

HBM显存技术与市场前景
HBM显存技术与市场前景
HBM(High Bandwidth Memory)作为一种GPU显存存在时,现在似乎已经不算罕见了。很多人可能都知道HBM成本高昂,所以即便不罕见,也只能在高端产品上见到。部分游戏玩家应该知道,HBM是一种带宽远超DDR/GDDR的高速内存,而且内部结构还用上了3D堆叠的SRAM,听起来就十分高级,虽然成本高,但这行业有钱的主也不少,况且GPU不是就在用HBM。未来HBM会替代DDR,成为计算机内存吗?
本文围绕HBM内存和CPU搭配会发生什么、HBM的三个缺点以及HBM是否适用于PC内存等方面进行系统的分析。
HBM(High Bandwidth Memory)作为一种GPU显存存在时,现在似乎已经不算罕见了。很多人可能都知道HBM成本高昂,所以即便不罕见,也只能在高端产品上见到。如英伟达面向数据中心的GPU;AMD在消费级GPU上用HBM算是比较少见的例子。
部分游戏玩家应该知道,HBM是一种带宽远超DDR/GDDR的高速内存,而且内部结构还用上了3D堆叠的SRAM,听起来就十分高级。有PC用户曾经畅想过,要是HBM内存能用到一般的个人电脑、笔记本产品上,和一般的CPU搭配,岂不是美翻天了吗——虽然成本高,但这行业有钱的主也不少啊,况且GPU不是就在用HBM吗?

AMD Radeon R9 Nano显卡旁边的四颗封装就是HBM
1. HBM内存和CPU搭配怎么样?
其实与HBM搭配的中央处理器并不是不存在的,去年在无数篇文章里提过的富士通的超级计算机富岳(Fugaku)内部所用的芯片A64FX,就搭配了HBM2内存。另外Intel很快要发布的Sapphire Rapids至强处理器明年就会有HBM内存版;还有像是NEC SX-Aurora TSUBASA之类的。
那就知道了CPU搭配HBM起码是可行的(虽然可能从严格意义看,A64FX之类的芯片已经超越了CPU的范畴),只不过这些产品怎么说都还是面向数据中心或者HPC应用的。是不是因为贵,所以才没有下放到消费级市场呢?这可能是一个重要或相对靠近源头的原因。本文就借着浅谈HBM的机会,聊聊这种内存的特性和使用场景,以及未来会不会替代现在计算机上十分常见的DDR内存。
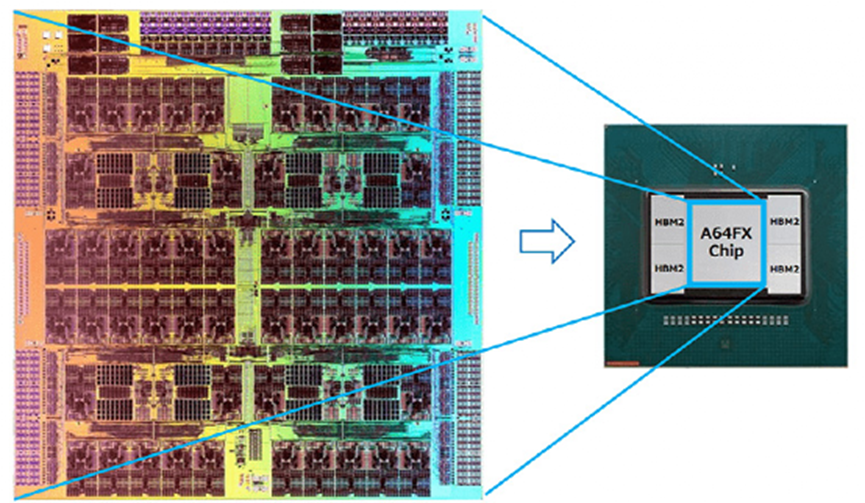
从上方看HBM,来源:富士通
就HBM常见的形态看,通常以从表面看起来几颗die(package)的方式存在,和主芯片(如CPU、GPU)靠得很近,一般就挨着主芯片。如像上面这张图,A64FX就长这样,周围的那4颗package都是HBM内存。这样的存在形态,与一般的DDR内存就存在着比较大的区别。
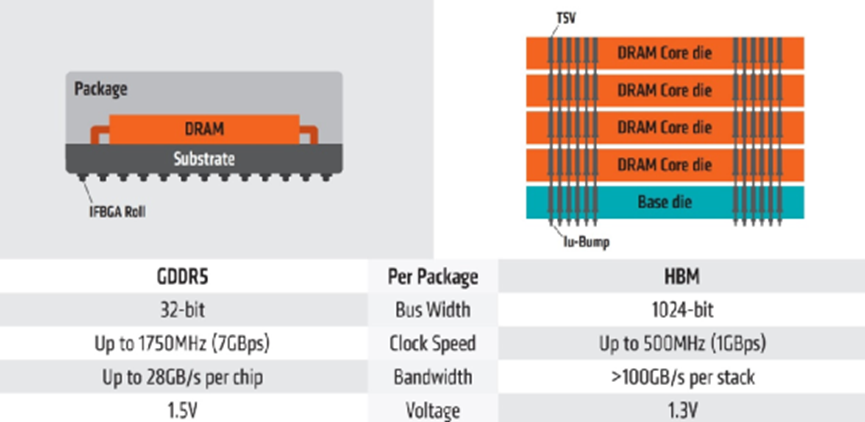
HBM的特点之一,也是以相比DDR/GDDR更小的尺寸、更高的效率(部分)实现更高的传输带宽。而且实际上每个HBM封装内部是叠了好多层DRAM die的,所以也是个3D结构;DRAM die之间以TSV(硅通孔)和microbump连接;除了堆叠的DRAM die以外,下层会有个HBM控制器逻辑die。然后最下层通过base die(如硅中介silicon interposer),与CPU/GPU等互联。
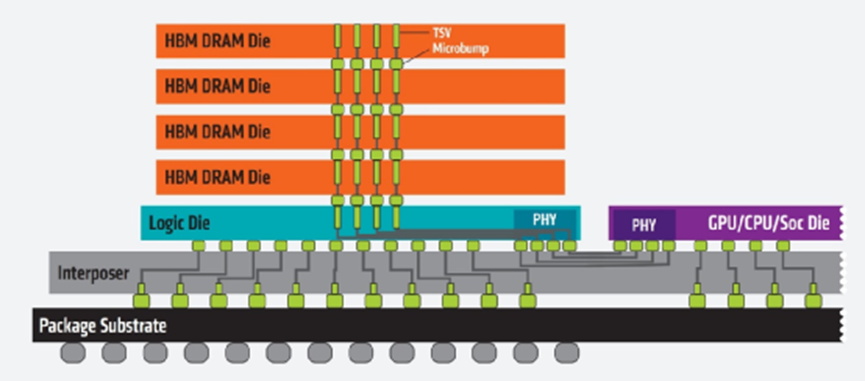
从侧面看HBM,来源:AMD
从这种结构就不难发现,其互联宽度是远大于DDR/GDDR的,下方互联的触点数量可远远多于DDR内存连接到CPU的线路数量。HBM2的PHY接口实施规模,和DDR接口不在一个层面上;HBM2的连接密度高出太多。从传输位宽的角度看,每层DRAM die是2个128bit通道,4层DRAM die高度的HBM内存总共就是1024bit位宽。很多GPU、CPU周围都有4片这样的HBM内存,则总共位宽就是4096bit。
作为对比,GDDR5内存每通道位宽32bit,16通道的话总共就是512bit;DDR4的总位宽就更不用多谈了。事实上,现在主流的第二代HBM2每个堆栈可以堆至多8层DRAM die,在容量和速度方面又有了提升。HBM2的每个堆栈支持最多1024个数据pin,每pin的传输速率可以达到2000Mbit/s,那么总带宽就是256Gbyte/s;在2400Mbit/s的每pin传输速率之下,一个HBM2堆栈封装的带宽就是307Gbyte/s。
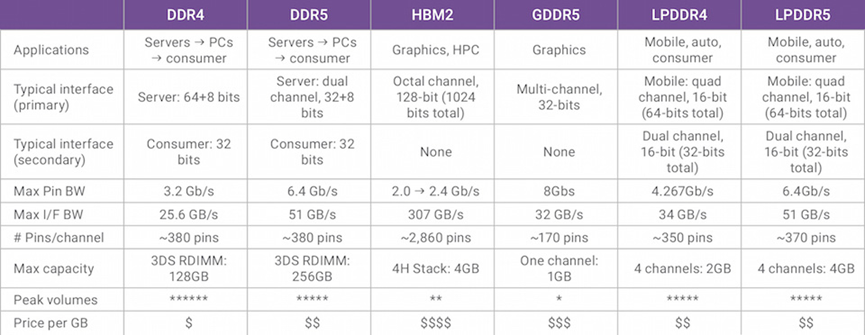
来源:Synopsys
上面这张图是Synopsys给出的DDR、LPDDR、GDDR和HBM的对比,可以看看Max I/F BW这一栏其他选手的能力,与HBM2压根不在一个量级。这么高的带宽,在高度并行计算、科学计算、计算机视觉、AI之类的应用上,简直就是爽翻的节奏啊。而且从直觉上看,HBM和主芯片靠得那么近,理论上可以获得更高的传输效率才对(从每bit数据传输消耗的能量看,HMB2的确有很大优势)。
感觉HBM除了成本和内存总容量落了下风,要真的用在个人电脑上做内存,岂不是相当完美?
2. HBM的缺点1:灵活性欠佳
真的是这样吗?HBM这类型的内存,最早是由AMD于2008年发起的。AMD提出HBM的初衷就是对计算机内存做出功耗、尺寸方面的变革。后续多年时间中,AMD一直在尝试解决die堆叠的技术问题,后来找到了业界具备存储介质堆叠经验的合作伙伴,包括SK Hynix,以及一些interposer、封装领域的厂商。
HBM是在2013年,由SK Hynix首度制造问世的。而且这一年HBM被JEDEC(电子元器件工业联合会)的JESD235标准采用。第一颗应用了HBM存储的GPU是2015年的AMD Fiji(Radeon R9 Fury X);次年三星开始大规模量产HBM2——英伟达Tesla P100是最早采用HBM2存储的GPU。
从HBM的形态就不难发现其第一个缺点:系统搭配缺乏灵活性。对于早年的PC而言,内存容量的扩展是个比较常规的能力。而HBM与主芯片封装在一起,不存在容量扩展的可能,在出厂时就已经将规格定死。而且与现在笔记本设备上,DDR内存焊死在主板上还不一样,HBM是由芯片制造商整合到芯片上的——其灵活性会更弱,对OEM厂商而言尤其如此。(虽然现在某些高端系统,可能存在HBM+DDR的解决方案,两种内存作为不同层级的存储系统来调配)
对于绝大部分芯片制造商而言,面向大众市场(包括基础设施市场)推处理器,基于包括成本在内的各方面考虑,也不大可能推出各种内存容量的芯片SKU型号。这些厂商所推的处理器本身就有各种配置型号(如Intel酷睿处理器有各种型号)——如果再考虑细分内存容量的不同,制造成本恐怕也很难支撑。
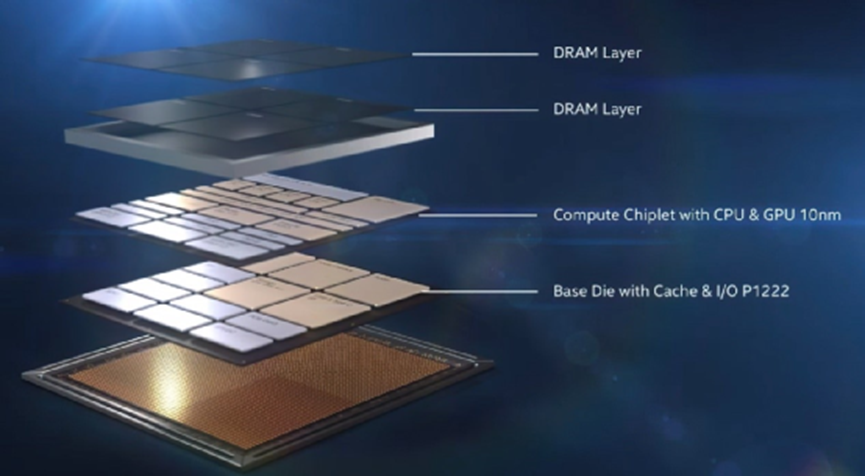
Intel Lakefield处理器的内存是叠在芯片上方的,来源:Intel
不过在消费市场上,更注重便携性的用户可能并不是很在意内存的扩展性。如苹果M1就是其中的典型代表,8GB/16GB内存是靠在M1芯片一侧的。消费级产品中,为数不多会将内存都封装到芯片上的产品,还有Intel LakeField。这两颗芯片的确都牺牲了内存的扩展性。但即便是奢侈如苹果M1和Intel Lakefield,其实也都没有采用HBM内存(当然这两者的封装方式也不是采用silicon poser这种wafer级2.5D封装)。这是为什么呢?
3. HBM的缺点2:容量偏小
HBM的第二个问题就是,内存容量相比DDR会更受局限。虽说一片HBM封装就可以堆8层DRAM die,但实际上每层也就8Gbit,那么8层就是8GByte。像A64FX这种超算芯片留4个HBM接口,也就是4个HBM堆栈封装,则一颗芯片也就是总共32GByte容量。
这样的容量,在DDR面前还是太小了。消费市场上普通PC要堆大于32GByte的内存真的太常见了。不仅是PC、服务器主板上可扩展的内存插槽一大堆,某些DDR4/5 DIMMs内存颗粒也在搞DRAM die的堆叠。采用比较高端的DRAM die堆叠,2-rank的RDIMM(registered DIMMs)就能做到128GByte容量——考虑高端服务器96个DIMM插槽,那就是至多12TByte的容量。
前文也提到了HBM和DDR可以混合着一起用,HBM2负责高带宽但小容量,DDR4负责稍低的带宽但大容量。从系统设计的角度来说,HBM2内存在处理器这里就更像是L4 cache了。

HBM的DRAM die长这样,来源:Wikipedia
3. HBM的缺点3:访问延迟高
对于PC而言,HBM一直都没有应用于CPU主内存的一个重要原因在于其延迟很高。就延迟的问题,虽然很多科普文章会说其延迟表现不错,或者像赛灵思针对搭载HBM的FPGA形容其延迟与DDR相似,但可能很多文章谈的“延迟”并不是同一个延迟。
当代的DDR内存,在规格上普遍也都会标CL(CAS延迟,列寻址所需的时钟周期,表示读取延迟的长短)。这里所说的CAS延迟,是指从读取指令(与Column Address Strobe)发出,到数据准备就绪的过程,中间的一个等待时间。
在内存控制器告诉内存,需要访问某个特定位置的数据后,需要若干个周期的时间以后才能抵达该位置并执行控制器发出的指令。CL是内存延迟中最重要的参数。就延迟长短来说,这里的“周期”其实还需要乘以每周期的时间(越高的整体工作频率,则表明每周期时间越短)。
对于HBM而言,如前所述其特性之一就是互联宽度超宽(或者说并行的传输线路超多,虽然市面上似乎也有更低位宽的版本),这就决定了HBM的传输频率不能太高,否则总功耗和发热撑不住(而且也并不需要那么高的总带宽)。
HBM的频率的确会比DDR/GDDR低很多,三星此前的Flarebolt HBM2内存每pin的传输带宽是2Gbit/s,差不多是1GHz的频率;后来有加压提频到1.2GHz的产品。三星当时提到这个过程还需要考虑降低超过5000个TSV之间的并行时钟干扰;而且要增加DRAM die之间的散热bump数量,来缓解发热问题。上图中AMD在列出HBM的频率其实才500MHz。
此前浙江大学、苏黎世联邦理工学院有发一篇题为Benchmarking High Bandwidth Memory on FPGA的paper。这篇paper主要是研究HBM在FPGA上的细节特性,以及如何基于这些特性来提高FPGA的工作效率。这项研究是基于赛灵思的Alveo U280进行的——这款FPGA之上就带两个堆栈的HBM子系统。
来源:Benchmarking High Bandwidth Memory on FPGA
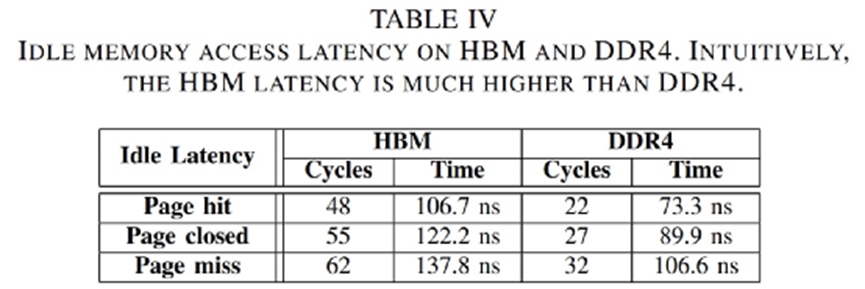
这篇paper特别提到了:“HBM延迟远高于DDR4。HBM芯片与对应FPGA的连接是通过串行I/O连接进行的,需要针对并行-串行-并行转换的处理。”上面这张表是这项研究中呈现的HBM与DDR4闲时内存访问延迟,这里的page hit是指在内存列访问之前不需要Precharge和Activate指令(行访问时,bank处于open状态),可达成最小延迟的状态。page closed/miss等详情可以参见paper原文。
来源:Benchmarking High Bandwidth Memory on FPGA
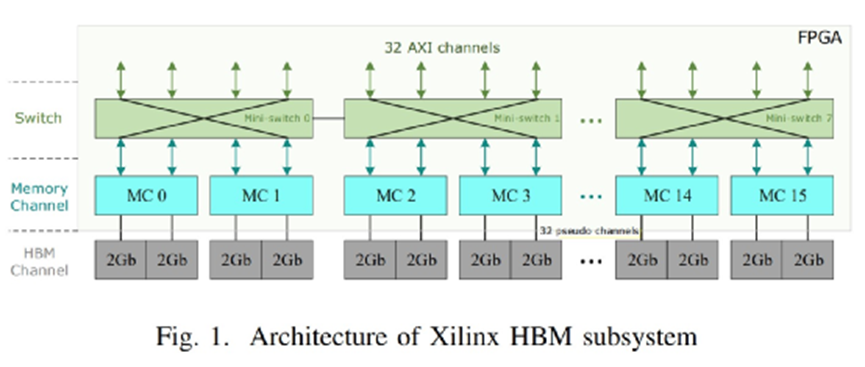
可能从系统的角度看,Alveo U280存在一定的特殊性,不过应该还是能够说明问题的。这里面的每个HBM堆栈都分成了8个独立的内存通道(前面提到的叠4层DRAM die),每个内存通道又进一步切分成了2个64bit的伪通道(pseudo channels)。好像其他包含HBM的系统也是类似的构成方式。
在总共16条内存通道之上,有32个AXI通道与用户逻辑做交互:每个AXI通道提供面向FPGA编程的标准接口,每个AXI通道只允许访问各自的内存区域。为了让每条AXI通道都能访问完整的HBM空间,赛灵思引入了通道之间的switch——后面具体的就不再深入了,可能往上是更具FPGA特殊性的设计。网上还有更多针对HBM延迟的研究。
更宽的位宽,以及更复杂的系统始终是造成HBM访问延迟更高的重要因素。
5. 所以HBM适合用于PC内存吗?
高带宽、高延迟这个特性,决定了HBM是非常适用于作为GPU显存的,因为游戏、图形处理本身就是较大程度可预测的高并发工作任务。这类负载的特点就是需要高带宽,而对延迟并没有那么敏感。所以HBM会出现在高端GPU产品上。根据这个道理,其实也决定了HBM非常适合HPC高性能计算、AI计算,所以A64FX和下一代至强处理器虽然是CPU,但也会选择考虑用HBM作内存。
但对于个人电脑来说,CPU要处理的任务具有极大的不可预测性,要求各种随机存储访问,对延迟天生有着更高的敏感度;而且对低延迟的要求往往还高于对高带宽的要求。更何况HBM成本也很高。这就决定了至少就短期看,HBM很难在PC上替代DDR。似乎这个问题也和GDDR是否可应用于PC内存是类似的。
不过就长远看,情况是谁也无法预料的。就如前文提到的,可以考虑混合方案;而且不同层级的存储资源正在发生显著的变化,如前不久还撰文谈到了AMD已经把处理器上的L3 cache堆到了192MB。对于die内cache这种本来就在隐藏外部存储延迟的组成部分而言,可能随着处理器芯片上的cache越来越大,对系统内存的延迟要求反倒没那么高了。
把CPU三级缓存堆到192MB,AMD与台积电的合谋
专栏又很久很久没更文章了,这周趁着不需要给 EE Times China 供稿的空档,这篇文章就更在个人的面包板和知乎专栏上吧;捕捉的其实是上个礼拜的热点了。水平有限,纯做半导体技术爱好者之间的内容共享。
在 HotChips 2019 之上, Lisa Su 曾经呈现过下面这张图(这张图是大神官同学友情找到的…),是在过去 10 年间,造成处理器性能提升的主要因素。其中包括编译器改进、微架构迭代、更大的 die size 等,而处理器性能提升的最重要因素,占到 40% 比重的乃是制造工艺技术的改进。
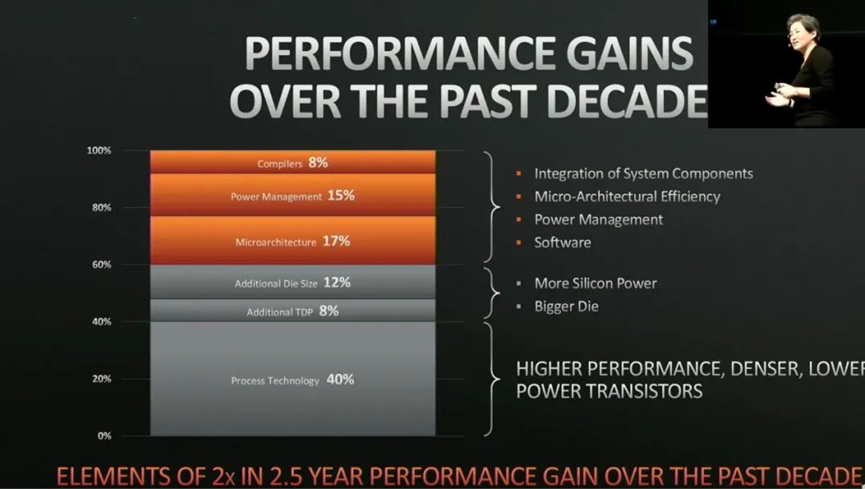
虽然知道制造工艺改进对于芯片性能与效率提升很重要(摩尔定律嘛),但没想到会这么重要。不过也提过,AMD 如今在桌面 CPU 市场的风生水起,最重要的恐怕还是台积电的助力;而其 CPU 微架构在 Intel 面前大概也没有什么独特的优势。
如 AMD 锐龙处理器在桌面 CPU 市场率先应用了 chiplet 方案,把原本的大 die 切成一个个小 die,采用 chiplet 的方案“串联”起来,所以看到 AMD 锐龙处理器也比同价位的 Intel 酷睿处理器更能堆核心,在多线程性能上有相当的领先优势。
前不久的 Computex 2021 大会上,AMD 又抛出了几枚足以对 Intel 造成威慑力的炸弹,其中有一个与制造工艺又有很大的关系,即处理器上的 3D V-Cache,让处理器的 L3 cache 能比较容易地堆到 192MB 大小,并且演示借此在游戏上获得 15% 的性能提升。
这项技术本质上是 2.5D/3D 封装技术,借此机会也恰好聊聊台积电的 3DFabric 技术,或者说真正用人话来谈谈台积电的 2.5D 和 3D 封装技术,未来有机会的话可以着重介绍介绍 Intel 的封装技术。
毕竟 3D 封装技术不是被人称作 More
than Moore's Law 之类的么,也是此前很多媒体喊了很久的让摩尔定律在芯片制造业延续的重要解决方案。(叠在一起,是不是也算单位面积内的晶体管数量翻番之类的...不过感觉叠层越往后越是几何级数增长...呃...可能多虑了。
当三级缓存叠在 CPU 上方
知道 AMD 最新的 Zen 架构处理器普遍在用多 chiplet(或者说多 die)的方案,每个chiplet 上都有几个 CPU 核心——多加几枚 chiplet,也就自然多出不少处理器核心。这么做的好处在于更小的 die size,能获得更高的芯片制造良率和成本效益。这些 chiplet 之间还需要藉由一枚 IO die(cIOD)来做通讯、互联,就像下图这样:

这里的 CPU die(或者Compute Dies)可以按照需要做删减,做成不同规格的处理器卖出去。不过 AMD Zen 架构处理器的这种 chiplet 封装方案并不稀罕,虽然确是 AMD 在这两代产品中克敌制胜的法宝,但充其量也就是个 2D 封装方案。如果用 Intel 的总结,那么这种方案更偏于直接在 package substrate 基板上走线,完成多 chiplet 之间的互联,便宜而密度低。
当然这不是本文要讨论的重点。Computex 大会上,Lisa Su 拿出了一颗全新的锐龙 9 5900X 处理器原型产品,如下图所示。其中有一片 die 看起来是略有“异样”的:

左上角的那片 die(被称作 CCD,core complex die)之上堆叠了额外的 64MB SRAM 三级缓存——注意,是叠在原本的 CCD 上面的,尺寸为 6 x 6mm,这种垂直堆叠的 cache 被 AMD 称作 3D V-Cache。这颗芯片应该只是作为演示之用的,以表明左右两颗 CCD 看起来有显著不同。
据说未来的成品,每一片 CCD 都可以叠 96MB SRAM(以前只能做到 32MB),那么对于一颗 12 或 16 核心的锐龙 5000 处理器而言,就能比较轻松地堆出 192MB 的 L3 cache(想当年,Windows XP 的推荐安装内存大小才 128MB,如今消费级处理器 cache 都这么大了…)。这就属于比较地道的 3D 封装技术了。
关键是上方的 SRAM 和下方的 CCD,采用 hybrid bonding + TSV(Through Silicon Via,硅通孔)连接——TSV 负责传递电力和数据。台积电这个工艺的亮点就在于 hybrid bonding。
上方那片 cache die 与下方的 CCD 在尺寸上还是不同的,所以就需要额外的结构硅来达成上下层的同等应力。

AMD 宣称如此一来,这种 L3 cache 的总带宽能够超过 2TB/s,虽然考虑到更大容量的访问延迟也会增加。Cache 本身容量和带宽增加实则都有助于整体性能的提升。
AMD 在主题演讲中演示的是用这种采用了 3D V-Cache 的处理器与传统方案做比较,对比的是 12 核的锐龙 9 5900X 处理器,一颗是一般的 64MB L3 cache,另一颗就是 192MB L3 cache;处理器主频都固定在 4GHz,配的 GPU 未知。
对比的游戏包括了 DOTA 2、战争机器 5、英雄联盟、堡垒之夜等,均设定在 1080p 分辨率下,不同的游戏有着平均 15% 的帧率提升。果然是印证了前年 Lisa Su 所说的,工艺技术的变化对于推升处理器性能起到了主要作用。

而且这种采用 3D V-Cache 技术的锐龙处理器预计会从今年年末开始量产,定位于高端型号。看来 3D 封装技术的 CPU 来到消费者身边还挺快。

2.5D 与 3D 封装之间
不知道这项技术会带来哪些副作用,如延迟,如堆叠散热问题(不仅是下层 CCD 更不易散热,也包括增加的厚度带来对散热方案的影响),如功耗(无论是 cache 需要经由下层通往主存,还是更高的带宽本身带来更高的功耗问题),以及更大的 cache 是否对游戏之外的其他使用场景带来质的变化。
据说堆叠的这部分 SRAM,在密度上高于 AMD 锐龙处理器原本的 L3 cache,原因是采用了台积电优化过的 7nm SRAM 库。而且台积电原本的技术还可以堆更多层 die。
Lisa Su 还提到 3D V-Cache 的这种封装技术,相比于传统的 2D 封装在互联密度上提升 200 倍;相比 micro-bump 技术也有 15 倍的密度领先——此前解读 Intel Lakefield 处理器的文章,谈到过 Intel 的 Foveros 3D 封装技术,这种技术所用的就是 micro-bump 做互联的(当然下文也会提到台积电的 3DFabric 后端封装方案也用 micro-bump);并且比 micro-bump 有 3 倍以上的互联效率领先。Lisa Su 说这是行业内最先进和最具弹性的 active-on-active 芯片堆叠技术。
3D V-Cache 在封装上的实质,应该就是台积电的某种前端 3D 封装技术,如 CoW(chip-on-Wafer)。这两年有关 2.5D 和 3D 封装的话题也算是相当活跃。那么所谓的 2D、2.5D、3D 封装,尤其后两者究竟有什么区别呢?
很多日常关注半导体新闻的同学,对于台积电 CoWoS、InFO,Intel 的 EMIB、Foveros 这些(把不同
die 做在一个封装内并互联的)封装技术应当都有所耳闻。时而 2.5D,时而 3D,好像非常神秘的样子。

举一些比较现成的例子,2016 年英伟达面向数据中心或 HPC 市场的 Pascal 架构 P100 GPU,在 GPU 四周就封装了 4 片 HBM 存储芯片——这是采用 CoWoS 封装的一个典型例子,现在英伟达的数据中心 GPU 也差不多是这样。从上面这张图就不难发现,这类封装的不同芯片仍然处在同一平面内。
不过 CoWoS 封装和前文提到的 AMD Zen 的 chiplet 方案还是不同的,多芯片(或者多个chiplet)下面有个 interposer (硅中介层)做互联支持,而不是暴力地直接从 substrate 走线的(下图第一个方案),形如下面这张图中的第二个方案(顺带一提,下图的第三个方案就是 Intel 的 EMIB):
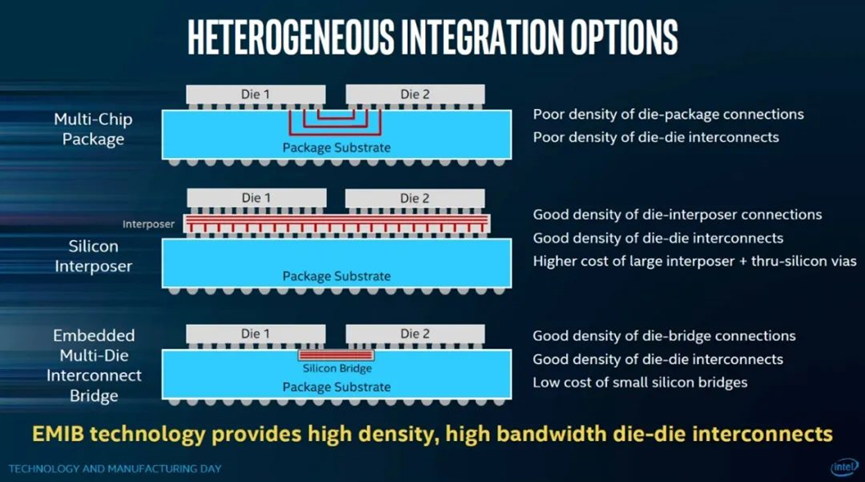
类似有 interposer 硅中介层这类封装方案,一般称其为 2.5D 封装(也有称其为 3D 封装的)。这类方案中颇具知名度的芯片,除了英伟达 GPU 以外,还有赛灵思比较早就在用的 Virtex FPGA,去年富士所推的 HPC 芯片 A64FX(富岳超算)也在其中。当然 CoWoS 并不是台积电唯一的 2.5D/3D 封装技术。
至于真正的 3D 封装,那就是类似于 AMD 的 3D V-Cache(以及Intel 的 Lakefield)这种 chiplet 可以垂直堆叠的方案了——虽然这么说也不尽然,但大致上就是这么回事。
台积电的 3DFabric
为了对 2.5D/3D 封装技术做品牌上的归一化,去年台积电发布了一个新的品牌名:3DFabric。3DFabric 分成两大块,分别是前端芯片堆叠技术,如 CoW(Chip on Wafer,AMD 这次发布的 3D V-Cache 应当就属于 CoW);还有后端封装技术,包括 InFO、CoWoS。

前端的“芯片堆叠(Chip Stacking)”就属于名副其实的 3D 方案,毕竟 die 都叠起来了——CoW 和 WoW 这两者也被统称为 SoIC(System on Integrated Chips)。SoIC 的本质是设计把芯片“粘”在一起的介面(interface),就像前文提到 AMD 把 SRAM“粘”在处理器核心 die 上面。当然这个过程还是相当复杂的。
台积电此前宣传中提到芯片之间面对面的 SoIC bonding 相比于用
micro-bump 连接(Intel 的 EMIB
和 Foveros 都是 micro-bump 连接),至多减少了 35% 的热阻。台积电宣传中也提到了高出很多的互联密度(台积电宣传中提到其 bonding 间距可以达到了 0.9μm,对芯片的 BOEL 互联做扩展;不过实际 N7/N6 工艺下的 SoIC bonding 间距大约在 9μm 左右,N5 则可下探到 5μm)——似乎比 Intel 的
micro-bump 间距要小(Lisa Su 宣传相比
micro-bump 方案有 15 倍的密度领先,不知具体对比的是谁),随晶体管工艺节点迭代,bonding 间距也会随之发生变化;与此同时有更高的效率(pJ/bit 更低)。
内容选读添加:SoIC 是 hybrid bonding 封装的一个重要实施方案,相比 micro-bump,也是实现更小的 bonding 间距,以及芯片之间数十倍通讯性能和效率的关键。铜 hybrid bonding 技术比较早见于索尼 CIS 图像传感器的应用(逻辑电路层与像素层的 bonding),Xepri 比较知名的 DBI 也是。针对更复杂的先进芯片封装,台积电是 hybrid bonding 封装技术的主要推进者。
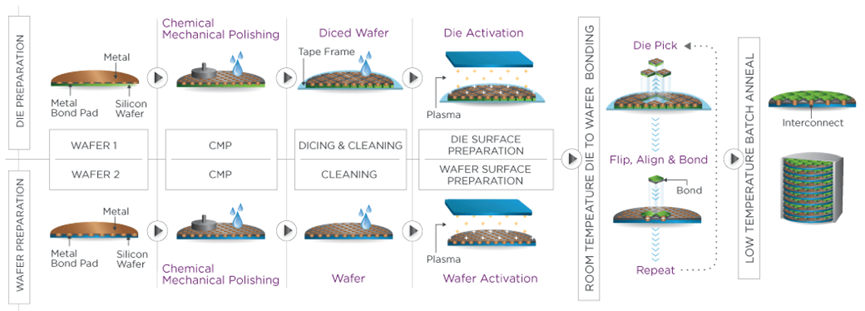
上面这张图是 Xperi 的 die-to-wafer 的 hybrid bonding 流程示意图,整个过程在 fab 进行,帮助各位理解吧... Semiconductor Engineering 的这篇文章对 Xperi 的 die-to-wafer hybrid bonding 做了大致的解释,有兴趣的同学可以去看看。
不过应用 SoIC 技术的不同芯片需要从头做配合设计,所以其弹性就没那么高;不像其他 micro-bump 的方案,不同的芯片可以是来自完全不同的制造商,连 interposer 本身都可以。
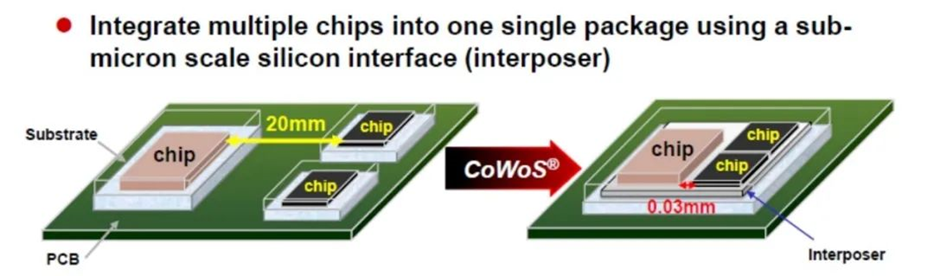
后端的封装,实则主要就属于常说的 2.5D 封装,如前文提到的把两片 die 放到同一个封装内,die 可以并列放在一个平面上,然后用各种方案做连接,如硅中介 interposer——也就是一大片硅片位于所有 die 之下,如英伟达的 GPU+HBM。硅中介本身可以是被动的(即只用于 die-to-die 连接,而没有主动电路),也可以是主动的(active)。
CoWoS 如前面图中提到的,还可以进一步细分,这里探讨的主要是 CoWoS-S;而 CoWoS-L 与 Intel EMIB 类似的,互联依靠的是 LSI(local silicon interconnets)和 RDL(redistribution layer),die 与 die 之间的连接是“本地化”的连接,用的是硅 bridge 和 RDL,应该能够实现更高的成本效益(就像前文中 Intel 的 PPT 提到的)。
除了这种 side-by-side 式把多 die 放在硅中介上的方案,在后端封装上也可以用 die-on-die 垂直堆叠的方式,但和前端的 SoIC 实施方案有区别。台积电后端封装的垂直堆叠也采用 micro-bump(而前文谈到了,SoIC 是 die 之间金属层的对齐和 bonding),如此一来就能实现更具弹性的芯片搭配,在密度和效率方面自然是不及 SoIC 的。
值得一提的是,台积电的前后端技术是可以混合使用的,即前端做芯片堆叠和后端再做封装。CoWoS 的全称是 Chip-On-Wafer-on-Substrate,这个词组的前面半截就是前端的 CoW。Wikichip 在对 CoWoS 的介绍中,就将其与 CoW 放在了一起,提到一方面做 side-by-side 的多 die 封装,另一方面通过 CoW 把芯片再 3D 垂直堆起来,就像下面这样:
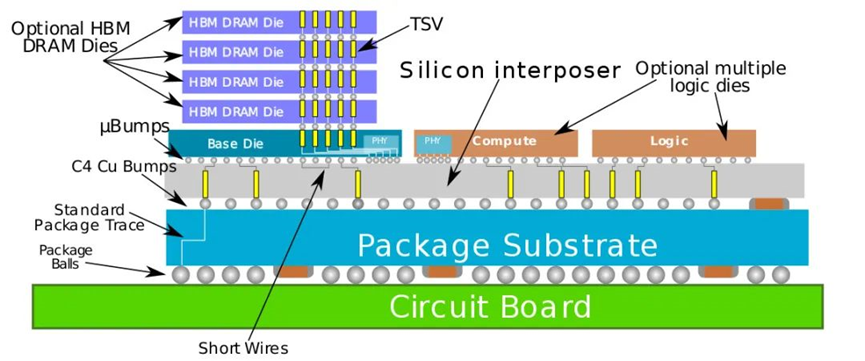
来源:Wikichip
另外,CoWoS本身的进化还体现在 interposer 硅中介层能做多大的面积——这一层做得越大,能够容纳的 chip 数量自然也就越多。在此前探讨 GPU 的 die 尺寸过大的一篇回答里,提到光刻机所能做出最大的 die size 是有个极限的,这个极限叫做 reticle limit(或 reticle size)。CoWoS 技术本身就在不停突破 reticle limit,台积电此前就已经实现了所谓的 multi-reticle 尺寸的硅中介技术,也就是让硅中介层 interposer 面积更大。
去年台积电就宣布 interposer 层(CoWoS-S)的尺寸 2023 年可以达到 4x reticle size,突破 3000mm²,主要是对叠加更多的 HBM 存储资源有意义。
除了 CoWoS 之外,前面那张台积电
3DFabric 的图,后端的封装技术还有个 InFO(Intergrated Fan Out)——也应该是比较知名的封装技术了,在 SoC 的标准 floorplan 之外 fan out(好像被译作扇出)出额外的连接。通常在一颗芯片的逻辑电路部分之外,容纳了更多需要的 pin-out 连接。
InFO 的存在也有些年头了,这同样是一种 WLP 晶圆级封装解决方案。这类方案采用
RDL 和 TIV(through-InFO vias,貌似是指贯穿封装的 via 通孔)实现连接。
比较知名的应该是 iPhone 6s 的 A10 芯片,就用上了 InFO_POP 封装——替代传统封装级的 POP。不过不知道具体是怎么做的,TechInsights 有做一份 A10 芯片拆解的报告就提到了这一点,但报告是收费的,有兴趣的同学可以花几千美金去购买……
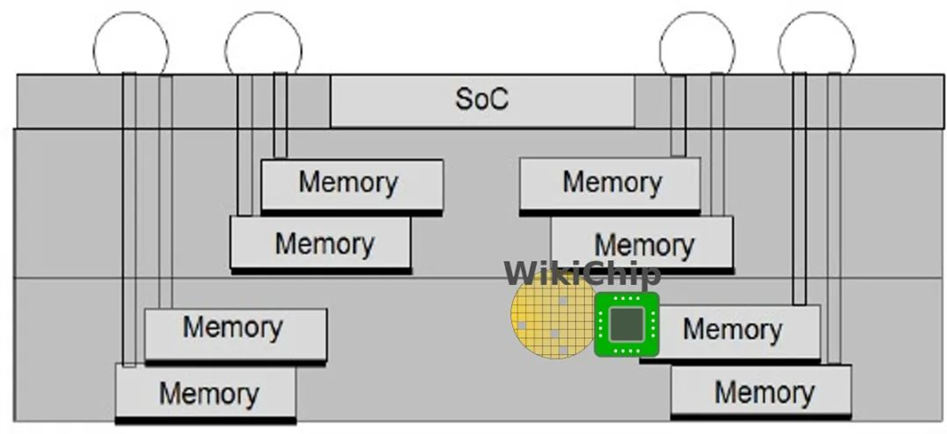
来源:Wikichip
看 Wikichip 的介绍,InFO_POP 受限于存储带宽,后续台积电有更新一个 3D-MUST-in-MUST(Multi-Stack)封装技术,把多个垂直堆叠的存储芯片通过高密度 RDL 和小间距的 TIV,以 InFO 的方式做多个存储芯片的垂直堆叠,形如上面这张图。大概苹果 A10 也有类似的结构吧。
前两年台积电对 InFO 封装似乎有更多的划分,如 InFO_POP 是为移动 AP(应用处理器)准备的;另外 InFO_AiP(Antenna-in-package),面向的是 RF 前端模块应用,InFO_MUST(Muti-stack)则针对基带 modem;还有什么 InFO_oS(on substrate)、InFO_MS(memory on substrate)、InFO_UHD(ultra-high-density)等各种应用。

看去年台积电更新的图,InFO 大方向就分成了两块即 InFO-R 和 InFO-L,不知道是把上面这些应用整合成了大方向的两个,还是去掉了一些方案——可能在具体的封装策略上,InFO 和 CoWoS 的分工也有了一些调整。
这里 InFO-R(InFO_oS)是在 die 和 micro-bump 之间增加 RDL 层,将多个 die 放到一个封装内;InFO-L 则是用 LSI 连接多个
die,和 CoWoS-L 类似。
各种封装方案有对应的应用领域,之前台积电把 CoWoS 定位于 AI、networking、HPC,而 InFO 定位于
networking 和移动应用,现在看来可能是有变化的。
具体的介绍差不多就是这些了。这篇文章的后两部分,属于针对 AMD 3D V-Cache 的延伸,算是开阔下这些技术爱好者的视野吧。这些此前只放在嘴上谈的东西,不知不觉间就已经应用到消费电子产品上了;如年底就要量产的 192MB L3 cache,当然不同 SKU 也不一定是 192MB 就是了。虽然可能光堆个 L3 cache 也没什么大不了,不过感觉 Intel 腹背受敌的现状,还真是相当严峻啊。
参考链接:
https://www.eet-china.com/news/202107010730.html
https://iczhiku.cn/hotspotDetail/efBqShfDb1CauCrjCYJzCg==

