

深度学习编译器综述The Deep Learning Compiler
深度学习编译器综述The Deep Learning Compiler
The Deep Learning Compiler: A Comprehensive Survey
参考文献:
https://arxiv.org/pdf/2002.03794v4.pdf
在不同的DL硬件上部署各种深度学习(DL)模型的困难,推动了社区DL编译器的研究和开发。DL编译器已经从工业和学术界提出,如TysFraceXLA和TVM。类似地,DL编译器将不同DL框架中描述的DL模型作为输入,然后为不同的DL硬件生成优化代码作为输出。然而,现有的探索都没有全面分析DL编译器的独特设计架构。在本文中,通过详细剖析常用的设计,对现有的DL编译器进行了全面的探索,重点是面向DL的多级IRs和前端/后端优化。详细分析了多级IRs的设计,举例说明了常用的优化技术。最后,强调了一些见解作为潜在的研究方向
DL编译器的设计。这是第一篇关于DL编译器设计体系结构的调查论文,希望能为DL编译器的未来研究铺平道路。
TensorFlow,Keras,PyTorch,Caffe/Caffe2,MXNet,CNTK,PaddlePaddle,ONNX。
本文主要贡献
•剖析了现有DL编译器普遍采用的设计架构,对关键设计组件(如多级IRs、前端优化)进行了详细分析(包括节点级、块级和数据流级优化)和后端优化(包括特定于硬件的优化、自动调优和优化的内核库)。
•从各个方面提供了现有DL编译器的综合分类法,这与本文中描述的关键组件相对应。该分类法的目标是为从业人员提供关于选择DL编译器的指南,需求,并为研究人员提供DL编译器的全面总结。提供了CNN模型上DL编译器的定量性能比较,包括成熟模型和轻量级模型。比较了端到端和每层(卷积层,因为控制推理时间)的性能,显示优化的有效性。评估脚本和结果都是开源的,仅供参考。
•重点介绍了DL编译器未来发展的一些见解,包括动态形状和前后处理、高级自动调整、多面体模型、子图分区、量化、统一优化、可微编程和隐私保护,希望这些能够推动DL编译器界的研究。

Fig. 1. DL framework landscape: 1) Currently popular DL frameworks; 2) Historical DL frameworks; 3) ONNX supported frameworks.
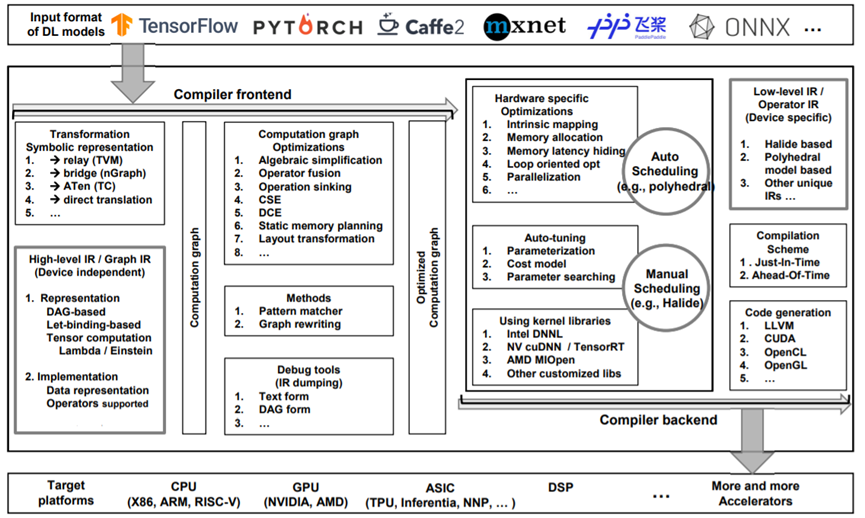
Fig. 2. The overview of commonly adopted design architecture of DL compilers.
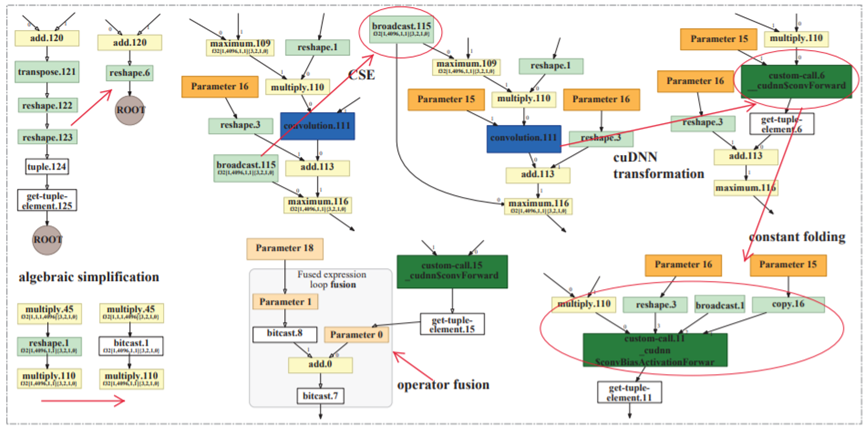
Fig. 3. Example of computation graph optimizations, taken from the HLO graph of Alexnet on Volta GPU using Tensorflow XLA.

Fig. 4. Overview of hardware-specific optimizations applied in DL compilers.

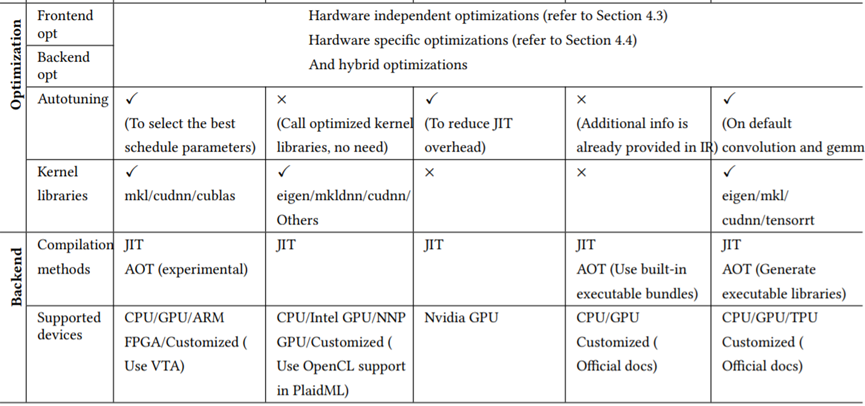
Table 1. The comparison of DL compilers, including TVM, nGraph, TC, Glow, and XLA.

Table 2. The hardware configuration.
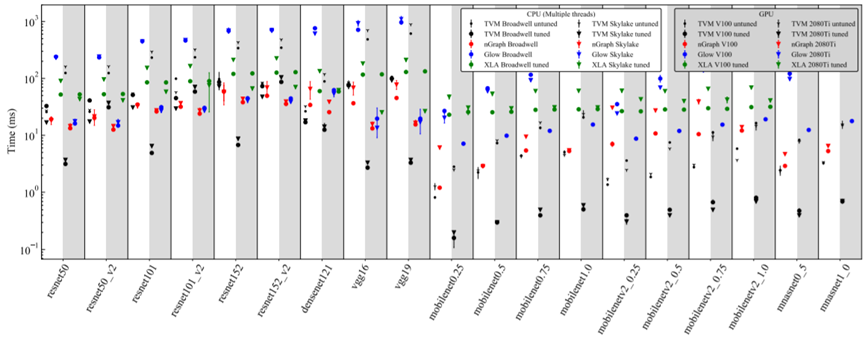
Fig. 5. The performance comparison of end-to-end inference across TVM, nGraph, Glow and XLA on CPU and GPU.

Fig. 6. The performance comparison of convolution layers in MobileNetV2_1.0 across TVM, TC, Glow and XLA on V100 GPU.

Fig. 7. The performance comparison of convolution layers in MobileNetV2_1.0 across TVM, nGraph and Glow on Broadwell CPU.

Fig. 8. The performance comparison of convolution layers in ResNet50 across TVM, TC and Glow on V100 GPU.

Fig. 9. The performance comparison of convolution layers in ResNet50 across TVM, nGraph and Glow on Broadwell CPU.
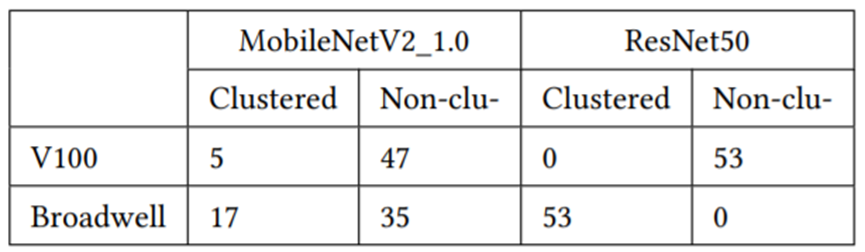
Table 3. The number of the clustered and non-clustered convolutions of XLA on V100 GPU and Broadwell CPU.
参考文献
https://arxiv.org/pdf/2002.03794v4.pdf


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)