
芯片架构与编程分析
芯片架构与编程分析
参考文献链接
https://mp.weixin.qq.com/s/Kt4TQlg7N84fJi2R1PLluw
https://mp.weixin.qq.com/s/2T691TEQN7UoRCMueLkTxw
https://mp.weixin.qq.com/s/xdxX17JWpxeq3VGlw0tajg
https://mp.weixin.qq.com/s/YuizUf9HM9BMoq67Eorzcw
CUDA GPU编程原理
CUDA作为一个并行数据计算设备的图形处理器单元,仅仅几年的时间,可编程的图形处理器单元演变成为了一匹绝对的计算悍马,当极高的内存带宽驱动多核处理器时,当今的GPU 为图型和非图型处理提供了难以置信的资源。
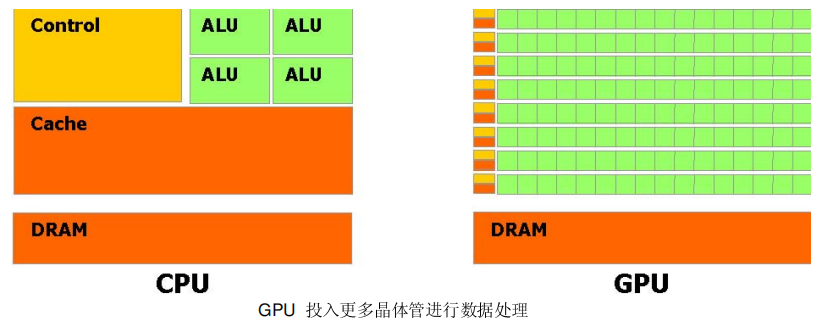
这个演变背后的主要原因是由于GPU 被设计用于高密度和并行计算,更确切地说是用于图形渲染。因此更多的晶体管被投入到数据处理而不是数据缓存和流量控制。
GPU 是特别适合于并行数据运算的问题-同一个程序在许多并行数据元素,并带有高运算密度(算术运算与内存操作的比例)。由于同一个程序要执行每个数据元素,降低了对复杂的流量控制要求; 并且,因为它执行许多数据元素并且据有高运算密度,内存访问的延迟可以被忽略。
并行数据处理,意味着数据元素以并行线程处理。许多处理大量数据集,例如数组的应用程序可以使用一个并行数据的编程模型来加速计算。在3D 渲染上,大的像素集和顶点被映射到并行线程。同样,图像和媒体处理的应用程序例如着色的图像后处理,录像编码和解码,图像缩放比例,立体视觉,以及图像识别也可以映射图像块和像素到并行处理线程。实际上,在图像着色和处理领域外的许多算法同样可以通过并行数据处理得到加速,从一般信号处理或物理模拟到金融计算或者生物计算。
然而直到今天,尽管强大的计算能力包装进了GPU,而它对非图形应用的有效支持依然有限:
- GPU 只能通过图型API 来编程,导致新手很难学习和非图形API 上很不充分的应用。
- GPU DRAM 可以用一般方式下读取,GPU 程序可以从任何DRAM 部分收集数据元素。但不可写,在一般方式下的GPU 程序不能写入信息到DRAM 的任何部分,相比CPU 丧失了很多编程的灵活性。
- 有些应用是由于DRAM 内存带宽而形成的瓶颈,未能充分利用GPU 的计算能力。
CUDA是一个在GPU 上计算的新架构CUDA(Compute Unified Device Architecture) 统一计算设备架构,在GPU 上发布的一个新的硬件和软件架构,它不需要映射到一个图型API 便可在GPU 上管理和进行并行数据计算。从G80 系列和以后的型号都可以支持。操作系统的多任务机制通过几个CUDA 和图型应用程序协调运行来管理访问GPU。
CUDA 软件堆栈由几层组成,如图所示:一个硬件驱动程序,一个应用程序编程接口(API)和它的Runtime, 还有二个高级的通用数学库,CUFFT 和CUBLAS。硬件被设计成支持轻量级的驱动和Runtime 层面,因而提高性能。

CUDA API 更像是C 语言的扩展,以便最小化学习的时间。CUDA 提供一般DRAM 内存寻址方式:“发散” 和“聚集”内存操作,如图所示。从而提供最大的编程灵活性。从编程的观点来看,它可以在DRAM的任何区域进行读写数据的操作,就像在CPU 上一样。

CUDA 允许并行数据缓冲或者在On-chip 内存共享,可以进行快速的常规读写存取,在线程之间共享数据。如图所示,应用程序可以最小化数据到DRAM 的overfetch 和round-trips ,从而减少对DRAM 内存带宽的依赖。

当通过CUDA 编译时,GPU 可以被视为能执行非常高数量并行线程的计算设备。它作为主CPU 的一个协处理器。换句话说,运行在主机上的并行数据和高密度计算应用程序部分,被卸载到这个设备上。
更准确地讲,一个被执行许多次不同数据的应用程序部分,可以被分离成为一个有很多不同线程在设备上执行的函数。达到这个效果,这个函数被编译成设备的指令集(kernel 程序),被下载到设备上。
主机和设备使用它们自己的DRAM,主机内存和设备内存。并可以通过利用设备高性能直接内存存取(DMA)的引擎(API)从一个DRAM 复制数据到其他DRAM。
线程批处理就是执行一个被组织成许多线程块的kernel,如图所示。

主机发送一个连续的kernel 调用到设备。每个kernel 作为一个由线程块组成的批处理线程来执行。一个线程块是一个线程的批处理,它通过一些快速的共享内存有效地分享数据并且在制定的内存访问中同步它们的执行。更准确地说,它可以在Kernel 中指定同步点,一个块里的线程被挂起直到它们所有都到达同步点。
为一个应用程序使用多GPU 作为CUDA 设备,必须保证这些GPU 是一样的类型。如果系统工作在SLI 模式下,那么只有一个GPU 可以作为CUDA 设备,由于所有的GPU 在驱动堆栈中被底层的融合了。SLI 模式需要在控制面板中关闭,这样才能事多个GPU 作为CUDA设备。
存算分离,该如何分离?
过去由于网络带宽的限制,我们习惯性的把计算和存储偶合在一起,以减少网络传输的压力,但随着网络技术的发展,网络带宽和网络质量已经不再是瓶颈,磁盘IO反而没有明显的增长,计算和存储耦合在架构上的缺点也逐渐暴露出来……本文解读了存算分离的原因、应用场景,以及大数据架构中的存算分离应用。
存算分离,作为一种架构潮流,在架构设计和项目规划的时候经常被提及。现如今,数字化转型已经从选择题变成了必修课,企业IT架构的重塑也势在必行,所以有必要把这些所谓潮流的东西解构清楚。翻阅了不少资料,也参考了网上一些文章,简单来分析一下。
二、计算与存储分离的应用场景计算和存储分离主要应用在哪些方面呢,主要是数据库和消息队列:1、数据库以传统的主从结构的数据库系统为例,主库接收数据变更,从库读取binlog,通过重放binlog以实现数据复制。在这种架构下,当主库负载较大的时候,由于复制的是binlog,需要走完相关事务,所以主从复制就会变得很慢。当主库数据量比较大的时候,我们增加从库的速度也会变慢,同时数据库备份也会变慢,我们的扩容成本也随之增加。因此我们也逐渐开始接受走计算和存储分离的道路,让所有的节点都共享一个存储。也许我们对这样的场景习以为常,其实这就是典型的计算和存储分离设计,现在很多的数据库都在逐渐向“计算和存储分离”靠拢,包括现在的PolarDB、OceanBase ,TiDB等等。所以“计算和存储分离”应该是未来数据库的主要发展方向。2、消息队列消息队列不论是Kafka还是RocketMQ其设计思想都是利用本地机器的磁盘来进行保存消息队列,这样其实是由一定的弊端的。首先容量有限,本地空间毕竟容量有限很容易造成消息堆积,会导致我们要追溯一些历史数据的时候就会导致无法查询,然后在扩容的时候只能扩容新节点,扩展成本也比较高。针对这些问题ApachePulsar出现了。在Pulsar的架构中,数据计算和数据存储是单独的两个结构。数据计算也就是Broker,其作用和Kafka的Broker类似,用于负载均衡,处理consumer和producer等,如果业务上consumer和producer特别的多,我们可以单独扩展这一层。数据存储也就是Bookie,pulsar使用了Apache Bookkeeper存储系统,并没有过多的关心存储细节。这样做的好处就是,只需要关系计算层的细节和逻辑,存储部分采用成熟的方案和系统。其实Kafka也在向这些方面靠拢,比如也在讨论是否支持分层存储,但是是否会实现存储节点的单独设置也不一定,但“计算和存储分离”的方向应该是消息队列未来发展的主要方向。
三、大数据架构中的存算分离应用传统的大数据架构中,数据计算和存储的资源都是共用的,比如CDH的集群配置,每个节点既是YARN计算节点又是HDFS存储节点,其实这种设计也是源于Google的GFS。在Hadoop面世之初,网络带宽很低,为了减少大数据量的网络传输,Hadoop采用了尽量使用节点本地存储的设计,这就形成了计算和存储耦合的架构。近年来CPU算力和网络速度增速远快于存储,数据中心有足够的带宽来传输数据,随着数据量的增长,多副本的设计和考虑也造成了成本的飙升,计算和存储绑定的设计实用性开始变差。随着Spark和Flink等框架逐渐代替MapReduce,批处理和流处理同时共存,也改变了旧有的业务模型,这些都需要新的大数据架构去适配。计算和存储分离的大数据架构开始进入视野。现在很多新的大数据引擎都支持计算存储分离,可以通过外部存储引用的方式进行数据对接,而不是通过ETL加载到本地。Hadoop生态圈也开始拥抱计算与存储分离,Hadoop除了HDFS之外还支持S3,用户可以在私有云或者是公有云上运行Hadoop计算集群,连接共享存储和云存储。这样做的好处也是显而易见的,首先是可以实现计算和存储资源的单独扩容,然后原本分散的数据实现集中存储,打造统一数据湖。更重要的一点,可以真正实现大数据混合云,数据存储保留在本地,机器学习等计算资源部署在公有云,既考虑了安全性,又实现了计算的敏捷。计算存储的分离,也可以方便实现软件版本的灵活管理,存储部分求稳,要保持软件版本的稳定,计算部分求快,可以通过数据沙盒和容器技术,实现不同算力模型的快速交付,各部分独立升级互不影响。这样我们积极可以,构建以企业数据湖为核心的稳态数据资源服务,构建以数据计算为核心的敏态数据能力服务,在实现数据治理的基础上实现数据运营。
其实计算与存储分离这个提法,多少有点噱头的意思,没有那么复杂,当然也没那么简单。还是那句话:没有一成不变的架构,只有不变的以业务为核心的架构意识。
在Chiplet芯片架构中,接口互联总线协议有哪些?
目前,在Chip-let 架构的芯片中,用于Die之间实现互连的接口总线协议主要分为 2 类3种,一类是基于单端方式(intel AIB),一类是基于差分方式,后一类又包括了完全差分和数据差分(如 BoW)两种。
1、BoW 协议简介
BoW 接口的基本单元称为 slice。BoW slice 包括一对差分时钟信号,16 个单端的并行数据线和可选的 FEC、AUX 线。slice 可以配置成只具有 TX 或 RX 功能,也可以配置成同时具备这两者,但在工作时必须是单向的。BoW 接口时钟由 PLL 提供,TX slice 会将本地 PLL时钟转发给 MAC 以及链路的另一侧,RX slice 则会接收来自远端的时钟并转发到 MAC。可选的 FEC 信号用于前向纠错降低误码率,AUX 信号可用于实现 DBI、流控、冗余等。多个slice 的组合称为 stack,BoW 链路由一个或多个 stack 沿着芯片边缘排列组成。BoW 标准规定了链路传输的基本模式和快速模式,每种模式下可以有多个时钟频率。连接的双方可以采用不同的模式,但是需要保证每根数据线的速率相等。
影响 BoW 时钟频率和数据线速率的因素有:封装工艺的选择、芯片连接的物理距离、bump 间距。BoW 数据线均采用 DDR 方式传输数据,在基本模式下采用 Interposer 方式封装,要求时钟频率至少为 1GHz,每根 BoW数据线速率为 2Gbps。在快速模式下,采用 Laminate 封装方式,可以支持的最大时钟频率为 8GHz,速率为 16Gbps。
BoW 接口向后兼容,可以灵活支持各种先进封装工艺,支持 5nm~28nm 工艺节点。BoW 以低成本、低功耗、低延迟和高带宽为设计目标,它的优势还包括:既能以较低数据传输速率与现有并行标准兼容,也能以比现有并行标准更高的速率运行,不需要硅基板互连,两个 BoW 接口可以在不同的 bump pitch 上实现等。BoW 的不足之处在于它的封装路由较其他的基于 XSR 或 USR 的串行差分互连技术更为复杂,这增加了测试、封装的复杂度与成本。
2、AIB 协议简介
AIB(Advanced Interface Bus)是 Intel 提出的一种在物理层实现互连的方案。与传统接口相比,AIB 可以支持数千根线路信号,提升芯片之间数据传输的速度。AIB 标准为芯片规定了一个接口,这个接口可以连接到不同芯片上的兼容接口上,从而达到简化设计的目的。AIB 标准规定了与 MAC 相连的接口信号参数配置,同时规定了封装的物理布局要求。接口信号参数配置用于 AIB 接口的逻辑功能实现,物理布局用于 AIB 接口的具体实现。
AIB 有 AIB Base 和 AIB Plus 两种配置,AIB Base 用于轻量级实现,AIB Plus 可以提供更高的传输速度。为了便于芯片开发人员设计,AIB 将正在芯片上创建的接口称为近端端口,与近端端口相连的端口称为远端端口,在设计过程中芯片开发人员只需考虑近端端口即可。
AIB 接口中一共定义了四种信号:分别为数据信号,时钟信号,控制信号和异步信号。数据信号中包括数据输入信号(RX),数据输出信号(TX);时钟信号中包含从近端端口发出的数据时钟输出信号,从远端端口发出的数据时钟输入信号和控制信号所需要的时钟信号;控制信号仅用在 AIB Plus 版本中,用于实现端口之间的精准握手,主要负责时钟的占空比校正和前向时钟相位调整;异步信号中包含指示芯片是否完成供电和复位的供电复位信号,用于检测另一设备的设备检测信号,显示是否已准备好和 MAC 层进行数据传输的 MAC 信号以及芯片开发人员自行设计的其他信号。
AIB 接口之中包含有很多的 I/O 块,这些 I/O 块分组堆叠为一列通道,一列之中包含 1,2,4,8,12,16 或 24 个通道,在 55 微米的微凸块上最多可以支持一个通道有 160 个 I/O 块,这些 I/O 块可以分为 TX 或者 RX 进行数据传输。同时,AIB 支持冗余技术,如果 AIB 信号的线路出现故障,可以转而使用相邻的线路,从而确保设计可用性。在物理布局上,需要尽可能的缩小凸块间距,即将这些凸块交错放置到每一行之中,同时还需保证各条线路之间的长度相同。
AIB 接口能够用于芯片和芯片之间的高速连接,能够大大提升数据传输速率,紧凑型的布局可以缩小芯片的面积,使用冗余技术可以提高芯片的良品率。但是与此同时,封装布局要求较严格,使得封装难度加大,增加了封装的复杂度和设计成本。
企业级SSD技术与应用报告(2022)
企业级 SSD 概述
企业级 SSD(enterprise solid-state drive,企业级固态硬盘)是指应用于高性能计算、边缘计算、高端存储、数据中心等各种企业级场景中的固态硬盘,具备不间断工作能力,能够处理 I/O 密集型工作负载,如数据库文件、索引日志、数据分析以及其它对性能要求较高的事务处理操作。与消费级 SSD 相比,它具备更强性能、更高可靠性、更强耐用性。企业级 SSD 面向企业级用户,要求保证数据安全性、速度稳定性和长期耐用性,对产品高可靠性交付要求更严。企业级SSD 与消费级 SSD 的情况对比如表所示。

技术概述
与个人电脑、笔记本电脑和平板电脑等设备中使用的消费级 SSD 相比,企业级 SSD 性能优势明显,增强服务能力和耐用性。企业级 SSD 能够在断电时为DRAM 存储数据提供有效保护,同时采用了更强大的纠错码(ECC)技术,提供始终如一的高质量服务和期限更长的保修服务。与此同时,企业级 SSD 通过优化 NAND 闪存技术,实现比消费级 SSD 更强的耐用性。由于向芯片写入新数据时,需要经历反复的编程和擦除,导致 NAND 闪存磨损,而企业级 SSD 通过损耗均衡算法、自我修复功能和超量配置等技术,使企业级 SSD 可以更大程度保留 NAND 闪存,以备芯片磨损或出现故障时使用,提高了 NAND 闪存的续航能力。
企业级 SSD 的快速发展与相关技术的持续迭代密切相关,接口速率、存储密度等技术不断升级,带动企业级 SSD 性能稳步增强。接口技术的优化使得传输速率明显提高,满足应用的高速访问需求。SSD 相比于 HDD,最大的优势在于随机读写的能力 IOPS,HDD SATA 接口仅能达到数百量级,而 SSD PCIe 接口的 IOPS 可以提高数千倍;即使同为 SATA 接口的 SSD,也比相同接口的 HDD的 IOPS 要高上百倍。随着企业级 SSD 接口从 SATA 升级到 PCIe 的过程中,速率也从 SATA3.0 的 6GB/s 飙升到 PCIe6.0 x16 的 128GB/s。NAND 闪存密度增加可以提升企业级 SSD 性能。最早的企业级 SSD 通常使用 SLC(Single-Level Cell,一阶存储单元)NAND 闪存,即每个单元存储一位。SLC NAND 可以提供高性能和高耐用性,全生命周期内每个单元的写入次数可以达到十万次。随着NAND 闪存技术优化,企业级 SSD 可以选用耐用性更低但成本更少、容量更大的 NAND 闪存,包括 MLC(Multi-Level Cell,二级存储单元)、TLC(Triple-Level Cell,三级存储单元)、QLC(Quad-Level Cell,四阶存储单元)和多层数 3D NAND。
分类方式
企业级SSD有多种接口类型和外形规格。在接口类型方面,包括串行ATA(Serial ATA,SATA)、串行连接SCSI(Serial-attached SCSI,SAS)和PCI接口(PCI Express,PCIe),可以与中央处理器(CPU)进行数据传输;在外形规格方面,企业级SSD包括可与硬盘驱动器安装在同一插槽中的2.5英寸驱动器,HHHL(Half-height Half-length)插卡或可插入计算机PCIe总线的M.2模块,以及带有双列直插式内存模块(Dual In-line Memory Module,DIMM)芯片的小型电路板,该电路板可以与计算机主板连接。
NVMe凭借高速率、低功耗、低时延、强兼容的特性,成为企业级SSD的主流传输协议。在速率方面,相比于SCSI和SATA传输协议,NVMe所需的CPU指令集数量减少了一半左右,将I/O命令和响应映射到主机的共享内存,支持多核处理器并行,充分利用并行数据路径,极大提升传输速度和吞吐量和,缓解CPU的压力;在时延方面,与SATA相比,NVMe协议使得数据不再需要通过控制器再中转到CPU,而是可以通过PCIe通道直接与CPU连接,延时几乎可以忽略;在功耗方面,NVMe协议采用功耗管理(Power Management,PM)命令集以及相应的功耗管理模型,加入自动功耗状态切换和动态能耗管理功能,有效降低功耗水平;在兼容性方面,NVMe协议能够匹配不同的平台和系统,无需使用相应驱动就能够正常运行。
全球企业级 SSD 市场分析
全球企业级 SSD 市场总体呈现上升趋势,市场规模稳步扩大,PCIe 所占份额将进一步增大。IDC 数据显示,企业级 SSD 全球出货量将从 2020 年的约 4750万块增长到 2021 年的 5264 万块左右,年均增长率为 10.7%,预计到 2025 年,将增加到 7436 万块左右。从整体上看,2020 年到 2025 年期间,企业级 SSD 出货量始终保持上升趋势。企业级 SSD 市场主要包括 SAS SSD、SATA SSD、PCIe SSD、DDR SSD 四个类别,PCIe SSD 所占比重大幅增长。企业级 PCIe SSD 出货量份额从 2020 年的 46.9%,增长到 2025 年的 88.9%,成为企业级 SSD 的市场的主流产品;DDR SSD 的重要性在持续增高,2020 年到 2025 年期间的年均增长率高达 105%,甚至超过了 PCIe;而 SAS SSD、SATA SSD 的出货量和所占比重都在逐年下降。具体增长情况如图 1 所示。

企业级 SSD 不断提升数据完整性等各性能指标的同时,使得容量成本不断下降,大容量企业级 SSD 逐渐成为市场主流。根据 IDC 统计数据,全球企业级SSD 单位容量价格呈持续下降趋势,由 2020 年接近 0.19 美元/GB 下降至 2025年的 0.07 美元/GB,6 年价格下降超过 63%。随着 3D NAND 技术、NVME 协议和其他固件算法的使用范围逐渐扩大,企业级 SSD 容量、运行速度,处理能力,耐久度得到巨大的飞跃。企业级 SSD 单盘容量实现持续增长,IDC 数据显示,2020 年到 2025 年期间,大容量企业级 SSD 出货量总体呈现上升趋势,1TB 以上的 SSD 出货量年复合增长率均超过 10%,容量超过 4T 的企业级 SSD 增长率超过 30%,16T 以上的 SSD 出货量在 2020 年仅为 2.5 万块,而到 2025 年将达到316.9 万块,年复合增长率高达 125%。2020 年-2025 年全球企业级 SSD 不同容量出货量及容量成本变化情况如图所示。

我国企业级 SSD 市场分析
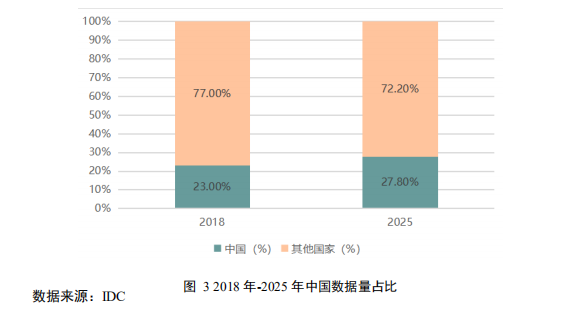
我国数据总量快速增长,对数据存储能力提出更高要求,带动企业级 SSD快速发展。IDC 数据显示,到 2025 年,全球数据总量将达到 175ZB,中国数据量年复合增长率领先全球,预计到 2025 年将达到 48.6ZB,在全球数据总量中占比约 27.8%,成为数据量最大的地区,数据中心存储量占比将超过 70%。企业级SSD 作为数据中心的重要存储介质,出货量持续增长。TrendForce 数据显示,我国企业级 SSD 快速增长,2019 年出货量不到 400 万块,到 2025 年预计将超过1300 万片,年增长率保持在 18%以上,发展空间广阔。
我国企业级 SSD 市场规模持续扩大,PCIe SSD 成为企业级 SSD 市场的主要参与者。数据显示,2019 年,我国企业级 SSD 市场规模不足 100 亿元,到 2021年,总规模已经超过 200 亿元。预计未来,随着企业投资力度的加大和新兴技术带来的市场需求激增,企业级SSD将拥有更大的市场空间和更强的竞争能力,凭借速度快、零噪音、能便携、防摔震等优势,实现对企业级机械硬盘更深、更广、更多的替代。在企业级 SSD 市场中,PCIe 逐渐取代 SATA 及其他类别,成为企业端的主流产品。2019 年,PCIe 企业级 SSD 市场份额仅为 41%,在此后两年里,PCIe 总体规模和市场比重屡创新高,预计 2022 年,占比将达到 74%以上,到 2025 年,市场比重预计将突破 90%。
企业级 SSD 热点技术规范
1.4.1. EDSFF 响应存储性能迭代要求
企业级和数据中心 SSD 形态设计的更新迭代,适用于新一代 NVMe 硬盘规格的 EDSFF 标准应运而生,成为增强存储性能的重要依据。EDSFF(enterprise data center SSD form factor,企业级数据中心 SSD 外观尺寸)是应用于企业和数据中心 SSD 封装尺寸的系列规范,改进了 SSD 容量、散热、供电和可扩展性,在 1U 服务器上实现 PB 级的存储能力,更可以在 2U 服务器上获得更极致的存储性能。EDSFF 建立在 NVMe 功能的基础上,与传统 SSD 相比,吞吐量增加 6倍,延迟减少 7 倍,为客户提供了更强大的存储选项。
EDSFF 实现高密度和数据中心 TCO 降低灵活可选(E1.L), 可扩展的高性能(E1.S)和主流 2U 服务器/存储支持(E3)。E1.S 面向可扩展和高灵活度的性能型存储,有五种不同厚度的选择,具有尺寸小、可扩展、部署灵活等特性,在驱动器的前面是一个有两个螺丝孔的法兰盘,增强锁结构适配;E1.L 主要针对QLC 等高容量存储,比其他任何驱动器外形都要长得多,用于包含大量闪存的系统,适合容量为数十 TB 的 SSD;E3 适用于 3 英寸 SSD,主要针对 2U 服务器/存储中的高性能 SSD,也可以用于 1U 服务器,但相对于 1U 的 E1.S,可能存在制冷和密度分布的缺点;E3.S 的形状尺寸被拉伸了一点,以匹配 OCP NIC 3.0 标准的尺寸,是面向云服务和企业数据中心 NVMe SSD 新形态标准。E3.S 的重要特色就是针对 PCIe 5.0 乃至未来的 PCIe 6.0 做好了准备,扩展性更强,并在性能、散热、功耗等方面都做了改进和统一,支持 PCIe x4/x8 通道,非常适合大容量、高密度的全闪存存储阵列(AFA)。
EDSFF规范的突出优势使其应用范围持续扩大,为企业级SSD外形规格提供广阔的优化空间。EDSFF在占用最小空间的同时,能够实现高密度和高功率存储,满足了数据中心对密度、功率、容量、性能和冷却的需求,企业级SSD厂商和服务器设备商在平衡功耗、速度和冷却效率的同时优化存储空间,应当关注存储驱动器的外形,加快构建更高性能、更多类型的基础设施以满足EDSFF规范要求。
PCIe 赋能设备数据高速传输
PCI Express 规范为数据高速交互提供依据,是服务器总线提升传输速率的主要解决方案。PCI-Express(peripheral component interconnect express,PCIe)是一种高速串行计算机扩展总线标准,于 2003 年,由 PCI-SIG(PCI Special Interest Group,PCI 特设组)正式发布。PCIe 1.0 带宽为 8GB/s,到 2010 年的 PCIe 3.0,速度已经提升至 32GB/s,而实现规模化应用的 PCIe 4.0 速度可以达到 64GB/s。
PCIe 接口有 x1、x2、x4、x8、x16 等多种配置,数字表示数据通道的数量,通道越多,数据从固态硬盘传输到主板的速度就越快。目前,PCIe 6.0 规范已经正式发布,预计最高写入速度为 11GB/s,最高读取速度为 12GB/s,PCIe 5.0 SSD 设备将在 2022 年正式上市。

PCIe 市场规模持续扩大,服务器设备是规范迭代升级的主要受益者。企业级 SSD 的发展使得 PCIe 在 2021 年获得重大发展机遇,并在未来 5 年内获得持续增长。服务器厂商先后推出众多支持 PCIe 4.0 的服务器主板,支持 NVMe 硬盘、GPU、网卡等相对应设备;当 PCIe 5.0 实现商用后,市场规模将得到进一步扩大,大幅度弱化存储设备在整个计算机系统中的性能瓶颈,NVMe 存储设备将成为受益最大的设备;到 2023 年,服务器设备能够率先实现 PCIe 6.0 应用,为人工智能(机器学习)、数据中心、物联网(IoT)、汽车、航空航天和军事等领域提供有效支撑,为高性能计算中心建立组合式基础设施架构。
NVMe 满足高速存储访问需求
NVMe 系列标准规范了 SSD 访问接口,确保 NVMe 在网络架构、接口管理、服务器和系统管理规范化和明确化。NVMe 是由 NVM Express 非盈利组织发布的规范,定义了主机软件如何通过 PCIe 总线与非易失性内存通信。它是所有形式(U.2、M.2、AIC、EDSFF)的 PCIe 固态硬盘(SSD)的行业标准。除了 NVMe基本规范之外,还包括用于规范网络架构上使用 NVMe 命令的 NVMe over fabric(NVMe-oF),以及用于服务器和存储系统管理 NVMe/PCIe SSD 的 NVMe 管理接口(NVMe-MI)规范。随着使用非易失性存储器高速(NVMe)接口规范的技术从 HDD 发展到 SSD,再发展到 SCM,存储性能得到了巨大提升。通过 NVMe访问存储介质所花时间相比以前的硬盘技术减少了 1000 倍。不同技术之间的样本搜索时间存在差异,HDD 为 2-5 毫秒,SATA SSD 的搜索时间为 0.2 毫秒,NVMe SSD 样本需花费 0.02 毫秒。SCM 通常比 NVMe 闪存 SSD 快三到五倍。
NVMe 2.0 在企业级 SSD 方面进行重大调整,覆盖大量企业级用例,简化企业级存储池管理,加快推动新技术应用。采用全新存储管理机制,明确NVM Set 和 Endurance Group 创建和管理方式。NVMe 2.0 存储管理机制能够实现灵活创建和删除 NVM Sets 与 Endurance Groups,动态管理 SSD 容量,针对静态配置产品,解决主机与驱动之间的分工需求,根据不同用例进行 SKU 配置。支持 ZNS(Zoned Namespaces,分区命名空间)等新概念 SSD 技术。
基于NVMe 1.4a 版本,NVMe 2.0 正式引用 ZNS 技术,突破了传统区块设备模型的存储技术概念。NVMe SSD 包括 SSD 控制器、闪存空间和 PCIe 接口,闪存空间可以划分为若干个独立逻辑空间,按照 0 到 N-1 划分的逻辑空间被称为命名空间。采用 ZNS 技术的 SSD 比常规 SSD 性能更好,可以节约 10 倍左右的 OP预留空间,节约 8 倍的 DRAM 缓存需求,同时减少设备端写入放大,优化吞吐量和延迟。目前该技术已经在企业级 SSD 得到应用。
参考文献链接
https://mp.weixin.qq.com/s/Kt4TQlg7N84fJi2R1PLluw
https://mp.weixin.qq.com/s/2T691TEQN7UoRCMueLkTxw
https://mp.weixin.qq.com/s/xdxX17JWpxeq3VGlw0tajg
https://mp.weixin.qq.com/s/YuizUf9HM9BMoq67Eorzcw


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
2021-09-15 科技公司合作伙伴清单