

A100计算能力
A100计算能力
A100 GPU支持新的计算功能8.0。表1比较了NVIDIA GPU架构的不同计算功能的参数。

表1.计算能力:GP100 vs. GV100 vs. GA100。
MIG架构
尽管许多数据中心的工作量在规模和复杂性上都在继续扩展,但某些加速任务的要求却不高,例如早期开发或推断小批量的简单模型。数据中心经理的目标是保持较高的资源利用率,因此理想的数据中心加速器不仅会变大,还会有效地加速许多较小的工作负载。
新的MIG功能可以将每个A100划分为多达七个GPU实例,以实现最佳利用率,从而有效地扩展对每个用户和应用程序的访问权限。
图10显示了Volta MPS如何允许多个应用程序在单独的GPU执行资源(SM)上同时执行。但是,由于内存系统资源是在所有应用程序之间共享的,因此,如果一个应用程序对DRAM带宽有很高的要求或者其请求超额预订了L2高速缓存,则该应用程序可能会干扰其它应用程序。
图1中所示的A100 GPU新的MIG功能可以将单个GPU划分为多个GPU分区,称为GPU实例。 每个实例的SM都具有贯穿整个内存系统的单独且隔离的路径-片上交叉开关端口,L2缓存库,内存控制器和DRAM地址总线都被唯一地分配给单个实例。这样可以确保单个用户的工作负载可以以可预测的吞吐量和延迟运行,并且具有相同的二级缓存分配和DRAM带宽,即使其它任务正在颠覆自己的缓存或使DRAM接口饱和也是如此。
使用此功能, MIG可以对可用的GPU计算资源进行分区,以为不同客户端(例如VM,容器,进程等)提供故障隔离,从而提供定义的服务质量( QoS)。它使多个GPU实例可以在单个物理A100 GPU上并行运行。MIG还保持CUDA编程模型不变,以最大程度地减少编程工作量。
CSP可以使用MIG提高其GPU服务器的利用率,无需额外成本即可提供多达7倍的GPU实例。MIG支持CSP所需的必要QoS和隔离保证,以确保一个客户端(VM,容器,进程)不会影响另一客户端的工作或调度。
CSP通常根据客户使用模式对硬件进行分区。仅当硬件资源在运行时提供一致的带宽,适当的隔离和良好的性能时,有效分区才有效。
借助基于NVIDIA Ampere架构的GPU,可以在其新的虚拟GPU实例上查看和调度作业,就好像它们是物理GPU一样。MIG可与Linux操作系统及其管理程序一起使用。用户可以使用诸如Docker Engine之类的运行时运行带有MIG的容器,并很快将支持使用Kubernetes进行容器编排。

图1.今天的CSP多用户节点(A100之前的版本)。加速的GPU实例仅在完全物理GPU粒度下可供不同组织中的用户使用,即使用户应用程序不需要完整的GPU。
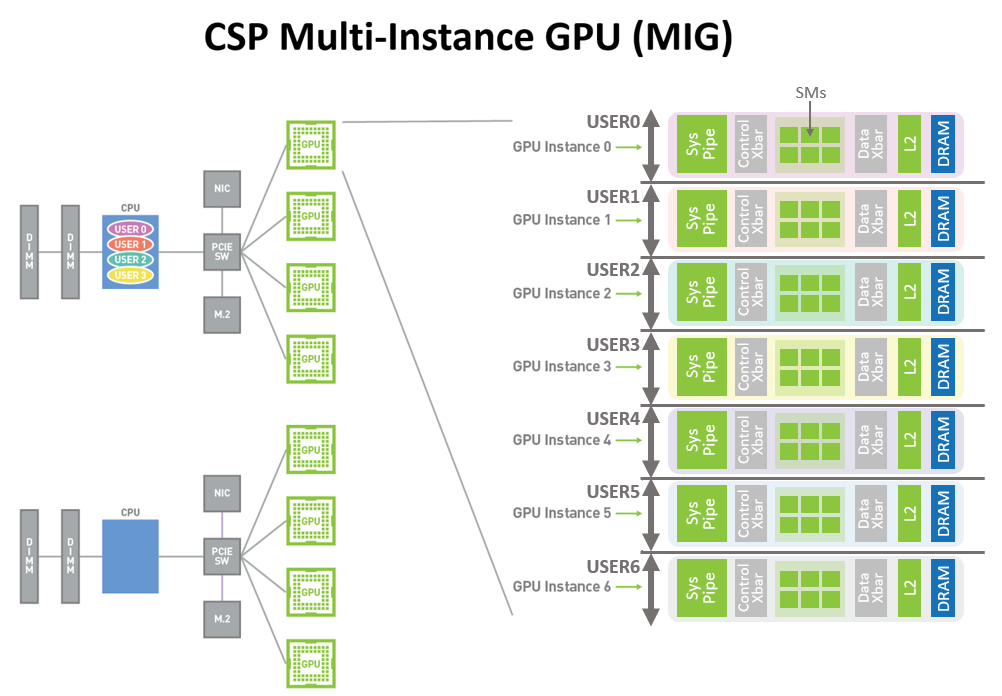
图2. CSP多用户和MIG图。来自同一组织或不同组织的多个独立用户可以在单个物理GPU中分配其自己的专用,受保护和隔离的GPU实例。
错误和故障检测,隔离和控制
通过检测,包含并经常纠正错误和故障来提高GPU的正常运行时间和可用性至关重要,而不是强制GPU重置。这对于大型的多GPU群集和单GPU多租户环境(例如MIG配置)尤其重要。
NVIDIA Ampere架构A100 GPU包括新技术,可改善错误/故障归因(归因于导致错误的应用程序),隔离(隔离有故障的应用程序,以使它们不会影响在同一GPU或GPU集群中运行的其它应用程序),和限制(确保一个应用程序中的错误不会泄漏并影响其它应用程序)。这些故障处理技术对于MIG环境尤其重要,以确保共享单个GPU的客户端之间的适当隔离和安全性。
连接NVLink的GPU现在具有更强大的错误检测和恢复功能。远程GPU的页面错误会通过NVLink发送回源GPU。远程访问故障通信是大型GPU计算群集的一项关键弹性功能,有助于确保一个进程或VM中的故障不会导致其它进程或VM停机。
A100 GPU包括其它几个新的和改进的硬件功能,可以增强应用程序性能。有关更多信息,请参阅即将发布的NVIDIA A100 Tensor Core GPU架构白皮书。
CUDA 11在NVIDIA Ampere架构GPU方面的进步
在NVIDIA CUDA并行计算平台上构建了成千上万个GPU加速的应用程序。CUDA的灵活性和可编程性使其成为研究和部署新的DL和并行计算算法的首选平台。
NVIDIA Ampere架构GPU旨在提高GPU的可编程性和性能,同时还降低软件复杂性。NVIDIA Ampere架构的GPU和CUDA编程模型的改进可加速程序执行,并降低许多操作的延迟和开销。
CUDA 11的新功能为第三代Tensor核心,稀疏性,CUDA图形,多实例GPU,L2缓存驻留控件以及NVIDIA Ampere架构的其它一些新功能提供了编程和API支持。
有关新CUDA功能的更多信息,请参阅即将发布的NVIDIA A100 Tensor Core GPU体系结构白皮书。有关新DGX A100系统的更多信息,请参阅使用NVIDIA DGX A100定义AI创新。有关开发人员专区的更多信息,请参阅NVIDIA Developer,有关CUDA的更多信息,请参见新的CUDA编程指南。
结论
NVIDIA的使命是加速时代的达芬奇和爱因斯坦的工作。科学家,研究人员和工程师致力于使用高性能计算(HPC)和AI解决世界上最重要的科学,工业和大数据挑战。
NVIDIA A100 Tensor Core GPU在的加速数据中心平台中实现了下一个巨大飞跃,可在任何规模上提供无与伦比的加速性能,并使这些创新者能够终其一生。A100支持众多应用领域,包括HPC,基因组学,5G,渲染,深度学习,数据分析,数据科学和机器人技术。
推进当今最重要的HPC和AI应用程序(个性化医学,会话式AI和深度推荐系统),需要研究人员不断发展。A100为NVIDIA数据中心平台提供支持,该平台包括Mellanox HDR InfiniBand,NVSwitch,NVIDIA HGX A100和Magnum IO SDK,以进行扩展。这个集成的技术团队可以有效地扩展到成千上万个GPU,以前所未有的速度训练最复杂的AI网络。
A100 GPU的新MIG功能可将每个A100划分为多达七个GPU加速器,以实现最佳利用率,从而有效地提高GPU资源利用率以及GPU对更多用户和GPU加速应用程序的访问。借助A100的多功能性,基础架构管理人员可以最大化其数据中心中每个GPU的利用率,以满足从最小的工作到最大的多节点工作负载的不同规模的性能需求。
