


自动驾驶芯片-模型轻量化-安全性
自动驾驶芯片-模型轻量化-安全性
参考文献链接
https://mp.weixin.qq.com/s/UXuD_-xWpei-V0KGzCjgFA
https://mp.weixin.qq.com/s/nlHRPZF1P8lXKE32fASuGA
https://mp.weixin.qq.com/s/CXI5FGmKDZM5ruUHl9SKDQ
https://mp.weixin.qq.com/s/IiG2Wi--mlwpn9nD494l8Q
高可靠性设计保障车规安全
汽车电子的快速发展对芯片的功能安全提出了更高的要求。芯片由于热应力、腐蚀和磨损等物理因素会产生随机硬件故障,工程师们需要通过安全的设计和合理的物理布局来规避或者减轻这些随机性的故障,以达到功能安全ISO 26262标准。
先进集成电路技术的快速发展推动着汽车行业走向智能化的未来,将这些先进技术应用到汽车中的同时,安全要求也在不断发展并变得更加严厉。为了应对这些挑战,工程师们正在寻求一种高度自动化的集成功能安全解决方案,以帮助产品更快地获得安全标准认证。
ISO 26262 标准[1]定义了四种不同的汽车安全完整性等级 (ASIL)——A、B、C 和 D——其中 ASIL-D 代表最高安全等级。根据 ASIL 级别,应计算和满足硬件架构指标,包括单点故障指标 (SPFM)、潜在故障指标 (LFM) 和硬件故障概率指标 (PMHF),如表 1 所示。其中,实时故障 (FIT) 率指的是在十亿个设备运行小时内可预期的随机故障数。

表1. 各个汽车安全完整性等级的目标指标
汽车芯片各个部件的安全等级取决于其所需实现的功能。如图1所示,安全气囊、防抱死刹车或动力转向等系统需要 ASIL-D 等级——适用于安全保证的最高严格程度——因为与它们故障相关的风险最高。此外,所有电气和电子系统都必须经过安全分析,例如尾灯和其他部件归类为 ASIL-A,前照灯和刹车灯归类为 ASIL-B,而自适应巡航控制归类为 ASIL-C或D[2]。
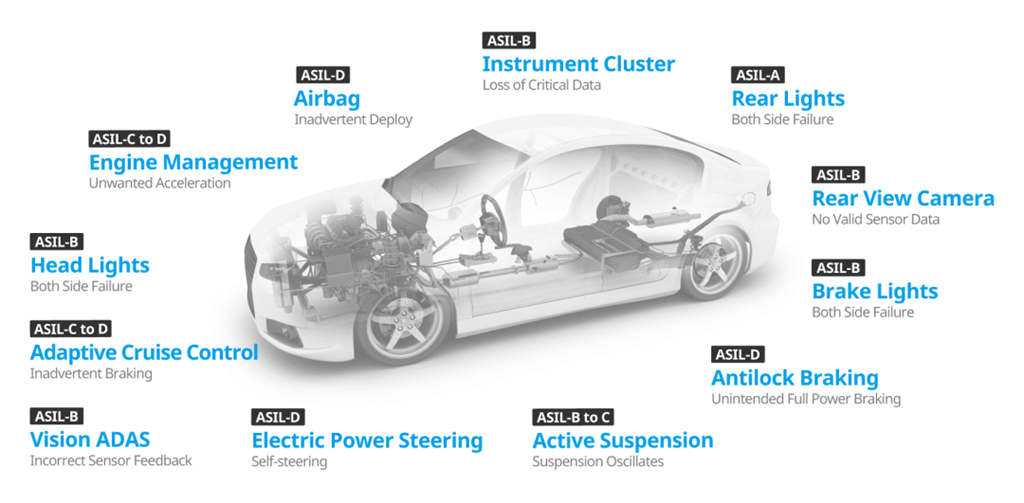
图1. 汽车各个功能安全完整性等级要求[2]
安全机制是芯片上检测和减轻故障的一种功能,它能使设计容忍故障并在检测到故障时反馈故障。为了正常工作,安全机制必须尽可能可靠。从芯片设计角度,工程师既需要在芯片架构上进行安全机制的设计,还需要考虑芯片安全策略在物理实现中的保障。下面本文将从芯片安全机制策略及其在物理实现过程中的保障两个方便进行简要概述。
2.芯片安全机制策略
芯片的故障分为随机硬件故障与系统硬件故障。系统故障是设计中的错误或疏忽。系统硬件故障是由人为错误引起的。相比之下,随机硬件故障是在硬件元件的生命周期内不可预测地发生并且遵循概率分布的故障。它以一种不确定的方式产生,并且与任何明显的问题或错误无关。因此,即使在没有明显缺陷或疏忽的正确设计中,我们也必须考虑随机故障发生的可能性。我们可以通过冗余、运行时间监控、验证测试等来缓解这种故障带来的危害。
2.1硬件冗余
硬件冗余是缓解随机硬件故障的有效方式。寄存器硬件冗余首先需要识别那些易受此类故障影响的逻辑路径。然后必须将这些路径上的寄存器进行冗余设计或替换成容错寄存器。实现的方式有 3 种,选择哪种方式取决于 ASIL 级别。
对于较低ASIL级别的路径,关键路径可以简单地使用容错寄存器来加强,以减少失败的机会,如图2A。在这种情况下,既不能纠正也不能检测到故障,只是简单地降低了故障的可能性。
第二种选择是使用双重模块冗余(DMR),如图2B。但是,这种方式仅对错误检测有用,对纠正无效。需要实施其他逻辑来确定发生错误时要做什么。
最严格的设计依赖于可以纠正故障的三重模块冗余 (TMR),如图2C。每个受影响的寄存器由三个相同功能的寄存器和特定逻辑组成的投票器替换。如果其中一个寄存器发生了其他两个没有发生的故障,则两个正确的值将占上风,从而投票器能隐藏故障。重要的是使三个寄存器彼此远离,并将它们与电路的其他部分电气隔离,以尽量减少可能损害它们相互独立性的任何交互。在这三种策略中,这种方案消耗的芯片面积最多。
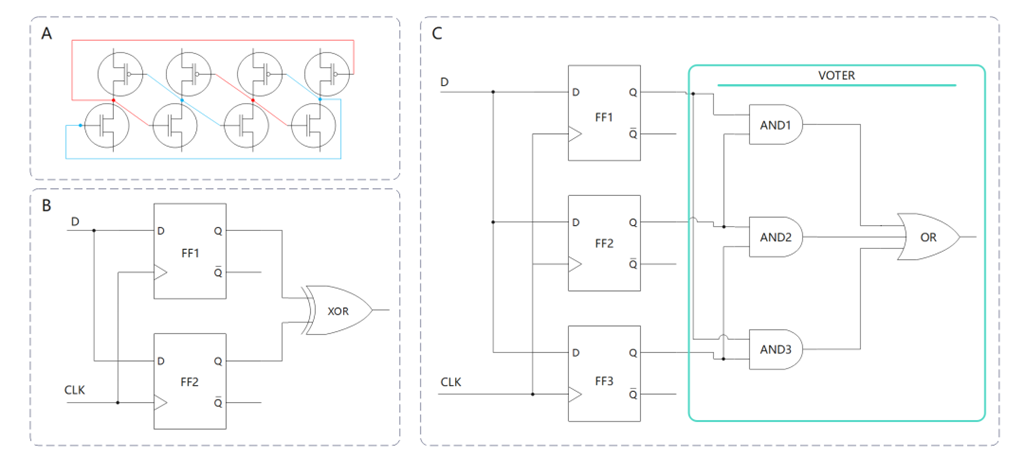
图2. 寄存器冗余设计方案示意图。A. 容错寄存器,B. 双模块冗余,C. 三模块冗余。
除了对关键路径中的寄存器进行冗余设计以外,另一种硬件冗余设计称为双核锁步(DCLS)。如图3所示,DCLS是通过复制同一个核,同时并行运行同一组操作时,可以比较锁步操作的输出以确定是否发生故障。与DMR类似,DCLS只能判断是否存在故障而无法纠正故障。
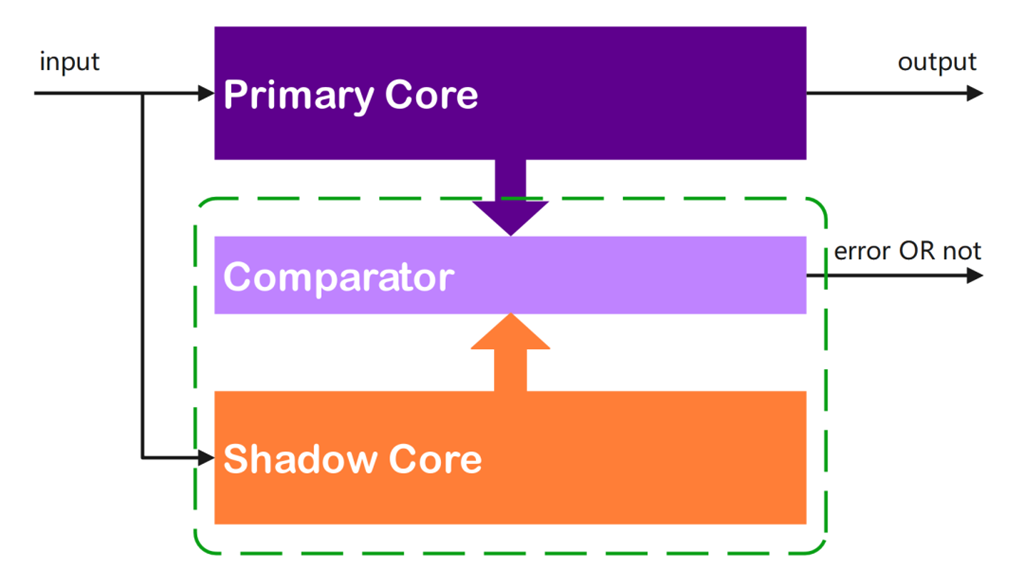
图3. 双核锁步示意图。
2.2校验/纠错码
在计算机、电信、信息理论和编码理论中,校验码(EDC)/纠错码(ECC)是信息传输中错误检测/纠正的工具,它们通常用在不可靠或者嘈杂的信道中。实现错误检测和纠正的一般思路是添加一些信息冗余(例如一些额外数据)到消息,从而使接收器可以用它来检查消息的一致性,并恢复被确定为损坏的数据。它们将消息作为二进制数传输的编码方案,即使某些位被错误地翻转,消息也可以被检测或者恢复。它们几乎用于所有消息传输情况,尤其是在 ECC 保护数据损坏的数据存储中。
奇偶校验位(Parity bit) 或称校验比特(check bit) 是最简单的错误检测码,通过增加1bit信息冗余表示一个给定位数的二进制数中1的个数是奇数还是偶数。如表2所示,对于7位数据,在偶校验的情况下,如果该1的个数为奇数,则奇偶校验位值设置为 1,从而使整个集合(包括奇偶校验位)中出现 1 的总数为偶数。如果给定一组比特中 1 的计数已经是偶数,则奇偶校验位的值为 0。在奇校验的情况下,编码反转。如果值为 1 的位计数为偶数,则奇偶校验位值设置为 1,使整个组(包括奇偶校验位)中 1 的总计数为奇数。奇偶校验位只有在包括校验位在内的奇数个数据位发生改变时,才能检测出错误且不能对错误进行校正。

表2. 奇偶校验位原理示意图。
重复码是一种简单的纠错码。(n,1)重复码将每个数据位发送n次(n≥3),通过对比投票的方式进行解码得到正确数据位。以(3,1)重复码为例,经过嘈杂信道,接收器可能收到8个不同版本的输出,如表3。

表3. (3,1)重复码解码纠错对照表。
2.3共存免于干扰
在同一硬件单元中有时不可避免会出现具有不同ASIL安全级别开发的系统,由于在分配了不同ASIL的系统之间控制潜在故障的程度不同,因此以较高ASIL开发的系统的功能(如汽车制动系统)可能受到以较低ASIL开发的系统(如汽车制动灯系统)的影响。

如图4示,为了防止具有较高错误率 (ASIL-A) 的系统驱动需要较低错误率 (ASIL-C) 的系统,具有不太关键 ASIL 级别的(子)系统不能影响具有更关键 ASIL 的系统。左侧的设计表明 ASIL-A 系统不可能影响 ASIL-C 系统。这意味着 ASIL-C 系统相对于 ASIL-A 系统实现了免于干扰。但是在右侧的系统设计中,存在从 ASIL-A 到 ASIL-C 系统的数据/控制流。因此,ASIL-C 系统并没有实现免于干扰,至少在没有任何进一步分析的情况下,ASIL-C 系统会受到 ASIL-A 系统的影响。在这种情况下,需要采取进一步的设计或验证措施以实现不受干扰。例如,ASIL-C 系统可以首先检查 ASIL-A 系统数据的正确性。考虑到这一措施,ASIL-C 组件将实现免于干扰[3]。
图4. 两个不同安全级别系统之间免受干扰实现策略示意图。
3.安全机制物理实现保障
安全机制的设计需要通过物理布局布线之后才能移交给芯片代工厂加工。随着工艺的演进,单位面积内晶体管数量大幅增加,芯片中金属绕线层阻抗也增加。这些都对于芯片的功能安全具有极大的挑战,因此工程师们还需要从物理层面保障芯片的功能安全性。
3.1强健的绕线设计
通孔是先进 IC 设计的关键结构,它通过垂直连接层来帮助扩展设计空间。尽管通孔在电路设计中很重要,但通常被认为是工艺和可靠性问题的主要来源之一,这些问题可能会降低电路性能,甚至可能使电路失效 [4]。通孔可靠性问题的一个主要来源是电迁移 (EM),即由电子电流引起的金属原子扩散。随着 IC 技术的进步,电流密度会因横截面通孔面积的减少而增加,这会增加故障发生概率。高温和通孔周围的机械应力甚至会进一步增加 EM 故障概率。对于 EM,通孔和金属线的界面是 EM 的最薄弱环节之一。我们可以在图 5中通过局部通孔和导线的 SEM 图像看到这种现象 [5]。

图5. 电迁移导致的通孔损坏SEM图以及对照示意图[5]。
通孔按照形状可分为正方形(square)和长方形(bar)通孔;按照数量可分为单孔(single)和双孔(double)。如图6所示,通孔冗余设计即将方孔替换成面积更大的长方形孔,或者将单孔替换成双孔。通孔冗余设计能减小开路的可能性,减小电阻与电位差,增加抗应力迁移能力,进而改善故障发生概率。
除此以外,我们也可以通过NDR(non-default routing rule,非默认绕线规则)的绕线方式加强布线网络,增强金属线抗干扰能力。NDR绕线指的是在绕线的时候给某些net制定的特殊的绕线规则。现在工具在绕线之前需要制定一个默认规则(default rule),默认所有net都按default rule来绕。而对于指定了NDR的net,EDA工具就会区别对待指定的net。因为NDR的rule和default rule有所区别,绕线的最终结果就会有所不同,相应的也会影响芯片的各项性能。一般来说,使用NDR方式绕线方式(如double width double spacing)能保持更好的信号完整性,但也会占用更多的绕线资源。
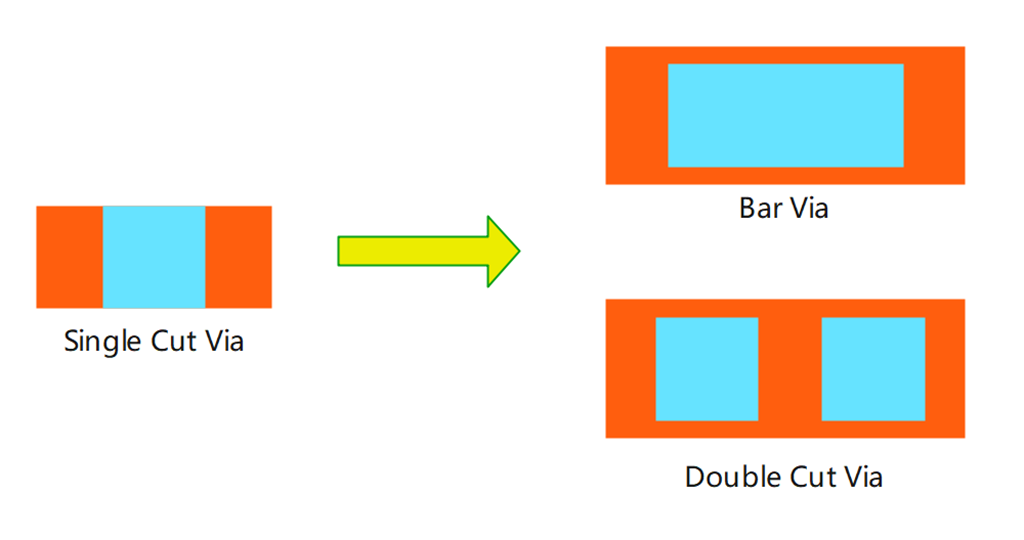
图6. 通孔冗余设计示意图。
3.2冗余寄存器物理隔离
上文中提到了可以通过寄存器的三重模块冗余的方式实现功能安全性能的提升,实际上就是将寄存器复制两份。如果这三个寄存器间距很近,局部的干扰可能会对这三个寄存器中的两个甚至三个产生同样的错误,经过投票机制后仍会导致错误的结果。为了尽可能的降低这种风险,在物理实现中,刻意地将冗余寄存器的位置在横纵方向上进行分离操作将会有助于改善这种风险,如图7所示。我们在物理实现过程中还会使用物理单元(tap cell)将各个寄存器保护起来,以免受到周围其他单元的影响和防止闩锁效应,如图中红色方块所示。为了避免来自时钟树和复位树中存在的共同干扰,可以采取分开生长各个寄存器的时钟树和复位树,减少寄存器之间共同的路径。
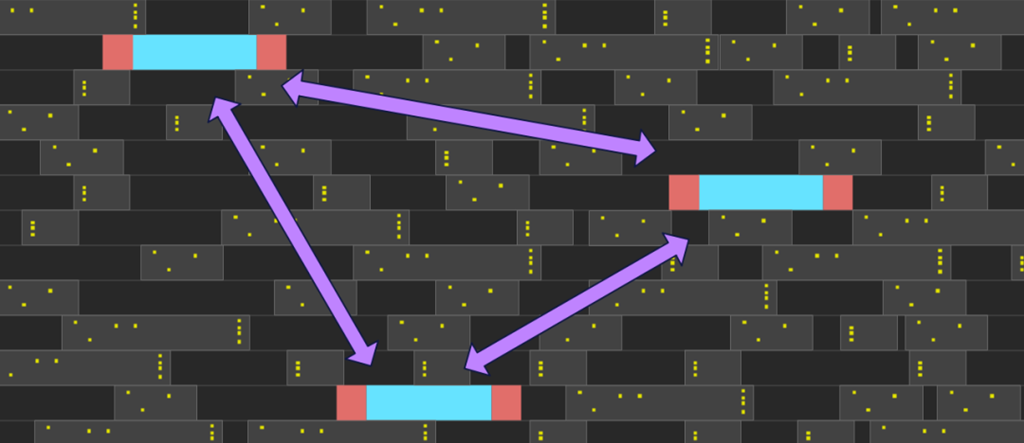
图7. TMR寄存器物理隔离示意图。
3.3双核锁步物理隔离与绕线约束
类似地,双核冗余也需要分隔一定距离。如果不考虑功能安全,后端工具会自动根据线长、时序、拥塞和功耗来确定标准单元的位置,因此会打散双核中标准单元的摆放。为了降低双核同时遭遇随机错误的几率,在物理布局布线时,我们首先要规划两个核的“安全区域”使其彼此排斥。如图8所示,双核锁步中的主核(Primary Core)与冗余核(Shadow Core)需要分组实现,并在两个类似镜像的“安全区域”之中各自布局和布线。时钟树综合中,主核和冗余核的时钟树要彼此分离,避免共用时钟路径和时钟缓冲器。同时,还要设置时钟树绕线障碍,防止一个核的时钟线在另一个核的区域里经过或者穿越,确保主核与冗余核的时钟线互相保持一定的距离。数据的对比/校验逻辑是在Comparator中完成的,避免两个隔离核之间有数据的直接交互,在每一个时钟周期对双核的输出进行比较,在发生故障时输出错误标识信号,以供系统及时采取应对措施。
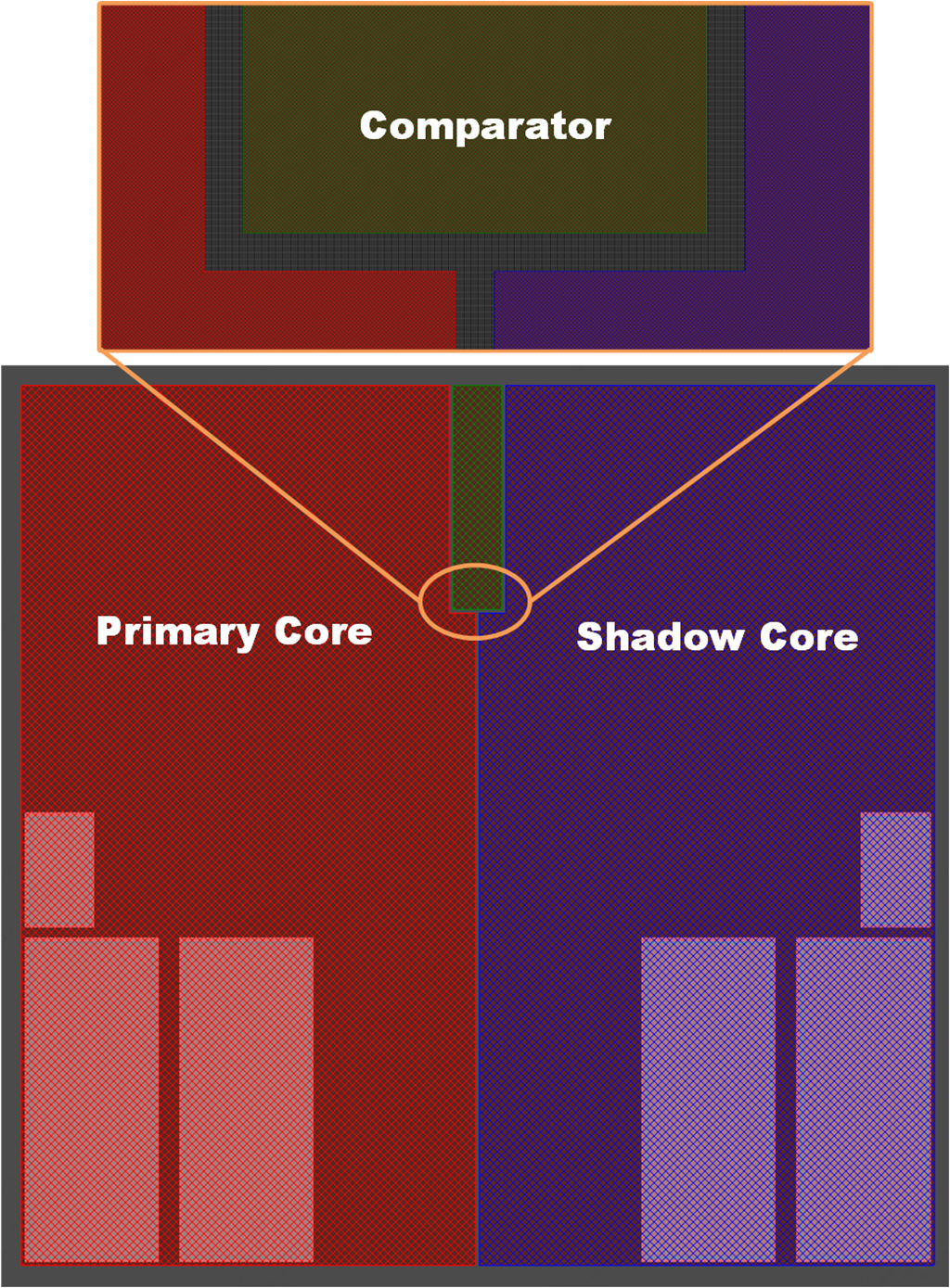
图8. DCLS物理布局布线示意图。
4.结语
随着汽车电子系统功能安全要求的不断提升,对车规芯片安全性的需求也在不断加强,符合功能安全要求已然成为了车规芯片进入市场的必需要求。汽车自动驾驶技术的发展带来的汽车电子复杂度的提升,先进制造工艺带来的晶体管密度的提升,都对芯片的功能安全提出了更高的要求。如何设计生产出国产高安全可靠的车规芯片,需要工程师们对技术难关进行不断攻克并总结经验。
reference:
1.International Organization for Standardization, “ISO 26262-1:2018 – Road Vehicles – Functional Safety”:https://www.iso.org/standard/68383.html
2.ABLIC Inc. "Introduction – What is Functional Safety?":https://www.ablic.com/en/semicon/products/automotive/asil/
3.HEICON Global Engineering GmbH, "ISO 26262 Freedom from interference – What is that?":https://heicon-ulm.de/en/iso26262-freedom-from-interference-what-is-that/
4.Zhou, Han, Liang Chen, and Sheldon X-D. Tan. "Robust power grid network design considering EM aging effects for multi-segment wires." Integration 77 (2021): 38-47.
5.Pak, Jiwoo, Bei Yu, and David Z. Pan. "Electromigration-aware redundant via insertion." In The 20th Asia and South Pacific Design Automation Conference, pp. 544-549. IEEE, 2015.
芯片算法成本占比竟超四分之三,国产毫米波雷达如何破局?
9月15日-16日,盖世汽车主办的“2022第五届自动驾驶与人机共驾论坛”在上海绿地公馆会议中心成功举办。本次大会中,多家毫米波雷达企业出席并荣获“自动驾驶毫米波雷达优质供应商”称号,被收录于2022盖世汽车优质供应商名录。

图片来源:盖世汽车
从全球市场看,车载毫米波雷达市场份额绝大部分被博世、大陆、安波福、海拉、维宁尔、电装等巨头瓜分,留给国内厂商的市场空间有限而竞争者众多,虽有少数如森思泰克、华域汽车、大华股份、德赛西威、纵目科技等优秀厂商已做到量产上车,但国产毫米波雷达上车厂商依然很少,国产替代之路才刚刚开始。

图表1 车载毫米波雷达市占率
数据来源:盖世汽车研究院
基于此背景,盖世汽车推出2022版毫米波雷达供应链报告,希望带大家了解更多毫米波雷达行业的情况信息。

(分享文末海报 免费获取完整报告)
毫米波雷达产业链全景
经过多年发展,毫米波雷达越发集成化,产业链已非常成熟。上游为软件算法及硬件零部件企业,其中射频前端MMIC、信号处理芯片及高频PCB(微带贴片天线)为核心部件,中游为各大毫米波雷达生产集成厂商,下游为国内外各大车企及造车新势力。
近些年,因TI芯片开发门槛较低,助力国内诞生了一众中游毫米波雷达创业企业。而上游零部件厂商以芯片和高频PCB供应商为主,目前国内厂商较少,依旧为国外所主导。
图表2 毫米波雷达产业链示意图

以上为毫米波雷达产业链部分优秀企业
分享文末海报 获取毫米波雷达供应链报告
了解更多产业链信息
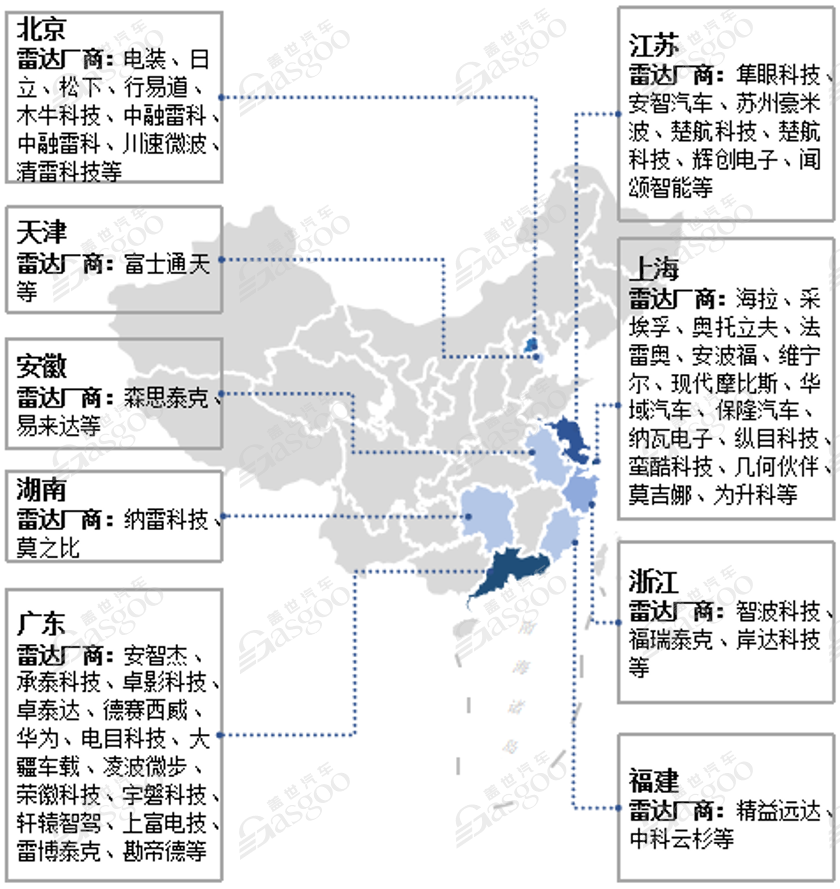
随着国内大批毫米波雷达创业企业的涌现,国内外市场上已经存在着大量的市场参与者;从地域分布上看,北京、上海、广东三地毫米波雷达企业最多,并以各自为中心向周边地区扩散;其中,上海市聚集了大量国外厂商的中国分公司,如海拉、采埃孚、法雷奥、安波福、维宁尔、现代摩比斯等。广东省创业企业较多,如电目科技、凌波微步、宇磐科技、雷博泰克等。
图表3 车载毫米波雷达各地区部分代表性企业
分享文末海报 获取毫米波雷达供应链报告
查看产业链全景及产业地区热力图高清原图
另外,当今市场上毫米波雷达已被大范围采用,从配置方案上主要有1前Radar、1前Radar+2角Radar、1前Radar+4角Radar、2前Radar+2角、2前Radar+4角Radar几种选择。从市场上所装载的车型来看,目前车载毫米波雷达渗透率比较高,但市场依然由国外巨头垄断。国内虽雷达厂商众多,但上车进度缓慢,僧多粥少的情形下国内毫米波雷达该如何破局?
图表3 2022上半年主机厂车型
毫米波雷达搭载情况表

分享文末海报 获取毫米波雷达供应链报告
查看更多毫米波雷达装载车型
笔者认为,国内毫米波雷达想要实现国产替代,不仅要从中游雷达制造厂商入手,还要与上游企业共同发力。从供应链角度来看,国内上游企业力量薄弱,尤其在算法、芯片、高频PCB方面实力竞争者数量较少。因此,毫米波雷达的国产替代之路,不是仅有雷达整机制造企业的替代,而是整条毫米波雷达供应链的替代之路。下面我们将继续分析毫米波雷达成本构成与行业发展趋势,从而探究毫米波雷达国产替代的方向。
毫米波雷达成本构成
图表4 毫米波雷达成本分析
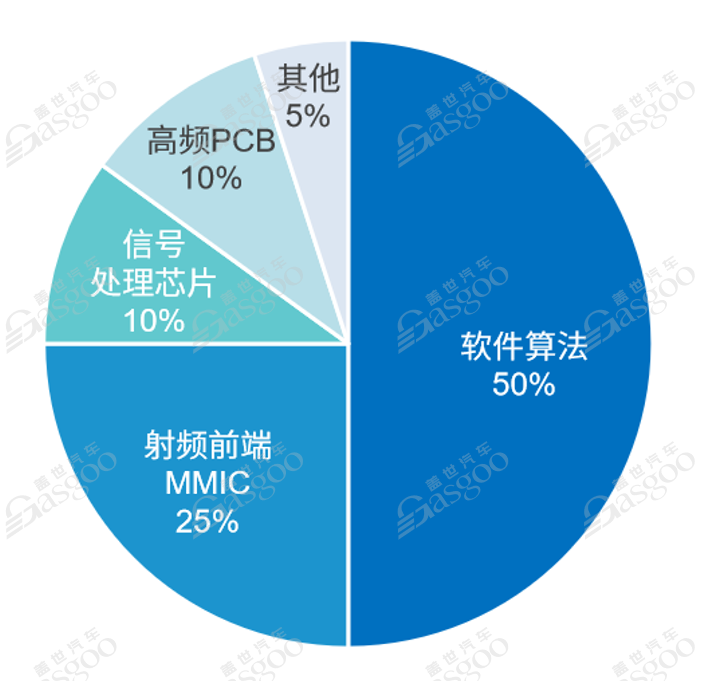
毫米波雷达成本由软件硬件共同构成,其中,国内雷达算法测量精度和范围具有一定局限性,而国外算法受专利保护,价格非常昂贵,成本占比约50%;硬件则由射频前端MMIC(25%),信号处理芯片(10%),高频PCB(10%)构成主要成本。总体来说,芯片算法成本占毫米波雷达总成本四分之三以上,体现了毫米波雷达高度芯片化集成化的趋势。
车载毫米波雷达中,MMIC芯片、信号处理芯片和软件算法等关键部件仍被国外企业掌控,而如博世、恩智浦等企业在软件硬件层面具备双重优势,各类MMIC、DSP、FPGA、CMOS厂商的芯片产品也以过硬的品质成为业内首选。
国内目前急缺能够在软件算法方面有所突破的供应商,芯片供应商则开始有了一定的积累,如CMOS供应商中国电科、加特兰、岸达科技等。除CMOS芯片,国内也有涉足SoC芯片的厂商如问智微电子、晟德微、矽杰微等,它们具备经验丰富的研发团队,正在为芯片国产化贡献自己的力量。
高频PCB板的合格供应商较少,国际市场上主要是看罗杰斯、Isola和Schweizer等,国内仍需从国外进口;国内厂商沪电股份收购了Schweizer 19.74%的股权,期待未来将能填补国产毫米波雷达天线PCB板的空白。
毫米波雷达行业发展趋势
毫米波雷达未来总体向着更高的频段、更加芯片集成化以及4D毫米波雷达方向发展,同时,多传感器融合与冗余设计将成为未来的主流趋势。
基于频率段来看,车载毫米波雷达将逐步淘汰24GHz,并逐渐替代为77GHz、79GHz甚至81GHz频段,目前77GHz和79GHz成为典型产品。
从芯片角度,车载毫米波雷达芯片将更加集成化,主要体现在多芯片向多通道单芯片发展,全集成SoC,以及天线芯片的集成;芯片工艺方面,相较于砷化镓和锗硅,CMOS工艺拥有高集成度、更小体积和成本低等明显优势,将成为未来毫米波雷达射频芯片的主流工艺。
此外,4D毫米波雷达正在被行业采用,因其可测高、点云质量相当于16线激光雷达但成本仅为激光雷达十分之一、对静态障碍物目标分类以及探测距离长等优势,未来有望成为激光雷达的“平替”雷达,以及恶劣天气情形下的主雷达;但4D毫米波雷达当前成本大约在150-200美元之间,远高于普通毫米波雷达70-80美元的价格,需进一步降本。
图表7 部分4D毫米波雷达厂商及产品

结语:
综合上述分析,我们可以发现,国产毫米波雷达可从以下三个方向发力——芯片算法、高频PCB、4D毫米波雷达。立足当下,放眼未来,国内毫米波雷达供应链上中下游应当协同发力,增强上游芯片算法和高频PCB的研发供应能力,同时4D毫米波雷达方兴未艾,国内也有很多厂商开始研发并取得了一定成果,未来有望在行业下一阶段发展中掌握先机,实现弯道超车,最终实现国产替代。
YOLOv4-Tiny -轻量化特征提取网络
YOLOv4 算法通过特征提取网络提取目标的特征,然后对提取的特征进行检测,生成检测结果。在原始 YOLOv4 算法中采用的特征提取网络是 CSPDarknet53 网络,CSPDarknet-53 网络使用残差结构和 CSP 结构,使得模型的深度达到了 162 层,训练参数高达 64363101 个,因此具有出色的检测性能。但是显而易见的 YOLOv4 算法模型体积大,在检测速度上也没有达到极致,本节将对该问题进行 YOLOv4 网络的轻量化,来提升模型检测速度。
对网络进行轻量化的原则:轻量化的网络结构能够使模型同时进行多路检测实现对出租车司机违规行为的实时检测;轻量化的网络结构中过多的组卷积(卷积核池化层构成的组卷积)越多,检测速度越慢。我们在轻量化网络时要避免这种情况;网络中除了卷积核池化层之外的特征提取操作都会增加网络负担,所以在轻量化网络时,要尽可能的避免加入其它操作。
为了能够更好的在移动端落地并且对 CPU 处理也比较友好的前提,我们评估了一些非常适用于移动端设备的轻量化网络系列,ShuffleNet[55],GhostNet[56]还有最近的EfficientNet 网络,最后选择使用了更加轻量化的主干网络 GhostNet 网络来替代 YOLOv4原本的 CSPDarknet53 主干网络。因为它是这些模型里面在相似精度下体积最小的,而且对移动端 CPU 推理也比较友好。GhostNet 网络堆叠结构图如图所示。

Ghost 模型的提出目的是能够用更少的参数擦提取更多的 Ghost 模块,使用输出很少的原始卷积操作(非卷积层的操作)进行特征的输出,然后通过线性变化手段来生成更多的特征,使得网络模型的参数和计算量都大大降低。由图中可知,GhostNet 中主要有两个 Ghost module 堆叠组成。其中第一个 module 用来增加特征维度,第二个模块用于减少特征维度,使得最终的特征维数与最终输出路径中的维度保持一致,Ghost 中的特征提取网络目前有两个版本,其网络结构图如上图所示。图 中的(a)图是一种模型结构,图 中的(b)图是第二种模型结构。本文使用的检测精度更高的模块也就是图 中的(b)图,在该模型中,输出路径采用下采样手段来获取多维特征,同时为了模型的检测速度更快,Ghost 模型中的卷积层都采用 PW(PointWise)卷积。
从NVIDIA自动驾驶芯片Thor,看大芯片的发展趋势
北京时间,9月21凌晨,NVIDIA GTC 2022秋季发布会上,CEO黄仁勋发布了其2024年将推出的自动驾驶芯片。因为其2000TFLOPS的性能过于强大,英伟达索性直接把它全新命名为Thor,代替了之前1000TOPS的Altan。
Thor的发布,代表着在汽车领域,已经由分布式的ECU、DCU转向了完全集中的功能融合型的单芯片。也预示着一个残酷的现实:“许多做DCU级别的ADAS芯片公司,产品还在设计,就已经落后”。
云和边缘计算的数据中心,以及自动驾驶等超级终端领域,都是典型的复杂计算场景,这类场景的计算平台都是典型的大算力芯片。
大芯片的发展趋势已经越来越明显的从GPU、DSA的分离趋势走向DPU、超级终端的再融合,未来会进一步融合成超异构计算宏系统芯片(Macro-SOC)。
1 NVIDIA自动驾驶芯片Thor
1.1 自动驾驶汽车芯片的发展趋势

上图是BOSCH给出的汽车电气架构演进示意图。从模块级的ECU到集中相关功能的域控制器,再到完全集中的车载计算机。每个阶段还分了两个子阶段,例如完全集中的车载计算机还包括了本地计算和云端协同两种方式。
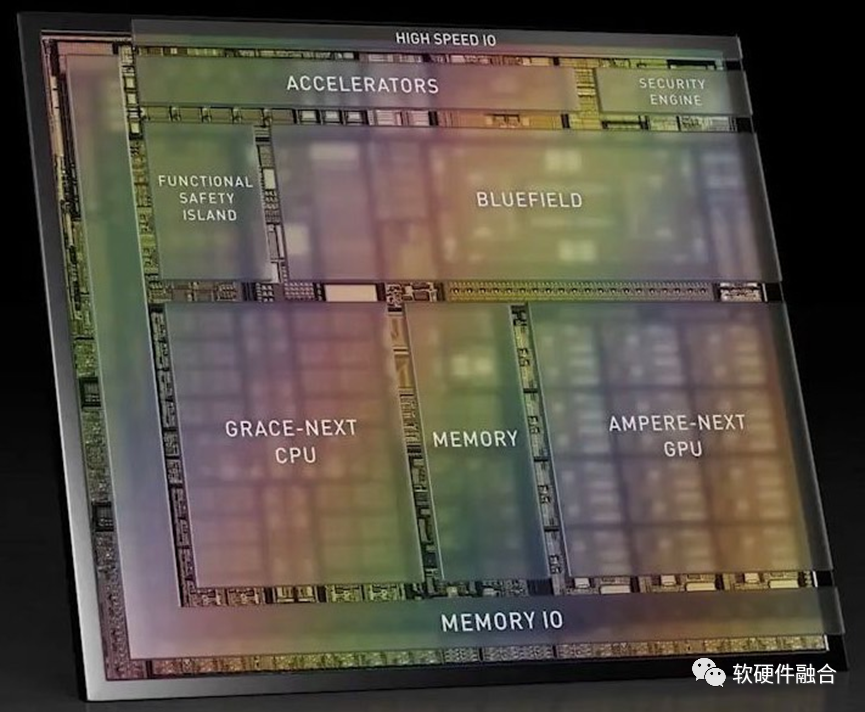
上图是NVIDIA Altan的芯片架构示意图(Thor刚出来,没有找类似的图),从此图可以看出:Altan&Thor的设计思路是完全的“终局思维”,相比BOSCH给出的一步步的演进还要更近一层,跨越集中式的车载计算机和云端协同的车载计算机,直接到云端融合的车载计算机。云端融合的意思是服务可以动态的、自适应的运行在云或端,方便云端的资源动态调节。Altan&Thor采用的是跟云端完全一致的计算架构:Grace-next CPU、Ampere-next GPU以及Bluefield DPU,硬件上可以做到云端融合。
1.2 Intel Mobileye、高通和NVIDIA芯片算力比较

我们可以看到,Mobileye计划2023年发布的用于L4/L5的最高算力的EyeQ Ultra芯片只有176 TOPS。
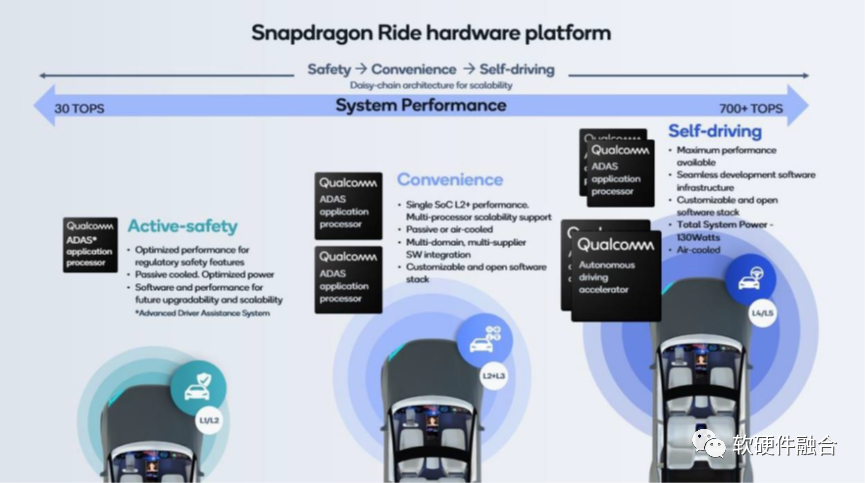
从上图我们可以看到,高通计划的L4/L5自动驾驶芯片是700+TOPS,并且是通过两颗AP和两个专用加速器共四颗芯片组成。

再对照NVIDIA Altan,之前计划的用于L4/L5自动驾驶芯片Altan是1000TOPS算力。
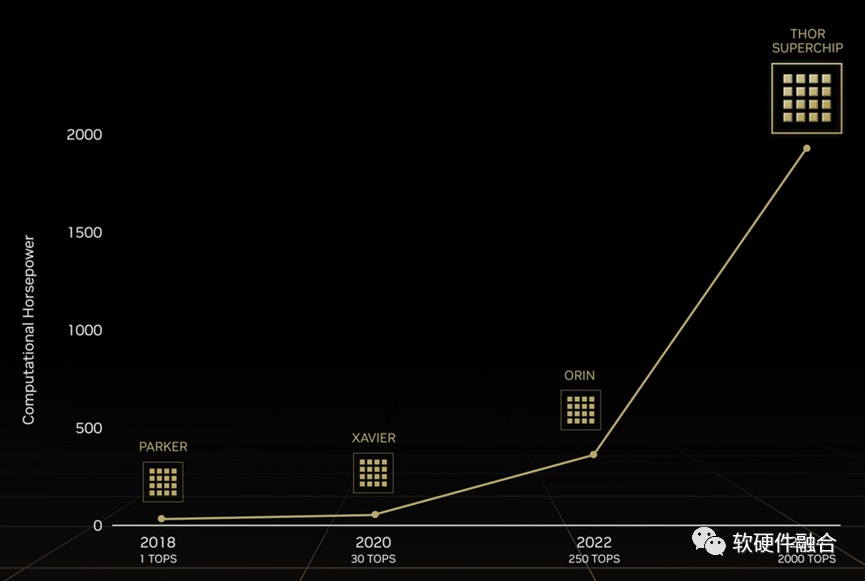
NVIDIA的王炸!推翻了之前的Altan,直接给了一个全新的命名Thor(雷神索尔),其算力达到了惊人的2000TOPS。
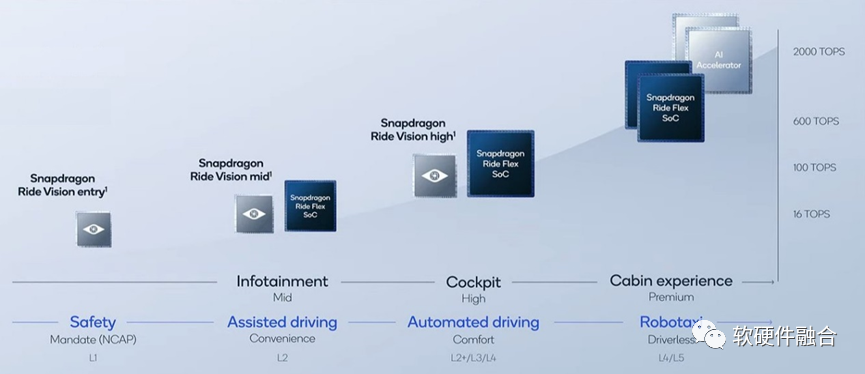
NVIDIA Thor发布之后,高通“快速”的发布了自己的4芯片2000TOPS算力的解决方案。
1.3 单芯片实现通常5颗以上芯片的多域计算

NVIDIA Thor提供2000TFLOPS的算力(相比较Atlan提供的2000TOPS)。

Thor SoC能够实现多域计算,它可以为自动驾驶和车载娱乐划分任务。通常,这些各种类型的功能由分布在车辆各处的数十个控制单元控制。制造商可以利用Thor实现所有功能的融合,来整合整个车辆,而不是依赖这些分布式的ECU/DCU。

这种多计算域隔离使得并发的时间敏感的进程可以不间断地运行。通过虚拟化机制,在一台计算机上,可以同时运行Linux、QNX和Android等。
参考文献
https://mp.weixin.qq.com/s/KKJ0hsxvOoIhBgMPMgcEgQ,英伟达发布最强汽车芯!算力2000TOPS,车内计算全包了,车东西
https://mp.weixin.qq.com/s/lA8h9jTtgsPIjYAX3p5cvg,英伟达「史诗级」自动驾驶芯片亮相!算力2000TOPS,兼容座舱娱乐功能,新智驾
2 自动驾驶SOC和手机SOC的本质区别
这里我们给出一个概念:复杂计算。复杂计算指的是,在传统AP/OS系统之上,还需要支持虚拟化、服务化,实现单设备多系统共存和跨设备多系统协同。因此,如果把AP级别的系统看做一个系统的话,那么复杂计算是很多个系统组成的宏系统。
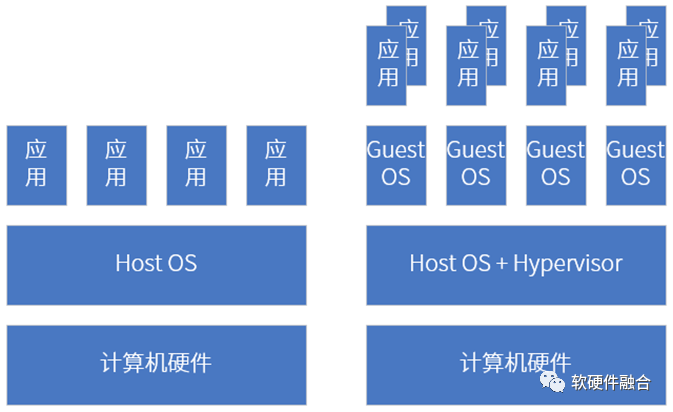
手机、平板、个人电脑等传统AP上部署好操作系统之后,我们在上面运行各种应用软件。整个系统是一个整体,各个具体的进程/线程会存在性能干扰的问题。
但在支持完全硬件虚拟化(包括CPU、内存、I/O、各种加速器等的完全硬件虚拟化)的平台下,不仅仅是要把宏系统切分成多个独立的系统,并且各个系统之间是需要做到应用、数据、性能等方面的物理隔离。
自动驾驶汽车,通常需要支持五个主要的功能域,包括动力域、车身域、自动驾驶域、底盘域、信息娱乐域。因此,集中式的自动驾驶汽车超级终端芯片,必须要实现完全的硬件虚拟化,必须要支持各个功能域的完全隔离(相互不干扰)。
我们把这一类虚拟化和多系统的计算场景称为复杂计算,支持复杂计算的芯片才能算是“大”芯片。这类场景目前主要包括:云计算、超算、边缘计算、5G/6G核心网的数据中心,以及自动驾驶、元宇宙等场景的超级终端。
3 绝对的算力优势面前,定制ASIC/SOC没有意义
随着云计算的发展,随着云网边端不断的协同甚至融合,随着系统的规模越来越庞大,ASIC和传统基于ASIC的SOC的发展道路越来越走向了“死胡同”。越简单的系统,变化越少;越复杂的系统,变化越多。复杂宏系统,必然是快速迭代,并且各个不同的用户有非常多差异性的,传统ASIC的方式在复杂计算场景,必然遇到非常大的困境。
在自动驾驶领域,在不采用加速引擎的情况下,传统的SOC可以把AI算力做到10 TOPS左右;很多公司通过定制加速引擎的方式,快速的提升算力,可以把AI算力提升到100甚至200 TOPS。然而,传统SOC的实现方式有很多问题:
- 自动驾驶的智能算法以及各类上层应用,一直在快速的演进升级中。定制ASIC的生命周期会很短,因为功能确定,车辆难以更新更先进的系统升级包,这样导致ASIC无法很好的支持车辆全生命周期的功能升级。
- 整个行业在快速演进,如果未来发展到L4/L5阶段,目前的所有工作就都没有了意义:包括芯片架构、定制ASIC引擎,以及基于此的整个软件堆栈及框架等,都需要推倒重来。
越来越体会到,在大芯片上,做定制ASIC是噩梦;现实的情况,需要是某种程度上软硬件解耦之后的实现通用芯片。只有软硬件解耦之后:硬件人员才能放开手脚,拼命的堆算力;软件人员才能更加专心于自己的算法优化和业务创新,而不需要关心底层硬件细节。
在同样的资源代价下,通用芯片为了实现通用,在性能上存在一定程度的损失。因此,做通用大芯片,也需要创新:
- 需要创新的架构,实现足够通用的同时,最极致的性能以及性能数量级的提升;
- 需要实现架构的向前兼容,支持平台化和生态化设计;
- 需要站在更宏观的视角,实现云网边端架构的统一,才能更好的构建云网边端融合和算力等资源的充分利用。
在绝对的算力优势面前,一切定制芯片方案都没有意义。
4 大芯片的发展趋势:从分离到融合
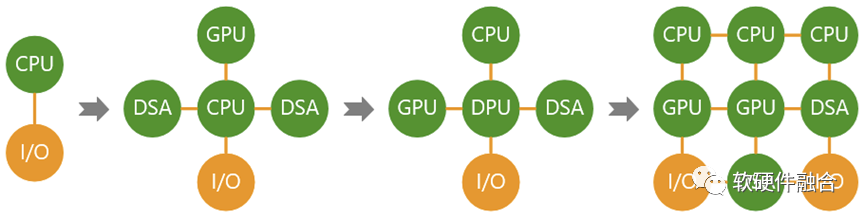
计算机体系结构在从GPU和DSA的分离向融合转变:
- 第一阶段,CPU单一通用计算平台;
- 第二阶段,从合到分,CPU+GPU/DSA的异构计算平台;
- 第三阶段,从分到合的起点,以DPU为中心的异构计算平台;
- 第四阶段,从分到合,众多异构整合重构的、更高效的超异构融合计算平台。
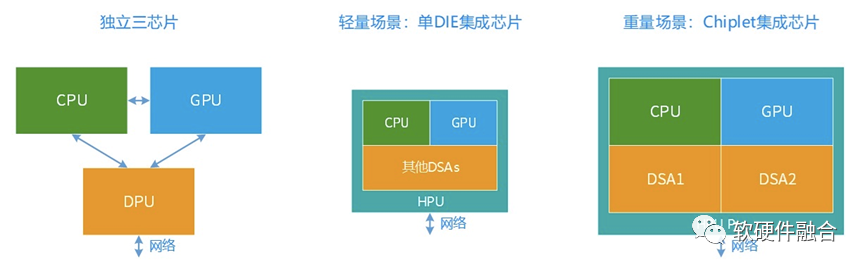
自动驾驶领域已经是Thor这样的功能融合的独立单芯片了,在边缘计算和云计算场景,独立单芯片还会远吗?
在边缘计算等轻量级场景,可以通过功能融合的独立单芯片覆盖;在云计算业务主机等重量级场景,可以通过Chiplet的方式实现功能融合的单芯片。
5 各领域大芯片发展趋势
开门见山,简而言之。大芯片的发展趋势就是:功能融合的、超异构计算架构的单芯片MSoC。
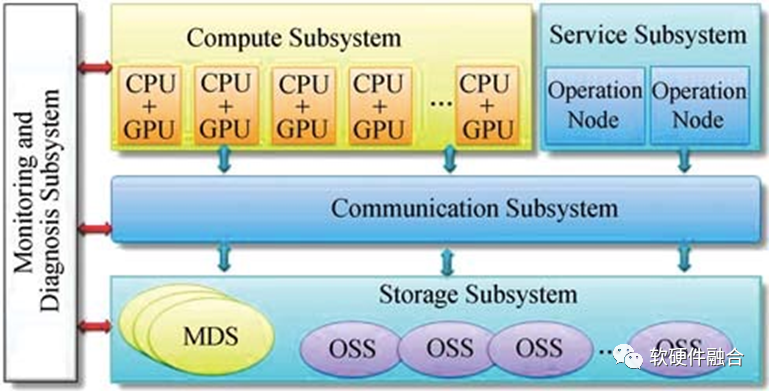
上图为基于CPU+GPU的异构计算节点的天河1A超级计算机架构图。

E级的天河三依然是异构计算架构。

最新TOP500第一名的Frontier,也选择的是基于AMD处理器的异构计算架构(每个节点配备一个 AMD Milan “Trento” 7A53 Epyc CPU 和 四个AMD Instinct MI250X GPU,GPU核心总数达到了37,632)。

日本的富岳超算所采用的ARM A64FX处理器,是在常规的ARMv8.2-A指令集的基础上扩展了512Bit的SIMD指令,也可以看做是某种形态上的异构计算。
总结一下,在超算领域,千万亿次、百亿亿次(E级)超算使得异构计算成为主流。下一代超算,是十万亿亿次(Z级),几乎所有的目光都投向了超异构计算。
自动驾驶领域,NVIDIA Drive Thor提供2000TOPS的算力(目前,主流自动驾驶芯片AI算力为100TOPS),Thor之所以能有如此高的算力,跟其内部GPU集成的Tensor Core有很大的关系。Thor是功能融合的单芯片,其架构由集成的CPU、GPU和DPU组成,可以看做是超异构SOC。
在云和边缘服务器侧,CPU、GPU和DSAs融合的趋势也越来越明显,预计未来3年左右,服务器端独立单MSoC芯片(或者说超异构计算芯片)会出现。
6 大芯片需要考虑计算资源的协同和融合

大芯片,担负着宏观算力提升的“重任”。
如果计算资源是一个个孤岛,那就没有宏观算力的说法。宏观算力势必需要各个计算节点芯片的协同甚至融合。这就需要考虑计算的跨云网边端。
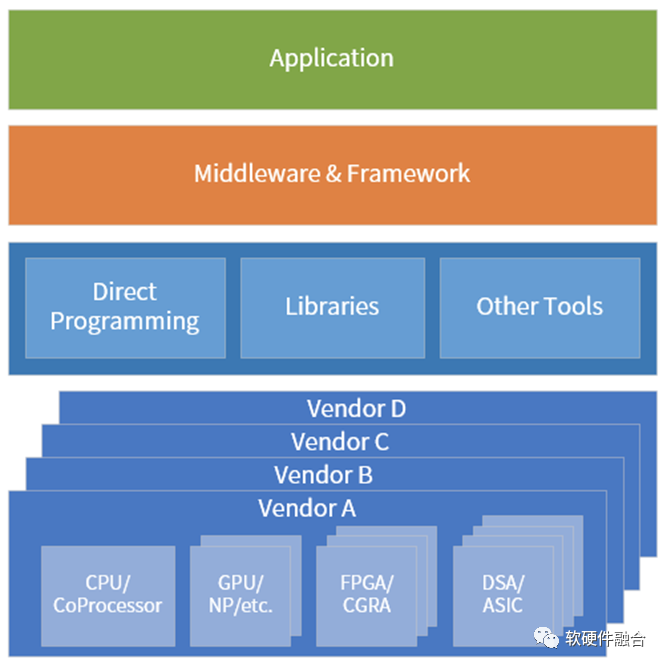
异质的引擎架构越来越多,计算资源池化的难度也越来越高。在超异构计算时代,要想把异质的资源池化,计算需要做到:
- 维度一:跨同类型处理器架构。如软件可以跨x86、ARM和RISC-v CPU运行。
- 维度二:跨不同类型处理器架构。软件需要跨CPU、GPU、FPGA和DSA等处理器运行。
- 维度三:跨不同的芯片平台。如软件可以在Intel、AMD和NVIDIA等不同公司的芯片上运行。
- 维度四:跨云网边端不同的位置。计算可以根据各种因素的变化,自适应的运行在云网边端最合适的位置。
- 维度五:跨不同的云网边服务供应商、不同的终端用户、不同的终端设备类型。
参考文献链接
https://mp.weixin.qq.com/s/UXuD_-xWpei-V0KGzCjgFA
https://mp.weixin.qq.com/s/nlHRPZF1P8lXKE32fASuGA
https://mp.weixin.qq.com/s/CXI5FGmKDZM5ruUHl9SKDQ
https://mp.weixin.qq.com/s/IiG2Wi--mlwpn9nD494l8Q

