

图像与点云三维重建算法
图像与点云三维重建算法
单图像三维重建算法介绍
在开始讨论之前先说一下为什么要做单图像三维重建,原因其实很直观。总结起来就是两个字,“需要”。我们很需要这类应用,如果可以做出来,不论是学术上、产品上都有很大价值。
比如像是国外的英伟达(NVIDIA)、脸书,国内的阿里巴巴达摩院、快手做的虚拟人、虚拟场景等的应用。但是三维重建不好做,因为三维数据真值很难获得,或者收集起来很花钱。
所以这就带来一个问题,如何以成本更低的方式完成三维重建。其中的一个思想是,我们能不能使用二维数据来去做一个弱监督学习,曲线救国实现这个任务。这个方式被证明可以取得很好的效果,所以在接下来的讨论里面,我们会以此为基础,给大家介绍单图像做三维重建的一些方法。
参考文献链接
https://mp.weixin.qq.com/s/dRTbRQqVBdSRwqqIi3P2ZQ
https://mp.weixin.qq.com/s/qzIUF4SvTeb73f8rbGws2g
单图像三维重建算法是怎么实现的
从整体来看,最近两年顶会的三维重建算法绝大多数都是基于深度学习的。在深度学习中,又进一步分出了三条主要路径,这三条路径分别是:
1) 先对单图片中的目标物体进行建模,直接取得其三维形体(template), 之后再使用另一个模型去上色并处理光照。整个流程不是一个端到端的流程(这里并不是说不能做到单模型统一,只是目前没论文这样做),需要分开训练。
2) 直接使用给定的先验形体(prior template)进行体态学习,同时进行采样(UV sampling)来学习色彩特征,全部叠加到一起就可以实现三维型体重建。
主要的实现方式是,使用可导渲染器(也叫神经渲染器,英文是neural rendering)去渲染然后再后处理,来生成某一个三维形态投射到二维的投影,拿到投影再生成分割图,关键点坐标,RGB像素等等,之后去优化分割、以及染色分支。这里提到的先验形体,一般指的是高对称性三维物体,比如球体。
3) 使用神经辐射场(NERF)外加体素渲染进行三维结构的学习,可以直接学习到物体的形体以及色彩。使用这种方式进行三维重建是现在的学术界主流,很多去年相关的论文基本都是以此为技术核心发表。目前比较成型的探索结果包括虚拟人形象以及动物形象等。
相比较其他算法,基于NERF的算法一般可以生成更高像素质量、更高分辨率、更高清晰度的虚拟形象。但是这种算法也是有自带的问题,就是不能生成基于特定输入的图像(因为这类算法基于生成对抗网络),所以对于产品化而言,这种方案还是有进一步提升的需要。其中一种可能的方式就是去做3D GAN inversion,也就是进行图像编辑。
单图像三维重建具体算法
以下篇幅我们来看一下这三种方案都对应有哪些论文,他们各自的都提出了什么方法来解决具体的问题。
路径一:形体建模+色彩渲染
这一套方案采用分阶段的方式,希望能够将三维重建分拆两个子任务,也就是形体建模+色彩渲染。每个子任务引入一个子模型来去建模,同时使用两个sota的算法分别把形体和色彩做到极致。
这样子的话既可以控制难度,对于各个模块又可以精调,可以做到合适的取舍。比如你更希望形体做的出色,那么对于色彩的要求可以降低,对应模型的复杂度也可以下调,反之亦然。
这里我们首先看一下WLDO[1]。这篇论文中作者研究了怎么重建动物(主要是狗)的形体,可以在不使用3d数据真值的情况下实现对动物形体的重建。模型重建过程基于SMAL的3d先验、二维的关键点与分割图来实现。
具体而言,作者使用了一个encoder进行特征学习,之后使用学习到的特征来拟合形体、姿态以及相机参数,三者结合就可以实现整体身形的学习。具体学习的时候,由于给定先验体态和数据集实际的形态不是很匹配,为了更精确的估计形体,作者使用EM算法。E阶段去估测期望形体参数并冻结其他形体参数的更新;M阶段来更新其他形体参数。最后通过迭代更新来实现整个形体的学习。
在完成形体的学习后,另外一个要解决的问题就是如何上色。这里我们介绍一下Texformer[2]是怎么做的。Texformer是来做人体建模的,可以通过使用输入图像的全局信息进行更加精细的学习,同时尝试融合输入图像与色彩信息来进行完整的染色。模型使用了SMPL来预测体态,同时采用Vision transformer来实现全局信息的学习。
具体来说,使用预计算色彩图作为query,图上每个像素对应于三维空间下的一个顶点;使用输入图像作为value;使用二维组件分割图(2D part segmentation map)作为映射图像到UV空间的载体。作者同时使用一个混合蒙版来合并texture flow与RGB色彩来生成效果更好的色彩预测结果。这里我们附上Texformer的结构图供大家参考。
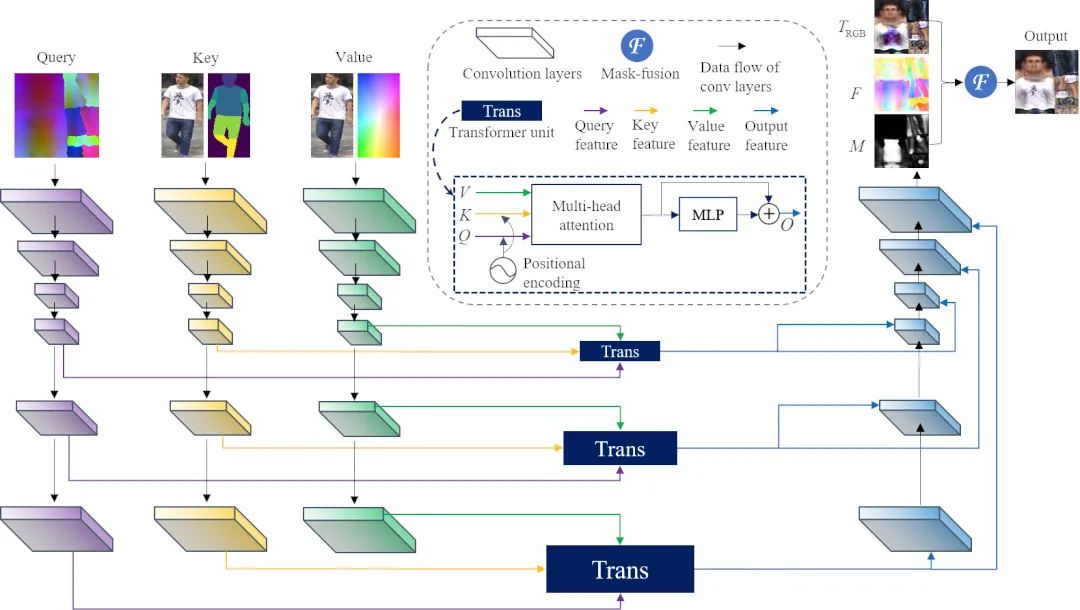
Texformer 结构图,摘录自论文原文
类似方向的论文还有很多。比如使用基于SMPL的人体模型参数建模,或特别裁出人脸模型进行面部精细化建模等等。这里我们仅举两个例子(作者偷懒就看了这些),然后来总结一下这种方式的优劣。
优势
- 先训练体态后训练色彩信息,分开双阶段之后,任务平摊到每个阶段,训练难度降低
- 分阶段下理论上每个子模型都可以学到比较好的效果,整体的效果可以保证
缺点
需要的输入多,包括输入图像、蒙版、关键点或part segmentation map,缺一类就无法训练;数据要求高。只能针对每类,输出体态估计值,所以输出的体态会非常接近,没有独特性
多阶段导致训练、测试时间同步拉长
路径二:使用神经渲染器在神经渲染器没出现之前,我们学习三维模型的基本方式是使用准备好的三维真值,比如给定一个玩具模型以及三维的坐标信息,我们直接去回归基于三维的参数来实现三维建模。
神经渲染器的出现则免去了这个麻烦,因为有办法直接用它获得二维投影,这样子的话用二维的真值就可以学习三维的模型特性了,相比较于使用三维真值,绝对是非常有价值而且能商业化的一条路。
使用神经渲染器可以实现端到端的学习,学习目标为姿态、身形、相机拍摄参数以及色彩信息等。神经渲染器通过优化像素采样过程支持可导。常见的有neural-render[10], soft-render[13]与Dib-R[12]等。
通过使用可导渲染器构建2D->3D的渲染结果,并使用投影投射回2D,可以计算生成的渲染结果与原始图像的差异,因而可以做到快速估计并学习关键的重建参数。
以下我们来看一些例子。
首先我们介绍CMR。CMR这篇论文第一次提出通过学习类目模板来解决三维重建问题,但是模板需要使用运动推断结构(SFM)去计算初始化模板,并且使用蒙版和关键点进行弱监督学习;
同时使用球坐标转换的方式映射UV sampling结果,学习并进行渲染上色。具体的框架图请见下图。CMR是一篇非常经典的论文,后面我们提到的UMR、SMR以及我们没有提到的u-cmr都是以此为蓝本进一步提升的。尤其是染色的解决方案,基本上后面的论文都是仿照这种方案来做的。
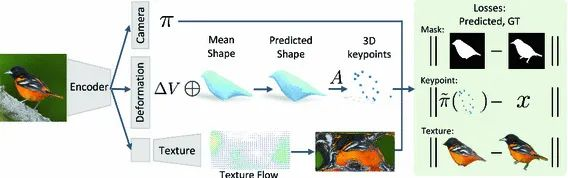
CMR 结构图,摘录自论文原文
然后我们来看一下UMR。这篇论文尝试使用part segmentation map来代替蒙版和关键点以简化三维重建问题。作者认为物体可以切分为多个子区域,每个区域相互连通,且区域内、区域间的色彩信息是连贯的。
因此2D、3D间相互的转换应能维持这种关系。借由这种思路,UMR算法不需要构造类目模板,因而没有类目的限制。同时UMR借助part-segmentation map进一步明晰了物体边界,这对于更加细节的学习物体的色彩有着十分重要的作用。我们之前提到的texformer,选择了part-segmentation map,便是有一部分原因来源于此。
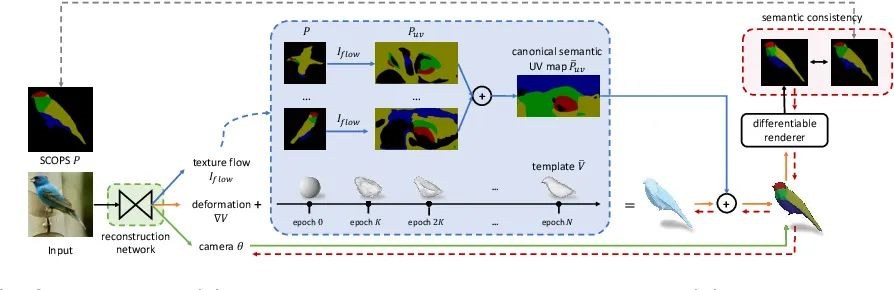
UMR 结构图,摘录自论文原文
我们再来看一下SMR[5]。SMR通过插值三维重建过程中的关键属性来实现建模。由于物体重建后,身形、纹理以及身体关键部位对应关键点位置应尽量与原图保持一致,作者提出(c)、(d)两种限制来保持重建后物体的一致性。
此外通过保持2D->3D->2D的双向投影来确保2D输入与预测一致,并使用GAN来对相机拍摄角度、纹理信息、物体三维等信息进行插值,生成新的数据,补充训练集,以获得较好的效果。
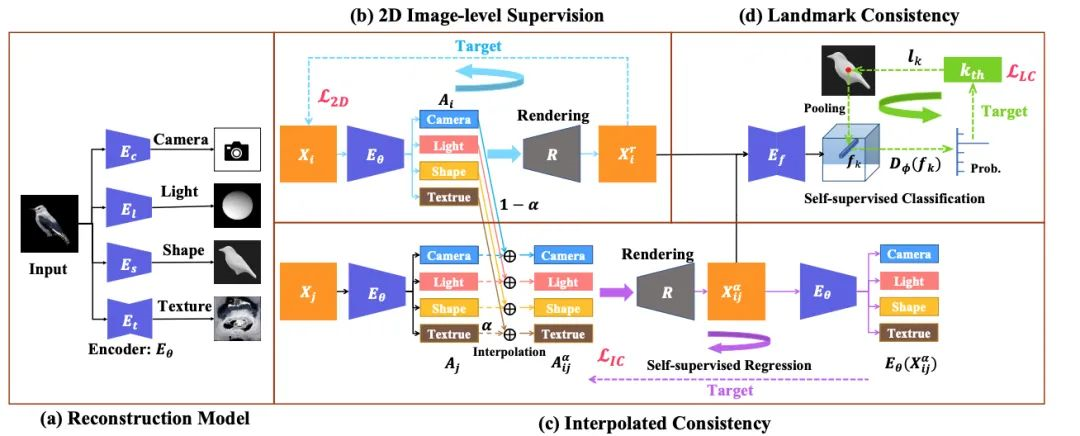
这里我们总结一下路线二的优点和劣势。
优势
- 直接进行单阶段学习,框架更加简洁清晰
- 所需的数据量逐步减少,最优情况下只使用蒙版即可生成期望结果
缺点
- 数据假设训练物体是对称物体,训练需要初始化模板(球体),对于无模板、非刚体、非对称物体,学习难度显著增强
- 由于是自监督学习,没有明确的真值定义,容易收敛到次优状态,或无法收敛
- 受限于物体的体积、复杂程度。对于复杂物体效果不佳、对于学习物体的细节把握不佳。
路径三:使用神经辐射场(NERF)
神经辐射场[11]也是最近兴起的渲染器,和神经渲染器的功能类似,但是相比较而言,有其自身更独特的优点。神经辐射场的工作原理是,使用三维空间信息以及二维姿态信息,基于视图的辐射场以及体积密度,学习三维空间坐标与二维视角并投射到RGB颜色值上。
具体实现方式是使用固定的条件编码加上多层感知机(MLP)把输入翻译成像素值以及体素密度。之后进行体态重建将二维输入直接映射到三维。在神经辐射场之前,三维重建的做法是,使用基于voxel-grid的方法表示三维物体,或三维物体对应的特征;
前者极大地消耗了内存,因而只能用于低精准度的三维物体重建;后者需要额外的解码器去解码特征为RGB像素,使得多维度的一致性不够好。在使用神经辐射场之后,相比于基于网格的方法,这种方法不会空间离散、不限制拓扑形态,对于物体的学习有更好的效果。最后还是要提一下,NERF实现很多都是基于GAN的。其中的原因之一是,GAN对于训练数据不足有着很大的补充作用。
这里我们还是看一下相关论文是怎么使用NERF的。首先我们看一下Graf[6]。Graf基于神经辐射场,引入生成对抗网络,使用unpose图像进行训练。目的是生成未知视域下的三维重建结果。
其中生成器主要负责基于图像二维坐标进行采样,每次取得一个patch(K*K个点),然后从这些点里面使用分层采样的方式再采样出N个点进行精细化学习。生成器额外引入了Z_shape和Z_appearance两种隐层编码,可以直接学习体态和表观特征,同时将两种特征解耦,做到分别预测。判别器主要负责比较采样得到的patch与预测生成的patch。训练过程中从感知域比较大的patch开始,然后逐步缩小。
Pi-gan[7]基于Graf做了改进。它使用基于周期激发函数的正弦表示网络来加强神经辐射场中的位置编码效果,以生成更宽视角下的重建结果。相比较于graf,使用siren替代了位置编码,使用基于style-gan的映射网络使得形态和表观特征只依赖于给定输入。同时使用阶段训练以逐步收敛模型。
ShadeGAN[8]在pi-gan的基础上考虑了光照对于三维重建的影响,目的是去进一步解决三维重构场景下形态和颜色相互影响导致重建效果不佳的问题。作者认为,一个好的三维重建模型,在不同的光照条件下去渲染,形态应该相差不大。
同时,作者提出了表面追踪的方法来提升体素渲染的速度。相比于pi-gan的唯一不同是,作者引入了基于光照的限制,同时输出不再直接输出颜色,而是输出经过映射前的输入,目的是希望引入光照来进行后处理,具体处理方法为Lambertian shading。
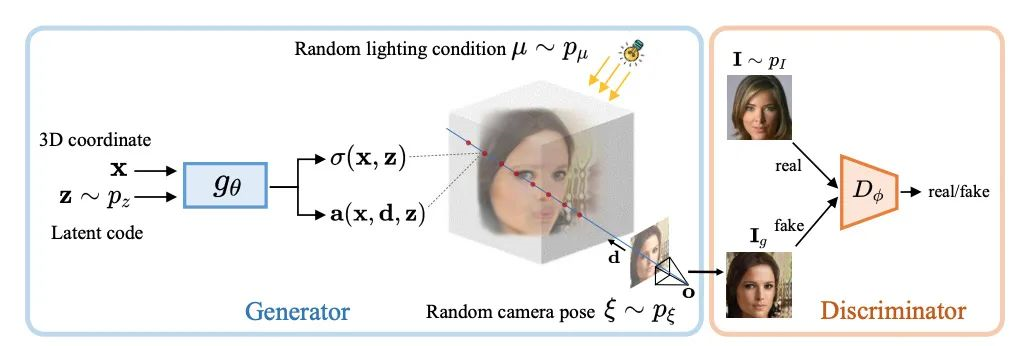
ShadeGAN 结构图,摘录自论文原文
CIPS-3D[9]基于pi-gan进一步改进。作者发现现有方法(比如pi-gan)通过编辑浅层向量来隐性控制角度,然而并不能实现基于高分辨率下任意渲染角度的重建;同时在训练不完全的情况下会出现镜像对称的次优解。因此,作者提出调制SIREN模块来去处理生成的不同图像的尺度对于重建的影响。
同时,作者发现使用方向作为输入会导致不同维度成像不一致,因而采用输入点的方式来替代。另外,作者发现了生成结果有概率出现镜像对称问题。为了处理这个问题,使用隐式神经表达网络来把隐式特征化为对应的RGB像素,同时追加了一个附加判别器,以处理镜像对称问题。实验证明这种处理方式起到了很好的效果。
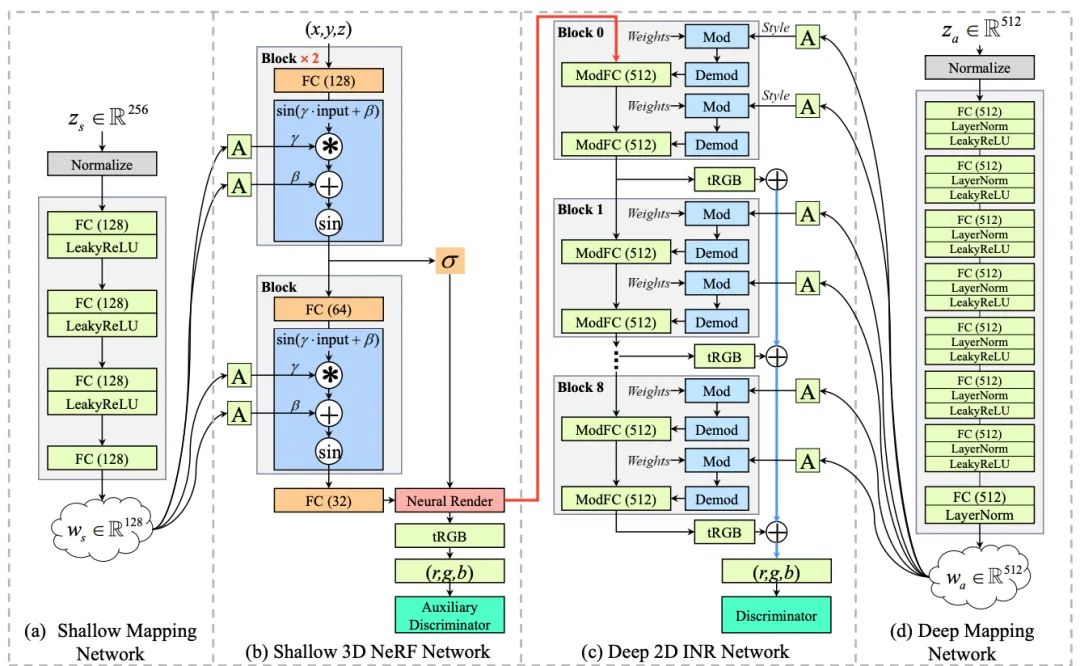
CIPS-3D 结构图,摘录自论文原文
聊完了相关例子之后,我们最后再来比较一下NERF自己的优点和劣势。
优势
用gan去解决数据稀缺的问题,同时sota版本下只需要单一图像输入,便可以进行多角度重现。相比较上述两种方式,整体方案成本较低。神经辐射场本身使用隐性学习方式学习三维特征,相比较于基于三维模板的方式,无对称性要求,使用范围可拓展至非刚体类目,泛化能力更强。
具有可解释性,生成的浅层特征经过加工后可以用来可视化学到的三维重建模板。
缺点- 只能拟合单轴下的单图像重建。
- 无法基于给定图像重建。
总结
这篇文章为大家重点介绍了一下单图像三维重建的一些最近顶会,并且分成了三组主流路径。大家可以对比一下看看,如果有哪里说的不清楚或者欠妥,欢迎在评论区讨论。感谢各位看官花时间阅读本文。
PS: 本文引用的所有论文都是已开源代码的,大家搜索论文标题就可以找到对应代码。
基于激光雷达增强的三维重建
尽管运动恢复结构(SfM)作为一种成熟的技术已经在许多应用中得到了广泛的应用,但现有的SfM算法在某些情况下仍然不够鲁棒。例如,比如图像通常在近距离拍摄以获得详细的纹理才能更好的重建场景细节,这将导致图像之间的重叠较少,从而降低估计运动的精度。在本文中,我们提出了一种激光雷达增强的SfM流程,这种联合处理来自激光雷达和立体相机的数据,以估计传感器的运动。结果表明,在大尺度环境下,加入激光雷达有助于有效地剔除虚假匹配图像,并显著提高模型的一致性。在不同的环境下进行了实验,测试了该算法的性能,并与最新的SfM算法进行了比较。

CMU Smith Hall重建点云模型(灰色),覆盖视觉特征点(红色)
相关工作与主要贡献
基于机器人的检测需求越来越大,需要对桥梁、建筑物等大型土木工程设施的高分辨率图像数据进行处理。这些应用通常使用高分辨率、宽视场(FOV)相机,相机在离结构表面近距离处拍摄,以获得更丰富的视觉细节。这些特性对标准SfM算法提出了新的挑战。首先,大多数可用的全局或增量SfM方案都是基于单个摄像机的,因此不能直接恢复比例。更重要的是,由于视场的限制,相邻图像之间的重叠区域被缩小,从而导致姿态图只能局部连通,从而影响运动估计的精度。这个问题在大规模环境中变得更加重要。
为了解决上述挑战本文提出了一种新的方案,它扩展了传统的SfM算法,使之适用于立体相机和LiDAR传感器。这项工作基于一个简单的想法,即激光雷达的远距离能力可以用来抑制图像之间的相对运动。更具体地说,我们首先实现了一个立体视觉SfM方案,它计算摄像机的运动并估计视觉特征(结构)的三维位置。然后将激光雷达点云和视觉特征融合到一个单一的优化函数中,迭代求解该优化函数以最优化相机的运动和结构。在我们的方案中,LiDAR数据从两个方面增强了SfM算法:
1)LiDAR点云用于检测和排除无效的图像匹配,使基于立体相机的SfM方案对视觉模糊具有更强的鲁棒性;
2)LiDAR点云与视觉特征在联合优化框架中相结合,以减少运动漂移。我们的方案可以实现比最先进的SfM算法更一致和更精确的运动估计。
本文的工作主要有以下几个方面:
1)将全局SfM技术应用于立体摄像系统,实现了摄像机在真实尺度下的运动初始化。
2) 激光雷达数据被用来排除无效的图像匹配,进一步加强了方案的可靠性。
3) 通过联合立体相机和激光雷达的共同的数据,扩展了我们先前提出的联合优化方案,提高了所建模型的精度和一致性。
激光雷达增强的双目SFM
该方案以一组立体图像和相关的LiDAR点云作为输入,以三角化特征点和合并的LiDAR点云的格式生成覆盖环境的三维模型。下图显示了我们的LiDAR增强SfM方案的过程
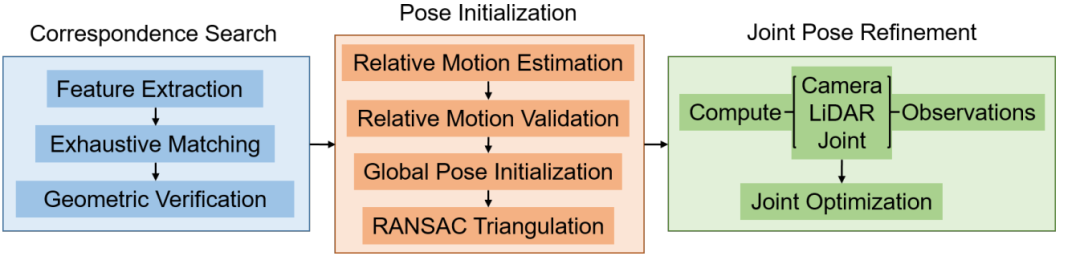
激光雷达增强的双目SFM方案
A、 对应特征点搜索
给定立体图像对,计算对应关系包括特征提取、匹配和几何验证。首先,我们依赖OpenMVG库从图像中提取SIFT特征。然后使用所提供的级联哈希方法对特征进行穷尽匹配。最后,通过对双目极线约束进行几何的验证,验证了两幅图像之间的匹配。具体地说,利用RANSAC估计基本矩阵F,然后用来检查匹配特征的极线误差。只保留几何上一致的特征,以便进一步计算。
B、 相对运动估计
由于立体图像对是预先校准的,所以我们将一对左右图像作为一个独立的单元,为了估计相对运动,标准的立体匹配方法依赖于两对图像中所有四幅图像所观察到的特征点,而我们观察到许多点只被三幅甚至两幅图像共享。忽略这些点可能会丢失估计相机运动的重要信息,特别是在图像重叠有限的情况下。因此,这里选择显式地处理两个位姿点之间共享视图的不同情况。具体来说,我们考虑至少3个视图共享的特征点,以确保尺度的重建。虽然只有2个视图的点可以帮助估计旋转和平移方向,但是由于这些点通常来自于下图所示的小重叠区域,所以这里忽略它们。另一方面,两个位姿点之间也可能存在多种类型的共享特性。为了简化问题,我们选择对应关系最多的类型来求解相对运动。在三视图情况下,首先用立体图像对,对特征点点进行三角化,然后用RANSAC+P3P算法求解。在四视图的情况下,我们遵循标准的处理方法,首先对两个站点中的点进行三角化,然后应用RANSAC+PCA配准算法找到相对运动。在这两种情况下,都使用非线性优化程序来优化计算的姿态和三角化,通过最小化内线的重投影误差。最后,对所有姿态进行变换以表示左摄像机之间的相对运动。

两视图要素的区域示例。左:一位姿右图像;中右:另一位姿的左右图像。共同的小区域靠近边界并用红框标记。
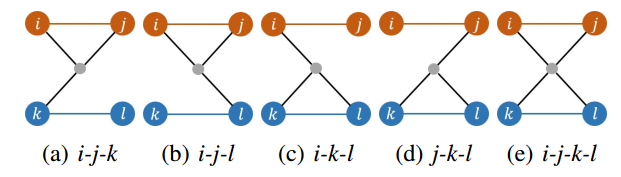
两个位姿点(红色和蓝色圆圈对)之间共享特征(灰点)的示例。彩色条表示已知的校准后的立体图像对。(a)-(d)三视图;(e)四视图。
C、 相对运动验证
一旦找到了相对运动,就可以建立一个姿态图,其中节点表示图像帧的姿态,边表示相对运动。全局姿态可以通过平均位姿图上的相对运动来求解。然而,由于环境中的视觉模糊性(见下图),可能存在无效的边缘,并且直接平均相对运动可能会产生不正确的全局姿势。因此,设计了一个两步边缘验证方案来去除异常值。
(1)在第一步中,检查所有图像帧对的激光雷达点云的重叠,并剔除不一致的点云。
(2)第二步中检查回环的一致性。(具体方法可在论文中有详细说明)
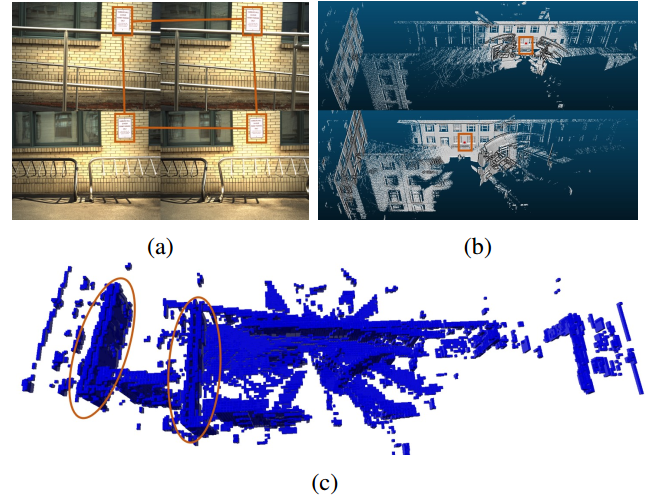
由于视觉模糊导致的无效相对运动的例子。(a) 由于相同的停车标志,两对图像匹配不正确。(b) 相应的点云来自两个车站,标志用红框标出。(c) 合并的占用网格显示不正确的对齐方式(红色椭圆)。在这种情况下,一致性比为0.56,而有效相对运动的一致性比通常超过0.7
D、 全局位姿初始化
这部分主要介绍优化全局帧的代价函数:
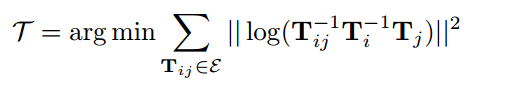
E、三角化与RANSAC
本文采用文鲁棒三角化方法,对每个三维特征点使用RANSAC来寻找最佳的三角化视图。对于每个轨迹,它是不同相机视图中一个特征点的观察值的集合,随机对两个视图进行采样,并使用DLT方法对该点进行三角化。通过将该点投影到其他视图上并选择具有较小重投影误差的视图,可以找到更匹配的视图。此过程重复多次,并保留最大的一组内部视图(至少需要3个视图)。最后,通过最小化重投影误差,利用内联视图优化特征点在全局结构中的位姿。
F、联合位姿优化
基于视觉的SfM算法的位姿优化通常通过束调整(BA)来实现。然而,由于多个系统原因,如特征位置不准确、标定不准确、对应异常值等,位姿估计在长距离内可能会产生较大的漂移,尤其是在无法有效地发现闭合环路的情况下。为了解决这个问题,我们考虑利用激光雷达的远距离能力来限制相机的运动,该方案将相机机和激光雷达观测值联合最优化。这部分内容可查看原文理解公式。
实验结果
A、实验装置
下图具有多个机载传感器,包括两个Ximea彩色摄像头(1200万像素,全局快门)和一个安装在连续旋转电机上的Velodyne Puck激光雷达(VLP-16)。利用编码器测量的电机角度,将VLP-16的扫描点转换成固定的基架。

传感器盒子和数据集。
B、 相对运动估计
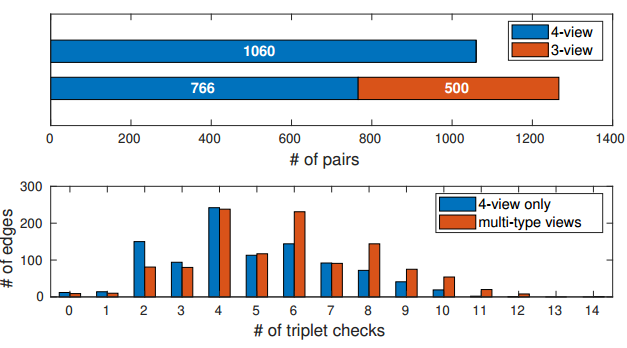
上图:从4个视图和3个视图点显示求解的对数。下图:不同三元组检查的边数直方图。
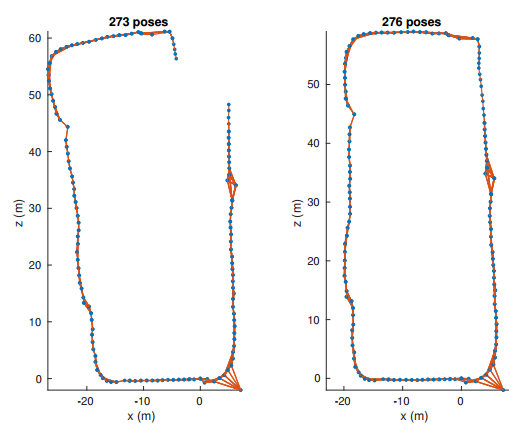
左图:初始化的位姿图有4个视图特征。右:使用多视图初始化位姿图
C、 相对运动验证
这里比较了所提出的基于网格的检查(GC,阈值为0.6)和成功率检查(SR)与OpenMVG使用的旋转循环检查和transform(旋转和平移)循环检查(TC)的异常值排除法的性能。
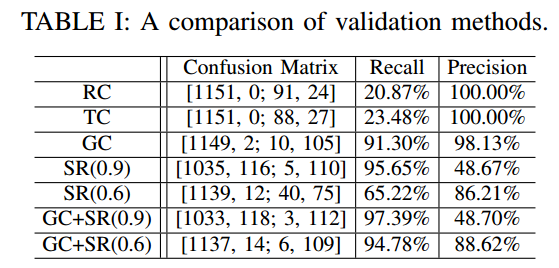
D、 联合测量
这里展示联合观测建模在联合优化中的优势。如下图所示
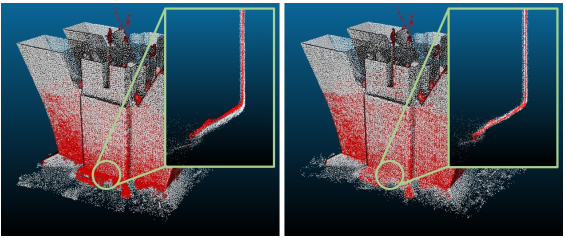
激光雷达点云(灰色)与重建视觉特征(红色)叠加。左:没有联合观测。右:联合观测。
E、重建
对收集到的数据集的重建结果下图所示。在第一行,展示了小型混凝土结构的重建。第二行比较了使用COLMAP、OpenMVG和我们的方案Smith-Hall重建结果。在这三个测试中,使用左右图像进行重建。然而,COLMAP和OpenMVG都无法处理由停车标志,和有限的重叠图像造成的视觉模糊。因此,生成的模型要么不一致,要么不完整。使用我们的方案有助于有效地排除无效的运动,并允许建立一个更一致的模型。

重建的结果对比
小结
提出了一种利用激光雷达信息提高立体SfM方案的鲁棒性、准确性、一致性和完备性的LiDAR增强立体SfM方案。实验结果表明,该方法能有效地找到有效的运动位姿,消除视觉模糊。此外,实验结果还表明,结合相机和激光雷达的联合观测有助于完全约束外部变换。最后,与最先进的SfM方法相比,LiDAR增强SfM方案可以产生更一致的重建结果。
参考文献链接:
https://mp.weixin.qq.com/s/dRTbRQqVBdSRwqqIi3P2ZQ
https://mp.weixin.qq.com/s/qzIUF4SvTeb73f8rbGws2g
[1] Biggs, B., Boyne, O., Charles, J., Fitzgibbon, A., and Cipolla, R., “Who Left the Dogs Out? 3D Animal Reconstruction with Expectation Maximization in the Loop”, arXiv e-prints, 2020.
[2] Xu, X. and Change Loy, C., “3D Human Texture Estimation from a Single Image with Transformers”, arXiv e-prints, 2021.
[3] Kanazawa, A., Tulsiani, S., Efros, A. A., and Malik, J., “Learning Category-Specific Mesh Reconstruction from Image Collections”, arXiv e-prints, 2018.
[4] Li, X., “Self-supervised Single-view 3D Reconstruction via Semantic Consistency”, arXiv e-prints, 2020.
[5] T. Hu, L. Wang, X. Xu, S. Liu and J. Jia, "Self-Supervised 3D Mesh Reconstruction from Single Images," 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 5998-6007, doi: 10.1109/CVPR46437.2021.00594.
[6] Schwarz, K., Liao, Y., Niemeyer, M., and Geiger, A., “GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis”, arXiv e-prints, 2020.
[7] Chan, E. R., Monteiro, M., Kellnhofer, P., Wu, J., and Wetzstein, G., “pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis”,arXiv e-prints, 2020.
[8] Pan, X., Xu, X., Change Loy, C., Theobalt, C., and Dai, B., “A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis”, arXiv e-prints, 2021.
[9] Zhou, P., Xie, L., Ni, B., and Tian, Q., “CIPS-3D: A 3D-Aware Generator of GANs Based on Conditionally-Independent Pixel Synthesis”, arXiv e-prints, 2021.
[10] Kato, H., Ushiku, Y., and Harada, T., “Neural 3D Mesh Renderer”, arXiv e-prints, 2017.
[11] Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., and Ng, R., “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis”, arXiv e-prints, 2020.
[12] Chen, W., “Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer”, arXiv e-prints, 2019.
[13] Liu, S., Chen, W., Li, T., and Li, H., “Soft Rasterizer: Differentiable Rendering for Unsupervised Single-View Mesh Reconstruction”,arXiv e-prints, 2019.
参考文献

