


Tesla自动标注-新能源-短视频-长期技术分析
Tesla自动标注-新能源-短视频-长期技术分析
参考文献链接
https://mp.weixin.qq.com/s/G9sAaPkUl3s7QbN5gs0yBQ
https://mp.weixin.qq.com/s/sn6t_BsR7LtzwyyjGbJjEQ
https://mp.weixin.qq.com/s/E9qh7hGVRGbjnMBxMpEVEQ
https://mp.weixin.qq.com/s/kFlCVamnz4p6cJ7p5ynxzg
自动驾驶如何做数据标注?特斯拉EP3 Auto Labeling深度分析
Tesla对自动标注的技术和要求:
● 首先是在Vector Space上的标注, 需要对数据做出分析处理,数据标注工具的搭建;● 一个离线大模型对数据进行标注,车载模型相当于对大模型进行蒸馏;并且拥有强大的数据采集能力;
● 核心技术方面:三维重建与视觉SLAM等算法。

下面我们就来为这三点慢慢展开。
特斯拉高级主管提供的信息
首先我们recall一下特斯拉高级主管Andrej Karpathy在2021 CVPR上对特斯拉自动驾驶现状讲解时提供的信息。

● 要想成功训练出一个网络,对数据的需求特征:1. 你需要有大量的数据,这里可以指成千上万个视频片段;2. 需要有Sanity Check, 需要干净的数据,数据的标注需要涵盖深度、速度、加速度信息;3. 需要多种多类的数据,即使在同一个简单场景跑一万年,实际上的作用也不大,更重要的是需要大量的corner cases。● 整体的数据闭环体系:
数据采集 → 搭建数据集 → 自动+人工标注 → 送入模型训练 → 量化部署到车端上。
● 重视Data labelling:
在整个特斯拉自动驾驶里面,Data labelling可能比网络部分还要重要,因为数据这一块容易用一些技巧去提升效果。
特斯拉数据标注策略的演变
一开始tesla选择和第三方公司合作,但很快就发现标注效率很低,并且沟通的成本很高,后来他们选择自己建立标注团队,也实现了比较好的产出。
我们可以从图片的下方看到数据标注量在后面时间段产出都比较稳定。

我们猜测其中有两点起到了作用:
1. Tesla自主开发了一个数据标注平台,包括数据标注工具与数据分析工具;2. 公司自己组建了一个千人标注团队,(不确定是否都是全职)专门负责数据的标注。
NO.1
早期的2D平面标注
回到最初,Tesla是在2D的平面上对数进行精细的标注, 例如上图,不仅对车道线+朝向,红绿灯,行人做标注,连对锥形雪糕筒,左边路面的拖拉机,大卡车也会去做标注(估计归类为construction)。
但是对于这种方法, Tesla就发现这么一张一张去标注不太work, 并且一直这么标也不知道什么时到终点。

2D 标注demo
NO.2
4D Space + Time Labelling
接下来Tesla马上转变到一个4D Space + Time Labelling 的标注模式,在我们看来其实像一个vector space 下 3D 标注 + 时间序列,加入时间序列主要作用是知道前面发生了什么,把前面的东西保留,可以将信息投到后面,例如3D版的CVAT。
整个思想是,在3D空间下标注,然后再投到8个摄像机里面,简单来说,可以理解为 amount of the labels in 3D space (vector space) = ⅛ amount of labels in 8 camera views (image space)。这里可能会涉及到2D标注与3D标注之前的成本问题,很明显我们都知道标注一张2D的图像会比标注一张3D的图像成本低,但如果是 8张2D的图像对比1张3D的图像,从Tesla 的做法来看,是标注1张3D图像的成本效果要比较好。
但其实即使你标注获得了8倍的数据,对自动驾驶而言也还是不够用的。我们在之前的图片也看到,在CVPR2021 WAD的时候, Tesla 有60亿个标注,和1.5 Pentabytes (PB) 的数据,如果单单利用人工劳动力去标注,是不大可能做到如此庞大的数据量的。
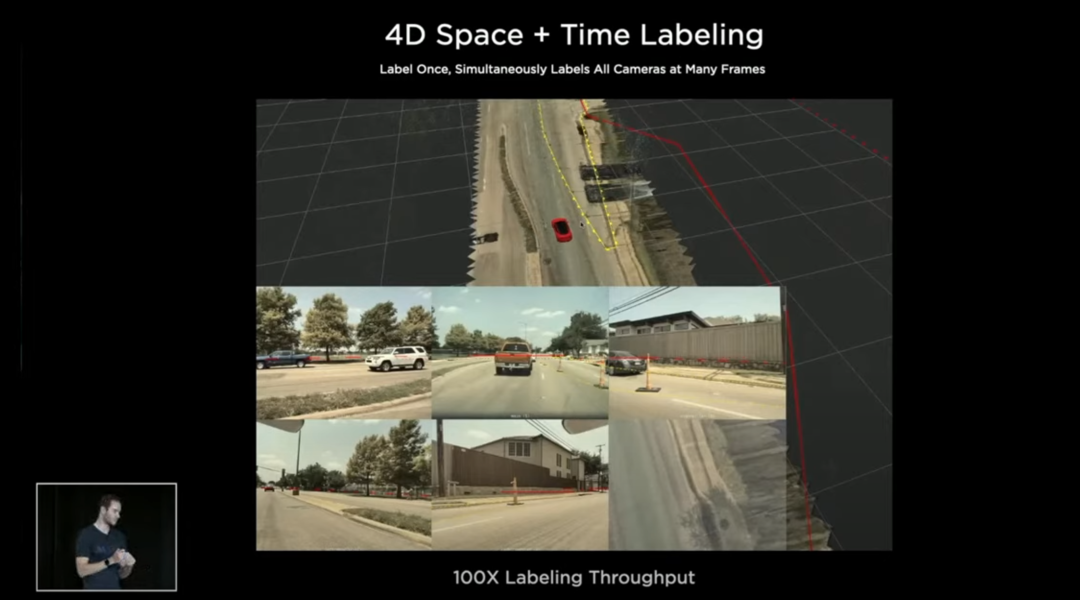
特斯拉的auto-labeling分析

这是Tesla Auto-Labelling 的整个pipeline, 它会有视频片段,大概就是10s到60s的视频,这些视频来源可以是他们车队采集,或者是shadow mode 上传的,这些视频片段包括了图像,IMU,GPS,Odometry(里程计)的数据,压缩成一个个packages,传到服务器上面。
然后服务器上面会有Offline Neural Networks, 离线神经网络,这里相当于一个大规模模型,是他们针对图像上的物体做的。
检测识别精度会比较准,会对不同的camera输出的图像做预处理,可以输出semantic segmentation, depth estimation,还可以多帧之间点matching的结果;
接着通过一个机器人行业流行的AI 算法,在我们看来就是利用nerf,SLAM等算法,把整个三维场景重建出来,然后构建出不同的label, 有道路的重建,动态/静态物体的重建,这样就可以打包成不同的labels,其实label这一模块是依托于大模型的输出的,所以tesla 在整个autolabelling 和网络训练的过程,其实是让车端运行的neural network去蒸馏大网络的输出,是这样的一个过程。
接着我们会有一个问题:tesla是怎么重建道路的呢?或者会有疑问,检测网络是有了(HydraNet),然后数据是怎么获得的呢?

首先会用一个隐式MLP(multilayer perceptron)表示道路,然后给每一个道路(x,y)的request,然后可以收获 Ground Height, Lane Line, Crub, Asphalt(沥青), crosswalk 等信息,可以视为BEV视角下的一个栅格化表示。

获得这些信息之后,我们可以把他们投影到8个camera上,如上图右上的地方,相当于对每一个点作分类处理,如车道线。右下的图片是大模型对右上图做的一个Segmentation的结果,当3D投影结果跟2D 重合的时候,我们就认为我们道路重建准确。
为了让大家更加理解这个过程,其实这个过程是基于一篇 paper,ECCV 2020 NeRF的 paper, (Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." ECCV, 2020.)
Nerf 所解决的是一个什么问题呢?可以看到图片中下放nearest input 这一部分,有一些离散的,不同视角下的一些输入,然后我们的目的是输出一个三维重建的图,作为物体的重建。
然后nerf对物体的重建的过程也比较有意思,一般我们表示一个物体,例如会用match去表示,或者用各种显式去表示,但这篇文章并没有用一种显式的方式去表示,而是用一个多层神经网络,即MLP,去表示物体的本身。
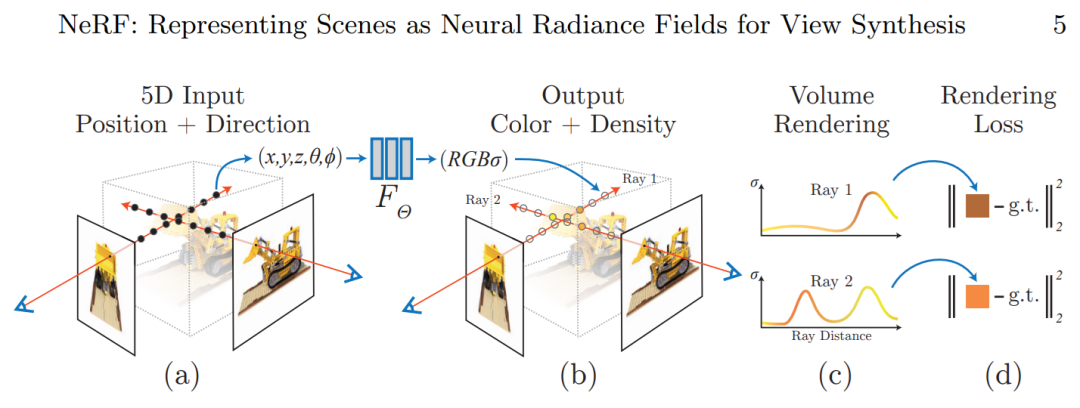
如上图左边,当我们有(x,y,z,θ,ϕ),即三维空间点x,y,z,以及视角θ,ϕ;如图(a),在每条射线上的每个点,都带着(x,y,z),以及(θ,ϕ)信息,通过MLP后输出RGB信息,如果我们采集的点越来越多,我们得到更多不同的RGB,这样我们就可以把整个物体重建出来,也就是说我们要让这个网络过拟合某一个特殊的场景,其实这个MLP表示的就是这个场景本身。
在图(b)中,我们在不同视角下会有一ground truth(真值),即不同视角下的图片。然后当图(b) output 中 2D 的投影与我们的真值吻合的时候,我们就可以认为这3D的modelling 建立得比较好。然后从input隐式3D,通过MLP,到2D的过程,这一流程其实也就是一个渲染的过程。用到了Volume Rendering, 并且整个pipeline是可导的,保证了rendering loss function 可以把梯度反向传播回到MLP,不断地去优化我们的模型,模型就会逐渐贴近我们的这个三维物体。
这个过程里面,有一点很重要,就是MLP这个模型,可以理解为物体本身,如果对应到Tesla 方案上,MLP就是道路本身(一个隐式表示)。
可能说的有点散了,我们现在来梳理一下,具体来说:
为什么要这么做呢?因为我们需要一ground truth 来给Tesla vision去训练, 然而我们又怎么去建立这个ground truth 呢?
答案:借鉴NeRF的思想,这过程有几处具有挑战的地方:
1. 在场景重建的时候,我们需要获得每一个摄像头的位置信息,比如说我们需要知道每个摄像头的外参,这里TESLA可能是通过SLAM(camera+IMU)来获得相机在帧与帧之间的转移矩阵;
2. 第二个挑战是要保证渲染的过程是一个可微渲染,这样才能对道路模型进行梯度优化。
Restructuring the Road 结果:重建的结果还是挺好的。
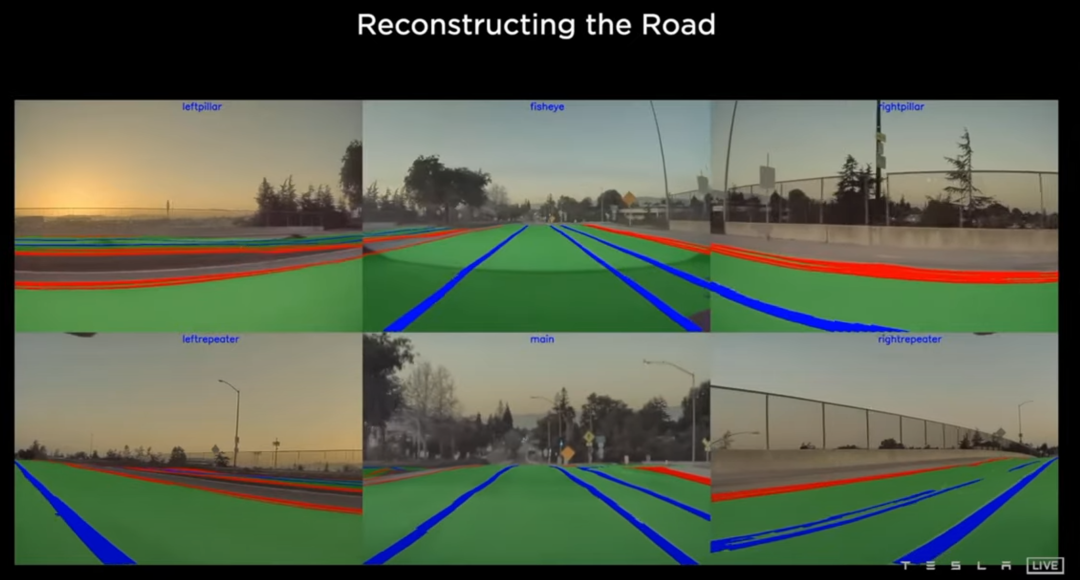
Restructuring the Road 结果
● Static Objects 静态物体标注

整个静态物体的构建过程,其实就是一个SLAM,然后把地图重建出来。建完图后,我们可以把地图当作psudo lidar了,可以用lidar算法去做目标检测等任务。当然,也可以人工去标注,但tesla 大概率是大模型做auto labeling, 然后人工去做refine。
● Dynamic Objects 动态物体标注

对于动态物体的标注,如运动的车辆等:1.首先第一个,用psudo lidar 的方式,构建出深度信息。tesla 在这方面估计会有很多大模型,并且利用自监督的深度估计算法去得到距离信息,据发布会说这效果也做得挺好。2.利用radar,直接得出深度信息。因为在auto-labeling 的过程中,其实是离线的,所以可以用到前后帧的信息,即事件发生之前,与之后的信息模型都能知道,可以做一个全局优化。并且在离线训练的状态下,也没有实时的要求,tesla 在这过程可以上一些复杂的算法,来达到更加好的效果。3. 然后Tesla 通过 Static objects & Dynamic objects 的方法,对路面及行人信息做出标注。由于离线训练,可以知道当前帧前后的信息,所以即使行人被车挡住了,跟进时序信息,也可以追踪车后的行人。


车辆自动标注调研
关于车辆标注,我们也找了一些自动化标注的资料:Zakharov, Sergey, et al. "Autolabeling 3d objects with differentiable rendering of sdf shape priors." CVPR 2020
详情请看:
https://www.youtube.com/watch?v=VQcDcYsWk00
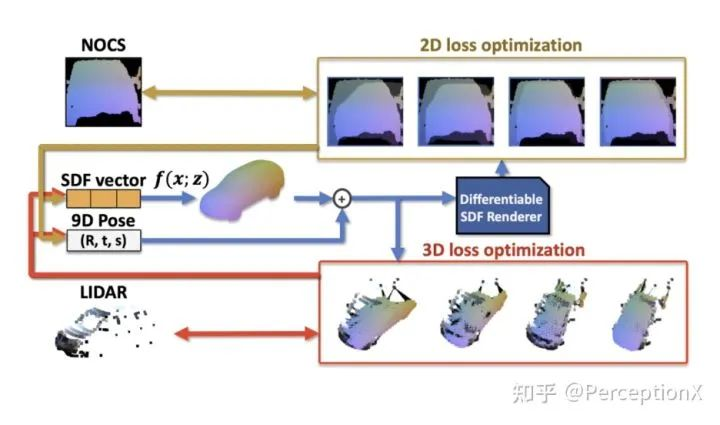
TRI的这篇工作中,首先使用车辆的三维模型训练一个SDF模型(类似Nerf,也是三维场景的一种表示),该SDF模型含有latent code(上图中的SDF vector)。通过修改latent code,可以控制车辆的形状,以生成不同的车型。
当获取到输入图像后,首先进行segmentation,并预估一个车辆的初始位置。根据车辆的初始位置及SDF模型,可以渲染出车辆在图像上的投影。结合车辆的segmentation,车辆位姿及其二维投影,可以构建出2D、3D两个loss。对loss做梯度下降,优化SDF vector及车辆位姿。
当车辆投影在二维上跟分割结果重合、三维上和lidar点重合时,车辆的形状及位姿较为准确,从而获取车辆的三维标注信息。作者使用该方法在KITTI数据集上生成的数据,在BEV指标下达到了人工标注的性能。
● Auto-labeling Datasets 预览

我们可以看到整个clip相当于对整个场景做三维重建了,然后最近有一趋势,即把车身信号,image,lidar point cloud, prediction, 等数据都整合到一起,形成一段video clip,这我比较方便我们去train multi-task model。
特斯拉的数据集包含了车的位置,行人的位置,以及周围场景信息,算是比较丰富的数据集。目前学术界所开源的自动驾驶数据集并没有这么丰富,例如waymo open datasets 普遍是一段一段的,perception and prediction模块之间的标注也没有集合到一起。Nuscene虽然有给到各种数据,但也不是那么让人满意。
这里我们PerceptionX 先宣传一波我们自建的数据集OpenLane,集合了当前自动驾驶数据集未涉及到的标注任务,是 community 首次推出真实场景 3D 车道线标注;同时也是规模最大的、同时包含了车道线和物体检测等内容,方便后续感知任务的扩展。
OpenLanes数据集下载链接:
https://opendatalab.com/OpenLane
(点击阅读原文查看)
● Removing radar:

这里仍然不得不提到特斯拉利用autolabeling pipeline在自动驾驶上去雷达的举措,相信有很多文章也提到过,radar跟camera在一些场景下会产生矛盾,例如在高速通过拱桥的时候,桥是静态物体,但路面的车是动态物体,radar检测到的桥容易mismatch并错误认为车也是静态物体,然后tesla自动驾驶在高速上减速了。
但这不是重点,重点是右边的部分,要去掉radar,就需要camera做得比radar要好,但在右边这种一系列的大雾场景,传统的相机做的检测、深度估计任务确实没有radar好,这种问题可以怎么解决呢?
Tesla 派了一庞大的车队,采集了1万+恶劣天气场景的video clips, 然后通过auto-labeling pipeline,一周内就标注完了,然后送到网络里面去训练,最后得到的效果如下所示:

正是因为特斯拉拥有开篇总结的三点自动标注的技术和要求,才能在短时间内收集大量且在特殊场景的数据,对数据进行快速(自动)标注,达到模型快速迭代,快速解决corner cases的效果,应对了第一段我们提到的“打造自动驾驶的数据闭环”中的核心技术。
牛创新能源改名,量产车即将上市
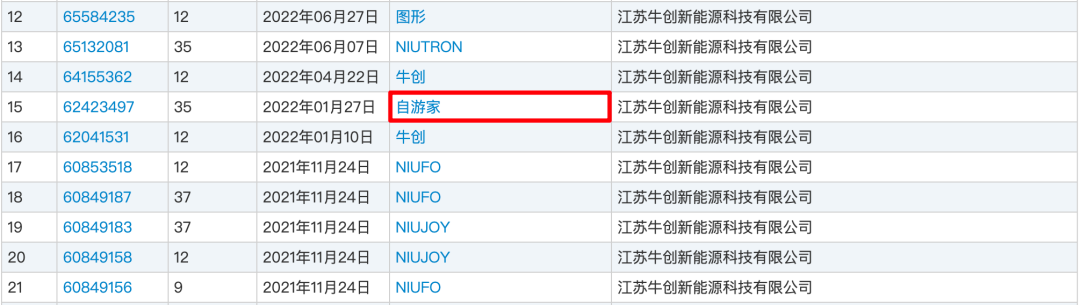
日前,牛创新能源宣布,为避免用户混淆“NIUTRON”、“自游家”品牌和牛创新能源的关系,该公司正式更名“火星石科技有限公司”。据悉,自游家是牛创新能源全新新能源品牌,首款车型自游家NV将于10月8日正式上市。

牛创新能源(NIUTRON)造车项目立项于2018年11月,品牌总部位于北京,在上海设立研发中心,研发及智能制造基地位于常州。2020年12月,江苏牛创新能源科技有限公司完成注册登记,注册资本5000万美元,该公司为台港澳法人独资的外资企业。2021年8月,牛创新能源地址变更为常州市金坛区,同时注册资本由5000万美元增长4亿美元。2021年12月,牛创新能源发布旗下全新汽车品牌“NIUTRON”正式发布,并公布其中文名为“自游家”。

牛创新能源地址变更的原因与生产资质有关,原计划通过盘活大乘汽车位于常州金坛区的工厂,同时借助大乘汽车的生产资质实现造车。资料显示,江西大乘汽车有限公司前身为江西江铃集团轻型汽车有限公司,注册于1996年7月3日。2018年3月,江西江铃集团轻型汽车有限公司正式更名为江西大乘汽车有限公司,意味着大乘汽车获得江铃轻汽的生产资质。2018年9月,大乘汽车在北京举行品牌发布会,宣布正式入局汽车行业。然而,还不到两年时间,大乘汽车就陷入绝境,留下一堆烂摊子欠下一屁股债。


作为造车的新成员,牛创新能源首车量产需要生产资质,最终选择了大乘汽车。对于诸多入局造车的新品牌来说,生产资质的获取要么通过收购,要么通过代工,而牛创新能源选择了后者。
在发布自游家品牌时,创始人李一男接受采访时表示,“汽车制造毫无疑问是一个高资金门槛的行业。别人也问过我,为什么之前没做汽车,现在想着要做汽车。2014年的时候,我自己判断融不到30亿美金来做这个事情,现在我大概率应该能够融得到这个钱来做这个事情。”
今年3月,自游家宣布,第一款车自游家NV将于3月31日正式发布并开启预订,9月份开始交付。然而,随着疫情的全面爆发,以及汽车供应链危机,自游家不得不在官方微信上宣布新车发布会将延期举办。

按照官方说法,疫情打乱了自游家原本的计划,但也正如李一男所说,自游家一天也没有懈怠。4月11日,自游家发布自游家NV挑战极寒测试。7月份以来,自游家工作人员在朋友圈更新了武汉、杭州、成都、广州等线下门店的建成事宜。
不过,似乎一切都有条不紊地推进着,但“自游家”这个品牌标识甚至都还没敲定。在今年1月自游家发布的外观官图中,车尾有“自游家NV”这一车型名称与“NIUTRON”这一品牌标识,但北京线下直营门店内,车尾已经部件“自游家”这三个字,除了“NIUTRON”标识外,只有左侧的“大乘汽车”与右侧的“NV”。不过,各地直营店里展车的车尾部分也不尽相同,有些直营店的新车车尾就有“大乘汽车”的标识,有些则是“自游家NV”。

对此,自游家汽车相关负责人表示,NV车型将于今年12月开启首批用户交付,而车辆尾标之所以新增“大乘汽车”标识,是因为自游家品牌为牛创新能源与大乘汽车合作推出的品牌,并非牛创新能源单独推出。牛创新能源更多扮演赋能、技术输出的角色。
之所以各地展车尾标不同,正是因为“自游家”这个品牌商标还未获批。从国家商标局了解到,大乘汽车早在2018年3月就申请了“自游家”商标,国际分类为12(汽车类),而牛创新能源曾两次申请“自游家”商标,一次是在2022年1月,一次是在2018年3月,但国际分类为35(广告类)。这也是为什么自游家在海报中提示:“自游家”商标由大乘汽车注册的原因。

李一男曾在接受采访时说,“我车都没有造出来,还没有上台,能做到第几能不能活这种问题,我回答不了。”目前,留给自游家的时间不多了,蔚来、理想、小鹏等新势力之间互相厮杀,大众、丰田、奔驰、宝马等持续加注新能源汽车,而自游家想在新能源汽车这片红海中求得生存,量产只是考验新势力车企的第一关。
谷歌AI生成视频两连发:720p高清+长镜头,网友:对短视频行业冲击太大
内容生成AI进入视频时代!
Meta发布「用嘴做视频」仅一周,谷歌CEO劈柴哥接连派出两名选手上场竞争。
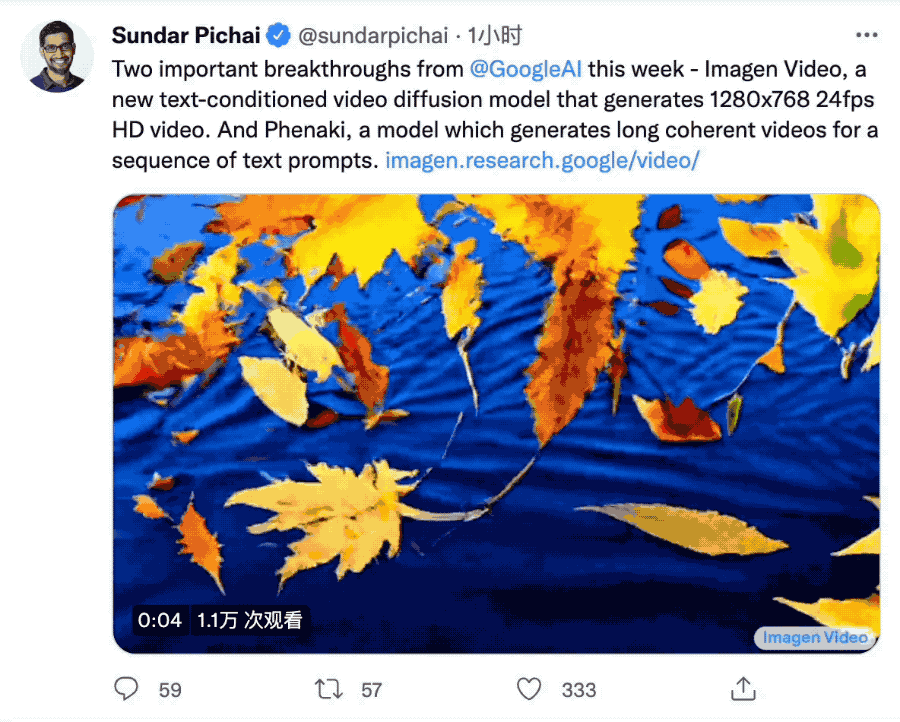
第一位Imagen Video与Meta的Make-A-Video相比突出一个高清,能生成1280*768分辨率、每秒24帧的视频片段。

另一位选手Phenaki,则能根据200个词左右的提示语生成2分钟以上的长镜头,讲述一个完整的故事。

网友看过后表示,这一切进展实在太快了。

也有网友认为,这种技术一旦成熟,会冲击短视频行业。

那么,两个AI具体有什么能力和特点,我们分别来看。
Imagen Video:理解艺术风格与3D结构
Imagen Video同样基于最近大火的扩散模型,直接继承自5月份的图像生成SOTA模型Imagen。
除了分辨率高以外,还展示出三种特别能力。
首先它能理解并生成不同艺术风格的作品,如“水彩画”或者“像素画”,或者直接“梵高风格”。

还能理解物体的3D结构,在旋转展示中不会变形。

最后它还继承了Imagen准确描绘文字的能力,在此基础上仅靠简单描述产生各种创意动画,

这效果,直接当成一个视频的片头不过分吧?

除了应用效果出色以外,研究人员表示其中用到的一些优化技巧不光对视频生成有效,可以泛化至一般扩散模型。
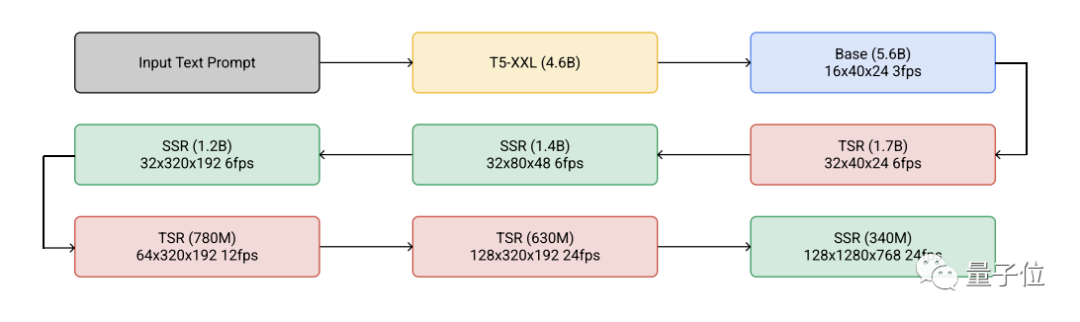
具体来说,Imagen Video是一系列模型的集合。
语言模型部分是谷歌自家的T5-XXL,训练好后冻结住文本编码器部分。
与负责从文本特征映射到图像特征的CLIP相比,有一个关键不同:
语言模型只负责编码文本特征,把文本到图像转换的工作丢给了后面的视频扩散模型。
基础模型,在生成图像的基础上以自回归方式不断预测下一帧,首先生成一个48*24、每秒3帧的视频。

接下来,一系列空间超分辨率(Spatial Super-Resolution)与时间超分辨率(Temporal Super-Resolution)模型接连对视频做扩展处理。
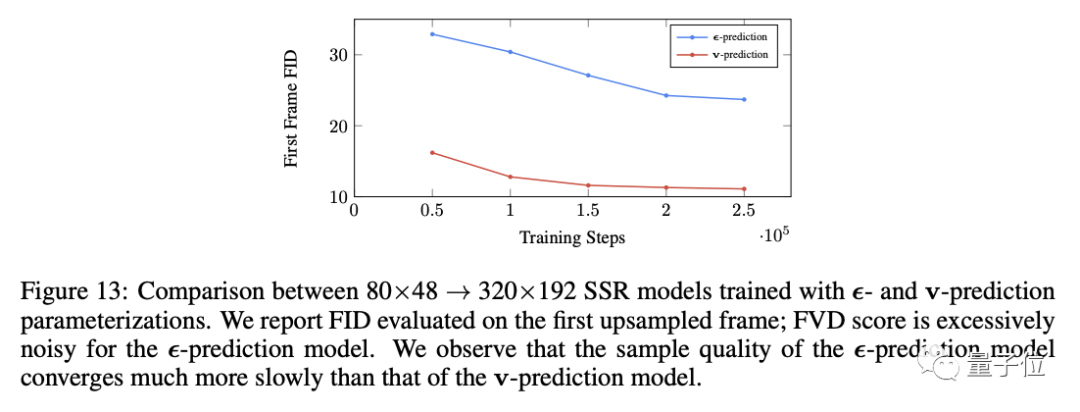
所有7种扩散模型都使用了v-prediction parameterization方法,与传统方法相比在视频场景中可以避免颜色偏移。

这种方法扩展到一般扩散模型,还使样本质量指标的收敛速度更快。
此外还有渐进式蒸馏(Progressive Distillation),将每次迭代所需的采样步骤减半,大大节省显存消耗。
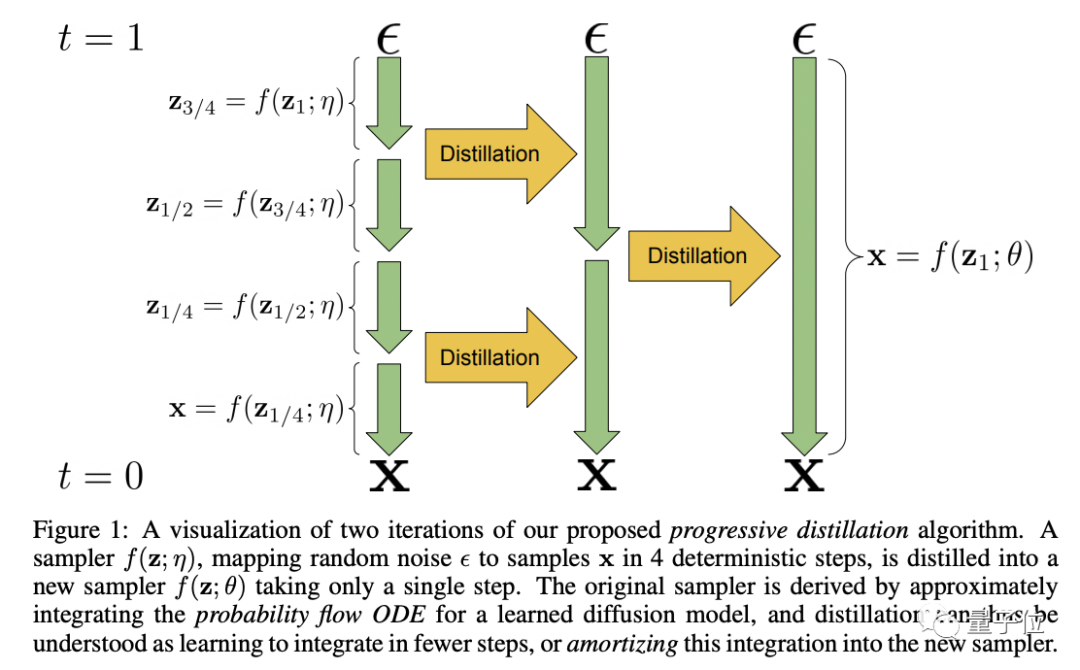
这些优化技巧加起来,终于使生成高清视频成为可能。
Phenaki:人人都能是“导演”
Phenaki的论文投了ICLR 2023会议,在一周前Meta发布Make-a-video的时候还是匿名双盲评审状态。
如今信息公开,原来研究团队同样来自谷歌。
在公开的信息中,Phenaki展示了它交互生成视频的能力,可以任意切换视频的整体风格:高清视频/卡通,还能够切换任意场景。

还可以向Phenaki输入一个初始帧以及一个提示,便能生成一段视频。
这都还是开胃小菜,Phenaki真正的大招是:讲故事,它能够生成2分钟以上的长视频,通过输入长达200多个字符的系列提示来得到。
(那有了这个模型,岂不是人人都能当导演了?手动狗头)

从文本提示到视频,计算成本高、高质量文本视频数据数量有限以及视频长度可变一直以来都是此类模型发展的难题。
以往的大多数AI模型都是通过单一的提示来生成视频,但若要生成一个长时间并且连贯的视频这远远不够。
而Phenaki则能生成2分钟以上的视频,并且还具备故事情节,这主要归功于它能够根据一系列的提示来生成视频的能力。
具体来说,研究人员引入了一个新的因果模型来学习表示视频:将视频视作图像的一个时间序列。
这个模型基于transformer,可以将视频分解成离散的小表示,而分解视频则是按照时间的因果顺序来进行的。
再讲通俗一点,就是通过空间transformer将单个提示进行编码,随后再用因果transformer将多个编码好的提示串联起来。
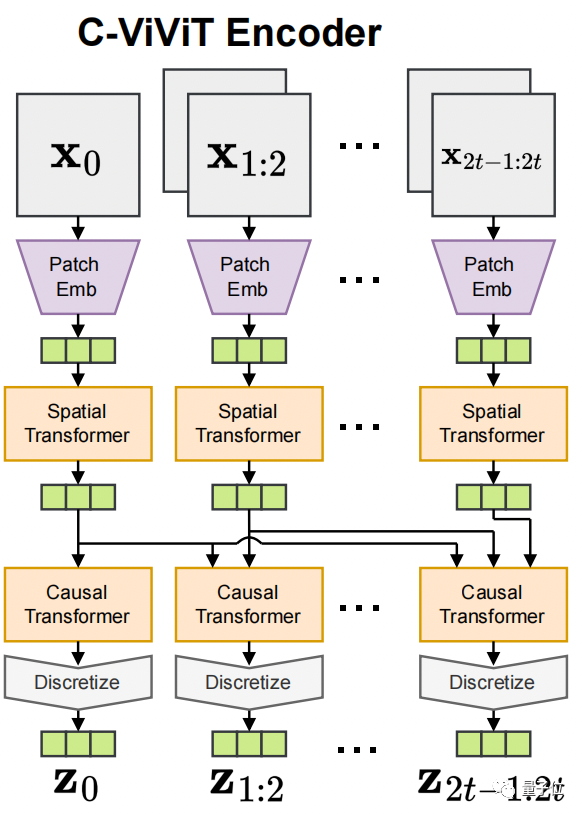
一个提示生成一段视频,这样一来,视频序列便可以沿着提示中描述的时间序列将整个“故事”串在一起。
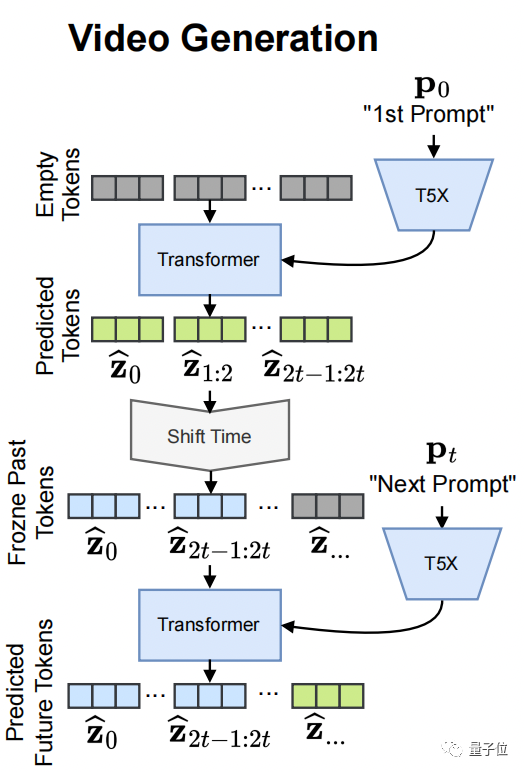
因为将视频压缩为离散的图像序列,这样也大大减少了AI处理标记视频的数量,在一定程度上降低了模型的训练成本。
提到模型训练,和大型图像系统一样,Phenaki也主要使用文本-图像数据进行训练,此外,研究人员还用1.4秒,帧率8FPS的短视频文本对Phenaki进行训练。
仅仅通过对大量图像文本对以及少量视频文本例子进行联合训练,便能达到突破视频数据集的效果。
Imagen Video和Phenaki,谷歌接连放出大招,从文本到视频的AI发展势头迅猛。
值得一提的是,Imagen Video一作表示,两个团队将合作进行下一步研究。
嗯,有的网友已经等不及了。

One More Thing
出于安全和伦理的考虑,谷歌暂时不会发布两个视频生成模型的代码或Demo。

不过既然发了论文,出现开源复刻版本也只是时间问题。
毕竟当初Imagen论文出来没几个月,GitHub上就出现了Pytorch版本。
另外Stable Diffusion背后的StabilityAI创始人兼CEO也说过,将发布比Meta的Make-A-Video更好的模型,而且是大家都能用上的那种。
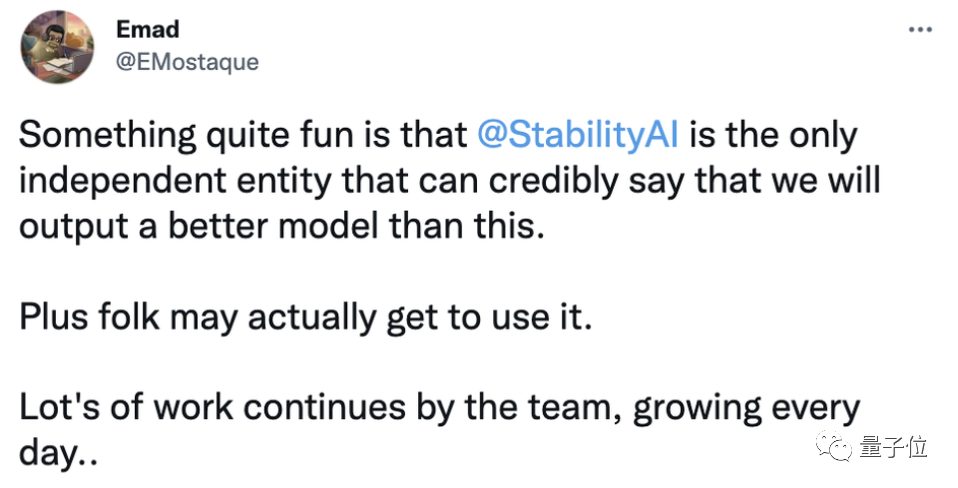
当然,每次AI有了新进展后都会不可避免地碰到那个话题——AI会不会取代人类。

目前来说,一位影视行业的工作者表示还不到时候:
老实说,作为一个在电影行业工作了十年的人,这个话题令人沮丧。

在他看来,当前的视频生成AI在外行看起来已经足够惊艳,不过业内人士会认为AI还缺乏对每一个镜头的精细控制。
对于这个话题,StabilityAI新任首席信息官Daniel Jeffries此前撰文表示,AI最终会带来更多的工作岗位。
如相机的发明虽然取代了大部分肖像画家,但也创造了摄影师,还开辟了电影和电视这样的全新产业。
5年后再回看的话,反对AI就像现在反对Photoshop一样奇怪,AI只不过是另一个工具。
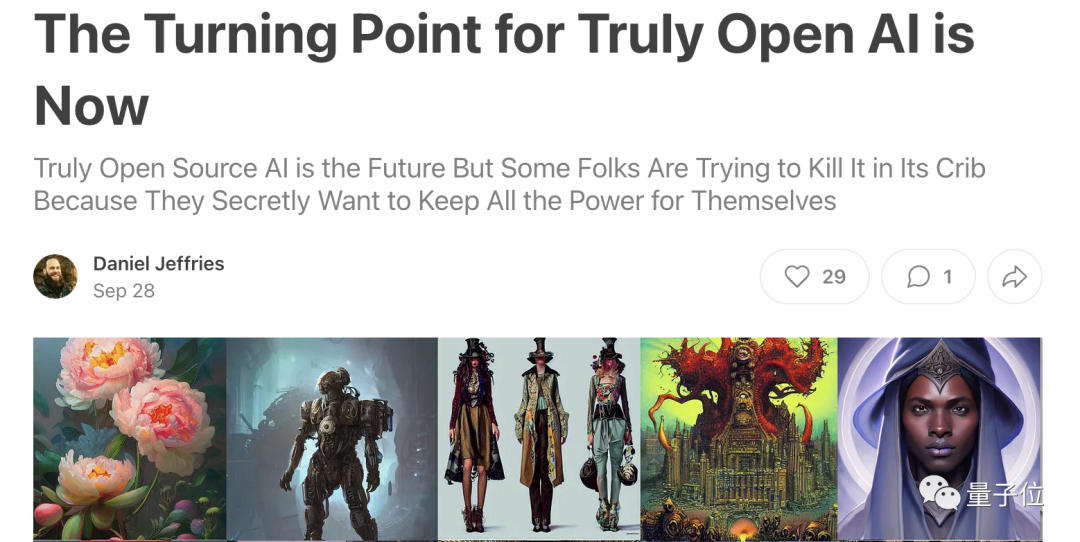
Jeffries称未来是环境人工智能(Ambient AI)的时代,各个行业、各个领域都会在人工智能的加持下进行发展。
不过现在我们需要的是一个更开放的人工智能环境,也就是说:开源!
最后,如果你现在就想玩一下AI生成视频的话,可以先到HuggingFace上试试清华与智源实验室的Cogvideo。
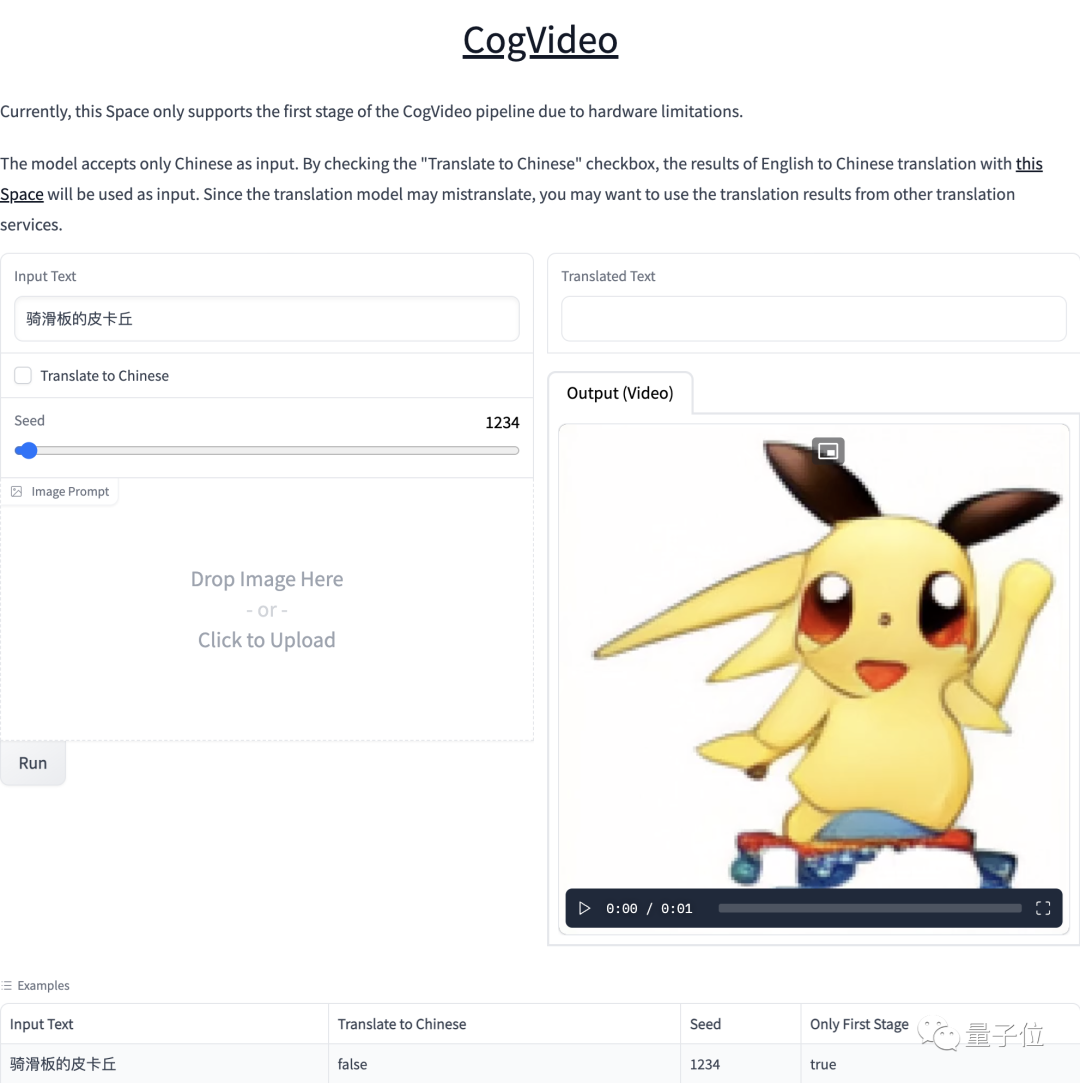
Imagen:
https://imagen.research.google/video/
Phenaki:
https://phenaki.github.io
Cogvideo试玩:
https://huggingface.co/spaces/THUDM/CogVideo
参考链接:
[1]https://twitter.com/sundarpichai/status/1578162216335179778
[2]https://twitter.com/hojonathanho/status/1577713864812236817
[3]https://news.ycombinator.com/item?id=33098704
[4]https://danieljeffries.substack.com/p/the-turning-point-for-truly-open
长期主义者技术积累,没有对手
你是怎么理解长期主义的?长期主义难在哪里?我们如何成为长期主义者?北大国发院宫玉振教授对“长期主义”做了一次非常精彩的分享。文章较长,请耐心看完。
长期主义者,没有对手音频:00:0016:07
(本期音频由倒映有声AI主播播报)
一、两个故事
我先讲两个故事。第一个是华为关于小灵通与3G的战略选择。
上世纪末,中国电信推出了小灵通,当时的UT斯达康和中兴通讯依靠这项业务取得了高速发展。
UT斯达康一年的销售收入曾经达到100亿,在当时这是足以让所有企业都为之动心的数字。
华为管理层当然也看到了这样的机会,所以很快就提交了从事小灵通业务的计划。但是出乎所有人意料的是,任正非否决了这个计划。
任正非否决小灵通的理由是,小灵通注定是一个过渡的、短暂的技术,而3G才代表未来,华为不能做机会主义者。

在他看来,错过小灵通,华为可能失去的是一大块利润,但这还是可以接受的。
如果华为错过了3G,那就将严重影响华为成为一个伟大企业的进程,那才是一个根本性的失策,是绝对不可饶恕的。
华为因此把大部分人力和财力投入在全球范围内还没有商用的3G业务,8年后的2009年,华为终于获得了第一块3G牌照。
从那以后的故事我们都知道了——华为一飞冲天,把所有竞争者都抛到了身后。正是因为华为当年在3G的豪赌和持续投入,才成就了今天的华为。
至于当时风光一时、占据中国小灵通市场半壁江山的UT斯达康,主流市场上,现在已经很难看到这家企业的身影了。
第二个故事是马云与阿里云。
今天的云计算领域中,阿里云排名亚太第一,世界第三。百度按理说在这方面更具优势,可是百度云为什么远远不如阿里云?
当年云计算所需的投入非常大,每年十几亿,连续几年的时间,这给阿里造成了巨大的资金压力,而且还看不到希望。
当时在阿里负责云计算的王坚,现在是中国工程院院士,当年一度被认为是个骗子。
那几年阿里每年的战略会都要讨论一个问题:要不要取消这个项目、解散这个团队?云计算团队很长时间都是惶恐不安,不知什么时间会被解散。
在最艰难的时候,马云来到了云计算团队,跟他们讲:云计算我们一定要做,而且我要投100亿。整个团队的士气一下子就上来了,大家知道没事儿了。
2012年,认为云计算前途无望的百度解散了自己的云计算团队,这个团队后来被阿里完整接收。云计算的最终结局,从那一刻基本就已经确定了。
马云讲过一句话:阿里今天做的所有决策,都是为了七、八年以后的战略布局。
阿里云的最终胜出,靠的就是这种长期主义的战略。

二、长期主义为什么难?
1.三种类型的胜利
我们都想打胜仗,“打胜仗”在今天已经成为一个热词。但我们究竟应该打什么样的胜仗?我们究竟应该要什么样的胜利?
陈春花老师关于“打胜仗”有一个非常精彩的观点,她说胜利分三种类型:机会主义者只能得到暂时性的胜利,实用主义者会获得阶段性的胜利,长期主义者才能赢得持续性的胜利。
我非常同意陈老师这个观点。我最早是学历史的,我可以从历史上组织兴衰的长远规律来呼应一下陈老师的观点。
从历史上看,从来没有哪一支土匪或军阀的队伍能够真正成事。当尘埃落定的时候人们就会发现,最后胜出的一定是有着清晰的长期理念的那支力量。
这是历史告诉我们的一个基本道理:坚持长期主义才能赢得长久的胜利。
2.坚持长期主义为什么非常难?
既然长期主义这么重要、这么好,那么问题来了:为什么长期主义者少之又少?为什么我们今天在这里还要谈长期主义?
很简单:坚持长期主义非常难。
回顾任正非关于小灵通的决策,今天我们会赞叹任正非的高瞻远瞩、雄才大略,做出了正确的选择。可是有谁知道任正非当时承受了多大的压力?
任正非放弃了小灵通,但是小灵通在2000年到2003年取得了持续的增长。
UT斯达康因此从一个名不见经传的小企业变成了一家明星企业,中兴也在小灵通市场里赚得盆满钵满,而且他们利用小灵通取得的高额利润不断挤压华为的市场。
2003年中兴的销售额一度达到了华为的80%。
华为是中国通信设备制造商的老大,但在那段时期内几乎没有什么收获。
华为失去了瓜分小灵通市场的时机,更雪上加霜的是,3G牌照迟迟不发放,因此华为在3G领域的巨大投入长期得不到任何回报。
2002年,华为首次尝到了巨额亏损的苦头。
那时候很多人对华为失去了信心,认为任正非犯了一个致命且愚蠢的错误,不少人离开华为,选择了在当时看来更好的公司。
任正非后来讲:“我当年精神抑郁,就是为了一个小灵通,为了一个TD,我痛苦了8到10年。我不让做,会不会使公司就走向错误,崩溃了?做了,是否会损失我争夺战略高地的资源?”
我们今天复盘一下任正非当时的处境:眼前的利益唾手可得,当前的压力实实在在,但是未来的收益却并不确定。如果你是任正非,你会怎么办?

焦虑、抑郁、彷徨,中途反悔甚至放弃。这就是长期主义者常常必须面对的现实。
上世纪60年代有一个著名的“斯坦福棉花糖实验”。
美国斯坦福大学心理学教授沃尔特·米歇尔选了十几名幼儿园的孩子,让他们坐在房间里的椅子上,要求坐满15分钟。面前的桌子上,放的是孩子们最爱吃的棉花糖。
实验的规则是,如果你马上吃掉糖,就不能获得奖励;如果你能等15分钟以后再吃,就会额外得到一块糖作为奖励;不愿意等的孩子可以按桌子上的铃。
实验开始以后,研究人员发现一少部分孩子不假思索立即抓起眼前的糖吃掉了;有些孩子30秒以后陆续开始按铃;最后,只有30%左右的孩子等到15分钟期满才吃糖。
研究人员对参加实验的孩子进行跟踪,发现那些愿意等待的孩子在后来的人生中取得了更大的成功,包括职业的成功;那些不擅长等待的孩子,成年以后体重更容易超标,成就相对较低,而且不少人染上了毒品。
这个实验提出了“延迟满足”的概念。能够做到延迟满足的人总是会取得更大的成就。
字节跳动创始人张一鸣最喜欢讲的一个词就是“延迟满足”。张一鸣的成功也告诉我们延迟满足确实很重要。
问题是,道理我们都懂,但是为什么能够真正做到“长远思考”“延迟满足”的企业和个人少之又少?为什么长期主义特别难?
这是今天神经科学、心理学、行为经济学等学科都在关注的一个重要研究话题:“跨期选择(intertemporal choice)理论”。也就是在大而迟(Larger - Later,LL)的收益与小而早(Smaller - Sooner,SS)的收益之间,人们的选择倾向。
所有这方面的研究都得出了同样的结论:相对于未来的收益,人们通常会对当下可以获得的收益赋予更大的权重。直白地说,就是人们更看重眼前马上能够得到的收益。
原因很简单,人类是从动物进化而来的。在进化的过程中,人类虽然发展出了对未来进行计划和规划的能力,但是在跨期选择时,我们同其它动物一样,依然偏好于即刻的奖赏。
一些研究者还探讨了跨期选择的神经机制。
2004年,《科学》(Science)杂志发表了一篇著名的报告,第一次从神经机制上证明人的大脑有β、δ两种不同的评估机制。
β机制集中于早期进化的中脑边缘多巴胺系统,主要负责加工当前选项,也就是当前马上要做出的决策、当前的诱惑、当前的利益等;δ系统是相对较晚进化成的额-顶系统,主要负责加工延迟选项,也就是延迟满足的决策。
前者是生存的本能,后者是进化的需要。
两个系统的相对激活水平,决定了被试者的选择。选择过程中,如果我们的β系统被激活,我们就会选择当前的收益;如果δ系统被激活,选择的就是延迟满足。
与此相关的,还有一个跨期选择的认知机制理论,即热/冷系统理论。
这一理论认为,人脑认知机制中存在热、冷两个系统。热系统与个体的冲动行为有关,它是情绪驱动的,表现为简单的条件反射,因而反应速度较快,是较早成熟的一套系统;
冷系统则与个体的自我控制有关,它是认知驱动的,比较审慎,因此也比较慢,是较晚成熟的一套系统。
热/冷系统的交互作用决定了个体在延迟满足中的表现。热系统起主导作用时,个体倾向于选择小而早的收益;冷系统起主导作用时,个体倾向于选择大而迟的收益。
在此基础上,学者们还提出了人类跨期选择的多重自我理论(Multiple-Selves Theory):“目光短浅(myopic)的自我”与“目光长远(farsighted)的自我”,“计划者(planner)”和“实施者(doer)”,“老练(sophisticated)的自我”与“幼稚(naïve)的自我”,等等。
理论是枯燥的,我在这里不想过多介绍理论本身。我们感兴趣的是,这些研究结果告诉管理者什么道理?
我们每个人都是一体两面的,我们身上都有短期主义的影子。更看重眼前的收益,是人性的组成部分,况且未来有很大的不确定性。
对于普通人来说,面临的当前压力或眼前诱惑越大,人的短视的一面就相对越容易被激活,人就越容易表现出短期主义的倾向。

即使是长期主义者也会有短期行为的冲动,也会中途动摇,每个人都会有内心深处的天人交战。
这就是为什么任正非在已经选择了3G这条长期主义赛道后,仍然会为了放弃小灵通而感到抑郁和压力。
我相信李彦宏也是长期主义者,百度也是有长远追求的企业,但是为什么会中途一度放弃云计算?也是同样的道理。
这就是长期主义很难坚持的基本背景。
三、艰难的长期主义者,有丰厚的回报
1.短期主义会带来长远的伤害
长期主义很难,但我们为什么还需要选择长期主义?很简单,因为短期主义会给我们带来长远的伤害。
今天我们谈的话题主要是管理,我们看看短期主义对管理者、对组织至少会造成哪些方面的伤害。
短期主义对于管理的第一个危害在领导力层面。
短期主义的领导者个人必然表现出缺乏远见、自私自利的特征。缺乏远见的人注定成不了事,而自私自利的人注定没有人追随。

人都有私心,但是领导者必须让更多的人为己所用,甚至还要用比自己更强的人,这样才能成就大事业。
因此,领导者必须走出小我,才能成就大我。自私自利的结果一定是众叛亲离。
短期主义对于管理的第二个危害在决策层面。
在两千五百年前就用两句话很好地揭示了短期主义的危害——“见小利,则大事不成。”“人无远虑,必有近忧。”

决策就像下棋一样,有些人可以看到三步、五步之后,甚至更为长远,有些人走一步看一步,只顾眼前。
棋力到了一定程度之后,为什么有些人就是没法成为一流的高手?就是因为大局观薄弱,因而特别容易陷入眼前和局部的争夺,却无法掌控整个的棋盘。
你可以也会取得局部的胜利,但是你并不知道如何利用这些胜利。
什么叫人无远虑,必有近忧?没有长远的眼光,人就很容易在复杂的环境中迷失方向,陷入各种纠结之中,陷入各种患得患失之中。
企业也是如此,赢了眼前,但输掉了长远,赢了局部,但输掉了全局。
过于看重眼前的业绩,就会忽略其他更重要的东西,反而会给企业带来更多更大的问题,伤害了企业的长远发展。
短期主义对于管理的第三个危害在组织层面。
习惯了赚快钱的组织,就再也打不了硬仗。一哄而上,结果一定是一哄而散。
对组织而言最忌讳的就是胜则一日千里,负则一败涂地。历史上这样的组织非常多。
黄巢、李自成、张献忠这样的农民起义军为什么最终成不了事?他们的共同特点就是攻城拔寨,招兵买马,走州过府,随掠而食,哪里粮多就去哪,吃完了再换个地方。
这些人忽略了一个根本,就是组织能力本身的建设,从来没有稳固的根基。这就是所谓的“流寇主义”。
流寇主义在商业世界的表现就是赚快钱,比如那些买买买,但是没有自己核心竞争力的企业;那些今天这个有机会就做这个,明天那个有机会就做那个,却没有核心优势的企业。
历史上,流寇取得的所有胜利都是无根的胜利,注定都只是历史的匆匆过客,永远是草莽英雄,成不了大事。
就根本而言,短期行为表面看来是理性的选择,但从长远来看,其实恰恰是非理性的,因为这种短期行为是以明天为代价换取眼前的利益。
从进化的历史可以清楚看到:短期行为只是基于生存的本能,长期主义才是真正成熟的标志。不管对个人还是对组织都是如此。

我们不能仅仅生活在本能之中不可自拔,要对未来进行思考和规划,这是人类区别于动物最重要的品质。
是否具备这种未来的取向,以及未来取向的高低,其实也是优秀的人和平庸的人、优秀的组织和平庸的组织之间的区别。
我们每个人都有局限和弱点,只有承认局限才能超越局限,只有直面弱点才能跳出短期主义的陷阱。
2.长期主义的价值
短期与长期的选择,其实是一个资源分配的过程。
短期行为是将资源投到当前,被动应对环境的变动;而长期主义是将资源投到未来,主动塑造自己的命运。
个人和组织的资源永远是有限的,你的资源分配到什么地方,你就会收获什么样的结果。
我们究竟为什么需要长期主义?可以从以下几个角度来分析:
第一,从目标感来讲,如果一个人只知投机,那么他即使精于算计、苦心经营,也无法走得长远。
投机者的路会越走越窄,处境越来越差。更主要的是,失去了更好的未来的可能。
而长期主义可以为我们的人生提供明确的方向和持续的动力。方向感和动力是人生成功和组织成功所需的非常关键的两个条件。
第二,从认知上来讲,短期主义是以浮躁应对浮躁,以短视应对短期。
长期主义赋予我们全新的认知框架,让我们从更长的时间维度,看清哪些是一时的喧嚣、泡沫、杂音,哪些才是真正的大势,从而可以在浮躁多变的时代保持内心的从容、宁静与定力。
《大学》里有一句话,“知止而后有定,定而后能静,静而后能安,安而后能虑,虑而后能得。”其实就是从认知到最终结果的全过程。
知道未来方向要什么,才能有定力,心定之后,才会静,心不妄动才能从容安详,才能展开深层的思考,才会找出解决问题的最佳方法,得到最好的结果。
中国人讲“势利”,“利”和“势”是分不开的,有势就有利,有大势才能有大利。
所以不要先求利,而要先取势。如果只盯着眼前的小利,那得到的最多也只是小利;只有取得大势,才会获得大利。
《孙子兵法》讲过,真正的高手是“求之于势,不责于人”,也就是在借势、造势方面下功夫,而不是苛求自己的团队成员或下属。
企业管理也是这样,遇到问题时如果没有长远的思考,不能跳出来看问题,就只会在具体的人、具体的事上去争对错。长期主义者会从“势”的角度考虑问题,从根本上解决问题。
这是两种完全不同的认知模式。长期主义才会让你做出基于长期的选择,这是认知的价值。

第三,从行动上来讲,长期主义可以赋予我们眼前的行动以深远的意义,让我们的努力有了一致性和连续性。
长期主义并不排斥短期行为,不排斥眼前的选择。
前面讲过下棋,棋当然要一步一步地下。但一个棋子如果没有长远的考虑,就是个废子,只有用清晰的战略将棋子联系起来,每个棋子的战略价值和意义才会真正体现出来。
对未来进行长远思考和规划,会使我们更多地考虑到当前行为会对未来产生的影响,从而把长期目标渗透到眼前的决策中,用长期主义来过滤我们的短期行为。
这样的好处是让我们懂得每一步在做什么,懂得每一个具体目标的实现会如何促成总体、长远目标的达成。
这样我们在梳理、筛选眼前的行动时,就不会受短期诱惑的影响,不会掉入短期主义的陷阱,做到有所为,有所不为,防止短期行为伤害长远的发展。
这样一来,我们就可以把战术性的机会发展成为战略性的胜利,把眼前的机会发展成为长远的胜利。
第四,从竞争的角度来讲,长期主义是跳出内卷式竞争的最好选择。
并不是所有人或组织都会选择长期主义,这就是为什么最后胜出的一定是长期主义者。
亚马逊的前CEO贝佐斯讲过:做一件事把眼光放到未来三年,和你同台竞技的人就很多,但能放到未来七年,和你同台竞争的人就很少了,因为很少有公司愿意做那么长远的打算。

贝佐斯曾问过巴菲特:你的投资理念非常简单,为什么大家不会复制你的做法呢?巴菲特说,因为没有人愿意慢慢地变富。
长期主义其实是违背人类基于生存的本能的,长期主义并不是所有人都能够做到,也不是所有人都会选择的。
但是我们知道,少人走的路才是最好的路。在长期主义的道路上,你不会遇到多少竞争者。所以长期主义才是跳出眼前内卷式竞争的最好选择。
四、如何成为长期主义者?
首先,长期主义是一种觉醒。
想做到长期主义,我们首先必须认识到,我们自身或者我们的组织都有两套系统在起作用,我们身上都有短期主义的一面。
这是我们首先必须认知和承认的现实。因此我们要随时警惕短期主义的冲动,要有意识地选择并不断强化自己的长期主义特质。
长期主义是需要激活、也是可以激活的;是需要强化、也是可以强化的。长期主义是一种价值观,也可以变成一种习惯性的思维与行为模式。
换言之,人和组织都是可塑的,短期主义是像地心引力一样的存在,我们要做的,就是始终用长期主义来校正我们的行为,保证我们不会偏离长期主义的主线。
古人说“吾日三省吾身”,如果你没有认识到自身和组织的两套系统,你就很容易滑向短期主义而不自觉。
其次,长期主义是一种信念。
长期主义是关于未来的选择,而未来是不确定的,还并不是现实。所以,一旦失去对未来的信念,人们就会放弃长期主义,追求短期利益。
我和胡大源教授在国发院有一门课,带着学生去实地体验“四渡赤水”,告诉大家在不确定的环境中究竟该怎么做决策、带团队。
四渡赤水是长征中的一部分,长征很伟大,但是参加长征的每个人都走到了最后吗?不会的。
有人会离队,有人会叛变,有人会投降,甚至有些早期很有名的人消失了。这些离开的人有一个共同特点——信念出现了动摇。

悲观主义者更容易选择眼前,乐观主义者更容易相信未来。
人只有对未来有信心,才会放下眼前较小的回报,去追求长远较大的回报。
人关于未来的信念越强烈,做选择时我们就会越倾向于长期主义,就越能忍受寂寞和痛苦。
有些人甚至把这种坚持视作一个愉悦的过程,当成是一个自我突破和自我实现的过程,从中获得巨大成就感,因为这样是超出了其他人。
作为长期主义者,你必须相信你的信念,你才能实实在在地看见你的未来,未来才会变成真正的现实。
长期主义是个人和组织具有持久和持续发展可能性的唯一支撑点。
具体而言,在我看来我们需要有以下六点“相信”:
第一,相信长期的力量。
要相信你的长期理性。在大和小之间,要选大不选小;在长和短之间,要选长不选短。
长期理性可以让你从更大的框架、更高的视角、更长的时限来思考你遇到的问题,这样你就会做出最理性的选择。
不要因为短期的理性反而导致了长期的非理性,要相信你的长期理性一定是对的。
克制与耐心是人类理性最高贵的品质。相信长期的力量,你就可以具备这样的品质。
第二,相信信念的力量。
我们前面提到的跨期选择研究发现,积极的希望情绪可以提高个体在跨期选择中的自我控制能力。越积极,越相信,选择过程中的自控性就越强。
所谓信念,就是相信正面的理念一定能够实现。
强烈的信念是人和组织最主要的力量来源。
无论是战争的历史,还是今天企业的创业,一个弱小的组织最终取得胜利,核心原因之一就是从一开始就具有强烈的信念,并且相信自己的信念。
“相信信念”这个层面中非常关键的一点,是一定要形成团队的氛围,因为组织内部成员的观点和行为可以相互影响,信念可以相互激励。
一个特别有意思的现象是,长期主义的领导会吸引长期主义的追随者,短期主义的领导必然会吸引那些只追求短期利益的下属或者团队成员。
从这个角度来讲,其实信念、信任、信心、信仰可以良性地互相促进。
团队内部的相互信任会使得成员都更倾向于相信这个团队的整体信念,一群人在一起相互吸引,相互激发,释放出无穷的潜力,最后把信念变成现实。这就是信念的力量。
曾鸣教授讲过一句话我非常认可:组织的愿景是用来相信的,不是用来挑战的。如果成员怀疑和质疑组织的愿景,事情就根本做不成,必须相信它,它才会变成现实。

第三,相信共生的力量。
不管在任何领域里,竞争和敌对意识会影响你的战略和思考。
如果你陷入跟对手较劲的死结当中不可自拔,那么即使你赢了,也是残局。
如果从现在看未来,那么你的眼光一定会局限于资源的争夺,你的眼中全是对手。
但是如果从未来看现在,从长期主义的角度回头看现在,你关注的就是如何创造出未来的大局,甚至眼前的竞争者都可以被纳入到你共创未来的大局中。
所以,不要只盯着一时的胜负得失,而要着眼于不断演化的大局。相信共生的力量,你才能超越一时一地的得失。
第四,相信基本面的力量。
基本面就是管理中的基本优势,包括人才、文化、战略、组织、领导力、执行。
无论是在军事还是在商业化的今天,我们常常发现自己处于浮躁的环境中,人和组织很容易在走的过程迷失自己。
最终是管理中最基本、最简单、最普通、最质朴的常识性要素,以及它们之间的动态匹配程度,决定了你和组织到底能走多远。
有了扎实的组织才能更好地打仗,才会取得更大的、持续性的胜利。
我们经常会把眼前的短期业绩跟组织的长远投入对立起来,看重眼前的业绩往往就忽略了组织长远的发展。
但是,真正的好组织、真正的长期主义,就是通过组织能力的构建、基本面的夯实来给自己创造取得更好更大的业绩的机会。
更长远来讲,夯实你和组织的基本面,才能夯实组织的根基,才可以在动荡的环境中经历大风大浪而岿然屹立。
第五,相信专注的力量。
我们要在一个清晰的方向持续不断地投入和累积。
长期的价值创造一定是一个持续的过程。只要你的大方向没有错,只要你愿意在这个大方向上持续不断地投入,最终你大赢的可能性反而比你四处出击要高出很多。
第六,相信向善的力量。
今天的行业和市场一直在不断变化,但是我们看到,人类向善利他的大方向从来没有变过。从进化的角度讲,这是人类生存和发展的需要。
因为只有有利于社会整体利益的行为,才会得到社会长期的奖励。只有形成合作、利他、向善意识的社会,才能在进化的竞争中生存和发展。
几乎所有世界性的宗教和世界性的思想体系都是教人向善的。
其实企业也是如此,企业的终极意义就是创造社会价值,推动人类进步,只有这样的企业才能赢得社会的认同和尊重,才能与社会形成良性互动和正向循环。
企业当然要追求利润,但是缺乏道德感的企业无法走得长远。
长期的成功一定是价值观的成功,伟大的企业一定是向善的企业。
这是让自己和组织变得强大的一种精神内核,能够历经任何挫折,实现长期生存和不断发展的根本原则。这就是平庸和卓越的最大区别。
那些为社会创造长远价值的企业,社会最终一定会给它长远的奖励。

最后,长期主义是一场修炼。
认识到长期主义很容易,做到非常难。我们必须认知到这个现实,因为人性是有弱点的,我们永远要面对大脑中两套系统的纠结。
知易行难。
在长期与短期之间、在全局与局部之间、在追求使命与追逐眼前利益之间,当这些纠结出现的关键时刻,你究竟如何抉择,最能暴露你深层次的追求究竟是什么,也最能决定你和组织的最终命运。
在坚持长期主义的过程中,你会动摇,会怀疑,也会犹豫,但这反而恰恰是你和你的组织成长、成熟的过程。
五、结束语
如何成为长期主义者?很简单,做难而正确的事情。
管理就是要做难而正确的事情,人生也是要做难而正确的事情。
回到我们的主题:浮躁的时代,我们为什么需要长期主义?因为这是唯一难而正确的事情。

我非常喜欢下面这段话:“真正的光明绝不是没有黑暗的时间,只是永不被黑暗所掩蔽罢了。真正的英雄绝不是永没有卑下的情操,只是永不被卑下的情操所屈服罢了。”
套用这段话我想说:真正的长期主义者绝不是永没有短期选择的冲动,只是永不被短期的冲动所动摇罢了。
最后我想用一段歌词来结束我的分享:“是否找个理由,随波逐流;或是勇敢前行,挣脱牢笼;我该如何存在?”
这是歌手汪峰的追问,也是我们每个人自己的追问。
路就在脚下,人是可以选择的,选择什么样的道路,你就会有什么样的人生。
参考文献链接
https://mp.weixin.qq.com/s/G9sAaPkUl3s7QbN5gs0yBQ
https://mp.weixin.qq.com/s/sn6t_BsR7LtzwyyjGbJjEQ
https://mp.weixin.qq.com/s/E9qh7hGVRGbjnMBxMpEVEQ
https://mp.weixin.qq.com/s/kFlCVamnz4p6cJ7p5ynxzg

