
CVPR2020:点云三维目标跟踪的点对盒网络(P2B)
CVPR2020:点云三维目标跟踪的点对盒网络(P2B)
P2B: Point-to-Box Network for 3D Object Tracking in Point Clouds
代码:https://github.com/HaozheQi/P2B
论文地址:
摘要
针对点云中的三维目标跟踪问题,提出了一种新的点对盒网络P2B。主要思想是首先在嵌入目标信息的三维搜索区域中定位潜在的目标中心。然后进行点驱动三维验证。这样,可以避免耗时的3D穷尽搜索。具体地说,首先从模板和搜索区域的点云中提取种子。然后,通过置换不变特征增强,将模板中的目标线索嵌入到搜索区域种子中,并用目标特征表示。因此,扩大搜索区域种子通过Hough投票来回归潜在的目标中心。中心进一步加强种子的目标性得分。最后,每个中心将其邻域聚为一组,利用集合能力进行联合3D目标的提出和验证。以PointNet++为主干,在KITTI跟踪数据集上的实验证明了P2B的优越性(比最先进的技术提高了10%)。请注意,P2B可以在单个NVIDIA 1080Ti GPU上以40FPS的速度运行。
1.介绍
点云中的三维目标跟踪对于自主驾驶和机器人视觉应用至关重要[25,26,7]。然而,点云的稀疏性和无序性给这项任务带来了很大的挑战,导致了现有的二维目标跟踪方法(如Siamese网[3])无法直接应用。现有的大多数3D目标跟踪方法[1,4,24,16,15]继承了2D的经验,严重依赖于RGB-D信息。但当RGB视觉信息因光照变化而退化甚至无法访问时,可能会失效。因此,将重点放在仅使用点云的三维目标跟踪上。关于这一主题的首创性成果见[11]。主要使用Kalman滤波[12]来执行3D模板匹配,以生成一组3D目标建议。同时,利用形状补全对点集上的特征学习进行正则化。然而,该算法存在四个主要缺陷:1)跟踪网络不能进行端到端的训练;2)采用卡尔曼滤波的三维搜索耗费大量时间;3)每个目标方案仅用一维全局特征表示,可能会丢失有限的局部几何信息;4) 形状完备网络具有较强的类先验性,削弱了通用性。
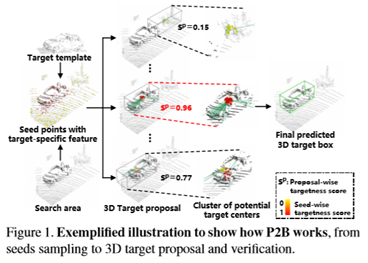
针对以上问题,提出了一种新的点对盒网络P2B,可以进行端到端的三维目标跟踪。与[11]中使用box的直观三维搜索不同,转而通过首先定位潜在目标中心,然后联合执行点驱动目标建议和验证来解决三维目标跟踪问题。直觉依赖于两点。首先,点态跟踪模式可以帮助更好地利用三维局部几何信息来描述点云中的目标。其次,采用端到端的方式制定三维目标跟踪任务,具有较强的跟踪目标三维外观变化的能力。
在图1中举例说明P2B是如何工作的。首先将模板和搜索区域分别输入到主干中并获得种子。搜索区域种子将因此预测潜在的目标中心,以便联合目标建议和验证。然后利用目标特征对搜索区域种子进行增强,得到三个主要组成部分:1)三维位置坐标存储空间几何信息;2)与模板种子逐点相似,挖掘相似模式并揭示局部跟踪线索;3)模板编码目标全局特征。这种增强对种子的排列是不变的,并产生一致的特定目标特征。之后,通过Hough投票将增强的种子投射到潜在的目标中心[28]。同时,对每一个种子进行目标性评价,以规范早期特征学习,结果的目标得分进一步增强了其预测目标中心的表征能力。最后,每个潜在的目标中心将邻域聚集在一起,以利用集成能力进行联合目标建议和验证。在KITTI跟踪数据集[10]上的实验表明,P2B显著优于最先进的方法[11],在很大程度上(成功率和精确度均为10%)。请注意,P2B可以在单个NVIDIA 1080Ti GPU上以约40FPS的速度运行。总体而言,本文的主要贡献包括
•P2B:一种新颖的点对盒网络,用于点云中的三维目标跟踪,可以进行端到端的训练;
•目标特定特征增强,包括3D目标跟踪的全局和局部3D视觉线索;
•整合3D目标提案和验证。
2.相关工程
将简要介绍与P2B最相关的工作:三维目标跟踪、二维连体跟踪、点集深度学习、目标提议和Hough投票。
三维目标跟踪
据所知,在最近的先驱尝试之前,很少有人研究仅使用点云的三维目标跟踪[11]。早期的相关跟踪方法[24,16,15,27,1,4]通常依赖于RGB-D信息。尽管经过不同理论层面的努力,可能存在两个主要缺陷:1)对RGB视觉线索的依赖和退化甚至不可接近性的失败。这限制了一些实际应用;2)没有设计用于三维跟踪的网络,这可能会限制代表性的能力。除此之外,中的一些[24,16,15]专注于生成二维盒。上述问题在[11]中进行了阐述。利用对点集的深度学习和三维目标的提出,实现了仅使用点云的三维目标跟踪的最新成果。然而,仍然像Sec一样存在一些缺陷。1,这激发了研究。
二维Siamese跟踪
许多最先进的二维跟踪方法[33,3,34,13,42,35,20,8,40,36,21]建立在Siamese网络上。通常,Siamese网络有两个分支,模板和搜索区域具有共享的权重,以衡量在隐式嵌入空间中的相似性。最近,[21]联合区域建议网络和Siamese网络,以提高性能。因此,可以避免耗时的多尺度搜索和在线微调。后来,许多努力[42,20,40,36,8]都遵循这一范式。然而,上述方法都是由2dcnn驱动的,不适用于点云。因此,目标是通过有效的三维目标方案,将Siamese跟踪范式扩展到三维目标跟踪。
关于点集的深度学习
近年来,关于点集的深度学习引起了越来越多的研究兴趣[5,30]。为了解决点云的无序性、稀疏性和旋转变化等问题,这些努力促进了三维物体识别[18,23]、三维目标检测[28,29,32,39]、三维姿态估计[22,9,6]和三维目标跟踪[11]的研究。然而,[11]中的3D跟踪网络不能联合执行端到端的3D目标提议和验证,这构成了P2B的重点。
目标提案
在二维跟踪任务中,许多trackingby detection方法[41,37,14]利用模板中包含的目标线索来获得高质量的目标特定建议。以目标感知的方式对具有边缘特征[41]、区域建议网络[37]或注意力图[14]的(2D)基于区域的像素进行操作。相比之下,P2B将每个点视为对潜在目标中心的一个回归因子,这与三维目标的提出直接相关。
霍夫投票
Hough voting的开创性工作[19]提出了一种高度灵活的对象形状学习表示,可以在广义Hough变换[2]的概率扩展中结合不同训练示例上观察到的信息。最近,[28]将Hough投票嵌入到一个端到端可训练的deep网络中,用于点云中的三维目标检测,进一步聚合了局部上下文,产生了很好的结果。但如何将其有效地应用于三维目标跟踪,仍然是一个有待探索的问题。

3. P2B: A Novel Network on Point Set for 3D Object Tracking
3.1.概述
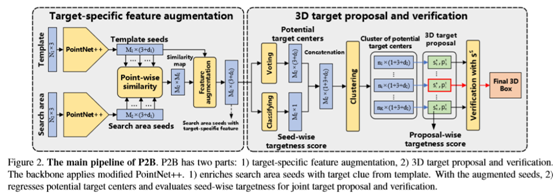
在三维目标跟踪中,着重于在搜索区域中逐帧定位目标(由模板定义)。目的是将模板的目标线索嵌入到搜索区域中,预测潜在的目标中心,并以端到端的方式执行联合目标建议和验证。P2B有两个主要部分(图2):1)目标特定特征增强,2)3D目标建议和验证。首先将模板和搜索区域分别输入到主干中并获得种子。然后模板种子有助于增加搜索区域种子与目标特定的特征。然后,通过Hough投票将这些扩大的搜索区域种子投影到潜在的目标中心。通过计算种子的目标得分来规范特征学习,增强这些潜在目标中心的识别能力。然后每个潜在的目标中心将其邻域聚集起来,进行三维目标定位。具有最大提案针对性得分的提案被确认为最终结果。将详细说明如下。表1定义了P2B中的主要符号。为了便于理解,还绘制了算法1的详细技术流程。
3.2. 目标特定特征增强
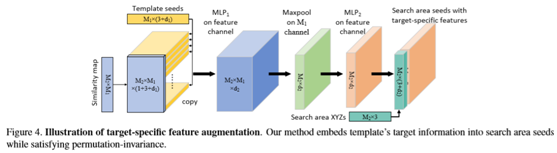
在这里,目的是将模板的目标信息合并到搜索区域种子中,以包含全局目标线索和局部跟踪线索。首先将模板和搜索区域分别输入到特征主干中,得到种子。利用模板中嵌入的目标信息,利用模式匹配的思想,在搜索区域种子中增加目标的特定特征,同时满足置换不变性,解决了点云的无序性问题。
3.3.基于潜在目标中心的目标建议
嵌入目标线索,每个rj可以直接预测一个目标方案。但直觉是,单个种子只能捕捉到有限的局部线索,这可能不足以满足最终的预测。遵循VoteNet[28]的思想:1)通过Hough投票将搜索区域种子回归到潜在的目标中心;2)对相邻中心进行聚类,利用集合的能力获得目标方案。
3.4.基于种子目标度得分的改进目标方案
认为每一个具有特定目标特征的种子都可以通过其目标性直接进行评估,以1)规范早期特征学习,2)加强其预测潜在目标中心的表示。因此,可以获得更高质量的目标提案。
4. Experiments
使用KITTI跟踪数据集[10](使用激光雷达扫描点云)作为基准。遵循了[11]中的设置(为了简单起见,将其简称为SC3D)中的数据分割、轨迹生成1和评估指标,以便进行公平比较。由于KITTI中的汽车数量最多且种类繁多,主要集中在车辆跟踪上,并像SC3D一样对其进行烧蚀研究,还对其三种目标类型(行人、货车、自行车)进行了大量的实验,以便更好地进行比较。

点云稀疏性
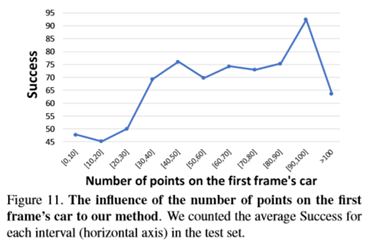
虽然每帧平均报告120k个点,但假设目标上的点可能非常稀疏,因为一般遮挡和激光雷达在远处目标上的缺陷。为了验证想法,在图5中计算了KITTI汽车上的点数。可以观察到大约34%的汽车持有低于50分的分数。对于体型较小的行人和骑自行车的人来说,情况可能更糟。这种稀疏性给基于点云的三维目标跟踪带来了很大的挑战。
评价指标
使用一次评估(OPE)[38]来衡量不同方法的成功率和精确度。“成功”被定义为预测框和基本真相(GT)框之间的借据。“精度”定义为0到2m误差(两个盒子中心之间的距离)的AUC。
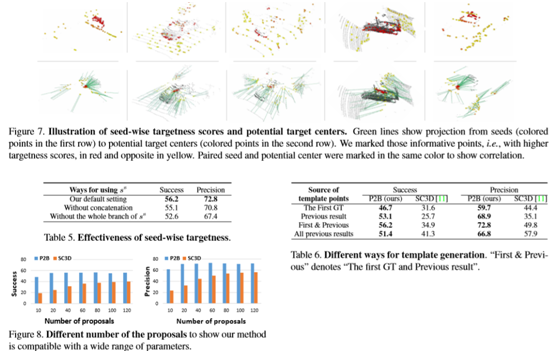
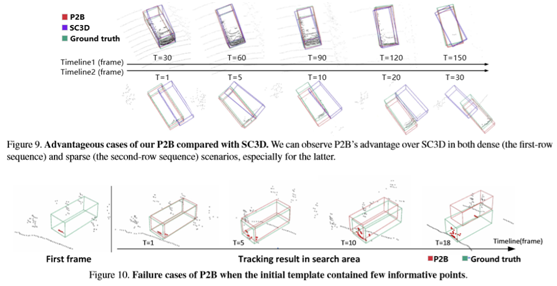
实施细节
模板和搜索区域
对于template2,收集并规范化其点为N1=512个点,随机放弃或复制。对于搜索区域,同样地收集和规范化的点为N2=1024个。生成模板和搜索区域的方法在训练和测试中有所不同。
网络体系结构
采用了PointNet++[30]作为主干。定制包含三个集合抽象(SA)层,接收半径分别为0.3、0.5、0.7米和3倍半尺寸缩小采样。
4.2.综合比较
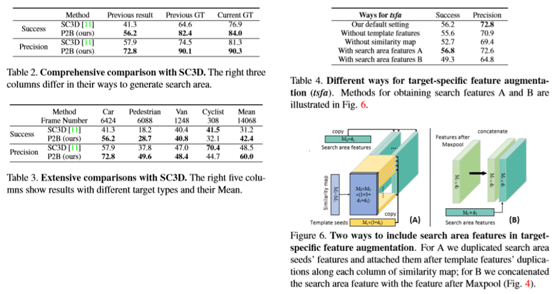
只比较了P2B和SC3D[11],SC3D是第一个也是唯一一个基于点云的三维目标跟踪。在表2中报告了3D汽车跟踪的结果。生成了以上一个结果、上一个GT或当前GT为中心的搜索区域。使用先前的搜索结果作为搜索中心可以满足实际场景的要求,而使用先前的GT有助于近似评估短期跟踪性能。对于这两种情况,SC3D应用卡尔曼滤波生成建议。使用现有的GT是不合理的,但在SC3D中被认为是近似穷举搜索并评估SC3D的分辨力。具体而言,SC3D围绕目标中心进行网格搜索,以便在生成的提案中包含GT box。然而,P2B聚类潜在的目标中心,以生成建议,而不显式依赖于GT-box。
如表2所示,当移除GT盒时,P2B可以适应各种情况,而SC3D可能会退化。综合来看,P2B的表现远远超过SC3D。所有后来的实验都采用了更现实的设置,即使用先前的结果。
广泛的比较
进一步比较了P2B和SC3D在行人、货车和自行车上的差异(表3)。P2B的平均表现超过SC3D 10%。P2B的优势在数据丰富的汽车和行人上变得显著。但是P2B随着训练数据的减少而降低,就像货车和自行车手一样。推测P2B可能依赖更多的数据来学习更好的网络,特别是当回归潜在的目标中心时。相比之下,SC3D需要相对较少的数据来完成两个区域之间的相似性测量。为了验证这一点,使用在数据丰富的汽车上训练的模型来测试Van,相信汽车类似于Van并且包含潜在的可转移信息。正如预期的那样,P2B的成功/精密度结果显示提高了49.9/59.9(原始值:40.8/48.4),而SC3D报告的a下降了37.2/45.9(原始值:40.4/47.0)。
烧蚀研究
目标特定特征增强的方法
除了在P2B中的默认设置之外,还有另外四种可能的特征增强方法:删除(重复的)模板特征,删除相似性映射,使用搜索区域特征A和B(图6)。比较了表4中的五个设置。在这里删除模板特征或相似性映射大约降低1%或3%,这验证了这两个部分在默认设置中的贡献。搜索区域功能A和B没有改善甚至损害性能。请注意,已经在这两种情况下组合了模板功能。这可能揭示出,搜索区域特征只捕捉空间上下文而不是目标线索,因此对于目标特定特征的增强毫无用处。相比之下,默认设置从模板种子带来更丰富的目标线索,从而生成更“定向”的建议生成。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律