


芯片-内存-异构计算漫谈
芯片-内存-异构计算漫谈
参考文献链接
https://mp.weixin.qq.com/s/yV8Ww0vVmXEs17aXygJqUw
https://mp.weixin.qq.com/s/vPEwdgn0jQsoZ4I81Ehfsg
https://mp.weixin.qq.com/s/fOhlQcggRxg3cOiE05mwVA
https://mp.weixin.qq.com/s/F4QE-PwOZ81H82TJuhjy2g
https://mp.weixin.qq.com/s/LK0An7n_4d9jol-X-xuypw
基于CXL技术的大内存池化

CXL是行业支持的处理器、内存扩展和加速器的Cache-Coherent互连,该技术保持CPU内存空间和附加设备上内存的一致性,允许资源共享,从而获得更高的性能,降低软件栈的复杂性,降低整体系统成本,用户也借此摆脱加速器中的冗余内存管理硬件带来的困扰,将更多精力转向目标工作负载。
CXL被设计为高速通信的行业开放标准接口,因为加速器越来越多地用于补充CPU,以支持诸如人工智能和机器学习等新兴应用。
CXL 2.0规范增加了对扇区数据交换的支持,以连接到更多的设备,内存容量按需提供,使用效率大大提高。CXL
2.0完全支持CXL 1.1和1.0,为行业用户节省了投资。
什么是CXL?
- CXL是行业支持的处理器、内存扩展和加速器的Cache-Coherent互连,该技术保持CPU内存空间和附加设备上内存的一致性,允许资源共享,从而获得更高的性能,降低软件栈的复杂性,降低整体系统成本,用户也借此摆脱加速器中的冗余内存管理硬件带来的困扰,将更多精力转向目标工作负载。
- CXL被设计为高速通信的行业开放标准接口,因为加速器越来越多地用于补充CPU,以支持诸如人工智能和机器学习等新兴应用。
- CXL 2.0规范增加了对扇区数据交换的支持,以连接到更多的设备,内存容量按需提供,使用效率大大提高。CXL 2.0完全支持CXL 1.1和1.0,为行业用户节省了投资。
详细的介绍我们可以看知乎大V @老狼 这篇文章 zhuanlan.zhihu.com/p/65由于自己做持久内存方面的研究,因此更关注 CXL 与持久内存的关系。Meta(FaceBook) 公司采用基于 CXL 的内存层级系统1. FaceBook 在内存池化方面做的努力FaceBook 一直大力提倡将DRAM内存从使用它的CPU中分离出来,并创建由许多系统共享的池内存层(pooled memory)。FaceBook 多年来一直致力于分离(disaggregate)和池化(pool)内存,以使内存在其服务器中更好地工作,并试图控制内存成本,同时提高其性能。FaceBook 多年来一直在与密歇根大学助理教授Mosharaf Chowdhury合作研究内存池化技术,从Infiniswap Linux内核扩展开始,该扩展在InfiniBand或Ethernet之上通过RDMA协议池化内存,在2017年6月就对此进行了分析。Infiniswap是一种跨服务器的内存负载均衡器,它以几种不同的传输和内存语义协议首次出现——IBM的OpenCAPI内存接口协议、Xilinx的CCIX协议、Nvidia的NVLink协议、惠普企业版的Gen-Z协议,由戴尔支持,在内存池化方面也有类似的想法。在这一点上,至少在机架中的内存池化方面,Intel的CXL协议已成为分离(disaggregate)内存的主导标准,而不仅仅是用于将加速器中的 far memory 以及 flash memory 连接到CPU,该协议将在新的和未来的服务器中很常见。FaceBook 的研究人员(Chowdhury)正在对分离 (disaggregate) 内存的想法进行另一次尝试,通过称为透明页面放置(Transparent Page Placement,TPP)的Linux内核扩展,将Infiniswap的一些想法向前推进,它以与连接到CPU的DRAM略有不同的方式进行内存页管理,并考虑了CXL主存的相对距离。研究人员在一篇论文中概述了这项最新的工作,arxiv.org/abs/2206.0287。TPP协议是 FaceBook 平台开源的,该协议正与该公司的变色龙内存跟踪工具结合使用,变色龙内存跟踪工具在Linux用户空间中运行,因此人们可以跟踪CXL内存在其应用程序中的工作情况。
2.CXL-Memory
随着CPU的发展,系统架构师从主存向下移动,在内核和主存之间添加了一、二、三、有时四个级别的缓存,并通过系统总线输出到磁带,然后是磁盘和磁带,然后是闪存、磁盘和磁带。最近几年,我们增加了诸如3D XPoint之类的持久内存。
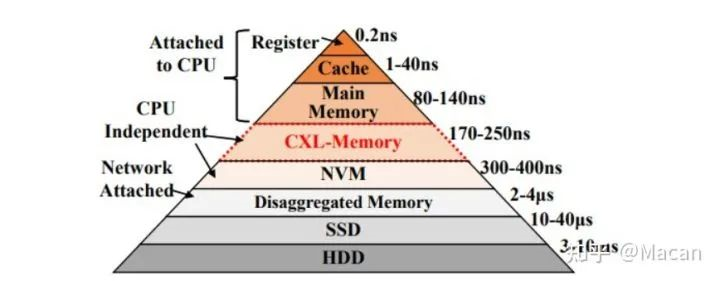
正如 FaceBook 平台、MemVerge 公司和许多其他系统制造商所相信的那样,将把CXL主内存从CPU上卸下来,CXL内存看起来像一个普通的NUMA插槽,但里面没有任何CPU。如果 FaceBoo k平台创建的TPP协议是正确的,那么它将有一个不同的内存分页系统,可以更好地解决由于在服务器主板之外有大量池化内存而带来的稍高的延迟。
以下是脸书在几代机器的内存容量、带宽、功率和成本方面所面临的挑战:
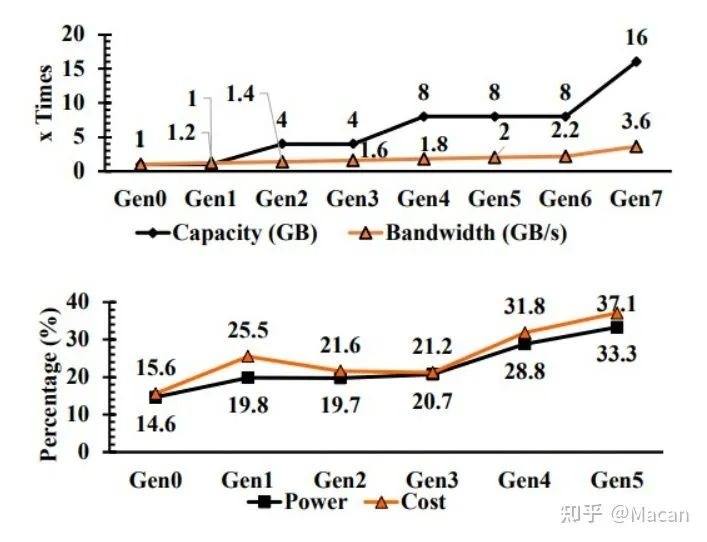
从上图可以看出,内存容量的增长速度快于内存带宽,这对性能有重要影响。如果带宽更高,那么在一定数量的CPU上完成一定量的工作,可能需要更少的内存容量。就像CPU的时钟速度是10GHz一样,这比2.5GHz要好得多。但是更快的CPU和内存时钟会产生指数级热量,因此系统架构会试图做更多的工作,并保持在合理的功率范围内。但它不起作用。由于需要更高的性能,每代服务器上的系统功率和内存功率都在不断增加,内存成本占系统总成本的比例也在不断上升。在这一点上,系统的主要成本是内存,而不是CPU本身。(不仅是在FaceBook ,全世界都是如此)
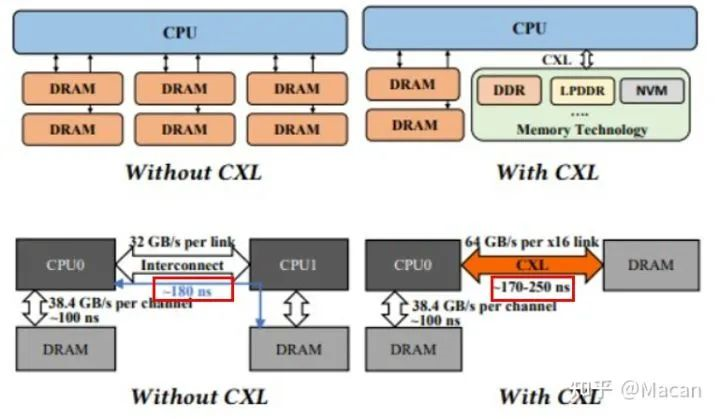
用CXL扩展系统内存容量和带宽,延迟与NUMA访问基本相同
因此,基本上必须使用CXL协议覆盖将主内存移动到PCI Express总线,以在不向CPU芯片添加更多内存控制器的情况下,扩展系统中的内存容量和内存带宽。如下图所示,该内存中有一点延迟,但其大小与共享内存系统中两个CPU之间的NUMA链路相同:
试图找出如何使用CXL内存的诀窍,就像Optane 3D XPoint DIMM和各种速度的闪存一样,就是找出在内存中使用的数据有多少是 hot , warm , cold 的,然后找出一种机制,在最快的内存中获取 hot 数据,在最冷的内存中获取 cold 数据,在warm 内存中获取 warm 数据。您还需要知道每个温度层上有多少数据,以便获得正确的容量。这就是 FaceBook Platform和Chowdhury创建的变色龙工具的全部内容。
CXL 把我们带入大内存时代 --从MemVerge视角
MemVerge 公司CEO Charles Fan指出 :动态组合服务器并获取10TB以上内存池容量的能力将推动更多应用在内存中运行,避免外部存储IO流读写。存储级内存将成为主要的热数据存储层,NAND和HDD分别用于温数据,而 tape 用于冷数据。现在CXL市场经历了一年的发展,这是业内近十年来一次重大的架构变革,可能会带来一个跨多服务器共享内存结构的新市场。MemVerge软件将DRAM和Optane DIMM持久内存组合到一个集群存储池中,供服务器应用使用,无需更改代码。换句话说,这款软件已经结合了快速和慢速内存。

CXL v2.0增加了对CXL交换的支持,通过该支持,多个连接CXL 2.0的主机处理器可以使用分布式共享内存和持久(存储类)内存。CXL 2.0主机将拥有自己的直接连接DRAM,并能够通过CXL 2.0链路访问外部DRAM。这种外部DRAM访问将比本地DRAM访问慢几纳秒,需要系统软件来弥合这一差距。(顺便提一下,MemVerge提供的系统软件。)范说,他认为CXL2.0交换机和外部内存盒最早可能出现在2024年。不过,我们将更早地看到原型。MemVerge正在和组合系统供应商Liqid合作,让MemVerge创建的DRAM和Optane内存池能通过当今的PCIe 3和4总线能全部或部分动态分配给服务器。CXL 2.0应该引入外部内存池及其对服务器的动态可用性。范承工表示有了CXL,内存动态组合可以和云服务模型高度协同。因此,云服务提供商会成为这项技术的首批采用者之一。Blocks & Files认为,包括公有云供应商在内的所有超大规模企业都会依赖CXL连接内存池。而且他们没有可用于提供外部池化内存资源的现有技术,因此要么自己建,要么得寻找合适的供应商。MemVerge将推动由CXL交换机、扩展器、存储卡和设备供应商组成的CXL 2.0生态系统的兴起。MemVerge的软件能在公有云上运行。有一家生物技术研究公司SeekGene已经通过在阿里云i4p计算实例运行上使用MemVerge Memory Machine,从而显著减少了处理时间和成本。阿里云是第一家面向用户提供Optane实例支持的云服务提供商,和MemVerge的联合服务就是在此之上,允许封装应用,并使用MemVerge的快照技术实现回卷恢复。MemVerge会以开源形式提供基础版大内存软件来扩大应用范围,并提供付费扩展功能,比如快照和检查点服务。
外部内存池示例
想象一下,今天有一个20台服务器的机架,每个服务器都有2TB的内存。这是20 x 2TB内存块,40TB,任何应用程序的内存都限制在2TB。MemVerge的软件可以用于将任何一台服务器中的内存地址空间扩展到3TB左右,但每台服务器的DRAM插槽数量有限,一旦用完就不再可用。CXL 2.0消除了这一限制。
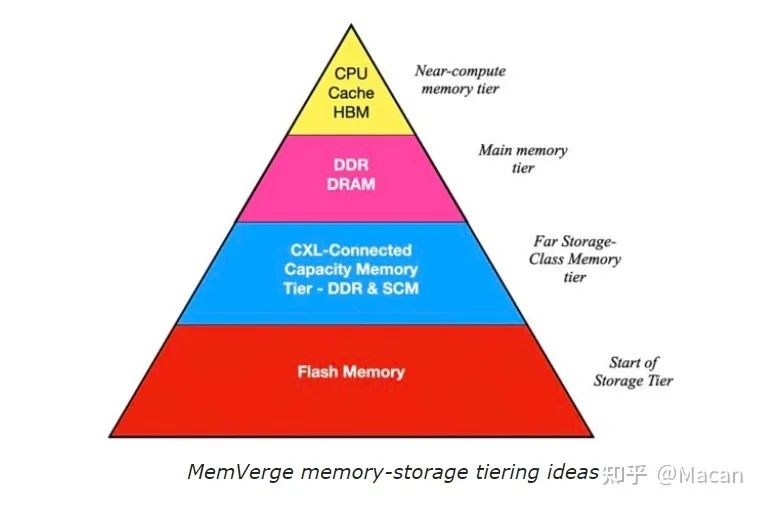
现在,让我们重新想象一下由20台服务器组成的机架,其中每台服务器都有512GB的内存,机架上有一个CXL 2.0连接的内存扩展器机箱,具有30TB的DRAM。我们的DRAM总量仍然与以前相同,为40TB,但现在的分布有所不同,有20 x 512GB的块,每台服务器一个,以及30TB的可共享池。内存中的应用程序可能会消耗高达30.5TB的DRAM,是以前的10倍,这从根本上增加了它可以处理的工作数据集,并减少了其存储IO。我们可以有三个内存应用程序,每个应用程序占用30TB内存池中的10TB。此类应用程序执行速度更快的能力将显著提高。范说:“它提高了应用程序的上限,即你可以使用多少内存,你可以根据需要动态地配置它。所以我认为这是革命性的。”不仅仅是服务器可以使用它,GPU还可以使用更具可扩展性的内存层。新创建的DRAM内容仍然必须是持久的,将30TB的数据写入NAND将需要相当长的时间,但可以使用 Intel Optane 或类似的存储类内存,如ReRAM,而IO速度要快得多。然后,最活跃的数据将存储在SCM设备中,随着时间的推移,活动性较差的数据将首先传输到NAND,然后传输到磁盘,最后传输到磁带,其活动性配置文件越来越低。这种连接 CXL 的SCM可以在同一个或单独的机箱中,并且可以动态组合。我们可以设想使用这种分层外部DRAM和 Optane系统的超大规模供应商服务运行更快,能够以更高的利用率支持更多用户。应用程序设计也可能发生变化。范补充道:“应用程序的一般逻辑是使用尽可能多的内存。只有在内存不足的情况下才使用存储。对于其他数据密集型应用程序,它将以同样的方式运行,包括数据库。我认为内存数据库是一个大趋势。对于许多互联网服务提供商来说,我认为基础设施提供更无限的内存将影响他们的应用程序设计,因为它更以内存为中心。这反过来又减少了他们对存储的依赖。”
参考:
1、CXL-led big memory taking over from age of SAN.(https://blocksandfiles.com/2022/06/20/cxl-led-big-memory/)
2、META PLATFORMS HACKS CXL MEMORY TIER INTO LINUX.(https://www.nextplatform.com/2022/06/16/meta-platforms-hacks-cxl-memory-tier-into-linux/)
计算机体系结构将何去何从
软件热点层出不穷,并且快速迭代;CPU性能瓶颈,摩尔定律失效;图灵奖获得者John Hennessy和David Patterson在2017年提出了“计算机体系结构的黄金年代”,给出的解决方案是特定领域架构DSA。
如今,“黄金年代”时间已经过半,我们再对这一时期的体系结构发展进行分析、总结和展望:
- DSA成功吗?DSA是体系结构的发展趋势吗?
- 在黄金年代之后,体系结构新的发展趋势又是什么?
1 “体系结构的黄金年代”成色不足
软件热点层出不穷,从以前的云计算、大数据、AI到后来的区块链、5G/6G、自动驾驶、元宇宙等,几乎每2年左右时间,就会有一个全新的技术应用出现。并且,已有的技术应用,仍在快速地演进和迭代。比如,2012-2018年6年时间里,人们对于算力的需求增长了超过 30万倍;也就说,AI算力大约每3.5个月翻一倍。
2017年,图灵奖获得者John Hennessy和David Patterson提出“计算机体系结构的黄金年代”,并指出,由于目前通用计算的性能瓶颈,需要针对特定应用场景开发针对性优化的架构,他们给出的解决方案是DSA(Domain Specific Architecture)。
通过CPU+(集成或独立的)GPU/FPGA/DSA处理器,把软件业务通过异构计算加速,如网络、存储、虚拟化、安全、数据库、视频图像、深度学习等场景。但目前,最大的问题在于,这些领域的加速,从CPU计算的整体,变成了异构计算的一个个各自为战的“孤岛”。
从目前主要的几个领域DSA(成功或不成功)的案例,来进行分析:
- AI DSA。谷歌的TPU,是第一款真正意义上的DSA芯片。很多AI芯片的架构也是类似思路下的产物,都是期望在ASIC级别性能的基础上实现一定程度的可编程能力。但不幸的是,AI场景仍属于应用层次:应用算法迭代迅速,并且种类繁多;这导致AI DSA的落地并不算很成功。本质原因是:DSA架构的灵活性无法达到应用层算法对灵活性的要求。
- 存算一体。存算一体是一个非常宽泛的概念,包括近存计算、存内计算等,甚至存内计算还可以分为内存储计算和内存执行计算。不管是聚焦AI或其他领域,严格来说,存算一体是一种微架构及实现的技术;在系统架构层次,存算一体属于DSA的范畴。存算一体也必须要面对DSA的核心问题:芯片架构灵活性和领域算法灵活性的匹配问题。
- 网络DSA。Intel通过PISA架构的网络DSA实现了ASIC级别性能的基础上的软件可编程,可实现绝大部分网络协议和功能的编程。网络DSA是DSA理念下比较成功的案例。本质的原因是,网络任务属于基础设施层工作,其灵活性要求相对不高。因此可以总结:DSA架构的灵活性可以满足基础设施层任务对灵活性的要求。
除此之外,还需要考虑最终场景落地的问题。站在最终落地场景和解决方案的视角:
- 客户不可能只需要一个DSA,客户需要的是综合性的解决方案,DSA实现的只是客户场景的一小部分。
- 并且,在云和边缘数据中心,当CSP投入数以亿计资金,上架数以万计物理服务器的时候,它并不知道具体的某台服务器最终会售卖给哪个用户,这个用户到底会在服务器上面跑什么应用。并且,未来,这个用户的服务器资源回收之后再卖个下一个用户,下一个用户又用来干什么,也是不知道的。
因此,最终的落地场景需要的一定是综合的并且相对通用的解决方案;并且,还需要在通用的基础上尽可能地提升性能降低成本。
各种独立DSA,使得系统越来越碎片化,这跟互联网云和边缘计算、云网边端融合等宏观综合宏场景的发展趋势是背道而驰的。
2 DSA的价值所在
2.1 相比ASIC,DSA具有一定的灵活性优势
在系统复杂度较低的时候,ASIC的极致性能和效率,是非常合适的。但随着系统复杂度的上升,ASIC的劣势逐渐就暴露出来了:
- ASIC的迭代跟系统迭代不匹配。复杂系统的变化要远高于简单系统,而ASIC是紧耦合的设计,没法随着系统功能和业务逻辑的快速变化而变化。随着系统复杂度的进一步上升,ASIC和系统的灵活性冲突会愈演愈烈。
- ASIC性能效率不一定最高。ASIC功能确定,为了覆盖更多的场景,势必需要功能超集。但随着系统功能的增多,以及每个用户能使用到的功能比例相对减小,功能超集反而拖累了ASIC的性能和资源效率。
- ASIC硬件开发难度大。硬件开发的难度远大于软件,ASIC由于系统紧耦合的缘故,需要把业务逻辑都细化到硬件电路设计中去,这反而显著地增加硬件开发的难度。
- ASIC难以大规模。因为上述ASIC硬件开发的难度,这反过来使得ASIC设计很难做到非常大的规模,而这就约束了其可以支撑的系统规模大小。
- 完全硬件ASIC,用户对功能和业务逻辑没有太多话语权。用户只是“User”,而不是“Developer”,ASIC会约束用户的业务创新。
DSA可以在ASIC级别,一定程度上实现功能和业务逻辑的可编程,实现性能和部分灵活性的兼顾,并且显著改善ASIC的上述各种问题和挑战。因此,DSA逐渐成为目前领域加速的主流解决方案。
例如,网络DSA的发展。SDN之前,网络芯片的主流实现是ASIC;SDN发展的第一步,通过Openflow实现了控制面可编程;第二步,通过P4实现了数据面的可编程,并且拥有了支持P4可编程的DSA:Barefoot的PISA架构和Tofino芯片。
2.2 DSA比较适合基础实施层加速

系统是由分层分块的各个组件组成的,这些组件大体上分为三类:
- 基础设施层。底层的业务逻辑相对最稳定。
- 应用层。由于硬件平台运行具体哪些应用的不确定性,以及应用的快速升级迭代等,使得应用层的变化是最快的。
- 应用层可加速部分。应用层可抽离出来的一些性能敏感的算法,其灵活性介于基础设施层和应用之间,变化相对适中。
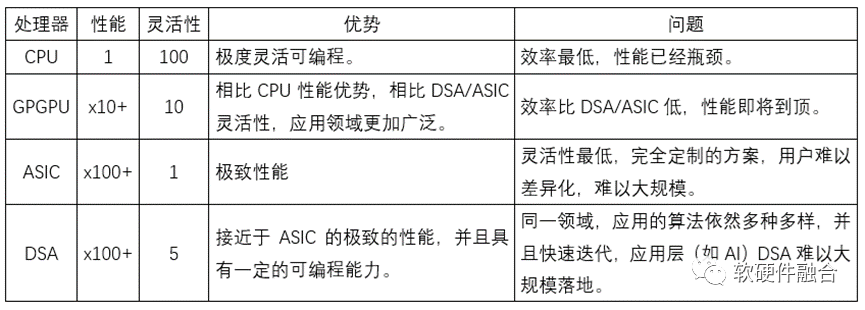
如上表格所示,每一个处理器引擎类型都有其优势之处,也都有其劣势之处:
- CPU灵活性最好,目前数据中心由于对灵活性的要求很高,因此服务器主要还是以CPU处理器为主。但CPU的性能是相对最低的。
- GPGPU相比CPU提升了性能,灵活性虽然有了一些降低,但依然能够满足很多场景的要求。比如AI算法和应用性能敏感,并且更新换代很快,就比较适合GPGPU架构。
- ASIC由于其最低的灵活性,导致在云和边缘等复杂系统中没有用武之地。
- DSA是ASIC的回调,增加了一些灵活性。实践证明:DSA不适合变化较快对灵活性要求较高的应用级的场景,如AI加速场景;DSA适合变化较慢灵活性要求较低的场景,如网络加速场景。
2.3 DSA,是算力的主力支撑
一方面,复杂系统都存在一个显著的规律“二八定律”,也即是说,系统的大约80%的计算量属于基础设施层,属于适合DSA加速的部分;另一方面,DSA能够覆盖足够大的一个领域,并且其一定程度的可编程能力,可以满足系统的基础设施层特定领域任务对灵活性的要求。
DSA架构的处理器(引擎)就可以在满足系统灵活性要求的情况下,实现最极致的性能,以及最极致的性价比。
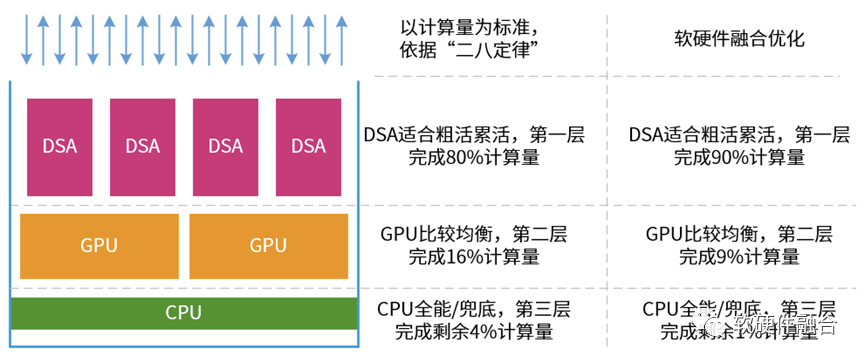
我们再从整个系统角度分析,可以通俗地将系统要进行的工作处理当做一个塔防游戏:
- 依据系统的“二八定律”,在一个系统里,DSA完成80%计算量,GPU完成16%计算量,CPU兜底完成4%计算量。
- 软硬件融合技术,可以让硬件的功能更加强大,具有一些通常软件才有的特征和能力,从而进一步提高系统硬件加速的比例。这样,DSA可以完成90%的计算量,而留给CPU和GPU的只有剩下的10%。
总之,DSA架构处理器必然是整个系统中的算力中坚。
3 DSA的不足之处
3.1 DSA不太适合应用层工作
应用层DSA最典型案例,非AI芯片莫属。
AI领域对算力的极致需求,以及行业巨头谷歌发布的全球第一款DSA架构处理器TPU,瞬间引爆了AI芯片的全行业大潮。
但5年左右时间过去了,即使是谷歌具有从芯片、框架、生态到服务的全链条的全球顶尖技术,以及几乎全球第一的行业号召力,整个TPU体系仍然难算成功。谷歌的AI框架,目前在逐渐地往GPU迁移,可以说,AI平台目前的趋势是:从DSA往GPU回调。
其他的DSA架构的AI芯片,落地的场景和数量更少。
本质原因也很简单:AI DSA芯片提供的灵活性跟上层AI算法所需的灵活性要求,相差甚大。我们把这个表述更加泛化一些:DSA芯片提供的灵活性比较低,而应用层算法对灵活性的要求比较高,两者相差巨大。
系统是分层分块的系统,一般来说:越底层越确定,越适合DSA架构处理;越上层越不确定,越适合CPU这样的通用处理器处理;而性能敏感的应用层算法,比较适合于GPU及同指令复杂度级别架构(例如Graphcore IPU)的处理器。
AI芯片未来要想落地,需要芯片和应用算法的相向而行:
- 芯片增加更多的灵活性能力(典型案例:Tenstorrent Wormhole,在提升灵活性的同时,提供极致的系统可扩展性);
- 随着时间推移,AI算法的灵活性降低,逐渐的沉淀成基础设施层任务。
3.2 DSA使得系统越来越碎片化,跟云网边端融合的大趋势背道而驰
我们的IT设备和系统,通常是经过如下四个演进的阶段,逐渐走向云网边端大融合:
- 第一个阶段,孤岛。所有的设备是独立的,没有联网,也就没有云网边端的说法。
- 第二个阶段,互联。也就是我们的互联网,把设备连到一起,设备和设备之间可以通信。
- 第三个阶段,协同。通常的C/S架构就是典型的协同,这个时候,有了云边端的划分,谁更擅长于干什么事情就分配什么事情,大家协同着一起把整个系统的事情做好。
- 第四个阶段,融合。协同某种程度上代表着静态,随着时间的发展,可能初始任务划分不一定能适应系统的发展;而融合代表着动态以及更多的自适应性。服务拆分成微服务,客户端拆分成瘦客户端和微服务。这些微服务可以完全自适应的运行在云端、网端、边缘端或者终端,或者各个位置端可能都有。
云网边端融合的时代,所有的服务器和设备的计算、网络、存储等资源都统统连成了唯一的一个巨大的资源池,可以非常方便的共享各种各样的资源,软件可以非常方便的部署在任何位置,并且可以非常方便的自适应迁移。
然而,DSA的做法,却跟这一切是背道而驰的:
- 首先,一个领域DSA芯片,就意味着架构上的一个孤岛。
- 其次,即使同一领域,也有不同公司的不同架构实现。这些不同架构处理器的算力,很难被整合到宏观大算力池里。
DSA作为“体系结构黄金年代”的重要理念和解决方案,意味着“百花齐放,百家争鸣”,也意味着计算的架构越来越多,越来越碎片化,越来越难以整合成一个整体,越来越一盘散沙。从技术发展的角度,必然需要走过DSA这样的阶段。但随着各项技术的成熟,必然会逐步走向收敛:通用的、融合的、综合的处理器,通过更少的架构,实现覆盖更多的用户、更多的场景、更多的迭代。
3.3 DSA没有解决体系结构的根本矛盾
如果不考虑性能劣势的话,CPU是最好的处理器。其通过最基础的加减乘除指令,实现了软件和硬件的解耦。硬件工程师可以不用关心具体场景,只关心处理器的微架构和实现;软件工程师不关心硬件细节,只关心自己的软件编程,基于这些基础的指令集,构建起了软件庞大的生态体系。
GPGPU,依然是成功的。GPGPU相比DSA的优势:
- GPGPU可以覆盖很多个领域,而DSA只能覆盖一个。在芯片一次性成本越来越高的今天,覆盖更多领域意味着更多的产品销量以及更低的成本(大芯片成本中一次性均摊成本占比很高)。
- NVIDIA GPGPU以及CUDA构建起完整的生态,而DSA架构则趋向碎片化,构建生态的难度很大。
- 热点应用意味着最丰厚的价值。GPGPU的性能和灵活性均衡使其能很好地满足目前很多热点应用的性能和灵活性要求;而DSA则难以满足热点应用所需的灵活性(因为热点应用必然快速迭代)。
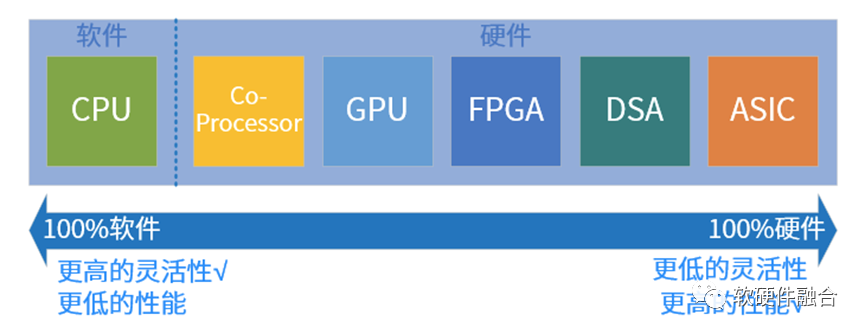
体系结构最根本的矛盾是什么?简单地说,就是性能和灵活性的矛盾,是两者如何平衡甚至兼顾的问题。通常情况下,两者是反比关系,提升一个,另一个会降低。体系结构的优化和创新,本质的,就是在一个要素不变的基础上,尽可能地提升另一要素。
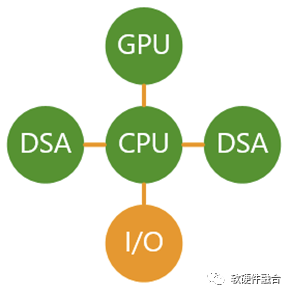
DSA在ASIC基础上,提升了一些灵活性,这是其价值所在。但与此同时,也引入了一些问题。在整个系统中,如果只需要一个特定领域的DSA加速卡,并且不需要GPU等其他加速卡的话,那么整个系统是典型的CPU+DSA的异构计算系统,问题还不突出。
实际的云和边缘场景,是很多场景叠加在一起的综合性场景,不仅仅需要AI加速,还需要虚拟化加速、网络加速、存储加速、安全加速、数据库加速、视频图形处理加速等等。如果每一个领域加速都需要一个物理的加速卡的话:
- 首先服务器的物理空间和接口,就无法满足这么多张卡的使用。
- 此外这些卡之间的交互又是一笔额外的代价,在CPU性能捉襟见肘的今天,CPU根本无法承担DSA之间的数据交互处理。
站在DSA局部的视角,DSA带来了性能的显著提升,并且还确保了一定程度的灵活性。但站在整个系统角度,额外增加的各个DSA之间的数据交互(类似系统解构微服务化之后急速增加的内网东西向流量)是需要CPU来处理的,这使得CPU的性能瓶颈问题变得更加严峻。
4 黄金年代之后,体系结构何去何从?
4.1 从分离到融合
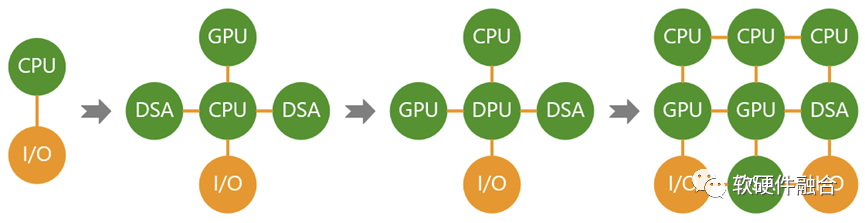
DPU目前已经成为行业一个重要的处理器类型,DPU跟智能网卡最大的区别在于:智能网卡是单领域的加速卡,而DPU是多领域加速的集成平台。DPU的出现,说明了,计算机体系结构在从DSA的分离向融合转变:
- 第一阶段,CPU单一通用计算平台;
- 第二阶段,从合到分,CPU+GPU/DSA的异构计算平台;
- 第三阶段,从分到合的起点,以DPU为中心的异构计算平台;
- 第四阶段,从分到合,众多异构整合重构的、更高效的超异构融合计算平台。
4.2 从单异构到超异构

不考虑物理上多芯片协同的情况下,我们只考虑计算架构。计算架构从串行到并行,从同构到异构,接下来会持续进化到超异构:
- 第一阶段,串行计算。单核CPU和ASIC等都属于串行计算。
- 第二阶段,同构并行计算。CPU多核并行属于同构并行计算。
- 第三阶段,异构并行计算。CPU+GPU、CPU+DSA以及SOC等属于异构并行计算。
- 未来,将走向第四阶段,超异构并行阶段。把众多的CPU+GPU+DSAs“有机”整合起来,形成超异构。
4.3 从软硬件协同到软硬件融合
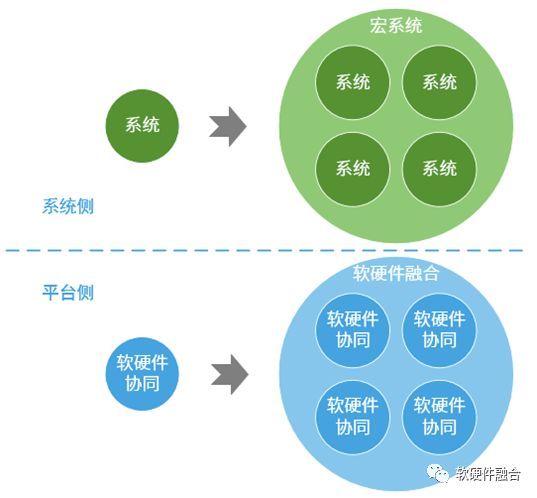
系统变得越来越庞大,系统可以分解成很多个子系统,子系统的规模已经达到传统单系统的规模。于是系统变成了宏系统,子系统变成了系统。
软硬件协同是研究单个系统软硬件如何划分、解耦以及再协同的,根据系统的特点,选择CPU、GPU、DSA等硬件处理器类型,如果是DSA等需要开发的硬件,则需要仔细考虑软硬件的工作划分和交互的接口。
软硬件融合是研究宏系统的软硬件“协同”的,每一个系统都是不同层次的软硬件协同,这些系统间还需要确定任务划分、数据交互和工作协同,从而在整个宏系统层次,呈现出:“软件中有硬件,硬件中有软件,软硬件深度地融合在一起”。
4.4 从开放到更开放

x86架构主要在PC和数据中心领域;ARM架构主要在移动领域,目前也在向PC和服务器领域拓展;加州大学伯克利分校开发了RISC-V,RISC-V已成为行业标准的开放ISA。理想情况,如果形成RISC-V的开放生态,没有了跨平台的损耗和风险,大家可以把精力专注于CPU微架构及上层软件的创新。
RISC-V的优势体现在:
- 免费。指令集架构免费获取,不需要授权,没有商业上掣肘。
- 开放性。任何厂家都可以设计自己的RISC-v CPU,共建一套开放的生态,共荣共生。
- 标准化。最关键的价值。RISC-v的开放性,使得其生态会更加强大;RISC-v如果变成主流架构,就没有了跨平台成本。
- 简洁高效。没有历史包袱,ISA更高效。
如果说CPU选择开放的RISC-v是“选择”(因为还有x86和ARM可以选)的话,那么在未来的超异构计算时代,开放则是“不得不选的唯一选项”。
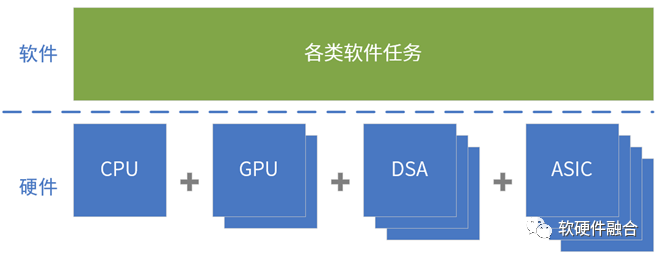
当一个平台需要支持的处理器类型和架构越来越多,势必意味着在其上运行程序越来越困难,处理器资源利用越来越低,构建生态的难度越来越高。这样,我们就需要:
- 一方面,需要从硬件定义软件,逐步转向软件定义硬件。并且,软件需要原生支持硬件加速。
- 另外,一定需要构建高效的、标准的、开放的生态体系(尽可能减少各种类型架构的数量,让架构的数量逐渐收敛)。
- 最后,还需要开放的、不同类型架构处理器(引擎)的,以及跨同类型处理器的不同架构的应用开发框架。
谈谈新型存储
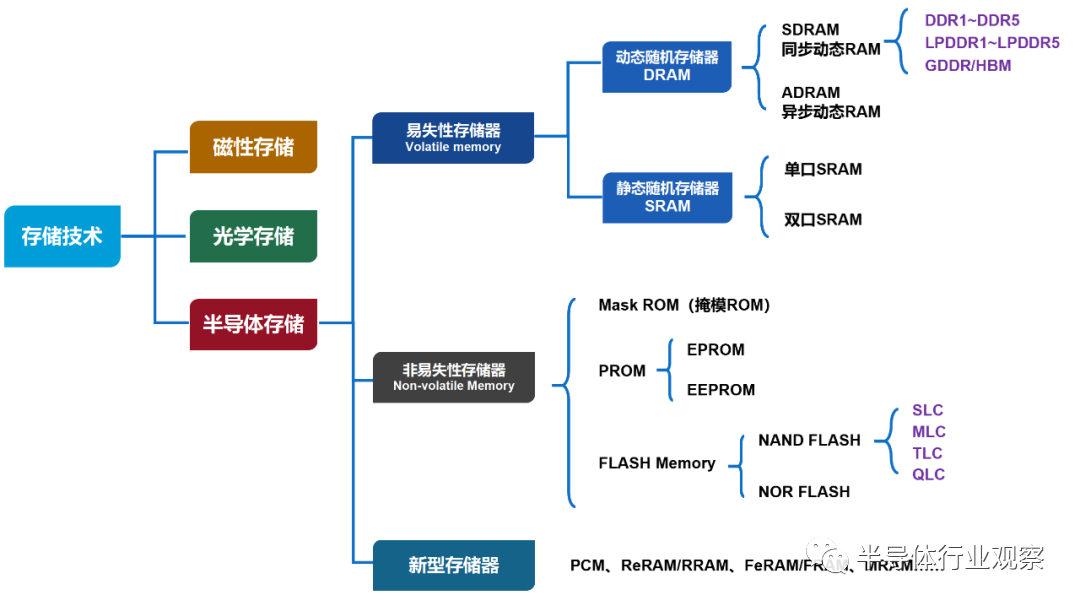
存储器是半导体的重要市场之一,其约占据了半导体近1/3的市场份额。其中,从存储芯片细分产品来看,DRAM和NAND Flash占据了存储芯片95%以上的市场份额,NOR闪存占比1%,其他存储芯片份额较小。
DRAM读写速度快,断电后数据无法保存,长期以来一直是计算机、手机内存的主流方案。计算机的内存条(DDR)、显卡的显存(GDDR)、手机的运行内存(LPDDR),都是DRAM的一种;NAND Flash属于数据型闪存芯片,可以实现大容量存储,且断电后数据不会丢失,但读写速度较慢,被广泛用于eMMC/EMCP、U盘、SSD等市场。
回顾存储器的发展历程来看,其技术演进路线主要取决于应用场景的变化。

上世纪70年代起,DRAM进入商用市场,并以其极高的读写速度成为存储领域最大分支市场;功能手机出现后,迎来NOR Flash市场的爆发;进入PC时代,人们对于存储容量的需求越来越大,低成本、高容量的NAND Flash成为最佳选择。
如今,随着万物智联时代的到来,5G、人工智能、智能汽车等新兴应用场景对数据存储在速度、功耗、容量、可靠性等层面提出了更高要求。DRAM虽然速度快,但功耗大、容量低、成本高,且断电无法保存数据,使用场景受限;NOR Flash和NAND Flash读写速度低,存储密度受限于工艺制程。
当传统路径中延续性技术创新的弊端已经暴露出来,市场亟待能够满足新场景需求的存储器产品,新型存储迎来机会窗口。
与此同时,今年存储市场逐渐遇冷,价格连续下跌,存储行业进入下行周期;英特尔关闭傲腾业务空出20亿高速增长的市场缺口;日益严重的“存储墙”和“性能墙”问题对计算系统的制约以及CXL协议的推出等等因素之下,新型存储凭借颠覆性的技术创新路径,迎来赶超传统存储技术寡头的一次机会。
据Objective Analysis和Coughlin Associates发布的报告显示,新型存储器已经开始增长,预计到2032年市场规模将会攀升至440亿美元,迎来广阔的市场空间。
目前,新型存储器主要有PCM、MRAM、FRAM、ReRAM存储器,以及DNA存储、Racetrack内存等诸多新兴技术。同时,存内计算(存算一体)也正在成为解决当前存储挑战的热门趋势之一。
相变存储器PCM
相变存储器,Phase-change RAM,简称PCM或PCRAM。
PCM的原理是通过改变温度,让相变材料在低电阻结晶(导电)状态与高电阻非结晶(非导电)状态间转换。

PCM原理图(图源:Intel)
PCM技术特点:
低延时、读写时间均衡:PCM在写入更新代码之前不需要擦除以前的代码或数据,所以PCM读写速度比NAND Flash有所提高,读写时间较为均衡。
寿命长:PCM读写是非破坏性的,故其耐写能力远超过闪存,用PCM来取代传统机械硬盘的可靠性更高。
功耗低:PCM没有机械转动装置,保存代码或数据也不需要刷新电流,故PCM的功耗比HDD、NAND、DRAM都低。
密度高:部分PCM采用非晶体管设计,可实现高密度存储。
抗辐照特性好:PCM存储技术与材料带电粒子状态无关,故其具有很强的抗空间辐射能力,能满足国防和航天的需求。
虽然PCM有诸多优势,但其RESET后的冷却过程需要高热导率,会带来更高功耗,且由于其存储原理是利用温度实现相变材料的阻值变化,所以对温度十分敏感,无法用在宽温场景。其次,为了使相变材料兼容CMOS工艺,PCM必须采取多层结构,因此存储密度过低,在容量上无法替代NAND Flash。除此之外,成本和良率也是瓶颈之一。
大家都比较熟悉的Intel和Micron合作开发的3D XPoint技术,就是PCM的一种。
3D Xpoint技术在非易失存储器领域实现了革命性突破,虽然其速度略微比DRAM慢,但其容量却比DRAM高,比闪存快1000倍。但缺点也较为明显,3D Xpoint采用堆迭结构,一般是两层结构。因为堆迭层数越多,需要的掩模就越多,而在整个IC制造工业中,掩模板成本占比最大。因此,从制造的角度来说,要想实现几十层的3D堆迭结构非常困难。
随着英特尔傲腾内存业务的关闭,3D XPoint内存技术也走到了尽头。
磁性存储器MRAM
磁性存储器,Magnetic RAM,简称MRAM,是一种基于隧穿磁阻效应的技术。
目前主流的MRAM技术是STT MRAM,使用隧道层的“巨磁阻效应”来读取位单元,当该层两侧的磁性方向一致时为低电阻,当磁性方向相反时,电阻会变得很高。
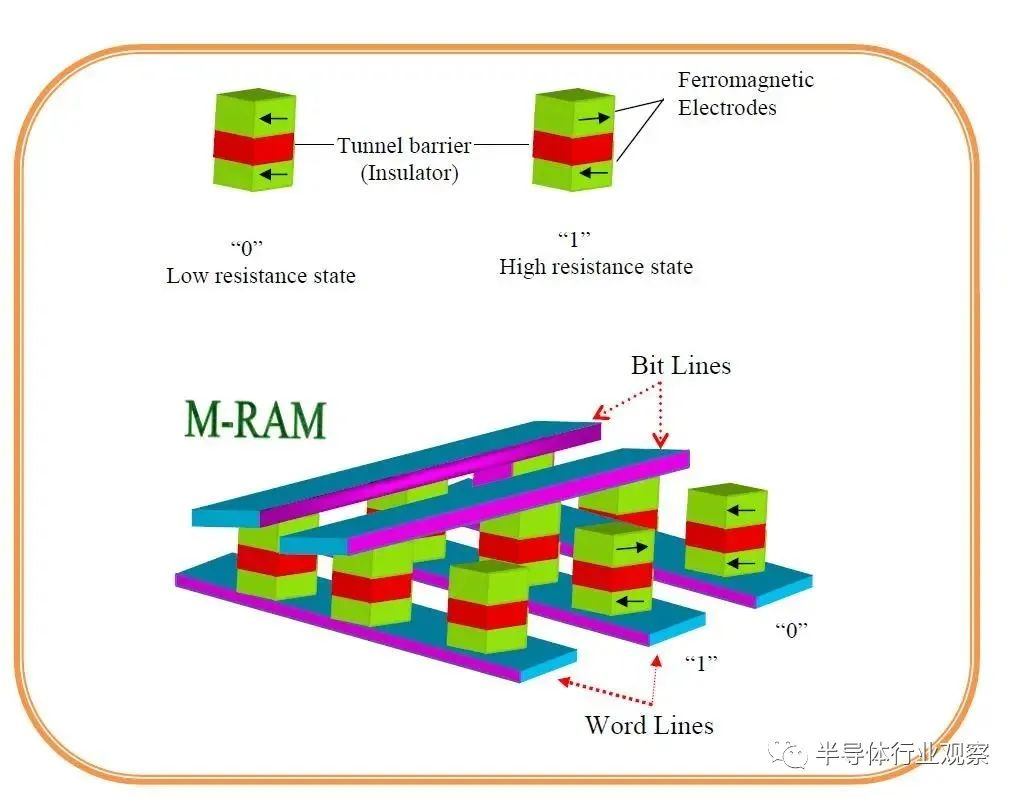
MRAM原理图
MRAM技术特点:
非易失:铁磁体的磁性不会由于断电而消失,故MRAM具备非易失性。
读写次数无限:铁磁体的磁性不仅断电不会消失,而是几乎可以认为永不消失,故MRAM和DRAM一样可以无限次重写。
写入速度快、功耗低:MRAM的写入时间可低至2.3ns,并且功耗极低,可实现瞬间开关机并能延长便携机的电池使用时间。
和逻辑芯片整合度高:MRAM的单元可以方便地嵌入到逻辑电路芯片中,只需在后端的金属化过程增加一两步需要光刻掩模版的工艺即可。再加上MRAM单元可以完全制作在芯片的金属层中,甚至可以实现2-3层单元叠放,故具备在逻辑电路上构造大规模内存阵列的潜力。
MRAM性能较好,但临界电流密度和功耗仍需进一步降低。目前MRAM的存储单元尺寸仍较大且不支持堆叠,工艺较为复杂,大规模制造难以保证均一性,存储容量和良率爬坡缓慢。在工艺取得进一步突破之前,MRAM产品主要适用于容量要求低的特殊应用领域,以及新兴的IoT嵌入式存储领域。
阻变存储器ReRAM
阻变存储器,全称为电阻式随机存取存储器,Resistive Random Access Memory,简称为ReRAM或RRAM。
ReRAM是以非导性材料的电阻在外加电场作用下,在高阻态和低阻态之间实现可逆转换为基础的非易失性存储器。作为结构最简单的存储技术,ReRAM结构看上去像一个三明治,绝缘介质层(阻变层)被夹在两层金属之间,形成由上、下电极和阻变层构成金属-介质层-金属(MIM)三层结构。
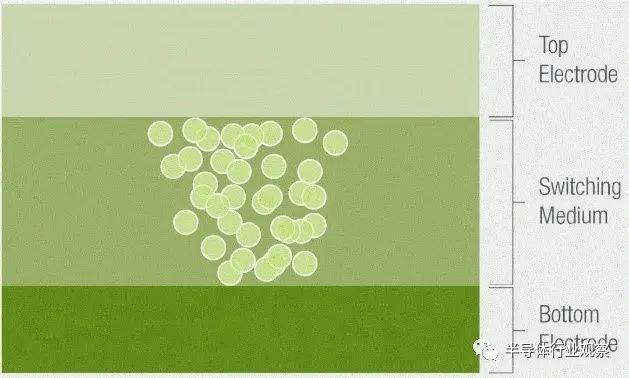
导电细丝在阻变层中呈现导通或断开两种状态:非易失性的低阻态或高阻态,从而实现了“0”,“1”状态的区分和存储。
ReRAM包括许多不同的技术类别,目前主流的技术路线主要有:氧空缺存储器OxRAM、导电桥存储器 CBRAM、金属离子存储器MeRAM以及纳米碳管CaRAM,通常是通过将金属离子或氧空位等导电元素移动到桥中,或者通过将它们从现有桥中移除,来表示1或者0。
ReRAM技术特点:
高速度:ReRAM擦写速度由触发电阻转变的脉冲宽度决定,一般小于100ns。
耐久性:ReRAM读写和NAND不同,采用的是可逆无损害模式,从而可以大大提高其使用寿命。
具备多位存储能力:部分ReRAM材料还具备多种电阻状态,使得单个存储单元存储多位数据成为可能,从而提高存储密度。
ReRAM可以将DRAM的读写速度与SSD的非易失性结合于一身,拥有上述多个优势,多用于神经拟态计算领域,基于ReRAM的类脑计算还能在中长期突破冯·诺伊曼计算架构瓶颈,它支持多种不同的AI算法,还具有算力高、功耗低等特点。
从密度、能效比、成本、工艺制程和良率各方面综合衡量,ReRAM存储器在目前已有的新型存储器中具备明显优势。此外,ReRAM的材料需求种类和额外的光罩数量更少,可以实现更低的生产成本。同时,业界普遍认为ReRAM能够充分满足神经形态计算和边缘计算等应用对能耗、性能和存储密度的要求,预期将在AIoT、智能汽车、数据中心、AI计算等领域获得广泛的运用,被认为是实现存算一体的最佳选择之一。
但ReRAM器件还并不完全成熟,它仍有器件非理想性、基于高精度模数转换器的读出电路,以及ReRAM设备中非线性的以及不对称电导更新后会严重降低训练的准确度等构成的问题。
铁电存储器FRAM
铁电存储器,简称FRAM或FeRAM,FRAM采用铁电晶体材料作为存储介质,利用铁电晶体材料电压与电流关系具有特征滞后回路的特点来实现信息存储。

FRAM结构图
FRAM技术特点:
非易失性:断电后数据不会丢失,是非易失性存储器;
读写速度快:无延时写入数据,可覆盖写入;
寿命长:可重复读写,重复次数可达到万亿次,耐久性强,使用寿命长;
功耗低:待机电流低,无需后备电池,无需采用充电泵电路;
可靠性高:兼容CMOS工艺,工作温度范围宽,可靠性高。
FRAM产品将ROM的非易失性数据存储特性和RAM的无限次读写、高速读写以及低功耗等优势结合在一起。FRAM产品包括各种接口和多种密度,像工业标准的串行和并行接口,工业标准的封装类型,以及4Kbit、16Kbit、64Kbit、256Kbit和1Mbit等密度。
FRAM凭借诸多特性,正在成为存储器未来发展方向之一,根据新思界产业研究中心发布的《2022-2027年中国FRAM(铁电存储器)行业市场深度调研及发展前景预测报告》显示,FRAM存储密度较低,容量有限,无法完全取代DRAM与NAND Flash,但在对容量要求不高、读写速度要求高、读写频率高、使用寿命要求长的场景中拥有发展潜力。FRAM可以应用于消费电子领域,比如智能手表、智能卡以及物联网设备制造中;汽车领域,比如高级驾驶辅助系统(ADAS)制造;工业机器人领域,比如控制系统制造等领域。
目前主流的铁电材料主要是锆钛酸铅(PZT)和钽酸锶铋 (SBT),但其存在疲劳退化问题,并导致对环境的污染。目前氧化铪 (HfO2) 中被发现存在铁电相,可以通过将硅 (Si) 掺杂到 HfO2中来稳定铁电相,且不会污染晶圆厂。尽管如今HfO2并未用于生产FRAM,但它具有广阔的前景,业界正在研究这一技术路线。
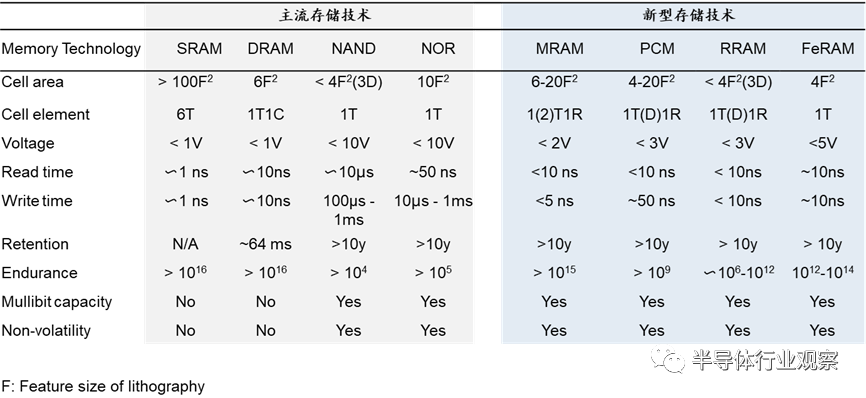
主流存储技术与新型存储技术对比
新型内存技术已经出现几十年,如今发展到一个在更多应用中表现更重要的关键期。通过上述各种存储技术对比能看到,新型存储器优势明显,具备超强性能,延迟堪比内存,而且具备超长寿命及可靠性,耐高温等特性。
由于未来的制程微缩和规模经济提升将促使价格降低,并开始将新兴内存作为独立芯片以及嵌入于ASIC、微控制器(MCU)以及甚至运算处理器中,从而使其变得比现有的内存技术更具竞争力。
同时,新型存储的发展也推动了存算一体技术的创新和迭代。
存算一体迎来突破?
在冯·诺伊曼架构之下,存储单元和计算单元独立分开,搬移数据的过程需要消耗大量时间和能量,并且由于处理器和存储器的工艺路线不同,存储器的数据访问速度难以跟上CPU的数据处理速度,性能已远远落后于处理器。所以,冯诺依曼架构在数据处理速度和能效比等方面存在天然限制,这被称为“存储墙”。
存算一体架构通过将存储单元和计算单元融为一体,消除了数据访存带来的延迟和功耗,是解决存储墙问题的最佳方案之一,实现更高的算力和更高的能效比。
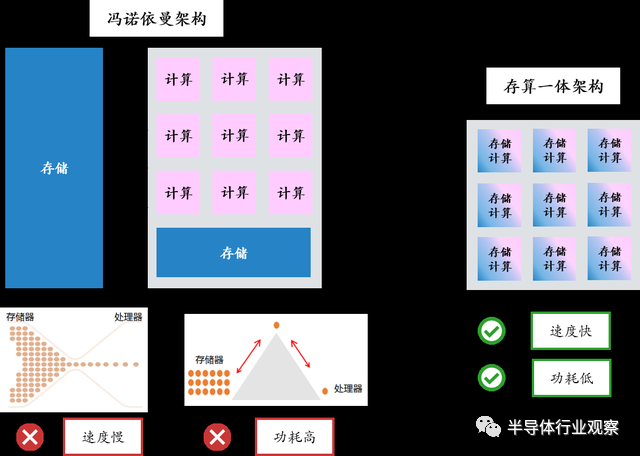
存算一体突破存储墙
(图源:云岫资本)
当前的存算一体技术路径中,既有使用DRAM、SRAM、NAND等传统存储器的方案,也有使用ReRAM、PCM、MRAM等新型存储器的方案。
前者由于存储器制造工艺和逻辑计算单元的制造工艺不同,无法实现良好的融合,目前只能实现近存计算,仍存在存储墙问题,甚至因为互连问题可能还会带来性能损失。并且,因为SRAM和DRAM是易失性存储器,需要持续供电来保存数据,仍存在功耗和可靠性的问题。
后者则是结合非易失性新型存储器,可以利用欧姆定律和基尔霍夫定律在阵列内完成矩阵乘法运算,而无需向芯片内移入和移出权重。新型存储器是通过阻值变化来存储数据,而存储器加载的电压等于电阻和电流的乘积,相当于每个单元可以实现一个乘法运算,再汇总相加便可以实现矩阵乘法,所以新型存储器天然具备存储和计算的属性。
在这种情况下,同一单元就可以完成数据存储和计算,消除了数据访存带来的延迟和功耗,是真正意义上的存算一体。
除了上述提到的当前较为成熟的四大新型存储之外,Racetrack内存、DNA存储等新兴技术也在不断涌现。
Racetrack内存
Racetrack内存,又称磁畴壁内存(domain-wall memory,DWM),是一种新的内存技术,利用磁性纳米管中的原子来存储信息,每通过一个晶体管可以读出16位数据,因此其读写信息的速度比闪存快10万倍。
同时,Racetrack内存可以保存大量可以非常快速地访问的数据,资料储存密度比现有的闪存还高,与现有的硬盘技术接近,可以作为通用型内存(Universal memory)使用。
与其他内存技术相比,Racetrack内存可能具有无与伦比的密度,Racetrack 存储器与闪存一样是固态的,没有笨重的移动部件,并且是非易失性的,即使在断电后也能存储数据。
这些设备不仅能够在同样的空间内存储更多的信息,而且其所需的电量及产生的热量也要少得多,同时几乎不会损坏。其结果是海量的个人存储内容仅使用一块电池便可运行几个星期,而且这些内容几十年也不用担心损坏。
Racetrack内存仍然处于研究的初期,迄今为止,大多数关于Racetrack存储的研究都集中在2D设备上。科学家们正在探索建立3D Racetrack存储的许多不同方法。实现三维构建的赛道内存将不遵从于摩尔定律,将为开发成本更低、速度更快的设备提供新的可能性。
DNA存储
为了寻找更高效能的存储载体,研究者将目光对准到了自然界中遗传信息的载体DNA。
DNA存储是一种以生物大分子DNA作为信息载体的存储技术,具有容量大、密度高、能耗低和存储时间长等优点。
技术层面上来看,DNA存储已经被证明是可行的。
前不久,天津大学合成生物学团队创新了DNA存储算法,将十幅精选敦煌壁画存入DNA中,通过加速老化实验验证壁画信息在实验室常温下可保存千年,在9.4℃下可保存两万年。
这项技术不仅证实了DNA是可靠的存储介质,同时也使信息存储技术进入一个新时代。DNA存储技术更适用于存储重要且无需经常访问、调用的“冷数据”。“冷数据”在接近零能耗的情况下,理论上来看可保存千年以上。在未来DNA存储极有可能成为庞大冷数据存储的主要存储介质。
DNA存储是一个新兴的、多学科深度交叉融合的技术,近几年DNA存储的研究已经取得了一些突破。DNA 已经被研究人员用来以不同的方式管理数据,这些研究人员正在努力理解海量数据。但目前DNA存储技术的落地还存在一些技术难题,想要把实验室的样品变成市场上的产品,需要科研机构、高校、企业等通力合作。
随着市场和技术不断发展,AI、5G、IoT和工业4.0等使得数据量呈现爆炸式增长,全新的运算需求驱动存储朝更高容量、高读写次数、更快读写速度、更低功耗方向发展。
如上文所述,当传统路径中延续性技术创新的弊端已经暴露出来,市场亟待能够满足新场景需求的存储器产品,新型存储迎来机会窗口。
然而,纵然当前主流存储技术存在很多局限和挑战,以及众多新型存储技术层出不穷,但现在说谁将胜出还为时过早,尽管新型内存技术的未来前景光明,但其仍然很难打入一些根深蒂固的技术市场。即使经济效益有所提升,新型内存也很难快速颠覆现有市场的主导地位,只是在当前的市场现状和境遇下,新型存储凭借颠覆性的技术创新路径,迎来了一次追赶传统存储技术寡头的机会。
破解发展智能制造的薄弱环节
2011年,浙江、广东等发达地区都出现了招工难、用工贵的现象,当地企业和政府相继提出了“机器换人”的对策,并进而演进为数字化改造、智能化改造,可见企业的需求是催生智能制造发展的主要动因。同时,国家发改委、工信部、财政部也适时提出了智能制造装备发展专项,这是战略性新兴产业发展规划最先启动的专项计划之一。2015年,由工信部、财政部组织实施了智能制造综合标准化与新模式应用专项,政府的引导作用是推动智能制造发展的重要推动力。
还应指出的是,新世纪以来,移动互联网、超级计算、大数据、云计算、物联网、人工智能等新一代信息技术的迅猛发展,以及与制造技术的融合,是引领智能制造迅速热起来的一个重要驱动力。市场需求、政府引导、技术驱动这三力共同作用,10年来在全国形成了智能制造热。当今广大企业已经普遍认识到,用数字化、网络化、智能化对企业进行改造,是提高企业竞争力的主要手段和迫切需求。企业既是智能制造需求的主体,也是投入、实施的主体。
归纳起来,智能制造的作用体现在:它是制造业创新发展的主要抓手,是制造业转型升级的主要途径,是建设制造强国的主攻方向。有成千上万家企业推行了数字化、智能化制造,其在解决招工难、用工贵、提高生产效率、缩短交货期、降低能源和资源消耗、降低成本等方面发挥了重要作用,特别是在提高产品质量和质量的一致性方面作用凸现。许多建成了数字化制造、生产线、车间、工厂的企业,在市场竞争中处于十分有利的地位,用户实地调查后很容易下决心签订合同。
十年来,虽然在制造业企业推行数字化、智能化取得了重大成效,但应该看到,推广应用的只能是少数企业,技术水平和效果有待迭代升级,改造所需装备和软件主要依赖进口,特别是广大中小微企业受资金、技术、人才、经验的制约,绝大多数处于观望状态,因此推行数字化、智能制造任重道远。上述存在的问题,也是当前存在的突出短板。
重视工艺创新和优化
智能制造,可能更容易被理解为智能、信息化、数字化,而它的根本其实是制造。什么叫制造?就是把矿产和农产品通过物理、化学、生物的办法变成最终可以使用的产品。这里的物理、化学、生物的方法就是工艺,以及工艺优化的装备,它是推行智能化制造的一个核心和基础。只有工艺和装备的创新、优化工业流程的再造,才能够给产业带来巨大的变化。所以,一些企业在推行智能制造的时候有些盲目,一开始就考虑如何信息化,对于工艺的优化创新总是力度不够,这是一个非常重要的问题。
我国有一批产业后来居上,由落后到世界先进或领先,共同的路径是工艺的创新+制造装备的自主化。我国装备制造业2019年主营收入37.98万亿元,其中用于制造业自身的制造装备主营收入10.69万亿元。《“十四五”智能制造发展规划》提出,到2025年,智能化改造所需智能制造装备要实现70%的市场满足度,每年将有数万亿元的智能制造装备需求。这是一个巨大的内需市场。
众所周知,近10年光伏发电产业发生了蝶变。以行业领头羊西安隆基为例,西安隆基2000年创业以来,摒弃了当时国内外普遍采用的多晶硅片技术路线,另辟新路,专注于光电转换效率高的单晶硅片技术路线。他们认为,多晶硅片的转化效率比较低,只有17%~18%,而单晶硅片转化效率可以达到23%~24%,目前已经在实验室做到了26.5%,很有发展前途。
但是单晶硅片成本太高,所以这十多年来,隆基坚持不懈攻克了两大工艺难题:一是用金刚线切单晶硅代替传统的砂浆切割;二是用多次装料拉单晶工艺和连续拉单晶工艺代替一次只能拉一根单晶棒的传统工艺。同时,还与设备制造商合作,共同研发多次装料拉单晶装备和金刚砂切割等数字化装备,形成了100%自主化的产业链布局。两大工艺的改进,使得光伏发电的成本大幅度降低。
2021年,隆基实现销售收入809.32亿元,净利润90.86亿元。2021年5月,隆基荣登“2021年全球光伏50强第一”,在隆基带领下,中国光伏发电技术和装备市场占有均处于全球领先地位。
所以,我们的企业在推行数字化、智能化改造转型时,一定要注意工艺的优化、工艺流程的优化、装备的自主化,这个问题很容易被忽视。
解决中小企业数字化转型难题
据国家统计部门公布的数据,工业中小企业的数量占全国工业企业总量的90%以上。在企业推行智能制造的浪潮中,普遍存在着“大企业唱戏,中小微企业观望”的现象。中小微企业难在“缺技术、缺人才、缺资金”等痛点问题。因此,解决这一世界性的难题,需要制订针对性、操作性强的举措。
当前要重点抓两件工作。第一是加强对“专精特新”小巨人企业和冠军企业数字化转型的支持。这些企业是我国产业基础再造的中坚力量和主要保障。第二是支持在一些地区进行探索和试点。近几年,以民营企业、中小企业和块状经济为特点的浙江已成为先行者,取得一定的经验,形成了支持中小轴承企业数字化转型的“新昌模式”、支持中小纺织企业数字化转型的“兰溪模式”,并培育了一批为中小企业提供“轻量化、低成本”的智能制造装备、工业软件和系统解决方案的公司。
浙江以民营企业和块状经济为特点,两年来,当地企业和政府联手,取得了很大进展,有望破解中小微企业数字化转型难这个世界难题。
重视大数据的积累应用
大数据是实现真正意义上智能制造的基石。工业大数据是工业互联网的核心,是实现智能化生产、个性化定制、网络化协同、共享制造、服务化延伸等智能化应用的基础和关键。工业大数据是我国制造业转型升级的重要战略资源。当前企业在数据采集和积累,特别是应用方面关注不够,应引起重视。
大数据是一个非常宝贵的金矿,但这个金矿还没有被开采出来,大数据也没有被很好地应用起来。我们要推行智能制造,大数据的作用是很重要的,所以在这方面应该引起高度重视。
工业软件已成为关键环节
最近,美国政府宣布对中国断供芯片之母EDA软件,将给中国发展芯片产生重大影响。对此应引起我们高度重视。越来越多的人已经意识到,一个芯片、一个传感器,可能会使一个企业甚至一个产业窒息。所以,我们已开始重视产业基础的再造,提出了产业基础高级化这一新的战略任务。通过EDA软件事件,我们更应该认识到工业软件的问题需要得到重视。
我国企业发展智能制造存在两大误区:一是重硬件,轻软件;二是重设备的自动化、智能化,轻视管理的改善和优化。如何解决工业软件这个薄弱环节,这里特别强调将各行业、各企业实战经验固化到软件中的专用工业软件的开发。也就是说,企业要把自己的实施经验、工艺参数固化到软件中,形成专用的工业软件。
目前,我们在开发专用软件方面已经有了突破,例如上海宝钢下属公司多年来从事钢铁行业的应用软件开发,软件方面的年营业收入已超过10亿元,冶金行业超过一半的软件是由这家公司提供的专用软件。他们的经验很值得我们借鉴,希望各个行业、各个企业都能够重视软件的开发。
当前,虽然智能制造已发展得热火朝天,企业普遍认识到了它的重要性,但是我们要居安思危,经过十年的发展,我们在智能制造领域还存在一些短板,需要去解决,只有这些问题解决了,我们智能制造的发展才能够取得更好的经济效益,才能够不断地迭代升级。
超异构计算:大算力芯片的未来
回顾计算机的发展历史,从串行到并行,从同构到异构,接下来会持续进化到超异构:
- 第一阶段,串行计算。单核CPU和ASIC等都属于串行计算。
- 第二阶段,同构并行计算。CPU多核并行和GPU数以千计众核并行均属于同构并行计算。
- 第三阶段,异构并行计算。CPU+GPU、CPU+FPGA、CPU+DSA以及SOC都属于异构并行计算。(SOC属于异构的原因是,其他所有引擎的处理都是在CPU的控制之下,其他引擎难以直接数据通信。)
- 未来,将走向第四阶段,超异构并行阶段。把众多的CPU+xPU“有机”集成起来,形成超异构。

1 回顾历史,从串行计算到并行计算
1.1 串行计算和并行计算
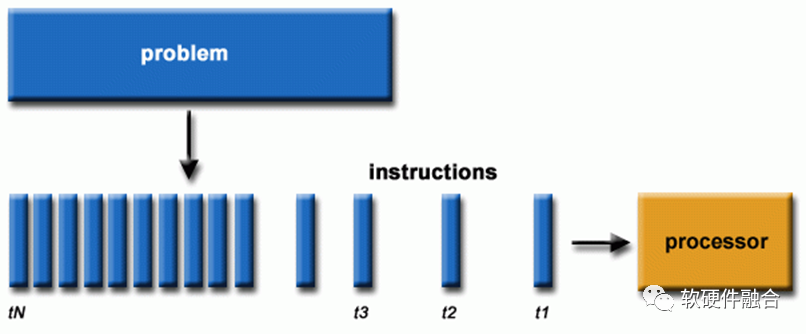
软件一般是为串行计算编写的:
- 一个问题被分解成一组指令流;
- 在单个处理器上执行;
- 指令是依次执行的(处理器内部可能存在非依赖指令乱序,但宏观效果上依然是串行指令流的执行)。
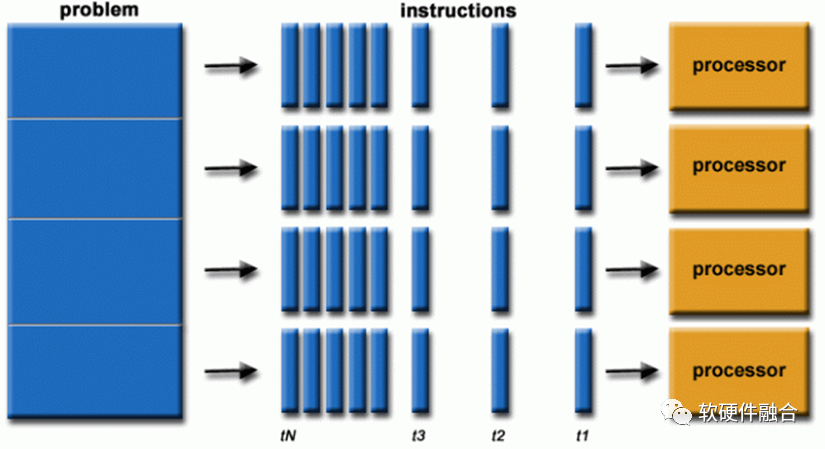
并行计算就是同时使用多个计算资源来解决一个计算问题:
- 一个问题被分解成可以同时解决的部分;
- 每个部分进一步分解为一系列指令;
- 每个部分的指令在不同的处理器上同时执行;
- 需要采用整体控制/协调机制。
计算的问题应该能够:分解成可以同时解决的离散工作;随时执行多条程序指令;使用多个计算资源比使用单个计算资源在更短的时间内解决问题。
计算的资源通常是:具有多个处理器/内核的单台计算机;通过网络(或总线)连接的任意数量的此类计算机。
1.2 多核CPU和众核GPU
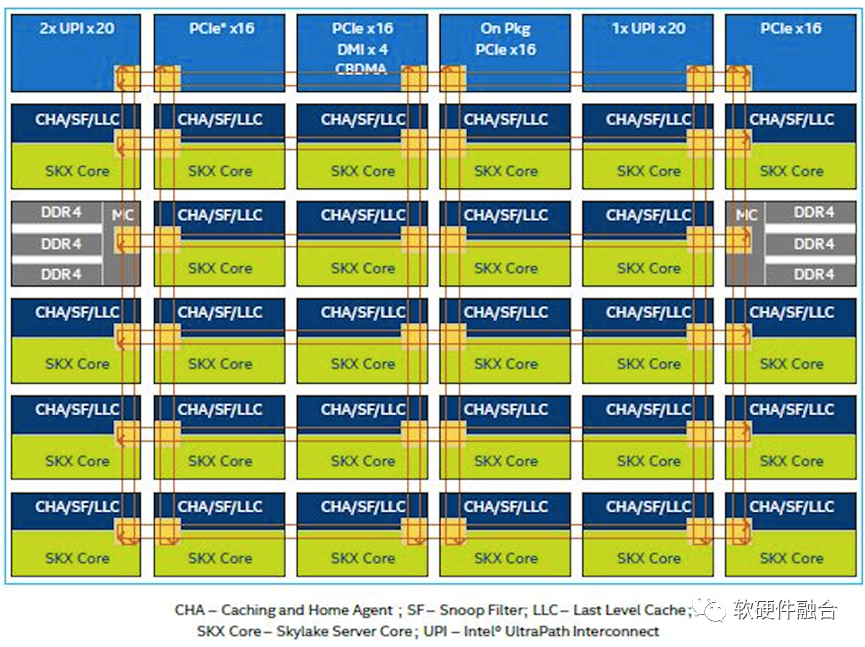
如上图,是Intel Xeon Skylake的内部架构。可以看到,此CPU是由28个CPU核组成的同构并行。
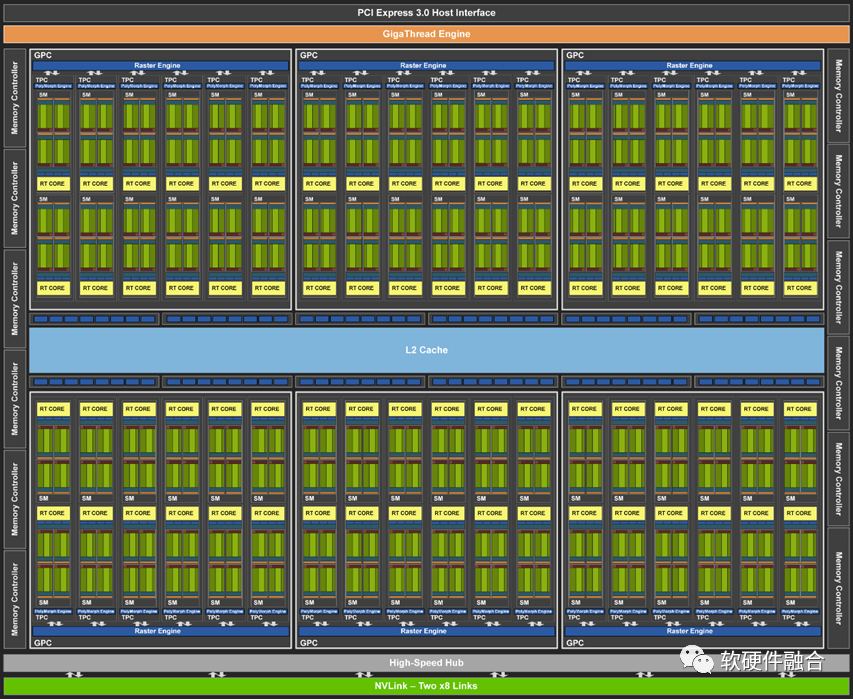
上图是NVIDIA发布的图灵架构GPU,此架构GPU的核心处理引擎由如下部分组成:6个图形处理簇(GPC);每个GPC有6个纹理处理簇(TPC),共计36个TPC;每个TPC有2个流式多核处理器(SM),总共72个SM。每个SM由64个CUDA核、8个Tensor核、1个RT核、4个纹理单元。
因此,图灵架构GPU总计有4608个CUDA核、576个Tensor核、72个RT核、288个纹理单元。
需要注意的是:GPU非图灵完备,无法单独运行,需要和CPU一起,通过CPU+GPU的异构方式才能工作。
2 从同构并行到异构并行,异构计算蓬勃发展
2.1 同构并行和异构并行

如上一节讲到的,因为CPU是图灵完备的,可以自主运行,因此,存在基于多核CPU组成的CPU芯片是同构并行的。
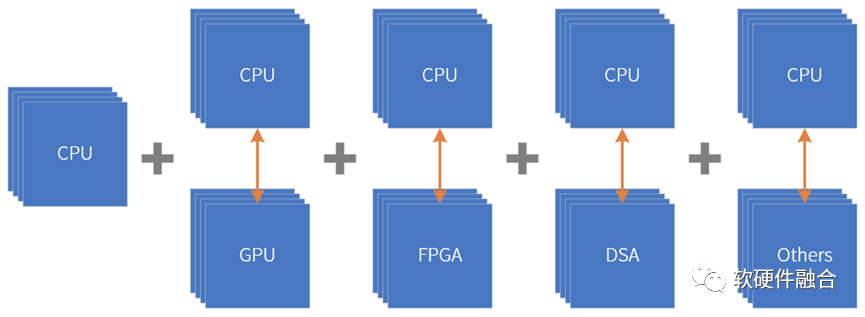
但是,不存在除CPU外其他处理器引擎单独存在的并行计算系统,如GPU、FPGA、DSA、ASIC等引擎同构并行的系统。因为这些处理引擎/芯片是非图灵完备的,它们都是作为CPU的加速器而存在。因此,其他处理引擎的并行计算系统即为CPU+xPU的异构并行,大体分为三类:
- CPU+GPU。CPU+GPU是目前最流行的异构计算系统,在HPC、图形图像处理以及AI训练/推理等场景得到广泛应用。
- CPU+FPGA。目前数据中心流行的FaaS服务,利用FPGA的局部可编程能力,基于FPGA开发运行框架,以及借助第三方ISV支持或自研的方式,构建面向各种应用场景的FPGA加速解决方案。
- CPU+DSA。谷歌TPU是第一个DSA架构处理器,TPUv1采取独立加速器的方式,实现CPU+DSA(TPU)的方式实现异构并行。
此外,需要说明的是,由于ASIC功能固定,缺乏一定的灵活适应能力,因此不存在CPU+单个ASIC的异构计算。CPU+ASIC形态通常是CPU+多个ASIC组,或在SOC中,作为一个逻辑上独立的异构子系统存在的,需要与其他子系统协同工作。

SOC本质上也是异构并行,SOC可以看做是CPU+GPU、CPU+ISP、CPU+Modem等多个异构并行子系统组成的系统。
超异构也可以看做是由多个逻辑上独立的异构子系统有机组成的,但SOC和超异构不同:SOC的不同模块通常无法直接高层次数据通信,而是通过CPU调度才能间接通信。SOC和超异构的区别会在超异构部分详细介绍。
2.2 基于CPU+GPU的异构并行

如图所示,是典型的用于机器学习场景的GPU服务器主板拓扑结构,是一个典型的SOB(System on Board,板级系统)。在此GPU服务器的架构里,通过主板,连接了两个通用CPU和8个GPU加速卡。两个CPU通过UPI/QPI相连;每个CPU通过两条PCIe总线,分别连接1个PCIe交换机;每个PCIe交换机再连接到两个GPU;另外,GPU间还通过NVLink总线相互连接。
2.3 基于CPU+DSA的异构并行
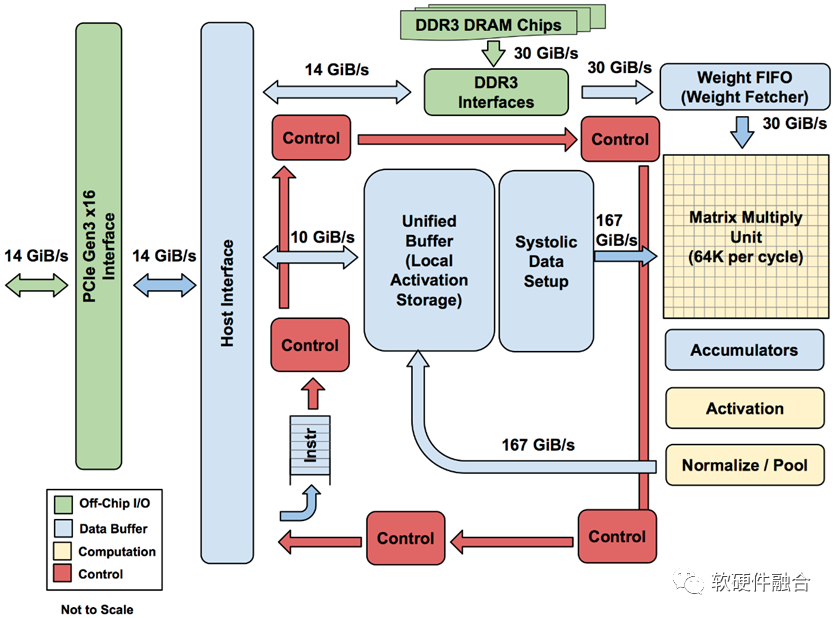
TPU是业界第一款DSA架构芯片,上图是TPU v1的结构框图。TPU v1通过PCIe Gen3 x16总线和CPU相连,从CPU发送指令到TPU的指令缓冲区,由CPU控制TPU的运行;数据交互在两者的内存之间进行,由CPU发起控制,TPU的DMA执行具体的数据搬运。
3 从异构持续进化到超异构
3.1 CPU、GPU、DPU、AI等大算力芯片面临的共同挑战
在云计算、边缘计算、终端超级计算机(如自动驾驶)等复杂计算场景,对芯片的可编程能力要求非常高,甚至高过对性能的要求。如果不是基于CPU的摩尔定律失效,数据中心依然会是CPU的天下(虽然CPU的性能效率是最低的)。
性能和灵活可编程性,是影响大算力芯片大规模落地非常重要的两个因素。两者如何均衡,甚至兼顾,是大芯片设计永恒的话题。
CPU、GPU、DPU、AI等大算力芯片,面临着共同的挑战,包括:
- 单类型引擎性能和灵活性的矛盾。CPU灵活性好,但性能不够;ASIC性能极致,但灵活性不够。
- 不同用户的业务差异以及用户的业务迭代。针对这一问题,目前主要做法是针对场景定制。通过FPGA定制,规模太小,成本和功耗太高;通过芯片定制,导致场景碎片化,芯片难以大规模落地,难以摊薄成本。
- 宏观算力要求芯片能够支撑大规模部署。宏观算力与单位芯片算力,以及芯片的落地规模成正比。但各类性能提升的方案会损失可编程灵活性,使得芯片难以实现大规模部署,从而进一步影响宏观算力的增长。最典型的例子就是目前AI芯片的大规模落地困难。
- 芯片的一次性成本过高。数以亿计的NRE成本,需要芯片的大规模落地,才能够摊薄一次性成本。这就需要芯片足够“通用”,在很多场景可以落地。
- 生态建设的门槛。大芯片需要框架和生态,门槛高且需要长期积累,小公司难以长期大量投入。
- 计算平台的融合。云网边端融合,需要构建统一的硬件平台和系统堆栈。
- 等等。
3.2 解决方案,把异构计算的孤岛连接在一起,形成超异构
超异构可以看做是CPU+CPU的同构并行和CPU+其他xPU的异构并行“有机”组合到一起,形成的一个新的超大系统。
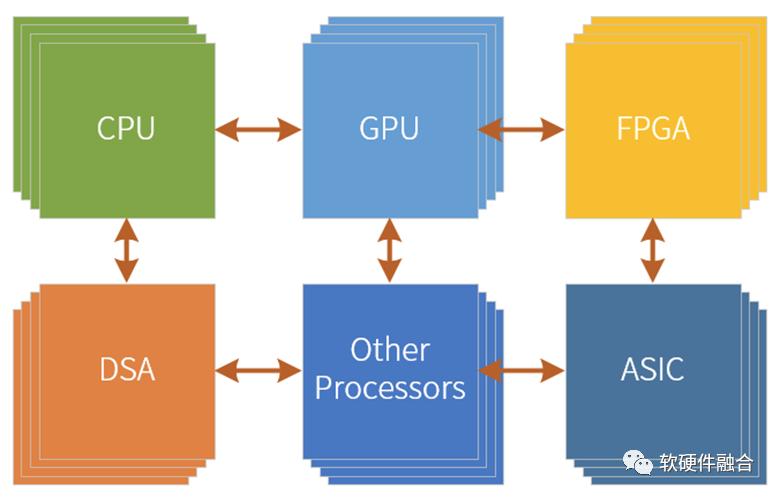
超异构是由CPU、GPU、FPGA、DSA、ASIC以及其他各种加速引擎“有机”组成的新的宏系统。
3.3 超异构和SOC的不同之处
超异构处理器HPU,可以算是SOC,但又跟传统的SOC有很大的不同。如果无法认识到这些不同,就无法理解到HPU的本质。下表是一些典型的差异性对比。

4 为什么是现在(才兴起超异构计算)?
4.1 基于CPU的摩尔定律失效,引发连锁反应
系统越来越复杂,需要选择越来越灵活的处理器;而性能挑战越来越大,需要我们选择定制加速的处理器。这是一对矛盾,拉扯着我们的各类算力芯片设计。本质矛盾是:单一处理器无法兼顾性能和灵活性,即使我们拼尽全力平衡,也只“治标不治本”。
CPU灵活性很好,在符合性能要求的情况下,在云计算、边缘计算等复杂计算场景,CPU是最优的处理器。但受限于CPU的性能瓶颈,以及对算力需求的持续不断上升,(站在算力视角)CPU逐渐成为了非主流的算力芯片。
CPU+xPU的异构计算,由于主要算力是由xPU完成,因此,xPU的性能/灵活性特征,决定了整个异构计算的性能、灵活性特征:
- CPU+GPU的异构计算。虽然在足够灵活的基础上,能够满足(相对CPU的)数量级的性能提升,但算力效率仍然无法极致。
- CPU+DSA的异构计算。由于DSA的灵活性较低,因此不适合应用层加速。典型案例是AI,目前主要是由基于CPU+GPU完成训练和部分推理,DSA架构的AI芯片目前还没有大范围落地。
4.2 Chiplet技术成熟,量变引起质变:需要架构创新,而不是简单集成
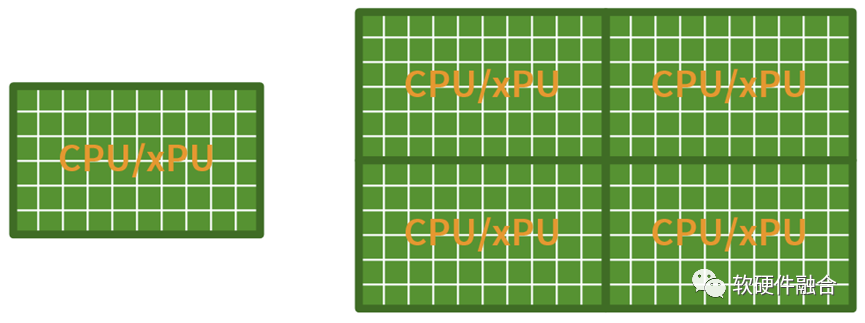
假设,在没有Chiplet的时候,我们的CPU或xPU可以集成50个核,有了Chiplet互联,把4个DIE拼起来,我们就可以单芯片集成200个核心。
但是,上图的平行扩展方式,真的就是Chiplet的价值吗?
结论是,这样的Chiplet集成,暴殄天物!

Chiplet使得我们在单个芯片的层次,可以构建规模数量级提升的超大系统。这样,我们可以利用大系统的一些“特点”,来进一步优化。这些特点是:
- 复杂系统是由分层分块的任务组成;
- 基础设施层的任务,相对确定,适合放在DSA/ASIC。可以在满足任务基本灵活性的基础上,极限的提升性能;
- 应用不可加速部分的任务,最不确定,适合CPU。系统符合二八定律,用户关心的应用只占整个系统的20%,而不可加速部分,占比通常会少于10%。为了提供用户极致的体验,这部分任务最好放在CPU上。
- 应用可加速部分的任务,由于应用的算法差异化和迭代较大,适合放在GPU、FPGA等弹性加速引擎。可以提供足够灵活可编程的同时,可以提供尽可能好的性能。
这样,基于超异构实现的整个系统:
- 从宏观视角看,80%甚至90%以上的计算,都是在DSA中完成。这样,整个系统是接近于DSA/ASIC的极致性能;
- 用户关心的应用不可加速部分,只占10%以内,依然运行在CPU上。也即用户看到的仍然是100%的CPU级别的灵活可编程性。
也即,通过超异构架构,可以在实现极致灵活性的同时,实现极致的性能。
4.3 超异构更难驾驭,需要创新的理念和技术
异构编程很难,NVIDIA经过数年的努力,才让CUDA的编程对开发者足够友好,形成了健康的生态。超异构就更是难上加难:超异构的难,不仅仅体现在编程上,也体现在处理引擎的设计和实现上,还体现在整个系统的软硬件能力整合上。那么,该如何更好的驾驭超异构?经过慎重思考,我们从以下几个方面入手:
- 性能和灵活性。从系统的角度,系统的任务从CPU往硬件加速下沉,如何选择合适的处理引擎,达到最优性能的同时,有最优的灵活性。并且不仅仅是平衡,更是兼顾。
- 编程及易用性。系统逐渐从硬件定义软件,转向了软件定义硬件。如何利用这些特征,如何利用已有软件资源,以及如何融入云服务。
- 产品。用户的需求,除了需求本身之外,还需要考虑不同用户需求的差异性,和单个用户需求的长期迭代。该如何提供给用户更好的产品,满足不同用户短期和长期的需求。授人以鱼不如授人以渔,该如何提供用户没有特定的具体功能的、性能极致的、完全可编程的硬件平台。
- 等等。
软硬件融合,为解决上述问题,提供了成体系化的理念、方法、技术和解决方案,为轻松驾驭超异构提供了切实可行的路径。
关于软硬件融合,请看文章:软硬件融合:超异构算力革命。
5 未来,所有的大算力芯片都是超异构芯片

Intel高级副总裁兼加速计算系统和图形部门负责人Raja Koduri表示:要想实现《雪崩》和《头号玩家》中天马行空的体验,需将现在的算力至少再提升1000倍。应用不断发展,软硬件最根本的矛盾仍然是“硬件的性能提升,永远赶不上软件对性能的需求”。可以说,对算力的需求,永无止境!
要保证宏观算力的最大化,一方面是要持续不断的提升性能,另一方面还要保证芯片的灵活可编程性。唯有通过超异构的方式,分门别类,针对每个任务的特征采用最优的引擎方案,才能在确保最极致灵活可编程的同时,实现最极致的性能。从而,真正实现性能和灵活性的既要又要。
单兵作战,顾此失彼;团队协作,互补共赢。
未来,唯有超异构计算,才能保证算力数量级提升的同时,不损失灵活可编程性。才能够真正实现宏观算力的数量级提升,才能够更好的支撑数字经济社会发展。
参考文献
https://hpc.llnl.gov/documentation/tutorials/introduction-parallel-computing-tutorial
参考文献链接
https://mp.weixin.qq.com/s/yV8Ww0vVmXEs17aXygJqUw
https://mp.weixin.qq.com/s/vPEwdgn0jQsoZ4I81Ehfsg
https://mp.weixin.qq.com/s/fOhlQcggRxg3cOiE05mwVA
https://mp.weixin.qq.com/s/F4QE-PwOZ81H82TJuhjy2g
https://mp.weixin.qq.com/s/LK0An7n_4d9jol-X-xuypw

