


文本生成图像技术杂谈
文本生成图像技术杂谈
艺术创作的事,以后人类只要动手打几个字,其他的交给 AI 就行了。
自然语言与视觉的次元壁正在被打破。这不,OpenAI 最近连发大招,提出两个连接文本与图像的神经网络:DALL·E 和 CLIP。DALL·E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。OpenAI 的新工作引起了 AI 圈的一阵欢呼。
Coursera 创始人、斯坦福大学教授吴恩达也表示祝贺,并选出了自己喜欢的「蓝色衬衫 + 黑色长裤」AI 设计。
参考文献链接
https://mp.weixin.qq.com/s/JEugZJr1q2U2GyIViFhPHg
https://mp.weixin.qq.com/s/P33fhrOJrug3Df-EFyTaXg

那么,大佬打算购入几件其他「蓝色」的衬衫吗
OpenAI 联合创始人、首席科学家 Ilya Sutskever 表示:人工智能的长期目标是构建「多模态」神经网络,即 AI 系统能够学习多个不同模态的概念(主要是文本和视觉领域),从而更好地理解世界。而 DALL·E 和 CLIP 使更接近「多模态 AI 系统」这一目标。

第一个神经网络 DALL·E 可以将以自然语言形式表达的大量概念转换为恰当的图像。值得注意的是,DALL·E 使用了 GPT-3 同样的方法,只不过 DALL·E 将其应用于文本 - 图像对。

DALL·E 示例。给出一句话「牛油果形状的椅子」,就可以获得绿油油、形态各异的牛油果椅子图像。
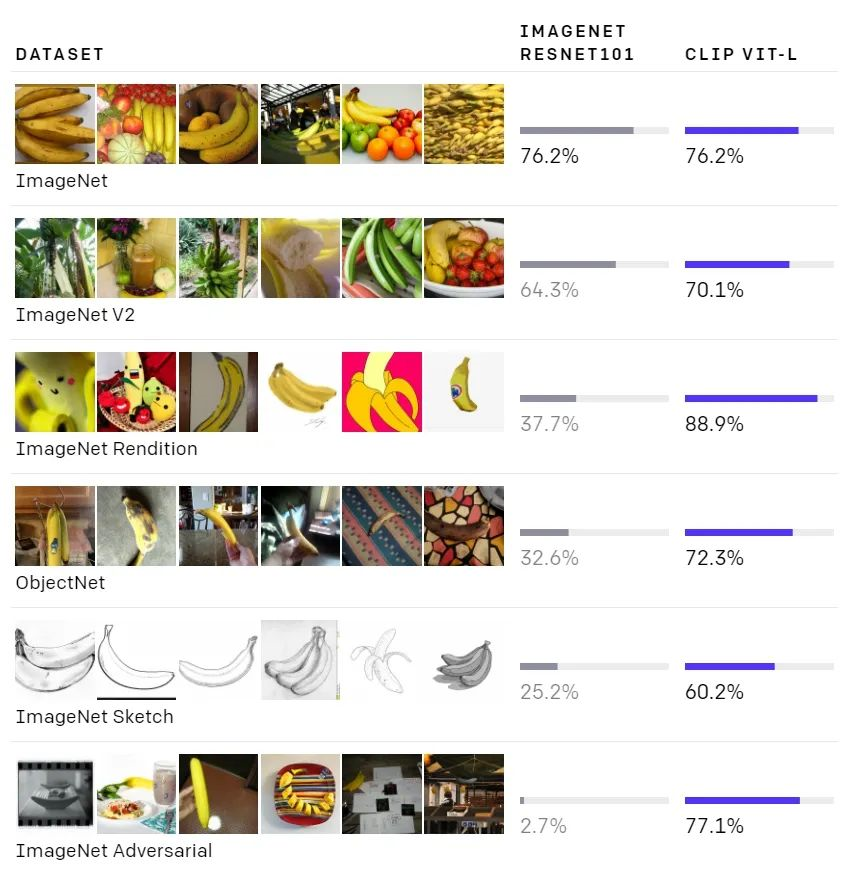
另一个神经网络 CLIP 能够可靠地执行一系列惊人的视觉识别任务。给出一组以语言形式表述的类别,CLIP 能够立即将一张图像与其中某个类别进行匹配,而且不像标准神经网络那样需要针对这些类别的特定数据进行微调。在 ImageNet 基准上,CLIP 的性能超过 ResNet-50,在识别不常见图像任务中的性能远超 ResNet。
DALL·E:从文本生成图像
DALL·E 是 GPT-3 的 120 亿参数版本,经文本 - 图像对数据集训练后,可基于文本描述生成图像。DALL·E 这个名称来源于皮克斯动画经典作品《机器人总动员(WALL·E)》。
有意思的是,还可以将动物和物体拟人化,将一些无关的概念以一种合理的方式组合起来。
比如,穿着芭蕾 tutu 裙遛狗的胡萝卜:

细细观察,可以看出 DALL·E 是怎样将人体构造迁移到其他生物的。如果想让一支胡萝卜喝拿铁咖啡或骑独轮车,DALL·E 会把生成图像中的方巾、手脚放在合理的位置。
还比如,生成写着 OpenAI 的商店招牌:

通常 DALL·E 写入的字符串越长,成功率会降低一些。而文字有重复的时候,成功率会变高。尽管样本变得更简单,但随着采样温度的降低,成功率有时候会提升。
和 GPT-3 一样,DALL·E 是一种 Transformer 语言模型。以包含多达 1280 个 token 的单数据流形式接收文本和图像,并利用最大似然进行训练,逐个生成所有 token。
token 是来自不连续词汇表的任意符号。对于人类来说,每个英文字母都是来自字母表的 token。DALL·E 的词汇表有文本和图像的 token。每个图像的文本描述使用最大 256BPE 编码的 token 表示,词汇表的大小是 16384;图像则使用 1024 个 token 表示,词汇表大小是 8192。
在最新博客中,OpenAI 详细介绍了 DALL·E 的「百变功能」,每一段文字的生成示例展示了 512 个生成结果中的前 32 名(根据 CLIP 的排序,过程中没有任何人工参与挑选的步骤)。
控制属性
在修改对象属性的能力方面,研究者对 DALL·E 进行了测试。DALL·E 可以用多边形形状渲染熟悉的对象,甚至是在现实世界中不太可能发生的情况。比如这些诡异的「绿色闹钟」:

绘制多物体图像
同时控制多个对象及其属性、空间关系,是一个新的挑战。比如「戴红色帽子、黄色手套,穿蓝色衬衫、绿色裤子的刺猬」,DALL·E 生成效果如下:

尽管 DALL·E 对少量物体的属性和位置提供了一定程度的可控性,但成功率可能仍取决于文本的表述方式。此外,DALL·E 还很容易混淆不同对象及其颜色之间的关联。
可视化透视图和三维图
DALL·E 还可以控制场景视点和渲染场景的 3D 样式,例如:

不同角度的美洲狮。
可视化内外部结构
DALL·E 还能够渲染出横截面视图的内部结构,以及通过微距相片展现事物的外部结构。例如核桃的横截面视图:

推断语境细节
文本转图像任务是非明确指定的,一个文本描述通常对应许多合理图像,因此图像并非唯一指定的。例如,对于文本描述「坐着看日出的水豚鼠」,可能需要根据水豚鼠的方位画出阴影,尽管这并没有在文本描述中明确提及。DALL·E 能够解决以下三种情景中的非指定问题:改变风格、设置和时间;在不同场景中绘制相同的对象;生成带有特定文本的对象(例如上文提到的写着 OpenAI 的商店招牌)。
下图展示了 AI 生成的「看日出的水豚鼠」,这些图像具备不同的风格,如波普艺术风格、超现实主义风格、浮世绘风格等等。

时尚和室内设计
DALL·E 还可以应用到时尚设计与室内设计,例如身穿蓝色衬衫和黑色裤子的橱窗模特:

将不相关的概念结合起来
语言的复合性使得可以将多个概念组合在一起来描述真实和想象中的事物。而 DALL·E 也具备将不同 idea 结合起来并合成物体的能力,甚至有的物体在现实世界中并不存在。例如,将多种不同概念的特点迁移到动物身上,从不相关的概念中汲取灵感来设计产品(例如本文开头提到的牛油果椅子)。
下列示例就将「竖琴」和「蜗牛」这两个八竿子打不着的事物组合到了一起:

动物插图
DALL·E 不仅能将不相关的概念连接到一起,还能将这一能力应用到艺术领域。例如,动物和物体的拟人化版本、动物嵌合体和 emoji。
下图展示了「长颈鹿龟」这一新物种:

奇怪的物种又增加了。
零次视觉推理
只需给出文本描述或提示,GPT-3 就能执行多种任务,且无需额外训练。这种能力叫做「零次推理」(zero-shot reasoning)。而 DALL·E 将该能力扩展到视觉领域,在给出恰当提示的情况下,能够执行多种图像翻译任务。
例如给出文本「为上方猫图提供简笔画版本」,会得到:

不过,任务要求不同,得到图像的可靠性也不相同。
地理知识
DALL·E 还能学习地理事实、地标建筑和街区。有时候可以非常精确地学习这些知识,但有时候又会在其他方面出现缺陷。例如,给出文本「中国美食」,可以生成大量相关美食图像,但无法完全涵盖现实中中国美食的多样性。
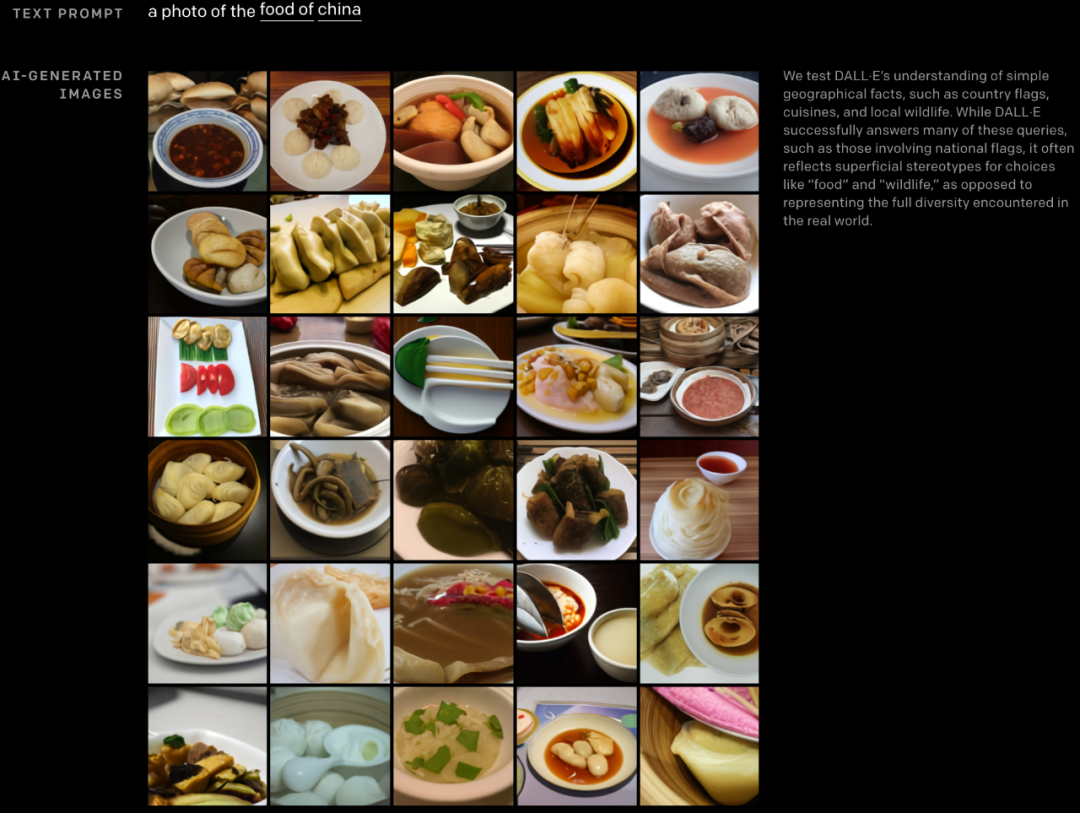
这些美食的确似曾相识,但又感觉并没吃过
时间知识
DALL·E 的能力可不止于此,还可以展示某个概念的时代变迁史。例如给出文本「上世纪 20 年代以来的手机图像」,将会得到各个年代的手机照片:

CLIP:连接文本与图像
除了基于文本生成图像的 DALL·E,OpenAI 还介绍了另一项工作 CLIP。
CLIP 旨在解决深度学习方法在计算机视觉领域中所面临的的一些主要问题,如创建视觉数据集的人力和成本问题、数据集涵盖的视觉概念过于狭窄、标准视觉模型只擅长一种任务且需要很多努力才能适应新任务、基准测试中表现良好的模型在压力测试中表现糟糕等等。
为此,CLIP 模型在多种多样的图像上进行训练,这些图像具备多种自然语言监督,并且很容易在网络上获得。
在设计上,CLIP 可以利用自然语言获得指导以执行多种分类基准任务,无需针对基准性能直接优化,这类似于 GPT-2 和 GPT-3 的「zero-shot」能力。这是一个关键改变:由于不直接针对基准进行优化,研究者发现 CLIP 更具有表征性。该系统将这种「鲁棒性差距」缩小了 75%,同时在不使用任何原始 1.28M 标注示例的情况下,CLIP 在 ImageNet zero-shot 上的性能媲美原版 ResNet 50。
下图为 CLIP VIT-L 与 ResNet101 在 ImageNet 数据集上的性能对比。尽管两者在原始 ImageNet 测试集上具有相同的准确率,但在不同的非 ImageNet 设置下测量准确率的数据集上,CLIP 更具有表征性。
方法
CLIP 使用了大量可用的监督资源,即网络上找到的文本 - 图像对。这些数据用于创建 CLIP 的代理训练任务,即给定一张图像,然后预测数据集中 32,768 个随机采样文本片段中哪个与该图像匹配。
为了解决这一任务,研究者认为 CLIP 模型需要学习识别图像中各种各样的视觉概念,并将这些概念与各自的名称联系起来。这样一来,CLIP 模型可用于几乎所有视觉分类任务中。例如,如果数据集的任务是对狗和猫的照片进行分类,则会针对每张图像检查 CLIP 模型预测的文本描述「狗的照片」或「猫的照片」是否更有可能与之相匹配。
狗和猫照片的分类任务流程如下图所示,其中包括对比预训练、从标签文本中创建数据集分类器和 zero-shot 预测。

CLIP 的亮点
CLIP 非常高效,从未过滤、多种类和高噪声的数据中学习,并希望以 zero-shot 的方式应用。为了减少所需的计算量,研究者重点探究了如何从算法角度提升 CLIP 的训练效率。
研究者提供了两种大幅降低计算量的算法。第一种算法采用对比目标(contrastive objective)来连接文本和图像。最初探究了类似 VirTex 的图像到文本方法,但在将其扩展以实现 SOTA 性能过程中遇到了困难。在中小规模试验中,研究者发现,CLIP 使用的对比目标方法在 zero-shot ImageNet 分类中的效率提升了 3 至 9 倍。
第二种算法采用 Vision Transformer,使得计算效率相比标准 ResNet 有 3 倍提升。最后,表现最好的 CLIP 模型在 256 个 GPU 上训练了 2 周左右的时间,这与目前大型图像模型类似。
结果表明,经过 16 天的 GPU 训练,在训练 4 亿张图像之后,Transformer 语言模型在 ImageNet 数据集上仅实现了 16% 的准确率。CLIP 则高效得多,实现相同准确率的速度快了大约 9 倍。具体如下图所示:

此外,CLIP 灵活且通用。这是因为 CLIP 模型直接从自然语言中学习多种多样的视觉概念,所以比现有 ImageNet 模型更灵活且具有更强的通用性。研究者发现 CLIP 模型可以 zero-shot 执行很多不同任务。为了验证这一点,研究者在包含细粒度目标检测、地理定位以及视频动作识别和 OCR 等任务的 30 多种不同数据集上测量了 CLIP 的 zero-shot 性能。
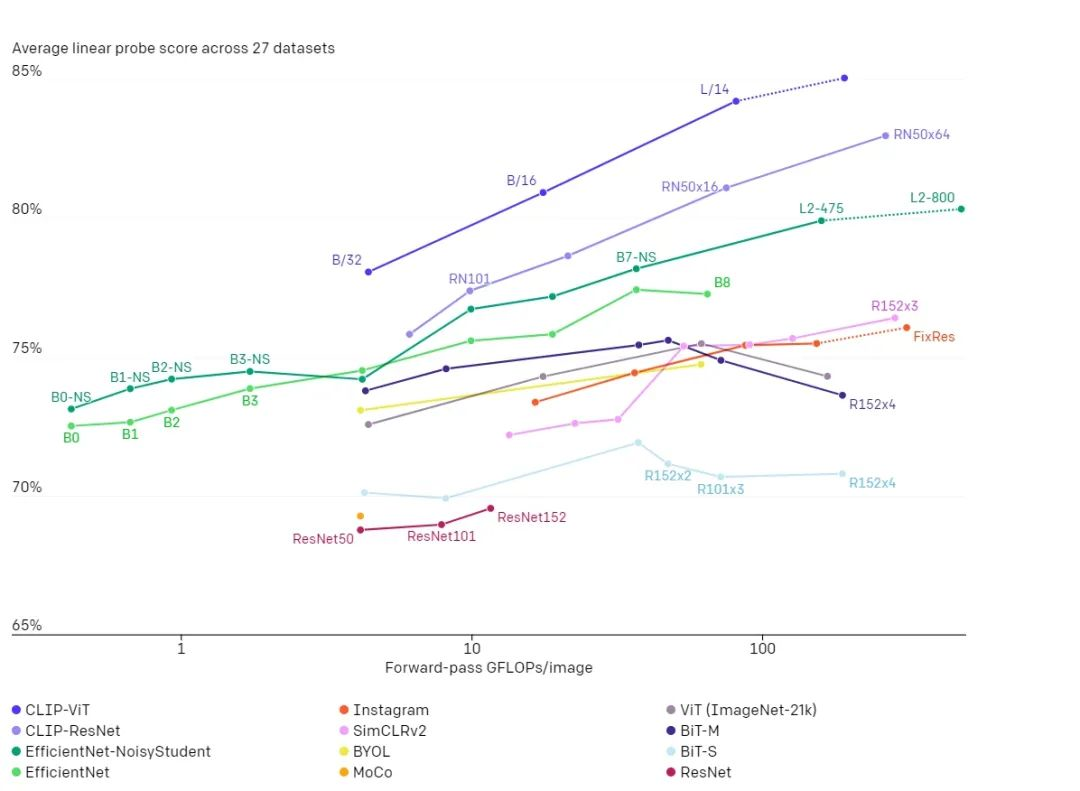
结果表明,在 26 个测试的不同迁移数据集上,表现最好的 CLIP 模型在其中 20 个数据集上优于 Noisy Student EfficientNet-L2(公开可用的最佳 ImageNet 模型)。具体如下图所示:
局限性
虽然 CLIP 在识别常见对象时往往表现良好,但在计算图像中对象数量等更抽象或更系统的任务,以及预测照片中最靠近车辆间的距离等更复杂任务上的表现不佳。在这两项任务上,zero-shot CLIP 的效果也只比随机猜测好一点。
此外,与特定于任务的模型相比,zero-shot CLIP 在非常细粒度的分类任务上表现不佳,比如区分汽车模型、飞机型号或者花卉种类等。CLIP 对其预训练数据集中未涵盖的图像也表现出糟糕的泛化性能。
最后,研究者发现,CLIP 的 zero-shot 分类器对用词或措辞也非常敏感,有时需要反复试验和误差「prompt engineering」才能表现良好。
原文链接:
https://openai.com/blog/dall-e/
https://openai.com/blog/clip/
https://openai.com/blog/tags/multimodal/
文本生成图像示例
目前多模态任务成为行业热点,本文梳理了较为优秀的多模态文本图像模型:DALL·E、CLIP、GLIDE、DALL·E 2 (unCLIP)的模型框架、优缺点,及其迭代关系。
OpenAI 最近发布了 DALL·E 2 系统,在 AI 界引发了「地震」,该系统能够根据文本描述创建图像。这是 DALL·E 系统的第二个版本,第一个版本是在近一年前发布的。然而,在 OpenAI 内部,DALL·E 2 背后的模型被称为 unCLIP,更接近于 OpenAI 的 GLIDE 系统,而不是原始的 DALL·E。
对笔者来说,DALL·E 2 系统的冲击力可以与
AlphaGo 相媲美。看起来该模型捕获了许多复杂的概念,并且以有意义的方式将组合起来。就在几年前,计算机能否从这样的文本描述中生成图像还是一件难以预测的事情。Sam Altman 在博客文章中提到,对 AI 的预测似乎是错误的,是需要更新的,因为 AI 已经开始影响创造性的工作,而非只是机械重复的工作。
本文旨在带领读者一览 OpenAI 的文本引导图像生成模型的演变,包括 DALL·E 的第一个和第二个版本以及其他的模型。
DALL·E 演变史
DALL·E 1
DALL·E 的第一个版本是 GPT-3 风格的
transformer 解码器,可以根据文本输入和可选的图像开头自回归生成 256×256 大小的图像。
一定见过这些牛油果椅子:

来自原始博客文章。
如果想了解类似 GPT 的
transformer 的工作原理,请参阅 Jay Alammar 的精彩视觉解释:https://jalammar.github.io/how-gpt3-works-visualizations-animations/
文本由 BPE tokens 编码(最多 256 个),图像由离散变分自编码器 (dVAE) 生成的特殊图像 tokens(其中 1024 个)编码。dVAE 将
256×256 图像编码为 32×32 tokens 的网格,词汇表包含 8192 个可能的值。dVAE 会在生成的图像中丢失一些细节和高频特征,所以 DALL·E 生成图像的特征采用了一些模糊和平滑。

原始图像(顶部)和 dVAE 重建(底部)的比较。图片来自原始论文。
这里使用的 transformer 是有着 12B 大小参数的大模型,由 64 个稀疏 transformer 块组成,内部具有一组复杂的注意力机制,包括:1) 经典的文本到文本注意力掩码机制,2) 图像到文本的注意力,3) 图像到图像稀疏注意力。所有三种注意力类型都合并为一个注意力运算。该模型是在 250M 图像 - 文本对的数据集上训练的。
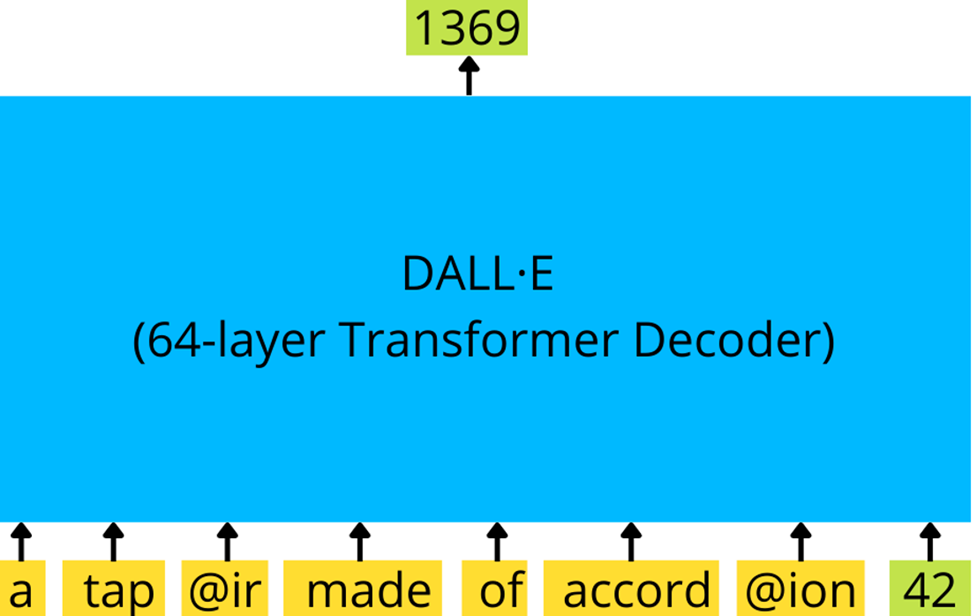
类似 GPT-3 的 transformer 解码器使用一系列文本 token 和(可选)图像 token(此处为 id 为 42 的单个图像 token)并生成图像的延续(此处为 id 为 1369 的下一个图像 token)
训练后的模型根据提供的文本生成了几个样本(最多 512 个),然后将所有这些样本通过一个名为 CLIP 的特殊模型进行排序,并选择排名靠前的一个作为模型的结果。

原始论文中的几个图像生成示例。
CLIP
CLIP 最初是一个单独的辅助模型,用于对 DALL·E 的结果进行排序。名字是 Contrastive Language-Image Pre-Training 的缩写。
CLIP 背后的想法很简单。笔者从互联网上抓取了一个图像 - 文本对数据集(400M 的规模),然后在这样的数据集上训练一个对比模型。对比模型可以给来自同一对的图像和文本产生高相似度得分(因此是相似的),而对不匹配的文本和图像产生低分(希望在当前训练批次中某个图像和任何其他对的文本之间得到高相似度结果的机会很小)。
该模型由两个编码器组成:一个用于文本,另一个用于图像。编码器产生嵌入(一个对象的多维向量表征,例如一个 512
字节的向量)。然后使用两个嵌入计算点积,并得出相似度得分。因为嵌入会被归一化,所以这个计算相似度得分的过程输出的是余弦相似度。对于指向相同方向的向量(之间的角度很小),余弦相似度接近 1,对于正交向量,余弦相似度接近 0,对于相反的向量,余弦相似度接近 -1。
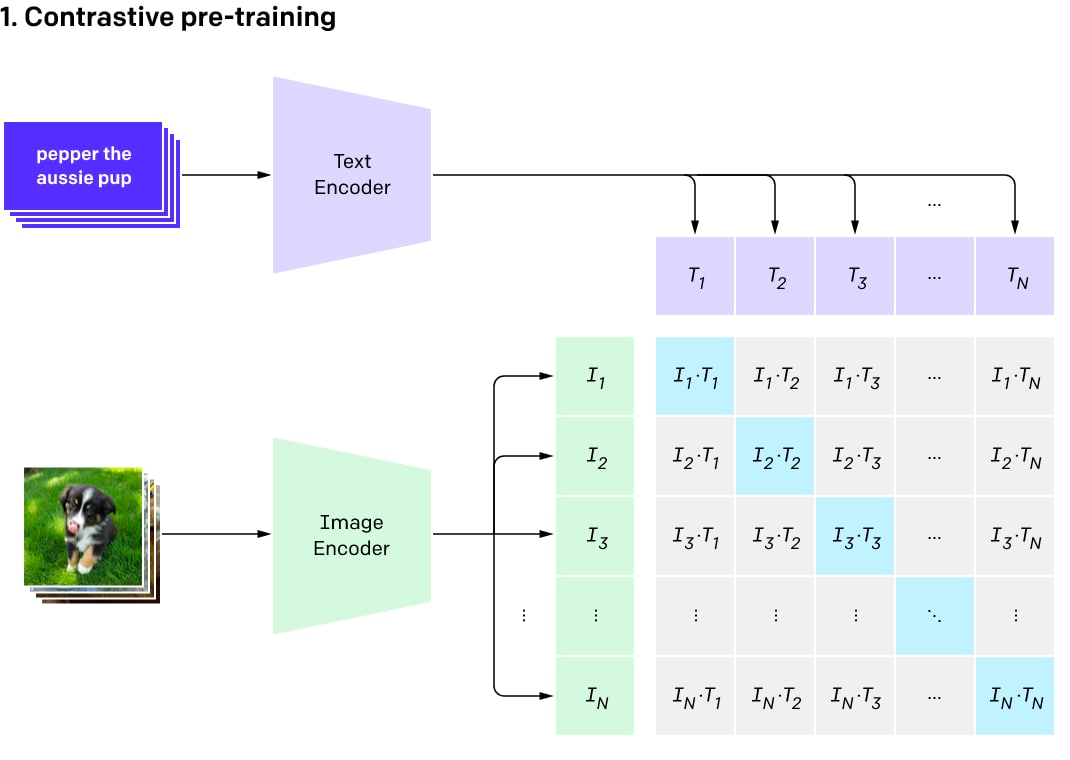
对比预训练过程可视化(图片来自原帖)
CLIP 是一组模型。有 9 个图像编码器、5 个卷积编码器和 4 个
transformer 编码器。卷积编码器是 ResNet-50、ResNet-101 和类似 EfficientNet 的模型,称为 RN50x4、RN50x16、RN50x64(数字越大,模型越好)。transformer 编码器是视觉 Transformer(或称之为 ViT):ViT-B/32、ViT-B/16、ViT-L/14 和 ViT-L/14@336。最后一个在分辨率为 336×336 像素的图像上进行微调,其他的则在 224×224 像素上进行训练。
OpenAI 分阶段发布了程序,首先发布了 ViT-B/32 和 ResNet-50,然后是 ResNet-101 和 RN50x4,然后 RN50x16 和
ViT-B/16 于 2021 年 7 月发布,然后是 RN50x64 和 ViT-L /14 在 2022 年 1 月发布,2022 年 4 月终于出现了 ViT-L/14@336。
文本编码器是一个普通的 transformer 编码器,但具备掩码注意力机制。这个编码器由 12 层组成,每层有 8 个注意力头,总共有 63M 的参数。有趣的是,注意力跨度只有 76 个 token(相比之下,GPT-3 有
2048 个 token,标准 BERT 有 512 个 token)。因此,模型的文本部分只适用于相当短的文本,不能在模型中放入大段文本。由于 DALL·E 2 和 CLIP 大致相同,应该也有相同的限制。
CLIP 预训练之后,可以将其用于不同的任务(有良好基础模型的优势)。
最重要的是,读者可以使用在 DALL·E 中排序好的模型对多个结果进行评分,并选择最好的一个。或者,也可以使用 CLIP 功能在其之上训练自定义分类器,但是目前成功的例子还不是很多。
接下来,可以使用 CLIP 对任意数量的类进行零样本分类(当没有专门训练模型以使用这些类时)。这些类可以在不重新训练模型的情况下进行调整。
简单来说,可以为所需的多个类创建一个描述图片中物体的文本数据集。然后为这些描述生成文本嵌入并将存储为向量。当图像用于分类时,使用图像编码器生成图像嵌入,并计算图像嵌入和所有预先计算的文本嵌入之间的点积。选择得分最高的对,其对应的类就是结果。
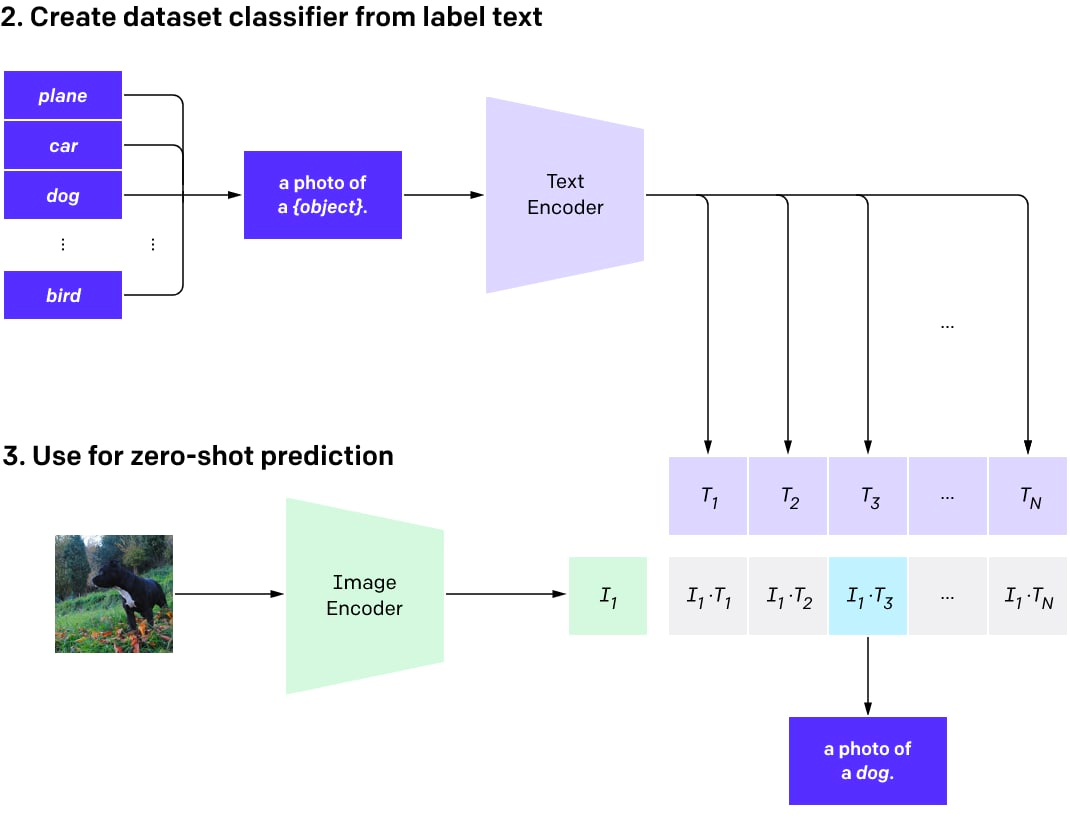
用于使用 CLIP 进行零样本分类的程序。
零样本分类模型是说并未针对特定类别集训练模型。现在可以选择使用预训练的
CLIP 进行即时工程(与使用 GPT 模型相同),而不是从头开始训练分类器或通过微调预训练的图像模型。
很多人没有想到,也可以使用 CLIP 生成图像(即使并没有被预设可以这样做)。成功案例包括 CLIPDraw 和 VQGAN-CLIP。

CLIPD 绘制示例。图片来自原论文。

VQGAN-CLIP 及其文本 prompt 的生成示例。图片来自原论文。
该过程简单而美观,与 DeepDream 非常相似。从想要的图像的文本描述和初始图像(随机嵌入、样条线或像素中的场景描述、任何以可区分方式创建的图像)开始,然后运行一个生成图像的循环,加入一些增强以提高稳定性,获得结果图像的 CLIP 嵌入,并将其与描述图像的文本的 CLIP 嵌入进行比较。根据此差异计算损失,并运行梯度下降程序,以此来更新图像、减少损失。经过一些迭代后,可以得到很好地匹配文本描述的图像。创建初始场景的方式(使用样条线、像素、渲染基元、来自 VQGAN 的潜在代码等)会显著影响图像特征。

CLIPDraw 生成过程:从一组随机的 Bezier 曲线开始,优化曲线的位置和颜色,使生成的图形与给定的描述 prompt 最匹配。图片来自原论文。

VQGAN-CLIP 生成过程。图片来自原论文。
CLIP 嵌入并不能捕获所有内容,一些有趣的演示证明了弱点。其中一个广为人知的例子是印刷攻击。在这种攻击中,图像上的文本可能导致图像的错误分类。
目前有一些与 CLIP 结构相似的替代模型,例如 Google
的 ALIGN 或华为的 FILIP。
GLIDE
GLIDE,即 Guided Language to Image Diffusion for
Generation and Editing,是 OpenAI 推出的文本引导图像生成模型,目前已经击败了 DALL·E,但受到的关注相对较少。甚至在 OpenAI 网站上也没有专门的帖子。GLIDE 生成分辨率为 256×256 像素的图像。
拥有 3.5B 参数的 GLIDE 模型(但似乎正确的数字是 5B 参数,因为有一个单独的具有 1.5B 参数的上采样模型)比 12B 参数 DALL·E 更受人们的青睐,并且在 FID 得分上也击败了 DALL·E。
来自 GLIDE 的样本。图片来自原始论文。
GLIDE 模型还可以进行微调以执行图像修复,从而实现强大的文本驱动图像编辑,这在 DALL·E 2 中使用。

来自 GLIDE 的文本条件图像修复示例。绿色区域被擦除,模型根据给定的提示填充这个区域。该模型能够匹配周围环境的风格和光线,产生逼真的完成效果。示例来自原论文。
GLIDE 在发布时可以称作「DALL·E 2」。现在,当一个单独的 DALL·E 2 系统发布时(实际上在论文中称为 unCLIP 并且大量使用 GLIDE 本身),可以将 GLIDE 称为 DALL·E 1.5 :)
GLIDE 类似于另一种称为扩散模型的模型。简而言之,扩散模型通过扩散步骤链向输入数据添加随机噪声,然后会学习逆向扩散过程以从噪声中构造图像。

去噪扩散模型生成图像。
下图是 Google 使用扩散模型生成图像的可视化说明。

扩散模型与其他类别的生成模型的比较。
首先,作者训练了一个 3.5B 参数扩散模型,该模型使用文本编码器以自然语言描述为条件。接下来,比较了两种将扩散模型引导到文本 prompt 的技术:CLIP 引导和无分类器引导(后者能产生更好的结果)。
分类器引导允许扩散模型以分类器的标签为条件,并且来自分类器的梯度用于引导样本朝向标签。
无分类器引导不需要训练单独的分类器模型。这只是一种引导形式,在有标签和没有标签的扩散模型的预测之间进行插值。
正如作者所说,无分类引导有两个吸引人的特性。首先,允许单个模型在引导过程中利用自己的知识,而不是依赖于单独(有时更小的)分类模型的知识。其次,简化了对难以用分类器预测的信息(例如文本)进行调节时的引导。
在 CLIP 引导下,分类器被替换为 CLIP 模型。使用图像的点积和相对于图像的标题编码的梯度。
在分类器和 CLIP 引导中,必须在噪声图像上训练 CLIP,以便在反向扩散过程中获得正确的梯度。作者使用了经过明确训练具有噪声感知能力的 CLIP 模型,这些模型被称为噪声 CLIP 模型。尚未在噪声图像上训练的公共 CLIP 模型仍可用于引导扩散模型,但噪声 CLIP 引导对这种方法表现良好。
文本条件扩散模型是一种增强的 ADM 模型架构,基于噪声图像
xₜ 和相应的文本标题 c 预测下一个扩散步骤的图像。
视觉部分是修改后的 U-Net 架构。U-Net 模型使用一堆残差层和下采样卷积,然后是一堆带有上采样卷积的残差层,使用残差连接(skip connection)连接具有相同空间大小的层。

原始的 U-Net 架构。图片来自原论文。
GLIDE 对原始 U-Net 架构的宽度、深度等方面有不同的修改,在 8×8、16×16 和 32×32 分辨率下添加了具有多个注意力头的全局注意力层。此外,还将时间步嵌入的投影添加到每个残差块中。
对于分类器引导模型,分类器架构是 U-Net 模型的下采样主干网络,在 8×8 层有一个注意力池以生成最终输出。
文本通过 transformer 模型被编码成 K 个(最大注意力跨度尚不清楚)tokens 的序列。
transformer 的输出有两种使用方式:首先,使用最终的 token 嵌入替代 ADM 模型中的类嵌入;其次,token 嵌入的最后一层(K 个特征向量的序列)分别投影到整个 ADM 模型中每个注意力层的维度,然后连接到每一层的注意力上下文。
文本 transformer 有 24 个宽度为 2048 的残差块,产生大约 1.2B 的参数。为 64×64 分辨率训练的模型的视觉部分由 2.3B 个参数组成。除了 3.5B 参数的文本条件扩散模型,作者还训练了另一个 1.5B 参数的文本条件上采样扩散模型,将分辨率提高到 256×256(这个想法在 DALL·E 中也会用到)。
上采样模型以与基本模型相同的方式以文本为条件,但使用宽度为 1024 而不是 2048 的较小文本编码器。对于 CLIP 引导,还训练了带噪声的 64×64 ViT-L CLIP 模型。
GLIDE 在与 DALL·E 相同的数据集上进行训练,总的训练计算量大致等于用于训练 DALL·E 的计算量。
GLIDE 在所有设置中都是最优,即使设置允许 DALL·E 使用更多的测试时间计算来得到优越的表现,同时降低 GLIDE 样本质量(通过 VAE 模糊)。
该模型经过微调以支持无条件的图像生成。这个训练过程与预训练完全一样,只是将 20% 的文本 token 序列替换为空序列。这样,模型保留了生成文本条件输出的能力,但也可以无条件地生成图像。
该模型还经过显式微调以执行修复。在微调期间,训练示例的随机区域被删除,其余部分与掩码通道一起作为附加条件信息输入模型。
GLIDE 可以迭代地使用 zero-shot 生成产生复杂场景,然后进行一系列修复编辑。

首先生成 prompt「一个舒适的客厅」的图像,然后使用修复蒙版,后续文本 prompt 在墙上添加了一幅画、一个茶几,茶几上还有一个花瓶,最后把墙移到沙发上。示例来自原论文。
DALL·E 2/unCLIP
OpenAI 于 2022 年 4 月 6 日发布了 DALL·E 2 系统。DALL·E
2 系统比原来的 DALL·E 显著提升了结果。生成的图像分辨率提高了 4 倍(与原来的 DALL·E 和
GLIDE 相比),现在高达 1024×1024 像素。DALL·E
2 系统背后的模型称为 unCLIP。
作者发现,就照片写实而言,人类略微喜欢 GLIDE 而不是
unCLIP,但差距非常小。在具有类似真实感的情况下,在多样性方面,unCLIP 比 GLIDE 更受青睐,突出了好处之一。请记住,GLIDE 本身比 DALL·E 1 更受欢迎,所以说 DALL·E 2 比前身 DALL·E 1 有了显著改进。

对于「用克劳德 · 莫奈的风格画一幅狐狸坐在日出时分田野里的画」的要求,两个版本的系统生成的图片,图片来自原文章。
DALL·E 2 可以将概念、属性和风格结合起来:
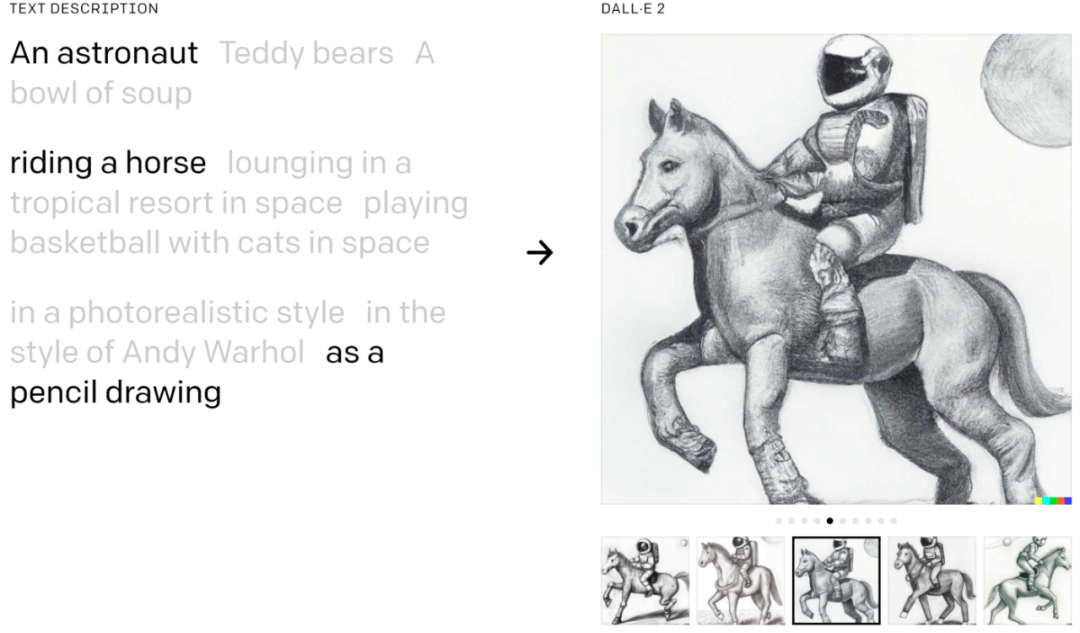
原文中的示例。
DALL·E 2 还可以基于文本引导进行图像编辑,这是 GLIDE 中的功能。可以在考虑阴影、反射和纹理的同时添加和删除元素:
将柯基犬添加到图像上的特定位置,图片来自原论文中。
DALL·E 2 还可用于生成原始图像的变体:

生成图像的变体,图片来自原文。

DALL·E 2 也存在一些问题。特别是 unCLIP 在将属性绑定到对象方面比 GLIDE 模型更差。例如,unCLIP 比 GLIDE 更难面对必须将两个单独的对象(立方体)绑定到两个单独的属性(颜色)的 prompt:

unCLIP 生成连贯的文本上也有一些困境:


另一个问题是 unCLIP 很难在复杂场景中生成细节:

模型内部发生了一些改变。下图是 CLIP 和 GLIDE 的结合,模型本身(全文条件图像生成堆栈)在论文内部称为 unCLIP,因为通过反转 CLIP 图像编码器生成图像。
该模型的工作方式如下:CLIP 模型是单独训练的。然后 CLIP 文本编码器为输入文本(标题)生成嵌入。然后一个特殊的先验模型基于文本嵌入生成图像嵌入。然后扩散解码器基于图像嵌入生成图像。解码器本质上将图像嵌入反转回图像。
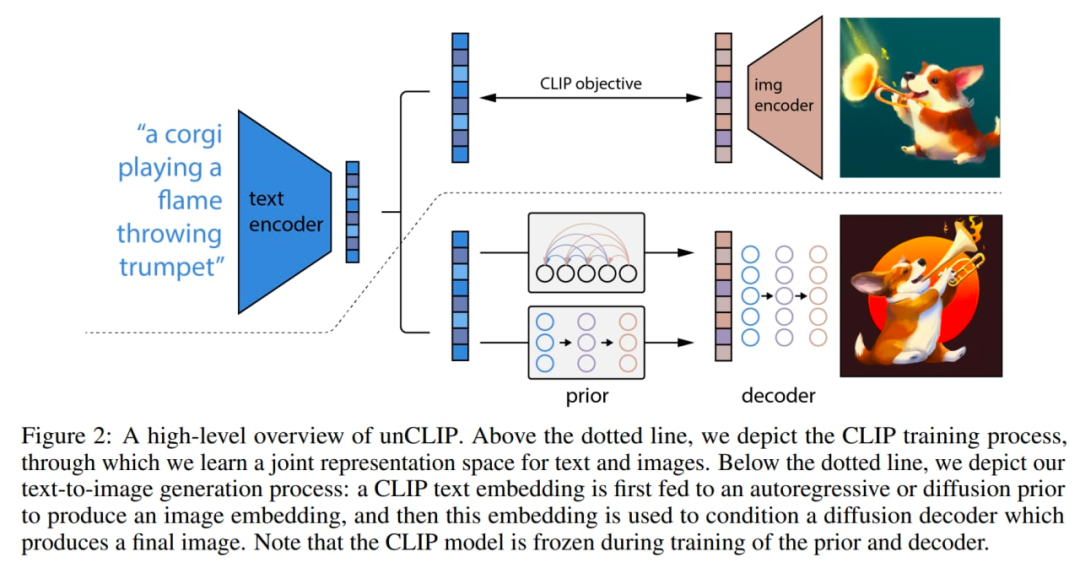
系统的宏观概述。一些细节(如解码器文本条件)没有显示。图片来自原论文。
CLIP 模型使用 ViT-H/16 图像编码器,使用 256×256 分辨率的图像,宽度为 1280,带有 32 个 Transformer 块(比原始 CLIP 工作中最大的 ViT-L 更深)。文本编码器是一个带有因果注意掩码的 Transformer,宽度为 1024 和 24 个 Transformer 块(原始 CLIP 模型有 12 个
Transformer 块)。尚不清楚文本 transformer 的注意力跨度是否与原始 CLIP 模型中的相同(76 个
token)。
扩散解码器是经过修改的 GLIDE,具有 3.5B 参数。CLIP 图像嵌入被投影并添加到现有的时间步嵌入中。CLIP 嵌入也被投影到四个额外的上下文 token 中,这些 token 连接到 GLIDE 文本编码器的输出序列。保留了原始 GLIDE 的文本条件路径,因为可以让扩散模型学习 CLIP 未能捕获的自然语言方面(然而,帮助不大)。在训练期间,10% 的时间用于将 CLIP 嵌入随机设置为零,50% 的时间随机删除文本标题。
解码器生成 64×64 像素的图像,然后两个上采样扩散模型随后生成 256×256 和 1024×1024 的图像,前者具有 700M 参数,后者具有 300M 参数。为了提高上采样的鲁棒性,在训练过程中条件图像被轻微损坏。第一个上采样阶段使用高斯模糊,第二个阶段使用更多样化的 BSR 降级,包括 JPEG 压缩伪影、相机传感器噪声、双线性和双三次插值、高斯噪声。这些模型在目标大小的四分之一的随机图像上进行训练。文本调节不用于上采样模型。
先验根据文本描述生成图像嵌入。作者探索了先验模型的两个不同模型类:自回归 (AR) 先验和扩散先验。两种先验的模型都有 1B 参数。
在 AR 先验中,CLIP 图像嵌入被转换为一系列离散代码,并根据标题进行自回归预测。在扩散先验中,连续嵌入向量直接使用以标题为条件的高斯扩散模型进行建模。
除了标题之外,先验模型还可以以 CLIP 文本嵌入为条件,因为是标题的确定性函数。为了提高采样质量,作者还通过在训练期间 10% 的时间随机删除此文本条件信息,启用了对 AR 和扩散先验使用无分类器引导的采样。
对于 AR 先验,主成分分析 (PCA) 降低了 CLIP 图像嵌入的维数。1024 个主成分中有 319 个保留了 99% 以上的信息。每个维度量化为 1024 个桶。作者通过将文本标题和 CLIP 文本嵌入编码为序列的前缀来调节 AR 先验。此外,在文本嵌入和图像嵌入之间添加一个表征(量化的)点积的 token。这允许在更高的点积上调整模型,因为更高的文本图像点积对应于更好地描述图像的标题。点积是从分布的上半部分采样的。使用带有因果注意掩码的 Transformer 模型预测生成的序列。
对于扩散先验,具有因果注意掩码的仅解码器(decoder-only) Transformer 在由以下成分组成的序列上进行训练:
- 编码的文本
- CLIP 文本嵌入
- 扩散时间步长的嵌入
- 噪声 CLIP 图像嵌入
- 最终的嵌入,其来自
Transformer 的输出用于预测无噪声 CLIP 图像嵌入。
不使用点积来调节扩散先验。相反,为了提高采样时间的质量,生成了两个图像嵌入样本,并选择了一个具有更高点积和文本嵌入的样本。
对于可比较的模型大小和减少的训练计算,扩散先验优于 AR 先验。在与 GLIDE 的成对比较中,扩散先验也比 AR 先验表现更好。
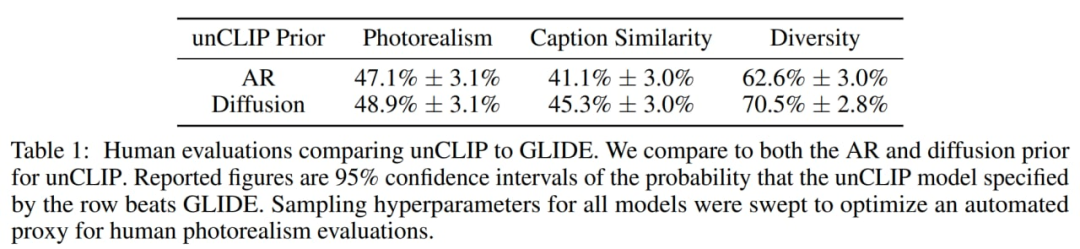
作者还对先验的重要性进行了调查。尝试使用不同的信号来调节相同的解码器:1、文本标题和零 CLIP 嵌入,2、文本标题和 CLIP 文本嵌入(就好像是图像嵌入一样),3、由先验生成的文本和 CLIP 图像嵌入。仅根据标题对解码器进行调节显然是最差的,但对文本嵌入零样本进行调节确实会产生符合期望的结果。

使用不同的调节信号,图片来自原文。
在训练编码器时,作者以相同的概率从 CLIP 和 DALL-E 数据集(总共约 6.5 亿张图像)中采样。在训练解码器、上采样器和之前的模型时,只使用了 DALL-E 数据集(大约 2.5 亿张图像),因为在训练生成堆栈时合并了噪声更大的 CLIP 数据集,从而在初始评估中对样本质量产生了负面影响。
模型总大小似乎是:632M?参数(CLIP ViT-H/16 图像编码器)+ 340M?(CLIP 文本编码器)+
1B(扩散先验)+ 3.5B(扩散解码器)+ 1B(两个扩散上采样器)=~ 大约 6.5B 参数(如果没记错的话)。
这个方法允许基于文本描述生成图像。然而,其他一些有趣的应用也是可能的。

原论文中的示例。
每个图像 x 可以被编码成一个二分 latent 表示 (z_i, x_T),这足以让解码器产生准确的重建。latent z_i 是一个 CLIP 图像嵌入,描述了 CLIP 识别的图像方面。latent x_T 是通过使用解码器对 x 应用 DDIM(去噪扩散隐式模型)反演获得的,同时以 z_i 为条件。换句话说,是在生成图像 x(或等效为 x_0,参见 GLIDE 部分中的去噪扩散模型方案)时扩散过程的起始噪声。
这种二分表示可以实现三种有趣的操作。
首先,可以通过在解码器中使用 η > 0 的 DDIM 进行采样,为给定的二分潜在表示 (z_i, x_T) 创建图像变体。当 η = 0 时,解码器变得具有确定性,并将重建给定的图像 x。η 参数越大,变化越大,可以看到在
CLIP 图像嵌入中捕获了哪些信息并呈现在所有样本中。

探索图像的变化。
其次,可以在图像 x1 和 x2 之间进行插值。为此,必须采用 CLIP 图像嵌入 z_i1 和 z_i2,然后应用 slerp(球面线性插值)来获得中间 CLIP 图像表示。对应的中间 DDIM latent x_Ti 有两个选项:1)使用 slerp 在 x_T1 和 x_T2 之间进行插值,2)将 DDIM latent 固定为轨迹中所有插值的随机采样值(可以生成无限数量的轨迹)。以下图像是使用第二个选项生成的。

探索两个图像的插值。
最后,第三件事是语言引导的图像操作或文本差异。为了修改图像以反映新的文本描述 y,首先获取其 CLIP 文本嵌入 z_t,以及描述当前图像的标题的 CLIP 文本嵌入 z_t0(可能是像「照片」这样的虚拟标题或一个空的标题)。然后计算文本差异向量 z_d = norm(z_t - z_t0)。然后使用 slerp 在嵌入 z_i 的图像 CLIP 和文本差异向量 z_d 之间旋转,并在整个轨迹中生成具有固定基本 DDIM 噪声 x_T 的图像。
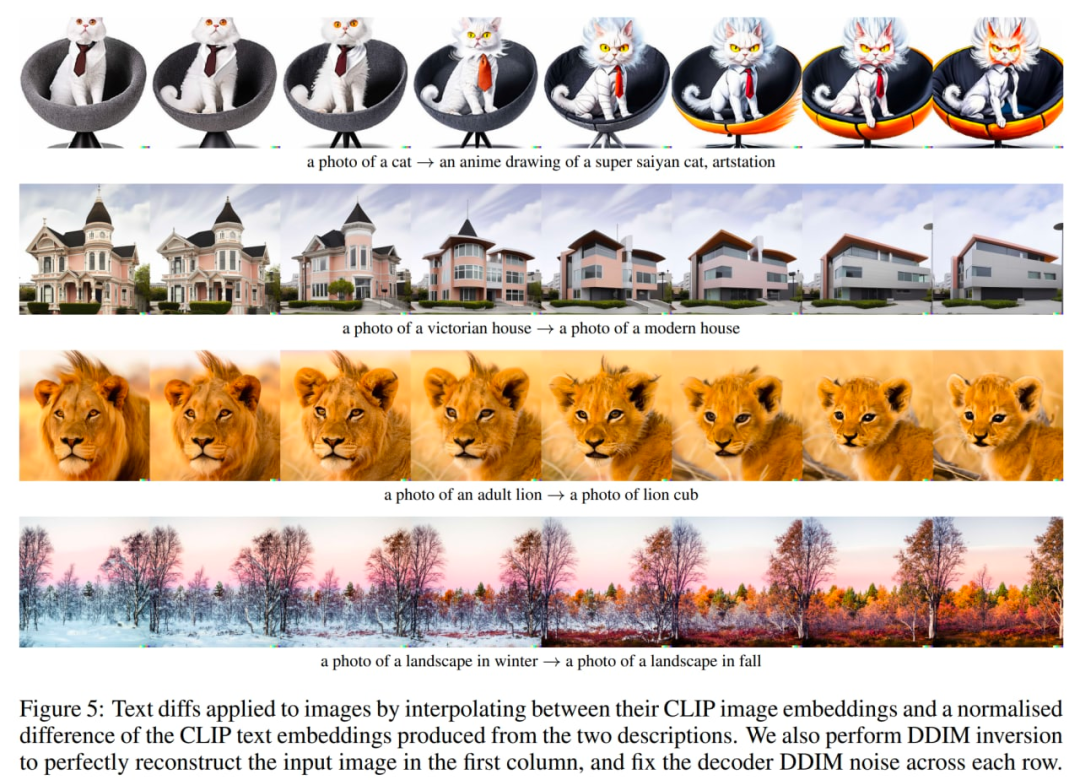
探索文本差异,来自原文中。
作者还进行了一系列实验来探索 CLIP 潜在空间。先前的研究表明,CLIP 容易受到印刷攻击。在这些攻击中,一段文本覆盖在一个对象的顶部,这导致 CLIP 预测文本描述的对象而不是图像中描述的对象(还记得带有 “iPod” 横幅的苹果吗?)。现在,作者尝试生成此类图像的变体,发现尽管图像正确分类的概率非常低,但生成的变体以很高的概率是正确的。尽管该标题的相对预测概率非常高,但该模型从未生成 iPod 的图片。

印刷攻击案例。
另一个有趣的实验是用越来越多的主成分重建图像。在下图中,获取了少量源图像的 CLIP 图像嵌入,并以逐渐增加的 PCA 维度重建,然后使用带有 DDIM 的解码器将重建的图像嵌入可视化。这允许查看不同维度编码的语义信息。

越来越多的主成分,来自原始论文。
还要记住 unCLIP 在属性绑定、文本生成和复杂场景中的细节方面遇到的困难。
前两个问题可能是由于 CLIP 嵌入属性。
可能会出现属性绑定问题,因为 CLIP 嵌入本身并没有将属性显式绑定到对象,因此解码器在生成图像时会混淆属性和对象。

另一组针对难绑定问题的重构,来自原文。
文本生成问题可能是因为 CLIP 嵌入没有精确编码渲染文本的拼写信息。
由于解码器层次结构以 64×64 的基本分辨率生成图像然后对其进行上采样,可能会出现低细节问题。因此,使用更高的基本分辨率,问题可能会消失(以额外的训练和推理计算为代价)。
已经看到了 OpenAI 基于文本的图像生成模型的演变。也有其他公司在这个领域展开工作。

DALL·E 2(或 unCLIP)是对系统的第一个版本 DALL·E 1 的巨大改进,仅用了一年时间。不过,还有很大的提升空间。
遗憾的是,这些强大而有趣的模型一直未开源。作者希望看到更多这样的模型被发布或至少通过 API 提供。否则,所有这些成果都只能适用于一些非常有限的受众。
不可否认,此类模型可能存在误差,有时会产生不正确类型的内容,或被恶意代理使用。作者呼吁人们有必要讨论如何处理这些问题。这些模型有无数潜在的良好用途,但未能解决上述问题阻碍了这些探索。
希望 DALL·E 2(或其他类似模型)能很快通过开放的
API 来使得所有人都可以使用。
原文链接:https://blog.inten.to/openai-and-the-road-to-text-guided-image-generation-dall-e-clip-glide-dall-e-2-unclip-c6e28f7194ea
参考文献链接
https://mp.weixin.qq.com/s/JEugZJr1q2U2GyIViFhPHg
https://mp.weixin.qq.com/s/P33fhrOJrug3Df-EFyTaXg

