
A100 Tensor核心可加速HPC
A100 Tensor核心可加速HPC
HPC应用程序的性能需求正在迅速增长。众多科学研究领域的许多应用程序都依赖于双精度(FP64)计算。
为了满足HPC计算快速增长的计算需求,A100 GPU支持Tensor操作,以加速符合IEEE的FP64计算,提供的FP64性能是NVIDIA Tesla V100 GPU的2.5倍。
A100上新的双精度矩阵乘法加法指令替换了V100上的八条DFMA指令,从而减少了指令提取,调度开销,寄存器读取,数据路径功率和共享存储器读取带宽。
A100中的每个SM总共计算64个FP64 FMA操作/时钟(或128个FP64操作/时钟),这是Tesla V100吞吐量的两倍。具有108个SM的A100 Tensor Core GPU的FP64峰值吞吐量为19.5 TFLOPS,是Tesla V100的2.5倍。
借助对这些新格式的支持,A100 Tensor Core可用于加速HPC工作负载,迭代求解器和各种新的AI算法。
|
|
V100 |
A100 |
A100稀疏度1 |
A100加速 |
A100稀疏加速 |
|
A100 FP16和 V100 FP16 |
31.4 TFLOPS |
78 TFLOPS |
不适用 |
2.5倍 |
不适用 |
|
A100 FP16 TC和 V100 FP16 TC |
125 TFLOPS |
312 TFLOPS |
624 TFLOPS |
2.5倍 |
5倍 |
|
A100 BF16 TC和V100 FP16 TC |
125 TFLOPS |
312 TFLOPS |
624 TFLOPS |
2.5倍 |
5倍 |
|
A100 FP32和 V100 FP32 |
15.7 TFLOPS |
19.5 TFLOPS |
不适用 |
1.25倍 |
不适用 |
|
A100 TF32 TC和 V100 FP32 |
15.7 TFLOPS |
156 TFLOPS |
312 TFLOPS |
10倍 |
20倍 |
|
A100 FP64和 V100 FP64 |
7.8 TFLOPS |
9.7 TFLOPS |
不适用 |
1.25倍 |
不适用 |
|
A100 FP64 TC和 V100 FP64 |
7.8 TFLOPS |
19.5 TFLOPS |
不适用 |
2.5倍 |
不适用 |
|
A100 INT8 TC与 V100 INT8 |
62 TOPS |
624 TOPS |
1248 TOPS |
10倍 |
20倍 |
|
A100 INT4 TC |
不适用 |
1248 TOPS |
2496 TOPS |
不适用 |
不适用 |
|
A100二进制TC |
不适用 |
4992 TOPS |
不适用 |
不适用 |
不适用 |
表1. A100在V100上的提速(TC = Tensor Core,GPU以各自的时钟速度)。
1)使用新的稀疏性功能实现有效的TOPS / TFLOPS
A100引入了细粒度的结构化稀疏性
借助A100 GPU,NVIDIA引入了细粒度的结构稀疏性,这是一种新颖的方法,可将深度神经网络的计算吞吐量提高一倍。
深度学习中可能会出现稀疏性,因为各个权重的重要性会在学习过程中演变,并且到网络训练结束时,只有权重的一个子集才具有确定学习输出的有意义的目的。不再需要剩余的权重。
细粒度的结构化稀疏性对稀疏性模式施加了约束,从而使硬件更有效地执行输入操作数的必要对齐。因为深度学习网络能够在训练过程中根据训练反馈调整权重,所以NVIDIA工程师通常发现结构约束不会影响训练网络进行推理的准确性。这使得可以稀疏地推断加速。
对于训练加速,需要在过程的早期引入稀疏性以提供性能优势,并且在不损失准确性的情况下进行训练加速的方法是一个活跃的研究领域。
稀疏矩阵定义
通过新的2:4稀疏矩阵定义强制执行结构,该定义在每个四项向量中允许两个非零值。A100在行上支持2:4的结构化稀疏性,如图1所示。
由于矩阵的定义明确,可以对其进行有效压缩,并将内存存储和带宽减少近2倍。
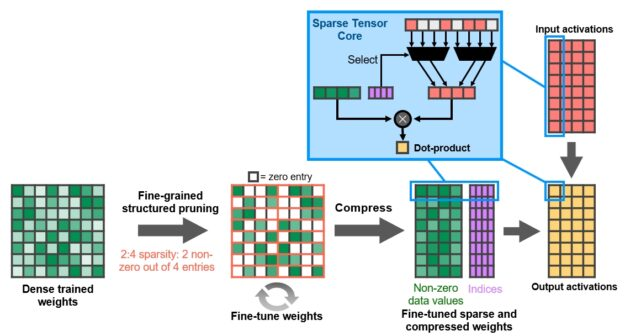
图1. A100细粒度的结构化稀疏修剪训练了权重,其中有2分之4的非零模式,然后是用于调整非零权重的简单通用方法。权重经过压缩,可将数据占用空间和带宽减少2倍,并且A100稀疏Tensor Core通过跳过零将数学吞吐量提高了一倍。
NVIDIA开发了一种简单而通用的配方,用于使用这种2:4结构化的稀疏模式来稀疏深度神经网络进行推理 。首先使用密集权重对网络进行训练,然后应用细粒度的结构化修剪,最后使用其它训练步骤对剩余的非零权重进行微调。基于跨视觉,目标检测,分割,自然语言建模和翻译的数十个网络的评估,该方法几乎不会导致推理准确性的损失。
A100 Tensor Core GPU包括新的Sparse Tensor Core指令,这些指令会跳过具有零值的计算,从而使Tensor Core计算吞吐量翻倍。图1示出了张量核心是如何使用压缩元数据(非零索引),以配合适当选择激活压缩权重输入到张量核心点积计算。
结合了L1数据缓存和共享内存
NVIDIA在L1数据高速缓存和共享内存子系统体系结构中首次引入NVIDIA Tesla V100,在显著提高性能的同时,还简化了编程并减少了达到或接近峰值应用程序性能所需的调整。将数据缓存和共享内存功能组合到单个内存块中,可为两种类型的内存访问提供最佳的整体性能。
L1数据高速缓存和共享内存的总容量在A100中为192 KB / SM,而在V100中为128 KB / SM。
同时执行FP32和INT32操作
与V100和Turing GPU相似,A100 SM还包括独立的FP32和INT32内核,允许以全吞吐量同时执行FP32和INT32操作,同时还提高了指令发布的吞吐量。
许多应用程序具有内部循环,这些循环执行指针算术(整数存储器地址计算),并结合浮点计算,这得益于同时执行FP32和INT32指令。流水线循环的每次迭代都可以更新地址(INT32指针算法)并为下一次迭代加载数据,同时在FP32中处理当前迭代。
A100 HBM2 DRAM子系统
随着HPC,AI和分析数据集的不断增长,寻找解决方案的问题变得越来越复杂,必须具有更大的GPU内存容量和更高的内存带宽。
Tesla P100是世界上第一个支持高带宽HBM2内存技术的GPU架构,而Tesla V100提供了更快,更高效和更高容量的HBM2实现。A100再次提高了HBM2的性能和容量标准。
HBM2内存由与GPU处于同一物理封装上的内存堆栈组成,与传统的GDDR5 / 6内存设计相比,可节省大量功率和面积,从而可在系统中安装更多GPU。
A100 GPU的SXM4型电路板上包括40 GB的快速HBM2 DRAM内存。存储器被组织为五个活动的HBM2堆栈,每个堆栈具有八个内存管芯。A100 HBM2的数据速率为1215 MHz(DDR),可提供1555 GB /秒的内存带宽,比V100内存带宽高1.7倍以上。
ECC内存弹性
A100 HBM2内存子系统支持单错误纠正双错误检测(SECDED)错误纠正代码(ECC)以保护数据。ECC为对数据损坏敏感的计算应用程序提供了更高的可靠性。在GPU处理大型数据集或长时间运行应用程序的大规模集群计算环境中,这一点尤其重要。A100中的其它关键存储器结构也受到SECDED ECC的保护,包括L2缓存和L1缓存以及所有SM内的寄存器文件。
A100 L2快取
A100 GPU包含40 MB的L2缓存,比V100 L2缓存大6.7倍.L2缓存分为两个分区,以实现更高的带宽和更低的延迟内存访问。每个L2分区都将本地化和缓存数据,以供直接连接到该分区的GPC中的SM进行内存访问。这种结构使A100的带宽增加了V100的2.3倍。硬件缓存一致性在整个GPU上维护CUDA编程模型,并且应用程序自动利用新L2缓存的带宽和延迟优势。
L2缓存是GPC和SM的共享资源,位于GPC之外。A100 L2缓存大小的大幅增加显着改善了许多HPC和AI工作负载的性能,因为现在可以缓存和重复访问数据集和模型的大部分,而读取和写入HBM2内存的速度要快得多。受DRAM带宽限制的某些工作负载将受益于更大的L2缓存,例如使用小批量的深度神经网络。
为了优化容量利用率,NVIDIA Ampere体系结构提供了L2缓存驻留控件,可管理要保留或从缓存中逐出的数据。可以预留一部分L2缓存用于持久性数据访问。
例如,对于DL推理工作负载,乒乓缓冲区可以持久地缓存在L2中,以实现更快的数据访问,同时还避免了回写到DRAM。对于生产者-消费者链,例如在DL训练中发现的链,L2缓存控件可以优化跨写到读数据依赖项的缓存。在LSTM网络中,循环权重可以优先在L2中缓存和重用。
NVIDIA Ampere体系结构增加了计算数据压缩功能,以加速非结构化稀疏性和其它可压缩数据模式。L2中的压缩使DRAM读/写带宽提高了4倍,L2读带宽提高了4倍,L2容量提高了2倍。
|
数据中心GPU |
NVIDIA Tesla P100 |
NVIDIA Tesla V100 |
NVIDIA A100 |
|
GPU代号 |
GP100 |
GV100 |
GA100 |
|
GPU架构 |
NVIDIA Pascal |
NVIDIA Volta |
NVIDIA安培 |
|
GPU板尺寸 |
SXM |
SXM2 |
SXM4 |
|
短信 |
56 |
80 |
108 |
|
TPC |
28 |
40 |
54 |
|
FP32核心/ SM |
64 |
64 |
64 |
|
FP32核心/ GPU |
3584 |
5120 |
6912 |
|
FP64核心/ SM |
32 |
32 |
32 |
|
FP64核心/ GPU |
1792 |
2560 |
3456 |
|
INT32内核/ SM |
不适用 |
64 |
64 |
|
INT32核心/ GPU |
不适用 |
5120 |
6912 |
|
张量芯/ SM |
不适用 |
8 |
4 2 |
|
张量核心/ GPU |
不适用 |
640 |
432 |
|
GPU加速时钟 |
1480兆赫 |
1530兆赫 |
1410兆赫 |
|
FP16的峰值FP16张量TFLOPS累计1 |
不适用 |
125 |
312/624 3 |
|
带FP32的峰值FP16张量TFLOPS累计1 |
不适用 |
125 |
312/624 3 |
|
带有FP32的BF16张量TFLOPS峰值累加1 |
不适用 |
不适用 |
312/624 3 |
|
峰值TF32张量TFLOPS 1 |
不适用 |
不适用 |
156/312 3 |
|
峰值FP64 Tensor TFLOPS 1 |
不适用 |
不适用 |
19.5 |
|
峰值INT8张量TOPS 1 |
不适用 |
不适用 |
624/1248 3 |
|
峰值INT4张量TOPS 1 |
不适用 |
不适用 |
1248/2496 3 |
|
峰值FP16 TFLOPS 1 |
21.2 |
31.4 |
78 |
|
峰值BF16 TFLOPS 1 |
不适用 |
不适用 |
39 |
|
峰值FP32 TFLOPS 1 |
10.6 |
15.7 |
19.5 |
|
峰值FP64 TFLOPS 1 |
5.3 |
7.8 |
9.7 |
|
峰值INT32 TOPS 1,4 |
不适用 |
15.7 |
19.5 |
|
纹理单位 |
224 |
320 |
432 |
|
记忆体介面 |
4096位HBM2 |
4096位HBM2 |
5120位HBM2 |
|
记忆体大小 |
16 GB |
32 GB / 16 GB |
40 GB |
|
内存数据速率 |
703 MHz DDR |
877.5 MHz DDR |
1215 MHz DDR |
|
记忆体频宽 |
720 GB /秒 |
900 GB /秒 |
1555 GB /秒 |
|
L2快取大小 |
4096 KB |
6144 KB |
40960 KB |
|
共享内存大小/ SM |
64 KB |
最多可配置96 KB |
最多可配置164 KB |
|
注册文件大小/ SM |
256 KB |
256 KB |
256 KB |
|
注册文件大小/ GPU |
14336 KB |
20480 KB |
27648 KB |
|
技术开发计划 |
300瓦 |
300瓦 |
400瓦 |
|
晶体管 |
153亿 |
211亿 |
542亿 |
|
GPU晶粒尺寸 |
610平方毫米 |
815平方毫米 |
826平方毫米 |
|
台积电制造流程 |
16 nm FinFET + |
12 nm FFN |
7纳米N7 |
表2. NVIDIA数据中心GPU的比较。
1)峰值速率基于GPU增强时钟。
2)A100 SM中的四个Tensor核心具有GV100 SM中八个Tensor核心的原始FMA计算能力的2倍。
3)使用新的稀疏功能有效的TOPS / TFLOPS。
4)TOPS =基于IMAD的整数数学
注意:由于A100 Tensor Core GPU设计为安装在高性能服务器和数据中心机架中以为AI和HPC计算工作量提供动力,因此它不包括显示连接器,用于光线追踪加速的NVIDIA RT Core或NVENC编码器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号