


TensorFlow-小米汽车-特斯拉分析
TensorFlow-小米汽车-特斯拉分析
已开始着手规划 TensorFlow 的未来,并希望通过本文跟大家分享我们的愿景。
在 2015 年 11 月 9 日,大约 7 年前,我们开放了 TensorFlow 的源代码。自那之后,在全球数千位开源创作贡献者的帮助,以及由谷歌开发者专家、社区组织者、研究人员和教育工作者所组成的出众社区的支持下,TensorFlow 逐步确立了其地位。
- TensorFlow
https://tensorflow.google.cn/
如今,TensorFlow 已被数百万开发者采用,成为使用率最高的机器学习平台。TensorFlow 不仅是 GitHub 上星标数量排名第 3 的软件代码库(仅次于 Vue 和 React),还是 PyPI 上下载量最高的机器学习软件包。TensorFlow 已将机器学习引入了移动生态系统:目前约 40 亿台设备在运行 TFLite,您的设备或许就是其中之一。TensorFlow 还将机器学习引入了 Web 领域:TensorFlow.js 目前的每周下载量已达 17 万次。
如今,我们的用户群和开发者生态系统比以往任何时候都庞大,并且还在不断扩展!
我们不仅将 TensorFlow 的发展视为一项值得庆祝的成就,还将其视为进一步发展机器学习社区、创造更多价值的机会。
我们的目标是提供全球最好的机器学习平台。让 TensorFlow 成为每位开发者工具箱中新的强大软件,同时将机器学习从小众技术转变为同网络开发一样成熟的领域。
为实现这一目标,我们倾听用户需求、预测新的行业趋势、迭代我们的 API,并努力让您更轻松地进行大规模创新。就像 TensorFlow 最初推动深度学习兴起一样,我们希望为您提供一个可以挑战无限可能的平台,以便继续促进机器学习的发展。机器学习正在快速发展,TensorFlow 亦是如此。
现在,很高兴地宣布,我们已经开始着手开发下一个 TensorFlow 迭代,以实现机器学习的下一个十年发展目标。我们正在构建出色的 TensorFlow 功能,同时专注于四大支柱。
TensorFlow 的四大支柱
快速和可扩展
XLA 编译
我们高度关注 XLA 编译,以 XLA 在 TPU 上的性能优势为基础,致力于加快大多数模型训练和推理工作流在 GPU 和 CPU 上的运行速度。我们还计划将 XLA 打造成为行业标准的深度学习编译器,并已将其作为 OpenXLA 计划的一部分,开放给开源协作。
- OpenXLA 计划
https://cloud.google.com/blog/products/ai-machine-learning/googles-open-source-momentum-openxla-new-partnerships
分布式计算
我们正专注于 DTensor 的研究,这是一种用于大规模模型并行的全新 API。DTensor 开启了超大模型训练和部署的未来之门,让您可以像在单个设备上进行训练一样开发模型,甚至在使用多个客户端时亦可如此。DTensor 将与 tf.distribute API 整合,让柔性模型和数据并行成为现实。
- DTensor
https://tensorflow.google.cn/guide/dtensor_overview
性能优化
除编译外,我们还进一步投入于算法性能优化技术,例如混合精度和降低精度计算,从而在 GPU 和 TPU 上带来可观的提速表现。
应用机器学习
用于 CV 和 NLP 的新工具
我们正投入于构建应用机器学习生态系统,特别是通过 KerasCV 和 KerasNLP 软件包为应用 CV 和 NLP 用例(包括多种先进的预训练模型)提供模块化、可组合的组件。
- KerasCV
https://github.com/keras-team/keras-cv
- KerasNLP
https://tensorflow.google.cn/
生产级解决方案
我们正在扩展 TF Model Garden (GitHub),以覆盖广泛的机器学习任务和领域。Model Garden 可以提供端到端生产级建模解决方案。它包含许多前沿 (State of the Art, SOTA) 的模型实现,此类实现适用于计算机视觉和自然语言处理 (NLP),不仅可以重现,而且符合规范。此外,Model Garden 还提供训练代码库,以便您快速运行使用此类模型的机器学习实验,并导出为标准 TF Serving 格式。
- TF Model Garden (GitHub)
https://tensorflow.google.cn/guide/model_garden
开发者资源
我们正在为热门以及新兴的应用机器学习用例添加更多代码示例、指南和文档。这样做的目的是为了逐渐降低机器学习领域的准入门槛,使其成为每位开发者得心应手的工具。
随时可供部署
更易导出
我们正在简化将模型导出到移动设备(Android 或 iOS)、边缘设备(微控制器)、服务器后端或 JavaScript 的流程。用户可以将模型导出到 TFLite 和 TF.js 并优化其推理性能。操作起来与调用“model.export()”一样简单。
- TFLite
https://tensorflow.google.cn/lite
- TF.js
https://github.com/keras-team/keras-cv
面向应用的 C++ API
我们正在开发一个公共 TF2 C++ API,以作为 C++ 应用的一部分用于本地服务器端推理。
部署 JAX 模型
我们正努力让您更轻松地部署使用 JAX 和 TensorFlow Serving 开发的模型,以及让您更轻松地使用 TensorFlow Lite 和 TensorFlow.js 将模型部署到移动设备和网站中。
- JAX
https://github.com/google/jax
简单化
NumPy API
随着机器学习领域在过去几年中的快速发展,TensorFlow 的 API 接口也在随之增加,但 API 的增加方式并非总是一致或易于理解的,因此我们正在积极致力于整合和简化这些 API。例如,我们将会针对数字采用 NumPy API 标准。
- NumPy API 标准
https://tensorflow.google.cn/guide/tf_numpy
简化调试
框架不仅包含其 API 接口,调试体验也同样重要。我们的目标是专注于优化调试功能,从而最大限度缩减开发各种应用机器学习系统所需的时间。
TensorFlow 未来将会 100% 向后兼容
我们希望 TensorFlow 可以成为机器学习行业赖以发展的基石,并将 API 稳定性视为其中最重要的一个特性。作为在产品中依赖 TensorFlow 的工程师,以及 TensorFlow 生态系统软件包的构建者,您应该能够升级到最新 TensorFlow 版本,并即刻受益于它的新功能和性能改进,而无需担心现有代码库可能会崩溃。因此,我们承诺从 TensorFlow 2 开始到下一个版本,TensorFlow 将会完全向后兼容。您的 TensorFlow 2 代码将按原样运行,无需运行转换脚本,也无需进行手动更改。
时间线
我们计划在 2023 年第 2 季度发布全新 TensorFlow 功能的预览版,并在同年晚些时候发布正式版本。在此期间,我们将会定期发布最新进展情况。您可以关注 TensorFlow 博客和 TensorFlow YouTube 频道,以及我们的官方微信公众号获悉进展。
- TensorFlow 博客
https://blog.tensorflow.org/
打造 TensorFlow 的未来
为赶工期砍功能!曝小米汽车进展不如意,或放弃自动驾驶全栈自研
小米汽车2024年的量产目标又增加了不确定性。11月28日,有媒体报道,小米汽车的开发项目不及预期,最终可能导致产品竞争力下降。上述媒体援引知情人士信息称,“明面上看起来在顺利推进,但实际进度慢了不少。”据其介绍,小米进度慢主要是内部流程的问题。如:部分定义中要交付的东西却因为各种因素出现延迟。“本身该交付的内容就不多,现在还会因为交付进行的卡点被砍掉一些,就会更少了。”上述知情人士说道。

另外,根据出行范儿爆料,从接近小米内部人士获悉,小米自动驾驶业务正在进行人员调整,原定的全栈自研或将暂时转为供应商方案。原因如下:一方面,小米自动驾驶前期测试效果不佳,短期内很难有实质性突破,为了保证2024年量产计划,选择成熟的供应商方案显然更明智;另一方面,自动驾驶全栈自研面临的是前期的巨大投入远超预期,雷军再“有钱”再“亏得起”,也不希望在智能手机等主营业务整体萎缩时给陷入低谷的小米集团带来更大的资金负担。
消息一出,立即引起热议。这也是11月份第二次传出的小米造车受阻的消息。月初,有消息称,小米造车已经被叫停,而内部也正在重新评估小米汽车项目。对此,小米汽车方面当时回复称:“小米汽车项目正在顺利推进。”

据了解,小米汽车工程车已经于9月28日正式下线。在稍早的8月11日小米发布会上,小米汽车还首次对外展示了小米自动驾驶技术的路测视频,路测场景包括最常用的高速、城市、泊车等,测试功能包括主动选择车道、进出匝道,并线超车、避让障碍物、记忆泊车等。小米方面对于自动驾驶的预期是,到2024年进入自动驾驶行业第一阵营。不过,小米的自动驾驶技术主要来源于其收购的子公司深动科技。
事实上,小米在自动驾驶上的进展也遭遇了不少挑战。上述报道援引一位来自研发体系的员工说法称:“在发布的自动驾驶测试视频中,我们很少可以看到一镜到底,很多都是经过剪辑拼接的,这也是研发进度的一个真实体现。”该报道指出,由于前期自动驾驶测试效果不佳,不少员工对小米汽车的首款产品缺乏信心。这些员工担忧,小米汽车的量产车型在自动驾驶上明显缺乏竞争力。

与此同时,还有消息称,部分小米此前高薪挖来的员工在近期离职。据了解,这些离职员工大部分属于上海团队。而上海是小米整车、三电系统以及底盘等业务部门的所在地。小米总裁王翔在小米三季度财报会议上披露,截至目前,小米智能汽车的研发人员已经超过1800人。对上述报道提到的造车进展不及预期和技术人员离职等信息,截至发稿,小米方面暂时未对此做出官方回复。
在小米高调宣布造车之后,小米集团并没有因为“造车”这一概念市值起飞。特别是随着在造车上的投入逐步增加,小米正在经历一段难熬的时光。财报显示,今年前三季度,小米集团营收为2140亿元,同比减少11.8%;经调整利润为70.57亿元,去年同期为175.66亿元,同比减少59.8%。截至9月底,小米集团现金及现金等价物为人民币281亿元,现金资源总额为人民币943亿元。
在业绩会上,王翔表示小米造车目前有实质性的进展,该公司要全力保证第一辆车的成功,而且要在2024年准时面世。从财报来看,小米方面对于造车资金上的持续投入。
自2021年3月份宣布造车以来,雷军高调宣布要斥资100亿美元造车。从财报来看,小米在造车业务的投入也在持续攀升。今年1-3季度,小米研发支出分别为35亿元、38亿元和41亿元。其中,1-3季度小米在新能源和创新业务的相关支出分别为4.25亿元、6.11亿元和8.25亿元,前三季度累计支出为18.65亿元。王翔表示,目前小米在造车上投资的效率和规模对于集团不会构成重大影响。

当然,这一资金投入在几家造车新势力中,并不算多。作为对比,仅三季度蔚来研发投入为29.45亿元;理想和小鹏二季度研发投入分别为15.3亿元和12.65亿元,且三家在研发投入方面仍然呈现着持续攀升之势。当然,与蔚来、小鹏、理想相比,小米的汽车业务并不在同一阶段,因而也不能简单对比。另外,小米在手机领域的技术积累或许能够节省一定的研发成本,如小米造车团队中有不少人是公司内部转岗过去的。若小米汽车能够如期上市和量产,其也将节省渠道扩张的费用,而这也是其未来的优势所在。
与此同时,小米还通过全资并购以及对上下游企业的产业投资等方式,快速在汽车行业展开全产业链布局。先后投资了泰睿思、比亚迪半导体、黑芝麻智能、泽景电子、博泰车联网、睿米科技、Momenta、禾赛科技、卫蓝新能源、珠海冠宇、中航锂电等,投资范围涵盖了芯片、智能座舱、自动驾驶和动力电池四大领域。

小米造车曾经在2021年成为业内最重磅的消息之一,不少车企人士认为小米造车会对行业产生巨大冲击。不过,随着时间窗口的缩短,整个形势在不断变化,这使得小米造车的挑战更加艰巨。小米集团创始人雷军此前在社交媒体上发表了多条自己对电动汽车行业的看法。雷军认为,当电动汽车行业成熟时,世界前五大品牌将占据80%以上的市场份额。“我们成功的唯一途径是成为前五名之一,每年出货量超过1000万辆。竞争将是残酷的。”
在1000万辆的年销量目标前,在不断受挫的现实之下,小米造车正走向撕裂的两个方向。
特斯拉最新演讲:利用Bazel,大规模开发,构建和评估autopilot
Bazel是谷歌开源的分布式软件构建系统。BazelCon是Bazel软件社区的首要年度分享活动。今年的BazelCon在纽约的57号码头举行。
特斯拉的本次分享长约19分钟,本文字数约4千。
使用Bazel构建autopilot软件
Gabriel:大家好,我叫Gabriel。
Romu:我叫Romi。
Gabriel:我们是特斯拉的软件工程师,从事Autopilot的工作。我们很高兴今天能在这里,讨论我们如何使用Bazel开发汽车和机器人的软件。
但在我们开始之前,我想播放一个简短的视频,向你们展示我们的成果。

那是我们的完全自动驾驶,或FSD beta项目的运行视频。现在,让我们来看看,它是如何运作的。
这个系统的运作机制是,接收来自环绕汽车的八个摄像头的信号,将其输入神经网络,以三维的方式重建汽车周围的场景。我们称之为三维向量空间。
然后,我们混合使用C++和神经网络,运行规划和控制模块。有大量的数据需要在低延迟的条件下进行处理,而且都是保证安全的关键要素。
我们不得不搭建自己的FSD计算机,更快更有效地进行神经网络各种操作的计算。我们正在为这款FSD计算机开发软件。
为了快速取得进展,我们需要两个要素:能够快速迭代我们的技术栈,以及用以支持这一目标的合适的基础设施。
这是我们工作流程的一个简化图,我们从顶部开始。

我们使用从我们的车队收集得到的视频片段,训练我们的神经网络。我们在我们的AI集群(我们称之为Dojo)和GPU集群上进行训练。训练完神经网络后,我们将其整合到构建版本中,对它进行评估,然后部署到我们的工程车队,以获得实测里程数据。最后,我们将分批部署到主车队。
在这次演讲中,我们想把重点放在构建,评估,以及FSD计算机集群上。从构建开始。
我简单提到过,我们的技术栈,是C++和神经网络的混合。我们有许多工程师在C++代码库上开展工作,而他们需要能够快速迭代。

为了演示我们如何做到这一点,我们将创建一个新的C++库。
为了创建一个新的库,我们需要创建一个新的头文件和源文件。然后,我们增加include语句,添加依赖。最后,我们需要在构建文件中用正确的依赖关系创建一个cc库目标。
从另一个角度看,我们似乎把依赖关系图更新了两次,一次在C++中,另一次在Bazel中。
我们的目标,是让工程师们专注于C++代码,而Bazel的目标应该能从源代码中推断出来。
为了做到这一点,我们使用了一个叫做gazelle的工具。gazelle读取源代码,并更新或生成构建文件,而且它可以被扩展为支持任何语言。我们增加了对C++的支持。
为了充分利用该插件,我们建立了一些最佳实践方式。
要让插件管理一个目录,这个目录中的构建文件必须包括我们的自定义指令。我们在构建文件的顶部添加我们的指令。我们运行工具,gazelle将给我们提供右边的构建文件。每个生成的cc库只有一个头文件和一个源文件,这让我们能够更细粒度的构建版本。
但它也有另一个属性,那就是,我们必须让include语句使用从根开始的完整路径。这让我们可以通过阅读include语句,推断出Bazel的依赖关系,而且也很容易就能弄清楚所有的依赖关系。
我们从头文件中提取include,这些成为了deps。而我们从源文件中获取include,这些成为了实现的deps。
我们已经看了C++的情况,现在让我们来看看神经网络。

就像我们把C++代码编译成可以在机器上运行的二进制文件一样,我们必须将神经网络编译成汽车或机器人能够理解的二进制文件。
我们正在为这台FSD计算机进行开发,它有CPU,GPU和一个称为Trip的AI加速器。每种形式的计算,都针对不同的工作负载进行了优化。例如,我们很多的神经网络矩阵操作在Trip上运行得更好。
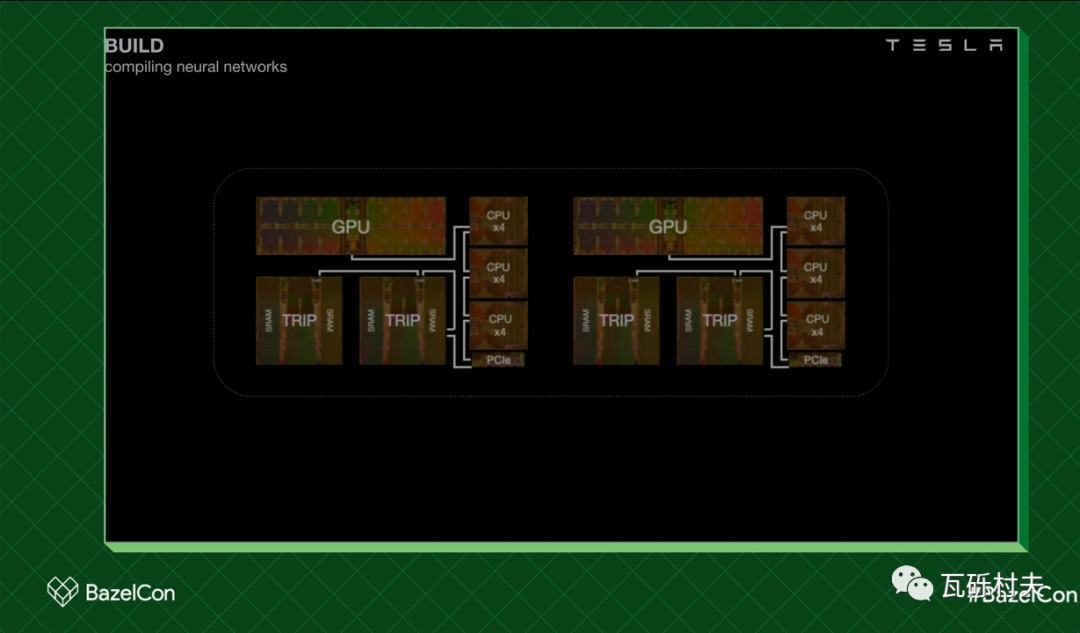
让我们看一个例子,这是占用网络。顾名思义,它用来确定向量空间中的任意给定坐标是否被占用。
而这是它的架构。每个节点都是一个神经网络的操作,流向是从上到下。

这个网络非常庞大,其中一些操作在CPU或GPU上运行得更好,而其他操作在Trip上运行得更好。我们要做的是,把网络分割成子图,为合适的计算进行优化。
进行分割的代码,是Basel资源库的一个角色,我们称之为分割器。
我们一开始用一个手写的构建文件来管理这些模型,但它变得非常非常庞大。而最初的分割器是一套自定义规则,但要声明每个子图的依赖关系以及不同子图间的连接方式,很快就变得让人沮丧了。
最终,我们把分割器变成了一个资源库的规则。
而现在,它加载了仓库中的所有模型,对它们进行分割,并针对合适的Trip创建每个子图。在将模型分割成子图之后,每个子图都使用合适的编译器进行编译。
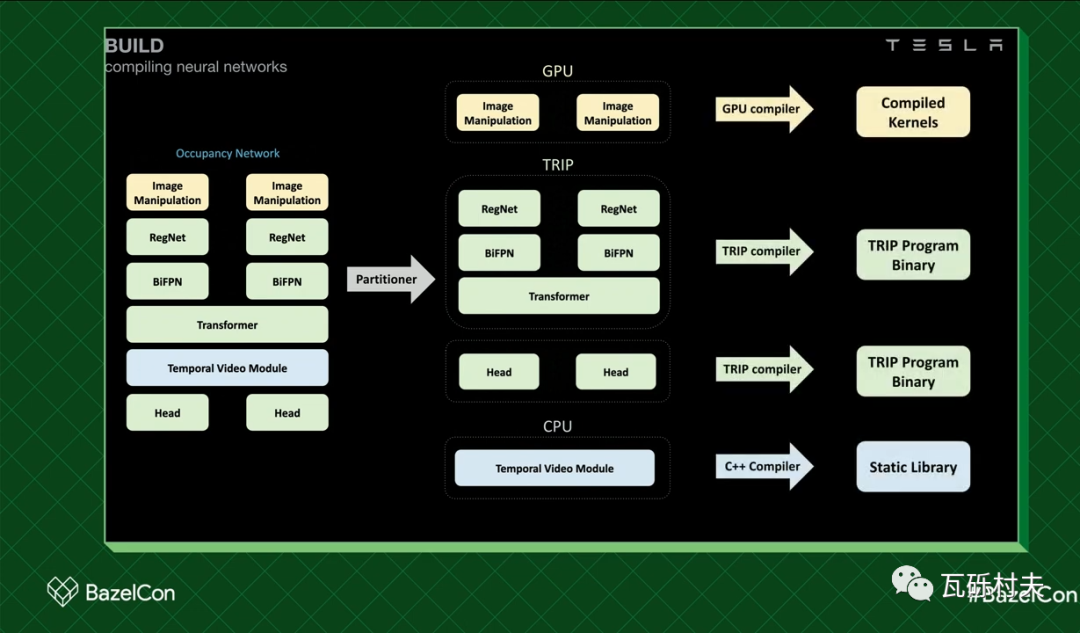
当对一个神经网络进行修改时,主要的工作流程是更新末端节点,在这里被展示为左边的两个头部节点。
如果我们改变这两个头部节点,中间的头部子图将必须要重新编译,但其他的子图都会被高速缓存击中,这让我们能够非常快速地迭代神经网络的改动。
已经将占用网络分割成子图,这些子图可以进行并行编译,但我们也需要考虑到关键路径,我们需要让每个子图都快速编译。
因为我们开发了编译器,我们能把它分解成三个步骤,每个步骤都在Bazel中使用自定义规则进行建模。
整条流水线则以宏的形式实现,工程师可以快速尝试不同的策略。
而且如果临时构建产物是相同的,那么它们就可以受益于缓存命中,而且它们就不需要重新运行。这可以让从事编译器工作的工程师能够非常快速地进行迭代
虽然在这个演讲中,我们只涉及了神经网络和C++的编译工具链,我们正在处理软件2.0技术栈的所有部分。但我们会把那些部分留给下一次演讲。

现在,Romy将谈谈我们如何评估改动。
评估autopilot的性能,仿真及FSD计算机集群
Romy:我们已经讨论了我们如何构建autopilot,现在,我们会谈谈如何评估autopilot的性能。

我们有两种形式的评估,第一种形式叫做开环评估。
开环评估,我们从我们的特斯拉车队中收集数据,获取这些预先记录的传感器数据,将其输入autopilot。并从那里开始记录控制模块的输出,验证autopilot是否按预期执行。
第二种评估形式,被称为闭环评估。这里,我们通过仿真,产生人工合成的传感器数据。我们将其送入autopilot,并和之前一样,记录控制模块的输出。然而,由于这些数据完全是人工合成的,我们可以获取控制模块的输出,并在仿真中使用它来产生新的人工合成数据,从而形成闭环。

现在,我们了解了这两种评估方式,让我们看看如何利用它们来解决autopilot的问题。
在接下来的这个视频中,你会看到一个骑自行车的人迅速进入autopilot的车道。
为了避开这个骑自行车的人,autopilot向左偏了一下。你可以看到,在这里的左边,汽车非常接近左边车道上的汽车。

从我们的数据可以看出,这是一个非常不舒服的体验,需要我们加以解决。autopilot工程师们能够在控制和视觉模块上做出改变,并重新运行仿真。在重新运行的过程中,我们可以看到,一切都按预期进行。
仿真给了我们无限的可能性,因为我们可以改变景观,角色,光照和地形,这为我们所有的测试案例提供了可观的能力。

现在,我们了解了开环和闭环仿真是如何帮助我们的autopilot的,让我们深入了解Bazel如何与评估互动,以及两者如何都在我们的服务器上运行。
我们的数据中心有三个组成部分:存储,评估服务器和FSD计算机。让我们深入了解每一部分。

我们的数据是由存储在Bazel缓存中的构建产物,我们的docker镜像,以及来自我们客户车队的数据组成的。这些数据被送入我们的评估服务器。
这里,你可以看到整个评估循环。评估世界的状态被送入渲染器,这些渲染得到的图像和仿真的传感器,被送入autopilot计算机。这会产生控制输出,用来更新评估世界的状态。从那里,我们可以为下一个循环生成新的渲染图像。
我们的数据中心在同一批机器上运行构建和评估。现在,我们已经探索了高层次的软件架构,让我们来看看,使这一切成为可能的硬件。
构建和评估是要求极高的任务,需要大量的带宽和计算。每次构建,我们从我们的Bazel缓存中取出53G数据,而每次仿真需要45G。

这些带宽要求带来了各种挑战,我们将在本次演讲的后面部分谈及。
最终的仿真图像是以每台FSD计算机10G链路进行流式传输的。
我们介绍了单次评估和单次构建的硬件和软件,接下来,我们将介绍,如何通过我们的FSD计算机群来扩展这两者。
这是一台FSD计算机。在我们添加了散热器,冷却器,高速网络和外壳之后,为了让这台计算机适合于数据中心,我们把它们和风扇,继电器,电源和热传感器组合起来一起放入托盘。

这些托盘垂直堆放在机架上。我们的数据中心有很多排这样的机架。我们在全球有多个数据中心,并拥有超过5000台计算机,FSD计算机,而且我们还在不断扩大这个规模。

在2018年,我们让FSD计算机能在桌面上运行,而且我们的评估量相对较低。
我们在2019年搭建了我们的第一个完整的机架,并在2020年底,以年仿真量3000万次,让我们的第一个数据中心达到了饱和。
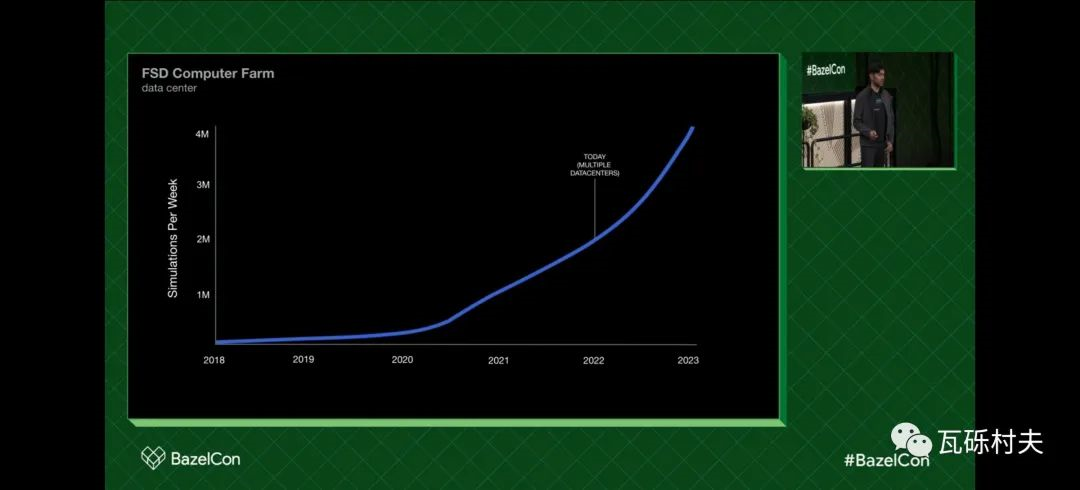
在2022年,我们每周运行200万次仿真。
而这个规模给我们带来了很多独特的软件上的挑战,包括网络,分布式计算和存储。鉴于我们现在是在BazelCon会议上,让我们谈谈,这样的规模如何影响我们的Bazel缓存。
在开始的时候,我们有几台机器,击中单个Bazel缓存,这个缓存是作为nginx服务器实现的。这个简单的配置应该很熟悉,因为它是BazelCon网站的建议之一。
随着规模的扩大,我们碰到了磁盘IO的限制,以及单一缓存服务器的空间问题。
为了解决这个问题,我们决定进行横向扩展。我们添加了一个负载均衡服务,这解决了我们的磁盘IO问题,以及磁盘空间问题。但是,随着每次构建的8G峰值带宽,进入负载均衡服务的带宽成了问题的关键所在。
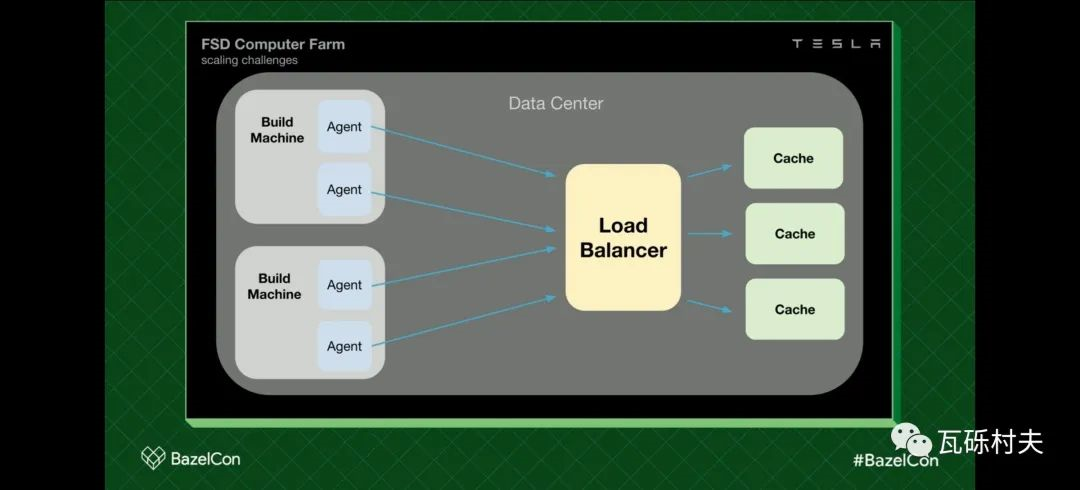
我们添加了客户端的负载均衡服务,并特意考虑了我们数据中心的网络拓扑结构,以消除这个瓶颈。
我们在多个节点上采用一致的hash算法,以确保我们在单个数据中心内,能实现缓存命中。
如果我们把前面的图放大,我们就可以完整地看到单个数据中心的情况。随着时间的推移,我们把数据中心扩展到了几个,我们希望避免数据中心之间的高速缓存不命中,并理解数据中心之间的入口和出口是一种宝贵的资源。
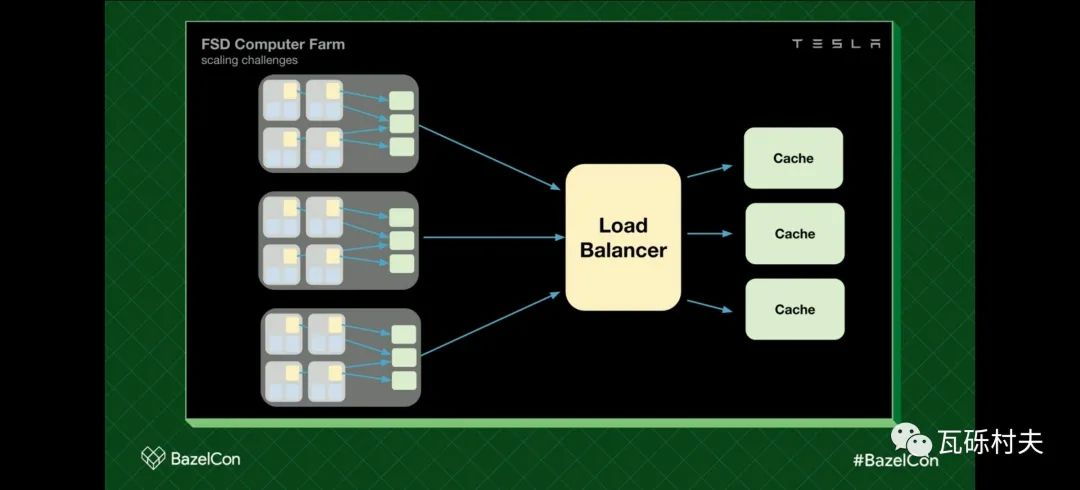
为了解决这个问题,我们实现了分层Bazel缓存。每个数据中心都实现了写直通和读直通缓存。每一个新的构建产物,Bazel都会写直通到数据中心的本地缓存上,并把它保存在位于独立数据中心的黄色主缓存中。数据中心内的缓存不命中,会读直通到主缓存上,并把构建产物拉取到数据中心的本地缓存。
通过以上方式,我们就能保证很高的缓存命中率。
Bazel的读负载是非常重的,而且大部分的读取都是在数据中心内完成的。正因为如此,主缓存的负载仍然相对较低,主要是写入负载较重。
目前为止,这个方案对我们来说扩展性不错。
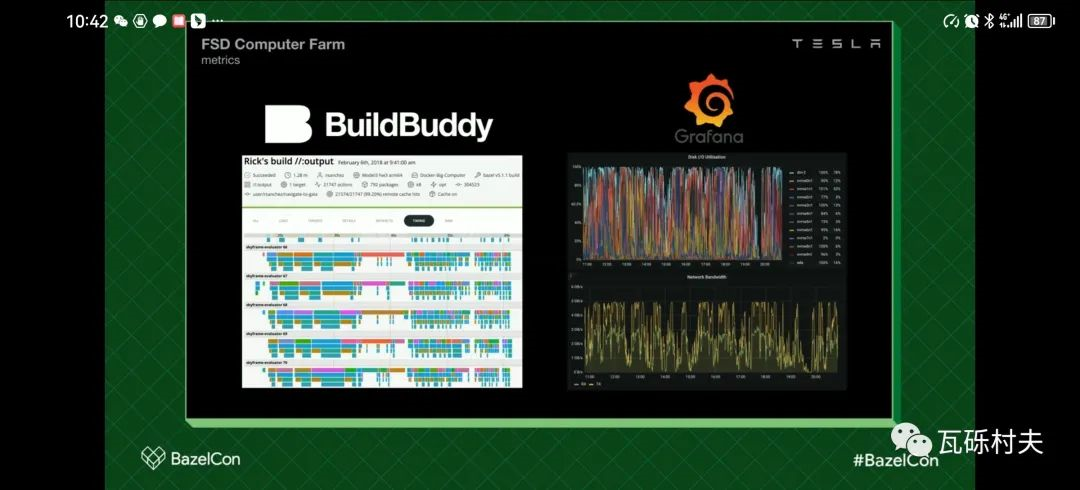
在我们的技术栈中,我们用BuildBuddy和Grafana记录指标。我们自己fork了BuildBuddy的代码,并利用它来收集额外的指标。
我们使用Bazel事件服务来记录每个构建目标所花费的时间,并检测回退问题。通过Grafana,我们为我们的负载和聚合记录了高层面的基础设施指标。

基于所有这些测量数据,我们记录了我们的负载是200万次评估,90000次构建。每周生成1PB的构建产物,每周进行1000万次测试。

为了支持这个级别的负载,我们必须搭建最先进的计算机,跨越五个数据中心,达到1exa-ops算力。超过5000台FSD计算机,使用了超过90000个内核。
这些数字每几个月就会增加。
我们不仅仅是在扩展我们的基础设施,我们也在扩大我们的团队,我们正在进行招聘。如果你有兴趣加入我们的团队,请查看tesla.com/ai。
参考文献链接
https://mp.weixin.qq.com/s/8SlhtLY9mQWUOvnEa3Bn2A
https://mp.weixin.qq.com/s/EJnQUe6dckvltox8Hw09EA
https://mp.weixin.qq.com/s/NAGErVCWsXG8ZI9b3voshQ

