意义的原因有很多:
它使与其他360°传感器的融合更加自然,即LiDAR和RADAR,因为之后将在360°BEV中运行;
若在BEV中操作,则可以更好地模拟动态场景的时间一致性。与透视图(相机视图)相比,BEV中的运动补偿(即平移和旋转建模)要简单得多。例如在BEV视图中:姿态变化仅取决于代理的运动,而在透视视图中,姿势变化取决于深度以及代理的运动;
目标的比例在BEV中是一致的,但在透视图中不是如此。在透视图中,当物体离我们更近时,它们看起来更大。因此,BEV视图使学习特征尺度一致性变得更容易;
在自动驾驶中,感知后的下游任务(如运动预测和运动规划)在BEV上运行。所有软件堆栈在机器人平台上的通用坐标视图系统中工作是很自然的;
新研究的领域-协作感知,论文将在后面的章节中讨论,它也利用BEV表示在公共坐标系中表示代理,否则每个代理都有自己的视角。
基于单视图的检测器
论文将基于单视图图像的物体检测分为三类:两阶段、一阶段和基于集合的检测器。然而,论文要提到的是Viola Jones(Viola&Jones,2001)、HOG探测器(Dalal&Triggs,2005)、可变形部件模型(DPM)(Girshick等人,2014)等先驱作品,它们在2009年的PASCAL VOC挑战中彻底改变了计算机视觉(Zhang等人,2007)。这些方法使用依赖于提取启发式特征的经典计算机视觉技术。两阶段检测器
这是一类探测器,分为两个阶段。第一阶段是预测任意数量的object proposals,然后在第二阶段,他们通过分类和定位这些object
proposals来预测框。然而,此类方法具有推理时间慢、缺乏全局上下文(甚至在单个图像内)和复杂架构的固有问题。两阶段方法的先驱工作是:基于区域的全卷积网络(R-FCN)(Dai等人,2016)、特征金字塔网络(FPN)(Lin等人,2017)和基于R-CNN(Girshick等人,2013)工作线的Mask R-CNN(He等,2017)。Pseudo-LiDAR(Wang et al.,2018)也有一个平行的工作流程,其中在第一阶段预测密集深度,从而将像素转换为伪点云,然后将类似激光雷达的检测头应用于点云,以进行3D物体检测,如在Point-pillars中所做的(Lang等人,2018)。
一阶段检测器
YOLO(Redmon等人,2015年)和SSD(Liu等人,2015)为一阶段探测器打开了大门。这些检测器使用密集预测在single shot中对语义目标进行分类和定位。然而,作为问题之一,它们严重依赖于后处理非最大抑制(NMS)步骤来过滤重复预测。他们对anchor boxes启发法的依赖性在全卷积一阶段目标检测(FCOS)中得到了解决(Tian等人,2019),以预测2D盒。在FCOS3D(Wang等人,2021a)中可以看到这项工作的扩展,他们通过回归每个目标的3D参数来解决3D目标检测问题。这些方法仍然严重依赖于重复检测的后处理。
基于集合的检测器
该方法使用基于集合的全局损失来消除手动设计的NMS,该全局损失通过二分匹配强制每个目标进行一对一预测。先驱论文DETR(Carion等人,2020)开始了这一系列工作。然而,由于收敛速度慢,限制了特征的空间分辨率。然而,它后来在可变形DETR(Zhu等人,2020)方法中得到了解决,该方法用只关注一小组采样特征的可变形注意力代替了原始的全局密集注意力,从而降低了复杂性,从而加快了收敛速度。另一种加速收敛的方法是SAM-DETR(Zhang等人,2022),它通过使用语义对齐匹配的最具辨别性的特征来限制注意力模块的搜索空间。这项工作仍然有基于CNN的主干,但他们使用基于Transformer(Vaswani等人,2017)的检测头。
上述方法按每个摄像头操作,但自动驾驶应用程序需要处理整个360°场景,包括覆盖整个空间场景的6~12个环视摄像头。每摄像机检测通常使用另一组NMS滤波来聚合,以消除源自摄像机重叠视场(FOV)区域的重复检测。AVs需要保持这种长距离FOV重叠,以最小化短距离内的盲点。通过回归每个目标的深度或使用基于启发式的方法,通过估计地面高度,将透视图检测提升到BEV视图。
基于环视图像的检测器
基于环视摄像头的计算机视觉(CV)系统有多种应用,如监控、运动、教育、移动电话和自动驾驶汽车。运动中的环视系统在运动分析行业中发挥着巨大的作用。它可以让我们在正确的视角下,在正确的时刻记录下整个球场的正确时刻。环视视觉也在课堂监控系统中得到了广泛的应用,这使得教师可以对课堂上的每个学生给予个性化的关注。如今,很难找到任何一款只有一个摄像头的智能手机。对于这些应用,环视系统能够以最小失真的良好视野捕获正确的分辨率。然而,为了限制本文的范围,论文将重点关注基于自动驾驶的CV。
环视系统利用来自不同视图的特征来理解自动驾驶车辆周围场景的整体表示。任何两个或多个摄像机的组合需要与固定传感器安装及其标定相关的基础设施工作。相机的标定简单地意味着提取两个相机之间的外参变换矩阵。该相机矩阵使我们能够将相机中的一个像素与另一个相机中的像素进行一对一映射,从而在多个相机之间创建一个关系,从而实现它们之间的推理。
为什么在AV中使用环视?
很多时候,很难将整个物体放在单帧中,以准确地检测和分类它。这是长车辆中特别常见的问题。让我们从图5中直观地了解这意味着什么:

环视检测器的类型
SOTA环视检测可大致分为两个子组:基于几何的视图变换器和基于交叉注意力的视觉变换器(ViT)。View Transformer
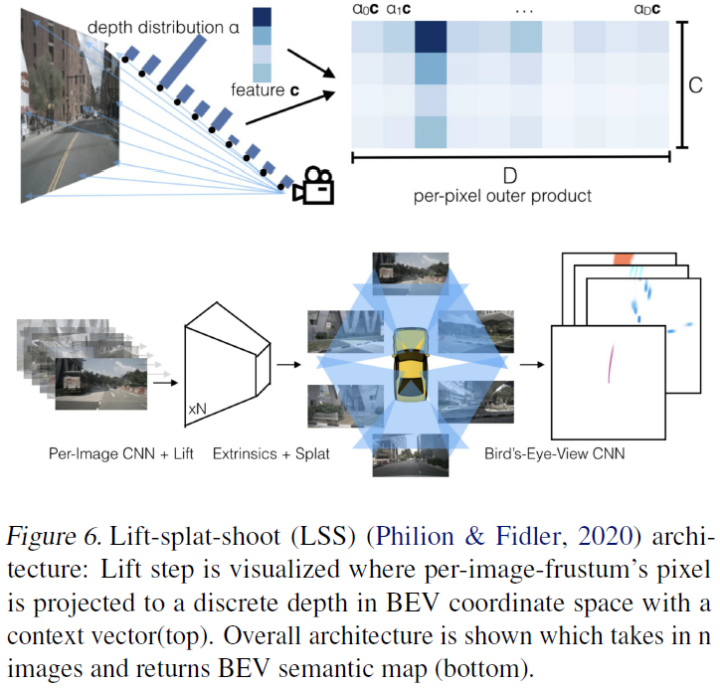
先驱作品Lift,Splat,Shoot(Philion&Fidler,2020)开始了一项链式工作,他们将每个图像单独提升为一个特征的视锥,然后将所有视锥拍到栅格化的BEV网格上。外参和内参一起定义了n个摄像机中每个摄像机从参考坐标到局部像素坐标的映射。这种方法不需要在训练或测试期间访问任何深度传感器,只需要3D框注释就足够了。该体系结构如图6所示。这一工作领域的最新发展之一是BEVDet(Huang等人,2021),它改进了预处理和后处理技术。
BEVDet4D(Huang&Huang,2022a)为该方法增加了时间维度,并使其成为一个4维问题。他们试图解决基于视觉的检测器中高速误差的固有问题。与基于激光的传感器相比,基于单帧视觉的检测器通常具有更高的速度误差,因为LiDAR检测器通常使用具有嵌入在点云中的时间信息的多次扫描数据;雷达的固有点云包括使用多普勒效应的速度属性。在视觉检测器中添加时间帧使我们能够学习道路上动态代理的时间线索。
作为进一步的扩展,BEVDepth(Li等人,2022b)方法增加了相机感知深度估计模块,这有助于物体深度预测能力。他们证明,增强深度是nuScenes基准上高性能相机3D检测的关键。他们已将LSS中的朴素分割头替换为用于3D检测的CenterPoint(Yin等人,2020)头。对于辅助深度头基线,他们仅使用检测损失的监督。然而,由于单目深度估计的困难,单个检测损失远远不足以监督深度模块。然后使用校准的LiDAR数据,使用相机变换矩阵将点云投影到图像上,从而形成2.5D图像坐标。为了减少内存使用,M2BEV的进一步开发(Xie等人,2022)减少了可学习参数,并在推理速度和内存使用方面实现了高效率。这些检测器包括四个部件:1、用于提取图像特征的图像编码器,2、一个深度模块生成深度和上下文,然后对它们进行外积以获得点特征,3、视图转换器,用于将特征从相机视图转换为BEV视图,以及4、提出最终3D边界框的3D检测头。BEVStereo(Li等人,2022a)引入了动态时间立体方法,以在计算成本预算内增强深度预测。Simple-BEV(Harley等人,2022)在LSS方法上引入了雷达点云。根据nuScenes视觉检测排行榜,BEVPoolv2(Huang&Huang,2022b)是基于out of view transformers的当前SOTA。他们使用具有密集深度和时间信息的基于BEVDet4D的主干进行训练。他们还展示了TensorRT加速,TensorRT是英伟达部署硬件通常使用的模型格式。
Vision Transformer
根据(Ma等人,2022),可以根据Transofmer解码器中查询(object proposals)的粒度来划分ViT(,即基于稀疏查询和基于密集查询的方法。我们将详细介绍这两个类别的代表性工作。
Sparse Query-based ViT:在这一行中,论文尝试从具有代表性的训练数据中学习要在场景中查找的object proposals,然后在测试时使用这些学习到的object proposals进行查询。这里假设测试数据目标代表训练数据目标。
DETR(Carion et al.,2020)在单图像(透视图)中的论文中开始了这一工作,后来将其扩展到使用DETR3D的BEV中的环视图图像。作为元数据,相机变换矩阵也用作输入。需要这些矩阵来在2D坐标空间上创建3D参考点映射,并对相应的2D特征进行采样。
在Transformer解码器中,object queires由自注意力模块、交叉注意力模块和前馈网络(FFN)顺序处理,然后最终到达多层感知器(MLP),以产生3D BEV检测作为输出。对于解释:对象查询表示BEV地图上不同位置的潜在目标;自注意力模块在不同的对象查询之间执行消息传递;在交叉注意力模块中,对象查询首先搜索要匹配的对应区域/视图,然后从匹配区域提取相关特征以用于后续预测。大约在同一时间,特斯拉还发布了其基于Transformer的DETR3D产品。同样值得注意的是,基于Transformer的编码器是这里的可选附加组件,但这些检测器的核心部分是它们具有基于Transformer的解码器。这种方法的工作流程如图7所示:
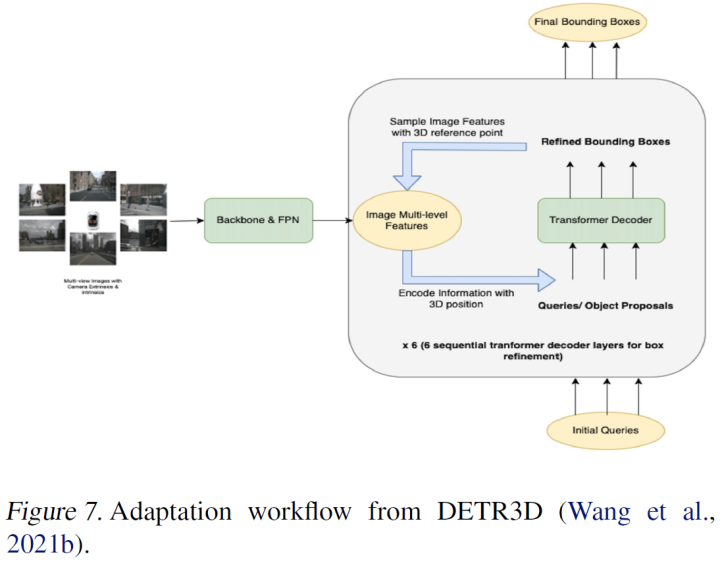
作为这项工作的进一步发展,Polar-DETR(Chen等人,2022a)将极坐标中的3D检测参数化,这重新表述了极坐标系统中的位置参数化、速度分解、感知范围、标签分配和损失函数。该方法简化了优化,并使中心上下文特征聚合能够增强特征交互。在Graph-DETR3D(Chen等人,2022b)中,他们量化了位于不同区域的目标,并发现“截断实例”(即,在每个图像的边界区域)是阻碍DETR3D性能的主要瓶颈。尽管DETR3D在重叠区域中合并了来自两个相邻视图的多个特征,但DETR3D仍然存在特征聚集不足的问题,因此错过了充分提高检测性能的机会。为了解决这个问题,Graph-DETR3D通过图形结构学习(GSL)来聚集环视图像信息。它在每个对象查询和2D特征图之间构建动态3D图,以增强对象表示,尤其是在边界区域。
DETR3D,PETR上的位置编码开发工作(Liu等人,2022a)引用了前一种方法中特征的2D编码的问题。他们通过对来自相机变换矩阵的3D坐标进行编码,将环视特征变换为3D域。现在,可以通过与3D位置感知特征交互来更新对象查询,并生成3D预测,从而使过程更简单。后续工作PETRv2(Liu等人,2022b)为其添加了时间维度,以获得时间感知的更密集的特征。Dense Query-based ViT:这里有一个基于BEV表示中感兴趣区域的密集查询。每个查询都预先分配了3D空间中的空间位置。这项工作比前者更好,因为我们仍然能够通过稀疏查询来检测未在训练数据中作为object proposals学习的特定类型的目标。换言之,当训练数据不是测试数据的完美代表时,这种方法对场景更加稳健。
BEVFormer(Li等人,2022c)是这一领域的先驱。他们通过预定义的网格形BEV查询与空间和时间交互,利用空间和时间信息。为了聚集空间信息,他们设计了空间交叉注意力,每个BEV查询从相机视图的空间特征中提取空间交叉注意力。对于时间信息,他们使用时间自注意力来反复融合历史BEV信息,如图8所示。当时,这种方法已经超过了上面提到的基于稀疏查询的ViT,其召回值更高,利用了密集查询。然而,密集查询以计算预算为代价,他们试图使用可变形DETR(Zhu等人,2020)围绕参考点采样策略的K点来解决这一问题。BEVFormer的完全基于Transformer的结构使其BEV特性比其他方法更通用,易于支持非均匀和非规则采样网格。
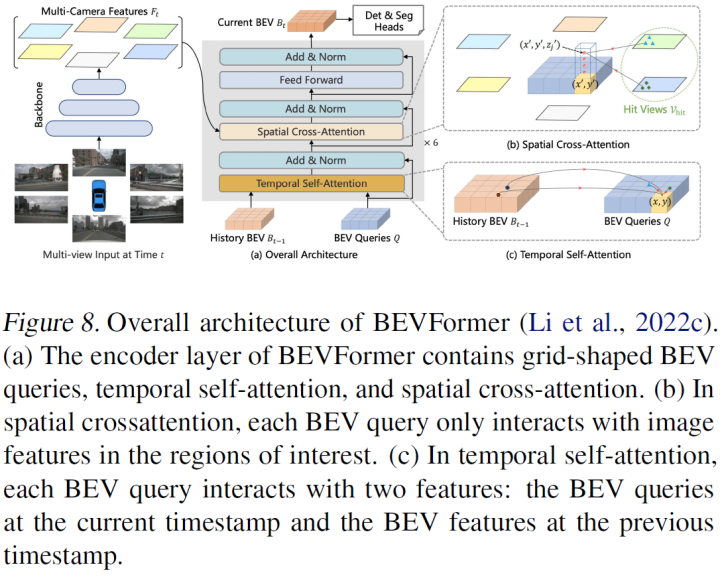
后续工作BEVFormerv2(Yang等人,2022)增加了透视监督,这有助于收敛并以更好的方式适合基于图像的主干。这带来了两阶段检测器,在那里,来自透视头的proposals被送入鸟瞰头,用于最终预测。除了透视头proposals,他们还使用DETR3D风格的学习查询。对于辅助透视损失,他们使用FCOS3D(Wang等人,2021a)头部来预测3D边界框的中心位置、大小、方向和投影中心度。
PolarFormer(Jiang et al.,2022)解释了自车视角的本质,因为每个车载摄像头都以具有激进(非垂直)轴的成像几何结构固有的楔形来感知世界。因此,他们主张在BEVFormer上使用极坐标系。
进一步扩展
基于环视BEV视觉检测的最新发展,论文现在将强调未来可能的研究方向。部署计算预算和耗时约束:自动驾驶汽车运行在一个紧凑的计算预算上,因为我们可以在车上拥有有限的计算资源。然而,当5G互联网成为主流,所有计算都可以传输到云计算机。整个行业应该开始关注这些计算昂贵的基于Transformer的网络的耗时限制。一个可能的方向是基于输入场景约束限制对象建议(查询)。然而,需要有一种聪明的方法来处理它,否则这些网络可能会遇到召回率低的问题。
智能object proposal初始化策略:论文可能会提供一种查询初始化策略,它混合匹配稀疏和密集查询初始化,以实现两者的优点。基于密集查询的方法的主要缺点是其高运行时间。这可以通过使用高清地图来处理,只关注最重要的道路区域。就像BEVFormerv2(Yang等人,2022)一样,也可以从不同的模式中获取对象建议。作为进一步的一步,这些建议也可以从过去的时间步骤中提取出来,合理的假设是,驾驶场景在一秒钟内不会发生太大变化。然而,为了使AVs具有可扩展性,研究人员需要更多地关注相机和雷达等价格合理的传感器,而不是过于关注激光雷达或高清地图。
协同感知:一个相对较新的领域是如何利用多代理、多视图转换器来实现协同感知。该设置需要最小的基础设施设置,以实现道路上不同车辆之间的顺畅通信。CoBEVT(Xu等人,2022)展示了车对车通信如何导致卓越感知性能的初步证据。他们在OPV2V(Xu等人,2021)V2V感知基准数据集上测试了他们的性能。
结论
本文介绍了围绕基于视觉的3D物体检测的开发工作,重点是自动驾驶汽车。论文阅读了60多篇论文和5个基准数据集来准备这篇论文。具体来说首先构建了一个案例,说明基于摄像头的环视检测头对于解决自动驾驶汽车非常重要。然后研究如何从单视图检测发展到环视检测头范式,从而提高检测性能开始。我们已将环绕视图相机检测器分为两大类,即基于LSS的和基于DETR的。最后提出了我们对环视检测趋势的看法,重点是将这些网络部署到实际的自动驾驶汽车上,这可能会启发未来的研究工作。
汽车视觉算法研究:聚焦城市场景 BEV演进出三种技术路线
BEV是Bird's Eye View(视觉为中心的鸟瞰图)的简写,也称作“上帝视角”,是一种端到端的,由神经网络将图像信息从图像空间转换到BEV空间的技术。
与传统图像空间感知相比,BEV感知可将多个传感器采集的数据,输入到统一的空间进行处理,有效避免误差叠加;同时更易进行时序融合形成4D空间。
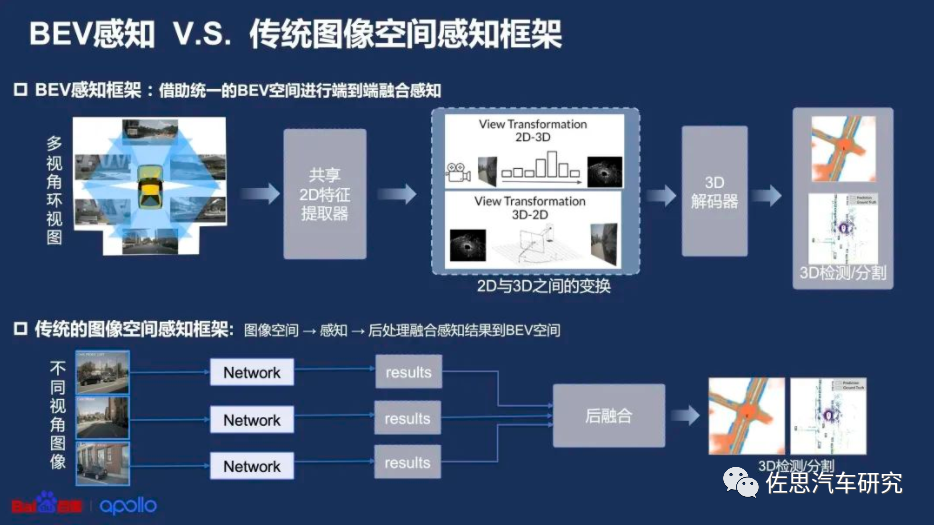
来源:百度
BEV并非新技术,2016年百度开始在BEV视角下实现点云感知;2021年特斯拉引入BEV后引发了业界的广泛关注。根据传感器输入层、基本任务,以及场景的不同,可给出相应的BEV感知算法。比如,基于纯视觉的BEVFormer算法、基于多模态融合策略的BEVFusion算法。
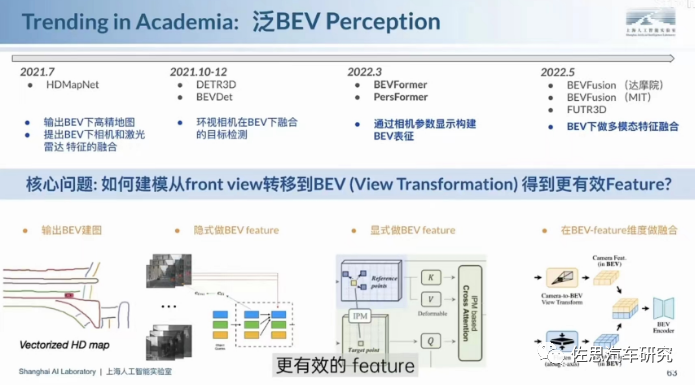
来源:上海人工智能实验室
从BEV技术落地来看,各家技术架构大致相同,但采取的技术方案有所不同。迄今,大致出现了三种技术路线:
- 纯视觉BEV感知路线,代表企业为特斯拉;
- BEV融合感知路线,代表企业为毫末智行;
- 车路一体BEV感知路线,代表企业为百度。
纯视觉BEV感知技术路线:特斯拉是纯视觉技术路线代表企业,2021年率先使用前融合BEV算法,将摄像头感知到的画面直接传到AI算法里,生成鸟瞰视角的3D空间,并在该空间内输出感知结果。包括汽车、行人等动态信息,车道线、交通标识、红绿灯、建筑物等静态信息,以及各元素的坐标位置、方向角、距离、速度、加速度等。
特斯拉利用8个摄像头采集数据通过神经网络输出3D向量空间

来源:特斯拉
特斯拉主要利用主干网(Backbone)对各个摄像头进行特征提取(Feature);借助Transformer等技术将多摄像头数据从图像空间转化为BEV空间。Transformer是一种基于Attention机制的深度学习模型,能处理大规模数据级学习任务,精确感知和预测物体深度。
特斯拉在感知网络架构引入BEV三维空间转化层
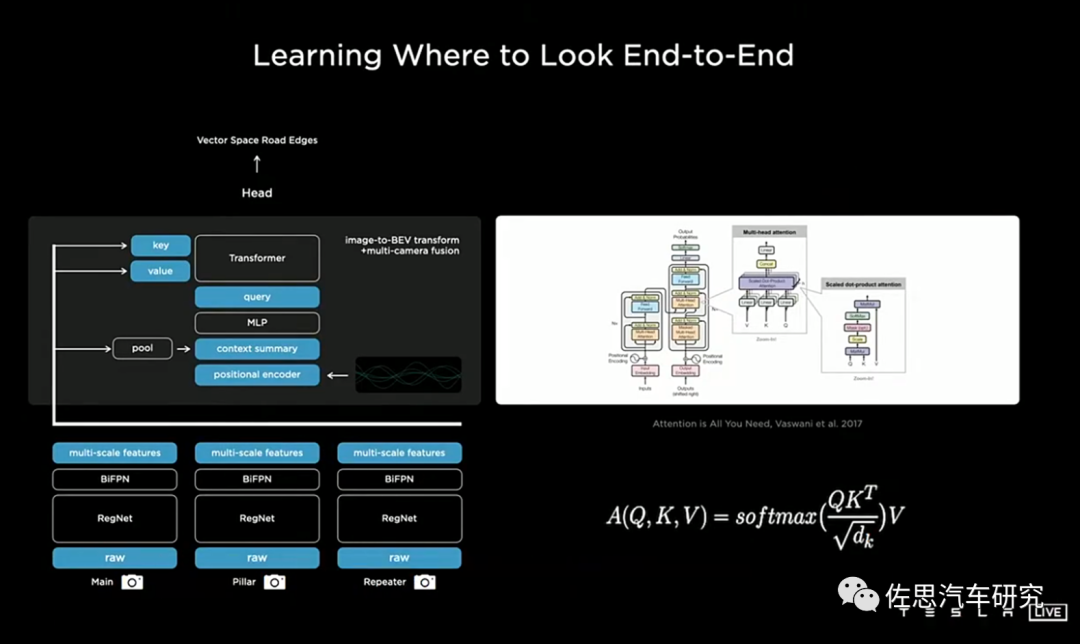
来源:特斯拉
BEV融合感知技术路线:毫末智行是长城汽车旗下自动驾驶公司,2022年推出“重感知,轻地图”的城市NOH方案,核心技术来自MANA(雪湖体系)。
在MANA感知架构中,毫末智行采用了BEV融合感知(视觉Camera+Lidar)技术。利用自研的Transformer算法,MANA既完成了对纯视觉信息的BEV转化,也完成了Camera和Lidar特征数据的融合,即跨模态raw data的融合。
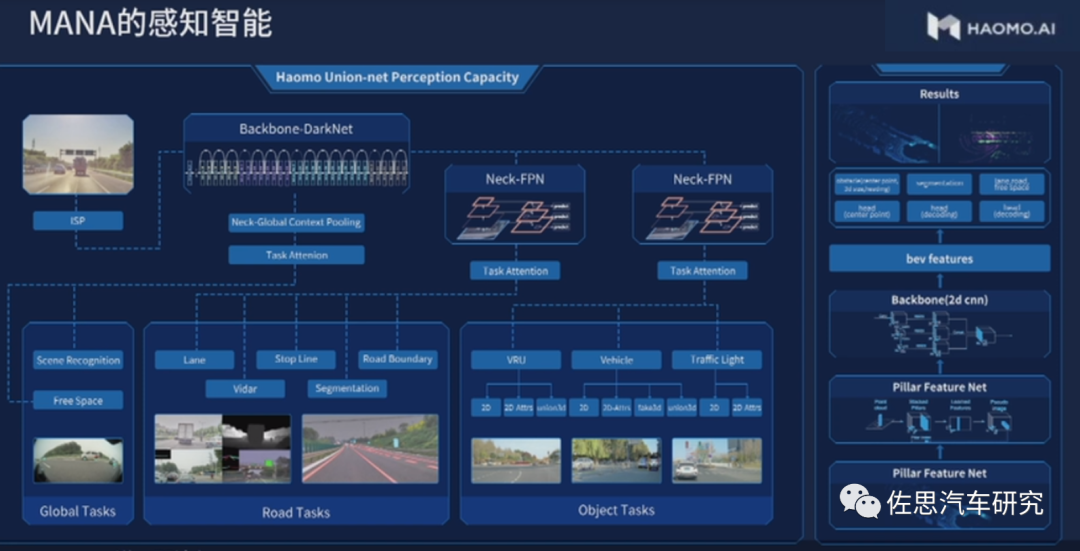
来源:毫末智行
自2021年底推出后,MANA持续演进,通过基于Transformer的感知算法解决了多个道路感知问题,如车道线检测、障碍物检测、可行驶区域分割、红绿灯检测&识别、道路交通标志检测等。
2023年1月,MANA进一步升级,引入五大模型,实现车端感知架构的跨代升级,完成了通用障碍物识别、局部路网、行为预测等任务。其中,五大模型包括视觉自监督大模型(实现4D Clip的自动标注)、3D重建大模型(低成本解决数据分布问题)、多模态互监督大模型(通用障碍物的识别)、动态环境大模型(使用重感知技术,降低对高精地图依赖)、人驾自监督认知大模型(驾驶策略更人性、安全、顺畅)。
毫末智行MANA体系感知算法迭代历程

来源:毫末智行
车路一体BEV感知技术路线:2023年1月,百度推出车路一体的解决方案UniBEV,是业内首个车路一体的端到端感知解决方案。
特点:
- 将车端、路端数据全部进行融合,包括车端多相机、多传感器的在线建图、动态障碍物感知,以及路侧视角下的多路口多传感器融合等;
- 自研内外参解耦算法,不管车端、路侧的传感器位置如何变化,UniBEV都可将其投影到统一的BEV空间下;
- 在统一的BEV空间,UniBEV更易实现多模态、多视角、多时间上的时空特征融合;
- 采用大数据+大模型+小型化的技术闭环,在车端路侧的动静态感知任务上更具优势。
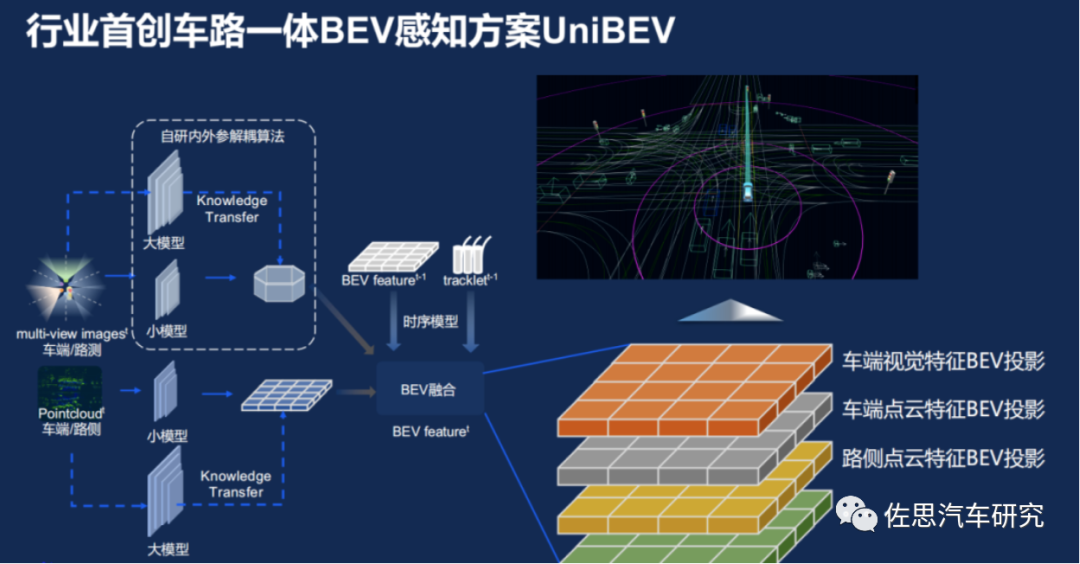
来源:百度
百度UniBEV方案将应用在百度高阶智驾产品ANP3.0上,计划2023年量产交付。当前,百度已开始在北、上、广、深多地进行ANP3.0泛化测试。
百度ANP3.0采用“纯视觉+Lidar”的双冗余方案。研发测试阶段,依靠“BEV环视三维感知”技术,ANP3.0已成为依靠纯视觉实现城市域多场景的智驾⽅案。量产阶段,ANP3.0将引入激光雷达,实现多传感器融合感知,以应对更为复杂的城市场景。
随着视觉算法的演进,BEV感知算法成为主机厂和自动驾驶公司发力城市场景的核心技术,如特斯拉、小鹏、长城、极狐汽车、轻舟智航、小马智行等。
小鹏汽车:全新一代感知架构XNet可将摄像头采集的数据,进行多帧时序前融合,输出BEV下的4D动态信息(如车辆速度、运动预测等)和3D静态信息(如车道线位置等)。
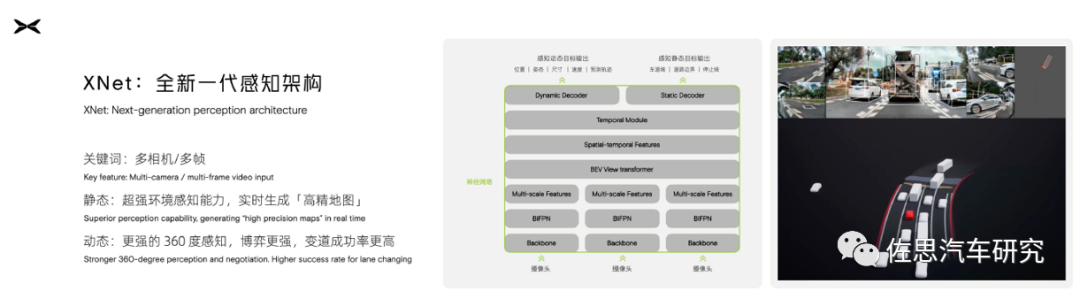
来源:小鹏汽车
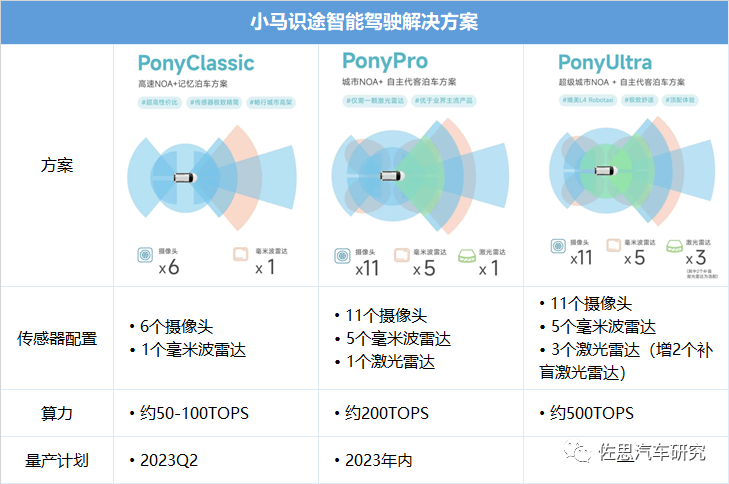
小马智行:2023年1月公布智能驾驶解决方案——小马识途,其关键能力就是自研BEV感知算法,可识别各类型障碍物、车道线及可通行区域等信息,最大限度降低算力需求,仅用导航地图就可实现高速与城市NOA。
参考
[1] Surround-View Vision-based 3D Detection for Autonomous Driving: A Survey
参考文献链接
https://mp.weixin.qq.com/s/m5B-Ao0-oRWjjylf8547KA
https://mp.weixin.qq.com/s/hmxR7RAcCMYhCl2kOKRfOw

