然后,ndarray本质是数组,其不同于一般的数组,或者Python 的list的地方在于它可以有N 维(dimentions),也可简单理解为数组里面嵌套数组。
最后,Numpy为ndarray提供了便利的操作函数,而且性能优越,完爆Python 的list,因此在数值计算,机器学习,人工智能,神经网络等领域广泛应用。
Numpy几乎是Python 生态系统的数值计算的基石,例如Scipy,Pandas,Scikit-learn,Keras等出色的包都基于Numpy。
本文的主要目的在于理解numpy.ndarray的内存结构及其背后的设计哲学。
NumPy provides an N-dimensional array type, the ndarray, which describes a collection of “items” of the same type. The items can be indexed using for example N integers.
ndarray是numpy中的多维数组,数组中的元素具有相同的类型,且可以被索引。
>>> a = np.array([[0,1,2,3],[4,5,6,7],[8,9,10,11]])
注:np.array并不是类,而是用于创建np.ndarray对象的其中一个函数,numpy中多维数组的类为np.ndarray。
ndarray的设计哲学在于数据存储与其解释方式的分离,或者说copy和view的分离,让尽可能多的操作发生在解释方式上(view上),而尽量少地操作实际存储数据的内存区域。
如下所示,像reshape操作返回的新对象b,a和b的shape不同,但是两者共享同一个数据block,c=b.T,c是b的转置,但两者仍共享同一个数据block,数据并没有发生变化,发生变化的只是数据的解释方式。
# reshape操作产生的是view视图,只是对数据的解释方式发生变化,数据物理地址相同
>>> from ctypes import string_at
'000000000100000002000000030000000400000005000000060000000700000008000000090000000a0000000b000000'
# b的转置c,c仍共享相同的数据block,只改变了数据的解释方式,“以列优先的方式解释行优先的存储”
'000000000100000002000000030000000400000005000000060000000700000008000000090000000a0000000b000000'
# copy会复制一份新的数据,其物理地址位于不同的区域
'000000000100000002000000030000000400000005000000060000000700000008000000090000000a0000000b000000'
# slice操作产生的也是view视图,仍指向原来数据block中的物理地址
data buff address from 80831392 to 80831440
副本是一个数据的完整的拷贝,如果我们对副本进行修改,它不会影响到原始数据,物理内存不在同一位置。
视图是数据的一个别称或引用,通过该别称或引用亦便可访问、操作原有数据,但原有数据不会产生拷贝。如果我们对视图进行修改,它会影响到原始数据,物理内存在同一位置。
2、调用 ndarray 的 view() 函数产生一个视图。
Python 序列的切片操作,调用deepCopy()函数。
调用 ndarray 的 copy() 函数产生一个副本。
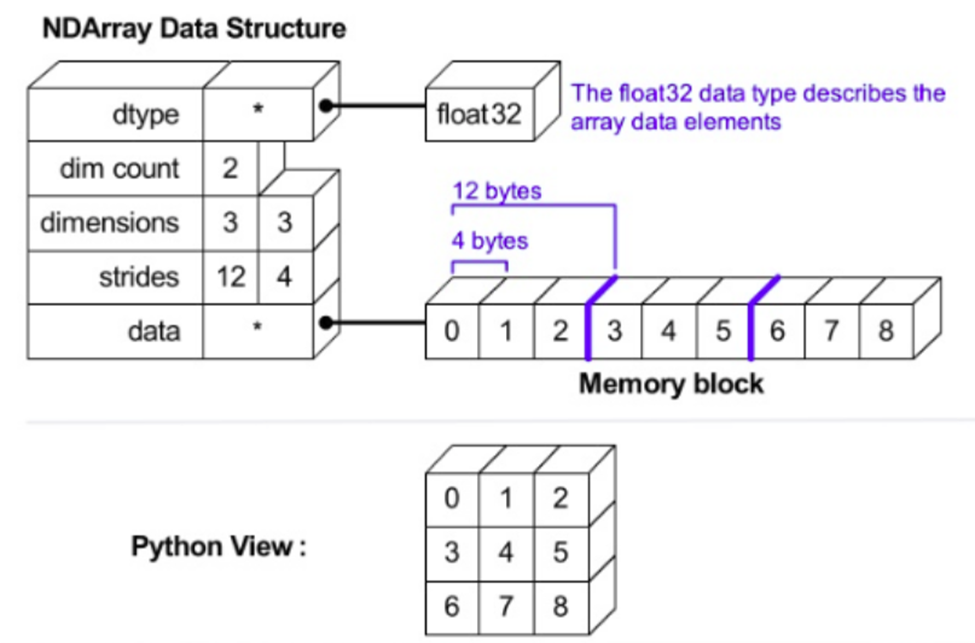
NumPy arrays consist of two major components, the raw array data (from now on, referred to as the data buffer), and the information about the raw array data. The data buffer is typically what people think of as arrays in C or Fortran, a contiguous (and fixed) block of memory containing fixed sized data items. NumPy also contains a significant set of data that describes how to interpret the data in the data buffer.
可大致划分成2部分——对应设计哲学中的数据部分和解释方式:
raw array data:为一个连续的memory block,存储着原始数据,类似C或Fortran中的数组,连续存储
dtype:数据类型,指示了每个数据占用多少个字节,这几个字节怎么解释,比如int32、float32等;
strides:维间距,即到达当前维下一个相邻数据需要前进的字节数,因考虑内存对齐,不一定为每个数据占用字节数的整数倍;
上面4个信息构成了ndarray的indexing schema,即如何索引到指定位置的数据,以及这个数据该怎么解释。
除此之外的信息还有:字节序(大端小端)、读写权限、C-order(行优先存储) or Fortran-order(列优先存储)等,如下所示,
ndarray的底层是C和Fortran实现,上面的属性可以在其源码中找到对应,具体可见PyArrayObject和PyArray_Descr等结构体。
图解Python numpy基本操作
参考文献链接
https://zhuanlan.zhihu.com/p/396444973
本文很长,你忍一下。
Numpy是python的一个非常基础且通用的库,基本上常见的库pandas,opencv,pytorch,TensorFlow等都会用到。
Numpy的核心就是n维array,这篇文章将介绍一维,二维和多维array。
Python是一种非常有趣且有益的语言,我认为只要找到合适的动机,任何人都可以熟练掌握它。但是要记住的是,如果你只想着凭借python去找一份工作的话,不是不行,但是很难。python这种语言更适合已经有一份工作的人,多学一个技能。
可以从最简单也是最直观的数据分析学起来,并且试着从知乎出品的数据分析课开始。
知乎数据分析 3
天实战训练营
¥0.10立即报名
python入门可以看这个详细回答:
毫无基础的人如何入门 Python ?654 赞同 · 30 评论回答
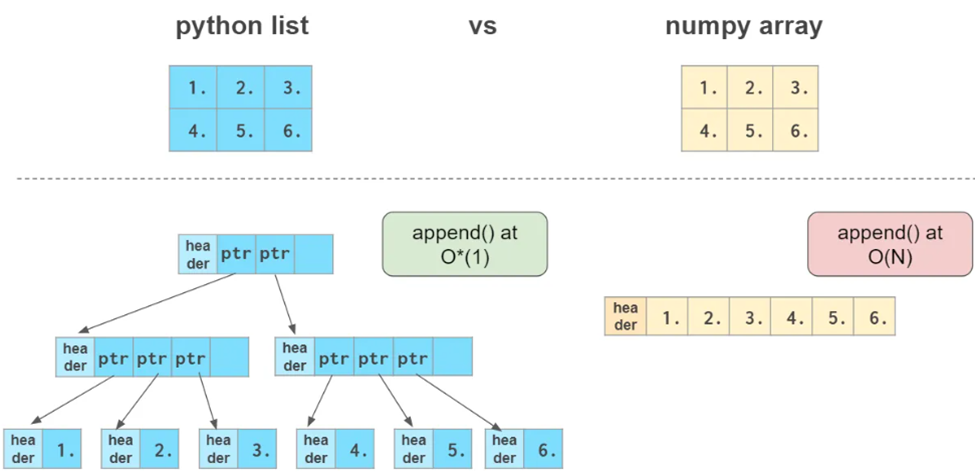
Numpy与List的异同点
他俩非常相似,同样都是容器,都能快速的取值的修改值,但是插入和删除会慢一点。
 Numpy的优点
Numpy的优点
- 更紧凑,特别是多维数据
- 当数据可以向量化的时候比list更快
- 通常是同质化的,数据相同时处理更快,比如都是浮点型或者整数型
 向量 Vector 或者一维向量 1D
array
向量 Vector 或者一维向量 1D
array
向量初始化
通过list转化,自动变成np类型,shape为(3,)

!注意,如果list里面的值类型不相同,那么dtype就会返回”object“
如果暂时没有想要转化的list,可以全用0代替

也可以复制一个已经存在的全0 向量

!注意,所有创建包含固定值vector的方法都有_like函数

还有经典的arange和linspace方法

 ! arange方法对于数据类型敏感,比如arange(3),dtype 为int,如果你需要float类型,可以arange(3).astype(float)
! arange方法对于数据类型敏感,比如arange(3),dtype 为int,如果你需要float类型,可以arange(3).astype(float)
生成随机array

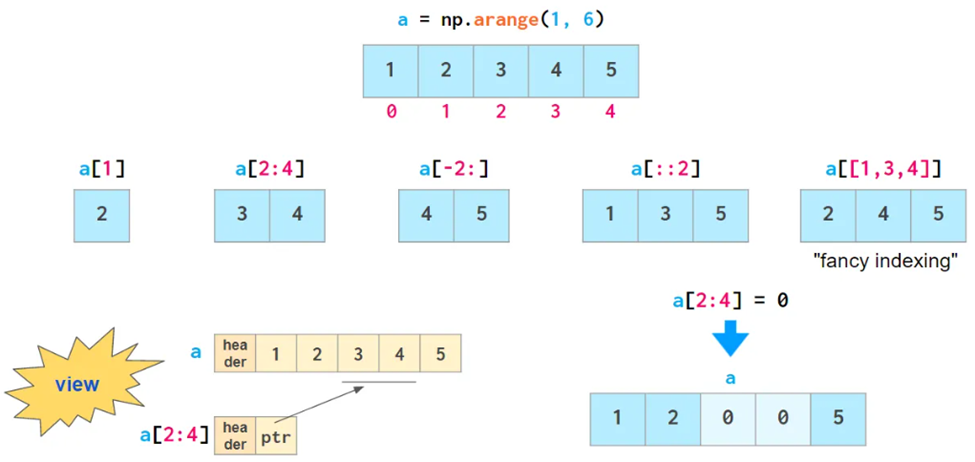
向量索引
基础的向量索引操作,只是展示部分数据,而不改变数据本身
布尔操作
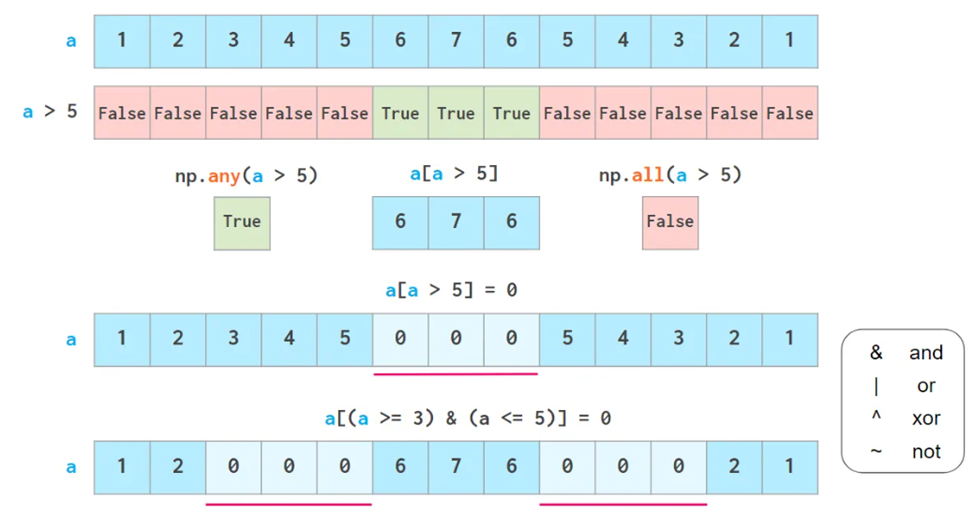
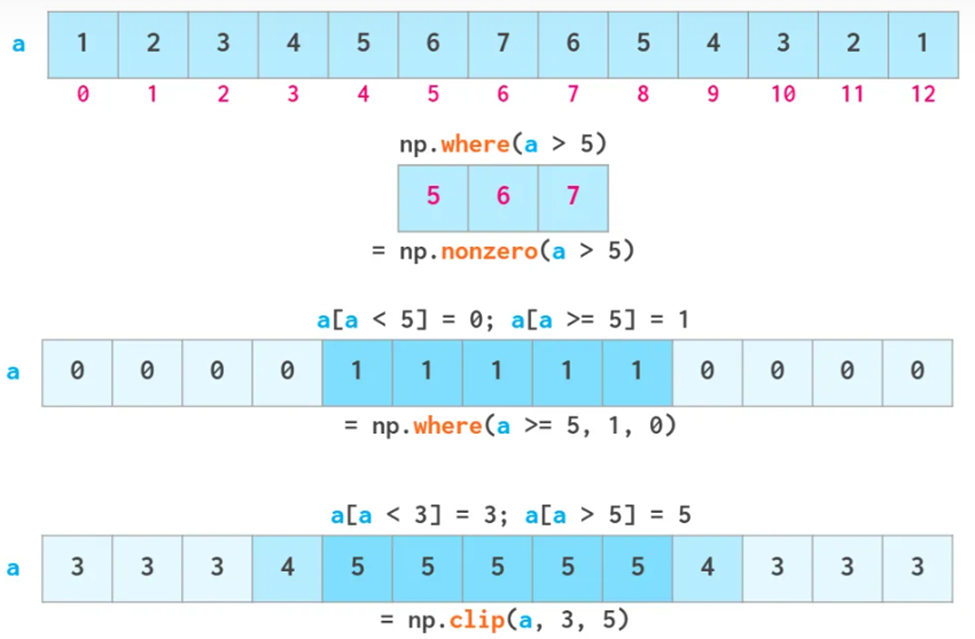
也可以用.where 和clip代替上面的方法
 向量操作
向量操作
numpy的优势就是把vector当做数做整体运算,避免循环运算
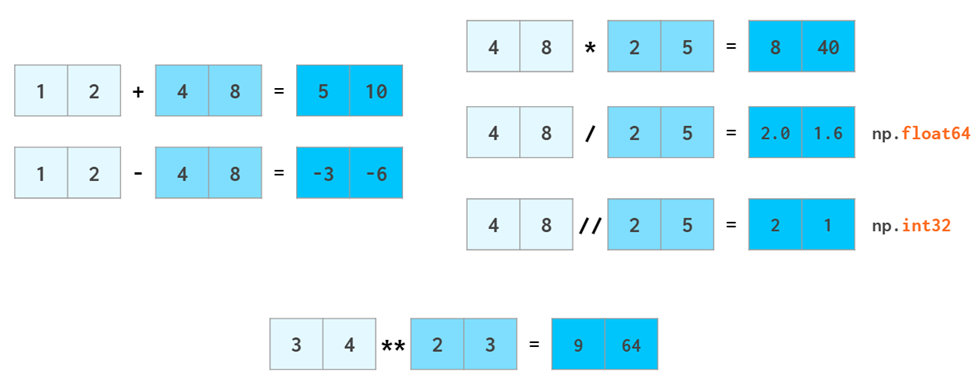
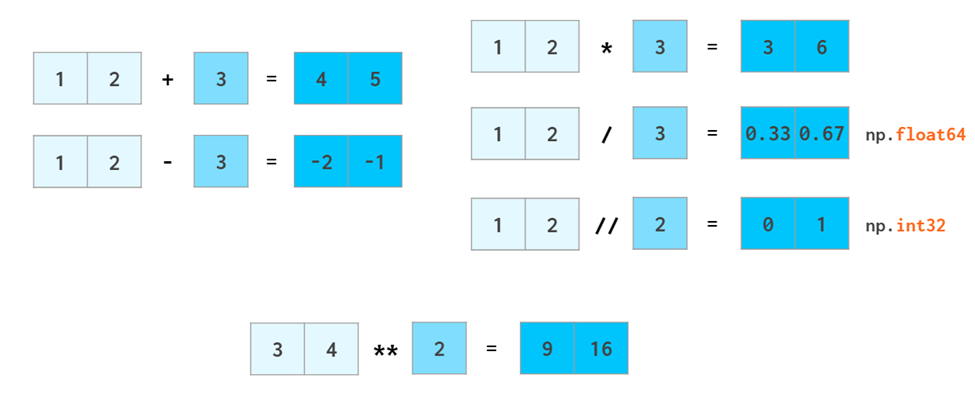
复杂的数学运算不在话下

标量运算
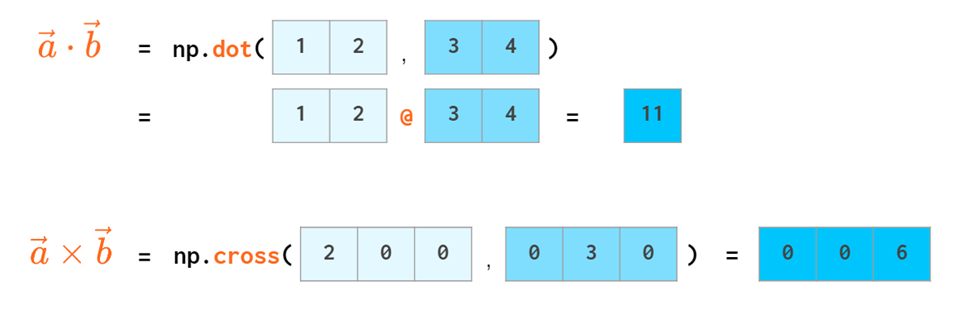
三角函数
整体取整

numpy还可以做基础的统计操作,比如max,min, mean,
sum等
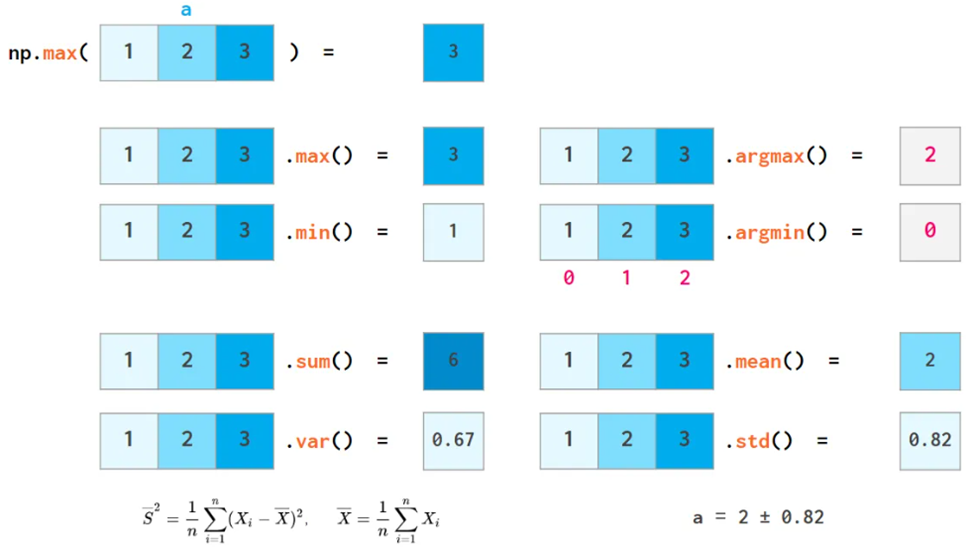 排序操作
排序操作

查找操作
numpy不像list有index函数,通常会用where等操作
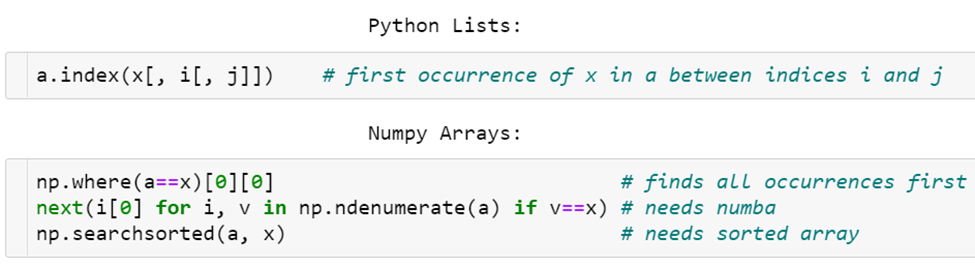
其中有三种方法:
- where,难懂且对于x处于array末端很不友好
- next,相对较快,但需要numba
- searchsorted,针对于已排过序的array
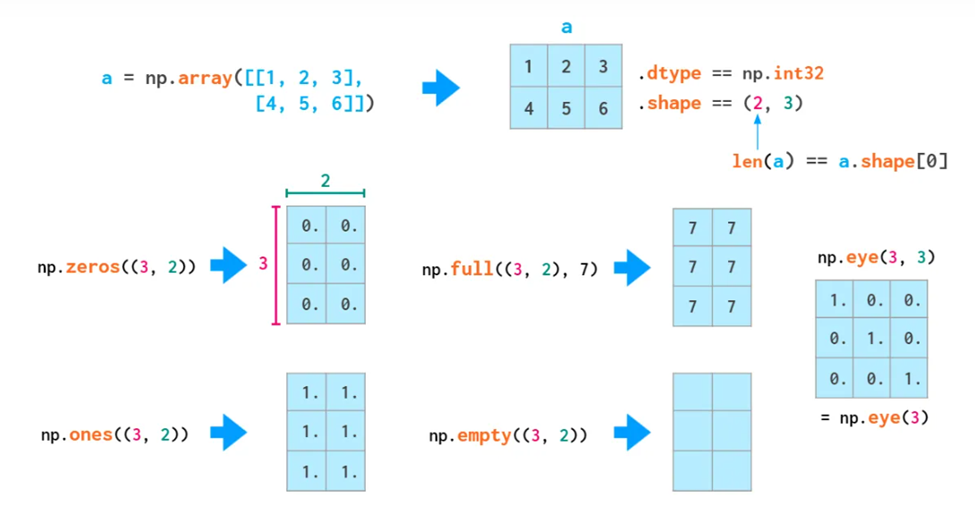
二维array,也称matrix矩阵
初始化,注意「双括号」
随机matrix,同一维类似

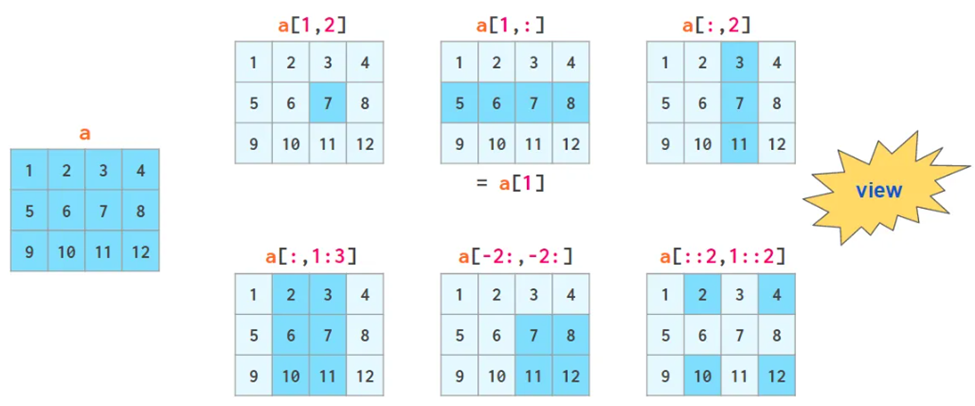
索引操作,不改变matrix本身
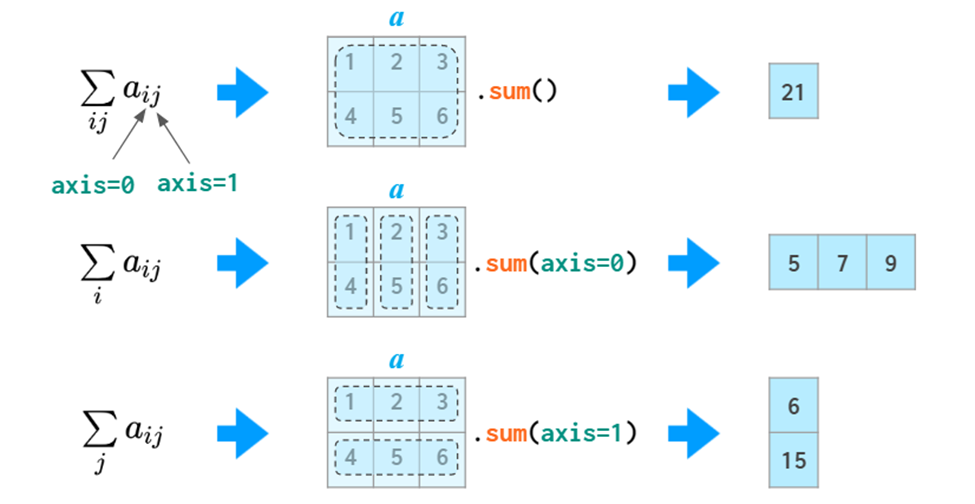
 Axis 轴操作,在matrix中,axis = 0 代表列, axis = 1 代表行,默认axis = 0
Axis 轴操作,在matrix中,axis = 0 代表列, axis = 1 代表行,默认axis = 0
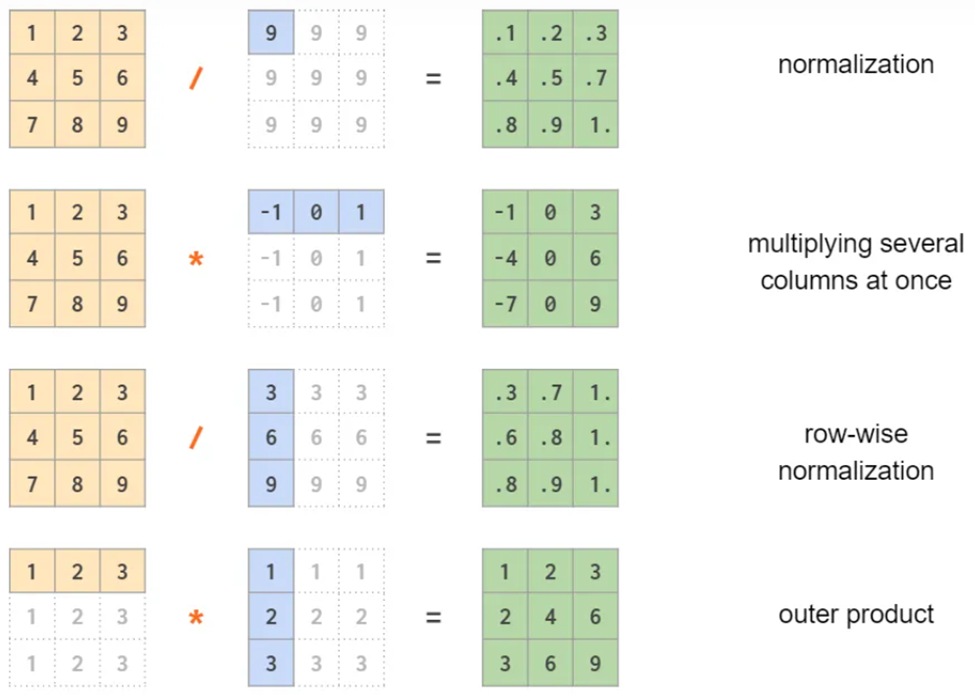
matrix算术 + - * / 和
** 都可

也可以matrix与单个数,matrix与vector,vector与vector进行运算

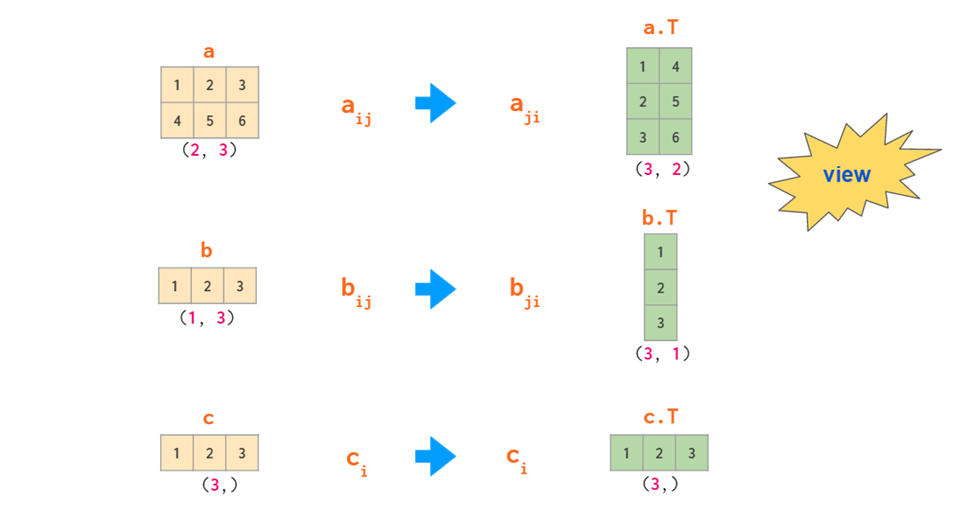
行向量 列向量
二维的转置如下,一维的也就是vector转置为自己本身
reshape改变形态

自此,三种向量,一维array,二维列vector,二维行向量
 矩阵操作
矩阵操作
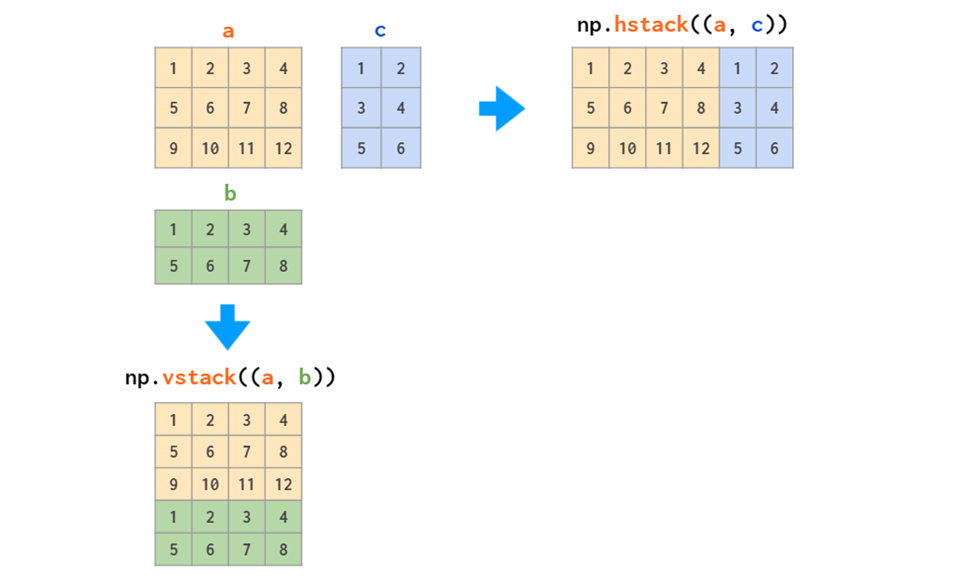
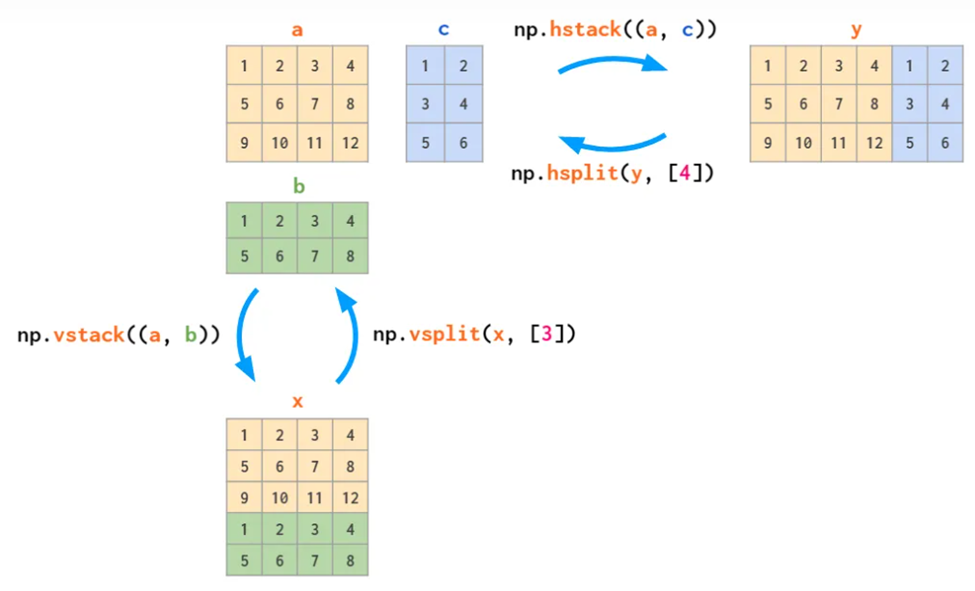
合并matrix,hstack横向,vstack纵向,也可以理解为堆叠
反向操作hsplit和vsplit
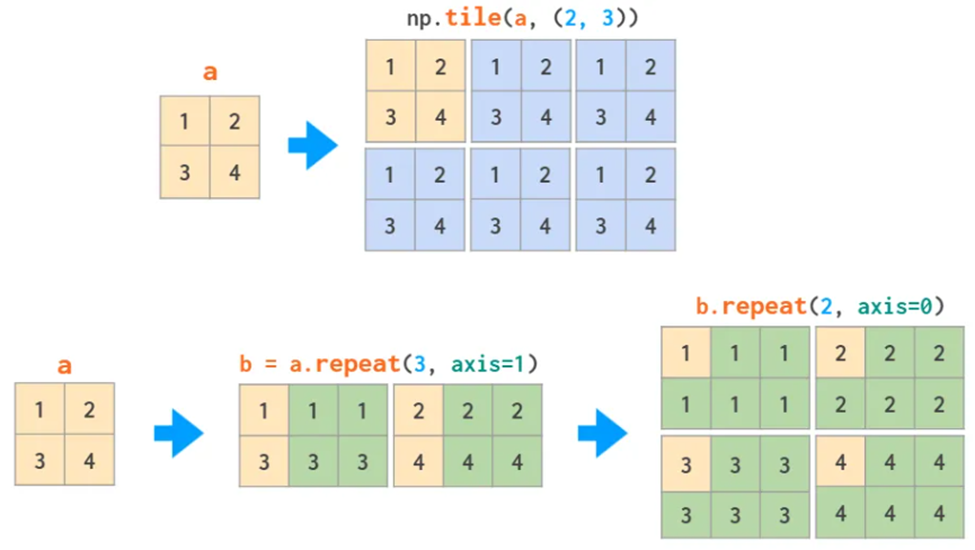
 matrix的复制操作,tile整个复制,repeat可以理解为挨个复制
matrix的复制操作,tile整个复制,repeat可以理解为挨个复制
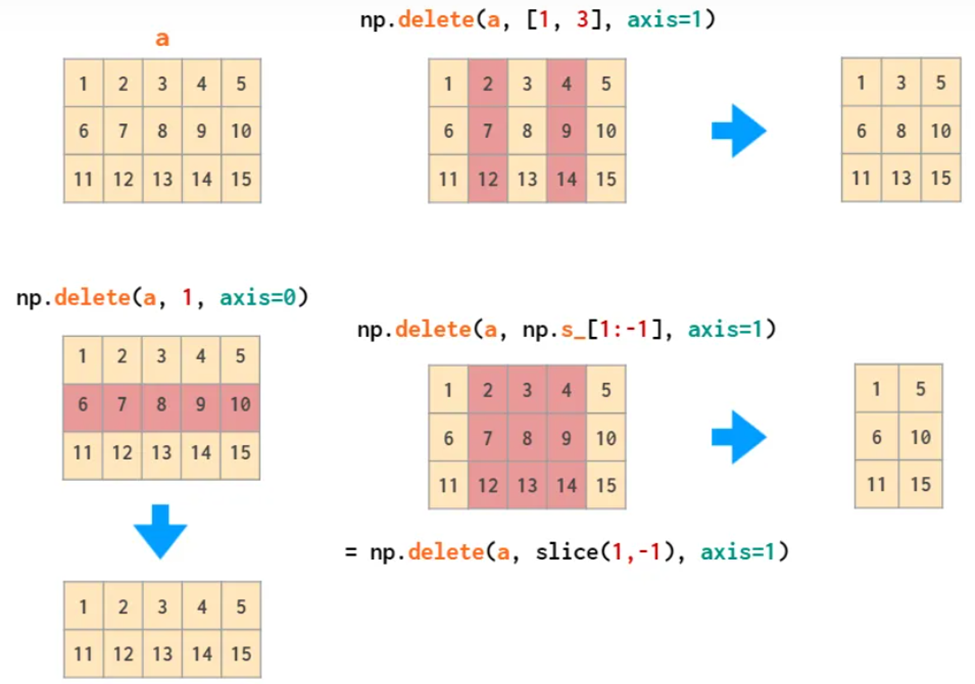
 delete删除操作
delete删除操作
删除的同时也可以插入
 append操作,只能在末尾操作
append操作,只能在末尾操作

如果只增加固定值,也可以用pad

网格化
c和python都很麻烦,跟别说再大点的数了

采用类似MATLAB会更快点
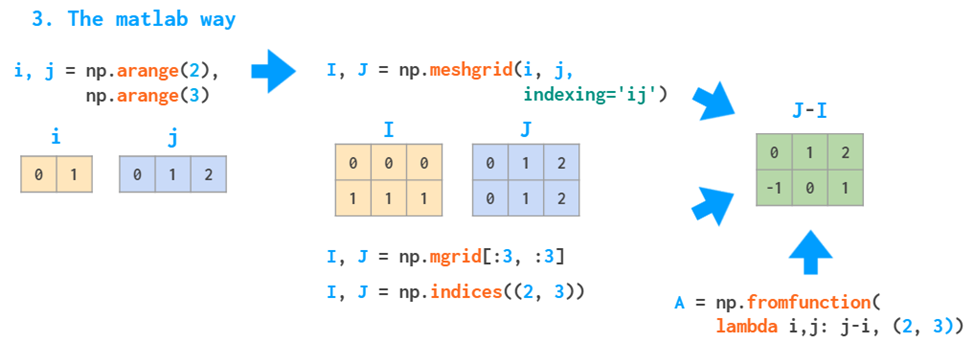
当然numpy有更好的办法

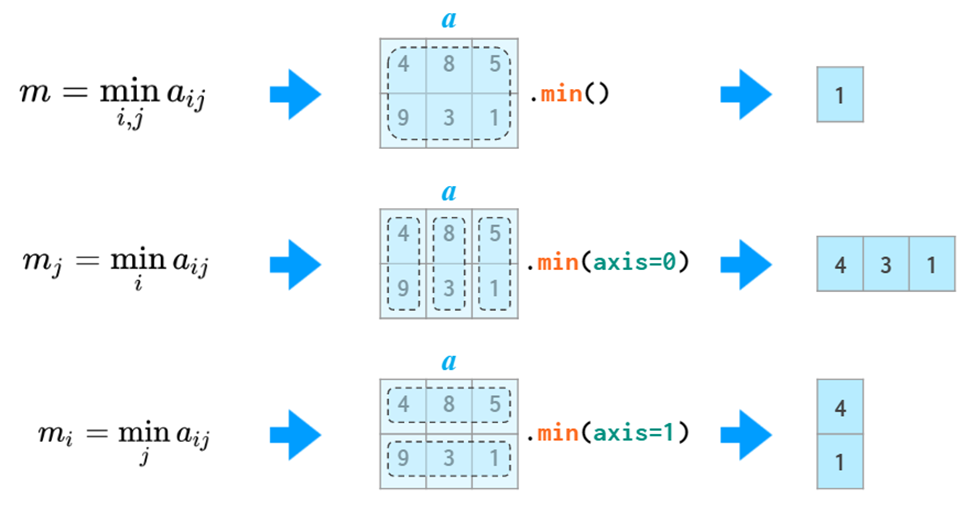
matrix统计
sum,min,max,mean,median等等
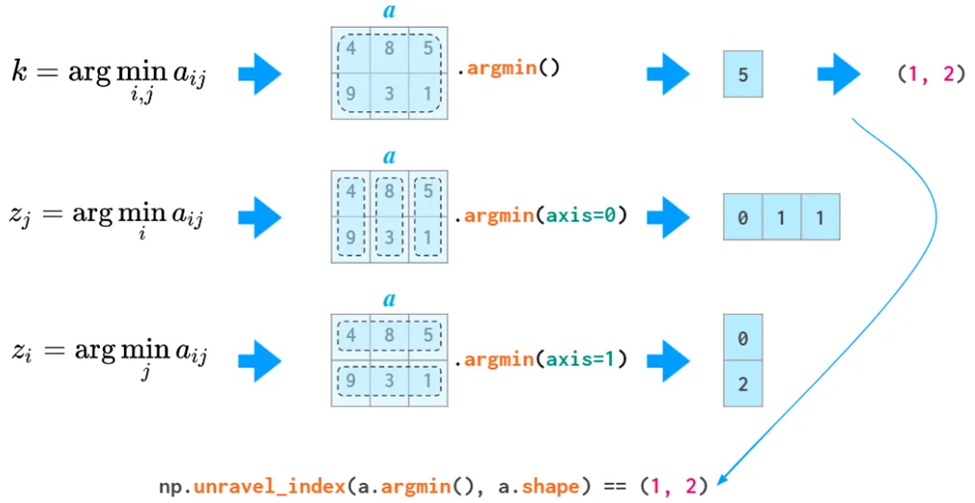
argmin和argmax返回最小值和最大值的下标
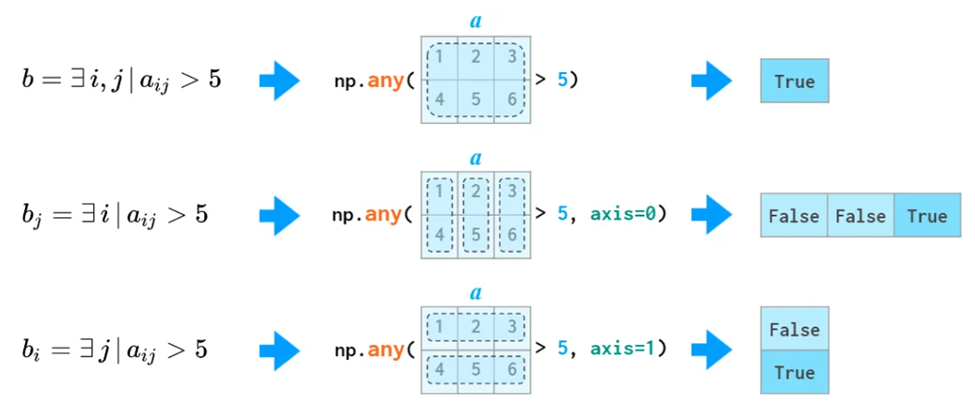
 all和any也可以用
all和any也可以用
 matrix排序,注意axis
matrix排序,注意axis

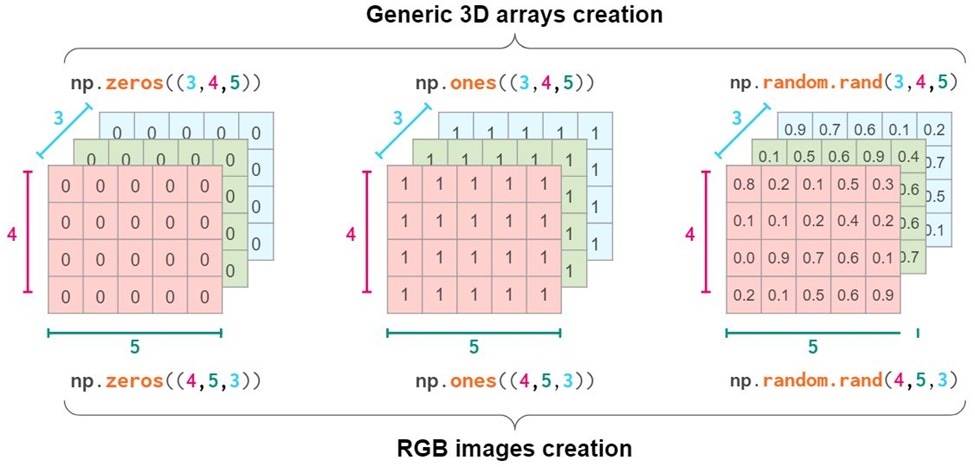
3D array或者以上
初始化,reshape或者硬来

可以考虑把数据抽象成一层层的数据
就像RGB值的图像一样

跟1D和2D类似的操作,zeros, ones,rand等
 vstack和hstack照样可以用,现在多了一个dstack,代表维度的堆叠
vstack和hstack照样可以用,现在多了一个dstack,代表维度的堆叠
 concatenate也有同样的效果
concatenate也有同样的效果

总结:
本文总结了numpy对于1D,2D和多维的基本操作。
参考文献链接
https://zhuanlan.zhihu.com/p/396444973
https://www.cnblogs.com/yibeimingyue/p/13762874.html