
序列感知推荐系统
序列感知推荐系统
Sequence-Aware Recommender Systems
在前面的章节中,我们将推荐任务抽象为一个矩阵完成问题,而不考虑用户的短期行为。在本节中,我们将介绍一个推荐模型,该模型考虑按顺序排列的用户交互日志。它是一种序列感知的推荐程序[Quadrana et al.,2018],其中的输入是过去用户操作的有序且通常带有时间戳的列表。最近的一些文献已经证明了在建模用户的时间行为模式和发现他们的兴趣漂移时结合这些信息的有用性。
我们将介绍的模型,Caser[Tang&Wang,2018]是卷积序列嵌入推荐模型的简称,它采用卷积神经网络捕捉用户最近活动的动态模式影响。Caser的主要组成部分包括一个水平卷积网络和一个垂直卷积网络,旨在分别揭示联合层和点级序列模式。点级模式表示历史序列中的单个项对目标项的影响,而联合级模式表示前几项操作对后续目标的影响。例如,同时购买牛奶和黄油会导致购买面粉的概率比只购买其中一种更高。此外,用户的一般兴趣或长期偏好也在最后一个完全连接的层中建模,从而使用户兴趣的建模更加全面。模型的细节描述如下。
1. Model Architectures


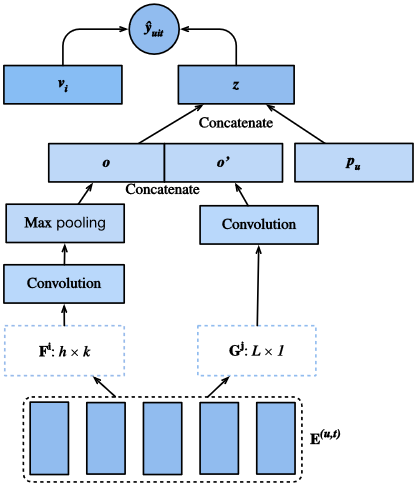
Fig. 1 Illustration of the Caser Model
首先导入所需的库。
from d2l import mxnet as d2l
from mxnet import gluon, np, npx
from mxnet.gluon import nn
import mxnet as mx
import random
import sys
npx.set_np()
2. Model Implementation
下面的代码实现了Caser模型。它由垂直卷积层、水平卷积层和全连通层组成。
class Caser(nn.Block):
def __init__(self, num_factors, num_users, num_items, L=5, d=16,
d_prime=4, drop_ratio=0.05, **kwargs):
super(Caser, self).__init__(**kwargs)
self.P = nn.Embedding(num_users, num_factors)
self.Q = nn.Embedding(num_items, num_factors)
self.d_prime, self.d = d_prime, d
# Vertical convolution layer
self.conv_v = nn.Conv2D(d_prime, (L, 1), in_channels=1)
# Horizontal convolution layer
h = [i + 1 for i in range(L)]
self.conv_h, self.max_pool = nn.Sequential(), nn.Sequential()
for i in h:
self.conv_h.add(nn.Conv2D(d, (i, num_factors), in_channels=1))
self.max_pool.add(nn.MaxPool1D(L - i + 1))
# Fully-connected layer
self.fc1_dim_v, self.fc1_dim_h = d_prime * num_factors, d * len(h)
self.fc = nn.Dense(in_units=d_prime * num_factors + d * L,
activation='relu', units=num_factors)
self.Q_prime = nn.Embedding(num_items, num_factors * 2)
self.b = nn.Embedding(num_items, 1)
self.dropout = nn.Dropout(drop_ratio)
def forward(self, user_id, seq, item_id):
item_embs = np.expand_dims(self.Q(seq), 1)
user_emb = self.P(user_id)
out, out_h, out_v, out_hs = None, None, None, []
if self.d_prime:
out_v = self.conv_v(item_embs)
out_v = out_v.reshape(out_v.shape[0], self.fc1_dim_v)
if self.d:
for conv, maxp in zip(self.conv_h, self.max_pool):
conv_out = np.squeeze(npx.relu(conv(item_embs)), axis=3)
t = maxp(conv_out)
pool_out = np.squeeze(t, axis=2)
out_hs.append(pool_out)
out_h = np.concatenate(out_hs, axis=1)
out = np.concatenate([out_v, out_h], axis=1)
z = self.fc(self.dropout(out))
x = np.concatenate([z, user_emb], axis=1)
q_prime_i = np.squeeze(self.Q_prime(item_id))
b = np.squeeze(self.b(item_id))
res = (x * q_prime_i).sum(1) + b
return res
3. Sequential Dataset with Negative Sampling
为了处理顺序交互数据,我们需要重新实现Dataset类。下面的代码创建一个名为SeqDataset的新数据集类。在每个示例中,它输出用户标识,即L交互的项目作为一个序列,下一个项目她交互作为目标。下面的图演示了用户加载数据的过程。假设这个用户喜欢8部电影,我们按照时间顺序组织这8部电影。最新的电影被排除在外作为测试项目。对于剩下的七部电影,我们可以得到三个训练样本,每个样本包含五个序列(L=5) 电影及其后续项目(its subsequent item)作为目标项。负样本也包括在自定义数据集中。
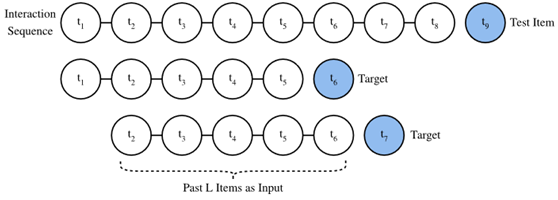
Fig. 2 Illustration of the data generation process
class SeqDataset(gluon.data.Dataset):
def __init__(self, user_ids, item_ids, L, num_users, num_items,
candidates):
user_ids, item_ids = np.array(user_ids), np.array(item_ids)
sort_idx = np.array(sorted(range(len(user_ids)),
key=lambda k: user_ids[k]))
u_ids, i_ids = user_ids[sort_idx], item_ids[sort_idx]
temp, u_ids, self.cand = {}, u_ids.asnumpy(), candidates
self.all_items = set([i for i in range(num_items)])
[temp.setdefault(u_ids[i], []).append(i) for i, _ in enumerate(u_ids)]
temp = sorted(temp.items(), key=lambda x: x[0])
u_ids = np.array([i[0] for i in temp])
idx = np.array([i[1][0] for i in temp])
self.ns = ns = int(sum([c - L if c >= L + 1 else 1 for c
in np.array([len(i[1]) for i in temp])]))
self.seq_items = np.zeros((ns, L))
self.seq_users = np.zeros(ns, dtype='int32')
self.seq_tgt = np.zeros((ns, 1))
self.test_seq = np.zeros((num_users, L))
test_users, _uid = np.empty(num_users), None
for i, (uid, i_seq) in enumerate(self._seq(u_ids, i_ids, idx, L + 1)):
if uid != _uid:
self.test_seq[uid][:] = i_seq[-L:]
test_users[uid], _uid = uid, uid
self.seq_tgt[i][:] = i_seq[-1:]
self.seq_items[i][:], self.seq_users[i] = i_seq[:L], uid
def _win(self, tensor, window_size, step_size=1):
if len(tensor) - window_size >= 0:
for i in range(len(tensor), 0, - step_size):
if i - window_size >= 0:
yield tensor[i - window_size:i]
else:
break
else:
yield tensor
def _seq(self, u_ids, i_ids, idx, max_len):
for i in range(len(idx)):
stop_idx = None if i >= len(idx) - 1 else int(idx[i + 1])
for s in self._win(i_ids[int(idx[i]):stop_idx], max_len):
yield (int(u_ids[i]), s)
def __len__(self):
return self.ns
def __getitem__(self, idx):
neg = list(self.all_items - set(self.cand[int(self.seq_users[idx])]))
i = random.randint(0, len(neg) - 1)
return (self.seq_users[idx], self.seq_items[idx], self.seq_tgt[idx],
neg[i])
4. Load the MovieLens 100K dataset
然后,我们以序列感知模式读取并分割MovieLens 100K数据集,并使用上面实现的序列数据加载器加载训练数据。
TARGET_NUM, L, batch_size = 1, 3, 4096
df, num_users, num_items = d2l.read_data_ml100k()
train_data, test_data = d2l.split_data_ml100k(df, num_users, num_items,
'seq-aware')
users_train, items_train, ratings_train, candidates = d2l.load_data_ml100k(
train_data, num_users, num_items, feedback="implicit")
users_test, items_test, ratings_test, test_iter = d2l.load_data_ml100k(
test_data, num_users, num_items, feedback="implicit")
train_seq_data = SeqDataset(users_train, items_train, L, num_users,
num_items, candidates)
num_workers = 0 if sys.platform.startswith("win") else 4
train_iter = gluon.data.DataLoader(train_seq_data, batch_size, True,
last_batch="rollover",
num_workers=num_workers)
test_seq_iter = train_seq_data.test_seq
train_seq_data[0]
(array(0, dtype=int32), array([110., 255., 4.]), array([101.]), 1645)
培训数据结构如上图所示。第一个元素是用户标识,下一个列表指示该用户喜欢的最后五个项目,最后一个元素是该用户在这五个项目之后喜欢的项目。
5. Train the Model
现在,让我们训练模型。我们使用与NeuMF相同的设置,包括学习率、优化器和k在最后一节中,使结果具有可比性。
ctx = d2l.try_all_gpus()
net = Caser(10, num_users, num_items, L)
net.initialize(ctx=ctx, force_reinit=True, init=mx.init.Normal(0.01))
lr, num_epochs, wd, optimizer = 0.04, 8, 1e-5, 'adam'
loss = d2l.BPRLoss()
trainer = gluon.Trainer(net.collect_params(), optimizer,
{"learning_rate": lr, 'wd': wd})
d2l.train_ranking(net, train_iter, test_iter, loss, trainer, test_seq_iter,
num_users, num_items, num_epochs, ctx, d2l.evaluate_ranking,
candidates, eval_step=1)
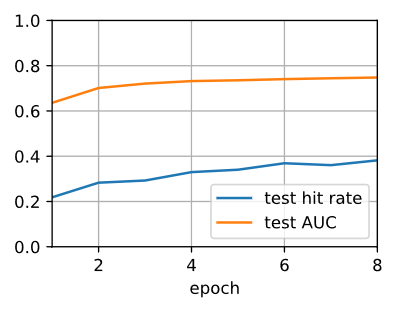
train loss 0.866, test hit rate 0.382, test AUC 0.748
29.3 examples/sec on [gpu(0), gpu(1)]
6. Summary
- Inferring a user’s short-term and long-term interests can make prediction of the next item that she preferred more effectively.
- Convolutional neural networks can be utilized to capture users’ short-term interests from sequential interactions.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律