

同向逆向、多车道线检测
同向逆向、多车道线检测
输入输出接口
Input:
(1)左右两个摄像头采集的实时图像视频分辨率(整型int)
(2)左右两个摄像头采集的实时图像视频格式 (RGB,YUV,MP4等)
(3)摄像头标定参数(中心位置(x,y)和5个畸变
系数(2径向,2切向,1棱向),浮点型float)
(4)摄像头初始化参数(摄像头初始位置和三个坐标方向
的旋转角度,车辆宽度高度车速等等,浮点型float)
Output:
(1)左右两边各个车道线的坐标位置(浮点型float)
(2)车辆偏移左右两边的相对位置(浮点型float)
(3)车道线坐标位置或者曲线拟合系数(浮点型float)
(4)车道线偏离预警 (char 字符型)
1. 功能定义
(1)左右两边各个车道线的坐标位置
(2)车辆偏移左右两边的相对位置
(3)车道线坐标位置或者曲线拟合系数
(4)车道线偏离预警
2. 技术路线方案
2.1 方案概述
本方案拟将每条车道线的检测问题对待为一个基于图像实例的分割问题。方案通过设计合适的深度神经网络,实现对同向、逆向多车道线不同实例的分割模型,实现基于原前视角图像的车道线特征提取,并将结果进行特征嵌入,得到不同实例的分割热图。其次,将分割结果应用俯仰角变换矩阵变换到俯视角场景,在此视角去除掉非车道线部分。后为每一条检测的车道线拟合一个三阶多项式,并将拟合的车道线重新映射回原始图像,作为整个网络的输出。本项目通过构建端到端的深度神经网络将车道线特征提取、车道线检测、俯仰角变换、车道线建模等统一通过深度学习的技术实现。通过网络学习得到视角变换参数,确保了对道路平面变化的鲁棒性,使其不依赖于固定的、预定义的参数。在将图片输入网络之前,首先将对其做一些预处理,当训练数据集中的夜间车道图像充分时,可以将白天的车道检测模型迁移到夜间数据上学习;当训练数据集中夜间车道图像数量较少时,拟采用去噪、感兴趣区域提取、甚至采用将夜晚图像转变为白天图像等的图像增强方法来提高模型的准确率。
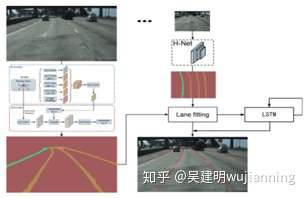
图1. 同向逆向多车道线检测技术方案图
如图 1 所示,给定一幅图像,将其输入到深度多车道线检测网络,通过网 络推理,得到一幅该车道线的实例分割图,并给每个车道线像素标记一个 Lane ID。随后,将实例分割图通过俯仰角变换网络 H-Net 进行推理,将原视角的车 道线图像转换到俯视角。 再次,将俯视角图像映射回原图视角,并使用小二乘为每条车道拟合一个三阶多项式,由此将曲线预测的车道线结果与实际的车道线结果计算误差,并训练网络。测试阶段将直接输出预测的车道线曲线坐 标。 后,结合深度循环网络 LSTM 实现对车道线的跟踪。
2.2数据集标注
数据集的标注质量直接影响模型的好坏,并且数据集的标注类型,取决于具体的计算机视觉任务。由于复杂条件下多车道线同向和逆向检测模型是一个基于深度学习的图像语义分割模型,因此需要采集真实驾驶条件下具有地理、 环境和天气多样性的样本集,并进行像素级标注。如,tuSimple 车道数据集的像素级标注是使用分割标注工具,对图片中的车道线轨迹进行打点标注,打点的密集程度决定了标注的细粒程度。连接标好的离散点,便会形成连续的车道 线,在表示数据集标注的 json 文件中存入了每张图像的车道线标注点的 x 坐 标、y 坐标和文件的相对路径信息。如图 168 所示,为了满足多车道线同向和逆 向检测的任务需求,标注的像素级分割数据集,需要定义 3 种类别车道线,其中黄色标注的车道线是区分与当前车辆行驶方向同向和逆向的标志,车辆在行驶过程中不得变道穿过具有黄色标注的车道线。与当前行驶车辆在相同方向的车道线,在如图 168 中被标注为绿色的车道线,这样当前行驶的车辆可以视当前交通情况变道行驶在任意绿色车道线内。红色标注的车道线为与当前车辆行驶 方向相反的车道线,车辆不能行驶在这样的车道线内。

图2.(左) 车道线标注;(右) 标注可视化说明
方案拟提出的多车道线同向和逆向检测算法,采用主流的基于深度学习 的实例分割方案。除了同上述 tuSimple 车道数据集需要对车道线的轨迹进行标点注释以外,还需要针对车辆遮挡或者车道线不明显的情况。根据图像上下 文标注车道线轨迹,在数据集的 label 中表明每条车道线是属于上述 3 种类别 中的哪种类别,并将这个标注信息存储在对应的 json 文件中。另外拟标注的数据集为了更好的训练模型的实例分割能力,对训练集和验证集中的每张图片 中的车道线都需要进行像素级的实例分割标注形成对应的图像真实标签。
2.3图像预处理
图像预处理步骤是车道线检测任务的重要组成部分,有助于减少计算时间并提高算法的性能。它还用于消除由于摄像机运动不稳定造成的传感器噪声 和误差,模型的输入样本是从摄像机获取的基于 RGB 的彩色图像序列,该摄像机沿着中心线安装在车辆正前方的正视图中这样可以清楚地看到前方的道路,而不会妨碍驾驶员的视野。针对在夜间低光条件下的车道线图像样本或者夜间极端光线情况下的样本,拟提出端到端的学习方法,即训练一个全卷积网 络 FCN 来直接处理快速成像系统中的低亮度图像。纯粹的 FCN 结构可以有效地代表许多图像处理算法。受此启发,拟调查并研究这种方法在极端低光条件 下成像系统的应用。相比于传统图像处理方法使用的 sRGB 图像,在这里使用 原始传感器数据。如图 169 展示了拟提出方法的模型结构图。
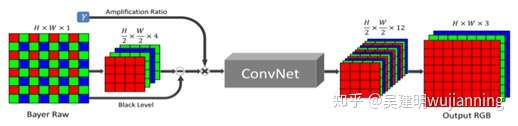
图3. 夜间图像处理模型结构
对于 Bayer 数组,将输入打包为四个通道并在每个通道上将空间分辨率 降低一半。对于 X-Trans 数组(图中未显示出),原始数据以 6×6 排列块组成; 通过交换相邻通道元素的方法将 36 个通道的数组打包成 9 个通道。此外,消 除黑色像素并按照期望的倍数缩放数据(例如,x100 或 x300)。将处理后数据 作为 FCN 模型的输入,输出是一个带 12 通道的图像,其空间分辨率只有输入 的一半。将两个标准的 FCN 结构作为模型的核心架构:用于快速图像处理的 多尺度上下文聚合网络(CAN)和 U-net 网络。避免使用完全连接结构及模型集 成方式,默认架构是 U-net。放大比率决定了模型的亮度输出。在这个方法中, 放大比率设置在外部指定并作为输入提供给模型,这类似于相机中的 ISO 设置。可以通过设置不同的放大率来调整输出图像的亮度,在测试时间,改方法 能够抑制盲点噪声并实现颜色转换,并在 sRGB空间网络直接处理图像,得到 网络的输出。 为了防止模型过拟合,除了在损失函数上使用正则项外,拟采用图像平移、翻转、剪切等图像增强技术,增加模型的泛化能力,提高模型在测试集和 实际车道线检测时的准确率和鲁棒性。
2.4 DeepLaneNet 结构
本项目拟使用基于深度学习的实例分割网络进行车道线的分割。在输入方面,将车的正前方视野图像与上方视野图像设置成相同的大小,将图像共同输 入至网络(如图 170 所示)。
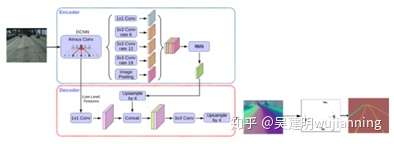
图4. DeepLaneNet 结构图
这里将网络分为编码器(Encoder)和解码器(Decoder)两部分组成,编 码器使用对于移动设备支持很好的轻量神经网络 MobileNetv2 架构(对应图中 DCNN 部分) 。MobileNetv2 架构是基于倒置残差结构(Inverted Residual Structure),原本的残差结构的主分支有三个卷积,两个逐点卷积通道数较多, 而倒置的残差结构刚好相反,中间的卷积通道数(依旧使用深度分离卷积结构)较多,旁边的较小。这个网络与新的 Densnet 相比,性能稍逊,但是对于参数量与计算量有着非常大的减少,对于计算速度有极大的提升,适合项目实时 性的需求。 解码器通过加入空洞卷积完成的。空洞卷积金字塔是由 3 个空洞率不同 的空洞卷积和一个 1×1 的卷积,以及全局平均池化的特征融合而成。通过深度卷积神经网络的特征提取之后,将特征通过“空洞卷积金字塔”,与深度卷 积神经网络的特征相融合,然后使用循环神经网络(RNN)对于视频图像的 前后层特征的相关性进行提取,后经过 3×3 的卷积进行融合的特征整合, 将分割结果还原成原图的大小,在经过聚类算法将车道线提取出来。
2.5 H-Net
通常将像素映射到俯视图中使用的是一个固定的转换矩阵,然而,由于转换参数是固定在所有图像上的,当地面不平时,例如在斜坡上,固定的转换矩 阵就不能解决这个问题。为了解决这个问题,本项目拟设计一个 H-Net 的网络 来学习变换的参数,该转换能够更好地对车道线进行拟合。 H-Net 是一个普通的卷积神经网络,输出是一个变换矩阵 H,该网络允许在地平面变化的情况下调整变换矩阵 H 参数,从而更加正确地拟合车道线。H有六个变量,其形式为:
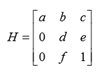
其中 0 用来执行约束条件,即水平线在转换下保持水平。
2.6 车道线拟合
对于给定的车道线像素 P,使用转换矩阵将其转换到俯视角,P0=HP,用小二乘算法来拟合一个三次多项式 ,后再映射回原图,如图 5所示。

图5. 左:使用 H-net 生成的矩阵 H 来转换通道点。
中:曲线拟合转换点。 右:拟合的点被映射回原图像
为了训练 H-Net,使其输出的变换矩阵优,构造了以下损失函数。给定N 个真实车道线像素
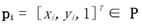
,首先用 H-Net 的得到的变换矩阵将其进行透视变换:
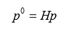
通过这些变换点,可使用小二乘闭式解来拟合多项式
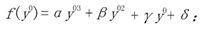
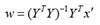
其中
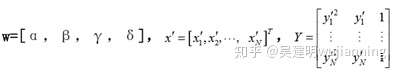
对每一个
![]()
位置预测其对应的
![]()
,并将其映射回原始图像
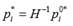
,其中
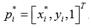
且
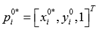
,损失函数定义为:
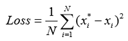
2.7 LSTM 车道跟踪
由于 LSTM 在处理序列数据上表现出的优越性能,本项目拟采用 LSTM 来对车道线进行跟踪。如图 172 所示,将拟合的车道线参数 w=[α,β,γ,δ]作 为 LSTM 的输入,把一段时间内每一时间步拟合的车道线参数输入 LSTM,使用预测参数与真实参数的交叉熵作为损失函数来训练网络,从而预测出后面时 间步车道线的参数。后,将车道线的拟合结果与 LSTM 的预测结果相结合,映射回原始图像作为整个网络的输出。当某一帧图像没有检测到车道线时,就 可以使用 LSTM 预测的车道线作为整个网络输出。
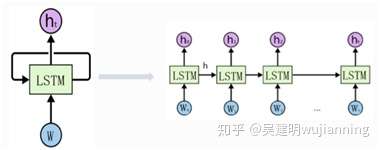
图6. LSTM 结构图
2.8特色与创新
(1)主要特色:把同向和逆向多车道线检测、恶劣天气和照明条件下同向和逆向多车道线检测中的关键技术,包括:车道线特征提取、车道线检测、前俯视角变换、车道线建模,统一在一个端到端的深度车道线检测网络模型中通过深度学习的方法实现。该方案相较于传统的车道线检测方 法,具有较强的鲁棒性和应对不同工况环境的泛化能力。
(2)项目主要面向夜间驾驶环境,数据集采集与标注难度大、图像光线与质 量不理想, 项目构建的夜间多车道线检测数据集填补了车道线研究领域的空白。项目提出的研究内容能够改进车道线在较差光线和夜间环境下的 检测及跟踪效果,能够提高企业核心技术竞争力和自主创新能力。
(3)主要创新:在深度多车道线检测模型的设计中,采用轻量化网络模型, 使用 Encoder-Decoder 的框架,把提取车道线特征和实例分割有机结合起来,同时训练一个网络学习图像视角变换中的变换矩阵。这是车道线检测研究领域的创新。
(4)主要创新:车道线检测方法要嵌入车载系统中,模型应该具有低功耗和实时性,需要对模型进行压缩或者改进。这是将科研成果和实际应用相结合的创新。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)