

Python分析离散心率信号(中)

一些理论和背景
心率信号不仅包含有关心脏的信息,还包含有关呼吸,短期血压调节,体温调节和荷尔蒙血压调节(长期)的信息。也(尽管不总是始终如一)与精神努力相关联,这并不奇怪,因为大脑是一个非常饥饿的器官,因此消耗了总葡萄糖的25%和氧气消耗的20%。如果活动增加,心脏需要更加努力地工作以保持其供应。
感兴趣的是这些措施可以被分为时间序列数据连接频域数据。如果熟悉傅立叶变换,则频率部分会很有意义。如果不是,请参阅维基百科页面具有很好的解释,并且对过程也非常直观。基本思想是,要获取随时间重复的信号(例如心率信号),并确定由哪些频率构成该信号。将信号从时域转换到频域。这是特别喜欢的另一种可视化效果,清楚地显示了如何将重复信号近似为随时间重复的不同正弦波之和。
时间序列数据
对于心率信号的时间序列部分,主要关注心跳之间的间隔及其随时间的变化。想要所有R复合物(R1,R2,... Rn)的位置,之间的间隔(RR1,RR2,... RRn,定义为 )以及相邻间隔之间的差异(RRdiff-1,…RRdiff-n,定义为)。
)以及相邻间隔之间的差异(RRdiff-1,…RRdiff-n,定义为)。
可视化:

在科学文献中经常发现的时间序列度量是:
§ BPM,即每分钟的心跳量,在上一部分中进行了计算;
§ IBI(心跳间隔),即心跳之间的平均距离,在前一部分中隐式地将其计算为BPM计算的一部分;
§ SDNN,心跳间隔的标准偏差:

§
SDSD,相邻RR间隔之间的连续差的标准偏差:

§
RMSSD,相邻RR间隔之间的连续差的均方根:

§ pNN50 / pNN20,比例差异大于50ms / 20ms。
IBI,SDNN,SDSD,RMSSD和pNNx(以及频域量度)通常归为“心率变异性”(HRV)量度,因为可提供有关心率随时间变化的信息。
频域数据
在心率信号的频率侧,最常发现的量度称为HF(高频),MF(中频)和LF(低频)频段,这是对创新性命名水平的永恒证明。MF en HF频段通常合并在一起,并被标记为“ HF”。LF和HF大致对应于LF频段的0.04-0.15Hz和HF频段的0.16-0.5Hz。LF频段似乎与短期血压变化有关,HF频段与呼吸频率有关。
通过在RR间隔数据序列上执行快速傅立叶变换来计算频谱。顾名思义,该方法与离散傅立叶变换方法相比是快速的。数据集越大,方法之间的速度差异就越大。
首先对信号进行重新采样,以计算频谱,然后将重新采样的信号转换到频域,然后以给定的间隔积分曲线下的面积,从而计算出HF和LF的量度。
时域度量–入门
查看上述时间序列度量,需要一些成分才能轻松计算所有这些度量:
§ 所有R峰的位置列表;
§ 所有后续RR对之间的间隔的列表(RR1,RR2,.. RR-n);
§ RR对之间所有后续间隔之间的差异的列表(RRdiff1,…RRdiffn);
§ RR对之间所有后续差之间的平方差的列表。
已经从第一部分的detect_peaks()函数获得了所有R峰位置的列表,该列表包含在dict ['peaklist']中。还有来自calc_RR()函数的RR对差异列表,位于dict ['RR_list']中。大!无需编写其代码,已经完成了50%的编写。
为了获得最后两个成分,使用dict ['RR_list']并计算差值和相邻值之间的平方差:
RR_diff = []
RR_sqdiff = []
RR_list = measures['RR_list']
cnt = 1 #Use counter to iterate over RR_list
while (cnt < (len(RR_list)-1)): #Keep going as long as there are R-R intervals
RR_diff.append(abs(RR_list[cnt] - RR_list[cnt+1])) #Calculate absolute difference between successive R-R interval
RR_sqdiff.append(math.pow(RR_list[cnt] - RR_list[cnt+1], 2)) #Calculate squared difference
cnt += 1
print(RR_diff, RR_sqdiff)
复制
计算时域度
量值现在有了所有成分,可以轻松计算所有度量值:
ibi = np.mean(RR_list) #Take the mean of RR_list to get the mean Inter Beat Interval
print("IBI:", ibi)
sdnn = np.std(RR_list) #Take standard deviation of all R-R intervals
print("SDNN:", sdnn)
sdsd = np.std(RR_diff) #Take standard deviation of the differences between all subsequent R-R intervals
print("SDSD:", sdsd)
rmssd = np.sqrt(np.mean(RR_sqdiff)) #Take root of the mean of the list of squared differences
print("RMSSD:", rmssd)
nn20 = [x for x in RR_diff if (x>20)] #First create a list of all values over 20, 50
nn50 = [x for x in RR_diff if (x>50)]
pnn20 = float(len(NN20)) / float(len(RR_diff)) #Calculate the proportion of NN20, NN50 intervals to all intervals
pnn50 = float(len(NN50)) / float(len(RR_diff)) #Note the use of float(), because we don't want Python to think we want an int() and round the proportion to 0 or 1
print("pNN20, pNN50:", pnn20, pnn50)
复制
时间序列度量就是这样。让将包装在可调用函数中。扩展calc_RR()函数以计算额外成分,并将其附加到字典对象中,还将calc_bpm()与其时间序列测量值合并到一个新函数calc_ts_measures()中,并将附加到字典中:
def calc_RR(dataset, fs):
peaklist = measures['peaklist']
RR_list = []
cnt = 0
while (cnt < (len(peaklist)-1)):
RR_interval = (peaklist[cnt+1] - peaklist[cnt])
ms_dist = ((RR_interval / fs) * 1000.0)
RR_list.append(ms_dist)
cnt += 1
RR_diff = []
RR_sqdiff = []
cnt = 0
while (cnt < (len(RR_list)-1)):
RR_diff.append(abs(RR_list[cnt] - RR_list[cnt+1]))
RR_sqdiff.append(math.pow(RR_list[cnt] - RR_list[cnt+1], 2))
cnt += 1
measures['RR_list'] = RR_list
measures['RR_diff'] = RR_diff
measures['RR_sqdiff'] = RR_sqdiff
def calc_ts_measures():
RR_list = measures['RR_list']
RR_diff = measures['RR_diff']
RR_sqdiff = measures['RR_sqdiff']
measures['bpm'] = 60000 / np.mean(RR_list)
measures['ibi'] = np.mean(RR_list)
measures['sdnn'] = np.std(RR_list)
measures['sdsd'] = np.std(RR_diff)
measures['rmssd'] = np.sqrt(np.mean(RR_sqdiff))
NN20 = [x for x in RR_diff if (x>20)]
NN50 = [x for x in RR_diff if (x>50)]
measures['nn20'] = NN20
measures['nn50'] = NN50
measures['pnn20'] = float(len(NN20)) / float(len(RR_diff))
measures['pnn50'] = float(len(NN50)) / float(len(RR_diff))
#Don't forget to update our process() wrapper to include the new function
def process(dataset, hrw, fs):
rolmean(dataset, hrw, fs)
detect_peaks(dataset)
calc_RR(dataset, fs)
calc_ts_measures()
复制
这样称呼:
import heartbeat as hb #Assuming we named the file 'heartbeat.py'
dataset = hb.get_data('data.csv')
hb.process(dataset, 0.75, 100)
#The module dict now contains all the variables computed over our signal:
hb.measures['bpm']
hb.measures['ibi']
hb.measures['sdnn']
#etcetera
#Remember that you can get a list of all dictionary entries with "keys()":
print(hb.measures.keys())
复制
在计算机上,分析信号并计算单个线程中的所有度量大约需要25毫秒。
频域度量–入门频域度量
计算比较棘手。主要原因是不想要将心率信号转换到频域(这样做只会返回等于BPM / 60(以Hz表示的心跳)的强频率)。相反,希望将RR间隔转换到频域。很难理解?这样思考:随着身体需求的变化,心率随着时间的变化而变化。这种变化表现为心跳之间的距离随时间变化(之前计算的RR间隔)。RR峰之间的距离随其自身频率随时间变化。为了可视化,绘制之前计算的RR间隔:

从图中可以清楚地看到,RR间隔不会随心跳而剧烈变化,而是随时间呈正弦波状变化(更准确地说是不同正弦波的组合)。想找到组成该模式的频率。
但是,任何傅立叶变换方法都依赖于均匀间隔的数据,并且RR间隔在时间上肯定不是均匀间隔的。这是因为间隔的时间位置取决于长度,每个间隔都不同。希望这是有道理的。
要找到措施,需要:
§ 创建一个带有RR间隔的均匀间隔的时间线;
§ 内插信号,既可以创建均匀间隔的时间序列,又可以提高分辨率;
§ 在某些研究中,此插值步骤也称为重新采样。
§ 将信号转换到频域;
§ 积分频谱的LF和HF部分下方的面积。
计算频域量度
首先,为RR间隔创建均匀间隔的时间线。为此,获取所有R峰的样本位置,这些样本位置位于在第1部分中计算的列表dict ['peaklist']中。然后,将y值分配给列表dict ['中的这些样本位置RR_list'],其中包含所有RR间隔的持续时间。最后,对信号进行插值。
from scipy.interpolate import interp1d #Import the interpolate function from SciPy
peaklist = measures['peaklist'] #First retrieve the lists we need
RR_list = measures['RR_list']
RR_x = peaklist[1:] #Remove the first entry, because first interval is assigned to the second beat.
RR_y = RR_list #Y-values are equal to interval lengths
RR_x_new = np.linspace(RR_x[0],RR_x[-1],RR_x[-1]) #Create evenly spaced timeline starting at the second peak, its endpoint and length equal to position of last peak
f = interp1d(RR_x, RR_y, kind='cubic') #Interpolate the signal with cubic spline interpolation
复制
请注意,时间序列不是从第一个峰值开始,而是从第二个R峰值的采样位置开始。因为使用间隔,所以第一个间隔在第二个峰值可用。
现在,可以使用创建的函数f()查找信号范围内任何x位置的y值:
print f(250)
#Returns 997.619845418, the Y value at x=250
复制
同样,可以将整个时间序列RR_x_new传递给该函数并进行绘制:
plt.title("Original and Interpolated Signal")
plt.plot(RR_x, RR_y, label="Original", color='blue')
plt.plot(RR_x_new, f(RR_x_new), label="Interpolated", color='red')
plt.legend()
plt.show()
复制

现在,要查找组成插值信号的频率,请使用numpy的快速傅立叶变换np.fft.fft()方法,计算采样间隔,将采样仓转换为Hz并作图:
#Set variables
n = len(dataset.hart) #Length of the signal
frq = np.fft.fftfreq(len(dataset.hart), d=((1/fs))) #divide the bins into frequency categories
frq = frq[range(n/2)] #Get single side of the frequency range
#Do FFT
Y = np.fft.fft(f(RR_x_new))/n #Calculate FFT
Y = Y[range(n/2)] #Return one side of the FFT
#Plot
plt.title("Frequency Spectrum of Heart Rate Variability")
plt.xlim(0,0.6) #Limit X axis to frequencies of interest (0-0.6Hz for visibility, we are interested in 0.04-0.5)
plt.ylim(0, 50) #Limit Y axis for visibility
plt.plot(frq, abs(Y)) #Plot it
plt.xlabel("Frequencies in Hz")
plt.show()
复制

可以清楚地看到信号中的LF和HF频率峰值。
剩下的最后一件事是对LF(0.04 – 0.15Hz)和HF(0.16 – 0.5Hz)频带下的曲线下面积进行积分。需要找到与感兴趣的频率范围相对应的数据点。在FFT期间,计算了单侧频率范围frq,因此可以在其中搜索所需的数据点位置。
lf = np.trapz(abs(Y[(frq>=0.04) & (frq<=0.15)])) #Slice frequency spectrum where x is between 0.04 and 0.15Hz (LF), and use NumPy's trapezoidal integration function to find the area
print("LF:", lf)
hf = np.trapz(abs(Y[(frq>=0.16) & (frq<=0.5)])) #Do the same for 0.16-0.5Hz (HF)
print("HF:", hf)
复制
返回:
LF: 38.8900414093
HF: 47.8933830871
复制
这些是感兴趣频谱处频谱下的区域。请记住,从理论上讲,HF与呼吸有关,而LF与短期血压调节有关。这些措施也与增加精神活动有关。
全面包装
已经走了很长一段路,现在可以从心率信号中提取许多有意义的指标。但是,如果输入其心率数据,则该模块很可能会失败,因为可能比理想数据更嘈杂,或者可能包含伪像。将处理信号过滤,错误检测和离群值剔除。


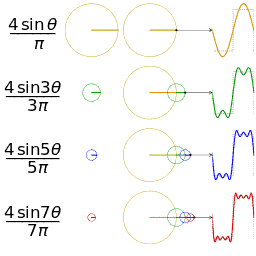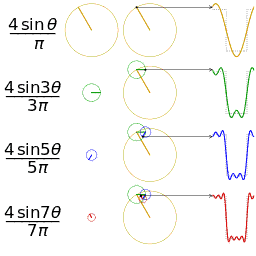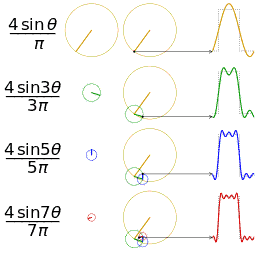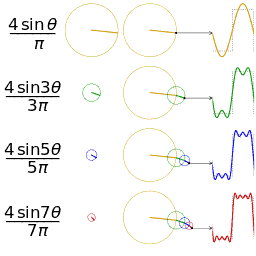{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)