

tvm模型部署c++ 分析
tvm c++部署官方教程
https://github.com/apache/tvm/tree/main/apps/howto_deploy
https://tvm.apache.org/docs/how_to/deploy/cpp_deploy.html
官方说执行run_example.sh脚本就可以完成部署。
使用C++ API部署TVM模块
提供了一个关于如何在apps/howto_deploy中,部署TVM模块的示例。要运行该示例,可以使用以下命令
cd apps/howto_deploy
./run_example.sh
获取TVM运行库
唯一需要的是链接到目标平台中的TVM运行时。TVM提供了一个最低运行时间,根据使用的模块数量,成本大约在300K到600K之间。在大多数情况下,可以使用libtvm_runtime.com,这是构建时附带的。
如果发现很难构建libtvm_运行时,checkout tvm_runtime_pack.cc。这是一个提供TVM运行时的示例。可以使用构建系统编译此文件,包含到项目中。
可以checkout应用程序,如在iOS、Android和其它平台上,使用TVM构建的应用程序。
动态库与系统模块
TVM提供了两种使用已编译库的方法。可以checkout prepare_test_libs.py(关于如何生成库)和cpp_deploy.cc(关于如何使用)。
将库存储为共享库,并将库动态加载到项目中。
以系统模块模式将编译后的库绑定到项目中。
动态加载更灵活,可以动态加载新模块。系统模块是一种更静态的方法。可以在禁止动态库加载的地方使用系统模块。
c++部署代码
https://github.com/apache/tvm/blob/main/apps/howto_deploy/cpp_deploy.cc
|
/* |
|
|
* Licensed to the Apache Software Foundation (ASF) under one |
|
|
* or more contributor license agreements. See the NOTICE file |
|
|
* distributed with this work for additional information |
|
|
* regarding copyright ownership. The ASF licenses this file |
|
|
* to you under the Apache License, Version 2.0 (the |
|
|
* "License"); you may not use this file except in compliance |
|
|
* with the License. You may obtain a copy of the License at |
|
|
* |
|
|
* http://www.apache.org/licenses/LICENSE-2.0 |
|
|
* |
|
|
* Unless required by applicable law or agreed to in writing, |
|
|
* software distributed under the License is distributed on an |
|
|
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY |
|
|
* KIND, either express or implied. See the License for the |
|
|
* specific language governing permissions and limitations |
|
|
* under the License. |
|
|
*/ |
|
|
|
|
|
/*! |
|
|
* \brief Example code on load and run TVM module.s |
|
|
* \file cpp_deploy.cc |
|
|
*/ |
|
|
#include <dlpack/dlpack.h> |
|
|
#include <tvm/runtime/module.h> |
|
|
#include <tvm/runtime/packed_func.h> |
|
|
#include <tvm/runtime/registry.h> |
|
|
|
|
|
#include <cstdio> |
|
|
|
|
|
void Verify(tvm::runtime::Module mod, std::string fname) { |
|
|
// Get the function from the module. |
|
|
tvm::runtime::PackedFunc f = mod.GetFunction(fname); |
|
|
ICHECK(f != nullptr); |
|
|
// Allocate the DLPack data structures. |
|
|
// |
|
|
// Note that we use TVM runtime API to allocate the DLTensor in this example. |
|
|
// TVM accept DLPack compatible DLTensors, so function can be invoked |
|
|
// as long as we pass correct pointer to DLTensor array. |
|
|
// |
|
|
// For more information please refer to dlpack. |
|
|
// One thing to notice is that DLPack contains alignment requirement for |
|
|
// the data pointer and TVM takes advantage of that. |
|
|
// If you plan to use your customized data container, please |
|
|
// make sure the DLTensor you pass in meet the alignment requirement. |
|
|
// |
|
|
DLTensor* x; |
|
|
DLTensor* y; |
|
|
int ndim = 1; |
|
|
int dtype_code = kDLFloat; |
|
|
int dtype_bits = 32; |
|
|
int dtype_lanes = 1; |
|
|
int device_type = kDLCPU; |
|
|
int device_id = 0; |
|
|
int64_t shape[1] = {10}; |
|
|
TVMArrayAlloc(shape, ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &x); |
|
|
TVMArrayAlloc(shape, ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &y); |
|
|
for (int i = 0; i < shape[0]; ++i) { |
|
|
static_cast<float*>(x->data)[i] = i; |
|
|
} |
|
|
// Invoke the function |
|
|
// PackedFunc is a function that can be invoked via positional argument. |
|
|
// The signature of the function is specified in tvm.build |
|
|
f(x, y); |
|
|
// Print out the output |
|
|
for (int i = 0; i < shape[0]; ++i) { |
|
|
ICHECK_EQ(static_cast<float*>(y->data)[i], i + 1.0f); |
|
|
} |
|
|
LOG(INFO) << "Finish verification..."; |
|
|
TVMArrayFree(x); |
|
|
TVMArrayFree(y); |
|
|
} |
|
|
|
|
|
void DeploySingleOp() { |
|
|
// Normally we can directly |
|
|
tvm::runtime::Module mod_dylib = tvm::runtime::Module::LoadFromFile("lib/test_addone_dll.so"); |
|
|
LOG(INFO) << "Verify dynamic loading from test_addone_dll.so"; |
|
|
Verify(mod_dylib, "addone"); |
|
|
// For libraries that are directly packed as system lib and linked together with the app |
|
|
// We can directly use GetSystemLib to get the system wide library. |
|
|
LOG(INFO) << "Verify load function from system lib"; |
|
|
tvm::runtime::Module mod_syslib = (*tvm::runtime::Registry::Get("runtime.SystemLib"))(); |
|
|
Verify(mod_syslib, "addonesys"); |
|
|
} |
|
|
|
|
|
void DeployGraphExecutor() { |
|
|
LOG(INFO) << "Running graph executor..."; |
|
|
// load in the library |
|
|
DLDevice dev{kDLCPU, 0}; |
|
|
tvm::runtime::Module mod_factory = tvm::runtime::Module::LoadFromFile("lib/test_relay_add.so"); |
|
|
// create the graph executor module |
|
|
tvm::runtime::Module gmod = mod_factory.GetFunction("default")(dev); |
|
|
tvm::runtime::PackedFunc set_input = gmod.GetFunction("set_input"); |
|
|
tvm::runtime::PackedFunc get_output = gmod.GetFunction("get_output"); |
|
|
tvm::runtime::PackedFunc run = gmod.GetFunction("run"); |
|
|
|
|
|
// Use the C++ API |
|
|
tvm::runtime::NDArray x = tvm::runtime::NDArray::Empty({2, 2}, DLDataType{kDLFloat, 32, 1}, dev); |
|
|
tvm::runtime::NDArray y = tvm::runtime::NDArray::Empty({2, 2}, DLDataType{kDLFloat, 32, 1}, dev); |
|
|
|
|
|
for (int i = 0; i < 2; ++i) { |
|
|
for (int j = 0; j < 2; ++j) { |
|
|
static_cast<float*>(x->data)[i * 2 + j] = i * 2 + j; |
|
|
} |
|
|
} |
|
|
// set the right input |
|
|
set_input("x", x); |
|
|
// run the code |
|
|
run(); |
|
|
// get the output |
|
|
get_output(0, y); |
|
|
|
|
|
for (int i = 0; i < 2; ++i) { |
|
|
for (int j = 0; j < 2; ++j) { |
|
|
ICHECK_EQ(static_cast<float*>(y->data)[i * 2 + j], i * 2 + j + 1); |
|
|
} |
|
|
} |
|
|
} |
|
|
|
|
|
int main(void) { |
|
|
DeploySingleOp(); |
|
|
DeployGraphExecutor(); |
|
|
return 0; |
|
|
} |
Makefile文件
https://github.com/apache/tvm/blob/main/apps/howto_deploy/Makefile
|
# Licensed to the Apache Software Foundation (ASF) under one |
|
|
# or more contributor license agreements. See the NOTICE file |
|
|
# distributed with this work for additional information |
|
|
# regarding copyright ownership. The ASF licenses this file |
|
|
# to you under the Apache License, Version 2.0 (the |
|
|
# "License"); you may not use this file except in compliance |
|
|
# with the License. You may obtain a copy of the License at |
|
|
# |
|
|
# http://www.apache.org/licenses/LICENSE-2.0 |
|
|
# |
|
|
# Unless required by applicable law or agreed to in writing, |
|
|
# software distributed under the License is distributed on an |
|
|
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY |
|
|
# KIND, either express or implied. See the License for the |
|
|
# specific language governing permissions and limitations |
|
|
# under the License. |
|
|
|
|
|
# Makefile Example to deploy TVM modules. |
|
|
TVM_ROOT=$(shell cd ../..; pwd) |
|
|
DMLC_CORE=${TVM_ROOT}/3rdparty/dmlc-core |
|
|
|
|
|
PKG_CFLAGS = -std=c++14 -O2 -fPIC\ |
|
|
-I${TVM_ROOT}/include\ |
|
|
-I${DMLC_CORE}/include\ |
|
|
-I${TVM_ROOT}/3rdparty/dlpack/include\ |
|
|
-DDMLC_USE_LOGGING_LIBRARY=\<tvm/runtime/logging.h\> |
|
|
|
|
|
PKG_LDFLAGS = -L${TVM_ROOT}/build -ldl -pthread |
|
|
|
|
|
.PHONY: clean all |
|
|
|
|
|
all: lib/cpp_deploy_pack lib/cpp_deploy_normal |
|
|
|
|
|
# Build rule for all in one TVM package library |
|
|
lib/libtvm_runtime_pack.o: tvm_runtime_pack.cc |
|
|
@mkdir -p $(@D) |
|
|
$(CXX) -c $(PKG_CFLAGS) -o $@ $^ |
|
|
|
|
|
# The code library built by TVM |
|
|
lib/test_addone_sys.o: prepare_test_libs.py |
|
|
@mkdir -p $(@D) |
|
|
python3 prepare_test_libs.py |
|
|
|
|
|
# Deploy using the all in one TVM package library |
|
|
lib/cpp_deploy_pack: cpp_deploy.cc lib/test_addone_sys.o lib/libtvm_runtime_pack.o |
|
|
@mkdir -p $(@D) |
|
|
$(CXX) $(PKG_CFLAGS) -o $@ $^ $(PKG_LDFLAGS) |
|
|
|
|
|
# Deploy using pre-built libtvm_runtime.so |
|
|
lib/cpp_deploy_normal: cpp_deploy.cc lib/test_addone_sys.o |
|
|
@mkdir -p $(@D) |
|
|
$(CXX) $(PKG_CFLAGS) -o $@ $^ -ltvm_runtime $(PKG_LDFLAGS) |
|
|
clean: |
结合Makefile文件和run_example.sh脚本一起看
脚本先创建lib目录,然后执行sudo make命令,make操作的执行要看Makefile文件
make命令会先在lib文件夹中编译一个名为libtvm_runtime_pack.o的静态链接库
然后运行prepare_test_lib.py文件生成将模型生成为test_addone_dll.so,test_addone_sys.o和test_relay_add.so三个库,给cpp_deploy.cc调用,生成两个可执行文件cpp_deploy_pack和cpp_deploy_normal
目标是用其它框架写的深度学习网络,通过tvm转换成so文件,使用c++部署,在gpu上进行调用,下面是cpu上部署的代码
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
/*!
* \brief Example code on load and run TVM module.s
* \file cpp_deploy.cc
*/
#include <dlpack/dlpack.h>
#include <tvm/runtime/module.h>
#include <tvm/runtime/packed_func.h>
#include <tvm/runtime/registry.h>
#include <cstdio>
#include <fstream>
#include <sstream>
#include <string>
using namespace std;
template <class Type>
Type stringToNum(const string& str)
{
istringstream iss(str);
Type num;
iss >> num;
return num;
}
void DeployGraphRuntime() {
ifstream in("/home/aiteam/tiwang/tvm-tfs-gpu-bkp/data.txt");
//int image[784];
string s;
int image_index=0;
/*
while(getline(in,s))
{
image[i]=stringToNum<int>(s);
++i;
}*/
LOG(INFO) << "Running graph runtime...";
// load in the library
DLContext ctx{kDLGPU, 0};
tvm::runtime::Module mod_factory = tvm::runtime::Module::LoadFromFile("/home/aiteam/tiwang/tvm-tfs-gpu-bkp/model.so");
// create the graph runtime module
tvm::runtime::Module gmod = mod_factory.GetFunction("default")(ctx);
tvm::runtime::PackedFunc set_input = gmod.GetFunction("set_input");
tvm::runtime::PackedFunc get_output = gmod.GetFunction("get_output");
tvm::runtime::PackedFunc run = gmod.GetFunction("run");
// Use the C++ API
tvm::runtime::NDArray x = tvm::runtime::NDArray::Empty({1,784}, DLDataType{kDLFloat, 32, 1}, ctx);
tvm::runtime::NDArray y = tvm::runtime::NDArray::Empty({1, 10}, DLDataType{kDLFloat, 32, 1}, ctx);
while(getline(in,s))
{
static_cast<float*>(x->data)[image_index]=((float)stringToNum<int>(s))/255;
image_index++;
}
// set the right input
set_input("x", x);
// run the code
run();
// get the output
get_output(0, y);
for(int i=0;i<10;++i)
{
LOG(INFO)<<static_cast<float*>(y->data)[i];
}
/*
for (int i = 0; i < 2; ++i) {
for (int j = 0; j < 2; ++j) {
ICHECK_EQ(static_cast<float*>(y->data)[i * 2 + j], i * 2 + j + 1);
}
}*/
}
int main(void) {
//DeploySingleOp();
DeployGraphRuntime();
return 0;
}
思路很简单就是把数据读进来,set_input,run然后get_output,修改了将target修改成cuda后并不能成功在gpu上运行,会出现core dump的问题
原因是想要让模型在gpu上运行,需要在gpu上开辟内存,然后将数据拷贝到gpu上运行,这个代码没有这些操作所以运行时会导致core崩溃。
下面是tvm c++部署调用gpu的完整过程,深度学习模型使用keras写的mnist手写体识别网络,保存成了pb格式,模型代码就不放了,这里直接读取pb文件进行转化,模型输入是(1,784),输出是(1,10)
导入头文件
import tvm
from tvm import te
from tvm import relay
# os and numpy
import numpy as np
import os.path
# Tensorflow imports
import tensorflow as tf
try:
tf_compat_v1 = tf.compat.v1
except ImportError:
tf_compat_v1 = tf
# Tensorflow utility functions
import tvm.relay.testing.tf as tf_testing
from tvm.contrib import graph_runtime
参数设置
#cpu
#target = "llvm"
#target_host = "llvm"
#layout = None
#ctx = tvm.cpu(0)
#gpu
target = "cuda"
target_host = 'llvm'
layout = "NCHW"
ctx = tvm.gpu(0)
处理数据
from tensorflow.python.keras.datasets import mnist
from tensorflow.python.keras.utils import np_utils
(x_train,y_train),(x_test,y_test)=mnist.load_data()
x_test1=x_test.reshape(x_test.shape[0],x_test.shape[1]*x_test.shape[2])
print(x_train.shape,x_test.shape)
print(y_train.shape,y_test.shape)
x_train=x_train.reshape(x_train.shape[0],x_train.shape[1]*x_train.shape[2])
x_test=x_test.reshape(x_test.shape[0],x_test.shape[1]*x_test.shape[2])
x_train=x_train/255
x_test=x_test/255
y_train=np_utils.to_categorical(y_train)
y_test=np_utils.to_categorical(y_test)
print(x_train.shape,x_test.shape)
print(y_train.shape,y_test.shape)
with open("data.txt",'w') as wf:
for i in range(784):
wf.write(str(x_test1[12][i]))
wf.write('\n')
读取模型
with tf_compat_v1.gfile.GFile('./frozen_models/simple_frozen_graph.pb', "rb") as f:
graph_def = tf_compat_v1.GraphDef()
graph_def.ParseFromString(f.read())
graph = tf.import_graph_def(graph_def, name="")
# Call the utility to import the graph definition into default graph.
graph_def = tf_testing.ProcessGraphDefParam(graph_def)
# Add shapes to the graph.
config = tf.compat.v1.ConfigProto(allow_soft_placement=True)
with tf_compat_v1.Session() as sess:
graph_def = tf_testing.AddShapesToGraphDef(sess, "Identity")
tensor_name_list = [tensor.name for tensor in tf.compat.v1.get_default_graph().as_graph_def().node]
for tensor_name in tensor_name_list:
print(tensor_name,'\n')
构建
shape_dict = {"x": x_train[0:1].shape}
print(shape_dict)
dtype_dict = {"x": "uint8"}
mod, params = relay.frontend.from_tensorflow(graph_def, layout=layout, shape=shape_dict)
print("Tensorflow protobuf imported to relay frontend.")

编译成tvm模型
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(mod, target=target, target_host=target_host, params=params)

测试一下tvm模型能不能用
from tvm.contrib import graph_runtime
tt=np.zeros([1,784])
i=0
file=open("data.txt")
while 1:
line=file.readline()
if not line:
break
tt[0][i]=int(line)
i+=1
file.close()
dtype = "float32"
m = graph_runtime.GraphModule(lib["default"](ctx))
# set inputs
m.set_input("x", tvm.nd.array(tt.astype(dtype)))
# execute
m.run()
# get outputs
tvm_output = m.get_output(0, tvm.nd.empty(((1, 10)), "float32"))
print(tvm_output.shape,tvm_output)

保存模型
from tvm.contrib import utils
temp=utils.tempdir()
path_lib=temp.relpath("/home/aiteam/test_code/model.so")
print(path_lib)
lib.export_library(path_lib)
print(temp.listdir())
然后进入到tvm/apps/howto_deploy目录,修改tvm_runtime_pack.cc文件,加上头文件
#include "../../src/runtime/cuda/cuda_device_api.cc"
#include "../../src/runtime/cuda/cuda_module.cc"
然后再写一个cc文件存放自己的部署代码,修改Makefile文件进行编译
文件名是cpp_deploy_bkp.cc
修改后的Makefile文件
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
# Makefile Example to deploy TVM modules.
TVM_ROOT=$(shell cd ../..; pwd)
DMLC_CORE=${TVM_ROOT}/3rdparty/dmlc-core
PKG_CFLAGS = -std=c++14 -g -fPIC\
-I${TVM_ROOT}/include\
-I${DMLC_CORE}/include\
-I${TVM_ROOT}/3rdparty/dlpack/include\
-I/usr/local/cuda/include
PKG_LDFLAGS = -L${TVM_ROOT}/build -ldl -pthread -L/usr/local/cuda/lib64 -lcudart -lcuda
.PHONY: clean all
all:lib/libtvm_runtime_pack.o lib/cpp_deploy_pack
#all: lib/cpp_deploy_pack lib/cpp_deploy_normal
# Build rule for all in one TVM package library
.PHONY: lib/libtvm_runtime_pack.o
lib/libtvm_runtime_pack.o: tvm_runtime_pack.cc
@mkdir -p $(@D)
$(CXX) -c $(PKG_CFLAGS) -o $@ $^ $(PKG_LDFLAGS)
# Deploy using the all in one TVM package library
.PHONY: lib/cpp_deploy_pack
lib/cpp_deploy_pack: cpp_deploy_bkp.cc lib/libtvm_runtime_pack.o
@mkdir -p $(@D)
$(CXX) $(PKG_CFLAGS) -o $@ $^ $(PKG_LDFLAGS)
里面要加上cuda头文件的位置和动态链接库的位置
cpp_deploy_bkp.cc
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
/*!
* \brief Example code on load and run TVM module.s
* \file cpp_deploy.cc
*/
#include <dlpack/dlpack.h>
#include <tvm/runtime/module.h>
#include <tvm/runtime/packed_func.h>
#include <tvm/runtime/registry.h>
#include <cstdio>
#include <fstream>
#include <sstream>
#include <string>
using namespace std;
template <class Type>
Type stringToNum(const string& str)
{
istringstream iss(str);
Type num;
iss >> num;
return num;
}
void DeployGraphRuntime() {
constexpr int dtype_code= 2U;
constexpr int dtype_bits=32;
constexpr int dtype_lines=1;
constexpr int device_type= 2;
constexpr int device_id=0;
int ndim=2;
int64_t in_shape[2]={1,784};
int64_t out_shape[2]={1,10};
DLTensor* DLTX=nullptr;
DLTensor* DLTY=nullptr;
TVMArrayAlloc(in_shape,ndim,dtype_code,dtype_bits,dtype_lines,device_type,device_id,&DLTX);
TVMArrayAlloc(out_shape,ndim,dtype_code,dtype_bits,dtype_lines,device_type,device_id,&DLTY);
float img[784];
float rslt[10];
ifstream in("/home/aiteam/tiwang/data.txt");
//int image[784];
string s;
int image_index=0;
/*
while(getline(in,s))
{
image[i]=stringToNum<int>(s);
++i;
}*/
bool enabled = tvm::runtime::RuntimeEnabled("cuda");
if (!enabled)
{
LOG(INFO) << "Skip heterogeneous test because cuda is not enabled."<< "\n";
return;
}
LOG(INFO) << "Running graph runtime...";
// load in the library
DLContext ctx{kDLGPU, 0};
tvm::runtime::Module mod_factory = tvm::runtime::Module::LoadFromFile("/home/aiteam/test_code/model.so");
// create the graph runtime module
tvm::runtime::Module gmod = mod_factory.GetFunction("default")(ctx);
tvm::runtime::PackedFunc set_input = gmod.GetFunction("set_input");
tvm::runtime::PackedFunc get_output = gmod.GetFunction("get_output");
tvm::runtime::PackedFunc run = gmod.GetFunction("run");
// Use the C++ API
while(getline(in,s))
{
if(image_index%28==0)
printf("\n");
//static_cast<float*>(x->data)[image_index]=((float)stringToNum<int>(s))/255;
img[image_index]=((float)stringToNum<int>(s))/255;
int a=stringToNum<int>(s);
printf("%4d",a);
image_index++;
}
TVMArrayCopyFromBytes(DLTX,&img[0],image_index*sizeof(float));
// set the right input
set_input("x", DLTX);
// run the code
run();
// get the output
get_output(0, DLTY);
TVMArrayCopyToBytes(DLTY,&rslt[0],10*sizeof(float));
for(int i=0;i<10;++i)
{
LOG(INFO)<<rslt[i];
//LOG(INFO)<<static_cast<float*>(y->data)[i];
}
}
int main(void) {
//DeploySingleOp();
DeployGraphRuntime();
return 0;
}
相比于之前cpu部署的代码,gpu部署多了一个拷贝张量的过程
参照
https://discuss.tvm.apache.org/t/deploy-nnvm-module-using-c-on-gpu-using-opencl-target/229
最终结果
首先在tvm/apps/howto_deplpy目录下执行sudo make
编译通过,运行可执行文件 ./lib/cpp_deploy_pack
参考链接:
https://www.cnblogs.com/wangtianning1223/p/14662970.html
https://github.com/apache/tvm/tree/main/apps/howto_deploy
https://discuss.tvm.apache.org/t/deploy-nnvm-module-using-c-on-gpu-using-opencl-target/229/17
https://discuss.tvm.apache.org/t/performance-tvm-pytorch-bert-on-cpu/10200/10
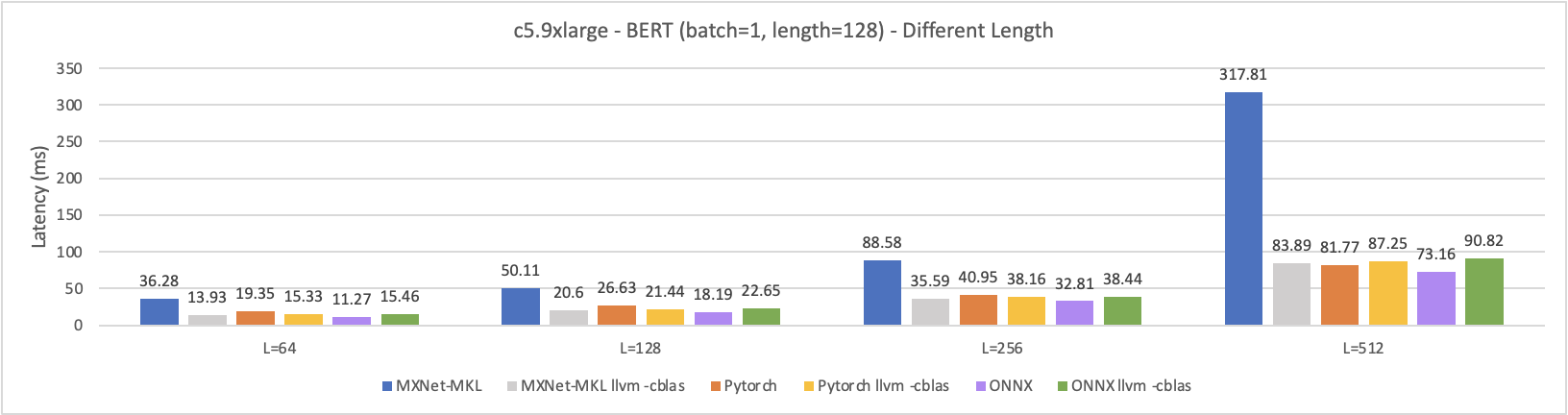
[Performance] TVM - pytorch BERT on CPU
@masahi I add ONNX for the experiments in the following and it seems using ONNX-runtime can get the best performance no matter the sequence length is (without tuning). I use ONNX-runtime with GraphOptimizationLevel.ORT_ENABLE_ALL showing in this link 1. Besides, I plot the IR graph for ONNX, which is quite complicated.
Experiment 1 - Different Target

Experiment 3 - Different Length

- ONNX IR Graph: drive link
Also, I have some questions about AutoSchedule tuning.
- Q1: @merrymercy I was confused that when I use AutoSchedule to tune TVM, can I use target like
llvm -libs=cblasor I should use onlyllvm. I found this will give different tasks to tune. - Q2: @comaniac I think MXNet IR is more friendly than Pytorch IR for AutoSchedule tuning. I set the same parameters for tuning but Pytorch cannot get the results as MXNet (16ms for seq_len=128) The following are their tuning tasks and it seems quite different due to different IR graph. I still work on where the problem comes from, TVM front-end or original code implementation. But I think maybe TVM will have some transforms to generate similar IR graph even if from different framework.
o 1st difference: MXNet will use nn.bias_add() and Pytorch will use relay.add(), which cause the tuning tasks not include this operation. (task 0,1,2,6)
o 2nd difference: Their attention softmax operation have different shape, but I think this doesn’t cause too much latency difference (task 4)
# Tasks for Pytorch AutoSchedule Tuning (Target = llvm)
========== Task 0 (workload key: [
, 128, 3072, 768, 3072, 128, 768]) ==========
placeholder = PLACEHOLDER [128, 3072]placeholder = PLACEHOLDER [768, 3072]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k]) ========== Task 1 (workload key: [
, 128, 768, 3072, 768, 128, 3072]) ==========
placeholder = PLACEHOLDER [128, 768]placeholder = PLACEHOLDER [3072, 768]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k]) ========== Task 2 (workload key: [
, 128, 768, 768, 768, 128, 768]) ==========
placeholder = PLACEHOLDER [128, 768]placeholder = PLACEHOLDER [768, 768]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k]) ========== Task 3 (workload key: [
, 12, 128, 128, 12, 64, 128, 12, 128, 64]) ==========
placeholder = PLACEHOLDER [12, 128, 128]placeholder = PLACEHOLDER [12, 64, 128]compute(b, i, j) += (placeholder[b, i, k]*placeholder[b, j, k]) ========== Task 4 (workload key: [
, 1, 12, 128, 128, 1, 12, 128, 128]) ==========
placeholder = PLACEHOLDER [1, 12, 128, 128]T_softmax_maxelem(i0, i1, i2) max= placeholder[i0, i1, i2, k]T_softmax_delta(i0, i1, i2, i3) = (placeholder[i0, i1, i2, i3] - T_softmax_maxelem[i0, i1, i2])T_fast_exp(ax0, ax1, ax2, ax3) = max((tir.reinterpret(tir.shift_left(int32((tir.floor(((max(min(T_softmax_delta[ax0, ax1, ax2, a ..(OMITTED).. max_delta[ax0, ax1, ax2, ax3], 88.3763f), -88.3763f)*1.4427f) + 0.5f))*0.693147f))) + 1f)), T_softmax_delta[ax0, ax1, ax2, ax3])T_softmax_expsum(i0, i1, i2) += T_fast_exp[i0, i1, i2, k]T_softmax_norm(i0, i1, i2, i3) = (T_fast_exp[i0, i1, i2, i3]/T_softmax_expsum[i0, i1, i2]) ========== Task 5 (workload key: [
, 12, 128, 64, 12, 128, 64, 12, 128, 128]) ==========
placeholder = PLACEHOLDER [12, 128, 64]placeholder = PLACEHOLDER [12, 128, 64]compute(b, i, j) += (placeholder[b, i, k]*placeholder[b, j, k]) ========== Task 6 (workload key: [
, 128, 768, 2304, 768, 128, 2304]) ==========
placeholder = PLACEHOLDER [128, 768]placeholder = PLACEHOLDER [2304, 768]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k]) ========== Task 7 (workload key: [
, 1, 128, 768, 1, 128, 1]) ==========
placeholder = PLACEHOLDER [1, 128, 768]placeholder_red(ax0, ax1, ax2) += placeholder[ax0, ax1, k2]T_divide(ax0, ax1, ax2) = (placeholder_red[ax0, ax1, ax2]/768f) ========== Task 8 (workload key: [
, 1, 128, 768, 1, 128, 1, 1, 128, 1]) ==========
placeholder = PLACEHOLDER [1, 128, 768]placeholder = PLACEHOLDER [1, 128, 1]T_subtract(ax0, ax1, ax2) = (placeholder[ax0, ax1, ax2] - placeholder[ax0, ax1, 0])T_multiply(ax0, ax1, ax2) = (T_subtract[ax0, ax1, ax2]*T_subtract[ax0, ax1, ax2])T_multiply_red(ax0, ax1, ax2) += T_multiply[ax0, ax1, k2]T_divide(ax0, ax1, ax2) = (T_multiply_red[ax0, ax1, ax2]/768f) ========== Task 9 (workload key: [
, 1, 768, 768, 768, 768, 1, 768]) ==========
placeholder = PLACEHOLDER [1, 768]placeholder = PLACEHOLDER [768, 768]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])placeholder = PLACEHOLDER [768]T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1])T_minimum(ax0, ax1) = min(T_add[ax0, ax1], 9f)T_maximum(ax0, ax1) = max(T_minimum[ax0, ax1], -9f)T_fast_tanh(ax0, ax1) = ((T_maximum[ax0, ax1]*(((T_maximum[ax0, ax1]*T_maximum[ax0, ax1])*(((T_maximum[ax0, ax1]*T_maximum[ax0, ..(OMITTED).. *T_maximum[ax0, ax1])*(((T_maximum[ax0, ax1]*T_maximum[ax0, ax1])*1.19826e-06f) + 0.000118535f)) + 0.00226843f)) + 0.00489353f))# Tasks for MXNet AutoSchedule Tuning (Target = llvm)
========== Task 0 (workload key: [
, 128, 3072, 768, 3072, 768, 128, 768]) ==========
placeholder = PLACEHOLDER [128, 3072]placeholder = PLACEHOLDER [768, 3072]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])placeholder = PLACEHOLDER [768]T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1]) ========== Task 1 (workload key: [
, 128, 768, 3072, 768, 3072, 128, 3072]) ==========
placeholder = PLACEHOLDER [128, 768]placeholder = PLACEHOLDER [3072, 768]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])placeholder = PLACEHOLDER [3072]T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1]) ========== Task 2 (workload key: [
, 128, 768, 768, 768, 768, 128, 768]) ==========
placeholder = PLACEHOLDER [128, 768]placeholder = PLACEHOLDER [768, 768]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])placeholder = PLACEHOLDER [768]T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1]) ========== Task 3 (workload key: [
, 12, 128, 128, 12, 64, 128, 12, 128, 64]) ==========
placeholder = PLACEHOLDER [12, 128, 128]placeholder = PLACEHOLDER [12, 64, 128]compute(b, i, j) += (placeholder[b, i, k]*placeholder[b, j, k]) ========== Task 4 (workload key: [
, 1536, 128, 1536, 128]) ==========
placeholder = PLACEHOLDER [1536, 128]T_softmax_maxelem(i0) max= placeholder[i0, k]T_softmax_delta(i0, i1) = (placeholder[i0, i1] - T_softmax_maxelem[i0])T_fast_exp(ax0, ax1) = max((tir.reinterpret(tir.shift_left(int32((tir.floor(((max(min(T_softmax_delta[ax0, ax1], 88.3763f), -88. ..(OMITTED).. oor(((max(min(T_softmax_delta[ax0, ax1], 88.3763f), -88.3763f)*1.4427f) + 0.5f))*0.693147f))) + 1f)), T_softmax_delta[ax0, ax1])T_softmax_expsum(i0) += T_fast_exp[i0, k]T_softmax_norm(i0, i1) = (T_fast_exp[i0, i1]/T_softmax_expsum[i0]) ========== Task 5 (workload key: [
, 12, 128, 64, 12, 128, 64, 12, 128, 128]) ==========
placeholder = PLACEHOLDER [12, 128, 64]placeholder = PLACEHOLDER [12, 128, 64]compute(b, i, j) += (placeholder[b, i, k]*placeholder[b, j, k]) ========== Task 6 (workload key: [
, 128, 768, 2304, 768, 2304, 128, 2304]) ==========
placeholder = PLACEHOLDER [128, 768]placeholder = PLACEHOLDER [2304, 768]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])placeholder = PLACEHOLDER [2304]T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1]) ========== Task 7 (workload key: [
, 128, 1, 768, 128, 1, 1]) ==========
placeholder = PLACEHOLDER [128, 1, 768]placeholder_red(ax0, ax1, ax2) += placeholder[ax0, ax1, k2]T_divide(ax0, ax1, ax2) = (placeholder_red[ax0, ax1, ax2]/768f) ========== Task 8 (workload key: [
, 128, 1, 768, 128, 1, 1, 128, 1, 1]) ==========
placeholder = PLACEHOLDER [128, 1, 768]placeholder = PLACEHOLDER [128, 1, 1]T_subtract(ax0, ax1, ax2) = (placeholder[ax0, ax1, ax2] - placeholder[ax0, ax1, 0])T_multiply(ax0, ax1, ax2) = (T_subtract[ax0, ax1, ax2]*T_subtract[ax0, ax1, ax2])T_multiply_red(ax0, ax1, ax2) += T_multiply[ax0, ax1, k2]T_divide(ax0, ax1, ax2) = (T_multiply_red[ax0, ax1, ax2]/768f) ========== Task 9 (workload key: [
, 1, 768, 768, 768, 768, 1, 768]) ==========
placeholder = PLACEHOLDER [1, 768]placeholder = PLACEHOLDER [768, 768]T_dense(i, j) += (placeholder[i, k]*placeholder[j, k])placeholder = PLACEHOLDER [768]T_add(ax0, ax1) = (T_dense[ax0, ax1] + placeholder[ax1])T_minimum(ax0, ax1) = min(T_add[ax0, ax1], 9f)T_maximum(ax0, ax1) = max(T_minimum[ax0, ax1], -9f)T_fast_tanh(ax0, ax1) = ((T_maximum[ax0, ax1]*(((T_maximum[ax0, ax1]*T_maximum[ax0, ax1])*(((T_maximum[ax0, ax1]*T_maximum[ax0, ..(OMITTED).. *T_maximum[ax0, ax1])*(((T_maximum[ax0, ax1]*T_maximum[ax0, ax1])*1.19826e-06f) + 0.000118535f)) + 0.00226843f)) + 0.00489353f))Sorry for my lots of questions. I’ll do my best to do more experiments and figure out the reasons why Pytorch AutoSchedule not working as MXNet and why TVM is not working as expected when sequence length increasing.
Thanks for the plentiful information.
For Q1, when you extract tasks with llvm -mcpu=skylake-avx512 -libs=cblas, some operators (i.e., dense) will be offloaded to cblas. It means those operators won’t be compiled by the TVM codegen, so AutoScheduler won’t see and tune them.
For Q2, the two differences you pointed out seem not really impactful. Maybe you can try to use debugger to compare the latency breakdown between two models: Debugger — tvm 0.8.dev0 documentation 4
@comaniac I follow your instructions to use debugger and compare the latency in the following IR graphs (latency > 100us with orange color). And I find maybe some operations are hard to tune, such as fused_nn_contrib_dense_pack. All my experiments are done with opt_level=3, required_pass=["FastMath"]
Experiment 1 - Compare BERT on MXNet (68.4ms) and Pytorch (122.9ms)
- MXNet Debug IR Graph: drive link
- Pytorch Debug IR Graph: drive link 3
- From the above graphs, we can find MXNet use
fused_nn_contrib_dense_pack_addwhile Pytorch usefused_nn_contrib_dense_packoperation. This is happened for all FC layers (4 in one transformer block) and I use the latency of first block as example.
o FC for Query, Key, and Value (M: 503us, P: 1314us)
o FC after self-attention (M: 202us, P: 651us)
o FC after layer normalization (M: 798us, P: 2578us)
o FC after GELU (M: 786us, P: 2572us)

Experiment 2 - Compare BERT on MXNet (68.4ms) and MXNet-tune (autoschedule) (15.4ms)
- MXNet Debug IR Graph: drive link
- MXNet-tune Debug IR Graph: drive link
- From the above graphs, it is easy to find we can reduce most of
denseandbatch_matmuloperations’ latency. I take the first transformer block as example.
o FC for Query, Key, and Value (M: 503us, M-tune: 229us)
o FC after self-attention (M: 202us, M-tune: 99us)
o FC after layer normalization (M: 798us, M-tune: 292us)
o FC after GELU (M: 786us, M-tune: 367us)
o batch_matmul for Quert and Key (M: 1828us, M-tune:41us)
o batch_matmul for Attention and Value (M: 1312us, M-tune:29us)
Experiment 3 - Compare BERT on Pytorch (122.9ms) and Pytorch-tune (autoschedule) (64.2ms)
- Pytorch Debug IR Graph: drive link 3
- Pytorch-tune Debug IR Graph: drive link 1
- From the above graphs, we can find we only reduce the latency of
batch_matmulbut notdenseoperation. I take the first transformer block as example.
o FC for Query, Key, and Value (P: 1314us, P-tune: 1276us)
o FC after self-attention (P: 651us, P-tune: 403us)
o FC after layer normalization (P: 2578us, P-tune: 1779us)
o FC after GELU (P: 2572us, P-tune: 1684us)
o batch_matmul for Quert and Key (P: 1624us, P-tune: 78us)
o batch_matmul for Attention and Value (P: 1265us, P-tune: 70us)
Therefore, I suspect the problem is come from the fused_nn_contrib_dense_pack operation, but I don’t know why this is slower than fused_nn_contrib_dense_pack_add. Even the latter has additional add operation for adding bias. If you want the whole debug files (json and logs), I provide in this drive link 1.
@comaniac I change the TVM version with commit id: 91e07e1f3a7 (Feb. 5, 2021) which is the same as this repo 1. And the problem is solved because we will use fused_nn_batch_matmul for all FC (dense) layers rather than fused_nn_contrib_dense_pack. I think the problem is coming from this PR 3 you provided, which also causes I cannot use -libs=mkl. I have the debug IR graphs in the following and now Pytorch can speed up from Pytorch script 26.63ms to 17.36ms after tuning with autoschedule.
- Pytorch Debug IR Graph: drive link 2
- Pytorch-tune Debug IR Graph: drive link 1
Hmm I don’t that PR is the root cause of using batch_matmul in BERT model tho. It might be due to this PR that uses dense instead of batch_matmul when the input shape is 2D and 3D:
Fix PyTorch matmul conversion when given (2-dim, N-dim) input pair 6
apache:main ← yuchaoli:main
opened
" style="color: var(--primary); cursor: pointer; border-bottom-color: var(--primary-low-mid);"> Apr 14, 2021
This PR change the matmul conversion in PyTorch when given (2-dim, N-dim) input … 6
There’s a known issue that TVM’s dense op and batch_matmul op with Y = X * W^T does have bad performance in some models.
There’re several matmul & batch_matmul ops in bert that takes data tensor as both input and weight(exp. those in multi-head attentions) rather than use const parameter as weight. In such situation, we would see some explicit transpose inserted when the model are imported from TensorFlow or Pytorch(they use X * W for matmul by default). For the MXNet, as far as I know, it uses X * W^T by default.
The PR you found looks like creating a special schedule for dense + transpose, I’m not sure if that’s the key of the performance improving you got because it is written for AutoTVM and AutoScheduler will never use these manual schedule. You can have a more detailed analyse among those dense/batch_matmul ops’ layout and shape.
I would agree with @comaniac that the miss conversion from dense to batch_matmul caused some waste of computation before.
3 MONTHS LATER
will auto-schedule work in case of “llvm -libs-cblas”? e.g. a network may contain matmul ops(leverage cblas) and other ops(leverage auto-schedule to get performance)?
Deploy NNVM module using C++ on GPU using OpenCL target
2 MONTHS LATER
@masahi Thanks for the sample .
In your sample code is “tvm_input” the CPU byte array copied to “x” (GPU array) ?
means is TVMArrayCopyFromBytes(destination,source,size) ?
for (int i = 0; i < n_samples; ++i) {
TVMArrayCopyFromBytes(x, &tvm_input[i * in_size], in_size * sizeof(float));
set_input(input_name.c_str(), x);
run();
get_output(0, y);
TVMArrayCopyToBytes(y, &tvm_output[i * out_size], out_size * sizeof(float));
}
Reply
yes, source is on cpu and x is on gpu. In my code, tvm_input should contain input data coming from your input image, for example.
Reply
@masahi
instead of tvm_input i created a DLTensor ‘z’ of device type = kdCPU , for storing input image .
I did copy byte array as shown below .
https://gist.github.com/rajh619/74538a7b3a7e1b89a2ae89db5ab24054 30
but the i couldnt find the copied bytes in the destination (x->data) .?
Reply
If you already have your data in DLtensor, you should use TVMArrayCopyFromTo.
Reply
@masahi
ok .now i tried with TVMArrayCopyFromTo
TVMArrayCopyFromTo(z, x, nullptr);
the same issue happens , i couldnt find the bytes copied to x->data .
I think x->data should be same as z->data(image data) . please correct me if am wrong ?
Reply
if x is on GPU, you should NEVER touch x->data. You either get segfault or complete junk.
If you want to access x->data, copy x to CPU first.
Reply
@masahi Thanks . got it working . i copied back from GPU to CPU(x->data to k->data) and validated the data.
After executing "run() " , i was able to get output to CPU in two ways :
- allocate tvm array to output tensor “y” with devicetype - CPU (1) , then tvm_output(0,y) . y->data contains output . ( i think internally tvm copies the output from device to cpu_host ?)
- allocate tvm array to output tensor “y” with devicetype - GPU (4) , tvm_output(0,y) ,then copy bytes from GPU to CPU ->out_vector[] . (similar to your sample code) .
Out of both which is the right way to extract output ?
Reply
The answer is 2.
See my sample code. The output y is GPU tensor. I copy y to tvm_output, which is on cpu.
1
Reply
Hi, @masahi I am still getting segfault even I use your sample 5 code also after allocating memory i am doing memeset to 0
DLTensor* x = nullptr;
DLTensor* y = nullptr;
const int in_ndim = 4;
const int out_ndim = in_ndim;
const int num_slice = 1;
const int num_class = 4;
const int shrink_size[] = { 256, 256 };
const int64_t in_shape[] = { num_slice, 1, shrink_size[0], shrink_size[1] };
const int64_t out_shape[] = { num_slice, num_class, shrink_size[0], shrink_size[1] };
TVMArrayAlloc(in_shape, in_ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &x);
TVMArrayAlloc(out_shape, out_ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &y);
memset(x->data, 0, 4265265);
it is happing for Cuda and OpenCL for llvm it’s working fine.
Reply
you can’t use memset on GPU memory.
Reply
hi, @masahi still i am not able working still it throws memory error.
void FR_TVM_Deploy::forward(float* imgData)
{
int in_size = (1 * 64 * 64 * 3 * 4);
constexpr int dtype_code = kDLFloat;
constexpr int dtype_bits = 32;
constexpr int dtype_lanes = 1;
constexpr int device_type = kDLCPU;
constexpr int device_id = 0;
constexpr int in_ndim = 4;
const int64_t in_shape[in_ndim] = {1, 64, 64, 3};
//Allocating memeory to DLTensor object
TVMArrayAlloc(in_shape, in_ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &input);//
TVMArrayCopyFromBytes(input, imgData, in_size);
//Get globl function module for graph runtime
tvm::runtime::Module* mod = (tvm::runtime::Module*)handle;
// get the function from the module(set input data)
tvm::runtime::PackedFunc set_input = mod->GetFunction("set_input");
set_input("input", input);
// get the function from the module(run it)
tvm::runtime::PackedFunc run = mod->GetFunction("run");
run();
int out_ndim = 2;
int64_t out_shape[2] = {1, 256};
TVMArrayAlloc(out_shape, out_ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &output);
// get the function from the module(get output data)
tvm::runtime::PackedFunc get_output = mod->GetFunction("get_output");
get_output(0, output);
size_t out_size = out_shape[0] * out_shape[1];
std::vector<float> tvm_output(out_size, 0);
TVMArrayCopyToBytes(output, &tvm_output[out_size], out_size);
TVMArrayFree(input);
TVMArrayFree(output);
}
when i print the tvm_output vector i am getting all 0’s means output is coming 0, in llvm case i am getting correct output. here i am printing vector tvm_output in loop, is there any othere way to check output?
参考链接:
https://www.cnblogs.com/wangtianning1223/p/14662970.html
https://github.com/apache/tvm/tree/main/apps/howto_deploy
https://discuss.tvm.apache.org/t/deploy-nnvm-module-using-c-on-gpu-using-opencl-target/229/17
https://discuss.tvm.apache.org/t/performance-tvm-pytorch-bert-on-cpu/10200/10


{kind=link}
{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)