


4D RADAR-TESLA汽车-nVidia-摄像头技术分析
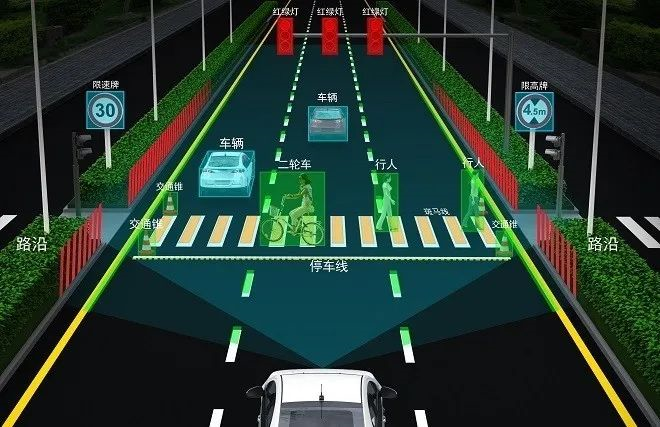
目前4D毫米波雷达首先要实现对传统毫米波雷达的替代。
成像雷达抢风头
- 4D成像毫米波雷达是消费级自动驾驶车辆的一个重要推动因素;
- 激光雷达不再是关键。
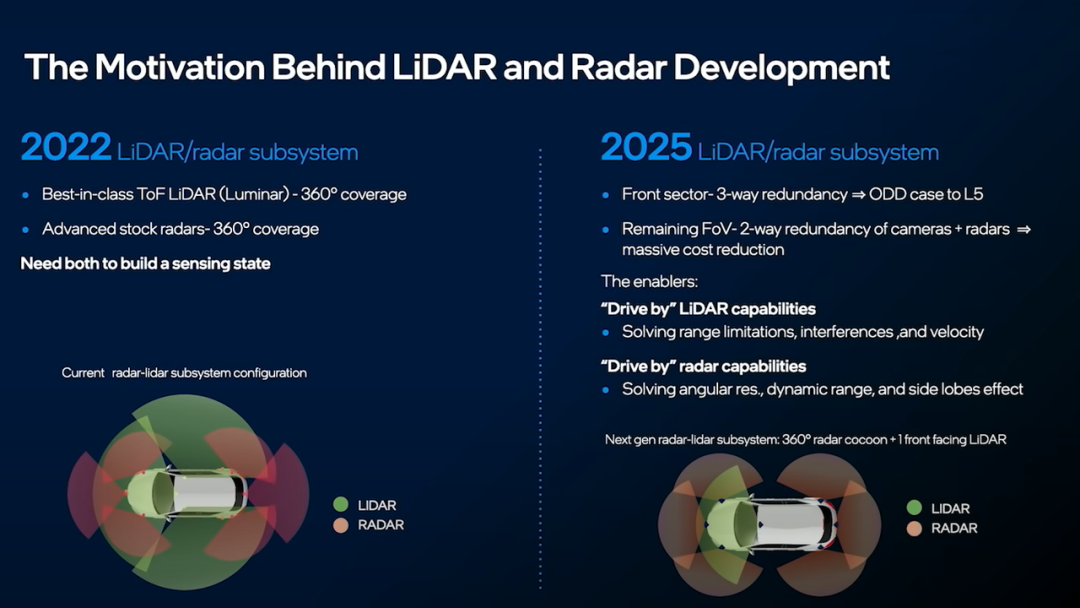
“除了正面,我们只想要毫米波雷达,不想要激光雷达。”Shashua表示。
- 一是基于传统CMOS雷达芯片,强调“软件定义的雷达”,主要厂家有傲酷、Mobileye等;
- 二则是将多发多收天线集成在一颗芯片,直接提供成像雷达芯片,比如Arbe、Vayyar等;
- 最传统的,则是将标准雷达芯片进行多芯片级联,以增加天线数量,比如大陆、博世、ZF等一众公司;
- 四则是通过超材料研发新型雷达架构,代表厂家有Metawave等。
成像雷达只是过渡方案吗?

严格意义上 AI Day 不像是「发布会」,而是「交流会」——马斯克本人也在推特上说,「此活动旨在招聘 AI 和机器人工程师,因此技术含量很高」——换句话说,这是马斯克的高山流水,为特斯拉的锺子期而开。

13 个月前还需要群演的 Tesla Bot,今天正式以原型机的形式出现——原型意思是它还没穿衣服(外壳)。

原型机的样子比 PPT 里面明显更粗放,线束、促动器等零件堆砌略显凌乱。但好消息是,Tesla Bot 原型机已经可以走路、打招呼,双手可以完整举过头顶。

在特斯拉的演示视频里,Optimus 已经可以做一些简单的工作,比如搬运箱子、浇花等等。



但更重要的可能是这个画面:Optimus 眼中的世界,通过纯视觉发现并分析周边的一切,然后识别出自己的任务对象。

事实上 Optimus 不是不能装上外壳,但出于工程原因,带外壳版本截止到发布会当天还不能自如地走路(原因后面再解释),只能简单挥舞一下手臂。

装上外壳之后我们发现,更接近量产版的 Optimus,变得更胖了——现在它重 73 公斤,比去年 PPT 版「增重」超过 20%,整个「人」圆了一大圈。
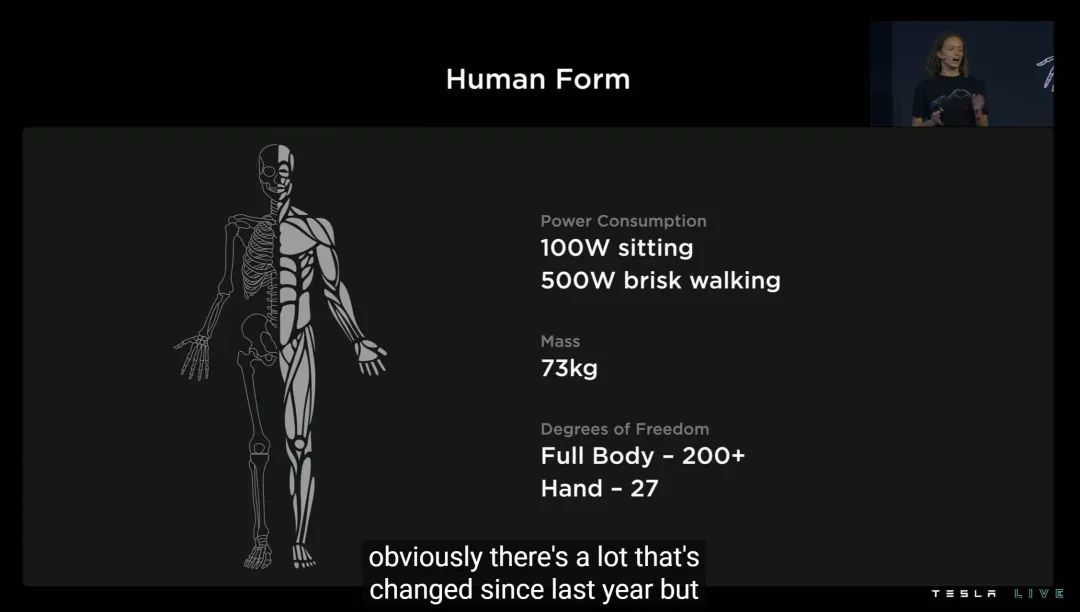
更接近量产,也意味着 Optimus 更高阶的参数也可以公布了:100W 静坐功耗、500W 快步走功耗、超过 200 档的关节自由度,光手部自由度就有 27 档。

另外,Optimus 的大脑由单块 FSD Chip 组成,意味着算力应该是 HW3.0 的一半(72TOPS);电池则是 52V 电压、2.3kWh 容量、内置电子电气元件的一体单元。

再比如利用汽车大规模零件的生产经验,为 Optimus 挑选尽可能保证成本+效率的原材料。「我们不会用碳纤维、钛合金这样的原材料。因为它们虽然很优秀,但像肩膀这样的易损部位,制造和维修成本都太贵了」。

除此以外,制造 Optimus 的中心思想,也基本和智能汽车相当:减少线束长度、计算和电子控制单元中心化,等等。
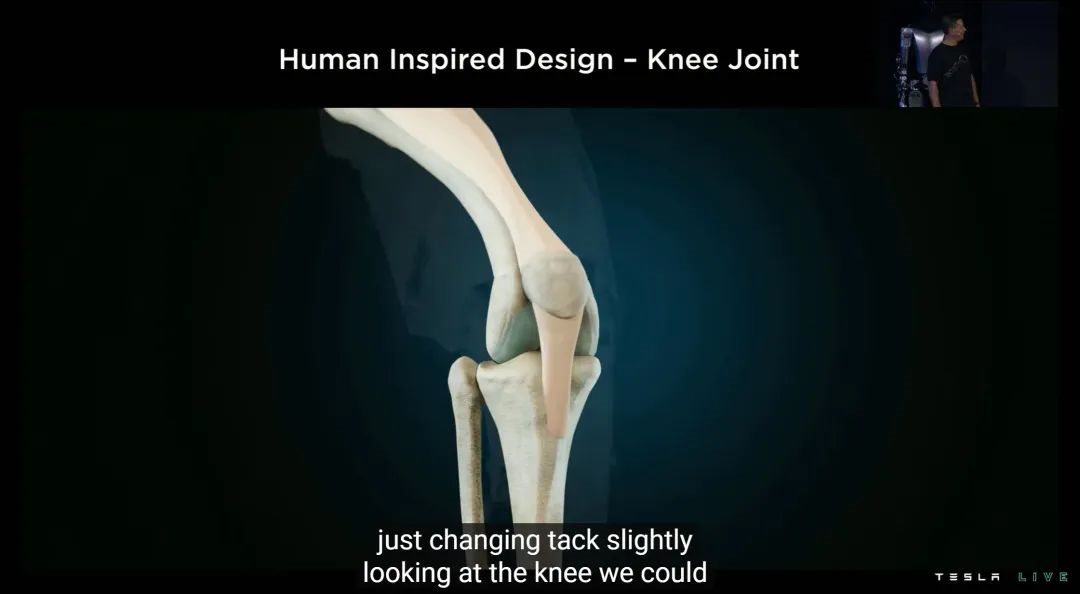
特斯拉用了几个例子解释 Optimus 的仿生学,首先是膝关节。特斯拉表示 Optimus 的关节希望尽量复刻生物学上的「非线性」逻辑,也就是贴合膝关节直立到完全弯曲时的受力曲线。

为此,Optimus 的膝关节使用了类似于平面四杆机构的设计,最终发力效果会更接近人类。

紧接着,我们创造人类文明的双手,才是 Optimus 类人之路更大的 boss。

Optimus 光手掌区域就用了 6 个促动器,具有 11 档的自由度。拥有自适应的抓握角度、20 磅(9 公斤)负荷、工具使用能力、小物件精准抓握能力等等。

此外,Optimus 的手掌用的是「non-backdrivable」无法反向驱动的指尖促动器。学术界的看法是,这样的促动器可以提升在「开放环境」下的性能。

为什么有外壳的 Optimus 还不会走?其中一个原因就是重量变了,运动重心控制算法需要重新调试。

事实上,Optimus 不仅要做到会走路,还要做到别摔倒。所以它不仅需要控制走路的重心,还要稳住受到外力(比如推搡)时的随机动态重心。

训练 FSD 用到的神经网络和在线仿真模拟,这次在 Optimus 身上大显身手。路径规划、视觉融合、视觉导航等等熟悉的名词都被「灌输」到 Optimus 脑子里。

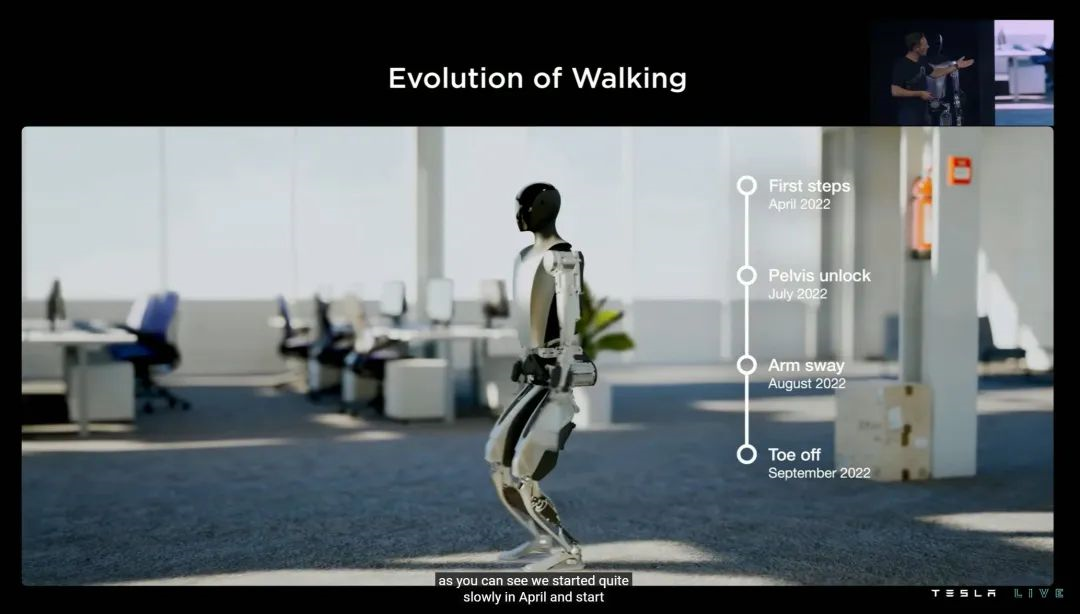
这样的努力下,Optimus 今年 4 月迈出了它的第一步;7 月份解锁了骨盆活动;8 月走路时可以摆手臂了——发布会前几周,实现了脚趾离地的类人行走动作。
3. 「肌肉」

如上图所示,橙色部分均为 Optimus 的促动器,这些促动器也都是特斯拉完全自研的。
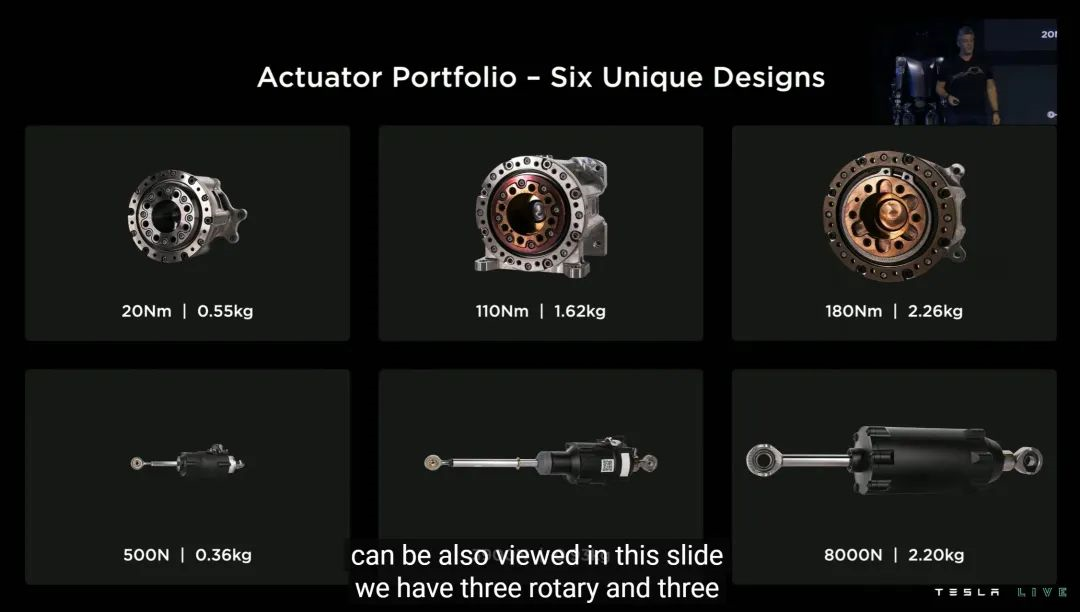
特斯拉为 Optimus 从力度大小的角度,设计了 6 种各自独特的促动器——这其实是很小的数字,业界平均是 20-30,甚至 50 种,目的是覆盖尽可能多的人类活动细节。
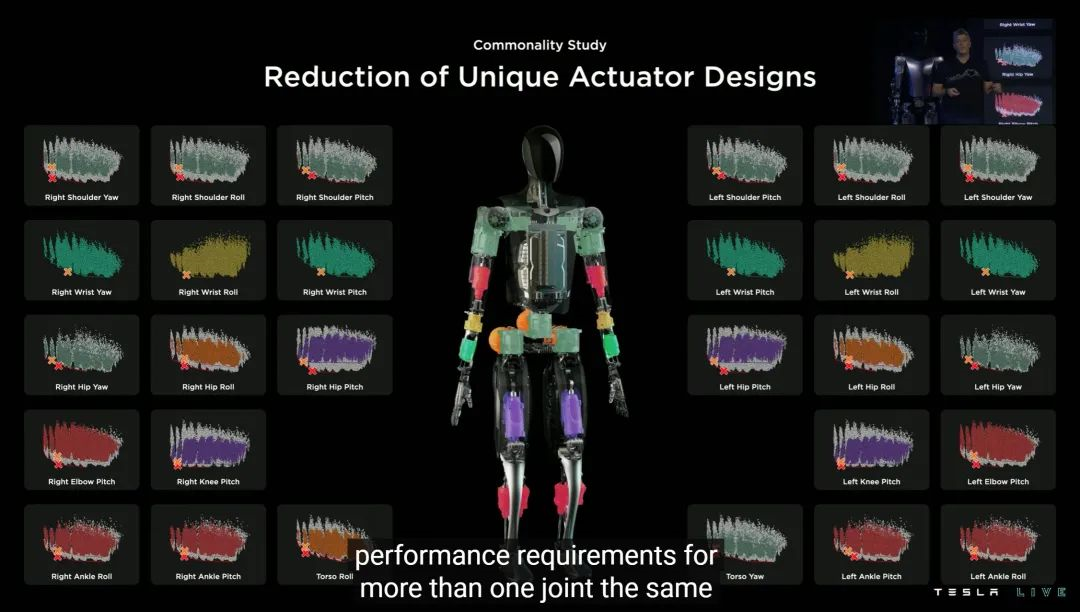
虽然只是轻描淡写的一张 PPT,但我认为促动器从 50 种减少到 6 种,意义实际上远大于借鉴特斯拉电机经验的促动器本体——因为它代表着数据为王的新工业时代。

首先是散热。

特斯拉在 DOJO POD 上使用了全自研的 VRM(电压调节模组),单个 VRM 模组可以在不足 25 美分硬币面积的电路上,提供超过 1000A 的电流。
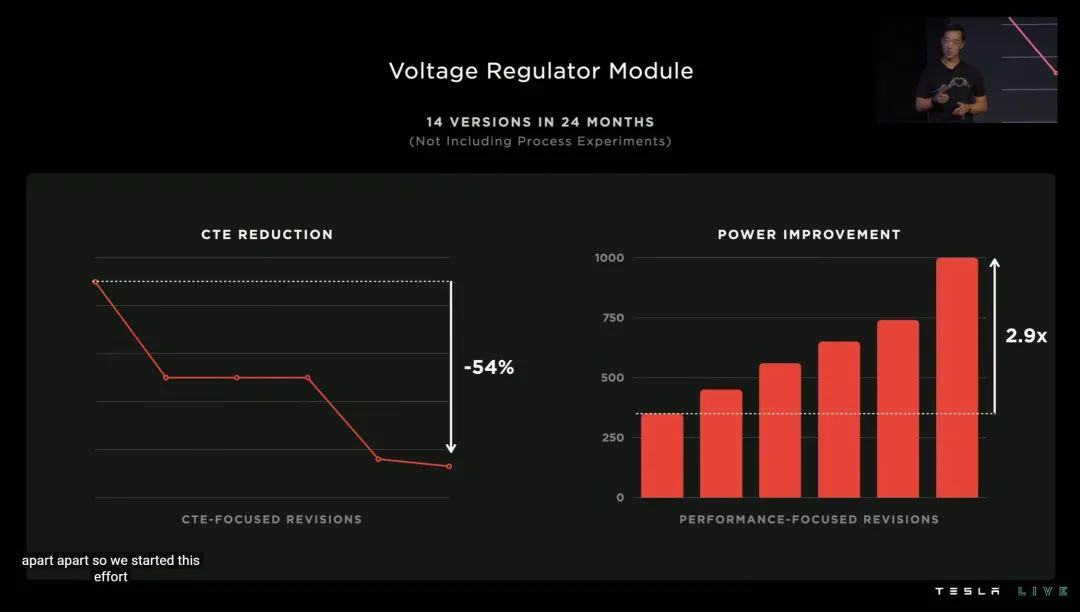
为此,这套自研 VRM 在过去两年内迭代了 14 个版本,最终才完全符合特斯拉对 CTE 指标的要求。

解决了散热,才有资格说集成度。

对了,DOJO POD 的供电模组也是 52V 电压的,Optimus 母亲实锤了。

为了适配训练软件以及运营/维护,每个托盘还配备了专属的管理计算中心。

最终,可以提供 1.1E 算力、13TB 运存、1.3TB 缓存的 EXA POD,将于 2023 年 Q1,正式量产——这也是今天发布会唯一一个有确定日期的特斯拉产品。

意大利炮有了,能不能轰下县城?
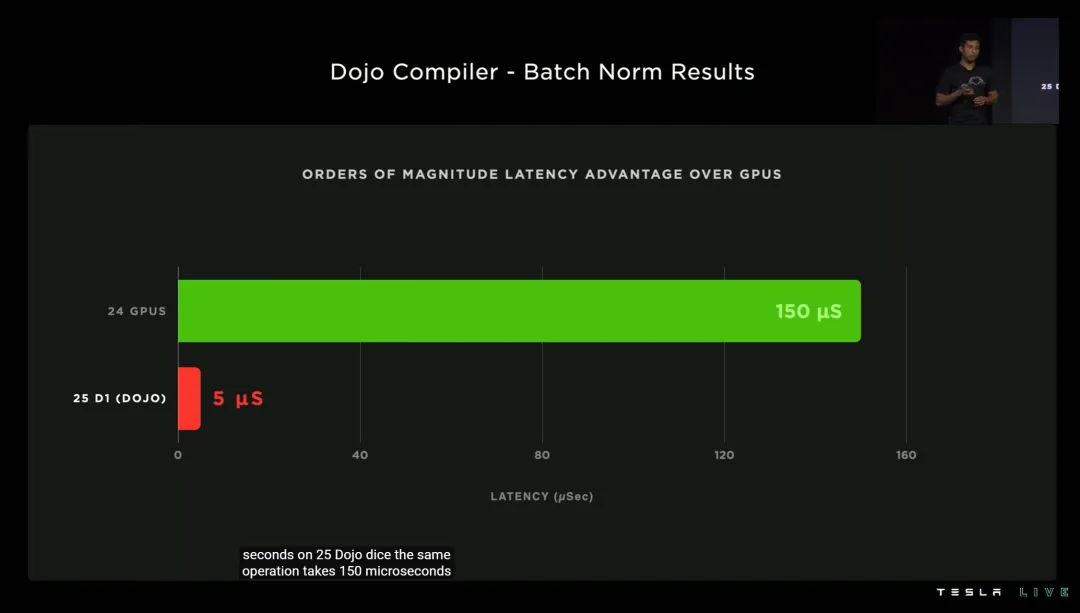
特斯拉表示,配合专属的编译器,DOJO 的训练延迟,最低可以做到同等规模 GPU 的 1/50!
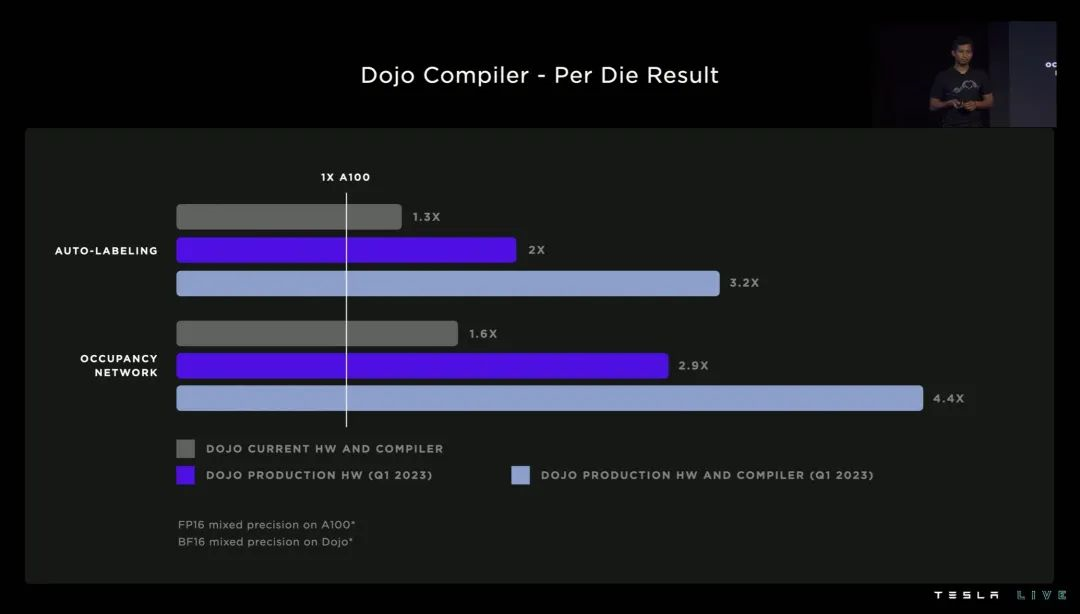
三、FSD 的新进化

篇幅有限,本届 AI Day 关于 FSD 的进展,我们只聊三个点:Occupancy Network、Training Optimization、Lanes。
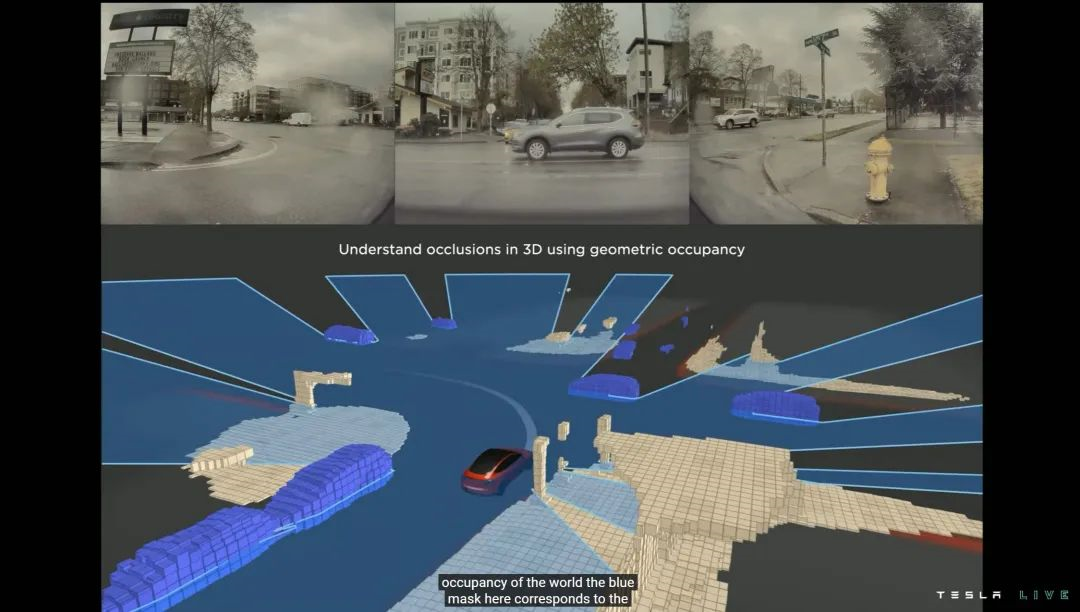
尽管 Occupancy Network 效率很高,但实际训练规模依然足够可观。目前特斯拉公布的数据是超过 14.4 亿帧视频数据,需要超过 10 万个 GPU 训练小时,实际视频缓存超过 30PB——而且全程 90℃ 满负载。

二、因此,Training Optimization 训练优化尤为重要。
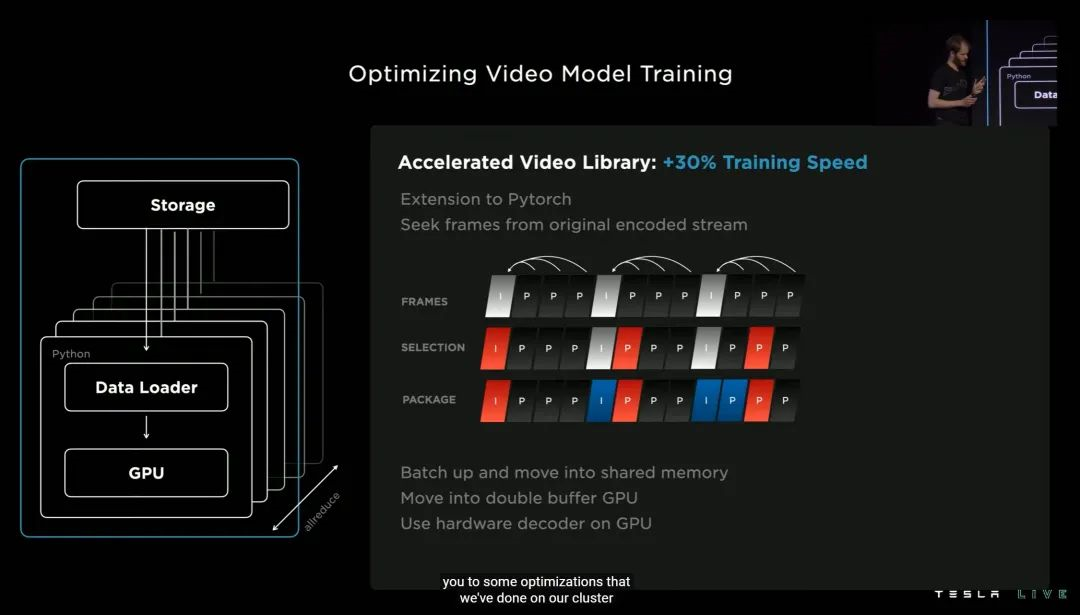
大概总结一下就是,优化过后,训练时视频帧选取会更智能,同时大幅度减少选取的视频帧数量——可以提高 30% 的训练速度。

另外视频模型训练时 smol 异步库文件体积可以缩小 11%,所需的读取次数足足缩小到 1/4...最终这套优化流程让特斯拉的 Occupancy Network 训练效率提升了 2.3 倍。
3. 最后聊聊车道线 Lanes。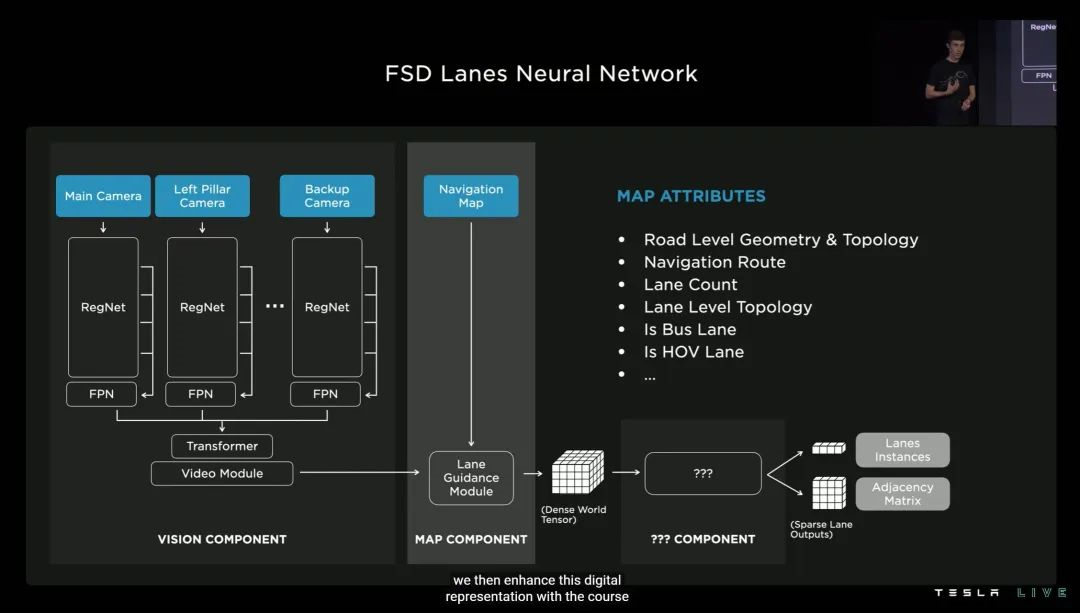
为了更准确高效应对车道线,特斯拉这次「编」了一套「属于车道的语言」。其中包括车道级别的地理几何学和拓扑几何学、车道导航、公交车道计算、多乘员车辆车道计算等等。
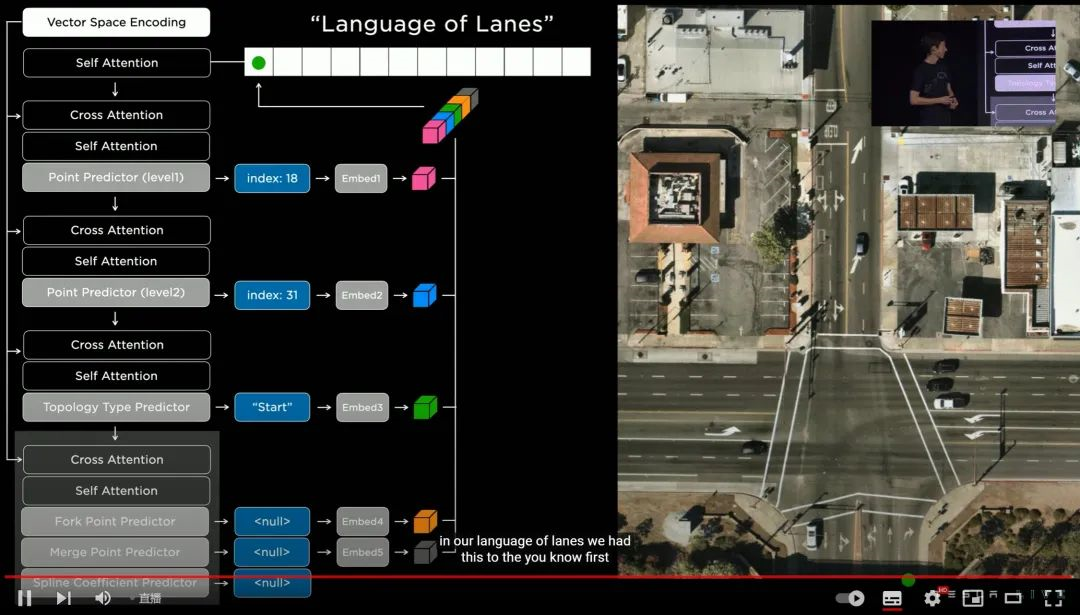
最终这套「车道的语言」,可以在小于 10 毫秒的延迟内,思考超过 7500 万个可能影响车辆决策的因素——而且 FSD 硬件「学会」这套语言的代价(功耗),还不足 8W。

四、四十年后,开始圆梦?
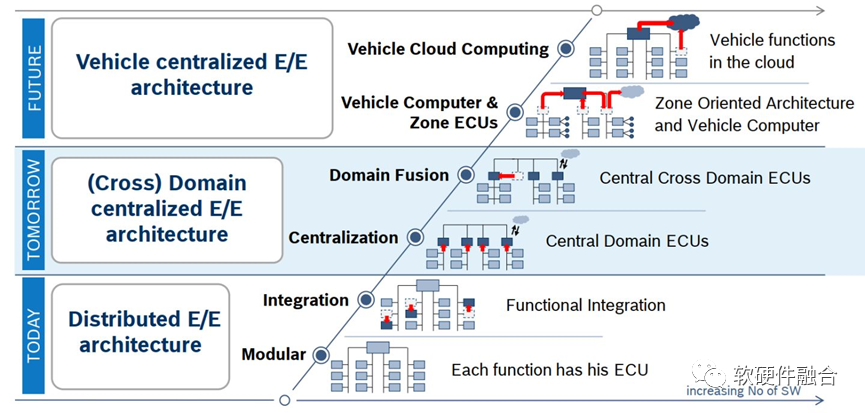
上图是BOSCH给出的汽车电气架构演进示意图。从模块级的ECU到集中相关功能的域控制器,再到完全集中的车载计算机。每个阶段还分了两个子阶段,例如完全集中的车载计算机还包括了本地计算和云端协同两种方式。
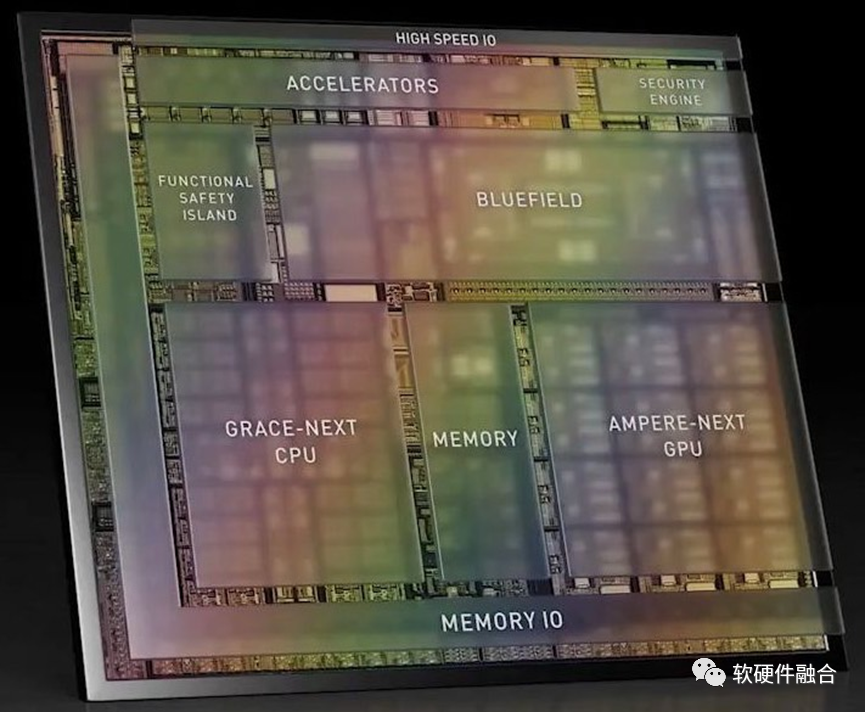
上图是NVIDIA Altan的芯片架构示意图(Thor刚出来,没有找类似的图),从此图可以看出:Altan&Thor的设计思路是完全的“终局思维”,相比BOSCH给出的一步步的演进还要更近一层,跨越集中式的车载计算机和云端协同的车载计算机,直接到云端融合的车载计算机。云端融合的意思是服务可以动态的、自适应的运行在云或端,方便云端的资源动态调节。Altan&Thor采用的是跟云端完全一致的计算架构:Grace-next CPU、Ampere-next GPU以及Bluefield DPU,硬件上可以做到云端融合。

我们可以看到,Mobileye计划2023年发布的用于L4/L5的最高算力的EyeQ Ultra芯片只有176 TOPS。
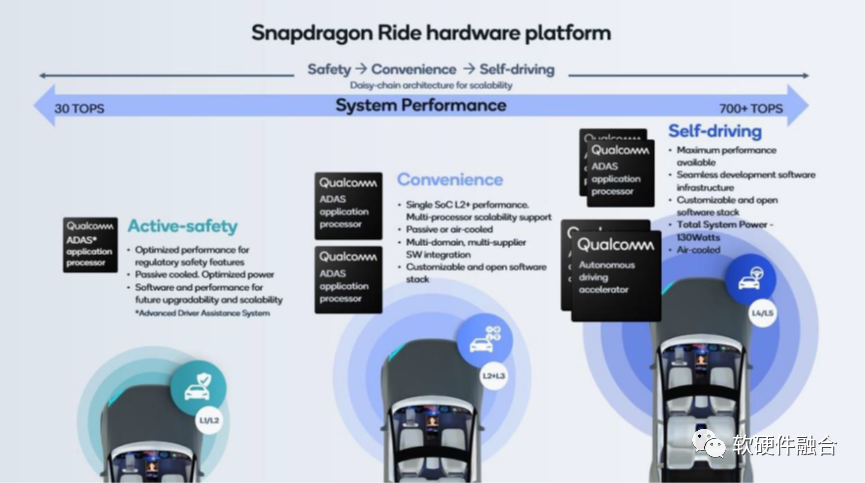
从上图我们可以看到,高通计划的L4/L5自动驾驶芯片是700+TOPS,并且是通过两颗AP和两个专用加速器共四颗芯片组成。
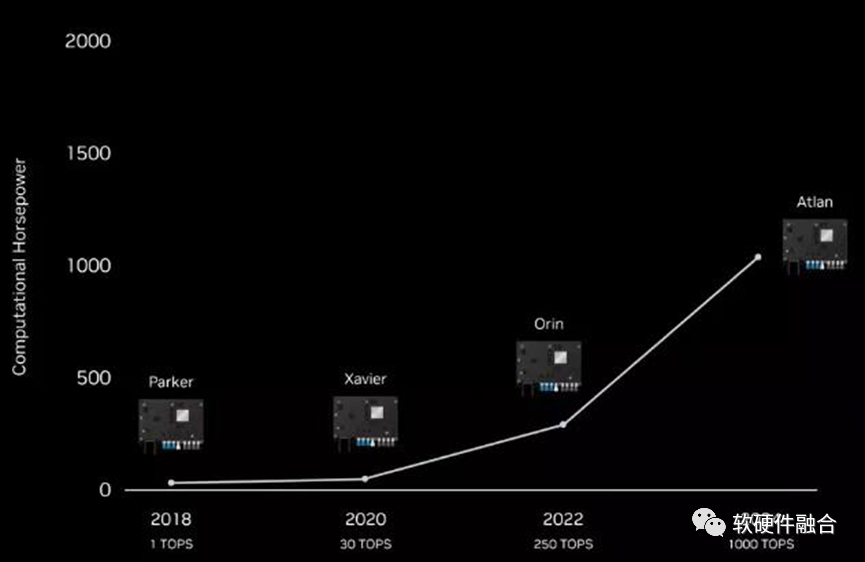
再对照NVIDIA Altan,之前计划的用于L4/L5自动驾驶芯片Altan是1000TOPS算力。
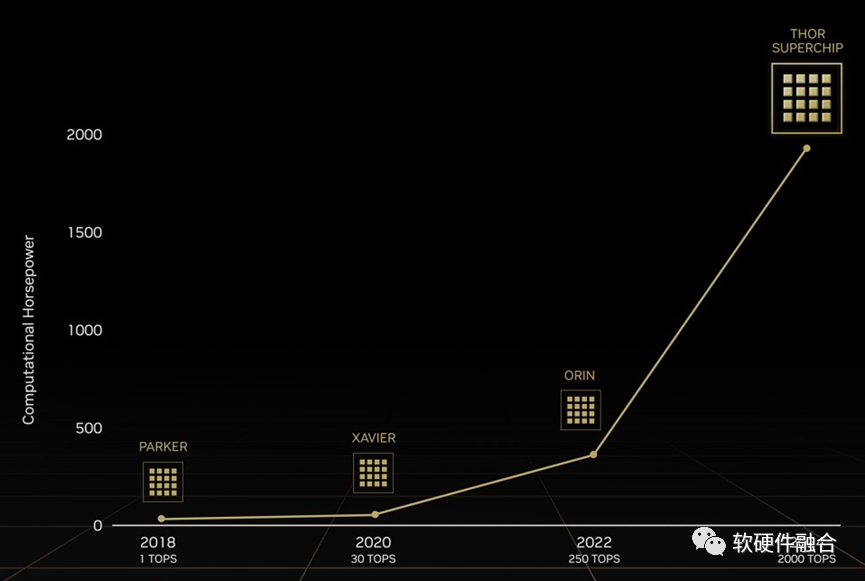
NVIDIA的王炸!推翻了之前的Altan,直接给了一个全新的命名Thor(雷神索尔),其算力达到了惊人的2000TOPS。
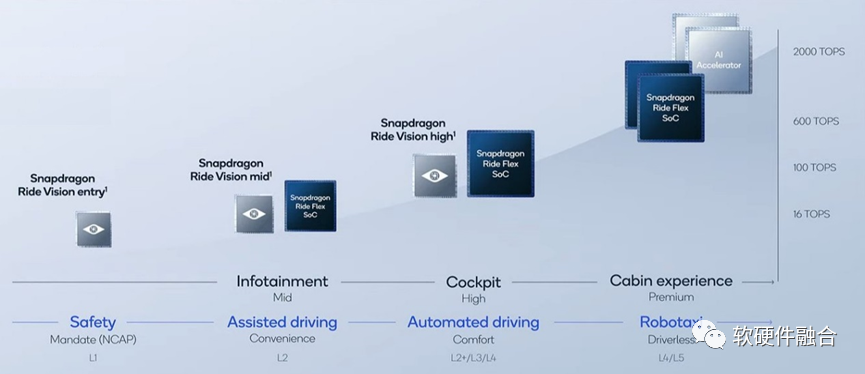
NVIDIA Thor发布之后,高通“快速”的发布了自己的4芯片2000TOPS算力的解决方案。

NVIDIA Thor提供2000TFLOPS的算力(相比较Atlan提供的2000TOPS)。

Thor SoC能够实现多域计算,它可以为自动驾驶和车载娱乐划分任务。通常,这些各种类型的功能由分布在车辆各处的数十个控制单元控制。制造商可以利用Thor实现所有功能的融合,来整合整个车辆,而不是依赖这些分布式的ECU/DCU。

这种多计算域隔离使得并发的时间敏感的进程可以不间断地运行。通过虚拟化机制,在一台计算机上,可以同时运行Linux、QNX和Android等。
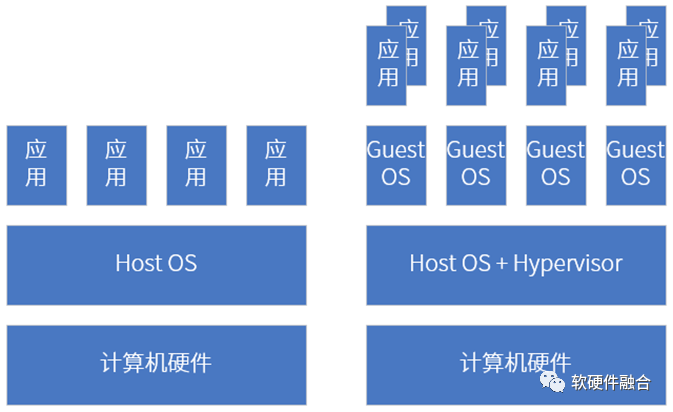
手机、平板、个人电脑等传统AP上部署好操作系统之后,我们在上面运行各种应用软件。整个系统是一个整体,各个具体的进程/线程会存在性能干扰的问题。
- 自动驾驶的智能算法以及各类上层应用,一直在快速的演进升级中。定制ASIC的生命周期会很短,因为功能确定,车辆难以更新更先进的系统升级包,这样导致ASIC无法很好的支持车辆全生命周期的功能升级。
- 整个行业在快速演进,如果未来发展到L4/L5阶段,目前的所有工作就都没有了意义:包括芯片架构、定制ASIC引擎,以及基于此的整个软件堆栈及框架等,都需要推倒重来。
- 需要创新的架构,实现足够通用的同时,最极致的性能以及性能数量级的提升;
- 需要实现架构的向前兼容,支持平台化和生态化设计;
- 需要站在更宏观的视角,实现云网边端架构的统一,才能更好的构建云网边端融合和算力等资源的充分利用。
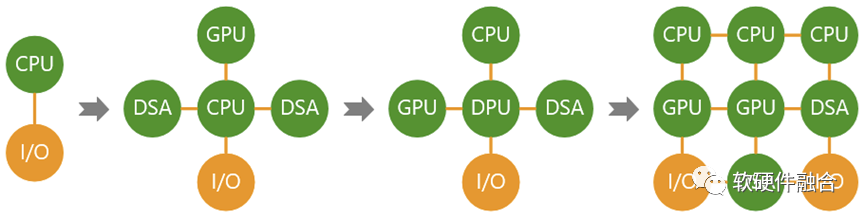
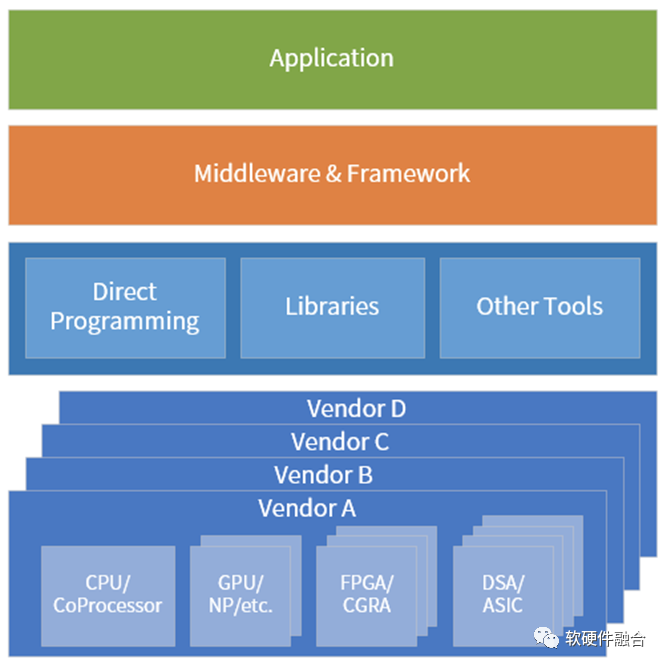
计算机体系结构在从GPU和DSA的分离向融合转变:
- 第一阶段,CPU单一通用计算平台;
- 第二阶段,从合到分,CPU+GPU/DSA的异构计算平台;
- 第三阶段,从分到合的起点,以DPU为中心的异构计算平台;
- 第四阶段,从分到合,众多异构整合重构的、更高效的超异构融合计算平台。
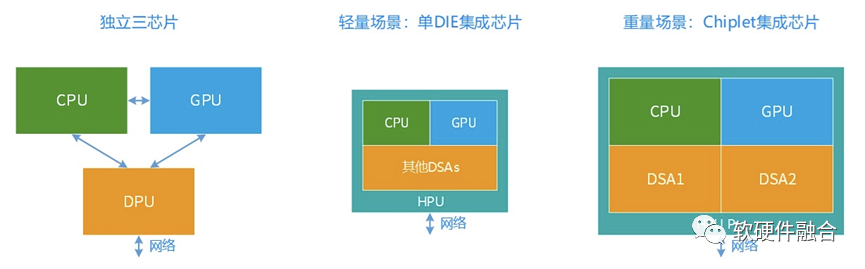
自动驾驶领域已经是Thor这样的功能融合的独立单芯片了,在边缘计算和云计算场景,独立单芯片还会远吗?
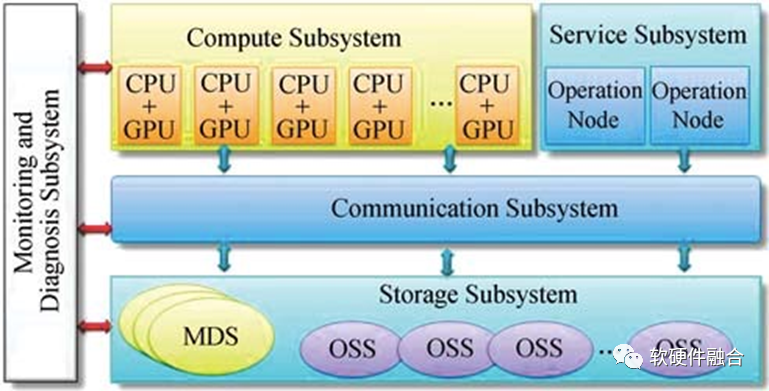
上图为基于CPU+GPU的异构计算节点的天河1A超级计算机架构图。

E级的天河三依然是异构计算架构。

最新TOP500第一名的Frontier,也选择的是基于AMD处理器的异构计算架构(每个节点配备一个 AMD Milan “Trento” 7A53 Epyc CPU 和 四个AMD Instinct MI250X GPU,GPU核心总数达到了37,632)。

日本的富岳超算所采用的ARM A64FX处理器,是在常规的ARMv8.2-A指令集的基础上扩展了512Bit的SIMD指令,也可以看做是某种形态上的异构计算。
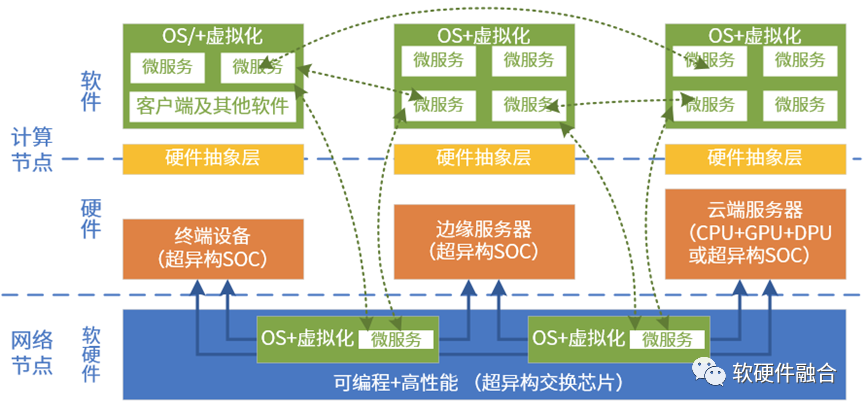
大芯片,担负着宏观算力提升的“重任”。
异质的引擎架构越来越多,计算资源池化的难度也越来越高。在超异构计算时代,要想把异质的资源池化,计算需要做到:
- 维度一:跨同类型处理器架构。如软件可以跨x86、ARM和RISC-v CPU运行。
- 维度二:跨不同类型处理器架构。软件需要跨CPU、GPU、FPGA和DSA等处理器运行。
- 维度三:跨不同的芯片平台。如软件可以在Intel、AMD和NVIDIA等不同公司的芯片上运行。
- 维度四:跨云网边端不同的位置。计算可以根据各种因素的变化,自适应的运行在云网边端最合适的位置。
- 维度五:跨不同的云网边服务供应商、不同的终端用户、不同的终端设备类型。
一. 业务背景
二. 原先的实现方式以及痛点
三. 使用 OpenCV 进行重构
object WImagesProcess { init { System.load("${FileUtil.loadPath}WImagesProcess.dll") } /** * 算法的版本号 */ external fun getVersion():String /** * 获取 OpenCV 对应相机的 index id * @param pidvid 相机的 pid、vid */ external fun getCameraIndexIdFromPidVid(pidvid:String):Int /** * 开启俯拍相机 * @param index 相机的 index id * @param cameraParaMap 相机相关的参数 * @param listener jni 层给 Java 层的回调 */ external fun startTopVideoCapture(index:Int, cameraParaMap:Map<String,String>, listener: VideoCaptureListener) /** * 开启侧拍相机 * @param index 相机的 index id * @param cameraParaMap 相机相关的参数 * @param listener jni 层给 Java 层的回调 */ external fun startRightVideoCapture(index:Int, cameraParaMap:Map<String,String>, listener: VideoCaptureListener) /** * 调用对应的相机拍摄照片,使用时需要将 IntArray 转换成 BufferedImage * @param cameraId 1:俯拍相机; 2:侧拍相机 */ external fun takePhoto(cameraId:Int): IntArray /** * 设置相机的曝光 * @param cameraId 1:俯拍相机; 2:侧拍相机 */ external fun exposure(cameraId: Int, value: Double):Double /** * 设置相机的亮度 * @param cameraId 1:俯拍相机; 2:侧拍相机 */ external fun brightness(cameraId: Int, value: Double):Double /** * 设置相机的焦距 * @param cameraId 1:俯拍相机; 2:侧拍相机 */ external fun focus(cameraId: Int, value: Double):Double /** * 关闭相机,释放相机的资源 * @param cameraId 1:俯拍相机; 2:侧拍相机 */ external fun closeVideoCapture(cameraId:Int)}interface VideoCaptureListener { /** * Native 层调用相机成功 */ fun onSuccess() /** * jni 将 Native 层调用相机获取每一帧的 Mat 转换成 IntArray,回调给 Java 层 * @param array 回调给 Java 层的 IntArray,Java 层可以将其转化成 BufferedImage */ fun onRead(array: IntArray) /** * Native 层调用相机失败 */ fun onFailed()}#include <jni.h>#ifndef _Include_xxx_WImagesProcess#define _Include_xxx_WImagesProcess#ifdef __cplusplusextern "C" {#endifJNIEXPORT jstring JNICALL Java_xxx_WImagesProcess_getVersion(JNIEnv* env, jobject);JNIEXPORT void JNICALL Java_xxx_WImagesProcess_startTopVideoCapture(JNIEnv* env, jobject,int index,jobject cameraParaMap ,jobject listener);JNIEXPORT void JNICALL Java_xxx_WImagesProcess_startRightVideoCapture(JNIEnv* env, jobject, int index, jobject cameraParaMap, jobject listener);JNIEXPORT jintArray JNICALL Java_xxx_WImagesProcess_takePhoto(JNIEnv* env, jobject, int cameraId);JNIEXPORT double JNICALL Java_xxx_WImagesProcess_exposure(JNIEnv* env, jobject, int cameraId,double value);JNIEXPORT double JNICALL Java_xxx_WImagesProcess_brightness(JNIEnv* env, jobject, int cameraId, double value);JNIEXPORT double JNICALL Java_xxx_WImagesProcess_focus(JNIEnv* env, jobject, int cameraId, double value);JNIEXPORT void JNICALL Java_xxx_WImagesProcess_closeVideoCapture(JNIEnv* env, jobject, int cameraId);JNIEXPORT int JNICALL Java_xxx_WImagesProcess_getCameraIndexIdFromPidVid(JNIEnv* env, jobject, jstring pidvid);#ifdef __cplusplus}#endif#endif#pragma onceJNIEXPORT void JNICALL Java_xxx_WImagesProcess_startTopVideoCapture(JNIEnv* env, jobject, int index, jobject cameraParaMap, jobject listener){ jobject topListener = env-> NewLocalRef(listener); std::map<string, string> mapOut; JavaHashMapToStlMap(env,cameraParaMap,mapOut); jclass listenerClass = env->GetObjectClass(topListener); jmethodID successId = env->GetMethodID(listenerClass, "onSuccess", "()V"); jmethodID readId = env->GetMethodID(listenerClass, "onRead", "([I)V"); jmethodID failedId = env->GetMethodID(listenerClass, "onFailed", "()V"); jobject listenerObject = env->NewLocalRef(listenerClass); try { topVideoCapture = wImageProcess.getVideoCapture(index, mapOut); env->CallVoidMethod(listenerObject, successId); jintArray jarray; topVideoCapture >> topFrame; int* data = new int[topFrame.total()]; int size = topFrame.rows * topFrame.cols; jarray = env->NewIntArray(size); char r, g, b; while (topFlag) { topVideoCapture >> topFrame; for (int i = 0;i < topFrame.total();i++) { r = topFrame.data[3 * i + 2]; g = topFrame.data[3 * i + 1]; b = topFrame.data[3 * i + 0]; data[i] = (((jint)r << 16) & 0x00FF0000) + (((jint)g << 8) & 0x0000FF00) + ((jint)b & 0x000000FF); } env->SetIntArrayRegion(jarray, 0, size, (jint*)data); env->CallVoidMethod(listenerObject, readId, jarray); waitKey(100); } topVideoCapture.release(); env->ReleaseIntArrayElements(jarray, env->GetIntArrayElements(jarray, JNI_FALSE), 0); delete []data; } catch (...) { env->CallVoidMethod(listenerObject, failedId); } env->DeleteLocalRef(listenerObject); env->DeleteLocalRef(topListener);}void JavaHashMapToStlMap(JNIEnv* env, jobject hashMap, std::map<string, string>& mapOut) { // Get the Map's entry Set. jclass mapClass = env->FindClass("java/util/Map"); if (mapClass == NULL) { return; } jmethodID entrySet = env->GetMethodID(mapClass, "entrySet", "()Ljava/util/Set;"); if (entrySet == NULL) { return; } jobject set = env->CallObjectMethod(hashMap, entrySet); if (set == NULL) { return; } // Obtain an iterator over the Set jclass setClass = env->FindClass("java/util/Set"); if (setClass == NULL) { return; } jmethodID iterator = env->GetMethodID(setClass, "iterator", "()Ljava/util/Iterator;"); if (iterator == NULL) { return; } jobject iter = env->CallObjectMethod(set, iterator); if (iter == NULL) { return; } // Get the Iterator method IDs jclass iteratorClass = env->FindClass("java/util/Iterator"); if (iteratorClass == NULL) { return; } jmethodID hasNext = env->GetMethodID(iteratorClass, "hasNext", "()Z"); if (hasNext == NULL) { return; } jmethodID next = env->GetMethodID(iteratorClass, "next", "()Ljava/lang/Object;"); if (next == NULL) { return; } // Get the Entry class method IDs jclass entryClass = env->FindClass("java/util/Map$Entry"); if (entryClass == NULL) { return; } jmethodID getKey = env->GetMethodID(entryClass, "getKey", "()Ljava/lang/Object;"); if (getKey == NULL) { return; } jmethodID getValue = env->GetMethodID(entryClass, "getValue", "()Ljava/lang/Object;"); if (getValue == NULL) { return; } // Iterate over the entry Set while (env->CallBooleanMethod(iter, hasNext)) { jobject entry = env->CallObjectMethod(iter, next); jstring key = (jstring)env->CallObjectMethod(entry, getKey); jstring value = (jstring)env->CallObjectMethod(entry, getValue); const char* keyStr = env->GetStringUTFChars(key, NULL); if (!keyStr) { return; } const char* valueStr = env->GetStringUTFChars(value, NULL); if (!valueStr) { env->ReleaseStringUTFChars(key, keyStr); return; } mapOut.insert(std::make_pair(string(keyStr), string(valueStr))); env->DeleteLocalRef(entry); env->ReleaseStringUTFChars(key, keyStr); env->DeleteLocalRef(key); env->ReleaseStringUTFChars(value, valueStr); env->DeleteLocalRef(value); }}jclass listenerClass = env->GetObjectClass(topListener);jmethodID successId = env->GetMethodID(listenerClass, "onSuccess", "()V");jmethodID readId = env->GetMethodID(listenerClass, "onRead", "([I)V");jmethodID failedId = env->GetMethodID(listenerClass, "onFailed", "()V");topVideoCapture = wImageProcess.getVideoCapture(index, mapOut);env->CallVoidMethod(listenerObject, successId); while (topFlag) { topVideoCapture >> topFrame; for (int i = 0;i < topFrame.total();i++) { r = topFrame.data[3 * i + 2]; g = topFrame.data[3 * i + 1]; b = topFrame.data[3 * i + 0]; data[i] = (((jint)r << 16) & 0x00FF0000) + (((jint)g << 8) & 0x0000FF00) + ((jint)b & 0x000000FF); } env->SetIntArrayRegion(jarray, 0, size, (jint*)data); env->CallVoidMethod(listenerObject, readId, jarray); waitKey(100); }topVideoCapture = wImageProcess.getVideoCapture(index, mapOut);VideoCapture WImageProcess::getVideoCapture(int index, std::map<string, string> cameraParaMap) { VideoCapture capture(index); for (auto & t : cameraParaMap) { int key = stoi(t.first); double value = stod(t.second); capture.set(key, value); } return capture;}JNIEXPORT jintArray JNICALL Java_xxx_WImagesProcess_takePhoto(JNIEnv* env, jobject, int cameraId) { Mat mat; if (cameraId == 1) { mat = topFrame; } else if (cameraId == 2) { mat = rightFrame; } int* data = new int[mat.total()]; char r, g, b; for (int i = 0;i < mat.total();i++) { r = mat.data[3 * i + 2]; g = mat.data[3 * i + 1]; b = mat.data[3 * i + 0]; data[i] = (((jint)r << 16) & 0x00FF0000) + (((jint)g << 8) & 0x0000FF00) + ((jint)b & 0x000000FF); } jint* _data = (jint*)data; int size = mat.rows * mat.cols; jintArray jarray = env->NewIntArray(size); env->SetIntArrayRegion(jarray, 0, size, _data); delete []data; return jarray;}val map = HashMap<String,String>()map[CAP_PROP_FRAME_WIDTH] = 4208.toString()map[CAP_PROP_FRAME_HEIGHT] = 3120.toString()map[CAP_PROP_AUTO_EXPOSURE] = 0.25.toString()map[CAP_PROP_EXPOSURE] = getTopExposure()map[CAP_PROP_GAIN] = getTopFocus()map[CAP_PROP_BRIGHTNESS] = getTopBrightness()WImagesProcess.startTopVideoCapture(index + CAP_DSHOW, map, object : VideoCaptureListener { override fun onSuccess() { ...... } override fun onRead(array: IntArray) { ...... } override fun onFailed() { ...... }})val bufferedImage = WImagesProcess.takePhoto(cameraId).toBufferedImage()fun IntArray.toBufferedImage():BufferedImage { val destImage = BufferedImage(FRAME_WIDTH,FRAME_HEIGHT, BufferedImage.TYPE_INT_RGB) destImage.setRGB(0,0,FRAME_WIDTH,FRAME_HEIGHT, this,0,FRAME_WIDTH) return destImage}四. 总结
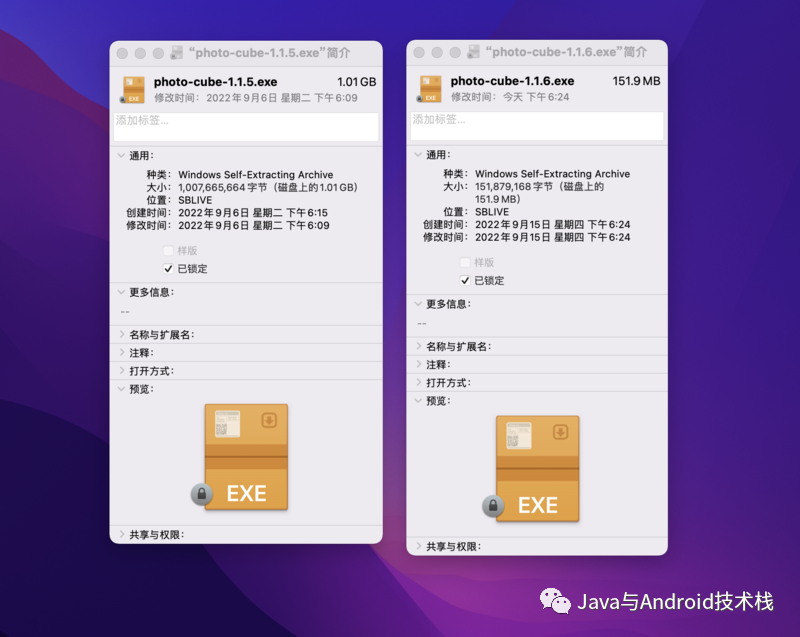
另外,软件在运行时占用大量内存的情况也得到明显改善。如果需要在展示实时画面时,对图像做一些处理,也可以在 Native 层使用 OpenCV 来处理每一帧,然后将结果返回给应用层。

