

LLVM IR与OpenCL分析
LLVM IR与OpenCL分析
参考文献链接
https://mp.weixin.qq.com/s/G36IllLOTXXbc4LagbNH9Q
https://www.thinbug.com/q/21009523
编译器与IR分析: LLVM IR,SPIR-V到MLIR
写过一篇文章“Deep Learning的IR“之争”“,彼时机器学习编译器(ML Compiler)的实践刚开始不久。经过几年的探索和演进,ML Compiler已经成为ML System中最重要的一环。ML Compiler既有其自身的特点,又和传统编译器有着密切的联系;既有新的挑战,又有很多前人的经验可以借鉴,是个有趣且有高价值的话题。本文作者除了直接参与ML Compiler研发,也对很多相关问题有深入的思考,之前的很多交流也给我很多启发,非常高兴能邀请他来和大家讨论这个话题。
编译器 (Compiler) 通常是各种提高开发效率的软件工具链中不可或缺的部分。编译器一般被认为是黑箱,吃进高抽象层次的源程序,产生语义不变,可在目标硬件上运行的低层次机器码。当然,编译器也有其内部结构,中间表示 (IR: Intermediate Representation) 串联起编译器内各层级和模块。
中间表示对编译器至关重要,也如编译器一样百花齐放。我在日常工作中有幸能够涉及三种主流编译器中间表示或者基础设施——LLVM IR, SPIR-V, 以及 MLIR, 尤其对于后两种,我都参与了早期的开发。我打算用一系列文章记录自己对于编译器以及中间表示的理解,希望对感兴趣的人有所帮助。
这是开坑第一篇,主要讨论我个人对于编译器以及中间表示的演进历史以及发展趋势的理解。着眼点在于为什么现有中间表示会设计成它们当前的形态,而非具体的机制以及如何使用。后者已经有详尽的规范和教程可以参考。话题所致,此篇会比较抽象,或者用最近比较拉风的词,形而上 (meta) ,在后续的文章中我会更加具体。另外,此篇也会尽量使用比较和类比,因为一般而言,借助于已熟悉概念来理解新概念会比较高效。讨论偶尔也会涉及非编译器的领域,但保证它们是相关的,一法通,万法通。不过,尽管我不会离题太久,依然可能比较适合爆米花食用。
编译器与中间表示
在讨论各种具体中间表示之前,先让我们总体看一下编译器和中间表示。
抽象与语义(Abstractions and Semantics)
自人类文明产生至今,虽然科技演进的速度飞快,人脑却没有多少变化。我们理解不断爆炸式提升的复杂度的方式是抽象 (abstraction)。抽象帮助我们忽略细枝末节,着眼于主要矛盾。抽象减少了人脑需要处理的变量数量,减轻了人脑的处理负担,这对于求解复杂问题至关重要。
自抽象而产生的问题描述被称为模型 (model),例如,在编程语言中,我们有机器模型 (machine model) 用以描述底层计算架构;在数据系统中,我们有数据模型 (data model) 用以描述数据关系结构;在分布式系统中,我们有系统模型 (system model) 用以描述时序和容错假设。模型通常是原体的理想化描述。有时模型会离现实情况非常远,例如,估计没人能够设计准确的股市模型。但无论如何,模型始终是保持复杂度可控不可或缺的工具——模型能够给我们清晰明确的语义 (semantics), 即因定义而一定成立的原理。有了这些,我们才能对模型所描述的原体进行逻辑甚至数学层次的严谨推理 (reasoning)。人脑本质性喜欢逻辑与解释(神话、科学、甚至迷信都是人类试图解释世界的方式)。此处似乎离题了,实际上我只是在用广义的方式引入一些常见的编译器开发术语——抽象、模型、语义、推理。当然,计算机可行的其它领域也会关注这些方面,比如,我们希望面向对象的“类”有良好的抽象,但这些领域通常多是“设计艺术”。相对而言,编译器更多关注理论科学的方面;编译器需要明确的语义用来证明 (prove) 代码转换的正确性。
正确性与优化(Correctness and Optimization)
编译器的首要任务是保证转换的正确性 (correctness);优化 (optimization) 是次要的考虑。产生不符合源程序意图的非常“优化”的代码没有任何意义。在整个编译流程中正确性都需要得到保障。离开清晰的语义,正确性就无法得到定义和保证。因此编译器对语义未知的操作 (operation) 无法进行任何转换。当然,这并不包括每一个微小转换,编译器内部也有不同层次的“边界”。每个转换遍历 (pass) 保持原子性;在其内部,可能会临时违反源程序语义,但在每个转换遍历之后,中间表示应该是正确的。编译器极度依赖每个遍历之后的中间表示验证 (validation) 来保证正确性。在正确性得到保障之后,我们才可以考虑优化。生成高性能代码似乎是无可争议的目标,但实际上也充满了微妙的细节。不同的源程序有着不同的模式,不同的硬件喜欢不同的指令流。编译器处于源程序和目标硬件之间,实际上能够动用来提升性能的手段是非常有限的。编译器需要在大量的限制因素下做抉择,并且保证这些抉择对大多数场景适用,特别是针对 C++ 这种通用编程语言。这其实是非常高的要求,导致最后只有少数一些转换(像是不可达代码消除DCE、常量折叠constant folding、指令标准化canonicalization等等)可以全局默认开启,很多其他转换只能在之后的第二阶段,针对目标硬件优化时使用。在编译器一步步转换程序的过程中,越来越多的高层次的简明的信息被打散,转换成低层次的细碎的指令,这个过程被称为代码表示的递降 (lowering)(不知道公认的中文翻译是啥,只能自己来了。);与之相反的过程被称为代码表示递升 (raising)。后者通常远比前者困难,因为后者需要在芜杂的细节中找出宏观脉络。代码表示递降是编译器的通常转换方式。不难理解,越晚执行的转换越有结构性劣势,原因是缺乏高层次信息。这限制了目标硬件相关优化所能解决的问题也决定了实现的复杂程度。其实这里的本质性问题是强耦合 (coupling)。这种强耦合绑定了不同应用领域(尤其是使用通用编程语言的情况)和编译器中不同垂直转换路径(尤其是编译器使用统一IR的情况)。解耦 (decoupling)是我们在各种领域中实现更加复杂系统和支持更加高级场景的一般方式。可以预见,领域专用语言以及编译器内部解耦能够更好地释放编译器的优化能力。在接下来的 MLIR 章节我会进一步展开这一点。总而言之,成熟的编译器可能会帮助其支持的各种场景挖掘出大部分的性能,比如说是 80%,但期待编译器对所有应用达到最优性能是不切实际的。编译器的真正优势是帮助我们节省达到前 80% 性能所需的工程投入,让我们可以集中资源在剩下的 20% 或者其他核心问题上。
效率工具
尽管已经近乎陈词滥调,还是再一次强调,编译器只是提升开发效率的工具。写汇编码或者机器码也许会显得特别酷,却很难是高效的开发方式(不过,对于某些适合的场景,通过手写汇编来获取极限性能却是非常合理和常见的方式)。能够使用高层次抽象的语言可以让开发者忽略底层芯片上具体的寄存器和指令,从而避免陷入耗时易错的繁杂细节之中,是对开发效率的极大提升。这就涉及我们管理不断提升的复杂度的方式——我们有了针对不同层次的抽象,只需要创建工具来对这些抽象进行自动转换。当然,并非所有的转换都可以自动化。对于可行的,我们都可以把这种工具看作广义上的编译器。比如,在数据处理系统中,Apache Beam 提供了统一的语言来描述任务。Beam 会把这些任务转换到具体的执行引擎 (Spark, Flink, 或者其他) 的描述。这些执行引擎再进一步把这些任务编译成运行在具体机器上的操作并负责调度。这里的整个流程也可以看做是一种编译。类编译器的工具通过隐藏底层细节、提供高层次抽象而极大地提升了开发者的效率。编译器通过对中间表示进行一系列变换 (transformation) 来链接不同层次的抽象。
IR的形态和兼容性
中间表示只是程序的一种表示,其设计注重支持变换操作,使其正确和高效。当然,后面我们也会发现中间表示也会实现一些其他目标。在早期,编译器通常有单一中间表示,但随着编译器的演进,情况变得更加复杂。现代编译器通常会有多层级的内部表示。比如,用 Clang 来编译 C++ 程序通常要经过 Clang AST, LLVM IR, MachineInstr, MC 等等多个层级[1]。针对 GPU,我们也会发现完整编译器被拆分成离线 (offline) 和在线 (online) 两部分。两部分之间的程序表示,像是 SPIR-V,也会被称为中间表示,但其实已经不再局限于编译器内部了。中间表示可以有三种形态:用以高效分析和变换的内存表示 (in-memory form),用以存储和交换的字节码 (bytecode form),以及用以阅读和纠错的文本表示 (textural form)。基于使用场景,我们通常会见到不同的设计折中来侧重不同的形态和提供不同程度的兼容性。比如,LLVM IR 更侧重于编译器内部使用,所以它的核心是高效的内存表示并提供相对较弱的兼容性以便于迭代改进。而 SPIR-V 则设计为硬件驱动的输入程序表示,所以它更注重于字节码的高效处理并提供强兼容性。此处无所谓对与错,只是满足不同的需求而已。但这些设计折衷依然对整个上层的生态系统产生深远影响。
IR的设计理念
现实中并不存在中间表示的普适设计规则。大部分情况下,中间表示的设计都是在各种限制条件下权衡各种利弊然后做出折中选择。这些选择会考虑具体问题的普遍性或者特殊性、给整个编译器栈带来的组合复杂性、对各种变换的影响等等。总体上,我们希望:
1. 中间表示中的操作 (operation) 能够具有清晰明确的语义。这是一切的根基。
2. 在这之上我们希望操作能够相互正交 (orthogonal),这有助于定义标准 (canonical) 形态以减少变换需要考虑的情况。
3. 另外我们也会希望在同一中间表示的不同部分中避免出现重复信息。重复信息在各种变换后有很大概率会导致中间表示的不一致,从而导致错误编译。
4. 尽可能地保持高层次信息也是非常有好处的,因为在代码表示递降后想重新找回丢失的信息很难。
5. 以及其他种种。
听起来似乎都是非常有道理的指导哈?其实对上面的大部分理念我们都可以举出反例:
2. 如果硬件实现了某特殊的功能模块,我们希望能够提供相应的软件和中间表示抽象, 即便这会“破坏”中间表示的正交性。举个栗子,在 GPU 中间表示中,除了基础的乘和加指令,都有 FMA 指令。
3. 在 SPIR-V 中,一个编译单元 (module) 会提前声明所需要的硬件能力 (capability)。这些信息完全是可以通过对中间表示的主体进行分析来得到的,所以是重复的信息。但是它们的存在减少了硬件驱动所需做的工作,从而加速了实际运行。
4. 如果输入语言已经足够低层次,比如 C,那么我们没有任何办法,只能想办法提升抽象的层次来产生更好的代码,像是对标量代码的自动向量化 (vectorization)。
以上其实只是试图说明中间表示的设计真的充满了依据领域和场景的折衷。如之前所述,如果同一个编译器试图支持多种应用,或者同一中间表示试图支持多个垂直转换路径,我们非常容易面临相互冲突的目标,使我们在讨论中达成一致变得很困难。这也意味着我们丧失了迅速迭代和演进的能力,在有些情况下代价很高。对编译器进行解绑 (unbundling)——面向特定领域、不同层级和模块化的中间表示——非常有用。这样每个领域可以以最符合其领域特征的方式来设计编译器,不同层级和模块化的中间表示也可以只关注它们的场景来做最合适的取舍。
LLVM IR
LLVM 最初发布于 2003 年。在经过了接近二十年的开发之后,LLVM 技术栈已经非常成熟,并有一个极好的生态系统。LLVM 支持许多前端语言和后端硬件,许多软硬件厂商有衍生版 LLVM 来针对自己产品的提供各种附加功能。我想 LLVM 对于整个业界的重要性无需我再赘言。
解绑和模块化编译器(Decoupling and modularizing compilers)
LLVM 带来的最重要的东西是对编译器解绑和模块化的实践,由此诞生了大量优秀的编译器库和工具。
在前 LLVM 时代,编译器通常是特殊设计并高度耦合。这些编译器虽然也分为三段——前端 (frontend) 用来对源语言进行解析,中端用来进行优化,后端 (backend) 用来产生机器码,但它们一般只针对某一特定语言(含衍生语言)或者目标硬件,编译器内部各个模块也没有明确界限。不同的编译器栈基本不共用代码,我们无法组合不同编译器栈中的现存的前端或者后端,从而无法真正发挥三段式编译器的优势。LLVM 依靠解绑带来巨大变革。LLVM IR [2]显而易见地处于 LLVM 生态的核心地位。LLVM IR 使用控制流 (control flow)、基础块 (basic block)、以及静态单赋值 (SSA) 形式来表示程序。这种表示是完备的,LLVM 从而可以独立于其他表示形态,实现作为前后端之间的单一桥梁。这就完全地解绑了编译器的前后端。[3]这之后我们所需的只是遵循模块化的最佳实践。LLVM 的代码是组织成一系列库 (library) 的。库的组织形式当然有其问题,但确实是经过实践检验的系统级模块化方式。库定义了不同模块之间的分界。通过合适的编程接口 (API),我们可以选择并且组合不同的编译器功能来完成不同的任务, 像是通过调用 Clang 功能库实现静态分析以及代码格式化。这些都是非常有用的。
文本IR形式(Textural IR forms)
除却解绑和模块化,LLVM IR 还带来了许多其他易用性和开发效率上的提升。在内存表示之外,对文本表示的原生支持将传统的 UNIX 哲学带入了编译器。
UNIX 哲学讲求每个工具负责一个简单任务,然后利用文件 (file) 以及管道 (pipe) 串联不同工具来实现复杂功能。在 UNIX 系统中,文件是对资源的统一抽象。尤其是文本文件,基本是大多数工具的信息交换媒介。文本文件足够灵活强大,能够支持不同的需求,同时又直观易用。在一个处理流程中(例如cat <file> | cut -f2 | sort | uniq -c)打印中间状态是非常自然的查看和纠错手段。长远来看,简单易用无可匹敌。当然,编译器的组件即便是模块化后也很难说是“简单”的工具。但 LLVM IR 的文本表示实现了 UNIX 文件一样的用途,能够串联起各个转换遍历 (pass),方便查看中间状态。这自然延伸到使用 FileCheck 来测试编译器本身,因为现在我们可以输入可读的文本表示并检查其输出。
一体两面
LLVM 是编译器开发的大幅跃进。其良好的设计和活跃的社区带来了许多提升效率的工具。但凡事都有一体两面。基于现有的 LLVM 生态,我们可以越来越明显地看到有些设计折中带来的影响。
中心化和各种衍生
LLVM IR 在整个 LLVM 生态中处于中心地位,这是编译器前后端解绑的基础,但这也意味着完整的编译路径必须通过 LLVM IR。因为 LLVM IR 的核心地位,对其进行修改需要满足极高的条件。各种工具都基于 LLVM IR,各种公司或者组织的内部流程都会通过它实现。即便你无需频繁地打通整个路径,对 LLVM IR 的局部小修改也会带来意想不到的间接效应。自然而然,这就意味着改动缓慢,需要长时间高强度的讨论,以及各利益相关者的同意。这对于保持 LLVM IR 本身的质量是必须的,但如果我只是有一个非常特殊的需求, 就很难劝服整个生态做出相应的修改。
一种常见的方式是分裂 LLVM,把修改保持在本地,创建衍生版。这依然会有很高的工程代价。LLVM IR 的中心地位对把所有改动贡献回上游更加友好。LLVM 的代码库每天有将近一百次提交,这些提交添加各种新功能或者修复各种问题。如果不及时追踪上游的提交,衍生版会偏离的越来越严重,最后可能无法再合并。另一方面,持续不断地追踪则意味着专门的人力和资源投入,很多小机构无法一直负担。总而言之,后果就是在现实中我们有各式各样的 LLVM 衍生代码,这些代码追踪着不同的上游版本, 有着不同的新鲜度。如果把全球作为一个整体来看,维持和更新这些衍生代码消耗了大量的人力和资源。当然这并不能说是 LLVM 独有的问题。以开源模式开发的大规模复杂系统在被各种组织商业化的时候都有类似问题。但类似项目通常会在设计时就考虑本地定制化的需求。相较而言,LLVM IR 的绝对中心地位使得其很难被本地定制化。某种意义上讲,这就是一种强耦合;MLIR 就在解耦上再进一步。
演进与兼容性
LLVM IR 的另一设计是能够协同演进中间表示和各种编译器分析以及变换。这对于工具链本身质量的提升是至关重要的,但它同时带来了相对较弱的兼容性保证[4]。当然社区不会无缘无故引入不兼容的变动,只是这一可能性确实存在。
编译器存在于近乎操作系统的层级,所以很容易理解人们为什么使用 LLVM IR 来作为程序的表示形式传送给硬件驱动,特别是考虑到 LLVM IR 极好的生态系统以及原生的字节码支持。但是 LLVM IR 真正的使用场景是作为不同软件模块之间的程序表示;涉及硬件和驱动则完全是另一个故事。硬件设备会存在于像是手机之类的终端产品之中,这些终端产品被产品制造商和最终消费者所掌控。驱动的升级是无法得到保障的,因此驱动依赖的 LLVM 库也可能永远无法得到升级。
实际上已经有许多如此使用 LLVM IR 的尝试,有成功,也有失败。一个比较突出的例子是 Standard Portable Intermediate Representation (SPIR)。SPIR 是为表示 OpenCL 设备程序 (kernel) 而设计的,它锁定了某一版本的 LLVM IR,使用 LLVM 内联函数 (intrinsic) 和元数据 (metadata) 来定义 OpenCL 的计算原语以及定义。但 Khronos Group 逐渐意识到 LLVM IR 实在不适合这种任务,遂转向了设计与开发 SPIR-V。
SPIR-V
SPIR-V 最初发布于 2015 年。SPIR-V 是多个 Khronos API 共用的中间语言,包括 Vulkan, OpenGL, 以及 OpenCL。定义全新的中间表示并且开发整套工具链需要大量的工作,但对 SPIR-V 的投入依然被认为是值得的。
标准规范的扩展性和兼容性
Khronos Group 的标语是“连接软件与硬件”,简明扼要地总结了它的任务。这种连接是通过标准规范 (standard) 和编程接口。Khronos Group 定义标准规范以及编程接口;硬件厂商提供它们的硬件实现,软件厂商则可以让软件在所有支持的平台与设备上运行。Khronos Group 定义维护了很多标准规范,比较著名的有 Vulkan, OpenGL, 以及 OpenCL。
标准规范的主要目的是抽象不同的硬件实现,并提供对上层软件的统一接口。但同时,标准规范也需要能够支持硬件特有的功能。这是对现实中存在各式各样硬件的一种承认,也让软件能够深度挖掘某些具体硬件的性能。这两个看似相互冲突的目标通过分等级的特性 (feature) 体系 (hierarchy) 得以支持。Khronos Group 内部有清晰的流程来管理各种特性,包括提议新的特性,提升某厂商专有的特性为通用特性等等。SPIR-V 也是一种标准,所以具有相同的设置。除了核心特性之外,SPIR-V 支持通过多种机制来扩展其功能,包括添加新的枚举值, 引入新的扩展 (extension),或者通过某个命名空间引入一整套指令 (extended instruction set)。其扩展也分为不同等级——厂商自有扩展 (vendor specific)、多厂商联合支持的扩展 (EXT)、 以及 Khronos 级别的扩展 (KHR)。任意厂商都可以提议新的扩展,但扩展越接近核心级别,就需要越多的厂商复议,并且要经过愈发严格的审核和批准流程。总体上 SPIR-V 和其工作组 (working group) 分别从技术和组织上提供了框架来支持标准的演进和扩展。[5]LLVM IR 也提供一些方式来扩展其中间表示,尤其是内联函数 (intrinsic) 和元数据 (metadata),但难以想象其支持所有厂商的各种自有内联函数,更不用说引入各种厂商自有的类型以及指令模式到核心 LLVM IR 指令中。除此之外,连接软硬件的标准规范也非常注重稳定性和兼容性,因为硬件驱动的更新频度远低于软件工具链。驱动在设备的生命周期内即便是永远得不到更新也并不稀奇。比如,许多在低端 Android 手机上的 Vulkan 驱动停留在发布于 7 年前的1.0 版本。如果我们使用 LLVM IR 作为设备程序表示 (kernel),则有很大的可能程序会由近期 LLVM 版本的工具链产生,但是驱动却依然停留在很早期的版本。这种版本错配会造成各种各样的麻烦问题。相对而言,SPIR-V 则通过版本和扩展机制以及稳定的字节码提供了必须的稳定性和兼容性。
稳定的字节码(Stable binary form)
完整的 GPU 编译器被分为两部分——首先通过离线工具链从高层次源代码生成 SPIR-V,然后通过驱动内部编译器将 SPIR-V 在线编译成机器码。虽然像 LLVM IR 一样在整个编译流程中处于“中间”位置,SPIR-V 更侧重于驱动内部二次编译的高效,因为这一步在运行时进行。所以 SPIR-V 的核心是其字节码。其编码有很多简化驱动二次编译的考量,像是用各种提前的显示声明来避免运行时复杂的分析。SPIR-V 并没有在规范中指定内存表示或者文本表示,这些都是实现 SPIR-V 标准规范的工具链自行定义的。比如 SPIRV-Tools 有其自己的内存表示和文本表示, 同样 MLIR 中的 SPIR-V dialect 也是。
GPU 领域专用
至此我解释了 SPIR-V 的 standard 和 portable,却还并未涉及其中 IR 的部分。其实 SPIR-V 的 IR 部分和 LLVM IR 相差并不太大。SPIR-V 借鉴了很多 LLVM IR 的设计——它同样是由控制流、基本块、以及静态单赋值来表示程序。指令的粒度和 LLVM IR 也相差不大。
SPIR-V 中独特的部分在于对很多 GPU 概念的原生支持。这种支持通过很多 SPIR-V 独有的机制来实现,比如 decorations, builtins, 以及特殊的指令(像是导数计算、图像取样)。另外为了支持图形图像和高性能计算的两种使用场景, SPIR-V 中有许多执行模型和模式。当然,对图形图像也有 structured control flow 的特殊需求。[6]一个 GPU 为主的标准规范需要原生支持各种 GPU 概念,能够提供不同等级的扩展需求, 以及提供稳定和兼容的字节码。这些需求并不符合 LLVM IR 的设计理念,所以 Khronos Group 推出了 SPIR-V。但是设计一套中间表示只是个开始,围绕其开发和维护整套工具链需要持续不断的工程投入。SPIR-V 与 LLVM IR 完全无关,SPIR-V 的编译器栈无法利用现有的 LLVM 库。所以 SPIR-V 的整个栈是从头开始独立开发的,从汇编、反汇编,一步步到各种语言的编译器和优化。如果我们当时能够有一套帮助开发编译器的基础设施——
MLIR
MLIR 在 2019 年底合并到了 LLVM 代码库,所以它才开源开发了两年左右。我个人感觉一个生态至少需要五年才能相对完善。从这个角度,MLIR 尚处于非常早期,许多开发尚待进行。但从目前的发展来看,MLIR给编译器开发带来了许多新颖的想法和深远的改变,比如通过基础设施化来进一步解耦编译器的中间表示。
基础设施化
基础设施化 (infrastructurization) 其实是技术演进的自然终点 (endpoint)。成为基础设施意味着一项技术已经足够成熟并且得到广泛部署。变成基础设施后,新的技术变革在其之上产生。电力、网络、公共云等等,都符合这个潮流。上述都是超大规模的基础设施化。基础设施化同样适用于影响规模小的技术,因为它能够通过共用来降低开发成本, 并让每个人只关注其核心商业逻辑的实现。
很多人通过机器学习编译器了解到 MLIR。这确实是 MLIR 最初关注的领域,但 MLIR 其实有着更加广泛的应用范围。MLIR 是用来开发编译器基础设施。它提供一系列可复用的易扩展的基础组件,用来搭建领域专用编译器。在 LLVM IR 和 SPIR-V 中,我们有唯一的中间表示,其中含有完备的指令集来编译所有的 CPU 和 GPU 程序。MLIR 中则没有完全处于中心地位的中间表示。MLIR 提供基础设施来帮助定义 operation 以及将逻辑相关的 operation 组合成 dialect。另外,MLIR 也提供一些普适的 pattern 或者 pass,这些 pattern 或者 pass 并不与具体的 operation 绑定,能够自适应。[7]
无论是对 operation 还是 pattern/pass 的支持都要求 MLIR 以更加细的粒度看待编译器。在 MLIR 中,operation 不再是最基础的部件,粒度进一步细化到类型, 值, attribute, region, 以及 interface (例如 attribute/type/operation interface).[8]
Operation 可以有任意数量的输入、输出、attribute,并包含任意数量的 region。其中 region 能够表示 operation 之间的嵌套关系,从而简化编译器的分析和转换。Operation 可以实现 operation interface,pattern 和 pass 绑定的是 operation interface,由此而实现与具体 operation 的解绑并做到自适应。
MLIR 里面的概念都设计的比较抽象,目的是能比较好地映射到不同的领域和场景。
Dialects, dialects, dialects
当然,这套基础设施存在的目的是帮助搭建最终编译器。我们在写 C++ 程序的的时候会调用 STL 或者更加高层次的库,很少会从头开始实现所有的细节。另外,基础设施也需要与其支持的领域协同发展,因为使用场景中会提供很多需求。因此,MLIR 代码库中自带很多用来给各种层级概念建模的 dialect。[9]
MLIR 的 dialect 生态目前还在扩张演进阶段,但 dialect 之间的组织结构以及有些 dialect 已经相对稳定了。比如我们有 LLVM 和 SPIR-V dialect 作为与其他系统转换的边界 dialect。(其实 MLIR 可以同时表示 LLVM IR 和 SPIR-V 这一点也表明了 MLIR 的基础设施角色。) 抽象层次居中的有 Linalg, Tensor, Vector, SCF dialect,它们协同合作用来生成代码。另外,MLIR 中还有 Affine, Math, Arithmetic dialect 用来描述底层计算。在 AI 框架层面,有 TensorFlow, TFLite, MHLO, Torch, TOSA 进行对接和导入模型。除此之外,还有很多其他用途的 dialect,像是 PDL 用来定义编译器转换等等。
Alex 之前在 MLIR 论坛上分享的各 dialect 之间的关系[10]非常值得一读,之后我也会写下我的理解。这些各式各样的 dialect 和以后包装它们而产生的局部或者完整的转换流程将极大简化领域相关编译器的开发。
进一步解耦编译器和中间表示
其实基础设施化以及由此产生的大量 dialect 都是进一步解耦和模块化编译器以及中间表示的一种自然结果。唯一的中间表示被许多以 dialect 形态存在的部分的中间表示取代。没有某个部分中间表示再处于中心地位,都是按需组合。如果现有的 dialect 不能满足需求,定义新的 dialect 非常简单。再过几年待 MLIR 更加完善后,可以预见,开发领域专用编译器只需要新加自己的边界 dialect 来定义项目相关的 operation,之后就是选取和组合现有 dialect 来形成整体的流程。如果这个构想实现,那肯定会极大缩减开发所需工程投入。
另外,进一步解耦中间表示也让我们可以灵活地根据领域进行设计和折中。我们只需选取所需的部分中间表示来组合成完整编译器,不再需要全盘接收像 LLVM IR 一样的一套完整中间表示。因为 interface 的存在,扩展模块的更能也变得更加简单——我们既可以定义新的 operation 来实现已有的 interface,也可以定义新的 interface 然后支持现有 operation。
换言之,LLVM IR 天然中心化并且偏好统一的编译流程,MLIR 的基础设施和 dialect 生态则天然是去中心化并且偏好离散的编译流程。
技术的一般发展趋势是从单一的强耦合整体到适用不同场景的多种多样的选择。对于技术栈的上层而言,这尤其明显,因为越往上越接近用户和商业需求,而用户和商业需求本身就各式各样,由层出不穷的前端框架可见一斑。
技术栈的底层一般相对稳定。少数几种硬件架构、编译器和操作系统统治很多年。但半导体进展的变慢和计算需求的爆炸式增长也在驱动着底层技术的变革。现在依然依靠通用架构和普适优化很难再满足各种需求,开发领域专用的整体的解决方案是一条出路。RISC-V 在芯片指令集层次探索模块化和定制化,MLIR 则是在编译器以及中间表示层面做类似探索。两者联手会给底层技术栈带来何种革新是一个值得拭目以待的事情。
跨系统边界的渐进式代码表示递降
在结束本章之前,再啰嗦最后一点。其实我们可以从两个维度看待 MLIR 带来的解耦:
水平方向上,dialect 把完整中间表示打散成许多局部中间表示;垂直方向上,MLIR 让我们可以对处于不同层级的概念进行建模。这对领域专用编译器是非常有用的,因为领域专用语言一般是高度抽象的声明式语言,只描述任务,需要编译器将其转换成具体的命令式机器指令。一步跨越这个巨大的抽象差距是非常难的,利用多级抽象和建模来进行渐进式 lowering 是更加适合的方式。我们可以分离各个层次关注的问题,整个系统也更加的易开发和维护。
当然这并不是什么全新的概念,在不同的项目中我们已然看到各种类中间表示的设置,像是 Clang AST 或者各种机器学习框架中的计算图。MLIR 的优势是使用同样的基础设施将这些不同层次的表示连接起来,让它们之间的信息流通变得更加顺畅。其实现代复杂系统的开发多是选取各种子系统然后将其组合。将来自前一个子系统的数据进行验证、转化然后传递给下一个子系统消耗掉很多工程资源。如果所有子系统使用相同的内部基础设施,这些资源投入就都可以节省下来,另外,使用相同工具也会使得跨组跨项目的沟通协调变得更加简单。
试图记录我对编译器以及中间表示发展的历史和趋势的理解,比较抽象,另外也有点东拉西扯。不过希望本篇能为以后探讨具体的编译器以及中间表示机制奠定基础。总结一下:
人类通过抽象来应对复杂性。编译器是能够自动转换抽象级别的效率工具。编译器首要考虑正确性,其次产生高效代码。正确性需要明确的语义以及各种验证来保障。编译器产生的代码可以给我们绝大部分的性能, 这可以让我们把工程力量集中到真正核心的对性能影响最大的部分。LLVM 通过其 LLVM IR 和库解耦并模块化了编译器。LLVM 同时用文本表示将 UNIX 哲学带入了编译器。但 LLVM 的设计折中意味着其并不适合所有的领域,比如 LLVM 并不对稳定性和兼容性提供强保障,LLVM IR 本身也是不可分割的中心化中间表示。SPIR-V 是着眼于 GPU 领域的行业标准规范。SPIR-V 通过技术上的机制和组织上的流程来维持其可扩展性。SPIR-V 有着稳定的字节码和兼容性保障。MLIR 进一步解耦了中间表示;完整的中间表示被分割成可以按需选取的 dialect;其基础设施极大地简化定义各种层级 operation 和转换。这符合技术发展的趋势——技术一般都是从单一的强耦合的解决方案渐渐演进到多种多样的可定制化的解决方案。将来开发领域专用编译器可能真的只是选取、定制、以及混合各种 dialect 这般简单。
参考资料
[1] “clang c++ compilation涉及的步骤 ”,https://eli.thegreenplace.net/2012/11/24/life-of-an-instruction-in-llvm
[2] “LLVM语言参考”,https://llvm.org/docs/LangRef.html
[3] “LLVM解耦的部分”,https://www.aosabook.org/en/llvm.html
[4] “LLVM兼容性的部分”,https://llvm.org/docs/DeveloperPolicy.html#ir-backwards-compatibility
[5] “SPIR Ecosystem”,https://www.khronos.org/spir/
[6] “SPIR-V的机制”,https://www.khronos.org/registry/SPIR-V/specs/unified1/SPIRV.html
[7] “MLIR语言参考”,https://mlir.llvm.org/docs/LangRef
[8] “MLIR Interface”,https://mlir.llvm.org/docs/Interfaces/
[9] “MLIR Dialects”,https://mlir.llvm.org/docs/Dialects/
[10] “MLIR dialect overview”,https://discourse.llvm.org/t/codegen-dialect-overview/2723
OpenCL通用异构开放环境
OpenCL通用异构开放环境
OpenCL全称Open Computing Language,第一个面向异构系统通用目的并行编程的开放式、免费标准,一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
OpenCL 1.0主要由一个并行计算API和一种针对此类计算的编程语言组成,此外还特别定义了:
1、C99编程语言并行扩展子集;
2、适用于各种类型异构处理器的坐标数据和基于任务并行计算API;
3、基于IEEE 754标准的数字条件;
4、与OpenGL、OpenGL ES和其他图形类API高效互通。
OpenCL是由苹果首次提出的,随后Khronos Group成立相关工作组,以苹果草案为基础,联合业界各大企业共同完成了标准制定工作。工作组的26个成员来自各行各业,且都是各自领域的领导者,具体包括3DLABS、 Activision Blizzard、AMD、苹果、ARM、Barco、博通、Codeplay、EA、爱立信、飞思卡尔、HI、IBM、Intel、 Imagination、Kestrel Institute、摩托罗拉、Movidia、诺基亚、NVIDIA、QNX、RapidMind、三星、Seaweed、TAKUMI、德州仪器、瑞典于默奥大学。
标准倡导者苹果将是最先应用OpenCL技术的厂商之一,代号Snow Leopard的新版操作系统Mac OS X 10.6就会集成该标准。相比之下,微软没有参与OpenCL的制定工作,Windows自然也不会提供支持,不过DirectX 11有类似的Computer Shader技术,很可能会重演DirectX与OpenGL之战。
同时,AMD Stream SDK、Codeplay Sieve C++等进行改革,适配OpenCL 1.0标准,NVIDIA的CUDA技术也借机大展拳脚。
添加图片注释,不超过 140 字(可选)
OpenCL 3.0 的 C++ 内核

添加图片注释,不超过 140 字(可选)
C++ for OpenCL 结合了 OpenCL 和 C++17 的功能
基本概念
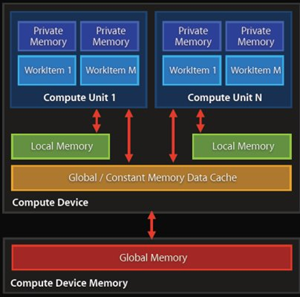
OpenCL程序分为两部分。
l 在主机(以CPU为核心)上运行
l 在设备(以GPU为核心)上运行
设备有一个或多个计算单元,计算单元又包含一个或多个处理单元。在设备上运行的程序被称为核函数。但是对于核函数的编写,CUDA一般直接写在程序内,OpenCL是写在一个独立的文件中,并且文件后缀是.cl,由主机代码读入后执行,这一点OpenCL跟OpenGL中的渲染程序很像。

添加图片注释,不超过 140 字(可选)
OpenCL平台由两部分组成,宿主机和OpenCL设备:
宿主机Host: CPU,扮演组织者的角色。包括kernel、kernel上下文、NDRange和队列等;队列控制着kernel如何执行,以及何时执行等。
设备Device:计算设备,可以是CPU、GPU、DSP或硬件提供以及OpenCL开发商支持的任何处理器。
SIMT(Single Instruction Multi Thread): 单指令多线程,GPU并行运算的主要方式,很多线程同时执行相同的运算指令,每个线程的数据有所不同,但执行的操作一致。
核函数(Kernel):在设备程序上执行运算的入口函数,在主机上调用。
工作项(Work-item): 类似于CUDA中的线程(Threads),多个工作项(线程)执行同样的核函数,每个Work-item都有一个ID号,通过ID号来区分处理数据。
工作组(Work-group):类似于CUDA中的线程块(Block),多个工作项组成一个工作组,Work-group内Work-item可以通信和协作。
ND-Range: 类似于CUDA中的网格,定义了Work-group的组织形式。
上下文(Context):整个OpenCL的运行环境,包括Kernel、Device、程序和内存。
设备:OpenCL程序调用的计算设备。
内核:在计算设备上执行的并行程序。
程序:内核程序的源代码(.cl文件)和可执行文件。
内存:计算设备执行OpenCL程序所需的变量。
通过llvm在OpenCL内核中创建了一个本地数组,称之为大小为[256 x i32]的可查询表。 稍后通过llvm插入代码以使用值填充数组。问题是,当尝试生成访问数组的代码时,似乎无法正确地将指针与希望的元素隔离开来。如果使用名为flattened的隐藏局部变量:
,可能会错误地索引元素
Value *xs_ys_mul = builder.CreateMul(shifted_x_size, y_size, "xs_ys_mul");
Value *xs_ys_z_mul = builder.CreateMul(xs_ys_mul, z, "xs_ys_z_mul");
Value *xs_y_mul = builder.CreateMul(shifted_x_size, y, "xs_y_mul");
Value *sum_1 = builder.CreateAdd(xs_ys_z_mul, xs_y_mul, "sum_1");
Value *flattened = builder.CreateAdd(sum_1, shifted_x, "FLATTENED");
这将是尺寸平坦的本地工作组ID。但这无关紧要。
这就是GEP的创建方式(构建器是IRBuilder的一个实例):
std::vector<llvm::Value *> tmp_args;
tmp_args.push_back(builder.getInt32(0));
tmp_args.push_back(flattened);
Value *table_addr = builder.CreateGEP(M.getNamedGlobal(tablename), tmp_args, tablename+"_IDX");
在这种情况下,M是Module对象。 table_addr产生的是:
%i32_cllocal_TABLE_IDX = getelementptr [256 x i32] addrspace(3)* @i32_cllocal_TABLE, i32 0, i32 %FLATTENED
但是,如果想通过遍历LLVM中的索引并使用for循环代码(省略循环结构,以及“index”是i32循环计数器)来正确填充它:
std::vector<llvm::Value *> tmp_args;
tmp_args.push_back(builder.getInt32(0));
tmp_args.push_back(builder.getInt32(index));
Value *table_addr = builder.CreateGEP(M.getNamedGlobal(tablename), tmp_args, tablename+"_IDX");
在这种情况下table_addr的dump()是(当index == 0时):
i32 addrspace(3)* getelementptr inbounds ([256 x i32] addrspace(3)* @i32_cllocal_CRC32_TABLE, i32 0, i32 0)
这意味着当进行商店时会进一步下降:
store_inst = builder.CreateStore(builder.getInt32(tablevalues[index]), table_addr);
得到了这个输出:
store volatile i32 0, i32 addrspace(3)* getelementptr inbounds ([256 x i32] addrspace(3)* @i32_cllocal_TABLE, i32 0, i32 0), align 4
哪个看起来不对,但更重要的是,当“index”&gt;时,会在断言上获得SIGABRT。 0:
Casting.h:194: typename llvm::cast_retty<To, From>::ret_type llvm::cast(const Y&) [with X = llvm::CompositeType, Y = llvm::Type*]: Assertion `isa<X>(Val) && "cast<Ty>() argument of incompatible type!"' failed.
不明白为数组中的索引提供显式值与在运行时计算的某些模糊值之间有什么区别。任何见解将不胜感激。
更新:最终做的是这个(alloc只执行一次,只是将它包含在这个代码块中用于视觉目的,它实际上在for循环之外):
std::vector<llvm::Value *> tmp_args;
tmp_args.push_back(builder.getInt32(0));
idxInst = builder.CreateAlloca(builder.getInt32Ty(), 0, "idxvalue");
//----- Inside the loop below --------------------------------------
idxStore = builder.CreateStore(builder.getInt32(index), idxInst);
indexValue = builder.CreateLoad(idxInst, "INDEX_VAL");
tmp_args.push_back(indexValue);
table_addr = builder.CreateGEP(table_ptr, tmp_args, "_IDX_PUT");
tmp_args.pop_back();
store_inst = builder.CreateStore(builder.getInt32(tableValues[index]), table_addr, "_ELEM_STORE");
store_inst->setAlignment(4);
发出此代码(对于index == 0和1):
%idxvalue = alloca i32
store i32 0, i32* %idxvalue
%INDEX_VAL = load i32* %idxvalue
%i32_cllocal_TABLE_IDX_PUT = getelementptr [256 x i32] addrspace(3)* @i32_cllocal_TABLE, i32 0, i32 %INDEX_VAL
store volatile i32 0, i32 addrspace(3)* %i32_cllocal_TABLE_IDX_PUT, align 4
store i32 1, i32* %idxvalue
%INDEX_VAL1 = load i32* %idxvalue
%i32_cllocal_TABLE_IDX_PUT2 = getelementptr [256 x i32] addrspace(3)* @i32_cllocal_TABLE, i32 0, i32 %INDEX_VAL1
store volatile i32 1996959894, i32 addrspace(3)* %i32_cllocal_TABLE_IDX_PUT2, align 4
现在看起来正确,对而言,虽然因为正在存储然后立即加载,但它似乎是一种奇怪的方式,但想这将得到优化,或者会尝试使用该mem2reg。
此代码段存在问题:
std::vector<llvm::Value *> tmp_args;
tmp_args.push_back(builder.getInt32(0));
tmp_args.push_back(builder.getInt32(index));
Value *table_addr = builder.CreateGEP(M.getNamedGlobal(tablename), tmp_args, tablename+"_IDX");
IRBuilder::getInt32创建常量 int。因此GEP将始终访问数组中的第一项,这不是您想要的。这也是IR显示constant expression GEP而不是真实GEP指令的原因。你需要的是创建一个Value并将其用作第二个索引 - 就像你在第一个例子中所做的那样。
参考文献链接
https://mp.weixin.qq.com/s/G36IllLOTXXbc4LagbNH9Q
https://www.thinbug.com/q/21009523
人工智能芯片与自动驾驶


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2021-11-08 TVM开发三个示例分析
2020-11-08 Nsight Compute Profilier 分析
2020-11-08 NSight Compute 用户手册(下)
2020-11-08 NSight Compute 用户手册(中)
2020-11-08 NSight Compute 用户手册(上)
2020-11-08 NVIDIA Nsight Systems CUDA 跟踪