


芯片-平台与自动驾驶技术
芯片-平台与自动驾驶技术
参考文献链接
https://mp.weixin.qq.com/s/IiG2Wi--mlwpn9nD494l8Q
https://mp.weixin.qq.com/s/uEoPuP_PwwJkgiHSRzF1xQ
https://mp.weixin.qq.com/s/uT_fD4MuP432Csy7WNauLw
https://mp.weixin.qq.com/s/P_XdxR0trQA7huXurgI2SQ
从NVIDIA自动驾驶芯片Thor,看大芯片的发展趋势
北京时间,9月21凌晨,NVIDIA GTC 2022秋季发布会上,CEO黄仁勋发布了其2024年将推出的自动驾驶芯片。因为其2000TFLOPS的性能过于强大,英伟达索性直接把它全新命名为Thor,代替了之前1000TOPS的Altan。
Thor的发布,代表着在汽车领域,已经由分布式的ECU、DCU转向了完全集中的功能融合型的单芯片。也预示着一个残酷的现实:“许多做DCU级别的ADAS芯片公司,产品还在设计,就已经落后”。
云和边缘计算的数据中心,以及自动驾驶等超级终端领域,都是典型的复杂计算场景,这类场景的计算平台都是典型的大算力芯片。
大芯片的发展趋势已经越来越明显的从GPU、DSA的分离趋势走向DPU、超级终端的再融合,未来会进一步融合成超异构计算宏系统芯片(Macro-SOC)。
1 NVIDIA自动驾驶芯片Thor
1.1 自动驾驶汽车芯片的发展趋势
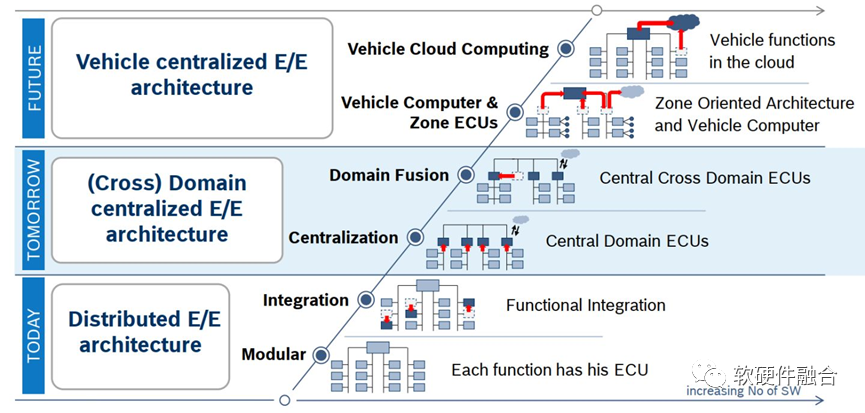
上图是BOSCH给出的汽车电气架构演进示意图。从模块级的ECU到集中相关功能的域控制器,再到完全集中的车载计算机。每个阶段还分了两个子阶段,例如完全集中的车载计算机还包括了本地计算和云端协同两种方式。
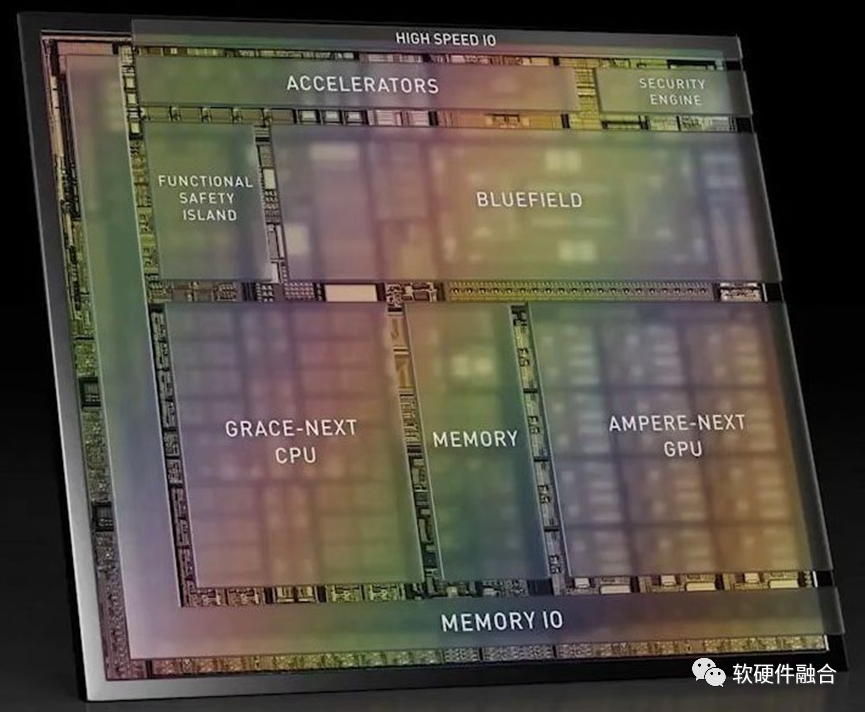
上图是NVIDIA Altan的芯片架构示意图(Thor刚出来,没有找类似的图),从此图可以看出:Altan&Thor的设计思路是完全的“终局思维”,相比BOSCH给出的一步步的演进还要更近一层,跨越集中式的车载计算机和云端协同的车载计算机,直接到云端融合的车载计算机。云端融合的意思是服务可以动态的、自适应的运行在云或端,方便云端的资源动态调节。Altan&Thor采用的是跟云端完全一致的计算架构:Grace-next CPU、Ampere-next GPU以及Bluefield DPU,硬件上可以做到云端融合。
1.2 Intel Mobileye、高通和NVIDIA芯片算力比较

我们可以看到,Mobileye计划2023年发布的用于L4/L5的最高算力的EyeQ Ultra芯片只有176 TOPS。
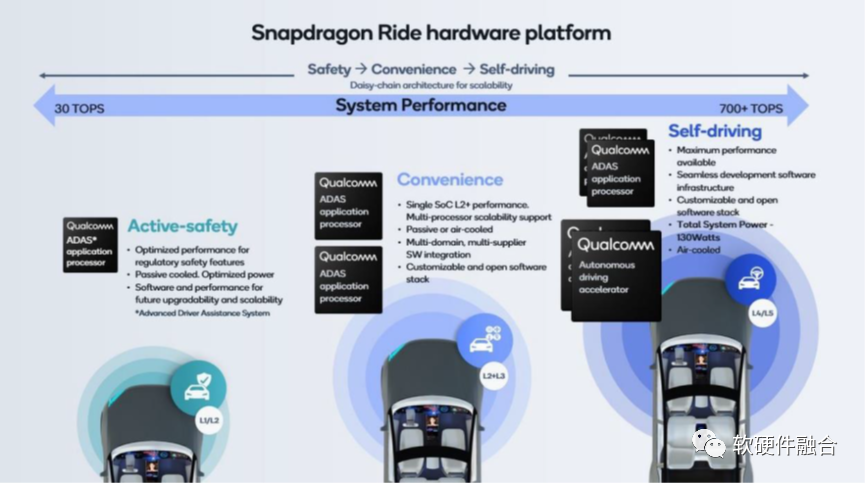
从上图我们可以看到,高通计划的L4/L5自动驾驶芯片是700+TOPS,并且是通过两颗AP和两个专用加速器共四颗芯片组成。
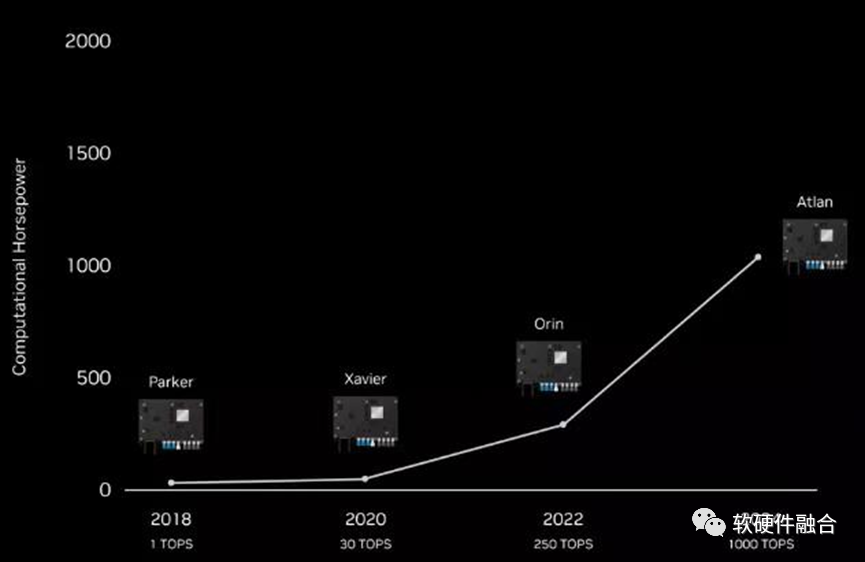
再对照NVIDIA Altan,之前计划的用于L4/L5自动驾驶芯片Altan是1000TOPS算力。
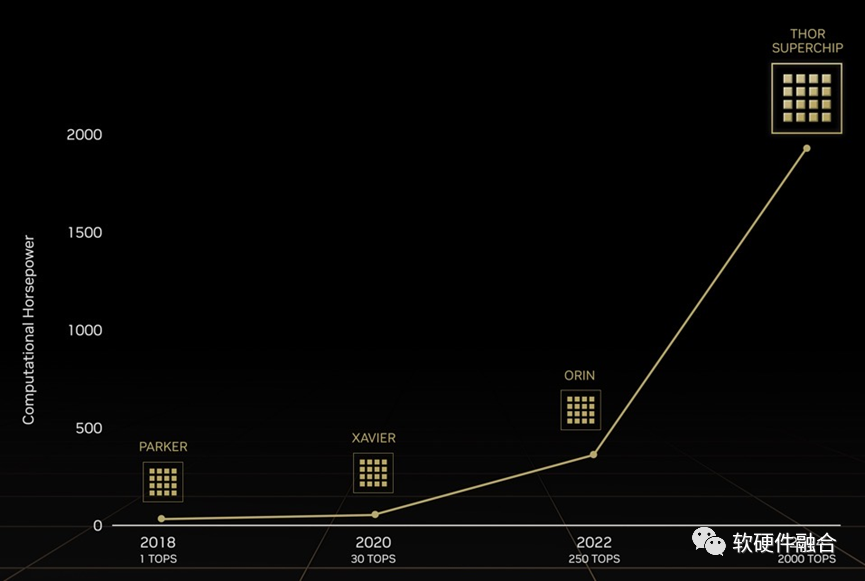
NVIDIA的王炸!推翻了之前的Altan,直接给了一个全新的命名Thor(雷神索尔),其算力达到了惊人的2000TOPS。
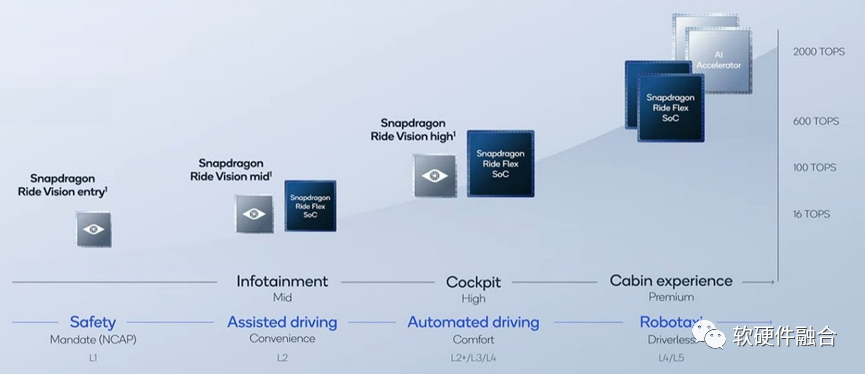
NVIDIA Thor发布之后,高通“快速”的发布了自己的4芯片2000TOPS算力的解决方案。
1.3 单芯片实现通常5颗以上芯片的多域计算

NVIDIA Thor提供2000TFLOPS的算力(相比较Atlan提供的2000TOPS)。

Thor SoC能够实现多域计算,它可以为自动驾驶和车载娱乐划分任务。通常,这些各种类型的功能由分布在车辆各处的数十个控制单元控制。制造商可以利用Thor实现所有功能的融合,来整合整个车辆,而不是依赖这些分布式的ECU/DCU。

这种多计算域隔离使得并发的时间敏感的进程可以不间断地运行。通过虚拟化机制,在一台计算机上,可以同时运行Linux、QNX和Android等。
参考文献
https://mp.weixin.qq.com/s/KKJ0hsxvOoIhBgMPMgcEgQ,英伟达发布最强汽车芯!算力2000TOPS,车内计算全包了,车东西
https://mp.weixin.qq.com/s/lA8h9jTtgsPIjYAX3p5cvg,英伟达「史诗级」自动驾驶芯片亮相!算力2000TOPS,兼容座舱娱乐功能,新智驾
2 自动驾驶SOC和手机SOC的本质区别
这里我们给出一个概念:复杂计算。复杂计算指的是,在传统AP/OS系统之上,还需要支持虚拟化、服务化,实现单设备多系统共存和跨设备多系统协同。因此,如果把AP级别的系统看做一个系统的话,那么复杂计算是很多个系统组成的宏系统。
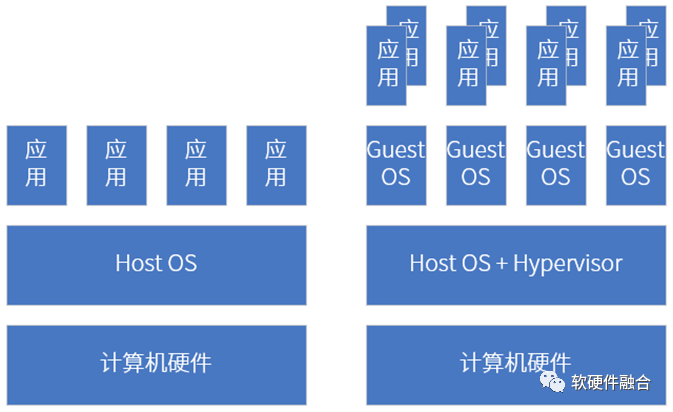
手机、平板、个人电脑等传统AP上部署好操作系统之后,我们在上面运行各种应用软件。整个系统是一个整体,各个具体的进程/线程会存在性能干扰的问题。
但在支持完全硬件虚拟化(包括CPU、内存、I/O、各种加速器等的完全硬件虚拟化)的平台下,不仅仅是要把宏系统切分成多个独立的系统,并且各个系统之间是需要做到应用、数据、性能等方面的物理隔离。
自动驾驶汽车,通常需要支持五个主要的功能域,包括动力域、车身域、自动驾驶域、底盘域、信息娱乐域。因此,集中式的自动驾驶汽车超级终端芯片,必须要实现完全的硬件虚拟化,必须要支持各个功能域的完全隔离(相互不干扰)。
我们把这一类虚拟化和多系统的计算场景称为复杂计算,支持复杂计算的芯片才能算是“大”芯片。这类场景目前主要包括:云计算、超算、边缘计算、5G/6G核心网的数据中心,以及自动驾驶、元宇宙等场景的超级终端。
3 绝对的算力优势面前,定制ASIC/SOC没有意义
随着云计算的发展,随着云网边端不断的协同甚至融合,随着系统的规模越来越庞大,ASIC和传统基于ASIC的SOC的发展道路越来越走向了“死胡同”。越简单的系统,变化越少;越复杂的系统,变化越多。复杂宏系统,必然是快速迭代,并且各个不同的用户有非常多差异性的,传统ASIC的方式在复杂计算场景,必然遇到非常大的困境。
在自动驾驶领域,在不采用加速引擎的情况下,传统的SOC可以把AI算力做到10 TOPS左右;很多公司通过定制加速引擎的方式,快速的提升算力,可以把AI算力提升到100甚至200 TOPS。然而,传统SOC的实现方式有很多问题:
- 自动驾驶的智能算法以及各类上层应用,一直在快速的演进升级中。定制ASIC的生命周期会很短,因为功能确定,车辆难以更新更先进的系统升级包,这样导致ASIC无法很好的支持车辆全生命周期的功能升级。
- 整个行业在快速演进,如果未来发展到L4/L5阶段,目前的所有工作就都没有了意义:包括芯片架构、定制ASIC引擎,以及基于此的整个软件堆栈及框架等,都需要推倒重来。
越来越体会到,在大芯片上,做定制ASIC是噩梦;现实的情况,需要是某种程度上软硬件解耦之后的实现通用芯片。只有软硬件解耦之后:硬件人员才能放开手脚,拼命的堆算力;软件人员才能更加专心于自己的算法优化和业务创新,而不需要关心底层硬件细节。
在同样的资源代价下,通用芯片为了实现通用,在性能上存在一定程度的损失。因此,做通用大芯片,也需要创新:
- 需要创新的架构,实现足够通用的同时,最极致的性能以及性能数量级的提升;
- 需要实现架构的向前兼容,支持平台化和生态化设计;
- 需要站在更宏观的视角,实现云网边端架构的统一,才能更好的构建云网边端融合和算力等资源的充分利用。
在绝对的算力优势面前,一切定制芯片方案都没有意义。
4 大芯片的发展趋势:从分离到融合
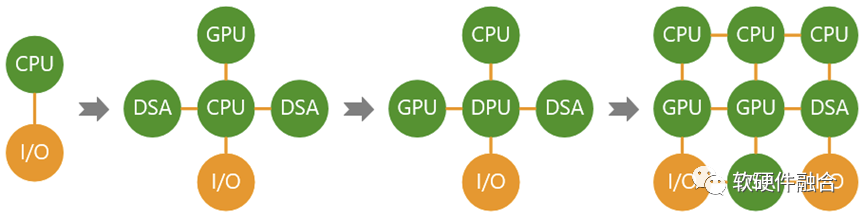
计算机体系结构在从GPU和DSA的分离向融合转变:
- 第一阶段,CPU单一通用计算平台;
- 第二阶段,从合到分,CPU+GPU/DSA的异构计算平台;
- 第三阶段,从分到合的起点,以DPU为中心的异构计算平台;
- 第四阶段,从分到合,众多异构整合重构的、更高效的超异构融合计算平台。
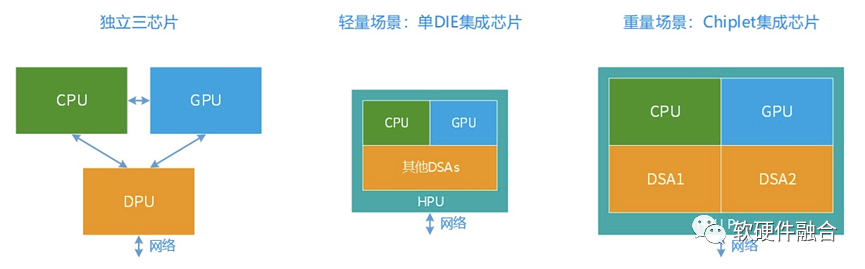
自动驾驶领域已经是Thor这样的功能融合的独立单芯片了,在边缘计算和云计算场景,独立单芯片还会远吗?
在边缘计算等轻量级场景,可以通过功能融合的独立单芯片覆盖;在云计算业务主机等重量级场景,可以通过Chiplet的方式实现功能融合的单芯片。
5 各领域大芯片发展趋势
开门见山,简而言之。大芯片的发展趋势就是:功能融合的、超异构计算架构的单芯片MSoC。
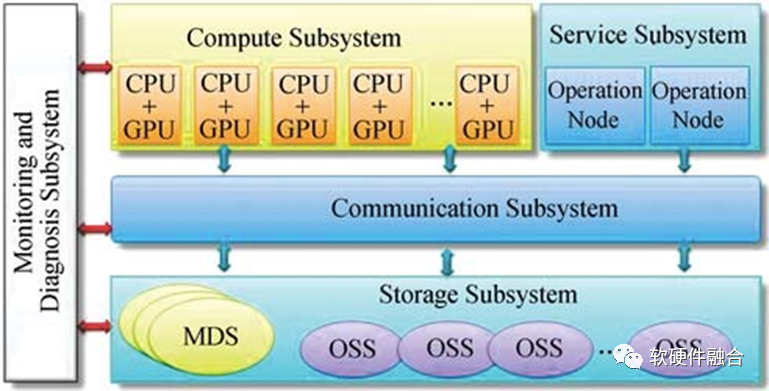
上图为基于CPU+GPU的异构计算节点的天河1A超级计算机架构图。

E级的天河三依然是异构计算架构。

最新TOP500第一名的Frontier,也选择的是基于AMD处理器的异构计算架构(每个节点配备一个 AMD Milan “Trento” 7A53 Epyc CPU 和 四个AMD Instinct MI250X GPU,GPU核心总数达到了37,632)。
日本的富岳超算所采用的ARM A64FX处理器,是在常规的ARMv8.2-A指令集的基础上扩展了512Bit的SIMD指令,也可以看做是某种形态上的异构计算。
总结一下,在超算领域,千万亿次、百亿亿次(E级)超算使得异构计算成为主流。下一代超算,是十万亿亿次(Z级),几乎所有的目光都投向了超异构计算。
自动驾驶领域,NVIDIA Drive Thor提供2000TOPS的算力(目前,主流自动驾驶芯片AI算力为100TOPS),Thor之所以能有如此高的算力,跟其内部GPU集成的Tensor Core有很大的关系。Thor是功能融合的单芯片,其架构由集成的CPU、GPU和DPU组成,可以看做是超异构SOC。
在云和边缘服务器侧,CPU、GPU和DSAs融合的趋势也越来越明显,预计未来3年左右,服务器端独立单MSoC芯片(或者说超异构计算芯片)会出现。
6 大芯片需要考虑计算资源的协同和融合
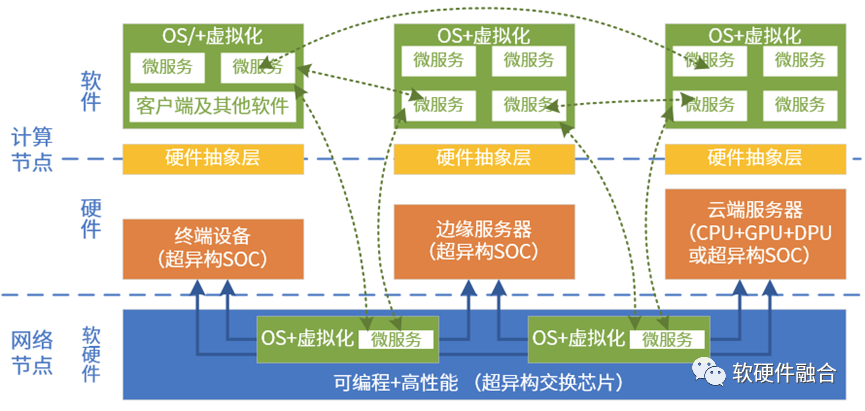
大芯片,担负着宏观算力提升的“重任”。
如果计算资源是一个个孤岛,那就没有宏观算力的说法。宏观算力势必需要各个计算节点芯片的协同甚至融合。这就需要考虑计算的跨云网边端。
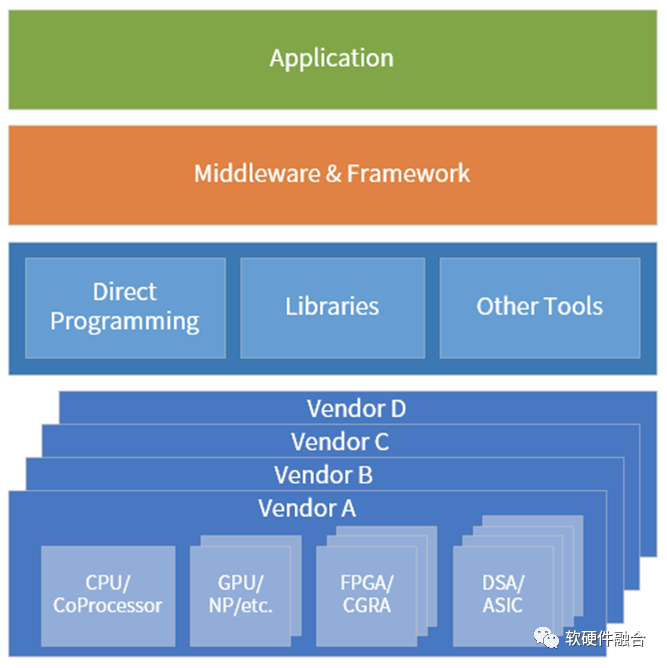
异质的引擎架构越来越多,计算资源池化的难度也越来越高。在超异构计算时代,要想把异质的资源池化,计算需要做到:
- 维度一:跨同类型处理器架构。如软件可以跨x86、ARM和RISC-v CPU运行。
- 维度二:跨不同类型处理器架构。软件需要跨CPU、GPU、FPGA和DSA等处理器运行。
- 维度三:跨不同的芯片平台。如软件可以在Intel、AMD和NVIDIA等不同公司的芯片上运行。
- 维度四:跨云网边端不同的位置。计算可以根据各种因素的变化,自适应的运行在云网边端最合适的位置。
- 维度五:跨不同的云网边服务供应商、不同的终端用户、不同的终端设备类型。
比亚迪反超松下成老三!宁德时代稳坐老大,中国军团霸榜电池江湖
宁德时代已经成为动力电池领域不折不扣的全球第一了。车东西10月12号消息,日前,外媒CleanTechnica统计今年全球动力电池领域的主要玩家情况,数据显示,宁德时代全球市场占有率达到了34%,几乎提前锁定了今年全球第一的桂冠。毕竟排在第二名的LG新能源(由LG化学拆分而来)的市场占有率仅为14%,双方的差距正在不断拉大。
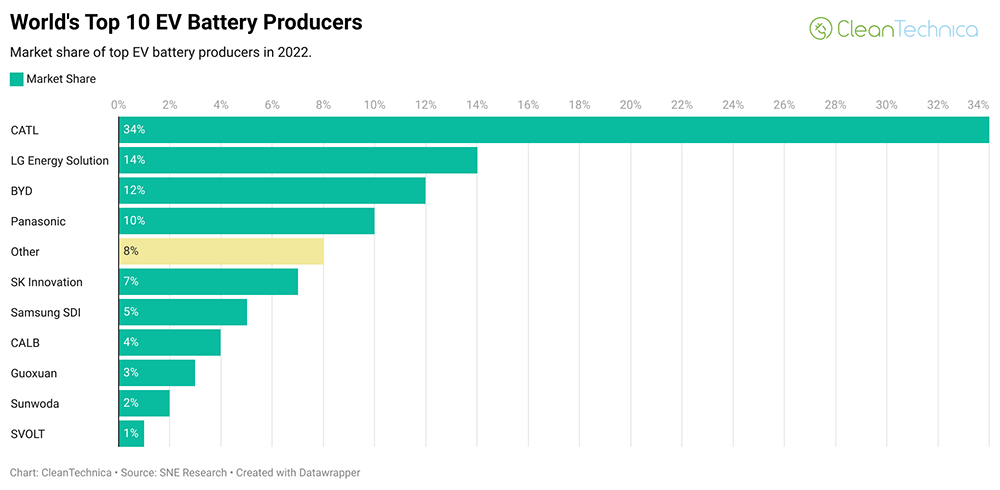
▲2022年全球十大电动汽车电池生产商市场份额对比
继续往下看的话,可以发现比亚迪已经反超了松下成为全球动力电池老三,而值得注意的是,LG新能源、比亚迪、松下三者的市场占有率之和才勉强超过宁德时代,从这点也可以看出宁德时代的强大。值得注意的是,宁德时代拿下这样成绩的速度简直可以被称为神速。CleanTechnica展示的表格来看,全球电动汽车快速发展的2014年、2015年,宁德时代还没有出现在榜单中,那时动力电池领域还被松下、LG新能源、比亚迪等老牌玩家轮流占领。而到了2017年,宁德时代的出货量就高达12GWh,成为了全球第一。官方信息显示,宁德时代2011年才正式成立,也就说,仅仅用了6年时间,宁德时代就做到了全球第一,并且一直蝉联到了现在。综合来看,宁德时代的成功并不是无迹可寻的,无论是自身对研发投入的扩大,公司经营方式的提升,还是与特斯拉等电动汽车厂商的合作,都在逐渐帮助它走向榜首,成为全球最大的电动汽车电池供应商。
01.宁德时代霸榜 中韩电池企业较多
CleanTechnica对今年全球动力电池企业的市场份额情况做了一个统计,从中也可以看到许多有趣的数据。从市场份额对比图来看,宁德时代基本独占了2022年全球电动车电池市场的三分之一以上(略高于三分之一,34%),今年第二大电动汽车电池供应商是LG新能源,它在全球电动车电池市场的份额要低得多,占14%,但其影响力不容小觑。
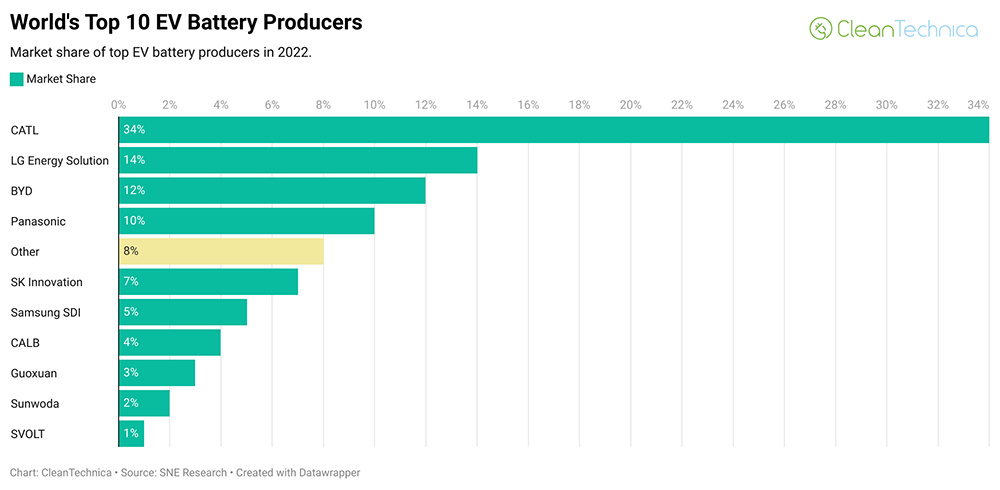
▲2022年全球十大电动汽车电池生产商市场份额对比
比亚迪紧随LG新能源之后,占有12%的市场份额,而松下紧随比亚迪之后,占有10%的份额。值得注意的是,此前松下一直是全球动力电池老三,而今年比亚迪的新能源汽车销量创下历史新高,所以连带其动力电池的装机量也上来了。而在榜单中,另外两家韩国动力电池企业也跟的非常紧。SK Innovation拥有7%的市场份额,三星SDI拥有5%的市场份额,分别位列第五名和第六名。榜单的后四名则被中国汽车包场了,分别是中创新航、国轩高科、欣旺达和蜂巢能源,市场占有率分别为4%、3%、2%、1%。值得注意的是,这个榜单中的前十名企业基本上都来自中日韩,其中国内的电池企业占了6家,已经超过了半数。不夸张的来说,中国已经成为了世界上头号动力电池强国。而在这一成绩背后,宁德时代可谓居功至伟。
02.八年间电池市场变化较大 宁德时代逆袭
回顾一下最近十年的动力电池发展史,就会发现宁德时代确实很了不起。在非常短的时间内就走到了世界前列。2014年时,松下(当时为特斯拉提供所有的电池)是电池大王,其次是日产相关的远景动力(AESC),第三名是LG新能源,然后比亚迪排在第四位,只是稍微领先于三菱/GS Yuasa。而那一年,宁德时代还在闷头苦练技术。
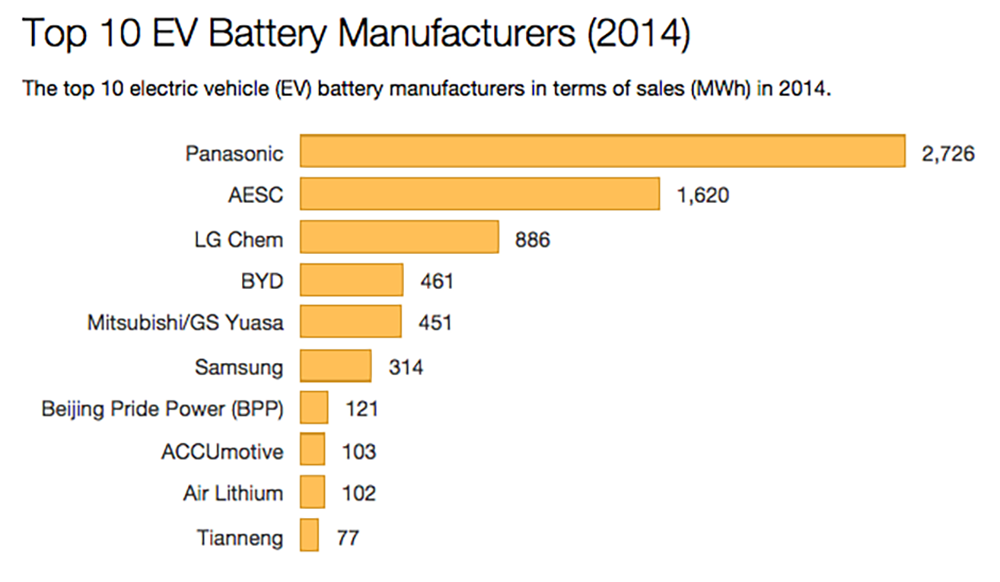
▲2014年全球十大电动汽车电池生产商产能
到了2015年,松下、比亚迪和LG新能源巩固了在榜单的位置,远景动力跌至第四。虽然比亚迪和LG新能源在前三名,但松下比他们高出很多。因为松下当时是特斯拉唯一的电池供应商,而特斯拉的生产速度比竞争对手快,这也帮助松下提升了市场地位。同样,彼时的宁德时代也还无法和这些老牌电池玩家过招。
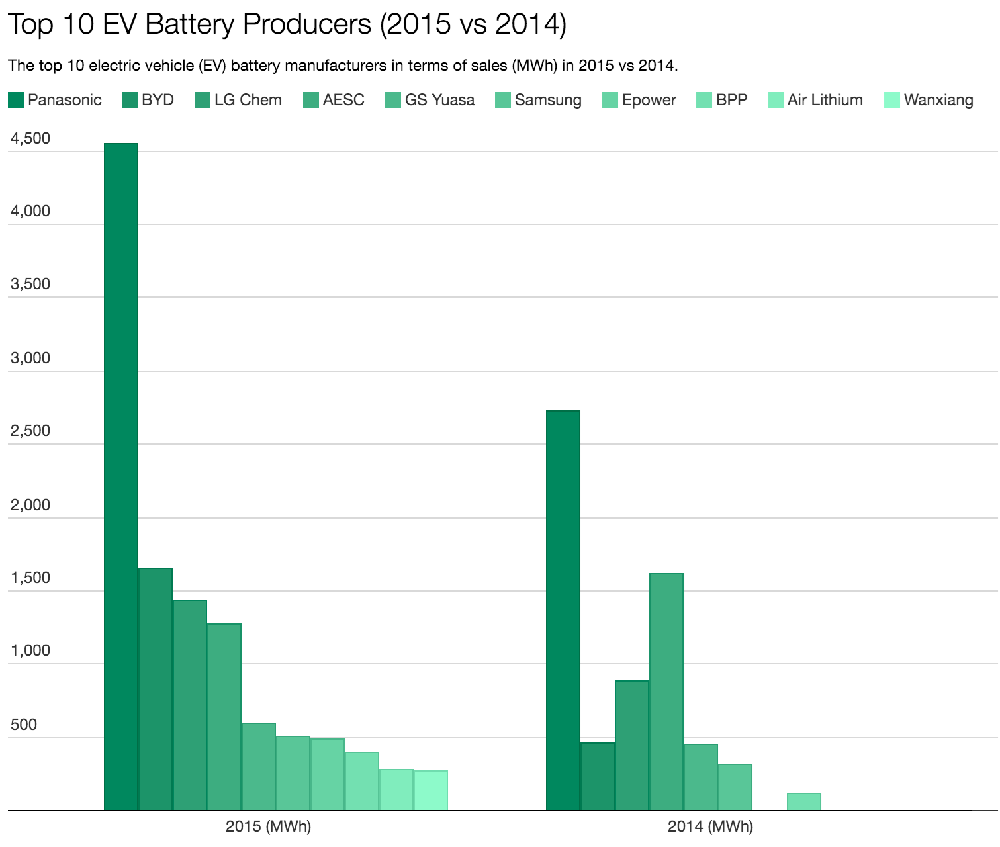
▲2014年和2015年全球十大电动汽车电池生产商产能对比
而在2017年,宁德时代异军突起,一举超越了松下和比亚迪,首次成为全球动力电池销量冠军。
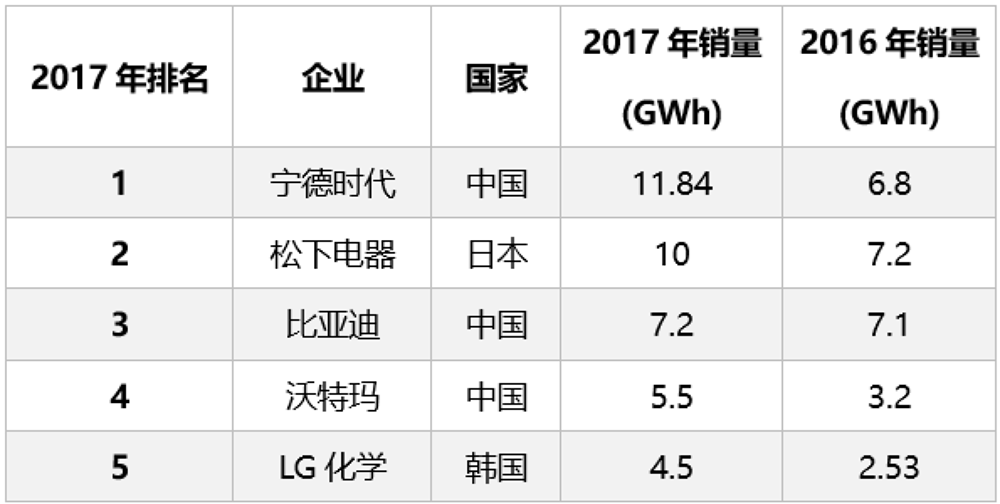
▲2017年各大厂商电池出货量对比(图源:网络)
之后,宁德时代便稳稳的占据了全球动力电池老大的位置,不出意外的话,今年将会是宁德时代第六年拿下全球动力电池老大的桂冠。
03.LG新能源是最强对手 双方缠斗已久
不过,宁德时代的发展过程中也不是顺风顺水的,来自韩国的LG新能源就曾对宁德时代造成过一定的挑战。SNE Research数据显示,2020年第一季度,LG新能源(当时名为LG化学)以27.1%的市场份额击败了实力强劲的松下和宁德时代,装机量也激增120%达到了5.5GWh,成为了全球市场占有率第一的动力电池企业。松下和宁德时代分别以25.7%和17.4%的市场占有率位列第二和第三,装机量分别为5.2GWh和2.8GWh。
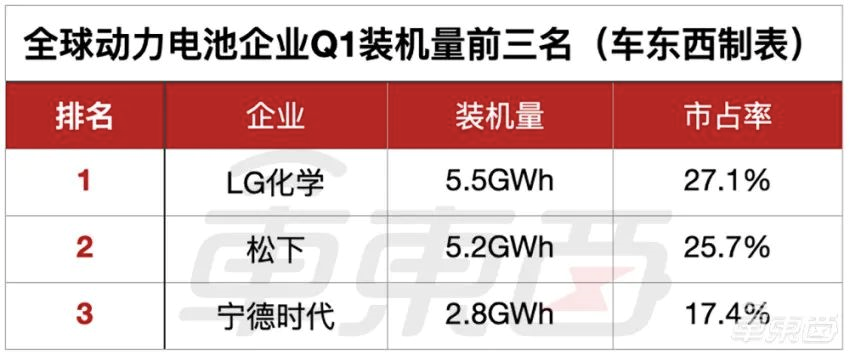
▲2020年第一季度全球动力电池装机量前三的企业
这还不算完,SNE Research公布的半年数据显示,LG新能源以24.6%的市场占有率再次稳坐全球第一的位置,装机量也从5.7GWh增长到了10.5GWh。宁德时代的市占率为23.5%位列第二,装机量则从13.10GWh下滑到了10GWh;松下则进一步下滑到了第三名,装机量仅有8.7GWh,全球市场份额仅为20.4%。
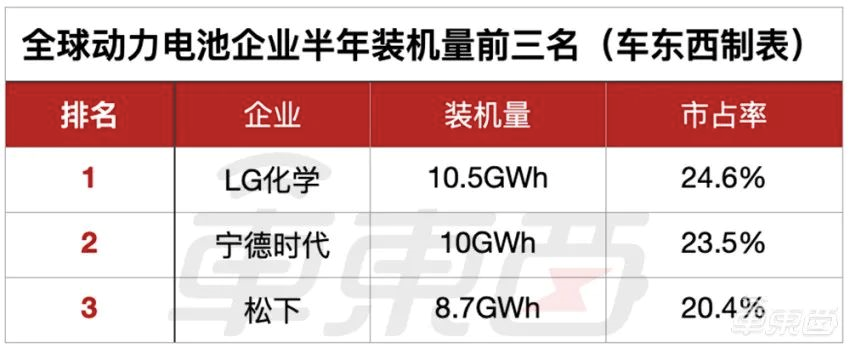
▲2020年前半年全球动力电池装机量前三的企业
虽然当年宁德时代仍然有惊无险的拿下了全球动力电池老大的位置,但是LG新能源显然已经成为宁德时代不得不提防的强力玩家。从趋势来看,宁德时代和LG新能源之间的竞争仍然非常激烈。从市场上来看,宁德时代已经稳稳的在国内市场站住了脚,仍然可以享受到全球最大的新能源汽车市场的红利,甚至在今年还加快了海外的布局,而LG化学基本上已经拿下了欧洲的大部分车企,在美国也拿下了通用和FCA。也就是说,宁德时代和LG化学的市场基础都非常大。所以双方的竞争基本上就落到了技术上。近些年来,宁德时代不断有的新的技术抛出,钠电池、麒麟电池、CTC技术等,仍然走在行业的最前面,而在磷酸铁锂电池复兴潮流中,宁德时代也稳稳处在第一的位置;反观LG能源,此前一直陷入到了自燃的危机中,目前发展并不是很顺利。但LG新能源也仍然是一个非常有实力的玩家,也一直在对宁德时代的市场地位虎视眈眈,而正是有了这样的实力玩家做对手,宁德时代也才能一直不断前进。
04.结语:宁德时代稳居全球动力电池老大
有趣的是,早在2018年4月,外媒CleanTechnica还曾质疑过宁德时代能否在2022年成为第一大电动车电池生产商。显而易见,宁德时代不仅在2017年和2021年做到了,并且在2022年将自身与对手的距离不断拉大。宁德时代的发展过程也提醒众多发展中的中国企业,只要瞄准一个有潜力的赛道,不断坚持,提升自己的产品质量,最终就有可能把自己的产品卖向全球。
马斯克与黄仁勋至少有一个共识

不是关于收购 Twitter 或者国际形势。
一家公司宣称自己是人工智能硬件与软件的领导者,它将实现五十年来最激进的计算架构变革。这句话出现在特斯拉今年 9 月 30 日召开的 Tesla AI Day 年度技术大会上,也可以用来形容英伟达在更早一周多召开的 GTC(GPU 技术大会)。
分别主导两家公司的马斯克和黄仁勋都是读书时移居美国并创业,如今各带领一家市值超过阿里巴巴的硬核科技公司。两人各 50 多岁,但依然保持对前沿技术的深层理解,能讲清楚细节。但相似到此为止,马斯克过着巨星般的生活,多任妻子十多个孩子、上节目抽大麻、习惯对一切发表评论、善于游说政策获得利益。黄仁勋私人生活低调,几乎不发表政治立场鲜明的评论,也几乎不游说政府——自 1993 年成立至今年 6 月底,英伟达在美国的游说开支为零。
两家公司一度密切合作,特斯拉造有自动驾驶功能的车,英伟达为它提供处理器。黄仁勋买过多代特斯拉车,马斯克去 GTC 站过台。直到 2019 年,特斯拉宣布新车改用自行研发的自动驾驶芯片。明年,特斯拉也将逐渐在数据中心采用自己的芯片替换英伟达产品。
造车的公司开始造机器人,造游戏显卡的公司几乎不在发布会上谈游戏。两家公司都将人工智能当作自己最核心的技术,对未来该是什么样子也有相同的看法。
这两家公司到目前为止还没有直接的商业竞争,特斯拉的芯片、软件只用在自己的硬件上;英伟达则将芯片卖给其他公司,既不造车、也不造机器人。和平未必能持续,特斯拉明确表达了将自己的芯片以云计算提供给第三方的野心。
PC 和智能手机时代的全球科技巨头,微软与苹果、Google 与苹果都曾有过无间合作,探索个人电脑和移动互联网的终极形态,但未来方向明确后便转为竞争,从商战一路走到诉讼。如果人工智能最终是下一代技术,特斯拉与英伟达走到这一步也没什么奇怪的。
汽车公司、游戏芯片公司……科技公司最终都是 AI 公司
马斯克:很多人认为我们只是一家汽车公司,但多数人不知道,特斯拉称得上现实世界人工智能硬件和软件的领导者。
黄仁勋:计算正以惊人速度发展。推动这枚火箭的引擎是加速计算,燃料是人工智能。
今年 AI Day,特斯拉初次展示了测试中的人形机器人 Tesla Bot。相比去年由真人套上紧身衣装机器人的 PPT“亮相”,真实的 Tesla Bot 没有那么多未来感,线缆裸露、双手动作缓慢、走起路来颤颤巍巍,临近的观众可以听到巨大的风扇响声。
图:特斯拉的人形机器人,从概念到现实。
Tesla Bot 不灵活,波士顿动力的人形机器人五年前就能做后空翻。它的独特之处在于,Tesla Bot 就像是一辆行走的微型特斯拉汽车:胸前装载的 FSD(全自动驾驶)芯片——2019 年开始,每辆新生产的特斯拉汽车都有;传感器就是摄像头和麦克风,和特斯拉汽车用的也差不多。诸多软件和零件,都有互通。Tesla Bot 像人一样,可以做多种工作:浇花、搬零件、送快递,虽然现在任何动作都非常慢。以往工业机器人每个动作都需要工程师编程,机器才会动。Tesla Bot 则是像特斯拉自动驾驶系统那样,用摄像头收集数据、训练系统,自主行动。
特斯拉的工程师在发布会上说,机器人的训练都不用从头开始,“Autopilot(自动辅助驾驶功能)上的计算机视觉神经网络”。不过车辆在一个平面里移动。人走路、搬东西要复杂得多。

图:特斯拉说人形机器人是有 28 个驱动器的汽车。
Tesla Bot 的存在佐证了马斯克的话。特斯拉造车,但它最根本的是让计算机看懂外界环境、知道如何自动运行的人工智能技术。为了让人工智能算法更有效运作,特斯拉自 2019 年开始将车上的英伟达处理器换成自己研发的 FSD 芯片,训练算法的超级计算机明年会换成自研芯片 D1 搭建的 Dojo。如计算机科学家艾伦·凯(Alan Kay)所说,“人要是对软件足够认真,就应该自己造硬件。” 现在反过来也一样。
今年 GTC,英伟达如期发布新的 RTX40 系列图形处理器耗电巨大、成本也更高。黄仁勋解释说,因为 “摩尔定律已经死了,芯片成本会逐渐降低的想法过时,计算是一个软件和芯片的问题”。
芯片的尺寸大致决定着芯片的成本,而芯片里的晶体管数量又决定着性能。根据摩尔定律,随着制造技术更精细,同尺寸芯片里的晶体管数量每 18 个月翻倍。现在芯片的制程已经小到 4 纳米,愈加逼近目前可以想象的极限。

图:射击游戏画质变化,QUAKE(1996)vs COD: MW2(2022),左右滑动查看。
作为最早提出图形处理器(GPU)概念的公司,英伟达和老伙伴台积电配合,跟着摩尔定律跑了 20 多年,让游戏画面极致逼真。走到尽头之后,人工智能成为帮助提升效率的主要动力。
黄仁勋从 2016 年就开始强调摩尔定律已经难以为继,自己开发人工智能算法提升芯片运行人工智能算法的效率,每年都有大幅提升。他称之为 “超级摩尔定律”。
GTC 发布会后,黄仁勋接受科技分析师本·汤普森(Ben Thompson)采访,描绘了更依赖人工智能的虚拟世界。“未来更有意思的游戏会像 Minecraft 或者 Roblox。玩家自己在里面创造一个虚拟世界、改造这个虚拟世界。”
Minecraft、Roblox 都是沙盒游戏,画面简单,但玩家可以改变一切。如果想要以假乱真的画面体验,得看《赛伯朋克 2077》或者《使命召唤》,但这样的游戏和拍电影一样:数百名美工人员、工程师绘制、调整游戏里的每个细节,确保游戏里的光影效果逼真,不违和。每个人走路的动作都得用上好莱坞拍片的动态捕捉,这和拍一部电影没有太大区别,需要海量人力投入,研发成本上亿美元。

图:COD: MW 2020 制作画面,每个表情和动作都需要演员表演。
黄仁勋希望在虚拟空间里做到这样的画质,不需要每个步骤都有人干预,而是让玩家自己改变一些。这需要:玩家可以完全创造一个拟真的世界、可以随意调整这个世界。
在世界里实现完全自然的物理效果。比如不同物体掉落在地,会有完全不同的反应。
游戏里有人工智能和玩家互动,比如玩家说 “建一座城堡”,人工智能会搭建一个漂亮的城堡,供玩家改造。
黄仁勋设想的每个条件,今天都有游戏能做到一部分,但没有一个能在三方面都做到极致。今天单个游戏开发成本已经可以超过 1 亿美元,最大的一项是人力。从工作室营造虚拟的游戏世界,到玩家的游戏机在屏幕上渲染逼真的画面,每个环节都将需要人工智能参与。
这届 GTC,黄仁勋主讲的发布会将近 100 分钟。直接与游戏相关的内容只占不到 20 分钟,剩下的时间都在展示英伟达的产品如何推动人工智能进步——比如新发布的自动驾驶芯片 Thor, 算力更强,支持更复杂的模型;新发布的 CV-CUDA 模型开源库,可以更快地处理图像任务, 如渲染、生成 3D 图像、视频推荐。2010 年,Google 人工智能科学家尝试教神经网络识别猫,动用了 1.6 万个 CPU,而英伟达只用 12 个 GPU 就达到了同样的效果。从那时起,能够并行处理任务的 GPU,成为了人工智能领域最重要的硬件,推着英伟达快速崛起。现在英伟达的一半的业务与人工智能有关。
AI 的希望在大模型,正好是这两家大公司的生意
马斯克:如果你有几千万或几亿辆自动驾驶汽车,数量相当甚至更多的人形机器人,你会有规模最大的数据集。这些视频数据经过处理,汽车很有可能比人类司机更出色,人形机器人和人类难以区分。它们会具备通用人工智能的特征。
黄仁勋:接受过大量人类知识训练的大型语言模型,可能是有史以来最大的软件机会之一。它是当今最重要的人工智能模型。它让我们有可能解决以前从未解决过的问题。
1990 年代开始,经济学家提出 “通用目的技术” (General Purpose Technologies)概念,认为通用的技术才能推动经济长期增长。比如轮子、青铜、铁、蒸汽机、内燃机或现代的计算机、互联网等等。人工智能是一个宽泛、通用的技术,但到实际应用中并非如此。一个人工智能模型,通常只能解决一个任务。比如 2016 年打败围棋世界冠军的 AlphaGo,只会下围棋。
现在训练好一个模型,稍微调整就可以完成翻译、对话、阅读理解、续写内容、补充代码等数十种任务,表现比很多人好。比如 OpenAI 的 GPT-3,自动生成的文本能以假乱真。
它们之间最明显的差距是训练模型使用的数据量。AlphaGo 只输入围棋对弈数据,规模数千万局。而 GPT-3 几乎吞掉了互联网上大多数英文文本,从各种网页、新闻、食谱、图书到程序代码等,整个英文维基百科,只占它训练数据整体的 0.6%。
GPT-3 从这些数据中提炼规律和特征,将它们存到模型中,通常称为 “参数”,等到新的数据输入模型后,它们决定输出什么样的结果。GPT-3 有 1750 亿个参数,几乎能处理大多数文本信息,需要它去解决特定的问题,比如生成文本,只需要简单训练。因此,有巨大参数的模型也被称为基础模型(Foundation Models)。基础模型发挥出来的作用以及它可能的潜力,引发公司和机构争相入场,推着单个模型的参数破万亿。现在没有一个大模型,几乎都不能说自己是个前沿科技公司。
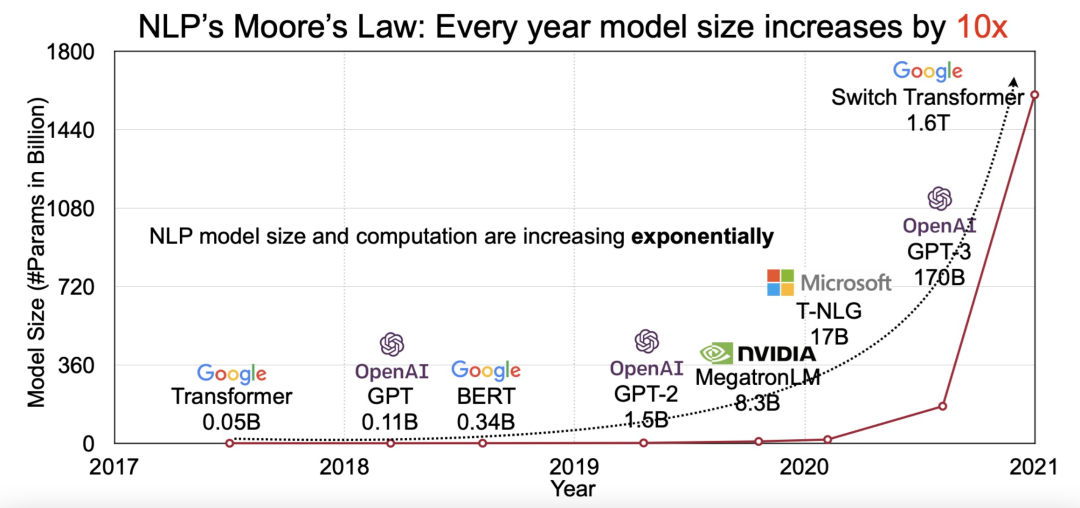
图:部分海外公司训练的基础模型规模。图片来自 MIT。
更大的模型要用更多 GPU ,黄仁勋从来不吝啬对大模型的赞赏,从最重要的人工智能模型,到推动人工智能跳跃式发展,英伟达还和微软一起训练参数 5300 亿的大模型 “威震天”,和 GPT-3 类似,能当聊天机器人,可以阅读理解,翻译等。具体到业务上,英伟达去年跟阿斯利康合作,训练了一个研发新药的大模型;今年交付的处理器 H100 专门为训练大模型优化,比上一代快 5 倍。这次 GTC 上,黄仁勋特意提到,新发布的自动驾驶芯片 Thor 会支持视觉 Transformer 架构——这是大模型的基础。
特斯拉也将大模型用到了业务中。去年的 AI Day 上,特斯拉透露使用 Transformer 架构训练大模型,把特斯拉上八个摄像机的信息融合成 3D 环境,提高系统认识周围环境的能力。特斯拉正在研发的超算 Dojo 也专门训练更大的模型做优化。
特斯拉的 Autopilot 软件总监阿肖克·埃卢斯瓦米(Ashok Elluswamy)在今年的 AI Day 上说,“人们认为我们没法用摄像头检测深度,(其他物体)的速度和加速度,用大型数据集和大型模型能让它变得更精准”。
今年 AI Day 后没几天,特斯拉宣布一些地区的 Model 3/Model Y 车型将不再搭载超声波雷达,只靠摄像头实现辅助自动驾驶。
技术将更普世,但需要有公司创造技术设施
马斯克:人形机器人成本可能不到 2 万美元。它的潜力令人难以置信,让人均生产力没有限制,意味着一个没有贫困的未来,一个人们可以拥有任何自己想要的产品和服务的未来。这是文明的根本转变。
黄仁勋:人们认为,人工智能将在更少的公司中聚集技术力量,但事实上,人工智能使计算机科学民主化。它使得任何人都可以编写软件,它使得每个人都成为创造者,它将使得每个人都成为游戏开发者。
这一代人工智能技术推进从 Google 开始不是巧合。这家公司 1998 年开始做的事就是理解全世界的信息,让人无门槛地找到自己想要的信息。从一开始的文字,到图片、地图、视频、自动驾驶、围棋、病例、医学影像……Google 训练人工智能理解一项一项更复杂的事物。全球超过 20 亿用户提供了无穷无尽的数据,帮 Google 训练。这个过程里 Google 展示了无数广告,成为全球收入和利润都最高的互联网公司,因此有钱继续投入人工智能技术研发。
这因此引起了关于巨头垄断人工智能技术的担忧。大多数公司没有这样可以支持人工智能数据收集和研发的完美商业模式,得找新的路径。
2015 年,马斯克与时任硅谷孵化器 YC 的总裁山姆·阿尔特曼(Sam Altman)等人出资 10 亿美元创办了非营利机构 OpenAI,对标 Google 旗下的 DeepMind,研究友好的、开放的人工智能,称将与世界分享技术。投资方多有自己的公司,特斯拉、YC(在数百家创业公司持股)、LinkedIn、微软等,没有 Google、Facebook 那么多的数据,但也需要人工智能。
2018 年初,马斯克退出 OpenAI 董事会,理由是跟特斯拉正在做的人工智能研究冲突。当时特斯拉已经开始生产 Model 3,当年就成为销量最高的电动车型。
完美的自动驾驶商业模式成型:到现在,特斯拉一共卖出 300 多万辆车,大部分是 Model 3,其中 16 万辆车启用了 FSD(完全自动驾驶能力)、更多车辆启用了 Autopilot(自动驾驶辅助系统)。这些车主给特斯拉付钱都在帮助特斯拉积累数据训练算法、免费当测试安全员,财力雄厚的 Google 也只有大约 1000 台无人驾驶测试车。
积累数据、训练算法的同时,特斯拉也成为了一家年产过百万辆的车企,且车型极少。到 2022 年底,特斯拉的年化产能预计将突破 200 万辆。产能决定成本,而 Tesla Bot 复用了特斯拉汽车的相当一部分零件和技术。
Tesla Bot 的大脑用了为汽车设计的 FSD 计算机和视觉神经网络。电池的管理芯片和系统,也和车用的一样。特斯拉汽车碰撞测试中的模拟分析软件、力学分析模型等都用到了机器人上,尽可能减少重复研发。
马斯克说特斯拉现在的目标是 “以最快的速度生产出有用的人形机器人”,有点用、大量用塑料造,尽量便宜——不需要完美,让更多的人愿意付钱购买就行。
这是特斯拉的人工智能研发路径,开发、大规模部署有自动驾驶技术的汽车,降低成本、让更多人购买,于是数据更多、算法更聪明、卖得更多更便宜,于是人工智能技术能被更多人用上。
英伟达则是压低技术的使用门槛。黄仁勋认为,计算机帮助社会的程度,限制不在成本,而是有多少人会编写计算机程序。
英伟达的显卡适合训练人工智能模型,但有门槛——它是为处理图形设计的,想用它训练神经网络,程序员得学习 OpenGL 等图形编程语言。
借助英伟达的软件平台 CUDA,不会图形编程的程序员,也能用自己擅长的编程语言,无障碍调用 GPU 快速训练算法。英伟达卖了更多 GPU,也让更多人有了训练人工智能的能力。这同样改变了英伟达,现在它 80% 的员工从事软件工作。
这次 GTC 上,英伟达更新的虚拟环境创造引擎 Omniverse 是压低门槛的另一个工具。在黄仁勋的设想中,Omniverse 是一个大型的虚拟世界数据库,里面的所有元素,不论是螺丝还是树木,只需要建造一次,然后共享给每一个需要使用的人。
在 GTC 后接受媒体采访时,黄仁勋描绘了它的未来,“说给我一片海洋。给我一条河 ...... 你想描述什么就描述什么,人工智能就会在你面前合成出 3D 世界。然后你可以修改它。”
黄仁勋希望 Omniverse 成为新技术的基础设施。特斯拉正在研发的超算 Doji 将会成为它首个基础设施服务。马斯克说,未来神经网络越来越多,让人更省钱地训练模型,是运营 Doji 最有效的方式。
过去十年,人工智能研究从学院主导变成商业公司主导。自动驾驶热、AlphaGo 赢过围棋冠军,一时间,中美的互联网、科技大公司快抢光了大学里研究人工智能的博士生——这在当时,是一家公司做人工智能的门槛。
现在没那么难。简化编程难度的开源软件包、更适合运算的处理器。写 AI 程序、调参数的不再需要博士,能用到相关技术的也不只是大公司。人工智能科学家、Google AI 负责人杰夫·迪恩(Jeffrey Dean)因此将过去十年称为这个行业的黄金时代。就像计算机、互联网等技术经历过的那样。大大小小的研究机构、商业公司一层一层搭建基础设施,当他们垒起的基石足够高,影响更大的改变就可能发生。
「 TECH TUESDAY 」系列
1957 年,人造物体第一次进入宇宙,绕着地球飞了三个星期。人类抬头就能在夜幕里看到一颗小小的闪光划过天空,与神话里的星宿并行。
这样的壮举跨越种族与意识形态,在全球各地激起了喜悦之情。但并不是我们可能猜想的那种为人类壮举所感动的胜利喜悦。根据政治哲学家汉娜·阿伦特(Hannah Arendt)当年的观察,人们的情绪更接近于一种等待多时的宽慰——科学终于追上了预期,“人类终于在摆脱地球这个囚笼的道路上迈出了第一步”。
人们总是根据技术探索,快速调整着自己对世界的预期。当科幻作家的一桩畅想变成现实,往往是技术终于追上了人们的预期,或者用阿伦特的话说,“科技实现并肯定了人们的梦想既不疯狂也不虚无。”
今天这样的时候,多一点梦想是更好的,也是更合理的。
毕竟,当射向那条绝对的上升通道被各种原因关闭,人和钱才会流向更广阔的世界,带来更多可能。
这些可能关于一项前沿研究的进展、可能是对一个技术应用的观察,也可能是对一些杰出技术、乃至一个时代的致敬。
这个栏目将从科学与技术的角度出发,记录这个世界的多样变化。在这个旅途中,希望读者能和我们一起,对这个世界增加一分理解。
DevOps 已死,平台工程才是未来
开发者不想做运维,对 DevOps 来说不是好事情。
最近, Scott Carey 发表了一篇调查文章,喊出了一些开发者的心声:“扯淡的 DevOps,我们开发者根本不想做运维!”除此之外,软件工程师兼 DevOps 评论员 Sid Palas 也在推特上写道,“DevOps 已死,平台工程才是未来。”
他的核心观点是:开发者不想跟基础设施打交道,企业在发展过程中又需要控制自己的基础设施。只有平台工程,能将这两个相互矛盾的命题统一起来。
Honeycomb 的首席技术官 Charity Majors 对此也有同样的观点,她认为在软件演进过程中,我们将运维技能从开发技能中剥离出来,形成了两个不同的职业,但结果证明这是一个巨大的错误。因此 DevOps 出现了,我们用它来重新统一开发和运维。然而开发周期应该是一个企业中最稀缺的资源,所以应该将尽可能多的资源花在核心产品上。

Majors 认为,在过去,有的工程师写代码,有的工程师跑代码。而现在,工程师不仅编写代码,还要运行他们编写的代码。这导致软件工程师觉得他们必须对所有事情都了如指掌,大大增加了“认知负担”。
这迫使许多团队重新在自动化带来的自由与认知负担之间进行权衡。平台工程也因此越来越受关注和热议。PlatformCon 是第一个面向平台工程师的会议,一出现就吸引了超过 6,000 名与会者。Gartner 也在其 2022 年 8 月发布的软件工程炒作周期中添加了“平台工程”(图中第四个小圆点)。
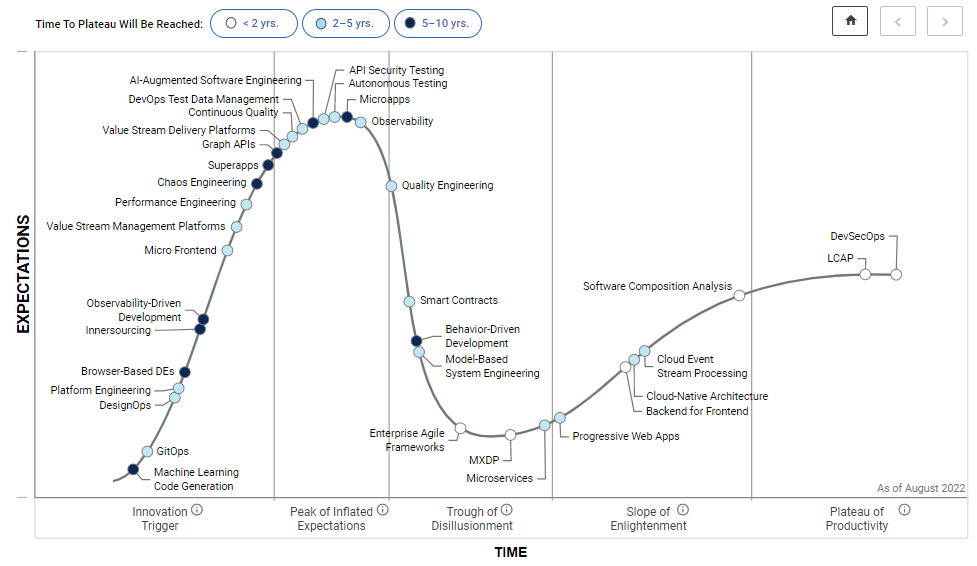
什么是平台工程?
按照“平台工程”社区主要贡献者和 Humanitec 的产品负责人 Luca Galante 的说法,平台工程是一门设计和构建工具链与工作流的学科。这些工具链和工作流可以为云原生时代的软件工程组织提供自助服务功能。平台工程师提供集成化产品,通常称为“内部开发平台(Internal Developer Platform)”,可以涵盖应用程序整个生命周期的所有操作需求。
内部开发平台(以下简称 IDP)是位于工程团队已有技术和工具之上的一层。它帮助操作人员进行系统性设置,并为开发人员提供自助服务。平台工程做好了,就好比是为个体开发人员铺就了金光大道,他们可以从 IDP 层获得合意的抽象等级。
从 DevOps 余烬中崛起
DevOps 和云原生的概念兴起之后,似乎是在突然之间,工程师们不得不掌握 10 种不同的工具、Helm charts、Terraform 模块等,仅仅是为了在多集群微服务设置中的多个环境中部署和测试一个简单的代码更改。问题是,在整个工具链的演进过程中,这个行业似乎认为,在全球经济的几乎其他所有领域都被证明有效的劳动分工(Ops 和 Dev)并不是一个好主意。相反,DevOps 范式备受推崇,被视为实现高效设置的方式。
开发人员应该能够端到端地部署和运行他们的应用。“谁构建,谁运行”,这才是真正的 DevOps。这种方法的问题是,对于大多数公司而言,这实际上并不现实。
虽然对于像谷歌、亚马逊、Airbnb 这些比较先进的组织来说,上述方法很有效,但对于其他大多数团队而言,要在实践中复制真正的 DevOps 并不简单。最主要的原因是,大多数公司都没有像他们那样的人才库,也不会仅仅为了优化开发工作流和体验而做他们那样的资源投入。
与此相反,当一个普通的工程组织试图实施真正的 DevOps 时,往往会出现一系列的反模式。我们通过一个例子来看下,当组织决定实施 DevOps 并取消正式的 Ops 角色或团队时,许多开发团队中出现了什么情况。开发人员(通常是比较资深的)最终承担起了管理环境、基础设施等的职责。这就导致了这样一种情况:“影子操作”由那些在编码和产品开发方面才能体现出最大价值的工程师来执行。没有赢家。高级工程师现在要负责设置,并需要处理比较初级的同事的请求。在组织层面,其最昂贵和最有才华的资源现在正在被滥用,他们无法再以同样的速度和可靠性来交付功能了。

这类反模式已经为许多研究所证明,比如 Puppet 的 DevOps 现状报告或是最近 Humanitec 的基准测试研究。后面这份报告根据标准的 DevOps 指标(准备时间、部署频率、MTTR 等),对表现最好和最差的组织进行了分组。如下图所示,44% 的低效组织存在着上述反模式,有些开发人员要自己完成 DevOps 任务,并帮助经验不足的同事。与此相比,表现最好的组织全部成功实施了真正的“谁构建,谁运行”方法。
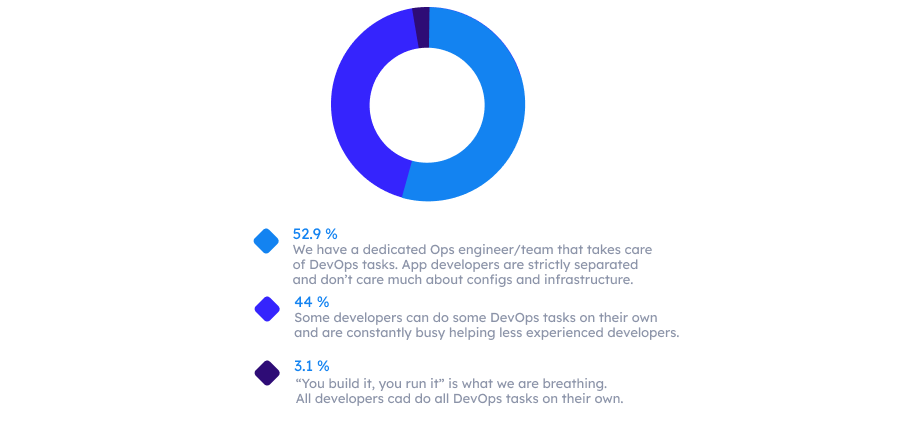
那么,低效组织和高效组织之间的关键区别是什么?最好的团队是如何确保他们的开发人员能够运行自己的应用程序和服务,而不需要借助资深同事的不断帮助?你猜对了,他们有一个搭建内部开发平台的平台团队。Puppet 的《2020 年 DevOps 现状报告》清楚地说明了内部平台的使用与组织 DevOps 演进程度之间的相关性。
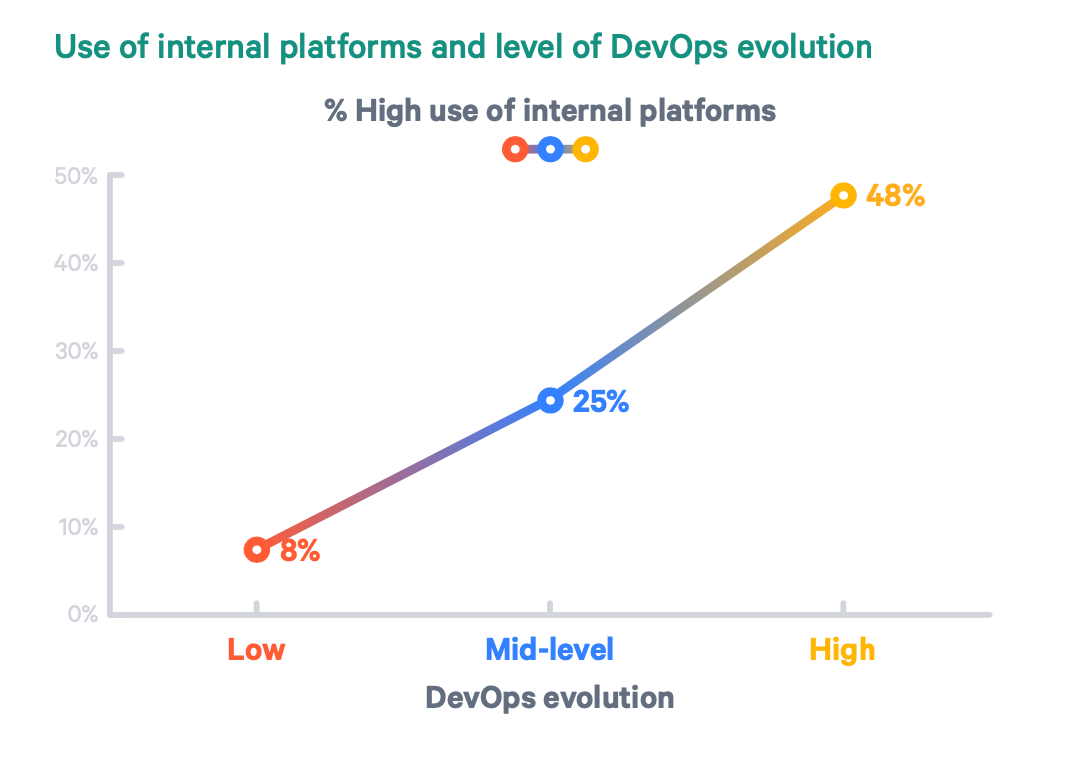
最好的工程组织就是这样做的。他们成立了内部平台团队,负责构建 IDP。在使用这些 IDP 时,开发者可以根据自己的喜好选择合适的抽象级别来运行他们的应用和服务。例如,他们喜欢摆弄 Helm charts、YAML 文件和 Terraform 模块吗?很好,他们可以这么做。他们是不关心应用是否在 EKS 上运行的新手吗?没问题,他们可以通过自助服务为自己提供一个环境,这个环境包含了他们部署和测试代码所需的一切,而且不用管它在哪里运行。
铺就金光大道
这里所说的铺就金光大道是什么意思呢?让我们具体看下。如今,大多数 CI/CD 设置的重点都只是简单地更新镜像。CI 构建它们,更新配置中的镜像路径,完成。这覆盖了大多数部署用例。但是,当我们需要做一些基本工作流程之外的事情时,情况就开始变得更加复杂和耗时,例如:
- 增加环境变量和修改配置
- 添加服务和依赖项
- 回滚和调试
- 启动一个新环境
- 重构
- 添加 / 修改资源
- 强制使用 RBAC
这样的例子不胜枚举。平台工程就是为所有这些需求铺好路。平台工程师提供粘合剂,将所有这些操作都绑定到一个一致的自助服务体验中,而不是让每个人什么操作都做,而且还必须了解整个工具链才能做到。
这种粘合剂就是内部平台。用 Evan Bottcher(https://martinfowler.com/articles/talk-about-platforms.html)的话来说,平台是“自助服务 API、工具、服务、知识和技术支持的基础,它们被定位成一个令人信服的内部产品。自主交付团队可以利用该平台更快地交付产品功能,减少协调时间。”
以这个定义为基础,我们可以将内部开发平台定义为“一个自助服务层,旨在让开发人员可以独立操作组织的交付设置,使他们能够通过自助服务获取环境、部署、数据库、日志以及任何他们运行应用程序所需的东西。”
平台工程的原则
许多组织开始意识到内部开发平台和开发者自助服务所带来的好处。按照 Puppet《2021 年 DevOps 现状报告》的说法,“平台团队的存在并不一定会解锁更高层次的 DevOps;不过,优秀的平台团队会扩大 DevOps 方案的好处。”
然而,招聘合适的人才来构建这样的平台和工作流程并不简单。更麻烦的是,要确保他们始终如一地向工程组织的其他部门提供可靠的产品,并将对方的反馈纳入 IDP。
以下是一些有用的原则,成功的平台团队和自助服务驱动的组织都是以此为主线。
明确使命和角色
要明确平台团队的任务。例如,“构建可靠的工作流,使工程师们能够独立地操作设置,并针对他们运行应用程序和服务所需的基础设施提供自助服务。”无论对你的团队来说哪块最重要,都要确保一开始就把这个定义好。为平台团队赋予一个明确的角色也极其重要,不应该将平台团队视为另一个按需提供环境的服务台,而应该将其视为一个专门为内部客户服务的产品团队。
将平台作为产品来对待
关于聚焦产品,我们再展开说明下。平台团队需要秉持产品思维,以内部客户也就是应用开发者的反馈为基础,专注于能够真正为他们提供价值的东西。要保证平台团队基于这个反馈循环来交付功能,而不被刚刚出现的新技术所吸引。
聚焦常见问题
对于内部其他团队共有的问题,平台团队要防止他们处理这些问题时重复发明轮子。找出这些常见问题的关键是:首先要了解导致开发进度放缓的开发痛点和阻力。这些信息既可以是通过开发人员反馈收集的定性信息,也可以通过查看工程 KPI 收集的定量信息。
粘合剂很有价值
通常,平台团队会被视为纯粹的成本中心,因为他们不为最终用户提供任何实际的产品功能。他们只是把我们的系统粘合在一起而已。这样的观点非常危险,当然,这种粘合剂非常有价值。平台工程师需要在内部肯定和宣传自己以及自己的价值主张。一旦你们为其他团队设计并铺就了金光大道,那么作为一个平台团队,你们所创造的主要价值是将工具链整合在一起,为工程师们提供顺畅的自助服务工作流。
不要重复发明轮子
同样,平台团队应该防止组织内的其他团队重复发明轮子,为同样的问题寻找新的创造性解决方案,他们自己也应该避免犯这样的错误。不管你自己开发的 CI/CD 解决方案多么优秀,商业供应商最终都会迎头赶上。平台团队应该经常问自己有什么不同之处。与其构建内部的 CI 系统或指标仪表板,并与能力强 20 或 50 倍的企业竞争,还不如专注于组织的特定需求,并根据这些需求定制现成的解决方案。无论如何,商业竞争对手更多的是针对行业中比较通用的需求进行优化。
现代工程组织
根据 Puppet 的《2021 年 DevOps 现状报告》,“高度发展的组织往往会遵循 Team Topologies 模式”。
Matthew Skelton 和 Manuel Pais 合著的 Team Topologies 一书于 2019 年出版,在成功的工程组织中,成为最具影响力的现代团队设置蓝图之一。根据他们描绘的蓝图,团队应该围绕四种基本拓扑结构来设置。


- 业务导向团队:与业务领域某个部分的工作流相匹配,处理核心业务逻辑。
- 赋能团队:帮助业务导向团队克服障碍并检测缺失的功能。
- 复杂子系统团队:在严重依赖数学 / 技术方面的专业知识时组建。
- 平台团队:提供一个令人信服的内部平台,提高业务导向团队的交付速度。如上图所示,平台团队与其他所有团队都是平行的,旨在确保从编码到生产的自助工作流的流畅运转。
什么时候应该考虑平台工程?
一个常见的误解是,平台工程只在大型团队中才有意义。如果你的团队只有 5 名开发人员,那么平台团队和 IDP 肯定是多余的,可一旦你的组织发展到超过 20-30 名开发人员,可能就应该考虑内部开发平台了,而且越早越好。
Luca Galante 对此强调道,“我听过无数团队的故事,他们构建 IDP 的时间太滞后了,并因此承受了许多本不必承受的痛苦,例如,唯一一名负责 DevOps 的员工休假,整个组织几周都不能部署。IDP 和招聘平台工程师可能是你今天就要考虑的投资。”
参考链接:
https://www.infoq.com/news/2022/10/platform-devops-summary/
https://thenewstack.io/devops-is-dead-embrace-platform-engineering/
https://www.honeycomb.io/blog/future-ops-platform-engineering
https://platformengineering.org/blog/what-is-platform-engineering
参考文献链接
https://mp.weixin.qq.com/s/IiG2Wi--mlwpn9nD494l8Q
https://mp.weixin.qq.com/s/uEoPuP_PwwJkgiHSRzF1xQ
https://mp.weixin.qq.com/s/uT_fD4MuP432Csy7WNauLw
https://mp.weixin.qq.com/s/P_XdxR0trQA7huXurgI2SQ

