

新能源-抖音- CPLD与FPGA技术
新能源-抖音- CPLD与FPGA技术
参考文献链接
https://mp.weixin.qq.com/s/k1P6-KOcF7e7aNTFK2TeQw
https://mp.weixin.qq.com/s/Z7H6wyGRj5BOJhXIqt3Btg
新型能源体系需要补哪些短板
二十大报告提出“加快规划建设新型能源体系,积极参与应对气候变化全球治理”。

那么如何理解中国乃至全球正在经历的能源变革?
协鑫集团董事长朱共山接受第一财经记者专访时表示:“要构建新型能源体系,我们目前应该解决的是储能和氢能两个板块。目前国内光伏产业和风电不论技术、制造、份额都已经走到全球第一。”
他认为储能端主要需要解决的问题是材料和装备。如果材料、热管理系统和功率区间的问题解决了,储能端有希望快速发展。“氢能这块,在最近的2~3年内,每立方的电耗已经从8.5度电降到了4.3度电,下一步还会有大幅度的下降空间。”朱共山说:“现在氢能产业发展的核心是要控制成本,随着硅、风电等技术进步,降本预期将很快得以实现。”
“在价格降下来的同时,我们也要强调科技革命和技术创新。”朱共山进一步告诉第一财经记者,“在储能技术没有发展完备以前,我们的风、光再强,还是需要火力发电来挑起大梁。目前大家都在专注于技术储备和技术攻关,等到绿色电力(风、光、储)成本同时降下来以后,能支撑新型能源体系大规模的发展。我们有信心,在十年以后,清洁的新能源将变成未来的能源的主力军,化石能源起到辅助的作用。”
“要推动构建新型能源体系,户用光伏领域需解决并网消纳、电站全生命周期运维等一系列问题。”正泰电器(601877.SH)旗下正泰安能总裁卢凯告诉第一财经记者,“近年来,我们通过电站建设为乡村了带来活力,未来我们也将继续助力提升电力系统稳定性和灵活调节能力,促进能源供给和能源消费协同,实现能源的安全、清洁、高效、低碳、绿色和可持续发展。”
在过去十年间,我国的能源生产结构加速转变,清洁能源占比正持续提升。国家统计局数据显示,2021年,我国非化石能源发电装机首次超过煤电,装机容量达到11.2亿千瓦,占发电总装机容量的比重为47.0%。水电、风电、太阳能发电装机均超过3亿千瓦,连续多年稳居世界首位。其中,水电发电装机为39094万千瓦,较2012年增长56.7%;并网风电装机为32871万千瓦,较2012年增长4.4倍;并网太阳能发电30654万千瓦,较2012年增长88.9倍。
10月17日,国家能源局党组成员、副局长任京东在二十大新闻中心第一场记者招待会上表示:“能源发展既要保障安全,也要推进转型。可再生能源发电总装机已经突破了11亿千瓦,比十年前增长了近三倍,占全球可再生能源装机总量的比重超过30%。水电、风电、光伏、生物质发电装机的规模和在建核电装机规模稳居世界第一。”
“下一步,我们按照党的二十大要求,立足我国能源资源禀赋,坚持先立后破,深入推进能源革命,加快规划建设新型能源体系,坚定不移推动能源绿色低碳发展。大力推动终端用能转型升级,加强重点用能领域节能降碳,积极推进电能替代,力争到2025年电能占终端用能的比重达到30%。” 任京东认为。
“能源是产业和民生的上游,能源安全会直接影响产业链、供应链的运行态势,因此是国家安全的重要方面,对经济安全有重要影响。”中国数实融合50人论坛副秘书长胡麒牧对第一财经记者分析称,“作为能源对外依存度较高的经济体,我们要通过能源革命来调整能源结构,提升能源保障能力。”
“在这个过程中,我们一方面是要扩大新能源产能,从增量供给上解决问题,然后调整存量,另一方面要做好需求端管理,提升现有产业体系的能源效率,三是发挥市场机制的作用,通过碳交易等机制来推动能源结构的调整和排放的降低。”胡麒牧认为。
飞腾CPU已在32个省市和128个部委单位部署应用,助力数字政府
要加快建设网络强国、数字中国,加快实施创新驱动发展战略,坚定不移贯彻总体国家安全观,确保国家安全和社会稳定。
强化政务信息化、数字政府是建设网络强国、数字中国的重要根基,网络安全则是国家安全的重要组成部分。作为芯片研发“国家队”的核心成员,飞腾公司始终牢记“聚焦信息系统核心芯片,支撑国家信息安全和产业发展”的使命,坚持核心技术自主创新,为政府信息化、数字政府提供强有力的算力支撑,助力政府服务水平不断提升。
从政务办公到数字政府,赋能信息安全和政府服务
国家“十四五”规划提出,“提高数字政府建设水平,将数字技术广泛应用于政府管理服务,推动政府治理流程再造和模式优化,不断提高决策科学性和服务效率”。2022 年 6 月颁发的《国务院关于加强数字政府建设的指导意见》强调指出,加强数字政府建设是适应新一轮科技革命和产业变革趋势的必然要求,是创新政府治理理念和方式、形成数字治理新格局、推进国家治理体系和治理能力现代化的重要举措。
在传统的政务办公和更复杂的电子政务、数字政府领域,随处可见“中国芯”的身影。以 湖南省政务服务大厅 为例,这是全国第一个在电子政务外网实现办公电脑、操作系统、办公软件、自主服务终端等全部国产化的政务大厅。服务大厅内的办公电脑全部采用基于飞腾 CPU 芯片的中国长城电脑,保障大厅内 113 个服务窗口日常工作,投入使用后,该大厅 2021 年总处理政务事项达 125 万件,为人民群众提供高效、便捷、绿色、安全的体验。

“让数据多跑路,让群众少跑腿”是对“科技惠民”的殷切期望。截至目前,飞腾 CPU 已经在全国 32 个省市和 128 个部委单位部署应用,覆盖了政务办公、电子政务、数字政府的核心应用领域。在中国系统与大理州信产投合资成立的数字大理建设运营有限公司建设运营的 大理理政中心,原生于 PKS 的中国电子云为大理州打造的“苍洱云”已经支撑了 超过 10 亿条 数据的高效、稳定上传,保障大理州数字政务业务的安全运行。在宁波市 12345 政务服务热线中心、某部委核心业务系统等众多项目中,飞腾 CPU 都获得了落地应用。飞腾 CPU 持续为政务领域提供核心算力支撑,助力政府服务效率提升,并保障数据安全,经受住了多样化场景的考验。
特别值得一提的是,FT-2000/4、飞腾腾锐 D2000 等芯片还支持飞腾安全架构规范 PSPA 1.0,真正将安全可信做到了“芯内”,强力守护信息安全。飞腾多款拳头产品和政务解决方案获得了权威认可,FT-2000/4 荣获第十五届“中国芯”优秀市场表现产品奖,飞腾腾锐 D2000 荣获中国电子信息博览会金奖,飞腾腾云 S2500 荣获“中国电子政务领域自主可控创新产品”奖,飞腾与腾讯云 TStack 解决方案荣获“中国电子政务安全优秀解决方案”奖。
面向县乡镇下沉,助力数字政府进程提速
数字政府建设是一个系统工程,县城、区、乡镇一级政府作为政府治理的基本单元,是数字政府建设中连接宏观与微观的枢纽环节,其数字化水平直接关系着整个数字政府建设的进程。
随着自主信息产业的逐渐发展壮大,基于飞腾平台的产品应用日益广泛,飞腾在政府信息化工程中日益成为主导技术路线。2021
年飞腾在国内政府信创领域处于市场领先地位,基于飞腾平台的产品 从部委、省、市的应用进一步面向县、乡镇下沉渗透。
在政府信息化领域,飞腾目前已经实现了“三个全覆盖”,即全国 300+ 集成商解决方案专家支持全覆盖,部委、省、市、县、乡镇全覆盖,办公系统到数字政府核心应用全覆盖。
十四五期间,飞腾将继续坚持“核心技术自主创新,产业生态开放联合”的发展理念,携手近 5000 家生态伙伴共同努力,助推全国各地数字政府建设水平提升,助力网络强国、数字中国进程提速。
抖音背后的RTC技术
直播、社交、在线教育等行业催生了实时音视频技术(RTC) 的兴起和发展。反过来, RTC 的发展和应用也为这些行业带来了巨大的增长。随着 RTC 对应用场景的不断渗透,业务伙伴关于场景体验的要求也越来越高,比如更低延时、更加顺畅、更高画质。LiveVideoStackCon 2021 北京站,火山引擎视频云 RTC 产品负责人 Julian,为大家分享火山引擎视频云 RTC 是怎样在抖音、西瓜、头条等产品的场景实践中,不断地追求极致的。

1. 简介
首先,我先简单介绍一下火山引擎 RTC 团队。

我们并不是来自抖音,我们来自火山引擎,抖音也是火山引擎服务的一个客户。我所在的团队是火山引擎的 RTC 团队,已经为抖音服务了 4 年时间。在 4 年中,抖音不断增长,拥有 6 亿 DAU,而火山引擎 RTC 团队的能力也有跨越式的提升。

我们先看一下抖音上的 RTC 应用场景。
最经典的是连麦 PK。两个抖音主播通过 RTC 进行连麦,转码生成两路音视频流,推到 CDN,分别给各自直播间的观众进行直播。在这个过程中,主播 PK,看谁收到的礼物更多。有些 PK 场景还会有主播和观众的互动:这边,主播和观众的互动也是通过 RTC 进行的。
抖音上也有一些很有意思,但是大家可能了解不是特别多的场景,比如一起看和好友私聊。
一起看就是我们在抖音上可以几个好友连线,一起看同一个视频,其中有一个人是房主,房主的视频刷到哪,其他人自动跟着刷到哪,大家还能通过语音实时交流视频内容。这里面除了语音聊天是用 RTC 实现之外,短视频的消息同步也是用 RTC 的低延时消息做的。
一起看就是几个好友连线,在抖音上同时看同一个视频。其中有一个房主,房主看到哪,其他人的视频也自动播放到哪。大家通过语音进行实时交流。这个场景下,除了语音聊天是用 RTC 实现的以外,视频播放进度的消息同步也是用 RTC 的低延时消息功能实现的。
还有一个场景是好友私聊。一些抖音重度用户知道,抖音现在也支持视频和语音通话,体验也非常不错。我自己和朋友用其他软件通话比较卡的时候,就会换抖音。经常换了抖音就不卡了,大家有兴趣也可以试一下。抖音上的视频通话还自带美颜,因此视频通话相对语音通话的比例会更高一点。

抖音上的通话效果好是有指标支持的。经过长期的合作,我们打磨出了一套指标体系。这个图中摘录了部分核心指标。左边是 RTC 的技术指标,包括卡顿率、端到端延迟、首帧时长、清晰度。右边是与 RTC 质量相关的抖音业务指标,包括用户反馈率、用户渗透率、用户使用时长以及业务营收。RTC 的优化都是在数据指标指导下进行的。优化过程中,我们做了很多 AB 实验和归因分析,通过优化技术指标,来优化业务指标。全量上线的标准是能够达成最优的业务指标。

2. 面临的挑战
下面说说我们的挑战是什么。

如果对 RTC 的核心指标进行归总的话,可以划分成清晰、流程、实时三个核心要求。但对 RTC 熟悉的同学都知道:这三个核心要求之间,有时是无法得兼的。网络好的时候没什么问题,网络比较差的时候,就要牺牲其中一个或两个指标。
举个简单的例子,当网络不好,视频有卡顿时,增加缓冲延时是最简单的优化手段。缓冲延时太高,会引起两个人抢话,严重影响通话体验。如果同时需要流畅和实时,那只能降低清晰度。抖音上有很多颜值主播,让主播的脸能被看清楚,又是一件优先级挺高的事情。
业务面对这样的选择题时,通常可以接受一点指标上的妥协,但总是会提出持续优化的要求。换句话说,就是“我全都要”。业务的需求都是合理的。接下来我们就来讲一下我们是如何应对这样的挑战的。
3. 最佳实践
3.1 流畅度

首先,讲一下流畅度。流畅度对应的指标是卡顿率。卡顿其实对于交流的影响是最大的,即使只卡掉一个字,你也会明显感觉到交流不畅。
卡顿是因为弱网。那弱网又是什么引起的呢?
我们建立一个最简单的 RTC 传输模型,终端 A 到终端 B,中间是 RTC 的云端传输网络。其实云端传输网络的传输质量现在已经非常好了。我们会监控 QoS 指标。
监控结果可以发现:云端丢包基本上是不存在的。国内云端传输延迟基本在 50ms 以内,全球范围基本都在 250ms 以内。
主要的弱网其实是在接入网,也是我们常说的 FirstMile 和 LastMile,也就是用户自己的客户端接入 RTC 网络的这一段。数据统计后发现,大概 30% 的用户会碰到弱网的情况,其中 26.8% 是轻度弱网,中度和重度都在4%左右。

这边弱网用户等级,是按瞬时网络指标进行区分的,分为好、轻度、中度和严重4个等级。

这边我们找了一个极端的线上 case,看看 RTC 能力的极限如何。
这是一个丢包率和延时参数的示意图,我们看到,最初比较平稳;突然发生弱网,持续了一段时间,丢包率最高达到了 49%。随着抗丢包策略的接入,延迟从 88ms 升到 700ms。经过优化,抗丢包策略的卡顿时长基本都控制在 1.2 秒以内。

要适应突发的极端弱网情况,我们的算法也会实时自动调节。
针对不同的场景,其实会适用不同的算法。比如 1v1 通信时,除了根据发送端的上下行网络调整发送策略外,也要关注接收端的下行网络情况。接收端下行网络不佳时,发送高规格的音视频数据并不会带来什么收益。多人通信时,我们会采用大小流(Simulcast)的方法。应用大小流时,大家常常会关注接收端。但其实发送端上行可能也会有压力,上行如果出现弱网的时候,也要考虑发大小流是否合适。
这些场景都在我们的算法考虑范围内。我们会通过对用户 QoS 数据的洞察,针对不同场景,自动下发对应的策略。算法的训练数据来自线上海量的真实用户网络环境。上面举的例子是抗丢包。真实的线上弱网环境非常复杂,纯丢包的场景几乎是不存在的,一定会叠加抖动、延时等网络问题。我们把线上用户真实的情况不断的加到训练库里,不断优化算法的应对。
另外,应对网络从好到差的过程要敏感,但恢复的过程要有一定的弛豫。有时候网络波动发生,消失的过程很快。多等待 3、4 秒,确定网络真的平稳了,算法才会把用户的码率恢复上去。

我们准备了一段视频进行弱网对抗的演示。是团队成员自己录制的,不涉及用户隐私。
演示中模拟了弱网情况,并且限制了最高可用带宽,分别降到三个弱网等级。网络从好的状态到轻度弱网的情况,码率和帧率有所下降;中度弱网时,网络丢包比较严重,分辨率也有所下降;重度弱网时,码率 500fps 都不到了。极差的情况下引入了一个 1 秒的卡顿,然后网络有所恢复,突然又到了极差的情况,最后恢复。
可以看到在极差的情况下,虽然有1秒的卡顿,但并没有漏字,在适应弱网之后,会把之前漏掉的音频用比较小的倍速去追上进度,不会影响内容。
3.2 实时性
实时性有两个指标,端到端延迟和首帧渲染速度。对通话场景来说,端到端延迟控制在 400ms 以内,用户体验都是没问题的。当然,也有对延迟要求更高的场景,比如云游戏,它对延迟要求极高,从用户触发指令开始,到收到首帧响应,来回需要在 100ms 以内。本次分享时间有限,就不展开了。
我们主要分享首帧渲染速度。

我们可以思考一下。为什么 CDN 的延时比 RTC 大很多,反而首帧响应又快更稳定?其实,CDN 会在边缘节点把命中率高的视频加入缓存,用户在拉流的时候可以从边缘节点直接拉,这样就比较快。因为业务特性的原因,RTC 不可能去做这样的缓存策略。但我们会去借鉴这样的思路。多人场景下,比如刚开始是两个人通话,后来第三个人进来,之前两个人的通话就已经在边缘节点上了。火山引擎 RTC 有一种策略是把最近 1 个 GOP 的音视频流缓存到边缘,加快新的音视频通话参与者打开首帧的速度。

GOP 是两个视频关键帧之间的时间间隔。大家对视频处理比较熟悉,就知道这个概念。业内 GOP 采用 1s、2s 的都有。
我们无法预测码流的请求什么时候来。如果没有缓存,只要不是落在 GOP 刚开始的时候,请求者就必须等到下一个 I 帧时,才能拉到首帧。很显然,这个等待时间根据 GOP 的大小有一个预期分布。而应用缓存策略之后,不管请求什么时候到,都可以即时获取到首帧。
这里录了个Demo,主要看的是每进一个房,3个流的加载速度。可以像抖音一样做上滑下滑的切换房间,最后是一个上麦的速度,这种情况下都是需要更快的首帧。这个 Demo 里面打开首帧的时长都在100ms 到 200ms 之间。,我们也检测了线上首帧的速度,基本都在700ms以内,有的业务形态好的,会控制在400ms以内,我们管这个叫瞬开。
3.3 清晰度

第三个优化方向是清晰度,清晰度提升的是用户体验的上限。前面的优化,用户感知起来是非常直接的,而清晰度的感知是潜移默化的。视频没有那么清晰,你一开始并不会有很明显的感觉,但看的时间长了以后,就可能不想继续看了。所以这个指标最后会影响用户使用时长。

清晰度是没有上限的。RTC 需要解决的问题是如何在有限的带宽下,让实时传输的视频质量更高。
- BVC1 - 字节跳动自研编码算法

这个视频里面显示的是自研的 BVC1 编码器,和主流的 H.264 和 H.265 在编码效率的对比。右侧的 RD-plot 曲线图里显示 BVC1 编码器能比主流的 H.265 编码器再提升 0.6dB。一般我们评价一个 Codec 算法好不好,会看它节省了多少带宽。但具体到 RTC 中,用户的带宽是平稳的,分辨率也是业务上所决定的,不需要把带宽用足,把分辨率变得更高。所以火山引擎 RTC 选择在带宽和分辨率不变的情况下,把编码效率用到画质提升上。

重点可以看背景上的粉色条。
- ROI(感兴趣区域)编码

ROI(感兴趣区域)编码我们也在广泛地使用,基本上连麦场景下都会使用。用白话讲,就是针对中间的人脸进行编码。在同样的帧率和码率之下,经过 ROI 编码后的效果,在脸部细节上更清晰。正好前面有同学问到,我们怎么去评测 ROI 的效果。ISO 提供了一种通过盲测得票比率映射 JND 的方式评测画质。我们通过内测邀请了 100+ 同学对比评测,得到了 2.3 分。这是一个比较高的分数了。
- 超分辨率 Super Resolution

最后我们也用到了超分算法。

可以看一下头发丝的细节。超分提升分辨率。这边把原本 360P 的视频超分到 720P。这边盲测的评分就更高一些,是 2.55 分。

不同场景下的优化策略
有了硬核的算法能力之后。我们也会针对每个场景适配最合适的优化策略。

比如在 PK 场景,运用的是最佳分辨率策略。

先简单介绍一下这个策略。PK 时,RTC 画面会占据画面的四分之一(长、宽各一半)。现在随着用户的手机越来越好,有些手机能支持 1080P 的音视频通话,有些只能支持 540P 等等。比如你作为一个主播,拿着 1080P 的收集和 720P 的主播进行 PK 连麦的话,其实你看到的,对面主播发过来的视频也就是 540P。对面主播采集 720P 的视频也没什么用;反过来也是一样的。最佳分辨率策略就是说,RTC 会自动根据对面主播的设备分辨率情况,来选择最合适的分辨率,而不是无脑用最高清的分辨率。

我们接收另外一个在 PK 连麦场景上应用的转推 CDN 的策略。大部分 RTC 都是在云端做转码,然后转推 CDN 的。这其实会引入多一次的编解码和传输。PK 场景是两个人,对端视频流一定是从远端过来的,这个没办法。但其实主播自己的画面转推 CDN 时,经过服务端转推的二次编解码,它的画质一定会有点受损,所以我们会碰到很多业务方提出要用客户端转码的方案。
但客户端转码也会来其他的问题:虽然减少了一次编解码传输,但是会带来设备性能消耗的提升。我们提出了端云一体转推 CDN 的方案。如果这个主播的设备,其性能和网络足够在客户端做转码,我们就在客户端做;如果不足,就降级到服务端进行。这样,设备性能高时,能享受到更好的清晰度;设备性能低,我们能保证正常使用。目前这个策略应用于线上超过 60% 的用户。

这就涉及了怎么去判断用户设备的性能的问题。
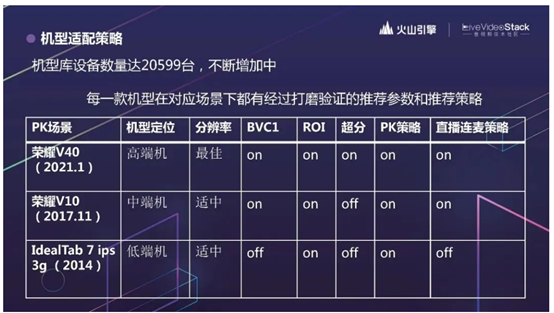
火山引擎 RTC 在后台维护了一个很大的机型数据库,设备总数达到 2w+,并且不断增加中。这边是部分截图。我们会保证每一款机型在对应场景下,都有经过打磨验证的推荐参数和推荐策略。
3.4 美颜特效

最后单独提一下 RTC 和美颜特效的结合。美颜特效其实对于 CPU 和内存的消耗是更大的,有这么大的一个模型在那边跑,对于 RTC 自适应算法带来了新的挑战。

我们在测试过程中碰到过美颜特效影响编码算法效率的事情。所以我们思考,怎么尽可能避免这样的影响?
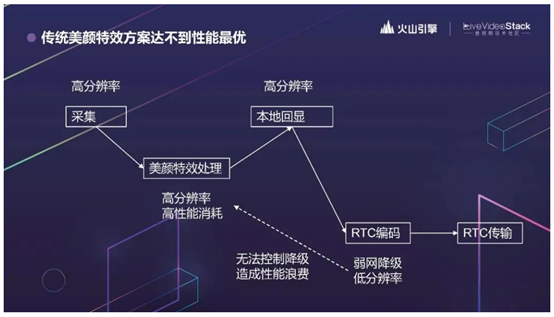
先看一下现在主流的做法,RTC 和 CV 是分开的,开发者需要先自己采集,送到美颜特效的 SDK 处理,拿到处理后的视频流,再在本地回显,并送到 RTC SDK 做编码,然后传输。这个逻辑很顺,但缺点在于, RTC 编码时会考虑弱网和设备性能的降级,如果因为弱网或设备性能不够,RTC 编码是会降级的。你想编码时候编的是一个 360P 的视频,采集和美颜用 1080P 就没什么意义,一点都不低碳。如果 RTC 的降级能够影响到采集和美颜,整体的性能消耗会更优。
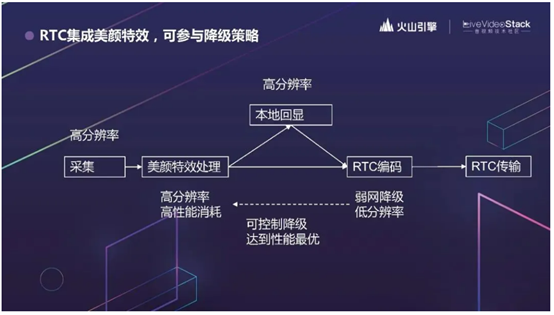
火山引擎 RTC 就把美颜特效的 SDK 和 RTC 统一调度了。采集就用的 RTC SDK 的能力,再通过 RTC SDK 调 CV 相关的接口。这样,采集和提交到美颜 SDK 的视频分辨率都是一个分辨率。再也不会出现采集、美颜 1080P,传输 360P 的情况了。
总结
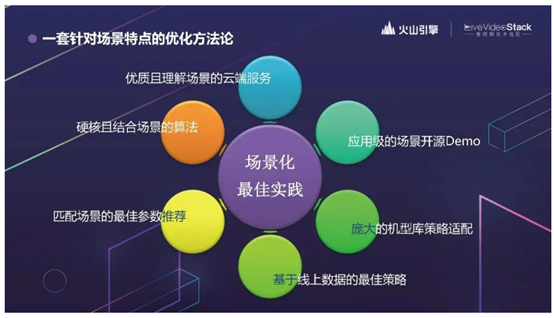
虽然今天介绍的是我们为抖音做的优化,但这实际上是一套针对场景特点优化的方法论,不局限于抖音。

目前我们除了服务抖音以外,还服务着字节内外部的其他客户。现在月均通话分钟数已经超过了 150亿。庞大的基数带来的巨大的数据,也是我们优化的着力点。

详解CPLD/FPGA架构与原理
可编程逻辑器件(Programmable Logic Device,PLD)起源于20世纪70年代,是在专用集成电路(ASIC)的基础上发展起来的一种新型逻辑器件,是当今数字系统设计的主要硬件平台,其主要特点就是完全由用户通过软件进行配置和编程,从而完成某种特定的功能,且可以反复擦写。在修改和升级PLD时,不需额外地改变PCB电路板,只是在计算机上修改和更新程序,使硬件设计工作成为软件开发工作,缩短了系统设计的周期,提高了实现的灵活性并降低了成本,因此获得了广大硬件工程师的青睐,形成了巨大的PLD产业规模。
目前常见的PLD产品有:编程只读存储器(Programmable Read Only Memory,PROM),现场可编程逻辑阵列(Field Programmable Logic
Array,FPLA),可编程阵列逻辑(Programmable
Array Logic,PAL),通用阵列逻辑(Generic
Array Logic,GAL),可擦除的可编程逻辑器件(Erasable
Programmable Logic Array,EPLA),复杂可编程逻辑器件(Complex Programmable Logic Device,CPLD)和现场可编程门阵列(Field Programmable Gate Array,FPGA)等类型。PLD器件从规模上又可以细分为简单PLD(SPLD)、复杂PLD(CPLD)以及FPGA。它们内部结构的实现方法各不相同。
可编程逻辑器件按照基本单元颗粒度可以分为3类:
①小颗粒度(如:“门海(sea of gates)”架构),②中等颗粒度(如:FPGA),③大颗粒度(如:CPLD)。
按照编程工艺可以分为四类:①熔丝(Fuse)和反熔丝(Antifuse)编程器件,②可擦除的可编程只读存储器(UEPROM)编程器件,③电信号可擦除的可编程只读存储器(EEPROM)编程器件(如:CPLD),④SRAM编程器件(如:FPGA)。在工艺分类中,前3类为非易失性器件,编程后,配置数据保留在器件上;第4类为易失性器件,掉电后配置数据会丢失,因此在每次上电后需要重新进行数据配置。
可编程逻辑器件的发展历史
可编程逻辑器件的发展可以划分为4个阶段,即从20世纪70年代初到70年代中为第1阶段,20世纪70年代中到80年代中为第2阶段,20世纪80年代到90年代末为第3阶段,20世纪90年代末到目前为第4阶段。
第1阶段的可编程器件只有简单的可编程只读存储器(PROM)、紫外线可擦除只读存储器(EPROM)和电可擦只读存储器(EEPROM)3种,由于结构的限制,它们只能完成简单的数字逻辑功能。
第2阶段出现了结构上稍微复杂的可编程阵列逻辑(PAL)和通用阵列逻辑(GAL)器件,正式被称为PLD,能够完成各种逻辑运算功能。典型的PLD由“与”、“非”阵列组成,用“与或”表达式来实现任意组合逻辑,所以PLD能以乘积和形式完成大量的逻辑组合。
第3阶段Xilinx和Altera分别推出了与标准门阵列类似的FPGA和类似于PAL结构的扩展性CPLD,提高了逻辑运算的速度,具有体系结构和逻辑单元灵活、集成度高以及适用范围宽等特点,兼容了PLD和通用门阵列的优点,能够实现超大规模的电路,编程方式也很灵活,成为产品原型设计和中小规模(一般小于10000)产品生产的首选。这一阶段,CPLD、FPGA器件在制造工艺和产品性能都获得长足的发展,达到了0.18 工艺和系数门数百万门的规模。
第4阶段出现了SOPC和SOC技术,是PLD和ASIC技术融合的结果,涵盖了实时化数字信号处理技术、高速数据收发器、复杂计算以及嵌入式系统设计技术的全部内容。Xilinx和Altera也推出了相应SOCFPGA产品,制造工艺达到65 ,系统门数也超过百万门。并且,这一阶段的逻辑器件内嵌了硬核高速乘法器、Gbits差分串行接口、时钟频率高达500MHz的PowerPC微处理器、软核MicroBlaze、Picoblaze、Nios以及NiosII,不仅实现了软件需求和硬件设计的完美结合,还实现了高速与灵活性的完美结合,使其已超越了ASIC器件的性能和规模,也超越了传统意义上FPGA的概念,使PLD的应用范围从单片扩展到系统级。目前,基于PLD片上可编程的概念仍在进一步向前发展。
开发工具
基于高复杂度PLD器件的开发,在很大程度上要依靠电子设计自动化(EDA)来完成。PLD的EDA工具以计算机软件为主,将典型的单元电路封装起来形成固定模块并形成标准的硬件开发语言(如HDL语言)供设计人员使用。设计人员考虑如何将可组装的软件库和软件包搭建出满足需求的功能模块甚至完整的系统。PLD开发软件需要自动地完成逻辑编译、化简、分割、综合及优化、布局布线、仿真以及对于特定目标芯片的适配编译和编程下载等工作。典型的EDA工具中必须包含两个特殊的软件包,即综合器和适配器。综合器的功能就是将设计者在EDA平台上完成的针对某个系统项目的HDL、原理图或状态图形描述,针对给定的硬件系统组件,进行编译、优化、转换和综合。
随着开发规模的级数性增长,就必须减短PLD开发软件的编译时间、并提高其编译性能以及提供丰富的知识产权(IP)核资源供设计人员调用。此外,PLD开发界面的友好性以及操作的复杂程度也是评价其性能的重要因素。目前在PLD产业领域中,各个芯片提供商的PLD开发工具已成为影响其成败的核心成分。
只有全面做到芯片技术领先、文档完整和PLD开发软件优秀,芯片提供商才能获得客户的认可。一个完美的PLD开发软件应当具备下面5点:
- 准确地将用户设计转换为电路模块
- 能够高效地利用器件资源
- 能够快速地完成编译和综合
- 提供丰富的IP资源
- 用户界面友好、操作简单
CPLD工作原理与简介
基于乘积项(Product-Term)的PLD结构
采用这种结构的PLD芯片有:Altera的MAX7000,MAX3000系列(EEPROM工艺),Xilinx的XC9500系列(Flash工艺)和Lattice,Cypress的大部分产品(EEPROM工艺)
我们先看一下这种PLD的总体结构(以MAX7000为例,其他型号的结构与此都非常相似):

图1 基于乘积项的PLD内部结构
这种PLD可分为三块结构:宏单元(Marocell),可编程连线 (PIA)和I/O控制块。宏单元是PLD的基本结构,由它来实现基本的逻辑功能。图1中兰色部分是多个宏单元的集合(因为宏单元较多,没有一一画出)。可编程连线负责信号传递,连 接所有的宏单元。I/O控制块负责输入输出的电气特性控制,比如可以设定集电极开路输出,摆率控制,三态输出等。图1 左上的INPUT/GCLK1,INPUT/GCLRn,INPUT/OE1,INPUT/OE2 是全局时钟,清零和输出使能信号,这几个信号有专用连线与PLD中每个宏单元相连,信号到每个宏单元的延时相同并且延时最短。
宏单元的具体结构见下图:
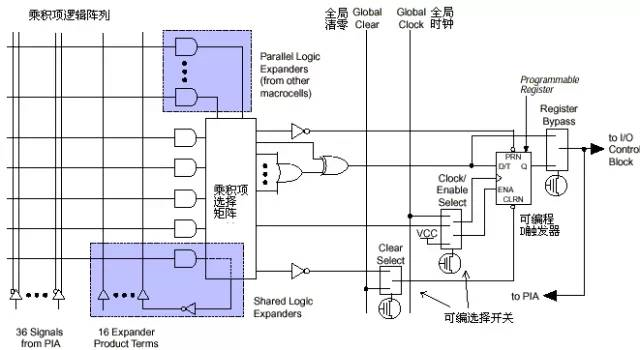
图2 宏单元结构
左侧是乘积项阵列,实际就是一个与或阵列,每一个交叉点都是一个可编程 熔丝,如果导通就是实现“与”逻辑。后面的乘积项选择矩阵是一个“或”阵列。两者一起完成组合逻辑。图右侧是一个可编程D触发器,它的时钟,清零输入都可 以编程选择,可以使用专用的全局清零和全局时钟,也可以使用内部逻辑(乘积项阵列)产生的时钟和清零。如果不需要触发器,也可以将此触发器旁路,信号直接 输给PIA或输出到I/O脚。
乘积项结构PLD的逻辑实现原理
下面我们以一个简单的电路为例,具体说明PLD是如何利用以上结构实现逻辑的,电路如下图:
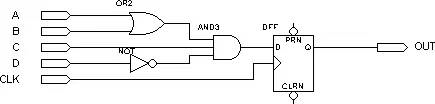
图3假设组合逻辑的输出(AND3的输出)为f,则f=(A+B)*C*(!D)=A*C*!D + B*C*!D ( 我们以!D表示D的“非”)PLD将以下面的方式来实现组合逻辑f:
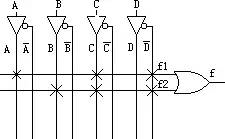
图4
A,B,C,D由PLD芯片的管脚输入后进入可编程连线阵列 (PIA),在内部会产生A,A反,B,B反,C,C反,D,D反8个输出。图中每一个叉表示相连(可编程熔丝导通),所以得到:f= f1 + f2 = (A*C*!D) + (B*C*!D) 。这样组合逻辑就实现了。图3电路中D触发器的实现比较简单,直接利用宏单元中的可编程D触发器来实现。时钟信号CLK由I/O脚输入后进入芯片内部的全局时钟专用通道,直接连接
到可编程触发器的时钟端。可编程触发器的输出与I/O脚相连,把结果输出到芯片管脚。这样PLD就完成了图3所示电路的功能。(以上这些步骤都是由软件自 动完成的,不需要人为干预)
图3的电路是一个很简单的例子,只需要一个宏单元就可以完成。但对于一个复杂的电路,一个宏单元是不能实现的,这时就需要通过并联扩展项和共享扩展项将多个宏单元相连,宏单元的输出也可以连接到可编程连线阵列,再做为另一个宏单元的输入。这样PLD就可以实现更复杂逻辑。
这种基于乘积项的PLD基本都是由EEPROM和Flash工艺制造的,一上电就可以工作,无需其他芯片配合。FPGA工作原理与简介
如前所述,FPGA是在PAL、GAL、EPLD、CPLD等可编程器件的基础上进一步发展的产物。它是作为ASIC领域中的一种半定制电路而出现的,即解决了定制电路的不足,又克服了原有可编程器件门电路有限的缺点。
由于FPGA需要被反复烧写,它实现组合逻辑的基本结构不可能像ASIC那样通过固定的与非门来完成,而只能采用一种易于反复配置的结构。查找表可以很好地满足这一要求,目前主流FPGA都采用了基于SRAM工艺的查找表结构,也有一些军品和宇航级FPGA采用Flash或者熔丝与反熔丝工艺的查找表结构。通过烧写文件改变查找表内容的方法来实现对FPGA的重复配置。
根据数字电路的基本知识可以知道,对于一个n输入的逻辑运算,不管是与或非运算还是异或运算等等,最多只可能存在2n种结果。所以如果事先将相应的结果存放于一个存贮单元,就相当于实现了与非门电路的功能。FPGA的原理也是如此,它通过烧写文件去配置查找表的内容,从而在相同的电路情况下实现了不同的逻辑功能。
查找表(Look-Up-Table)简称为LUT,LUT本质上就是一个RAM。目前FPGA中多使用4输入的LUT,所以每一个LUT可以看成一个有4位地址线的 的RAM。当用户通过原理图或HDL语言描述了一个逻辑电路以后,PLD/FPGA开发软件会自动计算逻辑电路的所有可能结果,并把真值表(即结果)事先写入RAM,这样,每输入一个信号进行逻辑运算就等于输入一个地址进行查表,找出地址对应的内容,然后输出即可。
下面给出一个4与门电路的例子来说明LUT实现逻辑功能的原理。
例:给出一个使用LUT实现4输入与门电路的真值表。
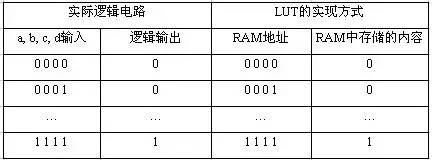
表1-1 4输入与门的真值表
从中可以看到,LUT具有和逻辑电路相同的功能。实际上,LUT具有更快的执行速度和更大的规模。
由于基于LUT的FPGA具有很高的集成度,其器件密度从数万门到数千万门不等,可以完成极其复杂的时序与逻辑组合逻辑电路功能,所以适用于高速、高密度的高端数字逻辑电路设计领域。其组成部分主要有可编程输入/输出单元、基本可编程逻辑单元、内嵌SRAM、丰富的布线资源、底层嵌入功能单元、内嵌专用单元等,主要设计和生产厂家有Xilinx、Altera、Lattice、Actel、Atmel和QuickLogic等公司,其中最大的是Xilinx、Altera、Lattice三家。
如前所述,FPGA是由存放在片内的RAM来设置其工作状态的,因此工作时需要对片内RAM进行编程。用户可根据不同的配置模式,采用不同的编程方式。FPGA有如下几种配置模式:
- 并行模式:并行PROM、Flash配置FPGA;
- 主从模式:一片PROM配置多片FPGA;
- 串行模式:串行PROM配置FPGA;
- 外设模式:将FPGA作为微处理器的外设,由微处理器对其编程。
目前,FPGA市场占有率最高的两大公司Xilinx和Altera生产的FPGA都是基于SRAM工艺的,需要在使用时外接一个片外存储器以保存程序。上电时,FPGA将外部存储器中的数据读入片内RAM,完成配置后,进入工作状态;掉电后FPGA恢复为白片,内部逻辑消失。这样FPGA不仅能反复使用,还无需专门的FPGA编程器,只需通用的EPROM、PROM编程器即可。Actel、QuickLogic等公司还提供反熔丝技术的FPGA,只能下载一次,具有抗辐射、耐高低温、低功耗和速度快等优点,在军品和航空航天领域中应用较多,但这种FPGA不能重复擦写,开发初期比较麻烦,费用也比较昂贵。Lattice是ISP技术的发明者,在小规模PLD应用上有一定的特色。早期的Xilinx产品一般不涉及军品和宇航级市场,但目前已经有Q Pro-R等多款产品进入该类领域。
FPGA芯片结构
目前主流的FPGA仍是基于查找表技术的,已经远远超出了先前版本的基本性能,并且整合了常用功能(如RAM、时钟管理和DSP)的硬核(ASIC型)模块。如图1-1所示(注:图1-1只是一个示意图,实际上每一个系列的FPGA都有其相应的内部结构),FPGA芯片主要由6部分完成,分别为:可编程输入输出单元、基本可编程逻辑单元、完整的时钟管理、嵌入块式RAM、丰富的布线资源、内嵌的底层功能单元和内嵌专用硬件模块。
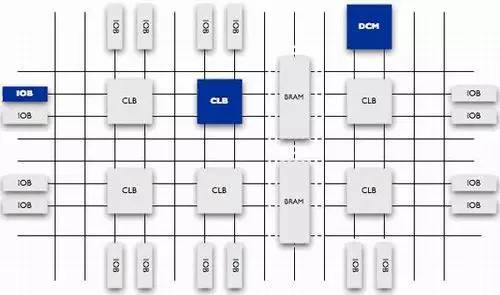
图1-1 FPGA芯片的内部结构
每个模块的功能如下:
1. 可编程输入输出单元(IOB)
可编程输入/输出单元简称I/O单元,是芯片与外界电路的接口部分,完成不同电气特性下对输入/输出信号的驱动与匹配要求,其示意结构如图1-2所示。FPGA内的I/O按组分类,每组都能够独立地支持不同的I/O标准。通过软件的灵活配置,可适配不同的电气标准与I/O物理特性,可以调整驱动电流的大小,可以改变上、下拉电阻。目前,I/O口的频率也越来越高,一些高端的FPGA通过DDR寄存器技术可以支持高达2Gbps的数据速率。

图1-2 典型的IOB内部结构示意图
外部输入信号可以通过IOB模块的存储单元输入到FPGA的内部,也可以直接输入FPGA 内部。当外部输入信号经过IOB模块的存储单元输入到FPGA内部时,其保持时间(Hold Time)的要求可以降低,通常默认为0。
为了便于管理和适应多种电器标准,FPGA的IOB被划分为若干个组(bank),每个bank的接口标准由其接口电压VCCO决定,一个bank只能有一种VCCO,但不同bank的VCCO可以不同。只有相同电气标准的端口才能连接在一起,VCCO电压相同是接口标准的基本条件。
2. 可配置逻辑块(CLB)
CLB是FPGA内的基本逻辑单元。CLB的实际数量和特性会依器件的不同而不同,但是每个CLB都包含一个可配置开关矩阵,此矩阵由4或6个输入、一些选型电路(多路复用器等)和触发器组成。开关矩阵是高度灵活的,可以对其进行配置以便处理组合逻辑、移位寄存器或RAM。在Xilinx公司的FPGA器件中,CLB由多个(一般为4个或2个)相同的Slice和附加逻辑构成,如图1-3所示。每个CLB模块不仅可以用于实现组合逻辑、时序逻辑,还可以配置为分布式RAM和分布式ROM。
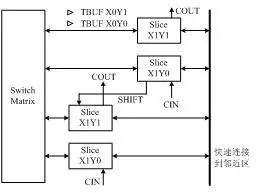
图1-3 典型的CLB结构示意图
Slice是Xilinx公司定义的基本逻辑单位,其内部结构如图1-4所示,一个Slice由两个4输入的函数、进位逻辑、算术逻辑、存储逻辑和函数复用器组成。算术逻辑包括一个异或门(XORG)和一个专用与门(MULTAND),一个异或门可以使一个Slice实现2bit全加操作,专用与门用于提高乘法器的效率;进位逻辑由专用进位信号和函数复用器(MUXC)组成,用于实现快速的算术加减法操作;4输入函数发生器用于实现4输入LUT、分布式RAM或16比特移位寄存器(Virtex-5系列芯片的Slice中的两个输入函数为6输入,可以实现6输入LUT或64比特移位寄存器);进位逻辑包括两条快速进位链,用于提高CLB模块的处理速度。
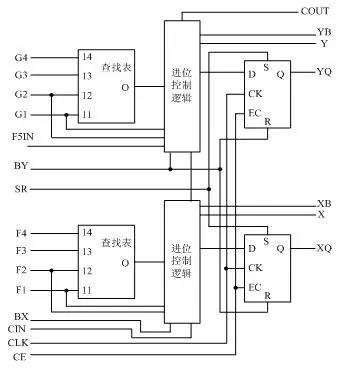
图1-4 典型的4输入Slice结构示意图
3. 数字时钟管理模块(DCM)
业内大多数FPGA均提供数字时钟管理(Xilinx的全部FPGA均具有这种特性)。Xilinx推出最先进的FPGA提供数字时钟管理和相位环路锁定。相位环路锁定能够提供精确的时钟综合,且能够降低抖动,并实现过滤功能。
4. 嵌入式块RAM(BRAM)
大多数FPGA都具有内嵌的块RAM,这大大拓展了FPGA的应用范围和灵活性。块RAM可被配置为单端口RAM、双端口RAM、内容地址存储器(CAM)以及FIFO等常用存储结构。RAM、FIFO是比较普及的概念,在此就不冗述。CAM存储器在其内部的每个存储单元中都有一个比较逻辑,写入CAM中的数据会和内部的每一个数据进行比较,并返回与端口数据相同的所有数据的地址,因而在路由的地址交换器中有广泛的应用。除了块RAM,还可以将FPGA中的LUT灵活地配置成RAM、ROM和FIFO等结构。在实际应用中,芯片内部块RAM的数量也是选择芯片的一个重要因素。
单片块RAM的容量为18k比特,即位宽为18比特、深度为1024,可以根据需要改变其位宽和深度,但要满足两个原则:首先,修改后的容量(位宽
深度)不能大于18k比特;其次,位宽最大不能超过36比特。当然,可以将多片块RAM级联起来形成更大的RAM,此时只受限于芯片内块RAM的数量,而不再受上面两条原则约束。
5. 丰富的布线资源
布线资源连通FPGA内部的所有单元,而连线的长度和工艺决定着信号在连线上的驱动能力和传输速度。FPGA芯片内部有着丰富的布线资源,根据工艺、长度、宽度和分布位置的不同而划分为4类不同的类别。第一类是全局布线资源,用于芯片内部全局时钟和全局复位/置位的布线;第二类是长线资源,用以完成芯片Bank间的高速信号和第二全局时钟信号的布线;第三类是短线资源,用于完成基本逻辑单元之间的逻辑互连和布线;第四类是分布式的布线资源,用于专有时钟、复位等控制信号线。
在实际中设计者不需要直接选择布线资源,布局布线器可自动地根据输入逻辑网表的拓扑结构和约束条件选择布线资源来连通各个模块单元。从本质上讲,布线资源的使用方法和设计的结果有密切、直接的关系。
6. 底层内嵌功能单元
内嵌功能模块主要指DLL(Delay Locked Loop)、PLL(Phase Locked Loop)、DSP和CPU等软处理核(Soft
Core)。现在越来越丰富的内嵌功能单元,使得单片FPGA成为了系统级的设计工具,使其具备了软硬件联合设计的能力,逐步向SOC平台过渡。
DLL和PLL具有类似的功能,可以完成时钟高精度、低抖动的倍频和分频,以及占空比调整和移相等功能。Xilinx公司生产的芯片上集成了DLL,Altera公司的芯片集成了PLL,Lattice公司的新型芯片上同时集成了PLL和DLL。PLL 和DLL可以通过IP核生成的工具方便地进行管理和配置。DLL的结构如图1-5所示。

图1-5 典型的DLL模块示意图
7. 内嵌专用硬核
内嵌专用硬核是相对底层嵌入的软核而言的,指FPGA处理能力强大的硬核(Hard Core),等效于ASIC电路。为了提高FPGA性能,芯片生产商在芯片内部集成了一些专用的硬核。例如:为了提高FPGA的乘法速度,主流的FPGA中都集成了专用乘法器;为了适用通信总线与接口标准,很多高端的FPGA内部都集成了串并收发器(SERDES),可以达到数十Gbps的收发速度。
Xilinx公司的高端产品不仅集成了Power PC系列CPU,还内嵌了DSP Core模块,其相应的系统级设计工具是EDK和Platform Studio,并依此提出了片上系统(System on Chip)的概念。通过PowerPC、Miroblaze、Picoblaze等平台,能够开发标准的DSP处理器及其相关应用,达到SOC的开发目的。
软核、硬核以及固核的概念
IP(Intelligent Property)核是具有知识产权核的集成电路芯核总称,是经过反复验证过的、具有特定功能的宏模块,与芯片制造工艺无关,可以移植到不同的半导体工艺中。到了SOC阶段,IP核设计已成为ASIC电路设计公司和FPGA提供商的重要任务,也是其实力体现。对于FPGA开发软件,其提供的IP核越丰富,用户的设计就越方便,其市场占用率就越高。目前,IP核已经变成系统设计的基本单元,并作为独立设计成果被交换、转让和销售。
从IP核的提供方式上,通常将其分为软核、硬核和固核这3类。从完成IP核所花费的成本来讲,硬核代价最大;从使用灵活性来讲,软核的可复用使用性最高。
1. 软核
软核在EDA设计领域指的是综合之前的寄存器传输级(RTL)模型;具体在FPGA设计中指的是对电路的硬件语言描述,包括逻辑描述、网表和帮助文档等。软核只经过功能仿真,需要经过综合以及布局布线才能使用。其优点是灵活性高、可移植性强,允许用户自配置;缺点是对模块的预测性较低,在后续设计中存在发生错误的可能性,有一定的设计风险。软核是IP核应用最广泛的形式。
2. 固核
固核在EDA设计领域指的是带有平面规划信息的网表;具体在FPGA设计中可以看做带有布局规划的软核,通常以RTL代码和对应具体工艺网表的混合形式提供。将RTL描述结合具体标准单元库进行综合优化设计,形成门级网表,再通过布局布线工具即可使用。和软核相比,固核的设计灵活性稍差,但在可靠性上有较大提高。目前,固核也是IP核的主流形式之一。
3. 硬核
硬核在EDA设计领域指经过验证的设计版图;具体在FPGA设计中指布局和工艺固定、经过前端和后端验证的设计,设计人员不能对其修改。不能修改的原因有两个:首先是系统设计对各个模块的时序要求很严格,不允许打乱已有的物理版图;其次是保护知识产权的要求,不允许设计人员对其有任何改动。IP硬核的不许修改特点使其复用有一定的困难,因此只能用于某些特定应用,使用范围较窄。
参考文献链接
https://mp.weixin.qq.com/s/k1P6-KOcF7e7aNTFK2TeQw
https://mp.weixin.qq.com/s/Z7H6wyGRj5BOJhXIqt3Btg
